
Submitted:
10 December 2023
Posted:
11 December 2023
You are already at the latest version
Abstract
For years, effort has been devoted to establishing an effective bull breeding soundness evaluation procedure; usual research on the subject is based on BBSE (Bull Breeding Soundness Examination) methodologies, which have significant limitations in terms of their evaluation procedure, such as high cost, time-consuming and administratively difficult. This research focuses on the creation of a prediction model to supplement and/or improve the BBSE approach, through the study of two algorithms, Clustering and Artificial Neural Network (ANN), to find the optimum Machine Learning (ML) approach for our application, with an emphasis on data categorization accuracy. The tool is designed to assist veterinary medicine and farmers in identifying key factors and increasing certainty in their decision-making during the selection of bulls for breeding purposes, providing data from a limited number of factors generated from a deep pairing study of bulls. Zebu Bulls, European Bulls, and Crossbred Bulls were the general groupings. The data utilized in the model's creation (N =359) considers five variables that influence improvement decisions. This approach enhances decision-making by 12%. ANN obtained an accuracy of 90%; Precision was 97% for satisfying, 92% for unsatisfying, and 85% for Bad.
Keywords:
BBSE
; Artificial Neural Networks
; K-Means
; Data Engineering
1. Introduction
Bulls have a significant impact on herd reproductive efficiency, independently of the reproductive strategy used: natural, controlled mating, or artificial insemination. As a result, the absence or decrease in bull fertility reduces productive parameters, which may reduce farm profitability, particularly in extensive livestock production systems. In certain cases, fertility refers not only to the semen characteristics but also to the bull´s capability to deliver enough pregnancies even under difficult environmental conditions, including natural mounts. Breeding programs for beef and dual-purpose cattle are prevalent in tropical countries, to increase calf numbers and sell weight [1]. Livestock production in Veracruz began in the first age of Spanish colonization in the XV century with the introduction of southern Spain’s animals (Bos taurus), which originated the Creole cattle population [2]. Since the 1950s, Bos Indicus cattle (Indo-Brazil, Brahman) and Bos taurus cattle (Brown Swiss, Holstein, Charolais, and Simmental) from Brazil have been brought in to bring improved production performance through progressive adaptation to environmental conditions [3,4]. To maintain agricultural profitability, bulls must be extremely fertile in all respects in the region’s extensive farming system. Highly fertile bulls can achieve a pregnancy rate of more than 60% in females with acceptable reproductive activity; a BBSE is required to achieve this [5,6]. BBSE is a procedure that decreases risk while improving strategic bull use and herd fertility [7]. BBSE comprises biometric data, namely scrotal circumference (SC), and semen analysis (sperm concentration, motility, and morphology), but it fails to include behavior (libido), even though this parameter may be used to predict prospective bull fertility [8]. The need for tools that promote a more objective and quantifiable assessment and measurement of behavior is not new [9]; recognizing technology´s potential not only to empower the human observer in terms of accuracy and volume of processed data but also to lead to the discovery of behavioral characteristics that are inaccessible through simple human observation. A predictive model’s objective is to make accurate predictions from previously unseen data; thus, data mining and its application in animal husbandry were studied [10], where authors emphasized the complexity of the structure of animal husbandry management systems, with multiple problems due to the large volume of information. Machine Learning (ML) can assist in the creation of models for predictions by analyzing substantial amounts of data, providing a decision-making baseline. Sensors, cloud computing, artificial intelligence (AI), and specifically ML, are already revolutionizing various sectors and bringing advantages. AI and cognitive-based technologies are the most disruptive and significant advanced analytics tools for supply chain decision-making [11,12]. Intelligent systems integrate many technologies [13], and ML, which is a branch of AI algorithms, is used to identify patterns in data. ML is frequently used as a decision-making tool in the sustainable agriculture supply chain [14]. Digitalization sets up a massive volume of data in supply chains, which is meaningless unless relevant information is categorized, interpreted, and gathered using appropriate data analysis tools [15,16,17,18]. In recent years, ML algorithms have been employed in agriculture trying to solve problems such as cattle concerns [19] and forecasting different temperatures on piglets [20]. Additionally, ML has been employed to examine the complexity of livestock reproduction dynamics, often influenced by genetic factors, as demonstrated in previous works [ [21], wherein K-means algorithms played a pivotal role in their analysis and findings.
ML is divided into several subcategories depending on its approach; two of them are supervised learning and unsupervised learning algorithms. To learn to distinguish classes, supervised learning algorithms require the data to be labeled by an expert. The dataset is split into two (or three) parts: training data, validation data, and test data. The model is trained using data from the first set, and its performance is assessed with test and/or validation data. Once trained and evaluated, the model may be used to generate predictions on test data. Unsupervised learning algorithms, also known as clustering algorithms, set up values into a defined number of classes based on the similarity distance between variables in the presented data, and one of the best-known is K-means. This algorithm establishes k seeds on n-dimension features obtained from data and then generates clusters that are proximal one from the other. Artificial Neural Networks (ANNs) by their side, are supervised algorithms that use labeled data, this labeling is made (mostly) by human experts and serves as a guide for adjusting its parameters until it fits training data. It is important to compare both approaches to make a more informed decision about which technique is more suitable for this problem, data, and objectives. This paper performs this ML algorithms comparison in the behavioral and productive traits determinants of bull survival in Mexico´s tropical altitudes. With this insight, it is feasible to design appropriate animal breeding and management approaches to reduce bull mortality rates. To the best of the authors’ knowledge, there is no ML application dedicated to bull breeding classification. The main contribution of this work is the machine learning automation of bull breeding classification for reproductive efficiency based on morphological, behavioral and semen quality data.
2. Materials and Methods
2.1. Animals
The Animal Biology Reproduction Laboratory and the Cell Biology Laboratory of Veracruz University utilized a Bull breeding soundness examination (N=359). [22] recommended assigning the genetic groupings to be evaluated. Zebu bulls (n=73), “Bos indicus” (Gyr and Brahman), European bulls (n=136), “Bos taurus” (Brown Swiss, Holstein, Charolais, and Simmental), and Crossbreed bulls (n=150) (Holstein x Zebu, Brown Swiss x Zebu, synthetic breed bulls x Ze; Beef Master, Brahman x Hereford x Shorthorn). All bulls aged 1 to 8 years were fed under an extensive grazing system that grazed Cynodon nlemfuensis and Brachiaria humidicola grasses [23,24], with no evident health impairment at the time of evaluation. During the 2018-2019 period, animals and semen samples were collected and evaluated on farms.
The pregnancy rate was determined by dividing the total number of pregnant cows evaluated per bull. The calving interval was calculated as the number of days between the birth of one calf and the birth of the next one, both from the same cow. This information was derived from herd productive and reproductive records, considering the time each bull remained in the herd [25,26].
2.2. Morphological and behavioral evaluation
The Society for Theriogenology’s Manual for Breeding Soundness Examination (BBSE) in Bulls was followed [27]. Body condition scores (scale 1-5) were evaluated in each bull using the approach published by [28]. Scrotal circumference was measured in each bull using the technique provided by [29]. The technique established by [30,31] was used to rate libido (0 to 10 scale). Identifying a proper set of variables correlating bull breading reproductive efficiency based on morphological, behavioral and semen quality evaluation is a challenging task. The most relevant variables are depicted in Table 1, [27].
2.3. Semen quality evaluation
The semen samples were collected from January 2018 until December 2019, and each one was assessed in the field within five minutes of being collected. Semen was obtained in a test tube with a graduation of 1-15 ml, and volume, color, and density were evaluated macroscopically [30,31]. A three-electrode probe (Minitube, Verona, WI, USA; Ø: 2’’ / 5.08 cm; long: 33 cm) was used to try electro-ejaculation to get a semen sample from each bull. No more than one electro-ejaculation attempt was undertaken on each bull during each examination session [32]. The sperm motility of the semen sample was promptly examined, and the materials in contact with the sperm were at the same temperature as the sperm (to minimize temperature shock), clean, dry, and non-toxic. Individual motility was measured in a sample that had been diluted with warmed saline solution. At 37 °C, a drop of diluted sperm was deposited on a thermoplatin slide, covered with a coverslip, and examined at 40X. The fraction of sperm traveling progressively across the field of vision was calculated by locating multiple groups of ~10 sperm and estimating how many are progressive against how many are not [33]. Sperm concentration (x106/mL), was determined using a spectrophotometric technique. Once the sample was obtained, a drop of undiluted semen was taken and placed in the Micro-cuvette for SDM-1 (Minitube®) with a capacity of 2 µl, then inserted into SDM-1 photometer (Minitube®) calibrated for bovine, and finally, the reading provided by screen equipment was obtained [34]. Semen density was categorized as very good (creamy, 4), grainy consistency with 750 to 1000 x106/ml, Good (milk-like, 3) with 450 to 750 X106/ml, fair (skim milk-like, 2) with 250 to 450 x106/ml, poor (translucent, 1) < 250 x106/ml [35]. A study of the complete set of characteristics specified in Table 2 was required to determine a higher classification accuracy and identify the satisfactory, unsatisfactory, and bad elements from the genetic group, analyzing their correlations and effects on a clear classification. It is important to highlight that gross motility, color and density variables were not selected for the analysis, given the high subjectivity of such tests.
2.4. Machine Learning analysis
Traditionally, farmers and bull breeding experts perform subjective bull breeding classification based on the above data provided by veterinaries. This approach has been effective but can be greatly improved using modern machine learning, data analysis tools and pattern recognition techniques. Nonetheless, in real world applications such data might not be ideal, rendering challenges as incomplete or unbalanced data. In Mexico, this difficulty arises from the fact that local bull-sperm market is not relevant, therefore, data availability is hard to get.
Bull Breeding data from Sections 2.1 – 2.3 is condensed in Table 2. Dataset provides information of 359 bulls; nevertheless, only for 213 bulls information about all the variables is present, as shown in the filtered dataset in Figure 1. The first concern identified is that the dataset is unbalanced, as practically all the bulls fit into one of the following categories performed by experts:
- Satisfactory (A class): bulls have a high pregnancy rate in a short time.
