
Submitted:
03 December 2023
Posted:
05 December 2023
You are already at the latest version
Abstract
Topological data analysis (TDA) is a recent approach for analyzing and interpreting complex data sets, based on ideas a branch of mathematics called algebraic topology. TDA has proven useful to disentangle non-trivial data structure in a broad range of data analytics problems including the study of cardiovascular signals. This review aims to provide an overview of the application of TDA to cardiovascular signals and its potential to enhance the understanding of cardiovascular diseases and their treatment. We first introduce the concept of TDA and its key techniques, including persistent homology, Mapper, and multidimensional scaling. We then discuss the use of TDA in analyzing various cardiovascular signals, including electrocardiography, photoplethysmography, and arterial stiffness. We also discuss the potential of TDA to improve the diagnosis and prognosis of cardiovascular diseases, as well as its limitations and challenges. Finally, we outline future directions for the use of TDA in cardiovascular signal analysis and its potential impact on clinical practice. Overall, TDA has shown great promise as a powerful tool for the analysis of complex cardiovascular signals and may offer significant insights into the understanding and management of cardiovascular diseases.
Keywords:
topological data analysis
; cardiovascular signals
; alegbraic topology
; persistent homology
; mapper algorithm
1. Introduction: Data analytics in modern cardiology
Cardiovascular diseases (CVDs) have been, for a long time, a major global health problem that has caused more deaths than any form of cancer or respiratory disease combined. The detection and prediction of CVDs is made difficult by the numerous etiological factors, complex disease pathways, and diverse clinical presentations [1,2]. However, with the advent of an enhanced capability for the generation of complex high-dimensional data from electronic medical records, mobile health devices, and imaging data, one is presented with both, challenges and opportunities for data-driven discovery and research. While traditional statistical approaches for risk stratification have been broadly developed, leading to important improvements of diagnosis, prognosis and in some cases therapeutics; most of these models have limitations in terms of individualized risk prediction. Recently, data analytics, artificial intelligence and machine learning have emerged as potential solutions for overcoming the limitations of traditional approaches in the field of CVD research.
Advance analytics algorithms can have a major impact on cardiovascular disease prediction and diagnosis. CVD data however remains challenging to common machine learning and data analytics approaches due to the wide variety and large heterogeneity of the diverse cardiovascular signals currently being probed [3,4]. Among the several different approaches that are arising to cope with such disparate data, one that results particularly outstanding for its generality and its ability to handle data integrating diverse dynamic ranges and scales is topological data analysis [5,6].
Topological data analysis (TDA) is, in short, a family of analytic methods that has been gaining relevance and recognition to model, predict and understand the behavior of complex biomedical data. TDA is founded on the tenets of algebraic topology, a mathematical field that deals with the shape of data and has a set of methods for studying it [7]. In this review article, we want to present the fundamentals of TDA and its applications in the analysis of cardiovascular signals. We aim to make these techniques accessible to non-experts by explaining their theoretical foundations and surveying their use in computational cardiology. We also discuss the limitations of these methods and suggest possible ways to incorporate them into clinical care and biomedical informatics in the context of cardiovascular diseases.
Figure 1 presents a graphic overview of the main ideas, starting with one or several data sources on cardiovascular signals coming from medical devices, wearables, clinical monitors, electronic health records and so on. Data is used to generate data clouds that are turned into Metric data sets that are then processed and analyzed with the tools of topological data analysis (see below) to generate homology groups, persistence diagrams and signatures, useful to classify signals towards a deeper understanding of their phenomenology.
2. Fundamentals of Topological Data Analysis
Topology is a branch of mathematics that deals with the shapes of objects. It provides a framework for understanding how objects can be deformed and still retain their essential properties. For example, a circular rubber band can be stretched into an oval, but a segment of string cannot. Topologists study the connectedness of objects by counting their number of pieces and holes, and use this information to classify objects into different categories.
A related field, algebraic topology, provides a framework for describing the global structure of a space in a precise and quantitative way. It uses methods that take into account the entire space and its objects, rather than just local information. Algebraic topology uses the concept of homology to classify objects based on their number and type of holes, and topological spaces, which consist of points and neighborhoods that satisfy certain conditions to do so. The notion of a topological space allows for flexibility in using topological tools in various applications, as it does not rely on numerical values to determine the proximity of points, but rather whether their neighborhoods overlap.
More formally, an Homology is a set of topological invariants represented by homology groups that describe the k-dimensional holes in a topological space X. The rank of (known as the kth Betti number), is analogous to the dimension of a vector space and indicates the number of k-dimensional holes. For example, corresponds to zero-dimensional features or connected components, corresponds to one-dimensional features or cycles, and corresponds to two-dimensional features or cavities. It is also possible to study for larger values of k, but it becomes more difficult to visualize the associated features.
At this stage, homology seems to be a rather abstract concept, however it can be connected in a straightforward manner to data analytics, once we recognize that one quite important property of data points: their shape as a set. That is, how do data points are distributed in the feature’s space. One can get an approximation to this shape by looking at how do holes are distributed in data space. Our understanding of why points accumulate in one region of data space and are missing in other regions will be a powerful tool to look for trends in the data. In order to understand the topological shape of a data set and identify its holes, it is useful to assign a topological structure to the data and calculate topological invariants. Homology groups are useful for this purpose because there are efficient algorithms for computing some of the more relevant of these invariants in the context of TDA [8].
Homology groups hence, are used to classify topological spaces based on the topological features of their shape, such as connectedness, loops, and voids. The homology groups of a topological space are invariant under continuous deformations, meaning that if two spaces have different homology groups, then they cannot be continuously deformed into one another and are therefore topologically distinct. Homology can thus be used to distinguish between spaces that may appear to be the same from other perspectives, such as those that have the same dimension or the same symmetries.
In the context of topological data analysis (TDA), the interpretation of topological features like connectedness, loops, holes, and voids involves understanding the geometric and structural properties of the data that these features represent. Let us briefly review some of these ideas.
Connectedness: Connectedness refers to the property of data points or regions being connected in a topological space. In TDA, connectedness typically corresponds to the number of connected components in a data set. The number of connected components can provide insights into the overall structure of the data. High connectedness implies that the data is relatively well-connected, while low connectedness may indicate separate clusters or isolated data points.
Loops: Loops represent closed paths or cycles in the data. They can occur when points or regions in the data form closed curves or circles. Loops can capture repetitive or periodic patterns in the data. They are often associated with cyclic structures or data points arranged in circular or ring-like formations.
Holes: Holes correspond to empty spaces or voids in the data where there are no data points. These voids can take various shapes, including spherical voids, tunnel-like voids, or irregular voids. The presence and characteristics of holes provide information about data emptiness. They can indicate the absence of data in specific regions or reveal patterns in the data distribution, such as clustering around voids.
Voids: Voids are regions of space that lack data points. They are similar to holes but can be more generalized and may not necessarily be enclosed by data. Voids are often used to study the spatial distribution and density of data points. Large, persistent voids may suggest regions where data is scarce, while small, transient voids may highlight local fluctuations.
To interpret these topological features effectively, TDA often employs persistence diagrams or barcode diagrams. These diagrams summarize the births and deaths of topological features across a range of spatial scales, providing a quantitative way to assess the significance and persistence of these features. Here’s how persistence diagrams relate to the interpretation of topological features:
Connectedness: The number of connected components is quantified by points in the persistence diagram. Longer persistence (vertical distance from birth to death) indicates more robust connected components.
Loops: Loops are associated with features in the persistence diagram. Longer loops correspond to more persistent cyclic patterns in the data.
Holes and Voids: Holes and voids are represented by clusters of points in the persistence diagram. The position of points in the diagram indicates the spatial scale and persistence of these features.
In summary, interpreting topological features in TDA involves understanding the presence, size, and persistence of connectedness, loops, holes, and voids in your data. Persistence diagrams provide a concise visual representation of these features and their characteristics across different scales, aiding in the exploration and analysis of complex data sets. A more formal explanation of these concepts will be discussed in the next subsection.
2.1. Persistent Homology
We will discuss some of the main homology groups used for data analytics. We will start by presenting the Persistent Homology Group or Persistent Homology, PH.
