
Submitted:
26 December 2023
Posted:
27 December 2023
You are already at the latest version
Abstract
Oxygen extraction fraction (OEF), the fraction of oxygen that tissue extracts from blood, is an es-sential biomarker for directly assessing tissue viability and function in neurologic disorders. For quantitative mapping of OEF, an integrative model of quantitative susceptibility mapping and quantitative blood oxygen level-dependent magnitude (QSM+qBOLD or QQ) was recently pro-posed. However, QQ assumes Gaussian noise in both susceptibility and multi-echo gradient echo (mGRE) magnitude signals for OEF estimation. This assumption is unreliable in low sig-nal-to-noise ratio (SNR) regions like disease-related lesions, risking inaccurate OEF estimation and potentially impacting clinical decisions. Addressing this, our study presents a novel multi-echo complex QQ (mcQQ) that models realistic noise in mGRE complex signals. The proposed mcQQ was implemented using a deep learning framework (mcQQ-NET) and compared with the existing deep learning-based QQ (QQ-NET) in simulations, ischemic stroke patients, and healthy subjects. Both mcQQ-NET and QQ-NET used identical training and testing datasets and schemes for a fair comparison. In simulations, mcQQ-NET provided more accurate OEF than QQ-NET. In the sub-acute stroke patients, mcQQ-NET showed a lower average OEF ratio in lesions relative to unaf-fected contralateral normal tissue than QQ-NET. In the healthy subjects, mcQQ-NET provided uniform OEF maps, similar to QQ-NET, but without unrealistically high OEF outliers in areas of low SNR. Therefore, mcQQ-NET improves OEF accuracy by better reflecting realistic data noise characteristics.
Keywords:
oxygen extraction faction
; quantitative susceptibility mapping
; quantitative blood oxygen level-dependent imaging
; multi-echo complex quantitative susceptibility mapping and quantitative blood oxygen level dependent magnitude
; QSM+qBOLD
; QQ
; mcQQ
; deep learning
; magnetic resonance imaging
; MRI
1. Introduction
Mapping metabolic oxygen consumption is essential for assessing brain tissue viability and function in cerebrovascular [1-3] and neurodegenerative disorders [4-8]. In MRI, quantitative oxygen extraction fraction (OEF) mapping methods have been developed by considering the strong paramagnetic effects of deoxyhemoglobin in blood on (1) the magnitude signal including calibrated functional MRI [9-12], T2-based methods [13-16], and quantitative blood oxygen level dependent magnitude (qBOLD) [17-21], and (2) the phase signal including susceptometry-based whole brain oximetry [22-24], and macrovascular [25-27] and microvascular [28-32] OEF mapping using quantitative susceptibility mapping (QSM) [33-35].
Recently, the integration of QSM and qBOLD (QSM+qBOLD=QQ) accounted for the OEF effect on both magnitude and phase of a routinely accessible multi-echo gradient echo (mGRE) dataset [36-42]. QQ was then validated using calibrated fMRI [36] and 15O-PET [39] in healthy subjects. By eliminating impractical vascular challenges, QQ has demonstrated its clinical feasibility in ischemic stroke [43,44], multiple sclerosis [45], brain cancer [46,47], dementia [48], pre-eclampsia [49], Parkinson’s disease [50]. Moreover, a deep learning approach further improved the robustness against noise and the reconstruction speed in QQ [51].
Current QQ data processing approaches, which encompass both machine learning and deep learning, commonly assume Gaussian noise for both QSM and mGRE magnitude signals [37,38,40,51]. However, this assumption may not always be valid, especially in low signal-to-noise ratio (SNR) regions, such as stroke lesions. This is due to multiple nonlinear steps required for QSM estimation from mGRE phase signals with non-Gaussian noise [16,52,53], as well as Rician noise in mGRE magnitude signals [54]. Such a problematic assumption can compromise OEF accuracy, particularly in disease-related abnormal lesions, which possibly influence clinical decisions for neurologic disorders.
This study introduces a novel multi-echo complex QQ approach (mcQQ) that accurately assumes Gaussian noise in the mGRE complex signals. Given that measurement noise has been found to substantially affect OEF accuracy in QQ approaches [37,38], more realistic noise consideration in mcQQ is expected to enhance OEF accuracy. For a fair comparison with the current deep learning-based QQ (QQ-NET) [51], we implemented a deep learning approach to solve mcQQ (mcQQ-NET), using the same training scheme, test scheme, and data as QQ-NET. We then compared the proposed mcQQ-NET with QQ-NET in simulations, ischemic stroke patients, and healthy subjects.
2. Materials and Methods
2.1. Data Acquisition
The datasets utilized in this study were retrospectively acquired from a previous QQ-NET study [51]. The study was approved by the local Institutional Review Board and involved MRI scans of 34 ischemic stroke patients (occurring within a unilateral cerebral artery territory) between 6 hours to 42 days post-stroke. The scans were conducted on a clinical 3T scanner (GE MR Discovery 750) utilizing a 32-channel brain receiver coil. The 3D mGRE imaging protocol was applied, with the following parameters: 0.47×0.47×2.0 mm3 voxel size, eight equally spaced echoes (TE1/ΔTE/TE8 = 4.5/5/39.5 ms), TR= 42.8 ms, bandwidth=244.1 Hz/pixel, 20o flip angle, and 5 min 15 second scan time. Further, DWI (24 cm FOV, 0.94×0.94×3.2 mm3 voxel size, 1953.1 Hz/pixel bandwidth, 0, 1000 s/mm2 b-values, TE=71 ms, TR=3000 ms, and four signal averages), and a T1 weighted fluid attenuated inversion recovery sequence (24 cm FOV, 0.5×0.5×5 mm3 voxel size, TE=23.4 ms, TR=1750 ms) were used.
To check whether a network trained with simulated stroke datasets can provide reasonable uniform OEF maps in healthy subjects without producing false negatives, MRI scans of four healthy subjects (age 31 ± 6 years) on a 3T GE scanner were also retrospectively obtained from the QQ-NET study [51]. The MRI scans employed 3D mGRE with imaging parameters that matched those used for the stroke patients.
2.2. Data processing: QSM
QSM reconstruction consisted of the following steps: calculating the total field () with a non-linear fit of the mGRE [55], estimating the local field from the background field () via the Projection onto Dipole Fields (PDF) method [56], and obtaining susceptibility through morphology-enabled dipole inversion with automatic uniform CSF zero-reference algorithm [52,53,57]. The FSL FLIRT algorithm was used to co-register all images with the QSM maps [58,59]. QQ-NET used the QSM maps as the network’s inputs for OEF estimation, whereas mcQQ-NET did not.
2.3. Data processing: OEF using multi-echo complex QQ (mcQQ)
In the mcQQ model, a nonlinear formulation is used when integrating the QSM-based and qBOLD-based OEF mapping methods to obtain OEF where and (=0.98) [40] denotes venous and arterial oxygenation. The mGRE complex signal at the j’th echo with the compensation of the initial phase and background field contribution on phase [55,56], (), can be modeled as Equation 1.
Here, Larmor frequency, the dipole kernel, * the convolution operator. In the phase term, the QSM distinguishes the venous blood deoxyhemoglobin’s susceptibility contribution (OEF effect) from the non-blood neural tissue susceptibility () on a voxel-wise basis.
where the fully oxygenated blood susceptibility (-108.3 ppb with tissue hematocrit Hct =0.357) [30], the ratio between the venous blood volume () and total blood volume (0.77) [60], the hemoglobin volume fraction (0.0909 with Hct=0.357) [28,61-63], the susceptibility difference between deoxy and oxyhemoglobin (12522 ppb) [29,64]. The qBOLD models the OEF effect on the mGRE magnitude [40]:
where is signal intensity a ; is the transverse relaxation rate; [21]; is the signal decay due to the blood vessel network [19]; is the characteristic frequency by the susceptibility difference between deoxygenated blood and the surrounding tissue [40]: with =267.51 rads-1T-1 the gyromagnetic ratio; the main magnetic field; and is the macroscopic field effect on mGRE signal [40].
2.4. Deep neural network for mcQQ (mcQQ-NET)
In order to account for realistic measurement noise (i.e., Gaussian noise in complex mGRE signals), mcQQ-NET introduces two modifications compared to the current QQ deep learning model (QQ-NET) [51]: changes in network structure and model loss.