- Unsatisfactory (B class): Bulls have a low pregnancy rate.
- Bad (C class): Bulls nearly seldom have cow pregnancies.
where most of the data fall into Class A, as depicted in Figure 1, making it difficult to identify the second and third classes. This distribution occurs because when bulls are purchased, they are already pre-selected for breeding based on their qualifications and an 81% accuracy rate (174/213 satisfactory bulls), which is considered a high estimation rate.
Figure 1.
Bull data distribution. It is possible to observe that the data obtained is unbalanced due to the traditional BBSE methodology.
Figure 1.
Bull data distribution. It is possible to observe that the data obtained is unbalanced due to the traditional BBSE methodology.
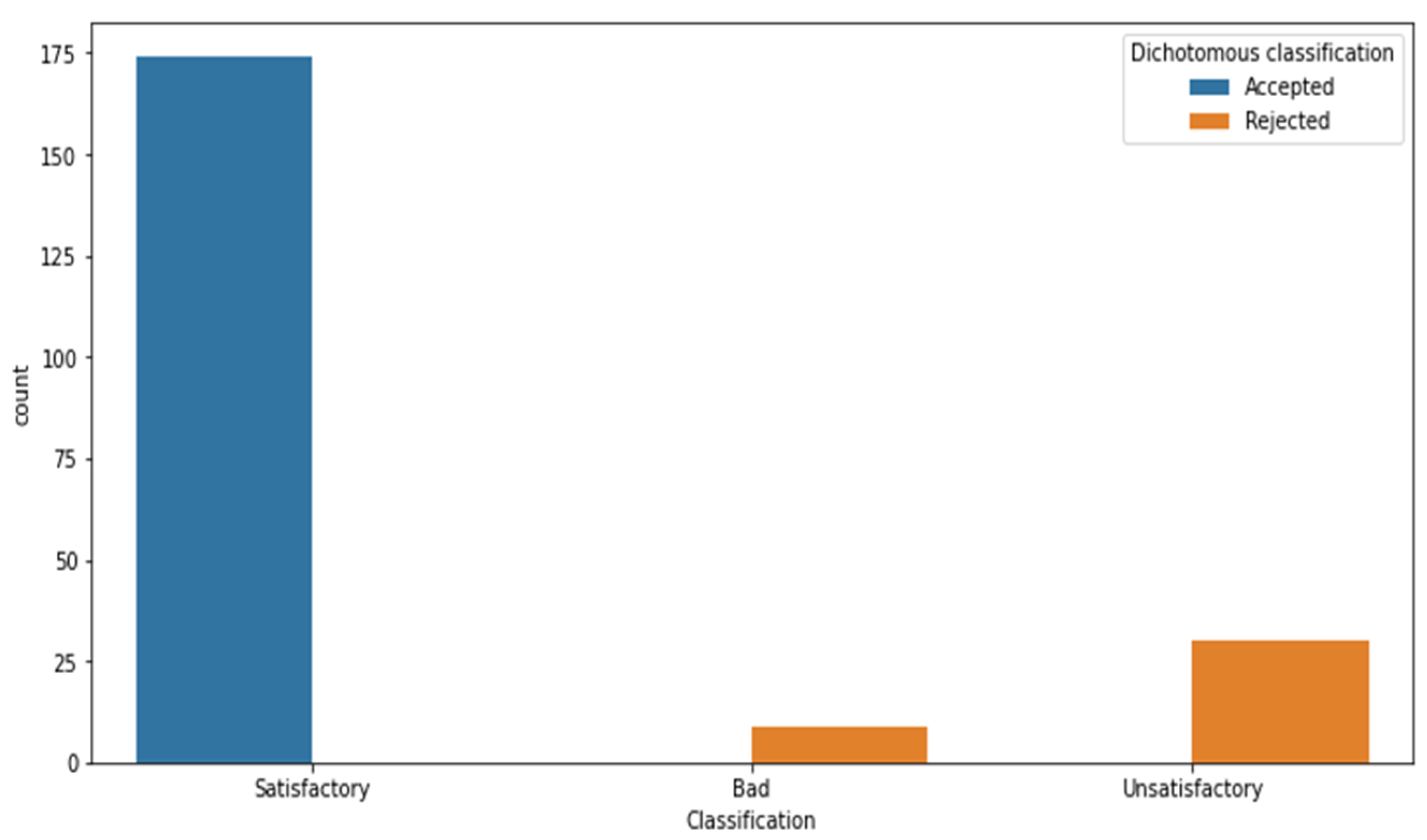

Table 2.
BBSE descriptive analysis in each local genetic group, showing average and standard mean error.
Table 2.
BBSE descriptive analysis in each local genetic group, showing average and standard mean error.
| BBSE parameters | Genetic Group N= 359 | ||||||||||||
| Zebu Bos indicus N=73 | European Bos taurus N= 136 | Crossbreed N=150 | |||||||||||
| Brahman (n=41) | Gyr (n=32) | Simmental (n=18) | Brown Swiss (n=24) | Charolais (n=78) | Holstein (n=3) | Angus (n=7) | Limousin (n=6) | Charolais X Ce (n=57) | Holst X Ce (n=2) | Swiss X Ce (n=62) | Symthetic X Ce (n=29) | ||
| BCS (1-5) | 3.59 ± 0.08 | 3.37 ± 0.08 | 3.63 ± 0.13 | 3.04 ± 0.07 | 3.27 ± 0.07 | 3.33 ± 0.33 | 3.50 ± 0.18 | 4.00 ± 0.22 | 2.85 ± 0.04 | 4.00 ± 0.04 | 3.24 ± 0.06 | 3.96 ± 0.03 | |
| Age (years) | 4.51 ± 0.24 | 3.97 ± 0.29 | 3.61 ± 0.32 | 3.17 ± 0.25 | 4.17 ± 0.24 | 4.33 ± 0.33 | 3.57 ± 0.57 | 4.66 ± 0.80 | 5.00 ± 0.37 | 5.50 ± 1.50 | 5.16 ± 0.17 | 3.59 ± 0.19 | |
| Libido (1-10) | 7.73 ± 0.19 | 7.31 ± 0.32 | 8.15 ± 0.32 | - | 7.43 ± 0.18 | - | - | - | 7.42 ± 0.16 | - | 7.05 ± 0.20 | - | |
| Scrotal Circ. (cm) | 37.14 ± 0.34 | 36.81 ± 0.54 | 37.44 ± 0.28 | 32.50 ± 0.70 | 35.83 ± 0.27 | 40.67 ± 1.86 | 36.57 ± 1.26 | 34.16 ± 1.07 | 36.87 ± 0.23 | 44.00 ± 0.23 | 38.30 ± 0.40 | 36.28 ± 0.68 | |
| Semen vol. (ml) | 5.48 ± 0.33 | 5.03 ± 0.24 | 4.25 ± 0.39 | 4.92 ± 0.60 | 4.16 ± 0.21 | 2.33 ± 0.33 | 5.85 ± 0.91 | 5.83 ± 1.70 | 3.56 ± 0.18 | 4.00 ± 2.00 | 5.76 ± 0.32 | 4.62 ± 0.33 | |
| Sperm Conc. (X106) | 507.2 ± 34.4 | 497.5 ± 48.7 | 494.3 ± 73.2 | 338.8 ± 43.4 | 496.0 ± 36.6 | 263.3 ± 28.8 | 384.2 ± 134.2 | 413.3 ± 115.8 | 621.2 ± 50.6 | 250.0 ± 50.0 | 477.4 ± 34.0 | 496.9 ± 49.4 | |
| Sperm Mot (%) | 53.41 ± 2.96 | 56.56 ± 3.57 | 53.61 ± 6.38 | 64.38 ± 4.46 | 60.91 ± 2.73 | 24.19 ± 1.44 | 55.71 ± 7.10 | 62.50 ± 12.63 | 68.84 ± 2.89 | 60.00 ± 10.00 | 49.03 ± 2.94 | 65.00 ± 2.57 | |
| Cows (n) | 27.17 ± 1.29 | 29.00 ± 1.92 | 25.92 ± 2.29 | - | 32.90 ± 0.76 | - | - | - | 28.78 ± 0.58 | - | 31.03 ± 1.08 | - | |
| Pregnancy rate (%) | 38.85 ± 1.70 | 36.00 ± 1.96 | 41.15 ± 1.46 | 3.04 ± 0.07 | 43.46 ± 2.19 | 3.33 ± 0.33 | 3.50 ± 0.18 | 4.00 ± 0.22 | 45.44 ± 1.78 | 4.00 ± 0.04 | 33.41 ± 1.62 | 3.96 ± 0.03 | |
| Satisfactory n (%) | 37 (90.24) | 25 (78.13) | 15 (83.33) | 14 (58.33) | 60 (76.92) | 0 (0.0) | 5 (71.42) | 5 (83.33) | 45 (78.95) | 2 (100) | 51 (82.26) | 29 (100) | |
| Unsatisfactory n (%) | 3 (7.32) | 6 (18.75) | 3 (16.67) | 10 (41.67) | 16 (20.51) | 3 (100) | 2 (28.57) | 1 (16.67) | 12 (21.05) | 0 (0.0) | 6 (9.68) | 0 (0.0) | |
| Bad n (%) | 1 (2.44) | 1 (3.13) | 0 (0.0) | 0 (0.0) | 2 (2.56) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 5 (8.06) | 0 (0.0) | |
Dealing with unbalanced data to perform a multiclass classification problem, when one class considerably dominates the others, is one of the most challenging difficulties in ML. In this work, this is approached by class augmentation paradigm. Furthermore, to identify an acceptable ML model for this difficulty, a variable pairing phase is conducted, involving a comprehensive analysis of the dataset's categorization, as outlined in Table 1. In it, data collected on the field is used to run an ML algorithm that classifies the animals according to the same BBSE standards, anticipating the validation of the benefits of technological tools for dealing with the abundance of information used in the design of automated processes to identify those individuals who exhibit the best breeding conditions.
