
Submitted:
26 January 2024
Posted:
29 January 2024
You are already at the latest version
Abstract
The current study characterizes the transient M/M/1 queue manifold info-geometrically, through devising Fisher Information matrix(FIM) and its inverse(IFIM). Additionally, the impact of stability on the existence of IFIM and explore the geodesic equations of motion has been revealed. More potentially, the paper discusses some info-geometric applications to Machine Learning are highlighted. Closing remarks with some challenging open problems combined with the next phase of research are given.
Keywords:
Transient M/M/1
; Information Geometry (IG)
; statistical manifold (SM)
; queue manifold (QM)
; Information Geodesic equations of motion (IEMs)
; Fisher Information matrix (FIM)
; Inverse Fisher Information matrix (IFIM)
; Machine Learning (ML)
1. Introduction
Numerous study areas, including statistical sciences, have extensively used IG [1]. In other words, the goal of IG is to use statistics to apply the methods of differential geometry (DG), which indicates the major goal of IG is to use stochastic processes and probability theoretic in the applications of methodologies of non-Euclidean geometry.
A manifold is a topological finite-dimensional Cartesian space, , in which an infinite-dimensional manifold exists[2]. Additionally, IG supports SMs’ descriptions that are based on intuitive reasoning. One might have a greater understanding of the crucial significance of IG[3,4].
According to the literature, a paper by[5] examined info-geometrically the stable M/D/1 queue based on queue length routes ‘characteristics, was the real motivator for the current study.
The main deliverables of this paper are described below.
- The discovery of the FIM and its inverse for the transient M/M/ 1 queue.
- Revealing the new discovery of the geodesic equations of motion of the coordinates of the transient M/M/ 1 queue.
- In the context of the research paper, a novel α-connection [6] is introduced, which maps each coordinate to a value.
- Highlighting potential IG applications to ML.
The remainder of the paper is divided into the following sections: Preliminary IG definitions are given in Section II. The transient M/M/1 QM’s FIM and it IFIM are introduced in Section III. While Section IV gives the Information Geometric Equations of Motion (IMEs) for the coordinates of the transient M/M/1 QM. Section V addresses IG applications to ML. Section VI wraps up the paper and provides some challenging open problems combined with further research.
2. Main IG Definitions
1 Statistical Manifold (SM)
is called an SM[7]if x is a random variable in sample space and is the probability density function, which satisfies certain regular conditions. Here, is an n-dimensional vector in some open subset , and can be viewed as the coordinates on manifold M.
2 Potential Function
The potential function [7] is the distinguished negative function of the coordinates alone of )
3 Fisher’s Information Matrix(FIM)
FIM, namely [] reads as:
with respect to natural coordinates.
4 IFIM
Given the FIM, the inverse matrix of [] is defined by[7]
5 -Connection
For each the (or )-connection [6] is the torsion-free affine connection with components:
where is the potential function and = .
6 Geodesic equations of motion
By the above definition, the geodesic equations are interpreted physically as the information geometric equations of motion , shortly (IGEMs), or the relativistic equations of motion (REMs) , or the Riemannian equations of motion. At this stage, the current study provides a ground- breaking discovery of the IG analysis of transient queueuing systems in comparison to that of non-time dependent queueing systems, namely IG analysis of stable queues[8,9].
3. Fim And IFIM of the Transient M/M/1QM
A single-channel model with exponential inter-arrival times, service times, and FIFO queue discipline is the simplest probabilistic queueing model that can be addressed analytically. In queueing theory, this is referred to as the M/M/1 queue [10].
Based on the introduction of the function, Parthasarathy[10] suggested a straightforward method for the transient solution of the M/M/1 system to read as
where stands for the mean rate per unit time at which arrival instants occur, is the mean rate of service time, defines the traffic intensity or utilization factor,
, [19] is the modified Bessel function and
Theorem 1.
The underlying queue of (5) has:
(i) FIM reads as
where
Provided that, . refers to the temporal derivative .
(ii) [] reads as
where
Proof.
(i) Following (5), we have:
We have
Thus,
Therefore, the Fisher Information Matrix, FIM, is obtained (c.f., (7)).
[] reads as:
Thus,
as requested,
It is notable that FIM should satisfy the symmetry requirement.
In what follows, the components of (or )- connection are obtained. These calculated expressions are needed to obtain the corresponding Geodesic Equations (GEs) of the parametric coordinates of M/M/1 QM.
From (3), the reader can check that
Engaging the same procedure, the remaining components can be determined.
