Submitted:
04 January 2024
Posted:
04 January 2024
You are already at the latest version
Abstract
We extend Ziv and Lempel's model of finite-state encoders to the realm of lossy compression of individual sequences. In particular, the model of the encoder includes a finite-state reconstruction codebook followed by an information lossless finite-state encoder that compresses the
reconstruction codeword with no additional distortion. We first derive two different lower bounds to the compression ratio that depend on the number of states of the lossless encoder. Both bounds are asymptotically achievable by conceptually simple coding schemes. We then show that when the number of states of the lossless encoder is large enough in terms of the reconstruction
block-length, the performance can be improved, sometimes significantly so.
In particular, the improved performance is achievable using a random-coding ensemble
that is universal, not only in terms of the source sequence, but also in terms
of the distortion measure.
Keywords:
rate-distortion
; source coding
; finite-state encoders
; random coding
; code ensemble
; lossy compression
; universal coding
; universal distribution
; LZ algorithm
1. Introduction
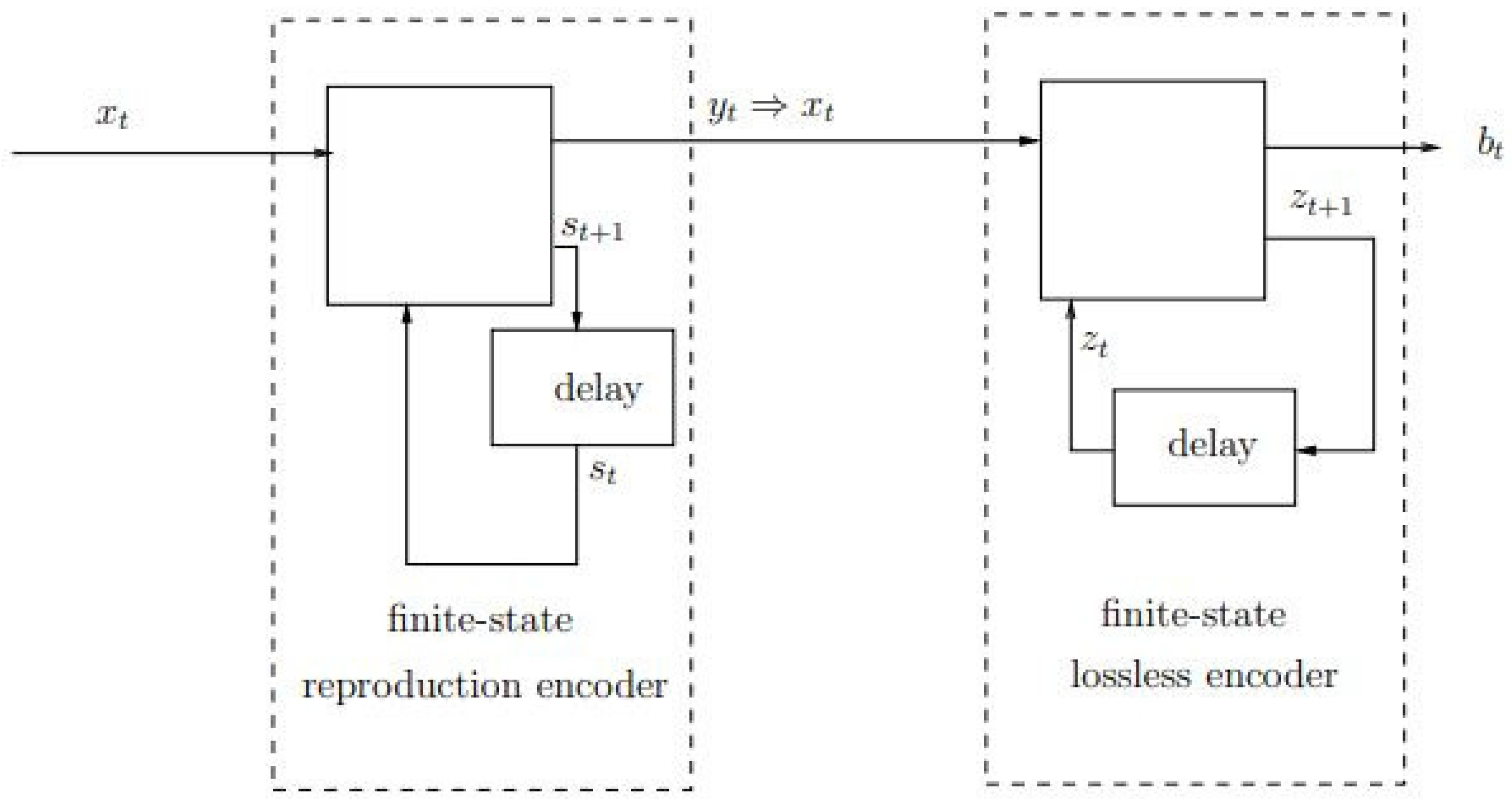
We revisit the classical domain of rate-distortion coding applied to finite-alphabet sequences, focusing on a prescribed distortion function [1], [2], Chap. 10, [3], Chap. 9, [4], [5], Chaps. 7,8. Specifically, our attention is directed towards encoders comprising finite-state reproduction encoders followed by information-lossless finite-state encoders that compress reproduction sequences without introducing additional distortion (see Figure 1). In essence, our principal findings are in establishing two asymptotically achievable lower bounds for the optimal compression ratio of an individual source sequence of length n, utilizing any finite-state encoder with the aforementioned structure, where the lossless encoder possesses q states. These lower bounds can both be conceptualized as the individual-sequence counterparts to the rate-distortion function of the given source sequence, akin to the lossless finite-state compressibility of a source sequence serving as the individual-sequence analogue of entropy. However, before delving into the intricacies of our results, a brief overview of the background is warranted.
