
Submitted:
19 December 2023
Posted:
20 December 2023
You are already at the latest version
Abstract
Inverse optimal control is a method for recovering the cost function used in an optimal control problem in expert demonstrations. Most studies on inverse optimal control have focused on building the unknown cost function through the linear combination of given features with unknown cost weights, which are generally considered to be constant. However, in many real-world applications, the cost weights may vary over time. In this study, we propose an adaptive online inverse optimal control approach based on a neural-network approximation to address the challenge of recovering time-varying cost weights. We conduct a well-posedness analysis of the problem and suggest a condition for the adaptive goal, under which the weights of the neural network generated to achieve this adaptive goal are unique to the corresponding inverse optimal control problem. Furthermore, we propose an updating law for the weights of the neural network to ensure the stability of the convergence of the solutions. Finally, simulation results for an example linear system are presented to demonstrate the effectiveness of the proposed strategy. The proposed method is applicable to a wide range of problems requiring real-time inverse optimal control calculations
Keywords:
inverse optimal control
; online calculation
; time-varying cost weights
; robust to noises
1. Introduction
The integration of biological principles with robotic technology heralds a new era of innovation, with a significant focus on applying optimal control and optimization methods to analyze animal motion. This approach guides robotic movement development, evident in the study [1], which explores the intricate control systems in mammalian locomotion. Such research underpins the development of robots that emulate the efficiency and adaptability found in nature.
These advancements in understanding animal locomotion through optimal control methods set the stage for the relevance of inverse optimal control (IOC). IOC offers a retrospective analysis of expert movements—human or animal—to infer underlying cost functions optimized in these motions. This methodology is crucial when direct modeling of optimal strategies is complex or unknown.
The use of inverse optimal control (IOC) to identify suitable cost functions from the observable control input and state trajectories of experts is becoming increasingly important. Several successful applications of IOC in estimating the cost weights of multi-features have been reported. For example, the knowledge and expertise of specialists can be categorized and exploited in several fields, including robot control and autonomous driving. [2], who employed game theory in tailoring robot–human interactions, proposed a method for estimating the human cost function and selecting the robot’s cost function based on the results, leading to the Nash equilibrium in human–robot interactions. [3] applied IOC to analyze taxi drivers’ route choices. To investigate the cost combination of human motion, [4] conducted an experiment using IOC techniques to study human motion during the performance of a goal-achieving task using one arm. Additionally, [5] represented the learning of biological behavior as an inverse linear quadratic regulator (LQR) problem and proposed adaptive methods for modeling and analyzing human reach-to-grasp behavior. Furthermore, [6] employed an IOC method to segment human movement.
Linear quadratic regulation is a common optimal control method for linear systems. In the 1960s and 1970s, numerous researchers offered solutions to the inverse LQR problem ([7,8,9]). Recently, the theory of linear matrix inequality was employed to solve the inverse LQR problem ( [5,10,11]). Regarding the application of the IOC method for nonlinear systems, several approaches involving methods such as passivity-based condition monitoring ([12]) or robust design ([13]) have been reported.
Feature-based IOC methods, which involve modeling the cost function as a linear combination of various feature functions with unknown weights, have gained acclaim in recent years ([14,15,16,17]). However, it may be difficult to apply these methods to the analysis of complex, long-term behaviors using simple feature functions, e.g., analyzing human jumping ([18]). To address this challenge, [19] proposed a technique for recovering phase-dependent weights that switch at unknown phase-transition points. This method employs a moving window along the observed trajectory to identify the phase-transition points, with the window length determined by a recovery matrix aimed at minimizing the number of observations required for successful cost-weight recovery. Although this method is effective in estimating phase-dependent cost weights, the complex computational requirements limit its use in real-time applications, such as human–robot collaboration tasks. Additionally, in this method, the cost weights in each phase are assumed to be fixed, which may not be generalizable. For example, the human jump motion in ([18]) was analyzed using time-varying, continuous cost weights.
Overall, the IOC still has several shortcomings that need to be addressed, particularly when applied in approximating complex, multi-phase, continuous cost functions in real-time. In this paper, we propose a method for recovering the time-varying cost weights in the IOC problem for linear continuous systems using neural networks. Our approach involves constructing an auxiliary estimation system that closely approximates the behavior of the original system, followed by determining the necessary conditions for tuning the weights of the neurons in the neural network to obtain a unique solution for the IOC problem. We demonstrate that the unique solution corresponds to achieving a zero error between the original system state and the auxiliary estimated system state, as well as zero error between the original costate and the integral of the estimated costate. Based on this analysis, we develop two neural-network frameworks: one for approximating the cost-weight function and the other for addressing the error introduced by the auxiliary estimation system. Additionally, we discuss the necessary requirements for the feature functions to ensure the well-posedness of our online IOC method. Finally, we validate the effectiveness of our method through simulations.
This work makes several significant contributions:
- We provide a solution for the recovery of time-varying cost weights, essential for analyzing real-world animal or human motion.
- Our method operates online, suitable for a broad spectrum of real-time calculation problems. This contrasts with previous online IOC methods that mainly focused on constant cost weights for discrete system control.
- We introduce a neural network and state observer-based framework for online verification and refinement of estimated cost weights. This innovation addresses the critical need for solution uniqueness and robustness against data noise in IOC applications.
2. Problem Formulation
2.1. System description and problem statement
Consider an object’s system dynamics formulated as
where and are two time-invariant matrixes, represents the system states, denotes the control input of the system, and denotes the initial state of the system.
To minimize the following cost function while accounting for dynamics (1), the classic optimal control problem is required to design the optimal control input , and generate a sequence of optimal states . (superscript ∗ stands for the optimal condition).
