Submitted:
13 December 2023
Posted:
14 December 2023
Read the latest preprint version here
Abstract
Accurate cloud quantification is essential in climate change research. In this work, we construct an automated computer vision framework by synergistically incorporating deep neural networks and finite element clustering to achieve robust whole sky image-based cloud classification, adaptive segmentation, and recognition under intricate illumination dynamics. A bespoke YOLOv8 architecture attains over 95% categorical precision across four archetypal cloud varieties curated from extensive annual observations(2020) at a Tibetan highland station. Tailor-made segmentation strategies adapted to distinct cloud configurations, allied with illumination-invariant image enhancement algorithms, effectively eliminate solar interference and substantially boost quantitative performance even in illumination-adverse analysis scenarios. In comparison to traditional NRBR threshold analysis methods, the cloud quantification accuracy computed within the framework of this paper exhibits an improvement of nearly 20%. Collectively, the methodological innovations provide an advanced solution to markedly escalate cloud quantification precision levels imperative for climate change research, while offering a paradigm for cloud analytics transferable to various meteorological stations.
Keywords:
cloud quantification
; deep neural networks
; adaptive segmentation
; finite element clustering
; whole sky image
1. Introduction
Clouds play an extremely critical role in regulating the Earth's climate system [1]. Clouds can reflect incoming solar shortwave radiation, reducing the amount of heat absorbed at the surface; meanwhile, they can also absorb outgoing longwave radiation from the surface, producing a greenhouse effect [2]. In essence, clouds serve as an important "sunshade" to maintain the balance of the greenhouse effect and prevent overheating of the Earth [3]. However, different cloud types at varying altitudes impact the climate system differently. For instance, high-level cirrus clouds mainly contribute to reflection and scattering, while low-level stratus and cumulus clouds more so cause the greenhouse effect [4]. Accurately determining cloud types, distributions and evolutions is vital for long-term climate change monitoring and forecasting [5]. Moreover, there are considerable regional disparities in cloud amount, and pronounced differences exist in regional climate characteristics, which makes precise cloud quantification even more crucial. Accurate cloud detection can provide critical climate change information to advance our understanding of the climate system from multiple dimensions [6]; it also helps validate the accuracy of climate model predictions, furnishing input parameters for climate sensitivity research [7]. Therefore, conducting accurate quantitative cloud observations is of great significance for climate change science, which is also the motivation behind this study's effort to achieve precise cloud quantification through image processing techniques.
Currently, accurate cloud typing and quantification still face certain difficulties and limitations. For cloud classification, common approaches include manual identification, threshold segmentation, texture feature extraction, satellite remote sensing, ground-based cloud radar detection, aircraft sounding observations, etc. [8,9,10,11,12]. Manual visual identification relies on the experience of professional meteorological observers to discern cloud shapes, colors, boundaries and other features to categorize cloud types. This method has long been widely used, but is heavily impacted by individual differences and lacks consistency, with low efficiency [13]. Threshold segmentation sets thresholds based on RGB values, brightness and other parameters in images to extract pixel features corresponding to different cloud types for classification. It is susceptible to illumination conditions and ineffective at distinguishing transitional cloud zones [14]. Texture feature analysis utilizes measurements of roughness, contrast, directionality and other metrics to perform multi-feature combined identification of various clouds, but adapts poorly to both tenuous and thick clouds [15]. Satellite remote sensing discerns cloud types based on spectral features in different bands combined with temperature inversion results, but has low resolution and inaccurate recognition of ground-level small clouds [16]. Ground-based cloud radar differentiation of water and ice clouds relies on measured Doppler velocity and other parameters, with inadequate detection of high thin clouds [17]. Aircraft sounding observations synthesize multiple parameters to make judgments, but have limited coverage and observation time. For cloud quantification, currently prevalent methods include laser radar measurement, satellite remote sensing inversion, ground-based cloud radar, and whole sky image recognition [18]. Laser radar emits sequenced laser pulses and estimates cloud vertical structure and optical depth from the backscatter to directly quantify cloud amount, but has large equipment size, high costs, limited coverage area, and cannot produce cloud distribution maps. Satellite remote sensing inversion utilizes parameters like cloud top temperature and optical depth, combined with inversion algorithms to obtain cloud amount distribution. However, restricted by resolution, it has poor recognition of local clouds [11]. Ground-based cloud radar can measure backscatter signals at different altitudes to determine layered cloud distribution, but has weak return signals for high thin clouds, resulting in inadequate detection. With multiple cloud layers, it struggles to differentiate between levels, unfavorable for accurate quantification [19]. The conventional whole sky image segmentation utilizes fisheye cameras installed at ground stations to acquire whole sky images, then segments the images based on color thresholds or texture features to calculate pixel proportions of various cloud types, which are converted to cloud cover. This method has the advantage of easy and economical image acquisition, but is susceptible to illumination changes that can impact segmentation outcomes, with poor recognition of small or high clouds [13]. In summary, the current technical means for cloud classification and quantification lack high accuracy, cannot precisely calculate regional cloud information, and need improved stability and reliability. They fall short of meeting the climate change science demand for massive fine-grained cloud datasets.
In recent years, with advances in computer vision and machine learning theories, some more sophisticated technical means have been introduced into cloud classification and recognition, making significant progress. For instance, cloud image classification algorithms based on deep learning have become a research hotspot. Deep learning can automatically learn feature representations from complex data and construct models to synthetically judge the visual information of cloud shapes, boundaries, textures, etc. to distinguish between different cloud types [20]. Meanwhile, unsupervised learning methods like k-means clustering are also widely applied in cloud segmentation and recognition. This algorithm can autonomously discover inherent data category structures without manual annotation, enabling cloud image partitioning and greatly simplifying the workflow [21]. Some studies train k-means models to swiftly cluster and recognize cloud and clear sky regions in whole sky images, improving cloud quantification speed and efficiency. It can be foreseeable that the combination of deep learning and unsupervised clustering for cloud recognition will find expanded applications in meteorology. We also hope to lay the groundwork for revealing circulation characteristics, radiative effects and climate impacts of different cloud types through this cutting-edge detection approach.
Despite some progress made in current cloud recognition algorithms, numerous challenges remain. Firstly, accurately identifying different cloud types is still difficult, especially indistinct high-altitude cirrus clouds and transitional mixed cloud types [10]. Secondly, illumination condition changes can drastically impact recognition outcomes, leading to high misjudgment rates in situations like polarization and shadowing. To address these issues and limitations, we propose constructing an end-to-end cloud recognition framework, with a focus on achieving accurate classification of cirrus, clear sky, cumulus and stratus clouds, paying particular attention to the traditionally challenging cirrus clouds. Building upon the categorization, we design adaptive dehazing algorithms and k-means clustering finite element segmentation to enhance recognition of cloud edges and tenuous regions. We hope that through optimized framework design, long-standing issues of cloud typing and fine-grained quantification can be solved, significantly improving ground-based cloud detection and quantification for solid data support in related climate studies. The structure of this paper is as follows. Section 2 introduces the study area, data acquisition, and construction of the cloud classification dataset. Section 3 elaborates the methodologies including neural networks, image enhancement, adaptive processing algorithms, and evaluation metrics. Finally, Section 4, Section 5 and Section 6 present the results, discussions, and conclusions respectively.
2. Study Area and Data
2.1. Study Area
The Yangbajing Comprehensive Atmospheric Observatory is located 90 kilometers northwest of Lhasa, Tibet, adjacent to the Qinghai-Tibet Highway and Railway, with an average altitude of 4300 meters. This region has high atmospheric transparency and abundant sunlight, creating a unique meteorological environment [22]. Yangbajing is far from industrial areas and cities, with relatively good air quality and low atmospheric pollution levels, which reduces the impact of air pollution on cloud observation and improves cloud quantification accuracy. Meanwhile, Tibet spans diverse meteorological types, meaning various cloud types can be observed in the same area, enabling better research on the evolution patterns of different cloud types.
2.2. Imager information
The cloud quantification automated observation instrument used in this study is installed at the Yangbajing Comprehensive Atmospheric Observatory (90°33'E, 30°05'N) and has been measuring since April 2019. The visible light imaging subsystem mainly comprises the visible light imaging unit (Figure 1a), the sun tracking unit (Figure 1b), the acquisition box, and the power box. As summarized in Table 1, this system images the entire sky every 10 minutes, measuring clouds ranging from 0 to 10 km with elevation angles above 15°. It can capture RGB images in the visible spectrum at a resolution of 4288 × 2848 pixels. The visible light imaging device is a CMOS imaging system with an ultra-wide-angle fisheye lens that periodically acquires images of the entire sky in the visible spectrum. The sun tracking unit calculates and tracks the sun's position, effectively shielding direct incident sunlight to prevent damage to the CMOS sensor's photosensitive elements. It also significantly reduces the impact of white light around the sun on subsequent processing.