Therefore, we proposed to perform ML data treatment as depicted in the end of section 3. For this sake, a first correlation analysis aims to compare Age versus Motility Percentage. Nevertheless, results indicate, as a relevant feature depicted in Figure 2, that Age is not correlated to Motility Performance since there is no increasing tendency in Age toward Motility Performance or vice versa. In addition, there is a significant tendency for Satisfactory elements concerning semen individual motility; higher than 40%, which is a suitable element for classification. Nonetheless, there is considerable overlap between 20% and 30%, with a few unsatisfactory elements clustered around 80% motility. Because of the skewed data, this becomes considerably more relevant.
Another finding from the semen analysis is a definite preference for Satisfying elements over 490 x106/mL of sperm concentration, as depicted in Figure 3. However, even when the motility percentage was considered, there was still insufficient information to distinguish between classes A and B (satisfying and unsatisfying). Nonetheless, based on the dichotomous classification presented in Figure 1, it is feasible to note that class C is a subset of class B, which might lead to both being misclassified.
Although libido is expected to be a significant feature in bull classification; however, as shown in Figure 4, it is not an important factor because there is no clear distinction between classes, and all are mixed. Furthermore, Figure 4 demonstrates that the B and C classes are difficult to differentiate due to their proximity, but it is ineffective in discerning between classes A and C. This implies that the B and C classes are difficult to differentiate since they are so similar. Although sperm motility is subjective, it is the most useful characteristic for discriminating between the three classes.
The variable pairing phase demonstrated no significant differences in this study. Nonetheless, some elements can be obtained. For instance, combining multiple variable subsets may result in more separation than other approaches; on the other hand, a subset of variables may be categorical, based on human judgment and/or instrument quality as detailed by [36]. Our approach, instead, is to assess whether an individual may be classified as a Satisfying element is based on two sorts of variables (A&P and Performance) as is seen in Table 3. Thus, the objective here is to determine the absolute minimum of variables necessary to distinguish each class. To determine the most representative set of variables it becomes essential to reduce them by eliminating categorical features, which are variables whose categorization has been determined based on observations that may lead to human error in classification. Thus, it is important to highlight that A&P variables represent raw and objective data from each bull. In contrast, Performance Variables are provided by the supplier or can be obtained long after the bull has been purchased. These variables are not entirely reliant on the bull as other aspects, such as the number of cows, climate, and so on, which might affect its performance. Therefore, the five A&P variables are selected as the input variables for the ML analysis of section 3.1.
It is worth to mention that there are several ML methods and architectures available in literature; the selection of each is highly dependent on the data and application. Considering this, we propose to explore two paradigms of ML unsupervised (K-means) and supervised (Fully connected Artificial Neural Network).
3. Results
In the proposed ML-based prediction model, selecting a bull with an uncertain classification is reduced by assigning a score to the bull and forecasting its performance in advance. There is a particular type of ML algorithm that is devoted to multiclass classification, such as a required categorization of bulls, and the current approach examines two subgroups to evaluate its efficiency: unsupervised (clustering analysis) and supervised learning algorithms (neural networks).
3.1. Unsupervised Algorithm
The first approach will examine if an uninformed ML algorithm recognizes differences between groups of individuals separated in a multiclass classification. The principal components (PCA) were extracted from the dataset to provide information to the algorithm, and the K-means algorithm was used [37]. As shown in Figure 5, where the three first components (PCA1 PCA2 and PCA analysis) from the eight-dimensional PCA feature vector are compared. Orange elements from categories B and C (the Unsatisfying and Bad elements) and blue items from category A (as Satisfying), may be noticed. When using this approach to construct the third class, the separation of the C class remained unclear, hence the problem was reduced to a binary classification comparing the A class to the B and C classes.
3.1. Supervised Algorithm.
Although the K-means clustering approach yields an acceptable accuracy (around BBSE) for determining whether a bull is suitable for breeding, the classification findings require improvement. Deep learning techniques used in ANN achieve excellent results for a wide range of classification applications. These techniques, however, are supervised which means they must learn from a collection of elements in the dataset.
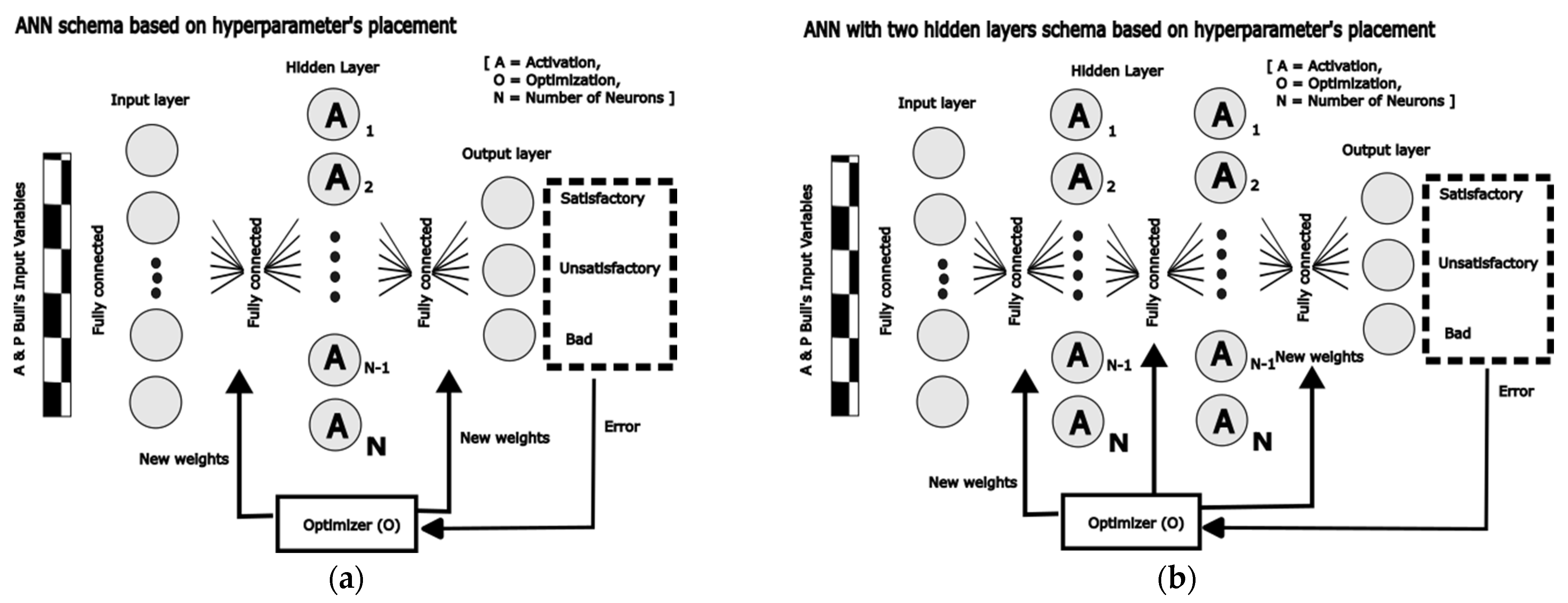
Different network morphologies and hyperparameters are used to evaluate which Fully-connected ANN (Dense) model provides the best results for our purposes, each model is represented as a tuple (A,O,N) described as follows and illustrated in Figure 6:
- A = Activation Function: Sigmoid (S) and Relu (R).
- O = Optimizer method: ADAM (A) and SGD.
- N = Number of neurons: 8, 16, 32, 64, 128, 256, and 512
Figure 6.
Schema of two Artificial Neural Network achitectures using five input Variables (A&P) and three the different hyperparameters [A,O,N] that have been evaluated. a) ANN with one hidden layer b) ANN with two hidden layers.
Figure 6.
Schema of two Artificial Neural Network achitectures using five input Variables (A&P) and three the different hyperparameters [A,O,N] that have been evaluated. a) ANN with one hidden layer b) ANN with two hidden layers.
Combining these three hyperparameters (neurons, optimizer, and activation function), the number of neurons determining input, and one or two hidden layers of neurons resulted in model comparison Figure 7, Figure 8 and Figure 9. Moreover, it was tested with different elements from the dataset that were randomly assigned between 70% and 30% for the training and validation procedures (Cross-fold validation). Notice that, to render a validation of the proposal, many different training and test sets were randomly considered to get maximum the mean precision with the minimum uncertainty (see Figures 7 to 9).
For one hidden layer ANN, two models generated the best results. On the one hand, there is a 512-512-3 model for the input and hidden layers with an ADAM optimizer and a sigmoid activation function. This model has a 96.71% average accuracy and a standard deviation (STD) of 0.0066. In contrast, the 256-256-3 model obtains 96.71% and an STD of 0.0175. Both models are accurate, but the one with 512 neurons has less variability.
For models 256-256-256-3 and 512-512-512-3, the two best ANNs with two hidden layers reach 96.71% and 96.24%, respectively, with an STD of 0.0175. We cannot observe any enhanced result with extra layers based on this study, but it does indicate the requirement for more hardware resources. Nevertheless, as discussed in Section 3, input variables are divided into two groups. A&P variables may be collected in situ; the other variables will be gathered over time based on their performance. To evaluate the bull straight away, only the A&P bull variables are examined, which are then put through to multiple neural network topologies in the same manner as before to discover the best fit for this case, as shown in Figure 9.
The best fit was reached by the 256-256-256-3 model with ADAM optimizer and sigmoid activation function, with 96.71% accuracy and STD of 0.0175, which was identical to the one attained with eight variables. Nevertheless, unlike models with eight input variables, it is simple to detect overfitting by comparing its loss and learning plots, as seen in Figure 10.
