
Submitted:
25 December 2023
Posted:
26 December 2023
You are already at the latest version
Abstract
The Internet of Things (also known as IoT), a revolution, has enhanced the relevance of mobile employees' job efficiency in mobile crowd sensing (MCS). Incentives based on reputation for mobile workers (MW) play an important role in increasing service utilization, motivating mobile employees, and developing confidence in the service. The cell phone is the most exploited entity in mobile crowd-sensing MCS and cloud computing. In the underlying investigation, we observed that they had not evaluated the complexity level of a task, resulting in a strong reputation for executing multiple basic tasks. A person who completes a tough task may have a lower reputation score. Complexity levels of tasks (CLT) were developed for reputation evaluation on a crowd-sensing network, which would be utilized to evaluate the MW reputation. We offered simple and complex levels of challenges to assess reputation scores. Tasks receive incentives based on their reputation. By measuring reputation on (CLT) complexity level of task, this research will help the system to Maintain the reputation of the mobile worker so that entities of the system get the maximum benefit out of it, by hiring well-reputed mobile workers and MW receive an incentive on it. Furthermore, we conduct a comparative analysis between our scheme and various machine learning algorithms to identify the algorithm that best performs in evaluating task complexity. Considering both the simple and complex reputation scores, the comparison suggests that after analyzing the data, it is clear that the CLT (proposed) scheme and the Linear regression scheme not only outperformed the Neural Network scheme in terms of Complex Reputation Scores but also in terms of Simple Reputation Scores. We also apply statistical tests, such as p-tests and t-tests, to determine the significance of the results obtained from different algorithms. Considering MW 308, MW 345, and MW 1045's efforts and abilities, the MCS system may offer incentives and awards to further motivate and consider their continuing contributions. This reputation-based incentivization technique not only encourages strong competition among mobile workers, but also makes sure the delivery of high-quality services inside the MCS system.
Keywords:
Internet of Things (IoT)
; mobile crowd sensing (MCS)
; Complexity Level
; Feedback
1. Introduction
The revolutionary advancement of technology and Internet of Things devices has enhanced the necessity of mobile crowd sensing. Sensors, smartwatches, smartphones, and wearable gadgets [1] are examples of Internet of Things (IoT) technologies that have been widely employed in recent years. The rise of IoT has altered both possibilities and difficulties. Because billions of gadgets and humans collaborate, trust is also demanded from services that are supplied. In this paradigm, the cell phone is a necessary thing. The cell phone is the most exploited entity in mobile crowd sensing MCS and cloud computing.
The availability of wireless sensors has increased the mobility of MCS computing and sensing, leading to the exploitation of mobile phone technology. The ubiquitous availability of mobile phones enables the general population to access wireless services [2].
System Model. The mobile crowd-sensing system consists of the following three main entities, as shown in Figure 1[3].
Crowd sensing Users: They are the participants who acquire sensory data with their own mobile-enabled devices (such as intelligent terminal equipment, wearable equipment, and automobile equipment). Crowd-sensing users complete sensing activities and earn the greatest money by sending sensing data to the mediator over mobile network. Consistent engagement will aid in the acquisition of further reputation rewards.
Service Providers: Due to the varying demands of service consumers, service providers are responsible for engaging in final aggregated data transactions and delivering various services to clients. The aggregated sensing data from the service provider is then utilized for machine learning, data visualization, and other investigations. A sensible service provider wants higher-value data from a mediator at an affordable price. To lower purchasing prices, the service provider may opt to share the data with other providers who share the data in order to average the overall expenses.
Mediators. They exchange information with both sensing users and service providers. The mediator offers the sensing job to mobile crowd-sensing users and uses a hybrid incentive mechanism to encourage additional users to upload their encrypted sensing data under the privacy protection mechanism, which combines differential privacy and homomorphic encryption. In exchange for monetary incentives, the mediator gathers and sells sensory data to service providers.
MCS mobility workers (MW) are employed to sense data in mobile crowd-sensing networks. On the contrary, the technique in [4] offers both advantages and drawbacks in terms of sensing quality. This is referred to as participatory sensing. Crowd contributors give services and, as a result, expect to be compensated. An incentive system that motivates network participants to contribute to extraordinary sensing. Because of mw's selfish behavior, significant incentive mechanisms have been established.
The contribution of untrustworthy individuals in CSN is dubious. Several methods to the issue were proposed in the literature by various scholars. Solutions for many areas (for example, received data veracity, delay, and report) were studied. Effective reputation-based techniques were taken into account in several aspects, which represents a breakthrough in high-quality data sensing. The author recommended two approaches: concentric and vote-based [4]. In contrast, we saw Literature as aiding in the achievement of reputation quality. Reputation, Quality aware Recruitment for Platform (RQRP) [5] and a decentralized solution based on block chain [6] both gave reputation scores based on user feedback. MCS is a forerunner to participatory sensing, which has different implicit and explicit involvement qualities. Data is obtained from multiple sources (for example, social networks and mobile sensing) by integrating human and machine intelligence [7]. MCS has a number of well-known applications, including traffic flow monitoring [8]. We presented this technique to reduce the reputation gap depending on work complexity. In this paper, we describe a reputation-based strategy based on task complexity (CLT). We offered simple and complex levels for measuring reputation score. Tasks are rewarded based on their reputation. Task complexity has an impact on a mobile worker's reputation. The Service provider will categories tasks based on complexity so that mobile employees have a clear image in mind for rewards. This increases faith in the system.
1.1. RESEARCH QUESTIONS
Following are the questions which are formulated for our research purpose:
- Which task of complexity level affects the reputation of a mobile worker?
- How is the reputation score affect the incentive of Mobile Workers?
1.2. PROBLEM STATEMENT
Existing schemes have considered the frequency of tasks performed for reputation and incentive calculation however, the complex level of a task, is highly ignored.
1.3. RESEARCH OBJECTIVES
- To identify the effect of the Complexity level of a task on the reputation of a mobile worker.
- To study the effect of post-quality parameters on incentives.
1.4. RESEARCH GAPS
In the existing literature, a lot of work is provided for Reputation and Incentive based schemes. However, there are still gaps in literature. These Gaps are:
The following are specific contributions of this study:
- We addressed a critical challenge in mobile crowd sensing (MCS) by focusing on how to encourage mobile workers to undertake jobs of varied levels of complexity. This is important since present incentive systems usually lack to account for complexity, resulting in lower-quality data collecting. Our contribution is significant since we highlighted the need of considering task complexity when motivating mobile workers.
- Innovative recruitment strategy: We created a one-of-a-kind way for recruiting qualified mobile workers based on their reputation and work-related requirements. We created a recruiting method that successfully values high-quality individuals by taking feedback and reputation feedback into account. This contribution ensures that qualified mobile workers are hired and underlines the importance of feedback in the selection process.
- Machine learning scheme comparison: In addition to our scheme, we carried out a detailed comparison with other machine learning-based schemes implemented in MCS. The purpose of this analysis was to evaluate the outcomes and effectiveness of various strategies. We gave insights into the benefits of each technique by analyzing aspects such as task allocation efficiency, data quality, and participant happiness.
This thesis is organized as follows. In section 2, Literature review is discussed. In section 3, the proposed methodology is presented. In section 4, the results obtained from the proposed method are analyzed. Finally, in section 5, the conclusion is presented about work and also future work is discussed.
2. SYSTEMATIC LITERATURE REVIEW
A systematic literature review (SLR) finds, chooses, and critically examines material to address a specific topic. The literature review should adhere to a well-established procedure or strategy where the criteria are specified explicitly before the review is undertaken. It is a thorough, transparent search of many databases and grey literature that other scholars may imitate and reproduce. It consists of developing a very well search strategy that has a specified emphasis or solves a particular query. The study reviews the sort of information sought, evaluated, and submitted within specified deadlines. In this research, some search protocols are defined. Then strings are developed using synonyms of each keyword. Also, a search strategy is discussed. Inclusion/exclusion criteria are defined. Duplications are removed. Title-based filtering, abstract-based filtering, objective-based clustering, quality assessment, and detailed literature is discussed.
2.1. SEARCH STRATEGY
The foundation of systematic review is a well-crafted search strategy. Most of the papers that were selected using the search strategy will be evaluated for inclusion and eligibility. The systematic literature review’s search strategy consists of the following methods:
2.1.1. SEARCHING PROTOCOL
Figure 3 shows that these years (2018, 2019, 2020, 2021, and 2022) are selected for search. Synonyms of each keyword are used to search papers on different databases. Mainly three databases (i.e., IEEE, Springer, and Elsevier) are used for the selection of papers. However, papers from different databases are also included. Only 5 papers are selected against a string.
2.2. STRINGS DEVELOPMENT
For the development of strings, synonyms of each keyword and Boolean operators are used.
2.2.1. RESEARCH QUESTIONS
RQ1.
Which task of difficulty level affects the reputation of a mobile worker?
RQ2
What is the reputation score effect on the incentive of Mobile Workers?
- STRING DEVELOPMENT FOR RQ1
For the first research question, the following search string was used:
((“Tasks Difficulty” OR “Reputation Score” OR “Task complexity” OR “Reputation”))
- b
- STRING DEVELOPMENT FOR RQ2
For the second research question, the following search string was used:( “Reputation” OR “Incentive” OR “Reputation” OR “Reward”) AND (“Incentive-based techniques” OR “Incentive-based Approach” OR “Incentive-based methods”))
2.3. SELECTION OF PUBLICATION
The following subsections outline the factors used to determine which publications to use for the systematic literature review:
2.3.1. INCLUSION CRITERIA
Everything a study needs to be included is listed in the inclusion criteria. Which piece of literature retrieved by the search string would be utilized for data gathering was decided upon using inclusion criteria. Below are the requirements:
- Publication should answer the question
- Title should be of related topic
- Papers should be published in journal and conference
- Paper of five years (2018 to 2022) should be included
2.3.2. EXCLUSION CRITERIA
Exclusion criteria are the elements that would exclude a study from inclusion. Below are the exclusion criteria that used to eliminate the publications returned by search string.
- Books, thesis, newspaper, and unpublished work is not included
- Papers in other language are not included
2.4. FILTERING
There are two stages of filtering. First phase is title-based filtering and the second phase is abstract-based filtering.
2.4.1. TITLE-BASED FILTERING
Read the title and then include those papers that are relevant to the topic and exclude papers that are irrelevant papers.
2.4.2. ABSTRACT-BASED FILTERING
After applying title-based filtering, read the abstract of the papers then include those papers which are relevant to the topic and exclude irrelevant papers. Figure 4 depicts the search strategy. According to this strategy, the research question is defined. Then strings are developed using synonyms of each keyword. Inclusion/exclusion criteria are defined. The thesis, books, newspapers, and unpublished work are not included.
Duplications are removed. Three databases IEEE, Springer, and Elsevier are used to select the literature papers. Papers of five years are selected. A total of 30 papers are selected from IEEE,10 papers are selected from Springer, 8 papers are selected from Elsevier, and 18 papers are selected from ACM of different journals. After that, title-based filtering and abstract-based filtering are performed on selected papers. After title and abstract-based filtering 24 papers remain from IEEE, 3 papers from Springer, 1 paper from Elsevier, and 14 remain from ACM.
2.5. OBJECTIVE BASED FILTERING FOR COMPLEXTY LEVEL TASKS
After title and abstract-based clustering, find the objectives of research papers and make filtering of the objectives as shown in Table 2. The objectives of the papers are as follows: Reputation score, Incentive, Privacy, and Complexity level.

Table 1.
Objective-based filtering.
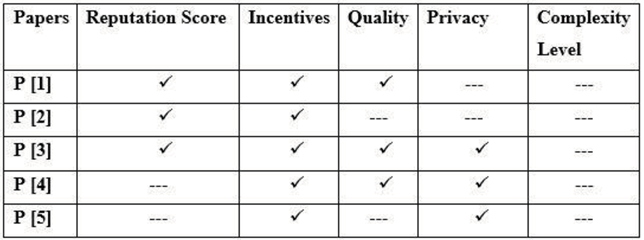 |
2.6. RELEVANCE ASSESSMENT
The relevance evaluation (RA) criteria of chosen research are created utilizing the Kitchehem and Charters standards [14].
The following Quality questions (QQ) are used to determine RA:
QQ1:
Is the study's goal/objectives described clearly?
QQ2:
Is the study intended to attain certain goals?
Q3:
Are the study's findings and outcomes well described?
QQ4:
Is the research adequately referenced?
Individual research RA is done using quality points that are based on the following rules:
- RULE1: If the selected research responds to the quality inquiry, its score
- RULE2: If a research only partially addresses the quality question, its score is 0.5.
- RULE3: If the chosen research does not respond to the quality question, its score is 0.
Table 3 shows the assessed relevance of each selected study.
Because the RA score is acceptable for all investigations, none of the studies were rejected because of it.
- Low: If total points <=1
- Medium: If total points=>1<=2
- Good: If total points=>2<=3
- Excellent: If total points=>3=4
Table 2.
Assessed relevancy of each selected study.
