
Submitted:
30 November 2023
Posted:
05 December 2023
You are already at the latest version
Abstract
This paper aims to contribute to refining the e-values for testing precise hypotheses, especially when dealing with nuisance parameters, leveraging the effectiveness of asymptotic expansions of the posterior. The proposed approach offers the advantage of bypassing the need for elicitation of priors and reference functions for the nuisance parameters and the multidimensional integration step. For this purpose, starting from a Laplace approximation, a posterior distribution for the parameter of interest only is considered and then a suitable objective matching prior is introduced, ensuring that the posterior mode aligns with an equivariant frequentist estimator. Consequently, both Highest Probability Density credible sets and the e-value remain invariant. Some targeted and challenging examples are discussed.
Keywords:
Asymptotic expansions
; Adjusted score function
; Bias reduction
; Evidence
; Full Bayesian Significance test
; Higher-Order asymptotics
; Matching priors
; Median bias reduction
1. Introduction
In this article we discuss an objective matching prior, that maintains the invariance of the posterior mode when testing specific hypotheses for parametric models, especially in the presence of nuisance parameters. These parameters are often introduced to establish flexible and realistic models, although the primary focus of inference is typically limited to a parameter of interest. The proposed approach offers the advantage of eliminating the need for eliciting information on the nuisance components and for conducting multidimensional integration, and it produces invariant values in the presence of nuisance parameters.
The parametric framework that we consider can be described as follows. Consider a random sample of size n from a random variable Y with parametric model , indexed by a paramater , with . Given a prior on , Bayesian inference for is based on the posterior density
where represents the likelihood function based on . Interest is in particular in the situation in which , where is a scalar parameter for which inference is required and represents the remaining nuisance parameters. In such case, Bayesian inference for is based on the marginal posterior density
which for its computation requires both elicitation on the nuisance parameter and multidimensional integration.
Asymptotic arguments are widely used in Bayesian inference through (1) and (2), based on developments of so-called higher-order asymptotics (see, e.g., [1,2,3,4,5]). Indeed, the theory of asymptotic expansions provides very accurate approximations to posterior distributions, and to various summary quantities of interest, including tail areas, credible regions and for the Full Bayesian Significance Test (see, e.g., [6,7]). Moreover, they are particularly useful for sensitivity analyses (see [8,9,10]) and also for the derivation of matching priors (see [11], and references therein). For instance, focusing on the presence of nuisance parameters, the Laplace approximation to (2) provides
where is the profile log-likelihood for , with the constrained maximum likelihood estimate (MLE) of given , is the full MLE, and is the profile observed information. Moreover, is the block of the observed information from the full log-likelihood , and the notation indicates that the approximation is accurate to order in moderate deviation regions (see, e.g., [12], Chapter 2). One appealing feature of higher-order approximations like (3) is that they may routinely be applied in practical Bayesian inference, since they require little more than standard likelihood quantities for their implementation, and hence they may be available at little additional computational cost over simple first-order approximations.
In the presence of nuisance parameters, starting from approximation (3) it is possible to define a general posterior distribution for of the form
where is now a prior distribution on only. Bayesian inference based on pseudo-likelihood functions – i.e. functions of only and of the data y with properties similar to those of a genuine likelihood function, such as the profile likelihood – has been widely used and discussed in the recent statistical literature. Moreover, it has been theoretically motivated in several papers (see, for instance, [13,14,15,16], and references therein), also focusing on the derivation of suitable objective priors. Especially when the dimension of is large, there are two advantages in using (4) instead of the marginal posterior distribution (2). First, the elicitation over is not necessary and, second, the computation of the integrals in (2) is circumvented.
Focusing on (4), in this paper it is of interest to test the precise (or sharp) null hypothesis
using the measure of evidence for the Full Bayesian Significance Test (see, e.g., [6,7]). The Full Bayesian Significance Test (FBST) quantifies evidence by considering the posterior probability associated with the least probable points in the parameter space under . Higher-order asymptotic computation of the FBST for precise null hypotheses in the presence of nuisance parameters has been discussed in [2].
The original measure of evidence for the FBST is not invariant under suitable transformations of the parameter, a property which has been reached however in the more recent definition of the value (see [17,18], and references therein). Neverthless, when working on a scalar parameter of interest, in the presence of nuisance parameters, the value is not invariant with respect to marginalisations of the nuisance parameter and it must be used in the full dimensionality of the parameter space. This requires elicitation on the complete parameters, numerical optimization and numerical integration, that can be computationally heavy especially when the dimension of is large.
The aim of this paper is to consider the value in the context of the pseudo-posterior distribution , suggesting in this respect a suitable objective prior to be used in (4). More precisely, focus is on a particular matching prior, which ensure invariance of the posterior mode of the pseudo-posterior distribution. As a consequence also Highest Probability Density credible (HPD) sets are invariant, as well as the value.
The paper is organized as follows. Section 2 provides a short review on the FBST for testing precise null hypotheses and also illustrates asymptotic approximations for the value, extending results of [2]. Section 3 discusses the derivation of the objective matching prior for the parameter of interest only, called median matching prior, that produces invariant values. Also several targeted and challenging examples are discussed. Finally, Section 4 closes with some concluding remarks.
2. The FBST measure of evidence
Suppose that we need to decide between two hypotheses: the null and the alternative . The usual Bayesian testing procedure is based on the well-known Bayes factor (BF), defined as the ratio of the posterior odds to the prior odds in favor of the null hypothesis. A high BF or its logarithm suggest evidence in favor of . However, it is well-known that, when improper priors are used, the BF can be undetermined and, when the null hypothesis is precise (as specified in (5)), the BF can lead to the so-called Jeffreys-Lindley’s paradox (see, e.g. [19]). Moreover, the BF is not calibrated, i.e. its finite sampling distribution is unknown and it may depend on the nuisance parameter.
To avoid these drawbacks, in recent years an alternative Bayesian procedure, called FBST, has been introduced by [7] in case of sharp hypothesis identified by the null set , a submanifold of of lower dimension. The FBST quantifies evidence by considering the posterior probability associated with the least probable points in the parameter space . When this probability is high, it favors the null hypothesis, providing a clear and interpretable measure of support for (see, e.g. [6,18,20], and references therein). The FBST is based on a specific loss function, and thus the decision made under this procedure is the action that minimizes the corresponding posterior risk.
The FBST operates by determining the value, a representation of Bayesian evidence associated to . To construct the value, the authors introduced the posterior surprise function and its supremum given, respectively, by
where is a suitable reference function to be chosen. Then, they introduce the tangential set defined as the set of parameter values for which the posterior surprise function exceeds the supremum , that is
This set, often referred to as the Highest Relative Surprise Set, includes parameter values with higher surprise than those within the null set . The value is then computed as
and is rejected for small values of .