Regarding the network structure, mcQQ-NET employs a combination of two Unet-based [65,66] sub-networks (Figure 1). Each sub-network processes either the mGRE magnitude or phase input, whereas QQ-NET uses a single Unet to handle mGRE magnitude and QSM. In detail, for each sub-network of mcQQ-NET, the original U-net was modified to (1) use zero-padding to maintain a uniform convolution layer output size, and (2) set the number of inputs to 8 for each sub-network (comprising 8 echo magnitude and phase signals, respectively) and outputs to 5 for the magnitude sub-network () and 3 for the phase sub-network (). The setting for the numbers of outputs and inputs are based on how magnitude and phase signals can be modeled as functions of these parameters, as described by Equations 2 and 3. Furthermore, two additional layers were integrated: one to combine common outputs () and another to apply the tanh function. The use of the tanh function limits model parameters (e.g., min and max) based on physiological expectation for Y (0~100%) and v (0.5~5.5%) and CCTV results for the other parameters, mirroring the approach in QQ-NET.
Regarding the model loss, mcQQ-NET has a weighed sum of three losses: (1) L1 difference between the normalized truth and the output of mcQQ (), (2) L1 difference of spatial gradient to preserve edge (), and (3) the model loss to consider physical model consistency). and are identical to those in QQ-NET [51]. Notably, is different between mcQQ-NET and QQ-NET: in mcQQ-NET, , whereas in QQ-NET, . The total loss () is set as with the weights being empirically determined as and .
To ensure a fair comparison between mcQQ-NET and QQ-NET, mcQQ-NET used the same training and testing scheme as QQ-NET [51] with one exception: noise consideration in data generation. While QQ-NET introduced Gaussian noise into the mGRE magnitude signals and QSM, mcQQ-NET incorporated Gaussian noise into the mGRE complex signals, offering a more realistic approach. In detail, mirroring QQ-NET, mcQQ-NET generated the training data using simulated stroke brains. First, the model parameters () were estimated from real 34 stroke patient cases using QQ-CCTV [37] and used as ground truth. The average (), standard deviation (), min, and max were (1.10, 0.04, 1.04, 2.12), R2 (19.6, 7.1, 7.3, 161.1 Hz), (0.67, 0.10, 0.31, 0.98), (2.3, 1.2, 0.3, 7.2 %), and (-11.6, 37.5, -957.2, 159.7 ppb). was set to satisfy that the first echo magnitude signal was unity. Second, from the model parameter maps (ground truth), the mGRE complex signals were simulated for each brain voxel using Equations 1, 2, and 3. Third, Gaussian noise was added to these complex signals to obtain SNR 100 at the first echo, with distinct noise instances for each training. This procedure produced pairs of ground truth (QQ-CCTV results) and simulated measurements (mGRE complex signals) for training. Out of 34 simulated datasets, 26/2/6 was used for training/validation/test, respectively.
mcQQ-NET was implemented using Pytorch 1.13.0 [67] and NVIDIA RTX A6000 GPU. Minimization was performed using ADAM [68] with a learning rate of 10-4. Training was stopped at 400 epochs when the validation loss became stable. Due to GPU memory constraints, batch size was set to 1 with a 4D patch (16×200×200×48) as input, which approximately covers a whole brain. The patch center was randomly positioned within a selected brain, a process repeated for all training brains (1 epoch). Validation was carried out in a manner identical to the training process. For each epoch, the sequence of the training brains was randomly rearranged.
The trained mcQQ-NET was tested with three separate datasets, similar to the original QQ-NET [51]: Test Data 1) an additionally simulated stroke brain created using the same process as the training datasets (SNR 100) (Figure 2). To reduce algorithm-dependent bias, the ground truth was set as the average of the QQ-NET and mcQQ-NET results from a real stroke patient (7 days post onset). This reconstruction was repeated five times with distinct instances of Gaussian noise to measure accuracy and precision. Test Data 2) 30 ischemic stroke patients, a subset of the 34 patients devoid of hemorrhage and reperfusion, were divided into three groups based on the time interval between stroke onset and MRI scan [69]: acute (6-24 hours, N=4), subacute (1-5 days, N=13), and chronic (≥ 5 days, N=13) phase (Figure 3 and Figure 4). A five-fold cross-validation was performed to prevent overlap between training and test data [51]: six real patient brains were selected as test data, while the simulated datasets of the remaining 28 patients were utilized for training (N=26) and validation (N=2) data. This yielded 5 trained networks. The first trained network was used for Test Data 1 and 3. Test Data 3) four healthy subjects scanned with identical imaging parameters (e.g., TE) to those used in training (Figure 5). The objective was to evaluate whether a network trained on simulated stroke brains could generate uniform OEF maps in healthy brains without introducing noticeable false positives, such as low OEF values typically observed in stroke lesions. During network testing, to ensure full brain coverage, patch sliding with 30% overlap was employed. Multiple overlapped patches were produced and subsequently combined to construct a single whole brain.
For real test data (Test Data 2 and 3), we compensated for the macroscopic field contribution in both magnitude and phase signal inputs. For the magnitude signal input at j’th echo (), voxel spread function method [70] was used to estimate : where the mGRE complex. For phase signal input (), the following steps were taken. First, the total () and background () fields were spatially unwrapped ( and ) using a region-growing algorithm [71]. Second, unwrapped phase () was calculated using : where is the initial phase at . Lastly, the phase by tissue field () was obtained by compensating the contributions of background field () and the initial phase (): .
We compared mcQQ-NET with QQ-NET [51], both of which were tested on the same test datasets. While they used an identical training and testing scheme and data, they differed in in two aspects as mentioned earlier: network structure and model loss.
2.5. Statistical Analysis
For the simulation (Test Data 1), accuracy and precision were measured using mean error () and mean standard deviation (MSD) where , , i: the voxel index, j: the trial index, : the number of voxels : the number of trials.
In the stroke patients (Test Data 2), lesion masks were constructed using DWI by an experienced neuroradiologist (S.J. with 7 years of experience). Corresponding contralateral normal tissue masks were created by mirroring the lesion mask to the other hemisphere and then trimmed by the same neuroradiologist. To measure lesion OEF abnormality, the OEF ratio was calculated between the lesion and its contralateral normal tissue () [27,72]. was compared between QQ-NET and mcQQ-NET using a Wilcoxon signed rank test. A P value less than 0.05 was considered statistically significant.
In the healthy subjects (Test Data 3), structural similarity index (SSIM) was used to compare OEF maps from mcQQ-NET and QQ-NET quantitatively [73].
3. Results
Figure 2 shows the OEF comparison between QQ-NET and mcQQ-NET in the simulated brain (Test Data 1). mcQQ-NET provided higher accuracy, particularly better capturing abnormal low OEF values within the lesion (smaller in the lesion: 1.13 vs. -0.34 %).
Figure 3 shows the ischemic stroke patients’ OEF maps (Test Data 2) as generated by QQ-NET and mcQQ-NET. Compared to QQ-NET, mcQQ-NET showed lower lesion OEF values in the subacute phase and improved spatial concurrence between low OEF regions and DWI-defined lesions in the chronic phase, e.g., 5 days post onset.
Figure 4 presents box plots of OEF ratio between lesion and its contralateral normal tissue, (Test Data 2). mcQQ-NET provided significantly lower in the subacute phase compared to QQ-NET, 0.68 ± 0.24 vs. 0.66 ± 0.23 (P=0.01). No significant difference was found in the acute (0.95 ± 0.13 vs. 0.97 ± 0.09, P=0.63) and chronic (0.51 ± 0.20 vs. 0.54 ± 0.16, P=0.34).