Here, has the following form:
where and represent the cost weight vectors, is referred to as the general union feature vector with respect to x and indicates the feature vector that is only relevant to the control input u. represents the feature’s number which is different from the dimension of system states. For simplicity, we assume that where R is an unknown matrix with . Additionally, it is assumed that () is controllable, B is a full column rank matrix, and A and B are bounded such that .
2.2. Maximum principle in forward optimal control
To minimize the cost function as is the case in (2) with defined in (3), there exists a costate variable vector that satisfies Pontryagin’s maximum principle as follows:
where and denote the costate variables (Lagrange multiplier). The initial value of can be represented as .
The optimal control input of the system expressed by (1) is given as
where is unknown. Thus, using this optimal control input, we have
where H denotes the matrix . Notably, given that B is a full column rank matrix, it is clear that H is invertible. In addition, since B is a bounded constant matrix, there exists a positive scalar such that H satisfies .
Additionally, the time derivatives of the system dynamics can be formulated as follows:
2.3. Analysis of the IOC problem
We assume that the system states and the control input , which represent the time series of the system states and control inputs from time point t to , provide the solution to the optimal minimization of the cost function (2). In addition, we assume that the optimal system states and control input satisfy the boundary conditions .
The objective of the IOC problem is to recover the unknown cost weight’s vector . Furthermore, IOC, for example, may be employed to analyze different behaviors such as the effect of different occasions on the relative importance of certain human motion feature functions. A rigorous analysis of the derived cost weights that can recreate the original data is required for the aforementioned applications. To begin, we consider two problems :
- What happens when a different feature function is selected?
In previous studies, it was assumed that the cost weight vector q is either a constant value ([14]) or a step function with multiple phases ([19]). These assumptions have been effective in recovering the cost weights used in the analysis of optimal control methods for a robot’s motion control, such as analyzing the motion of a robot controlled by a LQR approach. However, occasionally, it may be inappropriate to assume that the cost weights are constants or step functions when analyzing the complex behaviors of natural objects, such as human motion. In particular, deciding which feature function to adopt when evaluating the motion of natural objects could pose a challenge.
Proposition 1.
Depending on the different selections of feature functions for the IOC, the original constant cost weight q may become a time-varying continuous function.
Proof.
From (7), for the objects’ original feature function, we have
where denotes the original time-invariant cost weight vector, and denotes the partial derivative with respect to x of the original feature function. When we choose a different feature function , the above equation becomes
where denotes the partial derivative with respect to x of the new selected feature function and is the corresponding cost weights on . Thus, we have
From this equation, it follows that may be a time-varying function when and are not equivalent, and as and are continuous functions, we can reasonably conclude that is also a continuous function.
□
Based on this proposition, it is crucial to expand the definition of cost weights to include time-varying values, as this will facilitate a more accurate analysis of the motion of increasingly complex natural objects. Despite the need for time-varying cost weight recovery in many applications, it has received minimal research attention thus far.
- Whether or not the given set in the IOC problem has a unique solution .
The uniqueness of the solution to the IOC problem when cost weights are constant has been discussed in many studies. In this work, we determine if there is still a unique solution to the IOC problem when q is a time-varying function.
From (9), we can find different continuous functions such that the equation is satisfied for different values of R (different values of H). This implies that if q is considered as a time-varying function, the set will not have a unique solution.
Therefore, when we consider the unique solution of the IOC problem with the time-varying function , it is necessary to introduce additional conditions to ensure that the IOC problem has a unique solution and that the resulting unique solution is meaningful.
In this study, for simplicity, we assume that ([20,21]), where I is the identity matrix. In actual optimal control cost functions, when we focus on reducing one of the control inputs , the convergence of the i-th system state related to will also be affected. Consequently, the final control result shows that the change in each state of the system is not solely influenced by the chosen cost weights , but also by . In the IOC problem, setting allows the effect of different weights on different control inputs in the original system to be reflected in the current estimate of . This enables us to view the estimated weights on the system states as representing the relative importance of each state in the system’s dynamic evolution, without considering the impact of the control input on these weights.
Based on our conclusion that q may be time-varying when different feature functions are chosen and on the corresponding conditions under which a unique solution exists, we can define the IOC problem to be solved in this study as follows:

3. Adaptive Observer-based Neural Network Approximation of time-varying Cost Weights
In this study, we estimate time-varying cost weight functions online using an observer-based adaptive neural network estimation approach, as opposed to earlier studies that required a large number of time series of x and u to recover fixed cost weights offline.
3.1. Construction of the observer
Following the introduction of denoting the estimation of , we define the estimation of the associated costate variable as follows:
where denotes the partial derivatives of the feature functions that are only relevant to the estimated system states obtained by inserting into (7) :
where the initial state of this system is selected to be . Thus, compared with that of the original system, the error generated by the new estimation system can be expressed as
where and . Here, the feature function is selected such that its partial derivative with respect to x is bounded and it is assumed that , and where , and denote a positive scalar.
Additionally, the time derivatives of (13) can be expressed as
Thus, the following equation can be satisfied:
where , , , . denotes the error of estimating q. Here, implies that there exists a positive scalar such that holds. Based on the bound of , it follows that there are two positive scalars and such that the following inequalities hold: and .
Moreover, from (6) and (7), can be calculated as follows:
4. Neural Network Based Approximation of Time Varying Cost Weights
In this section, a neural network-based cost weight approximation algorithm is proposed. To calculate an approximation of the time-varying vector q, we adopt a neural network in which the chosen inputs are . Based on this, we assume that time-invariant weight matrixes exist that satisfy the following expression :
where denotes the activation function and denotes the structure approximation error of the neural networks. In addition, the activation function selected enables the activation function as well as its partial derivative to satisfy the following boundary condition: and where and represent two positive scalars. Additionally, where is a positive scalar.
