
You are currently viewing a beta version of our website. If you spot anything unusual, kindly let us know.
Preprint
Article
WDANet: Exploring Style Feature via Dual Cross-Attention for Woodcut-Style Design
Altmetrics
Downloads
155
Views
71
Comments
0


This version is not peer-reviewed
Abstract
People are drawn to woodcut-style designs due to their striking visual impact and strong contrast. However, traditional woodcut prints and previous computer-aided methods have not addressed the issues of dwindling design inspiration, lengthy production times, and complex adjustment procedures. We propose a novel network framework, the Woodcut-style Design Assistant Network (WDANet), to tackle these challenges. Notably, our research is the first to utilize diffusion models to streamline the woodcut-style design process. We've curated the Woodcut-62 dataset, featuring works from 62 renowned historical artists, to train WDANet in absorbing and learning the aesthetic nuances of woodcut prints, offering users a wealth of design references. Based on a noise reduction network, our dual cross-attention mechanism effectively integrates text and woodcut-style image features. This allows users to input or slightly modify a text description to quickly generate accurate, high-quality woodcut-style designs, saving time and offering flexibility. As confirmed by user studies, quantitative and qualitative analyses show that WDANet outperforms the current state-of-the-art in generating woodcut-style images and proves its value as a design aid.
Keywords:
Subject: Computer Science and Mathematics - Computer Vision and Graphics
1. Introduction
Woodcut is one of the oldest and simplest forms of printmaking art, carving reverse images onto a wooden board and printing them on paper for appreciation [1]. Traditional woodcut prints are predominantly black and white monochrome, offering reproducibility and ease of promotion. They demonstrate substantial control over light and shadow [2]. The intense color contrasts and the texture of woodcut marks create a powerful visual impact, establishing it as a captivating design style that captures the viewer’s attention. Woodcut printing has some limitations that contribute to its decline. The block printing method in woodcut prints requires designers to consider mirror composition, showcasing light changes through varying line densities rather than grayscale, posing a significant design challenge [3]. Once the knife makes an incision, it cannot be erased. Typically, the entire process—from draft drawing to engraving and printing—is predominantly executed by a single person, making production time-consuming and labor-intensive. Each printed copy’s outcome tends to be unstable, and woodcut prints cannot instantaneously display the paper effect during engraving, necessitating repeated modifications and adjustments [4].
Computer-aided woodcuts seek to replicate the manual texture of woodcut marks while simplifying the production process. Its technical research primarily centers around Non-Photorealistic Rendering (NPR) [5]. Despite its capability to render 3D models or 2D images in the woodcut style, it still presents several drawbacks. Firstly, being an art form, woodcut necessitates a solid aesthetic foundation and a timely burst of creative inspiration from the artist. Prior technologies primarily concentrated on imitating the visual texture, which needs more capacity to provide design assistance regarding composition, constituent elements, and score arrangement. Secondly, it demands highly polished works as input, making the preparatory work time-consuming, spanning hours or even days. Lastly, the flexibility is limited, requiring algorithmic adjustments to emulate different artistic styles.
Recently, large-scale models in the realm of generative art, such as Stable Diffusion (SD)[6], Midjourney [7], DALL-E 3 [8], have indeed provided new opportunities for artists. Despite this, the typical method to control the model and generate specific designs involves fine-tuning, which entails a substantial number of parameters. Some more efficient techniques include freezing the basic model parameters and exclusively training additional modules [9,10,11]. Research datasets available can drive advancements within a field. For example, the introduction of the VLD 1.0 dataset [12] significantly propelled log detection and recognition. Nevertheless, the domain of woodcut-style design remains largely unexplored, and a high-quality woodcut dataset is needed, along with the absence of a standardized processing pipeline.
Therefore, this paper introduces a dataset with images and textual annotations named Woodcut-62. This dataset is the dataset tailored explicitly for the woodcut style. Building upon this foundation, we present a groundbreaking model called Woodcut-style Design Assistant Network(WDANet), which, with lightweight training parameters, guides textual inputs to generate design references meeting specified criteria. Compared with previous methods, the advantages of our proposed method are shown in Figure 1.
In summary, this paper outlines the contributions as follows:
- We curate Woodcut-62, a high-quality dataset tailored for woodcut-style designs, comprising 3,058 text-image pairs. This dataset offers style references from 62 artists representing eight countries who greatly influenced history.
- Introducing the lightweight architecture WDANet, we pioneer the application of diffusion models in a woodcut-style design. WDANet accurately emulates the style of a specific artist and generates woodcut-style designs within seconds, relying solely on input text. We also provide comprehensive evaluation indicators.
- The fidelity, diversity, and aesthetic characteristics of the woodcut style design drawings generated with WDANet guidance have achieved SOTA while garnering better user preferences in the comprehensive artistic evaluation conducted during the user study.
2. Related Work
2.1. Woodcut-Style Design
The pioneering application of computer graphics in woodcut design is initiated by Mizuno et al. [13]. They integrate traditional woodcut production into an interactive simulation system, allowing users to carve within a virtual 3D space. This system synthesizes woodcut images with authentic printing effects on a 2D grid of virtual paper. Subsequent works by Mizuno et al. [14,15] perfect features such as automatic engraving based on grayscale map characteristics and color printing. Their research mainly focuses on the Ukiyo-e style [16,17]. To enhance the user experience, they were pioneers in migrating the system to a pressure-sensitive pen and tablet. Mello et al.[18] are the first to introduce image-based artistic rendering, specifically generating woodcut-style images. They obtain rendered images through image segmentation, direction field computation, and stroke generation. However, the simulated woodcut scores are relatively basic. Building upon this work, Jie Li et al. [19,20] allocate fractions gathered from authentic woodcut textures according to segmented areas, applying this method to Yunnan out-of-print woodcut. A recent study by Mesquita et al. [21] proposes woodcut generation based on reaction-diffusion, enhancing woodcut representation and user control by introducing noise.
Current research in woodcut-style image generation primarily focuses on simulating woodcut marks, sidelining the artistic design aspect of woodcut. Achieving aesthetically pleasing picture arrangements still requires user intervention. Woodcut-style design generation relies on rendering based on 3D models or images, where the quality and depth of prerequisites significantly impact the output. Crafting a visually appealing woodcut artwork entails a high threshold and considerable time investment. Additionally, the existing algorithms concentrate on specific styles, such as Ukiyo-e and Yunnan out-of-print woodcuts, lacking adaptability to versatile artistic styles.
2.2. Computer-Aided Art Generation
Over the past few decades, a series of rendering and texture synthesis algorithms proposed by computer-aided design research [22,23,24] have predominantly focused on image stylization. The intervention of artificial intelligence in art introduces more creative applications [25]. The confluence of these fields can be traced back to the advent of Generative Adversarial Networks (GAN) [26], where two neural networks—generators and discriminators—compete to produce images resembling actual sample distributions. DeepDream [27] is the first to explore neural networks’ potential to inspire artistic creation. Utilizing convolutional neural networks (CNNs), DeepDream transforms input images into highly interpretable, dream-like visualizations. Another CNN-based study, A Neural Algorithm of Artistic Style [28], separates and recombines semantics and style in natural images, pioneering Neural Style Transfer (NST). Although NST significantly influences artistic style treatment, it typically learns stylistic traits from existing images rather than facilitating original artistic creation. Elgammal et al. introduce Creative Adversarial Networks (CAN) [29] based on GAN, aiming to maximize divergence from established styles while preserving artistic distribution and fostering creativity.
The emergence of Transformer [30,31] propells the application of multimodal neural networks notably in many tasks [32,33]. For example, Hu et al. [34] proposed utilizing transformers for roof extraction and height estimation. Similarly, in the field of remote sensing detection [35,36] and re-identification [37,38,39], transformers have demonstrated tremendous potential. Recently, text-guided image generation through generative artificial intelligence, such as Glide[40], Cogview[41], Imagen[42], Make-a-scene[43], ediffi[44] and Raphael[45] gain widespread use, particularly with significant advancements in large-scale diffusion models [46]. In order to achieve favorable results on the downstream tasks, the past practice is to spend substantial technical resources to fine-tune the model. Many existing studies build upon SD, incorporating adapters for guided generation and requiring minimal additional training while keeping the original model parameters frozen. ControlNet [9] pioneered this method to learn specific task input criteria, such as Depth Map [47], Canny Edge [48]. ControlNet Reference-only efficiently transfers the style and subject from a reference diagram while conforming to textual descriptions, eliminating the need for additional training. In the T2I-Adapter [10] approach, the reference image is fed into the style adapter to extract stylistic features and integrate them with text features. Uni-ControlNet [49] employs two adapters—one for global and one for local control—enabling the combinability of diverse conditions. The IP-Adapter [11]supports the fusion of individual image features with text features via the cross-attention layer, ensuring the preservation of both the main subject of the image and its stylistic attributes. Additionally, PCDMs [50] suggest employing inpainting to fine-tune the entire SD for achieving pose-guided human generation. Nonetheless, this approach of training by fully releasing all parameters is not practically economical.
While these adapters effectively generate similar styles from image-guided models, the generated results tend to closely resemble specific reference images, posing challenges in providing valuable references within the design realm. Artistic creation often requires diverse images to draw inspiration from when exploring various themes. Therefore, generated images must exhibit diversity while maintaining coherence between visuals and accompanying text descriptions. Our study centers on woodcut-style design, employing dual cross-attention mechanisms to harmonize visual and textual features. Moreover, our approach facilitates the transfer of a specific artist’s style across different thematic contexts.
3. Method
3.1. Woodcut-62
3.1.1. Collect
Numerous datasets of artworks cater to a wide range of machine learning tasks, such as VisualLink[51], Art500k[52], and ArtEmis[53]. However, the domain of woodcut prints still needs to be explored regarding available datasets. We gather 3,248 woodcut images sourced from various open-source networks. The distribution of resolutions is depicted in Figure 2. We manually engage art experts to adjust these artworks to 512 × 512 resolution to standardize resolution and minimize training costs. Tailoring involves preserving the thematic essence and the most aesthetic characteristics. Larger-sized images are split into multiple images for better handling. As woodcuts are prints, their electronic copies lose some detail compared to the originals. Working closely with experts, we manually adjusted image parameters to enhance features, maintaining the characteristic texture while reducing noise. Under art expert guidance, we filter out low-resolution or duplicated images, resulting in 3058 high-quality woodcut images. These images represent 62 historically influential artists from eight countries, spanning genres like romanticism, abstract expressionism, and realism. Ultimately, this effort culminated in creating the inaugural woodcut style dataset for the text-to-image task—Woodcut-62. The style distribution of the dataset is shown in Figure 3.
3.1.2. Label
To accommodate the text-to-image generation task, we transition from the original caption to using natural language for annotation. This label process is outlined in Figure 4. Initially, we experiment with the BLIP[54]Captioning and Filtering (CapFilt), a new dataset bootstrapping method that filters out noisy titles and automatically composites captions for images. However, upon manual inspection, we discovered that this method’s efficacy could be improved, particularly for abstract expressionism or intricate content. To address this, we seek the expertise of art specialists to fine-tune annotations for these specific types of images manually. To distinctly mark the woodcut style, we append the keyword "woodcut" to each image, along with details such as the artist’s name and the country of origin. This meticulous labeling ensures that the model can discern between various artistic styles. Finally, we encapsulate text-image pair labels into a JSON file.
3.2. WDANet
3.2.1. Prelimiaries
Diffusion model[55] is an important method for describing complex systems’ dynamic behavior and stable state distribution. The image generation is likened to the diffusion of ink in water. It is divided into two processes. The forward diffusion process transforms the initial data into a Gaussian distribution by iteratively adding random Gaussian noise through T iterations. The reverse denoising process involves predicting noise from and gradually restoring . Governed by condition c, the simplified variant loss function of the training model is as follows:
Where . is the linear combination of the original signal and random noise , meeting .