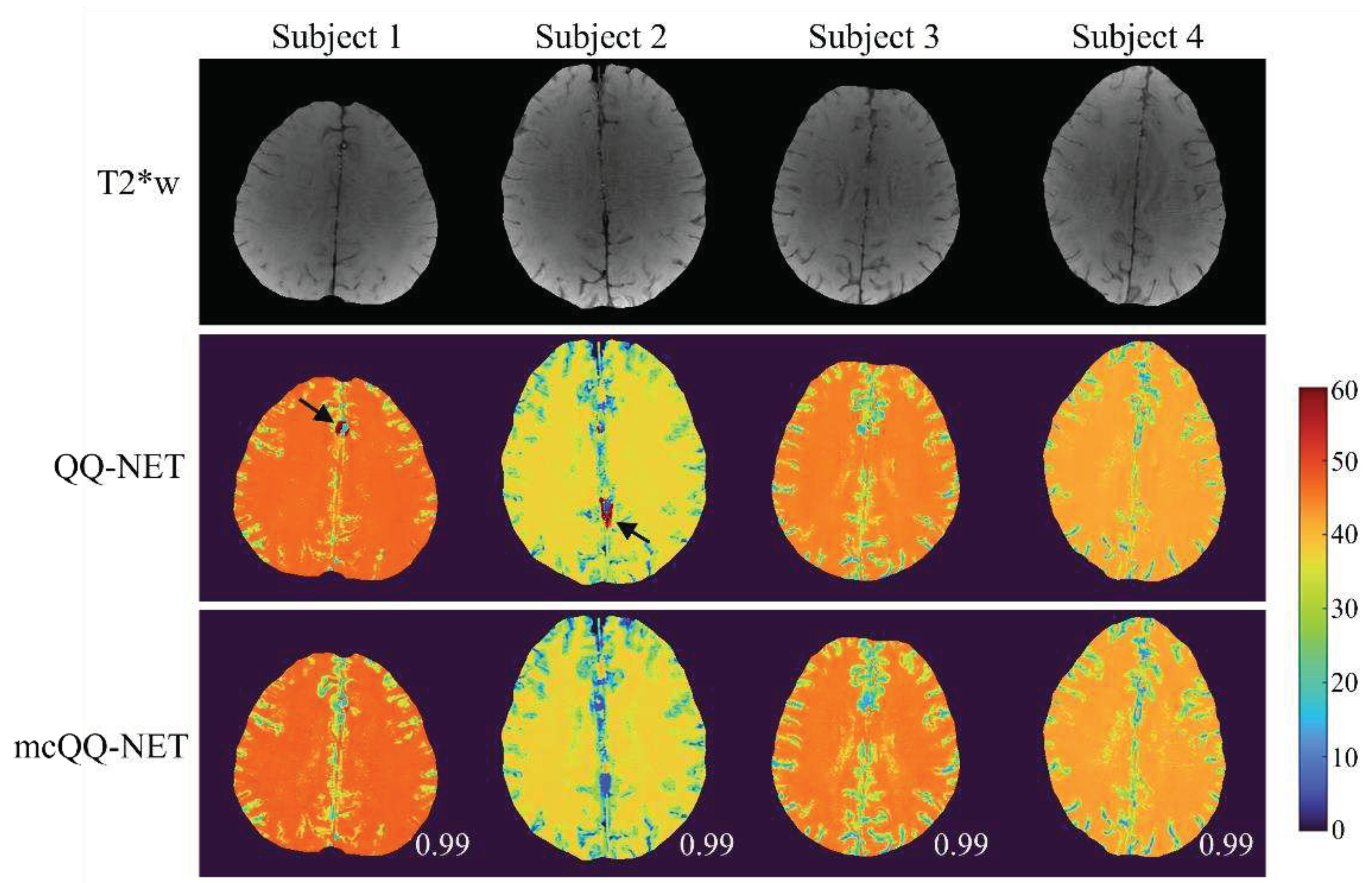
In Figure 5, the OEF maps from QQ-NET and mcQQ-NET are shown for the four healthy subjects (Test Data 3). mcQQ-NET showed uniform OEF maps, similar to those of QQ-NET (SSIMs ≥ 0.99). However, QQ-NET exhibited a few extremely high OEF outliers nearby large veins (black arrows), which were not observed in mcQQ-NET.
4. Discussion
Our results demonstrate the feasibility of mcQQ-NET, a multi-echo complex signal modeling approach with utilizing deep learning. mcQQ-NET outperformed QQ-NET [51] in OEF accuracy, especially in low OEF lesions in the simulation, and it more sensitively detected the expected low OEF abnormalities in subacute stroke patients. By considering the realistic noise characteristics in mGRE complex signals and embedding intermediate QSM processing steps into OEF quantification, mcQQ-NET provides robust OEF mapping. Furthermore, utilizing routinely applicable mGRE data, mcQQ-NET addresses the inaccessibility issues of the current reference standard for OEF technique, 15O PET, as acknowledged in QSM [74,75].
Precise modeling of MRI signal behavior is crucial for accurately extracting the corresponding biophysics parameters, as reported previously for QSM [76-78] and observed here for OEF. In the simulation (Figure 2), mcQQ-NET enhanced OEF accuracy, particularly in low OEF lesions, which is consistent with increased OEF abnormality detection in subacute stroke patients (Figure 3 and Figure 4). This improvement agrees with the enhanced accuracy in magnetic susceptibility provided by more realistic biophysical modeling in QSM [77,78]. Such findings suggest that mcQQ-NET’s realistic noise modeling might assist in decoupling OEF and v, a known challenge in qBOLD-based techniques, including QQ [21]. This is further evidenced by mcQQ-NET’s superior v accuracy (Supplementary Materials Figure S1). Additionally, mcQQ-NET’s reliable decoupling may result in low lesion v in real subacute stroke patients (e.g., 4 days post-onset, Supplementary Materials Figure S2), which is consistent with the expected blood volume decrease in ischemic stroke lesions [79].
mcQQ-NET provides lower lesion OEF than QQ-NET in the subacute stroke patients (Figure 3), which agrees with the significantly lower OEF ratio between the lesion and its contralateral normal tissue, OEFratio (Figure 4). This suggests that mcQQ-NET may quantify OEF abnormalities more accurately, considering that a low OEFratio in the subacute and chronic phase is anticipated based on the PET literature [80]. This notably lower lesion OEF, compared to its contralateral normal tissue, might indicate that the ischemic lesions are irreversibly damaged [81]. The acute phase shows heterogeneous lesion OEF values. For instance, in the 18 hours post-onset case, mcQQ-NET shows an OEF comparable to the contralateral normal tissue for most of the DWI-defined lesion, but a reduced OEF at the left bottom corner of the lesion boundary (green/blue vs. red in Figure 3). This OEF heterogeneity could reflect rapid lesion progression within the first few hours following stroke onset [82]. Areas within the lesion showing similar OEF to the contralateral normal tissue might indicate recoverable tissue, whereas regions with diminished OEF values could represent damaged tissues. Precisely measuring such OEF changes in the acute phase could be pivotal for clinical decisions, such as determining the necessity of thrombosis treatment.
In the healthy subjects (Figure 5), mcQQ-NET shows uniform OEF maps, similar to QQ-NET, which agrees with previous PET studies [83,84]. These uniform OEF maps indicate that, though trained with simulated stroke brains exhibiting OEF abnormalities, both QQ-NET and mcQQ-NET can generate OEF maps without significant artifacts in healthy subjects. However, QQ-NET shows a few extremely high OEF outliers adjacent to large veins (black arrows). Given that the veins show low SNR due to rapid signal decay, these outliers could point to potential OEF inaccuracies in regions with low SNR. In contrast, mcQQ-NET does not show such high OEF outliers. This implies that the more realistic noise consideration in mcQQ-NET might contribute to improved OEF accuracy in areas with low SNR.
This study has limitations that warrant further investigation. First, mcQQ currently employ a deep learning approach (mcQQ-NET) as in QQ-NET [51]. Thus, mcQQ-NET requires re-training for different TE sets, presenting a significant burden for clinical applications. It may also be necessary to retrain mcQQ-NET for different imaging resolutions or SNRs, even though a previous QQ-NET study suggested insensitivity to the resolution and SNR [51]. Second, a limited sample size could influence the training and testing of QQ-NET and mcQQ-NET. They were evaluated on 4 acute, 13 subacute, and 13 chronic ischemic stroke patients, showing notable difference only in the subacute phase. Testing on larger datasets may provide more comprehensive comparisons between QQ-NET and mcQQ-NET across all phases. For training, both QQ-NET and mcQQ-NET utilized identical training schemes and data, covering a wide physiological range for the model parameters, such as the entire possible range of OEF (0-100%). However, the limited number of 26 simulated stroke datasets might restrict parameter combinations. Training these models with a broader variety of parameter combinations, including diverse physiological brain datasets, could provide a more conclusive comparisons between QQ-NET and mcQQ-NET. Finally, to determine whether mcQQ-NET offers improved OEF accuracy over QQ-NET in a clinically relevant context, mcQQ-NET should be tested against patients with OEF abnormalities, using the gold standard 15O-PET as a reference.
5. Conclusions
With its improved sensitivity to OEF abnormality based on more realistic biophysics modeling, mcQQ-NET holds potential for investigating tissue variability in neurologic disorders [85-87].
Supplementary Materials
The following supporting information can be downloaded at: www.mdpi.com/xxx/s1, Figure S1: Comparison of OEF and v obtained by QQ-NET and mcQQ-NET in the simulated brain (Test Data 1); Figure S2: Comparison of OEF, v, R2, and maps between QQ-NET and mcQQ-NET in a stroke patient imaged 4 days post stroke onset (Test Data 2).
Author Contributions
Conceptualization, J.C., J.Z., P.S., and Y.W.; methodology, J.C., J.Z., P.S., H.Z., T.D.N., S.Z, A.G., and Y.W.; data curation, J.C, P.S., T.D.N, S.Z., A.G., and Y.W.; writing—original draft preparation, J.C.; writing—review and editing, P.S., A.G., and Y.W.; funding acquisition, J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Institutes of Health, R00NS123229.