The estimate of vector q is constructed as follows:
where denotes the estimation of W.
Therefore, the error of estimating q can be expressed as
where denotes the error of estimating W. By substituting into (15), we have
To profoundly comprehend the necessary condition for the convergence of the estimation error , we define uniformly ultimately bounded(UUB) below.
Definition 1.
A time-varying signal can be said as UUB if there exists a compact set so that for all , there exists a bound and a time T such that for all .
Lemma 1.
where and any term in C satisfies the persistent excitation (PE) condition defined below.
Here, is a positive value.
If the following conditions are satisfied, becomes UUB.
- become UUB after a time point (, and )
- The change in approaches zero
- Matrix C defined below will become a full row rank matrix.
Proof.
From (20)
Since reaches a steady state and is a constant, we can obtain the following:
where denotes a small positive scalar. Additionally, since both and are bounded, we have
where denotes a small positive scalar. The term captures the effect of the structural error of the neural network on state s. Since is bounded, when the neural network approximates the cost weight function adequately, the value of decreases, which in turn minimizes the overall integral value. In other words, a well-selected neural network structure with a good approximation of the cost weight function will produce a small structure error and therefore a small overall integral value .
Similarly, we can obtain a similar relation for the duration
Furthermore, considering after , the definition of s and , we have
where and represent the bounds of and respectively. Thus, we have
In this case, when approaches zero, we have
Based on this relation, we have
where .
Thus, we have
where C is defined in (21). Since C is full row rank, we have
From (22), we have
Thus, is UUB.
Notably, evaluates the lower bound of the norm of , it can increase when the data x cause the norm of the integral to deviate significantly from zero. The size of is related to the minimization of s and , and the size of is related to the approximation ability of the chosen neural network. The bound of after can be minimized by the excited x, successfully minimizing s and while appropriately designing the structure of the neural network.
□
4.1. Construction of the neural network
As shown in Lemma 1, the convergence of is essential in the convergence of to 0. Therefore, it is necessary to incorporate this consideration in the approximation design.
First, we divide the estimation of the weights of the neural network into two parts:
and
where and .
The state equation describing the error dynamics can be obtained as follows:
where , , , .
Further, to effectively minimize , we define vector e as follows:
where and . Parameters k and are two positive scalars, thus, (38) can be written as:
We suppose that an ideal time-invariant weight matrix exists, which guarantees that
where .
The estimation error of the neural network can be represented as
and e can be represented as
Therefore, (40) becomes
4.2. Tuning law of the neural network for the estimation of
An updating law for a neural network that estimates can be represented in Theorem 1, based on the error system’s dynamics that were derived in (44).
Theorem 1.
If we choose the updating laws for the neural network weights and as shown in (45), respectively, where , and are positive scalar constants, then state s, , and error e will be UUB.
In addition, if there exist positive constants , , , , and such that the inequalities in (46) are satisfied for all initial times , then the signals and will also be UUB.
Here, ,
Proof.
A proof of this theorem can be found in the appendix. □
Applying (45) results in s, , and e being UUB, as shown in Theorem 1. Additionally, (45) shows that when s and e decreases, and decrease as well, resulting in a decrease in . At this point, as stated in Lemma 1, if the condition of matrix C (defined in Lemma 1), being a full row rank matrix, is satisfied, then will also be UUB. Thus, the solution to the IOC problem can be derived by applying (37).
5. Simulations
5.1. Basic simulation conditions
To verify the effectiveness of our method, we performed the simulations using a sample linear system controlled by the optimal control method with the original cost weights R selected in two cases.
The sample linear system dynamics can be formulated as follows:
where represents the system states. We select , and denoting the control input.
The cost function selected in these simulations is formulated as
when all the elements of satisfying and is the continuous time-varying cost weights on system states . represents the cost weights on the control inputs.
Moreover, in our simulations, we select 0 as the initial value of all the elements of both and . Actuation function was selected as with designed as
where denotes a positive scalar.
Two cases are considered in the simulation:
(1) In the first case, we apply the optimal control of the sample system with cost weights as the signal ( and ). The proposed IOC method is employed online to estimate the cost weights, with the simultaneous online recovery of the original system trajectory. Parameters and in the updating law are set to and , respectively. Parameters k and are set to and , respectively. The initial values of and are set to matrixes with all elements equal to zero. The original and are set to and , respectively. The simulation also uses 49 nodes in the neural network.
(2) In the second case, we perform the simulation of our IOC method, but with the original and set to and , respectively. All other simulation settings are the same as in the first case.
Similar to the simulation sections in previous works ([19] and [6]), we use the control input from the simulation, which ignores the measurement issues with the control input and measurement errors that may occur in real-world applications. This allows us to purely evaluate the performance of our method in solving the IOC problem. In actual applications, the control input can be calculated by substituting the measured into (47), as described by [19].
5.2. Results
The simulation results are shown in the figures below.
In Figure 1, the blue solid line represents the original variation in the cost weights whereas the gray solid line represents the estimated cost weights. After a brief period of oscillation at the initial time, our method accurately recovers the original cost weights when . Notably, similar to the case in other adaptive control methods and adaptive neural network based control methods, the initial oscillation is a result of the adaptive initialization of the weights in (45) due to the large initial errors in and .
Figure 2 demonstrates the impact of selecting on the estimation results when the original R value is arbitrary. The solid blue line represents the original time-varying cost weights, whereas the dotted gray line represents the final estimated values. Although the estimated values differ from the original values, the general trend of the changes is preserved. In addition, the gray line represents the mutual weights in the dynamics of the system state, whereas the original weights among the control inputs are reflected in the current estimate of . From the figure, we can observe that the bottom lines in blue and gray colors represent the value of the original and estimated . Evidently, the blue line for is larger than that for from 4.8s to 5s. Additionally, in the original settings, is 4, which confers greater importance to the decrease in compared with the case when , leading to the weakening of the convergence of the term associated with . In our estimates, the value of the dashed line for the estimated , which also considers the impact from original setting of R is not greater than the value of estimated between 4.8s and 5s. This indicates that the convergence of is weakened by considering the impact from the cost weights on control input. Our dashed line more accurately reflects the actual situation compared to the blue line.