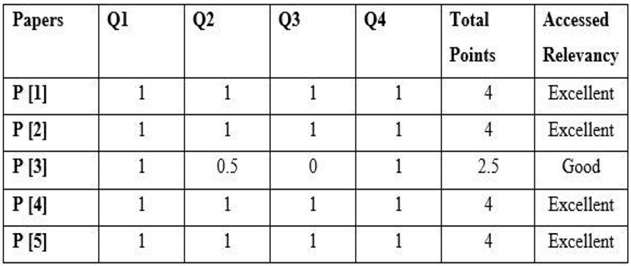 |
2.7. DETAILED LITERATURE
In the literature, data was gathered to get appropriate results. Calculations in certain study methodologies were based on the average of the stated task, with no adequate credibility and participation. Rewards were granted but not on the contribution level (sensors). In [5, 9], the authors proposed reputation quality aware recruitment (RQRP) as a framework for enabling high-quality reporting in mobile crowd sensing. They structured the plan into two parts: pre-quality measures and post-quality measures. Incentives are offered to mobile workers (MW) to maximize profit in IoT based on mobile quality reporting. According to [4,[4,] RQRP is broken into two major stages: filtering MW selection and checking the accuracy of reported tasks. The emphasis in the former is on selecting the best MWs based on a variety of parameters (such as reputation, a bid, anticipated quality, and forecast platform usefulness), whereas the emphasis in the latter is on incentives, sensing quality verification, and reputation score evaluation. Sensors for mobile apps collect data in an inefficient and costly manner in the crowd sensing network. Data is gathered from all devices and members, such as consumers, service providers, and data-gathering devices. To deal with all CNS members, centralized procedures are employed, which poses a significant security risk and makes privacy vulnerable to attack. In [6] and [10], the approach is decentralized and relies on block chain. The incentives are used to encourage mobile employees and data consumers to participate actively in network usage. They employed the advanced encryption standard AES (28) method to address privacy leakage concerns. A reputation framework was also implemented to assess misleading data and resolve other problems. The reputation system was built to solve issues such as the accuracy of data, fake reviews, and entity conflicts [5]. The method encourages data use by delivering accurate, consistent, and reliable data through the registration of reviews. Gas usage and string length are used to evaluate reputation. For network users and mobile workers, there is no suitable standard mechanism for incentive distribution. According to [24], the following MCS characteristics prevent existing incentive mechanisms from effectively encouraging users' active involvement and service contributions in multi-service exchange: lots of heterogeneous users have asymmetric service requirements; workers can choose their participation levels and sensing tasks; and several sensing tasks have heterogeneous values that may be falsely announced by the that corresponds requesters. To overcome this challenge and provide selected fairness, honesty, and limited efficiency while minimizing platform load, a green Stackelberg-game incentive system is created. To begin, the multi-service exchange issue is modelled as a Stackelberg multi-service exchange game with multiple leaders and many followers. In this game, every requester takes the role of a leader and chooses the reward announcement approach, which determines the payout for each sensing job.
Following that, each worker operates as a follower and chooses the sensing plan strategy that would maximize her utility. Current content-sharing methods are ineffective when it comes to personalized data sharing. On the basis of mobile crowd sensing, they devised a socially aware personalized content-sharing method. The first objective was to implement [11], which was to implement a two-stage pricing mechanism between the user and the service provider. Subgame perfect Nash equilibrium NE [10] and [12] of suggested game effective pricing method were solved. Two algorithms, Pareto optimal NE and Are developed, were utilized. They employ stochastic network models as well as real-world data sets. The downside of this strategy is that a third party is engaged in the uploading of personal content. It is difficult to avoid malicious individuals and untrustworthy task requesters in monetary incentive structures. Quality-aware incentive systems are unable to protect participants' anonymity, and data quality is not assessed. We evaluated PACE using a real-world dataset to demonstrate its usefulness and efficiency in [13]. The assessment and analysis outcomes show that PACE can prevent task respondents' and task requesters' aggressive conduct while also preserving privacy and measuring task participant data quality. They also suggested a zero-knowledge methodology for estimating data dependability [14], and real-world data sets were employed. The monetary rewards are the same as the data quality is the same.
Mobile crowd sensing is frequently employed in data collection and analysis. To address this issue, the authors of suggested a quality-based truth estimation approach and a surplus sharing mechanism in [15]. The unsupervised learning approach [16] is used to assess data quality and reputation by removing anomalies. Consider excess as a sharing game and suggest a shapely value best approach for each user's payment. In mobile crowd sensing MCS devices are equipped with sensors for data collection but ambiguities are seen in the data. Action-based techniques are widely used in incentive mechanisms but they have lots of challenges. In [17], addresses the effective task participant matching by, Completed task maximization, clearance rate (CR). They proposed a new bidding procedure for task allocation based on reputation aware auctioning [18]. For budget transfer, an intuitive look back method was used. Tasks with few bids should be given higher priority for completion. Introduced task returned and examined elements to complete further duplicate task assignments. It increases the clearance rate but decreases bidders for task accomplishment. According to research [19], Incentive-G is a game-based incentive system designed to efficiently attract mobile users while also boosting the reliability and quality of sensing data against untrustworthy or malicious users. The Incentive-G system comprises numerous design steps, including sensing data analysis, defining mobile user reputations, and assuring data quality and reliability through task group voting. This method employs a two-stage Stackelberg game to analyses the reciprocal relationship between service providers and mobile consumers, followed by backward induction to optimize incentive benefits. Our study demonstrates that determining the optimum data-provision techniques for mobile users helps prove the existence and uniqueness of the Stackelberg equilibrium. The results show that the Incentive-G mechanism may greatly incentivize mobile users to donate their efforts and optimize income for game-based crowd-sensing services. Uses social network influence propagation to aid in the recruitment of MCS workers. We begin by selecting a group of social network participants as initial seeds and assigning MCS tasks to them. Then, affected users who accept assignments are hired as workers, with the ultimate objective of increasing coverage. To be more specific, we present two methods, Basic-Selector and Fast-Selector, to pick a near-optimal collection of seeds. Basic-Selector uses an iterative greedy approach based on projected mobility, which has high performance but is inefficient. Fast-Selector, which is based on the interdependence of geographical placements among friends, is proposed to speed up the selection process[20]. However,[21] most quality-aware reward systems do not adequately secure task participants' privacy. Furthermore, these methods are intended for common MCS application situations in which data is collected by internal sensors integrated into participants' cellphones and are not appropriate for situations in which data is collected by additional sensors other than internal sensors (e.g., household medical devices).
Malicious players might In situations with several sensors, false sensing data is used instead of gathering data from additional sensors, indicating that the reliability of sensing data cannot be guaranteed. We propose P2 SIM, a privacy-preserving and source-reliable incentive mechanism scheme for MCS with extra sensors, to overcome these challenges. To provide source reliability verification of sensing data while maintaining participants' anonymity, we utilize a reachable signature with a private hash function. Furthermore, to increase the flexibility of incentive distribution, awards are separated into two categories: fixed rewards and floating rewards. In this research [22], we analyses a scenario If worker arrivals are unevenly distributed and job quality rises in line with the rule of decreasing margins of employee effort. We propose a quality-based online task-bundling reward system (QOTB). The purpose of the design is to increase social welfare while achieving work quality criteria to the maximum degree feasible. We apply Mental Accounting Theory at QOTB to build accounts for job execution profitability and reward, which are then used to determine workers' willingness to participate. We utilize task bundling to encourage employees to modify their initial travel plans in order to balance task participation depending on the popularity of task locations as well as the expense of travel. Furthermore, current systems tend to assign more work to people with high reputations, leaving fewer tasks for new users with poor reputations. To overcome these deficiencies, a restricted multi-objective optimization model of variable speed multi-task allocation is designed to maximize user incentives while reducing work completion time. Meanwhile, each user has a limited amount of fully compensated activities that are favorably connected with reputation. To solve the constructed model, a three-stage multi-objective shuffled frog leaping algorithm is proposed, which includes an objective defined a hybrid initialization operator is based on heuristic information, a region-based mining approach for archiving individuals and others, a discrete establishing rule to improve the interacting between individual details, and constraints performing operators for minimizing personal data loss. The performance of the proposed algorithm is evaluated by comparing it to five state-of-the-art approaches in both real-world and synthetic circumstances. The bulk of contemporary mobile crowd-sensing solutions rely on centralized systems, which have significant practical restrictions. The storage of data is overly reliant on third-party platforms, resulting in single-point failures. Furthermore, trust issues have a major influence on both user willingness to interact and data reliability [23]. To overcome these two challenges, this work presents a credible and distributed incentive system built on Hyper Ledger Fabric (HF-CDIM). The HF-CDIM, in instance, incorporates methodologies from auction, reputation, and data detection [24]. Based on the DRL and Stackelberg game models, we search to create a privacy-preserving incentive structure for MCS in this study. The suggested incentive system is built around a two phases Stackelberg game in which the service provider takes the lead and the user devices follow. We characterize the user device connection as a non-cooperative game and demonstrate that Nash equilibrium (NE) occurs and is unique in this game. We use the reputation constraint mechanism as the data quality evaluation standard, and we add sensing cost as an indicator, taking into consideration the cost and quality of sensing data. [25]. The Mobile Crowd Sensing (MCS) architecture, which leverages mobile devices as sensing systems, is a viable option. A promising option is the Mobile Crowd Sensing (MCS) architecture, which uses mobile devices as sensing platforms. A few field tests proved the technique's effectiveness as a feasible method of supporting municipal authorities and broadening the possibilities of collaborative urban noise monitoring [26]. MCS uses in industry and people's personal lives [27].
Developed the quality-aware incentive mechanism (QAIM) technique to cope with variable quality needs from task to task, which should be efficient enough to accurately quantify report quality [28]. Many strategies for ensuring sensing quality in MCS have been proposed. The list below includes some of them. MCS has a knowledgeable audience with low-cost services, but it may also be a major drawback (for example, when jobs might be submitted with fake or unsatisfactory quality). Participants who are selfish or strategically minded may act maliciously to improve utility by delaying or changing job completion features. Sensing reports may be malicious or supplied for the purpose of "free-riding." In any event, platforms must pay to obtain reports from MWs [29]. Data from the literature has been collected and established to generate approximated right findings. Aggregation was just the average of the reported tasks in certain ways, with no concern for reporter credibility or involvement level, and incentives were awarded regardless of contribution. A weighted reputation technique was then proposed [30]. Two models are proposed [31] (IMC-Z and IMC-G): incentive approaches for crowd sensing systems with zero and general instances. The zero model was formed when the departure and arrival timings were not taken into account. In contrast, the generic model, in which MW may report on in-out time, was described. Observations were made to set the norm for future recruitments; the strategy is purely focused on inexpensive costs, and honesty is considered. Another approach for assuring the honesty of declared bids under the restriction of a reasonable budget is presented in paper [32]. This study proposes Experience-Reputation (E-R) as a mechanism for analyzing trust connections between any two mobile device users in an MCS platform [33]. This study describes a unique technique for the VCS system called Security Protection Incentive Mechanism with Data Quality Assurance (SPIM-DQA). The goal is to solve the security problems connected with user data while also improving overall data quality. To do this, we use a block chain-enabled VCS framework and provide a set of smart contracts that allow the incentive mechanism to be executed automatically. We effectively overcome the user data security vulnerabilities commonly observed in traditional incentive methods by using this architecture and utilizing smart contracts. Furthermore [35], we present a data quality-aware incentive system aimed at improving the overall quality of the obtained data. This technique selects individuals based on factors such as cheap cost and good quality, guaranteeing that only trustworthy users engage in the crowd sensing job. We examine the quality of the data given by each user to maintain and update user reputation. We can identify and reward people who consistently give high-quality data using this review procedure. In the literature, [36] did a survey in which they classified several forms of crowd sensing based on numerous parameters. The amount of human engagement necessary in the crowd sensing system is one of the categorization criteria they mentioned. As a result, current studies may be divided into two types: participatory sensing and opportunistic sensing. In the literature, [37] presented a block chain-based solution to improve the security of the automotive ecosystem. Several research in this sector have offered block chain-based architectures and smart contracts to enable secure and automated crowd sensing operations. However, further study is needed to properly characterize the workflow of the block chain-based incentive system and the smart contract's triggering mechanism, as both features are vague in present studies. Furthermore, when it comes to data quality, many current studies focus exclusively on measuring the temporal and spatial coverage of the data, while ignoring the evaluation on data quality supplied by users. In order to solve this issue thoroughly, greater emphasis must be placed on analyzing the quality of user-provided data. For example, in this study [38], we offer a technique for assessing data quality based on temporal and geographical coverage. They also allow for user selection by defining minimal criteria for sensing task quality. [39] offer an unsupervised learning approach for evaluating and enhancing the quality of users' data through the merging of quality estimates and monetary incentives. While these techniques have improved data quality, their quantitative procedures include drawbacks such as high computing complexity and extended operation cycles. As a result, they are unsuitable for a reverse auction-based incentive system. In the rapidly evolving landscape of computer science and cybersecurity [40-52], the convergence of cutting-edge technologies such as deep learning and machine learning has become pivotal in fortifying digital systems against emerging threats.
- 2.7. CRITICAL ANALYSIS
In Table 3, a summary of the critical analysis of Reputation and Incentive based schemes is discussed
Table 3.