Balancing sample fidelity and pattern coverage in conditional diffusion models commonly involves employing a classifier as guidance, necessitating the additional training of an image classifier separate from the diffusion model. However, classifier-free guidance[56], as proposed in, trains both conditional and unconditional diffusion models, randomly discarding the control conditions c. The noise prediction during the sampling stage adheres to the following formula:
Here, represents the scale guiding the faithfulness to the control conditions c in the generated results. In this study, the foundational generative model utilized is SD[6]. SD maps the image to the low-dimensional latent space instead of the pixel space for diffusion, significantly reducing the diffusion model’s computation. Within SD, a U-Net[57] is trained as the core network for the noise prediction model. A cross-attention mechanism is introduced to integrate control information c into the intermediate layers of the U-Net. This inclusion forms a conditional denoising autoencoder, effectively governing the image synthesis. The cross-attention layer yields the following output:
Where , , are trainable weight parameter matrices, represents a learnable flattened embedding of the U-Net, and denotes a learnable domain-specific encoder that converts c into an intermediate representation.
3.2.2. Dual Cross-Attention
It is crucial to preserve the thematic essence described in the text for design image generation while learning coarse-grained details like style and composition from woodcut images during training. Previous methodologies often involved superimposing text and other features via a cross-attention layer in the diffusion model, which could be more effective in transferring and balancing various control conditions. In order to inject woodcut image guidance into the text-to-image diffusion model, we introduce a frozen CLIP image encoder based on SD and add a trainable linear layer (Linear) and a Layer Normalization[58](LayNorm). Their goal is to extract the scattered image features x and map them to the feature that best matches the target effect and aligns with the text embedding dimension. The Linear obtains , and the LayNorm transforms the input into a control condition with woodcut style characteristics :
In the above formula, , b, g, are learnable parameters, H is the number of hidden units, and ⊙ is the element-wise multiplication. Next, we can add to the new cross-attention layer:
Where and are learnable parameters for the new cross-attention layer. In this way, the cross-attention layers with text and woodcut style characteristics, respectively, can be combined into dual cross-attention:
The joint approach of dual cross-attention encompassed both text prompts, with their abstract and expansive semantic features, and woodcut images, which provided precise and concrete visual information. We borrowed the concept of unguided classifiers and introduced (default = 0.5) to balance the fidelity and diversity of the generated images by controlling weights. When = 0, WDANet reverted to the initial text-to-image model (i.e., SD).
3.2.3. Combined with Stable Diffusion
In the text-to-image task, CLIP[59] plays a crucial role as the link between text and image. CLIP comprises a text encoder and an image encoder. The text and image modalities could be aligned in the feature space through contrastive learning and extensive training on numerous text-image pairs. In SD, the text embedding is derived from the input text using the pre-trained CLIP text encoder, which serves as the guiding condition for the denoising process. However, relying solely on text guidance is insufficient for the model to grasp the aesthetic features of woodblock prints. To address this problem, the added image encoder provided finer details, yet fine-tuning parameters remained necessary to adapt it to the woodcut design task. Following the methodology of training the Adapter with freezing CLIP and SD, Our proposed WDANet only needs to learn parameters for Linear, LayNorm, and a cross-attention layer to achieve promising outcomes.
In the training stage, we randomly take the images from the dataset Woodcut-62 and the matching labels as inputs, map the woodcut-style features to the same dimension as the text features and inject the joint features into each middle layer of U-Net (16 layers in total) through dual cross-attention. We set the image conditions or text conditions as empty according to the probability of and set both conditions as empty at the same time under the same probability, that is . The training objectives we utilized are:
Accordingly, the target of noise prediction is:
We model the multi-conditional diffusion model as a text-to-image framework during inference. The overall structure of WDANet is depicted in Figure 5. Woodcut-62 served as the inherent input for the image encoder, eliminating the need for users to provide a specific Woodcut reference image. Instead, inputting text enabled WDANet to query Woodcut-62 to match either the artist’s style or a universal woodcut aesthetic. While seemingly straightforward, this approach relied more on text for WDANet’s style control than a single image, preventing an excessive focus on granularity that might compromise generative diversity. To expedite the generation of woodcut-style designs, we employed DDIM [60], an accelerated sampling method utilizing a non-Markov diffusion process to simulate the reverse process of Markov diffusion.
4. Experiment
4.1. Implementation Details
We utilize CLIP ViT-H/14 [61] as the image encoder and SD v1.5 1 as the backbone network. WDANet’s parameters were lightweight and enabled training on a 24GB RTX 3090 graphics card with 80GB RAM. Employing AdamW [62] as the optimizer, we train for 70k global steps on Woodcut-62 with a learning rate set at and a weight decay of 0.01. DDIM served as the sampling acceleration algorithm, executing 50 sampling steps during inference. The coefficient in dual cross-attention defaulted to 0.5. The prompt on the text input side should include the keyword "woodcut" to identify the woodcut style, and if the generation task needs to be specific to the artist’s style, then follow the country and artist name, separated by commas.
4.2. Quantitative Evaluation
Our aim in assisting design is to ensure that the model-generated woodblock prints exhibit diverse compositions, a rich array of elements, and aesthetically pleasing arrangements based on a given thematic description. Therefore, our chosen metrics primarily assess the alignment between text and image and the aesthetic quality of the generated images. For assessing the alignment between text and image, we utilized CLIPScore [63] based on CLIP ViT-B/32. As a supplementary evaluation criterion, BLIP[54] forecasts fine-grained alignment between visual and textual elements via a linear layer. Its output includes the likelihood of image-text matching (ITM) and the cosine similarity between the features of both modalities.When evaluating the influence of generated images on users’ aesthetic preferences, we incorporate ImageReward[64], a model trained on a dataset of 137k expert comparisons. This model automatically gauges the quality of text-to-image conversions and closely aligns with human preferences.
We presents a comparative analysis between our approach, WDANet, and several state-of-the-art methods such as ControlNet, T2I-Adapter, and IP-Adapter. We provide empirical data to showcase the advancements over the original SD model. To ensure diverse coverage of text descriptions across different categories and difficulties, we randomly select ten prompts from the PartiPrompts [65], which includes over 1600 English prompts. We generate 100 woodcut-style images from each prompt in the format "a black and white drawing of *, woodcut." 2The ultimate score is calculated by averaging the results from each dataset. The results in Table 1 indicate that our proposed WDANet achieved a CLIP Score of 34.20, nearly doubling the baseline score of 18.52. The BLIP-ITM (the likelihood of image-text matching) reaches 99.98%, confirming a high degree of alignment between the generated images by WDANet and the input text. Moreover, the BLIP-Cosine similarity between text and image features is notably high, recorded at 0.4826. When evaluating aesthetic preferences using ImageReward, our approach exhibits a 2.74 improvement over the baseline, surpassing the second-ranking IP-Adapter by 0.15. WDANet achieves the SOTA level in generating woodcut-style images.
4.3. Qualitative Analysis
In this study segment, we present woodcut-style images generated by prompts extracted from the PartiPrompts corpus using various methods. SD serves as the baseline for the text-to-image model, while other models modulate style features by incorporating an additional woodcut image.
In Figure 6, we observe that SD (baseline) and ControlNet display instability, while T2I-Adapter and IP-Adapter tend to mirror the composition, characters, or actions of the reference image too closely, as seen in figure (1), where both T2I-Adapter and IP-Adapter depict middle-aged men with a beard. Our method, however, focuses on learning the stylistic and textural features of woodcut images. In (5), WDANet showcases a more accurate representation of complex prompts such as "a woman with long hair" and "a luminescent bird," illustrating them in an incredibly artistic and expressive manner.
In Figure 7, we standardize the input to the same reference image to examine the diverse outputs generated by various methods under different prompts. Baseline and ControlNet struggle to adopt the woodcut style. However, when examining the columns for the outputs of T2I-Adapter and IP-Adapter separately, they exhibit striking similarities across different prompts, evident in figure, where IP-Adapter consistently depicts a towering tree on the left side. In contrast, our method demonstrates strong performance in both diversity and fidelity. Notably, when presented with long and complex prompts, as depicted in (4), WDANet accurately generates woodcut-style designs that align with the description.
4.4. User Study
User study evaluates four aspects: visual-textual consistency, learning style precision, aesthetic preference, and generative diversity. Users are asked to select the most effective image among those generated by the four models. Visual-textual consistency measures the alignment between the model-generated image and the provided text, akin to assessing a designer’s ability to create thematic designs without deviating from the subject—a fundamental requirement. Learning style precision assesses the model’s capability to replicate an artist’s style. As the artist Walter Darby Bannard expressed, "When inspiration dies, imitation thrives," suggesting that designers often enhance their skills by imitating masterpieces. Aesthetic preference gauges the overall quality of the generated woodcut images based on adherence to aesthetic principles like composition, element arrangement, and visual harmony. Generative diversity tests revealed that models with additional image-controlling conditions are often constrained by single-image features, leading to a loss of richness in the generated images. Consequently, concerning this aspect, we directly compare WDANet to state-of-the-art text-to-image models, Midjourney and DALL-E 3.
We collected 68 questionnaires from 14 cities in China, with 38 respondents having received art education and possessing some knowledge of woodcuts. In our questionnaire Figure 8, A represents ControlNet, B represents the image generated by T2I-Adapter, C depicts IP-Adapter’s output, and D represents WDANet, proposed by us. In , our generated results align best with the highlighted keywords. In contrast, option A lacks the imitation of woodcut style, and the actions portrayed in B and C are not sufficiently accurate. For , we evaluate the Learning style precision of different methods using Kathe Kollwitz’s woodcut works as a reference. As a German expressionist printmaker, her pieces evoke a heavy and melancholic atmosphere, where our approach closely aligns with her characterization and thematic tone. In , option D exhibits a stable effect while comparing Aesthetic preference, illustrating "a retro town by the river" with a tranquil aesthetic. Correspondingly, the collected data shown in Figure 9 demonstrates that WDANet gains more user preference across all three aspects of the evaluation.
In questionnaire , as Figure 10 shows, we investigate the performance of different models in generating different designs, specifically regarding generative diversity. A represents Midjourney, B stands for DALL-E 3, C depicts IP-Adapter, which performs better among the adapter methods, and D represents WDANet, our proposed method. It is noticeable that options A and B favor realism over artistic rendering in generating woodcut-style designs. Additionally, the diversity in picture composition, element arrangement, and texture distribution in options A, B, and C appears relatively limited. Conversely, our method demonstrates both stylistic variability and stable results. As the corresponding data in Figure 11, 60.29% of users chose D, affirming the diversity of our generated results.
5. Conclusions
This Work introduces Woodcut-62, the pioneering dataset categorizing woodcut prints by artist styles, and proposes WDANet as the inaugural text-to-image network architecture for aiding woodcut-style design. WDANet unites text features with embedded woodcut style image characteristics using dual cross-attention, guiding the diffusion model to generate woodcut-style design references aligned with design requisites. Compared to conventional computer-assisted approaches, WDANet offers a broader spectrum of inspirational references, is less time-consuming, and offers greater adjustability. Quantitative and qualitative experiments demonstrate WDANet’s superior performance in woodcut-style design compared to other conditionally controlled adapters. In the user study, WDANet outperformed in visual-textual consistency, learning style precision, aesthetic preference, and generative diversity—four indicators related to aesthetic design dimensions—garnering higher user preferences. Furthermore, this network framework can be extended to various art categories beyond woodcut prints. In the future. Despite the promising performance of WDANet in assisting woodcut-style design, its lightweight structure still relies on guided image embedding. Moving forward, we aim to explore more flexible methods for learning style features. Our goal is to accomplish design assistance tasks seamlessly without any need for input images, thereby enhancing the adaptability and autonomy of the system.
Author Contributions
Yangchunxue Ou: Conceptualization, Data curation, Formal analysis, Methodology, Investigation, Software, Validation, Writing – original draft, Writing – review & editing, Investigation, Visualization. Jingjun Xu: Project administration, Supervision.
Data Availability Statement
The data that has been used is confidential.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Ross, J.; Romano, C.; Ross, T. The Complete Printmaker; Free Press: New York, 1991; ISBN 978-0-02-927372-2. [Google Scholar]
- Saff, D.; Sacilotto, D. Printmaking: History and Process; Holt: Rinehart and Winston, 1978; ISBN 978-0-03-085663-1. [Google Scholar]
- Walker, G.A. The woodcut artist’s handbook: techniques and tools for relief printmaking; Firefly Books: Canada, 2005; ISBN 978-1-55407-635-2. [Google Scholar]
- Griffiths, A. Prints and printmaking: an introduction to the history and techniques; Univ of California Press, 1996.
