
Submitted:
24 January 2024
Posted:
25 January 2024
You are already at the latest version
Abstract
The partial information decomposition (PID) framework is concerned with decomposing the information that a set of (two or more) random variables (the sources) has about another variable (the target) into three types of information: unique, redundant, and synergistic. Classical information theory alone does not provide a unique way to decompose information in this manner and additional assumptions have to be made. One often overlooked way to do this decomposition is using a so-called measure of union information – which quantifies the information that is present in at least one of the sources – from which a synergy measure stems. In this paper, we introduce a new measure of union information based on adopting a communication channel perspective, compare it with existing measures, and study some of its properties. We also include a comprehensive critical review of characterizations of union information and synergy measures that have been proposed in the literature.
Keywords:
information theory
; partial information decomposition
; union information
; synergy
; communication channels.
; mutual information
1. Introduction
Williams and Beer [1] introduced the partial information decomposition (PID) framework as a way to characterize, or analyze, the information that a set of random variables (often called sources) has about another variable (referred to as the target). PID is a useful tool for gathering insights and analyzing the way information is stored, modified, and transmitted within complex systems [2,3]. It has been applied in several areas such as cryptography [4] and neuroscience [5,6], with many other potential use cases, such as in studying information flows in gene regulatory networks [7], neural coding [8], financial markets [9], and network design [10].
Consider the simplest case: a three-variable joint distribution describing three random variables: two so-called sources, and , and a target T. Notice that, despite what the names sources and target might suggest, there is no directionality (causal or otherwise) assumption. The goal of PID is to decompose the information that the sources have about T into the sum of 4 non-negative quantities: the information that is present in both and , known as redundant information, R; the information that only (respectively ) has about T, known as unique information, (respectively ); the synergistic information, S, that is present in the pair but not in or alone. In this case with two variables, the goal is thus to write
where is the mutual information between T and Y [11]. The redundant information R, because it is present in both and , is also referred to as intersection information and denoted as . Finally, refers to union information, i.e., the amount of information provided by at least one of the sources; in the case of two sources, , thus .
Because unique information and redundancy satisfy the relationship (for ), it turns out that defining how to compute one of these quantities (R, , or S) is enough to fully determine the others [1]. Williams and Beer [1] suggested a set of axioms that a measure of redundancy should satisfy, and proposed a measure of their own. Those axioms became well known as the Williams-Beer axioms, although the measure they proposed has subsequently been criticized for not capturing informational content, but only information size [12]. It is worth noting that, as the number of variables grows, the number of terms appearing in the PID of grows super exponentially [13].
Stimulated by that initial work, other measures of information and other sets of axioms for information decomposition have been introduced; see, for example, the work by Bertschinger et al. [14], Griffith and Koch [15], and James et al. [16], for different measures of redundant, unique, and synergistic information. There is no consensus about what axioms any measure should satisfy or whether a given measure captures the information that it should capture, except for the Williams-Beer axioms. Today, there is still debate about what axioms different measures of information should satisfy, and there is no general agreement on what is an appropriate PID [16,17,18,19,20].
Most PID measures that have been suggested thus far are either measures of redundant information [1,12,20,21,22,23,24,25] or measures of unique information [14,16]. Alternatively, it is possible to define union information of a set of sources as the amount of information provided by at least one of those sources. Synergy is then defined as the difference between the total information and union information [21].
In this paper, we introduce a new measure of union information based on the information channel perspective that we already pursued in earlier work [25] and study some of its properties. The resulting measure leads to a novel information decomposition that is particularly suited for analyzing how information is distributed in channels.
The rest of the paper is organized as follows. A final subsection of this section introduces the notation used throughout the paper. In Section 2, we recall some properties of PID and take a look at how the degradation measure for redundant information introduced by Kolchinsky [21] decomposes information in bivariate systems, while also pointing out some drawbacks of that measure. Section 3 presents the motivation for our proposed measure, its operational interpretation, its multivariate definition, as well as some of its drawbacks. In Section 4, we propose an extension of the Williams-Beer axioms for measures of union information and show that our proposed measure satisfies those axioms. We review all properties that have been proposed both for measures of union information and synergy, and either accept or reject them. We also compare different measures of synergy and relate them, whenever possible. Finally, Section 5 presents concluding remarks and suggestions for future work.
1.1. Notation
For two discrete random variables and , their Shannon mutual information is given by , where and are the entropy and conditional entropy, respectively [11]. The conditional distribution corresponds, in an information-theoretical perspective, to a discrete memoryless channel with a channel matrix K, i.e., such that [11]. This matrix is row-stochastic: , for any and , and , for any x.
Given a set of n discrete random variables (sources), , and a discrete random variable (target) with joint distribution (probability mass function) , we consider the channels between T and each , that is, each is a row-stochastic matrix with the conditional distribution .
We say that three random variables, say , form a Markov chain (which we denote by or by ) if X and Z are conditionally independent, given Y.
2. Background
2.1. PID Based of Channel Orders
In its current versions, PID is agnostic to causality in the sense that, like mutual information, it is an undirected measure, i.e., . Some measures indirectly presuppose some kind of directionality to perform PID. Take for instance the redundancy measure introduced by Kolchinsky [21], based on the so-called degradation order between communication channels (see recent work by Kolchinsky [21] and Gomes and Figueiredo [25] for definitions):
When computing the information shared by the m sources, , the perspective is that there is a channel with a single input T and m outputs . This definition of corresponds to the mutual information of the most informative channel, under the constraint that this channel is dominated (in the degradation order sense) by all channels . Since mutual information was originally introduced to formalize the capacity of communication channels, it is not surprising that measures that presuppose channel directionality are found useful in this context.
Although it is not guaranteed that the structure of the joint distribution is compatible with the causal model of single input, and multiple output channels (which implies that the sources are conditionally independent, given T), one may always compute such measures, which have interesting and relevant operational interpretations. In the context of PID, where the goal is to study how information is decomposed, such measures provide an excellent starting point. Although it is not guaranteed that there is actually a channel (or a direction) from T to , we can characterize how information about T is spread through the sources. In the case of the degradation order, provides insight about which variable to observe in order to obtain the most information about T, under the constraint that only one can be observed.
Arguably, the most common scenario in PID is finding out something about the structure of the information the variables have about T. In a particular system of variables characterized by its joint distribution, we do not make causal assumptions, so we can adopt the perspective that the variables are functions of T, hence obtaining the channel structure. Although it might not be faithful to the conditional independence properties implied by , this approach allows decomposing and drawing conclusions about the inner structure of the information that Y has about T. Some distributions, however, cannot have this causal structure. Take for instance the distribution generated by , where and are two equiprobable and independent binary random variables. We will call this distribution XOR. For this well-known distribution, we have and , whereas the implied channel distribution that assumes yields the exact opposite dependencies, that is, and . See Figure 1 for more insight.
Consider the computation of for the XOR distribution. This measure argues that, since
then a solution to is given by the channel and redundancy is computed as , yielding 0 bits of redundancy, and consequently 1 bit of synergy (as computed from (1)). Under this channel perspective (as in Figure 1 (b)), is not concerned with, for example or . If all that is needed to compute redundancy is and , this would lead to the wrong conclusion that the outcome has non-null probability, which it does not. With this, we don’t mean that is an incomplete or incorrect measure to do PID, we are using its insights to point us in a different direction.
2.2. PID Based on Redundancy Measures
At this point, the most often used approaches to PID are based on redundancy measures. Usually, these are in one of the two following classes:
- Measures that are not concerned with information content, only information size, which makes them easy to compute even for distributions with many variables, but at the cost that the resulting decompositions may not give realistic insights into the system, precisely because they are not sensitive to informational content. Examples are [1] or [22], and applications of these can be found in [27,28,29,30].
- Measures that satisfy the Blackwell property - which arguably do measure information content - but are insensitive to changes in the sources’ distribution (as long as remain the same). Examples are [21] (see Equation (2)) or [14]. It should be noted that is only defined for the bivariate case, that is, for distributions with at most two sources, described by . Applications of these can be found in [31,32,33].