4. The IGMES of the Coordinates of the Transient M/M/1 QM
A. The of the coordinate, of the transient M/M/1 QM
The IMEs corresponding to the coordinate, of the transient M/M/1 QM are:
Now, we are in a situation of trying to find the path of motion of family of families of IMEs corresponding to the server utilization coordinate,
It can be verified that one of the closed form solutions of (40) is determined by the paths of motion:
such that
B. The of the coordinate, of the transient M/M/1 QM
The IMEs of , of the transient M/M/1 QM are
Now, we are in a situation of trying to find the path of motion of family of families of IMEs corresponding to the mean service rate,
Let
Thus,
It is obvious that for arbitrary constant values of , we have a closed form solution for (48). As time becomes sufficiently large, i.e., , (48) reduces to
We propose the closed form solution, for some arbitrary non-zero constant substituting in (49) implies:
As , The only accepted value is , which tends to the value as .
C. The of the coordinate, of the transient M/M/1 QM
Engaging a similar lengthy mathematical manipulation, it can be verified that the of the coordinate, t of the transient M/M/1 QM, as time reaches infinity and for a constant server utilization will have a closed form solution that is characterized by the family of families of temporal curves:
for some arbitrary non-zero constants ,
5. IG Applications to ML
Stochastic gradient descent is a popular optimisation approach in ML that seeks to determine which direction of descent is the steepest within a parameter space of probability distributions. Amari[3] created the natural gradient, which is superior to the ordinary gradient since it more accurately captures this direction. Furthermore, even with gradient descent, FIM can be used to calculate the predicted change in output about parameter changes. Artificial neural networks (ANNs) are functions with multiple parameters that map input vectors to output vectors. They are widely applied in regression, computer vision, and speech processing. ANNs can be trained through supervised learning, where a training set of input-output pairs is used, or through unsupervised learning, which does not require a training set. The back-propagation algorithm efficiently computes the gradient descent by determining the contribution of each parameter to the error. Overfitting, a common issue in ANNs, can be mitigated by techniques such as using a validation set, early stopping, data augmentation, and dropout[11].
In reinforcement learning(RL) [12], when an agent needs to prepare for unknown tasks, one approach is unsupervised skill discovery. These algorithms learn a set of policies without using a reward function and are like representation learning algorithms in supervised learning. While prior work has shown that these methods can accelerate downstream tasks, our analysis reveals that they do not learn skills that are optimal for every possible reward function. However, the distribution over skills can provide an optimal initialization that minimizes regret against adversarially chosen reward functions, assuming a specific adaptation procedure. Notably, understanding which state marginals are achievable is crucial for analyzing the behavior of unsupervised skill learning algorithms[12] and their relevance to state-dependent reward functions. The set of achievable state marginal distributions can be characterized by a set of linear equations or by a complementary description based on a specific property. This alternative perspective provides insights into the relationship between learned skills and downstream tasks in reinforcement learning.
So, if we have a set of possible state distributions, any combination of those distributions within the convex hull is also possible. This means that there exists a policy that can achieve any state distribution within that convex hull. By taking the convex hull of the state distributions of all deterministic policies, we can obtain the set of all possible state distributions, which is referred to as a polytope. Each vertex of the polytope represents a deterministic policy, and any policy’s state distribution can be expressed as a combination of the state distributions at the vertices, as visualized by Figure 2.
The analysis of where the skills learned by Mutual Information-based Skill Learning (MISL) are positioned on the state marginal polytope, which has motivated [12] to undertake this analysis by examining the mutual information objective and dissecting it to understand how the learned skills align with the polytope. In the context of skill learning[12], maximizing mutual information is equivalent to minimizing the maximum difference between a prior distribution over states (represented by a green square) and any possible state distribution.
This concept, known as information geometry, helps optimize skill learning algorithms by assigning higher probabilities to policies with state distributions that deviate further from the average state distribution. The goal is to find skills that are as distinct as possible from each other and from the average state distribution. Most importantly, the opaque circles represent the skills discovered by the Mutual Information Skill Learning (MISL) algorithm.
The dashed line represents state marginals that are equidistant from the green square, indicating an equal divergence from the prior distribution over states. This visualization helps illustrate the relationship between the skills learned by MISL and their distribution in relation to the average state distribution. This is illustrated by Figure 3.
Reliable detection of out-of-distribution (OOD) samples[13] is crucial for ensuring the safety of modern machine learning systems. The work of [13] introduced IGEOOD, an effective method that can detect OOD samples using any pre-trained neural network, regardless of the level of access to the ML model. By leveraging the geodesic distance between data distributions, IGEOOD combines confidence scores from the neural network’s logits outputs and learned features to achieve superior performance compared to other state-of-the-art methods across different network architectures and datasets[13].