- Hertzmann, A. Introduction to 3d non-photorealistic rendering: Silhouettes and outlines. Non-Photorealistic Rendering. SIGGRAPH 1999, 99. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695.
- Borji, A. Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and dall-e 2. arXiv preprint, arXiv:2210.00586 2022.
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. International Conference on Machine Learning. PMLR, 2021, pp. 8821–8831.
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3836–3847.
- Mou, C.; Wang, X.; Xie, L.; Zhang, J.; Qi, Z.; Shan, Y.; Qie, X. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint, arXiv:2302.08453 2023.
- Ye, H.; Zhang, J.; Liu, S.; Han, X.; Yang, W. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint, arXiv:2308.06721 2023.
- Liu, J.; Shen, F.; Wei, M.; Zhang, Y.; Zeng, H.; Zhu, J.; Cai, C. A Large-Scale Benchmark for Vehicle Logo Recognition. 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC). IEEE, 2019, pp. 479–483.
- Mizuno, S.; Okada, M.; Toriwaki, J.i. Virtual sculpting and virtual woodcut printing. The Visual Computer 1998, 2, 39–51. [Google Scholar] [CrossRef]
- Mizunoy, S.; Okadayy, M.; Toriwakiy, J. An interactive designing system with virtual sculpting and virtual woodcut printing. Computer Graphics Forum. Wiley Online Library, 1999, Vol. 18, pp. 183–194.
- Mizuno, S.; Kasaura, T.; Okouchi, T.; Yamamoto, S.; Okada, M.; Toriwaki, J. Automatic generation of virtual woodblocks and multicolor woodblock printing. Computer Graphics Forum. Wiley Online Library, 2000, Vol. 19, pp. 51–58.
- Mizuno, S.; Okada, M.; Yamamoto, S.; Toriwaki, J.i. Japanese Traditional Printing" Ukiyo-e" in a Virtual Space. FORMA-TOKYO- 2001, 16, 233–239. [Google Scholar]
- Mizuno, S.; Okada, M.; Toriwaki, J.i.; Yamamoto, S. Improvement of the virtual printing scheme for synthesizing Ukiyo-e. 2002 International Conference on Pattern Recognition. IEEE, 2002, Vol. 3, pp. 1043–1046.
- Mello, V.; Jung, C.R.; Walter, M. Virtual woodcuts from images. Proceedings of the 5th international conference on Computer graphics and interactive techniques in Australia and Southeast Asia, 2007, pp. 103–109.
- Li, J.; Xu, D. A Scores Based Rendering for Yunnan Out-of-Print Woodcut. 2015 14th International Conference on Computer-Aided Design and Computer Graphics (CAD/Graphics), 2015, pp. 214–215. [CrossRef]
- Li, J.; Xu, D. Image stylization for Yunnan out-of-print woodcut through virtual carving and printing. International Conference on Technologies for E-Learning and Digital Entertainment. Springer, 2016, pp. 212–223.
- Mesquita, D.P.; Walter, M. Synthesis and Validation of Virtual Woodcuts Generated with Reaction-Diffusion. International Joint Conference on Computer Vision, Imaging and Computer Graphics. Springer, 2019, pp. 3–29.
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; 2023; pp. 557–570.
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific Bipartite-aware Similarity Learning for Text-based Person Retrieval. Proceedings of the 31th ACM International Conference on Multimedia, 2023, pp. 8922–8931.
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; 2023; pp. 571–576.
- Cetinic, E.; She, J. Understanding and creating art with AI: Review and outlook. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Advances in neural information processing systems 2014, 27. [Google Scholar]
- Mordvintsev, A.; Olah, C.; Tyka, M. Inceptionism: Going Deeper into Neural Networks, 2015.
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2414–2423.
- Elgammal, A.; Liu, B.; Elhoseiny, M.; Mazzone, M. Can: Creative adversarial networks, generating" art" by learning about styles and deviating from style norms. arXiv preprint, arXiv:1706.07068 2017.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser. ; Polosukhin, I. Attention is all you need. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Transactions on Image Processing 2023. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Shen, F.; Zhu, J.; Zeng, H. Viewpoint robust knowledge distillation for accelerating vehicle re-identification. EURASIP Journal on Advances in Signal Processing 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Xu, R.; Shen, F.; Wu, H.; Zhu, J.; Zeng, H. Dual modal meta metric learning for attribute-image person re-identification. 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC). IEEE, 2021, Vol. 1, pp. 1–6.
- Hu, J.; Huang, Z.; Shen, F.; He, D.; Xian, Q. A Rubust Method for Roof Extraction and Height Estimation. IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2023, pp. 770–771. [CrossRef]
- Weng, W.; Ling, W.; Lin, F.; Ren, J.; Shen, F. A Novel Cross Frequency-domain Interaction Learning for Aerial Oriented Object Detection. Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 2023.
- Qiao, C.; Shen, F.; Wang, X.; Wang, R.; Cao, F.; Zhao, S.; Li, C. A Novel Multi-Frequency Coordinated Module for SAR Ship Detection. 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2022, pp. 804–811.
- Shen, F.; Zhu, J.; Zhu, X.; Huang, J.; Zeng, H.; Lei, Z.; Cai, C. An Efficient Multiresolution Network for Vehicle Reidentification. IEEE Internet of Things Journal 2021, 9, 9049–9059. [Google Scholar] [CrossRef]
- Wu, H.; Shen, F.; Zhu, J.; Zeng, H.; Zhu, X.; Lei, Z. A sample-proxy dual triplet loss function for object re-identification. IET Image Processing 2022, 16, 3781–3789. [Google Scholar] [CrossRef]
- Shen, F.; Zhu, J.; Zhu, X.; Xie, Y.; Huang, J. Exploring spatial significance via hybrid pyramidal graph network for vehicle re-identification. IEEE Transactions on Intelligent Transportation Systems 2021, 23, 8793–8804. [Google Scholar] [CrossRef]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint, arXiv:2112.10741 2021.
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; others. Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems 2021, 34, 19822–19835. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; others. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 2022, 35, 36479–36494. [Google Scholar]
- Gafni, O.; Polyak, A.; Ashual, O.; Sheynin, S.; Parikh, D.; Taigman, Y. Make-a-scene: Scene-based text-to-image generation with human priors. European Conference on Computer Vision. Springer, 2022, pp. 89–106.
- Balaji, Y.; Nah, S.; Huang, X.; Vahdat, A.; Song, J.; Kreis, K.; Aittala, M.; Aila, T.; Laine, S.; Catanzaro, B. ; others. ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint, arXiv:2211.01324 2022.
- Xue, Z.; Song, G.; Guo, Q.; Liu, B.; Zong, Z.; Liu, Y.; Luo, P. Raphael: Text-to-image generation via large mixture of diffusion paths. arXiv preprint, arXiv:2305.18295 2023.
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Advances in neural information processing systems 2021, 34, 8780–8794. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence 2020, 44, 1623–1637. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 1986, PAMI-8, 679–698. [CrossRef]
- Zhao, S.; Chen, D.; Chen, Y.C.; Bao, J.; Hao, S.; Yuan, L.; Wong, K.Y.K. Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models. arXiv preprint, arXiv:2305.16322 2023.
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models. arXiv preprint, arXiv:2310.06313 2023.
- Seguin, B.; Striolo, C.; diLenardo, I.; Kaplan, F. Visual link retrieval in a database of paintings. Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part I 14. Springer, 2016, pp. 753–767.
- Mao, H.; Cheung, M.; She, J. Deepart: Learning joint representations of visual arts. Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1183–1191.
- Achlioptas, P.; Ovsjanikov, M.; Haydarov, K.; Elhoseiny, M.; Guibas, L.J. Artemis: Affective language for visual art. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11569–11579.
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. International Conference on Machine Learning. PMLR, 2022, pp. 12888–12900.
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems 2020, 33, 6840–6851. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv preprint, arXiv:2207.12598 2022.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015, pp. 234–241.
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv preprint, arXiv:1607.06450 2016.
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. ; others. Learning transferable visual models from natural language supervision. International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv preprint, arXiv:2010.02502 2020.
- Ilharco, G.; Wortsman, M.; Wightman, R.; Gordon, C.; Carlini, N.; Taori, R.; Dave, A.; Shankar, V.; Namkoong, H.; Miller, J.; Hajishirzi, H.; Farhadi, A. ;.; Schmidt, L. Openclip. OpenAI, 2021. https://github.com/mlfoundations/open_clip.
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv preprint, arXiv:1711.05101 2017.
- Hessel, J.; Holtzman, A.; Forbes, M.; Bras, R.L.; Choi, Y. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint, arXiv:2104.08718 2021.
- Xu, J.; Liu, X.; Wu, Y.; Tong, Y.; Li, Q.; Ding, M.; Tang, J.; Dong, Y. ImageReward: Learning and Evaluating 169 Human Preferences for Text-to-Image Generation. 2023; arXiv:cs.CV/2304.05977. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; others. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789 2022, 2, 5.
| 1 | |
| 2 | "*" Indicates replaceable prompt. The text input in this format is used to generate images that are closer to a woodcut than a realistic photograph. |
Figure 1.
Considering the significant challenges encountered in previous stages of woodcut-style design, WDANet simplifies the process by enabling users to input and modify text descriptions. In seconds, WDANet generates diverse woodcut images tailored to meet user specifications. The text highlighted in red indicates that WDANet supports replicating specific artistic styles or employing generic styles.
Figure 1.
Considering the significant challenges encountered in previous stages of woodcut-style design, WDANet simplifies the process by enabling users to input and modify text descriptions. In seconds, WDANet generates diverse woodcut images tailored to meet user specifications. The text highlighted in red indicates that WDANet supports replicating specific artistic styles or employing generic styles.
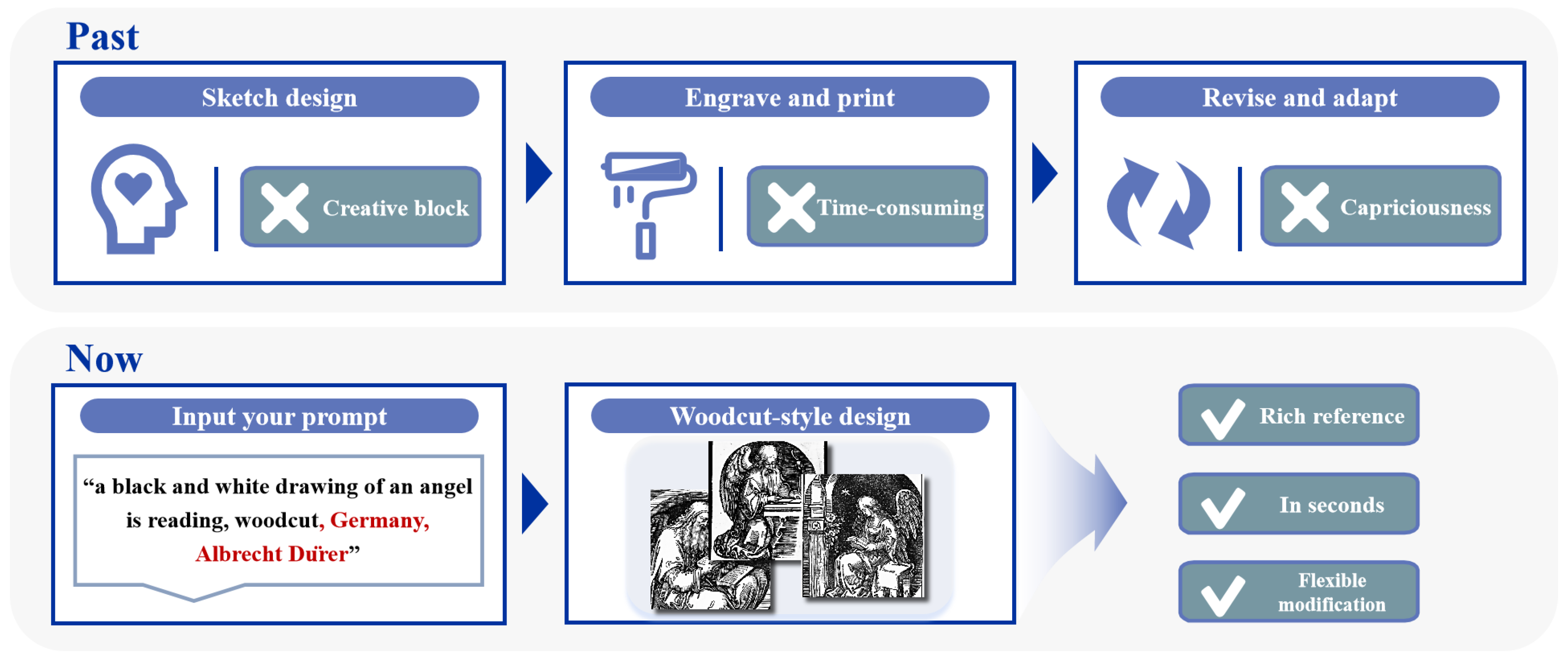
Figure 2.