Summary of critical analysis of Reputation and incentive based schemes.
| Year | Schemes | Objectives | Advantages | Limitation |
|---|---|---|---|---|
| 2018 | RQRP Reputation, Quality aware Recruitment for Platform [1] | On new requests, data connected to MW's prior history is supplied to improve the quality of sensing requests based on reputation. | The advantage of the proposed scheme is that it improves the truthfulness and quality of sensing data while maximizing platform profit in the Internet of Things (IoT) scenario |
The paper's drawback is that it concentrates on the single-task reputation updation situation, but more general scenarios with numerous requesters might be difficult to manage [4] |
| 2021 | Decentralized incentive and reputation mechanism [2] | To increase participation and data dependability in crowd sensing networks with a decentralised reward and reputation system. | improved data reliability, increased participation, and enhanced privacy protection in crowd sensing networks | The main drawback of the method suggested in the study is the usage of an unsecured communication platform, which could risk the workers' privacy [5] |
| 2023 | Data quality assurance and security protection incentive mechanism (SPIM-DQA) [3] |
This paper's goal is to suggest a security protection incentive system for vehicle crowd sensing that includes data quality assurance. | Enhancement of vehicular crowd sensing user engagement, job completion quality, data quality assurance, and security protection. | The proposed incentive structure assumes rationality and rewards as motivations but ignores factors like privacy, trust, and social conventions [35], impacting user engagement with VCS. |
| 2021 | PACE privacy-preserving and quality and data quality-aware incentive scheme [4] | A privacy-preserving and data-quality-aware incentive system for mobile crowd sensing is being developed to assure privacy preservation, avoid suspicious behaviour, and assess data quality. | PACE method: A privacy-preserving, data-quality-conscious incentive system for mobile crowd sensing that ensures accuracy, participant privacy, and fraud avoidance.. | The PACE scheme's drawback is its reliance on a trusted third party to estimate data dependability, which might be impracticable in some cases [10] |
| 2021 | Green Stackelberg-game incentive mechanism [5] | Develop an efficient, fair, and honest incentive system for mobile crowd sensing using a green Stackelberg game strategy, while minimizing platform burden. | Obtaining selected fairness, honesty, and restricted efficiency, reducing the stress on the platform, and balancing service requests and service provisions amongst users through the utilization of virtual currency. | They did not manage the procedure of converting virtual cash to actual money [7] |
3. METHODOLOGY AND SETUP
We have developed a Complexity Level Scheme (CLT) to incentivize and reward mobile workers (MWs) based on the complexity of the tasks they undertake. Our scheme incorporates both simple and complex levels of tasks for measuring reputation scores and determining appropriate incentives. Figure 2 shows the CLT scheme's design in the framework of Mobile Crowd Sensing (MCS).
The platform announces a variety of sensing tasks, and potential task applicants are given the option of selecting between simple or complex tasks depending on a specified threshold value, which is commonly set at 10. Once applicants have made their selection, they proceed to announce their tasks, specifying the desired quality and time constraints. A crucial aspect of our design mechanism revolves around selecting and updating the reputation of the participating MWs. The platform introduces work barriers and waits for MWs to bid on the tasks. The MWs who win the bids then perform the assigned tasks and submit their reports. The platform calculates reputation scores by employing a default threshold reputation score of 0.5, in conjunction with considering work completion hurdles and the expectations of the participants.
If the threshold value is lower than the current reputation score (R-score), the reputation is updated by aggregating feedback from multiple sources and actively motivating the MWs. This ensures that the reputation system remains dynamic and reflective of the MWs' performance and contributions.
By implementing the CLT scheme, our aim is to enhance the efficiency and effectiveness of task Complexity and incentivization in MCS. The scheme allows the platform to leverage task complexity and participants' reputation scores to appropriately assign tasks and incentive MWs, fostering a reliable and high-performing crowd-sensing ecosystem.
Figure 4, shows the architecture of proposed scheme. Firstly, platform announce task and requester request for task. If the task is less than miles threshold score, then the task is simple task and if the task is not less than miles threshold score then task is complex task. By using mobile worker detail check the feedback if the feedback is greater than 1 then select worker, calculate their reputation score and give incentive according to their complexity level.
Table 4.
NOTATION TABLE.
| Acronyms | Definition |
|---|---|
| CR, SR | Complex Reputation, Simple Reputation |
| CFS, SFS | Complex Feedback subset, Simple Feedback Subset |
| DRS | Default reputation score |
| W-F | Weightage Feedback |
| DT | Default Threshold |
| B_MW’s | Best _Mobile Worker’s |
| R-score | Reputation score |
| MW’s | Mobile Workers |
| CW, SW | Complex Weightage, Simple Weightage |
| FR_ Score | Final Reputation Score |
| l(group) | length (group) |
| MT | Miles Threshold |
| MW_Details | Mobile Worker Details |
| CT,ST | Complex Task ,Simple Task |
| CRS,SRS | Complex Reputation Score ,Simple Reputation Score |
| ACRS,ASRS | Average of Complex Reputation Score , Average of Simple Reputation Score |
| RDF | Reputation Driver Feedback |
| D_F | Driver _ Feedback |
| QS | Quality of Simple |
| QC | Quality of Complex |



Here is a brief explanation of the steps in the algorithm:
First, a dataset is created, and a Default reputation score (DRS) of 0.5 is assigned. The purpose of the algorithm is to evaluate the reputation of different groups based on the feedback they receive. It sets a threshold value of 10, classifying feedback with a 'Mile' value greater than 10 as complex feedbacks.
The algorithm then groups the dataset by the 'MW_Details' column and proceeds to iterate over each group. For each group, it separates the feedback into two categories: complex feedback subset (CFS) and simple feedback subset (SFS). It calculates the sum of CFS and SFS values within each group.
Reputation scores are determined based on the calculated sums. If CFS exists in the group, it calculates the complex reputation score (CR) by dividing the sum of CFS by the length of CFS. If CFS is empty, CR is set to a predefined value (DT). Similarly, if SFS exists in the group, it calculates the simple reputation score (SR) by dividing the sum of SFS by the length of SFS. If SFS is empty, SR is set to DT.
Next, the algorithm calculates the final reputation score (FR_score) for each group. If both CFS and SFS exist, it calculates a weighted average of CR and SR based on the lengths of CFS and SFS. The result is divided by the length of the group. If only CFS or SFS exists, the reputation score is set to CR or SR, respectively. If both CFS and SFS are empty, R_score is set to DT. The calculated reputation scores are stored in a dictionary (R_score) with the group names as keys.
The algorithm tracks the complex reputation scores in a dictionary (CRS) and the simple reputation scores in another dictionary (SRS). After iterating over all groups, it calculates the average complex reputation score (ACRS) by summing up the values in CRS and dividing the sum by the length of CRS. Similarly, it calculates the average simple reputation score (ASRS) by summing up the values in SRS and dividing the sum by the length of SRS.
To provide an overall reputation score, the algorithm calculates a combined reputation score (RS) by averaging the simple and complex reputation scores for each group. This score is added as a new column ('RS') in the data frame (RDF). The data frame is then sorted in descending order based on the 'RS' column, resulting in the variable Sorted_df.
Finally, the top three MW_Details with the highest reputation scores are extracted from Sorted_df using the head () function and stored in the variable Top_three_mw. This approach allows for the effective allocation
of tasks and incentives depending on service provider performance. This technique provides a more personalized approach to task management and gives incentives for MW-ids by assessing feedback and allocating tasks depending on the feedback threshold.
3.1. UBER DRIVER DATASET:
Figure 5 shows that Uber driver dataset this dataset is publically available and the dataset includes the following fields:
- Start Date: It represents the date when a specific task or ride started.
- End Date: It denotes the date when a particular task or ride ended.
- End Time: This field indicates the time at which a task or ride ended.
- Category Pickup: It describes the category or type of the pickup location for a task, such as residential, commercial, or airport.
- Destination: It specifies the destination or the location where the task or ride ended.
- Miles: This field represents the distance traveled during the task, typically measured in miles.
- Levels (simple=1, complex=0): It is a categorical field that indicates the complexity level of a task. A value of 1 denotes a simple task, while a value of 0 indicates a complex task.
- Levels Scores: This field contains the scores or ratings assigned to each task based on its complexity level.
- MW_Details: It refers to additional details or information about the ride, which may include specific driver or vehicle information related to a task.
- Driver Feedback: This field captures the feedback or ratings provided by the passengers regarding the driver or the overall experience of the task.
In Figure 5, the highlighted blocks represent additional features we introduced to simplify the identification of complexity levels. These features make it easier to recognize and differentiate between the various levels of complexity in the data.
4. RESULTS ANALYSIS
The implementation of this research was performed using Jupiter (Notebook). Python contains the most libraries, built-in classes, and functions for processing and displaying data, making it the most popular programming language for data science. The proposed approach of our study is evaluated based on various measures and discussed in this results section. These measurements will be performed to check whether the proposed scheme is considered better than and to check whether the proposed scheme works well for Complexity Level Task.
4.1. ENVIRONMENT SETUP
The approach is used on machines that have an Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz 2.70GHz processor, 8.0 GB RAM, and a 64-bit operating system running on an x64-based processor, and Windows 10 pro. Python and C++ programming languages are utilized.
4.2. EVALUATION MEASURES
We used Machine learning techniques and our proposed scheme in this framework will be measured based on performance parameters. This will be done for the sake of checking which technique is best for complex tasks and for specific parameters which technique is suitable for datasets.
4.2.1. DATASET:
In the following section, we provide the results of our designed (CLT) research against level-based schemes. We used the Uber driver dataset this dataset is publically available and the dataset includes the following fields: Start Date, End Date, End time, Category Pickup, Destination, Miles, Levels (simple=1, complex=0), Levels Scores, MW_Details and Driver Feedback.
Table 5 shows the factors used for evaluating task levels and their related values in the framework of CLT (Complexity Level of Task) systems. Each parameter is explained below:
- (1)
- Target area: This option specifies the specific region or location where the tasks will be performed. The measurement of 12204.7 square meters shows the size or depth of the target area.
- (2)
- Number of MWS: MWS stands for Mobile Workers. This option determines the number of Mobile Workers who will be participating in the CLT system. The indicated range is between 1000 and 1200 Mobile people, representing the approximate number of workers involved in the tasks.
- (3)
- Task Announced: This parameter specifies the set of tasks that are announced or made available to Mobile Workers within the CLT system. The defined range is 100 to 1200 jobs. It indicates the number of tasks announced or available for workers to choose and accomplish.
- (4)
- Default Reputation Score: This field indicates the CLT system's default reputation score applied to Mobile Workers. [0.2-0.5] are the values indicated. These values represent workers' initial reputation ratings, which may be applied as a starting point for following reputation evaluation and scoring.
- (5)
- Task: This parameter indicates the kind or complexity of the CLT system's tasks. It categorizes tasks into two types: simple tasks and complex tasks. This category helps in determining the amount of challenge or complexity of the work allocated to Mobile Workers
- (6)
- MT Factor: MT is an abbreviation for Mile Threshold. This value specifies a factor used to decide whether the feedback is simple or complex. The number 10 indicates that input with a 'Mile' value of more than 10 will be considered as being complex feedback.
4.2.2. MW SELECTION
The process of finding and choosing qualified Mobile Workers (MWs) to do activities on a mobile device is referred to as mobile worker selection. Mobile worker selection may include a variety of elements such as the MW's previous performance, availability, location, and skills. Requesters can choose between manually selecting workers based on their profiles, using screening questions to eliminate unqualified workers, and using software programs that match tasks with qualified workers based on their performance history and other relevant factors. The purpose of mobile worker selection is to guarantee that activities are completed efficiently and effectively by qualified MWs, resulting in high-quality work and reliable results.
4.2.3. FEEDBACK
The evaluation or feedback provided by a requester about the task accomplished by a Mobile Worker is referred to as feedback. (MW). Feedback can be positive or negative, and it may include remarks on the work's quality, correctness, completeness, communication, and timeliness. Feedback is an important element of the reputation calculating and updating process since it helps ensure that certified MWs conduct high-quality work. Depending on the level of detail necessary in the review, feedback might be "simple" or "complex." Overall, feedback is important for enhancing the quality of work performed by MWs and for establishing confidence between requesters and MWs.
4.2.4. INCENTIVE MECHANISM
We provide an incentive system for tasks that are based on the reputation score. More incentives are awarded to tasks with a higher reputation score, which motivates Workers to perform challenging tasks. The incentive for each assignment is determined by the complexity of the work and MW's reputation score. The incentive for a task is computed based on the reputation score of MW and is expressed as a percentage of the overall payout for the activity.
4.2.5. REPUTATION
Reputation calculation and updation involve various aspects, including the feedback assigned by requesters. It is important to consider feedback from multiple requesters, not just a single one. Equation (1)(2) explores CR, this is the reputation of a Complex task and SR this is the reputation of a Simple task MW based on the feedback provided by the requesters. CW and SW represent the weightage of the requester's input and the overall Final reputation score.
The formula for calculating the reputation score depends on whether there is at least one "complex" feedback in the group or not:
COMPLEX REPUTATION SCORE
If the number of trips with complex feedback is greater than zero, the complex feedback is weighted by the number of complex trips (complex weight). The complex reputation score (complex_ reputation) is calculated by dividing the sum of complex feedback by the complex weight. If there is no feedback for complex trips, the default threshold value (default_ threshold) is used as the complex reputation score.
CR = sum(complex_feedback_subset) + Default Threshold / CW
SIMPLE REPUTATION SCORE
If the number of task with simple feedback is greater than zero, the simple feedback is weighted by the number of simple task (simple_ weight). The simple reputation score (simple_ reputation) is calculated by dividing the sum of simple feedback by the simple weight. If there is no feedback for simple task, the default threshold value is used as the simple reputation score.
SR = sum(simple_feedback_subset) + Default Threshold / SW
FINAL REPUTATION SCORE:
Equation (3) the overall Final reputation score (R_score) is calculated based on the weighted average of the complex and simple reputation scores. If there is feedback for both complex and simple task, the reputation score is calculated using the formula:
(Complex _ Weight * Complex_ Reputation + Simple_ Weight * Simple_ Reputation) / Len(group).
If there is feedback for only complex or simple task, the respective reputation score is used. If there is no feedback for any task, the default threshold value is used as the reputation score.
FR_score=(CW*CR+SW*SR)/Len(group)
The final reputation score for the group is then determined based on whether there are "complex" feedback values in the group or not. If there are, the final reputation score is set to complex reputation, otherwise it is set to simple reputation.
AVERAGE REPUTATION SCORE:
The average complex reputation score (ACRS) and average simple reputation score (ASRS) are calculated equation (4), (5) using the formulae below. In both formulae, the average score is calculated by dividing the total of the reputation scores by the number of scores.
ACRS=sum(CRS())/Len(CRS)
ASRS=sum(SRS())/Len(SRS)
- 4.2. PROPOSED METHOD RESULTS (USING CLT AND MACHINE LEARNING ALGORITHM):
Figure 6, shows the proportion of simple and complex feedback in the dataset. The pink part shows that 74.2% of mobile workers have simple feedback and the other part shows 25.8% of mobile workers have complex feedback.