The authors [13] introduced the concept of IG and derived a metric based on the Fisher-Rao distance to measure the mismatch between probability density functions of a pre-trained neural classifier. Experimental results demonstrate that IGEOOD performs competitively with state-of-the-art methods in different setups, including black-box and grey-box scenarios, and achieves improved performance on various benchmarks.
Figure 4 showcases a comparison between Fisher-Rao and Mahalanobis distances for distinguishing between 1D Gaussian distributions in the context of out-of-distribution (OOD) detection. It highlights the motivation to use the Fisher-Rao metric, which measures the dissimilarity between probability models, as it shows better performance in distinguishing between in-distribution and OOD samples compared to other distance-based approaches.
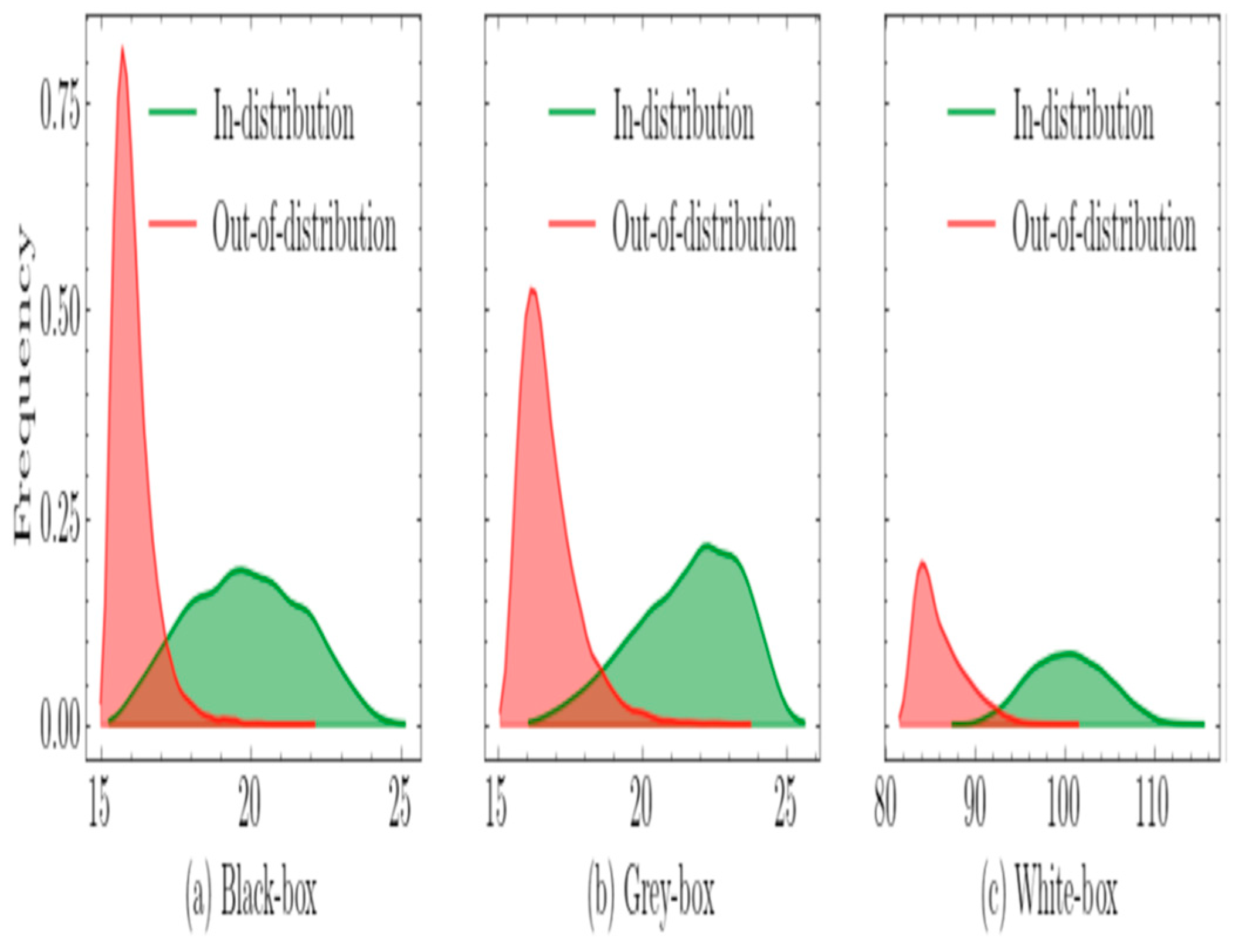
In the context of the experiment, the authors [13]compared three different settings for out-of-distribution (OOD) detection. They use a unified metric, but with different formulations based on the type of distribution. For the deep neural network (DNN) outputs, they use the softmax posterior probability distribution, while for the intermediate layers, they employ a model based on diagonal Gaussian probability density functions (pdfs). This unified framework combines a single distance measure for both the softmax outputs and the latent features of the neural network, contributing to the separation of in-distribution and OOD samples, as illustrated in Figure 5.