Particularly and satisfy the so-called (*) assumption [14], which argues that redundant and unique information should only depend on the marginal distribution of the target and on the conditional distributions of the sources given the target, that is, on the stochastic matrices . Section 4 James et al. [16] and Section 5 Ince [20], provide great arguments as to why the (*) assumption should not hold in general, and we agree with them.
Towards motivating a new PID, let us look at how decomposes information in the bivariate case. Any measure that is based on a preorder between channels and which satisfies Kolchinsky’s axioms yields similar decompositions [25], thus there is no loss of generality in focusing on . We next analyze three different cases.
-
Case 1: there is an ordering between the channels, that is, w.l.o.g., . This means that and the decomposition (as in (1)) is given by and . Moreover, if , then .As an example, consider the leftmost distribution in Table 1, which satisfies . In this case,yielding and , as expected, because .

Table 1.
Three joint distributions used to exemplify the three cases. Left: joint distribution satisfying . Middle: distribution satisfying , known as the COPY distribution. Right: the so-called BOOM distribution (see text).
Table 1.
Three joint distributions used to exemplify the three cases. Left: joint distribution satisfying . Middle: distribution satisfying , known as the COPY distribution. Right: the so-called BOOM distribution (see text).
| t | |||
|---|---|---|---|
| 0 | 0 | 0 | 0.25 |
| 0 | 0 | 1 | 0.25 |
| 1 | 1 | 0 | 0.25 |
| 1 | 1 | 1 | 0.25 |
| t | |||
|---|---|---|---|
| (0,0) | 0 | 0 | 0.25 |
| (0,1) | 0 | 1 | 0.25 |
| (1,0) | 1 | 0 | 0.25 |
| (1,1) | 1 | 1 | 0.25 |
| t | |||
|---|---|---|---|
| 0 | 0 | 2 | 1/6 |
| 1 | 0 | 0 | 1/6 |
| 1 | 1 | 2 | 1/6 |
| 2 | 0 | 0 | 1/6 |
| 2 | 2 | 0 | 1/6 |
| 2 | 2 | 1 | 1/6 |
-
Case 2: there is no ordering between the channels and the solution of is a trivial channel, in the sense that it has no information about T. The decomposition is given by and , which may lead to a negative value of synergy.As an example, consider the COPY distribution with and i.i.d. Bernoulli variables with parameter 0.5, shown in the center of Table 1. In this case, channels and have the formwith no degradation order between them. This yields and .
-
Case 3: there is no ordering between the channels and is achieved by a nontrivial channel . The decomposition is given by and .
This class of approaches has some limitations, as all PID measures do. In the bivariate case, the definition of synergy S from a measure of redundant information is the completing term such that holds. The definition of supports the argument that if and , then there is no synergy. This makes intuitive sense because, in this case, is a Markov chain (see Section 1.1 for the definition), consequently, , that is, has the same information about T as the pair .
If there is no ordering between the channels, as in the COPY distribution (Table 1, middle), the situation is more complicated. We saw that the decomposition for this distribution yields and . However, suppose we change the distribution such that has probability 0 and the other outcomes have probability . For example, consider the distribution in Table 2. For this distribution, we have . Intuitively, we would expect that would be decomposed as and , just as before, so that the proportions , for , in both distributions remain the same, whereas redundancy and synergy would remain zero. That is, we don’t expect that removing one of the outcomes while maintaining the remaining outcomes equiprobable would change the types of information in the system. However, if we do so and compute the decomposition yielded by , we obtain and , i.e., a negative synergy, arguably meaningless.
There are still many open questions in PID. One of those questions is: should measures of redundant information be used to measure synergy, given that they compute it as the completing term in equation (1). We agree that using a measure of redundant information to compute the synergy in this way may not be appropriate, especially because the inclusion-exclusion principle (IEP) should not necessarily hold in the context of PID. See [21] for comments on the IEP.
With these motivations, we propose a measure of union information for PID that shares with the implicit view of channels. However, unlike and – which satisfy the (*) assumption and thus are not concerned with the conditional dependencies in – our measure defines synergy as the information that cannot be computed from , but can be computed from . That is, we propose that synergy be computed as the information that is not captured by assuming conditional independence of the sources, given the target.
3. A New Measure of Union Information
3.1. Motivation and Bivariate Definition
Consider a distribution and suppose there are two agents, agent 1 and agent 2, whose goal is to reduce their uncertainty about T by observing and , respectively. Suppose also that the agents know , and that agent i has access to its channel distribution . Many PID measures make this same assumption, including . When agent i works alone to reduce the uncertainty about T, since it has access to and , it also knows and , which allows it to compute : the amount of uncertainty reduction about T achieved by observing .
Now, if the agents can work together, that is, if they have access to , then they can compute , because they have access to and . On the other hand, if the agents are not able to work together (in the sense that they are not able to observe Y together, but only and , separately) yet can communicate, then they can construct a different distribution q given by , i.e., a distribution under which and are conditionally independent given T, but have the same marginal and the same individual conditionals and .
The form of q in the previous paragraph should be contrasted with the following factorization of p which entails no conditional independence assumption: . In this sense, we would propose to define union information, for the bivariate case, as follows
where the subscript refers to the distribution under which the mutual information is computed. From this point forward, the absence of a subscript means that the computation is done under the true distribution p. As we will see, this is not yet the final definition, for reasons to be addressed below.
Using the definition of synergy derived from a measure of union information [21], for the bivariate case we have
Synergy is often posited as the difference between the whole and the union of the parts. For our measure of union information, the ‘union of the parts’ corresponds to the reduction of uncertainty about T - under q - that agents 1 and 2 can obtain by sharing their conditional distributions. Interestingly, there are cases where the union of the parts is better than the whole, in the sense that . An example of this is given by the Adapted ReducedOR distribution, originally introduced by Ince [20] and adapted by James et al. [16], which is shown in the left side of Table 3, where . This distribution is such that does not depend on r (), since neither nor and depend on r; consequently, also does not depend on r, as show in the right side of Table 3.
Table 3.
Left: the Adapted ReducedOR distribution, where . Right: the corresponding distribution
| t | |||
|---|---|---|---|
| 0 | 0 | 0 | 0.5 |
| 1 | 0 | 0 | r/4 |
| 1 | 1 | 0 | (1-r)/4 |
| 1 | 0 | 1 | (1-r)/4 |
| 1 | 1 | 1 | r/4 |
| t | |||
|---|---|---|---|
| 0 | 0 | 0 | 0.5 |
| 1 | 0 | 0 | 1/8 |
| 1 | 1 | 0 | 1/8 |
| 1 | 0 | 1 | 1/8 |
| 1 | 1 | 1 | 1/8 |
It can be easily shown that if , then , which implies that synergy, if defined as in (4), could be negative. How do we interpret the fact that there exist distributions such that ? This means that under distribution q, which assumes and are conditionally independent given T, and reduce the uncertainty about T more than in the original distribution. Arguably, the parts working independently and achieving better results than the whole should mean there is no synergy, as opposed to negative synergy.
The observations in the previous paragraphs motivate our definition of a new measure of union information as
with the superscript CI standing for conditional independence, yielding a non-negative synergy:
Note that, for the bivariate case, we have 0 synergy if is such that , that is, if the outputs are indeed conditionally independent given T. Moreover, satisfies the monotonicity axiom from the extension of the Williams-Beer axioms to measures of union information (to be mentioned in Section 4.1), which further supports this definition.
3.2. Operational Interpretation
For the bivariate case, if and are conditionally independent given T (Figure 1 (b)), then and (and ) suffice to reconstruct the original joint distribution , which means the union of the parts is enough to reconstruct the whole, i.e., there is no synergy between and . Conversely, a distribution generated by the DAG in Figure 1 (c) does not satisfy conditional independence (given T), hence we expect positive synergy, as is the case for the XOR distribution, and indeed our measure yields 1 bit of synergy for this distribution. These two cases motivate the operational interpretation of our measure of synergy: it is the amount of information that is not captured by assuming conditional independence of the sources (given the target).
