
Preprint
Article
A Low-Power BL Path Design for NAND Flash Based on Existing NAND Interface
Altmetrics
Downloads
117
Views
36
Comments
0
A peer-reviewed article of this preprint also exists.
supplementary.pdf (4.26MB )

This version is not peer-reviewed
Submitted:
31 January 2024
Posted:
31 January 2024
You are already at the latest version
Alerts
Abstract
This paper is an extended version of a previously reported conference paper regarding low power design for NAND Flash. As the number of bits per NAND Flash die increases with cost scaling, IO datapath speed increases to minimize the page access time with scaled CMOS in IOs. The power supply for IO buffers, namely VDDQ, has decreased from 3V to 1.2V, accordingly. In this paper, how a reduction in VDDQ can contribute to power reduction in BL path is discussed and validated. Conventionally, BL voltage of about 0.5V has been supplied from a supply voltage source (VDD) of 3V. BL path power can be reduced by a factor of VDDQ to VDD when BL voltage is supplied from VDDQ. To maintain a sense margin at sense amplifiers, the supply source for BLs is switched from VDDQ to VDD before sensing. As a result, power reduction and equivalent sense margin can be realized at the same time. The overhead of implementing this operation is an increase in BL access time of about 2% for switching the power supply from VDDQ to VDD and an increase in die size of about 0.01% for adding the switching circuit, both of which are not significant in comparison with a significant power reduction in BL path power of NAND die of about 60%. The BL path was designed in 180nm CMOS to validate the design. When the cost for powering SSD becomes quite significant especially for data center, an additional lower voltage supply such as 0.8V dedicated to BL charging for read and program verify operations may be the best option for the future.
Keywords:
Subject: Engineering - Electrical and Electronic Engineering
1. Introduction
As of 2020, data centers consumed about 1% of worldwide electricity use [1]. As cloud services such as artificial intelligence, autonomous vehicles, and distributed manufacturing systems have been expanding, more numbers of data centers are demanded. Their energy use was predicted to increase by a factor of three or four within the next decade. As a result, many researchers have been focusing on power reduction without affecting computing performance.
Figure 1 compares power breakdowns for data center in [2,3,4]: (1) servers and storage systems, (2) cooling and humidification systems, (3) power conditioning equipment, (4) networking equipment, and (5) lighting/physical security. Servers’ power strongly depends on workload. Cooling power depends on ambient weather conditions around the data center facility. Those three data sources show that servers and cooling consume about 80% of data center power. Figure 2 shows the breakdown of “servers” in to CPU, DRAM and storage. Storage includes hard disk drive (HDD) and NAND Flash based solid-state drive (SSD). NAND Flash memory is a nonvolatile semiconductor memory. As the bit density increases, Solid-State Drives (SSDs), whose storage components are NAND Flash memory dies, have been replacing hard disk drives in data center as well as personal computers because of lower power and faster latency.
Distributed temperature control units control local temperature surrounding the CPUs running in different workload [5]. As a result, the total power for servers and cooling can be minimized. Energy-efficient distribution of power converters is also important to reduce the total power of data centers [6]. Shuffled topologies spread secondary power feeds over power grid, which allows a single power unit failure. Power routing schedules workload dynamically. The network consumes much less power than servers and cooling at full utilization. However, since servers typically operate at much lower levels of utilization, the network power cannot be ignored. If the system is 15% utilized and the servers are fully energy-proportional, the network will consume about 50% of overall power [7]. Thus, the network power needs to be proportion to the workload. It is shown that a flattened butterfly topology itself is inherently more power efficient than the other commonly proposed topology for high-performance datacenter networks in [7]. Database software also affects the energy efficiency of servers. It is shown that the CPU power consumption varies by as much as 60% depending on operators for the same CPU utilization in [8]. Thus, data center energy consumption depends on each of individual hardware such as CPUs, memories, storage, cooling, and network; construction and control of the hardware and software; workload and environmental temperature. Therefore, energy consumption models are important to design energy-efficient data center and to optimize its operations. Reference [9] surveys more than 200 models for all the hierarchical levels of the hardware. In [10], analytical models called FlashPower were developed to estimate NAND flash memory chip energy dissipation during basic flash operations such as read, program and erase. Each component such as selected and unselected wordlines (WLs), bitlines (BLs) for data 0 and 1, source line, decoder and senseamp are parameterized for each operation.
Now, let’s take a look at the inside of an SSD. Figure 3 illustrates a block diagram of the internal structure of an SSD [11]. Multiple NAND Flash dies are integrated to store large volume of data. DRAM is used as a memory buffer for multiple NAND dies. SSD controller controls data traffic at the interface between SATA (Serial Advanced Technology Attachment) and the NAND dies. When data is written into the SSD, the sequential write data input to the SSD is stored in DRAM first, and then is transferred to one or more NAND dies through data bus inside the SSD according to the write address. When data is read out of the SSD, the sequential data is moved from one or more NAND dies to the DRAM die through data bus inside the SSD first, and then is transferred to SATA. DC/DC converter inputs power from 3 V power source to output multiple voltages for controller, NAND and DRAM.
The array access time of NAND is much longer than that of DRAM by factors of 1000 for read operation and of 10000 for write operation. In order to increase band width for read and write operations, multiple NAND dies in an SSD operate in parallel. The maximum number of NAND dies operating in parallel is determined by peak power [12]. Peak point occurs when heavily capacitive WLs and BLs are charged up. As shown in Figure 4, the peak point can be shifted by adding a suspend time (TSUSPEND) between the dies, which improves parallelism. It is more favorable to reduce the power itself not only for parallelism, but also for energy reduction of SSDs and data center.
As NAND bit density increases, page length increases from 512B to 16KB. Because read and program operations are done on a page basis, IO speed has needed to increase accordingly for preventing bottleneck at IO path in data traffic. In order to make it easier to develop advanced SSD controller and advanced SSD, two groups, Open NAND Flash Interface (ONFI) [13] and Toggle [14] working groups, have standardized the interface of NAND. Figure 5 illustrates power distribution for NAND die with ONFI 1.0 (a), 2.0 (b), 4.0 (c), and proposed power distribution in NAND die (d). MA, SA and IO are Memory Array, Sense amplifier, and IO buffers, respectively. In order to increase bandwidth of NAND interface, IO transistors have scaled. As a result, the power supply for IO buffers, namely VDDQ, has decreased from 3V to 1.8V and from 1.8V to 1.2V. 2.4 Gb/s IO speed was achieved in 1Tb 3D NAND Flash [15]. ONFI 1.0 NAND has one set of power supply VDD and ground VSS. IO operates at 3 V with VDD/VSS. Since ONFI 2.0 [16,17], power/ground for IO is dedicated as VDDQ/VSSQ to allow scaled transistors operating at lower voltage for faster IO operation. VDD remains the same as 3 V even when VDDQ is lowered because high voltages of over 20 V for program and erase operations need to be generated by charge pumps on chip [18]. If VDD was scaled as VDDQ, charge pumps would have increased circuit area, which affects cost. In order to further improve IO operation frequency for increasing band width, more scaled transistors required a lower VDDQ of 1.2V with ONFI 4.0 [19]. As shown in Figure 5(d), the proposed design [20] utilizes VDDQ not only for IO buffers but also for SA to significantly reduce power in the BL path as will be described in the following sections.
This paper is an extended version of a previously reported conference paper [20] regarding low power design for NAND Flash with existing NAND Flash interface. NAND Flash dies with this low power design can replace existing ones without any additional cost because there is no need to update in printed circuit boards for SSDs and in design of NAND controller.
This paper organizes as follows: Section 2 overviews and models two operations for BL read access; shielded BL (SBL) [21] and all BL (ABL) [22] read operations. Section 3 compares the circuit diagrams and read operations in the conventional and proposed circuits for ABL read operation. Experimental results are shown in Section 4. Section 5 discusses design considerations such as scalability in BL capacitance and noise immunity.
2. BL Access for Read Operation
Figure 6 illustrates BL path of NAND Flash. This section overviews and models two operations for BL read access; shielded BL (SBL) [21] and all BL (ABL) [22] read operations. Long, narrow, and tightly pitched BL has a relatively high parasitic resistance and capacitance as depicted by R and C. Multiple cells are connected with BL. (For simplicity, Figure 6 shows only one of them connected at the farthest node, which has the longest delay.) The gates of NAND Flash cells are connected with word-lines (WLs) and two select gates (SGD, SGS). A read operation is done as follows. Only a selected WL, e.g. WL127, goes up to a certain voltage, e.g., 1V while the other deselected WLs and the two select gates go up to a higher voltage such as 5V to turn on regardless of the cell threshold voltages. When the selected cell has a threshold voltage below (above) 1V, it turns on (off).
NAND string is modeled by a switching transistor controlled by SGD signal as a switch and a linear resistor RC for simplicity. In this paper, the cell data is related to RC as follows: the cell whose data is 0, namely 0-cell, has much lower current than the cell whose data is 1, namely 1-cell, i.e., the 0-cell has much higher RC than the 1-cell. BL is modeled by a simple 2 π RC model. PASS gate acts as a source follower to limit the BL voltage VBL at about 0.5V. The lower boundary is determined by the value at which the cell current enters into a linear region where the cell current ICELL has a strong function as VBL. The BL access time increases as ICELL decreases. The higher bound is limited by reliability. Too high VBL increases the probability that hot carrier injection into the gate of the cell transistors occurs, resulting in substantial shift in the cell threshold voltage. From the view point of power, VBL should be as low as possible. the lower VBL, the lower the power in BL path. SN indicates “storage node”. The parasitic capacitance CSN stores charges temporary, whose amount is translated into a digital value of 1 or 0 at DO by a clocked invertor controlled by a sensing signal SNS. BL is charged up through PREB transistor from VDDBL.
2.1. BL Delay Time in Case of Shielded BL Read
Figure 7 shows waveform of BL control signals and VBL for shielded BL (SBL) read operation. BL access time TBL (TSBL for SBL and TABL for ABL) is the sum of a pre-charge period TPRE and a discharge period TDIS. BL starts charging up with PASS high and PREB low. Because SGD is forced to ground during TPRE, VBLF and VBLN go up regardless of the cell data. The discharge period starts with PASS low and SGD high. Depending on the cell data, VBLN gradually lowers by ΔVBL for 1-cell whereas remains the same for 0-cell. After TDIS, PASS goes up to a voltage slightly lower by ΔVPASS than that in TPRE. SN rapidly lowers for the 1-BL with ΔVBL > ΔVPASS whereas keeps the voltage for the 0-BL as high as VDDBL. With SNS high, DO is set to present the cell data.
Next, TSBL is estimated with the simple model shown in Figure 6. Assuming VBLN, VBL at the nearest node to senseamp, is forced to a constant voltage of VBL_PRE with PASS high in TPRE, VBLF, VBL at the farthest node from senseamp, is given by (1).
In TDIS, differential equations for VBLN and VBLF are given by (2) and (3).
Using the initial conditions of (4) and (5),
VBLN(t) is solved to be (6).
where , f1, VA, VB are defined by (7) – (10), respectively.
ΔVBL = VBL_PRE – VBLN(TDIS) can be calculated by (6) at t = TDIS with specific RC values for 0-cell and 1-cell.
2.2. BL Delay Time in Case of all BL Read
Figure 8 shows waveform of BL control signals and VBL for all BL (ABL) read operation. BL starts charging up with SGD and PASS high and PREB low. VBLF goes up depending on the cell data. VBLF for 1-cell is lower than that for 0-cell. The sense current IS approaches the cell current. After TABL, PASS goes up to discharge CSN. SN rapidly lowers for the 1-BL in comparison with 0-BL. When VSN becomes low enough, SNS toggles to transfer the cell data to DO.
TABL is estimated as follows. VBLF is governed by (11), which is solved as (12) with the initial condition of VBLF (0) = 0.
IS can be calculated by (13).
A sense margin for ABL can be defined by %IS. Thus, TABL is a function of %IS.
2.3. Energy in BL Path
VDDBL supplies energy (ESBL) into every BL as given by (15) regardless of data 1 or 0 in case of SBL.