Institutional Review Board Statement
This study was approved by the local Institutional Review Board of Weill Cornell Medicine.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The datasets generated or analyzed during the study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors thank all the individuals who served as research participants.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Derdeyn, C.P.; Videen, T.O.; Yundt, K.D.; Fritsch, S.M.; Carpenter, D.A.; Grubb, R.L.; Powers, W.J. Variability of cerebral blood volume and oxygen extraction: Stages of cerebral haemodynamic impairment revisited. Brain A J. Neurol. 2002, 125, 595–607. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Chazen, J.L.; Hartman, M.; Delgado, D.; Anumula, N.; Shao, H.; Mazumdar, M.; Segal, A.Z.; Kamel, H.; Leifer, D.; et al. Cerebrovascular reserve and stroke risk in patients with carotid stenosis or occlusion: A systematic review and meta-analysis. Stroke 2012, 43, 2884–2891. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Baradaran, H.; Schweitzer, A.D.; Kamel, H.; Pandya, A.; Delgado, D.; Wright, D.; Hurtado-Rua, S.; Wang, Y.; Sanelli, P.C. Oxygen Extraction Fraction and Stroke Risk in Patients with Carotid Stenosis or Occlusion: A Systematic Review and Meta-Analysis. Am. J. Neuroradiol. 2014, 35, 250–255. [Google Scholar] [CrossRef]
- Nagata, K.; Buchan, R.J.; Yokoyama, E.; Kondoh, Y.; Sato, M.; Terashi, H.; Satoh, Y.; Watahiki, Y.; Senova, M.; Hirata, Y.; et al. Misery perfusion with preserved vascular reactivity in Alzheimer's disease. Ann N Y Acad Sci 1997, 826, 272–281. [Google Scholar] [CrossRef]
- Borghammer, P.; Vafaee, M.; Ostergaard, K.; Rodell, A.; Bailey, C.; Cumming, P. Effect of memantine on CBF and CMRO2 in patients with early Parkinson's disease. Acta Neurol Scand 2008, 117, 317–323. [Google Scholar] [CrossRef]
- Tanaka, M.; Kondo, S.; Hirai, S.; Sun, X.; Yamagishi, T.; Okamoto, K. Cerebral blood flow and oxygen metabolism in progressive dementia associated with amyotrophic lateral sclerosis. J Neurol Sci 1993, 120, 22–28. [Google Scholar] [CrossRef]
- Brooks, D.J.; Leenders, K.L.; Head, G.; Marshall, J.; Legg, N.J.; Jones, T. Studies on regional cerebral oxygen utilisation and cognitive function in multiple sclerosis. J. Neurol. Neurosurg. Psychiatry 1984, 47, 1182–1191. [Google Scholar] [CrossRef]
- Chandler, H.L.; Stickland, R.C.; Patitucci, E.; Germuska, M.; Chiarelli, A.M.; Foster, C.; Bhome-Dhaliwal, S.; Lancaster, T.M.; Saxena, N.; Khot, S.; et al. Reduced brain oxygen metabolism in patients with multiple sclerosis: Evidence from dual-calibrated functional MRI. J. Cereb. Blood Flow Metab. Off. J. Int. Soc. Cereb. Blood Flow Metab. 2023, 43, 115–128. [Google Scholar] [CrossRef]
- Bulte, D.P.; Kelly, M.; Germuska, M.; Xie, J.; Chappell, M.A.; Okell, T.W.; Bright, M.G.; Jezzard, P. Quantitative measurement of cerebral physiology using respiratory-calibrated MRI. NeuroImage 2012, 60, 582–591. [Google Scholar] [CrossRef] [PubMed]
- Gauthier, C.J.; Hoge, R.D. Magnetic resonance imaging of resting OEF and CMRO2 using a generalized calibration model for hypercapnia and hyperoxia. NeuroImage 2012, 60, 1212–1225. [Google Scholar] [CrossRef]
- Hoge, R.D. Calibrated FMRI. NeuroImage 2012, 62, 930–937. [Google Scholar] [CrossRef] [PubMed]
- Wise, R.G.; Harris, A.D.; Stone, A.J.; Murphy, K. Measurement of OEF and absolute CMRO 2: MRI-based methods using interleaved and combined hypercapnia and hyperoxia. NeuroImage 2013, 83, 135–147. [Google Scholar] [CrossRef]
- Bolar, D.S.; Rosen, B.R.; Sorensen, A.; Adalsteinsson, E. QUantitative Imaging of eXtraction of oxygen and TIssue consumption (QUIXOTIC) using venular-targeted velocity-selective spin labeling. Magn. Reson. Med. 2011, 66, 1550–1562. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Wong, E.C. Venous oxygenation mapping using velocity-selective excitation and arterial nulling. Magn. Reson. Med. 2012, 68, 1458–1471. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Ge, Y. Quantitative evaluation of oxygenation in venous vessels using T2-Relaxation-Under-Spin-Tagging MRI. Magn. Reson. Med. 2008, 60, 357–363. [Google Scholar] [CrossRef] [PubMed]
- Jiang, D.; Deng, S.; Franklin, C.G.; O'Boyle, M.; Zhang, W.; Heyl, B.L.; Pan, L.; Jerabek, P.A.; Fox, P.T.; Lu, H. Validation of T2-based oxygen extraction fraction measurement with 15O positron emission tomography. Magn. Reson. Med. 2021, 85, 290–297. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Yablonskiy, D.A. Quantitative BOLD: Mapping of human cerebral deoxygenated blood volume and oxygen extraction fraction: Default state. Magn Reson Med. 2007, 57, 115–126. [Google Scholar] [CrossRef]
- He, X.; Zhu, M.; Yablonskiy, D.A. Validation of oxygen extraction fraction measurement by qBOLD technique. Magn Reson Med. 2008, 60, 882–888. [Google Scholar] [CrossRef] [PubMed]
- Ulrich, X.; Yablonskiy, D.A. Separation of cellular and BOLD contributions to T2* signal relaxation. Magn Reson Med. 2016, 75, 606–615. [Google Scholar] [CrossRef]
- Yablonskiy, D.A.; Haacke, E.M. Theory of NMR signal behavior in magnetically inhomogeneous tissues: The static dephasing regime.
- Yablonskiy, D.A.; Sukstanskii, A.L.; He, X. BOLD-based Techniques for Quantifying Brain Hemodynamic and Metabolic Properties – Theoretical Models and Experimental Approaches. NMR Biomed. 2013, 26, 963–986. [Google Scholar] [CrossRef]
- Jain, V.; Langham, M.C.; Wehrli, F.W. MRI Estimation of Global Brain Oxygen Consumption Rate. J. Cereb. Blood Flow Metab. 2010, 30, 1598–1607. [Google Scholar] [CrossRef] [PubMed]
- Wehrli, F.W.; Fan, A.P.; Rodgers, Z.B.; Englund, E.K.; Langham, M.C. Susceptibility-based time-resolved whole-organ and regional tissue oximetry. NMR Biomed. 2017, 30. [Google Scholar] [CrossRef] [PubMed]
- Wehrli, F.W.; Rodgers, Z.B.; Jain, V.; Langham, M.C.; Li, C.; Licht, D.J.; Magland, J. Time-resolved MRI oximetry for quantifying CMRO(2) and vascular reactivity. Acad. Radiol. 2014, 21, 207–214. [Google Scholar] [CrossRef] [PubMed]
- Fan, A.P.; Benner, T.; Bolar, D.S.; Rosen, B.R.; Adalsteinsson, E. Phase-based regional oxygen metabolism (PROM) using MRI. Magn Reson Med. 2012, 67, 669–678. [Google Scholar] [CrossRef] [PubMed]
- Fan, A.P.; Bilgic, B.; Gagnon, L.; Witzel, T.; Bhat, H.; Rosen, B.R.; Adalsteinsson, E. Quantitative oxygenation venography from MRI phase. Magn. Reson. Med. 2014, 72, 149–159. [Google Scholar] [CrossRef]
- Kudo, K.; Liu, T.; Murakami, T.; Goodwin, J.; Uwano, I.; Yamashita, F.; Higuchi, S.; Wang, Y.; Ogasawara, K.; Ogawa, A.; et al. Oxygen extraction fraction measurement using quantitative susceptibility mapping: Comparison with positron emission tomography. J. Cereb. Blood Flow Metab. Off. J. Int. Soc. Cereb. Blood Flow Metab. 2016, 36, 1424–1433. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Cho, J.; Zhou, D.; Nguyen, T.D.; Spincemaille, P.; Gupta, A.; Wang, Y. Quantitative susceptibility mapping-based cerebral metabolic rate of oxygen mapping with minimum local variance. Magn. Reson. Med. 2017. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Liu, T.; Gupta, A.; Spincemaille, P.; Nguyen, T.D.; Wang, Y. Quantitative mapping of cerebral metabolic rate of oxygen (CMRO2) using quantitative susceptibility mapping (QSM). Magn. Reson. Med. 2015, 74, 945–952. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, D.; Nguyen, T.D.; Spincemaille, P.; Gupta, A.; Wang, Y. Cerebral metabolic rate of oxygen (CMRO2) mapping with hyperventilation challenge using quantitative susceptibility mapping (QSM). Magn. Reson. Med. 2017, 77, 1762–1773. [Google Scholar] [CrossRef]
