
Submitted:
28 December 2023
Posted:
28 December 2023
You are already at the latest version
Abstract
The aim of this study is to present a method for developing fragility curves for soil liquefaction that are consistent with the seismic hazard using Monte Carlo simulation. This method can account for all the uncertainties and variabilities of the input parameters. The seismic parameters of earthquake magnitude (M) and the associated peak ground acceleration (PGA) are considered together for the liquefaction assessment. The liquefaction potential and damages obtained by this method are more realistic. A case study is performed using data from a sand-boil site in Yuanlin, Changhua county, where liquefaction occurred during the Chi-Chi earthquake in Taiwan in 1999. The results show that the liquefaction potential index, IL, the post-liquefaction settlement, St, and the liquefaction probability index, PW, are all suitable parameters for evaluating the liquefaction damages. The fragility curves for soil liquefaction developed by this method can support the performance-based earthquake engineering (PBEE) approach, provide guidance for liquefaction evaluation to the ‘Taiwan Earthquake Loss Estimation System’-TELES, and serve as a basis for scenario simulation and an earthquake early warning system for liquefaction damages.
Keywords:
soil liquefaction
; fragility curve
; hazard consistent
; Monte Carlo simulation
1. Introduction
Taiwan lies on the ring of fire around the Pacific Ocean and has experienced many devastating earthquakes in its past. Earthquakes are unavoidable and their impact has to be taken seriously. One of the common types of ground failure during an earthquake is soil liquefaction [1,2,3]. Therefore, assessing liquefaction is a crucial issue for earthquake disaster management. To minimize seismic losses from earthquakes, earthquake disaster scenarios and earthquake early warning systems are important for updating the seismic code and for ensuring seismic safety and risk reduction [3]. Hence, developing fragility curves for soil liquefaction is a key part of these goals. In this study, we propose a method to construct hazard-consistent fragility curves for soil liquefaction using Monte Carlo simulation. We apply this method to the data from the sand-boil site in Yuanlin town of Changhua county that was affected by the Chi-Chi earthquake in Taiwan in 1999. The results can not only match the development trends of PBEE, but also provide guidance for the simulation of liquefaction damage scenarios in the ‘Taiwan Earthquake Loss Estimation System’-TELES [4,5].
2. Liquefaction Fragility
2.1. Fragility Assessment Method
If the damage index of liquefaction is denoted by the random variable X, the probability that X exceeds a specified value of x in t years can be evaluated by the total probability theorem to incorporate the contribution from all values of intensity measure (IM) of earthquake (e.g., peak ground acceleration, PGA) as:
where
Ht(a) is the hazard curve that describes the probability of exceeding a in t (for example, 50) years, which can be constructed from probabilistic models of the source, path, and site based on available regional seismicity information.
The item of in Equation (1) is now defined as the seismic fragility of liquefaction:
If three types of damage state (DS) are assumed: D3 (light to no damage), D2 (medium damage), and D1 (extreme damage), the probabilities for these three damage states of liquefaction of a soil layer subjected to an earthquake are defined as:
2.2. Damage Evaluation of Soil Liquefaction
In engineering practice, concerns are not only focused on the liquefaction potential at a specific depth, there is also a need to predict the overall potential of liquefaction to cause foundation damages. In this study, three liquefaction damage indices are adopted. It is liquefaction potential index (IL), liquefaction-induced settlement (St), and liquefaction probability index (PW). Each index and associated damage states are described in the following.
Iwasaki et al. (1982)[6] proposed a liquefaction potential index (IL) using the factor of safety (FS) against liquefaction and the depth weighting factor (W) to quantify the severity of the degree of liquefaction at depths ranging from 0 to 20m beneath the ground as below:
or in discrete form:
where
and
In which z is the depth of the soil in metres; H is the thickness of the soil layer considered. The severity of liquefaction was classified into four classes called ‘‘very low,’’ ‘‘low,’’ ‘‘high’’ and ‘‘very high’’, depending on the value of IL shown in Table 1, proposed by Iwasaki et al. (1982) [6].
The second damage index used in this study is liquefaction-induced settlement, which could result in collapse or partial collapse of a structure, especially if there is significant differential settlement between adjacent structural elements. The total settlement, St, for sandy soil is given by:
where Hi = thickness of layer i ; εvi = volumetric strain of layer i; and n = number of soil layers.
Ishihara and Yoshimine (1992)[7] developed a practical method by correlating volumetric strain with relative density and associated penetration resistances (SPT-N value and CPT tip resistance) and the factor of safety (FS) of the sand against the state of liquefaction. It can be used to compute the settlements in Equation (9). The relationship between the extent of the damage and the approximate settlements is shown in Table 2.
When evaluating IL and St in Equations (6) and (9), the simplified method [8,9] is used first to calculate the factor of safety against liquefaction, denoted by FSSeed. And then Equation (10) is adopted to convert FSSeed to FS (as mentioned above) based on the research by Huang [10] to determine the factor of safety in the case of equal probability of liquefaction.
FS = 1.1417 FSSeed0.5433
The third damage index used in this study is the liquefaction probability index (PW). Because the probability of liquefaction, PLiq, is the information required to make risk-based design decisions, the following expression of PLiq derived by Huang (2008)[11] using logistic regression is used to evaluate the potential for liquefaction in this study:
where
in which is the clean sand equivalence of the corrected SPT blow count defined in Youd et al. (2001) [9]. CSRN is the normalized cyclic stress ratio (CSR) shown in Equation (12) where MSF = magnitude scaling factor; amax= peak horizontal acceleration of ground surface; g = acceleration due to gravity; σv0 = total vertical stress in question; σ′v0 = effective vertical stress at the same depth; = stress reduction factor defined by Youd et al. (2001) [9]; and = moment magnitude.
To represent the overall liquefaction potential in the upper 20 m of the site profile, the liquefaction probability index, PW, is defined below [11]:
where is the value of PLiq at depth of z, and the weighting function W(z)=10-0.5z.
3. Hazard-Consistent Fragility Curves of Soil Liquefaction
To evaluate the liquefaction damage of soil, this study uses the Monte Carlo simulation to generate the combination of earthquake magnitude (M) and peak ground acceleration (PGA), which are the seismic parameters for the assessment. The simulation methods and the seismic source database are consistent with those used in probabilistic seismic hazard analysis, so the resulting parameters are also hazard-consistent. Moreover, the hazard-consistency is maintained in the fragility curves of the soil liquefaction analysis.
