Submitted:
20 December 2023
Posted:
21 December 2023
You are already at the latest version
Abstract
In addressing the challenges of data scarcity in biometrics, this study explores the generation of synthetic palmprint images as an efficient, cost effective, and privacy preserving alternative to real-world data reliance. Traditional methods for synthetic biometric image creation primarily involve orientation modifications and filter applications, with no established method specific to palmprints. We introduced the utilization of the “Style-based generator”, StyleGAN2-ADA, from the StyleGAN series, renowned for generating high-quality images. Furthermore, we explore the capabilities of its successor, StyleGAN3, which boasts enhanced image generation, facilitating smooth and realistic transitions. By comparing the performance of StyleGAN3 on public dataset, we aim to establish the most efficient generative model for this purpose. Evaluations were conducted using the SIFT (Scale-Invariant Feature Transform) algorithm into our evaluation framework. Preliminary findings suggest that StyleGAN3 offers superior generative capabilities, enhancing equivariance in synthetic palmprint generation.
Keywords:
Palm print synthesis
; Style-GAN-2-ADA
; StyleGAN3
; SIFT
1. Introduction
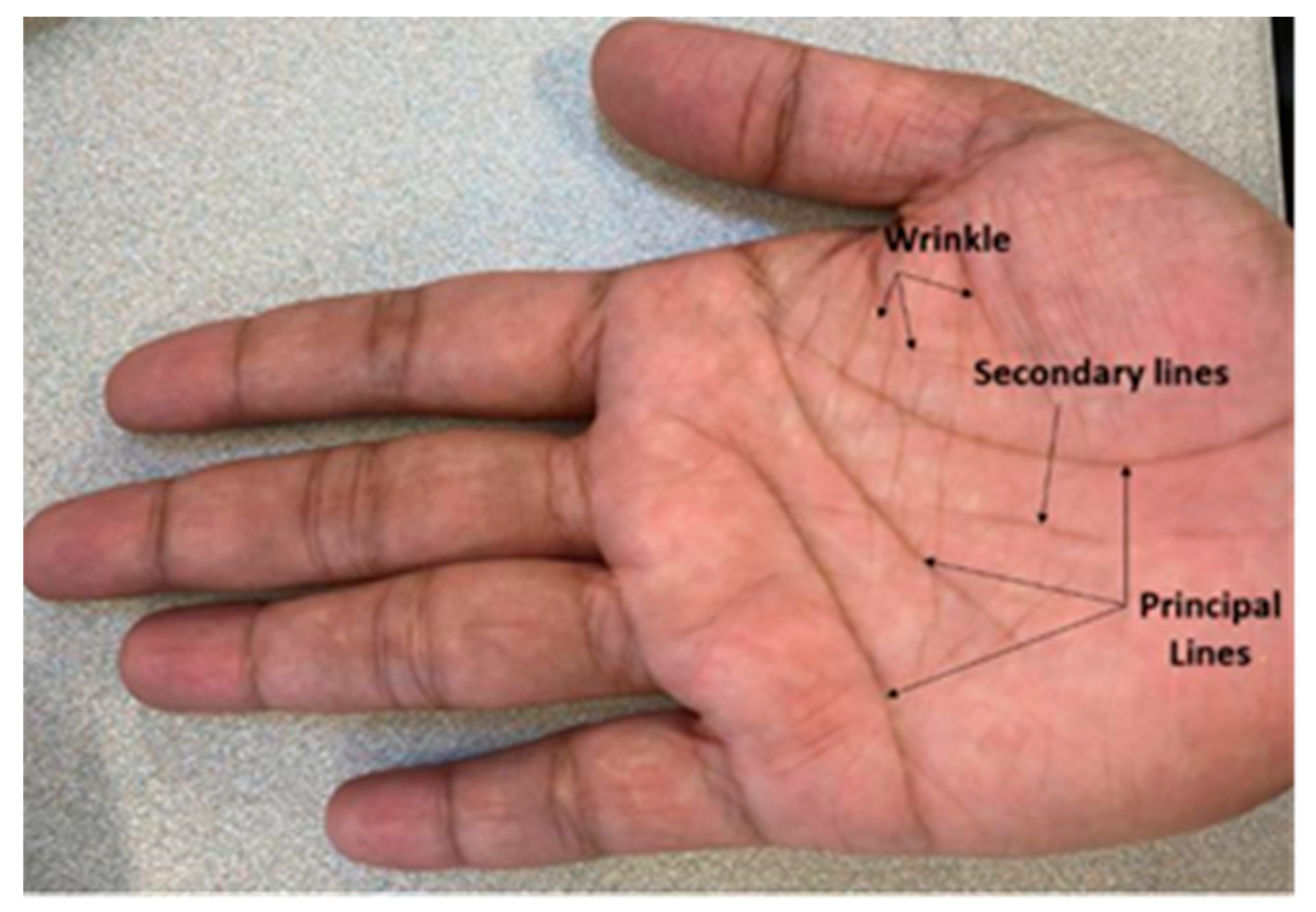
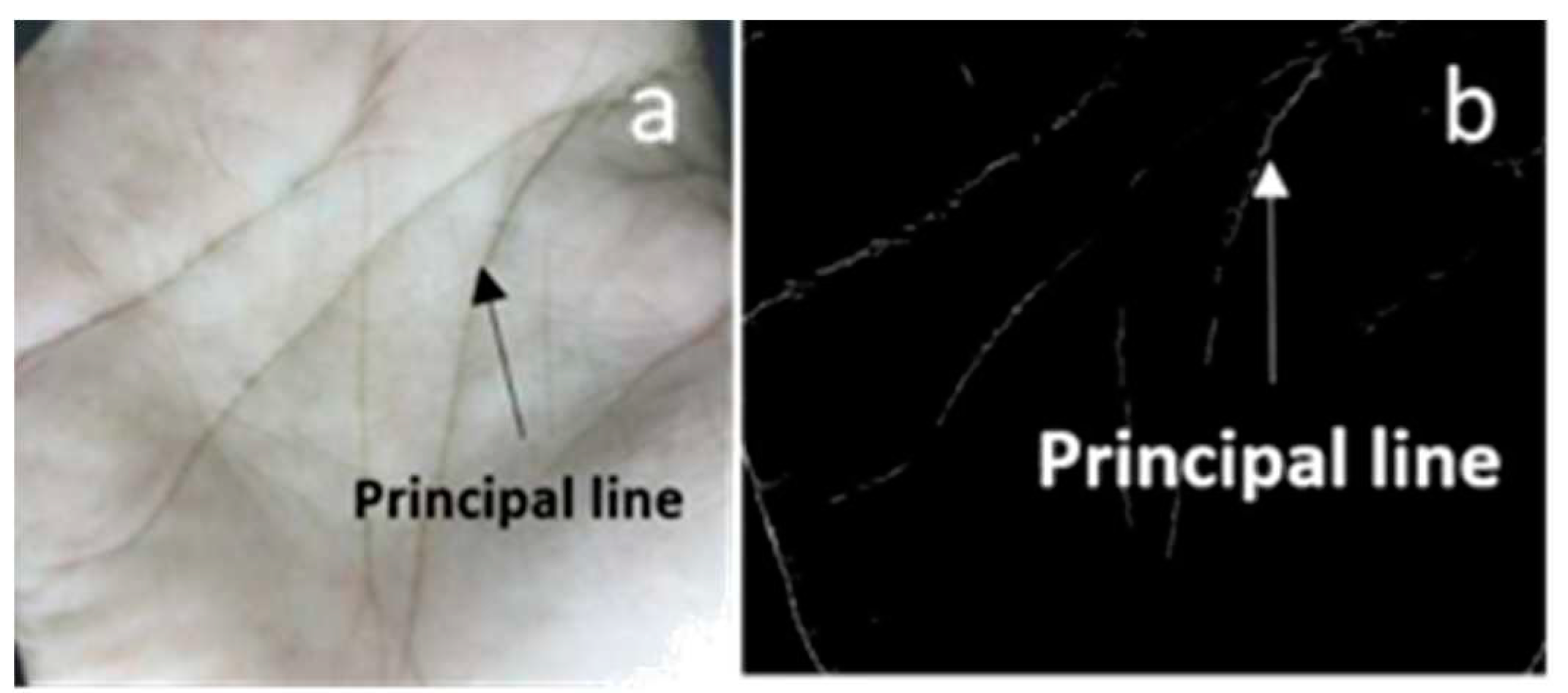
Biometric security systems use biometric data with advanced recognition technology to develop lock and capture mechanisms and limit access to specified data [1]. The main purpose here is the identification and verification of a person’s identity through his physiological or behavioral biometrics such as the face, iris, fingerprint, etc. [2]. One of the fast-growing, relatively new, biometrics is the palmprint [3].The palm is the inner surface of the hand between the wrist and the fingers [4]. Palmprint refers to an impression of the palm on a surface. A palmprint contains rich intrinsic features, including the principal lines and wrinkles (figure 1) [1] [5] [6] and abundant ridge and minutiae-based features similar to a fingerprint [3].These significant features make a palmprint very useful in the field of biometrics because these palmprint features have the potential to achieve high accuracy and reliable performance for personal verification and identification [4,8]. Many techniques have been proposed for palmprint recognition using minutiae-based features, geometry-based features, transformed-based features, [7] and more. To process these features many image processing methods such as i) encoding-based algorithm, ii) structure-based methods, iii) statistics-based methods exist [9]. Recently, most methods in the literature consider Deep Learning due to its high recognition accuracy and the capability to adapt to biometric. samples captured in heterogeneous and less-constrained conditions [8]. Current state-of-the-art palmprint recognition systems rely on large datasets. The National Institute of Standards and Technology (NIST) recently discontinued several publicly available datasets from its catalog due to privacy issues [10]– [13]. To overcome the scarcity of data, we have produced synthetic palmprints. One of the main reasons to generate synthetic images is low cost, high efficiency, and testing privacy. Moreover, the quality and resolution of images generated by generative adversarial networks (GANs) have experienced significant advancements recently [7,8,9]. The architecture of a standard GAN generator operates in a similar fashion: initially, it creates rough, low-resolution attributes that are progressively refined through upsampling layers. These features are then blended locally using convolution layers, and additional intricacies are added via nonlinear processes. However, it's noted that despite these apparent similarities, contemporary GAN structures don't generate images in a naturally hierarchical way. While the broader features primarily dictate the existence of finer details, they don't precisely determine their locations. Instead, it seems that a significant portion of the finer details is established in fixed pixel coordinates. Researchers do not need to depend on real-world data; they can work on synthetic data [14]. A generator model was learned over training images to generate a synthetic image. In this scenario, synthetic data has the edge over real data regarding enrollment, detection, and verification [15]. A huge number of synthetic datasets can be produced at low cost and with little effort while posing no privacy risk. A single synthetic image with well-controlled modifications can also be used to alter and expand the dataset. The traditional method to develop synthetic