To solve the overfitting problem, synthetic data for each class was required using conventional data augmentation techniques based on normal distributions. As seen in Figure 11, this procedure allowed us to have a more balanced dataset and run our model without overfitting. The following categorization results were obtained (Table 5)
As depicted in Figure 11, the ANN has an accuracy of 90%. Precision was 97% for class A (satisfying), 92% for class B (unsatisfying), and 85% for class C (Bad) (considering the ratio of True positive and True negative with the rest). In practice, all C Class members who are not labeled as C are classified as Class B, which is a rejected bull. The TensorFlow and SCI-Kit libraries, as well as the Python programming language, were used in the testing [38].
4. Discussion
The bull breeding soundness evaluation (BBSE) has grown into a low-cost veterinary treatment that offers benefits such as risk reduction and increases in strategic bull deployment, herd fertility, and economics [39]. The presence of many interactions or correlations between predictors significantly restricts the capability of traditional statistical approaches based on univariate hypotheses and independent explanatory variables. Although numerous statistical parametric algorithms [40] have been developed to increase prediction in huge datasets with few observations, these methods are computationally intensive. Because meaningful data are abundant, ML algorithms may be used to extract information from massive and complex data sets and learn patterns from sample observations to generalize them for whole populations [41]. Two algorithms, clustering, and ANN were studied to determine the optimum ML approach for our application, with an emphasis on data categorization accuracy. The proposed ML-based predictive model for bull classification is a two-step approach that combines clustering analysis followed by an ANN model to classify bulls into three categories: satisfying, unsatisfactory, or bad. The ANN model outperforms the clustering analysis approach with a 90% accuracy. One of the key advantages of the proposed model is that it may be used to predict the performance of a bull even if it has not yet been tested. As a result, the model is a significant tool for breeders who need to make informed decisions regarding which bulls to use for breeding. Another feature of the proposed model is its ease of implementation using a range of ML libraries. However, it is important to be aware of the limitations of the model, such as the necessity for representative training data and the risk of overfitting. The bull parameters were obtained from the Universidad Veracruzana's Faculty of Veterinary and Animal Sciences over several years. Regardless of whether the classification was meant to distinguish three classes, the primary purpose is to distinguish the "Satisfying" class from the others. For this classification, the ML model obtained a 90% accuracy rate with only five input variables, compared to 81% for traditional BBSE done by local farmers, using only the physiological and morphological features of the animal. This is a significant result indicating that a model is a reliable tool for selecting a bull classification. In addition, because the computational evaluation implies one task in no more than 3-5 minutes for offline training, depending on the volume of data, and less than a second for each classification result, it is not even comparable with the manual process, which may take several days to decide on the best group of bulls. Though the algorithms work well with small-scale cattle data, a larger sample with a more balanced dataset is expected to produce a more accurate classification closer to real data (without synthetic data). It is also envisaged that the actual use of this tool on farms would enhance livestock management; hence, data collecting will be a necessary duty. This is the first study to use ANN for automated classification in the context of bull breeding. Animal farming techniques in the Mexican tropics require upgrading to compete with modern systems, as is taking place in other regions of Mexico. The use of artificial intelligence (AI) technologies in specific prediction models based on neural networks will help livestock farmers to better evaluate such systems.
5. Conclusions
This paper performs this ML algorithms comparison in the behavioral and productive traits determinants of bull survival in Mexico´s tropical altitudes. With this insight, it is feasible to design appropriate animal breeding and management approaches to reduce bull mortality rates. To the best of the authors’ knowledge, there is no ML application dedicated to bull breeding classification. Furthermore, using only five variables in our classification model, we were able to determine bull viability with 90% accuracy, which is higher than traditional BBSE, and it could even be done using only the physiological and morphological features of the animal.
Author Contributions
Conceptualization, A. H. and P. C.; methodology, M. B.; software, L. M.; validation, B. D.; formal analysis, B. D. and M. B.; investigation, R. P. and P. G.; resources, A. V.; data curation, B. D. and M. B.; writing—original draft preparation, P. G.; writing—review and editing, P. G.; visualization, A. H. and P. C.; supervision, A. V.; project administration, L. M.; funding acquisition, R. P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The Bioethical Committee (School of Veterinary and Animal Sciences of Veracruz University) evaluated and approved with registration number COBIBA010/2017 all the procedures for handling, immobilization, and semen collection performed on bulls within farms by official veterinary services. The welfare of the animal is essential, and stimulation was ceased if it was causing undue stress or if physical harm to the bull was imminent.
Data Availability Statement
The datasets generated and analyzed during the current study are available in the repository (https://www.uv.mx/veracruz/uvca415-sistemas-dinamicos-autonomos/bull-breading-soundness-evaluation/) and show least squared means values and mean standard errors for each BBSE variable analyzed, as well as differences (p<.05) of post-hoc comparisons through Tukey method for each genetic group. Any other data generated or analyzed during this study are included in this published article or are available from the corresponding author upon reasonable request.
Acknowledgments
We thank Herminio Hernández-Flores for helpful advice and suggestions during proposal development. We also thank EmbryoEspermTM for their guidance in the evaluation of cattle sample collection.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Martínez, J.C., Castillo, S.P., Villalobos, A., and Hernández, J. Sistemas de producción con rumiantes en México. RCA. 2017, 26, 132–152.
- Cañón J, García D, Delgado J, Dunner S, Da Gama LT, Landi V, Martín-Burriel I, Martínez A, Penedo C, Rodellar C. Relative breed contributions to neutral genetic diversity of a comprehensive representation of Iberian native cattle. J. Animal. 2011, 5, 1323–1334. [Google Scholar] [CrossRef] [PubMed]
- Domínguez, B. , Hernández, A., Rodríguez, A., Cervantes, P., Barrientos, M., and Pinos, J.M. Changes in Livestock Weather Security Index (Temperature Humidity Index, THI) During the Period 1917–2016 in Veracruz, Mexico. J Anim Res. 2017, 7, 983–991. [Google Scholar] [CrossRef]
- Ginja, C. , Gama L.T., Cortés O., Burriel I.M., Vega, J.L., Penedo C., Sponenberg P., Cañón J., Sanz A., do Egito A.A., Alvarez, L.A., Giovambattista, G., Agha, S., Rogberg, A., Cassiano, M.A., BioBovis Consortium, Delgado, J.V., and Martínez, A. The genetic ancestry of American Creole cattle inferred from uniparental and autosomal genetic markers. Sci Rep. 2019, 9. [Google Scholar] [CrossRef]
- Nichi, M. , Bols, P., Züge, R.M., Barnabe, V.H., Goovaerts, I., Barnabe, R.C., and Cortada, C.N.M. Seasonal variation in semen quality in Bos indicus and Bos taurus bulls raised under tropical conditions. Theriogenology. 2006, 66. [Google Scholar] [CrossRef]
- Páez, E.M. , Corredor, E.S. Evaluación de la aptitud reproductiva del toro. Ciencia y Agricultura. 2014, 11, 49–59, ISSN 0122-8420. [Google Scholar] [CrossRef]
- Chenoweth, P. Bull Libido/Serving Capacity. Vet Clin North Am Food Ani. Pract. 1997, 13 (2): 331-344. [CrossRef]
- Lessard, C. , Siqueira, L.G., D'Amours, O., Sullivan, R., Leclerc, P., and Palmer, C. Infertility in a beef bull due to a failure in the capacitation process. Theriogenology. 2011, 76, 891–9. [Google Scholar] [CrossRef]
- Overall, K. The ethogram project. J Vet Behav. 2013, 1, 1–5. [Google Scholar] [CrossRef]
- Wang, H., Li, X.G., Liu, T.Y., and Wu, Q. Data mining and its application in animal husbandry management systems. Adv Mat Res. 2014, 926–930, 2525–2528. [CrossRef]
- Liakos, K.G. , Busato, P., Moshou, D., Pearson, S., and Bochtis, D. Machine Learning in Agriculture: A Review. Sensors. 2018, 18, 2674. [Google Scholar] [CrossRef]
- Islam, A. , and Al-Badi, A. Emerging Data Sources in Decision Making and AI. Procedia Comput. Sci. 2020, 177, 318–323. [Google Scholar] [CrossRef]
- Vinod, U. Integrating intuition and artificial intelligence in organizational decision-making. Bus. Horiz. 2021, 64, 425–438. [Google Scholar] [CrossRef]
- Sharma, R. , Kamble, S.S., Gunasekaran, A., Kumar, V., Kumar, A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput Oper Res. 2020, 119. [Google Scholar] [CrossRef]
- Plenio, J.L. , Bartel, A., Madureira, A.M.L., Cerri, R.L.A., Heuwieser, W., and Borchardt, S. Application note: Validation of BovHEAT — An open-source analysis tool to process data from automated activity monitoring systems in dairy cattle for estrus detection. Comput Electron Agric. 2021, 188. [Google Scholar] [CrossRef]
- Neethirajan, S. The role of sensors, big data, and machine learning in modern animal farming. Sens. Bio-Sens. Res. 2020, 29. [Google Scholar] [CrossRef]
- Bishop, J.C. , Falzon, G., Trotter, M., Kwan, P., and Meek, P.D. Livestock vocalization classification in farm soundscapes. Comput Electron Agric. 2019, 162, 531–542. [Google Scholar] [CrossRef]
- Qiao, Y. Kong, H., Clark, C., Lomax, S., Su, D., Eiffert, S., and Sukkarieh, S. Intelligent perception for cattle monitoring: A review for cattle identification, body condition score evaluation, and weight estimation. Comput Electron Agric. 2021, 185. [Google Scholar] [CrossRef]
- Bao, J, Xie, Q. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 2022, 331, ISSN 0959–6526. [Google Scholar] [CrossRef]
- Gorczyca, M. , Maia, H.F., Campos, A.S., and Gebremedhin, K. Machine learning algorithms to predict core, skin, and hair-coat temperatures of piglets. Comput Electron Agric. 2018, 151, 286–294, ISSN 0168-1699. [Google Scholar] [CrossRef]
- Torres, V.F., Barrientos, M., Hernández, H., Rodríguez, A., Cervantes, P., Landi, V., Hernández, A., Domínguez, B. Breeding soundness examination and herd proficiency of local genetic groups of bulls in tropical environment conditions in Veracruz. Mexico. Ital. J. Anim. Sci. 2020, 19, 840–855. [CrossRef]
- Oliveira, S.R. , Jardim, J.O., Peripolli V., Antunes, E., and Gonçalves, J.B. Reproductive success or failure in four breed groups of beef bulls. R. Bras. Zootec. 2015, 44, 240–247. [Google Scholar] [CrossRef]
- Sollenberger, L. Sustainable production systems for Cynodon species in the subtropics and tropics. R. Bras. Zootec. 2008, 37, 85–100. [Google Scholar] [CrossRef]
- Cruz, A, Hernández, A, Chay, AJ, Mendoza, SI, Ramírez, S, Rojas, AR, Ventura, J. Componentes del rendimiento y valor nutritivo de Brachiaria humidicola cv Chetumal a diferentes estrategias de pastoreo. Revista mexicana de ciencias agrícolas. 2017, 8. [Google Scholar] [CrossRef]
- Perea, F, Soto, E, González, C, Soto, G, Hernández, H. Factors affecting fertility according to the postpartum period in crossbred dual-purpose suckling cows in the tropics. Trop. Anim. Health Prod. 2005, 37, 559–572. [Google Scholar] [CrossRef] [PubMed]
- Galina, C.S. , Horn, M.M., and, Molina, R. Reproductive behavior in bulls raised under tropical and subtropical conditions. Horm Behav. 2007, 52, 26–31. [Google Scholar] [CrossRef] [PubMed]
- Koziol, J. H., and Chance, L. A. Society for Theriogenology Manual for Breeding Soundness Examination of Bulls. Second edition. Pike Road, Ala: Society for Theriogenology. 2018.
