
Submitted:
08 February 2024
Posted:
09 February 2024
You are already at the latest version
Abstract
Recent studies have elucidated the diversity of genes encoding venom in sea anemones. However, most of those genes are yet to be explored in an evolutionary context. Insulin is a common peptide across metazoans and has been coopted into a predatory venom in many venomous lineages. In this study, we focus on the diversity of insulin-derived venoms in sea anemones and on elucidating their evolutionary history. We sourced data for 34 species of sea anemones and found sequences belonging to two venom families that have Insulin PFAM annotations (Cono-Insulin, VP302). Our findings show that both families have undergone duplication events. Members of each of the independently evolving clades have consistent predicted protein structures and distinct dN/dS values. Our work also shows that VP302 is part of a multidomain venom contig and has experienced a secondary gain into the venom system of cuticulate sea anemones.
Keywords:
Insulin-like peptides
; Cono-toxins
; Venom
; Venomics
; Toxins
; Transcriptome
; Sea anemone
; Selection
; Actinaria
; Cnidaria
1. Introduction
Venom is a biological toolkit comprised of cocktails of molecules that disrupt the physiology of an organism when it is injected (envenomated) by the organism that produced it. The delivery mechanisms, behaviors, and ecological interactions of envenomation can be studied across the animal tree of life because venom has convergently evolved across most major lineages [1]. Among known venomous organisms, Cnidaria is the oldest lineage in which venom has evolved. Cnidarians are unique among venomous organisms because they have a microscopic and decentralized venom delivery apparatus, the nematocyst. Nematocysts are made by a kind of cell unique to cnidarians (nematocytes) and are highly diverse in shape, size, and in spatial distribution across the body [2].
Among cnidarians, venom is best understood in the cnidarian subphylum Anthozoa (corals and sea anemones), and particularly within the anthozoan order Actiniaria (sea anemones). Venom is integral to the biology of sea anemones because they use venom for a variety of functions, including prey capture, defense, digestion, and intraspecific competition [3,4]. Due to this biological breadth, the sea anemone venom arsenal is highly diverse in its molecular constituents, with most species making an array of different compounds [5,6,7,8,9]. The compounds found in sea anemone venom can be broadly categorized into larger functional categories, and include auxiliary toxins, allergens and innate immunity toxins, hemostatic and hemorrhagic activity toxins, mixed function enzymes, voltage-gated channel toxins, pore-forming toxins (cytolysins), protease inhibitors, and actiniarian toxins of unknown function [4,9,10,11]. At a genomic level, the genes encoding venom in any given species can vary in identity and in abundance, with abundance reflecting multiple copies of genes: [12] or differential transcription (variation in normalized expression)[13] or both.
Studies of genes encoding venom in sea anemones have shown that genes and gene families evolve under purifying selection [14,15]. This is distinct from genes and gene families for venom families in other lineages, where diversifying selection predominates [16,17,18]. This initial assessment of evolutionary trends in the genes for venom in sea anemones was based on a limited number of species and only members of the superfamily Actinioidea. Actinioidea is estimated to have diverged from other lineages of sea anemone approximately 450 mya [19], making it significantly older than venomous lineages like snakes and cone snails, which are estimated to be <100mya [16,17,18]. More recently, the taxonomic scope of study of evolution in venom genes of sea anemones has expanded, but the functional breadth of the venom families considered remains limited, emphasizing neurotoxins [12,20,21,22].
For sea anemones, as for many groups, the biomedical potential of venom has driven their study. This likely has played a role in the emphasis on neurotoxins, whose analogs in snakes and cone snails have strong potential for pharmaceutical application [23]. The peptide SHK1, originally isolated from the actinioidean Stichodactyla helianthus, has been explored for its potential in autoimmune disorders (reviewed in [22,24]) and its therapeutic potential has led to studies of its structure [25], function [24], and diversity [12,22,26]. Other sea anemone venom constituents, like the amylase inhibitors Helianthase [27] and Magnificamide [28] represent novel biological solutions to common metabolic problems like the breakdown of carbohydrates[29]. Yet other molecules within sea anemone venoms, like NV1 [22], have both genetic and structural similarities to human peptides and proteins and thus may offer biomedical insights.