2.3. Dataset
The image dataset used in this study is comprised of all-sky images during 2020. Considering images taken during sunset and sunrise are more easily influenced by lighting conditions, we only selected images taken between 9am to 4pm daily. Additionally, to reduce correlation, we only picked one image every half hour, amounting to 16 sample images per day. Among all selected images, cases of rain, snow as well as lens occlusion or contamination were removed. Finally, 4000 high quality, occlusion-free all-sky images with no rain or snow were screened out and categorized into four classes with 1000 images per class. The four classes are namely: cirrus, clear sky, cumulus, and stratus. It should be emphasized that the categorization into four dominant cloud types here is for accurately quantifying the cloud fraction of each individual category, rather than accounting for mixed or hybrid clouds (detailed in Figure 5). These screened images represent the visual characteristics of different cloud types well, forming the image dataset for this study.
3. Materials and Methods
The framework proposed in this study is illustrated in Figure 2. It can be summarized into the following steps:(1) Data quality control and preprocessing. First, quality control is performed on the collected raw all-sky images to remove distorted images caused by occlusion or sensor issues. Then, image size and resolution are standardized.(2) Deep neural network classification and evaluation metrics. The YOLOv8 deep neural network is utilized to categorize the cloud images, judging which of the four types (cirrus, clear sky, cumulus, and stratus) each image belongs to. Precision, recall, and F1-scores are used to evaluate the classification performance.(3) Adaptive enhancement. Different image enhancement strategies are adopted according to cloud type to selectively perform operations like dehazing, contrast adjustment etc. to improve image quality.(4) Finite element segmentation and K-means clustering. K-means clustering based on finite element segmentation is conducted on the enhanced images by category to extract cloud features and obtain accurate cloud detection results.
3.1. Quality Control and Preprocessing
Considering that irrelevant ground objects may occlude the edge areas of the original all-sky images, directly using the raw images to train models could allow unrelated ground targets to interfere with the learning of cloud features, reducing the model's ability to recognize cloud regions [23]. Therefore, we cropped the edges of the original images, using the geometric center of the all-sky images as the circle center and calculating the circular coverage range corresponding to a 26° zenith angle, to precisely clip out this circular image area and remove ground objects on the edges. This cropping operation eliminated ground objects from the original images that could negatively impact cloud classification, resulting in circular image regions containing only sky elements. To facilitate subsequent image processing operations while ensuring image detail features, the cropped images underwent size adjustment to set the target resolution to 680×680 pixels. Compared to the original 4288×2848 pixels, adjusting the resolution retained the main detail features of the cloud areas in the images, but significantly reduced the file size for easier loading and calculation during network training. Finally, a standardized dataset was constructed by cloud type - the resolution-adjusted images were organized and divided into four folders for cirrus, clear sky, cumulus, and stratus, with 1000 pre-processed images in each folder. A standardized all-sky image dataset containing diverse cloud morphologies was built.
3.2. Deep Neural Network Classification
3.2.1. Network Structure Design
This study employs YOLOv8 as the base model architecture for the cloud classification task. As illustrated in Figure 3, the YOLOv8 network structure consists primarily of the Backbone, Neck, Head and Loss components. The Backbone of YOLOv8 uses the Darknet-53 network, replacing all C3 modules in the backbone with C2f modules, which draw design inspiration from C3 modules and ELAN to extract richer gradient flow information [24]. The Neck of YOLOv8 implements a PAN-FPN structure to achieve model lightweightization while retaining original performance levels. The detection Head uses a decoupled structure with two convolutions respectively responsible for classification and regression [25]. For the classification task, binary cross entropy loss (BCE Loss) is utilized, while distribution focal loss (DFL) and complete IoU (CIoU) are used for predicting bounding box regression. This detection structure can improve detection accuracy and accelerate model convergence [26]. Considering the limited scale of cloud datasets, we load the YOLOv8-X-cls model pre-trained on ImageNet with 57.4M parameters as the initialized model. Through deliberate designs of modules, pre-trained model initialization and configuration of training parameters, a superior end-to-end cloud classification network is constructed.
3.2.2. Experimental Parameter Settings
After constructing the model architecture, we trained the model using the previously prepared classification dataset containing images of multiple cloud types. During training, the input image size was set to 680×680. We set the maximum number of training epochs to 400, and the number of samples used per iteration was 32. To prevent overfitting, momentum and weight decay terms were added to the optimizer and the patience parameter was adjusted to 50. To augment the sample space, various data augmentation techniques were employed such as random horizontal flipping (probability of 0.5) and mosaic (probability of 1.0). The SGD optimizer was chosen since its stochastic sampling and parameter update provide opportunities to jump out of local optima, helping locate the global optimum in a wider region. Considering initial and final learning rates, the initial learning rate was set to 0.01 and gradually decayed during training to enable more refined optimization of model parameters during later convergence.
3.2.3. Cloud Classification Evaluation Indicators
To comprehensively evaluate the cloud classification performance of the model, a combined qualitative and quantitative analysis scheme was adopted.Qualitatively, we inspected the model's ability in categorizing different cloud types, boundaries, and detail structures by comparing classification recognition differences between the validation set and test set.Quantitatively, metrics including precision, recall and F1-score were used to assess the model. Precision reflects the portion of true positive cases among samples predicted as positive, and is calculated as:
Recall represents the fraction of correctly classified positive examples out of all positive samples, and is calculated as:
F1-score considers both precision and recall via the formula:
Here, TP stands for true positives, TN true negatives, FP false positives, and FN false negatives. Through this combined qualitative and quantitative evaluation system, the cloud classification recognition performance can be fully examined.
3.3. Adaptive Enhancement Algorithm
When processing all-sky images, we face the challenges of visual blurring and low contrast caused by overexposure and haze interference. To address this, a dark channel prior algorithm is adopted in this study. The core idea of the dark channel prior algorithm is to perform haze estimation and elimination based on dark channel images [27]. The dark channel image selects the minimum value among the RGB channels at each pixel location, thus reflecting the minimum brightness within the pixel area. Low brightness values tend to manifest in regions with haze, thereby providing clues for haze. We utilize an image enhancement algorithm to further optimize image quality following these steps based on the dark channel prior assumption: First, calculate the dark channel for each pixel of the input image by taking the minimum value across the three RGB color channels. Next, estimate the global atmospheric light A using the non-zero minimums of the dark channel. Based on the atmospheric scattering model, obtain the transmission t for each pixel, which indicates the visibility of that pixel. Finally, apply the formula:
where J is the recovered haze-free image, and I is the original input image. The dehazing algorithm can effectively eliminate fog in images to yield more discernible cloud and sky boundaries, facilitating subsequent generation of high quality cloud covers.
In the image enhancement algorithm, the atmospheric light value A directly impacts the intensity of dehazing. Adaptive enhancement strategies are designed according to cloud type. For relatively thin cirrus, excessive enhancement may filter them out, hence smaller A values are chosen to preserve details. Meanwhile, thicker cumulus, stratus and clear sky images allow larger A values to strengthen haze removal, eliminating overexposed areas surrounding the sun and on edges to obtain more uniform sky distributions. We focused our analyses on the processing effects on two types of easily misclassified areas - surrounding the sun, where overexposure often leads to misjudgements; and white glows on sky edges, which can also readily cause errors. To improve segmentation quality, additional processing is implemented on these two areas. The sun's position can be determined by recognizing the location of the occulting disk, enabling application of enhanced dehazing to this circular region to reduce white glow. For the sky edge area, after removing ground elements, an annular region on the sky edge is designated for strengthened haze removal to alleviate white glow influence on identification. Through the above optimized designs, misjudgement issues surrounding the sun and edges can be effectively controlled to boost cloud segmentation quality.
3.4. Finite Element Segmentation and K-means Clustering
On the basis of obtained cloud type classification results, we propose an adaptive image segmentation method tailored to cloud morphology. Different cloud types exhibit varying shapes, necessitating customized segmentation strategies for optimal effects. Specifically, cirrus clouds appear faint against the sky with indistinct edges, requiring more delicate regional divisions. Clear sky images simply contain blue sky and black background - a few sectors sufficiently represent such simplicity. Cumulus has discernible but potentially unevenly lit edges, warranting more sectors. Finally, stratus images primarily show clouds and black backdrop - fewer sectors suffice. These differential approaches are formulated per cloud traits to extract representative features for improved cloud quantification.With cloud type adaptively segmented images, a K-means clustering algorithm is then implemented in each sector to further glean cloud information. It first randomly initializes K cluster centers, then categorizes samples to the nearest cluster based on distance, before recalculating cluster centers [28]. This iterative process converges when centers remain static. A proper k value is chosen per sector to partition it into sky, cloud and background. Each region is then recolored according to clustering outcomes to obtain a preliminary cloud detection image. This design capitalizes on K-means’ clustering capability to automatically distinguish sky and cloud elements in sectors.
