Submitted:
30 January 2024
Posted:
31 January 2024
You are already at the latest version
Abstract
In this paper, a distributed algorithm is proposed to solve a consensus convex optimization problem. It is a Jacobi-proximal alternating direction method of multipliers with a damping parameter $\gamma$ in the iteration of multiplier. Compared with existing algorithms, it has the following nice properties: (1) The restriction on proximal matrix is relaxed substantively, thus alleviating the weight of the proximal term. Therefore, the algorithm has a faster convergence speed. (2) The convergence analysis of the algorithm is established for any damping parameter $\gamma\in(0,2]$, which is larger ones in the literature. In addition, some numerical experiments and an application to a logistic regression problem are provided to validate the effectiveness and the characteristics of the proposed algorithm.
Keywords:
Consensus convex optimization problem
; Distributed Jacobi-proximal ADMM
; Multi-agent system
; Logistic regression
1. Introduction
Consider the following consensus convex optimization problem:
where is the global optimization variable, n is the number of agents in the multi-agent system and () : are convex functions. Each is known only by agent i and the agents cooperatively solve the consensus optimization problem. Many problems encountered in machine learning [1] and power network[2] can be posed in the model (1.1).
There are two types distributed algorithms to solve problem (1.1): continuous-time algorithms [3,4,5,6] and discrete-time algorithms, among which, discrete-time algorithms can be divided into primal algorithms and dual algorithms. In primal algorithms, each agent takes a (sub)gradient-related step and averages its local solution with those of neighbors [7,8,9]. One great advantage of these methods is their low computation burden. But slow convergence and low accuracy are two strikes against it. The typical dual algorithms include augmented Lagrangian method [10] and alternating direction method of multipliers (ADMM) [11,12,13,14,15,16], in which each agent needs to solve a subproblem at each iteration, which is responsible for high computation burden. However, the characteristic that they can quickly converge to exact optimal solutions can make up for it.
The ADMM algorithm has attracted significant research interests in recent years. With regard to distributed ADMM algorithms, almost all developments begin with transforming problem (1.1) into a equivalent form by introducing local copy for each agent , and enforcing consensus . For start networks, the reformulation of problem (1.1) can be shown as follows:
where and is so-called consensus variable. Considerable attentions have been paid to such formulation, which can be referred to [11,12] for details..
A central agent is required in the start network, and thus algorithms in [11,12] have high communication burden and low fault tolerance. This leads to growing research interests in general connected networks. For general connected networks, the consensus optimization problem (1.1) can be rewritten in the following compact form:
where , A, B are matrices related to network structure and z is the slack variable. For this kind of problems, Wei and Ozdaglar [13] proposed a distributed Gauss-Seidel ADMM algorithm and proved that its convergence rate was , where the objective function () are convex. Based on this algorithm, agents can only update in order. To save the waiting time of agents in [13], Yan[14] raised a parallel ADMM algorithm, which adopts Jacobi iterate method. Besides, some distributed ADMM algorithms for nonconvex but differentiable probelms are also established in[15,16].
In addition to the algorithms in [11,12,13,14,15,16], several ADMM algorithms can also solve problem (1). These algorithms were originally designed to solve multi-block separable problems, which can be can be cast as
where . A wide variety of the proximal ADMM algorithms were proposed for this kind of formulation. The researches on these algorithms mainly focus on proximal matrix and damping parameter . Deng et al.[17] presented a parallel ADMM algorithm and the proximal matrix is required to satisfy , where There are two specific choices for the proximal matrix in[18]: (1) Standard proximal matrix ; (2) Linearized proximal matrix . Therefore, the condition in [17] can be reduced to
Afterwards, Sun and Sun[19] came up with an improved proximal ADMM algorithm with partially parallel splitting, where and a lower bound of the proximal parameter is given by , where .
Inspired by the works in [13,14,17,19], this paper puts forward a distributed Jacobi-proximal ADMM algorithm to solve the consensus convex optimization problem (1.1) over a general connected network. Compared with the state-of-art ones, the proposed algorithm has the following outstanding features.
(1) Compared with the algorithm in [13], the optimization variables of all agents can be updated simultaneously. Hence, the waiting time is saved.
(2) Compared with [14], only half of dual variables are occupied in the proposed algorithm. Therefore, the communication burden among agents and storage cost for each agent are reduced.
(3) The proximal matrix of the presented algorithm is smaller than those in [17,19]. Thus, the distributed Jacobi-proximal ADMM algorithm is favorable based on the general principle given by Fazel et. al [20], that the proximal matrix should be as small as possible. Besides, the value range of damping parameter in the proposed algorithm is larger than that of [19].
The rest of this paper is organized as follows. In Section 2, the equivalent form of the consensus convex optimization problem (1.1) is introduced. In addition, based on this equivalent form, a distributed Jacobi-proximal ADMM algorithm is proposed. Section 3 supplies the convergence analysis of the algorithm. In Section 4, extensive numerical experiments are provided to verify the effectiveness of the proposed algorithm. Moreover, the impacts of the penalty parameter, damping parameter and connectivity ratio on the algorithm are investigated. In Section 5, the proposed algorithm is applied to a logistic regression problem and its numerical results are compared with those in [17]. Finally, the conclusions of this paper are presented in Section 6.
2. Problem Formulation and Distributed Jacobi-Proximal ADMM Algorithm
In this section, some notations related to the network are introduced, and the consensus convex optimization problem (1.1) is represented so that it can be solved by ADMM.
The network topology of the multi-agent system is assumed to be a general undirected connected graph, which is described as , where V denotes the set of agents, E denotes the set of the edges and , . These agents are arranged from 1 to n. The edge between agents i and j with is represented by or and means that agents i and j can exchange data with each other. The neighbors of agent i are denoted by and .
The edge-node incidence matrix of the network G is denoted by . The row in that corresponds to the edge is denote by , which is defined by
Here, the edges of the network are sorted by the order of their corresponding agents. For instance, the edge-node incidence matrix of the network G in Fig. 1 is given by
Figure 1.
An example of the network G.