Over the past several decades, numerous research endeavors have been spurred by the realization that source statistics are seldom, if ever, known in practical scenarios. Consequently, these efforts have been dedicated to the pursuit of universal coding strategies that remain independent of unknown statistics while asymptotically approaching lower bounds, such as entropy in lossless compression or the rate-distortion function in the case of lossy compression, as the block length extends indefinitely. Here, we offer a succinct and non-exhaustive overview of some pertinent earlier works.
In the realm of lossless compression, the field of universal source coding has achieved a high level of sophistication and maturity. Davisson’s seminal work [6] on universal-coding redundancies has introduced the pivotal concepts of weak universality and strong universality, characterized by vanishing maximin and minimax redundancies, respectively. This work has also elucidated the link between these notions and the capacity of the ’channel’ defined by the family of conditional distributions of the data to be compressed, given the index or parameter of the source in the class [7,8,9]. For numerous parametric source classes encountered in practice, the minimum achievable redundancy of universal codes is well-established to be dominated by , where k denotes the number of degrees of freedom of the parameter, and n is the block length [10,11,12,13]. Davisson’s theory gives rise to a central idea of constructing a Shannon code based on the probability distribution of the data vector with respect to a mixture, incorporating a certain prior function, of all sources within the class. Rissanen, credited with the invention of the minimum description length (MDL) principle [14], established a converse to a coding theorem in [15]. This theorem asserts that asymptotically, no universal code can achieve redundancy below with a possible exception of sources from a subset of the parameter space, the volume of which diminishes as for every positive . Merhav and Feder [16] generalized this result to more extensive classes of sources, substituting the term with the capacity of the aforementioned ’channel’. Subsequent studies have further refined redundancy analyses and contributed to ongoing developments in the field.
In the broader domain of universal lossy compression, the theoretical landscape is regrettably not as sharply defined and well-developed as in the lossless counterpart. In this study, we narrow our focus to a specific class known as d-semifaithful codes [17] codes that fulfill the distortion requirement with probability one. Zhang, Yang, and Wei [18] have demonstrated a notable contrast with lossless compression, establishing that, even when source statistics are perfectly known, achieving redundancy below in the lossy case is impossible, although is attainable. The absence of source knowledge imposes a cost in terms of enlarging the multiplicative constant associated with . Yu and Speed [19] established weak universality, introducing a constant that grows with the cardinalities of the source and reconstruction alphabets [20]. Ornstein and Shields [17] delved into universal d-semifaithful coding for stationary and ergodic sources concerning the Hamming distortion measure, demonstrating convergence to the rate-distortion function with probability one. Kontoyiannis [21] made several noteworthy contributions. Firstly, a central limit theorem (CLT) with a redundancy term, featuring a limiting Gaussian random variable with constant variance. Secondly, the law of iterated logarithm (LIL) with redundancy proportional to infinitely often with probability one. A counter-intuitive conclusion from [21] is the priceless nature of universality under these CLT and LIL criteria. In [22], optimal compression is characterized by the negative logarithm of the probability of a sphere of radius around the source vector with respect to the distortion measure, where D denotes the allowed per-letter distortion. The article also introduces the concept of random coding ensemble with a probability distribution given by a mixture of all distributions in a specific class. In two recent articles, Mahmood and Wagner [23,24] have delved into the study of d-semifaithful codes that are strongly universal concerning both the source and the distortion function. The redundancy rates in [23] behave like but with different multiplicative constants. Other illuminating results regarding a special distortion measure are found in [25].