In traditional cloud segmentation, the Normalized Red/Blue Ratio (NRBR) method exhibits certain shortcomings. Firstly, it struggles to effectively distinguish intense white light around the sun, often misclassifying these overexposed areas as cloud regions. Secondly, it fails to properly handle the bottom of thick cloud layers, where the regions appear dark due to the lack of penetrating light and may be erroneously classified as clear sky areas. Both misclassifications stem from the NRBR method overly relying on RGB color features without comprehensive consideration of lighting conditions. When atypical lighting distributions occur, accurate cloud and sky differentiation becomes challenging based solely on red/blue ratio values. Therefore, after obtaining the initial cloud segmentation results, we propose a mask-based refined segmentation method to further enhance the effectiveness.The specific approach involves first extracting the predicted sky regions from the aforementioned segmentation results, using them as a mask template. Subsequently, each sector undergoes k-means clustering to identify blue sky and white clouds, restricting the region after concatenating sectors within the mask-defined blue sky template. This process yields more nuanced identification results. By conducting secondary segmentation only on key areas and leveraging the results from adaptive k-means extraction, a finer segmentation is achieved. Ultimately, building upon the initial segmentation, this approach significantly improves potential misclassifications at the cloud edges, generating more accurate final cloud detection results. This design, guided by prior masks for localized refinement, effectively enhances the quality of cloud segmentation.
4. Results
4.1. Cloud classification results
This study constructs a dataset based on four dominant types of cloud images collected from the Yangbaqing station in Tibet and employs the YOLOv8 deep learning model for cloud classification. To quantitatively assess the training effectiveness of the YOLOv8 cloud classification model, we record the values of the loss function and training accuracy at different training epochs, as depicted in Figure 4a. With the increase in training iterations, the model's loss value consistently decreases, with the training set loss decreasing from around 0.4 to near 0 and the validation set loss dropping from 1.2 to approximately 0.7. The model gradually achieves improved predictive performance, reducing the gap between predicted values and true labels. Simultaneously, we analyze the classification accuracy curve during the model training process. As seen in Figure 4b, the model's Top-1 Accuracy rises from 0.5 to around 0.98. Through continuous training optimization, the model demonstrates sustained improvement in accuracy for distinguishing the four cloud types, progressively acquiring the ability to effectively discriminate the visual features of different cloud formations.
After training completion, we evaluated the classification performance of the YOLOv8 model on an independent test set containing four cloud types. The validation set and test set both contain 150 images each of cirrus, clear sky, cumulus and stratus clouds. Table 2 shows the classification accuracy of the model on different datasets. It can be seen that on the validation set and test set, the model demonstrates quite stable performance for the indistinct boundary cirrus clouds, with precision, recall and F1 scores maintained at a relatively high level between 95.45% to 97.94%. This indicates that the model has good robustness and generalization ability for cirrus cloud classification. The model achieves outstanding clear sky classification performance, with all metrics reaching or approaching 100%. This signifies that the model possesses powerful generalization capability for clear sky identification – delivering not only stellar performance on the training set, but also maintaining high accuracy on the unseen test set. On the validation set, the classification performance for cumulus clouds is relatively lower, especially in terms of precision. This could owe to the complex morphology of cumulus clouds and their susceptibility to illumination conditions. The model can focus optimizations on this category in future work to further improve recognition accuracy. The stratus category exhibits excellent performance on both the validation set and test set, with all metrics at 100%. This shows that the model classifies stratus clouds very accurately with stable performance unaffected by dataset variations, having successfully learned effective visual traits to discern the stratus type.
On the four-type weather test set, five randomly selected images from each type were tested. As Figure 5 shows, all images obtained accurate category labels with confidence scores of 1.00, again validating the reliability of the training results in Table 2. Through training, the model has acquired the capability to discern different cloud morphologies based on visual characteristics like shape, boundary and thickness to generate cloud type classification outcomes. In summary, the model can not only effectively tackle various challenges in cloud classification tasks but also delivers consistent performance across cloud types on validation and test sets. The robust overall performance provides a reliable cloud classification tool for practical applications.

Figure 5.
Categorization effects of the four cloud dominant types.
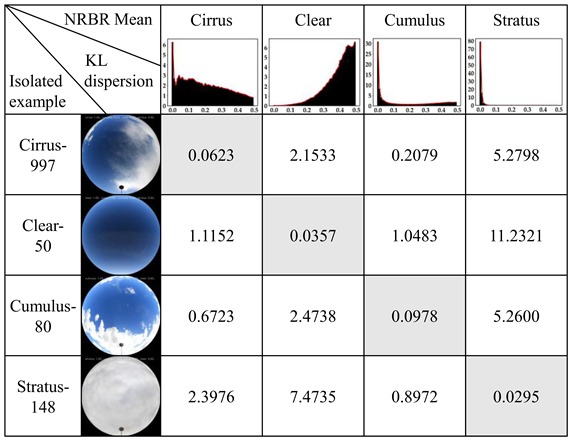
To further validate the model's discrimination of different cloud types, we computed the average probability density functions of normalized red-blue ratio (NRBR) distributions for 1000 RGB images per cloud dataset. Cloud image samples were then randomly drawn from each category and their NRBR distributions derived. Finally, the Kullback–Leibler (KL) divergences between the sample distributions and corresponding category averages were calculated. As Table 3 shows, the KL divergence between a sample and its ground truth category is markedly lower than divergences to other categories. For instance, a clear sky sample has an average KL divergence of 0.0357 to the clear sky category, but 11.2321 to the stratus category. This signifies that the NRBR distribution of the clear sky sample identified by YOLOv8 aligns closely with the true category average, with similar KL divergence relationships holding for other cloud type samples. It verifies that the model can effectively discriminate the NRBR traits of different cloud types to ultimately yield accurate cloud classification outcomes.
4.2. Cloud Recognition Effect
To improve the accuracy of subsequent cloud quantification, we first performed pre-processing enhancement on the whole sky images. However, considering different cloud types are impacted differently by illumination and haze, we designed an adaptive image enhancement strategy: applying lower intensity for cirrus clouds to preserve more edge details, while stronger intensity for other cloud types to eliminate overexposed areas. As shown in Figure 6b and Figure 8b,f, this image enhancement algorithm makes the boundaries between clouds and blue sky more pronounced, with clearer ground objects and richer detail features.
This study employs an adaptive finite element segmentation strategy for feature extraction. For stratus clouds and clear sky with distinct boundaries, just a few sectors are sufficient to accurately capture their traits. In contrast, more sectors are utilized for the indistinct boundary cirrus and cumulus clouds to enable more delicate partitioning that precisely seizes cloud edges. By further leveraging the k-means algorithm, we divide each sector region into three classes - blue sky, cloud and background. Compared to conventional holistic NRBR segmentation, the segmentation tailored to cloud types has significantly better adaptivity and partitioning outcomes. As depicted in Figure 7, the finite element segmentation and k-means clustering achieve remarkable results in three challenging scenarios: (1) The bottom of thick cloud layers that are prone to misjudgment as blue sky by traditional methods; (2) The overexposed vicinity of the sun where RGB values resemble clouds, potentially causing some blue sky around the sun to be wrongly judged as white clouds by conventional techniques; (3) Thin edge areas of cloud layers that are difficult to accurately recognize by standard NRBR algorithms, leading to deficient cloud quantification.