6. Conclusion, Open Problems and Future Work
This study offers a revolutionary info-geometrics of transient QM. For this queue, FIM and IFIM are established. The geodesic equations of motion for the queue’s coordinates are determined. More potentially, some IG applications to ML are provided.
Here are some challenging open problems to be addressed:
Open problem One:
According to the analysis in [12], a simplified model of skill learning algorithms that treated policy parameters and latent codes as a single representation, with different skills having distinct parameter sets was employed. However, practical implementations of skill learning algorithms are less flexible, which can alter the shape of the state marginal polytope.
This limited flexibility may lead to incomplete representation of certain state distributions, resulting in gaps or divisions in the polytope. It is yet to be determined if these practical implementations learn fewer unique skills and how these limitations impact the average state distribution, which is a really challenging open problem.
Open problem Two:
Following the derivation of the potential function, PF
Is the process of finding the threshold of PF based on its parameters decidable? The problem is still open.
Open problem Three:
Having discovered PF (c.f., (21)), is it feasible to examine its algebraic properties as well as doing the same for its inverse, if it exists? This is a challenging open problem, yet unsolved so far.
Open problem Four :
The discovery of Revolutionary relativistic connections with the investigated transient queue is still unsolvable problem, for example finding the corresponding Gaussian, Ricci, Scalar and Einesteinian tensors for the transient M/M/1 QM.
The frontiers are open for unlimited explorations.
The next phase of research includes answering the above open research problems and exploring more new avenues of IG applications to other scientific disciplines. More importantly, the possibility of employing Riemannian Geometric (RG) analysis, and the Theory of Relativity (TR) to the analysis of the dynamics of transient queues.
References
- A. Mageed, Y. Zhou, Y. Liu and Q. Zhang, “Towards a Revolutionary Info-Geometric Control Theory with Potential Applications of Fokker Planck Kolmogorov(FPK) Equation to System Control, Modelling and Simulation,” 2023 28th International Conference on Automation and Computing (ICAC), Birmingham, United Kingdom,2023,pp.1-6. [CrossRef]
- Z. Skoda, Z., 2019, available online at https://ncatlab.org/nlab/show/information+geometry.
- A. Mageed, Q. Zhang, T. C. Akinci, M. Yilmaz and M. S. Sidhu, “Towards Abel Prize: The Generalized Brownian Motion Manifold’s Fisher Information Matrix With Info-Geometric Applications to Energy Works,” 2022 Global Energy Conference (GEC), Batman, Turkey, 2022, pp. 379-384. [CrossRef]
- A. Mageed, X. Yin, Y. Liu and Q. Zhang, “Z(a,b) of the Stable Five-Dimensional M/G/1 Queue Manifold Formalism’s Info- Geometric Structure with Potential Info-Geometric Applications to Human Computer Collaborations and Digital Twins,” 2023 28th International Conference on Automation and Computing (ICAC), Birmingham, United Kingdom, 2023, pp. 1-6. [CrossRef]
- K. Nakagawa, “The geometry of M/D/1 queues on Large Deviation,” International Transactions of Operational Research, vol. 9, 2002.
- C.T. J. Dodson, “Topics in Information Geometry,” University of Manchester, 2005, Available online on http://eprints.maths.manchester.ac.uk/131/1/InfoGeom.pdf.
- L. Peg, H. Sun, and J. Jiu, 2007, “The Geometric Structure of the Pareto Distribution, ” Boletin de la Asociación Matemática Venezolana, vol. XIV, no.1, 2007.
- A. Mageed and D. D. Kouvatsos, “Information Geometric Structure of Stable M/G/1 Queue Manifold and its Matrix Exponential,” Proceedings of the 35th UK Performance Engineering Workshop, School of Computing, University of Leeds, Edited by Karim Djemame, 2019, p. 123-135. [Online] at: https://sites.google.com/view/ukpew2019/home.