The original FBST, as proposed by [7,21], relies on a flat reference function , so that this first version involved the determination of the tangential set starting only from the posterior distribution . However, this initial version lacked invariance under reparameterizations. Subsequent refinements of the FBST introduced the importance of reference density functions, making the value explicitly invariant under appropriate transformations of the parameter. Common choices for the reference function include uninformative priors, like the uniform distribution, maximum entropy densities, or Jeffreys’ invariant prior. In [22], the use of the Jeffreys’ prior, , where is the Fisher information derived from , is discussed as the reference function to derive invariant HPD sets and Maximum A Posteriori (MAP) estimators that are invariant under reparameterizations. Note that the uses the full dimensionality of the parameter space. Moreover, this measure is not invariant with respect to transformations of the nuisance parameters and the use of high posterior densities to construct credible sets may produce inconsistencies.
Concerning the asymptotic behavior of the it can be proven that, under suitable regularity conditions as the sample size increases, with representing the true parameter value (see [18]), it holds:
- If is false, i.e. , then converges in probability to 1.
- If is true, i.e. , then, denoting by the cumulative distribution function of , we have that , with , and the cumulative chi−square distribution with k degrees of freedom.
In practice, the computation of is performed in two steps: (a) a numerical optimization and (b) a numerical integration. The numerical optimization step consists in finding the maximizer of under the null hypothesis. The numerical integration step consists of integrating the posterior surprise function over the region where it is greater than , to obtain the value. These computational steps make the FBST a computationally intensive procedure. Despite efficient computational algorithms for local and global optimization, as well as numerical integration, obtaining precise results for hypotheses like (5) is highly demanding, especially with large nuisance parameter dimensions. Numerical integration can be tackled by resorting to higher-order tail area approximations, as reviewed in the Bayesian framework in [4]. An application of asymptotic approximation to the FBST in its first formulation, i.e. with reference function , has been discussed in [2].
2.1. Asymptotic approximations for the
A first-order approximation for the value, when testing (5), is simply given by (see, e.g., [23,24])
where the symbol "" indicates that the approximation is accurate to and is the standard normal distribution function. Thus, to first-order, agrees with the value based on the profile Wald statistic
In practice, the approximation (6) of may be inaccurate, in particular when the dimension of is large with respect to the sample size, because it forces the marginal posterior distribution to be symmetric.
The practical computation of requires the evaluation of integrals of the marginal posterior distribution. In order to have more accurate evaluations of , it may be useful to resort to higher-order asymptotics based on tail area approximations (see, e.g., [3,4], and references therein). Indeed, the measure of evidence involves integrals of the marginal surprise posterior density . In particular, extending the application of the tail area argument to the marginal surprise posterior density, we can derive a approximation to the marginal surprise posterior tail area probability, given by
where
with
profile likelihood root and
In the expression of , is the profile score function.
Using the tail area approximation (8), a third-order approximation of the measure of evidence can be derived. The approximation, assuming without loss of generality that is smaller than the MAP of , is given by
with the value of the parameter such that . Note that
in (9) gives the posterior probability of the HPD credible interval . Note also that the higher-order approximation (9) does not call for any condition on the prior , i.e. it can be also improper. Finally, when is symmetric, Equation (9) reduces to .
While tail area approximations require little more than standard likelihood quantities for their implementation and, in this respect, they are available at little additional computational cost over the first-order approximation, they require elicitation on the complete parameter and to choose the reference function .
3. An invariant objective prior
The aim of this section is to derive a default prior to be used in (4). To this end, following [11] we use the shrinkage argument, which is a crucial procedure in the development of matching priors, i.e. priors that ensure, up to the desired order of asymptotics, an agreement between Bayesian and frequentist procedures. Examples of matching priors are (see [11]) for posterior quantiles, for credible regions and for prediction. Here, we focus on a specific matching prior, that ensures the invariance of the posterior mode in the posterior distribution (4). As a consequence, the invariance extends to HPDs, as well as the value, achieved incorporating the reference function within the prior.
The proposed choice of the prior , that makes the MAP and thus also HPDs and the value invariant under 1-1 reparameterization, will depend on the log-likelihood and on its derivatives. In regular parametric estimation problems, both the MLE and the score estimating function exhibit an asymptotically symmetric distribution centered at the true parameter value and at zero, respectively. However, these asymptotic behaviours may poorly reflect exact sampling distributions particularly in cases with small or moderate sample information, sparse data, or complex models. Several proposals have been developed to correct the estimate or the estimating function. Most available methods are aimed at approximate bias adjustment, either of the MLE or of the profile score function, also when nuisance parameters are present (see [25] for a review of bias reduction for the MLE and [26] and subsequent literature for bias correction of the profile score). Lack of equivariance impacts the so-called implicit bias reduction methods, which achieve first-order bias correction by modifying the score equation (see [25,27]). To avoid this drawback, in this paper we focus on the median modification of the score, or profile score equation, whose solution respects equivariance under monotone reparameterizations ([28]). Similar to Firth’s implicit method ([27]), the median modification of the score, or profile score, does not rely on finiteness of the MLE, thereby effectively preventing infinite estimates.
In practice, to derive the median matching prior prior , we impose that the MAP of coincides with a refined version of the MLE, obtained as the solution of the median modified score function ([28]). To introduce this new invariant prior, we initially explore the scenario without nuisance parameters and then the situation in which nuisance parameters are present.
3.1. No nuisance parameters
Let’s explore first the scenario where is scalar. In order to obtain median bias reduction of the MLE, it is possible to resort to a modified version of the score function of the form
where is the score function and a suitable correction term of order . In particular, the median modified score function assumes for the expression
The solution to the equation not only upholds equivariance under componentwise monotone reparameterizations but also approximates median unbiasedness ([28]). Note that likelihood inference based on (10) does not depend explicitely on the MLE. Indeed, the modified score function has been found to overcome infinite estimate problems. Likewise the MLE, also is asymptotically , so that the Wald-type statistics only differ in location.
Since Bayes’ theorem is a statement of adittivity on the log scale constant, we observe that in the Bayesian framework can be interpreted as the derivative of the logarithm of a prior, that is . We are thus looking for a matching prior such that
In the scalar parameter case, it is straightforward to show that the proposed median matching prior takes the form
where and . The posterior based on the median matching prior is thus
A first-order approximation for the value, when testing , is simply given by
which differs in location with respect to the classical first-order approximation for the value based on the MLE. A second approximation for the value, when testing , can be obtained from the asymptotic distribution of the modified score function (10), that is
Although the first-order equivalence between (11) and (12), note that (11) is based on an easily understandable comparison between estimated value and hypothetical value, taking estimation error into account, and is widely used in applications, but does not satisfy the principle of parameterization invariance. On the other hand, is parameterization invariant.