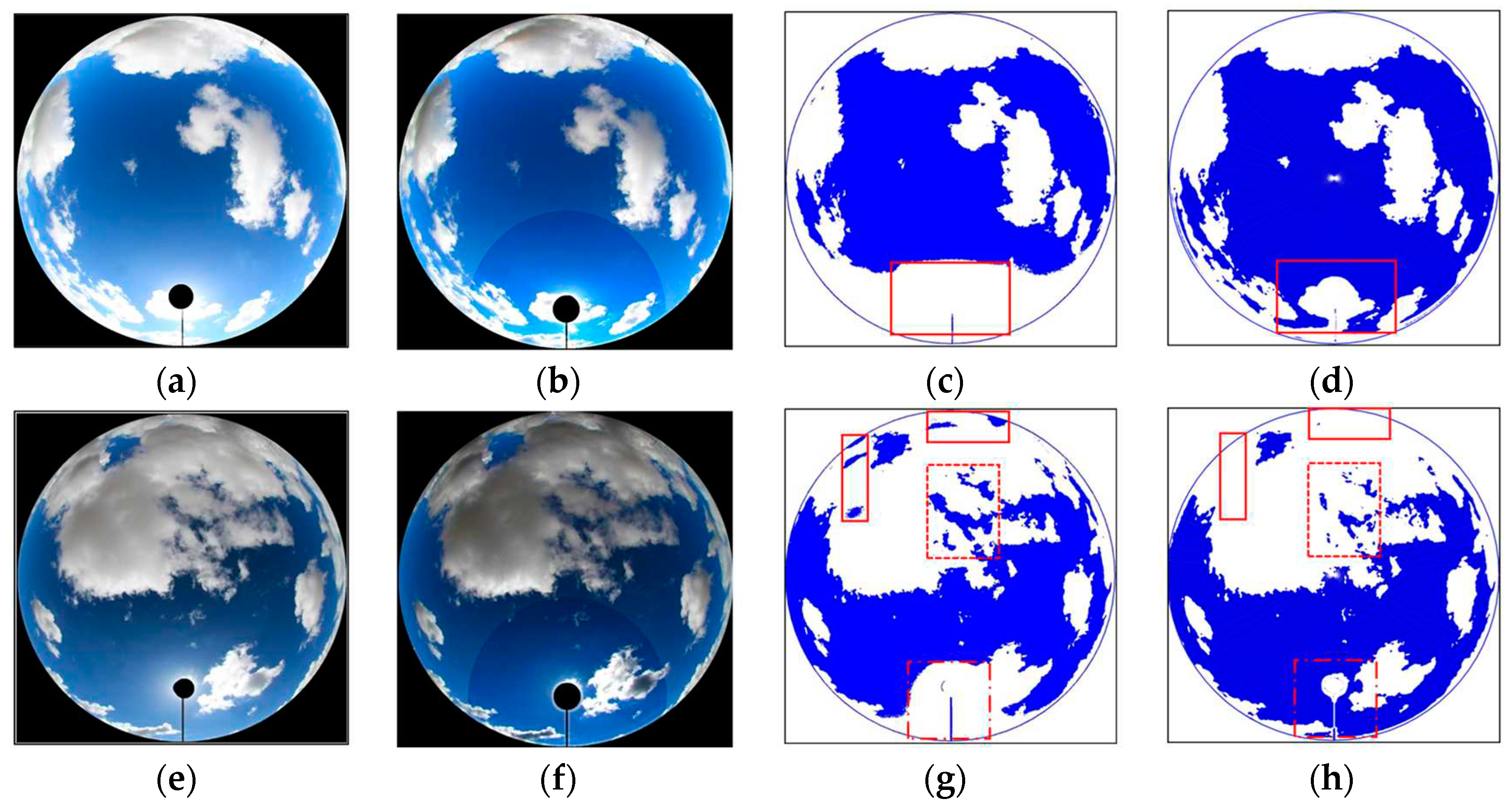
Figure 7.
Comparison of sector segmentation effects. (a/e) Cropped original image; (b/f) Adaptive enhancement processing results; (c/g) Traditional NRBR recognition processing results; (d/h) Finite element segmentation k-means clustering results.
Figure 7.
Comparison of sector segmentation effects. (a/e) Cropped original image; (b/f) Adaptive enhancement processing results; (c/g) Traditional NRBR recognition processing results; (d/h) Finite element segmentation k-means clustering results.
Through adaptive finite element segmentation, we partition the original image into multiple sectorial regions, reducing the complexity of directly processing the intact image. This facilitates more effective identification of clouds in each sector by the k-means clustering technique, thereby markedly improving detection accuracy. It becomes the key strategy for our success in cloud quantification. As shown in Figure 8, the curve profiles the cloud amount information from sunrise to sunset at Yangbajing area, comparing the cloud quantification effects between the conventional NRBR approach and image enhancement processing. On this particular day, after image enhancement, the outcomes significantly improve especially when sky cloud coverage is below 50%. The image in Figure 7a corresponds to the cloud amount data point at 10:30 on the curve. With image enhancement and finite element sectorial segmentation k-means clustering, the derived cloud fraction is 33.8%, versus 43.9% by the conventional NRBR method, translating to an enhanced precision of around 23%. After enhancement, the cloud detection around the sun is markedly improved in the original image, reducing erroneous judgment of blue sky regions as white clouds and increasing quantification accuracy. This is chiefly owing to the NRBR solely relying on color features, while the finite element method synthesizes multiple traits like shape and position for more robust identification of the overexposed solar vicinity. Likewise, the cloud cover recognition effect at the base of heavier clouds and the overexposed area surrounding the sun are greatly improved when the image is enhanced, as seen in Figure 8g,h.
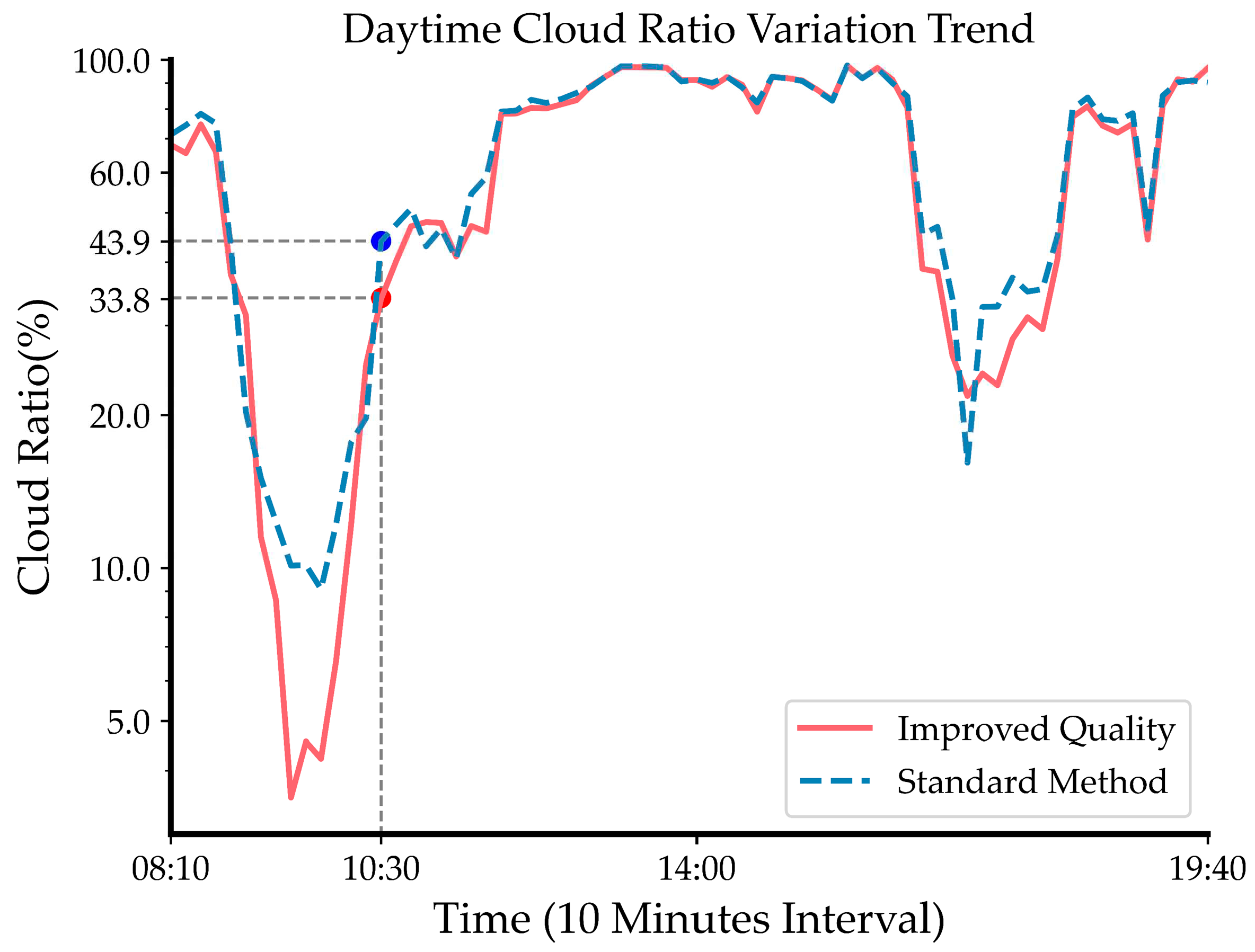
Figure 8.
Comparison of daytime cloudiness between the traditional NRBR method and the finite element partitioned K-mean clustering method.
Figure 8.