Recall, however, that some distributions are such that , i.e., such that the union of the parts ‘outperforms’ the whole. What does this mean? It means that under q, and have more information about T than under p: the constructed distribution q, which drops the conditional dependence of and given T, reduces the uncertainty that Y has about T more than the original distribution p. In some cases, this may happen because the support of q is larger than that of p, which may lead to a reduction of uncertainty under q that cannot be achieved under p. In these cases, since we are decomposing , we revert to saying that the union information that a set of variables has about T is equal to , so that our measure satisfies the monotonicity axiom (later introduced in Definition 2). We will comment on this compromise between satisfying the monotonicity axiom and ignoring dependencies later.
3.3. General (Multivariate) Definition
To extend the proposed measure to an arbitrary number of sources, we briefly recall the synergy lattice [17,34] and the union information semi-lattice [34]. For , these two lattices are shown in Figure 2. For the sake of brevity, we will not address the construction of the lattices or the different orders between sources. We refer the reader to the work of Gutknecht et al. [34], for an excellent overview of the different lattices, the orders between sources, and the construction of different PID measures.
In the following, we use the term source to mean a subset of the variables , or a set of such subsets, we drop the curly brackets for clarity, and refer to the different variables by their indices, as is common in most works on PID. The decomposition resulting from a measure of union information is not as direct to obtain as one obtained from a measure of redundant information, as the solution for the information atoms is not a Möbius inversion [13]. One must first construct the measure of synergy for source by writing
which is the generalization of (6) for an arbitrary source . In the remainder of this paper, we will often omit “" from the notation (unless it is explicitly needed), with the understanding that the target variable is always referred to as T. Also for simplicity, in the following, we identify the different agents that have access to different distributions as the distributions they have access to.
It is fairly simple to extend the proposed measure to an arbitrary number of sources, as illustrated in the following two examples.
Example 1:
to compute , agent knows , thus it can also compute, by marginalization, and . On the other hand, agent only knows . Recall that both agents also have access to . By sharing their conditionals, the agents can compute , and also . After this, they may choose whichever distribution has the highest information about T, while still holding the view that any information gain larger than must be disregarded. Consequently, we write
Example 2:
slightly more complicated is the computation of . In this case, the three agents may compute four different distributions, two of which are the same and defined in the previous paragraph, and the other two are , and .
Given these insights, we propose the following measure of union information.
Definition 1.
Let be an arbitrary collection of sources (recall sources may be subsets of variables). Without loss of generality, assume that no source is a subset of another source and no source is a deterministic function of other sources. We define
where and Q is the set of all different distributions that the m agents can construct by combining their conditional distributions and marginalizations thereof.
For instance, in Examples 1 above, ; in Example 2, . In Example 1, , whereas in Example 2, .
We now justify the conditions in Definition 1 and the fact that they do not entail any loss of generality.
- The condition that no source is a subset of another source (which also excludes the case where two sources are the same) implies no loss of generality: if one source is a subset of another, say , then may be removed without affecting either A or , thus yielding the same value for . The removal of source is also done for measures of intersection information, but under the opposite condition: whenever .
- The condition that no source is a deterministic function of other sources is slightly more nuanced. In our perspective, an intuitive and desired property of measures of both union and synergistic information is that their value should not change whenever one adds a source that is a deterministic function of sources that are already considered. We provide arguments in favor of this property in Section 4.2.1. This property may not be satisfied by computing without previously excluding such sources. For instance, consider , where and are two i.i.d. random variables following a Bernoulli distribution with parameter 0.5, (that is, is deterministic function of ), and . Computing without excluding (or ) yields and . This issue is resolved by removing deterministic sources before computing .
We conclude this section by commenting on the monotonicity of our measure. Suppose we wish to compute the union information of sources and . PID theory demands that (monotonicity of union information). Recall our motivation for : there are two agents, the first has access to and the second to . The two agents assume conditional independence of their variables and construct . The story is similar for the computation of , in which case we have three agents that construct . Now, it may be the case that ; considering only these two distributions would yield , contradicting monotonicity for measures of union information. To overcome this issue, for the computation of - and other sources in general - the agent that has access to must be allowed to disregard the conditional dependence of and on T, even if it holds in the original distribution p.
4. Properties of Measures of Union Information and Synergy
4.1. Extension of the Williams-Beer Axioms for Measures of Union Information
As Gutknecht et al. [34] rightfully notice, the so-called Williams-Beer axioms [1] can actually be derived from parthood distribution functions and the consistency equation [34]. Consequently, they are not really axioms, but consequences of the PID framework. As far as we know, there has been no proposal in the literature for the equivalent of the Williams-Beer axioms (which refer to measures of redundant information) for measures of union information. In the following, we extend the Williams-Beer axioms to measures of union information and show that the proposed satisfies these axioms. Although we just argued against calling them axioms, we keep the designation Williams-Beer axioms because of its popularity.
Definition 2.
Let be an arbitrary number of sources. A measure of union information is said to satisfy the Williams-Beer axioms for union information measures if it satisfies:
- 1.
- Symmetry: is symmetric in the ’s.
- 2.
- Self-redundancy: .
- 3.
- Monotonicity: .
- 4.
- Equality for monotonicity: .
Theorem 1.
satisfies the Williams-Beer axioms for measures of union information given in Definition 2.
Proof.
We address each of the axioms in turn.
- Symmetry follows from the symmetry of mutual information, which in turn is a consequence of the well-known symmetry of joint entropy.
- Self-redundancy follows from the fact that agent i has access to and , which means that is one of the distributions in the set , which implies that .
- To show that monotonicity holds, begin by noting thatdue to the monotonicity of mutual information. Let be the set of distributions that the sources can construct and that which the sources can construct. Since , it is clear thatConsequently,which means monotonicity holds.
- Finally, the proof that equality for monotonicity is the same that was used above to show that the assumption that no source is a subset of another source entails no loss of generality. If , then the presence of is irrelevant: and , which implies that .
□
4.2. Review of Suggested Properties: Griffith and Koch [15]
We now review properties of measures of union information and synergy that have been suggested in the literature, doing so in chronological order. The first set of properties was suggested by Griffith and Koch [15], with the first two being the following.
- Duplicating a predictor does not change synergistic information; formally,where , for some . Griffith and Koch [15] show that this property holds if the equality for monotonicity property holds for the “corresponding" measure of union information (“corresponding" in the sense of equation (7)). As shown in the previous subsection, satisfies this property, and so does the corresponding synergy .
- Adding a new predictor can decrease synergy, which is a weak statement. We suggest a stronger property: adding a new predictor cannot increase synergy, which is formally written asThis property simply follows from monotonicity for the corresponding measure of union information, which we proved above holds for .
The next properties for any measure of union information were also suggested by Griffith and Koch [15]:
- Global positivity: .
- Self-redundancy: .
- Symmetry: is invariant under permutations of .
- Stronger monotonicity: , with equality if there is some such that .
- Target monotonicity: for any (discrete) random variables T and Z, .
- Weak local positivity: for the derived partial informations are nonnegative. This is equivalent to
- Strong identity: .
We argued before that global positivity, self-redundancy, and symmetry are all properties that follow trivially from a well-defined measure of union information [34]. In the following, we discuss in more detail properties 4 and 5.
4.2.1. Stronger Monotonicity
Property 4 in the above list was originally called monotonicity by Griffith and Koch [15]; we changed its name because we had already defined monotonicity in Definition 2, a weaker condition than stronger monotonicity. The proposed inequality clearly follows from the monotonicity of union information (the third Williams-Beer axiom). Now, if there is some such that (equivalently, if is a deterministic function of ), Griffith and Koch [15] suggest that we must have equality. Recall Axiom 4 (equality for monotonicity) in the extension of the WB axioms (Definition 2). It states that equality must hold if . In this context, and are sets of random variables, for example and . There is a different point of view we may take. The only way that is a subset of is if , when viewed as a random vector (in this case, write and ), is a subvector of . A subvector of a random vector is a deterministic function, and no information gain can come from applying a deterministic function to a random vector. As such, there is no information gain when one considers , a function of , if one already has access to . Griffith and Koch [15] argue similarly: there is no information gain by considering – a function of – in addition to . In conclusion, considering the ‘equality for monotonicity’ strictly through a set inclusion perspective, stronger monotonicity does not follow. On the other hand, extending the idea of set inclusion to the more general context of functions of random variables, then stronger monotonicity follows, because is a subset of , hence there is no information gain by considering in addition to . As such, we obtain . Consequently, it is clear that stronger monotonicity must hold for any measure of union information.
