
Preprint
Article
Why Do Tree Ensemble Approximators Not Outperform the Recursive-Rule eXtraction Algorithm?
Altmetrics
Downloads
94
Views
79
Comments
0
A peer-reviewed article of this preprint also exists.


This version is not peer-reviewed
Submitted:
31 January 2024
Posted:
01 February 2024
You are already at the latest version
Alerts
Abstract
Machine learning models are increasingly being used in critical domains, but their complexity, lack of transparency, and poor interpretability remain problematic. Decision trees (DTs) and rule-based approaches are well-known examples of interpretable models, and numerous studies have investigated techniques for approximating tree ensembles using DTs or rule sets; however, tree ensemble approximators do not consider interpretability. These methods are known to generate three main types of rule sets: DT-based, unordered-based, and decision list-based. However, no known metric has been devised to distinguish and compare these rule sets. Therefore, the present study proposes an interpretability metric to allow comparisons of interpretability between different rule sets, such as decision list- and DT-based rule sets, and investigates the interpretability of the rules generated by the tree ensemble approximators. To provide new insights into the reasons why decision list-based and inspired classifiers do not work well for categorical datasets consisting of mainly nominal attributes, we compare objective metrics and rule sets generated by the tree ensemble approximators and the \textit{Recursive-Rule eXtraction algorithm (Re-RX) with J48graft}. The results indicated that \textit{Re-RX with J48graft} can handle categorical and numerical attributes separately, has simple rules, and achieves high interpretability, even when the number of rules is large.
Keywords:
Subject: Computer Science and Mathematics - Artificial Intelligence and Machine Learning
1. Introduction
Artificial intelligence (AI) has made great advances and AI algorithms are currently being applied to solve a wide variety of problems. However, this success has been driven by accepting their complexity and adopting “black box” AI models that lack transparency. On the other hand, eXplainable AI (XAI), which enhances the transparency of AI and facilitates its wider adoption in critical domains, has been attracting increasing attention [1,2,3,4,5,6,7,8,9,10].
Rudin [11] pointed out the limitations of some approaches to explainable machine learning, suggesting that interpretable models should be used instead of black box models for making high stakes decisions. In the field of health care, for example, it is not sufficient for a medical diagnosis model simply to be accurate; it must also be transparent to health professionals who use the output to make decisions about a given patient [6,12,13]. Moreover, in the field of finance, recent regulations, such as the General Data Protection Regulation and the Equal Credit Opportunity Act, have increased the need for model interpretability to ensure that algorithmic decisions are understandable and consistent. These issues have been addressed by interpretable machine learning models, which are characterized as models that can be easily visualized or described in plain text for the end user [14].
Tree ensembles are often used for tabular data. Bagging [15] and random forests (RFs) [16] are known as independent ensembles, whereas gradient boosting machines (GBMs) [17] such as XGBoost [18], LightGBM [19], and CatBoost [20] are known as dependent ensembles. Tree ensembles are extensively utilized in academic and research contexts. They are also applied in practical scenarios across a wide array of domains [21]. Recently, these models have been effective in many classification tasks. In fact, these models are used by most winners of Kaggle competitions 1. However, the structure of these algorithms is considered complex and very difficult to interpret. The effectiveness of ensemble trees generally improves as the number of trees increases, and in some cases, an ensemble can contain thousands of trees.
Decision trees (DTs), rule-based approaches, and knowledge graph-based approaches are widely used as examples of interpretable models [22,23,24,25,26,27,28,29]. Techniques for approximating tree ensembles with DTs or rule sets have also been investigated [30,31,32,33,34,35,36]. However, although tree ensemble approximators focus on reducing the number of rules and conditions, they do not consider the interpretability of the rules. For example, handling categorical and numerical attributes separately is known to increase interpretability [28].
There are three main types of rule sets generated by these methods: DT-based, unordered-based (the last rule in the rule set is Else), and decision list-based. Figure 1 shows the concept of these three types of rule sets. However, previous studies have not provided a metric to distinguish and compare these different rule sets. In the present study, we newly propose an interpretability metric, Complexity of Rules with Empirical Probability (), to allow comparisons of interpretability between different rule sets. enables a fair comparison of different types of rule sets, such as decision list- and DT-based rule sets. We also explore the interpretability of the rules generated by the tree ensemble approximators. Specifically, we present and compare not only objective metrics, but also rule sets generated by the tree ensemble approximators and the Recursive-Rule eXtraction algorithm (Re-RX) with J48graft [29].
2. Related Work
The Re-RX algorithm [28] is a rule-based approach that can handle categorical and numerical attributes separately and extract rules recursively. By separating categorical and numerical attributes, Re-RX can generate rules that are intuitively easy to understand. Re-RX with J48graft [29] is the extended version of Re-RX. Numerous studies have conducted research on Re-RX [37,38,39,40,41,42]. RuleFit [30] is a method that employs a linear regression model with a DT-based model to utilize interactions. The rules generated by the ensemble tree are used as new features and fitted using Lasso linear regression. inTrees [31] extracts, measures, prunes, and selects rules from tree ensembles such as RFs and boosts trees to generate a simplified tree ensemble learner for interpretable predictions. DefragTrees [32] involves simplifying complex tree ensembles, such as RFs, to enhance interpretability by formulating the simplification as a model selection problem and employing a Bayesian algorithm that optimizes the simplified model while preserving prediction performance. Initially introduced for independent tree ensembles by Sagi and Rokach [33], Forest-based Trees (FBTs) were later extended to dependent tree ensembles. Combined within both bagging (e.g., RFs) and boosting ensembles (e.g., GBMs), FBTs construct a singular DT from an ensemble of trees. Rule COmbination and SImplification (RuleCOSI+) [36], a recent advance in the field, is a fast post-hoc explainability approach. In contrast to its precursor, RuleCOSI, which was limited to imbalanced data and Adaboost-based small trees according to Obregon et al. [35], RuleCOSI+ was designed as an algorithm that extends the capabilities of RuleCOSI to function effectively in both bagging (e.g., RFs) and boosting (e.g., GBMs) ensembles. DefragTrees, FBTs, and Re-RX generate DT-based rule sets, inTree generates an unordered-based rule set, and RuleCOSI+ generates a decision list-based rule set.
Given this background, in the present study, we aim to provide new insights into the reasons why DL-based and DL-inspired classifiers do not work well for categorical datasets mainly consisting of nominal attributes [43].
3. Materials and Methods
3.1. Datasets
We used 10 diverse datasets from the University of California, Irvine, Machine Learning Repository [44] to compare each method. The details of the datasets are shown in Table 1. For each dataset, we split the data into training:test at a ratio of 8:2. Consistent splits were applied to all methods, with a unique seed-based split for each iteration. Each iteration means in the -fold cross-validation (CV) scheme described in Section 3.3.3.