The resolution details of the 3,248 collected original images, categorized by the shortest edge of each image, illustrate that most resolutions are concentrated within 500 to 3400 pixels. Notably, a significant portion of these images surpasses the 512 × 512 pixel mark.
Figure 2.
The resolution details of the 3,248 collected original images, categorized by the shortest edge of each image, illustrate that most resolutions are concentrated within 500 to 3400 pixels. Notably, a significant portion of these images surpasses the 512 × 512 pixel mark.
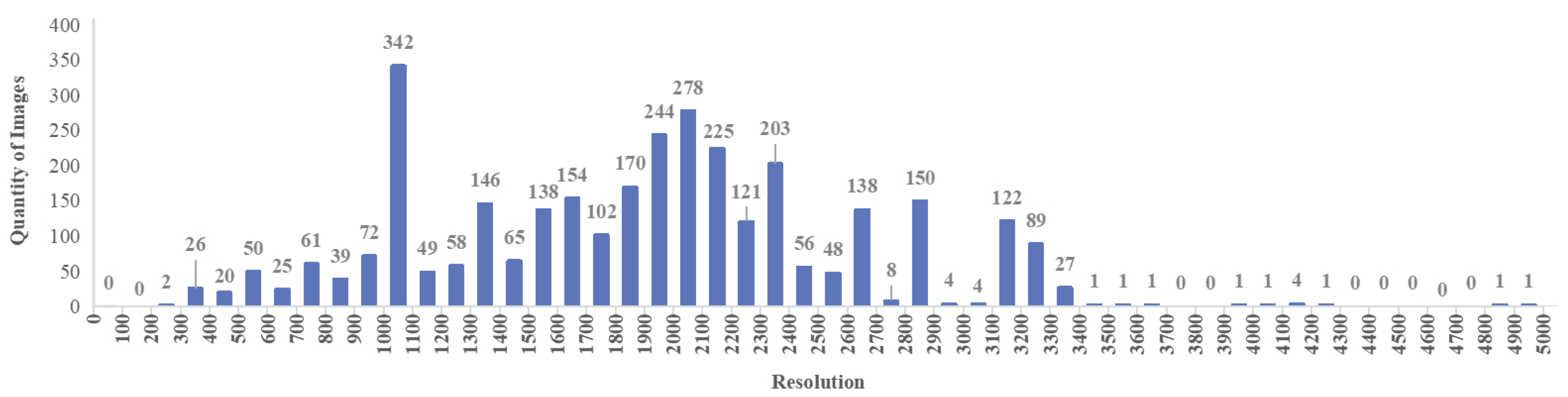
Figure 3.
Woodcut-62 is categorized based on the styles of 62 historically influential Woodcut artists, encompassing artworks from eight distinct countries, reflecting a diverse style distribution.
Figure 3.
Woodcut-62 is categorized based on the styles of 62 historically influential Woodcut artists, encompassing artworks from eight distinct countries, reflecting a diverse style distribution.
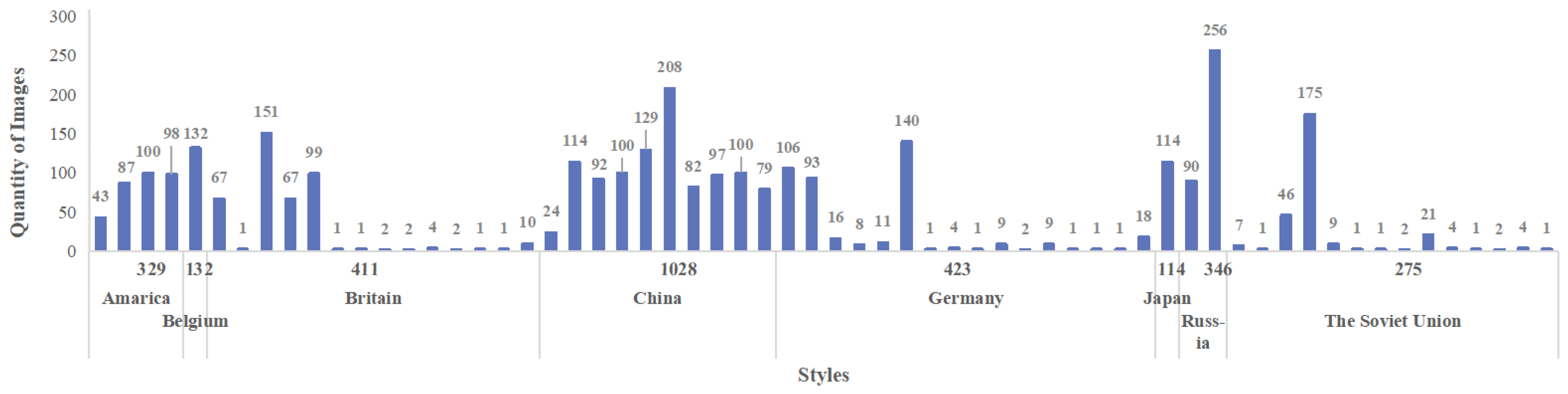
Figure 4.
The image processing workflow in Woodcut-62 involves several steps. Initially, the collected raw images undergo captioning by BLIP CapFilt, resulting in adaptive captions. With guidance from art experts, we meticulously verify and rectify the descriptions. Additionally, manual cropping and enhancement techniques are applied to the original images, resulting in uniformly sized 512 × 512 images and corresponding labels.
Figure 4.
The image processing workflow in Woodcut-62 involves several steps. Initially, the collected raw images undergo captioning by BLIP CapFilt, resulting in adaptive captions. With guidance from art experts, we meticulously verify and rectify the descriptions. Additionally, manual cropping and enhancement techniques are applied to the original images, resulting in uniformly sized 512 × 512 images and corresponding labels.

Figure 5.
The overall framework of WDANet. WDANet only trains Linear, LayNorm, and an added cross-attention layer while freezing the parameters of the other modules. The user input prompt aligns with the woodcut-style image embedded in Woodcut-62, guiding the diffusion model via dual cross-attention to generate woodcut-style designs.
Figure 5.
The overall framework of WDANet. WDANet only trains Linear, LayNorm, and an added cross-attention layer while freezing the parameters of the other modules. The user input prompt aligns with the woodcut-style image embedded in Woodcut-62, guiding the diffusion model via dual cross-attention to generate woodcut-style designs.
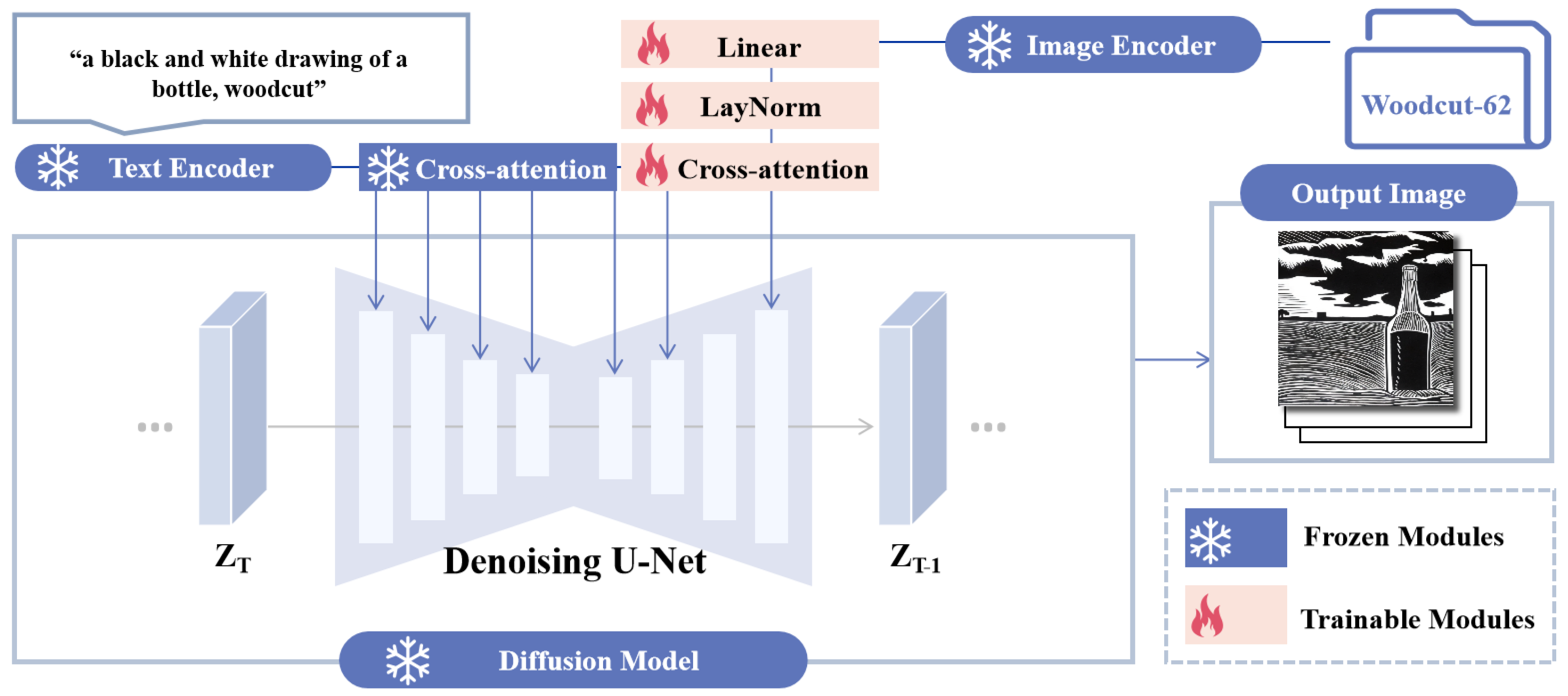
Figure 6.
The visual comparison result between WDANet and other methods under specific conditions. The prompt is randomly selected from the PartiPrompts corpus, with the reference image embedded as a control for woodcut style conditions.Those highlighted in red are keywords.
Figure 6.
The visual comparison result between WDANet and other methods under specific conditions. The prompt is randomly selected from the PartiPrompts corpus, with the reference image embedded as a control for woodcut style conditions.Those highlighted in red are keywords.

Figure 7.
Given the same reference image to control variables and inputting different prompts, our method is compared with other models, primarily to examine the diversity of the generated images.
Figure 7.
Given the same reference image to control variables and inputting different prompts, our method is compared with other models, primarily to examine the diversity of the generated images.
Figure 8.
We present questionnaire cases evaluating visual-textual consistency, learning style precision, and aesthetic preference. In these cases, A represents ControlNet, B stands for T2I-Adapter, C depicts IP-Adapter, and D represents WDANet, our proposed method.
Figure 8.
We present questionnaire cases evaluating visual-textual consistency, learning style precision, and aesthetic preference. In these cases, A represents ControlNet, B stands for T2I-Adapter, C depicts IP-Adapter, and D represents WDANet, our proposed method.