A parallel path of research in the field of universal lossless and lossy compression, spearheaded by Ziv, revolves around the individual-sequence approach. In this paradigm, no assumptions are made about the statistical properties of the source. The source sequence to be compressed is treated as an arbitrary deterministic (individual) sequence, but instead limitations are imposed on the implementability of the encoder and/or decoder using finite-state machines. This approach notably encompasses the widely celebrated Lempel-Ziv (LZ) algorithm [26,27,28], along with subsequent advancements broadening its scope to both lossy compression with and without side information [29,30], as well as joint source-channel coding [31,32]. In the lossless context, the work in [33] establishes an individual-sequence analogue akin to Rissanen’s result, where the expression continues to denote the best achievable redundancy. However, the primary term in the compression ratio is the empirical entropy of the source vector, deviating from the conventional entropy in the probabilistic setting. The converse bound presented in [33] is applicable to the vast majority of source sequences within each type, echoing the analogy with Rissanen’s framework concerning the majority of the parameter space. It is noteworthy that this converse result retains a semblance of the probabilistic setting, as asserting the relatively small number of exceptional typical sequences is equivalent to assuming a uniform distribution across the type and asserting a low probability of violating the bound. Conversely, the achievability result in [33] holds pointwise for every sequence. A similar observation applies to [34], where asymptotically pointwise lossy compression was established concerning first-order statistics (i.e., “memoryless” statistics), emphasizing distortion-universality, akin to the focus in [23] and [24]. A similar fusion of the individual-sequence setting and the probabilistic framework is evident in [35] concerning universal rate-distortion coding. However, akin to the approach in [34], there is no constraint on finite-state encoders/decoders as in [33]. Notably, the converse theorem in [35] states that for any variable-rate code and any distortion function within a broad class, the vast majority of reproduction vectors representing source sequences of a given type (of any fixed order) must exhibit a code length essentially no smaller than the negative logarithm of the probability of a ball with a normalized radius D (where D denotes the allowed per-letter distortion). This ball is centered at the specified source sequence, and the probability is computed with respect to a universal distribution proportional to , where denotes the code length of the LZ encoding of the reproduction vector .
The emphasis on the term “majority” in the preceding paragraph, as highlighted earlier, necessitates clarification. It should be noted that in the absence of constraints on encoding memory resources, such as the finite-state machine model mentioned earlier, there cannot exist any meaningful lower bound that universally applies to each and every individual sequence. The rationale is straightforward: for any specific individual source sequence, it is always possible to devise an encoder compressing that sequence to a single bit (even losslessly). For instance, by designating the bit ’0’ as the compressed representation of the given sequence and appending the bit ’1’ as a header to the uncompressed binary representation of any other source sequence. In this scenario, the compression ratio for the given individual sequence would be , dwindling to zero as n grows indefinitely. It is therefore clear that any non-trivial lower bound that universally applies to every individual source sequence at the same time, necessitates reference to a class of encoders/decoders equipped with constrained resources, such as those featuring a finite number of states.
In this work, we consider lossy compression of individual source sequences using finite-state encoders whose structure is as follows: Owing to the fact that, without loss of optimality, every lossy encoder can be presented as a cascade of a reproduction encoder and a lossless (or “noiseless”) encoder (see, e.g., [36], discussion around Figure 1), we consider a class of lossy encoders that can be implemented as a cascade of a finite-state reproduction encoder and a finite-state lossless encoder, see Figure 1. The finite-state reproduction encoder model is a generalization of the well-known finite-state vector quantizer (FSVQ), see, e.g., [37,38], Chap. 14. It is committed to produce reproduction vectors of dimension k in response to source vectors of dimension k, while complying with the distortion constraint for every such vector. The finite-state lossless encoder is the same as in [27]. The number of states of the reproduction encoder can be assumed very large (in particular, even large enough to store many recent input blocks). Both the dimension, k, and the number of states, q, of the lossless encoder are assumed small compared to the total length, n, of the source sequence to be compressed, similarly as in [27] (and other related works), where the regime is assumed too.
One of our main messages in this work is that it is important also how q and k related to each other, and not only how to they both relate to n. If q is large in terms of k, one can do much better than if it is small. Accordingly, we first derive two different lower bounds to the compression ratio under the assumption that , which are both asymptotically achievable by conceptually simple schemes that, within each k-block, seek the most compressible k-vector within a ball of `radius’ around the source block. We then compare it to the ensemble performance of a universal coding scheme that can be implemented when q is exponential in k. The improvement can sometimes be considerably large. The universality of the coding scheme is two-fold: both in the source sequence to be compressed and in the distortion measure in the sense that the order of codewords within the typical codebook (which affects the encoding of their indices) is asymptotically optimal no matter which distortion measure is used (see [35] for discussion of this property). The intuition behind this improvement is that when q is exponential in k, the memory of the lossless encoder is large enough to store entire input blocks and thereby exploit the sparseness of the reproduction codebook in the space of k-dimensional vectors with components in the reproduction alphabet. The asymptotic achievability of the lower bound will rely on the direct coding theorem of [35].