Comparison of daytime cloudiness between the traditional NRBR method and the finite element partitioned K-mean clustering method.
4.3. Spatial and Temporal Analysis of Cloud Types
To gain deeper insight into the seasonal variations and diurnal patterns of cloud types in the Yangbajing area, Tibet, more detailed classification statistics on the 2020 annual daylight data are conducted. As depicted in Figure 9, stratus clouds occurred most frequently throughout the year, accumulating 6622 times and accounting for 30% of total cloud occurrences. Clear sky and cumulus clouds took the second and third places, appearing 5447 and 5365 times respectively, both comprising around 24%. Cirrus clouds occurred least, at 5001 times making up 22%. This aligns with the climate characteristics of the Qinghai-Tibet Plateau. Stratus clouds primarily form from atmospheric water vapor condensation, facilitated by the high altitude and greater atmospheric thickness in Tibet. Cirrus clouds often develop at relatively lower altitudes and more humid climatic conditions [29], while the dry climate on the Tibetan plateau is less conducive to their formation. Analyzing by seasons, stratus clouds appeared most in spring (March-May), occurring 2678 times and occupying 42.9% of all daytime cloud types in the season. Cumulus clouds occurred most frequently in summer (June-August), reaching 3838 times and taking up 46.5% of total daytime cloud types. Clear sky dominated in autumn (September-November), appearing 2249 times and accounting for 42.8% of the daytime varieties. Winter (December-February) was also predominated by clear sky, which occurred 2150 times constituting 45.7% of the daytime population. The distinct seasonal shifts in cloud types across Tibet match its climate patterns - increased evaporation in spring facilitates thick cloud buildup; intense convection readily forms cumulus clouds in summer [30], aligning with the greater summer precipitation; while the relatively dry, less snowy winters see more clear sky days. Analyzing diurnal fluctuations reveals that stratus and cumulus clouds concentrate in afternoon hours, peaking at 17:00 and 18:00 for stratus (761 and 756 times respectively), and 13:00, 14:00 and 15:00 for cumulus (665, 707 and 684 times), potentially related to convective activity strengthened by afternoon surface heating. Clear sky occurrences are mainly distributed in the morning at 9:00, 10:00 and 11:00 (740, 812 and 743 times). Cirrus clouds vary more evenly throughout the day. Dividing the daylight hours of 7-20 into 7 periods, we statistically determine the peak timing of different cloud types: (1) Stratus clouds peak at 17-18:00, occupying 39.1% of the total occurrences. (2) Cumulus clouds peak at 13-14:00, taking up 34.2%. (3) Clear sky peaks at 9-10:00, constituting 40.6%. (4) Cirrus clouds peak at 17-18:00, comprising 24.9%. The common afternoon emergence of cumulus clouds may relate to intensified convective motions caused by daytime solar heating of the surface. Because the early air is less volatile and has a lower water vapor content than other times of the day, clear skies are more common in the morning. Generally speaking, the development of cirrus clouds requires relatively humid circumstances. Late afternoon solar radiation warms the surface and causes the air to rise, which aids in the vertical movement that carries water vapor to higher altitudes where it condenses as cirrus clouds.
5. Discussion
Cloud detection and identification has long been a research focus and challenge in meteorology and remote sensing. Current mainstream ground-based cloud detection methods can be summarized into two categories – traditional image processing approaches and deep learning-based techniques [31]. Traditional methods like threshold segmentation and texture analysis rely on manually extracted features with weaker adaptability to atypical cases, whereas deep learning can automatically learn features for superior performance. This study belongs to the latter, utilizing the YOLOv8 model for cloud categorization to capitalize on deep learning’s visual feature extraction strengths. Compared to other deep learning based cloud detection studies, the innovations of this research are three-fold: 1) An adaptive segmentation strategy tailored to different cloud types was designed, with segmentation parameters set according to cloud morphology to extract representative traits, improving partitioning accuracy. 2) Adaptive image enhancement algorithms were introduced, which markedly improved detection in regions with strong illumination impact like solar vicinity over conventional NRBR segmentation. 3) Multi-level refinement was adopted to enhance capturing of cloud edges and bottoms. These aspects enhanced adaptivity to various cloud types under complex illumination. Limitations of this study include: 1) Small dataset scale containing only Yangbajing area samples due to geographic and instrumentation constraints; 2) Sophisticated model training and tuning demanding substantial computational resources; 3) Room for further improving adaptability to overexposed regions. Future work may address these deficiencies via enlarged samples, cloud computing resources, and more powerful models.
Although only validated at the Yangbajing Comprehensive Atmospheric Observatory in Tibet, this approach exhibits considerable scalability and versatility. Firstly, the constructed end-to-end recognition framework has generalization capability – with appropriate fine-tuning, it can adapt to cloud morphological traits in other regions. Secondly, the adaptive image enhancement strategy functions irrespective of specific lighting conditions hence widely applicable to diverse environments; the finite element segmentation with k-means clustering philosophy can also generalize to cloud quantification at different sites – regions with more prevalent hazes would benefit well. The modularized design ensures convenient upgradability of individual components. Therefore, this proposed technique can be readily transferred within the cloud monitoring network to enable coordinated high-precision multi-regional recognition, providing a referential paradigm for cloud detection tasks under other challenging illumination circumstances.
An additional crucial area of research is correlation with solar radiation. We noticed that different cloud types impact radiation divergently throughout the day – occurrences of stratus and cumulus clouds closely associate with radiation, concentrating in the higher insolation afternoon periods, while clear sky and cirrus clouds vary less with radiation trends. Solar radiation is the vital energy source driving weather processes, directly influencing generation, evolution and dissipation of varied cloud types [32]. For the Tibetan region, solar radiation largely shapes its climate characteristics [33]. Abundant insolation provides the energy source for water vapor to fuel convective activity beneficial for thick cloud buildup. Additionally, solar radiation intricately intertwines with glacier ablation, ecological transformations and other changes over the Qinghai-Tibet Plateau [34]. Looking ahead, with intensifying global warming, solar intensity may continue strengthening, potentially raising stratus and cumulus clouds over Tibet, further impacting climate via cloud fraction changes. Hence persistent monitoring of relationships between cloud varieties and solar radiation carries significance for predicting future regional climate change tendencies. Our study established favorable grounds for constructing coupled models between cloud amount and radiation.
6. Conclusions
This research proposes a novel deep learning based whole sky image cloud detection solution, constructing a 4000-image multi-cloud dataset spanning cirrus, clear sky, cumulus and stratus categories that achieved markedly improved recognition and quantification outcomes in Tibet’s Yangbajing area. Specifically, an end-to-end cloud recognition framework was built, first leveraging the YOLOv8 model to accurately classify cloud types with over 95% accuracy. Building on this, tailored adaptive segmentation strategies were designed for different cloud shapes, notably enhancing segmentation precision through extracting representative traits, especially for indistinct cirrus clouds. Moreover, adaptive image enhancement algorithms were introduced to significantly improve detection in illumination-challenging areas around the sun. Finally, multi-level refinement modules based on finite element techniques further upgraded judgment precision of cloud edges and details. Validation on the 2020 annual Yangbajing dataset proves stratus clouds constitute the predominant type, appearing in 30% of daytime cloud images, delivering valuable data support for regional climate studies. In conclusion, this framework significantly raises the automation level of ground-based cloud quantification to create a strong technological foundation for research on climate change. It does this by integrating various modules that cover classification, adaptive segmentation, and image enhancement. Additionally, it offers a referable paradigm for other cloud recognition tasks under complex lighting environments.
Author Contributions
Conceptualization, Y.W. and J.L.; methodology, Y.W. and J.L.; software, Y.W. and J.L.; validation, Y.W. and J.L.; formal analysis, Y.W., J.L., D.L. and D.S.; investigation, Y.W., J.L. and Y.P.; resources, Y.W., J.L., Y.P., L.W., W.Z., J.Z., D.S. and D.L.; data curation, Y.W., J.L., Y.P., L.W., W.Z., X.H., Z.Q. and J.Z.; writ-ing—original draft preparation, J.L.; writing—review and editing, all authors; funding acquisition, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Second Tibetan Plateau Scientific Expedition and Research Program of China, grant number 2019QZKK0604; and by the National Natural Science Foundation of China (42293321 and 42030708).