According to the edge-node incidence matrix, the extended edge-node incidence matrix A of the network G is given by
where ⊗ denotes the . Obviously, A is a block matrix with blocks of matrix.
By introducing separating decision variable for each agent , the consensus convex optimization problem (1.1) has the following form:
where . Clearly, the problem (2.1) is equivalent to problem (1.1) if G is connected.
With the help of the extended edge-node incidence matrix A, the problem (2.1) can be rewritten in the following compact form:
Dividing the neighbors of the agent i into two sets: predecessors and successors . The distributed Jacobi-proximal ADMM (DJP-ADMM) algorithm is described as Algorithm 1.
| Algorithm 1: Distributed Jacobi-proximal ADMM Algorithm (DJP-ADMM) |
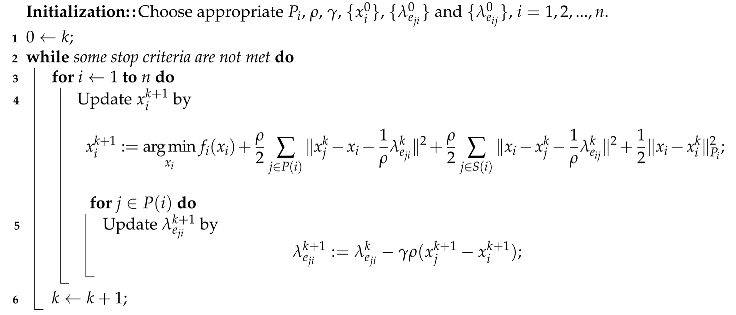 |
3. Convergence Analysis
In this section, some important notations and technical lemmas are given. Then, the convergence analysis of Algorithm 1 is investigated.
Let
Remark 2.
The extended degree matrix and extended sign Laplace matrix of the network G are denoted by
where is the degree matrix of the graph G.
To simplify the notation, let
and
where is the adjacency matrix of the graph G. To ensure the convergence of Algorithm 1, it is necessary to make an assumption about the matrix Q, which is shown below.
Assumption 1.
The matrix Q is a positive definite matrix.
Remark 3.
If proximal matrices () are symmetric, then Assumption 1 can be reduced to is a positive definite matrix. Therefore, is a feasible choice, where is the degree matrix of the graph G. In this case, .
Remark 4.
By the definition of Q, the matrix Q is symmetric positive definite under Assumption 1, and thus, there exists a matrix M such that
According to the convexity of the objective function, we have following result.
Lemma 1.
Assume that is the sequence produced by Algorithm 1 for the problem (2.2), where and . Then one has
Proof.
Define by
Using the iteration of x in Algorithm 1, one can conclude that is the optimizer of , i.e.,
Therefore, there exists a subgradient such that . Then
Due to the convexity of , we have
This together with (3.8) implies that
Substituting the gradient of the function into the above inequality, we have
From the iteration of the multipliers, one can obtain that
Similarly,
Hence,
By the definition of the matrix A, we simplify the above inequality as follows:
And then,
By the definition of matrices A and D, we have
In addition,
where is the adjacency matrix of the graph G. The above two relations indicate that
Therefore, by the definition of the extended sign Laplace matrix , one can conclude that
Analogously,
Besides, by the definition of matrix Q, we have
Thus, recalling (3.9)-(3.12), inequality (3.7) holds. □
The non-negative property of the norm is very important in the subsequent analysis of convergence. To this end, certain items in Lemma 1 will be concerted into norm form. To simplify some expressions in the proof of the following lemmas, is denoted by
where M is defined in (3.6).
Under Assumption 1, we can get the following lemma.
Lemma 2.
Assume that is the sequence produced by Algorithm 1 for the problem (2.2), where and . Then under Assumption 1, one has the following equality
where .
Proof.
To prove (3.14), we firstly claim that
Indeed, by the iteration of the multiplier: , we know
and
Therefore, equality (3.17) and (3.18) indicate that equality (3.15) is valid. In addition, by distorting some of the terms, we obtain
and
Combining the above two equalities, we yield
Taking into account , we can get the equality (3.16). Consequently, by (3.15) and (3.16), the equality (3.14) holds. □
