Submitted:
05 December 2023
Posted:
06 December 2023
You are already at the latest version
Abstract
Calligraphy works have high artistic value, but there is a rampant problem of forgery. Indeed, authentication of traditional calligraphy heavily relies on calligraphers' subjective judgment. Therefore, spurred by the recent development of neural networks, this paper proposes a method for authenticating calligraphy works based on an improved EfficientNet network. Specifically, the developed method utilizes the character box algorithm and the centroid algorithm to extract individual calligraphy characters, which are then augmented and used as the training set for the model. The training process employs CBAM and Self-Attention modules to enhance the attention mechanism of the EfficientNet network. The model is tested on authentic works, imitated works, and works from other calligraphers and is compared with other networks. The experimental results demonstrate that the proposed method effectively achieves the authentication of calligraphy works, and the improved CBAM-EfficientNet network and SA-EfficientNet network achieve better authentication performance.
Keywords:
Calligraphy work authentication
; neural networks
; attention mechanism
1. Introduction
Calligraphy, as one of the traditional art forms in China, possesses a high collectible value in the field of art, especially the works of renowned calligraphy masters, whose collection value is difficult to estimate. In June 2019, Guanzhong's work "Lion Grove" was sold for 143.75 million Yuan, setting a new record for calligraphy and painting auction prices [1]. However, as the prices of calligraphy works are high, counterfeiting in calligraphy art continues to emerge [2]. Indeed, the production level of counterfeit modern calligraphy artworks is very high, significantly harming the calligraphy collection market.
Traditional methods for distinguishing the authenticity of calligraphy work mainly rely on manual and physical authentication. Calligraphers rely on experience to determine authenticity, which is significantly subjective and cannot be quantified, making it prone to errors[3]. The physical methods mainly include seal authentication and paper composition analysis. Seal authentication involves determining whether the seal on the work is consistent with previous works[4], while paper composition analysis involves detecting whether the internal oxidizable components of the paper undergo the corresponding chemical reactions over time. However, with the continuous advancement of counterfeiting technology, computer scanning and mechanical reproduction of seals can almost perfectly replicate authentic seals, rendering the seal authentication method ineffective. Counterfeiters can also avoid paper composition analysis by purchasing paper from the same era to create forged calligraphy works.
Currently, research on calligraphy focuses on literature and arts. In computer science, research on calligraphy works primarily focuses on calligraphy recognition and generation, while research on the authenticity identification of calligraphy works is relatively scarce. For instance, Jing utilizes seven invariant moments to achieve calligraphy authenticity identification [5], and Zijun extracts calligraphy skeletons using generative adversarial networks [6]. Besides, Genting recognizes calligraphy characters based on an improved DenseNet network [7]. Wenhao generates calligraphy characters using generative adversarial networks [8]. Xiaoyan achieves calligraphy content and style recognition using deep learning and label power sets [9]. Moreover, Kang extracts calligraphy character features using high-resolution networks and detects calligraphy character areas using scale prediction branches and spatial information prediction branches to classify calligraphy characters and their boundaries, achieving calligraphy character detection [10]. Pan utilizes graph neural networks to compare the similarity between two calligraphy characters [11].
With the development and wide application of neural networks, using neural networks for handwriting recognition has become a research focus. Calligraphy has strong artistic qualities, diverse forms, and distinctive personal characteristics compared to ballpoint and pencil script. From the perspective of character morphology, calligraphy strokes have varying thicknesses that differentiate them from hard pen script. The writing techniques of the same strokes differ greatly among different calligraphers, which makes their calligraphic styles distinct and distinguishable from others' works. However, this also leads to imitators emphasizing imitating these writing techniques.
This paper proposes a method for authenticating calligraphy works based on the original works and imitations of two famous calligraphers from a well-known art museum. In the proposed method, first, individual calligraphy characters from the works are extracted using the character box and centroid point algorithms. The calligraphy training dataset is created by applying data augmentation techniques. Second, the attention mechanism of the EfficientNetv2-S network is improved by incorporating the CBAM and the Self-Attention modules. Then, the enhanced CBAM-EfficientNet and SA-EfficientNet networks are trained. Finally, the trained network models are used to test the authenticity of calligraphy works by the two calligraphers, imitation works, and others. The results are compared with mainstream image neural networks such as EfficientNetv2-S, revealing that the improved network models effectively authenticate calligraphy works and have significant implications in calligraphy authentication.
2. Calligraphy Dataset
This paper employs individual calligraphy characters as a training dataset for the network model. The character box algorithm and centroid algorithm are utilized to extract individual calligraphy characters from calligraphy works. Data augmentation was applied using small angular rotation, scaling, magnification, noise, and adjustment of the binary threshold. This enables the network to obtain a sufficient quantity of training data sets.
2.1. Character box algorithm
The writing method of calligraphy differs from that of other works of art, as calligraphy works have a relatively monochromatic color and are mostly written vertically. By utilizing these characteristics, binary processing can effectively separate the foreground and background of the artwork. Then, individual calligraphy characters can be segmented from the artwork by accumulating the projection values of the foreground in the vertical and horizontal directions of the image.
2.1.1. Split the foreground projection cumulative sum
Using the feature of vertical writing in calligraphy, the foreground of the image is projected onto the horizontal X-axis of the picture and the accumulated value function in the X-axis direction is obtained. Figure 1(a) shows that the projected accumulated value exhibits periodicity. This periodic feature of the function can be utilized for image segmentation. Assuming the image size is n*M, the image function is represented as equation(1):
The X-axis foreground projection cumulative value function is equation(2):
For function , the coordinates of the zeros where the derivative is greater than 0 are recorded as , and the coordinates of the zeros where the derivative is less than 0 are recorded as . To prevent the radicals of the characters from being separated, a deviation value is set. If , then and are not considered as segmentation coordinates. and are used as the starting and ending coordinates of the segmentation points in the image, as shown in Figure 1(a), resulting in Figure 1(b) after image segmentation.