Data Availability Statement
Data Availability Statement: The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
We would like to express our heartfelt gratitude to Institute of Atmospheric Physics, Chinese Academy of Sciences, Yangbajing Total Atmosphere Observatory for providing the data used in this study. Additionally, we extend our appreciation to the reviewers for their valuable feedback and insightful suggestions, which significantly contributed to enhancing the quality of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Voigt, A.; Albern, N.; Ceppi, P.; Grise, K.; Li, Y.; Medeiros, B. Clouds, radiation, and atmospheric circulation in the present-day climate and under climate change. Wiley Interdiscip. Rev. Clim. Change. 2021, 12, e694. [Google Scholar] [CrossRef]
- Feng, C.J.; Zhang, X.T.; Wei, Y.; Zhang, W.Y.; Hou, N.; Xu, J.W.; Yang, S.Y.; Xie, X.H.; Jiang, B. Estimation of Long-Term Surface Downward Longwave Radiation over the Global Land from 2000 to 2018. Remote Sens. 2021, 13, 1848. [Google Scholar] [CrossRef]
- Raghuraman, S.P.; Paynter, D.; Ramaswamy, V. Quantifying the Drivers of the Clear Sky Greenhouse Effect, 2000-2016. J. Geophys. Res.: Atmos. 2019, 124, 11354–11371. [Google Scholar] [CrossRef]
- Werner, F.; Siebert, H.; Pilewskie, P.; Schmeissner, T.; Shaw, R.A.; Wendisch, M. New airborne retrieval approach for trade wind cumulus properties under overlying cirrus. J. Geophys. Res.: Atmos. 2013, 118, 3634–3649. [Google Scholar] [CrossRef]
- Riihimaki, L.D.; Li, X.Y.; Hou, Z.S.; Berg, L.K. Improving prediction of surface solar irradiance variability by integrating observed cloud characteristics and machine learning. Sol. Energy. 2021, 225, 275–285. [Google Scholar] [CrossRef]
- Jafariserajehlou, S.; Mei, L.L.; Vountas, M.; Rozanov, V.; Burrows, J.P.; Hollmann, R. A cloud identification algorithm over the Arctic for use with AATSR-SLSTR measurements. Atmos. Meas. Tech. 2019, 12, 1059–1076. [Google Scholar] [CrossRef]
- Hutchison, K.D.; Iisager, B.D.; Dipu, S.; Jiang, X.Y.; Quaas, J.; Markwardt, R. A Methodology for Verifying Cloud Forecasts with VIIRS Imagery and Derived Cloud Products-A WRF Case Study. Atmosphere. 2019, 10, 521. [Google Scholar] [CrossRef]
- Li, Z.W.; Shen, H.F.; Li, H.F.; Xia, G.S.; Gamba, P.; Zhang, L.P. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar]
- He, L.L.; Ouyang, D.T.; Wang, M.; Bai, H.T.; Yang, Q.L.; Liu, Y.Q.; Jiang, Y. A Method of Identifying Thunderstorm Clouds in Satellite Cloud Image Based on Clustering. CMC-Comput. Mater. Continua. 2018, 57, 549–570. [Google Scholar] [CrossRef]
- Ma, N.; Sun, L.; Zhou, C.H.; He, Y.W. Cloud Detection Algorithm for Multi-Satellite Remote Sensing Imagery Based on a Spectral Library and 1D Convolutional Neural Network. Remote Sens. 2021, 13, 3319. [Google Scholar] [CrossRef]
- Rumi, E.; Kerr, D.; Sandford, A.; Coupland, J.; Brettle, M. Field trial of an automated ground-based infrared cloud classification system. Meteorol. Appl. 2015, 22, 779–788. [Google Scholar] [CrossRef]
- Wu, Z.P.; Liu, S.; Zhao, D.L.; Yang, L.; Xu, Z.X.; Yang, Z.P.; Liu, D.T.; Liu, T.; Ding, Y.; Zhou, W.; He, H.; Huang, M.Y.; Li, R.J.; Ding, D.P. Optimized Intelligent Algorithm for Classifying Cloud Particles Recorded by a Cloud Particle Imager. J. Atmos. Oceanic Technol. 2021, 38, 1377–1393. [Google Scholar] [CrossRef]
- Alonso-Montesinos, J. Real-Time Automatic Cloud Detection Using a Low-Cost Sky Camera. Remote Sens. 2020, 12, 1382. [Google Scholar] [CrossRef]
- Nakajima, T.Y.; Tsuchiya, T.; Ishida, H.; Matsui, T.N.; Shimoda, H. Cloud detection performance of spaceborne visible-to-infrared multispectral imagers. Appl. Opt. 2011, 50, 2601–2616. [Google Scholar] [CrossRef]
- Yu, C.H.; Yuan, Y.; Miao, M.J.; Zhu, M.L. CLOUD DETECTIONMETHOD BASED ON FEATURE EXTRACTION IN REMOTE SENSING IMAGES. 8th International Symposium on Spatial Data Quality, China, Hong Kong, 30 May - 1 June 2013.
- Yang, Y.K.; Di Girolamo, L.; Mazzoni, D. Selection of the automated thresholding algorithm for the Multi-angle Imaging SpectroRadiometer Radiometric Camera-by-Camera Cloud Mask over land. Remote Sens. Environ. 2007, 107, 159–171. [Google Scholar] [CrossRef]
- Irbah, A.; Delanoe, J.; van Zadelhoff, G.J.; Donovan, D.P.; Kollias, P.; Treserras, B.P.; Mason, S.; Hogan, R.J.; Tatarevic, A. The classification of atmospheric hydrometeors and aerosols from the EarthCARE radar and lidar: the A-TC, C-TC and AC-TC products. Atmos. Meas. Tech. 2023, 16, 2795–2820. [Google Scholar] [CrossRef]
- Li, W.W.; Zhang, F.; Lin, H.; Chen, X.R.; Li, J.; Han, W. Cloud Detection and Classification Algorithms for Himawari-8 Imager Measurements Based on Deep Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4107117. [Google Scholar] [CrossRef]
- van de Poll, H.M.; Grubb, H.; Astin, I. Sampling uncertainty properties of cloud fraction estimates from random transect observations. J. Geophys. Res.: Atmos. 2006, 111, D22218. [Google Scholar] [CrossRef]
- Yu, J.C.; Li, Y.C.; Zheng, X.X.; Zhong, Y.F.; He, P. An Effective Cloud Detection Method for Gaofen-5 Images via Deep Learning. Remote Sens. 2020, 12, 2106. [Google Scholar] [CrossRef]
- Krauz, L.; Janout, P.; Blazek, M.; Páta, P. Assessing Cloud Segmentation in the Chromacity Diagram of All-Sky Images. Remote Sens. 2020, 12, 1902. [Google Scholar] [CrossRef]
- Krüger, O.; Marks, R.; Grassl, H. Influence of pollution on cloud reflectance. J. Geophys. Res.: Atmos. 2004, 109, D24210. [Google Scholar] [CrossRef]
- Wu, L.X.; Chen, T.L.; Ciren, N.; Wang, D.; Meng, H.M.; Li, M.; Zhao, W.; Luo, J.X.; Hu, X.R.; Jia, S.J.; Liao, L.; Pan, Y.B.; Wang, Y.A. Development of a Machine Learning Forecast Model for Global Horizontal Irradiation Adapted to Tibet Based on Visible All-Sky Imaging. Remote Sens. 2023, 15, 2340. [Google Scholar] [CrossRef]
- Li, P.; Zheng, J.S.; Li, P.Y.; Long, H.W.; Li, M.; Gao, L.H. Tomato Maturity Detection and Counting Model Based on MHSA-YOLOv8. Sensors. 2023, 23. [Google Scholar] [CrossRef]
- Xiao, B.J.; Nguyen, M.; Yan, W.Q. Fruit ripeness identification using YOLOv8 model. Multimed. Tools Appl. 2023. [CrossRef]
- Wang, G.; Chen, Y.F.; An, P.; Hong, H.Y.; Hu, J.H.; Huang, T.E. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors. 2023, 23, 7190. [Google Scholar] [CrossRef]
- Kaiming, H.; Jian, S.; Xiaoou, T. Single image haze removal using dark channel prior. 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, 20-25 June 2009.
- Dinc, S.; Russell, R.; Parra, L.A.C. Cloud Region Segmentation from All Sky Images using Double K-Means Clustering. 2022 IEEE International Symposium on Multimedia (ISM), Italy, 5-7 Dec. 2022.