In Figure 3, Figure 4 and Figure 5, we show the results of error e, states s and in two cases. The blue lines show the results of the first case, whereas the gray dotted lines show the results of the second case. From the figures, we can observe that all the values effectively decrease to a low range during the simulation, and most importantly, in the second case, the different selections of R do not affect the convergence of these values. This demonstrates the effectiveness of our method and highlights that even with different values of R, the recovered cost weights are still feasible solutions to the IOC problem, as they can be utilized to regenerate a similar system trajectory and control inputs ().
6. Discussion
6.1. Robustness of the proposed method to noisy data
In (45), and decrease the error by regulating the updating speed of the estimated values. Adjusting these two terms may successfully reduce the impact of data noise to a certain degree. Their roles are similar to that of a low-pass filter’s time constant. For example, in the setting of the first case, when noise exists, and , the simulation results show that different sets of and (e.g. ,; ,) can significantly influence the noise reduction performance.
As shown in Figure 6, while relatively small values of and may result in a low convergence rate, they effectively reduce the impact of data noise. Our method demonstrates robustness against noise by allowing for the adjustment of parameters and .
6.2. Calculation complexity and real-time calculation
The proposed algorithm has a low computational complexity, as it only involves the calculation of dot products between matrixes and vectors as well as the summation of vectors. Additionally, it does not require any iterative or optimization calculations. This makes it an efficient solution for real-time calculations. In fact, our simulation shows that a single iteration of the algorithm using case 1 settings takes only approximately 0.23ms in Matlab 2016b to complete the SIOC’s calculation, which is fast enough to meet real-time calculation requirements.
6.3. Advantages of using
The simulation results suggest that one of the key advantages of setting R as a constant I is that it effectively consolidates the impact of cost weights on state convergence, which would have been influenced by different settings of R, into the estimated value of . This allows for a comprehensive evaluation of the system state convergence, as it only depends on , without needing to account for additional considerations. Furthermore, by maintaining a consistent value of , it is possible to standardize the analysis of the same motion across multiple agents, which is crucial for various applications.
7. Conclusion
In this paper, we proposed a neural network based method for recovering the time-varying cost weights in the IOC problem for linear continuous systems. Our approach involved constructing an auxiliary estimation system that closely approximates the behavior of the original system, followed by determining the necessary conditions for tuning the weights of the neurons in the neural network to obtain a unique solution for the IOC problem. We discussed the necessary requirements for the previous settings to ensure the well-posedness of our online IOC method. We showed that the unique solution corresponds to achieving a nearly zero error between the original system state and the auxiliary estimated system state, as well as nearly zero error between the original costate and the integral of the estimated costate. Based on this analysis, we developed two neural network frameworks: one for approximating the cost weight function and the other for addressing the error introduced by the auxiliary estimation system and terms. Finally, we validated the effectiveness of our method through simulations, highlighting its ability to recover time-varying cost weights and its robustness against different original choices of R. Overall, our method represents a significant advancement in the field of online IOC, and it is applicable to a wide range of problems requiring real-time IOC calculations.
8. Proof of Theorem 1
Proof.
Considering the Lyapunov candidate selected as follows
The derivative of V can be expressed as
By introducing (44) and utilizing the proposed updating law of and in (45), becomes
Here, with introducing a new vector p defined as and considering (43), (52) can be rewritten as
where .
By considering the boundedness condition of ,, and , we have
From this boundedness condition, (52) becomes
From (55), the left hand side of (55) would be negative when , implying that and p would maintain convergence when . Moreover, due to the vector , s as well as e would all be bounded satisfying
That is, s, e would all be UUB. Moreover, due to the continuity, would also be UUB satisfying the following condition as
Notably, with increasing k, the bound of p decreases. Furthermore, since V decreases continuously while , would also be UUB.
Conversely, from (40), we have
where denotes a positive scalar. Furthermore, by considering (42), we have
From (45), the dynamics related to and can be respectively given by
where and denote the outputs of two systems and are both bounded following (60) and (61).
Thus, the vector dynamics of the two systems can be given as
where and would be bounded with ensuring the boundedness of and . Thus, from Lemma 4.2.1 in [22], if (46) is satisfied, the boundedness of as well as those of s and assures the boundedness of ,. That is, there exist two positive scalars , such that ,. Thus, and would be UUB. □
References
- Frigon, A.; Akay, T.; Prilutsky, B.I. Control of Mammalian Locomotion by Somatosensory Feedback. Comprehensive Physiology 2021, 12, 2877–2947. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Tee, K.P.; Yan, R.; Chan, W.L.; Wu, Y. A framework of human–robot coordination based on game theory and policy iteration. IEEE Transactions on Robotics 2016, 32, 1408–1418. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Human Behavior Modeling with Maximum Entropy Inverse Optimal Control. AAAI spring symposium: human behavior modeling, 2009, Vol. 92.
- Berret, B.; Chiovetto, E.; Nori, F.; Pozzo, T. Evidence for composite cost functions in arm movement planning: an inverse optimal control approach. PLoS computational biology 2011, 7, e1002183. [Google Scholar] [CrossRef] [PubMed]
- El-Hussieny, H.; Abouelsoud, A.; Assal, S.F.; Megahed, S.M. Adaptive learning of human motor behaviors: An evolving inverse optimal control approach. Engineering Applications of Artificial Intelligence 2016, 50, 115–124. [Google Scholar] [CrossRef]
- Jin, W.; Kulić, D.; Mou, S.; Hirche, S. Inverse optimal control from incomplete trajectory observations. The International Journal of Robotics Research 2021, 40, 848–865. [Google Scholar] [CrossRef]
- Kalman, R.E. When is a linear control system optimal? 1964.