- I.A.Mageed and D. D. Kouvatsos, “ The Impact of Information Geometry on the Analysis of the Stable M/G/1 Queue Manifold,” In Proceedings of the 10th International Conference on Operations Research and Enterprise Systems - ICORES, ISBN 978-989-758- 485-5, vol. 1, 2021, p. 153-160. [CrossRef]
- [10] P. R. Parthasarathy, “A transient solution to an M /M /1 queue: a simple approach,” Adv. Appl. Prob., vol. 19, 1987, p. 997-998.
- I. A. Mageed and Q. Zhang, “Information Geometry? Exercises de Styles,” electronic Journal of Computer Science and Information Technology, vol. 8, no. 1, 2022, p. 9-14.
- B. Eysenbach, R. Salakhutdinov, and S. Levine S, “The information geometry of unsupervised reinforcement learning,” arXiv preprint arXiv:2110.02719, 2021.
- E. D. Gomes, et al, “Igeood: An information geometry approach to out-of-distribution detection,” arXiv preprint arXiv:2203.07798,2022.
Figure 1.
SM’s parametrization [3].
Figure 1.
SM’s parametrization [3].
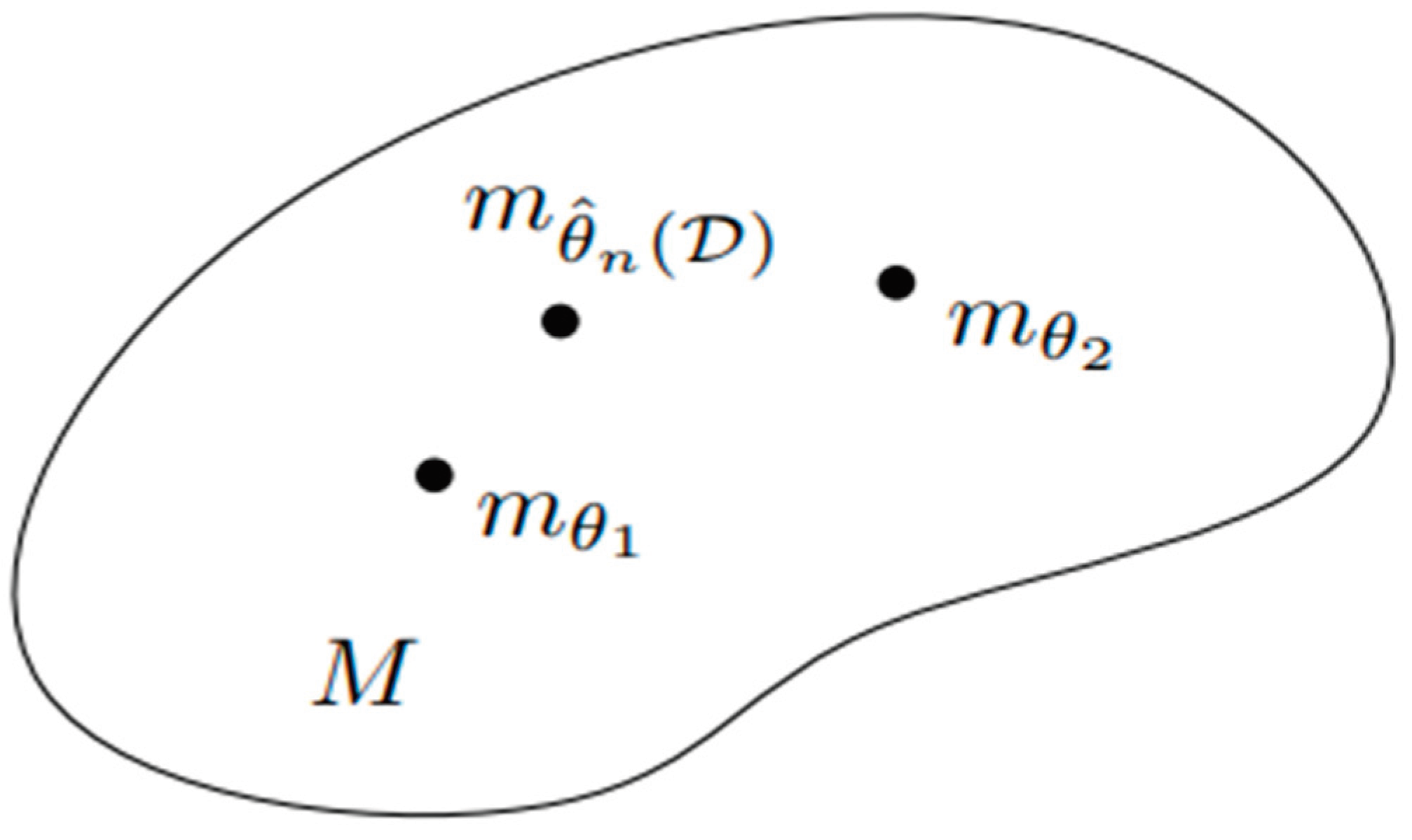
Figure 2.