With the help of the proceeding two lemmas, the convergence result of Algorithm 1 can be established.
Theorem 1.
Assume that is the sequence produced by Algorithm 1, where and . Let be the ergodic average of from step 1 to k. is the optimal solution of the problem (2.2). Then under Assumption 1, the following relation holds for any and for
where given in (3.13) is a non-negative term. Furthermore,
with the rate of .
Proof.
It follows from the optimality of that the first inequality in (3.19) is clearly true. Let in inequality (3.7), then one has
Take into consideration that and , the above inequality can be rewritten as:
By Lemma 4.2, one has
and then
Due to for any k, the following inequality holds for
Since the function f is convex, , and then using , we have
i.e.,
Therefore, inequality (3.19) stands. Furthermore, inequality (3.22) implies that
On the other hand, from the optimality of , we have
As a result, and the proof is completed. □
Remark 5.
Theorem 1 gives the theoretical upper bound for , which provides the error estimates for the optimal value at each iteration k. The upper bound is consist of two additive items. Both of them approach to zero at the rate . In addition, Theorem 1 implies that converges to the optimal value asymptotically. Furthermore, if at least one function is strongly convex, then the optimal solution is unique, and thus asymptotically approaches to .
Remark 6.
When solving the consensus optimization problem (1.1), the convergence condition of Algorithm 1 has less conservative than that in [17], wherein, the convergence of Algorithm 1 can be guaranteed if is symmetric and according to Remark 4.2, while algorithm in [17] requires that is a symmetric positive semi-definite matrix and .
4. Numerical Experiments
In this section, some numerical experiments are provided to show the validity of Algorithm 1. First, the convergence property of Algorithm 1 is verified. Then the impacts of penalty parameter , damping parameter and connectivity ratio d on Algorithm 1 are investigated.
In this section, each edge of the connected network G is generated randomly. The connectivity ratio of the network G is denoted by . Consider the following consensus optimization problem given in [21]:
where . Apparently, the optimal solution of this problem is The consensus optimization problem (4.1) can be reformulated into a distributed version:
where and f is convex. Therefore, Algorithm 1 can be used to solve the consensus optimization problem. For the consensus optimization problem (4.2), each is randomly generated by a normal distribution .
The proximal matrix of Algorithm 1 is set by . In this case, the iteration of x has a closed-form solution, which is shown as follows:
where is the number of neighbors of the agent i.
A. Convergence Property
To illustrate the convergence property of Algorithm 1 for the consensus optimization problem (4.2), ten networks are generated. Each network has agents and the connectivity ratio of these networks are set as , 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 and 1.0, respectively. The algorithm parameters are set as and . The algorithm will be stopped once reaches to or the number of iterations k reaches to 3500, where is the optimal solution of problem (4.1).
Fig. 2 and Fig. 3 respectively depict how the relative error and constraint violation vary with iteration k. One can find that Algorithm 1 has high accuracy since the relative error can achieve and the constraint violation can achieve .
Figure 2.
Relative error versus iteration.