On the other hand, ABL requires more energy because VDDBL also needs to supply the direct cell current in addition to the displacement current for BL parasitic capacitance, as given by (16), where ESBL is the averaged energy per BL.
2.4. Performance Comparison between SBL and ABL
TABL and EBL depend on a sensing scheme such as SBL or ABL, on technology-dependent parameters such as R and C, and on design parameters such as VBL_PRE, ΔVBL and %IS. It is challenging to determine which sensing scheme is better than the other in terms of performance generally, but it should be good to demonstrate their comparison under a specific condition. In this sub-section, the following parameters are used as demonstration: , , , , VDDBL = 2.0V, = 25, 50, 75 mV for SBL, and 70, 80, 90% for ABL. VBL_PRE is also skewed as shown in Table 1.
Figure 9 shows a performance comparison between SBL with = 25, 50, 75 mV (from left to right) and ABL with 70, 80, 90% (from left to right). Note that the condition was selected so as to have crossing points between SBL and ABL. More sensing margins result in longer BL delay, but do not contribute (for SBL) or do minor contribution (for ABL) on energy for read operation in BL path. A finite slope of EBL – TBL curves for ABL comes from the cell current. The longer TBL with more sensing margin, the more the integration of power due to the cell current. In Section 3 and afterwards, a proposed design is based on ABL, but its effectiveness on energy reduction is also expected with SBL.
3. BL Path Design: Conventional vs. Proposed
3.1. Circuits
Figure 10 (a), (b) illustrate conventional and proposed circuits in BL path, respectively. In the proposed circuit, a power switch is added to the conventional circuit in order to supply VDDBL from an internal VDD (VDDint) to VDD or vice versa.
Figure 11 (a), (b) show read operation waveform of conventional (a) and proposed (b) circuits, respectively. The differences in operation of the proposed circuit is that 1) VDDBL is switched to VDDQ during BL pre-charge with PREB low to reduce the power to BLs, and 2) the SN voltage boosts up to 2V after pre-charge operation before sensing by switching VDDBL to VDDint to keep the SN voltage as high as that in the conventional circuit for maintaining a sense margin which is defined by the voltage difference at SN between “1” and “0”. N-well of PREB transistors can be switched from VDDQ to VDDint in 100ns. The access overhead of the proposed design is about 2% when BL access time of the conventional design is 5μs.
3.2. Enegy in BL Path
The energy during the pre-charge period (EP) and the sense period (ES) of the conventional design are given by (17) and (18), respectively. (Note that power supplies are disconnected in the sense period.)
Therefore, the total energy per read cycle (EBL) is estimated by (19).
In case of the proposed design, (20) and (21) hold, instead of (17) and (18).
As a result, the total energy per read cycle of the proposed design is estimated by (22).
To estimate how much energy can be reduced with the proposed design in the worst case and to compare the estimates with SPICE results, the parameters in Table 2 are used. EP and ES of the conventional design are 6.7 pJ and 0 pJ whereas those of the proposed one are 2.6 pJ and 0.3 pJ. As a result, EBL is estimated 6.7 pJ for the conventional design and 2.9 pJ for the proposed one. A reduction in energy by 56% mainly comes from the difference in the most significant first terms of (19) and (22).
Figure 12 shows SPICE waveform of the conventional (in red) and proposed (in blue) designs. The energy in the operation cycle was 6.6 pJ and 3.0 pJ, respectively. A reduction by 55% was confirmed with SPICE.
4. Experimental
To validate the effectiveness of the proposed design on power reduction, a test circuit was designed and fabricated in 180nm CMOS, as shown in Figure 13. In actual NAND Flash memory, parasitic BL resistance and capacitance are based on the nature of wiring. In this test circuit, poly resistor and MIM capacitor were used to mimic parasitic BL resistance and capacitance. Without memory process, normal NMOSFETs were used as cell transistors. To have ICELL1 and ICELL0 with a normal NMOSFET, WL voltage (i.e., gate voltage of the transistors) was altered between high and low. Equivalently, 100 sets of BL and sense amp were implemented. Sufficiently small area was required for the power switch. Analog buffers were placed next to BL to monitor VBL at different locations.
Figure 14a illustrates an analog buffer. To monitor VBL in rage between 0 V and 0.5 V, PMOSFET is used as a source follower amp. Because 3V transistors are available in 180nm CMOS, VDDMON of 3V is sufficient to monitor VBL up to 1V, as shown in Figure 14b.
To estimate the energy of the conventional design, power switch was not toggled to force VDDBL with VDDint in entire cycles. Figure 15 shows the waveform in case of 0-1-0 access with a cycle time of 60μs in proposed circuit mode. Due to insufficient tail current of the fabricated analog buffers, the cycle time needed to be longer to accurately measure energy than expected. Therefore, the energy in a cycle time of 5μs was estimated by the data of Figure 16. Estimated energy per 5μs read cycle was 1.3 nJ in case of conventional circuit mode and 0.54 nJ in case of proposed circuit mode. As a result, a reduction in energy by 59% was achieved.
5. Design Consideration
In this section, how much the proposed design is effective for various NAND designs with different BL capacitance, different values of VDDQ and immunity against noise in VDDQ.
5.1. Enegy vs. BL Capacitacce
In Section 3 and Section 4, C of 3pF was assumed for validation of the proposed design. The value can vary by product when the BL length is longer or shorter depending on the number of blocks per die. The value can be also different by technology when the thickness, width or space of the BL wires is varied. Figure 17a shows the energy for one BL path in a single read operation as a function of C. Figure 17b shows the reduction rate with the proposed design over the conventional one. As discussed in Section 3, EBL has the components of C VBL VSupply and ICELL TC VSupply. As far as the first component is majority, the reduction rate in EBL does not significantly depend on C. Figure 8b indicates the proposed design can be effective over various products with different C.
5.2. Average Die Enegy vs. Energy Ratio of BL Path to WL Path
How much energy is reduced with the proposed design depends on the value of VDDQ. In addition, average die energy is the sum of the energy for BL and WL paths when the rest can be negligibly small relatively. The energy ratio of BL path to WL path depends on the array configuration, which varies by product. Thus, reduction in the average die energy with the proposed BL path design is a function of VDDQ and the energy ratio of BL path to WL path. Figure 18 shows the average die energy normalized by that of ONFI 1.0 NAND with 3V VDDQ. Three cases with respect to the energy ratio (EBL : EWL) are studied with 1:2, 1:1, and 2:1. As expected, the average die energy is reduced as VDDQ in reduced from 3V in ONFI 1.0 to 1.8V in ONFI 2.0, and to 1.2V in ONFI 3.0 and 4.0 regardless of the energy ratio of BL path to WL path. As far as VDDQ is high enough to operate PASS transistors in saturation region at VBL of 0.5V. Even at a low VDDQ of 0.8V, normal BL path operation and energy reduction were observed in SPICE result. Reduction of the average die energy with the proposed design is estimated about 22% for 1:2 case, 33% for 1:1 case, and 46% for 2:1 case. As a result, the proposed design can be still effective for NAND products with different VDDQ and different energy ratio of BL path to WL path.
5.3. Immunity against Noise in VDDQ
Because VDDQ is the supply voltage for IO buffers, it has a noise generated from IO operation. Another design concern is how much VBL is affected by such a noise in VDDQ during pre-charge period. SPICE simulations were run with single tone noises whose frequency is ranged from 1kHz to 1GHz. PASS transistors operating in saturation region had a sufficiently large drain-to-source impedance with 40dB rejection ratio, which means that VBL varies by 1mV when a ripple in VDDQ is 100mV. As a result, NAND dies applied by the proposed design could work even in severe environment of heavy traffic in IO data paths of SSDs. When the PASS signal line is routed in parallel with the VDDQ line, layout designers need to add a shielding line between the two with sufficiently low impedance.
In this paper, it is assumed that NAND interface does not change to eliminate additional cost for designing and producing new printed circuit boards. However, when the cost for powering SSD becomes quite significant especially for data center, an additional lower voltage supply such as 0.8V dedicated to BL charging for read and program verify operations may be the best option for the future.
6. Summary
Low power design in BL path of NAND Flash was proposed and validated. A reduction in entire energy per die of 20% to 40% can be expected for ONFI 3 or 4 NAND Flash with VDDQ of 1.2V depending on the energy ratio between BL and WL paths in comparison with a conventional BL path operation. Overheads of a delay time in BL path by 2% and an area of the additional power switch of 0.1% are drawback, but can be considered small enough against significant energy reduction. Further reduction with the proposed design will be possible for the future NAND with lower VDDQ or introducing an additional lower voltage supply dedicated to BL charging for read and program verify operations.
Author Contributions
Conceptualization, T.T.; methodology, H.M. and T.T.; software, H.M.; validation, H.M. and T.T.; formal analysis, H.M. and T.T.; investigation, H.M. and T.T.; writing—original draft preparation, H.M.; writing—review and editing, T.T.; funding acquisition, T.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially funded by Kioxia Corp.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This work is supported by Kioxia Corp.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Masanet, E., Shehabi, A., Lei, N., Smith, S., & Koomey, J. (2020). Recalibrating global data center energy-use estimates. Science, 367(6481), 984-986. [CrossRef]
- Pelley, S., Meisner, D., Wenisch, T. F., & VanGilder, J. W. (2009, June). Understanding and abstracting total data center power. In Workshop on energy-efficient design (Vol. 11, pp. 1-6).
- Info-Tech, “Top 10 energy-saving tips for a greener data center,” Info-Tech Research Group, London, ON, Canada, Apr. 2010. [Online]. Available: http://static.infotech.com/downloads/samples/070411_premium_oo_greendc_top_10.pdf.
- Uzaman, S. K., Shuja, J., Maqsood, T., Rehman, F., & Mustafa, S. (2019). A systems overview of commercial data centers: initial energy and cost analysis. International Journal of Information Technology and Web Engineering (IJITWE), 14(1), 42-65. [CrossRef]
- Pakbaznia, E., Ghasemazar, M., & Pedram, M. (2010, March). Temperature-aware dynamic resource provisioning in a power-optimized datacenter. In 2010 Design, Automation & Test in Europe Conference & Exhibition (DATE 2010) (pp. 124-129). IEEE. [CrossRef]
- Pelley, S., Meisner, D., Zandevakili, P., Wenisch, T. F., & Underwood, J. (2010). Power routing: dynamic power provisioning in the data center. ACM SIGARCH Computer Architecture News, 38(1), 231-242. [CrossRef]
- Abts, D., Marty, M. R., Wells, P. M., Klausler, P., & Liu, H. (2010, June). Energy proportional datacenter networks. In Proceedings of the 37th annual international symposium on Computer architecture (pp. 338-347). [CrossRef]
- Tsirogiannis, D., Harizopoulos, S., & Shah, M. A. (2010, June). Analyzing the energy efficiency of a database server. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 231-242). [CrossRef]
- Dayarathna, M., Wen, Y., & Fan, R. (2015). Data center energy consumption modeling: A survey. IEEE Communications surveys & tutorials, 18(1), 732-794. [CrossRef]
- Mohan, V., Bunker, T., Grupp, L., Gurumurthi, S., Stan, M. R., & Swanson, S. (2013). Modeling power consumption of nand flash memories using flashpower. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 32(7), 1031-1044. [CrossRef]
- M550 M.2 Type 2280 NAND Flash SSD. [online] https://www.micron.com/-/media/client/global/documents/products/data-sheet/ssd/m550_m2_2280_ssd.pdf.
- Siau, C., Kim, K. H., Lee, S., Isobe, K., Shibata, N., Verma, K., ... & Lin, L. (2019, February). 13.5 A 512Gb 3-bit/cell 3D flash memory on 128-wordline-layer with 132MB/s write performance featuring circuit-under-array technology. In 2019 IEEE International Solid-State Circuits Conference-(ISSCC) (pp. 218-220). IEEE. [CrossRef]
- ONFI, [online] https://www.onfi.org/.
- Toggle, [online] https://www.jedec.org/category/keywords/toggle.