4.2.2. Target Monotonicity
Let us move on to target monotonicity, which we argue should not hold. This precise same property was suggested, but for a measure of redundant information, by Bertschinger et al. [18]; they argue that a measure of redundant information should satisfy
for any discrete random variable Z, as they argue that this property ‘captures the intuition that if share some information about T, then at least the same amount of information is available to reduce the uncertainty about the joint outcome of ’. Since most PID approaches have been built built upon measures of redundant information, it is simpler to refute this property. Consider , one of the most well-motivated and accepted measures of redundant information (as defined in (2)) and the following distribution, which satisfies and .
From a game theory perspective, since neither agent ( or ) has an advantage when predicting T (because the channels that each agent has access to have the same conditional distributions), neither agent has any unique information. Moreover, redundancy - as computed by – evaluates to approximately 0.311. However, when considering the pair , the structure that was present in T is now destroyed, in the sense that now there is no degradation order between the channels that each agent has access to. Note that is a relabelling of the COPY distribution. As such, , contradicting the property proposed by Bertschinger et al. [18].
For a similar reason, we believe that this property should not hold (in general) for measures of union information, even if they satisfy the extension of the Williams-Beer axioms, as our proposed measure does. For instance, the following distribution
satisfies , meaning target monotonicity does not hold. This happens because, although , it is not necessarily true that . The union information measure derived from the degradation order between channels, defined as the ‘dual’ of (2), also agrees with our conclusion [21]. For the distribution in Table 5 we have , for the same reason as above: considering as the target variable destroys the structure present in T. We agree with the remaining properties suggested by Griffith and Koch [15] and we will address those later.
Table 4.
Counter-example distribution for target monotonicity
| T | Z | |||
|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0.419 |
| 1 | 1 | 2 | 1 | 0.203 |
| 2 | 1 | 3 | 0 | 0.007 |
| 0 | 0 | 3 | 1 | 0.346 |
| 2 | 2 | 4 | 4 | 0.025 |
4.3. Review of Suggested Properties: Quax et al. [35]
Moving on to additional properties, Quax et al. [35] suggest the following properties for a measure of synergy:
- Nonnegativity: .
- Upper-Bounded by Mutual Information: .
- Weak Symmetry: is invariant under any reordering of .
- Zero synergy about a single variable: for any .
- Zero synergy in a single variable: for any .
Let us comment on the proposed ‘zero synergy’ properties (4 and 5). Property 4 seems to have been proposed with the rationale that synergy can only exist for at least two sources, which intuitively makes sense, as synergy is often defined as ‘the information that is present in the pair, but that is not retrievable from any individual variable’. However, because of the way a synergy-based PID is constructed — or weak-synergy, as Gutknecht et al. [34] call it — synergy must be defined as in (7), so that, for example in the bivariate case, , because of self-redundancy of union information and the chain rule of mutual information [11], and since is in general larger than 0, we reject the property ‘Zero synergy about a single variable’.
Property 5, ‘Zero synergy in a single variable’, on the other hand, must hold because of self-redundancy. That is because, for any , .
4.4. Relationship with the extended Williams-Beer axioms
We now prove which of the introduced properties are implied by the extension of the Williams-Beer axioms for measures of union information. In what follows, assume that the goal is to decompose the information present in the distribution .
Theorem 2.
Let be a measure of UI that satisfies the extension of the Williams-Beer axioms (symmetry, self-redundancy, monotonicity, and equality for monotonicity) for measures of UI as in Definition (2). Then, also satisfies the following properties of Griffith and Koch [15]: global positivity, weak local positivity, and strong identity.
Proof.
Global positivity is a direct consequence of monotonicity and the non-negativity of mutual information:
Weak local positivity holds because monotonicity and self-redundancy imply that , as well as , hence . Moreover, .
Strong identity follows trivially from self-redundancy, since . □
Theorem 3.
Proof.
Nonnegativity of synergy and upper-bounded by mutual information follow from the definition of synergy and from the fact that for whichever source , with , we have that .
Weak symmetry follows trivially from the fact that both and are symmetric in the relevant arguments.
Finally, zero synergy in a single variable follows from self-redundancy together with the definition of synergy, as shown above. □
4.5. Review of Suggested Properties: Rosas et al. [36]
Based on the proposals of Griffith et al. [23], Rosas et al. [36] suggested the following properties for a measure of synergy:
- Target data processing inequality: if is a Markov chain, then .
- Channel convexity: is a convex function of for a given .
We disagree with both suggested properties, for the reasons presented next. Consider the following distribution, in which is a relabeling of the COPY distribution and .
Table 7.
Adapted XOR distribution
| T | |||
|---|---|---|---|
| 0 | 0 | 0 | |
| 1 | 0 | 0 | |
| 1 | 1 | 0 | 0.25 |
| 1 | 0 | 1 | 0.25 |
| 0 | 1 | 1 | 0.25 |
Start by noting that since is a deterministic function of , then is a Markov chain. Since , our measure leads to zero synergy. On the other hand, , contradicting the first property suggested by Rosas et al. [36]. This happens because , so synergy is positive. The loss of conditional independence of the inputs (given the target), when one goes from considering the target to is the reason why synergy increases.
The second suggested property argues that synergy should be a convex function of , for fixed . Our measure of synergy does not satisfy this property, even though it is derived from a measure of union information that satisfies the extension of the WB axioms. For instance, consider the XOR distribution with one extra outcome. We introduce it below and parameterize it using . Notice that this modification does not affect
Synergy, as measured by , is maximized when r equals 1 (the distribution becomes the standard XOR) and minimized when r equals 0. We don’t see an immediate reason as to why a general synergy function should be convex in , or why it should have a unique minimizer as a function of r. Recall that a function S is convex if , we have
In the following, we slightly abuse the notation of the input variables of a synergy function. Our synergy measure , when considered as a function of r, does not satisfy this inequality. For the adapted XOR distribution, take , and . We have
and
contradicting the property of Channel convexity.
, the synergy measure derived from Kolchinsky’s proposed union information measure , agrees with this [21]. We slightly change in the above distribution to obtain a new distribution, which we present in Table 8.
This distribution does not satisfy the convexity inequality, since
This can be easily seen since for any , hence we may choose to compute , which is not convex for this particular distribution. To conclude this section, we present a plot of and as a function of r, for the distribution presented in Table 7.
5. Previous Measures of Union Information and Synergy
We now review other measures of union information and synergy proposed in the literature. For the sake of brevity, we will not recall all their definitions, only some important conclusions. We suggest the interested reader consult the bibliography for more information.
5.1. Qualitative comparison
Griffith and Koch [15] review three previous measures of synergy:
- , derived from , the original redundancy measure proposed by Williams and Beer [1], using the IEP;
- the whole-minus-sum (WMS) synergy, ;
- the correlational importance synergy, .
These synergies can be interpreted as resulting directly from measures of union information; that is, they are explicitly written as , where may not necessarily satisfy our intuitions of a measure of union information, as in Definition 2, except for , which has the form of a Kullback-Leibler divergence.
Griffith and Koch [15] argue that overestimates synergy, which is not a surprise, as many authors criticized for not measuring informational content, only informational values [12]. The WMS synergy, on the other hand, which can be written as a difference of total correlations, can be shown to be equal to the difference between synergy and redundancy for , which is not what is desired in a measure of synergy. For , the authors show that the problem becomes even more exacerbated: equals synergy minus the redundancy counted multiple times, which is why the authors argue that underestimates synergy. Correlational importance, , is known to be larger than for some distributions, excluding it from being an appropriately interpretable measure of synergy.
Faced with these limitations, Griffith and Koch [15] introduce their measure of union information, which they define as
where the minimization is over joint distributions of , alongside the derived measure of synergy . This measure quantifies union information as the least amount of information that source has about T when the source-target marginals (as determined by ) are fixed by p. Griffith and Koch [15] also establish the following inequalities for the synergistic measures they reviewed:
where . At the time, Griffith and Koch [15] did not provide a way to analytically compute their measure. Later, Kolchinsky [21] showed that the measure of union information derived from the degradation order, , is equivalent to , and provided a way to compute it. For this reason, we will only consider .