3.1. Procedures for Seismic Hazard Analysis
The first step is to identify the earthquake sources. As Figure 2 illustrates, this study models the sources in the deep seismic zone (hypocentral depth > 35 km) as point sources [13]. On the other hand, in the shallow seismic zone (hypocentral depth < 35 km), the sources are modelled as area sources or line sources (such as active faults) [14].
The next step is to describe how often and how strongly each source produces earthquakes, or, in other words, the relationship between the frequency and the magnitude of seismic events. A maximum possible earthquake is selected for each source.
The third step is to assess the impact of the earthquake. To calculate how the peak ground acceleration (PGA) decreases with the magnitude (M) and the distance from the site to the source (R), this study uses the Campell's formula [15]:
where is the horizontal PGA value for hard site conditions; b1~b5 are regression coefficients with values of b1=0.00369, b2=1.75377, b3=2.05644, b4=0.12220 and b5=0.78315, respectively [16]. σlnE is the standard deviation of the natural logarithm of the model error.
σlnE = 0.68
The next step is to estimate the site's seismic hazard, which means calculating how likely it is that different levels of ground shaking will occur at the site in a given year. The seismic hazard analysis is based on the assumption that earthquakes follow a stationary Poisson process, which means that they occur randomly and independently over time.
If go through the above four steps, the annual probability of peak ground acceleration, PGAR, exceeding a value a can be expressed as [14]:
where n is the number of potential seismic sources in the region of the site; is the event that the earthquake with M ≥ M0 occurs in source i ; is the annual average occurrence rate of earthquakes with M ≥ M0 in source i; and M0 is the smallest magnitude of concern to engineering.
3.2. Simulation of Hazard-Consistent Seismic Parameters
To produce the pair of seismic parameters that match the hazard level, the earthquake magnitude (M) and the peak ground acceleration (PGA), we first simulate the magnitude, M, of a seismic event and the distance from the site to the source, R. Then, we use Equation (14) to calculate the horizontal peak ground acceleration, PGAR, at the hard site for the given scenario of M and R. This way, we obtain the pair of (M, PGAR) as well.
Table 4 lists the random variables that the Monte Carlo simulation uses. The seismic sources can be either line sources or area sources, depending on whether they are in the shallow zone or not. For well-defined faults (Type I sources [14]), the model uses line sources with known parameters such as position, direction and length of the fault line, for example, Type I active fault in Taiwan. The random variables for this type of source are magnitude (M), epicentral distance (Re), hypocentral depth (h), and the model error term (E). The future seismic events may start a rupture at any location along the fault line. The rupture length of the future events depends on magnitude M.
For area sources, we can use a line source to represent them, but we have to account for the uncertainty of the line source's location and orientation (Type III source [14]). The fault line's length depends on the magnitude M. The random variables in this case are the magnitude (M), the depth of the hypocenter (h), the direction of the fault rupture (θ), and the model error term (E). We can divide the source areas into grid points and assume that each grid point can be the origin of a fault rupture. Therefore, we only use the depth of the hypocenter (h) as a random variable to capture the uncertainty of the seismic event's position.
If the seismic sources are located in a deep zone, they can be approximated as point sources. In this case, the position error may exceed the rupture length, and the hypocentral distance is large enough to make the rupture length negligible. Thus, the only random variables to consider are the magnitude (M), the hypocentral depth (h), and the model error term (E).
The aforementioned random variables follow different distributions. The probability density function of earthquake magnitude, M, is [14]
where b is the seismic region coefficient; and are the smallest magnitude of concern to engineering (5.0 is used in this study) and the upper bound magnitude, which depends on the region, respectively.
We assume that the model error term, E, follows a log-normal distribution. The fault rupture azimuth, θ, has a uniform distribution over 2π. For the epicentral distance of Re and hypocentral depth of h, we also assume that they are uniformly distributed over the range given by the seismic source database.
3.3. Liquefaction Hazard and Fragility Curves
A diagram that illustrates the steps for assessing the risk of liquefaction is presented in Figure 2. The process begins by randomly creating a set of seismic parameters that are compatible with the hazard level, namely the earthquake magnitude, M, and the corresponding peak ground acceleration at stiff sites, . These parameters are then used to evaluate the liquefaction potential.
In the following, after considering the soft site effects and the uncertainties of associated parameters of geological data, the factor of safety against liquefaction (FS) and the liquefaction probability (PLiq) for every depth considered are first computed. Then, the liquefaction potential index (IL), liquefaction-induced settlement (St), and the liquefaction probability index (PW) are calculated as follows to evaluate the liquefaction damage of the site subject to earthquake.
The system will only process the samples of PGAR ≥ 0.05g to assess the liquefaction damage level of the site. The soil is considered to be non-liquefiable if it has a factor of safety above 1.0 and a zero liquefaction probability for the sample of PGAR < 0.05g. The simulation runs until the number of samples of PGAR ≥ 0.05g, denoted by Ng, exceeds 100,000.
If we denote the damage index of liquefaction as X, and assume that the occurrences of earthquakes follow the Poisson process, the annual probability of the damage index exceeding a specified state x can be expressed as
The symbols above are the same as those in Equation (16).
Based on the flowchart of the liquefaction hazard analysis shown in Figure 3 and the Equation (18), the damage state of the liquefaction for any specified return period T can be obtained as a reference for the engineering design. On the other hand, to meet the requirements of seismic scenario simulation and the early warning system for liquefaction damages, the fragility curves of the liquefaction of the site are another important part to be determined. As to how to build the fragility curves, the partial procedures are the same as those in Figure 3. When the pair of seismic parameters (M, PGAR) is generated, the soft site effects and the uncertainties of the associated parameters of the geological data are considered, and then the damage indices (IL, St, and PW) are calculated, the following equation is used to estimate the liquefaction fragility corresponding to a specified peak ground acceleration value of a:
In which IMi and Xi are the ith Monte Carlo simulation values of PGAR and the corresponding damage index, respectively. Δa is the interval of PGAR considered. The value of 0.02 g is adopted in this study.
4. Case Study
4.1. Site Condition
On 21 September 1999, the largest earthquake of the 20th century in Taiwan (Mw = 7.6, ML = 7.3) struck this island. The epicentre was near Chi-Chi, so it has been named the Chi-Chi earthquake. The earthquake killed more than 2400 people and caused serious damage to buildings, bridges, dams, and infrastructures. One of the causes of the severe damage to the structures was soil liquefaction and ground settlement during the earthquake. After the earthquake, Moh and Associates (MAA) [17,18] conducted a detailed site investigation at liquefaction sites and neighbouring zones, including Yuanlin city of Changhua county. Of these site investigation data, one borehole labelled BH-29 with definite evidence of liquefaction is taken as an example in this study to demonstrate the build-up of fragility curves for soil liquefaction and its application. The borehole site of BH-29 is located in an old well filled with boiling sand during the Chi-Chi earthquake.