- Kunkle, W.E., Sand, R.S., and Rae D.O. Effect of body condition on productivity in beef cattle. Department of Animal Science, Florida, Cooperative Extension Service, Institute of Food and Agricultural Sciences, University of Florida. 1994, SP-144. Available online: https://original-ufdc.uflib.ufl.edu/IR00004528/00001 (accessed on 30 Nov. 2023).
- Beggs, D., Bertram, J., Chenoweth, P., Entwistle, K., Fordyce, G., Johnston, H., Johnston, P., McGowan, M., Niethe, G., and Norman, S. Veterinary bull breeding soundness evaluation, 1st ed.; The University of Queensland, Australian Veterinary Association, Australia, 2013. pp. 75-88.
- Chenoweth, P. Bull Libido/Serving Capacity. Vet. Clin. North Am. Food Anim. 1997, 13, 331–44. [Google Scholar] [CrossRef] [PubMed]
- Chenoweth, P. , Hopkins, F.M., Spitzer, J.C., and Larsen, R.E. Guidelines for using the bull breeding soundness evaluation form. Clinical Theriogenology. 2010, 2, 43–50. [Google Scholar]
- Furman, J. W. , Ball L., and Seidel Jr., G.E. Electroejaculation of bulls using pulse waves of variable frequency and length. J. Anim. Sci. 1975, 40, 665–670. [Google Scholar] [CrossRef]
- Moskovtsev, S.I. , and Librach, C.L. Methods of sperm vitality assessment. Methods mol. biol. 2013, 927, 13–9. [Google Scholar] [CrossRef]
- Atiq, N. , Ullah, N., Andrabi, S., and Akhter, S. Comparison of photometer with improved Neubauer hemocytometer and Makler counting chamber for sperm concentration measurement in cattle. Pak Vet J. 2011, 31, 83–84. [Google Scholar]
- Barth, A. Bull breeding soundness evaluation, 2nd Edition; The Western Canadian Association of Bovine Practitioners. 2000, ISBN 0901016101.
- Barth, A. Review: The use of bull breeding soundness evaluation to identify subfertile and infertile bulls. J. Anim. 2018, 12, s158–s164. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Pretenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, É. Scikit-learn: Machine Learning in Python, JMLR 12, 2011, 2825-2830. Available online: https://www.semanticscholar.org/reader/168f28ac3c8c7ea63bf7ed25f2288e8b67e2fe74 (accessed on 30 Nov. 2023).
- Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Den, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., Kudlur, M., Levenberg, J., Monga, R., Moore, S., Murray, D.G., Steiner, B., Tucker, P., Vasudevan, V., Warden, P., Wicke, M., Yu, Y., and Zheng, X., Google Brain. Tensorflow: A system for large-scale machine learning. 12th “USENIX” Symposium on Operating Systems Design and Implementation, USA, 2-4 November 2016.
- Engelken, T.J. The development of beef breeding bulls. Theriogenology. 2008, 70, 573–575. [Google Scholar] [CrossRef] [PubMed]
- Fan, J. , and Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Shirfadizar, A., Miar, Y., Plastow, G., Basarab, J.A.J., Li, C., Fitzsimmons, C., Riazi, C., and Manafiazar, G. A machine learning approach to predict the most and the least feed-efficient groups in beef cattle. Smart Agricultural Technology. 2023, 5 100314. [CrossRef]
Figure 2.
Comparison between two variables, Age and Individual Motility (%).
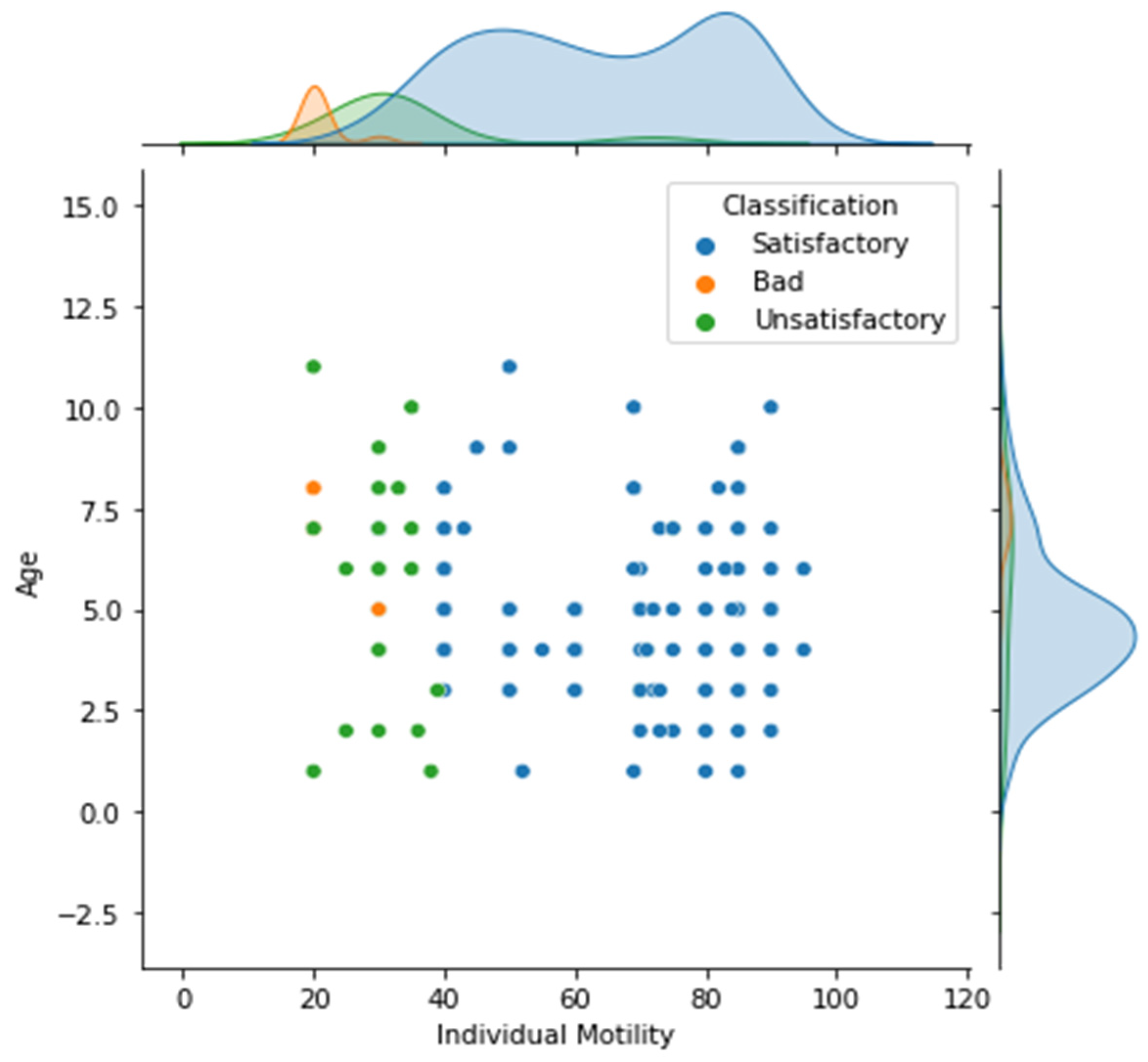
Figure 3.
Comparison between sperm concentration and individual motility (%).