images is by changing the orientation of images and using some filters such as the Gabor filter which changes the final structure for any image [4,10,11]. In the biometric field, the classical approach of developing synthetic images refers to changing the orientation of the fingerprint or changing the skin color for the facial biometric [12,13]. There is no traditional approach to generate synthetic palmprints [16,17]. Additionally, we previously introduced a framework for generating palm photos using a "Style-based generator" named "StyleGAN2-ADA," which is a variation within the StyleGAN family.” [18]– [20]. This research was motivated by the recent success of the GAN family in current literature to generate very high-quality images [16]– [19]. Our current objective is to develop the model from the StyleGAN family, StyleGAN3, to demonstrate a more natural transformation process, where the pixel position of each detail is exclusively derived from the base features. To the best of our knowledge, ours is the only StyleGAN-based approach that can generate high-resolution palm images up to 2048x2048 pixels. In a previous study, a TV-GAN based framework was applied to generate palmprints. However, high resolution images were not generated in this work [21]. Our contributions are as follows:
Figure 1.
Palmprint features definitions with principal lines and wrinkles.
• Our model utilizes a high resolution and progressive growth training approach [17,18] with realistic shapes and boundaries at 512 × 512 pixels and does not suffer from any quality issues.
• We explained the quality metric distributions to assess the diversity of the synthetic fingerprints and their similarity to original palm photos. We also match every synthetic palm photo to every original palm image to ensure that the synthetic palm images do not reveal the real identity.
•We made the pre-trained model and generated model publicly available. To the best of our knowledge, our study is the first publicly available StyleGAN-based palm photo synthesis model.
•To filter out unwanted images during the generation of synthetic images we applied the image processing method. To detect, describe the key-points of the images and also to match between original images to test images, we applied the Scale-Invariant Feature Transform (SIFT) algorithm.
The rest of the paper is organized as follows. Section II data discusses the pre-processing method and proposed model architecture. The data preparation for the experiment and model for training method is noted in Section III. Experimental results and evaluation are presented in Section iv. Finally, our conclusion is in Section v.
Methodology
A. StyleGAN-2-ADA Architechture Overview
In our previous proposed work was the use of GAN architecture from the StyleGAN family named “StyleGAN2-ADA” [19,20]. It is an improved version of StyleGAN that uses adaptive discriminator augmentation (ADA). StyleGAN, one of the most well-known image generations GANs, was first released by NVIDIA in 2018. It can generate thousands of synthetic face images based on training the real images. It demonstrated that the properties and the qualities of the images are the same as with the real images. For the best results, StyleGAN needs to be trained on tens of thousands of images and requires powerful GPU resources [21]. In 2020, NVIDIA released StyleGAN2 ADA, enabling new models to be cross trained from others. By starting with an existing high-quality model and resuming training with a different set of images, it is possible to get good results with a few thousand images and far less computing power [22,24]. The StyleGAN2-ADA [19] has two characteristics: generating high-resolution images using progressive growing [24] and incorporating image styles in each layer using adaptive instance normalization (AdaIN) [26]. For instance, 4x4 and gradually adding high-resolution generators and discriminators up to 2048x2048. The general architecture is shown below in Figure 2:
B. StyleGAN3 Architecture Overview
StyleGAN3, the most recent advancement in NVIDIA's StyleGAN series, brings forth a range of architectural enhancements over its predecessors, StyleGAN and StyleGAN2. One of the hallmark features of StyleGAN3 is its alias-free design. This design tackles the issue of aliasing, a common cause of visual artifacts in generated images, especially evident when these images undergo transformations like rotation or scaling. By ensuring that each operation within the generator network, from the initial input to the final output, is tailored to avoid aliasing, StyleGAN3 achieves a level of image consistency and clarity that is particularly beneficial for dynamic transformations.