- Molinari, B. The stable regulator problem and its inverse. IEEE Transactions on Automatic Control 1973, 18, 454–459. [Google Scholar] [CrossRef]
- Obermayer, R.; Muckler, F.A. On the inverse optimal control problem in manual control systems; Vol. 208, Citeseer, 1965.
- Boyd, S.; El Ghaoui, L.; Feron, E.; Balakrishnan, V. Linear matrix inequalities in system and control theory; SIAM, 1994.
- Priess, M.C.; Conway, R.; Choi, J.; Popovich, J.M.; Radcliffe, C. Solutions to the inverse LQR problem with application to biological systems analysis. IEEE Transactions on control systems technology 2014, 23, 770–777. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, A.; Ortega, R. Adaptive stabilization of nonlinear systems: the non-feedback linearizable case. IFAC Proceedings Volumes 1990, 23, 303–306. [Google Scholar] [CrossRef]
- Freeman, R.A.; Kokotovic, P.V. Inverse optimality in robust stabilization. SIAM journal on control and optimization 1996, 34, 1365–1391. [Google Scholar] [CrossRef]
- Johnson, M.; Aghasadeghi, N.; Bretl, T. Inverse optimal control for deterministic continuous-time nonlinear systems. 52nd IEEE Conference on Decision and Control. IEEE, 2013, pp. 2906–2913.
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. Proceedings of the twenty-first international conference on Machine learning, 2004, p. 1.
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. ; others. Maximum entropy inverse reinforcement learning. Aaai. Chicago, IL, USA, 2008, Vol. 8, pp. 1433–1438.
- Molloy, T.L.; Ford, J.J.; Perez, T. Online inverse optimal control for control-constrained discrete-time systems on finite and infinite horizons. Automatica 2020, 120, 109109. [Google Scholar] [CrossRef]
- Gupta, R.; Zhang, Q. Decomposition and Adaptive Sampling for Data-Driven Inverse Linear Optimization. INFORMS Journal on Computing 2022. [Google Scholar] [CrossRef]
- Jin, W.; Kulić, D.; Lin, J.F.S.; Mou, S.; Hirche, S. Inverse optimal control for multiphase cost functions. IEEE Transactions on Robotics 2019, 35, 1387–1398. [Google Scholar] [CrossRef]
- Li, Y.; Yao, Y.; Hu, X. Continuous-time inverse quadratic optimal control problem. Automatica 2020, 117, 108977. [Google Scholar] [CrossRef]
- Zhang, H.; Ringh, A. Inverse linear-quadratic discrete-time finite-horizon optimal control for indistinguishable homogeneous agents: A convex optimization approach. Automatica 2023, 148, 110758. [Google Scholar] [CrossRef]
- Lewis, F.; Jagannathan, S.; Yesildirak, A. Neural network control of robot manipulators and non-linear systems; CRC press, 2020.
Figure 1.
Estimated cost weights ()
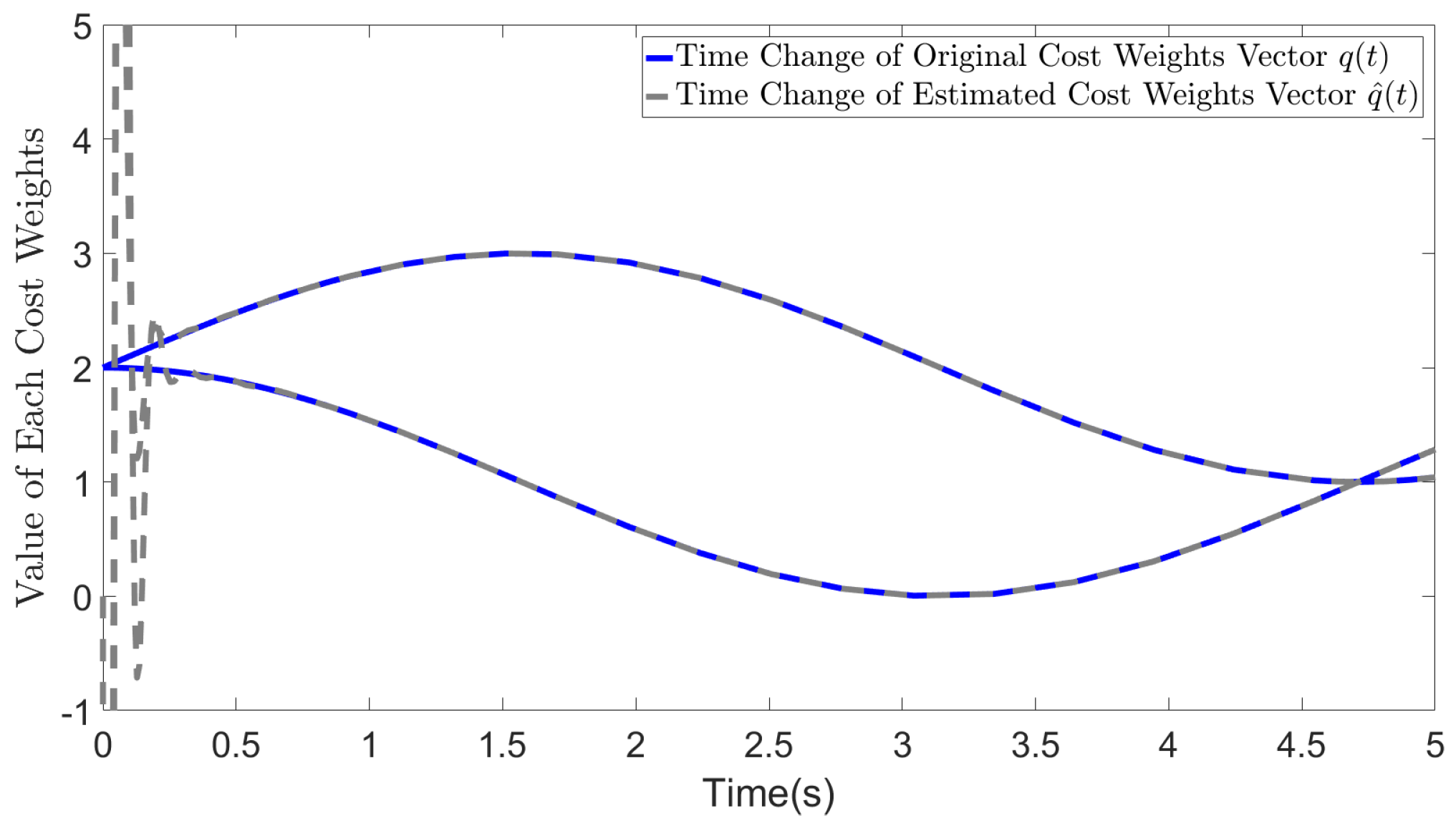
Figure 2.