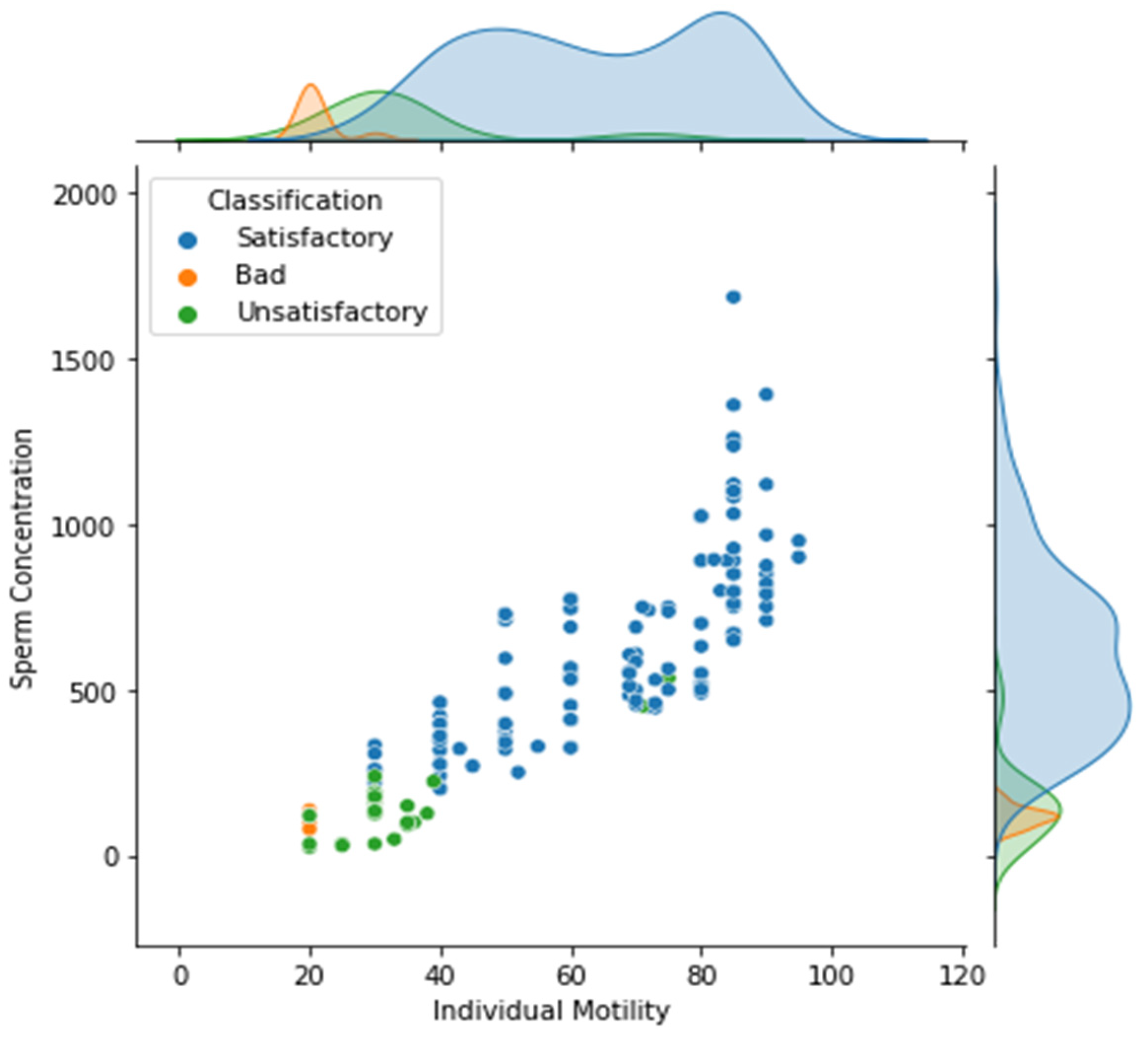
Figure 4.
Scaled comparison between sperm density and libido (1-10). The upper histogram shows how bad elements are concentrated inside the unsatisfactory region.
Figure 4.
Scaled comparison between sperm density and libido (1-10). The upper histogram shows how bad elements are concentrated inside the unsatisfactory region.
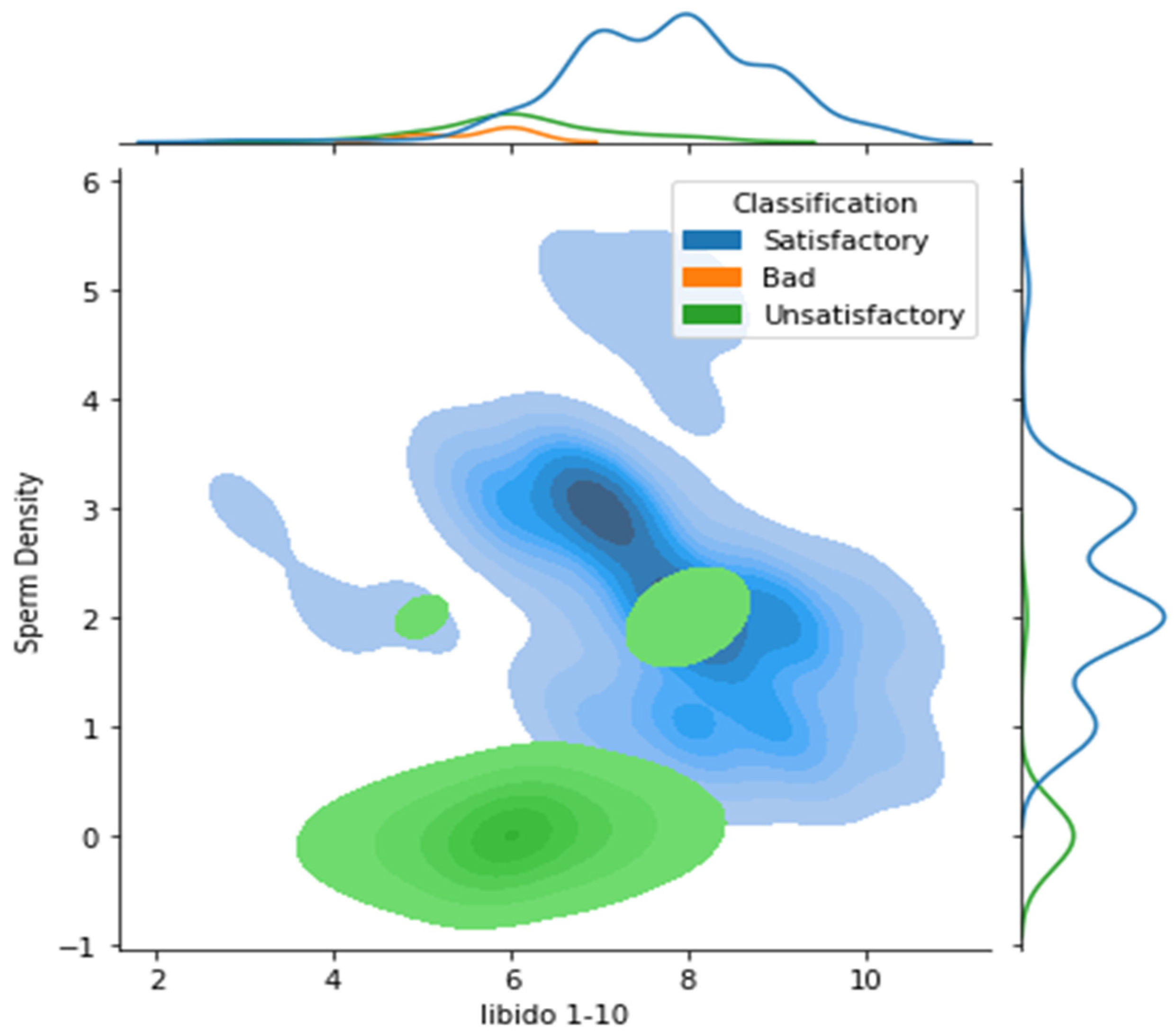
Figure 5.
Left: First, second, and third components, Right: first and second components. Both for a Dichotomous (binary) classification: Accepted for class A, and Rejected for B and C.
Figure 5.
Left: First, second, and third components, Right: first and second components. Both for a Dichotomous (binary) classification: Accepted for class A, and Rejected for B and C.
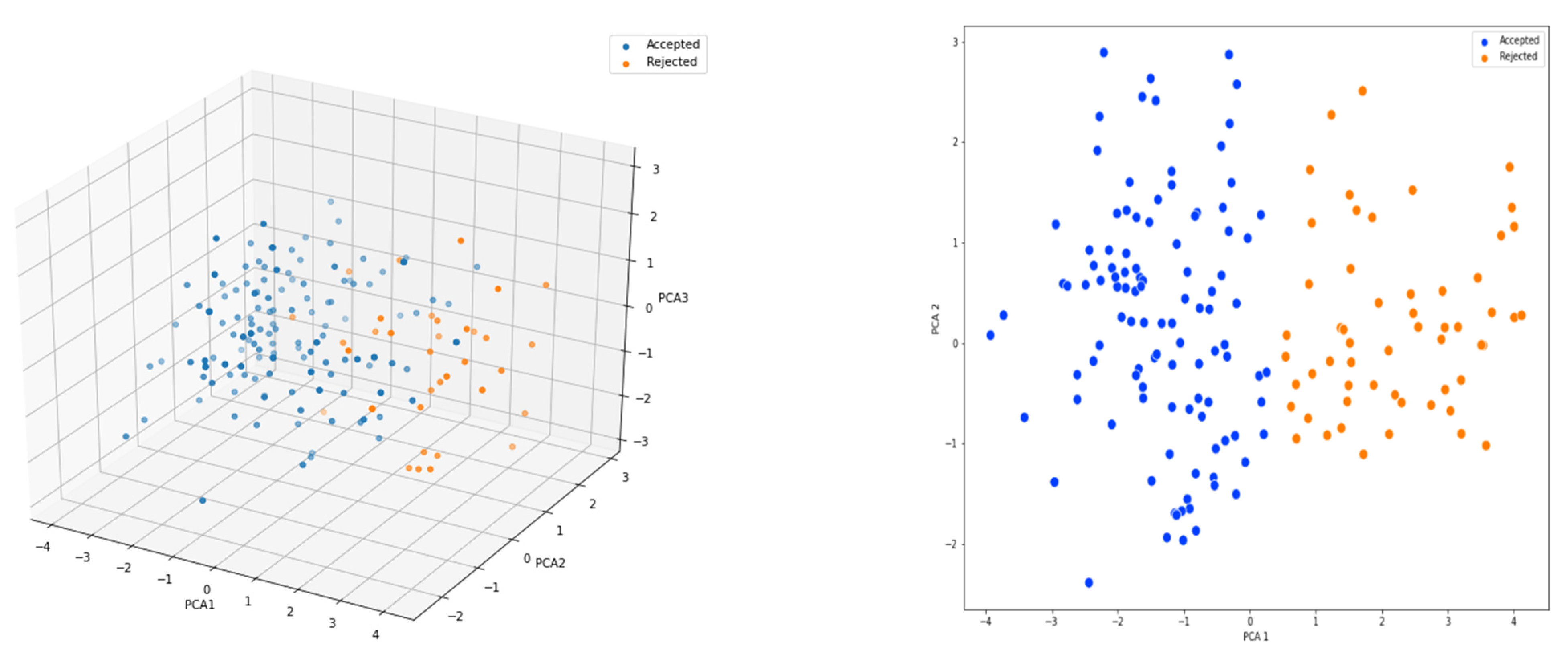
Figure 7.