3.2. Baseline
We used scikit-learn’s DT and J48graft [45] as simple DT-based methods. J48graft is a grafted (pruned or unpruned) C4.5 [46] DT. DT generates a binary tree, while J48graft, capable of handling categorical attributes, generates a m-ary tree.
We used FBTs and RuleCOSI+ for the tree ensemble approximator. Figure 2 and Figure 3 show overviews of FBTs and RuleCOSI+, respectively. Both FBTs and RuleCOSI+ were implemented using the official code provided by the authors 2 3.
As a rule-based method, we used Re-RX with J48graft, an overview of which is shown in Figure 4. In learning a multilayer perceptron (MLP) in Re-RX with J48graft, we apply one-hot encoding 4 to categorical attributes to enable efficient learning. With the application of the one-hot encoding to categorical attributes, we modify the pruning algorithm for the MLP. In the original pruning algorithm, the attributes are removed from when , where represents all weights in the first layer of the MLP connected to the i-th attribute. Let be the set of categorical attributes in the dataset , and be the set of one-hot encoded values for the i-th categorical attribute . In this study, we modified the pruning algorithm as follows: , if , then .
3.3. Experimental Design
In this section, we present the experimental design for comparing methods.
3.3.1. Data Preprocessing
We applied one-hot encoding to the categorical attributes because of the inability of FBTs, RuleCOSI+, and DT to handle categorical attributes. For the numeric attributes, we applied standardization only to the training and prediction of the MLP in Re-RX with J48graft.
3.3.2. Interpretability Metrics
The metrics of interpretability, such as the total number of rules () and average number of conditions, are often used. However, these metrics cannot distinguish between decision list-based, unordered, and DT-based rule sets.
We newly propose an interpretability metric, , to facilitate fair comparisons of interpretability between different rule sets. quantifies the complexity of rules based on their empirical probability (coverage on the training data), and is defined as follows:
where is the number of conditions in rule r, and is the coverage of rule r on training data . If the rule set is a decision list or an unordered rule set, the instances in the data refer to one or more rules in the rule set. Therefore, if the rule set is a decision list, is accumulated from the top, and if the rule set is an unordered rule set, of all rules is added together for the Else rule in the rule set. The operation of accumulation allows to compare different rule sets fairly.
represents the expected value of the number of conditions in the rules using the empirical probability obtained from the training data. In other words, if rules with a high likelihood of being referenced have fewer conditions, decreases, and if they have more conditions, increases. Conversely, rules with a low likelihood of being referenced may have many conditions, but their impact is minimal. Compared with and the average number of conditions, which evaluate the interpretability of the entire model, can be considered a more practical metric.
in Eq. (1) treats all classes equally and therefore underestimates the interpretability of minority class rules when the dataset is class-imbalanced. This problem can be solved by calcu-lating for each class. We redefine as follows:
where C is the set of all classes and is the subset for each class in the rule set. micro- is useful for both unbalanced datasets and evaluating entire rule sets. In this paper, we refer to micro- as .
3.3.3. Model Evaluation and Hyperparameter Optimization
We performed the experiment using a stratified -fold CV 6 scheme, which is a 10-fold CV repeated 10 times. In each cv-fold, we performed hyperparameter optimization using Optuna [48]. First, the hyperparameters of the base model, which is an MLP in Re-RX with J48graft and XGBoost in FBTs and RuleCOSI+, were optimized to maximize the classification performance. Then, other hyperparameters were optimized using multi-objective optimization 7 to maximize both classification performance and interpretability simultaneously. For both DT and J48graft, the first step was skipped because these methods do not have a base model. We used the area under the receiver operating characteristics curve (AUC-ROC) [49] for the classification performance metric, and the inverse of () for the interpretability metric. See Section A for details on the hyperparameters for each method.
In the case of multi-objective optimization, the optimal hyperparameters are provided on the Pareto front. From the Pareto front, we selected the hyperparameters that maximize the following equation:
where is a parameter that controls the trade-off between classification performance and interpretability. This equation indicates that increases by and decreases by half, which are equivalent. A higher prioritizes classification performance, whereas a lower prioritizes interpretability. In this experiment, we set . In other words, the value increasing by 4 points and decreasing by half are equivalent. We excluded the Pareto solution with . When , the rule set R classifies all instances into the same label, which is a meaningless rule set.
4. Results
In this section, we present the experimental results and their analyses.
4.1. Classification Results
The classification results are presented in Table 2. RuleCOSI+ outperformed the other methods in many datasets. DT was inferior to RuleCOSI+ but superior to the other baselines. FBTs and J48graft performed better than Re-RX with J48graft, but tended to generate more rules and less interpretability than the other baselines, as discussed in the next subsection. Re-RX with J48graft was inferior to the other baselines on average, but showed competitive results against RuleCOSI+ in some datasets.
4.2. Interpretability Results
The interpretability results and the number of rules in and are presented in Table 3 and Table 4. RuleCOSI+ outperformed the other methods for many datasets in . In particular, the variance was considerably smaller than that of the other methods, resulting in stable rule set generation. On the other hand, was larger than other methods. Because RuleCOSI+ generated a decision list-based rule set, tended to be large. This is discussed in detail in Section 4.4 and Section 5.4. DT obtained superior and for many datasets. FBTs and J48graft produced very large for some datasets. FBTs had higher variance in the tictactoe, german, biodeg, and bank-marketing datasets, indicating unstable rule set generation. Furthermore, was larger for FBTs, even though it is a tree-based method. Although Re-RX with J48graft resulted in being slightly higher than the other methods, except FBTs on average, was much lower than the other methods. Re-RX with J48graft and J48graft tended to have a large because they both handle categorical attributes.
4.3. Summary of Comparative Experiments
Table 5 shows a summary of all the classification and interpretability results presented in the previous subsections. RuleCOSI+ had the highest scores for and , a result that overwhelmed the other methods when was emphasized as an indicator of interpretability. Although DT and Re-RX with J48graft were inferior to RuleCOSI+ in terms of classification performance, they outperformed the other methods in . In other words, DT and Re-RX with J48graft are appropriate when the interpretability and classification frequency of the rules by which instances are classified are important. FBTs and J48graft were not significantly better than the other methods in any of the metrics, and were relatively unsuitable when interpretability was more important.
4.4. Two Examples
We present two examples of rules actually generated in the german and bank-marketing datasets and compare DT, Re-RX with J48graft, and RuleCOSI+. We excluded FBTs and J48graft from the comparison in this section because of the relatively large numbers of rules and the difficulty of analyzing the rules. For each method, rules with matching the median were adopted.
In RuleCOSI+ and DT, categorical attributes were renamed columns by one-hot encoding. For example, the one-hot encoding for element a of attribute x generates the attribute x="a". In other words, a rule such as is equivalent to , and a rule such as is equivalent to . To maintain consistency in notation, we converted all one-hot encoded categorical attributes in the rules to the format or .