Bounds on both lossless and lossy compression of individual sequences using finite-state encoders and decoders have been explored in previous works, necessitating a contextualization of the present work. As previously mentioned, the cases of (almost) lossless compression were examined in [26,27], and [30]. In [32], the lossy case was considered, incorporating both a finite-state encoder and a finite-state decoder in the defined model. However, in the proof of the converse part, the assumption of a finite-state encoder was not essential; only the finite number of states of the decoder was required. The same observation holds for [39]. In a subsequent work, [31], the finite number of states for both the encoder and decoder was indeed utilized. This holds true for [29] as well, where the individual-sequence analogue of the Wyner-Ziv problem was investigated with more restrictive assumptions on the structure of the finite-state encoder. In contrast, the current work restricts only the encoder to be a finite-state machine, presenting a natural generalization of [27] to the lossy case. Specifically, one of our achievable lower bounds can be regarded as an extension of the compressibility bound found in [27], Corollary 1 to the lossy scenario. It is crucial to note that, particularly in the lossy case, it is more imperative to impose limitations on the encoder than the decoder, as encoding complexity serves as the practical bottleneck. Conversely, for deriving converse bounds, it is stronger and more general not to impose any constraints on the decoder.
The outline of this paper is as follows. In Section 2, we establish notation, as well definitions, and spell out the objectives. In Section 3, we derive the main results and discuss them. Finally, in Section 4 we summarize the main contributions of this work and make some concluding remarks.
Figure 1.
Finite-state reproduction encoder followed by a finite-state lossless encoder.
2. Notation, Definitions and Objectives
Throughout the paper, random variables will be denoted by capital letters, specific values they may take will be denoted by the corresponding lower case letters, and their alphabets will be denoted by calligraphic letters. Random vectors and their realizations will be denoted, respectively, by capital letters and the corresponding lower case letters, both in the bold face font. Their alphabets will be superscripted by their dimensions. The source vector of length n, , with components, , , from a finite-alphabet, , will be denoted by . The set of all such n-vectors will be denoted by , which is the n–th order Cartesian power of . Likewise, a reproduction vector of length n, , with components, , , from a finite-alphabet, , will be denoted by . The notation will be used to designate the set of all finite-length strings of symbols from .
For , the notation will be used to denote the substring . For , the subscript `1’ will be omitted, and so, the shorthand notation of would be . Similar conventions will apply to other sequences. Probability distributions will be denoted by the letter P or Q with possible subscripts, depending on the context. The probability of an event will be denoted by , and the expectation operator with respect to (w.r.t.) a probability distribution P will be denoted by . The logarithmic function, , will be understood to be defined to the base 2. Logarithms to the base e will be denote by ln. Let be a given distortion function between source symbols and reproduction symbols. The distortion between vectors will be defined additively as for every positive integer, n, and every , .
Consider the encoder model depicted in Figure 1, which is a cascade of a finite-state reproduction encoder (FSRE) and a finite-state lossless encoder (FSLE). This encoder is fully determined by the set , where is the source input alphabet of size , is the reproduction alphabet of size , is a set of FSRE states, is a set of FSLE states of size q, u and v are functions that define the FSRE, f and g are functions that define the FSLE (both to be defined shortly), and k is a positive integer that designates the basic block length within which the distortion constraint must be kept, as will be described shortly. The number of states, , of the FSRE may be assumed arbitrarily large (as the lower bounds to be derived will actually be independent of this number). In particular, it can be assumed to be large enough to store several recent input k-blocks.
According to this encoder model, the input, , , is fed sequentially into the FSRE, which goes through a sequence of states , and produces an output sequence, of variable-length strings of symbols from , with the possible inclusion of the empty symbol, , of length zero. Referring to Figure 1, the FSRE is defined by the recursive equations,
for , where the initial state, , is assumed to be some fixed member of .
Remark 1.
The above defined model of the FSRE has some resemblance to the well known model of the finite-state vector quantizer (FSVQ) [37,38], Chap. 14, but it is in fact, considerably more general than the FSVQ. Specifically, the FSVQ works as follows. At each time instant t, it receives a source-vector and outputs a finite-alphabet variable, , while updating its internal state . The encoding function is and the next-state function is . Note that state evolves in response to (and not ), so that the decoder would be able to maintain its own copy of . At the decoder, the reproduction is generated according to and the state is updated again using . By cascading the FSVQ encoder and its decoder, one obtains a system with input and output , which is basically a special case of our FSRE with the functions u and v being given by and . □
As described above, given an input block of length k, , the FSRE generates a corresponding output block, , while traversing a sequence of states . The FSRE must be designed in such a way that the total length of the concatenation of the (non-empty) variable-length strings, , is equal to k as well. Accordingly, given , let denote the corresponding vector of reproduction symbols from , which forms the output of the FSRE. This formal transformation from to is designated by the expression in Figure 1.