Run tests for ANN with one hidden layer and three hyperparameters (neurons, optimizer, and activation function).
Figure 7.
Run tests for ANN with one hidden layer and three hyperparameters (neurons, optimizer, and activation function).
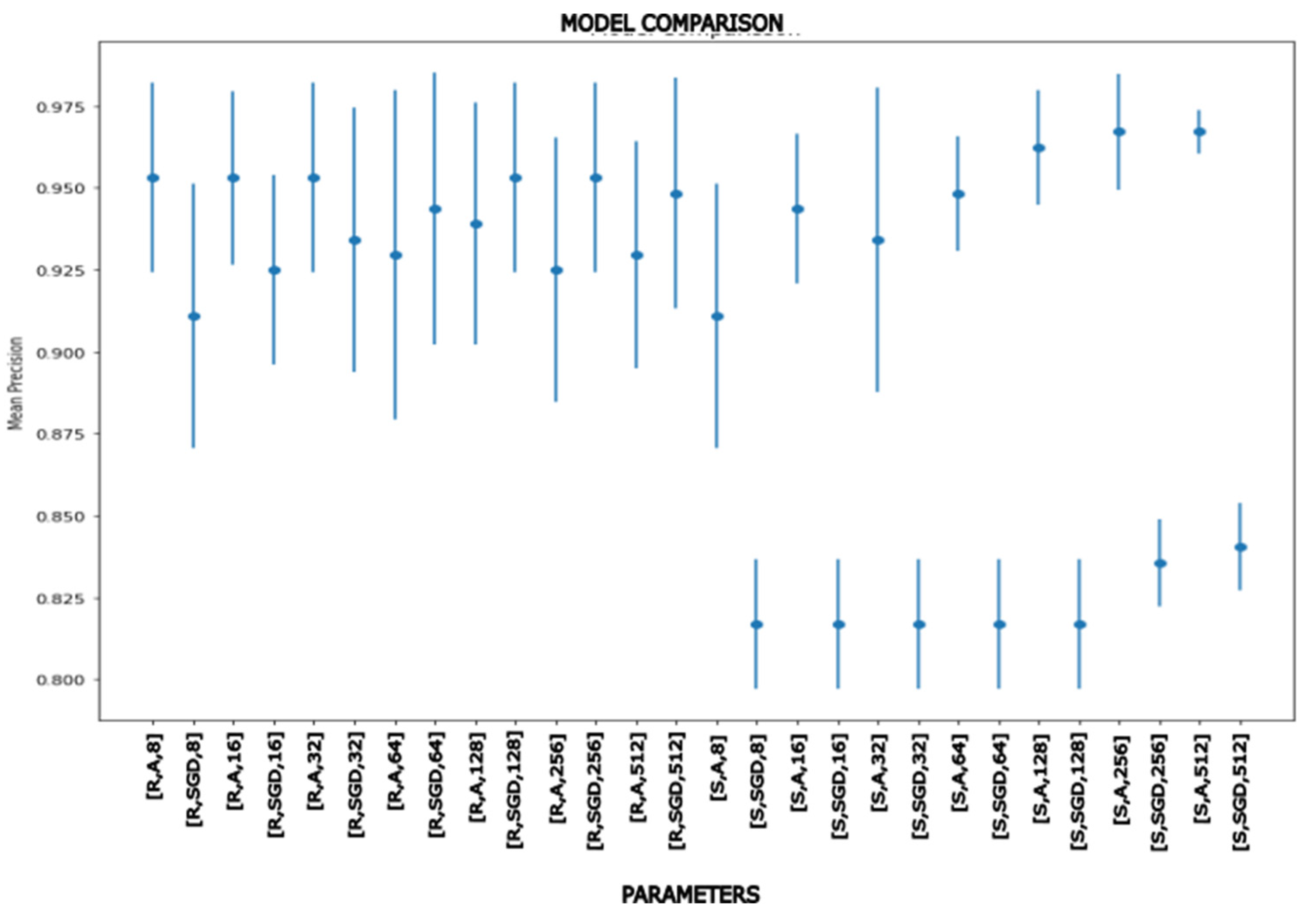
Figure 8.
Test for ANN with two hidden layers and different hyperparameters.
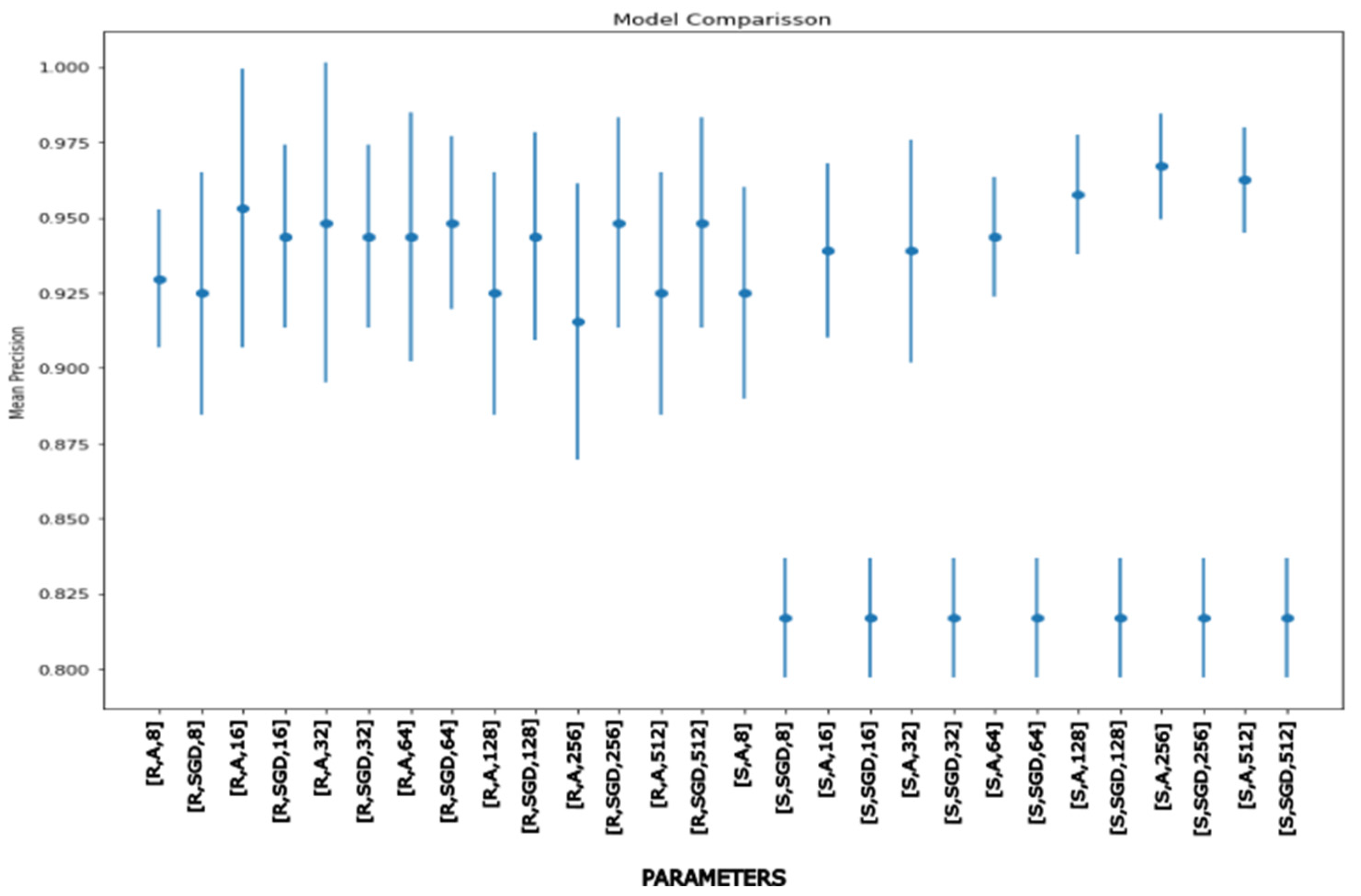
Figure 9.
Test for ANNs with two hidden layers and different hyperparameters trained with only five input variables.
Figure 9.
Test for ANNs with two hidden layers and different hyperparameters trained with only five input variables.