PH identifies topological features of a space at different scales. Features that are consistently detected across a broad range of scales are considered more likely to be true features of the space, rather than being influenced by factors such as sampling errors or noise. To use persistent homology, the space must be represented as a simplicial complex (i.e. a set of polytopes, like points, line segments, triangles, tetrahedra and so on) and a filtration, or a nested sequence of increasing subsets, must be defined using a distance function on the space.
To clarify such abstract concepts as simplicial complex and filtration, let us consider a set of measurements of some property (or properties) of interest in terms of the associated features for each point (see Figure 2A). We will customarily call this set a point cloud; this represents the data. Point clouds, which as we said, are simply collections of points, do not have many interesting topological properties per se. However, we can analyze their topology by placing a ball of radius around each point. This method (called filtration), allows us to encode geometric information by increasing the value of , which determines how much the boundaries of the shape blur and expand. As increases (Figure 2 panels B-E), points that were initially distinct may begin to overlap, altering the concept of proximity. Essentially, this process involves taking, let’s say an impressionist (when we partially close our eyes to reveal details, like we do to appreciate a picture from Claude Monet) look at the point cloud to give it a more defined shape.
A bit more formally, a simplicial complex is a collection of finite sets of points, called vertices, that are connected by edges, line segments connecting two vertices, and faces, which are polygons with three or more edges. The vertices, edges, and faces of a simplicial complex must satisfy certain conditions:
- Every face of the complex must be a simplex, that is, a triangle or a higher-dimensional analogue of a triangle.
- Every face of the complex must be a subset of one of the vertices of the complex.
- If a face of the complex is a subset of another face, then the larger face must be a subset of one of the vertices of the complex.
Once we have learned to build a simplicial complex for a given scale (value of ), by changing the value of , what we are doing is creating a filtered simplicial complex (FSC). Every topological property (such as the homologies ) that persists through the FSC is a PH. Intuitively different phenomena under study will give rise to different point clouds that when analyzed via a FSC will have different PHs.
2.1.1. Building the FSH
By building the PH to a given point cloud, one aims to create a complex that approximates the original manifold using the given points. To do this, connections are established between points by adding edges between pairs of points; faces between triples of points, and so on. To determine which connections to create, we introduce a parameter called the filtration value (the we already mentioned), which limits the maximum length of the edges that can be included in our simplices. We vary and build the complex at each value, calculating the homology of the complex at each step.
There are three main strategies for using to assign simplices: the Vietoris-Rips strategy, the witness strategy, and the lazy-witness strategy [9]. The Vietoris-Rips strategy adds an edge between two points if their distance is less than and a face between three points if their pairwise distance is less than , and so on. This approach is accurate but computationally expensive. The witness strategy uses two sets of points, called landmark points and witness points, to create the complex. Landmark points are used as vertices and edges are added between two landmark points if there is a witness point within distance of both points, and faces are added if there is a witness point within of all three points, and so on. The lazy-witness strategy is similar to the witness strategy in terms of how edges are assigned, but simplices of higher order are added anywhere there are n points that are all connected by edges.
2.1.2. Calculating the PH
Once we have chosen a filtration, it is possible to calculate the homology groups (the ’s) of each space in the filtration. Homology groups are a way of describing the topological features of a space, such as connected components, holes, and voids. Depending on the particular task, we may choose a maximum value of k to build the first k homology groups. Then we can use these homology groups to create a barcode or persistence diagram, which shows how the topological features of the space change as the scale changes [9].
To calculate persistent homology, it is possible to use a variety of algorithms, such as the already mentioned Vietoris-Rips complex, the Čech complex, or the alpha complex. These algorithms construct a simplicial complex from the data, which can then be used to calculate the homology groups of the space.
Calculating persistent homology and interpreting the results is a non-trivial task. Several issues need to be considered and decisions need to be taken in every step of the process. We can summarize the process as follows:
-
Simplicial Complex Construction: - Begin by constructing a simplicial complex from your data. This complex can be based on various covering maps, such as the Vietoris-Rips complex, Čech complex, or alpha complex, depending on the chosen strategy (See section 2.4 and section 2.5, as well as Table 1 below).- The simplicial complex consists of vertices (0-simplices), edges (1-simplices), triangles (2-simplices), and higher-dimensional simplices. The choice of the complex depends on your data and the topological features of interest.
-
Filtration: - Introduce a filtration parameter (often denoted as ) that varies over a range of values. This parameter controls which simplices are included in the complex based on some criterion (e.g., distance threshold).- As increases, more simplices are added to the complex, and the complex evolves. The filtration process captures the topological changes as varies.
-
Boundary Matrix: - For each value of in the filtration, compute the boundary matrix (also called the boundary operator) of the simplicial complex. This matrix encodes the relations between simplices.- Each row of the boundary matrix corresponds to a (k-1)-dimensional simplex, and each column corresponds to a k-dimensional simplex. The entries indicate how many times a (k-1)-dimensional simplex is a face of a k-dimensional simplex.
-
Persistent Homology Calculation: - Perform a sequence of matrix reductions (e.g., Gaussian elimination) to identify the cycles and boundaries in the boundary matrix.- A cycle is a collection of simplices whose boundaries sum to zero, while a boundary is the boundary of another simplex.- Persistent homology focuses on tracking the birth and death of cycles across different values of . These births and deaths are recorded in a persistence diagram or barcode.
-
Persistence Diagram or Barcode: - The persistence diagram is a graphical representation of the births and deaths of topological features (connected components, loops, voids) as varies.- Each point in the diagram represents a topological feature and is plotted at birth (x-coordinate) and death (y-coordinate).- Interpretation:- A point in the upper-left quadrant represents a long-lived feature that persists across a wide range of values.- A point in the lower-right quadrant represents a short-lived feature that exists only for a narrow range of values.- The diagonal represents features that are consistently present throughout the entire range of values.- The distance between the birth and death of a point in the diagram quantifies the feature’s persistence or lifetime. Longer persistence indicates a more stable and significant feature.
-
Topological Summaries: - By examining the persistence diagram or barcode, you can extract information about the prominent topological features in your data set.- Features with longer persistence are considered more robust and significant.- The number of connected components, loops, and voids can be quantified by counting points in specific regions of the diagram.
2.2. The Mapper algorithm
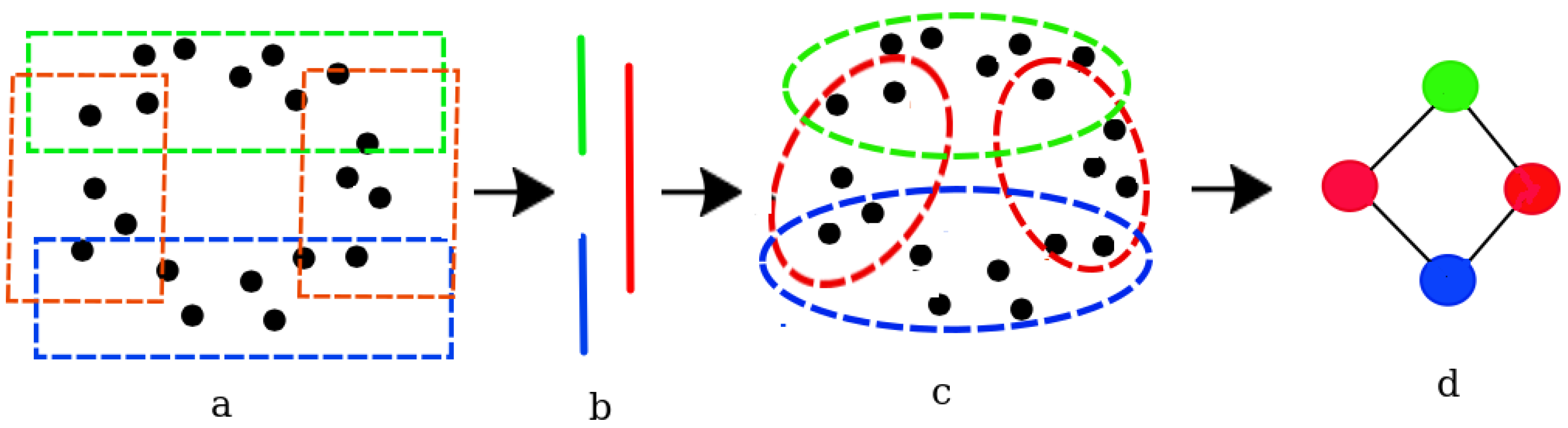
Mapper is a recently developed algorithm that provides a reliable tool for topological data analysis. Mapper allows researchers to identify and visualize the structure of a data set by creating a graph representation of the data [10].