- Ma, Y.; Sun, H.; Cho, J.; Mazerolle, E.L.; Wang, Y.; Pike, G.B. Cerebral OEF quantification: A comparison study between quantitative susceptibility mapping and dual-gas calibrated BOLD imaging. 2020, 83, 68–82. [CrossRef]
- Ma, Y.; Mazerolle, E.L.; Cho, J.; Sun, H.; Wang, Y.; Pike, G.B. Quantification of brain oxygen extraction fraction using QSM and a hyperoxic challenge. Magn. Reson. Med. 2020, 84, 3271–3285. [Google Scholar] [CrossRef]
- de Rochefort, L.; Liu, T.; Kressler, B.; Liu, J.; Spincemaille, P.; Lebon, V.; Wu, J.; Wang, Y. Quantitative susceptibility map reconstruction from MR phase data using bayesian regularization: Validation and application to brain imaging. Magn Reson Med. 2010, 63, 194–206. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, T. Quantitative susceptibility mapping (QSM): Decoding MRI data for a tissue magnetic biomarker. Magn Reson Med. 2015, 73, 82–101. [Google Scholar] [CrossRef] [PubMed]
- Kee, Y.; Liu, Z.; Zhou, L.; Dimov, A.; Cho, J.; Rochefort, L.d.; Seo, J.K.; Wang, Y. Quantitative Susceptibility Mapping (QSM) Algorithms: Mathematical Rationale and Computational Implementations. IEEE Trans. Biomed. Eng. 2017, 64, 2531–2545. [Google Scholar] [CrossRef] [PubMed]
- Cho, J.; Ma, Y.; Spincemaille, P.; Pike, G.B.; Wang, Y. Cerebral oxygen extraction fraction: Comparison of dual-gas challenge calibrated BOLD with CBF and challenge-free gradient echo QSM+qBOLD. Magn. Reson. Med. 2021, 85, 953–961. [Google Scholar] [CrossRef]
- Cho, J.; Spincemaille, P.; Nguyen, T.D.; Gupta, A.; Wang, Y. Temporal clustering, tissue composition, and total variation for mapping oxygen extraction fraction using QSM and quantitative BOLD. Magn. Reson. Med. 2021. [Google Scholar] [CrossRef]
- Cho, J.; Zhang, S.; Kee, Y.; Spincemaille, P.; Nguyen, T.D.; Hubertus, S.; Gupta, A.; Wang, Y. Cluster analysis of time evolution (CAT) for quantitative susceptibility mapping (QSM) and quantitative blood oxygen level-dependent magnitude (qBOLD)-based oxygen extraction fraction (OEF) and cerebral metabolic rate of oxygen (CMRO2) mapping. Magn. Reson. Med. 2020, 83, 844–857. [Google Scholar] [CrossRef]
- Cho, J.; Lee, J.; An, H.; Goyal, M.S.; Su, Y.; Wang, Y. Cerebral oxygen extraction fraction (OEF): Comparison of challenge-free gradient echo QSM+qBOLD (QQ) with 15O PET in healthy adults. J. Cereb. Blood Flow Metab. 2020, 0271678X20973951. [Google Scholar] [CrossRef]
- Cho, J.; Kee, Y.; Spincemaille, P.; Nguyen, T.D.; Zhang, J.; Gupta, A.; Zhang, S.; Wang, Y. Cerebral metabolic rate of oxygen (CMRO2) mapping by combining quantitative susceptibility mapping (QSM) and quantitative blood oxygenation level-dependent imaging (qBOLD). Magn. Reson. Med. 2018, 80, 1595–1604. [Google Scholar] [CrossRef] [PubMed]
- Hubertus, S.; Thomas, S.; Cho, J.; Zhang, S.; Wang, Y.; Schad, L.R. Using an artificial neural network for fast mapping of the oxygen extraction fraction with combined QSM and quantitative BOLD. Magn. Reson. Med. 2019, 82, 2199–2211. [Google Scholar] [CrossRef]
- Hubertus, S.; Thomas, S.; Cho, J.; Zhang, S.; Wang, Y.; Schad, L.R. Comparison of gradient echo and gradient echo sampling of spin echo sequence for the quantification of the oxygen extraction fraction from a combined quantitative susceptibility mapping and quantitative BOLD (QSM+qBOLD) approach. Magn. Reson. Med. 2019, 82, 1491–1503. [Google Scholar] [CrossRef]
- Zhang, S.; Cho, J.; Nguyen, T.D.; Spincemaille, P.; Gupta, A.; Zhu, W.; Wang, Y. Initial Experience of Challenge-Free MRI-Based Oxygen Extraction Fraction Mapping of Ischemic Stroke at Various Stages: Comparison With Perfusion and Diffusion Mapping. Front. Neurosci. 2020, 14. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Zhou, Y.; Cho, J.; Shen, N.; Li, S.; Qin, Y.; Zhang, G.; Yan, S.; Xie, Y.; Zhang, S.; et al. The Spatiotemporal Evolution of MRI-Derived Oxygen Extraction Fraction and Perfusion in Ischemic Stroke. Front. Neurosci. 2021, 15. [Google Scholar] [CrossRef] [PubMed]
- Cho, J.; Nguyen, T.D.; Huang, W.; Sweeney, E.M.; Luo, X.; Kovanlikaya, I.; Zhang, S.; Gillen, K.M.; Spincemaille, P.; Gupta, A.; et al. Brain oxygen extraction fraction mapping in patients with multiple sclerosis. J. Cereb. Blood Flow Metab. Off. J. Int. Soc. Cereb. Blood Flow Metab. 2021, 271678x211048031. [Google Scholar] [CrossRef]
- Shen, N.; Zhang, S.; Cho, J.; Li, S.; Zhang, J.; Xie, Y.; Wang, Y.; Zhu, W. Application of Cluster Analysis of Time Evolution for Magnetic Resonance Imaging -Derived Oxygen Extraction Fraction Mapping: A Promising Strategy for the Genetic Profile Prediction and Grading of Glioma. Front. Neurosci. 2021, 15. [Google Scholar] [CrossRef]
- van Grinsven, E.E.; de Leeuw, J.; Siero, J.C.W.; Verhoeff, J.J.C.; van Zandvoort, M.J.E.; Cho, J.; Philippens, M.E.P.; Bhogal, A.A. Evaluating Physiological MRI Parameters in Patients with Brain Metastases Undergoing Stereotactic Radiosurgery—A Preliminary Analysis and Case Report. Cancers 2023, 15, 4298. [Google Scholar] [CrossRef]
- Chiang, G.C.; Cho, J.; Dyke, J.; Zhang, H.; Zhang, Q.; Tokov, M.; Nguyen, T.; Kovanlikaya, I.; Amoashiy, M.; de Leon, M.; et al. Brain oxygen extraction and neural tissue susceptibility are associated with cognitive impairment in older individuals. J Neuroimaging 2022, 32, 697–709. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Cho, J.; Chen, T.; Gillen, K.M.; Li, J.; Zhang, Q.; Guo, L.; Wang, Y. Oxygen extraction fraction (OEF) assesses cerebral oxygen metabolism of deep gray matter in patients with pre-eclampsia. Eur Radiol 2022, 32, 6058–6069. [Google Scholar] [CrossRef]
- Yan, S.; Lu, J.; Li, Y.; Cho, J.; Zhang, S.; Zhu, W.; Wang, Y. Spatiotemporal patterns of brain iron-oxygen metabolism in patients with Parkinson’s disease. Eur. Radiol. 2023. [Google Scholar] [CrossRef] [PubMed]
- Cho, J.; Zhang, J.; Spincemaille, P.; Zhang, H.; Hubertus, S.; Wen, Y.; Jafari, R.; Zhang, S.; Nguyen, T.D.; Dimov, A.V.; et al. QQ-NET - using deep learning to solve quantitative susceptibility mapping and quantitative blood oxygen level dependent magnitude (QSM+qBOLD or QQ) based oxygen extraction fraction (OEF) mapping. Magn Reson Med 2021. [Google Scholar] [CrossRef]
- Liu, Z.; Spincemaille, P.; Yao, Y.; Zhang, Y.; Wang, Y. MEDI+0: Morphology enabled dipole inversion with automatic uniform cerebrospinal fluid zero reference for quantitative susceptibility mapping. Magn Reson Med. 2018, 79, 2795–2803. [Google Scholar] [CrossRef]
- Liu, J.; Liu, T.; de Rochefort, L.; Ledoux, J.; Khalidov, I.; Chen, W.; Tsiouris, A.J.; Wisnieff, C.; Spincemaille, P.; Prince, M.R.; et al. Morphology enabled dipole inversion for quantitative susceptibility mapping using structural consistency between the magnitude image and the susceptibility map. NeuroImage 2012, 59, 2560–2568. [Google Scholar] [CrossRef] [PubMed]