4.4.1. bank-marketing
Table 6 shows an example of the rule set generated by each method. The rule set generated by RuleCOSI+ consists of complex rules involving both numerical and categorical attributes. Furthermore, the rule for class 1 had extremely low interpretability because it was expressed as follows:
By contrast, the rule set generated by Re-RX with J48graft consists exclusively of rules based on categorical attributes, resulting in relatively high interpretability. Furthermore, it is simpler by post-processing, as shown in Table 7. The rule set generated by DT, while containing numerical attributes, was composed of simple rules.
4.4.2. german
Table 8 shows an example of the rule set generated by each method. As in Section 4.4.1, the rule set generated by RuleCOSI+ contained a complex mixture of numerical and categorical attributes, and the rule for class 1 was Eq. (3), which had extremely low interpretability. On the other hand, the rule set generated by Re-RX with J48graft was relatively highly interpretable because the rules were composed of categorical attributes, except for and . For and , Re-RX with J48graft performed subdivision and added a numerical attribute duration to improve the accuracy of the rule for . Also, as shown in Table 9, the rule set can be simpler, as in Section 4.4.1. The rule set generated by DT, while containing numerical attributes, was composed of simple rules.
5. Discussion
5.1. Why Should We Avoid a Mixture of Categorical and Numerical Attributes?
Many methods that have been proposed to enhance interpretability cannot handle categorical and numerical attributes separately. If we could adequately express a rule using only categorical attributes, the use of numerical attributes would reduce interpretability. Conditions for categorical attributes are easy to understand intuitively because they are categorized into a finite group. On the other hand, conditions for numerical attributes are difficult to understand intuitively because there are an infinite number of thresholds, so the division is not deterministic. Furthermore, it is not common for the division to be performed convincingly. For example, in the german dataset, there are only four conditions for the attribute , whereas the conditions for the attribute are infinite. In the division of the condition in in RuleCOSI+ in Table 8, it is difficult to understand why the value was chosen. Furthermore, rules that contain many numerical attribute conditions make it more difficult to understand how each condition relates to the other. Setting thresholds for numerical attributes is infinite, and an intuitive understanding of how such thresholds affect the other attributes and the overall rules is difficult. Combining the conditions of multiple numerical attributes exponentially increases the complexity of the rule. By contrast, the conditions for categorical attributes are clustered in a finite group, which makes their relationships and effects easier to understand. Therefore, to realize high interpretability, mixing categorical and numerical attributes should be avoided.
5.2. Optimal Selection of the Pareto Solutions
In this study, we selected the Pareto optimal solution from the Pareto front obtained by multi-objective optimization with Optuna using Eq. (2). However, the Pareto optimal solution selected by Eq. (2) is not always the optimal solution sought by the user. As shown in Figure 5, we observed that the Pareto front depends significantly on the dataset, method, and data splitting. In other words, to select the optimal Pareto solution in real-world applications, it is desirable to verify the Pareto front individually.
5.3. Decision Lists v.s. Decision Trees
DTs delineate distinct, nonoverlapping regions within the training data, which affects the depth of the tree when representing complex regions. Conversely, decision lists are superior to DTs in that they allow overlapped regions in the feature space to be represented by different rules, thereby generating more concise rule descriptions for decision boundaries for the classification problem.
On the other hand, when interpreting rules corresponding to an instance, DTs only require tracing the node corresponding to the instance, whereas decision lists require concatenating rules until the instance is classified, which makes the rules more complex. In other words, even if the apparent size of the decision list is small, such as and the average number of conditions, it is actually a very complex rule set with less interpretability than DTs. Therefore, if interpretability is important, DTs or DT-based rule sets are the better choice.
5.4. as a Metric of Interpretability
measures the complexity of a rule set based on empirical probabilities and is an intuitive metric of the interpretability of the rule set. can be used to compare the interpretability of both decision list- and DT-based rule sets because it is calculated separately for these models. RuleCOSI+, which is a decision list-based rule set that was concluded to have low interpretability in Section 4.4.1 and Section 4.4.2, has a high value compared with the other methods in Table 4, observing that examples and the indicator are consistent. From the above, we conclude that is an appropriate metric for evaluating the interpretability of rule sets.
5.5. Limitation
In this study, all datasets were used for the evaluation of binary classification. We found the Pareto optimal solution from the Pareto front obtained by multi-objective optimization using Eq. (2), but this equation is specialized for binary classification. In multi-class classification, effective results were not obtained using Eq. (2). For example, a solution in which there are no rules corresponding to a certain class was sometimes selected as the best solution. To solve this issue, it will be necessary to devise an equation specialized for multi-class classification.
6. Conclusions
In the present study, we compared the tree ensemble approximator with Re-RX with J48graft and showed the importance of handling categorical and numerical attributes separately. RuleCOSI+ obtained high interpretability on the measure with a small number of rules. However, the rules that are actually used to classify instances are complex and have quite low interpretability. On the other hand, Re-RX with J48graft obtained low interpretability on the measure with a large number of rules. However, it can handle categorical and numerical attributes separately, has simple rules, and achieves high interpretability, even when the number of rules is large. We newly proposed as a metric for interpretability, which is based on the empirical probability of the rules and measures their complexity. can be used for a fair comparison of decision list- and DT-based rule sets. Furthermore, by using macro-, interpretability can be evaluated appropriately, even for class-imbalanced datasets. Few studies have considered handling categorical and numerical attributes separately, and we believe that this is an important issue for future work. Existing tree ensembles do not distinguish between categorical and numerical attributes because they prioritize accuracy. Therefore, they cannot be distinguished by tree ensemble approximators such as RuleCOSI+ and FBTs. In the future, we plan to develop a tree ensemble that distinguishes categorical from numeric attributes and serves as an approximator with even better interpretability.
Author Contributions
Conceptualization, S.O. and Y.H.; methodology, S.O.; software, S.O., M.N. and R.F.; validation, S.O.; formal analysis, S.O.; investigation, S.O.; resources, S.O.; data curation, S.O., M.N. and R.F.; writing—original draft preparation, S.O.; writing—review and editing, S.O., M.N., R.F. and Y.H.; visualization, S.O.; supervision, Y.H.; project administration, S.O.; funding acquisition, Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All data were presented in the main text. The source code is available at https://github.com/somaonishi/InterpretableML-Comparisons.
Acknowledgments
The authors thank FORTE Science Communications 8 for English language editing.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Implementation details and hyperparameters
In this section, we provide the implementation details and hyperparameters for each method. See our repository 9 for more details.
Appendix A.1. XGBoost
Implementation. We used XGBoost 10 for the base tree ensemble for FBTs and RuleCOSI+. We fixed and did not tune the following hyperparameters:
In Table A1, we provide the hyperparameter space.

Table A1.