- Monier, M.; Wobrock, W.; Gayet, J.F.; Flossmann, A. Development of a detailed microphysics cirrus model tracking aerosol particles' histories for interpretation of the recent INCA campaign. J. Atmos. Sci. 2006, 63, 504–525. [Google Scholar] [CrossRef]
- Chen, B.; Xu, X.D.; Yang, S.; Zhao, T.L. Climatological perspectives of air transport from atmospheric boundary layer to tropopause layer over Asian monsoon regions during boreal summer inferred from Lagrangian approach. Atmos. Chem. Phys. 2012, 12, 5827–5839. [Google Scholar] [CrossRef]
- Hensel, S.; Marinov, M.B.; Koch, M.; Arnaudov, D. Evaluation of Deep Learning-Based Neural Network Methods for Cloud Detection and Segmentation. Energies. 2021, 14, 6156. [Google Scholar] [CrossRef]
- Ramanathan, V.; Cess, R.D.; Harrison, E.F.; Minnis, P.; Barkstrom, B.R.; Ahmad, E.; Hartmann, D. Cloud-Radiative Forcing and Climate: Results from the Earth Radiation Budget Experiment. Science. 1989, 243, 57–63. [Google Scholar] [CrossRef]
- Liu, L.; Sun, X.J.; Liu, X.C.; Gao, T.C.; Zhao, S.J. Comparison of Cloud Base Height Derived from a Ground-Based Infrared Cloud Measurement and Two Ceilometers. Adv. Meteorol. 2015, 2015, 853861. [Google Scholar] [CrossRef]
- Wu, G.X.; Liu, Y.M.; He, B.; Bao, Q.; Duan, A.M.; Jin, F.F. Thermal Controls on the Asian Summer Monsoon. Sci. Rep. 2012, 2, 404. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Automatic cloud observer. (a) Visible light imaging unit;(b) Sun tracking structure.

Figure 2.
Cloud detection flowchart. (a) Traditional NRBR threshold segmentation to compute the cloud amount; (b) YOLOv8 model to identify the cloud type; (c) Finite element segmentation k-mean clustering process; (d) Local refinement for cloud identification.
Figure 2.
Cloud detection flowchart. (a) Traditional NRBR threshold segmentation to compute the cloud amount; (b) YOLOv8 model to identify the cloud type; (c) Finite element segmentation k-mean clustering process; (d) Local refinement for cloud identification.
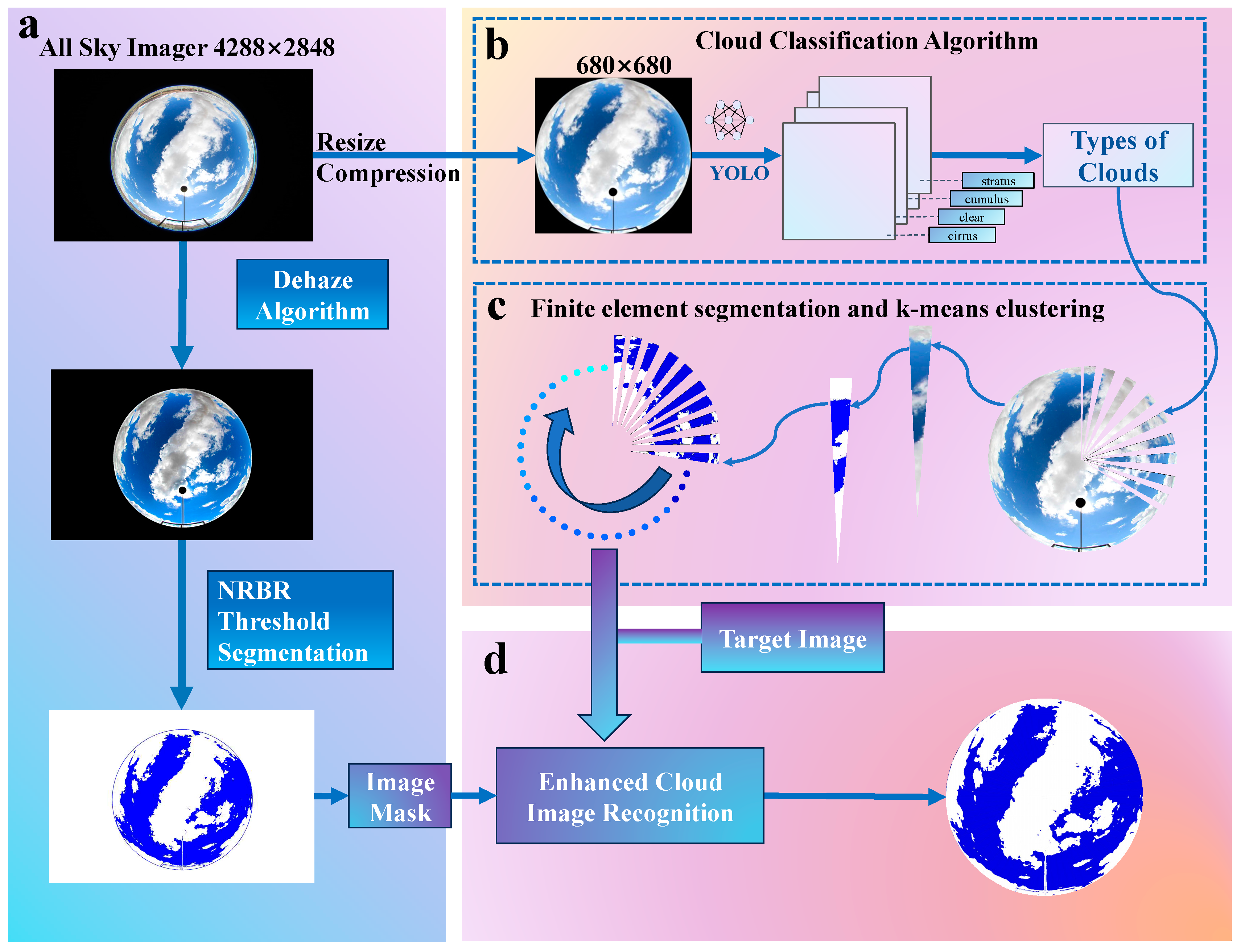
Figure 3.
YOLOv8 machine learning architecture, divided into four parts: Backbone, Neck, Head and Loss.
Figure 3.
YOLOv8 machine learning architecture, divided into four parts: Backbone, Neck, Head and Loss.
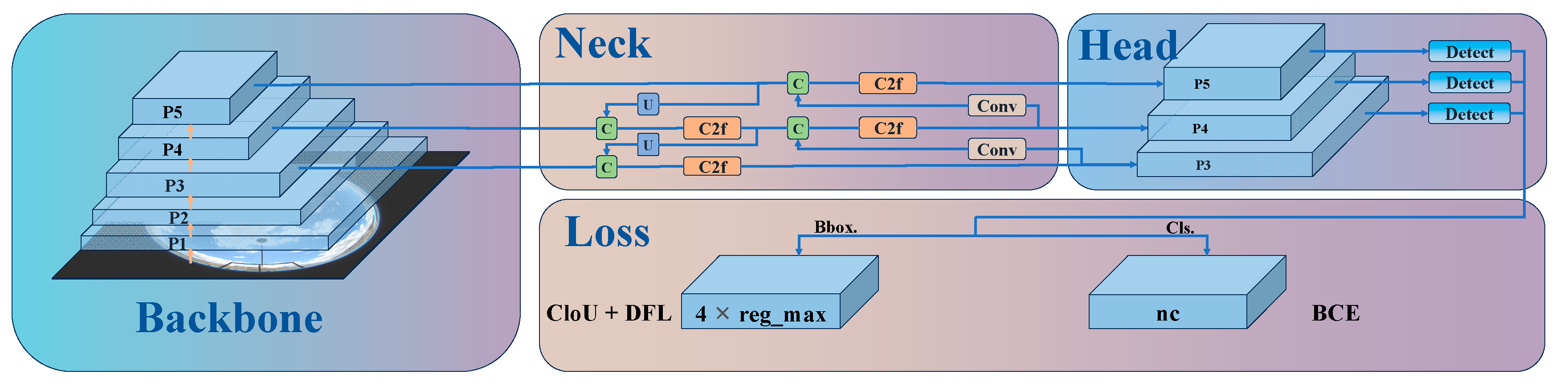
Figure 4.
YOLOv8 classification model training results. (a) Loss curve for network training; (b) Top-1 Accuracy curve for network training.
Figure 4.
YOLOv8 classification model training results. (a) Loss curve for network training; (b) Top-1 Accuracy curve for network training.