Another key advancement in StyleGAN3 is its emphasis on temporal coherence, which is essential for applications such as video generation. This feature ensures that slight modifications in the latent space variables lead to smooth and natural transitions in the generated images, a critical aspect for producing realistic animations and videos. Complementing these features, StyleGAN3 continues to utilize a style-based generator architecture, which allows for precise manipulation of various image aspects by adjusting different elements of the model's latent space. This refined approach not only caters to the needs of alias-free generation but also enhances temporal coherence. Figure 3 shows the architecture of StyleGAN3:
Figure 3.
StyleGAN3 generator architecture.
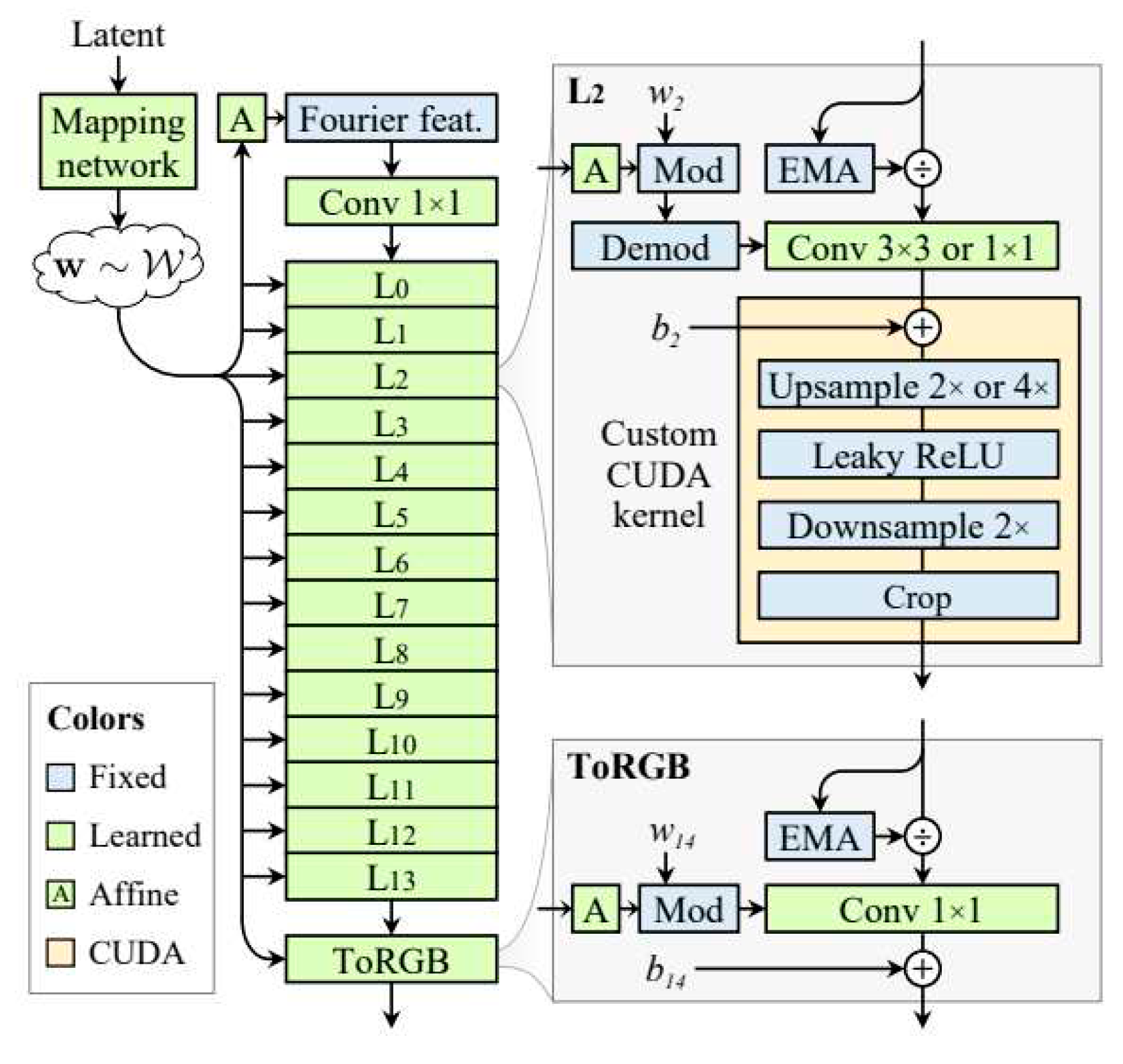
Moreover, StyleGAN3 builds upon the advanced training techniques introduced in StyleGAN2 and StyleGAN2-ADA. However, it shifts its focus towards eliminating aliasing artifacts, thereby fostering a more stable training process and yielding higher-quality image outputs. This combination of improved design and training methods positions StyleGAN3 as a groundbreaking tool in the realm of generative adversarial networks, especially for applications requiring high-quality, consistent imagery under a range of transformations.
Dataset
We have accumulated two publicly available datasets. Figure 3 shows sample images from both datasets:
•Polytechnic U [28] (DB1) has a total of 1610 images collected in an indoor environment with circular fluorescent illumination around the camera lens. The dataset contains both the left hand and right hand of 230 subjects. Approximately 7 images of each hand were captured for the age group of 12-57 years. The image resolution was 800x600 pixels.
•Touchless palm photo dataset [29] (DB2) consists of a total of 1344 images from 168 different people [8 images from each hand] taken with a digital camera at an image resolution of1600x1200 pixels.
The images in the dataset that our proposed approach StyleGAN2-ADA prefers to be square. Although there is no set restriction on source image scaling, in this study an image resolution of 512x512px was chosen to shorten the training period.
Training the Model with StyleGAN2-ADA
A. Preparing Datasets
To process with the progressive method, the dataset must be in (. tfrecords) format. An example script of StyleGAN2-ADA is provided by NVIDIA [18]. We have simplified the process. As left and right hands have different palm features such as principal lines and secondary lines, we have segmented the datasets in various formats such as (only Right-hand dataset, only Left-hand dataset, Dataset1 Right hand dataset with rest of the dataset, Dataset 2 Left hand dataset with rest of dataset) for better performance. However, it took different times to train each segment of the dataset. For example, Training Step 1 [Table 1] took a whole day. The rest of the training steps took one, three, three, and four days. The following steps we have segmented both for DB1 and DB2 to train the datasets:
B Training StyleGAN2-ADA
1) Device Selection: Our training time was approximately three weeks on a “Google Colaboratory” pro plus with 52 GB RAM and P100 GPU. The proposed model is trained for 500 epochs in a “Jupyter notebook” environment with much longer background execution times. After a certain period of training session each dataset from DB1, DB2 generated the model (. pkl) file. The (. pkl) file will be generate every 100 epochs. Once the training results obtained 512x512 pixels, we stopped the training and used the last (. pkl) file and saved it. In our dataset for training steps 1 and 2, we applied 200 epochs, and for steps 3, 4 and 5 we stopped training after 500 epochs. The epochs after 500 look similar, and there is no significant change. In Figure 4, Figure 5 and Figure 6, we present 35 generated palm print images over different epochs (0th, 200th, and 500th), to see the amount of diversity among the generated images (in terms of the position of the principal lines, the color of the palm print, and their contrast). The first training iteration appeared abnormal as they transitioned from the original images to a new one. Later in progress, the maximum number of iterations made a noticeable difference from the earlier iterations.