Example 1.
Let , and suppose that the FSRE is a block code of length . Suppose also that and . Then, . The current state, in this case, is simply the contents of the input, starting from the beginning of the current block and ending at the current input symbol. Accordingly, the encoder idles until the end of the input block, and then it produces the full output block. □
The parameter k of the encoder E is the length of the basic block that is associated with the distortion constraint. For a given input alphabet , reconstruction alphabet , and distortion function d, we denote by the class of all finite-state encoders of the above described structure, whose number of FSLE states is q, the dimension of the FSRE is k, and for every . For future use, we also define the `ball’
Remark 2.
Note that the role of the state variable, , might not be only to store information from the past of the input, but possibly also to maintain the distortion budget within each k-block. At each time instant t, the state can be used to update the remaining distortion allowed until the end of the current k-block. For example, if the entire allowed distortion budget, , has already been exhausted before the current k-block has ended, then in the remaining part of the current block, the encoder must carry on losslessly, that is, it must produce reproduction symbols that incur zero-distortion relative to the corresponding source symbols. □
The FSLE is defined similarly as in [27]. Specifically, the output of the FSRE, , , is fed sequentially into the FSLE, which in turn goes through a sequence of states , and produces an output sequence, of variable-length binary strings, with the possible inclusion of the empty symbol, , of length zero. Accordingly, the FSLE implements the recursive equations,
for , where the initial state, , is assumed to be some fixed member of .
With a slight abuse of notation, we adopt the extended use of encoder functions u, v, f and g, to designate output sequences and final states, which result from the corresponding initial states and inputs. We use the notations , , and for , , , and , respectively. We assume the FSLE to be information lossless, which is defined, similarly as in [27], as follows. For every , every positive integer n, and every , the triple uniquely determines .
Given an encoder , and a source string , where n is divisible by k, the compression ratio of by is defined as
where , being the length (in bits) of the binary string . Next, define
Our main objective is derive bounds to for large k and , with special interest in the case where q is large enough (in terms of k), but still fixed independent of n, so that the FSLE could take advantage of the fact that not necessarily every can be obtained as an output of the given FSRE. In particular, a good FSLE with long memory should exploit the sparseness of the reproduction codebook relative to the entire space of k-vectors in .
3. Lower Bounds
For the purpose of presenting both the lower bounds and the achievability, we briefly review a few terms and facts concerning the 1978 version of Lempel-Ziv algorithm (a.k.a. the LZ78 algorithm) [27]. The incremental parsing procedure of the LZ78 algorithm is a procedure of sequentially parsing a vector, , such that each new phrase is the shortest string that has not been encountered before as a parsed phrase, with the possible exception of the last phrase, which might be incomplete. For example, the incremental parsing of the vector is . Let denote the number of phrases in resulting from the incremental parsing procedure (in the above example, ). Let denote the length of the LZ78 binary compressed code for . According to [27], Theorem 2,
where we remind that is the cardinality of , respectively, and where and tend to zero as .
Our first lower bound on the compression ratio is conceptually very simple. Since each k-block, , , of the reconstruction vector, , is compressed using a finite-state machine with q states, then according to [27], Theorem 1, its compression ratio is lower bounded by
where the second inequality follows from [27], eq. (6). Since each k-block must comply with the distortion constraint, this quantity is further lower bounded by
and so, for the entire source vector , we have
For large enough k, the last two terms can be made arbitrarily small, provided that . Clearly, this lower bound can be asymptotically attained by seeking the vector that minimizes across within each k-block and compressing it by the LZ78 compression algorithm.
In order to state our second lower bound, we next define the joint empirical distribution of ℓ-blocks of . Specifically, let ℓ divide k which in turn divides n, and consider the empirical distribution, , of ℓ-vectors along the i-th k-block of , which is , , that is,
Let denote the empirical entropy of an auxiliary random ℓ-vector, , induced by , that is,
Now, our second lower bound is given by the following inequality:
Discussion
Note that both lower bounds depend on the number of states, q, of the FSLE, but not on the number of states, , of the FSRE. In this sense, no matter how large the number of states of the FSRE may be, none of these bounds is affected. For the purpose of lower bounds, that establish fundamental limitations, we wish to consider a class of encoders that is as broad as possible, for the sake of generality. We therefore assume that is arbitrarily large.