We can represent reward functions as vectors starting from the origin. The objective of maximizing expected return is equivalent to maximizing the dot product between the state marginal distribution and the reward vector. This visualization helps us understand how different reward-maximizing policies are related to the state marginal polytope and provides insights into the relationship between state-dependent reward functions and the optimal policies[12].
Figure 2.
We can represent reward functions as vectors starting from the origin. The objective of maximizing expected return is equivalent to maximizing the dot product between the state marginal distribution and the reward vector. This visualization helps us understand how different reward-maximizing policies are related to the state marginal polytope and provides insights into the relationship between state-dependent reward functions and the optimal policies[12].
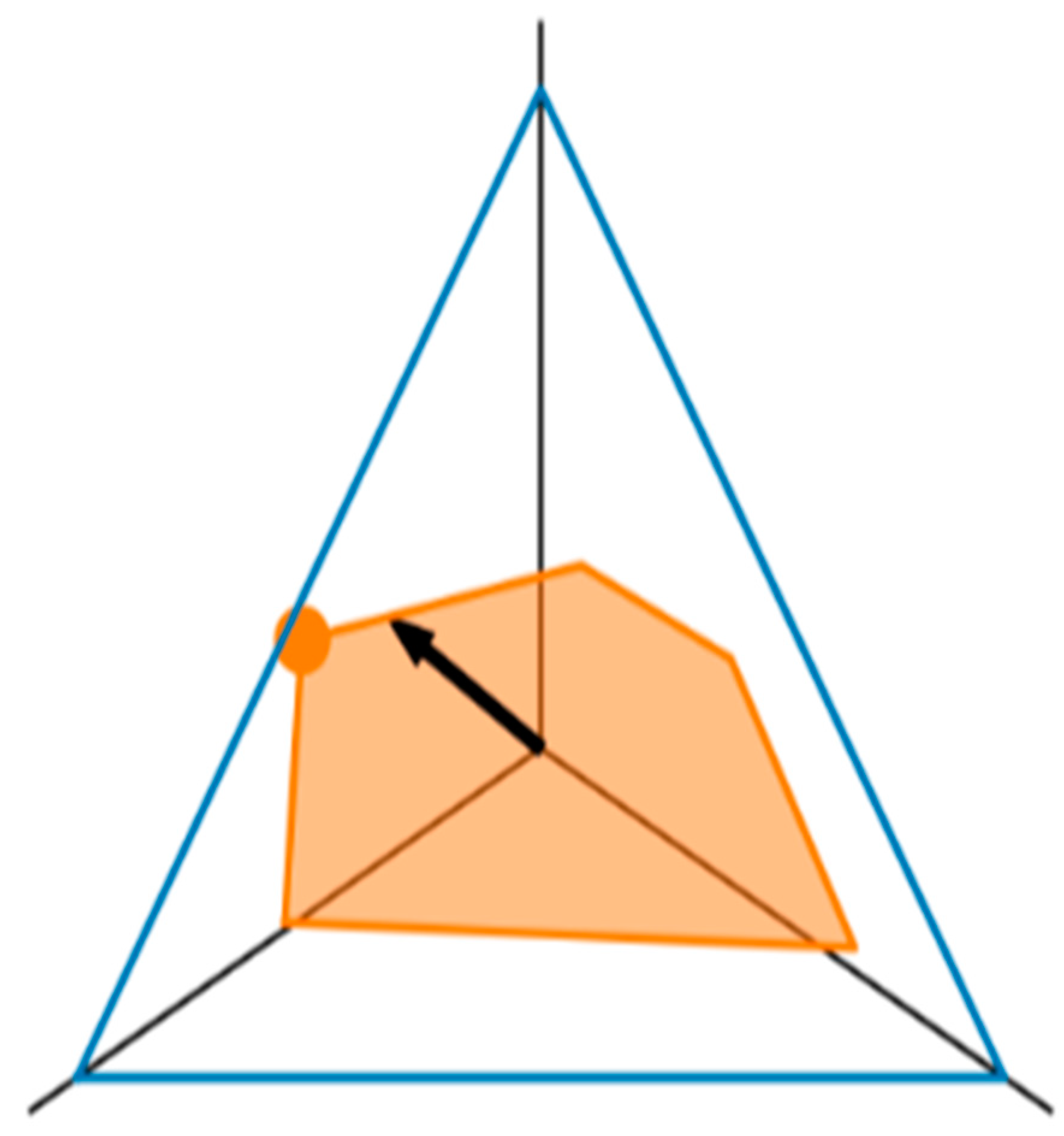
Figure 3.