The soil profile of the BH-29 site is shown in Figure 4. According to the condition of the site under investigation, to a depth of 20 m below the ground surface, the majority consisted of alluvium silty sands and silts, except for the depths of 7.9~9.8m and 19.6~20.0m with clay. The SPT-N values are below 10 within shallow depths. The groundwater table is located at a depth of 2.0 m.
For the Chinan Plain in Taiwan, the relationship of PGA between the soft site and the hard site conditions is shown in Figure 5 [3]. Because the BH-29 site is near the Chinan Plain, the median relationship curve in Figure 5 is adopted to consider the soft site effects when evaluating the seismic fragility of soil liquefaction. On the other hand, uncertainties about the SPT-N value and groundwater table will be included in the analyses.
4.2. Liquefaction Fragility
According to the flowchart of liquefaction hazard analysis shown in Figure 3, Equation (19), and the site condition of the BH-29 site, the fragility curves and the corresponding probability density of the liquefaction potential index (IL), the liquefaction-induced settlement (St), and the liquefaction probability index (PW) are shown in Figure 6, Figure 7 and Figure 8, respectively. If the PGA of the design earthquake is 0.3g and “Medium damage” or “Moderate liquefaction” is selected for reference, i.e., IL≥10, St ≥20cm, and PW≥0.5. The corresponding probabilities are 0.98, 0.97, and 0.89 from the fragility curves, respectively. Although these probabilities are different, they are all close to 1.0. The results fully respond to the soil characteristics of the liquefaction site and demonstrate the use of the developed fragility curves. Furthermore, it can be found that the damage state will get higher as the PGA becomes larger from the trend of the histogram of probability density for each damage index. That is, the larger the PGA, the higher the probability of heavy liquefaction damage.
Here, a lognormal cumulative distribution function is assumed to model the fragility curve, F(x;a) in Equation (3), as:
in which a represents PGA; m and are median and log-standard deviation, respectively; and Φ[⋅]= standardized normal distribution function.
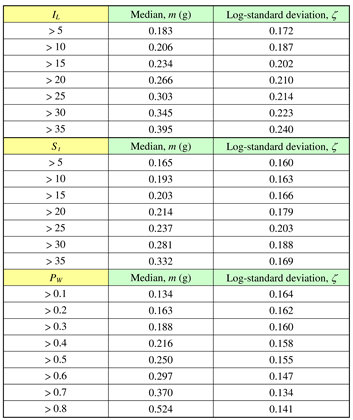
Table 5 shows the two parameters m and for the damage indices IL, St, and PW for several damage levels. It fits very well when comparing regression curves and data points, obtained from Equation (19), as shown in Figure 6, Figure 7 and Figure 8.
From Table 5, we can find that the median m is large when the damage level becomes high, whereas the log-standard deviation does not have this common trend.
5. Conclusions
- This research proposed a method to construct hazard-consistent fragility curves for soil liquefaction using Monte Carlo simulation. The seismic parameters for evaluating liquefaction damage are the pair of earthquake magnitude and associated peak ground acceleration (M, PGA). The results of the liquefaction potential and damages thus obtained are more reasonable.
- According to the results of the analysis of the case study for the sand-boil site located in Yuanlin city in Changhua county, the liquefaction potential index, IL, the settlement after liquefaction, St, and the liquefaction probability index, PW, have been shown to be appropriate parameters to assess the damage of liquefaction and to build fragility curves.
- By the hazard-consistent fragility curves of soil liquefaction developed here, a tool of scenario simulation for liquefaction damage is provided. It will be beneficial to the “Taiwan Earthquake Loss Estimation System”-TELES. Furthermore, it can serve as a guide for the decision-making of countermeasure design against liquefaction.
References
- Cubrinovski, M.; Ntritsos, N. 8th Ishihara lecture: holistic evaluation of liquefaction response. Soil Dyn. Earthq. Eng. 2023, 168, 107777. [Google Scholar] [CrossRef]
- Ko, Y.Y.; Tsai, C.C.; Hwang, J.H.; Hwang, Y.W.; Ge, L.; Chu, M.C. Failure of engineering structures and associated geotechnical problems during the 2022 ML 6.8 Chihshang earthquake, Taiwan. Nat. Hazards 2023, 118, 55–94. [Google Scholar] [CrossRef]
- Huang, F.K. Analysis for Seismic Risk of Soil Liquefaction, Ph.D. Dissertation, National Taiwan University, Taipei, Taiwan, 1996. [Google Scholar]
- Yeh, C.H. Taiwan Earthquake Loss Estimation System–TELES, Report No. NCREE-03-002, National Center for Research on Earthquake Engineering, Taipei, Taiwan, 2003.
- Risk Management Solutions, Inc., Earthquake Loss Estimation Method-HAZUS97 Technical Manual, National Institute of Building Sciences, Washington, DC, 1997.
- Iwasaki, T.; Arakawa, T.; Tokida, K. Simplified procedures for assessing soil liquefaction during earthquake. In Proceedings of the Conference on Soil Dynamics and Earthquake Engineering, Southampton, 13–15 July 1982; pp. 925–939. [Google Scholar]
- Ishihara, K.; Yoshimine, M. Evaluation of settlements in sand deposits following liquefaction during earthquakes. Soils Found. 1992, 32, 173–188. [Google Scholar] [CrossRef]
- Seed, H.B.; Idriss, I.M. Simplified procedure for evaluating soil liquefaction potential. J. Soil Mech. Found. Div. ASCE 1971, 97, 1249–1273. [Google Scholar] [CrossRef]
- Youd, T.L.; Idriss, I.M.; Andrus, R.D.; Arango, I.; Castro, G.; Christian, J.T.; Dobry, R.; Finn, W.D.L; Harder, L. F., Jr.; Hynes, M.E.; Ishihara, K.; Koester, J.P.; Laio, S.S.C.; Marcuson, W.F., III; Martin, G.R.; Mitchell, J.K.; Moriwaki, Y.; Power, M.S.; Robertson, P.K.; Seed, R.B.; Stokoe, II, K.H. Liquefaction resistance of soils: summary report from the 1996 NCEER and 1998 NCEER/NSF workshops on evaluation of liquefaction resistance of soils. J. Geotech. Geoenviron. Eng. ASCE 2001, 127, 817–833. [Google Scholar] [CrossRef]
- Huang, F.K. Establishment and application of the evaluation model for the liquefaction probability and associated damages based on the information theory. J. Chin. Inst. Civ. Hydraul. Eng. 2008, 20, 301–314. [Google Scholar]
- Huang, F.K. Establishment and application of the SPT evaluation model for the liquefaction probability and associated damages. J. Chin. Inst. Civ. Hydraul. Eng. 2008, 20, 155–174. [Google Scholar]
- Reiter, L. Earthquake Hazard Analysis: Issues and Insights, Columbia University Press, New York, 1990.