Similarly, projecting the foreground values of the segmented image onto the Y-axis of the screen yields the cumulative foreground value function is equation(3):
The coordinates of the zero points where all the derivatives of the function are greater than 0 are recorded as , and the coordinates of the zero points where the derivatives are less than 0 are recorded as . Then, a deviation value is set. If , then and are not included as segmentation coordinates. and are used as the starting and ending coordinates of the segmentation points to segment the image, as depicted in Figure 1(b).
2.1.2. Minimum bounding box
From Figure 1 (a) and (b), we obtain the minimum foreground value coordinate in the Y-axis direction for each calligraphy character, as well as the maximum value in the vertical direction.
As depicted in Figure 1(c), the minimum foreground value coordinate and the maximum coordinate in the X-axis direction of the graph are calculated to obtain the character box coordinates and .
The character box segmentation algorithm has a simple calculation principle but efficiently divides the required calligraphy characters from the entire work, which is very suitable for splitting calligraphy works with vertical writing scenes. However, the character box algorithm also has limitations and cannot completely solve the problem of calligraphy character extraction. This is because many calligraphy works are not arranged neatly, and calligraphers often write casually, so it is common to have large character deformations and span variations. Figure 2 illustrates an example where a work has a large stroke span and overlapping letters in the vertical direction. When calculating the foreground accumulation value function in the X-axis direction, the character box segmentation algorithm cannot find the corresponding zero point and fails to locate the character box coordinates of individual calligraphy characters accurately.
2.2. Centroid Algorithm
The disadvantage of the character box algorithm lies in the loss of geometric distance information on the plane based on the cumulative foreground value when analyzing the coordinates of individual characters. This leads to a significant offset in the strokes of individual characters, affecting the overall partitioning effect. To overcome this problem, this paper proposes the centroid algorithm to supplement the calligraphy character segmentation.
The centroid algorithm is a supplement to the character box algorithm. Its principle relies on the centroid points of individual strokes of a character being relatively close, while the centroid points of different characters’ strokes are relatively far apart. By calculating the centroid points of each stroke, setting a nearest point distance threshold and a relative distance threshold, and considering strokes within the specified threshold as part of the same character, calligraphy characters can be effectively segmented.
2.2.1. Centroid calculation
This is a multi-staged process where the character box algorithm first performs image segmentation. Then, binarization and the Canny edge detection operator are applied for edge recognition at the image regions that cannot be completely segmented using the character box algorithm. Thus, the edge point information of all strokes m is obtained, and the area of each stroke is calculated individually using the Gaussian shoelace formula as equation(4):
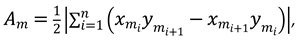 where m is the stroke, with a value range of 1, 2, ..., m, and n represents the number of edge points of the m-th stroke, with a value range of 1, 2, ..., n. When n+1=1, the stroke’s edge points are calculated in a loop. For example,
represents the coordinates of the n-th edge point of the m-th stroke. According to equation (5) and (6), the centroid point
of the m-th stroke is:
where m is the stroke, with a value range of 1, 2, ..., m, and n represents the number of edge points of the m-th stroke, with a value range of 1, 2, ..., n. When n+1=1, the stroke’s edge points are calculated in a loop. For example,
represents the coordinates of the n-th edge point of the m-th stroke. According to equation (5) and (6), the centroid point
of the m-th stroke is:
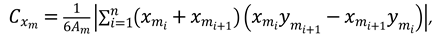
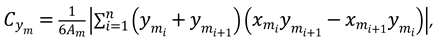
The effect is illustrated in Figure 3(1), where white dots represent the centroid points.
2.2.2. Character segmentation
The distance between each centroid point in the figure is calculated as equation(7):
For the distance between a shape's heart points, the heart point distance of strokes from the same character is closer in most cases. However, there are also situations where strokes connected by many strokes result in a bigger distance between the heart points. By setting the closest point distance threshold and the relative distance threshold , only one point that is closest but smaller than and all points smaller than are taken as strokes of the same character. Typically, .
As depicted in Figure 3, the following operations are performed:
- Only take the nearest point to the centroid that is less than distance , and recognize it as the centroid point of the stroke of the same character. There may be cases where points are mutually nearest to each other. Figure 3(b) illustrates the connection of centroid points.
- Recognize all centroid points based on threshold . If the centroid points are located within a distance less than from each other, they are recognized as centroid points of the stroke of the same character. Figure 3(c) illustrates the connection of centroid points.
- Combine the recognition results from (1) and (2) to obtain a set of centroid points that meet the conditions for a single character, representing strokes of the same character. Based on the recognition results, calculate the minimum foreground value and maximum foreground value Obtain the coordinates for the character box for all strokes belonging to the same character, as depicted in Figure 3(d).
The centroid Algorithm can effectively utilize the geometric information of foreground values to divide characters, avoiding the failure of the character box recognition algorithm caused by large character deformation. However, the algorithm itself also has disadvantages. When processing images with a large number of characters, it is challenging to determine suitable threshold values and for the Shape Center Algorithm. After testing, it is proven that this algorithm has a good effect when there are not many characters in the image, and thus, it can be used to supplement the character box algorithm.
This paper uses the character box algorithm combined with the Shape Center Algorithm in the data processing. Specifically, the character box algorithm first calculates the character box and sets the character box threshold width as W and height as H. If there is a character box width or height , the shape center point calculation is applied to that character box, as depicted in Figure 4. Compared to using only the character box algorithm, the Shape Center Algorithm effectively improves segmentation accuracy. Combining these two algorithms can achieve better segmentation results for calligraphy characters.