- J. Yuh, J. Li, H. Li et al., "A 1-Tb 4b/Cell 4-Plane 162-Layer 3D Flash Memory With a 2.4-Gb/s I/O Speed Interface", IEEE International Solid- State Circuits Conference (ISSCC), Feb. 2022. [CrossRef]
- Lassa, P. (2010). The new ez nand in onfi v2. 3. SanDisk-Flash Memory Summit-Aug.
- Tripathy, S., Sahoo, D., Satpathy, M., & Pinisetty, S. (2019, November). Formal modeling and verification of nand flash memory supporting advanced operations. In 2019 IEEE 37th International Conference on Computer Design (ICCD) (pp. 313-316). IEEE. [CrossRef]
- Tanzawa, T., Tanaka, T., Takeuchi, K., & Nakamura, H. (2002). Circuit techniques for a 1.8-V-only NAND flash memory. IEEE Journal of Solid-State Circuits, 37(1), 84-89. [CrossRef]
- Gonugondla, S. K., Kang, M., Kim, Y., Helm, M., Eilert, S., & Shanbhag, N. (2018, May). Energy-efficient deep in-memory architecture for NAND flash memories. In 2018 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 1-5). IEEE. [CrossRef]
- H. Makino, T. Tanzawa, “A 30% Power Reduction Circuit Design for NAND Flash by Utilizing 1.2V I/O Power Supply to Bitline Path”, IEEE the 18th Asia Pacific Conference on Circuits and Systems, Nov. 2022. [CrossRef]
- Tanaka, T., Tanaka, Y., Nakamura, H., Sakui, K., Oodaira, H., Shirota, R., et al, (1994). A quick intelligent page-programming architecture and a shielded bitline sensing method for 3 V-only NAND flash memory. IEEE Journal of Solid-State Circuits, 29(11), 1366-1373. [CrossRef]
- Cernea, R. A., Pham, L., Moogat, F., Chan, S., Le, B., Li, Y. et al. (2008). A 34 MB/s MLC write throughput 16 Gb NAND with all bit line architecture on 56 nm technology. IEEE Journal of Solid-State Circuits, 44(1), 186-194. [CrossRef]
- Hwang Huh, Wanik Cho, Jinhaeng Lee, Yujong Noh, “A 1Tb 4b/Cell 96-Stacked-WL 3D NAND Flash Memory with 30MB/s Program Throughput Using Peripheral Circuit Under Memory Cell Array Technique”, ISSCC, 2020. [CrossRef]
- Chulbum Kim; Doo-Hyun Kim; Woopyo Jeong, “A 512-Gb 3-b/Cell 64-Stacked WL 3-D-NAND Flash Memory”, ISSCC, 2018. [CrossRef]
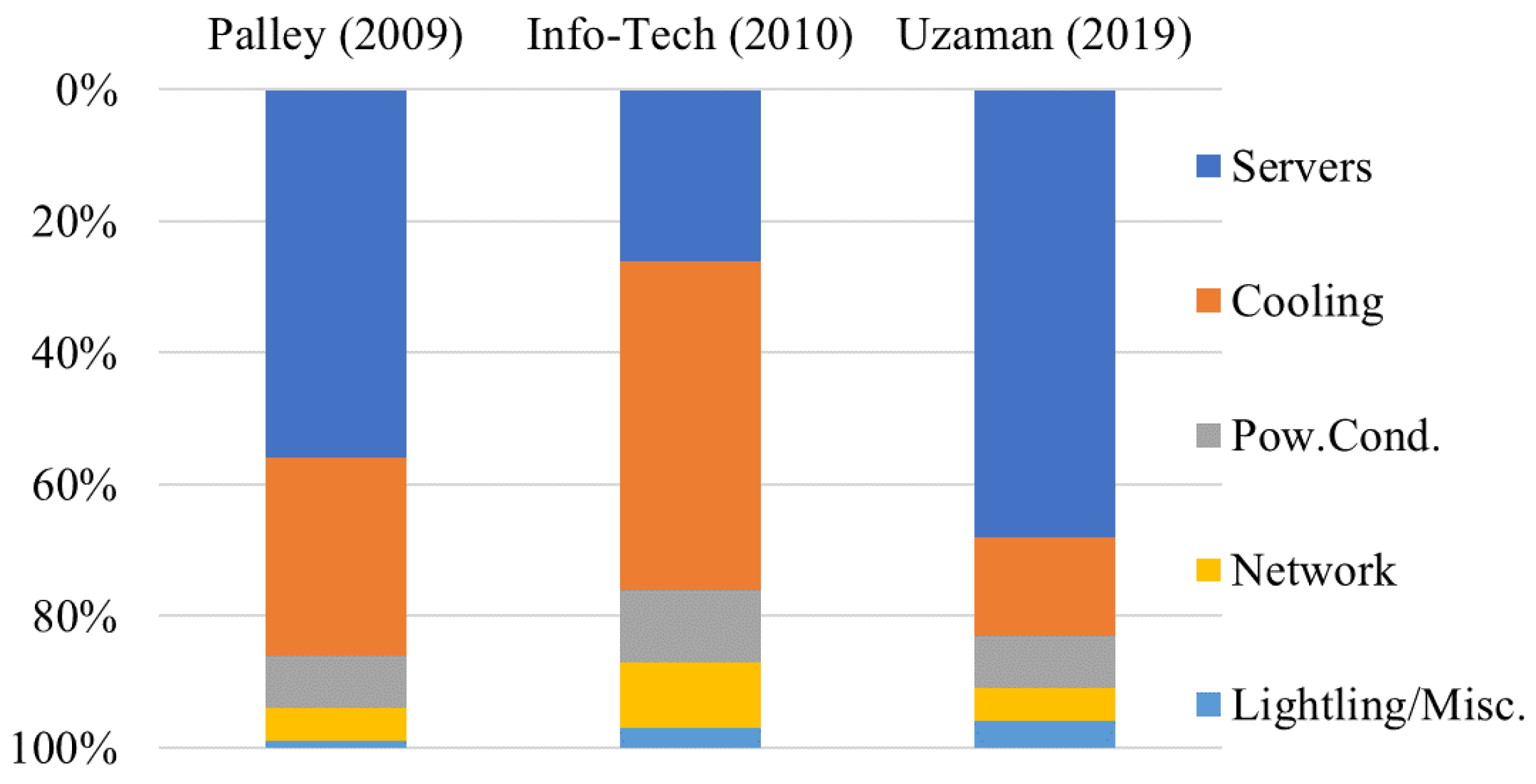
Figure 2.
Breakdown in “Servers” [4].
Figure 2.
Breakdown in “Servers” [4].
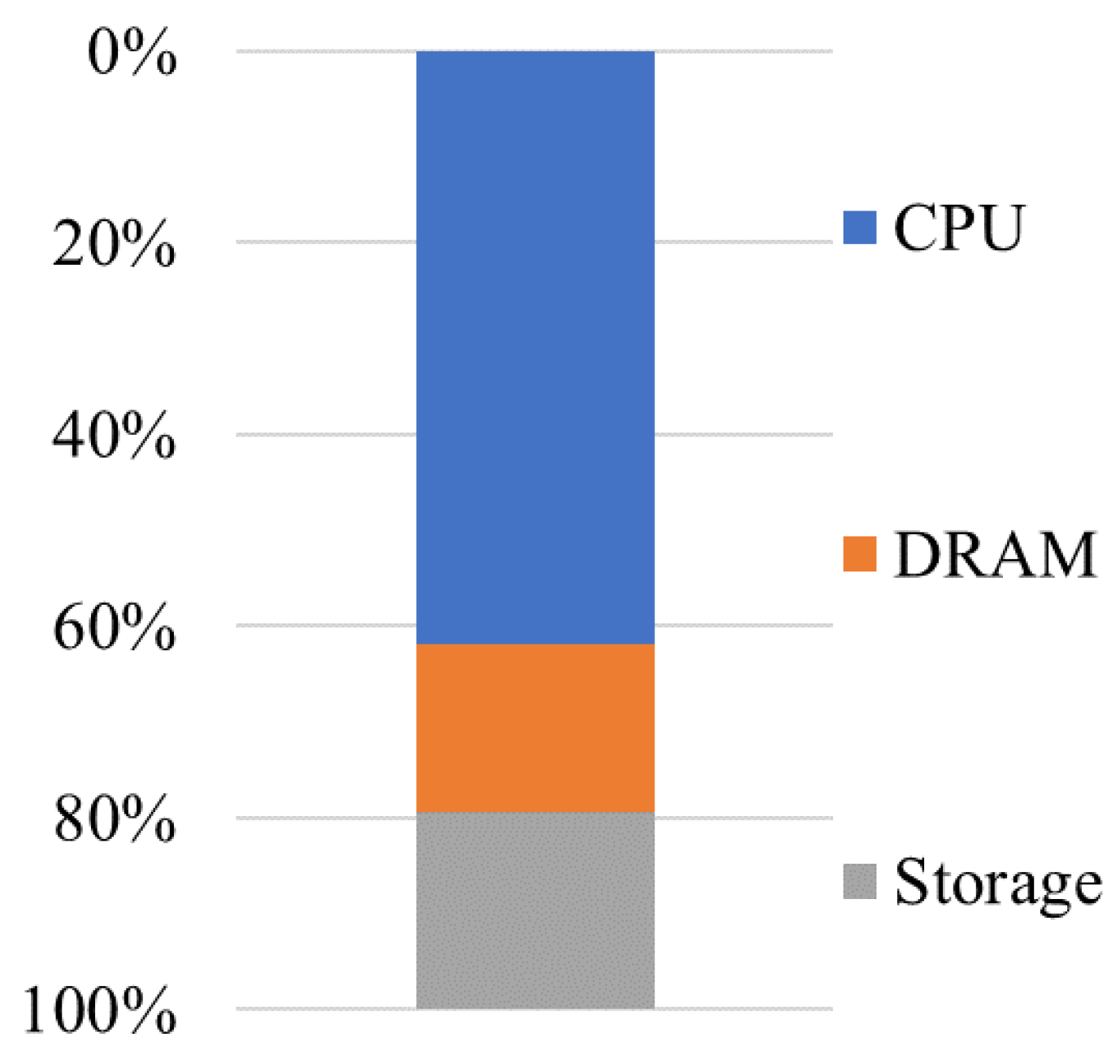
Figure 3.
Block diagram of the internal structure of an SSD.