Figure 9.
The user study results comparing our WDANet with SOTA methods indicate user preferences. Here introduce three metrics for evaluating the generative model for design tasks: visual-textual consistency, learning style precision, aesthetic preference.The corresponding questionnaire content can be seen in Figure 8.
Figure 9.
The user study results comparing our WDANet with SOTA methods indicate user preferences. Here introduce three metrics for evaluating the generative model for design tasks: visual-textual consistency, learning style precision, aesthetic preference.The corresponding questionnaire content can be seen in Figure 8.
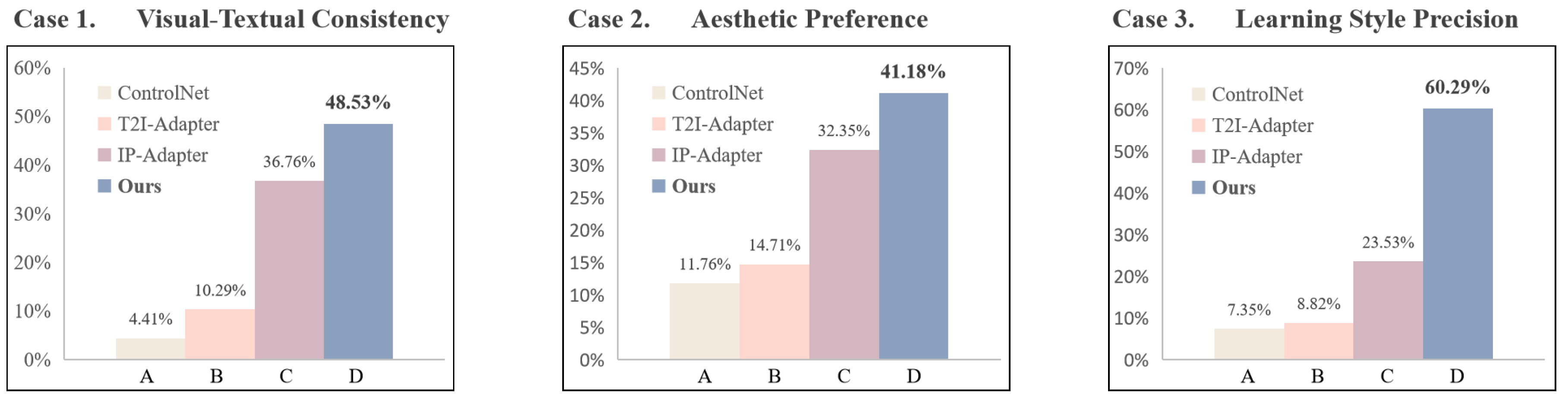
Figure 10.
Our method is compared against state-of-the-art text-to-image models and adapter methods to assess generative diversity. A, B, C, and D correspond to Midjourney, DALL-E 3, IP-Adapter, and WDANet, respectively.
Figure 10.
Our method is compared against state-of-the-art text-to-image models and adapter methods to assess generative diversity. A, B, C, and D correspond to Midjourney, DALL-E 3, IP-Adapter, and WDANet, respectively.

Figure 11.
In , the questionnaire results regarding generative diversity showcased that WDANet demonstrated a notable advantage in design richness, securing 60.29% of the votes.
Figure 11.
In , the questionnaire results regarding generative diversity showcased that WDANet demonstrated a notable advantage in design richness, securing 60.29% of the votes.
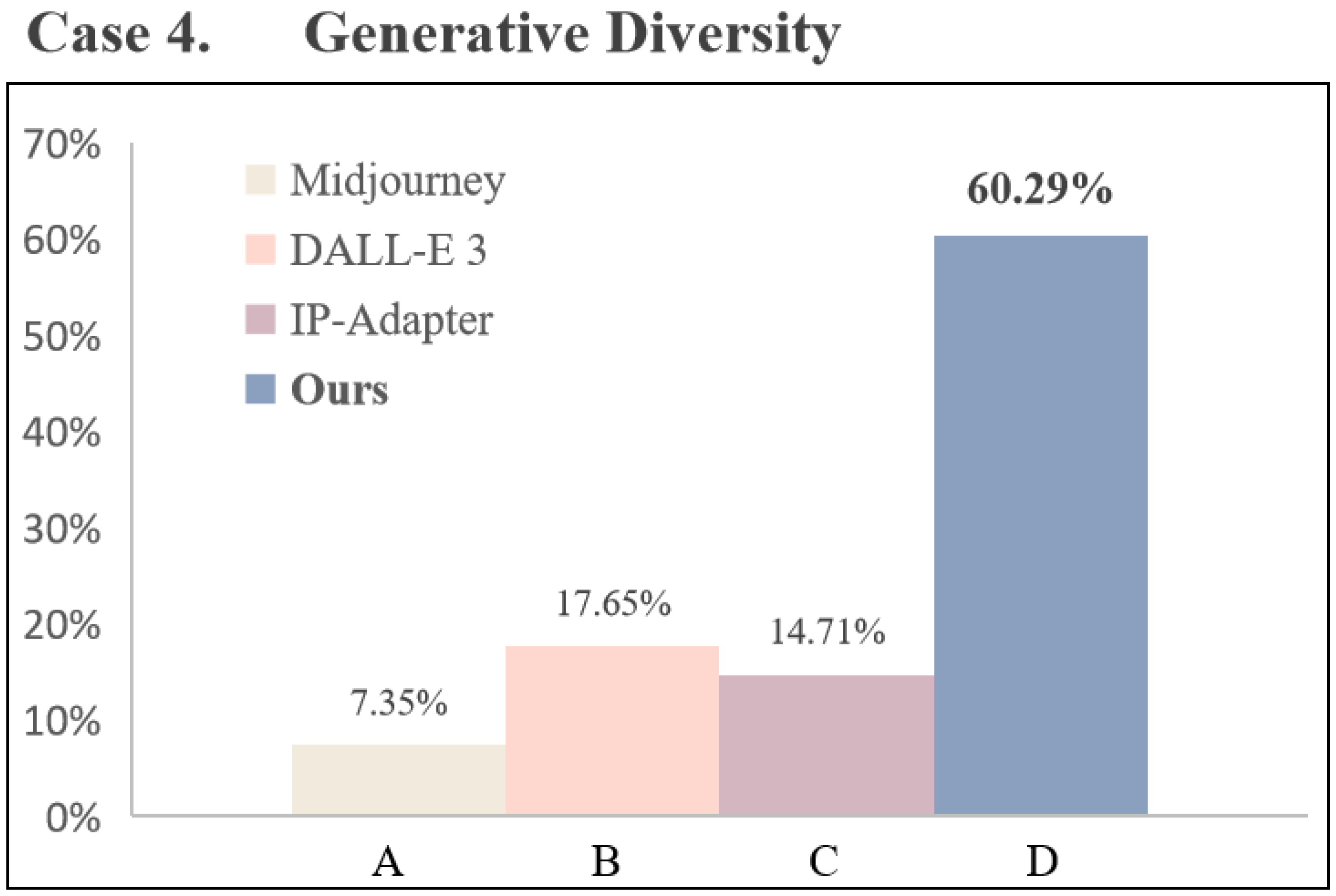

Table 1.
Our proposed WDANet and SOTA methods assess the alignment between text and image and the quantitative evaluation of aesthetic preferences, with SD as the baseline.
Table 1.
Our proposed WDANet and SOTA methods assess the alignment between text and image and the quantitative evaluation of aesthetic preferences, with SD as the baseline.
| Method | CLIP Score↑ | BLIP-ITM↑ | BLIP-Cosine↑ | ImageReward↑ |
|---|---|---|---|---|
| Baseline[6] | 18.52 | 76.42% | 0.4077 | -2.08 |
| ControlNet[9] | 27.11 | 98.97% | 0.4192 | -0.08 |
| T2I-Adapter (Style)[10] | 28.03 | 94.53% | 0.4693 | -0.95 |
| IP-Adapter[11] | 29.73 | 99.81% | 0.4776 | 0.15 |
| Ours | 34.20 | 99.98% | 0.4826 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.
Submitted:
15 December 2023
Posted:
19 December 2023
You are already at the latest version
Alerts
This version is not peer-reviewed
Submitted:
15 December 2023
Posted:
19 December 2023
You are already at the latest version
Alerts
Abstract
People are drawn to woodcut-style designs due to their striking visual impact and strong contrast. However, traditional woodcut prints and previous computer-aided methods have not addressed the issues of dwindling design inspiration, lengthy production times, and complex adjustment procedures. We propose a novel network framework, the Woodcut-style Design Assistant Network (WDANet), to tackle these challenges. Notably, our research is the first to utilize diffusion models to streamline the woodcut-style design process. We've curated the Woodcut-62 dataset, featuring works from 62 renowned historical artists, to train WDANet in absorbing and learning the aesthetic nuances of woodcut prints, offering users a wealth of design references. Based on a noise reduction network, our dual cross-attention mechanism effectively integrates text and woodcut-style image features. This allows users to input or slightly modify a text description to quickly generate accurate, high-quality woodcut-style designs, saving time and offering flexibility. As confirmed by user studies, quantitative and qualitative analyses show that WDANet outperforms the current state-of-the-art in generating woodcut-style images and proves its value as a design aid.
Keywords:
Subject: Computer Science and Mathematics - Computer Vision and Graphics
1. Introduction
Woodcut is one of the oldest and simplest forms of printmaking art, carving reverse images onto a wooden board and printing them on paper for appreciation [1]. Traditional woodcut prints are predominantly black and white monochrome, offering reproducibility and ease of promotion. They demonstrate substantial control over light and shadow [2]. The intense color contrasts and the texture of woodcut marks create a powerful visual impact, establishing it as a captivating design style that captures the viewer’s attention. Woodcut printing has some limitations that contribute to its decline. The block printing method in woodcut prints requires designers to consider mirror composition, showcasing light changes through varying line densities rather than grayscale, posing a significant design challenge [3]. Once the knife makes an incision, it cannot be erased. Typically, the entire process—from draft drawing to engraving and printing—is predominantly executed by a single person, making production time-consuming and labor-intensive. Each printed copy’s outcome tends to be unstable, and woodcut prints cannot instantaneously display the paper effect during engraving, necessitating repeated modifications and adjustments [4].
Computer-aided woodcuts seek to replicate the manual texture of woodcut marks while simplifying the production process. Its technical research primarily centers around Non-Photorealistic Rendering (NPR) [5]. Despite its capability to render 3D models or 2D images in the woodcut style, it still presents several drawbacks. Firstly, being an art form, woodcut necessitates a solid aesthetic foundation and a timely burst of creative inspiration from the artist. Prior technologies primarily concentrated on imitating the visual texture, which needs more capacity to provide design assistance regarding composition, constituent elements, and score arrangement. Secondly, it demands highly polished works as input, making the preparatory work time-consuming, spanning hours or even days. Lastly, the flexibility is limited, requiring algorithmic adjustments to emulate different artistic styles.
Recently, large-scale models in the realm of generative art, such as Stable Diffusion (SD)[6], Midjourney [7], DALL-E 3 [8], have indeed provided new opportunities for artists. Despite this, the typical method to control the model and generate specific designs involves fine-tuning, which entails a substantial number of parameters. Some more efficient techniques include freezing the basic model parameters and exclusively training additional modules [9,10,11]. Research datasets available can drive advancements within a field. For example, the introduction of the VLD 1.0 dataset [12] significantly propelled log detection and recognition. Nevertheless, the domain of woodcut-style design remains largely unexplored, and a high-quality woodcut dataset is needed, along with the absence of a standardized processing pipeline.
Therefore, this paper introduces a dataset with images and textual annotations named Woodcut-62. This dataset is the dataset tailored explicitly for the woodcut style. Building upon this foundation, we present a groundbreaking model called Woodcut-style Design Assistant Network(WDANet), which, with lightweight training parameters, guides textual inputs to generate design references meeting specified criteria. Compared with previous methods, the advantages of our proposed method are shown in Figure 1.