2.3. Data augmentation
Model training requires a large amount of data. Although we segment single characters for data production, many calligraphy works still struggle to meet the data volume required to train a model. Therefore, we utilize various data augmentation methods to expand the dataset and eliminate the influence caused by slight rotation, scaling, and different paper types used by calligraphers during their creative process.
As illustrated in Figure 5, the data augmentation methods used include rotation, amplification, reduction, Salt noise, Gaussian noise, and binary adjustment. Image zooming refers to enlarging the image and adjusting it back to its original size to eliminate the influence of character edge noise caused by image zooming during training. Binary adjustment adjusts the image based on the background color depth of calligraphy, which works in the range of 0-255 while ensuring the clear shape of the character to exclude the character edge interference caused by different binary thresholds. The generated dataset is a black background with white characters and single-channel images of size 224×224.
The calligraphy works data used in this paper include works of well-known calligrapher A in regular script, works of calligrapher B in regular script and cursive script, works of other calligraphers, and a large number of regular script and cursive script works collected through the internet. After data augmentation, the amount of calligrapher A's regular script data, calligrapher B's regular script data, calligrapher B's cursive script data, regular script data by other calligraphers, and cursive script data by other calligraphers is 300,752 characters, 85,406 characters, 128,811 characters, 443,015 characters, and 348,472 characters. These datasets are used as training sets to train a binary classification network to authenticate the authenticity of calligraphy works.
3. Network Design
EfficientNet[12], proposed by the Google Brain team in 2019, is a network that has demonstrated appealing performance in image classification projects in recent years. This paper uses the EfficientNetv2-S network and calligraphy dataset for training. Our modifications involve improving the attention mechanism and introducing the CBAM and self-attention modules to enhance the model’s generalization ability and achieve higher accuracy in calligraphy authentication.
3.1. EfficientNetv2-S Network and Attention Module Improvement
The characteristics of ResNet inspire EfficientNetv2-S, and thus, it employs MBConv blocks and Fused-MBConv blocks for higher accuracy and faster inference speed. The MBConv block includes dilated, depth-wise separable convolution and the SE attention module. Multiple Fused-MBConv blocks and MBConv blocks are stacked to form the EfficientNetv2-S network.
Zhang's improved CNN models for calligraphy style classification tasks using the CBAM attention module have achieved better classification results than the SE attention module[13]. Therefore, based on the EfficientNetv2-S network, the CBAM attention module and Self-Attention module are further utilized to improve the SE attention module in the MBConv blocks, resulting in the CBAM-EfficientNet network and SA-EfficientNet network. The CBAM module is a commonly used attention mechanism module in image processing that adaptively weights each channel and spatial position of the image, allowing the model to learn the most important features better and have a good image generalization and processing performance[14]. The Self-Attention module can identify the relationship between the features of each position in the image and all other positions. Besides, it calculates the correlation scores between each position and other positions in the image and weights the features of other positions. The advantage of the Self-Attention module is that it can establish global dependencies between different positions in the image, which is beneficial for the network to learn the overall features of calligraphy characters[15]. The network structures of both modules are depicted in Figure 6.
This paper employs the Regular Script (Kaishu) and Cursive Script (Caoshu) calligraphy works of two calligraphers to create a training set. We train the EfficientNetv2-S, CBAM-EfficientNet, and SA-EfficientNet networks horizontally compare InceptionResNetV2, InceptionV3, MobileNetV3L, ResNet50, and MobileNet. The training platform is an i9-13900k CPU, RTX4090 GPU, and 128GB of memory. The batch size for training is set to 64 and runs for 20 epochs in a loop. The optimizer used is Adam, and the loss function is binary cross-entropy.
4. Experimental Results
According to the research institute, forgery of calligraphy works usually focuses on imitating the handwriting style of the calligrapher. There are fundamental differences between the forgery writer's and the author's handwriting styles, and thus, the forgery writer cannot guarantee a stable imitation effect. Given that typically, the written characters are unnatural and not smooth [16], forgery of calligraphy works may present some characters similar to the authentic ones, while others may have differences. This paper uses a model to determine the probability of each character being authentic and calculates the average probability of authentic characters in the entire work as the probability of authentic work. This strategy detects whether the calligraphy style of the inspected work remains within a high probability and relatively stable range. The probability of authentic work is defined as equation(8):
where the probability is the overall authenticity of the work, and the probability is the individual calligraphy authenticity judged by the model, with n being the number of characters in the work.
To verify the model's effectiveness, the authentic works of calligraphers A and B were employed as the authentic test set, and the works of other calligraphers as the counterfeit test set. Calligrapher C was invited to imitate authentic works to test regular and cursive script models.
4.1. Calligrapher A's regular script model testing results
Table 1 reveals that for the calligraphy model test of Calligrapher A, authentic 1 and authentic 2 are small regular script works of Calligrapher A, while authentic 3 is a large regular script work of Calligrapher A. The test results show that since most regular script works in the training set are small, all networks effectively identify small regular script works. Besides, SA-EfficientNet has a higher score on Authentic 2 than other networks, and all models achieve good authenticity identification for imitations and works of other calligraphers.
The large regular script is a type of regular script with some differences in character shape compared to the small regular script, but the overall calligraphic style is similar to the small regular script. It is usually used in works like couplets with larger characters. The training set in this paper focuses on a small regular script, so whether the models can identify the large regular script works of the same calligrapher is also a test of whether they have learned the calligrapher's writing style. Table 1 highlights that SA-EfficientNet can better discriminate large regular script works than other models, with an accuracy of 59.233%. The model's generalization performance is also outstanding.