-
Covering the data set: The original data set (Figure 3 a) is partitioned into a number of overlapping subsets, called nodes (Figure 3 b). This is accomplished using a function called the covering map. The covering map assigns each point in the data set to a node. Since the nodes are allowed to overlap, every point potentially belongs to multiple nodes.There are several different ways to define a covering map. The choice of covering map, however, can significantly affect the resulting Mapper graph. Some common approaches to define a covering map include:
- (a)
- Filtering: The data set is partitioned based on the values of one or more variables. A data set may, for instance, be partitioned based on the values of a categorical variable, such as gender or race.
- (b)
- Projection: Data set partitioning is performed by calculating the distance between points in the data set and using it as a membership criteria. This can be done using a distance function, such as the Euclidean distance or the cosine similarity.
- (c)
- Overlapping intervals: The data set is partitioned into overlapping intervals, such as bins or quantiles. This can be useful for data sets that are evenly distributed or those having a known underlying distribution.
The choice of covering map depends on the characteristics of the data set and the research question being addressed. It is important to choose a covering map that is appropriate for the data set and that will yield meaningful results. - Clustering the nodes: The nodes are then clustered using a clustering algorithm, such as k-means or single-linkage clustering. The resulting clusters (Figure 3 c) represent the topological features of the data set, and the edges between the clusters represent the relationships between the features.
Figure 3.
The steps of Mapper algorithm. a) The data, a cloud of points. b) The projection of the data into a lower dimension space. c) The preimage is clustered and d) A graph is built based on the clustered groups. See texts
Figure 3.
The steps of Mapper algorithm. a) The data, a cloud of points. b) The projection of the data into a lower dimension space. c) The preimage is clustered and d) A graph is built based on the clustered groups. See texts
2.3. Multidimensional scaling
In the context of topological data analysis, multidimensional scaling (MDS) is a method to visualize the relationships between a set of complex objects as projected in a lower-dimensional space. MDS works by creating a map of the objects in which the distance between said objects reflects (to a certain point) the dissimilarity between them [13]. MDS is often used along other techniques, like clustering, to analyze patterns in data sets that have a large number of variables. Multidimensional scaling can help identify relationships between objects that are not immediately apparent: hence it is useful to visually explore complex data sets [14]. There are several different algorithms for performing MDS, including classical MDS, nonmetric MDS, and metric MDS.
Classical MDS is the most common method (see Figure 4). In a nutshell, we start with a set of n points in a space of high dimension (m), then we introduce a measure of similarity (or dissimilarity), for instance a distance (such as the Euclidean distance), then we have a square symmetric matrix with the pairwise distances, MDS is attained by performing Principal Coordinate Analysis (i.e. eigenvalue decomposition) of such matrix. The result is a set of lower dimensional coordinates for the n points. Hence, classic MDS is based on the idea of preserving the pairwise distances between objects in the projected low-dimensional map. Classical MDS finds the map that best preserves the distances between objects using an optimization algorithm. The Nonmetric MDS method is similar to classical MDS, but it does not assume that the dissimilarities between objects are metric –i.e. represented by a continuous scale–; instead, it preserves the rank order of the dissimilarities between objects, instead of the absolute values. Metric MDS, conversely, is a variant of classical MDS based on stress minimization, that is, by considering the difference between the distances in the low-dimensional map and the dissimilarities in the data set. This method is used when the dissimilarities between objects can be represented by a continuous scale.
In general, classical MDS is the most widely used method, but nonmetric MDS and metric MDS may be more appropriate in certain situations.
2.3.1. How to determine the scaling approach?
The choice between classical MDS, nonmetric MDS, and metric MDS depends ultimately on the characteristics of the data and the specific research question. Some general guidelines are as follows:
-
Classical MDS:- When to Use: Classical MDS is suitable when you have metric (distance) data that accurately represents the pairwise dissimilarities between objects. In classical MDS, the goal is to find a configuration of points in a lower-dimensional space (usually 2D or 3D) that best approximates the given distance matrix.- Pros: - It preserves the actual distances between data points in the lower-dimensional representation.- It provides a faithful representation when the input distances are accurate.- It is well-suited for situations where the metric properties of the data are crucial.- Cons: - It assumes that the input distances are accurate and may not work well with noisy or unreliable distance data.- It may not capture the underlying structure of the data if the metric assumption is violated.
-
Nonmetric MDS:- When to Use: Nonmetric MDS is appropriate when you have ordinal or rank-order data, where the exact distances between data points are not known, but their relative dissimilarities or rankings are available. Nonmetric MDS finds a configuration that best preserves the order of dissimilarities.- Pros: - It is more flexible than classical MDS and can be used with ordinal data.- It can handle situations where the exact distances are uncertain or difficult to obtain.- Cons: - It does not preserve the actual distances between data points, so the resulting configuration is only an ordinal representation.- The choice of a monotonic transformation function to convert ordinal data into dissimilarity values can affect the results.
-
Metric MDS:- When to Use: Metric MDS can be used when you have data that is inherently non-metric, but you believe that transforming it into a metric space could reveal meaningful patterns. Metric MDS aims to find a metric configuration that best approximates the non-metric dissimilarities.- Pros: - It provides a way to convert non-metric data into a metric representation for visualization or analysis.- It can help identify relationships in the data that may not be apparent in the original non-metric space.- Cons: - The success of metric MDS depends on the choice of the transformation function to convert non-metric data into metric distances.- It may not work well if the non-metric relationships in the data are too complex or cannot be adequately approximated by a metric space.
In summary, the choice between classical, nonmetric, and metric MDS depends on the nature of your data and the goals of your analysis. If you have accurate metric data and want to preserve the actual distances, classical MDS is appropriate. If you have ordinal data or uncertain dissimilarity measures, nonmetric MDS may be more suitable. Metric MDS can be considered when you want to convert non-metric data into a metric space for visualization or analysis, but it requires careful consideration of the transformation function.
2.4. Choosing the covering map
When choosing a covering map in TDA, there are several characteristics of the data sets which are relevant to consider, among these we can mention the following:
- Data Dimensionality: The dimensionality of the data under consideration is crucial. Covering maps should be chosen to preserve the relevant topological information in the data. For high-dimensional data, dimension reduction techniques may be applied before selecting a covering map.
- Noise and Outliers: The presence of noise and outliers in the data can affect the choice of a covering map. Robust covering maps can help mitigate the influence of noise and outliers on the topological analysis.
- Data Density: The distribution of data points in the feature space matters. A covering map should be chosen to account for variations in data density, especially if there are regions of high density and regions with sparse data.
- Topological Features of Interest: It is important to consider the specific topological features one is interested in analyzing. Different covering maps may emphasize different aspects of the data topology, such as connected components, loops, or voids. The election of a covering map should align with the particular research objectives.
- Computational Efficiency: The computational complexity of calculating the covering map should also be taken into account. Some covering maps may be computationally expensive, which can be a limiting factor for large data sets.
- Continuous vs. Discrete Data: Determine whether the data you are analyzing is continuous or discrete. The choice of a covering map may differ based on the nature of the data.
- Metric or Non-Metric Data: Some covering maps are designed for metric spaces, where distances between data points are well-defined, while others may work better for non-metric or qualitative data.
- Geometric and Topological Considerations: Think about the geometric and topological characteristics of your data. Certain covering maps may be more suitable for capturing specific geometric or topological properties, such as persistence diagrams or Betti numbers.
- Domain Knowledge: Incorporate domain-specific knowledge into your choice of a covering map. Understanding the underlying structure of the data can guide you in selecting an appropriate covering map.
- Robustness and Stability: Assess the robustness and stability of the chosen covering map. TDA techniques should ideally produce consistent results under small perturbations of the data or variations in sampling.
In practice, there are various covering maps and TDA algorithms available, such as Vietoris-Rips complexes, Čech complexes, and alpha complexes. The choice of covering map should be guided by a combination of these factors, tailored to the specific characteristics and goals of your data analysis. It may also involve some experimentation to determine which covering map best captures the desired topological features.
Different types of covering maps are thus best suited for different kinds of data. Some of the main covering maps used in TDA are presented in Table 1.