Table 6, shows the comparison of the average simple reputation scores and average complex reputation scores at different default reputation score thresholds. The threshold values range from 0.2 to 0.5. The table shows that as the threshold increases, both the average simple and complex reputation scores tend to increase as well. The highest average scores are observed at a threshold of 0.5, indicating that this threshold leads to the best results. The results for thresholds 0.3 and 0.4 are similar, with slightly lower average scores compared to the threshold of 0.5.
Figure 7, shows the comparison of the Average simple reputation score and Average complex reputation score by taking different default reputation scores. we have three schemes in the table: linear regression, neural network, and proposed CLT. Each scheme is assigned two average scores: Average Simple Reputation Score and Average Complex Reputation Score.
Beginning with Linear regression, the Average Simple Reputation Score is 2.4869107744107737, while the Average Complex Reputation Score is 1.1981481481481482. These values indicate the reputation of the Linear regression scheme, with higher scores suggesting greater performance. Linear regression has a better Average Simple Reputation Score than Complex Reputation Score based on these data.
Moving on, the Average Simple Reputation Score for the Neural Network scheme is 1.3177358339928036, while the Average Complex Reputation Score is 0.5997343889031039. Similarly, higher scores indicate better achievement. The Neural Network has a better Average Simple Reputation Score than its Average Complex Reputation Score in this scenario.
Finally, the suggested CLT system has a Simple Reputation Score of 2.236658249158249 and a Complex Reputation Score of 1.182996632996633. Higher scores, once again, represent better achievement. The CLT (proposed) scheme has a higher Average Simple Reputation Score than its Average Complex Reputation Score in this case.
Based on the given results, it is observed that both the CLT (proposed) scheme and the Linear regression scheme not only performed well in terms of Complex Reputation Scores but also had better Simple Reputation Scores compared to the Neural Network scheme. The Linear regression scheme had an Average Simple Reputation Score of approximately 2.4869107744107737, while the CLT (proposed) scheme had an Average Simple Reputation Score of approximately 2.236658249158249. On the other hand, the Neural Network scheme had an Average Simple Reputation Score of approximately 1.3177358339928036. This indicates that both the Linear regression and CLT (proposed) schemes had higher reputations for their simplicity compared to the Neural Network scheme. Each scheme has its strengths and weaknesses, and the best choice would vary based on the specific context and considerations.
Figure 8, shows that comparison of the Average simple reputation score and Average complex reputation score using machine learning algorithm linear regression and Neural network with the proposed scheme CLT using threshold 0.5.
Table 8 displays three Top Best Mobile worker’s entities. In this case, the reputation scores are obtained by applying a Linear Regression algorithm. MW 333 has a simple reputation score of 13.1666666666667 and a complex reputation score of 0.5, resulting in a final reputation score of 13.166666666666666. MW 101 has a simple reputation score of 13.125 and a complex reputation score of 3.5, resulting in a final reputation score of 11.2. MW 110 has a simple reputation score of 13.1666666666667 and a complex reputation score of 2.5, leading to a final reputation score of 10.5.
Based on these scores, MW 333 has the highest final reputation score among the three, indicating it has the best overall Final reputation score. MW 101 follows with a slightly lower final reputation score, and MW 110 has the lowest final reputation score.
Figure 9 demonstrates that higher reputation scores reflect better overall feedback and performance when evaluating the best MW_Details using the Linear Regression algorithm. The top three MW_Details in the sample exhibit the highest R_score, indicating that they consistently receive positive feedback and have a strong reputation.
Table 9 displays Top Three Best Mobile worker’s entities. In this case, the reputation scores are obtained by applying a neural network algorithm. For MW 345, the Simple Reputation Score is 2.00962715431412, the Complex Reputation Score is 2.51833046919337, and the Final Reputation Score is 2.263978811753746. For
MW 1045, the Simple Reputation Score is 2.01468674579499, the Complex Reputation Score is 2.5073420748168, and the Final Reputation Score is 2.2610144103058913. For MW 308, the Simple Reputation Score is 2.01123696459871, the Complex Reputation Score is 2.51019845372276, and the Final Reputation Score is 2.260717709160739.
It is observed that all three mobile workers are a slight difference in the Complex Reputation Score and Final Reputation Score. However, there is a slight difference in the Simple Reputation Scores, with MW 345 having a score of 2.00962715431412 and MW 1045 having a score of 2.01468674579499 and MW 308 having a score of 2.51019845372276.
Based on these scores, we can observe that the top 3 MW Details were selected in the overall analysis because they had higher Final Reputation Scores, as well as higher Simple and Complex Reputation Scores compared to other MW Details. These MW Details demonstrated a better overall reputation based on the collected feedback.
Figure 10 shows the higher reputation scores reflect better overall feedback and performance when evaluating the best MW_ Details using Neural network algorithm. The top three MW_ Details in the sample have the greatest R_ score, which indicates that they have frequently obtained good feedback and have a solid reputation.
Table 10 displays three Top Best Mobile worker’s entities with proposed (CLT) reputation scores using threshold 0.5. Each entity has a Simple Reputation Score of 4.5 and a Complex Reputation Score of 5.5. The Overall Final Reputation Score for all entities is 5, indicating a consistently high level of reputation.
Figure 11 shows the higher reputation scores reflect better overall feedback and performance when evaluating the best MW_ Details using proposed scheme (CLT). The top three MW_ Details in the sample have the greatest R_ score, which indicates that they have frequently obtained good feedback and have a solid reputation.
Table 11, shows that the p-values and t-values are used to compare the performance of different machine learning algorithms (Linear Regression, Neural network) and proposed scheme (CLT) in a given task (presumably some form of regression). In all three Schemes result a t-test is being performed to compare the reputation scores between two groups: simple and complex. The null hypothesis (H0) assumes that the average reputation scores of the simple and complex groups are equal. The alternative hypothesis (H1) assumes that the average reputation scores of the simple and complex groups are not equal or significantly different.
If the p-value is less than the significance level (usually set at 0.05), we reject the null hypothesis (H0) and conclude that there is a significant difference between the average reputation scores of the simple and complex groups (supporting the alternative hypothesis, H1). On the other hand, if the p-value is greater than the significance level, we fail to reject the null hypothesis (H0) and conclude that there is not enough evidence to suggest a significant difference between the average reputation scores of the two groups. Based on the p-values, all three schemes have extremely small p-values, indicating strong evidence against the null hypothesis. However, the CLT (proposed) scheme has the smallest (1.816803686571544e-45) p-value, suggesting the strongest evidence against the null hypothesis among the three.
Regarding the t-values, a larger absolute t-value suggests a larger difference between the sample means. In this case, the Neural network scheme has the largest t-value (20.155918519744528), indicating the largest difference between the means compared to the other two schemes.
Therefore, based on the p-value, the CLT (proposed) scheme has the best result, indicating the strongest evidence against the null hypothesis. However, based on the t-value, the Neural network scheme has the largest difference between the means.
5. Conclusion
The Internet of Things presents both benefits and difficulties. Most approaches in the literature for MCS are lacking because they do not take task complexity into consideration. Incentives provided to mobile workers (MW) on the basis of reputation play an important role in increasing service use, providing motivation to mobile workers, and building trust in the service. In the underlying study, we observed that they had not evaluated the complexity level of a task, resulting in a strong reputation for executing multiple basic jobs. A person who completes a tough task may have a lower reputation score. Complexity levels of tasks (CLT) were developed for reputation evaluations on a crowd-sensing network, which will be used to evaluate the MW reputation. Reputation parameters for mobile workers are set to assign work to well-reputed workers. By measuring reputation on (CLT) complexity level of task, this research will help the system to Maintain the reputation of the mobile worker so that entities of the system get the maximum benefit out of it, by hiring well-reputed mobile workers and MW receive an incentive on it.
The study examined the effectiveness of multiple machine learning algorithms in reputation scoring for mobile workers in MCS and showed that a threshold value of 0.5 produced the best results. After analyzing
the data, it is clear that the CLT (proposed) scheme and the Linear regression scheme not only outperformed the Neural Network scheme in terms of Complex Reputation Scores but also in terms of Simple Reputation Scores. The Linear Regression Scheme had an Average Simple Reputation Score of around 2.4869107744107737, whereas the CLT (proposed) Scheme had an Average Simple Reputation Score of about 2.236658249158249. The Neural Network method, on the other hand, had an Average Simple Reputation Score of around 1.3177358339928036. This indicates that the Linear Regression and CLT (proposed) schemes had a better reputation for simplicity than the Neural Network method.
Furthermore, based on the p-values, all three schemes have extremely small p-values, indicating strong evidence against the null hypothesis. However, the CLT (proposed) scheme has the smallest p-value, suggesting the strongest evidence against the null hypothesis among the three. However, based on the t-value, the Neural network scheme has the largest difference between the means. These findings may be utilized to increase the performance of MCS in IoT devices and ensure the reliability of the services provided. "The higher reputation scores reflect better overall feedback and performance when evaluating the best MW_ Details. These top three performers, MW 308, MW 345, and MW 1045, were selected based on their Reputation Scores (R_score) using the proposed scheme. The proposed scheme effectively identified these mobile workers as the best performers by considering various factors that contribute to their reputation. The top three MW_ Details in the sample, MW 308, MW 345, and MW 1045, have the greatest Reputation Scores (R_ score), indicating that they have consistently received positive feedback and have established a solid reputation. Considering MW 308, MW 345, and MW 1045's efforts and abilities, the MCS system may offer incentives and awards to further motivate and consider their continuing contributions. This reputation-based incentivization technique not only encourages strong competition among mobile workers, but also makes sure the delivery of high-quality services inside the MCS system.
As for the future, we will take for testing Purposes large dataset enhance them with new features such as the size and diversity of the dataset, on the performance of the algorithms. Furthermore, this area can focus on exploring more advanced machine learning techniques for reputation scoring in MCS.
Conflicts of Interest
There is no conflict of Interest.
References
- S. Cuomo, P. De Michele, F. Piccialli, A. Galletti, and J. E. Jung, “PT US CR,” Expert Syst. Appl., 2017. [CrossRef]
- J. Ren, Y. Zhang, and K. Zhang, “Exploiting Mobile Crowdsourcing for Pervasive Cloud Services : Challenges and Solutions,” no. March, pp. 98–105, 2015.
- J. Xiong, R. Ma, L. Chen, Y. Tian, L. Lin, and B. Jin, “Achieving Incentive, Security, and Scalable Privacy Protection in Mobile Crowdsensing Services,” Wirel. Commun. Mob. Comput., vol. 2018, pp. 1–12, Aug. 2018. [CrossRef]
- N. Of, “Mobile Crowdsensing: Current State and Future Challenges,” no. November, pp. 32–39, 2011.
- W. Ahmad, S. Wang, A. Ullah, and M. Y. Shabir, “Reputation-Aware Recruitment and Credible Reporting for Platform Utility in Mobile Crowd Sensing with Smart Devices in IoT”. [CrossRef]
- Z. Noshad et al., “An Incentive and Reputation Mechanism Based on Blockchain for Crowd Sensing Network,” vol. 2021, 2021.
- B. Guo, C. Chen, D. Zhang, Z. Yu, and A. Chin, “Mobile crowd sensing and computing: when participatory sensing meets participatory social media,” IEEE Commun. Mag., vol. 54, no. 2, pp. 131–137, Feb. 2016. [CrossRef]
- S. Panichpapiboon and P. Leakkaw, “Traffic Density Estimation: A Mobile Sensing Approach,” IEEE Commun. Mag., vol. 55, no. 12, pp. 126–131, Dec. 2017. [CrossRef]
- Z. Luo, J. Xu, P. Zhao, D. Yang, L. Xu, and J. Luo, “Towards High-Quality Mobile Crowdsensing : Incentive Mechanism Design based on Fine-grained Ability Reputation,” no. September 2021. [CrossRef]
- J. Lu, Z. Zhang, J. Wang, R. Li, and S. Wan, “A Green Stackelberg-game Incentive Mechanism for Multi-service Exchange in Mobile Crowdsensing,” vol. 22, no. 2, 2021.
- L. Zhao, X. Wei, J. Chen, L. Zhou, and M. Guizani, “Personalized Content Sharing via Mobile Crowdsensing,” vol. 4662, no. c, pp. 1–11, 2021. [CrossRef]
- L. Xiao, T. Chen, C. Xie, H. Dai, and H. V. Poor, “Mobile Crowdsensing Games in Vehicular Networks,” vol. 9545, no. 2, pp. 1–11, 2016. [CrossRef]
- B. Zhao, S. Tang, and X. Liu, “PACE: Privacy-Preserving and Quality-Aware Incentive Mechanism for Mobile Crowdsensing,” vol. 20, no. 5, pp. 1924–1939, 2021.
- J. Nie, J. Luo, Z. Xiong, D. Niyato, P. Wang, and M. Guizani, “An Incentive Mechanism Design for Socially Aware Crowdsensing Services with Incomplete Information,” no. April, pp. 74–80, 2019.
- S. Yang et al., “On Designing Data Quality-Aware Truth Estimation and Surplus SharingMethod for Mobile Crowdsensing,” vol. 35, no. 4, pp. 832–847, 2017.
- S. Kielienyu, “Bridging Predictive Analytics and Mobile Crowdsensing for Future Risk Maps of Communities Against COVID-19”.