Among the tested models, except for the unsatisfactory discriminative effect of ResNet50, the other models can learn Calligrapher A's calligraphic style well. Especially SA-EfficientNet, not only can it achieve good discrimination ability, but also the model's generalization ability is relatively good, resulting in good discrimination performance even when facing large regular script styles that have not been learned. Besides, the SA-EfficientNet network has improved based on the Self-Attention module, has better generalization ability, and performs well in calligraphy authenticity identification.
4.2. Calligrapher B's regular script model testing results
In Table 2, Authentic 1 refers to the authentic calligraphy work by calligrapher B in regular script style. As a comparison, the imitation piece is a work by calligrapher C imitating the writing style of calligrapher B, while the remaining two works are calligraphy works by other calligraphers.
According to the test results from Table 2, all models except for MobileNetv3-L converge well during training. Among them, the improved SA-EfficientNet model achieves a similarity of 90.997% when identifying Authentic 1, a significant improvement compared to the 81.762% and 85.717% similarity achieved by EfficientNetv2-S and CBAM-EfficientNet, respectively. Furthermore, compared to InceptionResNetv2 and MobileNet, while exhibiting comparable performance in identifying Authentic 1, SA-EfficientNet has better discrimination ability when identifying imitations. When faced with imitation works, SA-EfficientNet only achieves a similarity of 5.556%, effectively distinguishing between authentic and imitation pieces, while InceptionResNetv2 and MobileNet achieve 10.999% and 16.674%, respectively.
In conclusion, in the testing of calligrapher B's regular script model, the improved CBAM-EfficientNet shows better discrimination ability than EfficientNetv2-S, while SA-EfficientNet further improves the discrimination performance based on the CBAM-EfficientNet network.
4.3. Calligrapher B tests the effect of the cursive model
In Table 3, authentic 1 and authentic 2 are calligraphy works in cursive style by Calligrapher B, while the others are works by other calligraphers. Calligraphers are more casual when writing in cursive script than when writing regular script. Although cursive script works show a more distinct personal style, the deformation of the cursive script characters is greater, and the characteristics of the character shapes are more variable and abstract, posing greater challenges for online authentication.
Based on the test results in Table 3, except for the MobileNetv3-L model, which failed to converge, the other models could train well. In the test for authentic 1, CBAM-EfficientNet showed a slight improvement compared to EfficeintNetv2-S, while SA-EfficientNet achieved better authentication results than the previous two models, achieving accuracies of 78.411% and 85.562% in the authentication of authentic 1.
In summary, the improved CBAM-EfficientNet and SA-EfficientNet models both performed well and could accurately learn the abstract features of the images from the dataset for the challenging task of distinguishing the authenticity of calligraphy works. The CBAM module had more parameters than the Self-Attention module, resulting in the overall size of the CBAM-EfficientNet model reaching 5.5GB, while the SA-EfficientNet model size is only 891MB. The attention structure of the Self-Attention module achieved better results with fewer parameters than CBAM.
Among the tested models, the MobileNetV3L model is lightweight with the lowest number of parameters, and its model size is only 36MB. When training the regular script model of Calligrapher A, there was enough data for the model to learn features, and the model was able to converge. However, when training the regular script model and cursive script model of Calligrapher B, the training data was relatively limited, and the models could not converge, making them unable to complete training and testing. Moreover, in the authentication of authentic works by Calligrapher B, the model's accuracy was lower than that of the authentic works by Calligrapher A model. Therefore, distinguishing the authenticity of calligraphy works requires a certain number of network model parameters and sufficient training data.
5. Conclusion
The authentication of calligraphy works is a task that relies heavily on the subjective view of calligraphers and does not have clear mathematical indicators to quantify the similarity of calligraphy works. Furthermore, calligraphers intentionally add variations in character forms during creation to pursue artistic value in the overall work. Therefore, using neural networks to identify the authenticity of calligraphy works is difficult and poses a significant challenge to model algorithms.
This paper proposes an algorithm for identifying the authenticity of calligraphy works. It uses the character box and centroid algorithms to extract individual calligraphy characters from the works and expands the calligraphy dataset using data augmentation. Based on the EfficientNetv2-S model, the CBAM and Self-Attention modules improve network attention. The improved CBAM-EfficientNet and SA-EfficientNet networks are trained, and the effects are compared with EfficientNetv2-S, InceptionResNetv2, Inceptionv3, MobileNetv3-L, ResNet50, and MobileNet networks. The effects of the Kai script and Cao script models are tested using authentic calligraphy, other calligraphy works, and imitations of other calligraphers as the test set.
The experimental results show that the model can learn the personal style characteristics of calligraphers from the calligraphy dataset and identify authentic works, imitations, and works by other calligraphers in the test set. Among them, the improved CBAM-EfficientNet and SA-EfficientNet based on the Efficientv2-S model achieve better authentication results compared to the original model in this project. Additionally, SA-EfficientNet achieves better results than CBAM-EfficientNet with smaller model size and overall outperforms other networks. Therefore, the improvement based on the attention module has a good effect on identifying calligraphy authenticity.
The methods described in this paper mainly aim at works with more obvious personal styles like calligraphy. However, these methods can be extended and applied to more fields. Using neural networks to identify individual handwriting has good application prospects in judiciary, criminal investigation, banking, and cultural relic authentication.