2) Generated Palm Print Images and hyperparameters: The truncation parameter, “trunc”, determines the amount of variations in the images. The default value of ’trunc’ parameter is ’0.5’. The value near to ’1.0’ will provide maximum accuracy compared with the original image. A Value of “1.5” provides significantly more diversity.
C Training StyleGAN3
Device Selection: For our StyleGAN3, we utilized a high-performance setup with a focus on efficiency and power. Training was conducted using a single NVIDIA GeForce RTX 4080 GPU, renowned for its advanced processing capabilities. The system was powered by an AMD Ryzen 9 5900X CPU, providing a robust computational backbone, and was equipped with 64GB of RAM, ensuring smooth operation throughout the training process.
Training Environment: We carried out our training in a Jupyter notebook environment, benefiting from its versatile and user-friendly interface. The system was tailored for extended periods of background execution, a critical factor in deep learning projects.
Training Configuration: Our model underwent a rigorous training regimen, structured as follows:
GPUs: 1 (NVIDIA GeForce RTX 4080), Batch Size: 4, Batch per GPU: 4, Gamma: 5.5, tuned for balancing the model's stability and image quality, Mirroring: Enabled (mirror=1), to augment the dataset with mirrored images, enhancing the diversity and robustness of the training data.
Total Training Iterations (kimg): 1000, ensuring comprehensive learning and adaptation
Snapshot Frequency (snap): 5, for regular saving and evaluation of model checkpoints
Training Procedure and Observation: The training process was extensive, divided into distinct phases to monitor and adjust the model's performance. Initially, the model was trained for 1000 epochs. We observed significant improvements in image quality and model stability throughout the training.
In our observation, we focused on the quality of the generated images, particularly in terms of their resolution, detail, and fidelity to the input data. We also monitored the training progress through periodic snapshots, taken every 5 epochs, which allowed us to closely track the model's evolution and make necessary adjustments.
Results and Analysis: The final phase of the training resulted in the generation of high-quality images, showcasing the effectiveness of the StyleGAN3 architecture and our training strategy. The model, saved as a (.pkl) file, demonstrated notable improvements in image quality, with enhanced resolution and more realistic texturing, a testament to the capabilities of the StyleGAN3 model and our tailored training approach.
This framework follows the pattern of your initial description but is adapted for the StyleGAN3 model with the specified configuration and training parameters.
Figure 7.
Training situation of the palm-photos (100 epochs).

Figure 8.
Training situation of the palm-photos (200 epochs).

Figure 8.
Training situation of the palm-photos (500 epochs).

Experimental Results
A. Filter out Unwanted Images
With the help of SyleGAN2-ADA, we have generated 21000 images with up to 500 iterations. The total input image from DB1 and DB2 is approximately 3439. During the training, based on ’palm marker’ and ’finger issue’ features, 111 unwanted images were generated. Some images have hard to detect palm markers, and some have overlapped two images in one. We have named it “Bad Quality Images”. In Table 2 we present how much and what type of images can have “Bad quality images” more: A sample of bad images have shown in Figure 8.
Figure 9.
Four types of irregular images: “total imbalance” “Finger issue” “Shadow in the images”, “Overlapped with 2 images”, “No palm marker”.
Figure 9.
Four types of irregular images: “total imbalance” “Finger issue” “Shadow in the images”, “Overlapped with 2 images”, “No palm marker”.
B. Elimination Method to Remove Unwanted Images
Many recent studies have found that local features are more effective in describing an image’s detailed and stable information [30,31,32,33,34]. Among these local features, Scale Invariant Feature Transform (SIFT) is one of the popular in the field of biometrics. The SIFT is a technique for extracting local features from an image that has various advantages: (1) SIFT features preserve invariance when images are rotated, scaled, and illuminated; (2) SIFT features maintain a certain level of stability when viewpoint changes, affine transformation, and robustness to noise; (3) SIFT features are unique and informative. To eliminate the unwanted images, we have applied scale-invariant feature transform (SIFT) based image processing method. This method detects the key points of the images which can explains with the descriptors. The method works with the following equations:
X= {x11, .......xij} = Test sample Images
Y = {y11, .......yij} = Training sample
Where xij, yij are pixels at the image positions. The Euclidean distance between testsamples X and train samples Y as denote as D (X, Y):
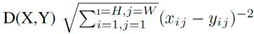
Where H, W is the height and width of the test images respectively. The training samples should have the same size as the test sample. To focus the region of interest (ROI) (in our case it is hand palm) we have fixed resized all the images into 205X345 pixels. As this method detects the principal lines of the palm images. It works by detecting and calculating gradient image intensity at each pixel in an image. We have calculated the pixel ratios of the images. For instance, d1, d2 respectively be the distances between a and b1, a and b2. We then calculate the ratio of d1, d1.
Ratio = d1/d2 > 0.5
Figure 10.
(a) Resized ROI image of Palm and (b) detected principal lines.
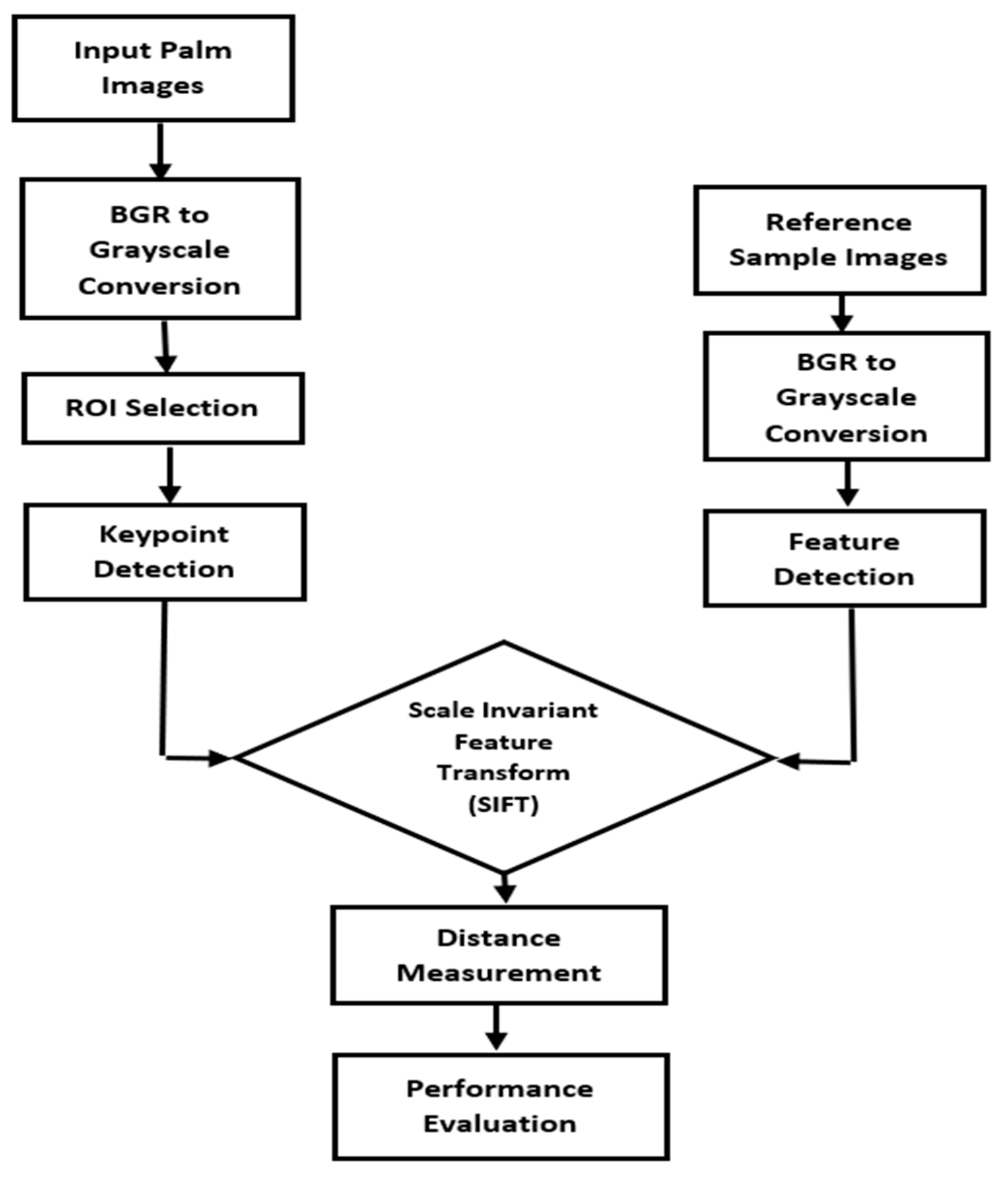
We have restricted the images in our dataset that do not detect the principal lines and filtered them out from the dataset with a ’score value.’ If the ratio value crosses the value of 0.5, it is a well-matched image pair for SIFT features. Figure 10 shows the palm’s scaled and resized images (ROI). The flowchart in figure 11 below represents how the SIFT algorithm works from input images to performance evaluations. Both test and 10 reference images must go with the converted BGR image to Grayscale image. After ROI the SIFT algorithm approached and later distance measurement worked, here we have used Euclidean distance.