- M. E. Gendy, S. Member, A. Al-kabbany, E. F. Badran, and S. Member, “Maximizing Clearance Rate of Budget-Constrained Auctions in Participatory Mobile CrowdSensing,” pp. 113585–113600, 2020. [CrossRef]
- Doi, “2017 IEEE 37th International Conference on Distributed Computing Systems,” pp. 1667–1676, 2017. [CrossRef]
- C.-L. Hu, K.-Y. Lin, and C. K. Chang, “Incentive Mechanism for Mobile Crowdsensing with Two-Stage Stackelberg Game,” IEEE Trans. Serv. Comput., pp. 1–14, 2022. [CrossRef]
- J. Wang, F. Wang, Y. Wang, D. Zhang, L. Wang, and Z. Qiu, “Social-Network-Assisted Worker Recruitment in Mobile Crowd Sensing,” ArXiv180508525 Cs, May 2018, Accessed: Oct. 20, 2022.
- X. Yan, W. W. Y. Ng, B. Zeng, B. Zhao, F. Luo, and Y. Gao, “P2SIM: Privacy-preserving and Source-reliable Incentive Mechanism for Mobile Crowdsensing,” IEEE Internet Things J., pp. 1–1, 2022. [CrossRef]
- G. Ji, Z. Yao, B. Zhang, and C. Li, “Quality-Driven Online Task-Bundling-Based Incentive Mechanism for Mobile Crowdsensing,” IEEE Trans. Veh. Technol., vol. 71, no. 7, pp. 7876–7889, Jul. 2022. [CrossRef]
- X. Shen, Q. Chen, H. Pan, L. Song, and Y. Guo, “Variable speed multi-task allocation for mobile crowdsensing based on a multi-objective shuffled frog leaping algorithm,” Appl. Soft Comput., vol. 127, p. 109330, Sep. 2022. [CrossRef]
- S. Chen et al., “A blockchain-based creditable and distributed incentive mechanism for participant mobile crowdsensing in edge computing,” Math. Biosci. Eng., vol. 19, no. 4, pp. 3285–3312, 2022. [CrossRef]
- J. Zhang, X. Li, Z. Shi, and C. Zhu, “A reputation-based and privacy-preserving incentive scheme for mobile crowd sensing: a deep reinforcement learning approach,” Wirel. Netw., Sep. 2022. [CrossRef]
- M. Zappatore, A. Longo, M. A. Bochicchio, D. Zappatore, A. A. Morrone, and G. De Mitri, “A Mobile Crowd-Sensing Platform for Noise Monitoring in Smart Cities,” EAI Endorsed Trans. Smart Cities, vol. 1, no. 1, p. 151627, Jul. 2016. [CrossRef]
- L. Shu, Y. Chen, Z. Huo, N. Bergmann, and L. Wang, “When Mobile Crowd Sensing Meets Traditional Industry,” IEEE Access, vol. 5, pp. 15300–15307, 2017. [CrossRef]
- L.-Y. Jiang, F. He, Y. Wang, L.-J. Sun, and H. Huang, “Quality-Aware Incentive Mechanism for Mobile Crowd Sensing,” J. Sens., vol. 2017, pp. 1–14, 2017. [CrossRef]
- H. Xie and J. C. S. Lui, “Incentive Mechanism and Rating System Design for Crowdsourcing Systems: Analysis, Tradeoffs, and Inference,” IEEE Trans. Serv. Comput., vol. 11, no. 1, pp. 90–102, Jan. 2018. [CrossRef]
- H. Jin, L. Su, H. Xiao, and K. Nahrstedt, “INCEPTION: incentivizing privacy-preserving data aggregation for mobile crowd sensing systems,” in Proceedings of the 17th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Paderborn Germany, Jul. 2016, pp. 341–350. [CrossRef]
- X. Zhang, Z. Yang, Y. Liu, J. Li, and Z. Ming, “Toward Efficient Mechanisms for Mobile Crowdsensing,” IEEE Trans. Veh. Technol., vol. 66, no. 2, pp. 1760–1771, Feb. 2017. [CrossRef]
- D. Zhao, X.-Y. Li, and H. Ma, “Budget-Feasible Online Incentive Mechanisms for Crowdsourcing Tasks Truthfully,” IEEE ACM Trans. Netw., vol. 24, no. 2, pp. 647–661, Apr. 2016. [CrossRef]
- N. B. Truong, G. M. Lee, T.-W. Um, and M. Mackay, “Trust Evaluation Mechanism for User Recruitment in Mobile Crowd-Sensing in the Internet of Things,” IEEE Trans. Inf. Forensics Secur., vol. 14, no. 10, pp. 2705–2719, Oct. 2019. [CrossRef]
- https://github.com/I-Gayatri-ENG19CS0122/UBER-Data-Analysis/find/main.
- Cai, X., Zhou, L., Li, F., Fu, Y., Zhao, P., Li, C., & Yu, F. R. (2023). An Incentive Mechanism for Vehicular Crowdsensing with Security Protection and Data Quality Assurance. IEEE Transactions on Vehicular Technology.
- Gong, W., Zhang, B., & Li, C. (2018). Task assignment in mobile crowdsensing: Present and future directions. IEEE network, 32(4), 100-107.
- Dorri, A., Steger, M., Kanhere, S. S., & Jurdak, R. (2017). Blockchain: A distributed solution to automotive security and privacy. IEEE Communications Magazine, 55(12), 119-125.
- Wang, J., Wang, Y., Zhang, D., Wang, F., Xiong, H., Chen, C., ... & Qiu, Z. (2018). Multi-task allocation in mobile crowd sensing with individual task quality assurance. IEEE Transactions on Mobile Computing, 17(9), 2101-2113.
- Yang, S., Wu, F., Tang, S., Gao, X., Yang, B., & Chen, G. (2017). On designing data quality-aware truth estimation and surplus sharing method for mobile crowdsensing. IEEE Journal on Selected Areas in Communications, 35(4), 832-847.
- Khalil, M. I., Jhanjhi, N. Z., Humayun, M., Sivanesan, S., Masud, M., & Hossain, M. S. (2021). Hybrid smart grid with sustainable energy efficient resources for smart cities. sustainable energy technologies and assessments, 46, 101211.
- Kok, S. H., Azween, A., & Jhanjhi, N. Z. (2020). Evaluation metric for crypto-ransomware detection using machine learning. Journal of Information Security and Applications, 55, 102646.
- Shafiq, M., Ashraf, H., Ullah, A., Masud, M., Azeem, M., Jhanjhi, N. Z., & Humayun, M. (2021). Robust Cluster-Based Routing Protocol for IoT-Assisted Smart Devices in WSN. Computers, Materials & Continua, 67(3).
- Lim, M., Abdullah, A., Jhanjhi, N. Z., & Supramaniam, M. (2019). Hidden link prediction in criminal networks using the deep reinforcement learning technique. Computers, 8(1), 8.
- Gouda, W., Sama, N. U., Al-Waakid, G., Humayun, M., & Jhanjhi, N. Z. (2022, June). Detection of skin cancer based on skin lesion images using deep learning. In Healthcare (Vol. 10, No. 7, p. 1183). MDPI.
- Sennan, S., Somula, R., Luhach, A. K., Deverajan, G. G., Alnumay, W., Jhanjhi, N. Z., ... & Sharma, P. (2021). Energy efficient optimal parent selection based routing protocol for Internet of Things using firefly optimization algorithm. Transactions on Emerging Telecommunications Technologies, 32(8), e4171.
- Hussain, K. Hussain, K., Hussain, S. J., Jhanjhi, N. Z., & Humayun, M. (2019, April). SYN flood attack detection based on bayes estimator (SFADBE) for MANET. In 2019 International Conference on Computer and Information Sciences (ICCIS) (pp. 1-4). IEEE.
- Adeyemo Victor Elijah, Azween Abdullah, NZ JhanJhi, Mahadevan Supramaniam and Balogun Abdullateef O, “Ensemble and Deep-Learning Methods for Two-Class and Multi-Attack Anomaly Intrusion Detection: An Empirical Study” International Journal of Advanced Computer Science and Applications(IJACSA), 10(9), 2019. [CrossRef]
- Lim, M., Abdullah, A., & Jhanjhi, N. Z. (2021). Performance optimization of criminal network hidden link prediction model with deep reinforcement learning. Journal of King Saud University-Computer and Information Sciences, 33(10), 1202-1210.
- Gaur, L., Singh, G., Solanki, A., Jhanjhi, N. Z., Bhatia, U., Sharma, S., ... & Kim, W. (2021). Disposition of youth in predicting sustainable development goals using the neuro-fuzzy and random forest algorithms. Human-Centric Computing and Information Sciences, 11, NA.
- Kumar, T., Pandey, B., Mussavi, S. H. A., & Zaman, N. (2015). CTHS based energy efficient thermal aware image ALU design on FPGA. Wireless Personal Communications, 85, 671-696.
- Nanglia, S., Ahmad, M., Khan, F. A., & Jhanjhi, N. Z. (2022). An enhanced Predictive heterogeneous ensemble model for breast cancer prediction. Biomedical Signal Processing and Control, 72, 103279.
- Gaur, L., Afaq, A., Solanki, A., Singh, G., Sharma, S., Jhanjhi, N. Z., ... & Le, D. N. (2021). Capitalizing on big data and revolutionary 5G technology: Extracting and visualizing ratings and reviews of global chain hotels. Computers and Electrical Engineering, 95, 107374.
Figure 1.
Figure 1. The mobile crowd-sensing network.
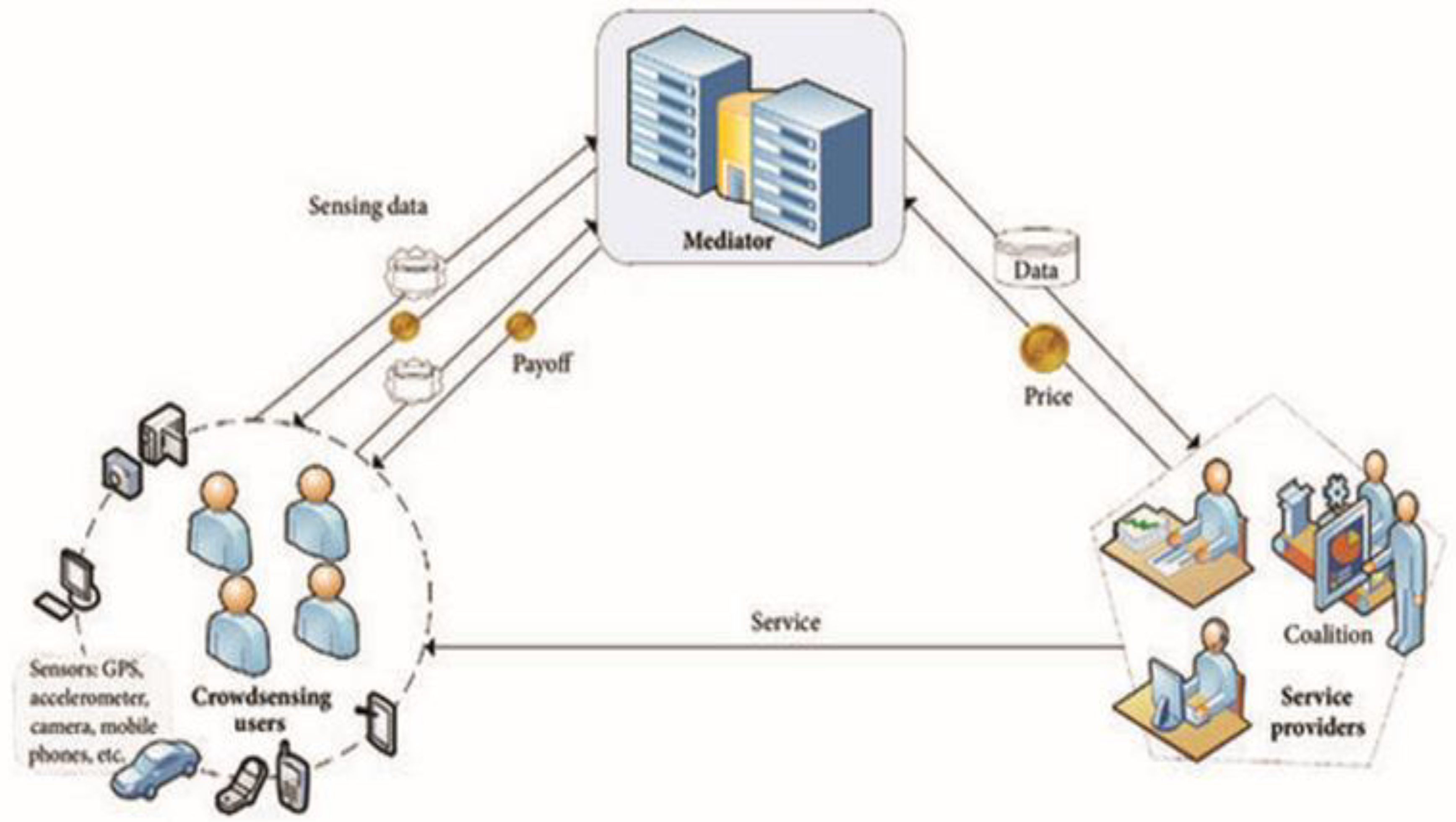
Figure 2.
Searching Protocol.