- Cornell, C.A. Engineering seismic risk analysis. Bull. Seismol. Soc. Am. 1968, 58, 1583–1606. [Google Scholar] [CrossRef]
- Der Kiureghian, A.; Ang, A.H.-S. Fault rupture model for seismic risk analysis. Bull. Seismol. Soc. Am. 1997, 67, 1173–1194. [Google Scholar]
- Campbell, K.W. Near-source attenuation of peak horizontal acceleration. Bull. Seismol. Soc. Am. 1981, 71, 2039–2070. [Google Scholar]
- Jean, W.Y.; Chang, Y. W.; Loh, C. H. Early Estimation Procedure for the Potential of Seismic Disaster, Report No. NCREE-04-001, pp.67-72, National Center for Research on Earthquake Engineering, Taipei, Taiwan, 2004.
- Moh and Associates (MAA), Soil Liquefaction Assessment and Remediation Study, Phase I (Yuanlin, Dachun, and Shetou), Summary Report and Appendices, Moh and Associates (MAA), Inc., Taipei, Taiwan (in Chinese), 2000.
- Moh and Associates (MAA), Soil Liquefaction Investigation in Nantou and Wufeng Areas, Moh and Associates (MAA), Inc., Taipei, Taiwan (in Chinese), 2000.
Figure 1.
Procedures for seismic hazard analysis.
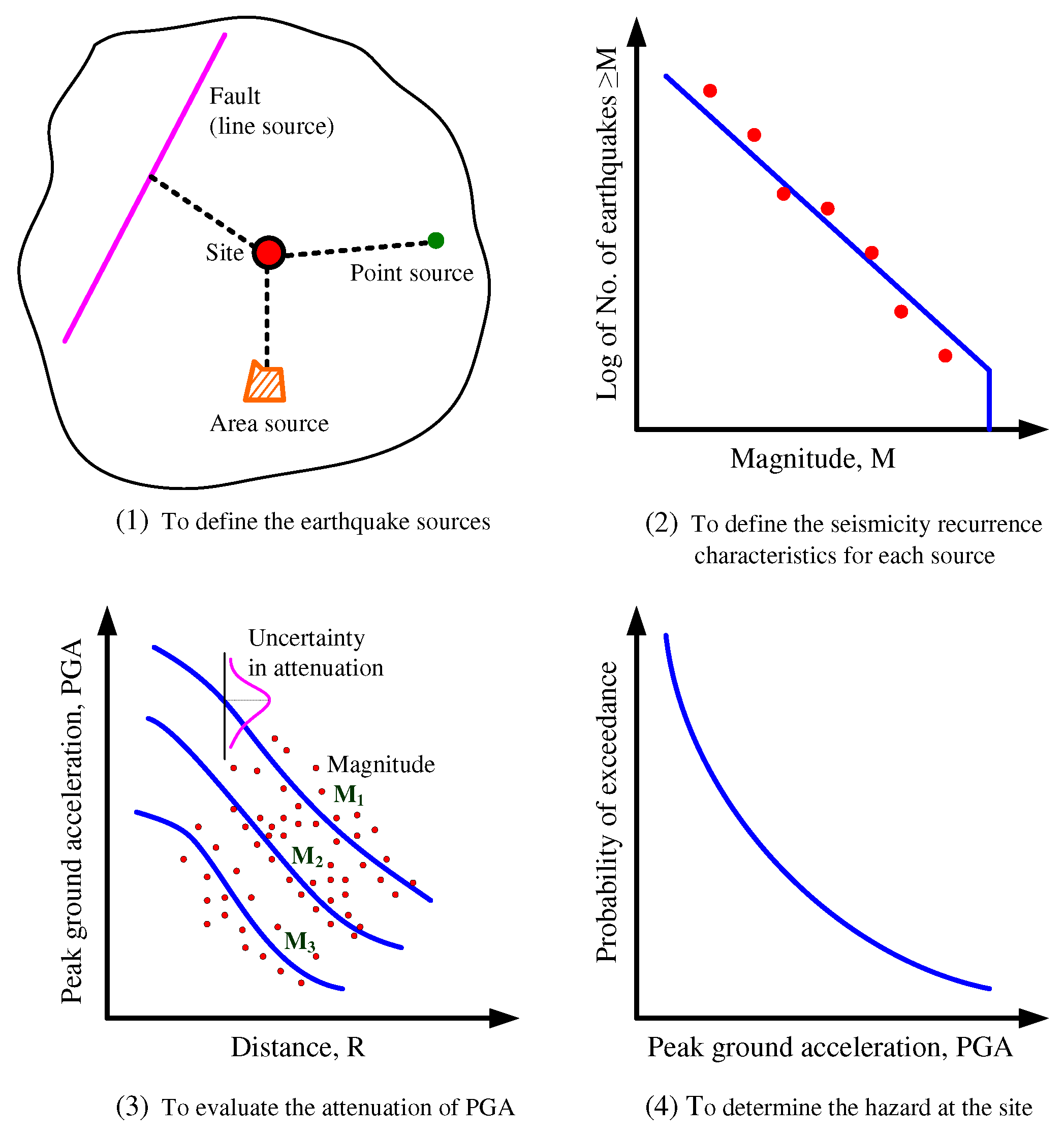
Figure 2.
Seismic zone and epicentral distribution for M>5.0.