After the work of Griffith and Koch [15] in 2014, we are aware of only three other suggested measures of synergy:
The first two proposals do not define synergy via a measure of union information. They define synergy through an auxiliary random variable, Z, which has positive information about the whole – that is, – but no information about any of the parts – that is, . While this property has an appealing operational interpretation, we believe that it is too restrictive; that is, we believe that information can be synergistic, even if it provides some positive information about some part of Y.
The authors of show that their proposed measure is incompatible with PID and that it cannot be computed for all distributions, as it requires the ability to compute orthogonal random variables, which is not always possible [35]. A counter-intuitive example for the value of this measure can be seen for the AND distribution, defined by , with and i.i.d. taking values in with equal probability. In this case, , a value that we argue is too large, because whenever (respectively ) is 0, then T does not depend on (respectively ) (which happens with probability 0.75). Consequently, may be too large of a synergy ratio for this distribution. As the authors note, the only other measure that agrees with for the AND distribution is , which Griffith and Koch [15] argued also overestimates synergy.
Concerning , we do not have any criticism, except for the one already pointed out by Gutknecht et al. [34]: they note that the resulting decomposition from is not a standard PID, in sense that it does not satisfy a consistency equation (see [34] for more details), which implies that ‘(...) the atoms cannot be interpreted in terms of parthood relations with respect to mutual information terms (...). For example, we do not obtain any atoms interpretable as unique or redundant information in the case of two sources’ [34]. Gutknecht et al. [34] suggest a very simple modification to the measure so that it satisfies the consistency equation.
For the AND distribution, evaluates to approximately , as does , whereas our measure yields , as the information that the parts cannot obtain when they combine their marginals, under distribution q. This shows that these four measures are not equivalent.
5.2. Quantitative comparison
Griffith and Koch [15] applied the synergy measures they reviewed to other distributions. We show their results below and compare them with the synergy resulting from our measure of union information, , with the measure of Rosas et al. [36], , and that of Kolchinsky [21], . Since the code for the computation of is no longer available online, we do not present it.
We already saw the definition of the AND, COPY and XOR distributions. The XORDUPLICATE and ANDDUPLICATE are built from the XOR and the AND distributions by inserting a duplicate source variable . The goal is to test if the presence of a duplicate predictor impacts the different synergy measures. The definitions of the remaining distributions are presented in the appendix. Some of these are trivariate, and for those we compute synergy as
unless the synergy measure is directly defined (as opposed to being defined via a union information measure). We now comment on the results. It should be noted that Kolchinsky [21] suggested that unique information and should be computed from measures of redundant information, and excluded information and should be computed from measures of union information, as in our case. However, since we will only present the decompositions for the bivariate case and in this case and , we present the results considering unique information, as is mostly done in the literature.
- XOR yields . The XOR distribution is the hallmark of synergy. Indeed, the only solution of (1) is , and all of the above measures yield 1 bit of synergy.
- AND yields . Unlike XOR, there are multiple solutions for (1), and none is universally agreed upon, since different information measures capture different concepts of information.
- COPY yields . Most PID measures argue one of two different possibilities for this distribution. They suggest that the solution is either or . Our measure suggests that all information flows uniquely from each source.
- RDNXOR yields . In words, this distribution is the concatenation of two XOR ‘blocks’, each of which with its own symbols, and not allowing the two blocks to mix. That is, both and can determine in which XOR block the resulting value T will be - which intuitively means that they both have this information, meaning it is redundant - but neither nor have information about the outcome of the XOR operation - as is expected in the XOR distribution - which intuitively means that such information must be synergistic. All measures except agree with this.
- RDNUNQXOR yields . According to Griffith and Koch [15], it was constructed to carry 1 bit of each information type. Although the solution is not unique, it must satisfy . Indeed our measure yields the solution , like most measures except and . This confirms the intuition by Griffith and Koch [15] that and overestimate and underestimate synergy, respectively. In fact, in the decomposition resulting from , there are 2 bits of synergy and 2 bits of redundancy, which we argue cannot be the case, as this would imply that , and given the construction of this distribution, it is clear that there is some unique information since, unlike in RDNXOR, the XOR blocks are allowed to mix, thus is a possible outcome, but so is . That is not the case with RDNXOR. On the other hand, yields zero synergy and redundancy, with and each evaluating to 2 bits. Since this distribution is a mix of blocks satisfying a relation of the form , we argue that there must be some non-null amount of synergy, which is why we claim that is not valid.
- XORDUPLICATE yields . All measures correctly identify that the duplication of a source shouldn’t change synergy, at least for this particular distribution.
- ANDDUPLICATE yields . Unlike in the previous example, both and yield a change in their synergy value. This is a shortcoming since duplicating a source should not increase either synergy or union information. The other measures are not affected by the duplication of a source.
- XORLOSES yields . Its distribution is the same as XOR but with a new source satisfying . As such, since uniquely determines T, we expect no synergy. All measures agree with this.
- XORMULTICOAL yields . Its distribution is such that any pair , is able to determine T with no uncertainty. All measures agree that the information present in this distribution is purely synergistic.
From these results, we agree with Griffith and Koch [15] that , , and are not good measures of synergy: they do not satisfy many of our intuitions and overestimate synergy, not being invariant to duplicate sources or taking negative values. For these reasons and those presented in Section 5, we reject those measures of synergy. In the next Section, we comment on the remaining measures , and .
5.3. Relation to other PID measures
Kolchinsky [21] introduced and showed that this measure is equivalent to [15] and to [14], in the sense that the three of them achieve the same optimum value [21]. The multivariate extension of was proposed by Griffith and Koch [15], defined as
which we present because it makes it clear what conditions are enforced upon the marginals. There is a relation between and whenever the sources are singletons. In this case, and only in this case, does the set involved in the computation of has only one element: . Since this distribution, as well as the original distribution p, are both admissible points in , we have that , which implies that . On the other hand, if there is at least one source that is not a singleton, the measures are not trivially comparable. For example, suppose we wish to compute . We know that the solution of is a distribution whose marginals and must coincide with the marginals under the original p. However, in the computation of , it may be the case that the solution of is not in the set , involved in the computation of , and it achieves a lower mutual information with T. That is, it might be the case that , for all . In such a case, we would have .
It is convenient to be able to upper-bound certain measures with other measures. For example, Gomes and Figueiredo [25] (see that paper for the definitions of these measures) showed that for any source ,
However, we argue that the inability to draw such strong conclusions (or bounds) is a positive aspect of PID. This is because there are many different ways to define the information (be it redundant, unique, union, etc) that one wishes to capture. If one could trivially relate all measures, it would mean that it would be possible to know a priori how those measures would behave. Consequently, this would imply the absence of variability/freedom in how to measure different information concepts, as those measures would capture, not equivalent, but similar types of information, as they would all be ordered. It is precisely because one cannot order different measures of information trivially that PID provides a rich and complex framework to distinguish different types of information, although we believe PID is still in its infancy.
James et al. [16] introduced a measure of unique information, which we recall now. In the bivariate case – i.e., consider – let q be the maximum entropy distribution that preserves the marginals and , and let r be the maximum entropy distribution that preservers the marginals , , and . Although there is no closed form for r, which has to be computed using an iterative algorithm [37], it may be shown that the solution for q is . This is the same distribution q that we consider for the bivariate decomposition (3). James et al. [16] suggest defining unique information as the least change (in sources-target mutual information) that involves the addition of the marginal constraint, that is
and analogously for . They show that their measure yields a nonnegative decomposition for the bivariate case. Since , some algebra leads to
where is the synergy resulting from the decomposition of James et al. [16] in the bivariate case. Recall that our measure of synergy for the bivariate case is given by
The similarity is striking. Computing for the bivariate distributions in Table 9 shows that it coincides with the decomposition given by our measure, except for the AND distribution, where we obtained and . We could not obtain for the RDNUNQXOR distribution because the algorithm that computes r did not finish in the allotted time of 10 minutes. James et al. [16] showed that, for whichever bivariate distribution, , therefore for the bivariate case we have . Unfortunately, the measure of unique information proposed by James et al. [16], unlike the usual proposals of intersection or union information, does not allow for the computation of the partial information atoms in the complete redundancy lattice if . The authors also comment that it is not clear if their measure satisfies monotonicity when . Naturally, our measure is not the same as , so it doesn’t retain the operational interpretation of unique information being the least amount that influences when the marginal constraint is added to the resulting maximum entropy distributions. Given the form of , one could define and study its properties. Clearly, it does not satisfy the self-redundancy axiom, but we wonder if it could be adjusted so that it satisfies all of the proposed axioms. The decomposition retains the operational interpretation of the original measure, but it is not clear whether this is true for . For the latter case, the maximum entropy distributions that we wrote as q and r have different definitions [16]. We leave this for future work.