XGBoost hyperparameter space.
| Parameter | Space |
|---|---|
| UniformInt(1, 10) | |
| LogUniform(1e-4,1.0) | |
| # Iterations | 50 |
Appendix A.2. FBTs
Implementation. We used the official implementation of FBTs 11. We fixed and did not tune the following hyperparameters:
In Table A2, we provide the hyperparameter space.
Table A2.
FBTs hyperparameter space.
| Parameter | Space |
|---|---|
| UniformInt(1, 10) | |
| {auc, None} | |
| # Iterations | 50 |
Appendix A.3. RuleCOSI+
Implementation. We used the official implementation of RuleCOSI+ 12. In Table A3, we provide the hyperparameter space.
Table A3.
RuleCOSI+ hyperparameter space.
| Parameter | Space |
|---|---|
| Uniform(0.0, 0.95) | |
| Uniform(0.0, 0.5) | |
| c | Uniform(0.1, 0.5) |
| # Iterations | 50 |
Appendix A.4. Re-RX with J48graft
Implementation. We used the repository 13 that we implemented for Re-RX with J48graft. We used , where d is the number of training data. In addition, we fixed and did not tune the following hyperparameters in the MLP:
- [51]
In Table A4, we provide the hyperparameter space of the MLP. We searched for the optimal parameters of the MLP and then the other parameters of Re-RX with J48graft. In Table A5, we provide the hyperparameter space for the other parameters of Re-RX with J48graft.
Table A4.
MLP hyperparameter space.
| Parameter | Space |
|---|---|
| UniformInt(1, 5) | |
| LogUniform(5e-3, 0.1) | |
| LogUniform(1e-6, 1e-2) | |
| # Iterations | 50 |
Table A5.
Re-RX with J48graft hyperparameter space.
| Parameter | Space |
|---|---|
| {2, 4, 8, …, 128} | |
| Uniform(0.1, 0.5) | |
| LogUniform(0.001, 0.25) | |
| Uniform(0.05, 0.4) | |
| Uniform(0.05, 0.4) | |
| # Iterations | 50 |
Appendix A.5. DT
Implementation. We used scikit-learn’s DT 14. In Table A6, we provide the hyperparameter space. We used the default hyperparameters of scikit-learn for the other parameters.
Table A6.
DT hyperparameter space.
| Parameter | Space |
|---|---|
| UniformInt(1, 10) | |
| Uniform(0.0, 0.5) | |
| Uniform(0.0, 0.5) | |
| # Iterations | 100 |
Appendix A.6. J48graft
Implementation. We used J48graft as implemented in the rerx repository 15. Table A7 shows the hyperparameter space.
Table A7.
J48graft hyperparameter space.
| Parameter | Space |
|---|---|
| {2, 4, 8, …, 128} | |
| Uniform(0.1, 0.5) | |
| # Iterations | 100 |
Appendix B. Results for other metrics
Table A8.
Results for the average number of conditions.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 4.0 | 2.1 | 2.5 | 4.1 | 2.3 |
Table A9.
Results for precision.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.8 | 3.3 | 3.3 | 2.5 | 3.1 |
Table A10.
Results for recall.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.9 | 1.1 | 3.9 | 3.8 | 3.0 |
Table A11.
Results for F1-score.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 3.0 | 2.1 | 4.0 | 3.0 | 2.9 |
References
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl. Based Syst. 2023, 263, 110273. [CrossRef]
- Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; Chatila, R.; Herrera, F. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top Comput. Intell. 2021, 5, 726–742. [CrossRef]
- Demajo, L.M.; Vella, V.; Dingli, A. Explainable AI for Interpretable Credit Scoring. Computer Science & Information Technology (CS & IT). AIRCC Publishing Corporation, 2020. [CrossRef]
- Petch, J.; Di, S.; Nelson, W. Opening the Black Box: The Promise and Limitations of Explainable Machine Learning in Cardiology. Can. J. Cardiol. 2022, 38, 204–213. [CrossRef]
- Weber, L.; Lapuschkin, S.; Binder, A.; Samek, W. Beyond explaining: Opportunities and challenges of XAI-based model improvement. Inf. Fusion 2023, 92, 154–176. [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [CrossRef]
- Cabitza, F.; Campagner, A.; Malgieri, G.; Natali, C.; Schneeberger, D.; Stoeger, K.; Holzinger, A. Quod erat demonstrandum? - Towards a typology of the concept of explanation for the design of explainable AI. Expert Syst. Appl. 2023, 213, 118888. [CrossRef]
- Deck, L.; Schoeffer, J.; De-Arteaga, M.; Kühl, N. A Critical Survey on Fairness Benefits of XAI, 2023, [arXiv:cs.AI/2310.13007]. [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [CrossRef]
- Zihni, E.; Madai, V.I.; Livne, M.; Galinovic, I.; Khalil, A.A.; Fiebach, J.B.; Frey, D. Opening the black box of artificial intelligence for clinical decision support: A study predicting stroke outcome. PLOS ONE 2020, 15. [CrossRef]
- Yang, C.C. Explainable Artificial Intelligence for Predictive Modeling in Healthcare. JOURNAL OF HEALTHCARE INFORMATICS RESEARCH 2022, 6, 228–239. [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability, 2017, [arXiv:cs.LG/1606.03490]. [CrossRef]
- Breiman, L. Bagging predictors. MACHINE LEARNING 1996, 24, 123–140. [CrossRef]
- Breiman, L. Random forests. MACHINE LEARNING 2001, 45, 5–32. [CrossRef]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting Algorithms as Gradient Descent. Advances in Neural Information Processing Systems; Solla, S.; Leen, T.; Müller, K., Eds. MIT Press, 1999, Vol. 12.
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: New York, NY, USA, 2016; KDD ’16, pp. 785–794. [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; NIPS’17, pp. 3149–3157.