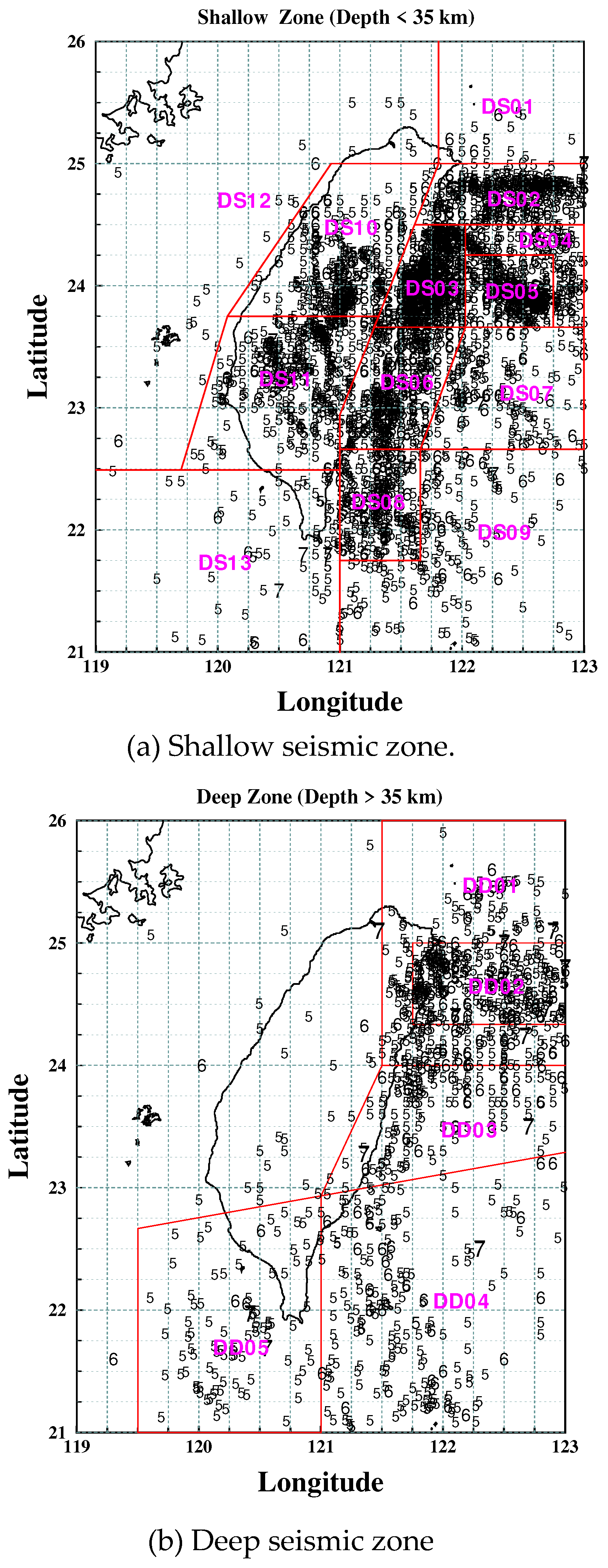
Figure 3.
Flowchart of liquefaction hazard analysis.
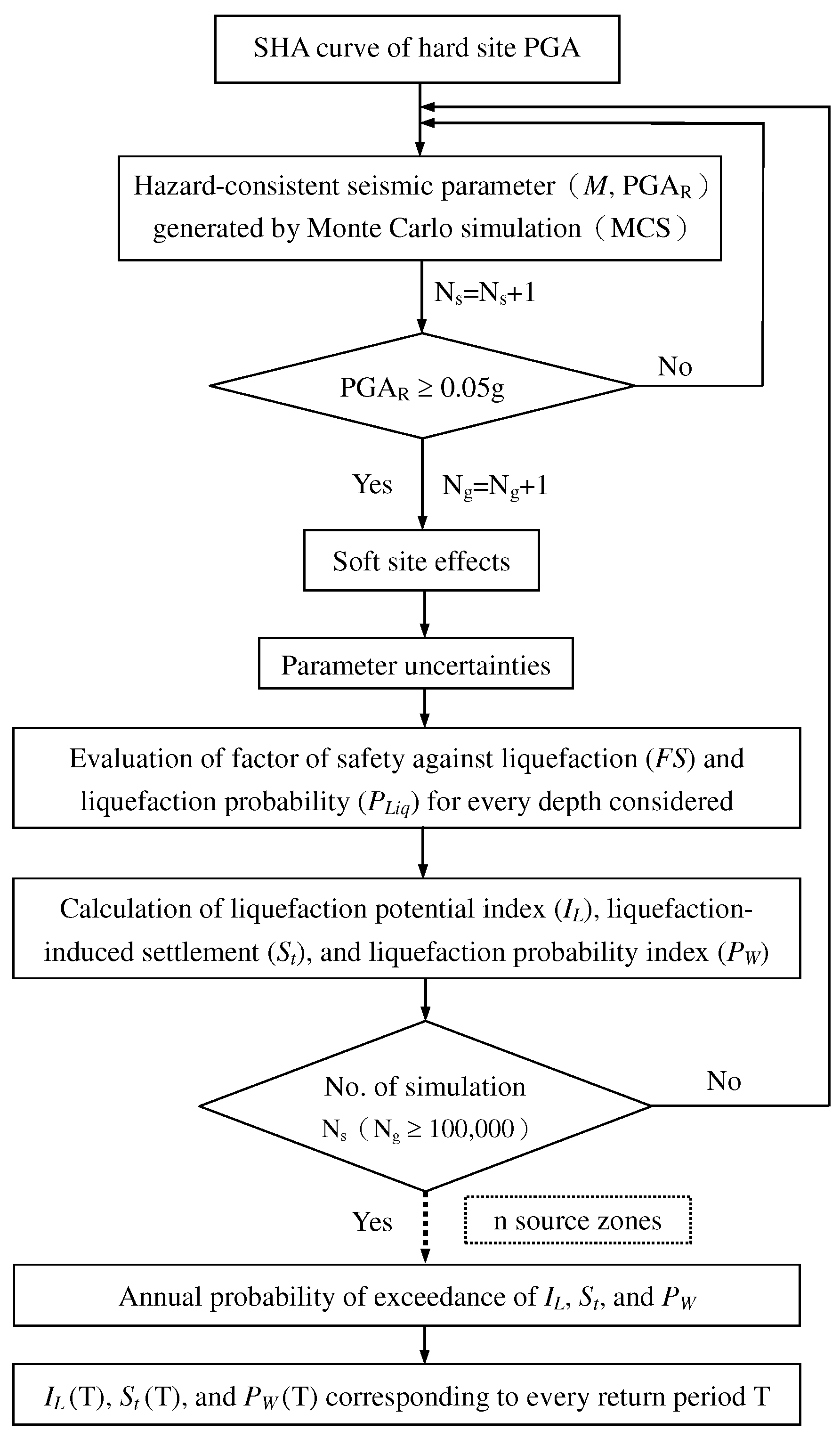
Figure 4.
Soil profile of the BH-29 site.