Author Contributions
Conceptualization, X.J., J.C. and Z.H.; methodology, W.W. and H.Y.; software, X.W. and Z.H.; validation, X.W., H.Y. and Z.H.; formal analysis, X.W., H.Y. and J.C.; investigation, J.C., X.J. and Z.H.; resources, X.W., J.C. and Z.H.; data curation, J.C., Z.H. and W.W.; writing—original draft preparation,X.J., J.C. and Z.H.; writing—review and editing, W.W., Z.H. and H.Y.; visualization, X.W., and J.C.; supervision, W.W., H.Y. and X.W.; project administration, W.W., and Z.H.; funding acquisition, W.W., and H.Y.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the National Key Research and Development Project of China (grant number 2018YFA0902900), the National Natural Science Foundation of China (grant number 62073092), the Natural Science Foundation of Guangdong Province (grant number 2021A1515012638), and the Basic Research Program of Guangzhou City of China (grant number 202002030320).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors would like to express their thanks to the Guangzhou Institute of Advanced Technology for helping them with the experimental characterization. The authors would like to express their gratitude to EditSprings (https://www.editsprings.cn) for the expert linguistic services provided.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Yunfei Meng. Ancient painting and calligraphy collecting traditions and current cultural consumption[J]. Art Observation,2019(12):76-77.
- Jiawei Zhu. Research on the prediction of calligraphy and painting market index based on Internet search data[D]. Zhejiang University of Finance and Economics, 2019.
- Shuangshuang Pang. Computer-aided identification of authenticity of Chinese calligraphy[D]. Xi'an University of Architecture and Technology, 2018.
- SiQiong Liang. Analyze the role of seal recognition in the identification of calligraphy and painting[J]. Cultural relics identification and appreciation, 2021(23):96-98. [CrossRef]
- Jing Ji. Research on calligraphy authenticity identification method based on invariant moment[J]. Journal of Engineering Mathematics, 2022, 39(02):196-208.
- Zijun Zhang, Jinsong Chen, Xiyuan Qian. Calligraphic character skeleton extraction based on improved conditional generation adversarial network[J/OL]. Computer Engineering:1-10[2023-05-15]. [CrossRef]
- Genting Mai, Yan Liang, Jiahui Pan. Calligraphy font recognition algorithm based on improved DenseNet network[J]. Computer system applications, 2022,31(02):253-259. [CrossRef]
- Wenhao Dai. Research on Calligraphy Text Generation Based on Generative Adversarial Network[D]. Chongqing University of Technology, 2021. [CrossRef]
- Xiaoyan Ji. Research on Calligraphy Character Content and Style Recognition Based on Deep Learning[D]. Xi'an University of Electronic Science and Technology, 2023. [CrossRef]
- J. Kang, Y. Wu, Z. Xia and X. Feng, "Application of Deep Convolution Neural Network Algorithm in Detecting Traditional Calligraphy Characters," 2022 International Conference on Image Processing and Media Computing (ICIPMC), Xi'an, China, 2022, pp. 12-16. [CrossRef]
- G. Pan et al., "A Graph based Calligraphy Similarity Compare Model," 2021 IEEE 21st International Conference on Software Quality, Reliability and Security Companion (QRS-C), Hainan, China, 2021, pp. 395-400. [CrossRef]
- Tan M , Le Q V .EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[J]. 2019. [CrossRef]
- J. Zhang, W. Yu, Z. Wang, J. Li and Z. Pan, "Attention-Enhanced CNN for Chinese Calligraphy Styles Classification," 2021 IEEE 7th International Conference on Virtual Reality (ICVR), Foshan, China, 2021, pp. 352-358. [CrossRef]
- WOO, Sanghyun, et al. Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). 2018. p. 3-19.
- Vaswani A, Shazeer N, Parmar N,et al.Attention Is All You Need[J]. arXiv, 2017. [CrossRef]
- Baoying Zeng. Research on Chinese Calligraphy Authenticity Identification Method Based on Image Recognition[D]. Xi'an University of Architecture and Technology, 2016.
Figure 1.
Character box segmentation algorithm: (a) Horizontal Foreground Projection; (b) Vertical foreground projection, (c)Minimum bounding box.
Figure 1.
Character box segmentation algorithm: (a) Horizontal Foreground Projection; (b) Vertical foreground projection, (c)Minimum bounding box.