Note that, when using a predictive matching prior, i.e. a prior ensuring asymptotic equivalence of higher-order frequentist and Bayesian predictive densities (see, e.g., [11]), the term in (10) corresponds to the Firth’s adjustment ([27])
In view of this, for general regular models, Firth’s estimate coincides with the mode of the posterior distribution obtained using the default predictive matching prior. However, lack of invariance affects this kind of adjustment ([25]), unless dealing with linear transformations.
Example 1:
One parameter exponential family. For a one parameter exponential family with canonical parameter , i.e. with density
the median modified score function has the form
where and . In this parameterization, can be seen as the first derivative of the log-posterior
On the other hand, Firth’s modified score takes the form . The effect of the median modification is to consider the median matching prior , while implies a Jeffreys’ prior . Note that, for a one parameter exponential family with canonical parameter , both and belong to the family of invariant priors discussed in [29,30].
Example 2:
Scale model. Consider the scale model , where is a given function. Let . We have , and , with , and . The median matching prior is thus , while the Jeffreys’ prior for a one-parameter scale model is and the prior associated to the Firth’s adjustment is .
Example 3:
Skew-normal distribution. Consider a skew-normal distribution with shape parameter , with density , where is the standard normal density function. The median correction term for the score function associated to the median matching prior is (see [28,31])
Numerical integration must be performed to obtain the expected values involved in .
In order to illustrate the proposed prior, we consider draws from the skew-normal model with true parameter and increasing sample sizes (Figure 1). The posterior distributions are obtained with the method by [32], i.e. drawing values and accepting the best . The values associated to the null (true) hypothesis and the (false) hypothesis are reported in Table 1. For comparison, also the Jeffreys’ prior ([33]), the predictive matching prior ([31]) and the flat prior, with uniform reference function, are considered. Progressive agreement among evidence values obtained with the proposed median matching prior and the other priors for larger sample size is shown. Also, as expected, progressively increasing n, the evidence values indicate agreement with the true hypothesis and disagreement with for all the priors used. Anyway, note that the posterior distribution obtained with a flat prior, and a uniform reference function, is proportional to the likelihood function that can be monotone. In view of this, while the MAPs of the posterior based on the default priors are always finite, in some samples the MAP of the posterior with the non-informative prior may be infinite. An example of this effect is illustrated in Figure 2.
The properties of first-order approximations of the values have been investigated by a simulation study, with sample sizes . Results are displayed in Figure 3. Distributions of the value from the posterior based on the median matching prior are better, both for small and moderate sample sizes, in terms of convergence to the Uniform distribution. Moreover, score-type values (12) are also preferable than Wald-type values (11). For the results with the posterior distribution obtained with a flat prior we found of infinite estimates for the sample sizes considered in the simulation study, and in these cases the value was considered as 0.
3.2. Presence of nuisance parameters
In the presence of nuisance parameters, in order to obtain median bias reduction of the MLE, it is possible to resort to a modified version of the profile score function of the form
where a suitable correction term of order . In particular, for the median modified profile score function, the adjustment assumes the expression
where , and are the first three cumulants of (see [28], Section 2.2, for their expression). For the estimator , defined as the solution of , parameterization equivariance holds under interest respecting reparameterizations ([28]).
Note that, also in the context of nuisance parameters, we are in the situation in which the proposed prior is known through its first derivative; this is typically the situation with matching priors (see, e.g., [11]). Since the parameter of interest is scalar, the posterior based on the median matching prior can be written as
A simple analytical way of approximating to first-order the posterior distribution (14) based on the median matching prior is to resort to a quadratic form of . In particular, the approximate posterior distribution for takes the form
where is a Rao score-type statistic based on (13) and the symbol "" means asymptotic proportionality to first-order. In this case, a first-order approximation of the value, when testing , is given by
In this case, an higher order approximation via (3) would be impractical since a closed form prior is not available. As an alternative, simulation-based approaches may be used to derive the implied posterior distribution (14) based on the median matching prior. The first one relies on Approximate Bayesian Computation (ABC) techniques, using or the modified profile score function as summary statistics; see [34] for the modification of the algorithm of [32] by using a profile estimating equation. This first method introduces an approximation at the level of the posterior estimation. The second one still relies on (13) but considers use of Manifold MCMC methods (see ,e.g., [35]) to conditioning exactly on the profile equation and not up to a tolerance level, as in ABC (see [36,37]). The algorithm moves on the constrained space , where is the solution of the estimating equation on the original data. For the latter method, we need minimal regularity assumptions on , which is assumed to be continuous, differentiable and available in closed form expression. Note, for instance, that in the skew-normal example in Section 3.1 these conditions are not met.
Example 4:
Exponential family. If is an exponential family of order d with canonical parameter , i.e. , quantities involved in are simply obtained from derivatives of ([28]). Note that, in this framework, is an approximation with error of order of the score for in the conditional model given (see e.g. [38],Section 10.2). Then, in the continuous case, the MAP is an approximation of the optimal conditional median unbiased estimator, and is related to the conditional likelihood for given by ; see [39] for a Bayesian interpretation of such pseudo-likelihoods.
Example 5:
Multivariate regression model. Consider a regression model of the form
where it is assumed that , with positive definite matrix, and are unknown parameters. This model is widely used for instance in time series analysis, in which as regression covariates the past of the observables y are used. We focus on the problem of testing hypothesis on the correlation coefficient .
Consider a draw with true parameter and . For obtaining the proposed posterior (14) for we first compute the MAPs with the median matching prior and also, for comparison, with the predictive matching prior, which are respectively 0.953 and 0.92. Note that the expression of the predictive matching prior for is given in [40] and it still corresponds to the Firth’s adjustment to the score function. The expressions of the modified profile estimating functions and are obtained from [41] and are available in closed form expressions. Hence, the Manifold MCMC method can be used to obtain the implied posteriors, whose approximation is comparable to that of any MCMC sampler. In particular we used 20000 iterations.
We compare the posterior distribution based on the proposed median matching prior, with those obtained with the predictive matching prior and with an inverse-Wishart prior for the covariance matrix with one degree of freedom and identity position, and uniform prior on the regression parameters. The posterior distributions are displayed in Figure 4. The hypothesis of interest is , and a smaller e-value indicating disagreement with the hypothesis should be preferable. The values are 0.25 with the median matching prior, 0.36 for the predictive matching prior and 0.60 with the inverse-Wishart prior. Note that the value based on the inverse-Wishart prior involves the constrained maximization and multidimensional integration thus is not directly readable in Figure 4. Indeed, one crucial difference is that the original value formulation links the evidence of the null hypothesis to the evidence of a more refined hypothesis, choosing the MAP under the null hypothesis for all the nuisance parameters, while in the alternative (tangential) set all values are used, and integration is performed on the full dimensionality of the space. On the contrary, in the proposed posterior based on the median matching prior, the maximizer of nuisance parameters are taken both in the null and non null sets.