Ultimately, the choice of covering map depends on the specific characteristics of your data, such as dimensionality, metric properties, and the topological features of interest. It’s often beneficial to experiment with different covering maps and parameters to determine which one best captures the desired topological information for a particular data set. Additionally, combining multiple covering maps and TDA techniques can provide a more comprehensive understanding of complex data sets.
2.5. Different strategies for topological feature selection
The Vietoris-Rips strategy, the witness strategy, and the lazy-witness strategy are some of the best known TDA methods to capture and analyze the topological features of data sets. Each of these strategies has its own advantages and disadvantages.
2.5.1. Vietoris-Rips (VR) Strategy:
The main advantage of the VR strategy is its simplicity, since the VR complex is relatively easy to understand and implement. It connects data points based on a fixed distance threshold, which is quite intuitive. Another advantage of the VR lies on its widespread use, for there is a significant body of literature and software implementations available. It works well with data in metric spaces where distances between points are well-defined.
Among the disadvantages are that VR is quite sensitive to parameters: The choice of the distance threshold (radius parameter) can significantly impact the topology of the resulting complex. Selecting an appropriate threshold can be challenging and may require prior knowledge of the data. VR can be also challenging for its computational burden: Constructing the VR complex can be computationally expensive, especially for large data sets or high-dimensional data. VR is also limited in terms of robustness: The VR complex is sensitive to noise and outliers, and small perturbations in the data can lead to significant changes in the complex topology.
2.5.2. Witness Strategy (WS):
The witness strategy (WS) in turn, is more robust to noise and outliers compared to the VR complex. It selects a subset of witness points that can capture the topology of the data more effectively. WS is more flexible, witness complexes can be applied to both metric and non-metric data, making them versatile for various data types and are able to handle data with varying sampling densities, making them suitable for irregularly sampled data sets.
Implementing the WS, however can be more involved than the VR complex, as it requires selecting witness points and computing their witness neighborhoods. Also, while witness complexes are more robust, they still depend on parameters like the number of witness points and the witness radius. Choosing appropriate parameters can indeed be a non-trivial task.
2.5.3. Lazy-Witness Strategy (LW):
The LW strategy is an optimization of the witness strategy that reduces computational cost. It constructs the witness complex on-the-fly as needed, potentially saving memory and computation time. Like the WS, the LW strategy is robust to noise and outliers.
In spite of these advantages, there are also shortcomings: Implementing the LW strategy can be more complex than the basic witness strategy, as it requires careful management of data structures and computational resources. While it can be more memory-efficient than precomputing a full witness complex, the LW strategy still consumes memory as it constructs the complex in real time. This may still be a limitation for very large data sets.
In summary, the choice between the Vietoris-Rips strategy, witness strategy, and lazy-witness strategy depends on the specific characteristics of your data and the computational resources available. The Vietoris-Rips complex is straightforward but sensitive to parameter choice and noise. The witness strategy offers improved robustness but may require more effort in parameter tuning. The lazy-witness strategy combines robustness with some memory and computation efficiency, making it a good choice for large data sets. Experimentation and a deep understanding of your data characteristics are essential when selecting the most appropriate strategy for your TDA analysis.
3. Applications of TDA to analyze Cardiovascular signals
3.1. General features
Aljanobi and Lee [5] recently applied the Mapper algorithm to predict heart disease. They selected nine significant features in each of the two UCI heart disease datasets (Cleveland and Statlog). The authors then used a tri-dimensional SVD filter to improve the filtering process. As a result, they observed an accuracy of 99.32% in the Cleveland dataset and 99.62% in the Statlog dataset in predicting heart disease.
TDA has also been applied to the analysis of structured and unstructured text in EHRs and clinical notes. Lopez and coworkers [15] used the Mapper algorithm to classify distinctive subsets of patients receiving optimal treatments post-acute myocardial infarction (AMI) in order to identify high risk subgroups of patients for having a future adverse event (AE) such as death, heart failure hospitalization, or recurrent myocardial infarction. A retrospective analysis of 31 clinical variables from the EHR of 798 AMI subjects was conducted at a single center. The subjects were divided into high- and low-risk groups based on their probability of survival without AEs at 1 year. TDA identified six subgroups of patients. Four of these subgroups, totaling 597 subjects, had a probability of survival without AEs that was greater than 1-fold change, and were considered low-risk. The other two subgroups, totaling 344 subjects, had a probability of survival without AEs that was less than 1-fold change, and were considered high-risk. However, 143 subjects (18% of the total) were classified as intermediate risk because they belonged to both the high- and low-risk subgroups. TDA was also able to significantly stratify AMI patients into three subgroups with distinctive rates of AEs up to 3 years after AMI. This approach to EHR-based risk stratification does not require additional patient interaction and is not dependent on prior knowledge, but more studies are needed before it can be used in clinical practice.
3.2. ECG data and heart rate signals
In another recent study, Yan and coworkers [16] explored the use of topological data analysis to classify electrocardiographic signals and detect arrhythmias. Phase space reconstruction was used to convert the signals into point clouds, which were then analyzed using topological techniques to extract persistence landscapes as features for the classification task. The authors found that the proposed method was effective, with a normal heartbeat class recognition rate of 100% when using just 20% of the training set, and recognition rates of 97.13% for ventricular beats, 94.27% for supraventricular beats, and 94.27% for fusion beats. This ability to maintain high performance with a small training sample space makes TDA particularly suitable for personalized analysis.
One particularly difficult problem in cardiovascular disease diagnostics with important implications for therapy is the evolution of atrial fibrillation [17]. Indeed, the progression of atrial fibrillation (AF) from paroxysmal to persistent or permanent forms has become a significant issue in cardiovascular disorders. Information about the pattern of presentation of AF (paroxysmal, persistent, or permanent) is useful in the management of algorithms for each category, which aims to reduce symptoms and prevent severe problems associated with AF. Until now, AF classification has been based on the duration and number of episodes. In particular, changes in complexity of Heart Rate Variation (HRV) may contain clinically relevant signals of impending systemic dysregulation. A number of nonlinear methods based on phase space and topological properties can provide further insight into HRV abnormalities such as fibrillation. In an effort to provide a tool for the qualitative classification of AF stages, Safarbaly and Golpayegani [18] proposed two geometrical indices (fractal dimension and persistent homology) based on HRV phase space, which were able to successfully replicate the changes in AF progression.
Their studied population included 38 lone AF patients and 20 normal subjects, which were collected from the Physio-Bank database [19]. "Time of Life (TOL)" was proposed as a new feature based on the initial and final Čech radius in the persistent homology diagram. A neural network was implemented to demonstrate the effectiveness of both TOL and fractal dimension as classification features, resulting in a classification accuracy of 93%. The proposed indices thus provide a signal representation framework useful for understanding the dynamic changes in AF cardiac patterns but also for classifying normal and pathological rhythms.
PH was also used to study HRV by Graff et al. [20], who suggested the use of persistent homology for the analysis of HRV, relying on some topological descriptors previously used in the literature and introducing new ones that are specific to HRV, to later discussing their relationship to standard HRV measures. The authors showed that this novel approach produces a set of indices that may be as useful as classical parameters in distinguishing between series of beat-to-beat intervals (RR-intervals) in healthy individuals as well as in patients who have experienced a stroke.
Also in the context of fibrillation (this time for the prediction of early ventricular fibrillation (VF)), Ling and coworkers [21] proposed a novel feature based on topological data analysis (TDA) to increase the accuracy of early ventricular fibrillation prediction. In their work, the heart activity is first treated as a cardiac dynamical system, which is described through phase space reconstruction. The topological structure of the phase space is then characterized using persistent homology, and statistical features of the topological structure are extracted and defined as TDA features. To validate the prediction performance of the proposed method, 60 subjects (30 VF, 30 healthy) from three public ECG databases were used. The TDA features show a superior accuracy of 91.7% compared to heart rate variability features and box-counting features. When all three types of features are combined as fusion features, the optimal accuracy of 95.0% is achieved. The fusion features are then ranked, and the first seven components are all from the TDA features. The proposed features may have a significant effect on improving the predictive performance of early VF.