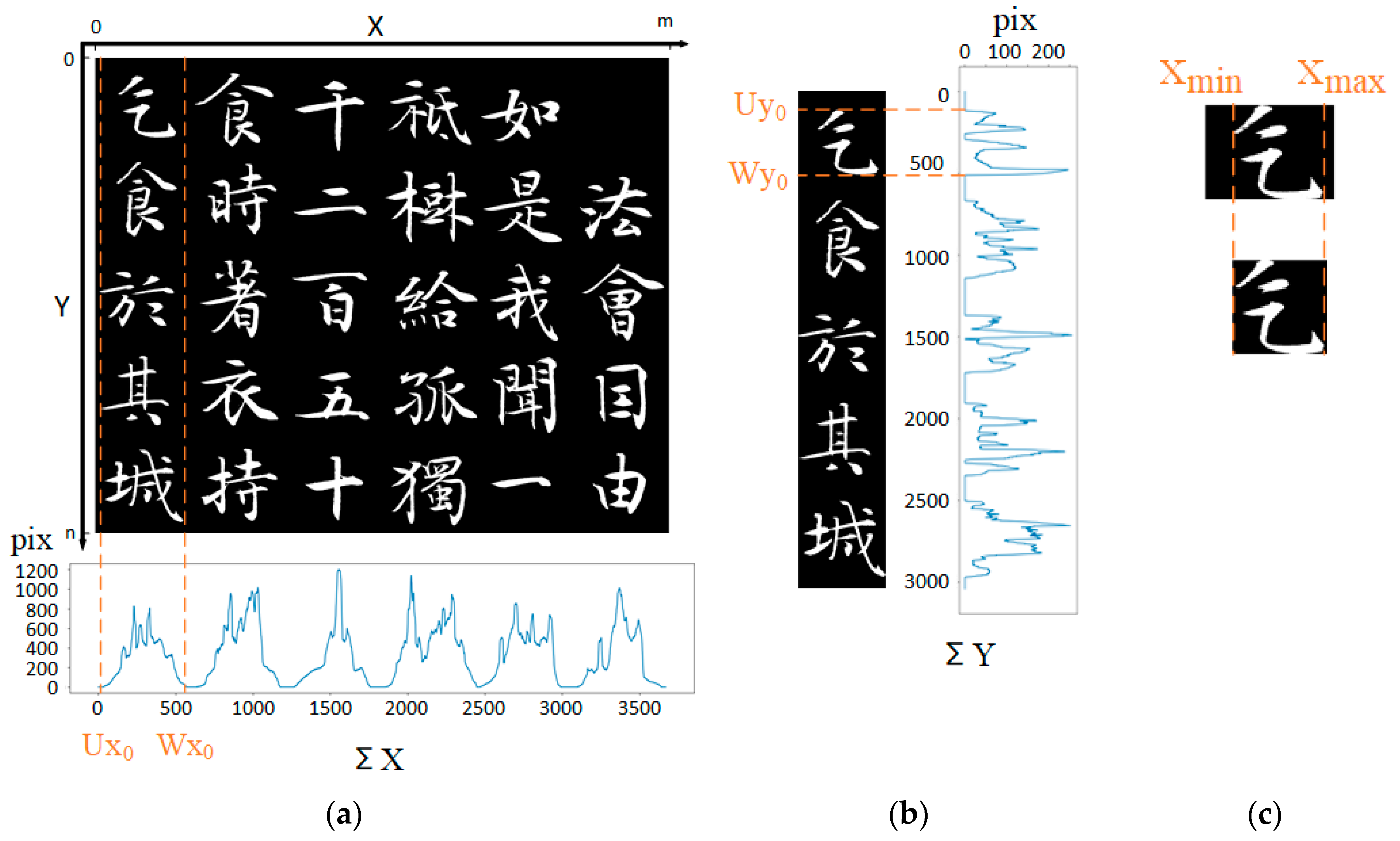
Figure 2.
The limitations of the character box algorithm: (a) Image of the original calligraphy work; (b) The processed image.
Figure 2.
The limitations of the character box algorithm: (a) Image of the original calligraphy work; (b) The processed image.
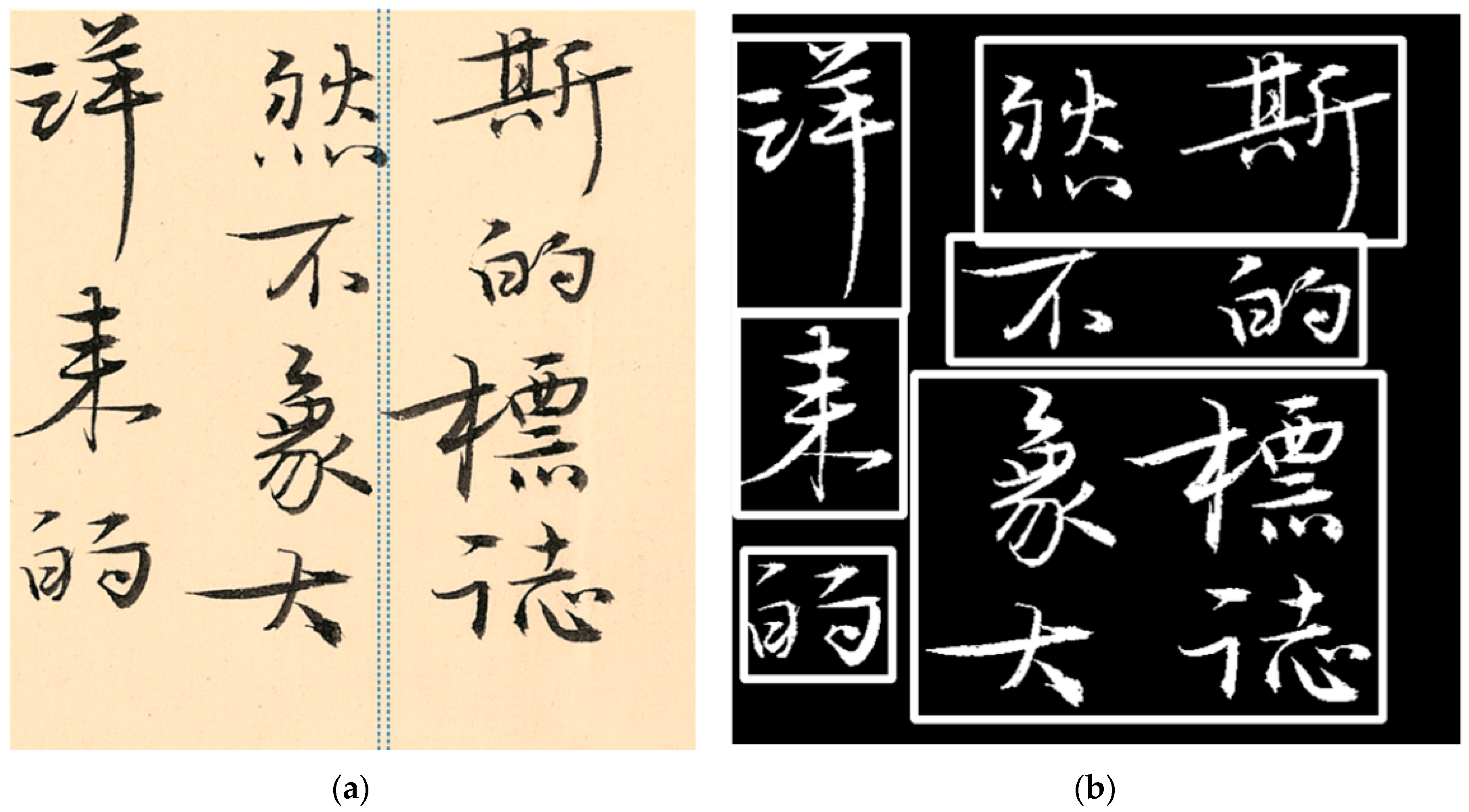
Figure 3.