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: unbiased boosting with categorical features, 2019, [arXiv:cs.LG/1706.09516]. [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. WIREs Data Mining and Knowledge Discovery 2018, 8, e1249, [https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/widm.1249]. [CrossRef]
- Mahbooba, B.; Timilsina, M.; Sahal, R.; Serrano, M. Explainable artificial intelligence (XAI) to enhance trust management in intrusion detection systems using decision tree model. Complexity 2021, 2021, 1–11. [CrossRef]
- Shulman, E.; Wolf, L. Meta Decision Trees for Explainable Recommendation Systems. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society; Association for Computing Machinery: New York, NY, USA, 2020; AIES ’20, pp. 365–371. [CrossRef]
- Blanco-Justicia, A.; Domingo-Ferrer, J.; Martínez, S.; Sánchez, D. Machine learning explainability via microaggregation and shallow decision trees. Knowl. Based Syst. 2020, 194, 105532. [CrossRef]
- Sachan, S.; Yang, J.B.; Xu, D.L.; Benavides, D.E.; Li, Y. An explainable AI decision-support-system to automate loan underwriting. Expert Syst. Appl. 2020, 144. [CrossRef]
- Yang, L.H.; Liu, J.; Ye, F.F.; Wang, Y.M.; Nugent, C.; Wang, H.; Martinez, L. Highly explainable cumulative belief rule-based system with effective rule-base modeling and inference scheme. Knowl. Based Syst. 2022, 240. [CrossRef]
- Li, H.; Wang, Y.; Zhang, S.; Song, Y.; Qu, H. KG4Vis: A Knowledge Graph-Based Approach for Visualization Recommendation. IEEE Transactions on Visualization and Computer Graphics 2022, 28, 195–205. [CrossRef]
- Setiono, R.; Baesens, B.; Mues, C. Recursive Neural Network Rule Extraction for Data With Mixed Attributes. IEEE Transactions on Neural Networks 2008, 19, 299–307. [CrossRef]
- Hayashi, Y.; Nakano, S. Use of a Recursive-Rule eXtraction algorithm with J48graft to achieve highly accurate and concise rule extraction from a large breast cancer dataset. Informatics in Medicine Unlocked 2015, 1, 9–16. [CrossRef]
- Friedman, J.H.; Popescu, B.E. Predictive learning via rule ensembles. The Annals of Applied Statistics 2008, 2, 916 – 954. [CrossRef]
- Deng, H. Interpreting tree ensembles with inTrees. International Journal of Data Science and Analytics 2019, 7, 277–287. [CrossRef]
- Hara, S.; Hayashi, K. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics; Storkey, A.; Perez-Cruz, F., Eds. PMLR, 2018, Vol. 84, Proceedings of Machine Learning Research, pp. 77–85.
- Sagi, O.; Rokach, L. Explainable decision forest: Transforming a decision forest into an interpretable tree. Inf. Fusion 2020, 61, 124–138. [CrossRef]
- Sagi, O.; Rokach, L. Approximating XGBoost with an interpretable decision tree. Information Sciences 2021, 572, 522–542. [CrossRef]
- Obregon, J.; Kim, A.; Jung, J.Y. RuleCOSI: Combination and simplification of production rules from boosted decision trees for imbalanced classification. Expert Syst. Appl. 2019, 126, 64–82. [CrossRef]
- Obregon, J.; Jung, J.Y. RuleCOSI+: Rule extraction for interpreting classification tree ensembles. Inf. Fusion 2023, 89, 355–381. [CrossRef]
- Hayashi, Y. Synergy effects between grafting and subdivision in Re-RX with J48graft for the diagnosis of thyroid disease. Knowl. Based Syst. 2017, 131, 170–182. [CrossRef]
- Hayashi, Y.; Oishi, T. High accuracy-priority rule extraction for reconciling accuracy and interpretability in credit scoring. New Generation Computing 2018, 36, 393–418. [CrossRef]
- Chakraborty, M.; Biswas, S.K.; Purkayastha, B. Recursive Rule Extraction from NN using Reverse Engineering Technique. New Generation Computing 2018, 36, 119–142. [CrossRef]
- Hayashi, Y. NEURAL NETWORK RULE EXTRACTION BY A NEW ENSEMBLE CONCEPT AND ITS THEORETICAL AND HISTORICAL BACKGROUND: A REVIEW. International Journal of Computational Intelligence and Applications 2013, 12, 1340006. [CrossRef]
- Hayashi, Y. Application of a rule extraction algorithm family based on the Re-RX algorithm to financial credit risk assessment from a Pareto optimal perspective. Operations Research Perspectives 2016, 3, 32–42. [CrossRef]
- Hayashi, Y.; Takano, N. One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes. Electronics 2020, 9. [CrossRef]
- Hayashi, Y. Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes? Electronics 2020, 9. [CrossRef]
- Kelly, M.; Longjohn, R.; Nottingham, K. UCI Machine Learning Repository. https://archive.ics.uci.edu.
- Webb, G.I. Decision Tree Grafting from the All-Tests-but-One Partition. Proceedings of the 16th International Joint Conference on Artificial Intelligence; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; Vol. 2, IJCAI’99, pp. 702–707.
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann, 1993.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; Passos, A.; Cournapeau, D.; Brucher, M.; Perrot, M.; Édouard Duchesnay. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research 2011, 12, 2825–2830.
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019. [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition 1997, 30, 1145–1159. [CrossRef]
- WELCH, B. THE GENERALIZATION OF STUDENTS PROBLEM WHEN SEVERAL DIFFERENT POPULATION VARIANCES ARE INVOLVED. BIOMETRIKA 1947, 34, 28–35. [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. International Conference on Learning Representations, 2019. [CrossRef]
| 1 | Kaggle is a platform for predictive modeling and analytics competitions in which statisticians and data miners compete to produce the best models for predicting and describing the datasets uploaded by companies and users. |
| 2 | |
| 3 | |
| 4 | We used OneHotEncoder from scikit-learn [47] |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 |
Figure 1.
Concepts of the three types of rule sets. Decision list-based rule sets classify instances by sequentially referencing rules from top to bottom. Unordered rule sets classify instances by referencing rules in any order. Decision tree-based rule sets are variable to decision trees and differ from the other two types of rule sets in that all instances are classified using only a single rule.
Figure 1.
Concepts of the three types of rule sets. Decision list-based rule sets classify instances by sequentially referencing rules from top to bottom. Unordered rule sets classify instances by referencing rules in any order. Decision tree-based rule sets are variable to decision trees and differ from the other two types of rule sets in that all instances are classified using only a single rule.