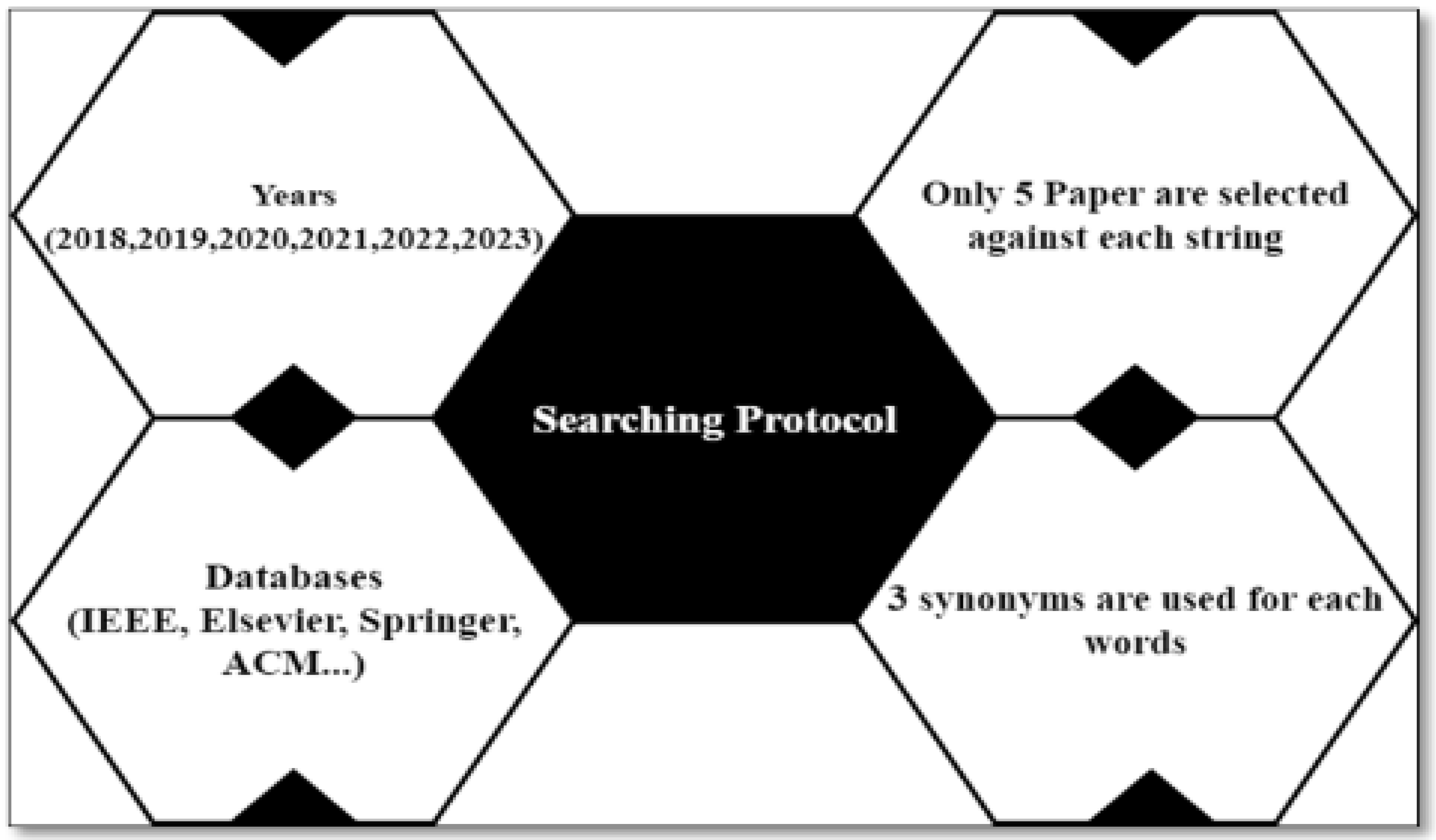
Figure 3.
Search Strategy.
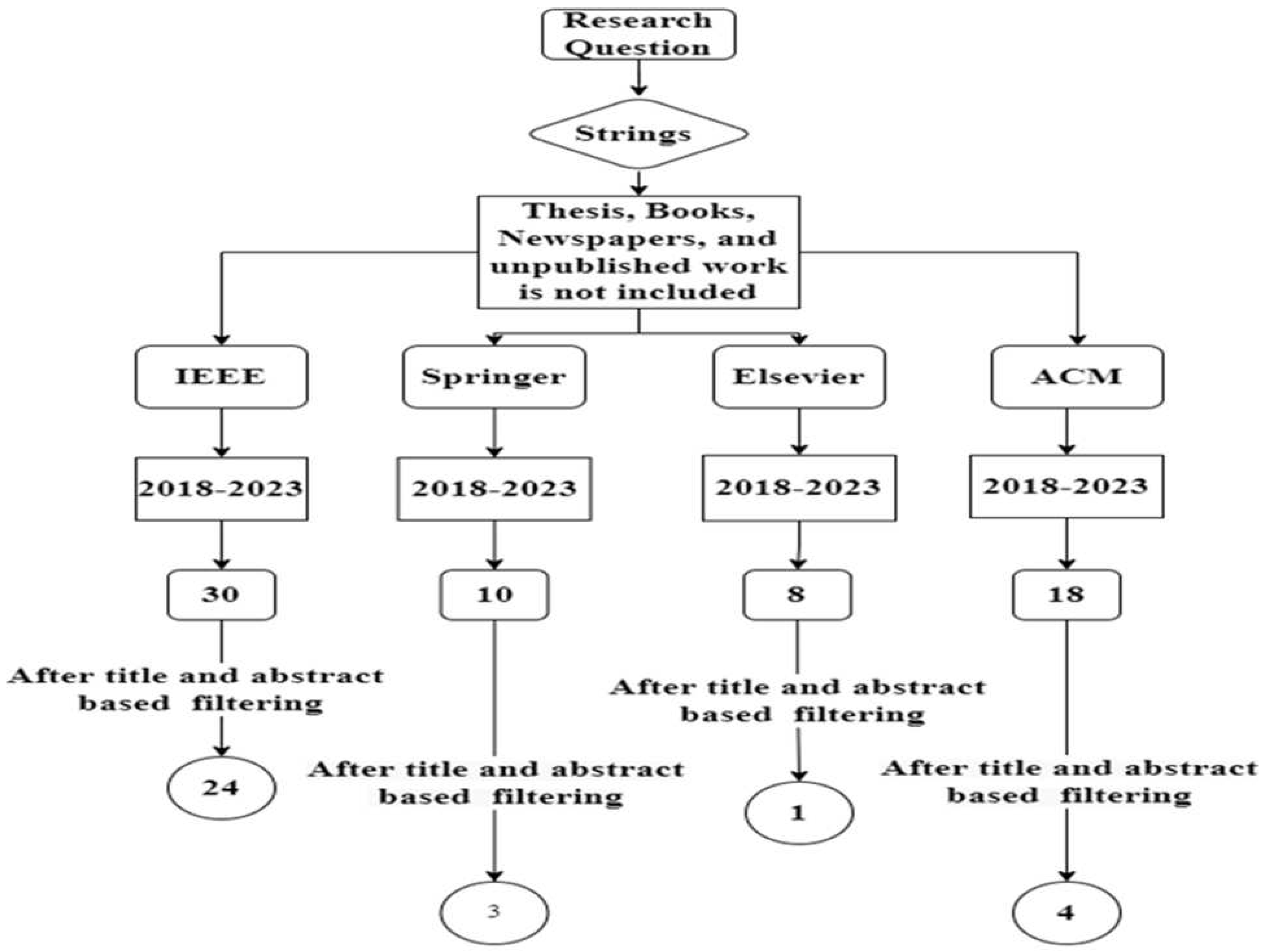
Figure 4.
Architecture of proposed scheme.
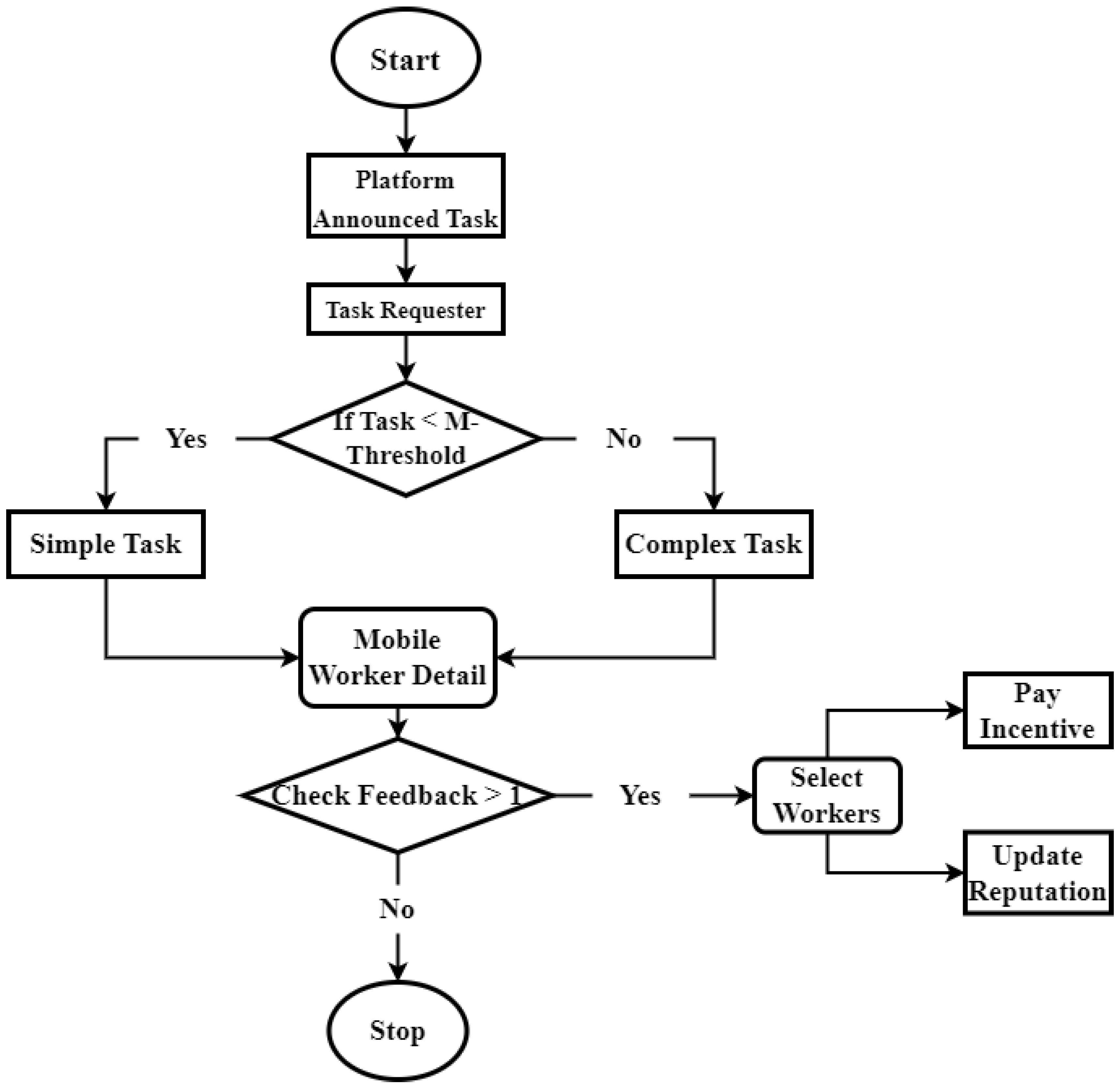
Figure 5.
Uber Driver Dataset.
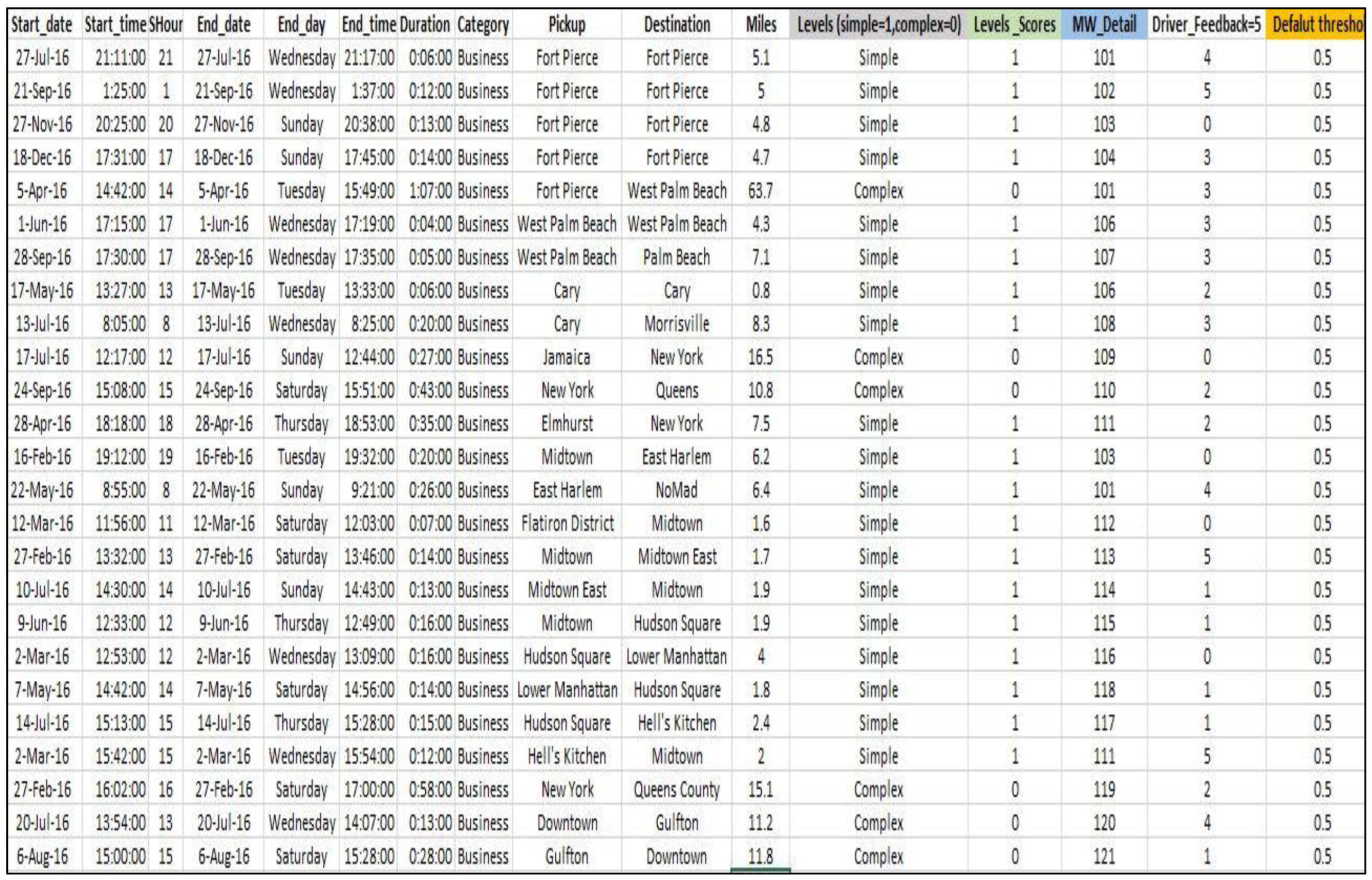
Figure 6.