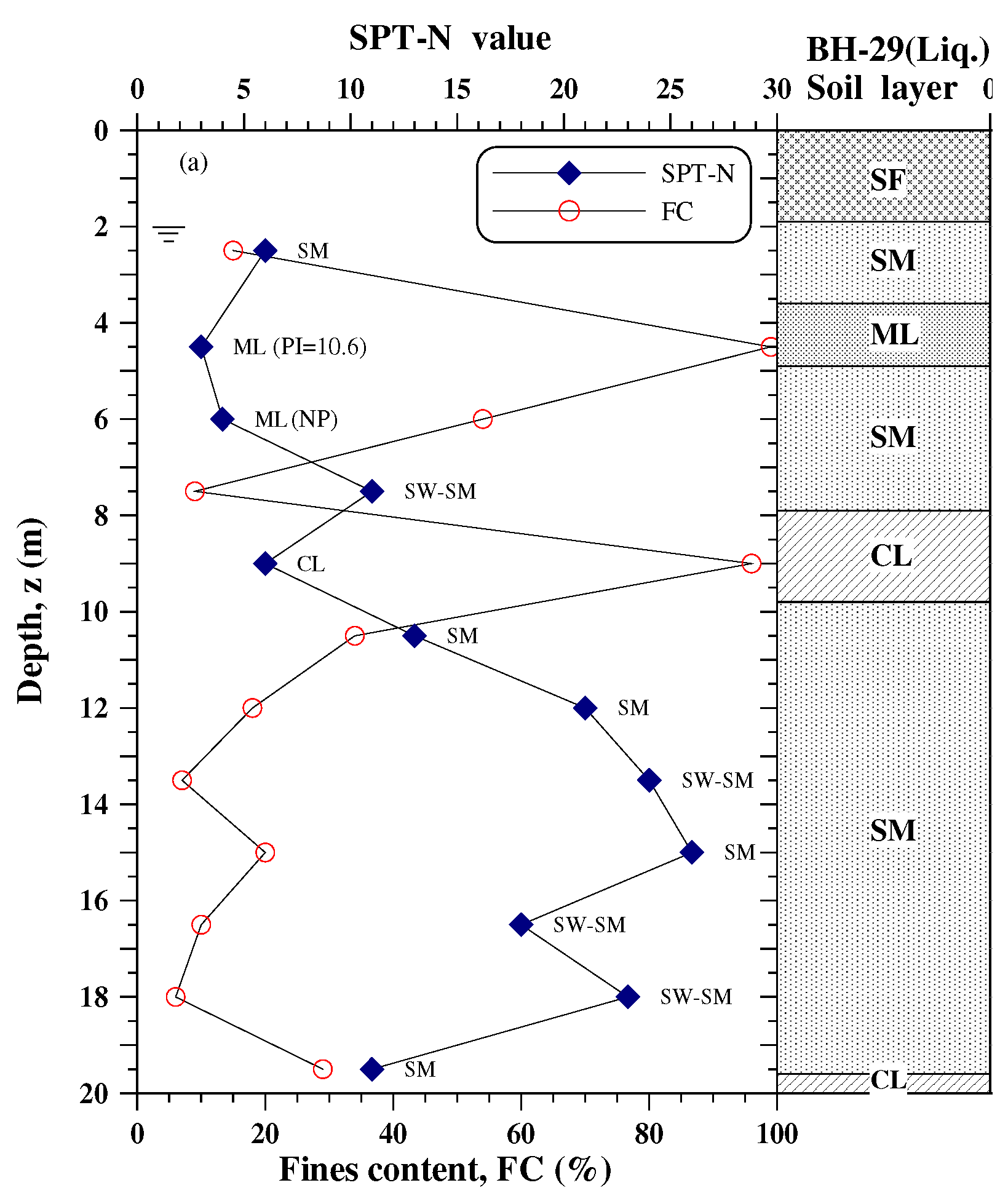
Figure 5.
PGA relationship between the soft site and the hard site condition. [3].
Figure 5.
PGA relationship between the soft site and the hard site condition. [3].
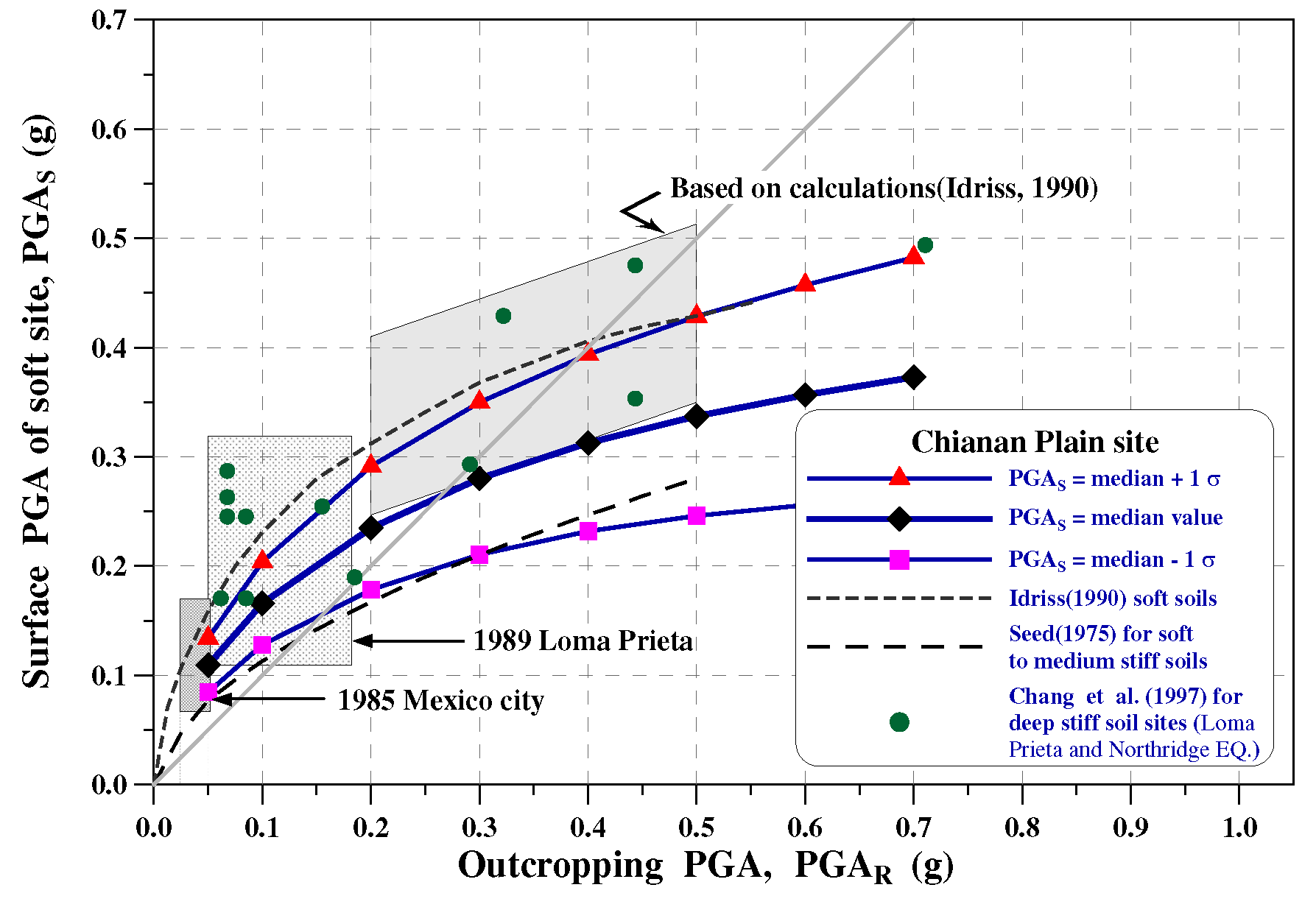
Figure 6.