Effectiveness of the centroid algorithm: (a) Stroke centroid points; (b) Closest centroid points, (c) Similar centroid points; (d) Algorithm result.
Figure 3.
Effectiveness of the centroid algorithm: (a) Stroke centroid points; (b) Closest centroid points, (c) Similar centroid points; (d) Algorithm result.
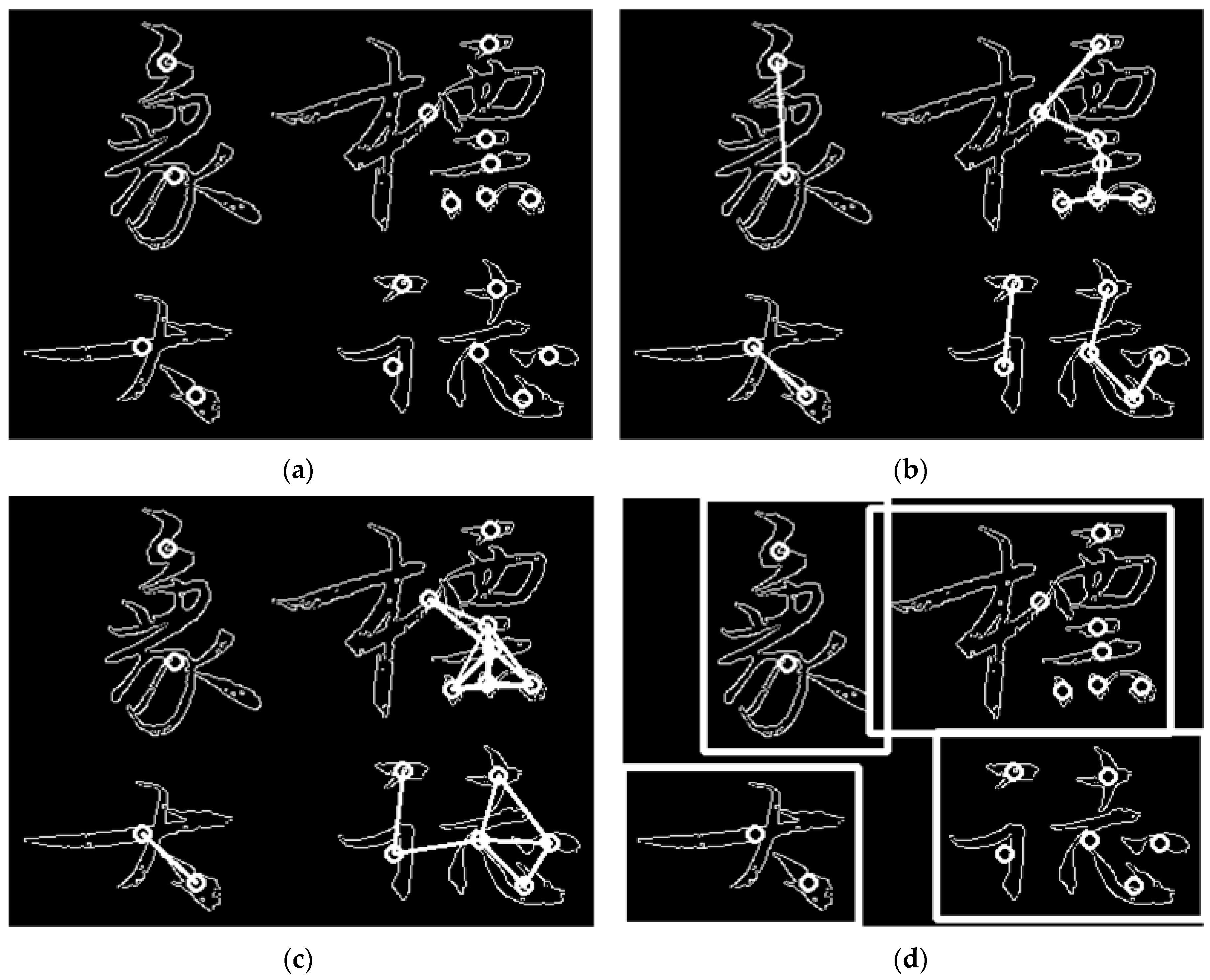
Figure 4.
Character box algorithm and the centroid algorithm: (a) Character Box Algorithm; (b) Character box algorithm, centroid algorithm.
Figure 4.
Character box algorithm and the centroid algorithm: (a) Character Box Algorithm; (b) Character box algorithm, centroid algorithm.

Figure 5.
Data augmentation.

Figure 6.
Network structure of CBAM-EfficientNet and SA-EfficientNet.