A similar approach was taken by Mjahad, et al. [22] which applied TDA to generate novel features contributing to improve, both detection and classification performance, of cardiac arrhythmias such as Ventricular Fibrillation (VF) and Ventricular Tachycardia (VT). The electrocardiographic (ECG) signals used for this evaluation were obtained from the standard MIT-BIH and AHA databases. The authors evaluated two types of input data for classification: TDA features as well as the so-called Persistence Diagram Image (PDI). When using the reduced TDA-derived features, a high average accuracy of nearly 99% was observed to discriminate between four types of rhythms (98.68% for VF; 99.05% for VT; 98.76% for normal sinus; and 99.09% for other rhythms), with specificity values higher than 97.16% in all cases. In addition, a higher accuracy of 99.51% was obtained when discriminating between shockable (VT/VF) and non-shockable rhythms (99.03% sensitivity and 99.67% specificity). These results show that the use of TDA-derived geometric features, combined with the k-Nearest Neighbor (kNN) classifier, significantly improves classification performance compared to previous works. These results were achieved without pre-selection of ECG episodes, suggesting that these features may be successfully used in Automated External Defibrillation (AED) [23,24] and Implantable Cardioverter Defibrillation (ICD) [25,26] therapies.
Jiang and collaborators studied non-invasive atrial fibrillation using TDA on ballistocardiographic (BCG) data [27]. In this research, BCG series was transformed into a high-dimensional point cloud in order to capture more rhythmic information. These point clouds were then analyzed using TDA, resulting in persistent homology barcodes. The statistics of these barcodes were extracted as 9 persistent homology features to quantitatively describe the barcodes. In order to test the effectiveness of this method for detecting atrial fibrillation (AF), the researchers collected BCG data from 73 subjects with both AF and non-AF segments, and applied 6 machine learning classifiers. The combination of these 9 features with 17 previously proposed features resulted in a 6.17% increase in accuracy compared to using the 17 features alone (p<0.001), with an overall accuracy of 94.50%. By selecting the most effective features using feature selection, the researchers were able to achieve a classification accuracy of 93.50%. According with the authors, these results suggest that the proposed features can improve AF detection performance when applied to a large amount of BCG data with diverse pathological information and individual differences.
TDA can also be combined with other data analytics/Ml approaches such as random forests (RF). Ignacio and collaborators developed a topological method to inform RF-based ECG classifiers [28]. In brief, in this approach, a two-level random forest model is trained to classify 12-lead ECGs using mathematically computable topological signatures as proxy for features informed by medical expertise. ECGs are treated as multivariate time series data and transformed into point cloud embeddings that capture both local and global structures and encode periodic information as attractor cycles in high-dimensional space. Topological data analysis is then used to extract topological features from these embeddings, and these features are combined with demographic data and statistical moments of RR intervals calculated using the Pan-Tompkins algorithm for each lead to train the classifier. This multi-class classification task aims to leverage the medical expertise represented in the topological signatures to accurately classify ECGs.
The same group combined TDA and ML approaches to study atrial fibrillation in ECGs [29] showing that topological features can be used to accurately classify single-lead ECGs, by applying delay embeddings to map ECGs onto high-dimensional point clouds, which convert periodic signals into algebraically computable topological signatures. Thus allowing them to use these topological features to classify ECGs.
A similar approach coupling TDA with Deep Learning to study ECGs has been recently developed [30]. Training deep learning models on time series data such as ECG, pose some challenges such as a lack of labeled data and class imbalance [31,32]. The authors used TDA to improve the performance of deep learning models on this type of data. The authors found that using TDA as a time-series embedding method for input to deep learning models resulted more effective than training these models directly on raw data. TDA in this context serves as a generic, low-level feature extractor that can capture common signal patterns and improve performance with limited training data. Experiments on public human physiological biosignal datasets show that this approach leads to improved accuracy, particularly for imbalanced classes with only a few training instances compared to the full dataset.
Conventional TDA of ECG time series can be further improved by considering the time delay structure to generate higher dimensional mappings of the original series [33] able to be analyzed via TDA. This was the approach taken by Fraser and coworkers [34] which found that TDA visualizations are able top unveil ectopic and other abnormal occurrences in long signals, indicating a promising direction for the study of longitudinal physiological signals.
A different approach to deal with ECG time series using TDA makes use of optimal representative cycles. In reference [35] the authors applied a topological data-analytic method to identify parts of an electrocardiogram (ECG) signal that are representative of specific topological features and propose that these parts correspond to the P, Q, S, and T-waves in the ECG signal. They then used information about these parts of the signal, identified as P, Q, S, and T-waves, to measure the PR-interval, QT-interval, ST-segment, QRS-duration, P-wave duration, and T-wave duration. The method was tested on simulated and real Lead II ECG data, demonstrating its potential use in analyzing the morphology of the signal over time and in arrhythmia detection algorithms.
3.3. Stenosis and vascular data
TDA has also been used to study stenosis. Nicponski and collaborators [36] demonstrated the use of persistent homology to assess the severity of stenosis in different types of stenotic vessels. They introduce the concept of critical failure value, which applies 1-dimensional homology to these vessels as a way to quantify the degree of stenosis. They also present the spherical projection method, which could potentially be used to classify various types and levels of stenosis, and show that the 2-dimensional homology of the spherical projection can serve as a new index for characterizing blood vessels. It is worth noticing that, as in many other instances in data analytics, data pre-processing often represent a crucial stage [37].
3.4. TDA in Echocardiography
Applications of TDA to echocardiographic data have also been developed. Such is the case of the work the group of Tokodi [38,39] who analyzed a cohort of 1334 patients to identify similarities among patients based on several echocardiographic measures of left ventricular function. A network was developed to represent these similarities, and a group classifier was used to predict the location of 96 patients with two consecutive echocardiograms in this network. The analysis revealed four distinct regions in the network, each with significant differences in the rate of major adverse cardiovascular events (MACE) rehospitalization. Patients in the fourth region had more than two times the risk of MACE rehospitalization compared to those in the other regions. Improvement or stability in regions I and II was associated with lower MACE rehospitalization rates compared to worsening or stability in regions III and IV. The authors conclude that TDA-driven patient similarity analysis may improve the precision of phenotyping and aid in the prognosis of patients by tracking changes in cardiac function over time.
4. Perspectives and Limitations
We have presented a panoramic (and by necessity incomplete) view of the applications of topological data analysis to the study of cardiovascular signals. We must however stress that, as every analytic technique, TDA has a set of limitations and a range of applicability. Among its limitations we can include its inherent complexity both to implement the analyses and to interpret the results. Also relevant is TDA’s sensitivity to noise and reliance to assumptions of the data distribution (for instance, one assumes that filtration can be carried out unambiguously). Another aspect to consider is that topological data analysis can be computationally intensive, particularly for large or complex data sets. This along potential biases in noisy signals may preclude the accurate identification of the topological features of certain data sets, especially if the data is of low quality. As we said, topological data analysis relies on assumptions about the data set, for instance the existence of a natural distance measure. This condition may not hold in all cases. This may potentially limit its applicability. Additionally, the results of topological data analysis can be difficult to interpret, particularly for non-experts, a fact that can make challenging to communicate the results of a topological analysis to a general audience. However, even at the light of this limitations, TDA is a quite powerful approach that (perhaps in combination with other data analytic approaches) may result very useful for the study of complex biosignals, such as those arising in cardiology.
Appendix: Computational tools
In Table 1, we present some commonly used algorithms used to perform topological data analysis calculations implemented in libraries for common programming languages. Implementation vary in their capabilities, computational complexity and depth of documentation. These are, however, well-documented enough, so that most people with scientific programming expertise may find them fairly usable and reliable. Where applicable, references to the underlying algorithms used have been included.

Table 2.