Performance Measurement
For StyleGAN2-ADA we have separated the “good” and the “bad” images into two classes from the total number of 3439 synthetic images. As there are 114 bad images, we have selected five different categories, and the rest, 3325, are good images. To get the proper number of quality images we have fed both the ‘good” images and “bad” images into our test script. To assure more we have scaled a number of grade points “5” to across the quality. With several reference images with proper principal lines, wrinkles, and secondary lines we tested our good images first. From the ground truth of 3439 images, we got 3297 those images passed the score level of “5”. The rest of the 142 images didn’t pass the score level of “5”. From the 111 “Bad images” 97 images didn’t pass the score level “5”. The other 14 which passed the threshold limit of ’5’, so we count as good images. The script for google colab link provided here: (https://github.com/rizvee007/palmphoto/blob/main/sift_algorithm_for_fingerprints.py) .For calculating F score we got Precision (0.99) and Recall (0.96). So, we have got Fscore which is (0.97).
Figure 11.
Elimination flowchart for filtering unwanted images using SIFT algorithm.
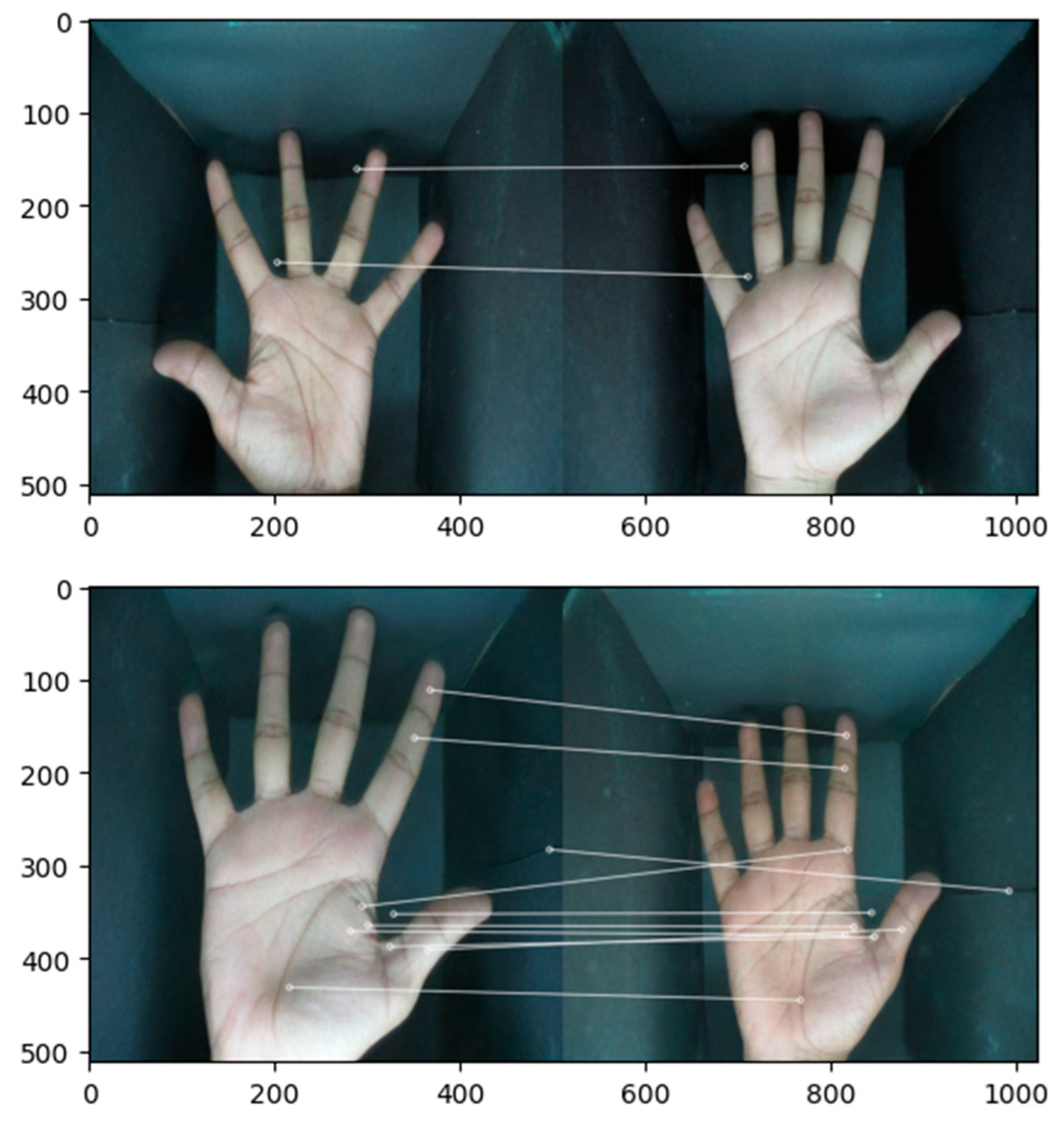
To ensure the uniqueness of synthetic palm images, we implemented the SIFT (Scale-Invariant Feature Transform) algorithm in our database for both StyleGAN2-ADA and StyleGAN3. We randomly selected pairs of images and compared them using the SIFT feature extraction. The output score represents the calculated similarity score between the key points and descriptors obtained from the SIFT algorithm. Specifically, we used to compute matches between two images, identified by their indices in the image List, based on their respective key points and descriptors. The score was calculated as a percentage, considering the number of matches, and the total number of key points in each image. We performed this process iteratively ten times, each time with different randomly selected images. The consistent similarity score of 19.55% across these comparisons indicates that all the images are distinct, reinforcing the uniqueness of the synthetic palm images in our database. Figure 12 shows comparison results, and the table shows the comparison results of 10 pairs.