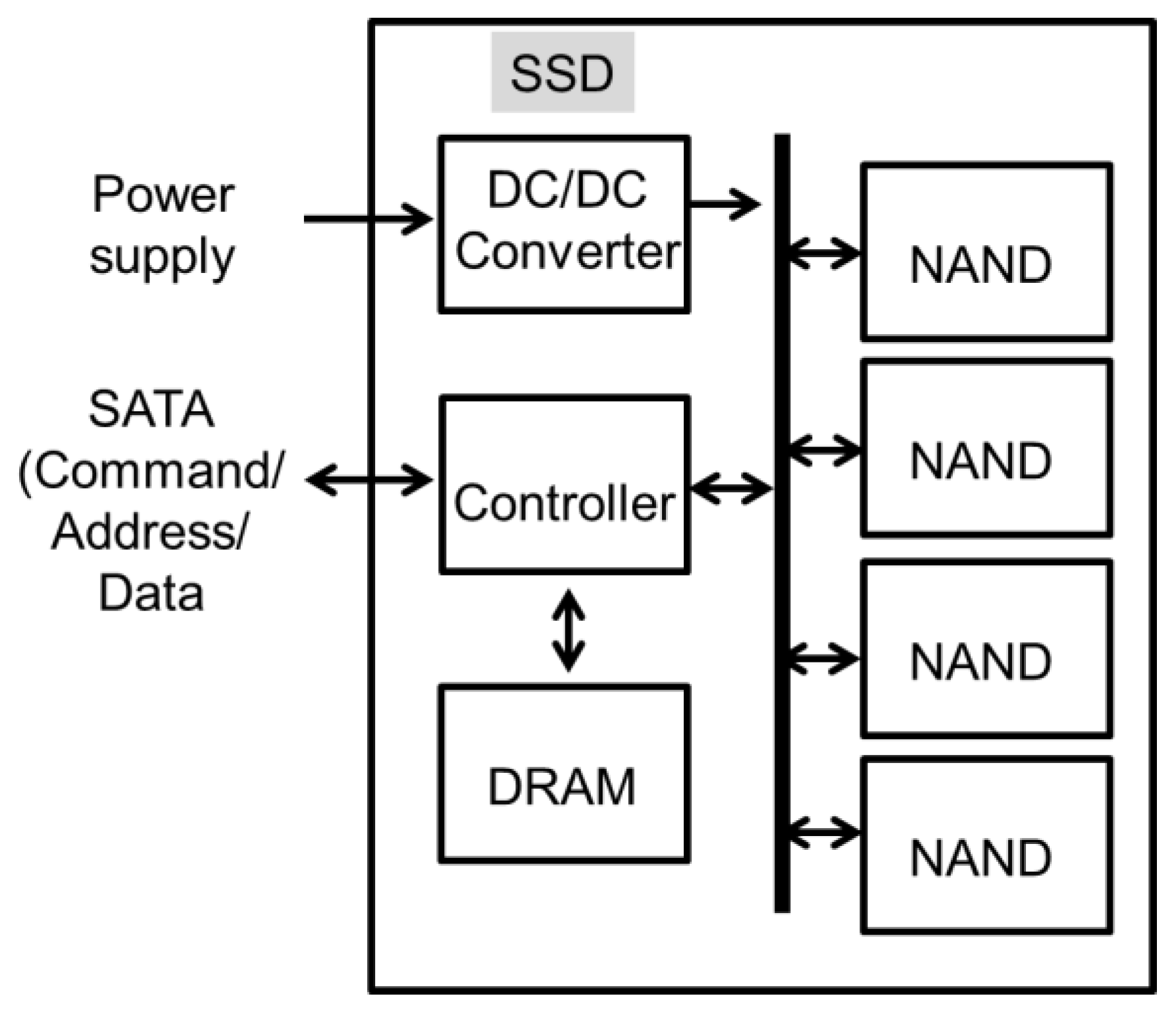
Figure 4.
IDD waveform of three dies operating in parallel.
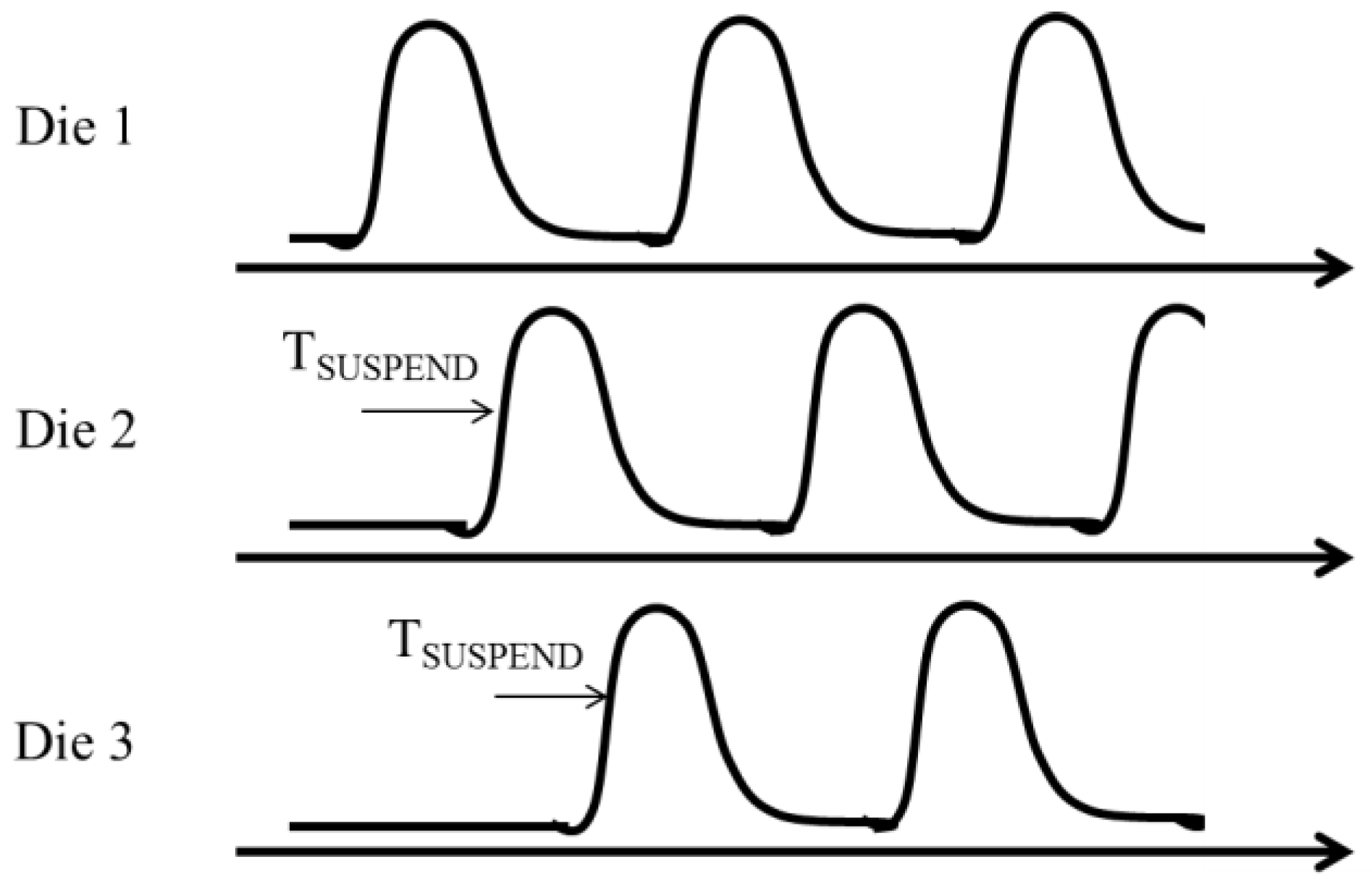
Figure 5.
Power distribution for NAND die with ONFI 1.0 (a), 2.0 (b), 4.0 (c). Proposed power distribution in NAND die (d). MA: Memory Array, SA: Sense amplifier, IO: IO buffers.
Figure 5.
Power distribution for NAND die with ONFI 1.0 (a), 2.0 (b), 4.0 (c). Proposed power distribution in NAND die (d). MA: Memory Array, SA: Sense amplifier, IO: IO buffers.
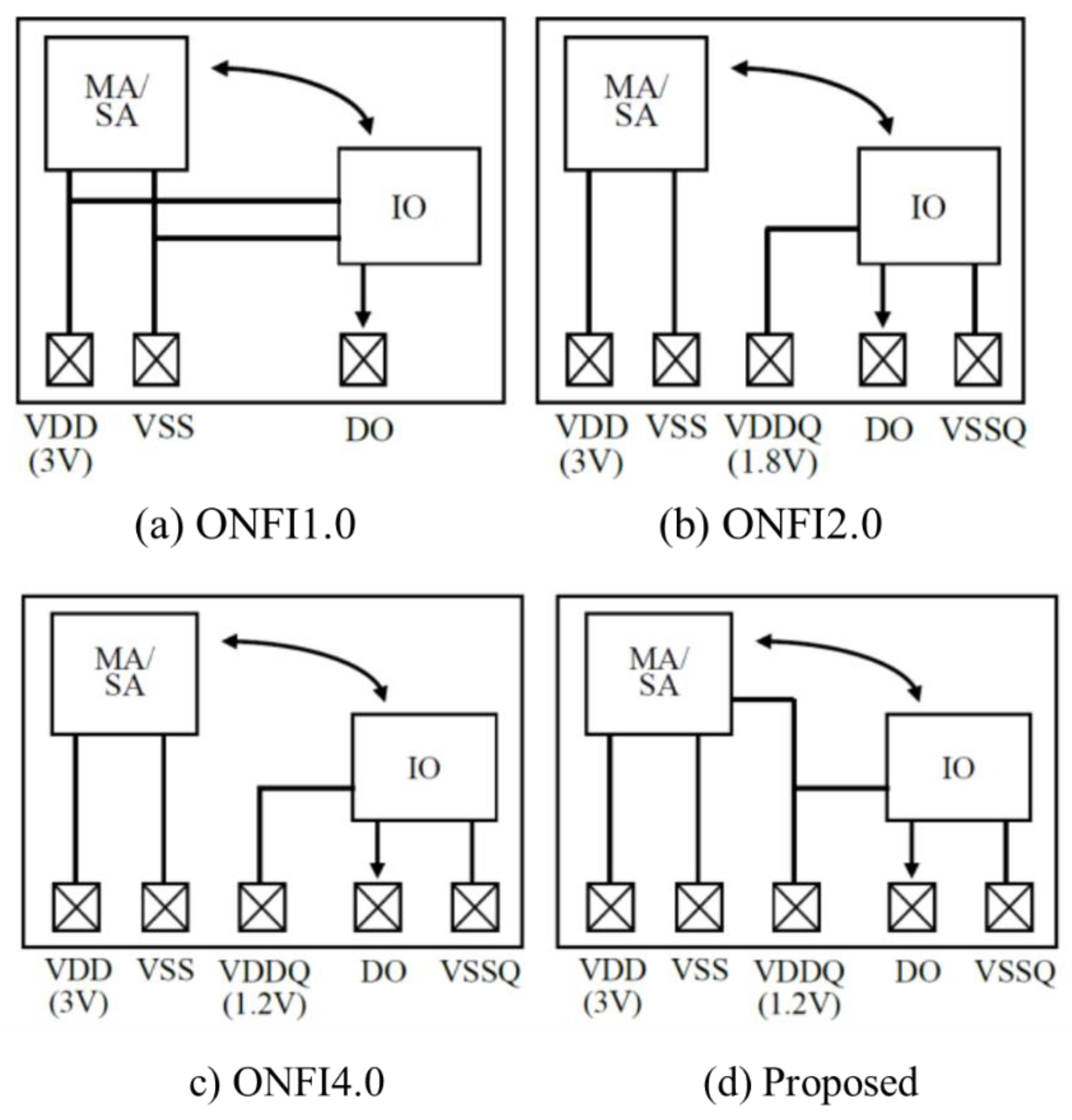
Figure 6.
BL path of NAND Flash.
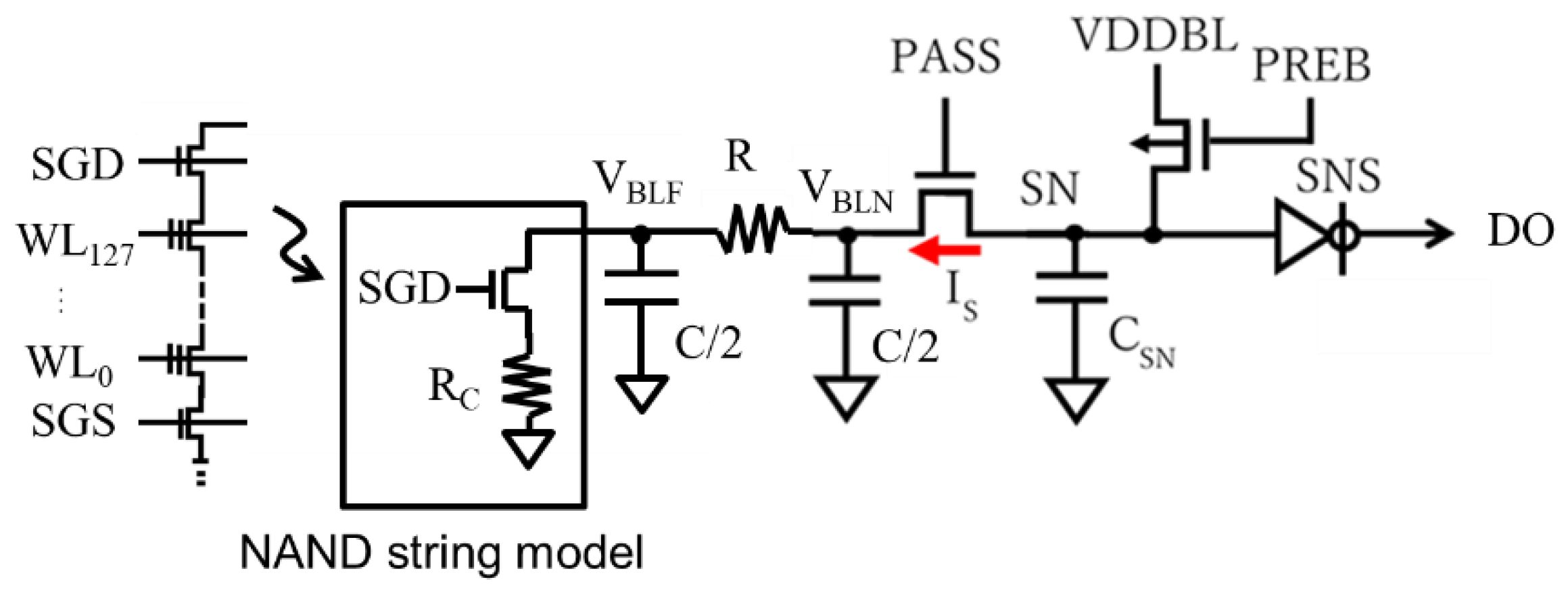
Figure 7.