Finally, for the posterior based on the inverse-Wishart prior, we also computed the value based on high-order tail area approximation (9) of the marginal surprise posterior, which is equal to 0.27. This procedure still avoids the multidimensional integration but the result is not invariant to changes of parametrization.
Example 6:
Logistic regression model. Let , , be independent realizations of binary random variables with probability , where and is a row vector of covariates. We assume that a generic scalar component of is of interest and we treat the remaining components as nuisance parameters.
As an example, we consider the endometrial cancer grade dataset analyzed, among others, in [42]. The aim of the clinical study was to evaluate the relationship between the histology of the endometrium (HG), the binary response variable, of patients and three risk factors: 1. Neovascularization (NV), that indicates the presence or extent of new blood vessel formation; 2. Pulsatility Index (PI), that measures blood flow resistance in the endometrium; 3. Endometrium Height (EH), that indicates the thickness or height of the endometrium. A logistic model for HG, including an intercept and using all the covariates (NV, PI, EH), has been fitted, but maximum likelihood leads to infinite MLE of the coefficient related to NV, due to quasi-complete separation. This phenomenon prohibits the use of diffuse priors for , since the corresponding posterior wouldn’t concentrate. Moreover, the value with non-informative priors cannot be obtained also for any hypothesis concerning parameters different from .
If we consider as the parameter of interest, while the remaining regression coefficients are treated as nuisance parameters, the analysis with the median matching prior allows to obtain a global proper posterior, with MAP equal to 3.86, open to interpretation both in the original scale and in terms of odds ratios. Similarly, the posterior based on the predictive matching prior, which in this model coincides with Jeffreys’ prior is proper, with the MAP set at 2.92. The latter suffers from lack of interpretability on different scales, since a different parametrization in estimation phase would affect the results.
If we consider as the parameter of interest, related to the risk factor PI, the MAPs are -0.038 when using the median matching prior and -0.035 when using the predictive matching prior. The values for the hypothesis are 0.60 and 0.55, respectively (see Figure 5). Likewise, the interpretation of e-values remains consistent and independent of parametrization solely in the first case.
4. Conclusions
Although (14) cannot always be considered as orthodox in a Bayesian setting, the use of alternative likelihoods is nowadays widely shared, and several papers focus on the Bayesian application of some well-known pseudo-likelihoods. In particular, the proposed posterior has the advantages of avoiding the elicitation on the nuisance parameter and of the computation of multidimensional integrations. Moreover, it provides invariant MAPs, HPDs and values, without the adoption of a reference function . The use of matching priors, i.e. priors that ensure, up to the desired order of asymptotics, an agreement between Bayesian and frequentist procedures, can be extended to compute other Bayesian measures of evidence in the presence of sharp hypotheses with nuisance parameters (see, for example, [43]). Finally, we remark that frequentist properties of the MAP of the posterior based of the proposed median matching prior in comparison with the MAP of the posterior based of the predictive matching prior have been investigated in [28,41] for some of the examples discussed in this paper.
For inference on a full vector parameter , with components, a direct extension of the rationale leading to (10) does not seem to be practicable due to lack of a manageable definition of multivariate median. Actually, in [28,44] it is shown how the method can be extended to a vector parameter of interest, in the presence of nuisance parameters, by simultaneously solving median bias corrected score equations for all parameter components. This leads to componentwise third-order median unbiasedness and parameterization equivariance. Moreover, the use of default priors involving all parameter components, also the nuisance, becomes necessary to regularize likelihoods in case of monotonicity.
As a final remark, we note that among the possible objective priors that ensures invariance of the posterior, we did not focus on the Jeffreys’ in the multidimensional case, since it often exhibits poor convergence properties. Conversely, the default matching priors considered in this paper are easily generalizable to the multidimensional case [44] preserving good convergence properties. Data and code used in the examples are available in https://github.com/elenabortolato/invariant_evalues.
Abbreviations
The following abbreviations are used in this manuscript:
| ABC | Approximate Bayesian Computation |
| BF | Bayes Factor |
| FBST | Full Bayesian Significance Test |
| HPD | Highest Probability Density |
| MAP | Maximum A Posteriori |
| MLE | Maximum Likelihood Estimator |
References
- Brazzale, A.R., Davison, A.C., Reid, N. Applied asymptotics. Case-studies in small sample statistics 2007. Cambridge University Press.
- Cabras, S., Racugno, W., Ventura, L. Higher-order asymptotic computation of Bayesian significance tests for precise null hypotheses in the presence of nuisance parameters. Journal of Statistical Computation and Simulation 2015, 85, 2989–3001. [CrossRef]
- Reid, N. The 2000 Wald memorial lectures: asymptotics and the theory of inference. Ann. Stat. 2003, 31, 1695–1731.
- Ventura, L., Reid, N. Approximate Bayesian computation with modified loglikelihood ratios. Metron 2014, 7, 231–245. [CrossRef]
- Ventura, L., Sartori, N., Racugno, W. Objective bayesian higher-order asymptotics in models with nuisance parameters. Comput. Stat. Data Anal. 2013, 60, 90–96. [CrossRef]
- Madruga, M., Pereira, C., Stern, J. Bayesian evidence test for precise hypotheses. Journal of Statistical Planning and Inference 2003, 117, 185–198. [CrossRef]
- Pereira, C., Stern, J.M. Evidence and Credibility: Full Bayesian Significance Test for Precise Hypotheses. Entropy 1999, 1, 99–110. [CrossRef]
- Kass, R.E., Tierney, L., Kadane, J. Approximate methods for assessing influence and sensitivity in Bayesian analysis. Biometrika 1989, 76, 663–674. [CrossRef]
- Reid, N., Sun, Y. Assessing sensitivity to priors using higher order approximations. Commun. Stat. Theory Methods 2010, 39, 1373–1386. [CrossRef]
- Ruli, E., Sartori, N., Ventura, L. Marginal posterior simulation via higher-order tail area approximations. Bayesian Analysis 2014, 9, 129–146. [CrossRef]
- Datta, G.S., Mukerjee, R. Probability Matching Priors: Higher-Order Asymptotics 2004. Lecture Notes in Statistics, Springer.
- Severini, T.A. Likelihood methods in statistics 2000. Oxford University Press.
- Giummolé, F., Mameli, V., Ruli, E., Ventura, L.. Objective Bayesian inference with proper scoring rules. Test 2019, 28, 728–755. [CrossRef]
- Leisen, F., Villa, C., Walker, S.G. On a class of objective priors from scoring rules (with discussion). Bayesian Analysis 2020, 15, 1345–1423. [CrossRef]
- Miller, J.W. Asymptotic normality, concentration, and coverage of generalized posteriors. Journal of Machine Learning Research 2021, 22, 1.