Estimated cost weights ()
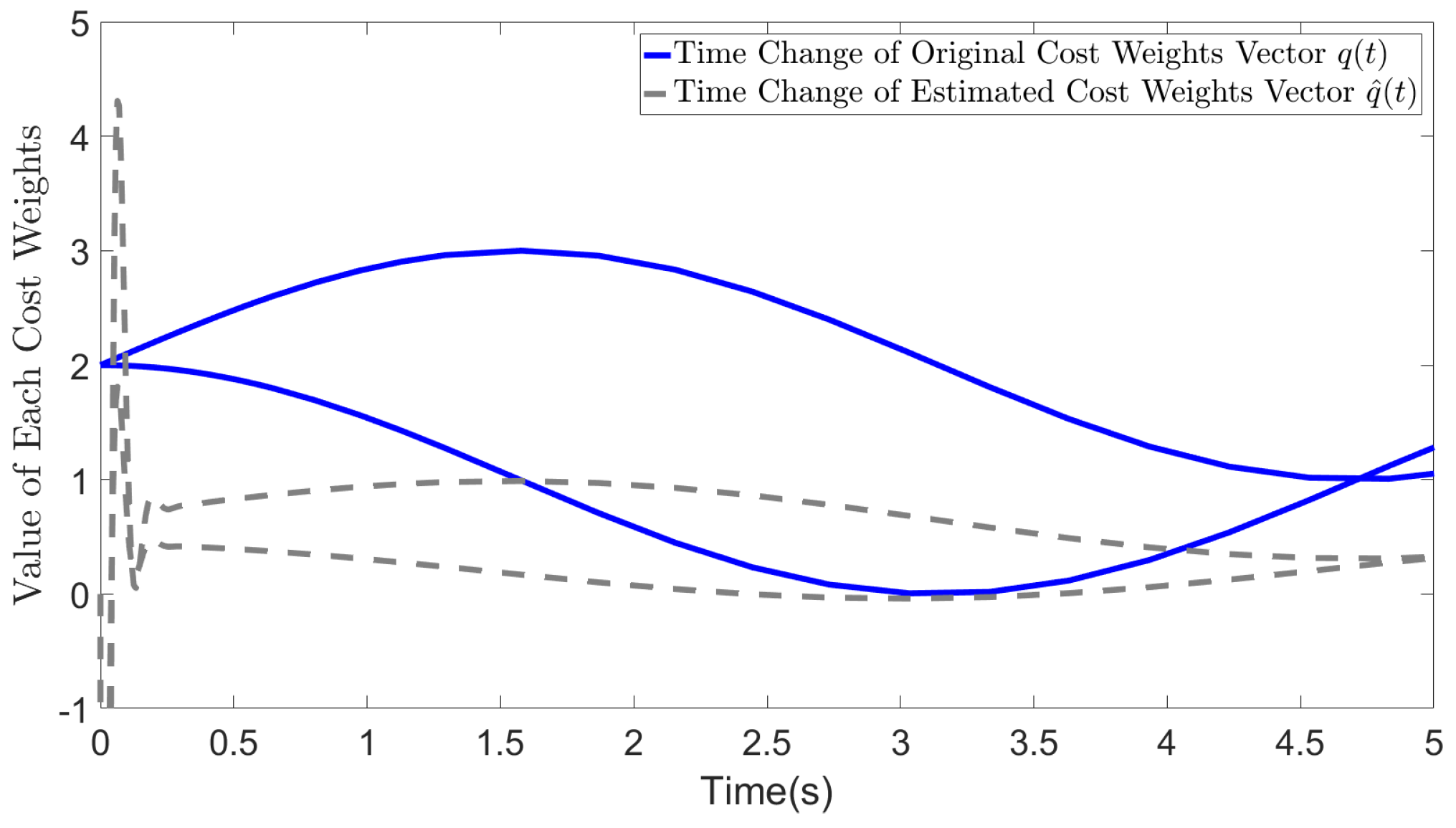
Figure 3.