Waveform for shielded BL (SBL) read operation.
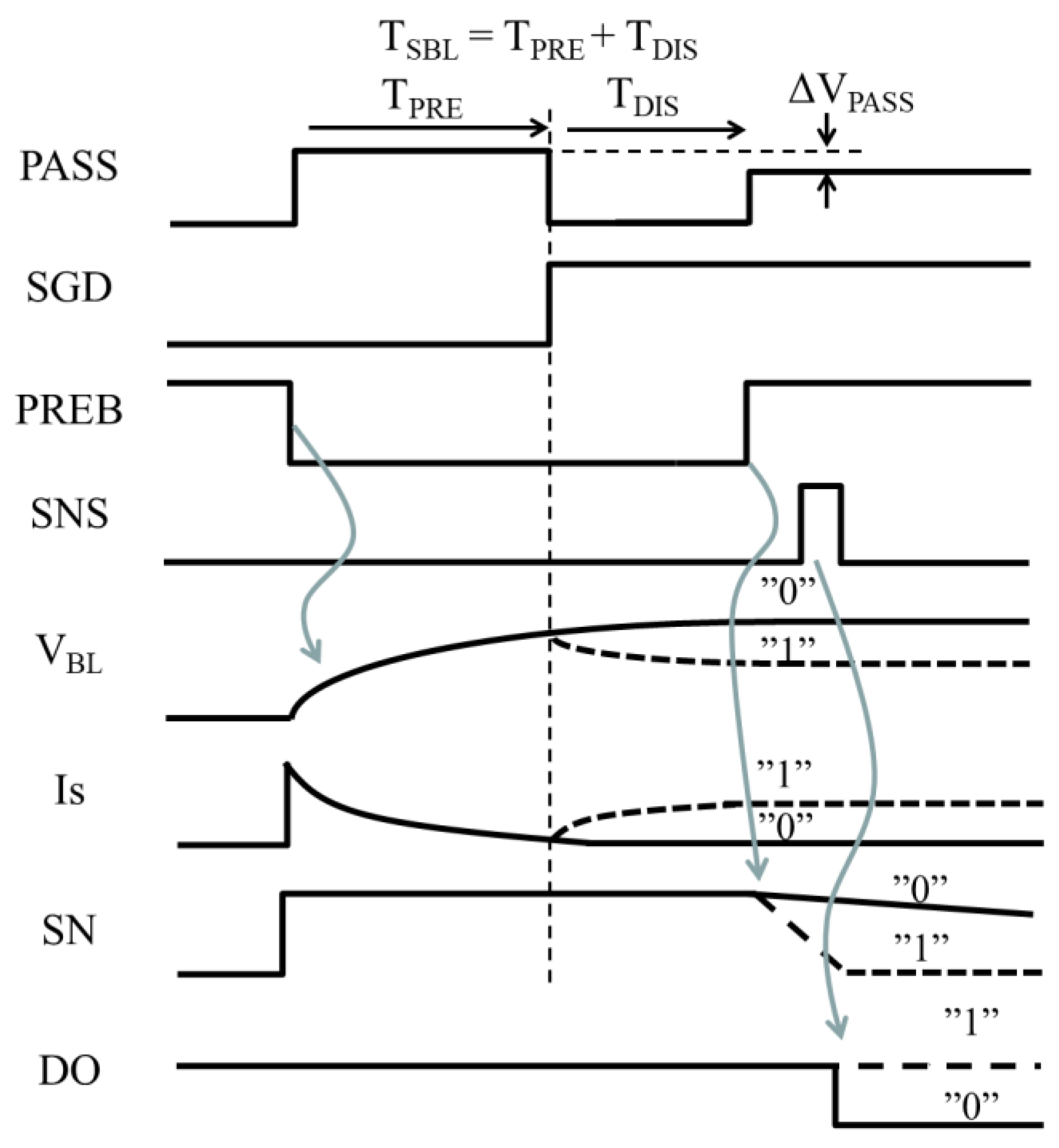
Figure 8.
Waveform for all BL (ABL) read operation.
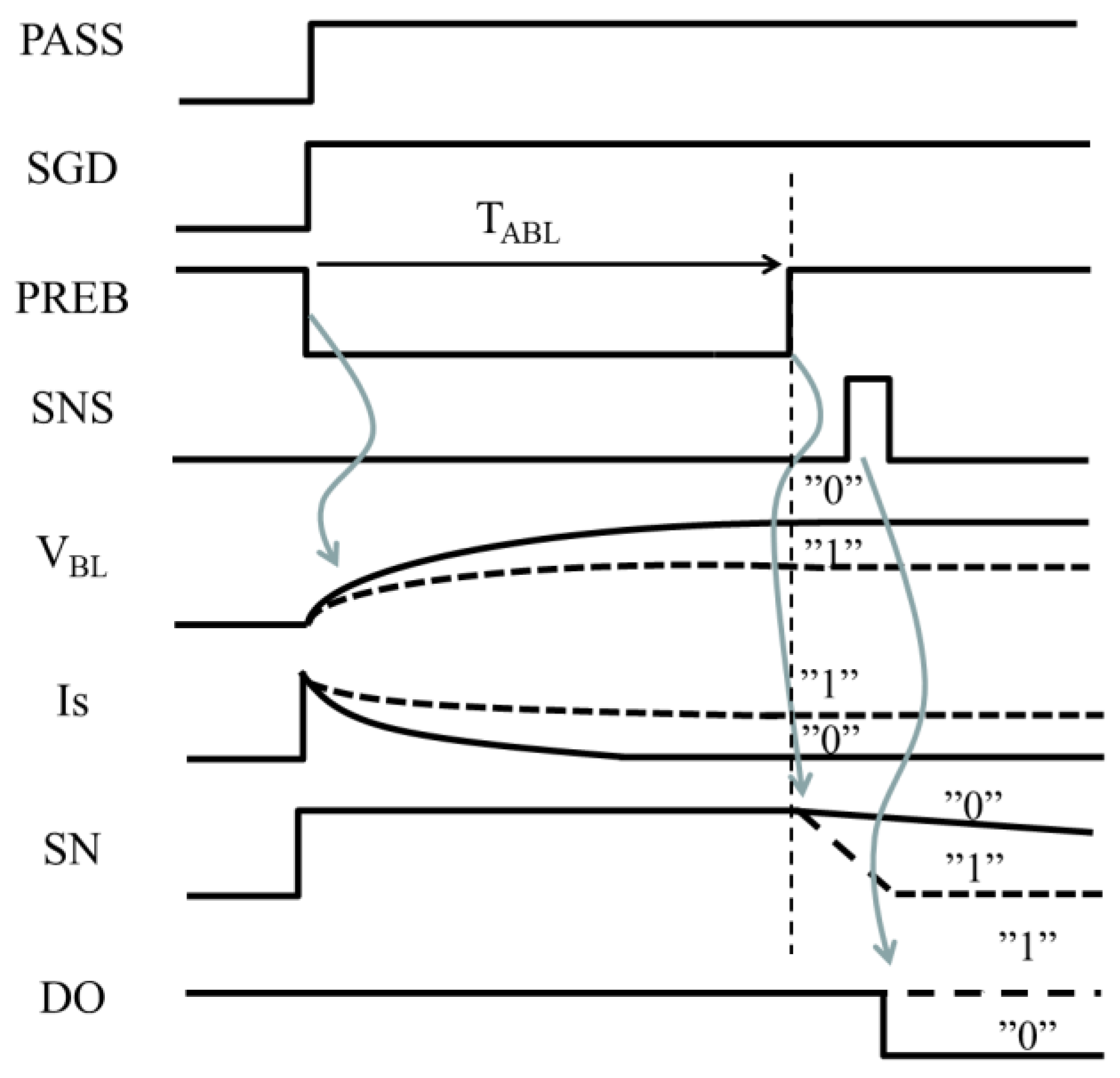
Figure 9.
Performance comparison between SBL and ABL.
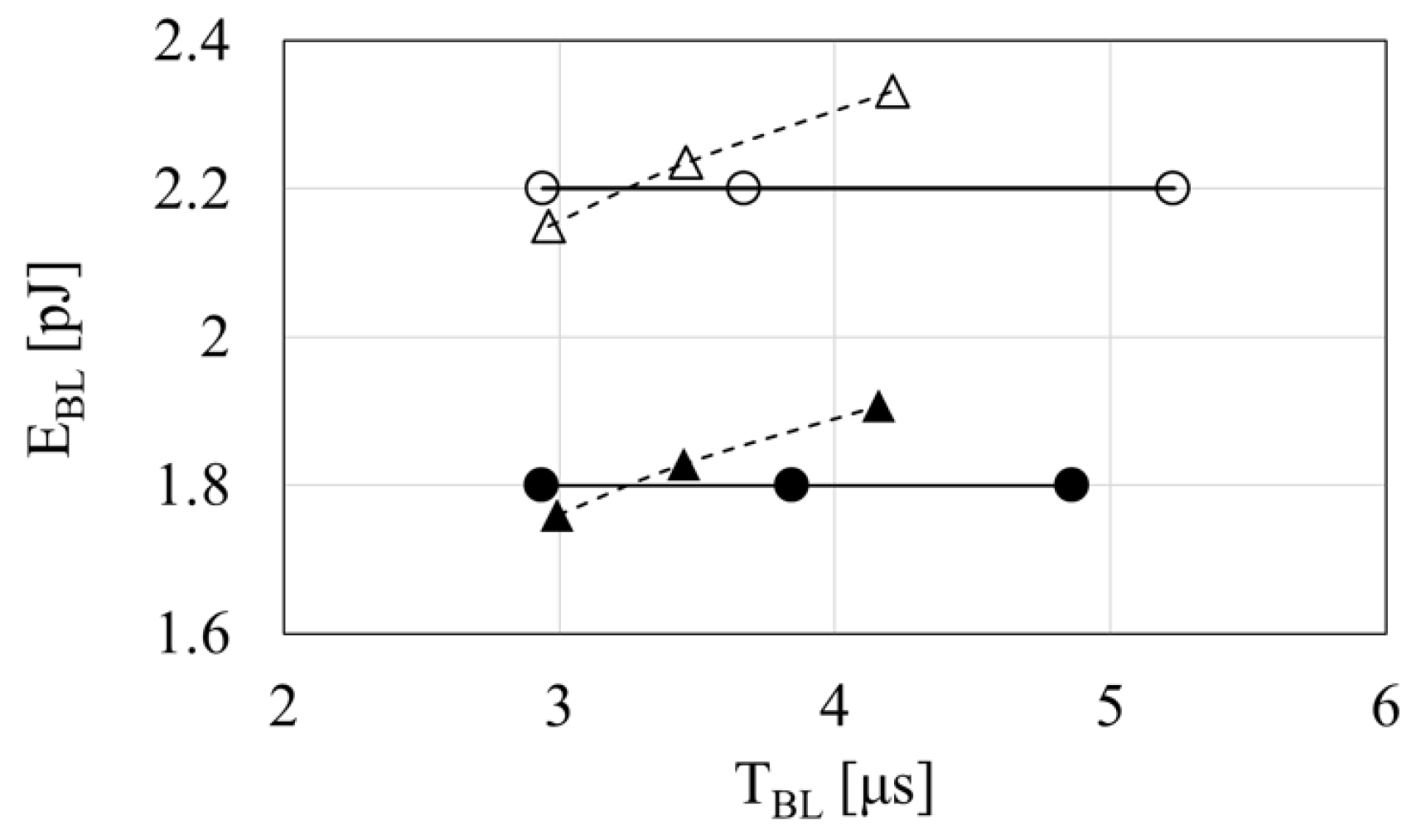
Figure 10.