The second term on the right-hand side of (13) is small when is small relative to ℓ, which is in turn smaller than k. This requirement is less restrictive than the parallel one in the first bound, which was . The bound is asymptotically achievable by universal lossless coding of the vector that minimizes within using a universal lossless code that is based on two-part coding: the first part is a header that indicates the type class using a logarithmic number of bits as a function of k and the second part is the index of the vector within the type class.
The main term of the second bound is essentially tighter than the main term of the first bound since can be lower bounded by minus some small terms (see, e.g., [35], eq. (26)). On the other hand, the second bound is somewhat more complicated due to the introduction of the additional parameter ℓ. It is not clear whether any one of the bounds completely dominates the other one for any . Anyway, it is always possible to choose the larger bound between the two.
To prove eq. (13), consider the following. According to [27], Lemma 2, since the FSLE is an information lossless encoder with q states, it must obey the following generalized Kraft inequality:
This implies that the description length at the output of the encoder is lower bounded as follows.
Clearly,
Now, by the generalized Kraft inequality above,
where the last inequality follows from the convexity of the exponential function and Jensen’s inequality. This yields
implying that
and since each must be in , the summand of the first term on the left-hand side cannot be smaller than . Since this lower bound on holds for every , it holds also for .
Returning now to the first lower bound, consider the following chain of inequalities:
It is conceivable that the last inequality may contribute most of the gap between the left-most side and the right-most side of the chain (20), since we pass from a single term in to the sum of all terms in . Since
the gap between the left-most side of (20) and the right-most side of (20) might take any positive value that does not exceed , which is in turn approximately proportional to k as is asymptotically exponential in k. Thus, the right-most side of (20), corresponds to a coding rate which might be strictly smaller than that of the left-most side. Yet, we argue that the right-most side of (20) can still be asymptotically attained by a finite-state encoder. But to this end, its FSLE component should possess states, as it is actually a block code of length k. In order to see this, we need to define the following universal probability distribution (see also [35,40,41]):
and accordingly, define also
Now, the first term on the right-most side of (20) can be further manipulated as follows.
where the last inequality is because thanks to Kraft’s inequality applied to the code-length function .
Now, the last expression in (24) suggests achievability using the universal distribution, U, for independent random selection of the various codewords. The basic idea is quite standard and simple: The quantity is the probability that a single randomly chosen reproduction vector, drawn under U, would fall within distance from the source vector, . If all reproduction coedwords are drawn independently under U, then the typical number of such random selections that it takes before one sees the first one in , is of the exponential order of . Given that the codebook is revealed to both the encoder and decoder, once it has been selected, the encoder merely needs to transmit the index of the first such reproduction vector within the codebook, and the description length of that index can be made essentially as small as . In [35], we use this simple idea to prove achievability for an arbitrary distortion measure. More precisely, the following theorem is stated and proved in [35] with some adjustment of the notation:
Theorem ([35], Theorem 2).
Let be an arbitrary distortion function. Then, for every , there exists a sequence of d-semifaithful, variable-length block codes of block length k, such that for every , the code length for is upper bounded by
where is a constant and .
Through the repeated application of this code for each one of the blocks of length of k, the lower bound of the last line of (24) is asymptotically attained. As elaborated on in [35], the ensemble of codebooks selected under the universal distribution U exhibits universality in both the source sequence slated for encoding and the chosen distortion measure. This stands in contrast to the classical random coding distribution, which typically relies on both the statistics of the source and the characteristics of the distortion measure.
4. Discussion
A natural question that may arise is whether this performance is the best that can be attained given that the number of FSLE states, q, is as large as . For now, this question remains open, but it is conjectured that the answer is affirmative, in view of the matching converse theorem of [35], Theorem 1, which applies to the vast majority of source sequences in each and every type class of any order, and even without the limitation of finite-state encoders.
It is natural to think of the memory resource used by a finite-state encoder in terms of the number of bits (or equivalently, the size of of a register) needed in order to store the current state at each time instant, namely, the base 2 logarithm of the total number of states. Indeed, both lower bounds derived earlier contain terms that are proportional to , the memory size pertaining to the FSLE. Since the memory size, of the FSRE is assumed arbitrarily large, as discussed earlier, the total size of the encoder memory, , is dominated by , and so, the contribution of to the total memory volume can be considered negligibly small. Therefore, one of our main messages in this work is that, as far as the total memory size goes, it makes very little difference if we allow to be as large as and thereby achieve the better performance, rather than keeping smaller and then ending up with the inferior compression performance of minimizing within for each block.
5. Conclusions
In this paper, we revisited the paradigm of lossy compression of individual sequences using finite-state machines, as a natural extension to the same paradigm in the lossless case, as established by Ziv and Lempel in [27] and other related works. This work can also be viewed as revisit of [35] from the perspective of finite-state encoding of individual sequences. Our model of a finite-state encoder is that of a cascade of the finite-state k-dimensional reproduction encoder (with an arbitrarily large number of states) and a finite-state lossless encoder, acting on the reproduction sequence. Our main contributions in this work are the following.