Table 4.
Different training steps with different segment of Datasets.
| Tests | Pairs | Similarity Score | Average |
|---|---|---|---|
| 1 | 112, 106 | 39.58% | 19.55% |
| 2 | 35,84 | 10.20% | |
| 3 | 77, 96 | 14.29% | |
| 4 | 2,21 | 3.84% | |
| 5 | 27,119 | 35.22% | |
| 6 | 54,57 | 0.00% | |
| 7 | 5,3 | 8.33% | |
| 8 | 88,52 | 9.86% | |
| 9 | 90,76 | 31.70% | |
| 10 | 24,67 | 42.5% |
Figure 12.
Using SIFT feature extractor to compare random original image with generated images from StyleGAN3.
Figure 12.
Using SIFT feature extractor to compare random original image with generated images from StyleGAN3.
Conclusion
In this study, we utilized the sophisticated capabilities of StyleGAN3 to develop an advanced model for generating synthetic palm images. This approach not only elevates the realism of the generated images but also addresses a key challenge in biometric authentication: creating unique and distinguishable palmprint images.
To confirm the uniqueness of these synthetic images, we integrated the SIFT (Scale-Invariant Feature Transform) algorithm into our evaluation framework. Renowned for its effectiveness in feature extraction, this methodology was crucial in our analysis. We conducted various tests wherein pairs of images from our generated dataset were randomly selected and compared for similarities. This involved to assess matches based on key points and descriptors as identified by the SIFT algorithm.
The results, summarized in our table, consistently showed a low similarity score across various image pairs. An average similarity score of 19.55% clearly indicates the distinctness of each image produced by our StyleGAN3 model. This low average score signifies the high variability within the dataset, ensuring that each synthetic palmprint is unique and not a mere duplication.
Such findings are not only pivotal in demonstrating the effectiveness of StyleGAN3 in generating diverse images but also serve as a critical benchmark for future developments in this field. The capability to produce a wide range of unique palm images is immensely valuable in enhancing datasets for palmprint recognition tasks, thus contributing to the progression of biometric authentication technologies.
Looking ahead, we intend to expand our dataset and release it to the public. This initiative will not only encourage wider research in the domain but also enable more comprehensive testing and refinement of recognition algorithms. By making our dataset publicly available, we aim to inspire collaboration and innovation within the community, leading to more accurate and secure biometric systems.
References
- H. K. Kalluri, M. V. Prasad, and A. Agarwal, “Dynamic roi extraction algorithm for palmprints,” in International Conference in Swarm Intelligence, pp. 217–227, Springer, 2012.
- Joshi, D.G.; Rao, Y.V.; Kar, S.; Kumar, V.; Kumar, R. Computer- vision-based approach to personal identification using finger crease pattern. Pattern Recognit. 1998, 31, 15–22. [Google Scholar] [CrossRef]
- Wong, M.; Zhang, D.; Kong, W.-K.; Lu, G. Real-time palmprint acquisition system design. IEE Proc. -Vis. Image Signal Process. 2005, 152, 527–534. [Google Scholar] [CrossRef]
- Zhang, D.; Kong, W.-K.; You, J.; Wong, M. Online palmprint identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1041–1050. [Google Scholar] [CrossRef]
- B. Bhanu, A. Kumar, et al., Deep learning for biometrics, vol. 7. Springer, 2017.
- Ozdenizci, O.; Wang, Y.; Koike-Akino, T.; Erdogmus, D. Adversarial deep learning in eeg biometrics. IEEE Signal Process. Lett. 2019, 26, 710–714. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, D.; Lu, G.; Luo, N. A novel 3-d palmprint acquisition system. IEEE Trans. Syst. Man Cybern. -Part A Syst. Hum. 2011, 42, 443–452. [Google Scholar] [CrossRef]
- Krishneswari, K.; Arumugam, S. A review on palm print verification system. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. (IJCISIM) 2010, 2150–7988. [Google Scholar]
- Rahman, M.S.; Haffari, G. A statistically efficient and scalable method for exploratory analysis of high-dimensional data. SN Comput. Sci. 2020, 1, 1–17. [Google Scholar] [CrossRef]
- Jia, W.; Huang, D.-S.; Zhang, D. Palmprint verification based on robust line orientation code. Pattern Recognit. 2008, 41, 1504–1513. [Google Scholar] [CrossRef]
- Luo, Y.-T.; Zhao, L.-Y.; Zhang, B.; Jia, W.; Xue, F.; Lu, J.-T.; Zhu, Y.-H.; Xu, B.-Q. Local line directional pattern for palmprint recognition. Pattern Recognit. 2016, 50, 26–44. [Google Scholar] [CrossRef]
- Fronthaler, H.; Kollreider, K.; Bigun, J. Automatic image quality assessment with application in biometrics. in 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), pp. 30–30, IEEE, 2006.
- Kalka, N.D.; Zuo, J.; Schmid, N.A.; Cukic, B. Image quality assessment for iris biometric,” in Biometric technology for human identification III, vol. 6202, pp. 124–134, SPIE, 2006.
- F. Mokhayeri, E. Granger, and G.-A. Bilodeau, “Synthetic face generation under various operational conditions in video surveillance,” in 2015 IEEE International Conference on Image Processing (ICIP), pp. 4052–4056, IEEE, 2015.
- K. Bahmani, R. Plesh, P. Johnson, S. Schuckers, and T. Swyka, “High fidelity fingerprint generation: Quality, uniqueness, and privacy,” in 2021 IEEE International Conference on Image Processing (ICIP), pp. 3018–3022, IEEE, 2021.
- E. Tabassi and C. L. Wilson, “A novel approach to fingerprint image quality,” in IEEE International Conference on Image Processing 2005, vol. 2, pp. II–37, IEEE, 2005.
- Bharadwaj, S.; Vatsa, M.; Singh, R. Biometric quality: a review of fingerprint, iris, and face. EURASIP J. Image Video Process. 2014, 2014, 1–28. [Google Scholar] [CrossRef]
- T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and improving the image quality of stylegan,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8110–8119, 2020.
- Kim, J.; Hong, S.-A.; Kim, H. A stylegan image detection model based on convolutional neural network. J. Korea Multimed. Soc. 2019, 22, 1447–1456. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. Styleclip: Text-driven manipulation of stylegan imagery. in Proceed-ings of the IEEE/CVF International Conference on Computer Vision, pp. 2085–2094, 2021.
- S. Minaee, M. Minaei, and A. Abdolrashidi, “Palm-gan: Generating realistic palmprint images using total-variation regularized gan,” arXiv preprint arXiv:2003.10834, 2020.
- T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4401–4410, 2019.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- K. Kurach, M. Lucic, X. Zhai, M. Michalski, and S. Gelly, “The gan landscape: Losses, architectures, regularization, and normalization,” 2018.
- G. Liu, L. F. Schneider, and S. Yuan, “Pianogan-generating piano music from magnitude matrices (generative modeling),”.