Conventional (a) and proposed (b) circuits in BL path.
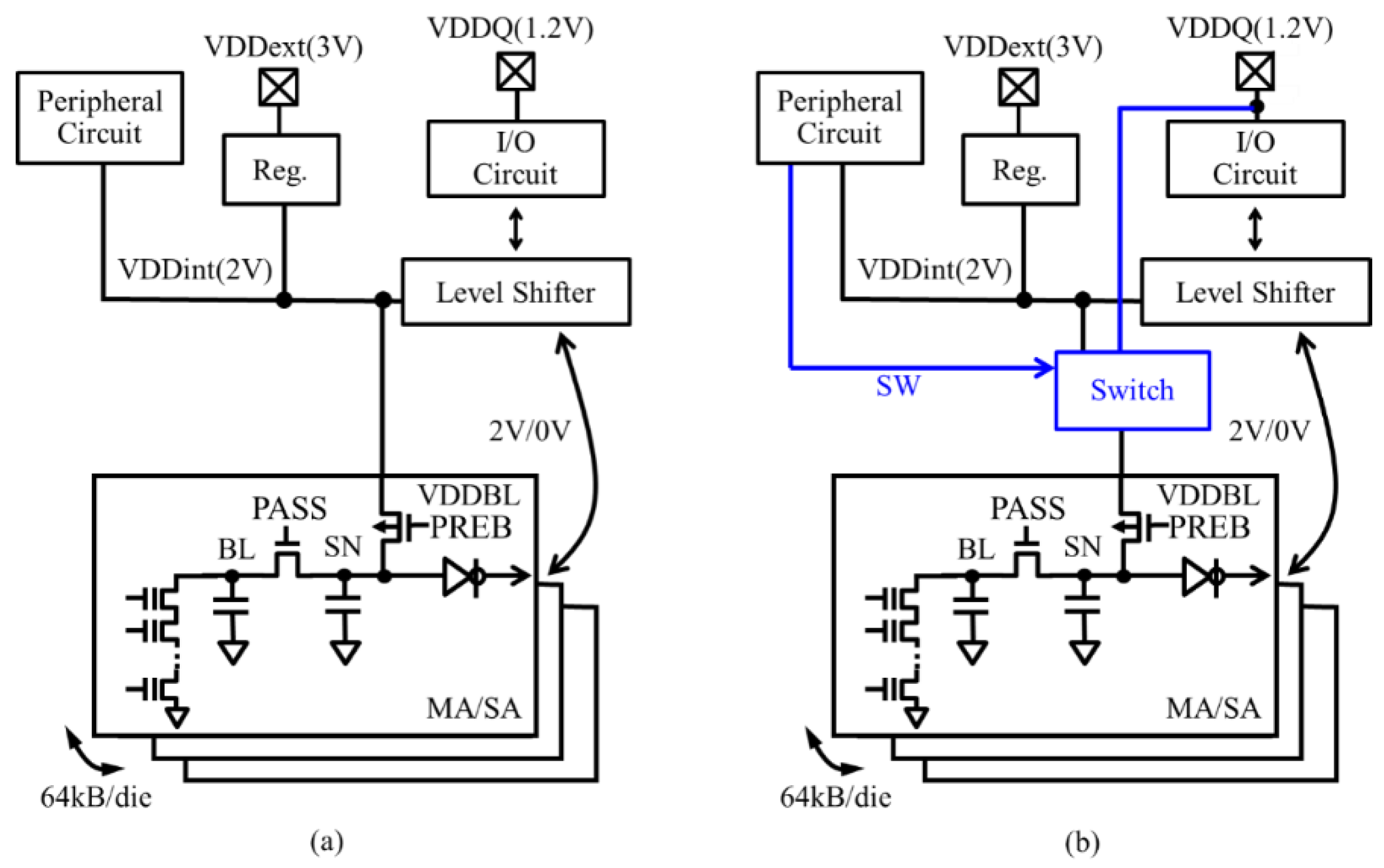
Figure 11.
Read operation waveform of conventional (a) and proposed (b) circuits.
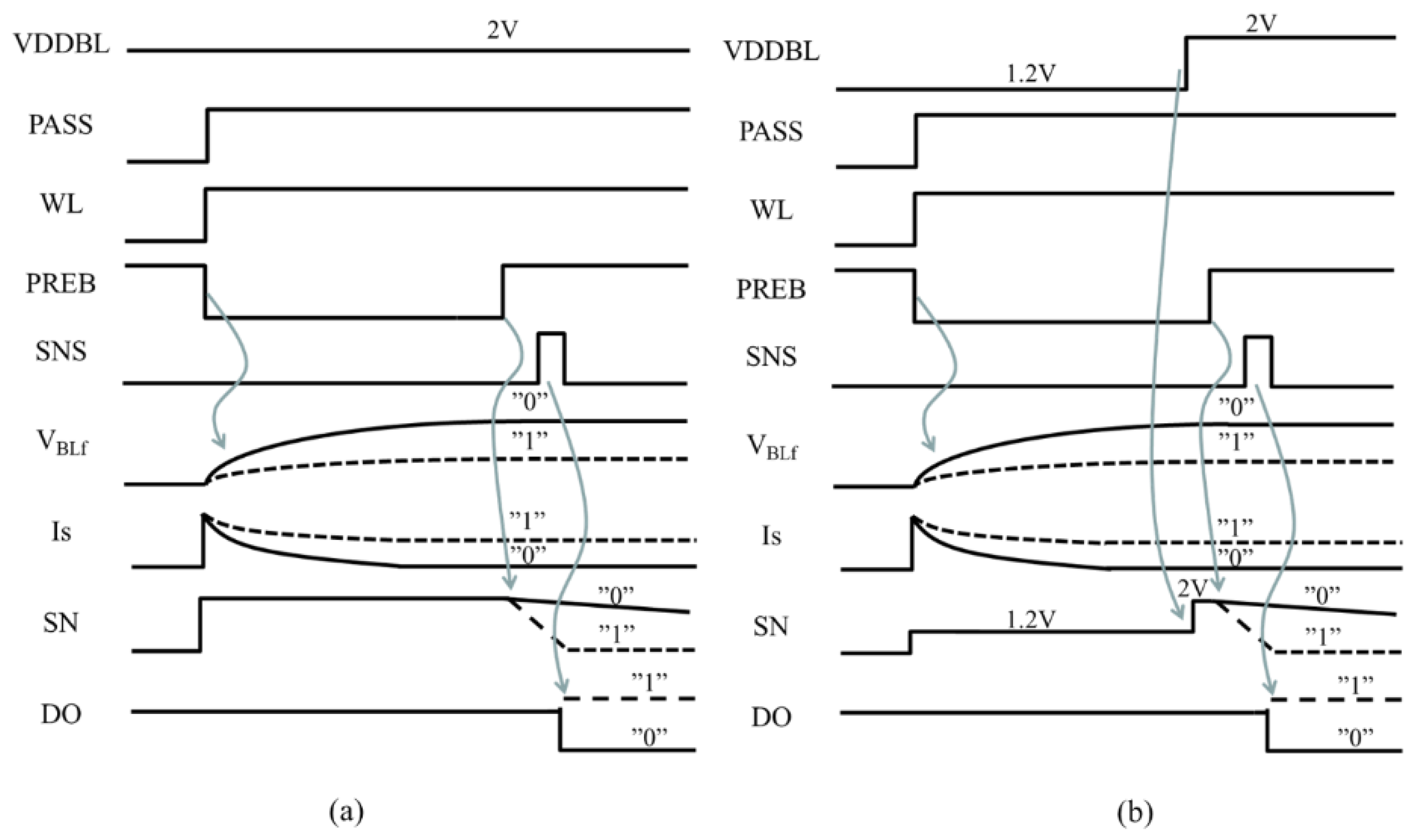
Figure 12.
Comparison of SPICE waveform: conventional in red and proposed in blue.
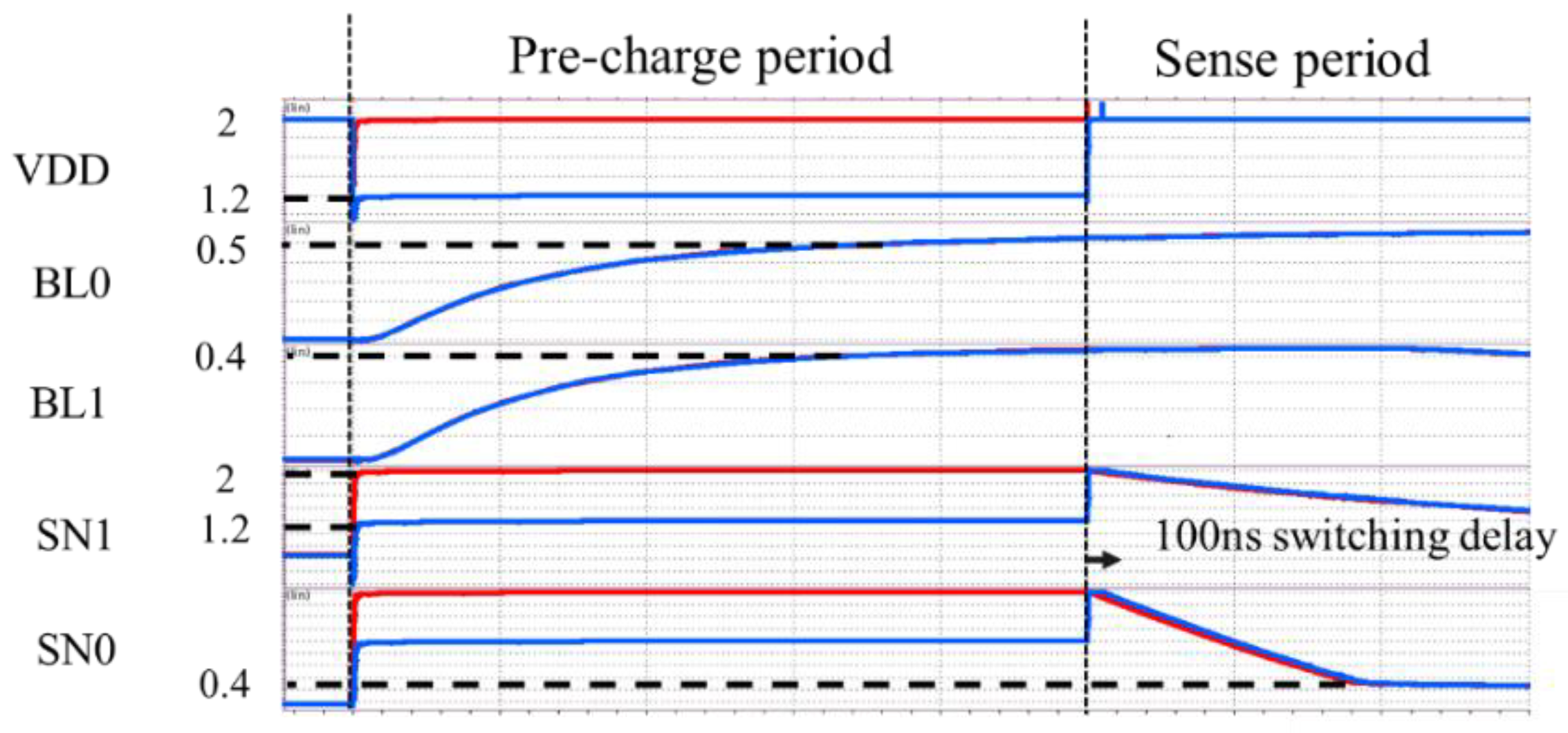
Figure 13.