Figure 3.
Constraint violation versus iteration.

B. Algorithm Parameters and
In this part, the impacts of algorithm parameters and on the convergence speed of Algorithm 1 are discussed. The networks are generated in the same way as Part A. In order to explore the influences of parameters and on Algorithm 1, the convergence speed is denoted by , where and is the number of iterations required to achieve . Here, the accuracy is set as .
Choosing damping parameter and selecting different penalty parameters to solve the problem (4.2), one can get the relationship between the convergence speed and parameter , which is displayed in Fig. 4. Obviously, if the penalty parameter is too large or too small, the convergence speed of the algorithm is slow. The penalty parameter can be selected from . In general, a smaller connectivity ratio leads to larger actual optimal parameter . As a consequence, when the network is sparse, it is better to select a larger penalty parameter and when it is dense, a smaller penalty parameter will be a nice choice.
Figure 4.
Convergence speed versus .

In order to explore the influence of parameter on Algorithm 1, the penalty parameter is set as and the damping parameter is set to 60 different values. The numerical results are shown in Fig. 5. Obviously, the convergence speed of Algorithm 1 increases with the damping parameter, and then remains constant. Therefore, is a great choice.
Figure 5.
Convergence speed versus .

C. Connectivity Ratio
In this part, the effect of connectivity ratio d on the convergence speed of Algorithm 1 is explored. From Fig. 4, one can find that when penalty parameter takes different values, the impact of connectivity ratio on convergence speed is different. Therefore, the penalty parameter is set to six different values and 2, respectively.
We generate 30 networks with agents, whose connectivity ratio are set to 30 different values : , , ..., 1. From Fig. 6, one can find that when the penalty parameter takes a smaller value, such as or 0.05, the convergence speed of Algorithm 1 generally slows down with the increase of connectivity ratio, and the opposite is true when the penalty argument takes a bigger value, such as or 2 from Fig. 7. It is worth noting that when the network is very sparse, for example , no matter what the penalty parameter value is, the convergence speed is slow. Therefore, on the premise of ensuring network connectivity, few edges can be added to increase information exchange between agents.
Figure 6.
Convergence speed versus d.

Figure 7.
Convergence speed versus d.

5. Application to A Logistic Regression Problem
In this section, the proposed distributed Jacobi-proximal ADMM algorithm is applied to a logistic regression problem, which is a widely used machine learning model[22,23].
The network is generated with agents. The connectivity ratio is set as and the edges are generated randomly. The network generated is given in Fig. 8. Each agent has training samples, which denoted by , where and .
Figure 8.
The network of problem (5.1).

The distributed logistic regression problem is described as follows:
where is the total number of samples. The dimension of feature is set as , the number of samples is generated by a uniform distribution , and the parameter is generated by a normal distribution . The generation rule of the label is shown as follows:
where is generated by a uniform distribution .
The distributed logistic regression problem (5.1) can be formulated as
where and . Obviously, problem (5.2) can be solved by Algorithm 1.
The convergence path of Algorithm 1 is compared with the Jocobi-Proximal ADMM (JP-ADMM) algorithm in [17]. To investigate the performances of the two algorithms, the penalty parameter is set to 0.01, 0.1 and 1, respectively. In addition, the damping parameter is set to two different values and . The proximal matrix of Algorithm 1 and algorithm in [17] are set as and , respectively. Every algorithm is stopped once reaches to or the number of iterations k reaches to 1000. One can find that the convergence speed of Algorithm 1 is significantly faster than that in [17] from Fig. 9 and Fig. 10.
Figure 9.
Objective value ().

Figure 10.
Objective value ().