- We derived two different lower bounds to the compression ratio.
- We have shown that both bounds depend on the number of states, q, of the lossless encoder, but not on the number of states of the reproduction encoder.
- We have shown that for relatively small q, one cannot do better than seeking the most compressible reproduction sequence within the ’sphere’ of radius around the source vector. Nonetheless, if we allow , we can improve performance significantly by using a good code from the ensemble of codes where each codeword is selected independently at random under the universal distribution, U. The resulting code is universal, not only in the sense of the source sequence, as in [27], but also in the distortion function, in the sense discussed in [35]. This passage from small q to large q will not increase the total memory resources of entire encoder significantly, considering the large memory that may be used by the reproduction encoder anyway.
- We suggest the conjecture that the performance achieved as described in item 3 is the best performance achievable for large q.
Finally, we comment that our derivations can be extended to incorporate side information, , available to both the encoder and decoder. In the model of the finite-state encoder, this amounts to allowing both the FSRE and the FSLE sequential access to , . The decoder, of course, should also have access to . Another modification needed is in replacing the LZ algorithm by its conditional version in all places (see, e.g., [31,42], and [43]).
Conflicts of Interest
The author declares no conflict of interest.
References
- Berger, T. Rate Distortion Theory - A Mathematical Basis for Data Compression, Prentice-Hall Inc., Englewood Cliffs, N.J., 1971.
- Cover, T. M.; Thomas, J. A. Elements of Information Theory, John Wiley & Sons, Hoboken N. J., 2006.
- Gallager, R. G. Information Theory and Reliable Communication, John Wiley & Sons, New York 1968.
- Gray, R. M. Source Coding Theory, Kluwer Academic Publishers, Boston, 1990.
- Viterbi, A. J.; Omura J. K. Principles of Digital Communication and Coding, McGraw-Hill Inc., New York, New York 1979.
- Davisson, L. D. “Universal noiseless coding,” IEEE Trans. Inform. Theory 1973, vol. IT–19, no. 6, pp. 783–795. [CrossRef]
- Gallager, R. G. “Source coding with side information and universal coding,” LIDS-P-937, M.I.T., 1976.
- Ryabko, B. “Coding of a source with unknown but ordered probabilities,” Problems of Information Transmission, 1979, vol. 15, pp. 134–138.
- Davisson, L. D.; Leon-Garcia, A. “A source matching approach to finding minimax codes,” IEEE Trans. Inform. Theory 1980, vol. 26, pp. 166–174. [CrossRef]
- Krichevsky, R. E.; Trofimov, R. K. “The performance of universal encoding,” IEEE Trans. Inform. Theory 1981, vol. 27, no. 2, pp. 199–207.
- Shtar’kov, Yu M. “Universal sequential coding of single messages,” Problems of Information Transmission, 1987, vol. 23, no. 3, pp. 175–186.
- Barron, A. R.; Rissanen, J.; Yu, B. “The minimum description length principle in coding and modeling,” IEEE Transactions on Information Theory, 1998, vol. 44, pp. 2734-2760. [CrossRef]
- Yang, Y.; and Barron, A. R. “Information-theoretic determination of minimax rates of convergence,” Annals of Statistics, 1999, vol. 27, pp. 1564-1599.
- Rissanen, J. “Modeling by shortest data description,” Automatica, 1978, vol. 14, no. 5, pp. 465–471. [CrossRef]
- Rissanen, J. “Universal coding, information, prediction, and estimation,” IEEE Transactions on Information Theory 1984, vol. IT–30, no. 4, pp. 629–636. [CrossRef]
- Merhav, N.; Feder, M. “A strong version of the redundancy–capacity theorem of universal coding,” 1995, IEEE Trans. Inform. Theory, vol. 41, no. 3, pp. 714-722. [CrossRef]
- Ornstein, D. S.; Shields, P. C. “Universal almost sure data compression,” Ann. Probab. 1990, vol. 18, no. 2, pp. 441–452.