Variation of Error e ( and )
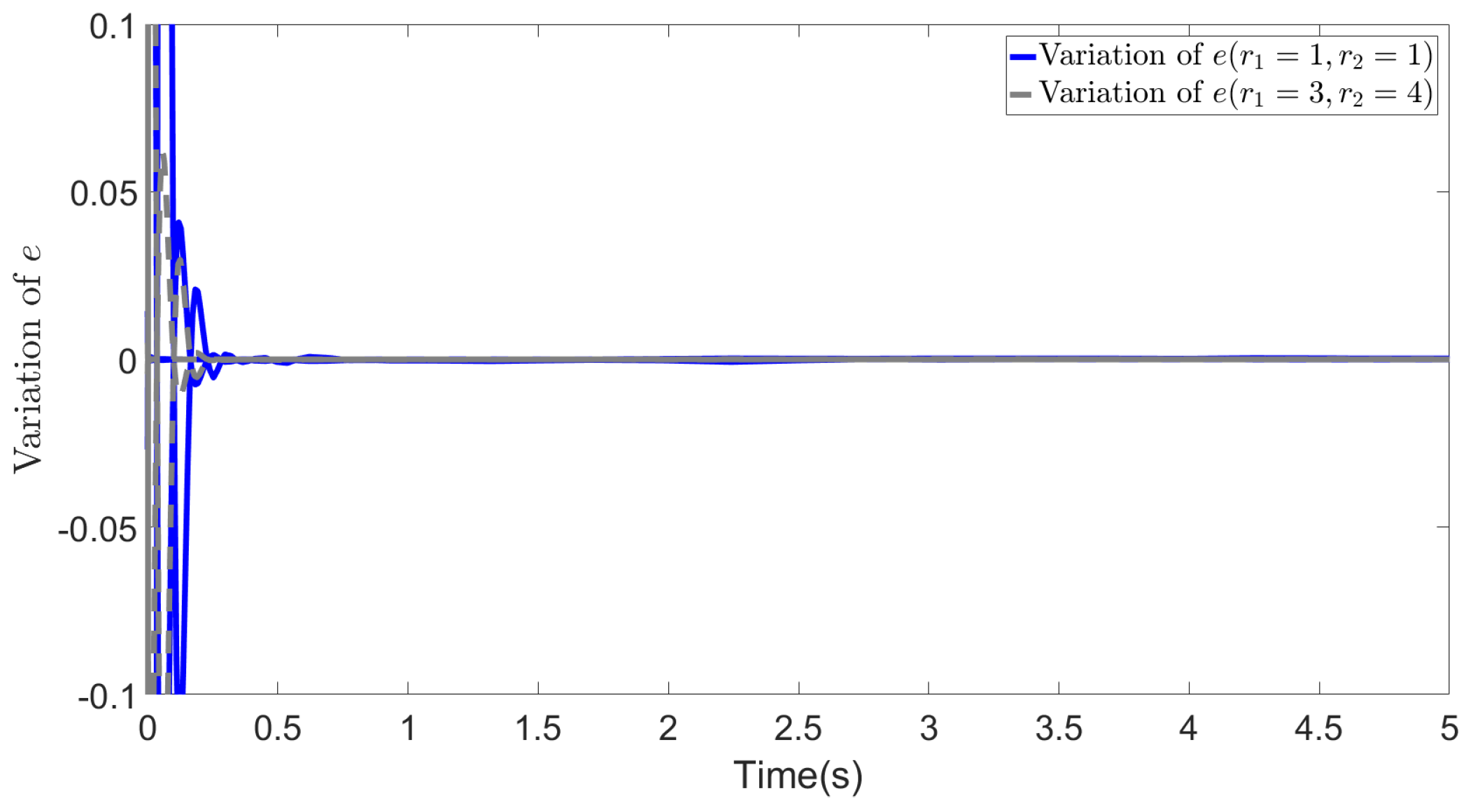
Figure 4.
Variation of Error s ( and )
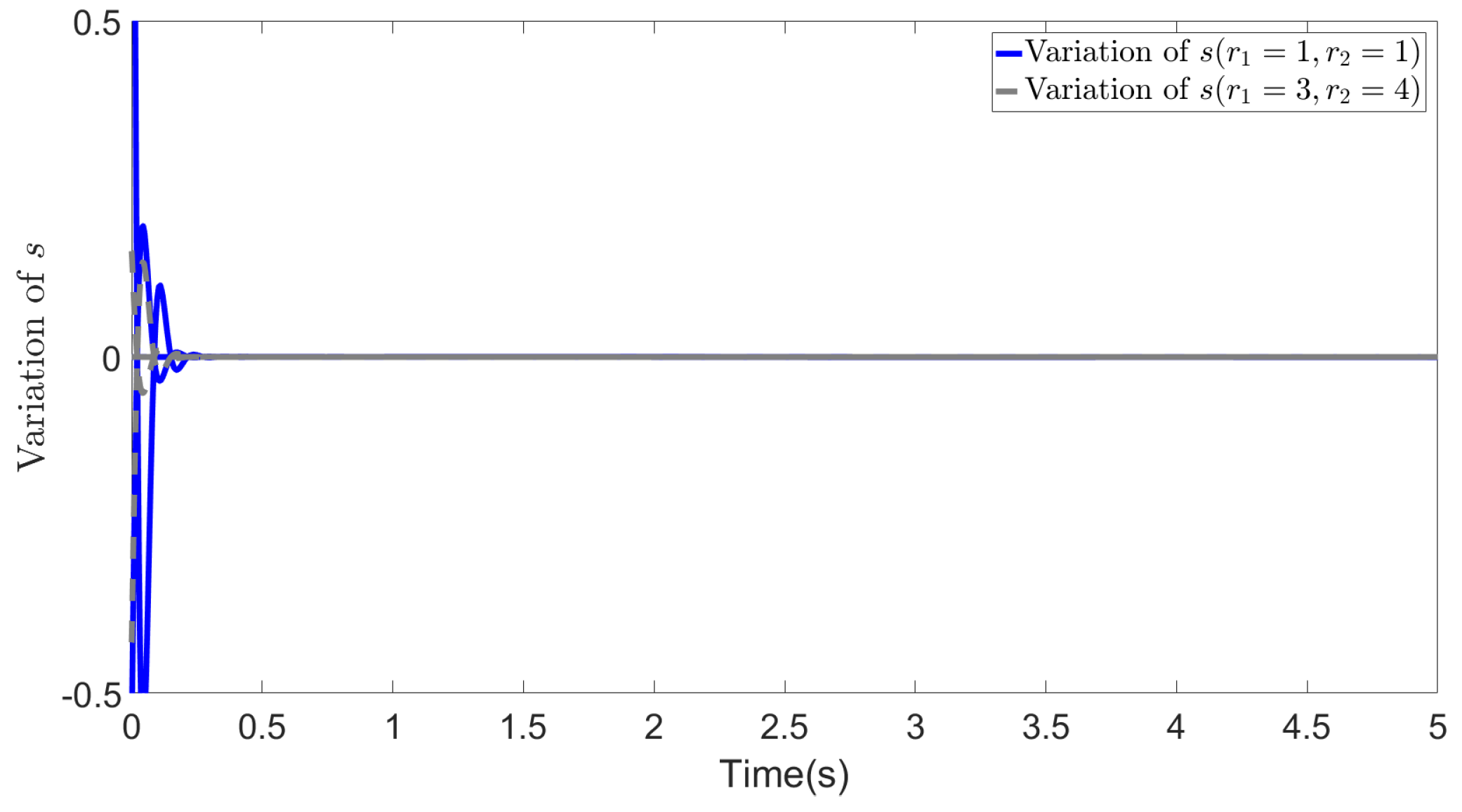
Figure 5.