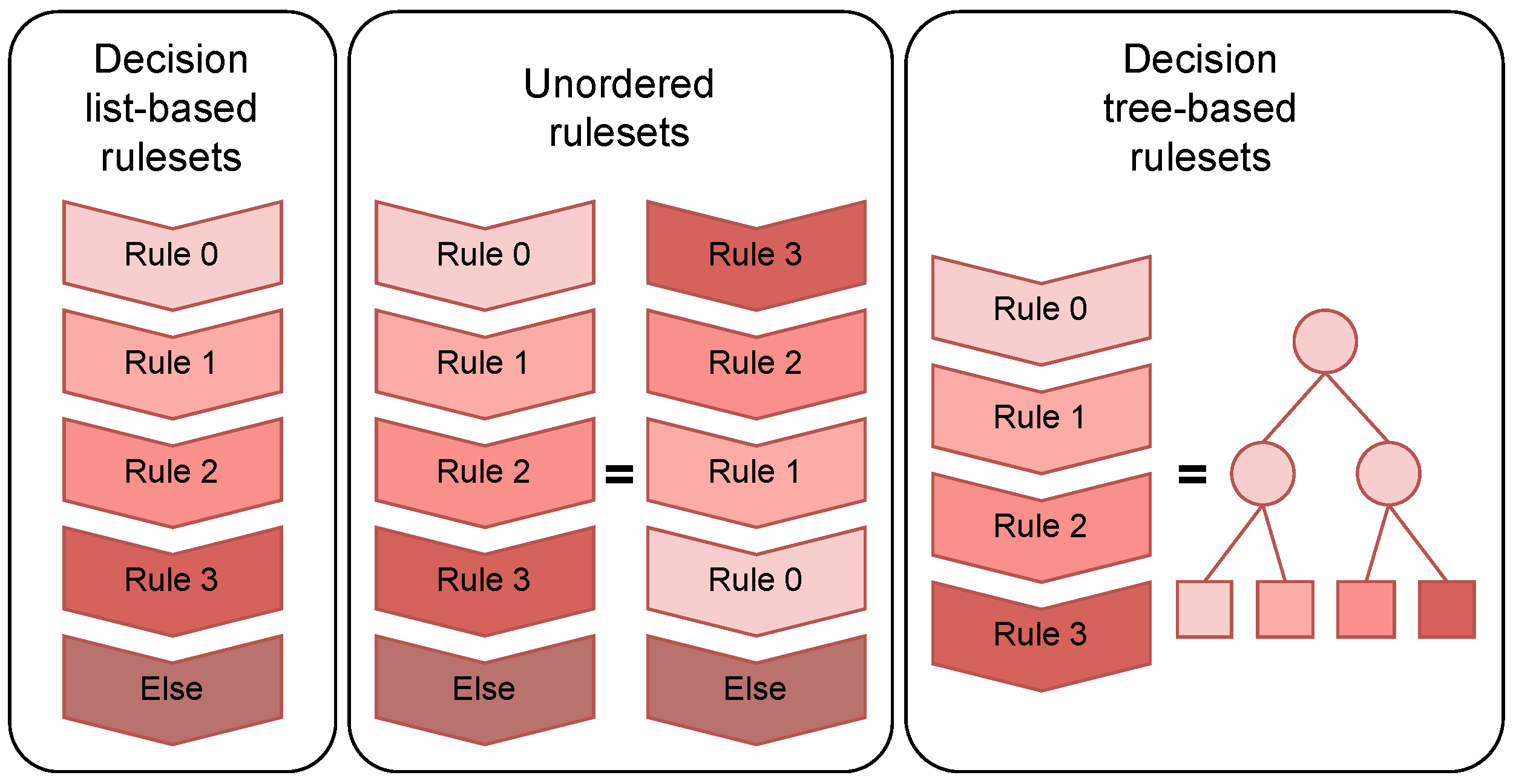
Figure 2.
Overview of FBTs. (a) Fit the ensemble tree, (b) Pruning: remove trees that do not improve the accuracy from the ensemble tree, (c) Convert the tree to rules, (d) Conjunction of rules: generate the conjunction set by gradually merging the conjunction sets of the base trees into a single set that represents the entire ensemble, (e) Convert to a decision tree.
Figure 2.
Overview of FBTs. (a) Fit the ensemble tree, (b) Pruning: remove trees that do not improve the accuracy from the ensemble tree, (c) Convert the tree to rules, (d) Conjunction of rules: generate the conjunction set by gradually merging the conjunction sets of the base trees into a single set that represents the entire ensemble, (e) Convert to a decision tree.
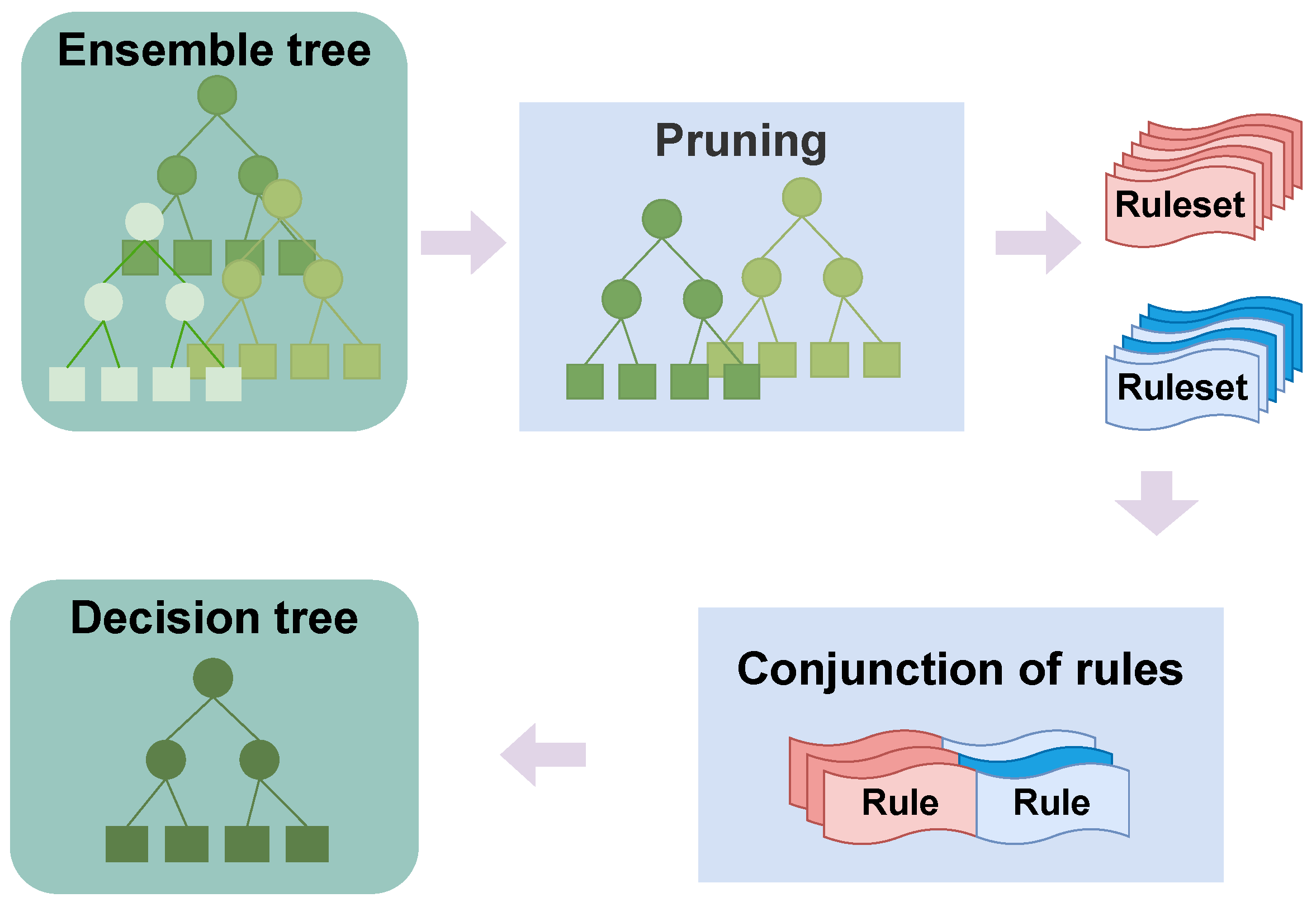
Figure 3.