- Zhang, Z.; Yang, E.-h.; Wei, V. “The redundancy of source coding with a fidelity criterion. I. known statistics,” IEEE Trans. Inform. Theory 1997, vol. 43, no. 1, pp. 71–91. [CrossRef]
- Yu, B.; Speed, T. “A rate of convergence result for a universal d-semifaithful code,” IEEE Trans. Inform. Theory 1993, vol. 39, no. 3, pp. 813–820. [CrossRef]
- Silva, J. F.; Piantanida, P. “On universal d-semifaithful coding for memoryless sources with infinite alphabets,” IEEE Transactions on Information Theory 2022, vol. 68, no. 4, pp. 2782–2800. [CrossRef]
- Kontoyiannis, I. “Pointwise redundancy in lossy data compression and universal lossy data compression,” IEEE Trans. Inform. Theory 2000, vol. 46, no. 1, pp. 136-152. [CrossRef]
- Kontoyiannis, I.; Zhang, J. “Arbitrary source models and Bayesian codebooks in rate-distortion theory,” IEEE Trans. Inform. Theory 2002, vol. 48, no. 8, pp. 2276–2290. [CrossRef]
- Mahmood, A.; Wagner, A. B. “Lossy compression with universal distortion,” IEEE Trans. Inform. Theory 2023, vol. 69, no. 6, pp. 3525–3543. [CrossRef]
- Mahmood, A.; Wagner, A. B. “Minimax rate-distortion,”IEEE Trans. Inform. Theory 2023, vol. 69, no. 12, pp. 7712–7737. [CrossRef]
- Sholomov, L. A. “Measure of information in fuzzy and partially defined data,” Dokl. Math., 2006, vol. 74, no. 2, pp. 775–779. [CrossRef]
- Ziv, J. “Coding theorems for individual sequences,” IEEE Trans. Inform. Theory 1978, vol. IT–24, no. 4, pp. 405–412. [CrossRef]
- Ziv, J.; Lempel, A. “Compression of individual sequences via variable-rate coding,” IEEE Trans. Inform. Theory 1978, vol. IT–24, no. 5, pp. 530–536. [CrossRef]
- Potapov, V. N. “Redundancy estimates for the Lempel-Ziv algorithm of data compression,” Discrete Appl. Math., 2004, vol. 135, no. 1–3, pp. 245-254. [CrossRef]
- Merhav, N.; Ziv, J. “On the Wyner-Ziv problem for individual sequences,” IEEE Trans. Inform. Theory 2006, vol. 52, no. 3, pp. 867–873. [CrossRef]
- Ziv, J. “Fixed-rate encoding of individual sequences with side information,” IEEE Transactions on Information Theory 1984, vol. IT–30, no. 2, pp. 348–452. [CrossRef]
- Merhav, N. “Finite-state source-channel coding for individual source sequences with source side information at the decoder,” IEEE Trans. Inform. Theory 2022, vol. 68, no. 3, pp. 1532–1544. [CrossRef]
- Ziv, J. “Distortion-rate theory for individual sequences,” IEEE Trans. Inform. Theory 1980, vol. IT–26, no. 2, pp. 137–143. [CrossRef]
- Weinberger, M. J.; Merhav, N.; Feder, M. “Optimal sequential probability assignment for individual sequences,” IEEE Trans. Inform. Theory 1994, vol. 40, no. 2, pp. 384–396. [CrossRef]
- Merhav, N. “D-semifaithful codes that are universal over both memoryless sources and distortion measures,” IEEE Trans. Inform. Theory 2023, vol. 69, no. 7, pp. 4746-4757. [CrossRef]
- Merhav, N. “A universal random coding ensemble for sample-wise lossy compression,” Entropy, 2023, 25, 1199. [CrossRef]
- Neuhoff, D. L.; Gilbert, R. K. “Causal source codes,” IEEE Trans. Inform. Theory 1982, vol. IT–28, no. 5, pp. 701–713. [CrossRef]
- Foster, J.; Gray, R. M.; Ostendorf Dunham, M. “Finite-state vector quantization for waveform coding,” IEEE Trans. Inform. Theory 1985, vol. IT-31, no. 3, pp. 348–359. [CrossRef]
- Gersho, A; Gray, R. M. Vector Quantization and Signal Compression, Springer Science+Business Media New York Eighth Printing 2001. Originally published by Kluwer Academic Publishers, New York in 1992.
- Merhav, N. “On the data processing theorem in the semi-deterministic setting,” IEEE Trans. Inform. Theory 2014, vol. 60, no. 10, pp. 6032-6040. [CrossRef]
- Cohen, A.; Merhav, N. “Universal randomized guessing subjected to distortion,” IEEE Trans. Inform. Theory 2022, vol. 68, no. 12, pp. 7714–7734. [CrossRef]
- Merhav, N.; Cohen, A. “Universal randomized guessing with application to asynchronous decentralized brute–force attacks,” IEEE Trans. Inform. Theory 2020, vol. 66, no. 1, pp. 114–129. [CrossRef]
- Merhav, N. “Guessing individual sequences: generating randomized guesses using finite-state machines,” IEEE Trans. Inform. Theory 2020, vol. 66, no. 5, pp. 2912–2920. [CrossRef]
- Ziv, J. “Universal decoding for finite-state channels,” IEEE Trans. Inform. Theory 1985, vol. IT–31, no. 4, pp. 453–460. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