Insulin is a widely-occurring and well-studied peptide in vertebrate systems[30,31]. It is also found in non-vertebrates, although only a handful of studies have examined the function of insulins across the tree of life. In amniotes, insulin is produced by the pancreas and functions to regulate blood sugar levels by promoting glucose uptake and the absorption of glucose from the blood into liver, fat, and skeletal muscle cells. In non-vertebrates, insulin-like molecules are referred to as Insulin-Like Peptides (ILPs) and typically hold distinct functions. In insects, ILPs regulate metabolism and growth [32,33] and are a key factor in reproduction and molt signaling [34]. In nematodes, ILPs act as pathway antagonists, stopping L1 arrest during development[35]. In mollusks, ILPs have been tied to neural regulation [36]. In a few lineages, including bees [37], monotreme mammals[38,39], snakes [40,41], lizards [42], and cone snails [43,44], insulin has been recruited into the venom cocktail, where it may block site-specific channels and/or act indirectly on prey by disrupting insulin homeostasis. The best-studied ILPs in a venomous system is in marine cone snails [17,43,44,45], in which ILP acts antagonistically towards prey by causing hypoglycemic shock, enabling the snail to slowly eat their prey [45].
Sea anemones produce ILPs that closely resemble those of cone snails [46]. These toxins are referred to as Cono-Insulins [46,47], distinct from the neurotoxic conotoxins also found in cone snails. In their study of venom of the undescribed actinioidean sea anemone, Oulactis sp., Mitchell and colleagues [46] found that Cono-Insulins showed signs of binding to both Kv1-3 binding sites and insulin growth receptors. Sequences encoding Cono-Insulins also occur in the genome of Nematostella vectensis [48]
Cono-Insulin is transcribed as a peptide with three chains (A+B+C) that undergoes post transcriptional modifications to cleave off the C chain and form a mature pro-peptide (A+B) [36]. The structure of the peptide offers an opportunity to examine selection across its functional chains. Work by Gibbs [16], and Jouiaei[15] and their colleagues point to the possibility of certain regions in venom encoding genes evolving rapidly under the influence of adaptive selection.
The only other known instance of an insulin-derived toxin is the protein VP302, originally discovered in the transcriptome of a swimming scorpion [49]. VP302 has also been identified in other cnidarians, including in transcriptomes of four species of Cerianthiaria [50], in the genome[51] of Hydra vulgaris, and in clownfish-hosting sea anemones [9]. Studies which annotate venom coding genes functional families have found that VP302 match to the protein family (PFAM) insulin receptor growth factor [9,50].
The diversity and evolutionary history of ILPs in the venom of actiniarians is poorly characterized [47]. The commonness of Cono-Insulin transcripts in species that span the sea anemone phylogeny suggests that ILPs may be found across all sea anemones, but their diversity is undocumented, both within taxa and across the breadth of Actiniaria. Fu and colleagues[47] interpret sea anemone ILPs to have a single origin relative to other metazoans, but their study did not include Cono-Insulin sequences from non-anemone cnidarians or exemplars of VP302. The breadth of occurrence of VP302 and its evolutionary history within sea anemones or Cnidaria is unknown.
Previous work on venom genes in actiniarians predict that ILPs will evolve under negative selection [14,15], but whether generalization from neurotoxins to ILPs is appropriate remains untested. Furthermore, genes encoding venom may undergo episodic and site-specific selection [14,15], and punctuated equilibrium may represent a more appropriate model in at least some actiniarian neurotoxins [12,14].
In this study, we document the diversity of ILPs in the transcriptomes of 34 species of sea anemone. Additionally, we model the structure of exemplar ILPs based on sequences from each of the major clades of actiniarians from which we document ILPs. We analyzed the ILPs we recovered to infer 1) the evolutionary history and diversity of each type of ILP within Actiniaria and 2) the mode of selection for the genes encoding ILPs in sea anemones. We explicitly consider both kinds of ILPs previously identified in sea anemones, Cono-Insulins and VP302.
2. Results
2.1. Identification
We recovered ILPs in 28 of the 34 species we studied. We found no sequences that matched ILPs in the transcriptome of the sole representative of superfamily Actinostoloidea, Stomphia coccinea (family Actinostolididae). We also found no ILPs in transcriptomes from the actinioideans Epiactis prolifera and Macrodactyla doreensis (both family Actiniidae), nor in those of the metridioidean Lebrunia danae (family Aliciidae).