Overview of RuleCOSI+. (a) Fit the ensemble tree, (b) Convert the tree to rule sets, (c) Combine rule sets: greedily verify all combinations and determine the rules to adopt and create a new rule set, (d) Sequential covering pruning: simplify the rule set, (e) Generalize rule set: remove any unnecessary conditions, (f) Repeat (c–e) using the rule set generated in (e) and the rule set obtained from the remaining ensemble tree (green rule set in the figure), (g) Obtain the final rule set.
Figure 3.
Overview of RuleCOSI+. (a) Fit the ensemble tree, (b) Convert the tree to rule sets, (c) Combine rule sets: greedily verify all combinations and determine the rules to adopt and create a new rule set, (d) Sequential covering pruning: simplify the rule set, (e) Generalize rule set: remove any unnecessary conditions, (f) Repeat (c–e) using the rule set generated in (e) and the rule set obtained from the remaining ensemble tree (green rule set in the figure), (g) Obtain the final rule set.
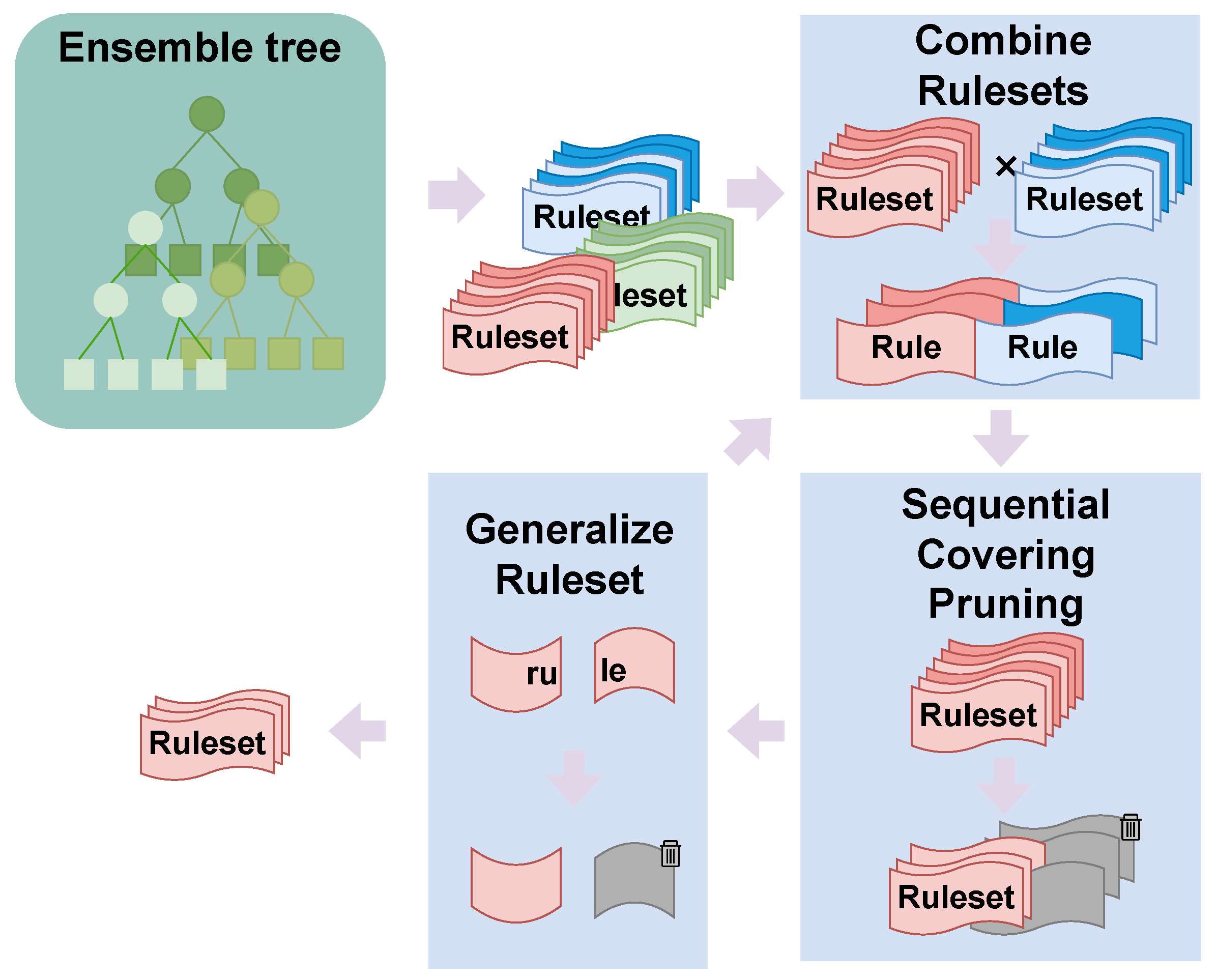
Figure 4.
Overview of Re-RX with J48graft. (a) Fit a multilayer perceptron, (b) Pruning: reduce the number of attributes, (c) Fit J48graft, (d) Convert the tree to a rule set, (e) Adopt a rule?: select a rule to adopt as is, (f) Subdivision: recursive (a–e) for a rule that is not adopted using data and attributes not included in the rule.
Figure 4.
Overview of Re-RX with J48graft. (a) Fit a multilayer perceptron, (b) Pruning: reduce the number of attributes, (c) Fit J48graft, (d) Convert the tree to a rule set, (e) Adopt a rule?: select a rule to adopt as is, (f) Subdivision: recursive (a–e) for a rule that is not adopted using data and attributes not included in the rule.
Figure 5.
The Pareto fronts for each method obtained by multi-objective optimization using Optuna with seed = 1 and CV-fold = 1, 2, 3 in the german (a-c) and bank-marketing (d-f) datasets.
Figure 5.
The Pareto fronts for each method obtained by multi-objective optimization using Optuna with seed = 1 and CV-fold = 1, 2, 3 in the german (a-c) and bank-marketing (d-f) datasets.