6. Conclusions
In this paper, a distributed ADMM algorithm is put forward to solve a consensus convex optimization problem over a connected network. The proposed algorithm is a Jacobi-proximal ADMM algorithm and the proximal matrix is smaller than existing algorithms. The convergence of the algorithm is proved and its convergence rate is . Extensive numerical experiments are provided to verify the convergence of the algorithm. Besides, the impacts of penalty parameter, damping parameter and connectivity ratio on the proposed algorithm are investigated. Finally, an application of the proposed algorithm to a logistic regression problem is implemented and its performance is compared with that of another ADMM algorithm in [17].
Acknowledgments
This research was supported by the National Natural Science Foundation of China (Grant number: 11801051) and the Natural Science Foundation of Chongqing (Grant number: cstc2019jcyj-msxmX0075).
References
- Y.L. Pan, Distributed optimization and statistical learning for large-scale penalized expectile regression, J. Korean Stat. Soc. 50 (2021) 290-314. [CrossRef]
- G. Chen, J.Y. Li, A fully distributed ADMM-based dispatch approach for virtual power plant problems, Appl. Math. Model. 58 (2018) 300-312. [CrossRef]
- G. Droge, H. Kawashima, M.B. Egerstedt, Continuous-time proportional-integral distributed optimisation for networked systems, J. Control Decis. 1 (2014) 191-213. [CrossRef]
- B. Gharesifard, J. Cortés, Continuous-time distributed convex optimization on weight-balanced digraphs, IEEE Trans. Autom. Control 59 (2014) 781-786.
- Y.N. Zhu, W.W. Yu, G.H. Wen, G.R. Chen, W. Ren, Continuous-time distributed subgradient algorithm for convex optimization with general constraints, IEEE Trans. Autom. Control 64 (2019) 1694-1701. [CrossRef]
- W. Zhu, H.B. Tian, Distributed convex optimization via proportional-integral-differential algorithm, Meas. Control 55 (2021) 13-20. [CrossRef]
- A. Nedic, A. Ozdaglar, Distributed subgradient methods for multi-agent optimization, IEEE Trans. Autom. Control 54 (2009) 48-61. [CrossRef]
- C. Xi, U.A. Khan, Distributed subgradient projection algorithm over directed graphs, IEEE Trans. Autom. Control 62 (2017) 3986-3992. [CrossRef]
- S. Liu, Z.R. Zhang, L.H. Xie, Convergence rate analysis of distributed optimization with projected subgradient algorithm, Automatic 83 (2017) 162-169. [CrossRef]
- D. Jakovetić, J. Xavier, J.M.F. Moura, Cooperative convex optimization in networked systems: augmented Lagrangian algorithms with directed gossip communication, IEEE Trans. Signal Process. 59 (2011) 3889-3902.
- S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Found. Trends Mach. Learn. 3 (2010) 1-122.
- R. Zhang, J.T. Kwok, Asynchronous distributed ADMM for consensus optimization, in: Proceedings of the 31st International Conference on Machine Learning, 2014, pp. 3689-3697.
- E. Wei, A. Ozdaglar, Distributed alternating direction method of multipliers, in: Proceedings of the IEEE Conference on Decision and Control, 2012, pp. 5445-5450.
- J.Q. Yan, F.H. Guo, C.Y. Wen, G.Q. Li, Parallel alternating direction method of multipliers, Inf. Sci. 507 (2020) 185-196. [CrossRef]
- W. Shi, Q. Ling, K. Yuan, G. Wu, W. Yin, On the linear convergence of the ADMM in decentralized consensus optimization, IEEE Trans. Signal Process. 62 (2014) 1750-1761. [CrossRef]
- M. Hong, H. Davood, M. Zhao, Prox-PDA: The proximal primal-dual algorithm for fast distributed nonconvex optimization and learning over networks, in: Proceedings of the 34th International Conference on Machine Learning, 2017, pp. 2402-2433.
- W. Deng, M.J. Lai, Z.M. Peng, W.T. Yin, Parallel multi-block ADMM with o(1/k) convergence, J. Sci. Comput. 71 (2017) 712-736.
- W. Deng, W.T. Yin, On the global and linear convergence of the generalized alternating direction method of multipliers, J. Sci. Comput. 66 (2016) 889-916. [CrossRef]
- M. Sun, H.C. Sun, Improved proximal ADMM with partially parallel splitting for multi-block separable convex programming, Appl. Math. Comput. 58 (2018) 151-181. [CrossRef]
- M. Fazel, T.K. Pong, D.F. Sun, P. Tseng, Hankel matrix rank minimization with applications to system identification and realization, SIAM J. Matrix Anal. Appl. 34 (2013) 946-977. [CrossRef]
- M. Rabbat, R. Nowak, Distributed optimization in sensor networks, in: Proceedings of the third International Symposium on Information Processing in Sensor Networks, 2004, pp. 20-27.
- L.J. Wang, M. Guo, K. Sawada, J. Lin, J.C. Zhang, A comparative study of landslide susceptibility maps using logistic regression, frequency ratio, decision tree, weights of evidence and artificial neural network, Geosci. J. 20 (2016) 117-236. [CrossRef]
- B.Y. Kim, S.J. Shin, Principal weighted logistic regression for sufficient dimension reduction in binary classification, J. Korean Stat. Soc. 48 (2019) 194-206. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