In summary, this paper outlines the contributions as follows:
- We curate Woodcut-62, a high-quality dataset tailored for woodcut-style designs, comprising 3,058 text-image pairs. This dataset offers style references from 62 artists representing eight countries who greatly influenced history.
- Introducing the lightweight architecture WDANet, we pioneer the application of diffusion models in a woodcut-style design. WDANet accurately emulates the style of a specific artist and generates woodcut-style designs within seconds, relying solely on input text. We also provide comprehensive evaluation indicators.
- The fidelity, diversity, and aesthetic characteristics of the woodcut style design drawings generated with WDANet guidance have achieved SOTA while garnering better user preferences in the comprehensive artistic evaluation conducted during the user study.
2. Related Work
2.1. Woodcut-Style Design
The pioneering application of computer graphics in woodcut design is initiated by Mizuno et al. [13]. They integrate traditional woodcut production into an interactive simulation system, allowing users to carve within a virtual 3D space. This system synthesizes woodcut images with authentic printing effects on a 2D grid of virtual paper. Subsequent works by Mizuno et al. [14,15] perfect features such as automatic engraving based on grayscale map characteristics and color printing. Their research mainly focuses on the Ukiyo-e style [16,17]. To enhance the user experience, they were pioneers in migrating the system to a pressure-sensitive pen and tablet. Mello et al.[18] are the first to introduce image-based artistic rendering, specifically generating woodcut-style images. They obtain rendered images through image segmentation, direction field computation, and stroke generation. However, the simulated woodcut scores are relatively basic. Building upon this work, Jie Li et al. [19,20] allocate fractions gathered from authentic woodcut textures according to segmented areas, applying this method to Yunnan out-of-print woodcut. A recent study by Mesquita et al. [21] proposes woodcut generation based on reaction-diffusion, enhancing woodcut representation and user control by introducing noise.
Current research in woodcut-style image generation primarily focuses on simulating woodcut marks, sidelining the artistic design aspect of woodcut. Achieving aesthetically pleasing picture arrangements still requires user intervention. Woodcut-style design generation relies on rendering based on 3D models or images, where the quality and depth of prerequisites significantly impact the output. Crafting a visually appealing woodcut artwork entails a high threshold and considerable time investment. Additionally, the existing algorithms concentrate on specific styles, such as Ukiyo-e and Yunnan out-of-print woodcuts, lacking adaptability to versatile artistic styles.
2.2. Computer-Aided Art Generation
Over the past few decades, a series of rendering and texture synthesis algorithms proposed by computer-aided design research [22,23,24] have predominantly focused on image stylization. The intervention of artificial intelligence in art introduces more creative applications [25]. The confluence of these fields can be traced back to the advent of Generative Adversarial Networks (GAN) [26], where two neural networks—generators and discriminators—compete to produce images resembling actual sample distributions. DeepDream [27] is the first to explore neural networks’ potential to inspire artistic creation. Utilizing convolutional neural networks (CNNs), DeepDream transforms input images into highly interpretable, dream-like visualizations. Another CNN-based study, A Neural Algorithm of Artistic Style [28], separates and recombines semantics and style in natural images, pioneering Neural Style Transfer (NST). Although NST significantly influences artistic style treatment, it typically learns stylistic traits from existing images rather than facilitating original artistic creation. Elgammal et al. introduce Creative Adversarial Networks (CAN) [29] based on GAN, aiming to maximize divergence from established styles while preserving artistic distribution and fostering creativity.
The emergence of Transformer [30,31] propells the application of multimodal neural networks notably in many tasks [32,33]. For example, Hu et al. [34] proposed utilizing transformers for roof extraction and height estimation. Similarly, in the field of remote sensing detection [35,36] and re-identification [37,38,39], transformers have demonstrated tremendous potential. Recently, text-guided image generation through generative artificial intelligence, such as Glide[40], Cogview[41], Imagen[42], Make-a-scene[43], ediffi[44] and Raphael[45] gain widespread use, particularly with significant advancements in large-scale diffusion models [46]. In order to achieve favorable results on the downstream tasks, the past practice is to spend substantial technical resources to fine-tune the model. Many existing studies build upon SD, incorporating adapters for guided generation and requiring minimal additional training while keeping the original model parameters frozen. ControlNet [9] pioneered this method to learn specific task input criteria, such as Depth Map [47], Canny Edge [48]. ControlNet Reference-only efficiently transfers the style and subject from a reference diagram while conforming to textual descriptions, eliminating the need for additional training. In the T2I-Adapter [10] approach, the reference image is fed into the style adapter to extract stylistic features and integrate them with text features. Uni-ControlNet [49] employs two adapters—one for global and one for local control—enabling the combinability of diverse conditions. The IP-Adapter [11]supports the fusion of individual image features with text features via the cross-attention layer, ensuring the preservation of both the main subject of the image and its stylistic attributes. Additionally, PCDMs [50] suggest employing inpainting to fine-tune the entire SD for achieving pose-guided human generation. Nonetheless, this approach of training by fully releasing all parameters is not practically economical.
While these adapters effectively generate similar styles from image-guided models, the generated results tend to closely resemble specific reference images, posing challenges in providing valuable references within the design realm. Artistic creation often requires diverse images to draw inspiration from when exploring various themes. Therefore, generated images must exhibit diversity while maintaining coherence between visuals and accompanying text descriptions. Our study centers on woodcut-style design, employing dual cross-attention mechanisms to harmonize visual and textual features. Moreover, our approach facilitates the transfer of a specific artist’s style across different thematic contexts.
3. Method
3.1. Woodcut-62
3.1.1. Collect
Numerous datasets of artworks cater to a wide range of machine learning tasks, such as VisualLink[51], Art500k[52], and ArtEmis[53]. However, the domain of woodcut prints still needs to be explored regarding available datasets. We gather 3,248 woodcut images sourced from various open-source networks. The distribution of resolutions is depicted in Figure 2. We manually engage art experts to adjust these artworks to 512 × 512 resolution to standardize resolution and minimize training costs. Tailoring involves preserving the thematic essence and the most aesthetic characteristics. Larger-sized images are split into multiple images for better handling. As woodcuts are prints, their electronic copies lose some detail compared to the originals. Working closely with experts, we manually adjusted image parameters to enhance features, maintaining the characteristic texture while reducing noise. Under art expert guidance, we filter out low-resolution or duplicated images, resulting in 3058 high-quality woodcut images. These images represent 62 historically influential artists from eight countries, spanning genres like romanticism, abstract expressionism, and realism. Ultimately, this effort culminated in creating the inaugural woodcut style dataset for the text-to-image task—Woodcut-62. The style distribution of the dataset is shown in Figure 3.
3.1.2. Label
To accommodate the text-to-image generation task, we transition from the original caption to using natural language for annotation. This label process is outlined in Figure 4. Initially, we experiment with the BLIP[54]Captioning and Filtering (CapFilt), a new dataset bootstrapping method that filters out noisy titles and automatically composites captions for images. However, upon manual inspection, we discovered that this method’s efficacy could be improved, particularly for abstract expressionism or intricate content. To address this, we seek the expertise of art specialists to fine-tune annotations for these specific types of images manually. To distinctly mark the woodcut style, we append the keyword "woodcut" to each image, along with details such as the artist’s name and the country of origin. This meticulous labeling ensures that the model can discern between various artistic styles. Finally, we encapsulate text-image pair labels into a JSON file.
3.2. WDANet
3.2.1. Prelimiaries
Diffusion model[55] is an important method for describing complex systems’ dynamic behavior and stable state distribution. The image generation is likened to the diffusion of ink in water. It is divided into two processes. The forward diffusion process transforms the initial data into a Gaussian distribution by iteratively adding random Gaussian noise through T iterations. The reverse denoising process involves predicting noise from and gradually restoring . Governed by condition c, the simplified variant loss function of the training model is as follows:
Where . is the linear combination of the original signal and random noise , meeting .
Balancing sample fidelity and pattern coverage in conditional diffusion models commonly involves employing a classifier as guidance, necessitating the additional training of an image classifier separate from the diffusion model. However, classifier-free guidance[56], as proposed in, trains both conditional and unconditional diffusion models, randomly discarding the control conditions c. The noise prediction during the sampling stage adheres to the following formula:
Here, represents the scale guiding the faithfulness to the control conditions c in the generated results. In this study, the foundational generative model utilized is SD[6]. SD maps the image to the low-dimensional latent space instead of the pixel space for diffusion, significantly reducing the diffusion model’s computation. Within SD, a U-Net[57] is trained as the core network for the noise prediction model. A cross-attention mechanism is introduced to integrate control information c into the intermediate layers of the U-Net. This inclusion forms a conditional denoising autoencoder, effectively governing the image synthesis. The cross-attention layer yields the following output:
Where , , are trainable weight parameter matrices, represents a learnable flattened embedding of the U-Net, and denotes a learnable domain-specific encoder that converts c into an intermediate representation.
3.2.2. Dual Cross-Attention
It is crucial to preserve the thematic essence described in the text for design image generation while learning coarse-grained details like style and composition from woodcut images during training. Previous methodologies often involved superimposing text and other features via a cross-attention layer in the diffusion model, which could be more effective in transferring and balancing various control conditions. In order to inject woodcut image guidance into the text-to-image diffusion model, we introduce a frozen CLIP image encoder based on SD and add a trainable linear layer (Linear) and a Layer Normalization[58](LayNorm). Their goal is to extract the scattered image features x and map them to the feature that best matches the target effect and aligns with the text embedding dimension. The Linear obtains , and the LayNorm transforms the input into a control condition with woodcut style characteristics :
In the above formula, , b, g, are learnable parameters, H is the number of hidden units, and ⊙ is the element-wise multiplication. Next, we can add to the new cross-attention layer:
Where and are learnable parameters for the new cross-attention layer. In this way, the cross-attention layers with text and woodcut style characteristics, respectively, can be combined into dual cross-attention:
The joint approach of dual cross-attention encompassed both text prompts, with their abstract and expansive semantic features, and woodcut images, which provided precise and concrete visual information. We borrowed the concept of unguided classifiers and introduced (default = 0.5) to balance the fidelity and diversity of the generated images by controlling weights. When = 0, WDANet reverted to the initial text-to-image model (i.e., SD).
3.2.3. Combined with Stable Diffusion
In the text-to-image task, CLIP[59] plays a crucial role as the link between text and image. CLIP comprises a text encoder and an image encoder. The text and image modalities could be aligned in the feature space through contrastive learning and extensive training on numerous text-image pairs. In SD, the text embedding is derived from the input text using the pre-trained CLIP text encoder, which serves as the guiding condition for the denoising process. However, relying solely on text guidance is insufficient for the model to grasp the aesthetic features of woodblock prints. To address this problem, the added image encoder provided finer details, yet fine-tuning parameters remained necessary to adapt it to the woodcut design task. Following the methodology of training the Adapter with freezing CLIP and SD, Our proposed WDANet only needs to learn parameters for Linear, LayNorm, and a cross-attention layer to achieve promising outcomes.
In the training stage, we randomly take the images from the dataset Woodcut-62 and the matching labels as inputs, map the woodcut-style features to the same dimension as the text features and inject the joint features into each middle layer of U-Net (16 layers in total) through dual cross-attention. We set the image conditions or text conditions as empty according to the probability of and set both conditions as empty at the same time under the same probability, that is . The training objectives we utilized are:
Accordingly, the target of noise prediction is:
We model the multi-conditional diffusion model as a text-to-image framework during inference. The overall structure of WDANet is depicted in Figure 5. Woodcut-62 served as the inherent input for the image encoder, eliminating the need for users to provide a specific Woodcut reference image. Instead, inputting text enabled WDANet to query Woodcut-62 to match either the artist’s style or a universal woodcut aesthetic. While seemingly straightforward, this approach relied more on text for WDANet’s style control than a single image, preventing an excessive focus on granularity that might compromise generative diversity. To expedite the generation of woodcut-style designs, we employed DDIM [60], an accelerated sampling method utilizing a non-Markov diffusion process to simulate the reverse process of Markov diffusion.