- Ventura, L., Racugno, W. Pseudo-likelihoods for Bayesian inference, In Topics on Methodological and Applied Statistical Inference, Series Studies in Theoretical and Applied Statistics 2016, Springer-Verlag, Book ISBN: 978-3-319-44093-4, 205-220.
- Diniz, M., B. Pereira, C., Stern, J. M. Cointegration and unit root tests: A fully Bayesian approach. Entropy, 2020 22, 968. [CrossRef]
- Pereira, C., Stern, J.M. The e-value: a fully Bayesian significance measure for precise statistical hypotheses and its research program. Sao Paulo J. Math. Sci. 2022, 16, 566–584. [CrossRef]
- Robert, C. P. On the Jeffreys Lindley paradox, Philosophy of Science 2014, 81, 216–232. [CrossRef]
- Madruga, M.R., Esteves, L.G. and Wechsler, S. On the bayesianity of pereira-stern tests. Test 2001, 10, 291–299. [CrossRef]
- Pereira, C., Stern, J.M.. Model Selection: Full Bayesian Approach Environmetrics 2001, 12, 559–568.
- Druilhet, P., Marin, J.M. Invariant HPD credible sets and MAP estimators. Bayesian Analysis 2007, 2, 681–692. [CrossRef]
- Diniz, M. A., Pereira, C., Polpo, A., Stern, J.M., Wechsler, S. Relationship between Bayesian and frequentist significance indices. Int. J. Uncertain. Quantif. 2012, 2, 161–172. [CrossRef]
- Pereira, C., Stern, J.M., Wechsler, S. Can a significance test be genuinely Bayesian? Bayesian Analysis 2008, 79–100.
- Kosmidis, I. Bias in parametric estimation: reduction and useful side effects. Wiley Interdisciplinary Reviews: Computational Statistics 2014, 6, 185–196. [CrossRef]
- Stern, S. E. A second-order adjustment to the profile likelihood in the case of a multidimensional parameter of interest. Journal of the Royal Statistical Society Series B 1997, 59, 653–665. [CrossRef]
- Firth, D. Bias reduction of maximum likelihood estimates. Biometrika 1993, 80, 27–38. [CrossRef]
- Kenne Pagui, E.C., Salvan, A., Sartori, N. Median bias reduction of maximum likelihood estimates. Biometrika 2017, 104, 923–938. [CrossRef]
- Hartigan, J.A. Invariant prior densities. Ann.Math.Statist. 1964, 35, 836–845.
- Hartigan, J.A. The asymptotically unbiased density. Ann. Math. Statist. 1965, 36, 1137–1152.
- Sartori, N. Bias prevention of maximum likelihood estimates for scalar skew normal and skew t distributions. Journal of Statistical Planning and Inference 2006, 136, 4259–4275. [CrossRef]
- Ruli, E., Sartori, N., Ventura, L. Robust approximate Bayesian inference. Journal of Statistical Planning and Inference 2020, 205, 10–22. [CrossRef]
- Liseo, B., Loperfido, N. A note on reference priors for the scalar skew-normal distribution. J. Statist. Plann. Inference 2006. 136, 373–389. [CrossRef]
- Bortolato, E., Ventura, L. On approximate robust confidence distributions, Econometrics and Statistics 2023, ISSN 2452-3062, DOI:10.1016/j.ecosta.2023.04.006. [CrossRef]
- Brubaker, M., Salzmann, M., Urtasun, R. A family of MCMC methods on implicitly defined manifolds Artificial intelligence and statistics 2012, 161–172.
- Graham, M., Storkey, A. Asymptotically exact inference in differentiable generative models. Artificial Intelligence and Statistics 2017, 499–508. [CrossRef]
- Lewis, J. R., MacEachern, S. N., Lee, Y. Bayesian restricted likelihood methods: Conditioning on insufficient statistics in Bayesian regression (with discussion). Bayesian Analysis 2021, 104, 1393-1462. [CrossRef]
- Pace, L., and Salvan, A., Principles of Statistical Inference 1997. World Scientific.
- Severini, T. A. On the relationship between Bayesian and non-Bayesian elimination of nuisance parameters. Statistica Sinica 1999, 9, 713–724.
- Ruli, E., Sartori, N., Ventura, L. Posterior distributions with non explicit objective priors. In Book of Short Papers SIS 2018 2018, ISBN-9788891910233, 1193–1199.
- Bortolato, E., Kenne Pagui, E.C. Bias reduction and robustness in gaussian longitudinal data analysis. Journal of Statistical Computation and Simulation 2023, DOI:10.1080/00949655.2023.2248334. [CrossRef]
- Agresti, A. Foundations of Linear and Generalized Linear Models 2015. John Wiley & Sons.
- Bertolino, F., Manca, M., Musio, M. Racugno, W., Ventura, L. (2023) A new Bayesian Discrepancy Measure. Under revision. [CrossRef]
- Kosmidis, I., Kenne Pagui, E. C., Sartori, N. Mean and median bias reduction in generalized linear models. Statistics and Computing 2020, 30, 43–59. [CrossRef]
Figure 1.
Inference for the scalar parameter of the skew-normal model with sample sizes (top-left, top-right, bottom-left and bottom-right panels, respectively). The red line is used for the posterior obtained from the median matching prior, the green one for the predictive matching prior, the violet one for the Jeffreys’ prior and the blue one from an improper flat prior. The horizontal lines identify the corresponding tangential sets associated to the hypothesis .
Figure 1.
Inference for the scalar parameter of the skew-normal model with sample sizes (top-left, top-right, bottom-left and bottom-right panels, respectively). The red line is used for the posterior obtained from the median matching prior, the green one for the predictive matching prior, the violet one for the Jeffreys’ prior and the blue one from an improper flat prior. The horizontal lines identify the corresponding tangential sets associated to the hypothesis .