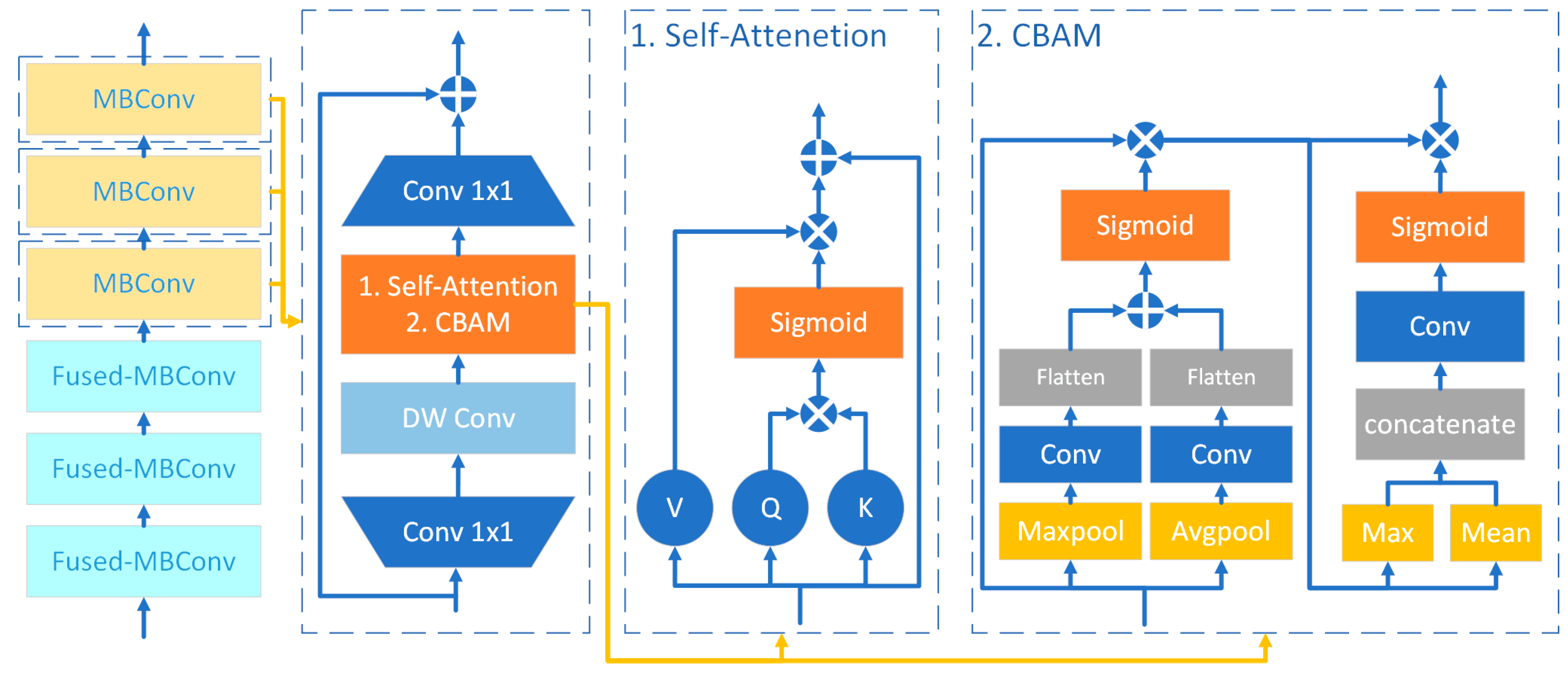

Table 1.
Calligrapher A's regular script model testing results.
| algorithm | Authentic 1 | Authentic 2 | Authentic 3 | Imitation | Others |
|---|---|---|---|---|---|
| EfficientNetv2-S | 98.877% | 93.911% | 34.856% | 4.003% | 15.598% |
| CBAM-EfficientNet | 98.633% | 93.922% | 35.900% | 7.937% | 13.557% |
| SA-EfficientNet | 98.846% | 95.611% | 59.233% | 17.265% | 21.714% |
| InceptionResNetv2 | 98.963% | 90.910% | 40.519% | 0.153% | 15.888% |
| Inceptionv3 | 98.276% | 90.918% | 40.503% | 5.587% | 18.011% |
| MobileNetv3-L | 98.278% | 90.930% | 41.143% | 15.760% | 21.630% |
| ResNet50 | 97.131% | 64.502% | 23.942% | 13.726% | 38.338% |
| MobileNet | 98.634% | 90.914% | 30.208% | 1.961% | 18.306% |
Table 2.
Calligrapher B's regular script model testing results.
| algorithm | Authentic 1 | Imitation | Other works 1 | Other works 2 |
|---|---|---|---|---|
| EfficientNetv2-S | 81.762% | 11.098% | 0% | 0.011% |
| CBAM-EfficientNet | 85.717% | 5.556% | 0% | 0% |
| SA-EfficientNet | 90.997% | 5.556% | 0% | 0.006% |
| InceptionResNetv2 | 92.584% | 10.999% | 0.373% | 0% |
| Inceptionv3 | 88.614 | 5.556% | 0% | 0% |
| MobileNetv3-L | - | - | - | - |
| ResNet50 | 88.950% | 16.660% | 3.890% | 0.429% |
| MobileNet | 91.385% | 16.674% | 0% | 0% |
Table 3.
Calligrapher B tests the effect of the cursive model.
| algorithm | Authentic 1 | Imitation | Other works 1 | Other works 2 |
|---|---|---|---|---|
| EfficientNetv2-S | 80.326% | 66.867% | 13.779% | 0.008% |
| CBAM-EfficientNet | 82.855% | 68.028% | 21.169% | 0% |
| SA-EfficientNet | 85.562% | 78.411% | 25.588% | 0.048% |
| InceptionResNetv2 | 84.846% | 70.616% | 18.885% | 0% |
| Inceptionv3 | 87.958% | 67.722% | 15.060% | 0% |
| MobileNetv3-L | - | - | - | - |
| ResNet50 | 86.218% | 79.113% | 25.254% | 0.253% |
| MobileNet | 80.000% | 69.813% | 10.448% | 0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