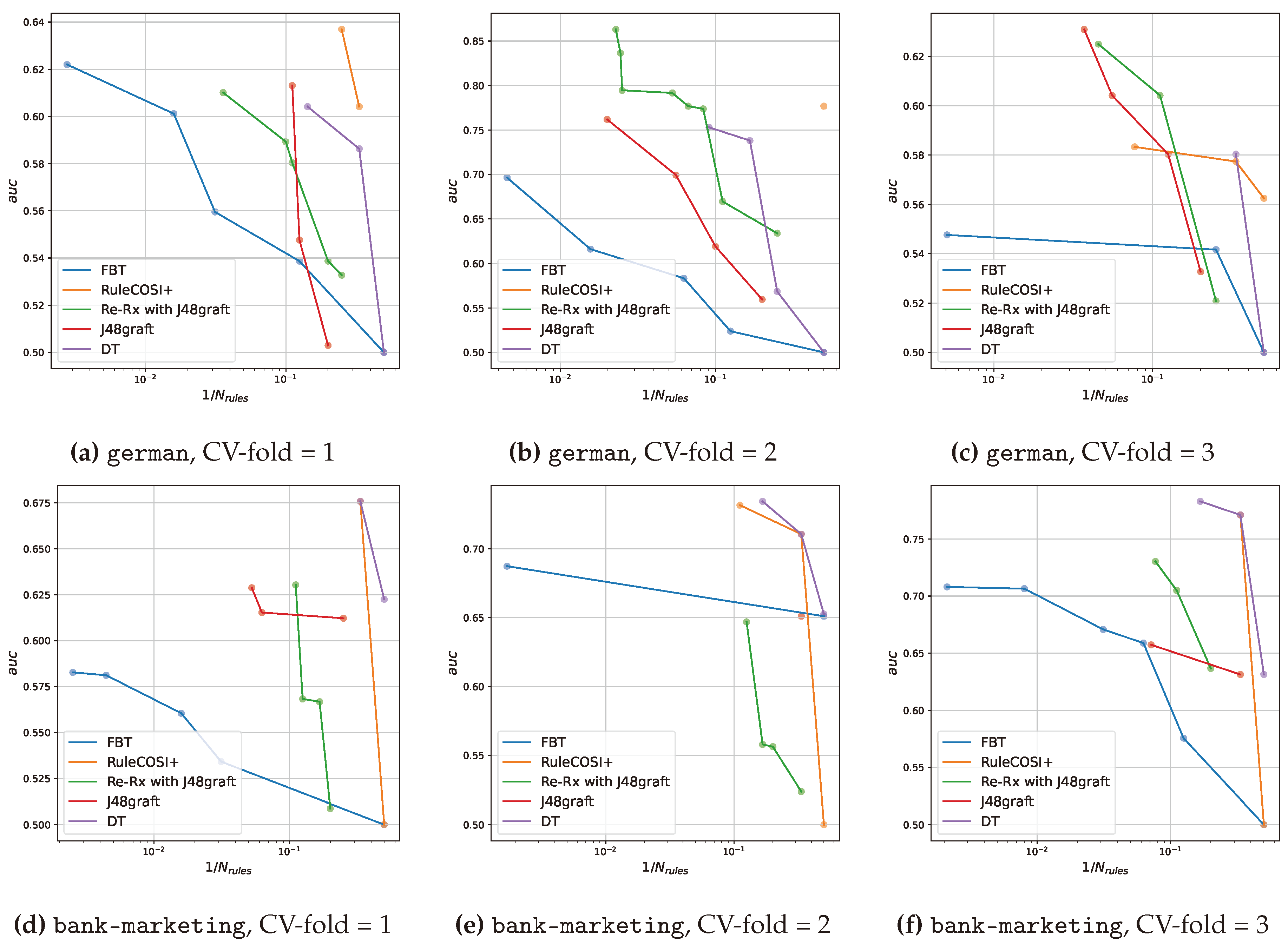
Table 1.
Dataset properties
| dataset | #instances | #features | #cate | #cont | major class ratio |
|---|---|---|---|---|---|
| heart | 270 | 13 | 7 | 6 | 0.55 |
| australian | 690 | 14 | 6 | 8 | 0.555 |
| mammographic | 831 | 4 | 2 | 2 | 0.52 |
| tictactoe | 958 | 9 | 9 | 0 | 0.65 |
| german | 1000 | 20 | 7 | 13 | 0.70 |
| biodeg | 1055 | 41 | 0 | 41 | 0.66 |
| banknote | 1372 | 4 | 0 | 4 | 0.55 |
| bank-marketing | 4521 | 16 | 9 | 7 | 0.89 |
| spambase | 4601 | 57 | 0 | 57 | 0.60 |
| occupancy | 8143 | 5 | 0 | 5 | 0.79 |
Table 2.
Results for classification performance (). All metrics are reported as AUCs. For each dataset, the top results are in bold (here, “top” means that the gap between this result and the result with the best score is not statistically significant at a level of 0.05 (Welch’s t-test [50])). For each dataset, ranks are calculated by sorting the average of the reported scores, and the “rank” row reports the average rank across all datasets.
Table 2.
Results for classification performance (). All metrics are reported as AUCs. For each dataset, the top results are in bold (here, “top” means that the gap between this result and the result with the best score is not statistically significant at a level of 0.05 (Welch’s t-test [50])). For each dataset, ranks are calculated by sorting the average of the reported scores, and the “rank” row reports the average rank across all datasets.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.9 | 2.1 | 4.0 | 3.2 | 2.8 |
Table 3.
Results for the number of rules.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 4.5 | 1.6 | 3.3 | 3.8 | 1.8 |
Table 4.
Results for CREP.
| dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tictactoe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 3.5 | 4.7 | 1.5 | 3.1 | 2.2 |
Table 5.
Summary of classification and interpretability performance () across all datasets.
| method | |||
|---|---|---|---|
| FBTs | |||
| RuleCOSI+ | |||
| Re-RX with J48graft | |||
| J48graft | |||
| DT |
Table 6.
Rule sets generated from the bank-marketing dataset.
| RuleCOSI+ | coverage | |
|---|---|---|
| 0.744 | ||
| 0.148 | ||
| 0.109 | ||
| Re-RX with J48graft | coverage | |
| 0.820 | ||
| 0.108 | ||
| 0.044 | ||
| 0.0 | ||
| 0.029 | ||
| DT | coverage | |
| 0.891 | ||
| 0.025 | ||
| 0.084 |
Table 7.
Post-processed rule set generated from the bank-marketing dataset in Re-RX with J48graft.
| Re-RX with J48graft | coverage | |
|---|---|---|
| 0.971 | ||
| 0.0 | ||
| 0.029 |
Table 8.
Rule sets generated from the german dataset.
| RuleCOSI+ | coverage | |
|---|---|---|
| 0.329 | ||
| 0.283 | ||
| 0.388 | ||
| Re-RX with J48graft | coverage | |
| 0.394 | ||
| 0.063 | ||
| 0.16 | ||
| 0.067 | ||
| 0.013 | ||
| 0.022 | ||
| 0.012 | ||
| 0.19 | ||
| 0.079 | ||
| DT | coverage | |
| 0.394 | ||
| 0.325 | ||
| 0.281 |
Table 9.
Post-processed rule set generated from the german dataset in Re-RX with J48graft.
| Re-RX with J48graft | coverage | |
|---|---|---|
| 0.394 | ||
| 0.063 | ||
| 0.067 | ||
| 0.207 | ||
| 0.19 | ||
| 0.079 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



MDPI Initiatives
Important Links
© 2024 MDPI (Basel, Switzerland) unless otherwise stated