Proportion of simple and complex feedback.
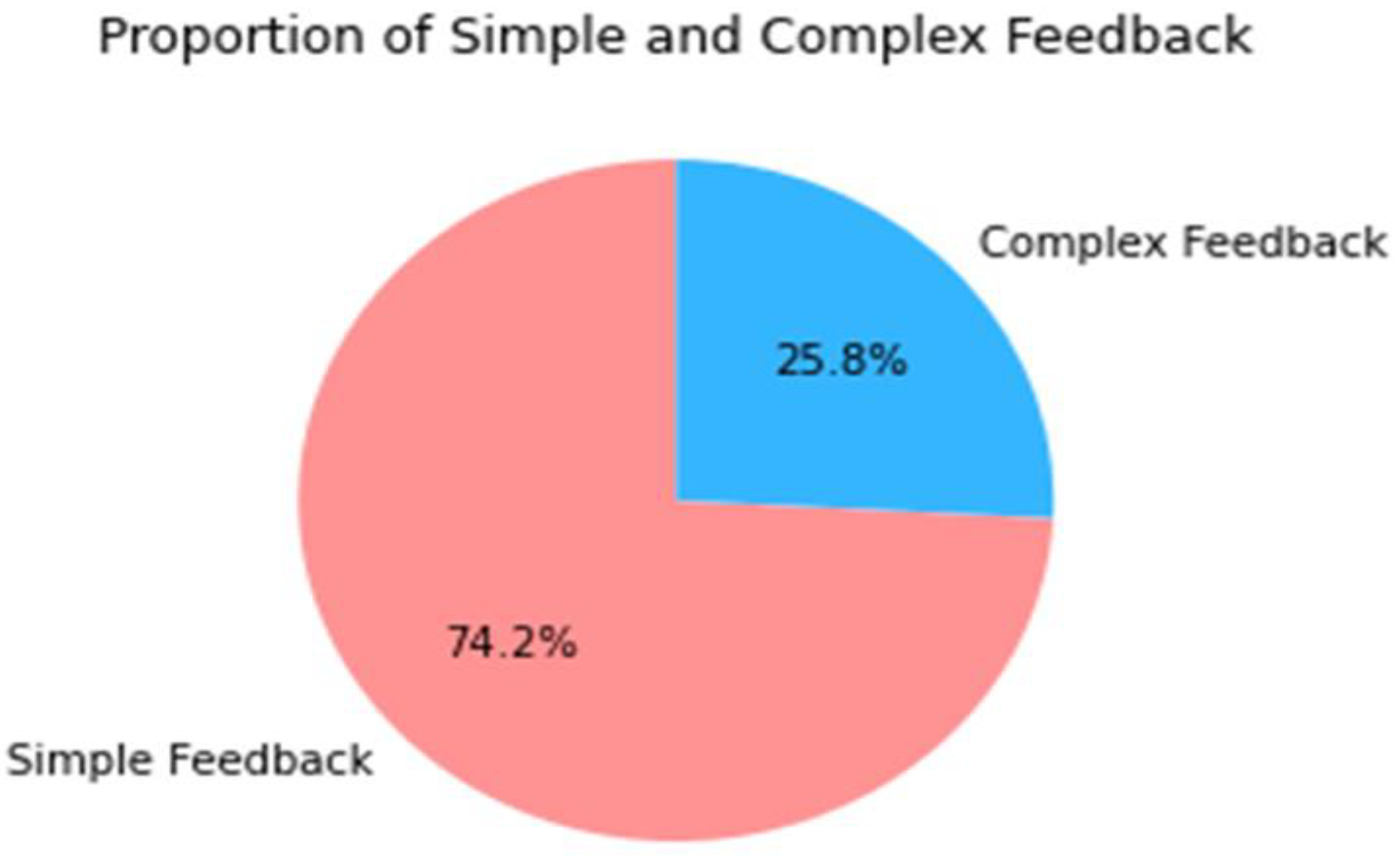
Figure 7.
Comparison of Default Reputation Score.
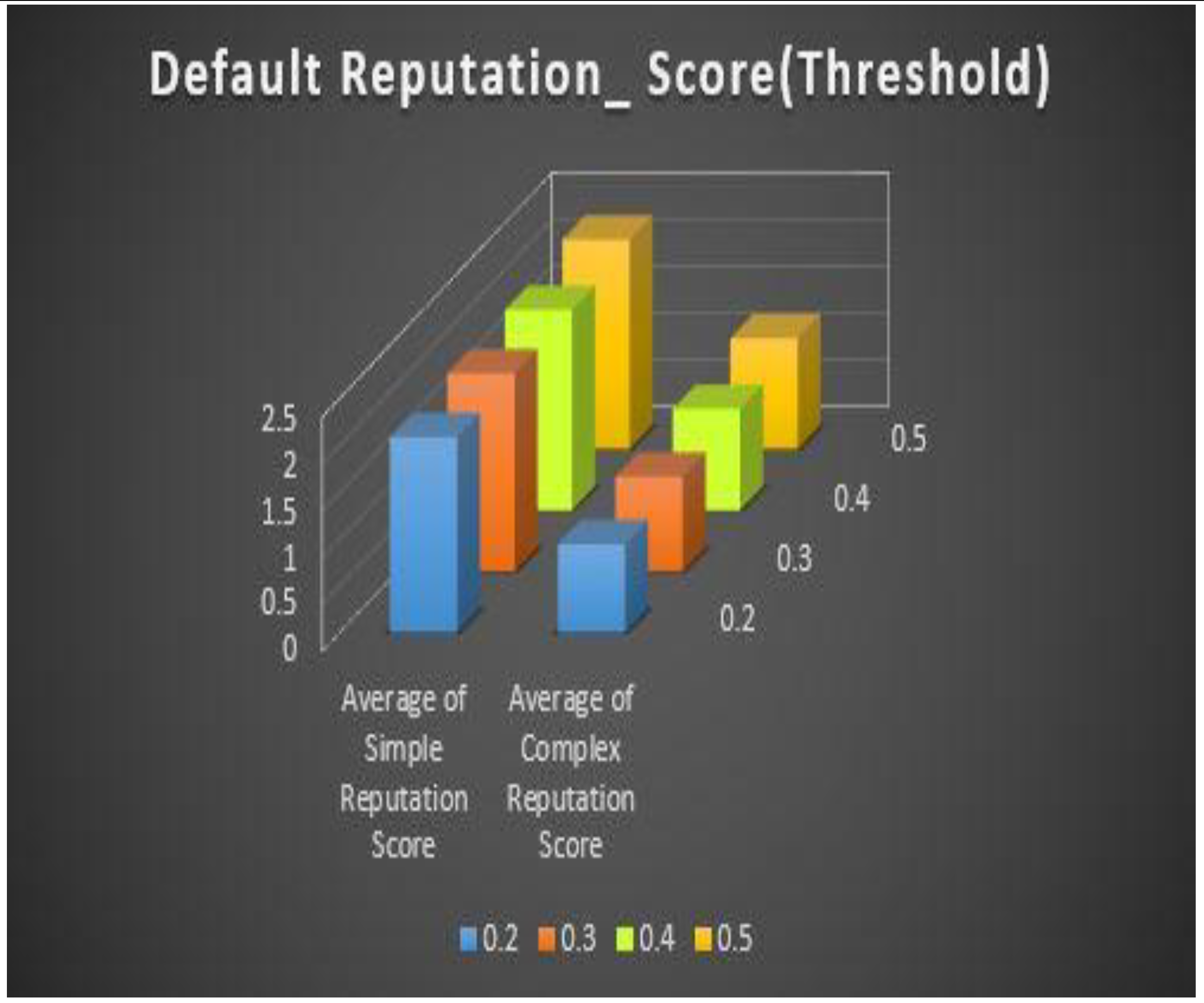
Figure 8.
Comparison of Linear Regression, Neural Network, and Proposed Method.
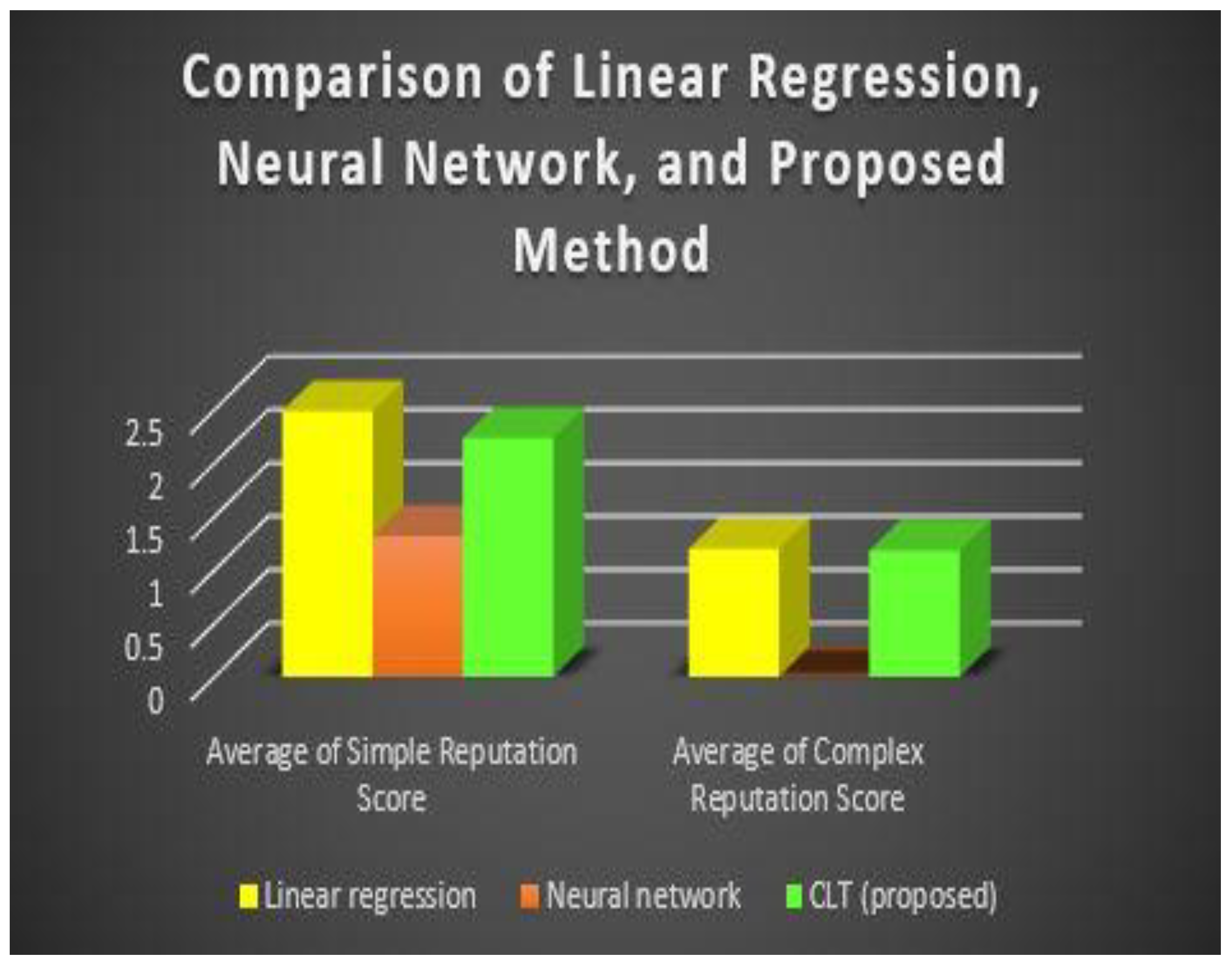
Figure 9.
Top Three Mobile worker’s by applying a Linear Regression algorithm.