Die photo.
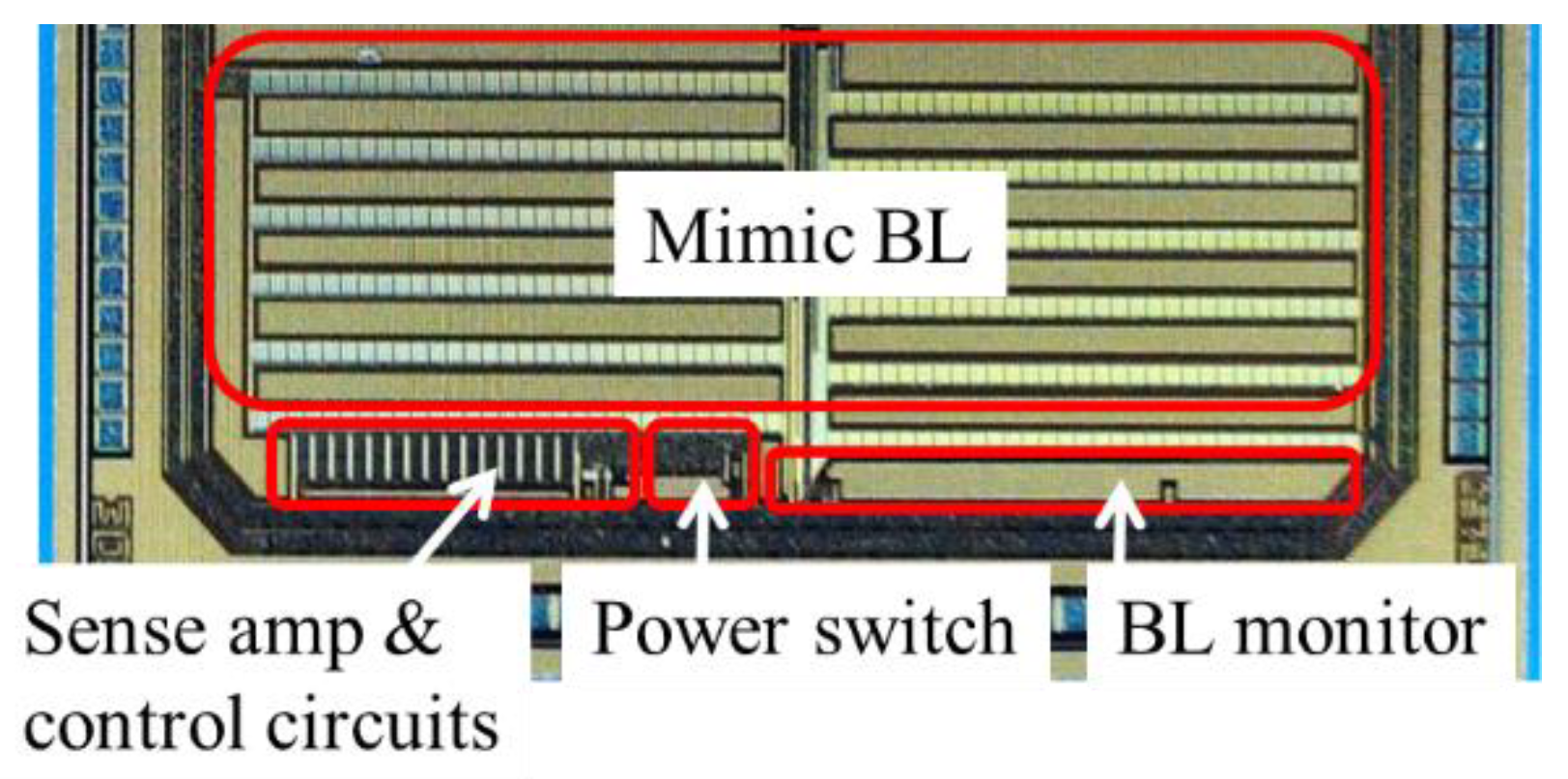
Figure 14.
Analog buffer (a) and VBL – VMON characteristic.
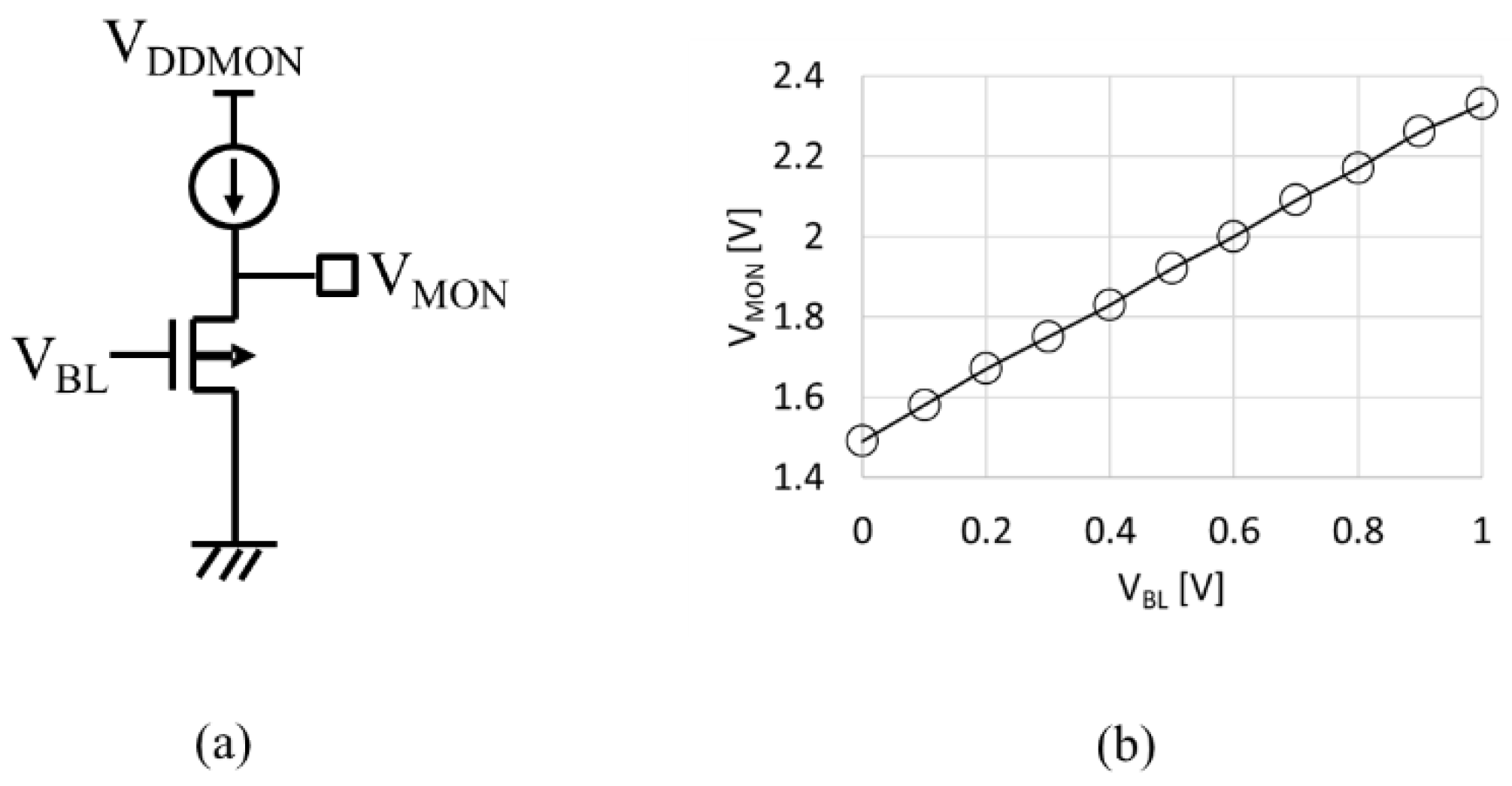
Figure 15.
(a) Simulated and (b) measured waveform.
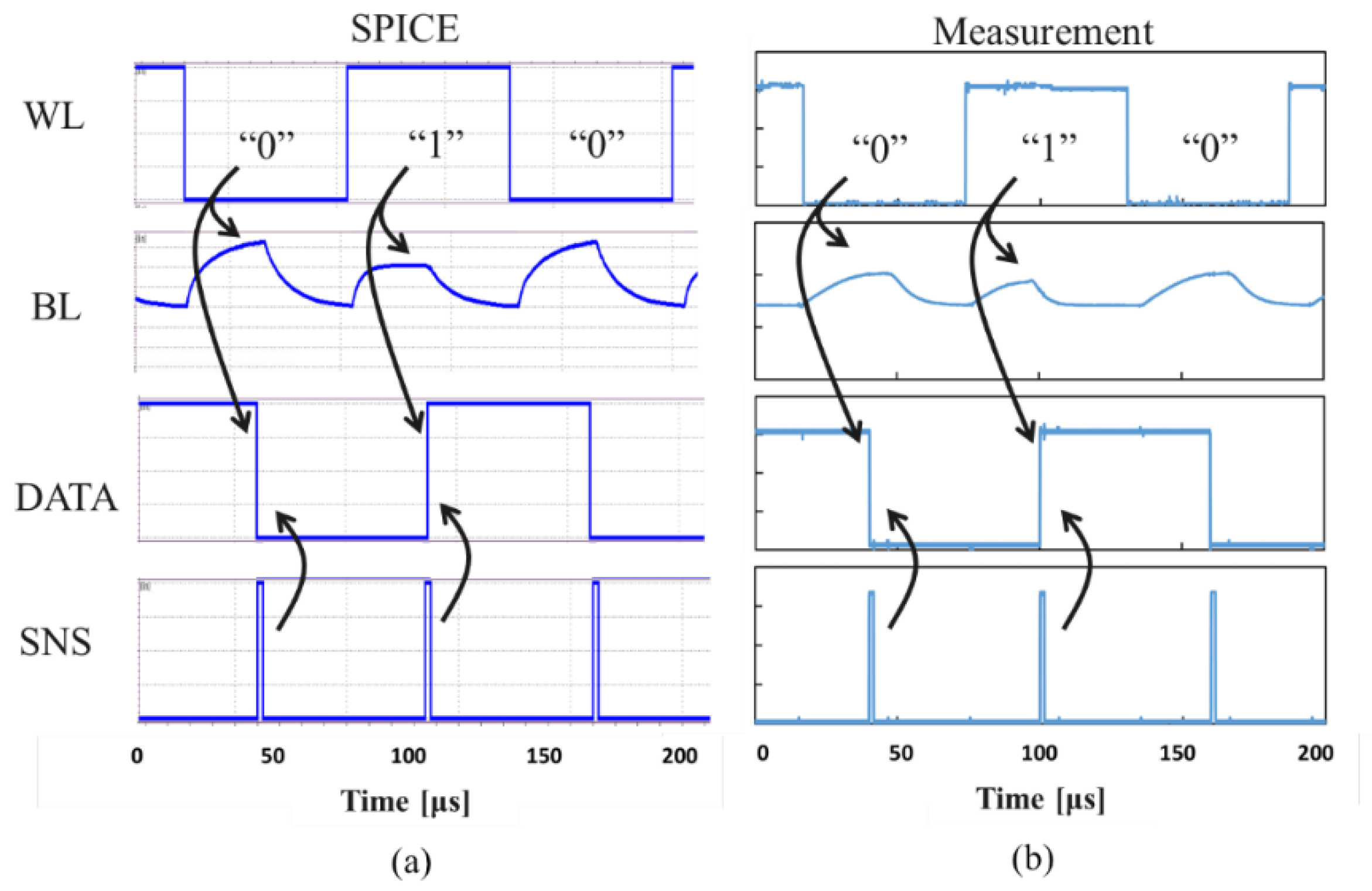
Figure 16.