6. Conclusion and future work
In this paper, we introduced a new measure of union information for the partial information decomposition (PID) framework, based on the channel perspective, which quantifies synergy as the information that is beyond conditional independence of the sources, given the target. This measure has a clear interpretation and is very easy to compute, unlike most measures of union information or synergy, which require solving an optimization problem. The main contributions and conclusions of the paper can be summarized as follows.
- We introduced new measures of union information and synergy for the PID framework, which thus far was mainly developed based on measures of redundant or unique information. We provided its operational interpretation and defined it for an arbitrary number of sources.
- We proposed an extension of the Williams-Beer axioms for measures of union information and showed our proposed measure satisfies them.
- We reviewed, commented on and rejected some of the previously proposed properties for measures of union information and synergy in the literature.
- We showed that measures of union information that satisfy the extension of the Williams-Beer axioms necessarily satisfy a few other appealing properties, as well as the derived measures of synergy.
- We reviewed previous measures of union information and synergy, critiqued them and compared them with our proposed measure.
- The new measure is easy to compute. For example in the bivariate case, if the supports of , and T have size , and , respectively, the computation time of our measure grows like .
- We provide code for the computation of our measure for the bivariate case and for source in the trivariate case.
Finally, we believe this paper opens several avenues for future research, thus we point out several directions to be pursued in upcoming work:
- We saw that the synergy yielded by the measure of James et al. [16] is given by . Given its analytical expression, one could start by defining a measure of union information as , possibly tweak it so it satisfies the WB axioms, study its properties and possibly extend it to the multivariate case.
- Our proposed measure may ignore conditional dependencies that are present in p in favor of maximizing mutual information, as we commented in Section 3.3. This is a compromise so that the measure satisfies monotonicity. We believe this is a potential drawback of our measure, and we suggest the investigation of a measure similar to ours, but that doesn’t ignore conditional dependencies that it has access to.
- Implementing our measure in the dit package [38].
- This paper reviewed measures of union information and synergy, as well as properties that were suggested throughout the literature. Sometimes we did so by providing examples where the suggested properties fail, and other times simply by commenting. We suggest something similar be done for measures of redundant information.
7. Code availability
The code is publicly available at https://github.com/andrefcorreiagomes/CIsynergy/.
Funding
This research was partially funded by: FCT – Fundação para a Ciência e a Tecnologia, under grants number SFRH/BD/145472/2019 and UIDB/50008/2020; Instituto de Telecomunicações; Portuguese Recovery and Resilience Plan, through project C645008882-00000055 (NextGenAI, CenterforResponsibleAI).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In this appendix, we present the remaining distributions for which we computed different measures of synergy. For these distributions each outcome has the same probability, so we don’t present their probabilities.
Table A1.
RDNXOR (left), XORLOSES (center) and XORMULTICOAL (right)
| T | ||
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
| 0 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 2 | 3 |
| 3 | 3 | 2 |
| 2 | 3 | 3 |
| T | |||
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 |
| 0 | 1 | 1 | 0 |
| T | |||
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 0 | 2 | 2 | 2 |
| 0 | 3 | 3 | 3 |
| 1 | 2 | 1 | 0 |
| 1 | 3 | 0 | 1 |
| 1 | 0 | 3 | 2 |
| 1 | 1 | 2 | 3 |
References
- Williams, P.; Beer, R. Nonnegative decomposition of multivariate information. arXiv preprint arXiv:1004.2515 2010. [CrossRef]
- Lizier, J.; Flecker, B.; Williams, P. Towards a synergy-based approach to measuring information modification. 2013 IEEE Symposium on Artificial Life (ALIFE). IEEE, 2013, pp. 43–51. [CrossRef]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.T.; Priesemann, V. Quantifying information modification in developing neural networks via partial information decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef]
- Rauh, J. Secret sharing and shared information. Entropy 2017, 19, 601. [Google Scholar] [CrossRef]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—a model-free measure of effective connectivity for the neurosciences. Journal of computational neuroscience 2011, 30, 45–67. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.; Van Rijsbergen, N.; Thut, G.; Rousselet, G.; Gross, J.; Panzeri, S.; Schyns, P. Tracing the flow of perceptual features in an algorithmic brain network. Scientific reports 2015, 5, 1–17. [Google Scholar] [CrossRef]
- Gates, A.; Rocha, L. Control of complex networks requires both structure and dynamics. Scientific reports 2016, 6, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Faber, S.; Timme, N.; Beggs, J.; Newman, E. Computation is concentrated in rich clubs of local cortical networks. Network Neuroscience 2019, 3, 384–404. [Google Scholar] [CrossRef]
- James, R.; Ayala, B.; Zakirov, B.; Crutchfield, J. Modes of information flow. arXiv preprint arXiv:1808.06723, 2018. [Google Scholar] [CrossRef]
- Arellano-Valle, R.; Contreras-Reyes, J.; Genton, M. Shannon Entropy and Mutual Information for Multivariate Skew-Elliptical Distributions. Scandinavian Journal of Statistics 2013, 40, 42–62. [Google Scholar] [CrossRef]
- Cover, T. Elements of information theory; John Wiley & Sons, 1999. [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Physical Review E 2013, 87, 012130. [Google Scholar] [CrossRef]
- Gutknecht, A.; Wibral, M.; Makkeh, A. Bits and pieces: Understanding information decomposition from part-whole relationships and formal logic. Proceedings of the Royal Society A 2021, 477, 20210110. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided self-organization: inception; Springer, 2014; pp. 159–190. [CrossRef]
- James, R.; Emenheiser, J.; Crutchfield, J. Unique information via dependency constraints. Journal of Physics A: Mathematical and Theoretical 2018, 52, 014002. [Google Scholar] [CrossRef]
- Chicharro, D.; Panzeri, S. Synergy and redundancy in dual decompositions of mutual information gain and information loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared information—New insights and problems in decomposing information in complex systems. Proceedings of the European conference on complex systems 2012. Springer, 2013, pp. 251–269. [CrossRef]
- Rauh, J.; Banerjee, P.; Olbrich, E.; Jost, J.; Bertschinger, N.; Wolpert, D. Coarse-graining and the Blackwell order. Entropy 2017, 19, 527. [Google Scholar] [CrossRef]
- Ince, R. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. [Google Scholar] [CrossRef] [PubMed]
- Barrett, A. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Physical Review E 2015, 91, 052802. [Google Scholar] [CrossRef] [PubMed]
- Griffith, V.; Chong, E.; James, R.; Ellison, C.; Crutchfield, J. Intersection information based on common randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef]
- Griffith, V.; Ho, T. Quantifying redundant information in predicting a target random variable. Entropy 2015, 17, 4644–4653. [Google Scholar] [CrossRef]
- Gomes, A.F.; Figueiredo, M.A. Orders between Channels and Implications for Partial Information Decomposition. Entropy 2023, 25, 975. [Google Scholar] [CrossRef]
- Pearl, J. Causality; Cambridge university press, 2009. [CrossRef]
- Colenbier, N.; Van de Steen, F.; Uddin, L.Q.; Poldrack, R.A.; Calhoun, V.D.; Marinazzo, D. Disambiguating the role of blood flow and global signal with partial information decomposition. NeuroImage 2020, 213, 116699. [Google Scholar] [CrossRef]
- Sherrill, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Partial information decomposition reveals that synergistic neural integration is greater downstream of recurrent information flow in organotypic cortical cultures. PLoS computational biology 2021, 17, e1009196. [Google Scholar] [CrossRef]
- Sherrill, S.P.; Timme, N.M.; Beggs, J.M.; Newman, E.L. Correlated activity favors synergistic processing in local cortical networks in vitro at synaptically relevant timescales. Network Neuroscience 2020, 4, 678–697. [Google Scholar] [CrossRef] [PubMed]
- Proca, A.M.; Rosas, F.E.; Luppi, A.I.; Bor, D.; Crosby, M.; Mediano, P.A. Synergistic information supports modality integration and flexible learning in neural networks solving multiple tasks. arXiv preprint arXiv:2210.02996, 2022. [Google Scholar] [CrossRef]
- Kay, J.W.; Schulz, J.M.; Phillips, W.A. A comparison of partial information decompositions using data from real and simulated layer 5b pyramidal cells. Entropy 2022, 24, 1021. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.P.; Cheng, Y.; Fan, X.; Ling, C.K.; Nie, S.; Chen, R.; Deng, Z.; Mahmood, F.; Salakhutdinov, R.; Morency, L.P. Quantifying & modeling feature interactions: An information decomposition framework. arXiv preprint arXiv:2302.12247, 2023. [Google Scholar] [CrossRef]
- Hamman, F.; Dutta, S. Demystifying Local and Global Fairness Trade-offs in Federated Learning Using Partial Information Decomposition. arXiv preprint arXiv:2307.11333, 2023. [Google Scholar] [CrossRef]
- Gutknecht, A.J.; Makkeh, A.; Wibral, M. From Babel to Boole: The Logical Organization of Information Decompositions. arXiv preprint arXiv:2306.00734, 2023. [Google Scholar] [CrossRef]
- Quax, R.; Har-Shemesh, O.; Sloot, P.M. Quantifying synergistic information using intermediate stochastic variables. Entropy 2017, 19, 85. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.; Rassouli, B.; Barrett, A.B. An operational information decomposition via synergistic disclosure. Journal of Physics A: Mathematical and Theoretical 2020, 53, 485001. [Google Scholar] [CrossRef]
- Krippendorff, K. Ross Ashby’s information theory: a bit of history, some solutions to problems, and what we face today. International journal of general systems 2009, 38, 189–212. [Google Scholar] [CrossRef]
- James, R.; Ellison, C.; Crutchfield, J. “dit“: a Python package for discrete information theory. Journal of Open Source Software 2018, 3, 738. [Google Scholar] [CrossRef]
Figure 1.