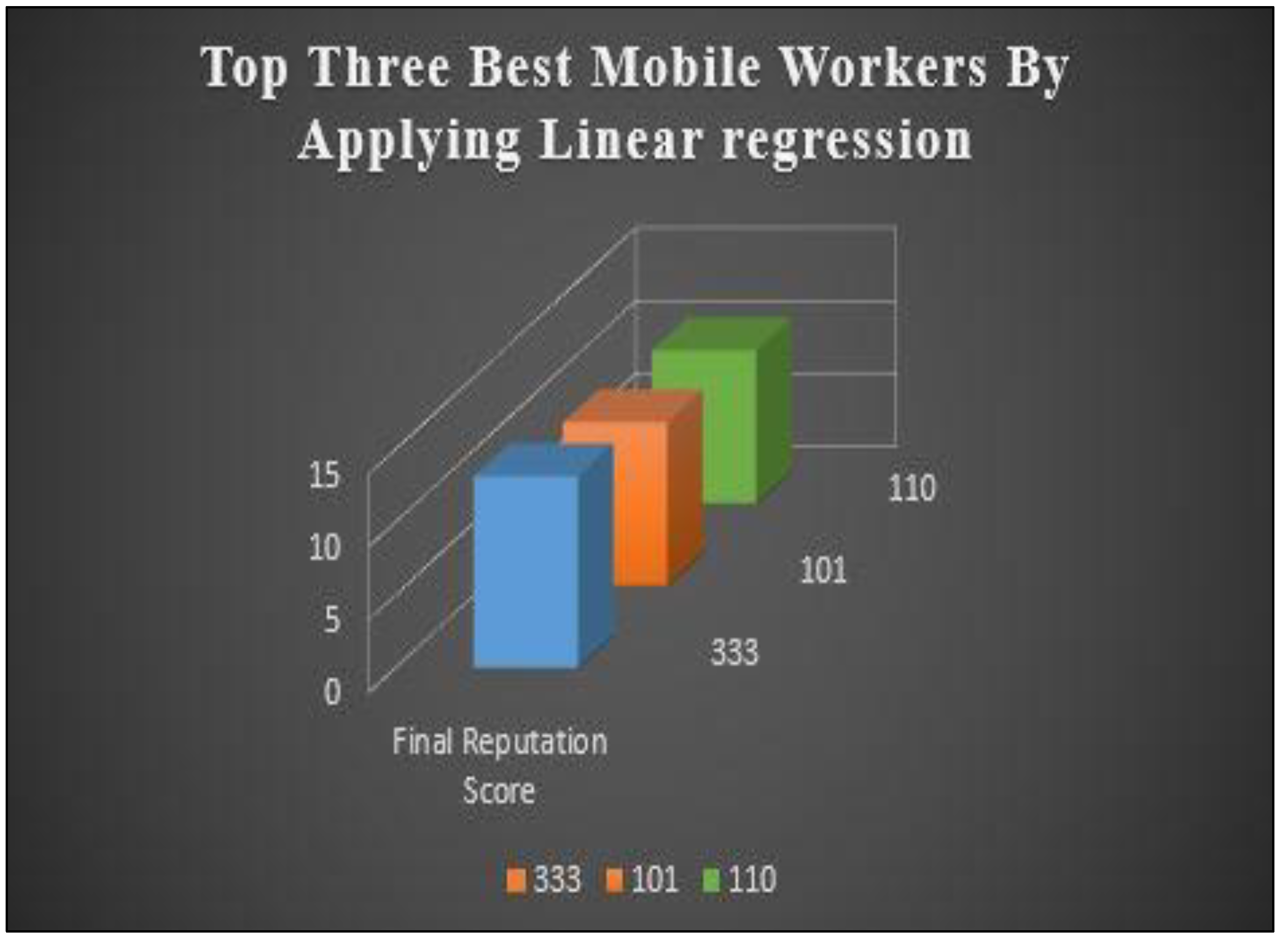
Figure 10.
Top Three Best Mobile Workers by applying a Neural Network algorithm.
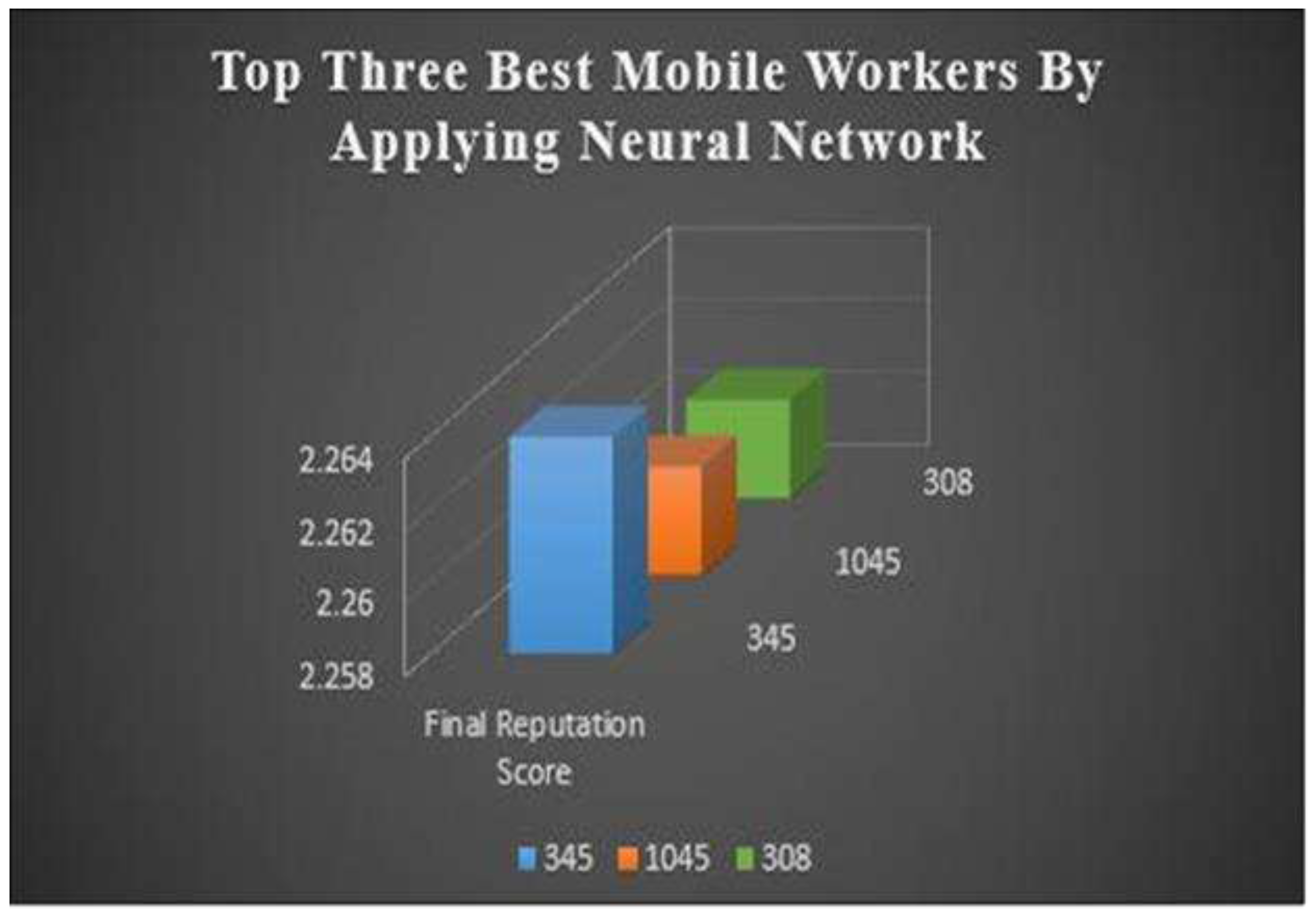
Figure 11.
Top Three Best MW_Details Using Proposed scheme(CLT).
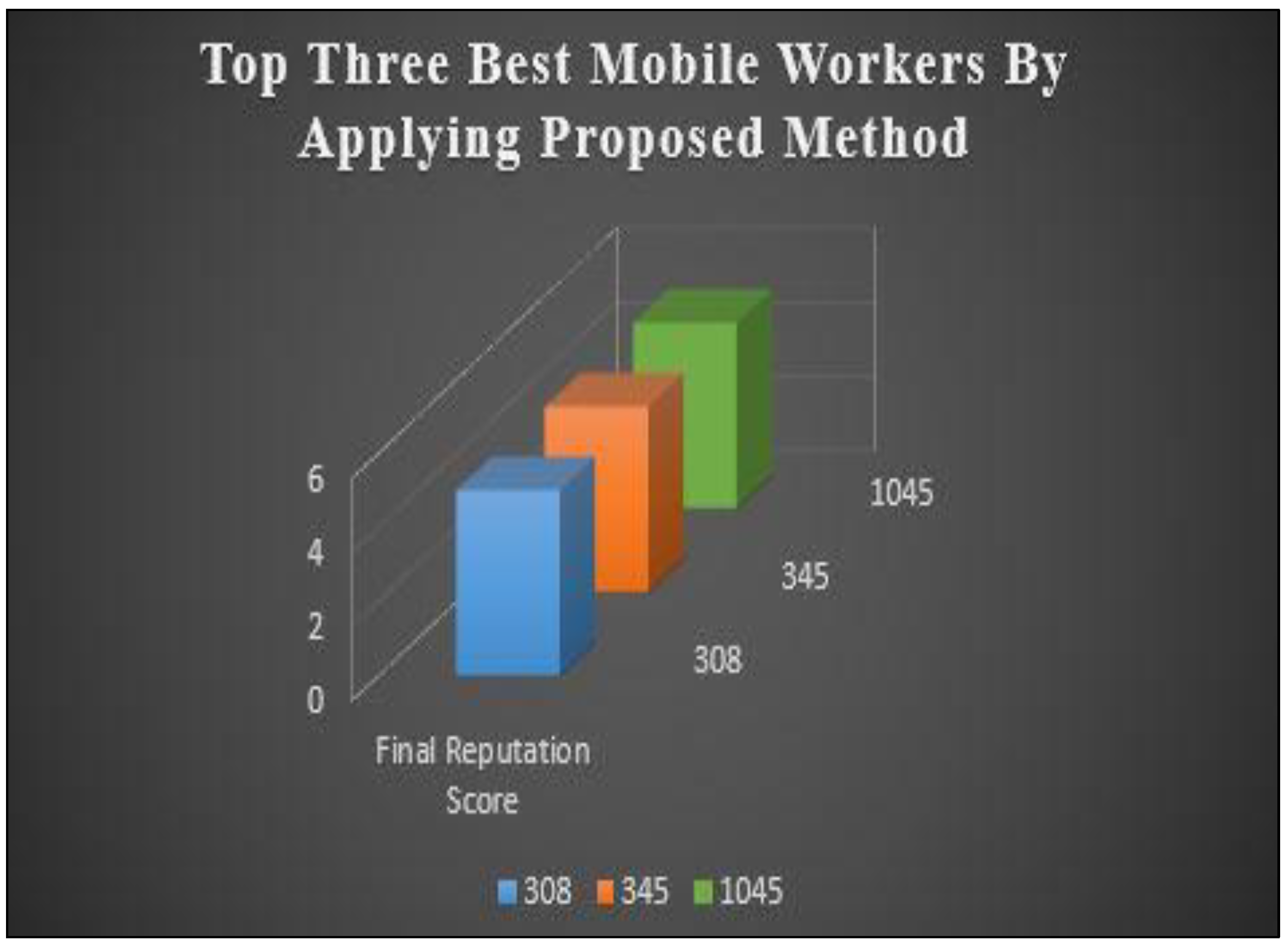
Table 5.
Parameters for the evaluation criteria of (CLT) levels of tasks and their counterpart.
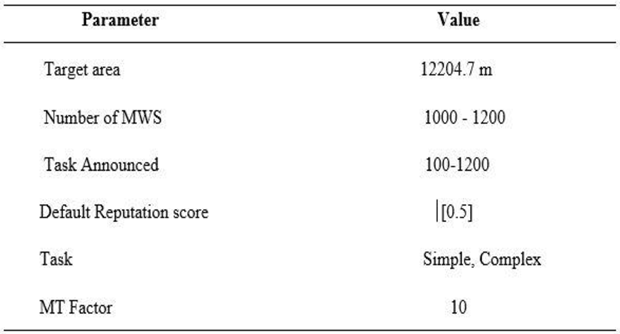 |
Table 6.
Result for Proposed Schemes (CLT).
| Default Reputation_Scre (Threshold) | Average of Simple Reputation Score | Average of Complex Reputation Score |
|---|---|---|
| 0.2 | 2.0907912457912827 | 0.945387205387211 |
| 0.3 | 2.1160437710437896 | 1.0143771043770853 |
| 0.4 | 2.1412962962963347 | 1.083367003366992 |
| 0.5 | 2.236658249158249 | 1.182996632996633 |
Table 7.
Comparison of Linear Regression, Neural Network, and Proposed Method Using Threshold 0.5.
| Schemes | Average Simple Reputation Score | Average Complex Reputation Score |
|---|---|---|
| Linear regression | 2.4869107744107737 | 1.1981481481481482 |
| Neural Network | 1.3177358339928036 | 0.5997343889031039 |
| CLT (proposed) | 2.236658249158249 | 1.182996632996633 |
Table 8.
Result of Top 3 Best MW_Details by Applying (Linear Regression algorithm).
| MW Detail | Simple Reputation Score | Complex Reputation Score | Final Reputation Score |
|---|---|---|---|
| 333 | 13.1666666666667 | 0.5 | 13.166666666666666 |
| 101 | 13.125 | 3.5 | 11.2 |
| 110 | 13.1666666666667 | 2.5 | 10.5 |
Table 9.
Result of Top 3 Best MW_Details by Applying Neural Network algorithm.
| MW Detail | Simple Reputation Score | Complex Reputation Score | Final Reputation Score |
|---|---|---|---|
| 345 | 2.00962715431412 | 2.51833046919337 | 2.263978811753746 |
| 1045 | 2.01468674579499 | 2.5073420748168 | 2.2610144103058913 |
| 308 | 2.01123696459871 | 2.51019845372276 | 2.260717709160739 |
Table 10.
Result of Top Three Best MW’s (Proposed scheme CLT).
| MW Detail | Simple Reputation Score | Complex Reputation Score | Final Reputation Score |
|---|---|---|---|
| 308 | 4.5 | 5.5 | 5 |
| 345 | 4.5 | 5.5 | 5 |
| 1045 | 4.5 | 5.5 | 5 |
Table 11.
Comparison of P-test and T-test of Machine learning algorithm and proposed Scheme (CLT).
| Schemes | Linear regression | Neural Network | CLT (proposed) |
|---|---|---|---|
| P-test | 7.699672071445626e-52 | 6.203759801754311e-87 | 1.816803686571544e-45 |
| T-test | 15.66626042986271 | 20.155918519744528 | -14.5387136194788 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