Energy per cycle vs. cycle time.
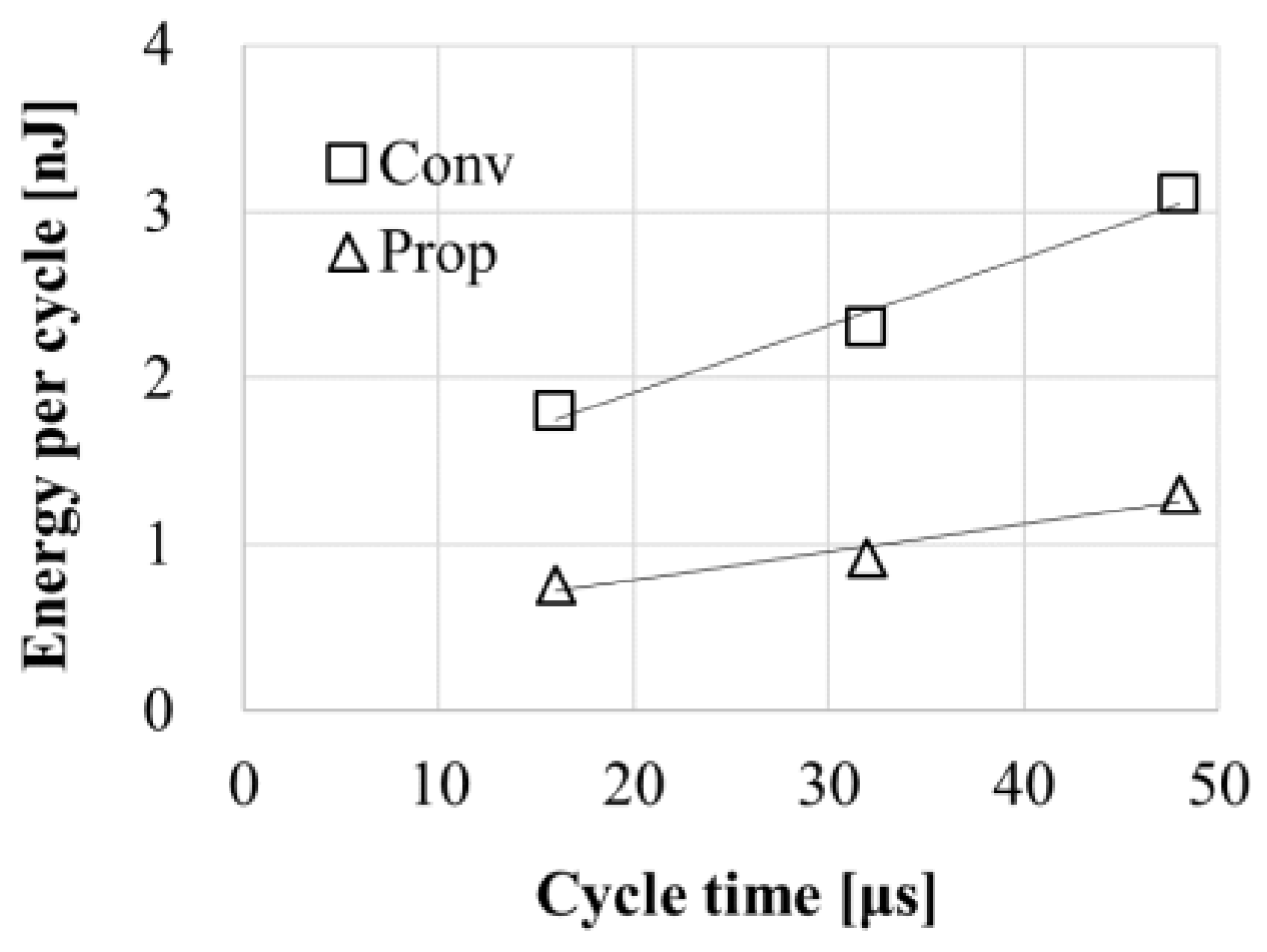
Figure 17.
(a) Energy vs. C and (b) and (b) reduction rate vs. C.
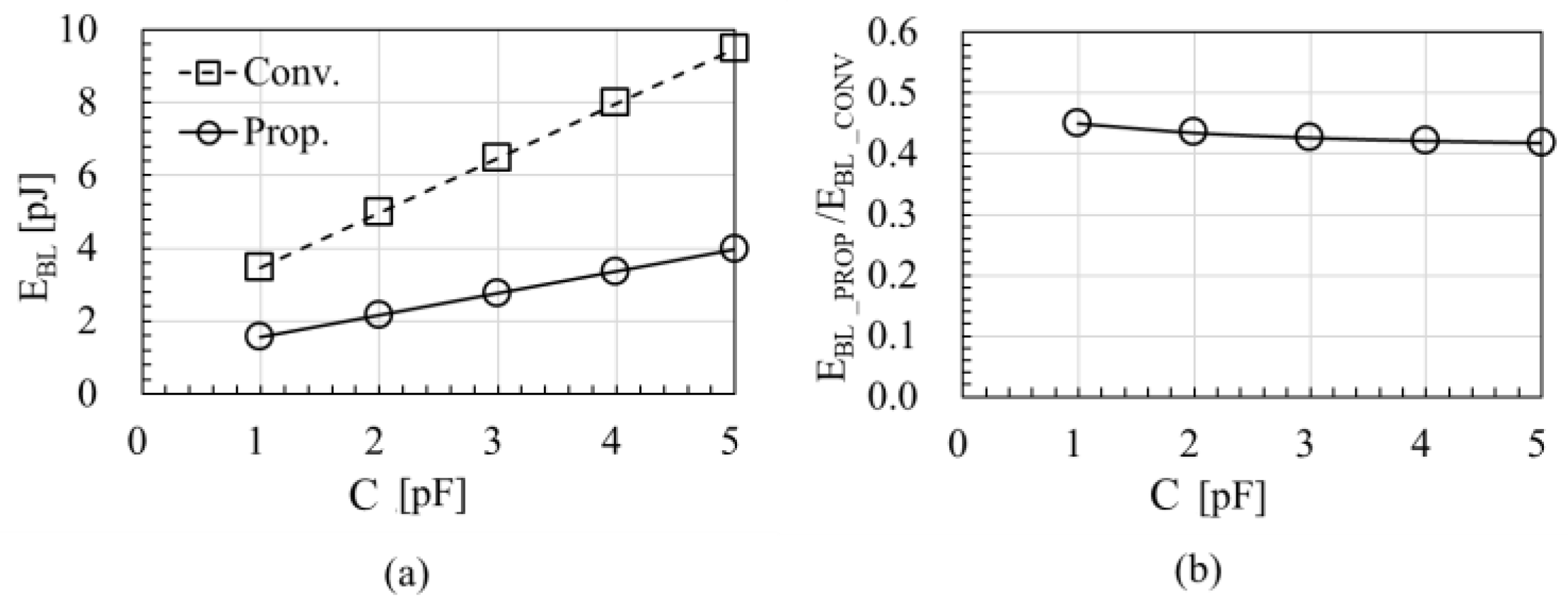
Figure 18.
Normalized energy vs. VDDQ.
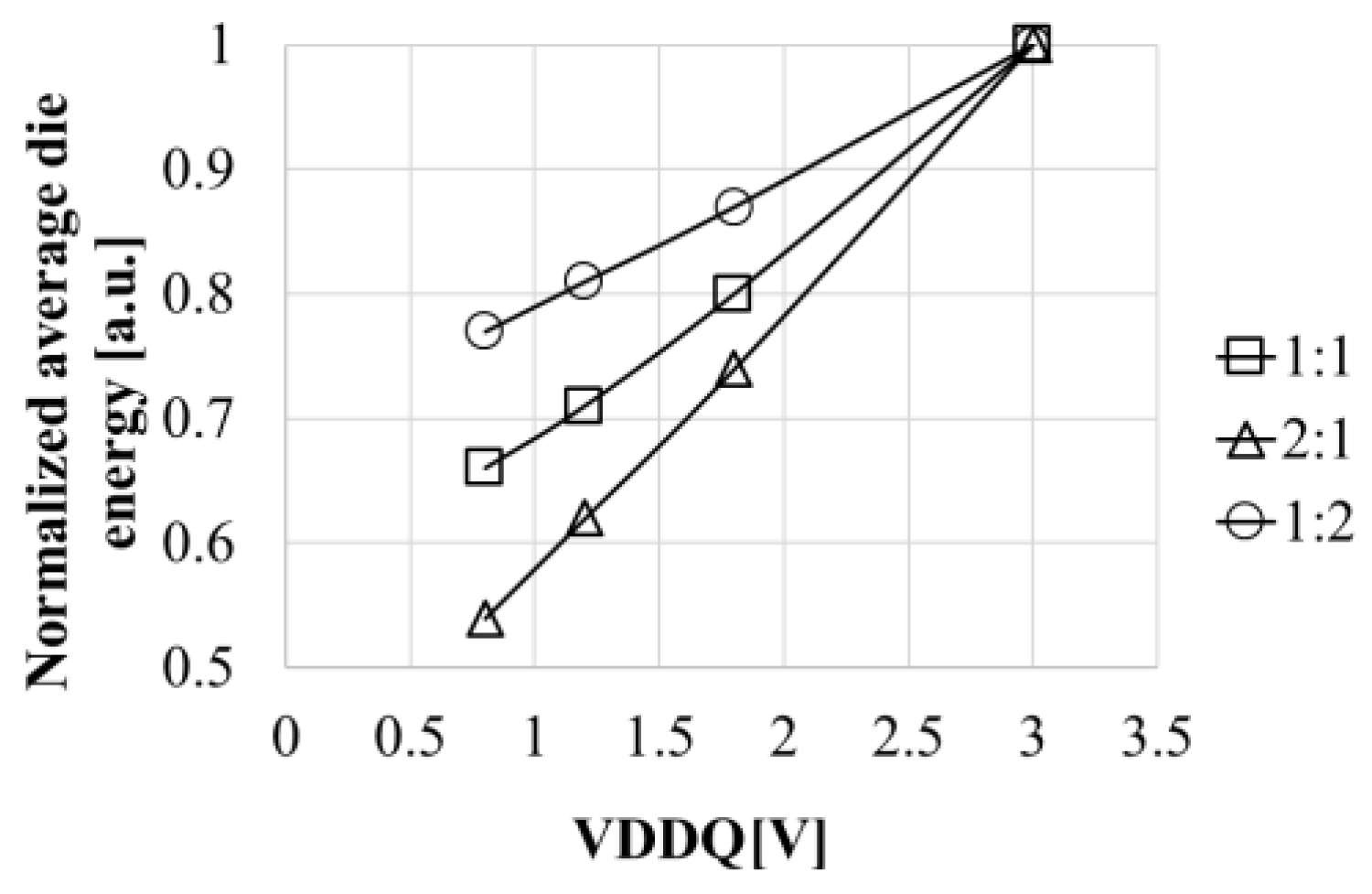

Table 1.
Condition of VBL_PRE for demonstration.
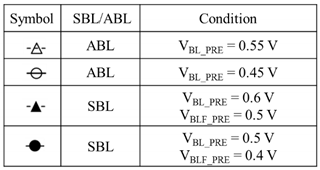
Table 2.
Device and design parameters used for circuit design.
| Parameter | Default Value |
|---|---|
| R | 3.0 MΩ |
| C | 3.0 pF |
| CSN | 0.1 pF |
| ICELL0 | 0 nA |
| ICELL1 | 100 nA |
| VDD | 3.0 V |
| VDDint | 2.0 V |
| VDDQ | 1.2 V |
| VBL | 0.5 V |
| TPC (Pre-charge time) | 5.0 μs |
| TSW (Switching time) | 100 ns |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



MDPI Initiatives
Important Links
© 2024 MDPI (Basel, Switzerland) unless otherwise stated