Computational tools for topological data analysis
References
- Seetharam, K.; Shrestha, S.; Sengupta, P.P. Artificial intelligence in cardiovascular medicine. Current treatment options in cardiovascular medicine 2019, 21, 1–14. [Google Scholar] [CrossRef]
- Silverio, A.; Cavallo, P.; De Rosa, R.; Galasso, G. Big health data and cardiovascular diseases: a challenge for research, an opportunity for clinical care. Frontiers in medicine 2019, 6, 36. [Google Scholar] [CrossRef] [PubMed]
- Kagiyama, N.; Shrestha, S.; Farjo, P.D.; Sengupta, P.P. Artificial intelligence: practical primer for clinical research in cardiovascular disease. Journal of the American Heart Association 2019, 8, e012788. [Google Scholar] [CrossRef] [PubMed]
- Shameer, K.; Johnson, K.W.; Glicksberg, B.S.; Dudley, J.T.; Sengupta, P.P. Machine learning in cardiovascular medicine: are we there yet? Heart 2018, 104, 1156–1164. [Google Scholar] [CrossRef] [PubMed]
- Aljanobi, F.A.; Lee, J. Topological Data Analysis for Classification of Heart Disease Data. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), 2021; pp. 210–213. [Google Scholar] [CrossRef]
- Phinyomark, A.; Ibáñez-Marcelo, E.; Petri, G. Topological Data analysis of Biomedical Big Data. In Signal Processing and Machine Learning for Biomedical Big Data; CRC Press, 2018; pp. 209–233. [Google Scholar]
- Carlsson, G. The shape of biomedical data. Current Opinion in Systems Biology 2017, 1, 109–113. [Google Scholar] [CrossRef]
- Skaf, Y.; Laubenbacher, R. Topological data analysis in biomedicine: A review. Journal of Biomedical Informatics 2022, 130, 104082. [Google Scholar] [CrossRef]
- Carlsson, G.; Vejdemo-Johansson, M. Topological Data Analysis with Applications; Cambridge University Press, 2021. [Google Scholar]
- Ristovska, D.; Sekuloski, P. Mapper algorithm and its applications. Mathematical Modeling 2019, 3, 79–82. [Google Scholar]
- Zhou, Y.; Chalapathi, N.; Rathore, A.; Zhao, Y.; Wang, B. Mapper Interactive: A scalable, extendable, and interactive toolbox for the visual exploration of high-dimensional data. In Proceedings of the 2021 IEEE 14th Pacific Visualization Symposium (PacificVis); IEEE, 2021; pp. 101–110. [Google Scholar]
- Brown, A.; Bobrowski, O.; Munch, E.; Wang, B. Probabilistic convergence and stability of random mapper graphs. Journal of Applied and Computational Topology 2021, 5, 99–140. [Google Scholar] [CrossRef]
- Wasserman, L. Topological data analysis. Annual Review of Statistics and Its Application 2018, 5, 501–532. [Google Scholar] [CrossRef]
- Chazal, F.; Michel, B. An introduction to topological data analysis: fundamental and practical aspects for data scientists. Frontiers in artificial intelligence 2021, 4. [Google Scholar] [CrossRef]
- Lopez, J.E.; Datta, E.; Ballal, A.; Izu, L.T. Topological Data Analysis of Electronic Health Record Features Predicts Major Cardiovascular Outcomes After Revascularization for Acute Myocardial Infarction. Circulation 2022, 146, A14875–A14875. [Google Scholar] [CrossRef]
- Yan, Y.; Ivanov, K.; Cen, J.; Liu, Q.H.; Wang, L. Persistence landscape based topological data analysis for personalized arrhythmia classification. 2019; Preprints (non-peer reviewed yet). [Google Scholar]
- Falsetti, L.; Rucco, M.; Proietti, M.; Viticchi, G.; Zaccone, V.; Scarponi, M.; Giovenali, L.; Moroncini, G.; Nitti, C.; Salvi, A. Risk prediction of clinical adverse outcomes with machine learning in a cohort of critically ill patients with atrial fibrillation. Scientific reports 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Safarbali, B.; Hashemi Golpayegani, S.M.R. Nonlinear dynamic approaches to identify atrial fibrillation progression based on topological methods. Biomedical Signal Processing and Control 2019, 53, 101563. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Graff, G.; Graff, B.; Pilarczyk, P.; Jabłoński, G.; Gąsecki, D.; Narkiewicz, K. Persistent homology as a new method of the assessment of heart rate variability. Plos one 2021, 16, e0253851. [Google Scholar] [CrossRef] [PubMed]
- Ling, T.; Zhu, Z.; Zhang, Y.; Jiang, F. Early Ventricular Fibrillation Prediction Based on Topological Data Analysis of ECG Signal. Applied Sciences 2022, 12. [Google Scholar] [CrossRef]
- Mjahad, A.; Frances-Villora, J.V.; Bataller-Mompean, M.; Rosado-Muñoz, A. Ventricular Fibrillation and Tachycardia Detection Using Features Derived from Topological Data Analysis. Applied Sciences 2022, 12. [Google Scholar] [CrossRef]
- Caffrey, S.L.; Willoughby, P.J.; Pepe, P.E.; Becker, L.B. Public use of automated external defibrillators. New England journal of medicine 2002, 347, 1242–1247. [Google Scholar] [CrossRef] [PubMed]
- Delhomme, C.; Njeim, M.; Varlet, E.; Pechmajou, L.; Benameur, N.; Cassan, P.; Derkenne, C.; Jost, D.; Lamhaut, L.; Marijon, E.; et al. Automated external defibrillator use in out-of-hospital cardiac arrest: Current limitations and solutions. Archives of cardiovascular diseases 2019, 112, 217–222. [Google Scholar] [CrossRef] [PubMed]
- Kamp, N.J.; Al-Khatib, S.M. The subcutaneous implantable cardioverter-defibrillator in review. American heart journal 2019, 217, 131–139. [Google Scholar] [CrossRef]
- Friedman, P.; Murgatroyd, F.; Boersma, L.V.; Manlucu, J.; O’Donnell, D.; Knight, B.P.; Clémenty, N.; Leclercq, C.; Amin, A.; Merkely, B.P.; et al. Efficacy and safety of an extravascular implantable cardioverter–defibrillator. New England Journal of Medicine 2022, 387, 1292–1302. [Google Scholar] [CrossRef] [PubMed]
- Jiang, F.; Xu, B.; Zhu, Z.; Zhang, B. Topological Data Analysis Approach to Extract the Persistent Homology Features of Ballistocardiogram Signal in Unobstructive Atrial Fibrillation Detection. IEEE Sensors Journal 2022, 22, 6920–6930. [Google Scholar] [CrossRef]
- Ignacio, P.S.; Bulauan, J.A.; Manzanares, J.R. A Topology Informed Random Forest Classifier for ECG Classification. In Proceedings of the 2020 Computing in Cardiology; IEEE, 2020; pp. 1–4. [Google Scholar]
- Ignacio, P.S.; Dunstan, C.; Escobar, E.; Trujillo, L.; Uminsky, D. Classification of single-lead electrocardiograms: TDA informed machine learning. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA); IEEE, 2019; pp. 1241–1246. [Google Scholar]
- Byers, M.; Hinkle, L.B.; Metsis, V. Topological Data Analysis of Time-Series as an Input Embedding for Deep Learning Models. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer, 2022; pp. 402–413. [Google Scholar]
- Seversky, L.M.; Davis, S.; Berger, M. On time-series topological data analysis: New data and opportunities. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops; 2016; pp. 59–67. [Google Scholar]
- Karan, A.; Kaygun, A. Time series classification via topological data analysis. Expert Systems with Applications 2021, 183, 115326. [Google Scholar] [CrossRef]
- Sun, F.; Ni, Y.; Luo, Y.; Sun, H. ECG Classification Based on Wasserstein Scalar Curvature. Entropy 2022, 24, 1450. [Google Scholar] [CrossRef] [PubMed]
- Fraser, B.A.; Wachowiak, M.P.; Wachowiak-Smolíková, R. Time-delay lifts for physiological signal exploration: An application to ECG analysis. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE); IEEE, 2017; pp. 1–4. [Google Scholar]
- Dlugas, H. Electrocardiogram feature extraction and interval measurements using optimal representative cycles from persistent homology. bioRxiv 2022. [Google Scholar]
- Nicponski, J.; Jung, J.H. Topological data analysis of vascular disease: A theoretical framework. Frontiers in Applied Mathematics and Statistics 2020, 6, 34. [Google Scholar] [CrossRef]
- Bresten, C.L.; Kweon, J.; Chen, X.; Kim, Y.H.; Jung, J.H. Preprocessing of general stenotic vascular flow data for topological data analysis. bioRxiv 2021. Available online: https://www.biorxiv.org/content/early/2021/01/07/2021.01.07.425693.full.pdf. [CrossRef]
- Tokodi, M.; Shrestha, S.; Ashraf, M.; Casaclang-Verzosa, G.; Sengupta, P. Topological Data Analysis for quantifying inter-patient similarities in cardiac function. Journal of the American College of Cardiology 2019, 73, 751–751. [Google Scholar] [CrossRef]
- Tokodi, M.; Shrestha, S.; Bianco, C.; Kagiyama, N.; Casaclang-Verzosa, G.; Narula, J.; Sengupta, P.P. Interpatient similarities in cardiac function: a platform for personalized cardiovascular medicine. Cardiovascular Imaging 2020, 13, 1119–1132. [Google Scholar] [PubMed]
- Fasy, B.T.; Lecci, F.; Rinaldo, A.; Wasserman, L.; Balakrishnan, S.; Singh, A. Confidence sets for persistence diagrams. The Annals of Statistics 2014, 2301–2339. [Google Scholar] [CrossRef]
- Chazal, F.; Fasy, B.T.; Lecci, F.; Rinaldo, A.; Wasserman, L. Stochastic convergence of persistence landscapes and silhouettes. In Proceedings of the thirtieth annual symposium on Computational geometry; 2014; pp. 474–483. [Google Scholar]
- Wadhwa, R.R.; Williamson, D.F.; Dhawan, A.; Scott, J.G. TDAstats: R pipeline for computing persistent homology in topological data analysis. Journal of open source software 2018, 3, 860. [Google Scholar] [CrossRef]
- Bauer, U.; Kerber, M.; Reininghaus, J.; Wagner, H. Phat–persistent homology algorithms toolbox. Journal of symbolic computation 2017, 78, 76–90. [Google Scholar] [CrossRef]
- Bauer, U.; Kerber, M.; Reininghaus, J. Distributed computation of persistent homology. In Proceedings of the 2014 proceedings of the sixteenth workshop on algorithm engineering and experiments (ALENEX); SIAM, 2014; pp. 31–38. [Google Scholar]
- Zhang, S.; Xiao, M.; Wang, H. GPU-accelerated computation of Vietoris-Rips persistence barcodes. arXiv 2020, arXiv:2003.07989. [Google Scholar]
- Kerber, M.; Nigmetov, A. Efficient approximation of the matching distance for 2-parameter persistence. arXiv 2019, arXiv:1912.05826. [Google Scholar]
Figure 1.