- Gudbjartsson, H.; Patz, S. The Rician distribution of noisy MRI data. Magn. Reson. Med. 1995, 34, 910–914. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Wisnieff, C.; Lou, M.; Chen, W.; Spincemaille, P.; Wang, Y. Nonlinear formulation of the magnetic field to source relationship for robust quantitative susceptibility mapping. Magn. Reson. Med. 2013, 69, 467–476. [Google Scholar] [CrossRef] [PubMed]
- Liu, T.; Khalidov, I.; de Rochefort, L.; Spincemaille, P.; Liu, J.; Tsiouris, A.J.; Wang, Y. A novel background field removal method for MRI using projection onto dipole fields (PDF). NMR Biomed. 2011, 24, 1129–1136. [Google Scholar] [CrossRef]
- Kressler, B.; de Rochefort, L.; Liu, T.; Spincemaille, P.; Jiang, Q.; Wang, Y. Nonlinear regularization for per voxel estimation of magnetic susceptibility distributions from MRI field maps. IEEE Trans Med Imaging 2010, 29, 273–281. [Google Scholar] [CrossRef]
- Jenkinson, M.; Bannister, P.; Brady, M.; Smith, S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. NeuroImage 2002, 17, 825–841. [Google Scholar] [CrossRef]
- Jenkinson, M.; Smith, S. A global optimisation method for robust affine registration of brain images. Med. Image Anal. 2001, 5, 143–156. [Google Scholar] [CrossRef] [PubMed]
- An, H.; Lin, W. Cerebral venous and arterial blood volumes can be estimated separately in humans using magnetic resonance imaging. Magn Reson Med 2002, 48, 583–588. [Google Scholar] [CrossRef]
- Sakai, F.; Nakazawa, K.; Tazaki, Y.; Ishii, K.; Hino, H.; Igarashi, H.; Kanda, T. Regional cerebral blood volume and hematocrit measured in normal human volunteers by single-photon emission computed tomography. J. Cereb. Blood Flow Metab. Off. J. Int. Soc. Cereb. Blood Flow Metab. 1985, 5, 207–213. [Google Scholar] [CrossRef]
- Savicki, J.P.; Lang, G.; Ikeda-Saito, M. Magnetic susceptibility of oxy- and carbonmonoxyhemoglobins. Proc. Natl. Acad. Sci. USA 1984, 81, 5417–5419. [Google Scholar] [CrossRef]
- Hoffman, R. Hematology: Basic Principles and Practice; Churchill Livingstone: 2005.
- Spees, W.M.; Yablonskiy, D.A.; Oswood, M.C.; Ackerman, J.J. Water proton MR properties of human blood at 1.5 Tesla: Magnetic susceptibility, T(1), T(2), T*(2), and non-Lorentzian signal behavior. Magn Reson Med 2001, 45, 533–542. [Google Scholar] [CrossRef] [PubMed]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2016, Cham; 2016; pp. 424–432. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Cham, 2015; 2015//; pp. 234–241. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. Conf. Proc. 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Birenbaum, D.; Bancroft, L.W.; Felsberg, G.J. Imaging in acute stroke. West J Emerg Med 2011, 12, 67–76. [Google Scholar] [PubMed]
- X., U.; DA., Y. 70. X., U.; DA., Y. Enhancing image contrast in human brain by voxel spread function method. In Proceedings of the 22nd Annual Meeting of ISMRM Milan, Italy, Abstract 3197.
- Cusack, R.; Papadakis, N. New robust 3-D phase unwrapping algorithms: Application to magnetic field mapping and undistorting echoplanar images. Neuroimage 2002, 16, 754–764. [Google Scholar] [CrossRef] [PubMed]
- Fan, A.P.; Khalil, A.A.; Fiebach, J.B.; Zaharchuk, G.; Villringer, A.; Villringer, K.; Gauthier, C.J. Elevated brain oxygen extraction fraction measured by MRI susceptibility relates to perfusion status in acute ischemic stroke. J. Cereb. Blood Flow Metab. Off. J. Int. Soc. Cereb. Blood Flow Metab. 2019, 271678X19827944. [Google Scholar] [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Y.; Spincemaille, P.; Liu, Z.; Dimov, A.; Deh, K.; Li, J.; Zhang, Y.; Yao, Y.; Gillen, K.M.; Wilman, A.H.; et al. Clinical quantitative susceptibility mapping (QSM): Biometal imaging and its emerging roles in patient care. J. Magn. Reson. Imaging JMRI 2017, 46, 951–971. [Google Scholar] [CrossRef]
- Schweitzer, A.D.; Liu, T.; Gupta, A.; Zheng, K.; Seedial, S.; Shtilbans, A.; Shahbazi, M.; Lange, D.; Wang, Y.; Tsiouris, A.J. Quantitative susceptibility mapping of the motor cortex in amyotrophic lateral sclerosis and primary lateral sclerosis. AJR Am J Roentgenol 2015, 204, 1086–1092. [Google Scholar] [CrossRef]
- Dimov, A.V.; Liu, Z.; Spincemaille, P.; Prince, M.R.; Du, J.; Wang, Y. Bone quantitative susceptibility mapping using a chemical species-specific R2* signal model with ultrashort and conventional echo data. Magn Reson Med. 2018, 79, 121–128. [Google Scholar] [CrossRef]
- Dimov, A.V.; Liu, T.; Spincemaille, P.; Ecanow, J.S.; Tan, H.; Edelman, R.R.; Wang, Y. Joint estimation of chemical shift and quantitative susceptibility mapping (chemical QSM). Magn. Reson. Med. 2015, 73, 2100–2110. [Google Scholar] [CrossRef] [PubMed]
- Wen, Y.; Spincemaille, P.; Nguyen, T.; Cho, J.; Kovanlikaya, I.; Anderson, J.; Wu, G.; Yang, B.; Fung, M.; Li, K.; et al. Multiecho complex total field inversion method (mcTFI) for improved signal modeling in quantitative susceptibility mapping. Magn. Reson. Med. 2021, 86, 2165–2178. [Google Scholar] [CrossRef] [PubMed]
- Hatazawa, J.; Shimosegawa E Fau - Toyoshima, H.; Toyoshima H Fau - Ardekani, B.A.; Ardekani Ba Fau - Suzuki, A.; Suzuki A Fau - Okudera, T.; Okudera T Fau - Miura, Y.; Miura, Y. Cerebral blood volume in acute brain infarction: A combined study with dynamic susceptibility contrast MRI and 99mTc-HMPAO-SPECT.
- Baron, J.C. Mapping the Ischaemic Penumbra with PET: Implications for Acute Stroke Treatment. Cerebrovasc. Dis. 1999, 9, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Bonova, P.; Burda, J.; Danielisova, V.; Nemethova, M.; Gottlieb, M. Development of a pattern in biochemical parameters in the core and penumbra during infarct evolution after transient MCAO in rats. Neurochem. Int. 2013, 62, 8–14. [Google Scholar] [CrossRef] [PubMed]
- Dirnagl, U.; Iadecola, C.; Moskowitz, M.A. Pathobiology of ischaemic stroke: An integrated view. Trends Neurosci. 1999, 22, 391–397. [Google Scholar] [CrossRef] [PubMed]
- Mintun, M.A.; Raichle, M.E.; Martin, W.R.; Herscovitch, P. Brain oxygen utilization measured with O-15 radiotracers and positron emission tomography. J. Nucl. Med. Off. Publ. Soc. Nucl. Med. 1984, 25, 177–187. [Google Scholar]
- Raichle, M.E.; MacLeod, A.M.; Snyder, A.Z.; Powers, W.J.; Gusnard, D.A.; Shulman, G.L. A default mode of brain function. Proc. Natl. Acad. Sci. 2001, 98, 676–682. [Google Scholar] [CrossRef]
- Sun, X.; He, G.; Qing, H.; Zhou, W.; Dobie, F.; Cai, F.; Staufenbiel, M.; Huang, L.E.; Song, W. Hypoxia facilitates Alzheimer's disease pathogenesis by up-regulating BACE1 gene expression. Proc Natl Acad Sci U S A 2006, 103, 18727–18732. [Google Scholar] [CrossRef]
- Acosta-Cabronero, J.; Williams, G.B.; Cardenas-Blanco, A.; Arnold, R.J.; Lupson, V.; Nestor, P.J. In vivo quantitative susceptibility mapping (QSM) in Alzheimer's disease. PLoS ONE 2013, 8, e81093. [Google Scholar] [CrossRef]
- Trapp, B.D.; Stys, P.K. Virtual hypoxia and chronic necrosis of demyelinated axons in multiple sclerosis. Lancet. Neurol. 2009, 8, 280–291. [Google Scholar] [CrossRef]
Figure 1.