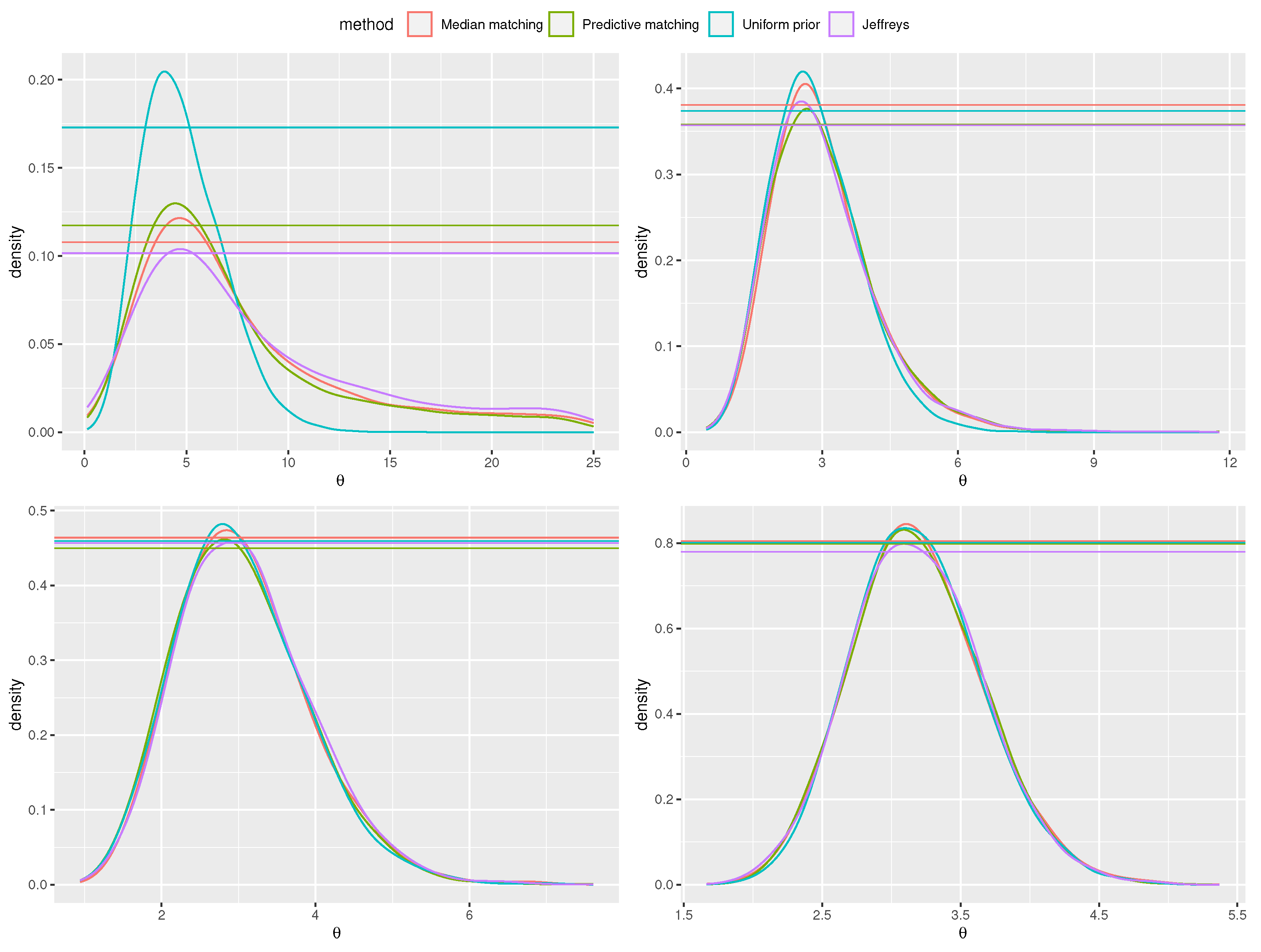
Figure 2.
Skew-normal model: An example of (estimating equation) with a flat prior (blue line), the median matching prior (red line) the predictive matching prior (green line) and the Jeffreys’ prior (violet line) in a sample where all the observations are positive.
Figure 2.
Skew-normal model: An example of (estimating equation) with a flat prior (blue line), the median matching prior (red line) the predictive matching prior (green line) and the Jeffreys’ prior (violet line) in a sample where all the observations are positive.
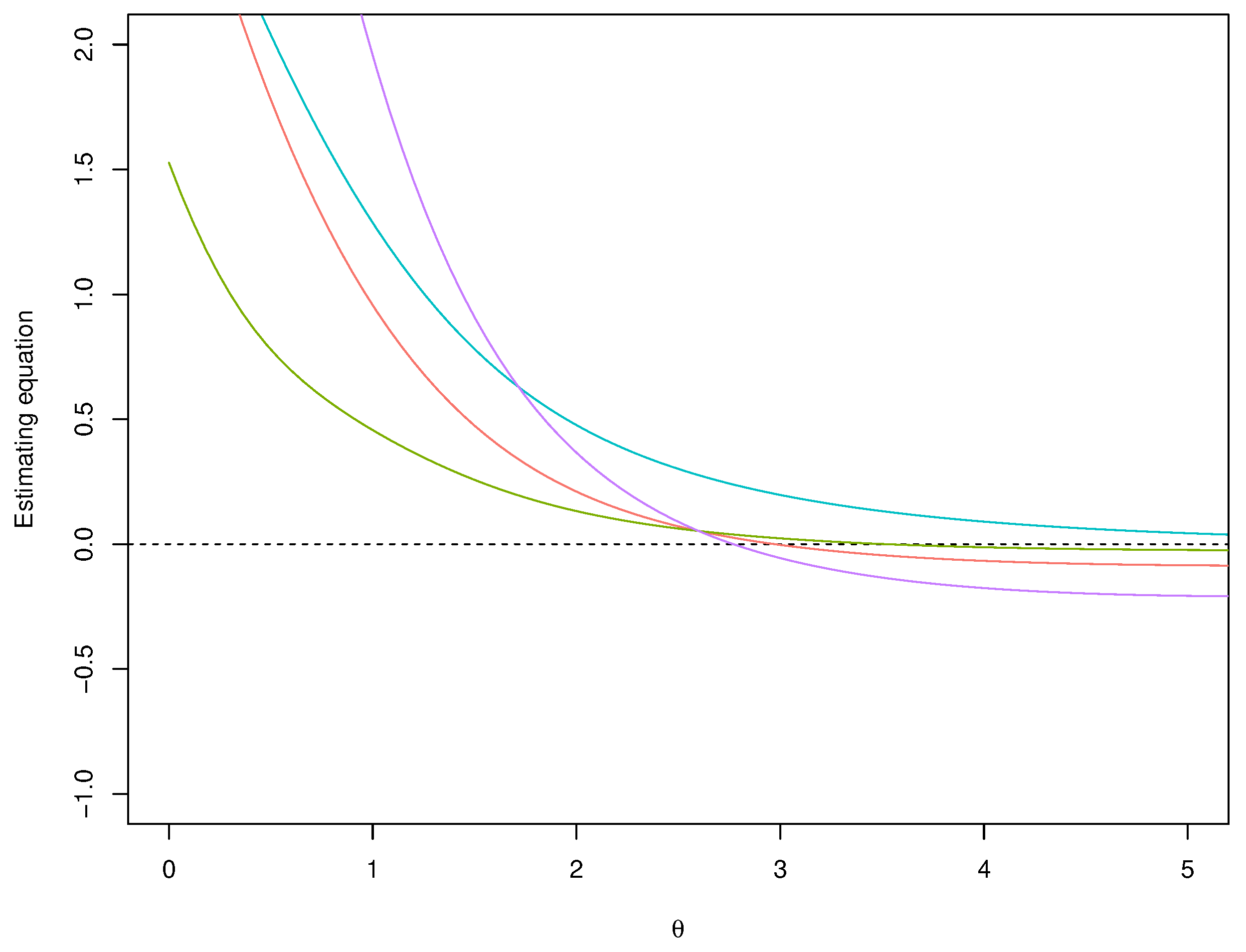
Figure 3.