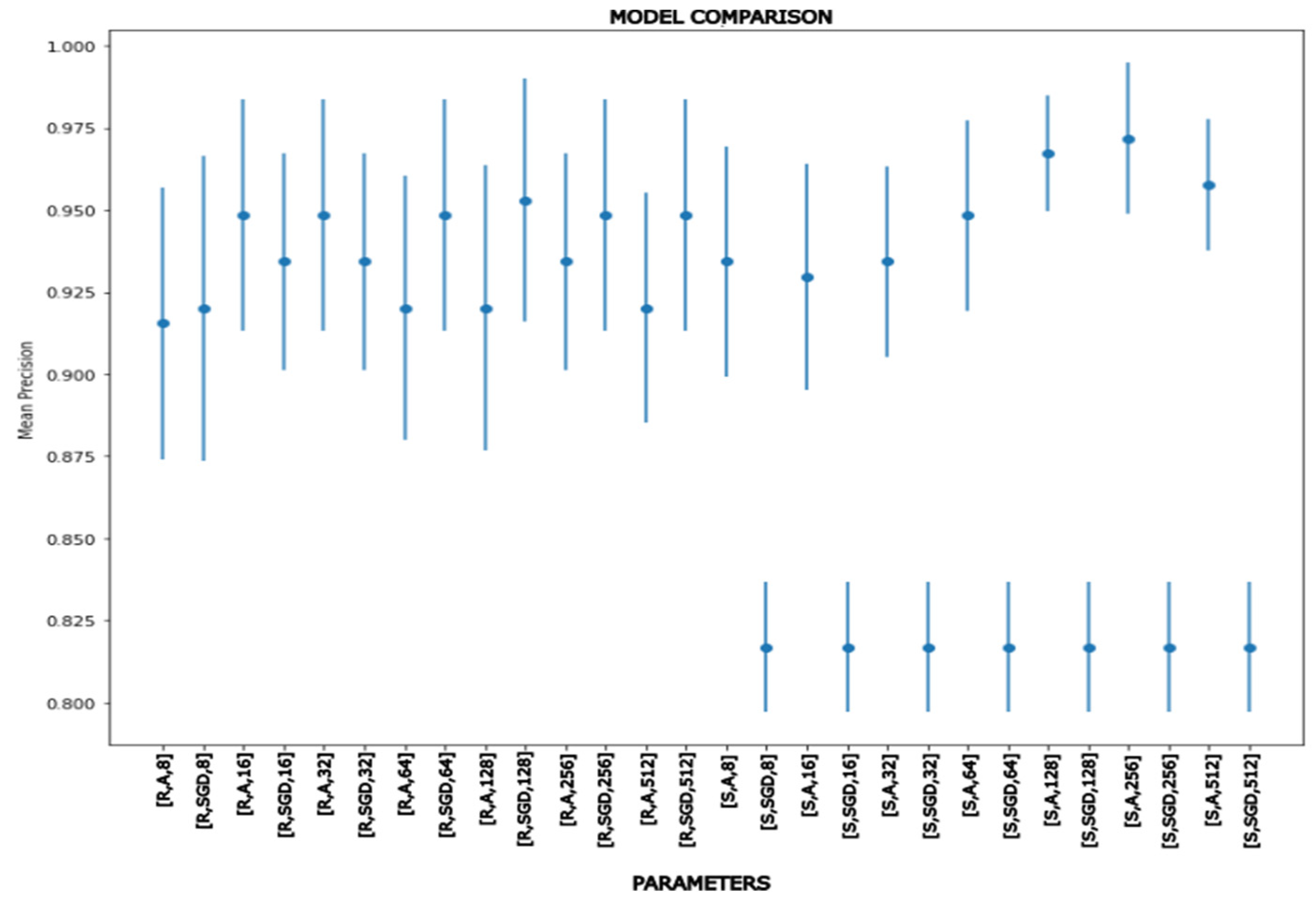
Figure 10.
Accuracy and Loss plots for ANN 256-256-256-3 model with five variables, overfitting may be recognized as early as 20 epochs.
Figure 10.
Accuracy and Loss plots for ANN 256-256-256-3 model with five variables, overfitting may be recognized as early as 20 epochs.
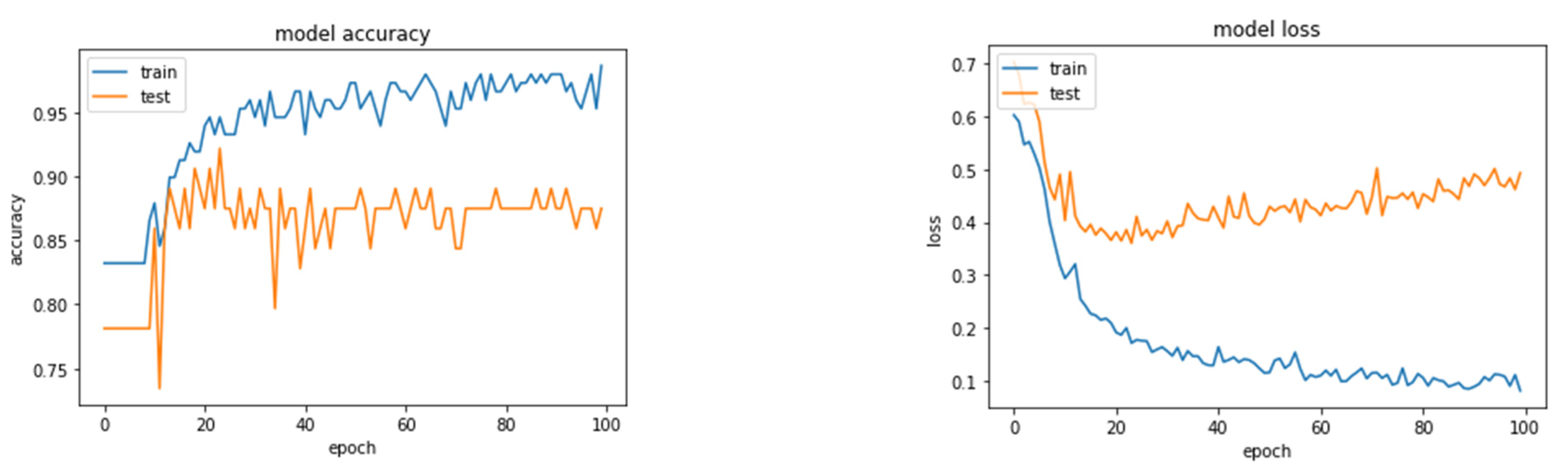
Figure 11.
Accuracy and Loss plots after the data augmentation process.
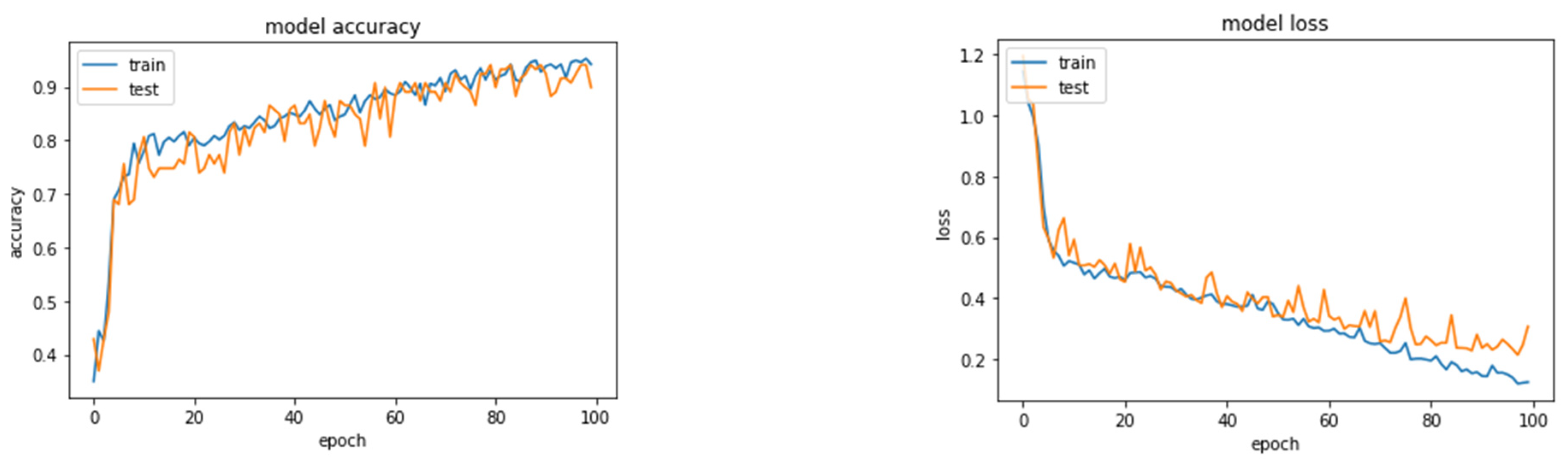
Table 1.
Variables for BBSE.
| Variable | Scale | Assessment | Reference |
|---|---|---|---|
| Genetic group | race | objective | [22] |
| Body Condition Score (BCS) | 1 to 5 | subjective | [28] |
| Age | years | objective | [31] |
| Scrotal circumference | cm | objective | [29] |
| Semen volume | ml | objective | [31] |
| Sperm Concentration | x106 | objective | [34] |
| Individual Sperm Motility | % | subjective | [33] |
| Gross motility | category | subjective | [31] |
| Color | creamy- translucent | subjective | [35] |
| Density | 4 to 1 | objective | [35] |
| Libido | 0 to 10 | objective | [31] |
| Pregnancy rate | % | objective | [25] [26] |
| Cows | n | objective | [26] |
| Calving interval | days | objective | [26] |
Table 3.
Selected variables to be used on ML models.
| Variable Type | Source | |
|---|---|---|
| Individual Motility (%) | ||
| Semen | Semen Volume | |
| Anatomy & Physiology (A&P) | Sperm Concentration | |
| Body | Age | |
| Scrotal Circumference | ||
| CI | ||
| Performance | Num. Cows | |
| Pregnancy Rate |
Table 4.
Confusion matrix for the clustering analysis with the K-means algorithm.
| Class | A | B & C | Total |
|---|---|---|---|
| A | 61.50% | 20.19% | 81.69% |
| B & C | 1.41% | 16.90% | 18.31% |
| Total | 62.91% | 37.09% | 100.00% |
Table 5.
Categorization results based on the proposed model.
| Class | Precision | Recall | f1-score | Support |
|---|---|---|---|---|
| Unsatisfying | 0.85 | 1.00 | 0.92 | 51 |
| Bad | 0.92 | 0.96 | 0.94 | 24 |
| Satisfying | 0.97 | 0.75 | 0.85 | 44 |
| Accuracy | 0.90 | 119 | ||
| Macro avg. | 0.91 | 0.90 | 0.90 | 119 |
| Weighted avg. | 0.91 | 0.90 | 0.90 | 119 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