Fragility for IL of the BH-29 site.
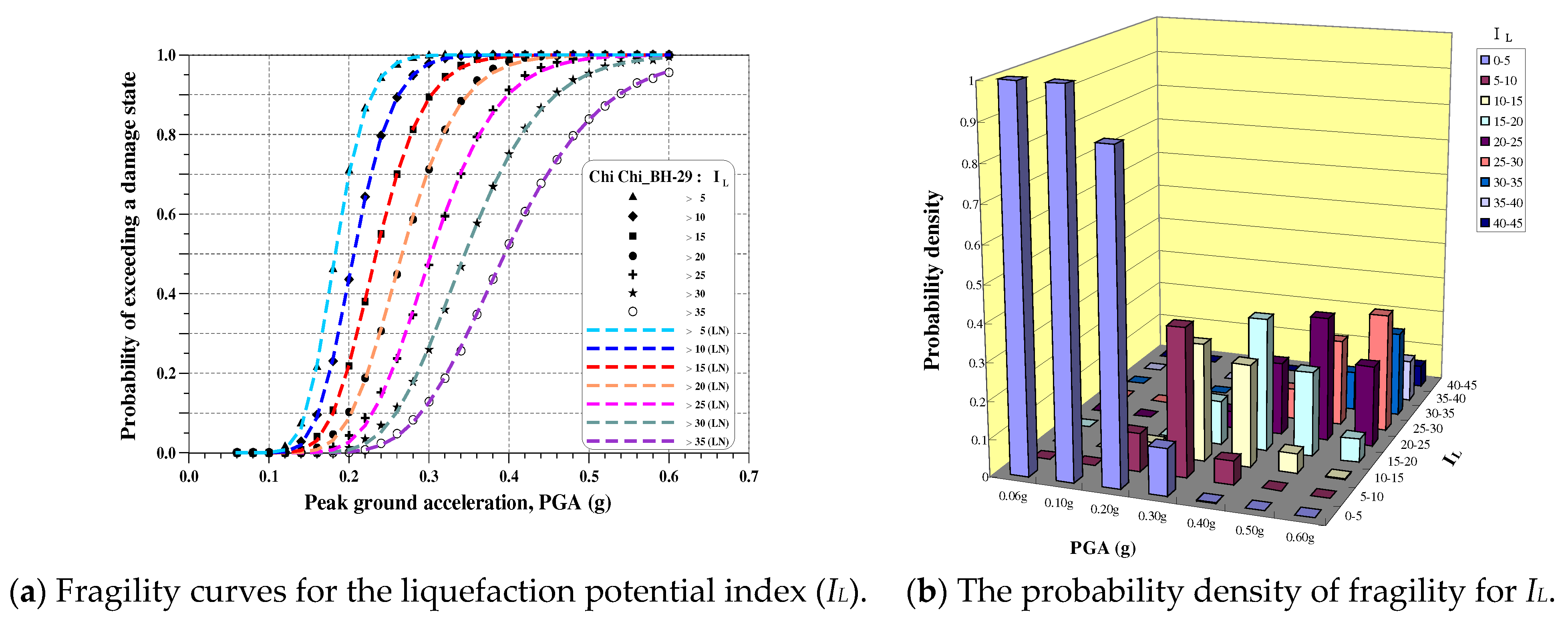
Figure 7.
Fragility for St of the BH-29 site.
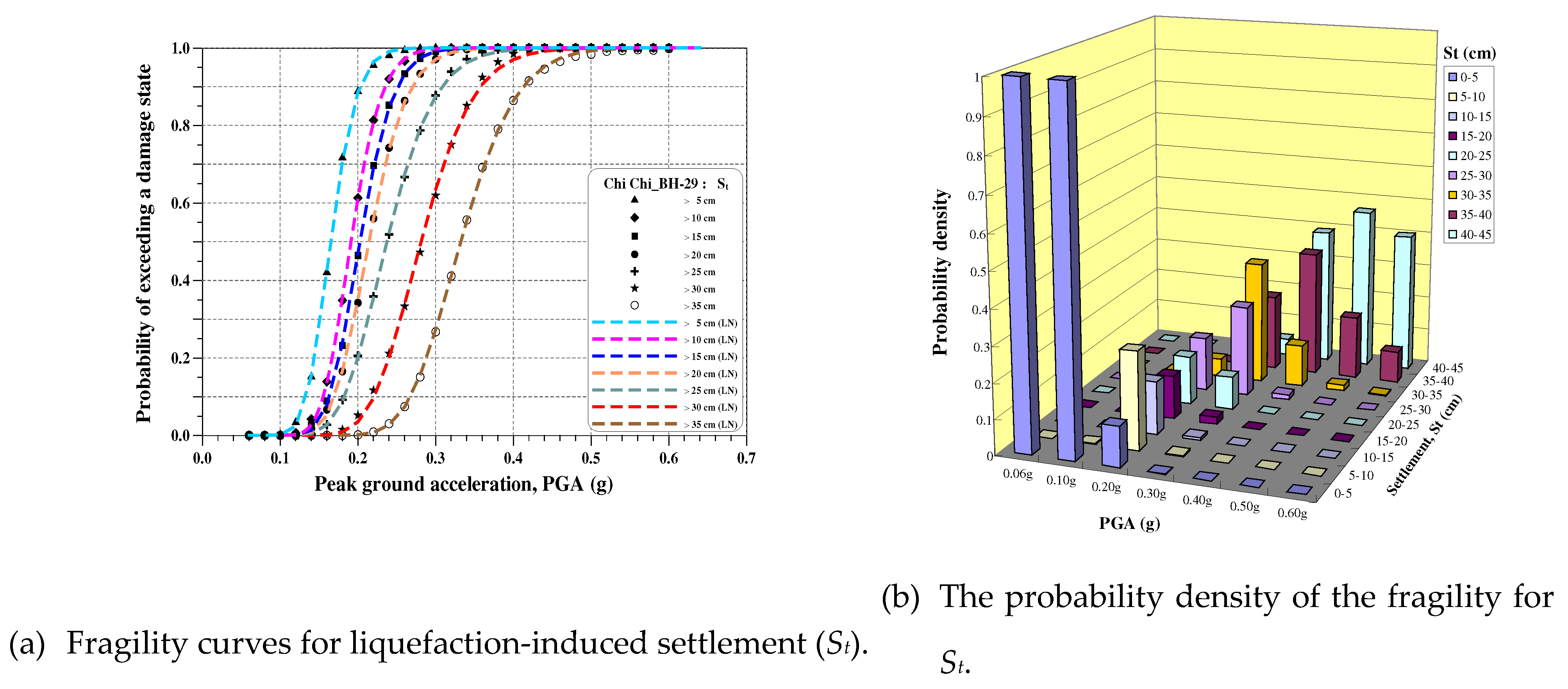
Figure 8.