(a) Assuming faithfulness [26], this is the only three-variable directed acyclic graph (DAG) that satisfies and , in general [26]. (b) The DAG that is "implied" by the perspective of . (c) A DAG that can generate the XOR distribution, but doesn’t satisfy the dependencies implied by . In fact, any DAG that is in the same Markov equivalence class as (c) can generate the XOR distribution (or any other joint distribution), but none satisfy the earlier dependencies, assuming faithfulness.
Figure 1.
(a) Assuming faithfulness [26], this is the only three-variable directed acyclic graph (DAG) that satisfies and , in general [26]. (b) The DAG that is "implied" by the perspective of . (c) A DAG that can generate the XOR distribution, but doesn’t satisfy the dependencies implied by . In fact, any DAG that is in the same Markov equivalence class as (c) can generate the XOR distribution (or any other joint distribution), but none satisfy the earlier dependencies, assuming faithfulness.
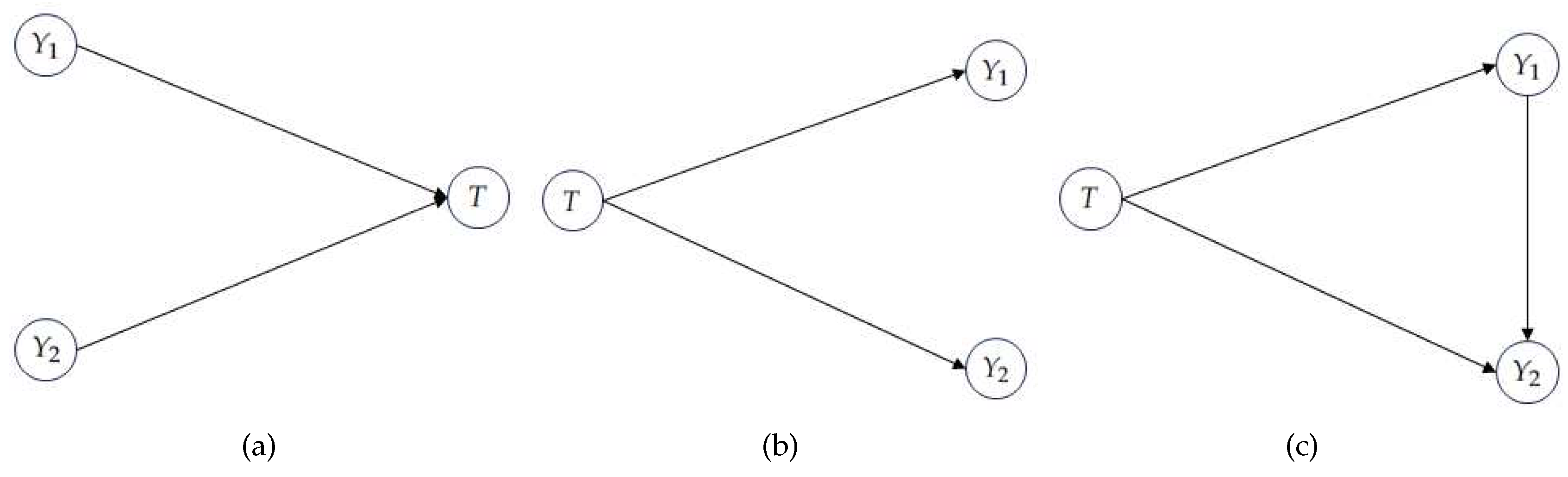
Figure 2.
Trivariate distribution lattices and their respective ordering of sources. Left: synergy lattice [17]. Right: union information semi-lattice [34].
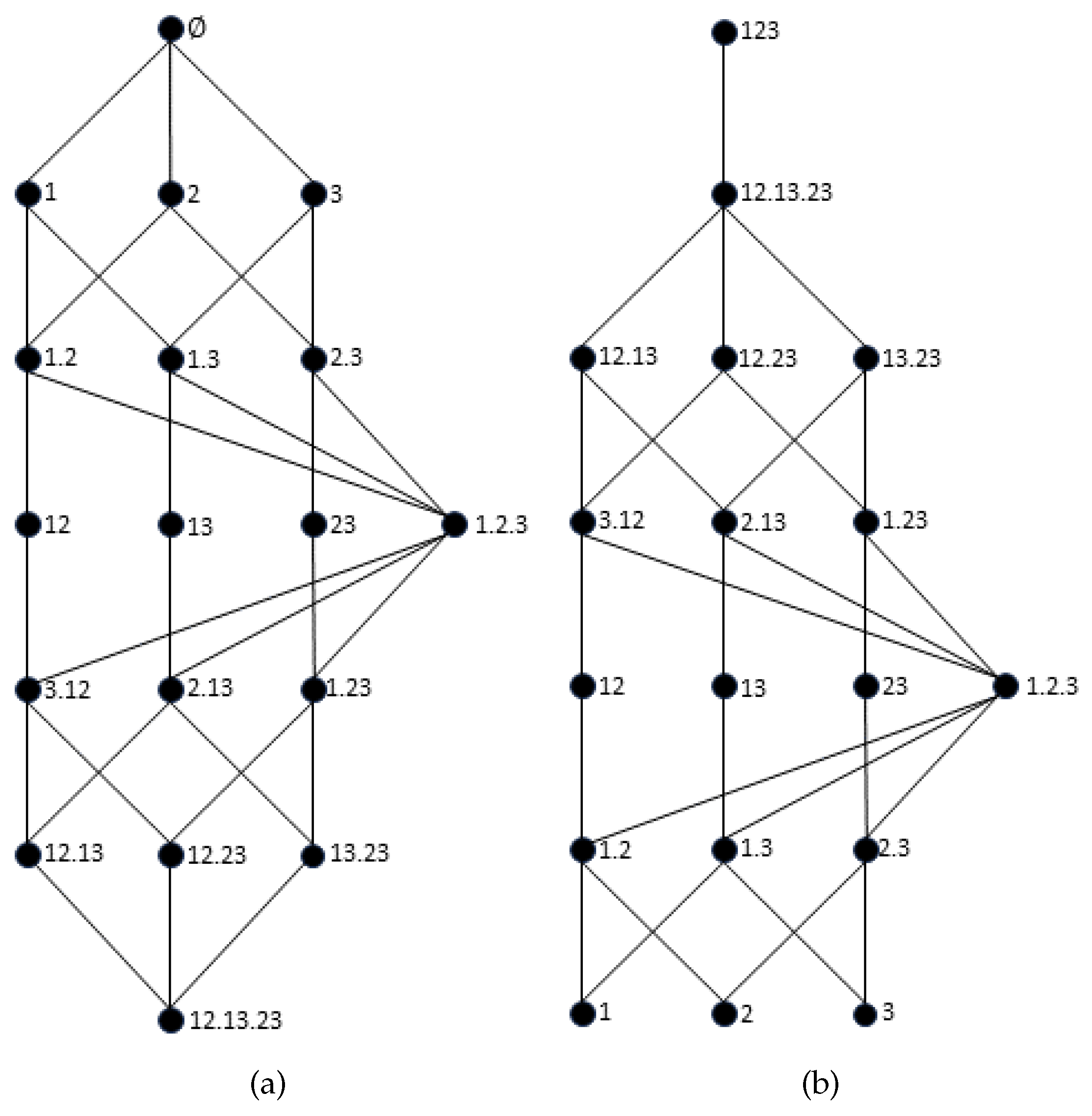
Figure 3.