Network structure for mcQQ-NET. mcQQ-NET consisnts of two 4D Unets, one for mGRE magnitude and the other for mGRE phase input. Each Unet consists of an encoding and decoding path with 18 convolutional layers with 3×3×3 kernel (black), 4 max pooling layers with 2×2×2 kernel (red), 4 deconvolution layers with 2×2×2 kernel (green), 4 feature concatenations (purple), 1 convolutional layer with 1×1×1 kernel (orange). Linear combination on the Y, v, χn channels of output of the two Unets (gray) and element-wise Tanh function were applied for setting parameter limit (blue).
Figure 1.
Network structure for mcQQ-NET. mcQQ-NET consisnts of two 4D Unets, one for mGRE magnitude and the other for mGRE phase input. Each Unet consists of an encoding and decoding path with 18 convolutional layers with 3×3×3 kernel (black), 4 max pooling layers with 2×2×2 kernel (red), 4 deconvolution layers with 2×2×2 kernel (green), 4 feature concatenations (purple), 1 convolutional layer with 1×1×1 kernel (orange). Linear combination on the Y, v, χn channels of output of the two Unets (gray) and element-wise Tanh function were applied for setting parameter limit (blue).
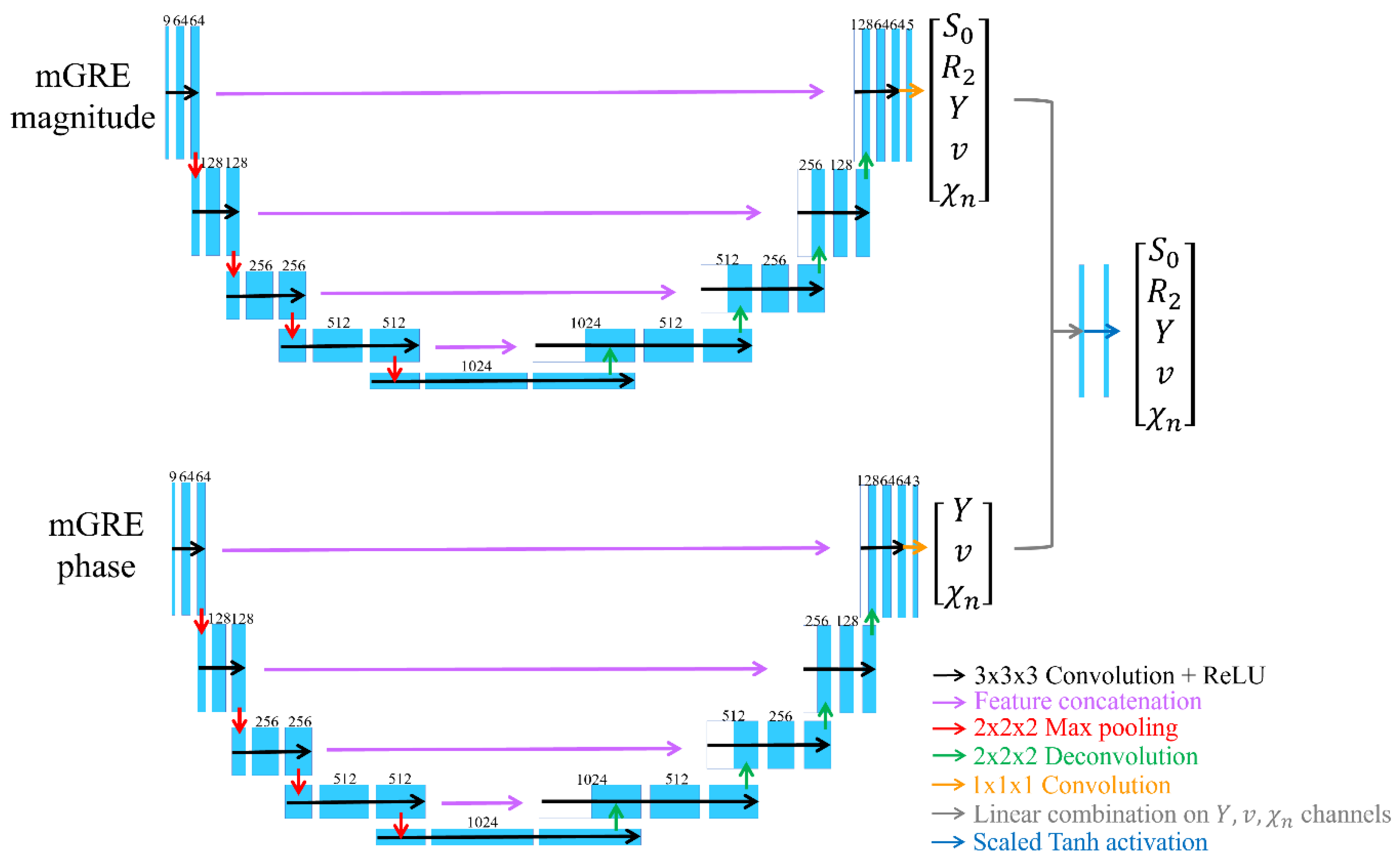
Figure 2.
Comparison of OEF between QQ-NET and mcQQ-NET in a simulated brain (Test Data 1). The number in white indicates lesion mean error. The OEF maps are shown in the unit of [%].
Figure 2.
Comparison of OEF between QQ-NET and mcQQ-NET in a simulated brain (Test Data 1). The number in white indicates lesion mean error. The OEF maps are shown in the unit of [%].
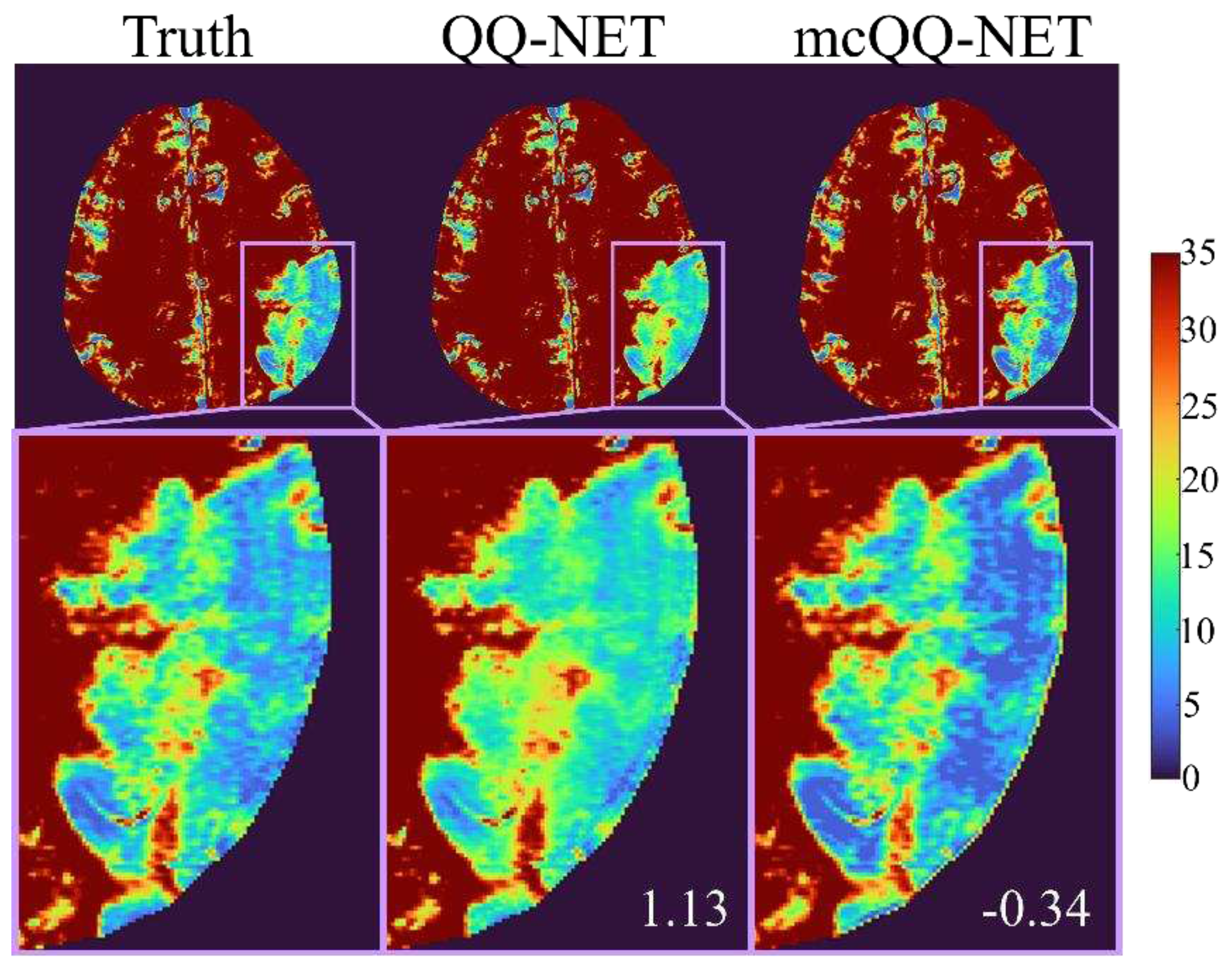
Figure 3.