Skew-normal model: Distributions of values from a simulation study under the null hypothesis , using a flat prior (blue line), the median matching prior (red line), the predictive matching prior (green line), and the Jeffreys’ prior (violet line). The darker line is used for the approximation (11) while the lighter for that based on (12).
Figure 3.
Skew-normal model: Distributions of values from a simulation study under the null hypothesis , using a flat prior (blue line), the median matching prior (red line), the predictive matching prior (green line), and the Jeffreys’ prior (violet line). The darker line is used for the approximation (11) while the lighter for that based on (12).
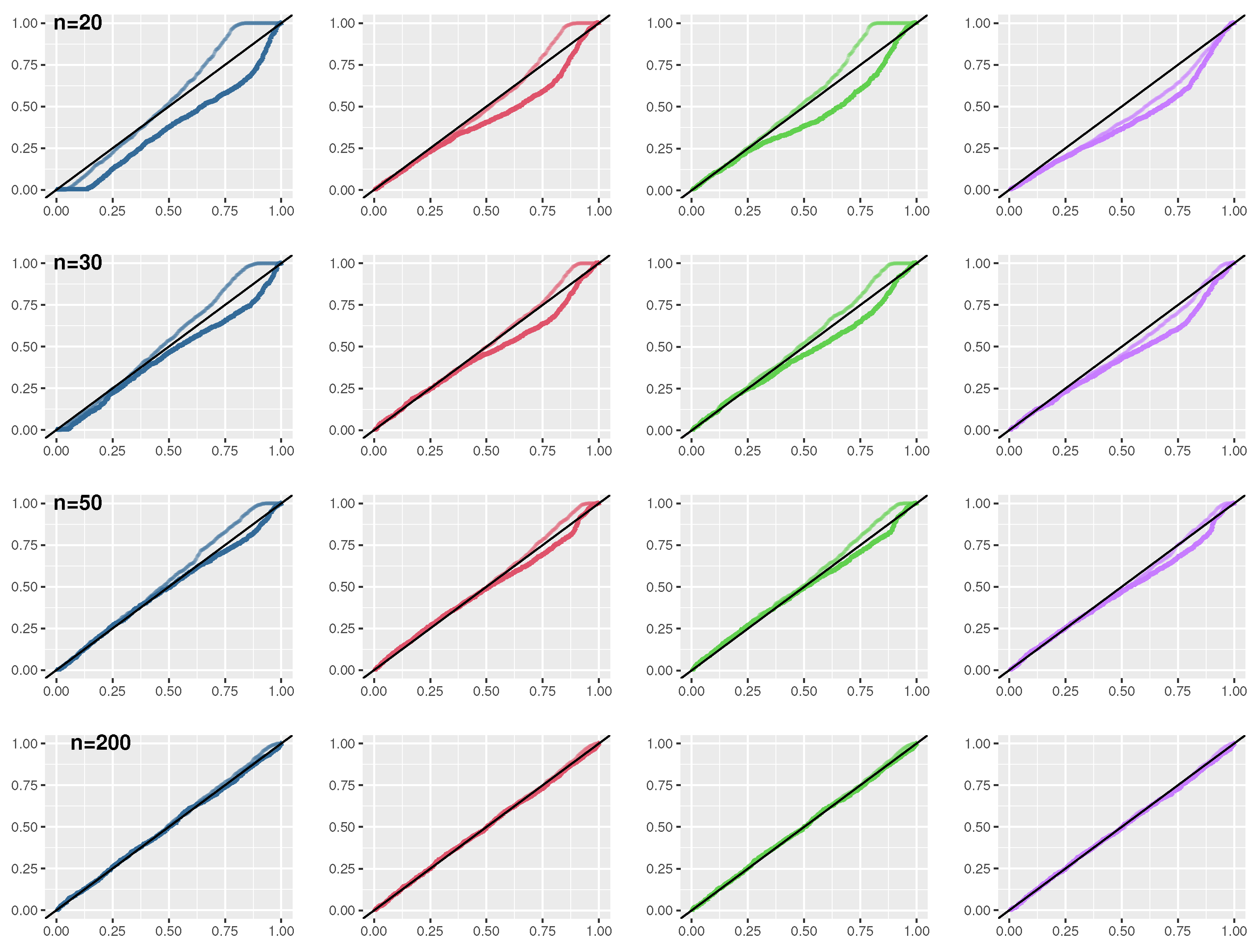
Figure 4.
Posterior distributions for the correlation parameter of the bivariate regression model obtained from MCMC draws and the three different priors.
Figure 4.
Posterior distributions for the correlation parameter of the bivariate regression model obtained from MCMC draws and the three different priors.
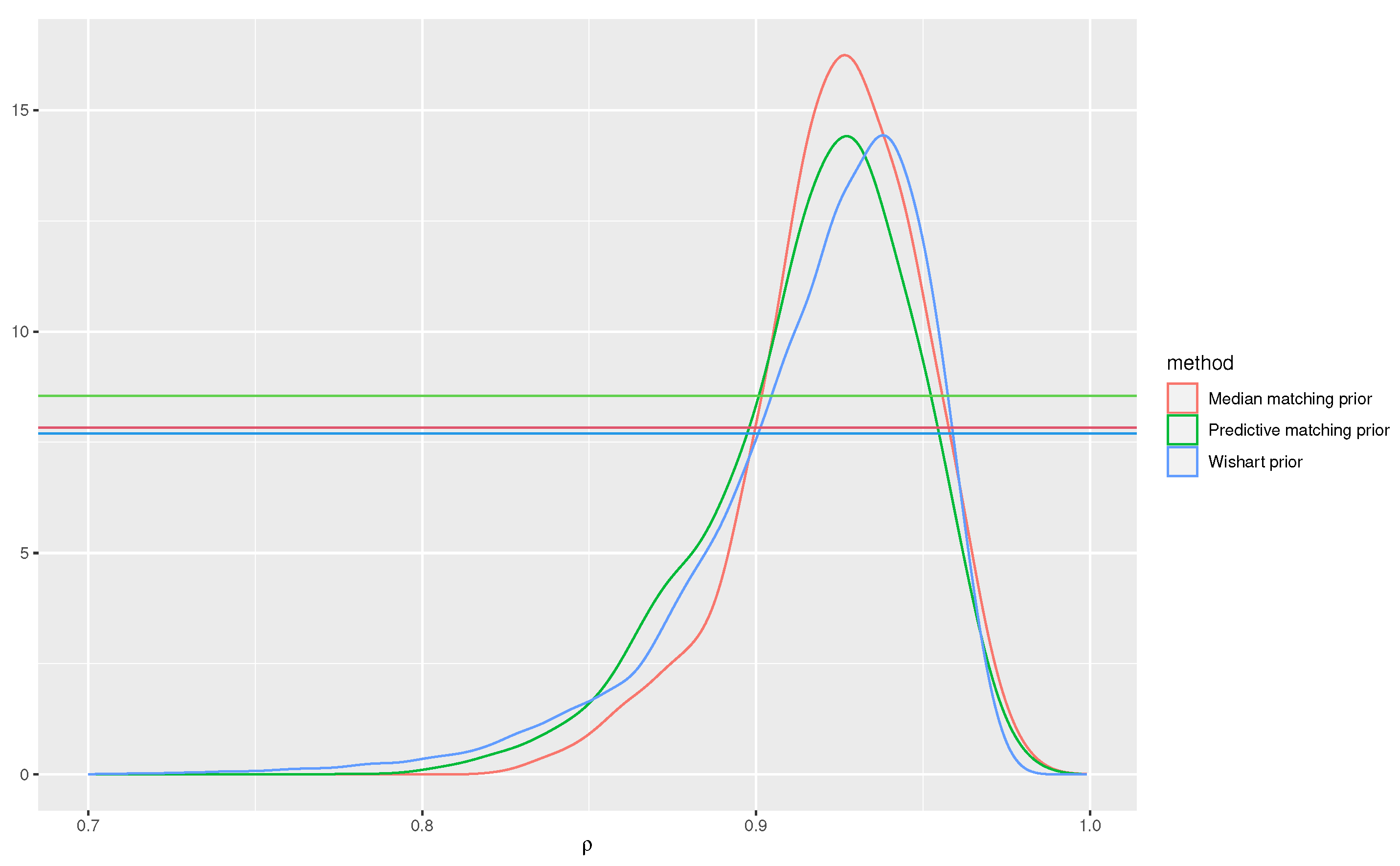
Figure 5.