4. Experiment
4.1. Implementation Details
We utilize CLIP ViT-H/14 [61] as the image encoder and SD v1.5 1 as the backbone network. WDANet’s parameters were lightweight and enabled training on a 24GB RTX 3090 graphics card with 80GB RAM. Employing AdamW [62] as the optimizer, we train for 70k global steps on Woodcut-62 with a learning rate set at and a weight decay of 0.01. DDIM served as the sampling acceleration algorithm, executing 50 sampling steps during inference. The coefficient in dual cross-attention defaulted to 0.5. The prompt on the text input side should include the keyword "woodcut" to identify the woodcut style, and if the generation task needs to be specific to the artist’s style, then follow the country and artist name, separated by commas.
4.2. Quantitative Evaluation
Our aim in assisting design is to ensure that the model-generated woodblock prints exhibit diverse compositions, a rich array of elements, and aesthetically pleasing arrangements based on a given thematic description. Therefore, our chosen metrics primarily assess the alignment between text and image and the aesthetic quality of the generated images. For assessing the alignment between text and image, we utilized CLIPScore [63] based on CLIP ViT-B/32. As a supplementary evaluation criterion, BLIP[54] forecasts fine-grained alignment between visual and textual elements via a linear layer. Its output includes the likelihood of image-text matching (ITM) and the cosine similarity between the features of both modalities.When evaluating the influence of generated images on users’ aesthetic preferences, we incorporate ImageReward[64], a model trained on a dataset of 137k expert comparisons. This model automatically gauges the quality of text-to-image conversions and closely aligns with human preferences.
We presents a comparative analysis between our approach, WDANet, and several state-of-the-art methods such as ControlNet, T2I-Adapter, and IP-Adapter. We provide empirical data to showcase the advancements over the original SD model. To ensure diverse coverage of text descriptions across different categories and difficulties, we randomly select ten prompts from the PartiPrompts [65], which includes over 1600 English prompts. We generate 100 woodcut-style images from each prompt in the format "a black and white drawing of *, woodcut." 2The ultimate score is calculated by averaging the results from each dataset. The results in Table 1 indicate that our proposed WDANet achieved a CLIP Score of 34.20, nearly doubling the baseline score of 18.52. The BLIP-ITM (the likelihood of image-text matching) reaches 99.98%, confirming a high degree of alignment between the generated images by WDANet and the input text. Moreover, the BLIP-Cosine similarity between text and image features is notably high, recorded at 0.4826. When evaluating aesthetic preferences using ImageReward, our approach exhibits a 2.74 improvement over the baseline, surpassing the second-ranking IP-Adapter by 0.15. WDANet achieves the SOTA level in generating woodcut-style images.
4.3. Qualitative Analysis
In this study segment, we present woodcut-style images generated by prompts extracted from the PartiPrompts corpus using various methods. SD serves as the baseline for the text-to-image model, while other models modulate style features by incorporating an additional woodcut image.
In Figure 6, we observe that SD (baseline) and ControlNet display instability, while T2I-Adapter and IP-Adapter tend to mirror the composition, characters, or actions of the reference image too closely, as seen in figure (1), where both T2I-Adapter and IP-Adapter depict middle-aged men with a beard. Our method, however, focuses on learning the stylistic and textural features of woodcut images. In (5), WDANet showcases a more accurate representation of complex prompts such as "a woman with long hair" and "a luminescent bird," illustrating them in an incredibly artistic and expressive manner.
In Figure 7, we standardize the input to the same reference image to examine the diverse outputs generated by various methods under different prompts. Baseline and ControlNet struggle to adopt the woodcut style. However, when examining the columns for the outputs of T2I-Adapter and IP-Adapter separately, they exhibit striking similarities across different prompts, evident in figure, where IP-Adapter consistently depicts a towering tree on the left side. In contrast, our method demonstrates strong performance in both diversity and fidelity. Notably, when presented with long and complex prompts, as depicted in (4), WDANet accurately generates woodcut-style designs that align with the description.
4.4. User Study
User study evaluates four aspects: visual-textual consistency, learning style precision, aesthetic preference, and generative diversity. Users are asked to select the most effective image among those generated by the four models. Visual-textual consistency measures the alignment between the model-generated image and the provided text, akin to assessing a designer’s ability to create thematic designs without deviating from the subject—a fundamental requirement. Learning style precision assesses the model’s capability to replicate an artist’s style. As the artist Walter Darby Bannard expressed, "When inspiration dies, imitation thrives," suggesting that designers often enhance their skills by imitating masterpieces. Aesthetic preference gauges the overall quality of the generated woodcut images based on adherence to aesthetic principles like composition, element arrangement, and visual harmony. Generative diversity tests revealed that models with additional image-controlling conditions are often constrained by single-image features, leading to a loss of richness in the generated images. Consequently, concerning this aspect, we directly compare WDANet to state-of-the-art text-to-image models, Midjourney and DALL-E 3.
We collected 68 questionnaires from 14 cities in China, with 38 respondents having received art education and possessing some knowledge of woodcuts. In our questionnaire Figure 8, A represents ControlNet, B represents the image generated by T2I-Adapter, C depicts IP-Adapter’s output, and D represents WDANet, proposed by us. In , our generated results align best with the highlighted keywords. In contrast, option A lacks the imitation of woodcut style, and the actions portrayed in B and C are not sufficiently accurate. For , we evaluate the Learning style precision of different methods using Kathe Kollwitz’s woodcut works as a reference. As a German expressionist printmaker, her pieces evoke a heavy and melancholic atmosphere, where our approach closely aligns with her characterization and thematic tone. In , option D exhibits a stable effect while comparing Aesthetic preference, illustrating "a retro town by the river" with a tranquil aesthetic. Correspondingly, the collected data shown in Figure 9 demonstrates that WDANet gains more user preference across all three aspects of the evaluation.
In questionnaire , as Figure 10 shows, we investigate the performance of different models in generating different designs, specifically regarding generative diversity. A represents Midjourney, B stands for DALL-E 3, C depicts IP-Adapter, which performs better among the adapter methods, and D represents WDANet, our proposed method. It is noticeable that options A and B favor realism over artistic rendering in generating woodcut-style designs. Additionally, the diversity in picture composition, element arrangement, and texture distribution in options A, B, and C appears relatively limited. Conversely, our method demonstrates both stylistic variability and stable results. As the corresponding data in Figure 11, 60.29% of users chose D, affirming the diversity of our generated results.
5. Conclusions
This Work introduces Woodcut-62, the pioneering dataset categorizing woodcut prints by artist styles, and proposes WDANet as the inaugural text-to-image network architecture for aiding woodcut-style design. WDANet unites text features with embedded woodcut style image characteristics using dual cross-attention, guiding the diffusion model to generate woodcut-style design references aligned with design requisites. Compared to conventional computer-assisted approaches, WDANet offers a broader spectrum of inspirational references, is less time-consuming, and offers greater adjustability. Quantitative and qualitative experiments demonstrate WDANet’s superior performance in woodcut-style design compared to other conditionally controlled adapters. In the user study, WDANet outperformed in visual-textual consistency, learning style precision, aesthetic preference, and generative diversity—four indicators related to aesthetic design dimensions—garnering higher user preferences. Furthermore, this network framework can be extended to various art categories beyond woodcut prints. In the future. Despite the promising performance of WDANet in assisting woodcut-style design, its lightweight structure still relies on guided image embedding. Moving forward, we aim to explore more flexible methods for learning style features. Our goal is to accomplish design assistance tasks seamlessly without any need for input images, thereby enhancing the adaptability and autonomy of the system.
Author Contributions
Yangchunxue Ou: Conceptualization, Data curation, Formal analysis, Methodology, Investigation, Software, Validation, Writing – original draft, Writing – review & editing, Investigation, Visualization. Jingjun Xu: Project administration, Supervision.
Data Availability Statement
The data that has been used is confidential.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Ross, J.; Romano, C.; Ross, T. The Complete Printmaker; Free Press: New York, 1991; ISBN 978-0-02-927372-2. [Google Scholar]
- Saff, D.; Sacilotto, D. Printmaking: History and Process; Holt: Rinehart and Winston, 1978; ISBN 978-0-03-085663-1. [Google Scholar]
- Walker, G.A. The woodcut artist’s handbook: techniques and tools for relief printmaking; Firefly Books: Canada, 2005; ISBN 978-1-55407-635-2. [Google Scholar]
- Griffiths, A. Prints and printmaking: an introduction to the history and techniques; Univ of California Press, 1996.
- Hertzmann, A. Introduction to 3d non-photorealistic rendering: Silhouettes and outlines. Non-Photorealistic Rendering. SIGGRAPH 1999, 99. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695.
- Borji, A. Generated faces in the wild: Quantitative comparison of stable diffusion, midjourney and dall-e 2. arXiv preprint, arXiv:2210.00586 2022.
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. International Conference on Machine Learning. PMLR, 2021, pp. 8821–8831.
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3836–3847.
- Mou, C.; Wang, X.; Xie, L.; Zhang, J.; Qi, Z.; Shan, Y.; Qie, X. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint, arXiv:2302.08453 2023.
- Ye, H.; Zhang, J.; Liu, S.; Han, X.; Yang, W. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint, arXiv:2308.06721 2023.
- Liu, J.; Shen, F.; Wei, M.; Zhang, Y.; Zeng, H.; Zhu, J.; Cai, C. A Large-Scale Benchmark for Vehicle Logo Recognition. 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC). IEEE, 2019, pp. 479–483.
- Mizuno, S.; Okada, M.; Toriwaki, J.i. Virtual sculpting and virtual woodcut printing. The Visual Computer 1998, 2, 39–51. [Google Scholar] [CrossRef]
- Mizunoy, S.; Okadayy, M.; Toriwakiy, J. An interactive designing system with virtual sculpting and virtual woodcut printing. Computer Graphics Forum. Wiley Online Library, 1999, Vol. 18, pp. 183–194.
- Mizuno, S.; Kasaura, T.; Okouchi, T.; Yamamoto, S.; Okada, M.; Toriwaki, J. Automatic generation of virtual woodblocks and multicolor woodblock printing. Computer Graphics Forum. Wiley Online Library, 2000, Vol. 19, pp. 51–58.
- Mizuno, S.; Okada, M.; Yamamoto, S.; Toriwaki, J.i. Japanese Traditional Printing" Ukiyo-e" in a Virtual Space. FORMA-TOKYO- 2001, 16, 233–239. [Google Scholar]
- Mizuno, S.; Okada, M.; Toriwaki, J.i.; Yamamoto, S. Improvement of the virtual printing scheme for synthesizing Ukiyo-e. 2002 International Conference on Pattern Recognition. IEEE, 2002, Vol. 3, pp. 1043–1046.
- Mello, V.; Jung, C.R.; Walter, M. Virtual woodcuts from images. Proceedings of the 5th international conference on Computer graphics and interactive techniques in Australia and Southeast Asia, 2007, pp. 103–109.
- Li, J.; Xu, D. A Scores Based Rendering for Yunnan Out-of-Print Woodcut. 2015 14th International Conference on Computer-Aided Design and Computer Graphics (CAD/Graphics), 2015, pp. 214–215. [CrossRef]
- Li, J.; Xu, D. Image stylization for Yunnan out-of-print woodcut through virtual carving and printing. International Conference on Technologies for E-Learning and Digital Entertainment. Springer, 2016, pp. 212–223.
- Mesquita, D.P.; Walter, M. Synthesis and Validation of Virtual Woodcuts Generated with Reaction-Diffusion. International Joint Conference on Computer Vision, Imaging and Computer Graphics. Springer, 2019, pp. 3–29.
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; 2023; pp. 557–570.
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific Bipartite-aware Similarity Learning for Text-based Person Retrieval. Proceedings of the 31th ACM International Conference on Multimedia, 2023, pp. 8922–8931.
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; 2023; pp. 571–576.
- Cetinic, E.; She, J. Understanding and creating art with AI: Review and outlook. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Advances in neural information processing systems 2014, 27. [Google Scholar]
- Mordvintsev, A.; Olah, C.; Tyka, M. Inceptionism: Going Deeper into Neural Networks, 2015.
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2414–2423.