Comparison of OEFs estimated from QQ-NET and mcQQ-NET in 5 real ischemic stroke patients (Test Data 2). The OEF maps are shown in the unit of [%].
Figure 3.
Comparison of OEFs estimated from QQ-NET and mcQQ-NET in 5 real ischemic stroke patients (Test Data 2). The OEF maps are shown in the unit of [%].
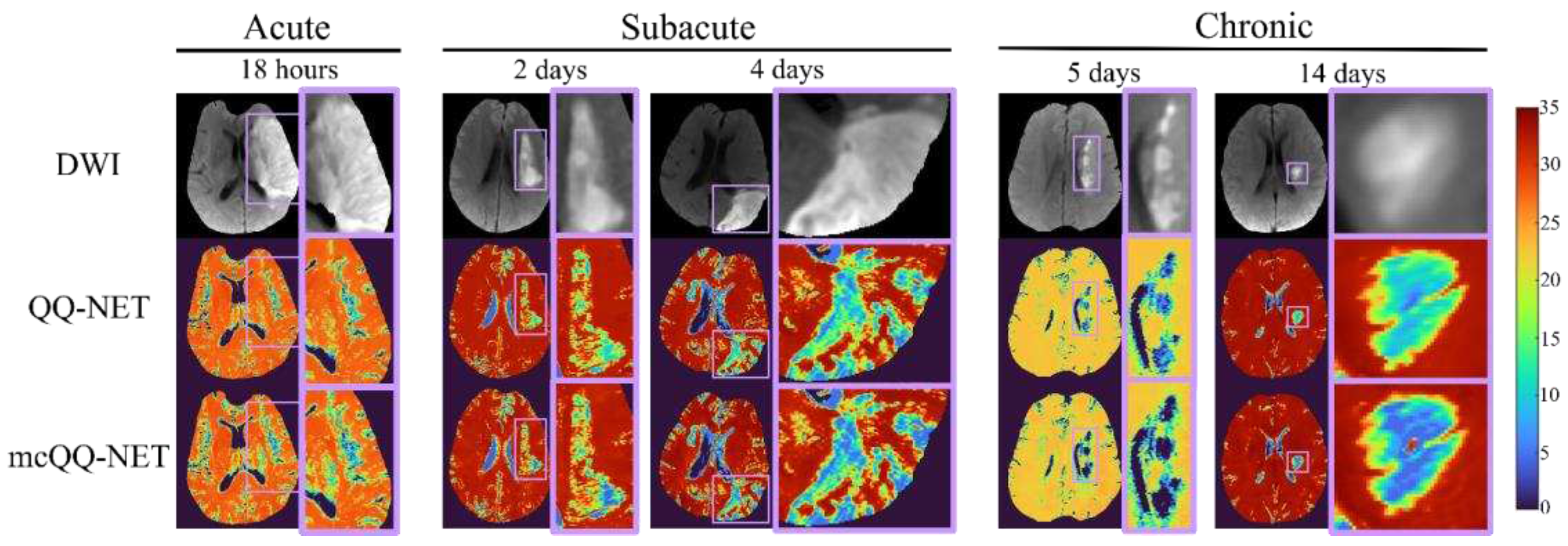
Figure 4.
Box plots of OEF ratio between the lesion and its contralateral normal tissue is acute (86-26 hours post onset, N=4), subacute (1-5 days post onset, N=13), and chronic (≥5 days post onset, N=13) ischemic stroke patients. Red line, blue box, and black whister indicate median, interquartile range, the ra extending to 1.5 of the interquartile range, respectively. Asterisk (*) indicates a significant difference (P<0.05, Wilcoxon signed rank test). Vertical histograms show the data distribution in each box plots.
Figure 4.
Box plots of OEF ratio between the lesion and its contralateral normal tissue is acute (86-26 hours post onset, N=4), subacute (1-5 days post onset, N=13), and chronic (≥5 days post onset, N=13) ischemic stroke patients. Red line, blue box, and black whister indicate median, interquartile range, the ra extending to 1.5 of the interquartile range, respectively. Asterisk (*) indicates a significant difference (P<0.05, Wilcoxon signed rank test). Vertical histograms show the data distribution in each box plots.
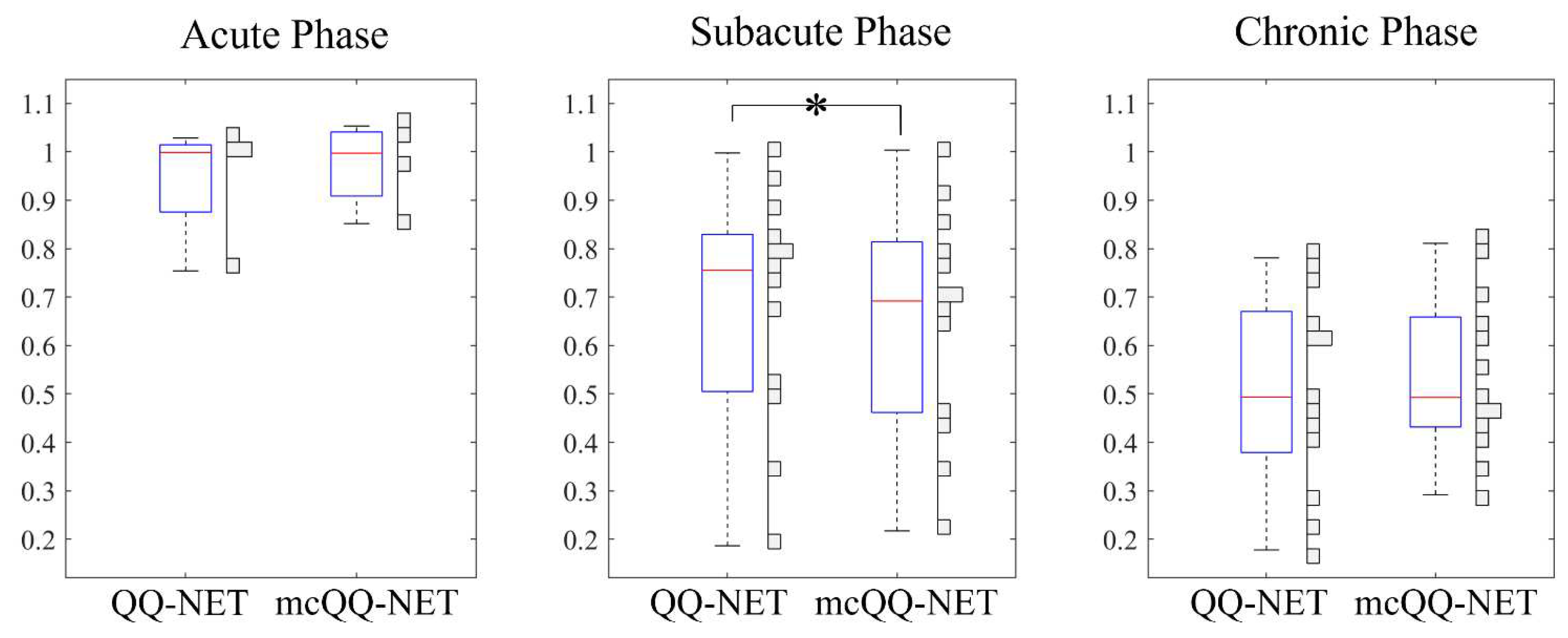
Figure 5.
Comparison of OEF determined by QQ-NET and mcQQ-NET in four healthy subjects (Test Data 3). Numbers in white represent SSIM. The OEF maps are shown in the unit of [%]. Black arrows indicate extremely high OEF outliers located near large veins in QQ-NET. .
Figure 5.
Comparison of OEF determined by QQ-NET and mcQQ-NET in four healthy subjects (Test Data 3). Numbers in white represent SSIM. The OEF maps are shown in the unit of [%]. Black arrows indicate extremely high OEF outliers located near large veins in QQ-NET. .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