- Jain, Y.; Juneja, M. Ridge energy based human verification using iris. Int. J. Trend Res. Dev. 2018, 5, 30–36. [Google Scholar]
- G. Chaudhary, S. Srivastava, and S. Bhardwaj, “Multi-level fusion of palmprint and dorsal hand vein,” in Information Systems Design and Intelligent Applications, pp. 321–330, Springer, 2016.
- Coelho, L.P.; Kangas, J.D.; Naik, A.W.; Osuna-Highley, E.; Glory-Afshar, E.; Fuhrman, M.; Simha, R.; Berget, P.B.; Jarvik, J.W.; Murphy, R.F. Determining the subcellular location of new proteins from microscope images using local features. Bioinformatics, 2013, 29, 2343–2349. [Google Scholar] [CrossRef] [PubMed]
- R. K. Saha, A. Chowdhury, K.-S. Na, G. D. Hwang, Y. Eom, J. Kim, H.-G. Jeon, H. S. Hwang, and E. Chung, “Ai-based automated meibomian gland segmentation, classification and reflection correction in infrared meibography,” arXiv preprint arXiv:2205.15543, 2022.
- A. M. M. Chowdhury and M. Imtiaz, “Computational Intelligence for Solving the Biometric Enrollment Issue”. Mathematics Conference and Competition of Northern New York (MCCNNY2022).
- A. M. Chowdhury, F. B. Kashem, A. Hossan, and M. M. Hasan, “Brain controlled assistive buzzer system for physically impaired people,” in 2017 International Conference on Electrical, Computer and Communication Engineering (ECCE), pp. 666–669, IEEE, 2017.
- A. Hossan and A. M. Chowdhury, “Real time eeg based automatic brainwave regulation by music,” in 2016 5th international conference on informatics, electronics and vision (iciev), pp. 780–784, IEEE, 2016.
Figure 2.
General architecture of StyleGAN2 ADA [27].
Figure 2.
General architecture of StyleGAN2 ADA [27].
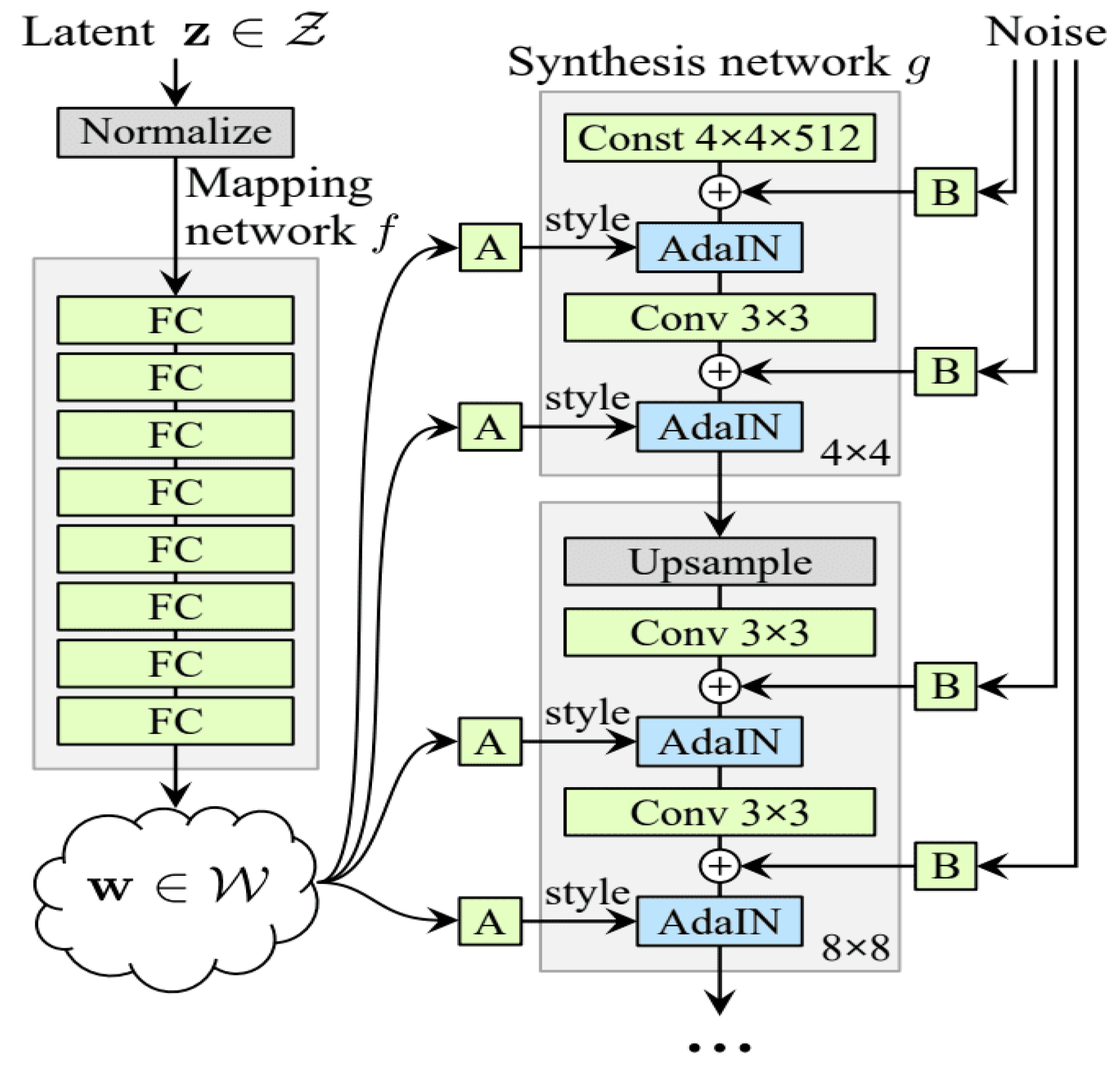
Figure 4.
Initial training situation of the palm-photos (00 epochs).