Variation of ( and )
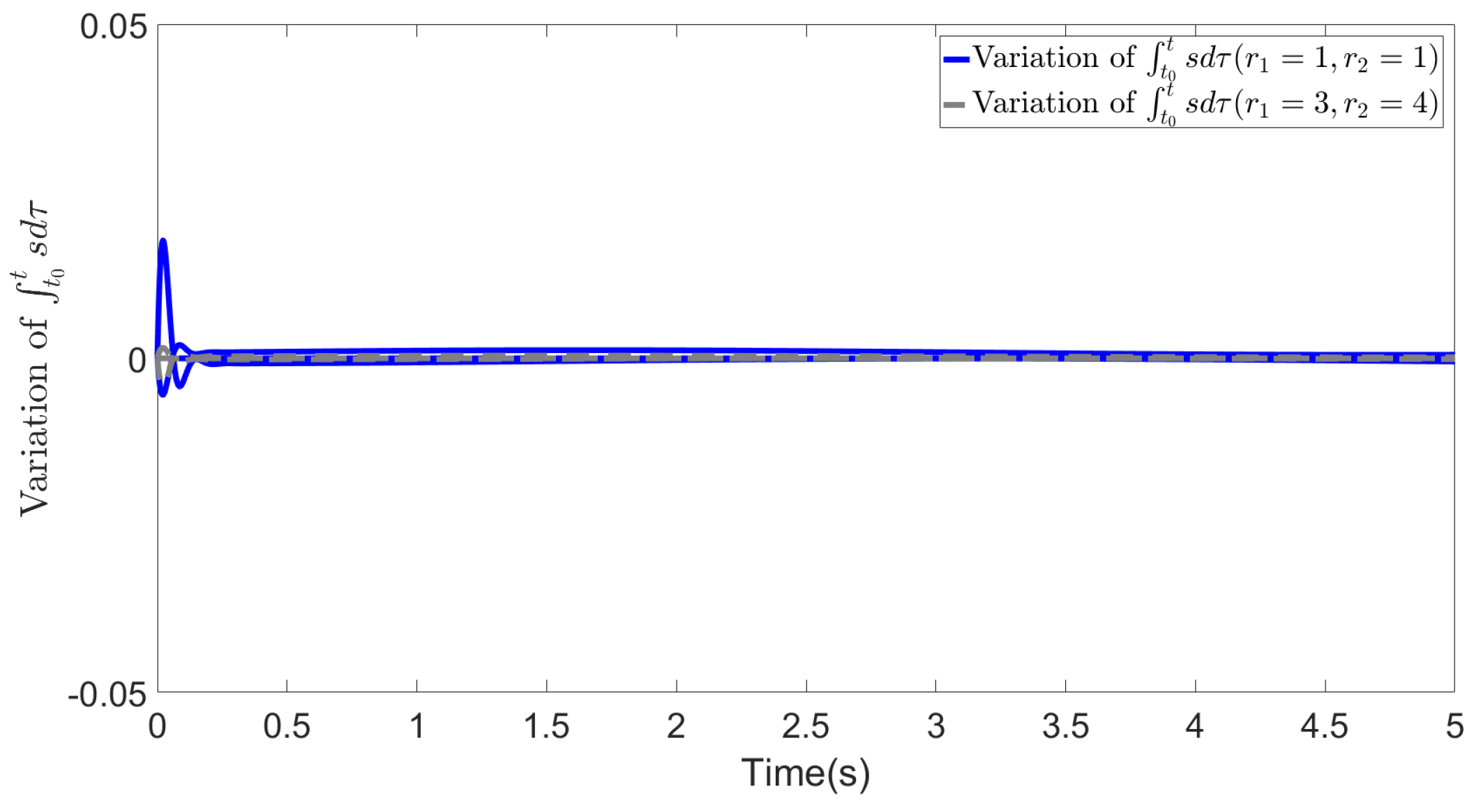
Figure 6.
Estimated cost weights (Noisy Case):(1) , (2) ,
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