Fragility for PW of the BH-29 site.
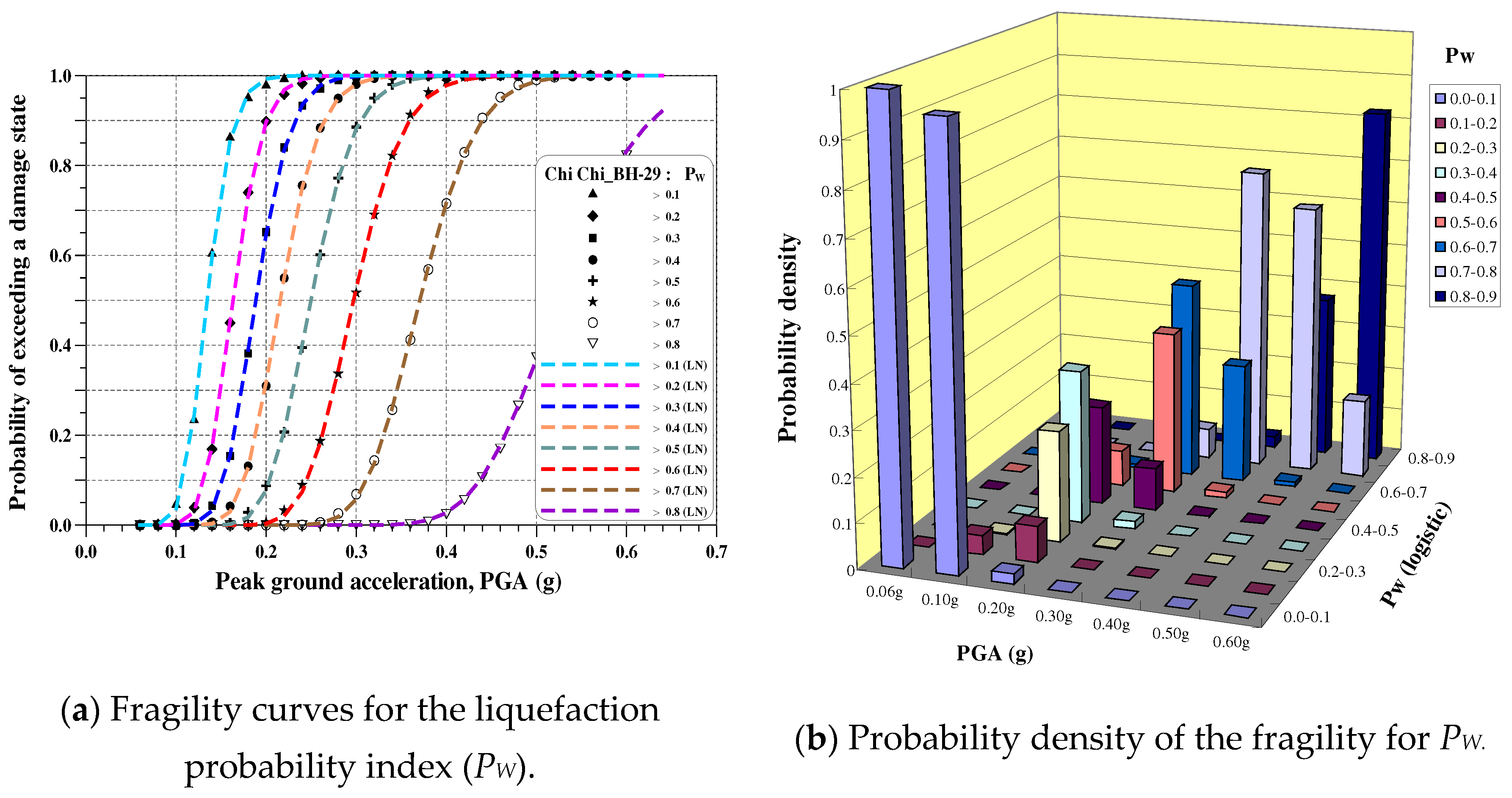

Table 1.
Liquefaction potential classes based on IL (Iwasaki et al., 1982) [6].
Table 1.
Liquefaction potential classes based on IL (Iwasaki et al., 1982) [6].
| IL | Liquefaction potential class |
| 0 | Very low |
| 0 < IL ≤ 5 | Low |
| 5 < IL ≤ 15 | High |
| IL >15 | Very high |
Table 2.
Relation between the extent of the damage and approximate settlements [7].
Table 2.
Relation between the extent of the damage and approximate settlements [7].
| Extent of damage | Settlements St (cm) | Phenomena on the ground surface |
|---|---|---|
| Light to no damage |
0 ~ 10 | Minor cracks |
| Medium damage | 10 ~ 30 | Small cracks, oozing of sand |
| Extensive damage | 30 ~70 | Large cracks, spouting of sands, large offsets, lateral movement |
Table 3.
Classification of the damage states of liquefaction according to PW.
| Class | PW | Description of damage state |
|---|---|---|
| I | < 0.30 | Minor liquefaction |
| II | 0.30 ~ 0.85 | Moderate liquefaction |
| III | > 0.85 | Heavy liquefaction |
Table 4.
Types of seismic sources and random variables.
 |
Table 5.
Parameters of the fragility curves of the BH-29 site.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