Topological Data Analysis in cardiology. Starting from diverse sources of cardiovascular signals, topological data analytics allowed a systematic study and categorization leading to a better understanding of the underlying phenomena, thus providing clues for clinicians and basic scientists. Figure generated with BioRender.com, central panel is taken from Larrysong, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
Figure 1.
Topological Data Analysis in cardiology. Starting from diverse sources of cardiovascular signals, topological data analytics allowed a systematic study and categorization leading to a better understanding of the underlying phenomena, thus providing clues for clinicians and basic scientists. Figure generated with BioRender.com, central panel is taken from Larrysong, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
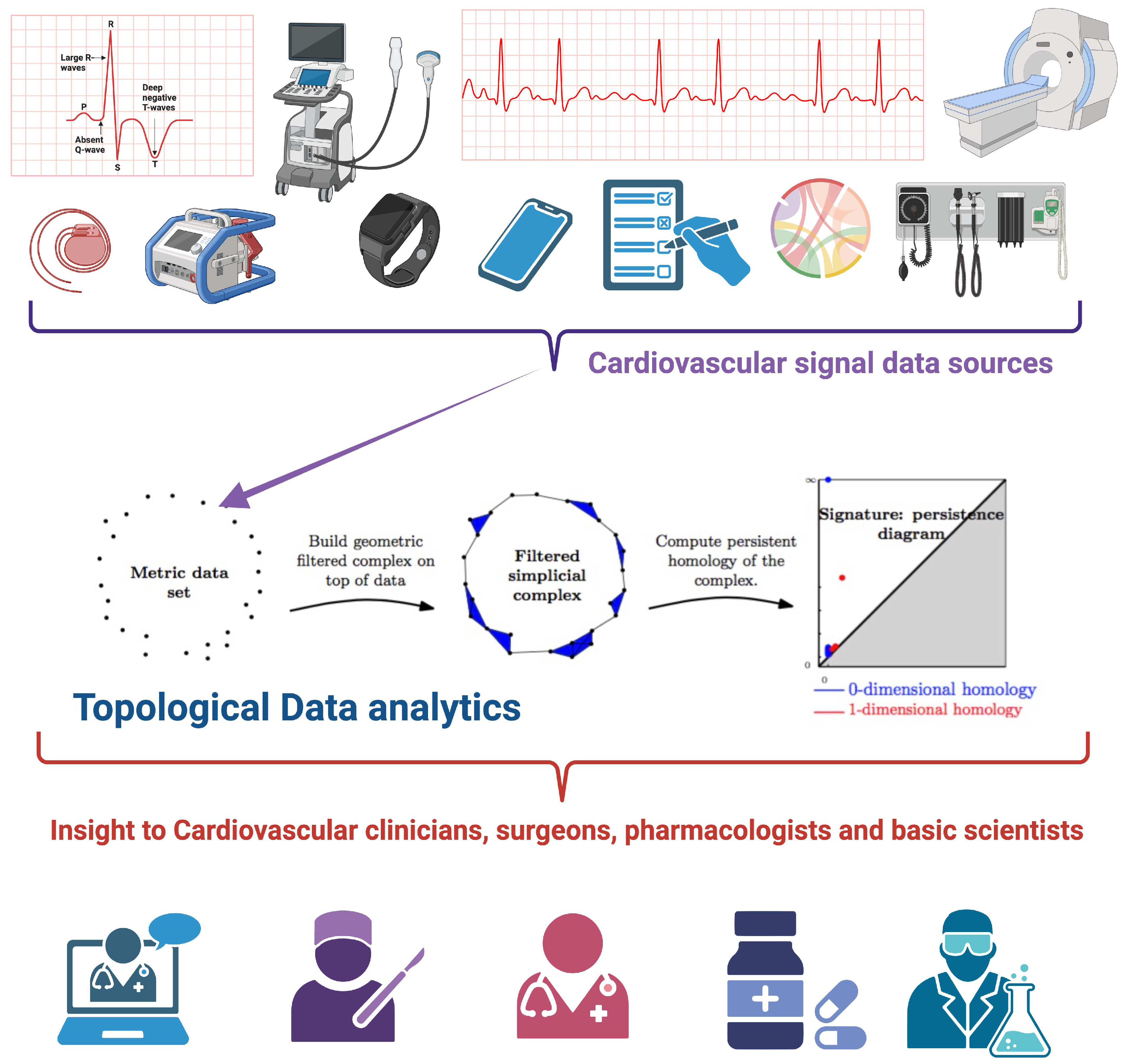
Figure 2.
Persistent homology via FSH. Panel A presents a set of data points in feature space. In panel B we put a ball of radius around each data point. In panels B to E, we increased the radius . Neighborhoods start to overlap giving rise to the establishment of a filtered simplicial complex.
Figure 2.
Persistent homology via FSH. Panel A presents a set of data points in feature space. In panel B we put a ball of radius around each data point. In panels B to E, we increased the radius . Neighborhoods start to overlap giving rise to the establishment of a filtered simplicial complex.