Median matching posterior distribution and predictive matching posterior distributions for in the logistic regression model.
Figure 5.
Median matching posterior distribution and predictive matching posterior distributions for in the logistic regression model.
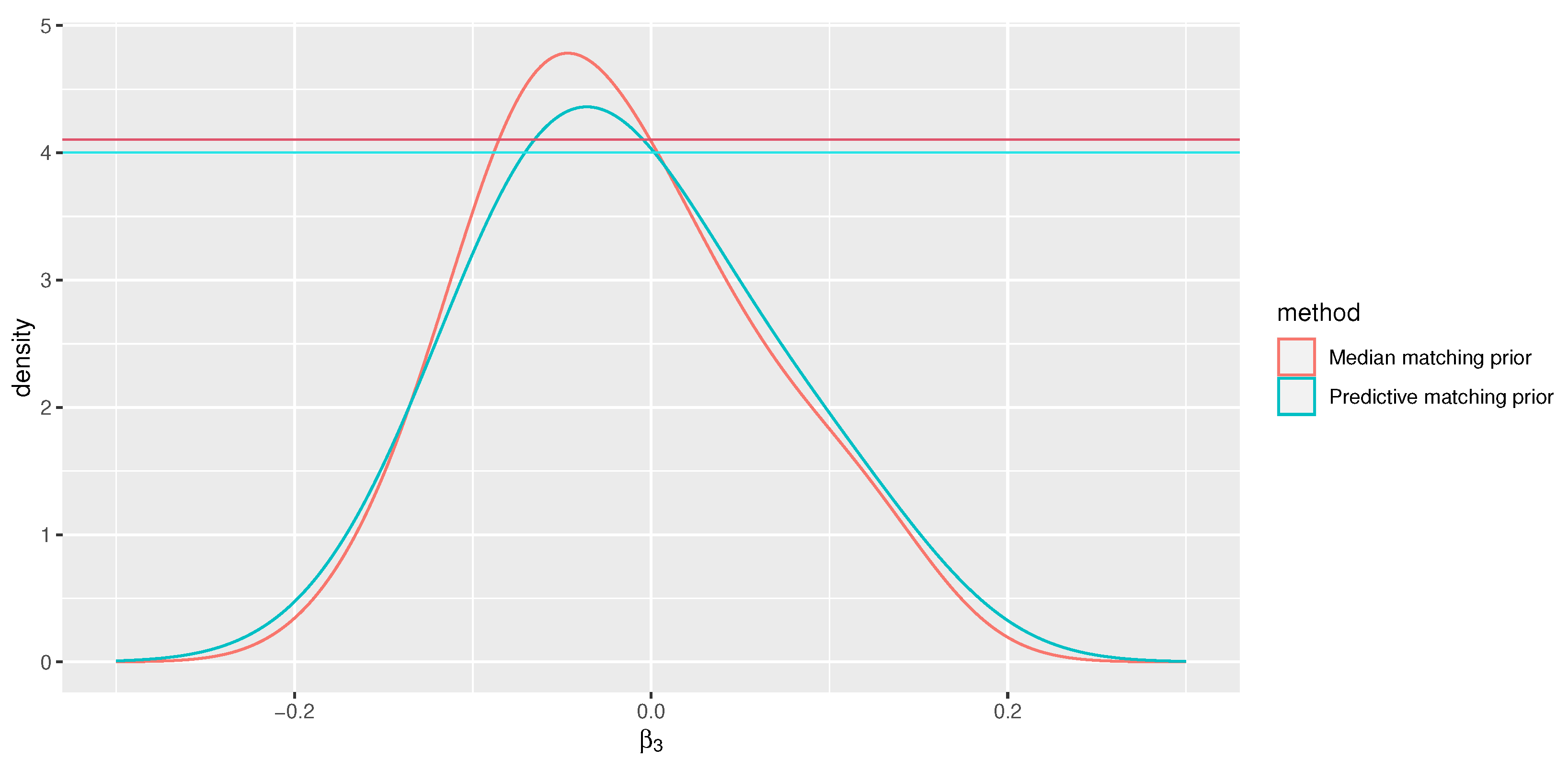

Table 1.
Skew-normal: values associated to the hypotheses and .
| hypothesis | n | Flat prior | Median matching prior | Predictive matching prior | Jeffreys’ prior |
|---|---|---|---|---|---|
| 20 | 0.59 | 0.62 | 0.56 | 0.65 | |
| 30 | 0.65 | 0.70 | 0.73 | 0.64 | |
| 50 | 0.81 | 0.84 | 0.82 | 0.91 | |
| 200 | 0.79 | 0.79 | 0.81 | 0.82 | |
| 20 | 0.82 | 0.91 | 0.98 | 0.84 | |
| 30 | 0.17 | 0.22 | 0.22 | 0.22 | |
| 50 | 0.20 | 0.20 | 0.20 | 0.21 | |
| 200 | 0.07 | 0.08 | 0.08 | 0.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