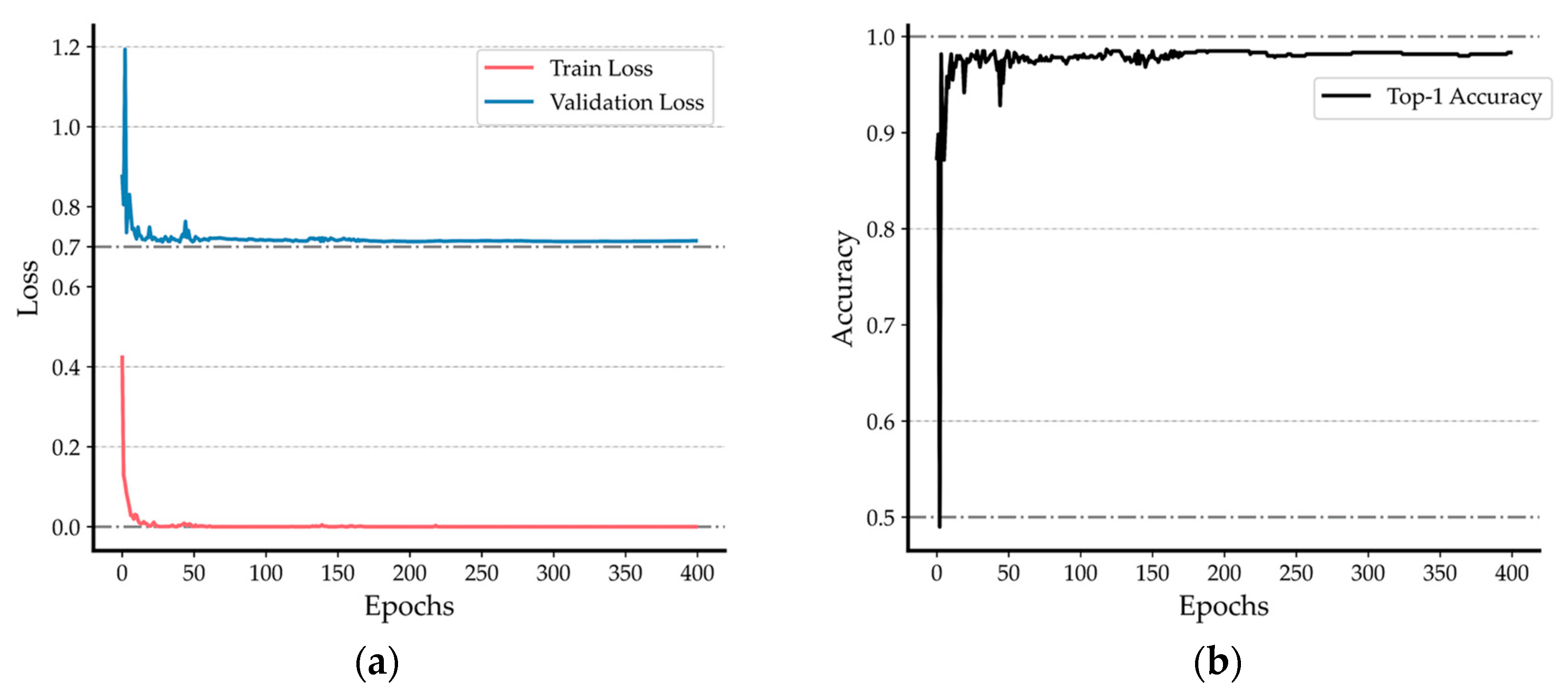
Figure 6.
Comparison of image preprocessing effects. (a) Original image; (b) Image enhancement result.
Figure 6.
Comparison of image preprocessing effects. (a) Original image; (b) Image enhancement result.

Figure 9.
Yangbajing Region's Monthly Distribution Trend of Four Types of Clouds for 2020.
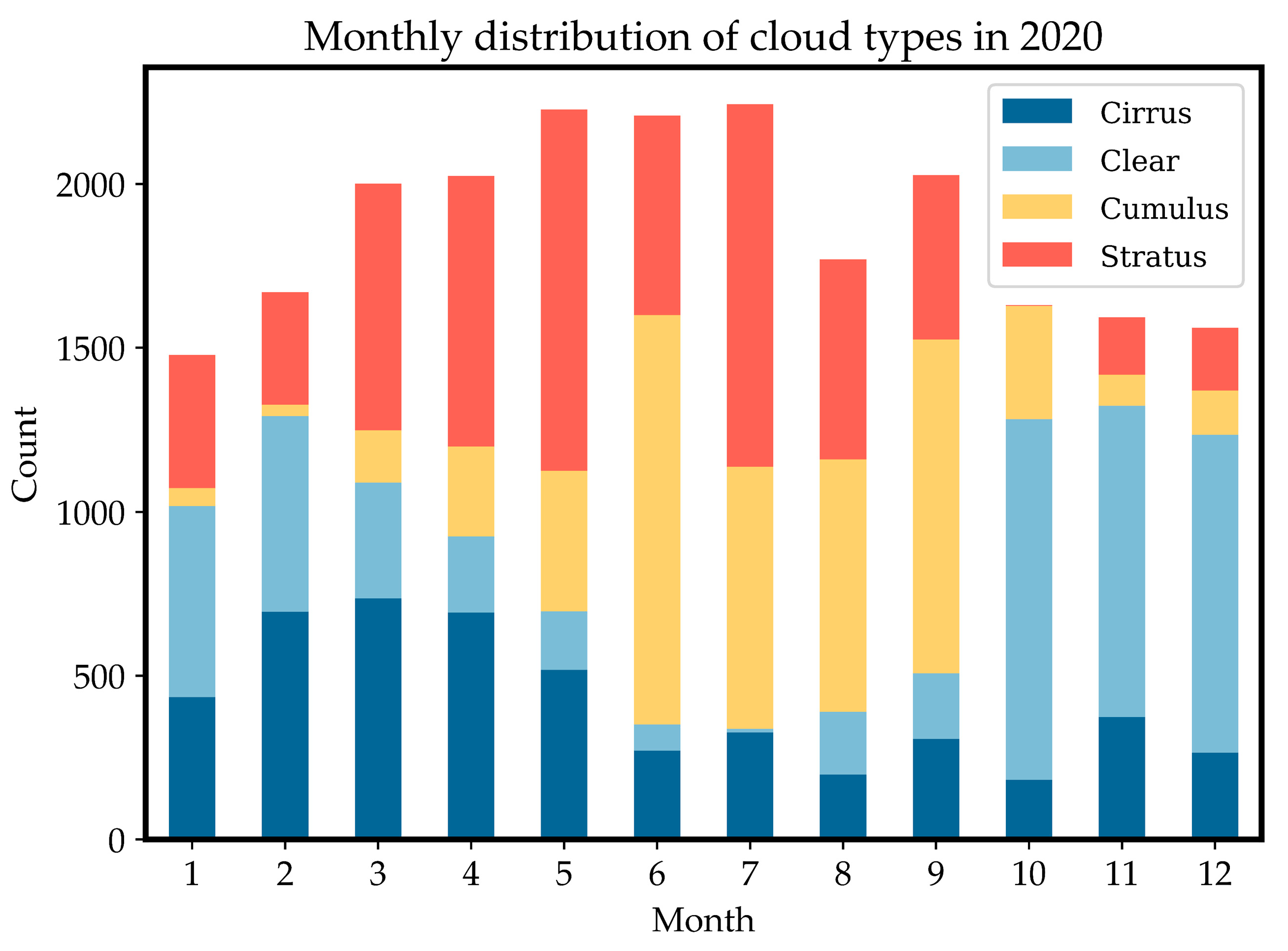

Table 1.
Detailed specifications of automatic cloud observer.
| Function | Description |
|---|---|
| Measure cloud distance | 0~10Km |
| Elevation angle above 15° | Elevation angle above 15° |
| Observation periods | Observe every 10 minutes |
| Horizontal visibility | ≥2km |
| Operating temperature | -40°~50° |
| Sensor | CMOS |
| Pixels | 4288 × 2848 |
| Etc. | 24 h operation, IP65 protection rating |
Table 2.
Performance comparison of cloud type classification and recognition: precision, recall and F1 score of validation set and test set.
Table 2.
Performance comparison of cloud type classification and recognition: precision, recall and F1 score of validation set and test set.
| Validation Set | Test Set | |||||
|---|---|---|---|---|---|---|
| Cloud Type | Precision(%) | Recall(%) | F1-Score(%) | Precision(%) | Recall(%) | F1-Score(%) |
| Cirrus | 97.94 | 95.33 | 96.62 | 95.45 | 98.00 | 96.71 |
| Clear | 100.00 | 100.00 | 100.00 | 100.00 | 98.67 | 99.33 |
| Cumulus | 95.45 | 98.00 | 96.71 | 97.30 | 96.00 | 96.65 |
| Stratus | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Average | 98.35 | 98.33 | 98.33 | 98.19 | 98.17 | 98.17 |
Table 3.
Verification of classification results by KL divergence. NRBR mean image: horizontal axis is Normalised RedBlue Ratio, vertical axis is probability density.
Table 3.
Verification of classification results by KL divergence. NRBR mean image: horizontal axis is Normalised RedBlue Ratio, vertical axis is probability density.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