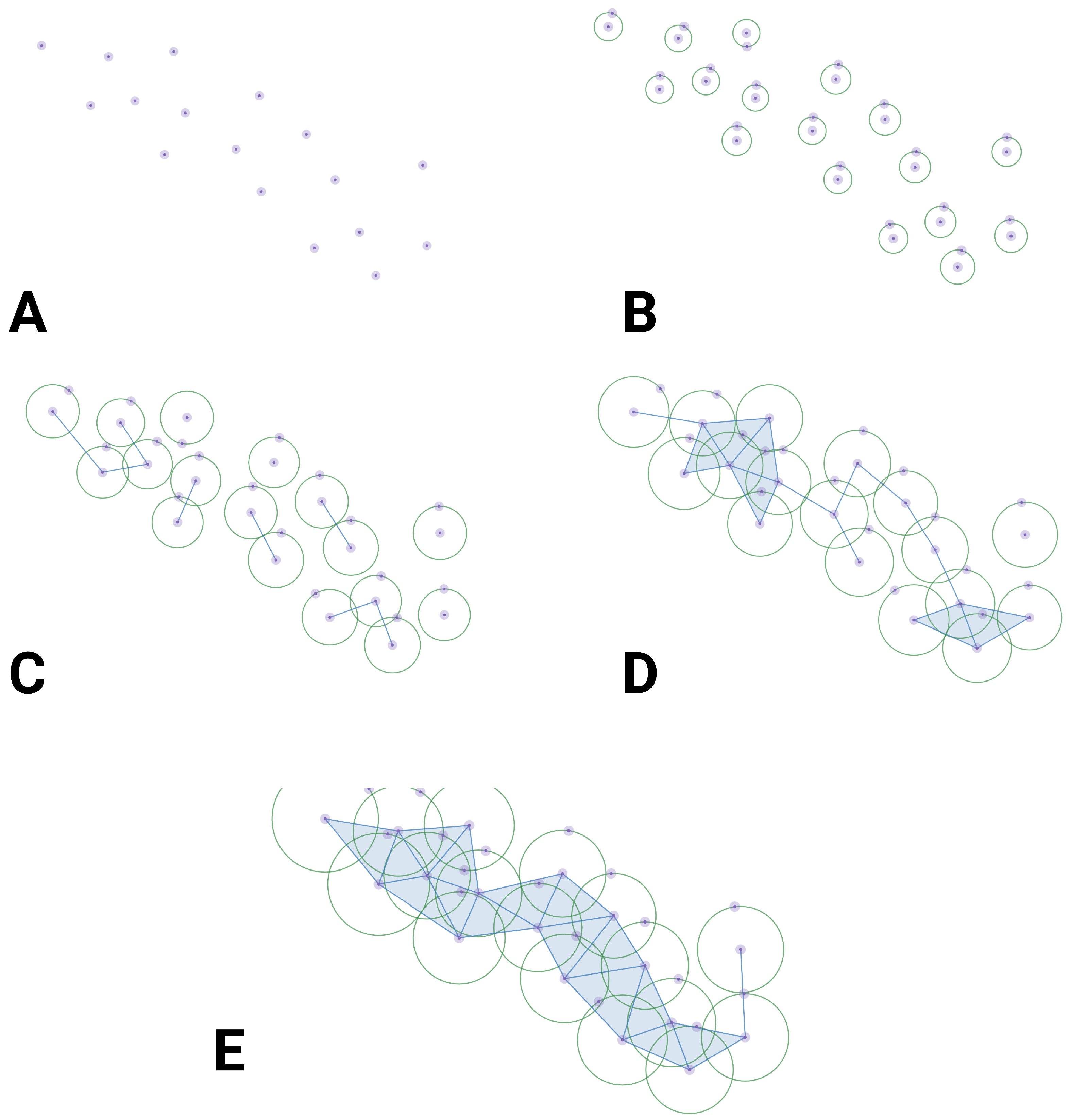
Figure 4.
Classic multidimensional scaling
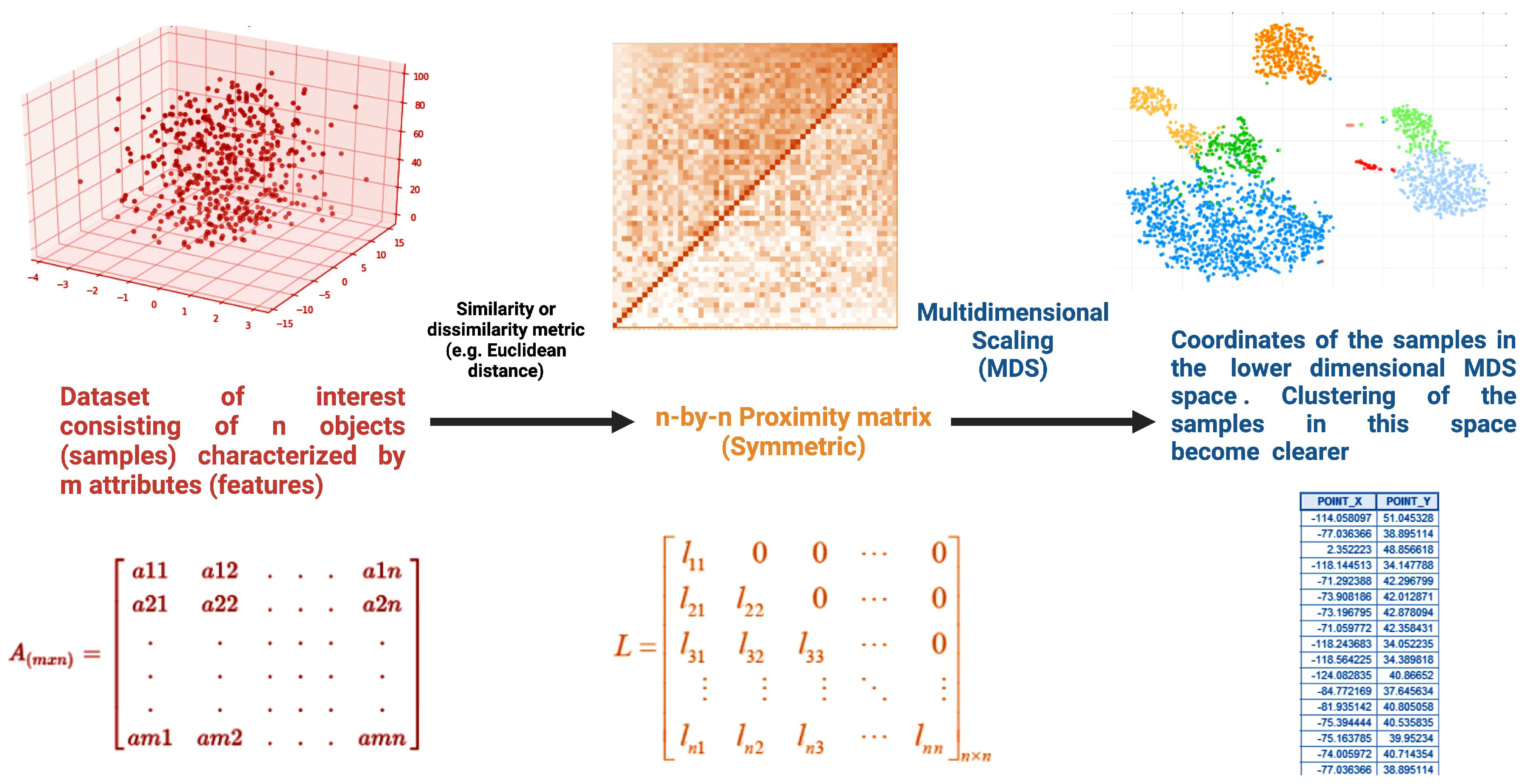
Table 1.
Some types of covering maps and their main applications
| Covering map | Type of data | Brief description |
|---|---|---|
| Vietoris-Rips Complex | Point cloud data, particularly when dealing with metric spaces. It is often used in applications like sensor networks, molecular chemistry, and computer graphics. |
The Vietoris-Rips complex connects points in the data if they are within a certain distance (the radius parameter) of each other, forming simplices (e.g., edges, triangles, tetrahedra) based on pairwise distances |
| Čech Complex | Similar to the Vietoris-Rips complex, Čech complexes are used for point cloud data in metric spaces |
The Čech complex connects points if they belong to the same open ball of a specified radius. It can capture similar topological features as the Vietoris-Rips complex but may have a different geometric structure |
| Alpha Complex | Alpha complexes are useful for point cloud data in metric spaces and provide an alternative representation of the topological structure |
The alpha complex connects points with a Delaunay triangulation, considering balls whose radii can vary at each point to ensure that the complex is a subcomplex of the Vietoris-Rips complex |
| Witness Complex | Witness complexes are used for point cloud data but are particularly useful when dealing with data that may not be uniformly sampled or when dealing with non-metric or qualitative data |
Witness complexes are constructed by selecting a subset of witness points from the data. Each witness point witnesses the presence of other data points within a specified distance. This can be used to capture topological features in a more robust way, especially when data is irregular |
| Mapper | Mapper is a flexible approach that can be applied to various types of data, including both metric and non-metric spaces |
Mapper is not a traditional covering map but rather a method for creating a topological summary of data by combining clustering and graph theory. It can be adapted to different data types and is useful for exploratory data analysis |
| Rips-Filtration and Čech-Filtration | These are extensions of the Vietoris-Rips and Čech complexes, respectively, that allow for the analysis of topological features at different scales |
By varying the radius parameter continuously, Rips-filtration and Čech-filtration produce a sequence of simplicial complexes. This can be useful for capturing topological features at different levels of detail and studying persistence diagrams |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