Skill Learning’s IG [12].
Figure 3.
Skill Learning’s IG [12].
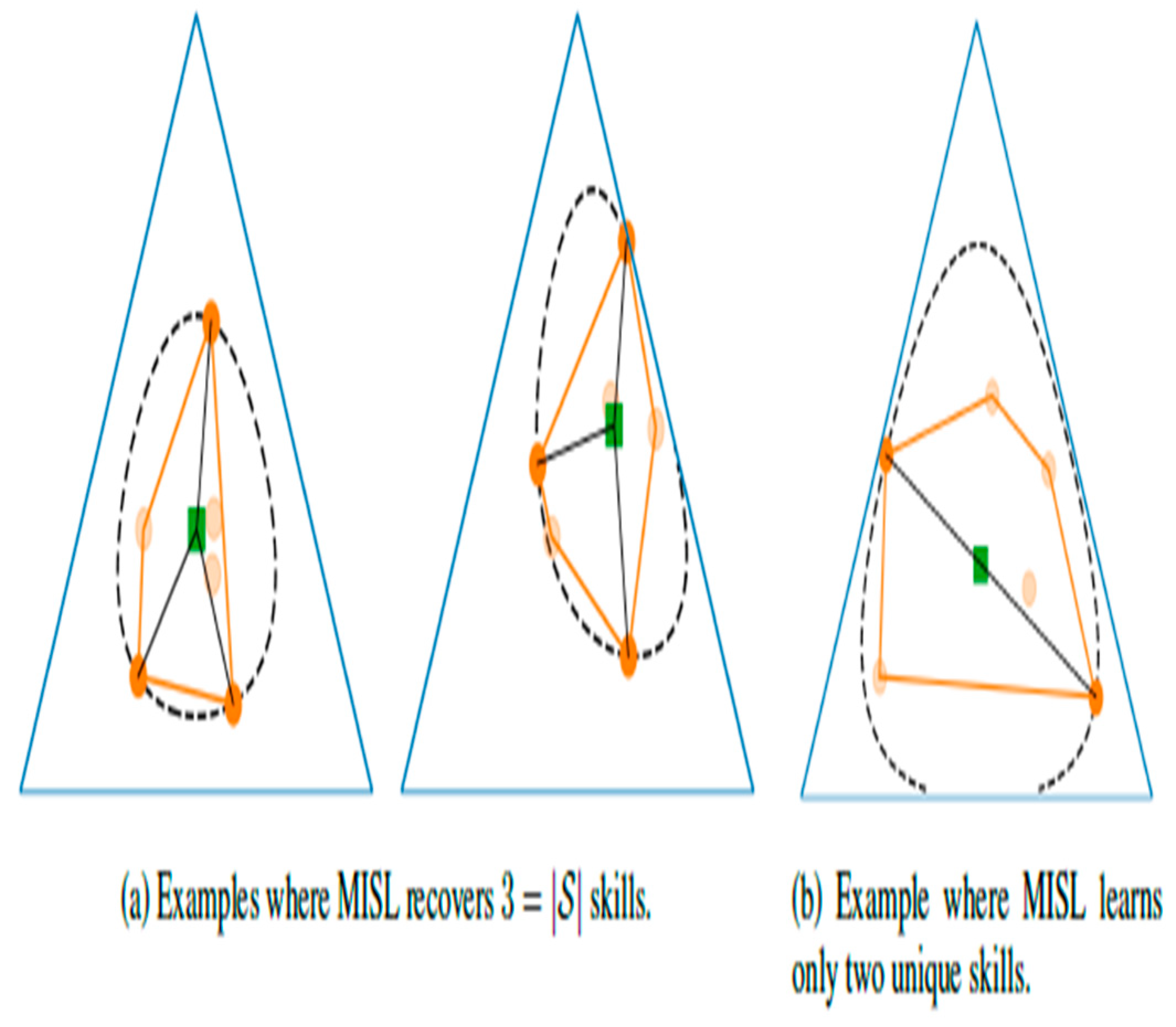
Figure 4.
Portraying the reason behind using Fisher-Rao OOD detection[13].
Figure 4.
Portraying the reason behind using Fisher-Rao OOD detection[13].