Computation of and as functions of . As we showed for this distribution, is not a convex function of r.
Figure 3.
Computation of and as functions of . As we showed for this distribution, is not a convex function of r.
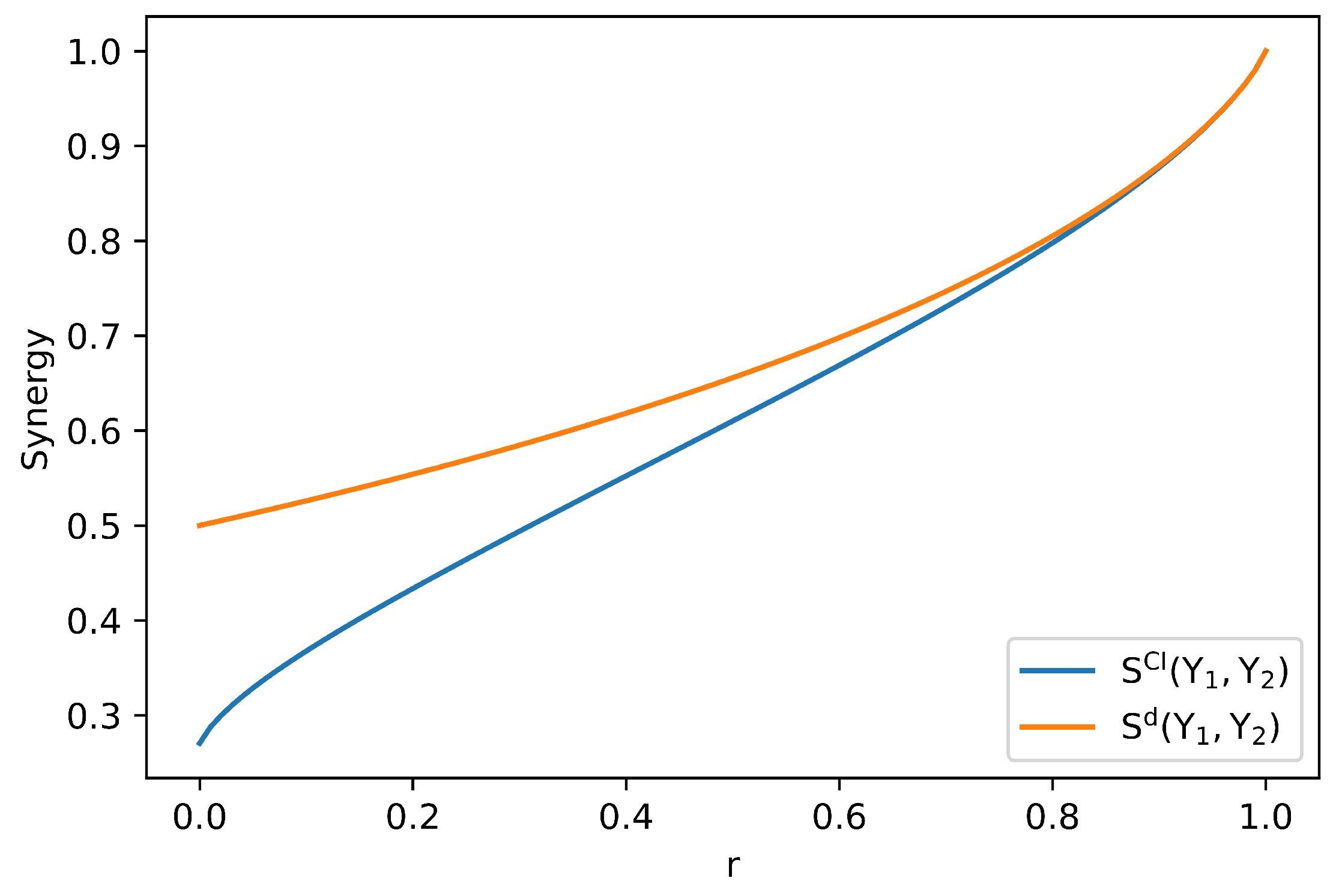
Table 2.
Tweaked COPY distribution, now without the outcome .
| T | |||
|---|---|---|---|
| (0,0) | 0 | 0 | 1/3 |
| (0,1) | 0 | 1 | 1/3 |
| (1,0) | 1 | 0 | 1/3 |
Table 5.
Counter-example distribution for target monotonicity
| T | Z | |||
|---|---|---|---|---|
| 0 | (0,0) | 0 | 0 | 0.25 |
| 0 | (0,1) | 0 | 1 | 0.25 |
| 0 | (1,0) | 1 | 0 | 0.25 |
| 1 | (1,1) | 1 | 1 | 0.25 |
Table 6.
COPY, XOR
| 0 | 0 | 0 | 0 | 0.25 |
| 1 | 1 | 0 | 1 | 0.25 |
| 1 | 2 | 1 | 0 | 0.25 |
| 0 | 3 | 1 | 1 | 0.25 |
Table 8.
Adapted XOR distribution v2
| T | |||
|---|---|---|---|
| 0 | 0 | 0 | |
| 1 | 0 | 0 | |
| 1 | 1 | 0 | 0.4 |
| 1 | 0 | 1 | 0.4 |
| 0 | 1 | 1 | 0.1 |
Table 9.
Application of the measures reviewed in Griffith and Koch [15], (, and ), introduced by Rosas et al. [36], introduced by Kolchinsky [21] and our measure of synergy to different distributions. The bottom four distributions are trivariate. We write DNF to mean that a specific computation did not finish within 10 minutes.
Table 9.
Application of the measures reviewed in Griffith and Koch [15], (, and ), introduced by Rosas et al. [36], introduced by Kolchinsky [21] and our measure of synergy to different distributions. The bottom four distributions are trivariate. We write DNF to mean that a specific computation did not finish within 10 minutes.
| Example | ||||||
|---|---|---|---|---|---|---|
| XOR | 1 | 1 | 1 | 1 | 1 | 1 |
| AND | 0.5 | 0.189 | 0.104 | 0.5 | 0.311 | 0.270 |
| COPY | 1 | 0 | 0 | 0 | 1 | 0 |
| RDNXOR | 1 | 0 | 1 | 1 | 1 | 1 |
| RDNUNQXOR | 2 | 0 | 1 | 1 | DNF | 1 |
| XORDUPLICATE | 1 | 1 | 1 | 1 | 1 | 1 |
| ANDDUPLICATE | 0.5 | -0.123 | 0.038 | 0.5 | 0.311 | 0.270 |
| XORLOSES | 0 | 0 | 0 | 0 | 0 | 0 |
| XORMULTICOAL | 1 | 1 | 1 | 1 | DNF | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