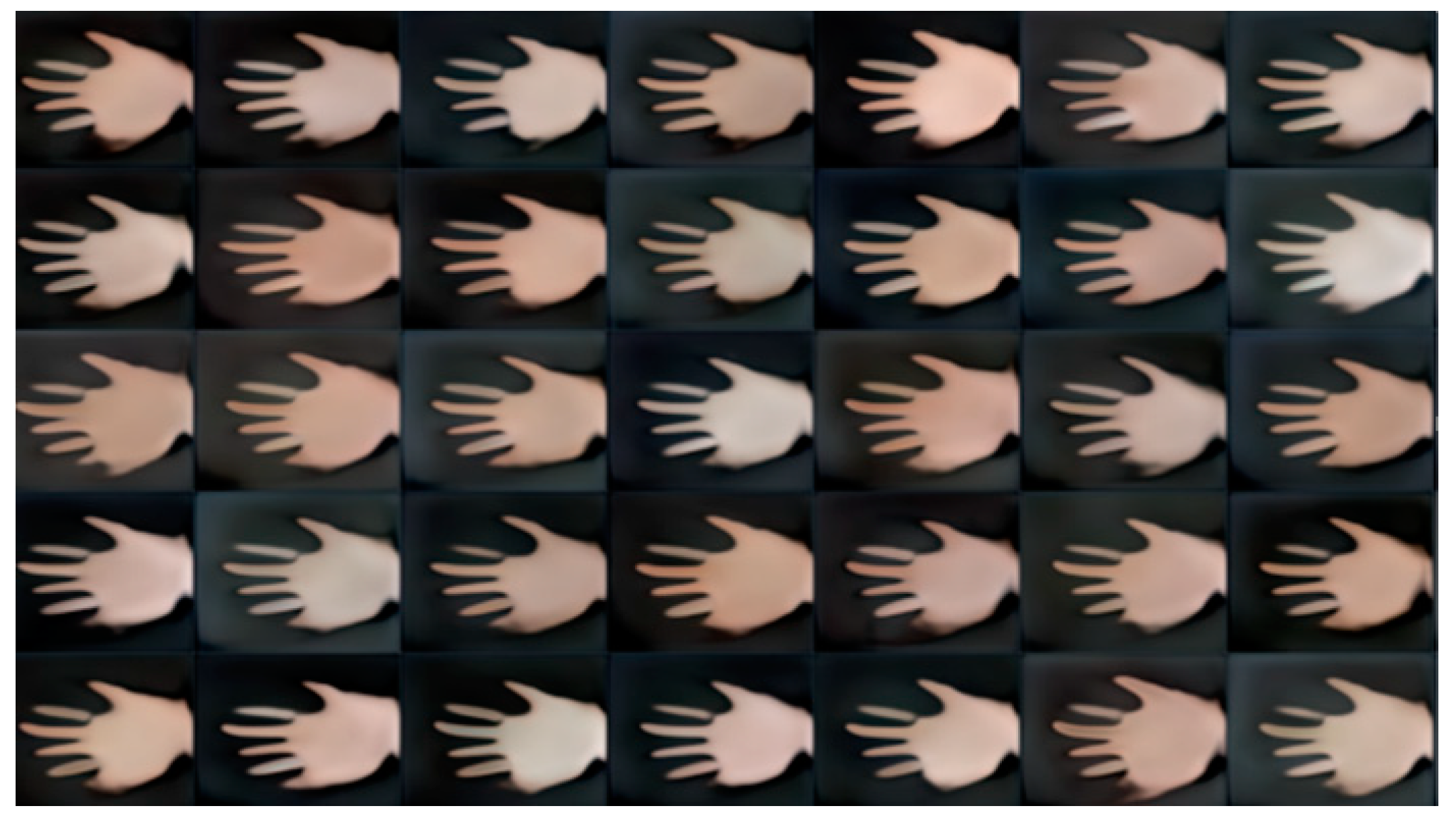
Figure 5.
Training situation of the palm-photos (200 epochs).
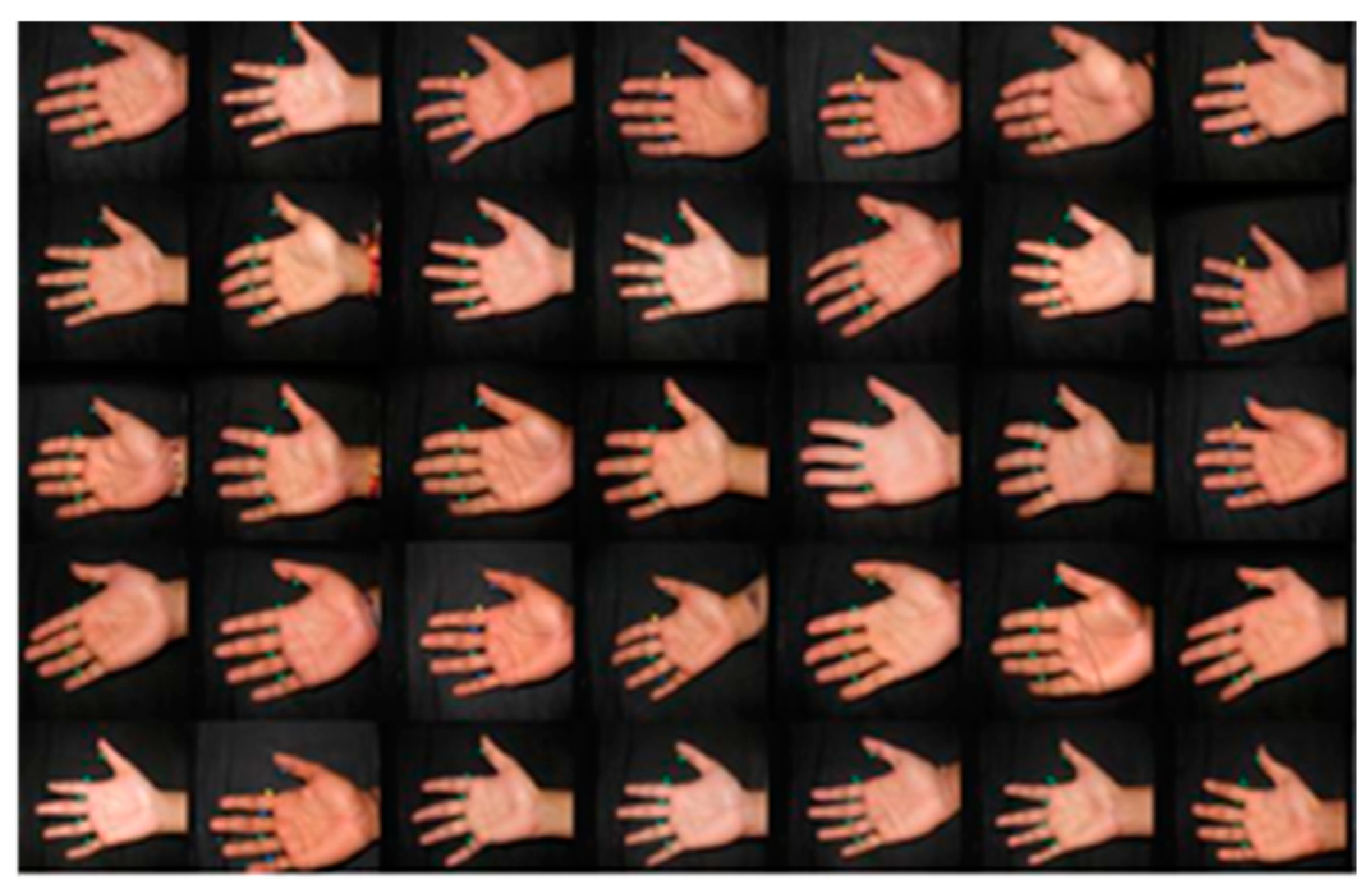
Figure 6.
Training situation of the palm-photos (500 epochs).

Table 1.
Different training steps with different segment of Datasets.
| Training Steps | Datasets |
|---|---|
| 1. DB1 Right Hand | 960 Images |
| 2. DB1 Left Hand | 960 Images |
| 3. DB1(Right Hand) + DB2 | 2304 Images |
| 4. DB1(Left Hand) + DB2 | 2304 Images |
| 5. DB1+DB2 | 2954 ges |
Table 2.
Types of “Bad quality images”.
| Name of the Images | Numbers |
|---|---|
| 1. Shadow on the palm | 41 |
| 2. Total Imbalance | 23 |
| 3. Overlap with two palms | 21 |
| 4. Finger Issue | 15 |
| 5. No palm marker | 11 |
| 6. Total | 111 |
Table 3.
Representation the number of image categories based on their score level.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