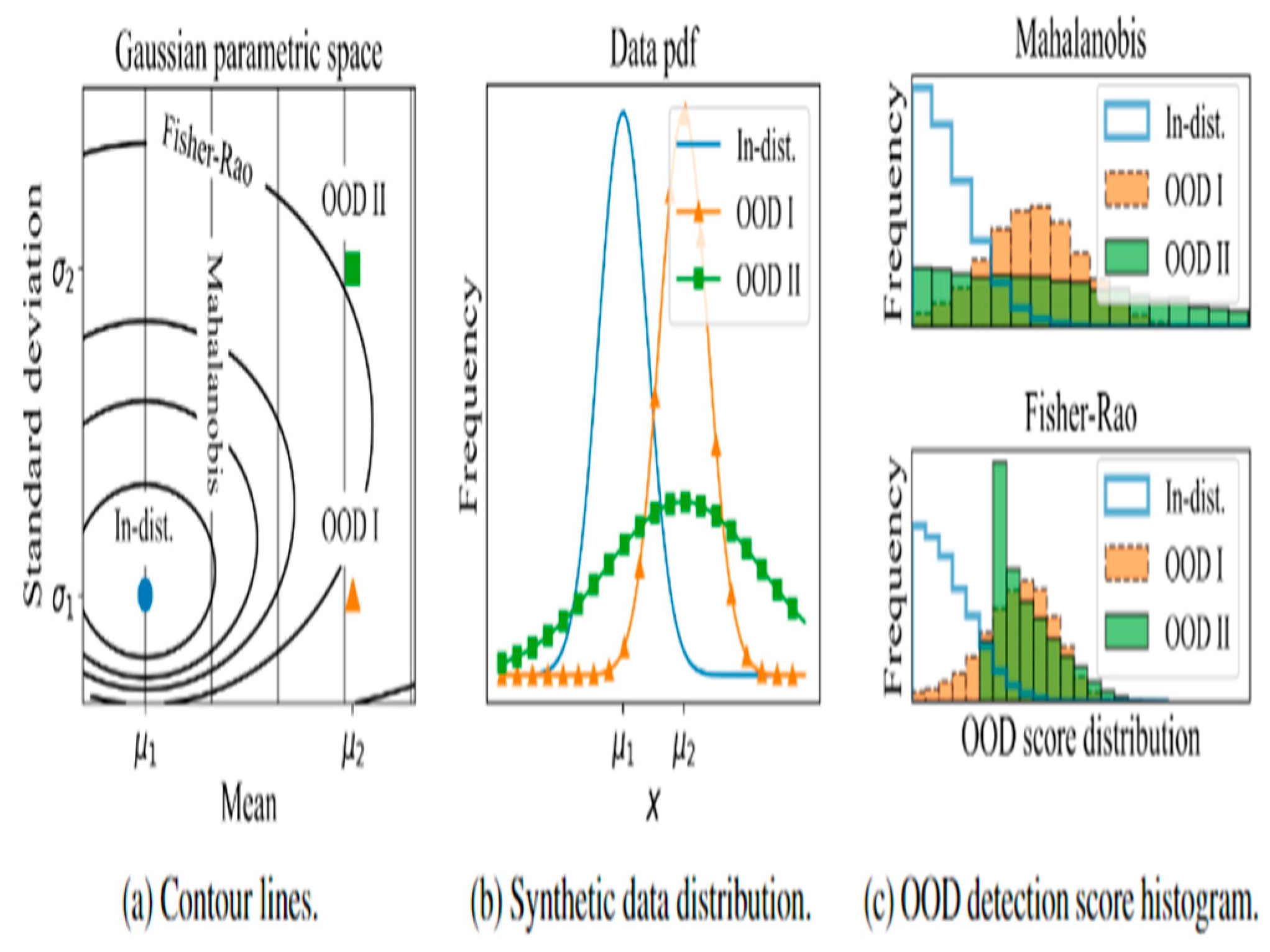
Figure 5.
The probability distributions of the IGEOOD score, which is a metric used for out-of-distribution (OOD) detection. The distributions are shown for three different settings, specifically for a pre-trained DenseNet model on CIFAR-10 dataset, considering both in-distribution and OOD data from TinyImageNet (downsampled). This analysis helps evaluate the effectiveness of the IGEOOD score in distinguishing between in-distribution and OOD samples[13].
Figure 5.
The probability distributions of the IGEOOD score, which is a metric used for out-of-distribution (OOD) detection. The distributions are shown for three different settings, specifically for a pre-trained DenseNet model on CIFAR-10 dataset, considering both in-distribution and OOD data from TinyImageNet (downsampled). This analysis helps evaluate the effectiveness of the IGEOOD score in distinguishing between in-distribution and OOD samples[13].
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