- Elgammal, A.; Liu, B.; Elhoseiny, M.; Mazzone, M. Can: Creative adversarial networks, generating" art" by learning about styles and deviating from style norms. arXiv preprint, arXiv:1706.07068 2017.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser. ; Polosukhin, I. Attention is all you need. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Transactions on Image Processing 2023. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Shen, F.; Zhu, J.; Zeng, H. Viewpoint robust knowledge distillation for accelerating vehicle re-identification. EURASIP Journal on Advances in Signal Processing 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Xu, R.; Shen, F.; Wu, H.; Zhu, J.; Zeng, H. Dual modal meta metric learning for attribute-image person re-identification. 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC). IEEE, 2021, Vol. 1, pp. 1–6.
- Hu, J.; Huang, Z.; Shen, F.; He, D.; Xian, Q. A Rubust Method for Roof Extraction and Height Estimation. IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2023, pp. 770–771. [CrossRef]
- Weng, W.; Ling, W.; Lin, F.; Ren, J.; Shen, F. A Novel Cross Frequency-domain Interaction Learning for Aerial Oriented Object Detection. Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 2023.
- Qiao, C.; Shen, F.; Wang, X.; Wang, R.; Cao, F.; Zhao, S.; Li, C. A Novel Multi-Frequency Coordinated Module for SAR Ship Detection. 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2022, pp. 804–811.
- Shen, F.; Zhu, J.; Zhu, X.; Huang, J.; Zeng, H.; Lei, Z.; Cai, C. An Efficient Multiresolution Network for Vehicle Reidentification. IEEE Internet of Things Journal 2021, 9, 9049–9059. [Google Scholar] [CrossRef]
- Wu, H.; Shen, F.; Zhu, J.; Zeng, H.; Zhu, X.; Lei, Z. A sample-proxy dual triplet loss function for object re-identification. IET Image Processing 2022, 16, 3781–3789. [Google Scholar] [CrossRef]
- Shen, F.; Zhu, J.; Zhu, X.; Xie, Y.; Huang, J. Exploring spatial significance via hybrid pyramidal graph network for vehicle re-identification. IEEE Transactions on Intelligent Transportation Systems 2021, 23, 8793–8804. [Google Scholar] [CrossRef]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint, arXiv:2112.10741 2021.
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; others. Cogview: Mastering text-to-image generation via transformers. Advances in Neural Information Processing Systems 2021, 34, 19822–19835. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; others. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 2022, 35, 36479–36494. [Google Scholar]
- Gafni, O.; Polyak, A.; Ashual, O.; Sheynin, S.; Parikh, D.; Taigman, Y. Make-a-scene: Scene-based text-to-image generation with human priors. European Conference on Computer Vision. Springer, 2022, pp. 89–106.
- Balaji, Y.; Nah, S.; Huang, X.; Vahdat, A.; Song, J.; Kreis, K.; Aittala, M.; Aila, T.; Laine, S.; Catanzaro, B. ; others. ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint, arXiv:2211.01324 2022.
- Xue, Z.; Song, G.; Guo, Q.; Liu, B.; Zong, Z.; Liu, Y.; Luo, P. Raphael: Text-to-image generation via large mixture of diffusion paths. arXiv preprint, arXiv:2305.18295 2023.
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Advances in neural information processing systems 2021, 34, 8780–8794. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence 2020, 44, 1623–1637. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 1986, PAMI-8, 679–698. [CrossRef]
- Zhao, S.; Chen, D.; Chen, Y.C.; Bao, J.; Hao, S.; Yuan, L.; Wong, K.Y.K. Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models. arXiv preprint, arXiv:2305.16322 2023.
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models. arXiv preprint, arXiv:2310.06313 2023.
- Seguin, B.; Striolo, C.; diLenardo, I.; Kaplan, F. Visual link retrieval in a database of paintings. Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part I 14. Springer, 2016, pp. 753–767.
- Mao, H.; Cheung, M.; She, J. Deepart: Learning joint representations of visual arts. Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1183–1191.
- Achlioptas, P.; Ovsjanikov, M.; Haydarov, K.; Elhoseiny, M.; Guibas, L.J. Artemis: Affective language for visual art. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11569–11579.
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. International Conference on Machine Learning. PMLR, 2022, pp. 12888–12900.
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems 2020, 33, 6840–6851. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv preprint, arXiv:2207.12598 2022.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer, 2015, pp. 234–241.
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv preprint, arXiv:1607.06450 2016.
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. ; others. Learning transferable visual models from natural language supervision. International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv preprint, arXiv:2010.02502 2020.
- Ilharco, G.; Wortsman, M.; Wightman, R.; Gordon, C.; Carlini, N.; Taori, R.; Dave, A.; Shankar, V.; Namkoong, H.; Miller, J.; Hajishirzi, H.; Farhadi, A. ;.; Schmidt, L. Openclip. OpenAI, 2021. https://github.com/mlfoundations/open_clip.
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv preprint, arXiv:1711.05101 2017.
- Hessel, J.; Holtzman, A.; Forbes, M.; Bras, R.L.; Choi, Y. Clipscore: A reference-free evaluation metric for image captioning. arXiv preprint, arXiv:2104.08718 2021.
- Xu, J.; Liu, X.; Wu, Y.; Tong, Y.; Li, Q.; Ding, M.; Tang, J.; Dong, Y. ImageReward: Learning and Evaluating 169 Human Preferences for Text-to-Image Generation. 2023; arXiv:cs.CV/2304.05977. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; others. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789 2022, 2, 5.
| 1 | |
| 2 | "*" Indicates replaceable prompt. The text input in this format is used to generate images that are closer to a woodcut than a realistic photograph. |
Figure 1.
Considering the significant challenges encountered in previous stages of woodcut-style design, WDANet simplifies the process by enabling users to input and modify text descriptions. In seconds, WDANet generates diverse woodcut images tailored to meet user specifications. The text highlighted in red indicates that WDANet supports replicating specific artistic styles or employing generic styles.
Figure 1.
Considering the significant challenges encountered in previous stages of woodcut-style design, WDANet simplifies the process by enabling users to input and modify text descriptions. In seconds, WDANet generates diverse woodcut images tailored to meet user specifications. The text highlighted in red indicates that WDANet supports replicating specific artistic styles or employing generic styles.
Figure 2.
The resolution details of the 3,248 collected original images, categorized by the shortest edge of each image, illustrate that most resolutions are concentrated within 500 to 3400 pixels. Notably, a significant portion of these images surpasses the 512 × 512 pixel mark.
Figure 2.
The resolution details of the 3,248 collected original images, categorized by the shortest edge of each image, illustrate that most resolutions are concentrated within 500 to 3400 pixels. Notably, a significant portion of these images surpasses the 512 × 512 pixel mark.
Figure 3.
Woodcut-62 is categorized based on the styles of 62 historically influential Woodcut artists, encompassing artworks from eight distinct countries, reflecting a diverse style distribution.
Figure 3.
Woodcut-62 is categorized based on the styles of 62 historically influential Woodcut artists, encompassing artworks from eight distinct countries, reflecting a diverse style distribution.
Figure 4.
The image processing workflow in Woodcut-62 involves several steps. Initially, the collected raw images undergo captioning by BLIP CapFilt, resulting in adaptive captions. With guidance from art experts, we meticulously verify and rectify the descriptions. Additionally, manual cropping and enhancement techniques are applied to the original images, resulting in uniformly sized 512 × 512 images and corresponding labels.
Figure 4.
The image processing workflow in Woodcut-62 involves several steps. Initially, the collected raw images undergo captioning by BLIP CapFilt, resulting in adaptive captions. With guidance from art experts, we meticulously verify and rectify the descriptions. Additionally, manual cropping and enhancement techniques are applied to the original images, resulting in uniformly sized 512 × 512 images and corresponding labels.
Figure 5.
The overall framework of WDANet. WDANet only trains Linear, LayNorm, and an added cross-attention layer while freezing the parameters of the other modules. The user input prompt aligns with the woodcut-style image embedded in Woodcut-62, guiding the diffusion model via dual cross-attention to generate woodcut-style designs.
Figure 5.
The overall framework of WDANet. WDANet only trains Linear, LayNorm, and an added cross-attention layer while freezing the parameters of the other modules. The user input prompt aligns with the woodcut-style image embedded in Woodcut-62, guiding the diffusion model via dual cross-attention to generate woodcut-style designs.
Figure 6.
The visual comparison result between WDANet and other methods under specific conditions. The prompt is randomly selected from the PartiPrompts corpus, with the reference image embedded as a control for woodcut style conditions.Those highlighted in red are keywords.
Figure 6.
The visual comparison result between WDANet and other methods under specific conditions. The prompt is randomly selected from the PartiPrompts corpus, with the reference image embedded as a control for woodcut style conditions.Those highlighted in red are keywords.
Figure 7.
Given the same reference image to control variables and inputting different prompts, our method is compared with other models, primarily to examine the diversity of the generated images.
Figure 7.
Given the same reference image to control variables and inputting different prompts, our method is compared with other models, primarily to examine the diversity of the generated images.
Figure 8.
We present questionnaire cases evaluating visual-textual consistency, learning style precision, and aesthetic preference. In these cases, A represents ControlNet, B stands for T2I-Adapter, C depicts IP-Adapter, and D represents WDANet, our proposed method.
Figure 8.
We present questionnaire cases evaluating visual-textual consistency, learning style precision, and aesthetic preference. In these cases, A represents ControlNet, B stands for T2I-Adapter, C depicts IP-Adapter, and D represents WDANet, our proposed method.
Figure 9.
The user study results comparing our WDANet with SOTA methods indicate user preferences. Here introduce three metrics for evaluating the generative model for design tasks: visual-textual consistency, learning style precision, aesthetic preference.The corresponding questionnaire content can be seen in Figure 8.
Figure 9.
The user study results comparing our WDANet with SOTA methods indicate user preferences. Here introduce three metrics for evaluating the generative model for design tasks: visual-textual consistency, learning style precision, aesthetic preference.The corresponding questionnaire content can be seen in Figure 8.
Figure 10.
Our method is compared against state-of-the-art text-to-image models and adapter methods to assess generative diversity. A, B, C, and D correspond to Midjourney, DALL-E 3, IP-Adapter, and WDANet, respectively.
Figure 10.
Our method is compared against state-of-the-art text-to-image models and adapter methods to assess generative diversity. A, B, C, and D correspond to Midjourney, DALL-E 3, IP-Adapter, and WDANet, respectively.
Figure 11.
In , the questionnaire results regarding generative diversity showcased that WDANet demonstrated a notable advantage in design richness, securing 60.29% of the votes.
Figure 11.
In , the questionnaire results regarding generative diversity showcased that WDANet demonstrated a notable advantage in design richness, securing 60.29% of the votes.
Table 1.
Our proposed WDANet and SOTA methods assess the alignment between text and image and the quantitative evaluation of aesthetic preferences, with SD as the baseline.
Table 1.
Our proposed WDANet and SOTA methods assess the alignment between text and image and the quantitative evaluation of aesthetic preferences, with SD as the baseline.
| Method | CLIP Score↑ | BLIP-ITM↑ | BLIP-Cosine↑ | ImageReward↑ |
|---|---|---|---|---|
| Baseline[6] | 18.52 | 76.42% | 0.4077 | -2.08 |
| ControlNet[9] | 27.11 | 98.97% | 0.4192 | -0.08 |
| T2I-Adapter (Style)[10] | 28.03 | 94.53% | 0.4693 | -0.95 |
| IP-Adapter[11] | 29.73 | 99.81% | 0.4776 | 0.15 |
| Ours | 34.20 | 99.98% | 0.4826 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.
JN-Logo: A Logo Database for Aesthetic Visual Analysis
Nannan Tian
et al.
Electronics,
2022
Product Innovation Design Based on Deep Learning and Kansei Engineering
Huafeng Quan
et al.
Applied Sciences,
2018
Research on Wickerwork Patterns Creative Design and Development Based on Style Transfer Technology
Tianxiong Wang
et al.
Applied Sciences,
2023



MDPI Initiatives
Important Links
© 2024 MDPI (Basel, Switzerland) unless otherwise stated