The ILPs we recovered from across Actiniaria matched two previously described venom types: 1) Cono-Insulin toxins found in cone snails [52,53]; and 2) Venom Protein 302 (VP302) originally described in Lychas mucronatus (Chinese swimming scorpion). Transcripts with high match to Cono-Insulins were recovered in 20 species. Transcripts with high match to VP302 were recovered in 21 species. Nineteen species had transcripts of both Cono-Insulins and VP302, and five species had no transcripts associated with either Cono-Insulins or VP302 (Table 1). We recover multiple isoforms for both Cono-Insulins and VP302, which our phylogenetic analyses designate as belonging to separate clades (see below). In seven of the 21 species having a VP302 transcript, we recover two isoforms; in ten of the 20 species having a Cono-Insulin transcript, we recover multiple isoforms (Table 2).
Transcripts that closely match Cono-Insulins were transcribed as a singular domain transcript of 107 amino acids, with a signaling region at amino acid (AA) position at 1-26 and the mature peptide at AA position 27-107. For our phylogenetic and selection analysis, we only used the functional Cono-Insulin (Chains A+B), which contains six conserved cystines. From UniProt, we sourced transcripts of other metazoans known to produce Cono-Insulins and used them in our alignment (Figure 1). All the reads showed high levels of similarity across all taxa. Among sea anemones, we found that chain A had more conserved AA than chain B (Figure 1).
VP302 was found within a multi-domain transcript with 1-4 domains. The multi-domain transcript maps to a region of the genome of Exaiptasia diaphana (GCA_001417965.1) that is un-scaffolded and is annotated as a four-domain Kazal protein (Figure 2). Considering the model sea anemone species Exaiptasia diaphana [venom302_TRINITY_DN2905_c0_g1_i25] as an example, VP302 has a signaling region at AA 1-14 and an insulin-like growth factor-binding proteins (IGFBP) domain from AA 15-96. A BLAST search of this region on UNiPROT returned matches with IGFBP proteins from a range of taxa, but its top hit (bit score 71.1, E value 5e-13) was to A0A8B7DI77_HYDVU, a sequence from the hydrozoan cnidarian Hydra vulgaris annotated as “Venom protein 302-like.” When aligned across all sea anemones, VP302 was found to have a conserved region at positions 37-67 and a total of 11 conserved cystines (Figure 3).
VP302 is followed by a Kazal domain protein, encoded at AA position 100-167 in the transcript from the sea anemone E. diaphana. The top hit for this region (bit score 182, E value of 6e-52) is to A0A913YN61_EXADI Uncharacterized protein from E. diaphana. Its top hit with an annotation is A0A8B6XI09_HYDVU BPTI/Kunitz domain-containing protein 4-like (bit score 179, E value 5e-10) from Hydra vulgaris. An intron occurs at AA position 168-195. Following the Kazal protein, at AA 196- 256, is a region that matches a PFAM domain Antistasin; the BLAST search of UNiPROT had its top hit (bit score 49.1, E value 8e-05) A0A817K5N8_9BILA, an Antistasin-like protein from an unknown rotarian protist. Antistasin is better known as blood coagulation factor Xa/proclotting enzyme inhibitor and was previously noted as a possible venom constituent in clownfish hosting anemones [9]. The region from AA 257-314 had a PFAM annotation of BPTI/Kunitz domain; its top hit (bit score 73.3, E value of 1e-14) via a BLAST search of UNiPROT was to A7SDB9 A7SDB9_NEMVE, a BPTI/Kunitz inhibitor from the sea anemone Nematostella vectensis. BPTI/Kunitz domain proteins are also known as venom Kunitz-type proteins.
In all sequences examined here, the four exons occurred in the same order: IGFBP (VP302) > Kazal > Antistasin > Kunitz_BPTI. The studied species of sea anemone show variation in number of transcripts, the length and sequence of the elements within the multidomain transcript, and the number of venom genes within those transcripts (Table 2). We found only one deviation from this canonical order: one transcript from Actinia tenebrosa [A0A6P8HV62_ACTTE] lacked an Antistasin and had a tandem repeat of Kunitz_BPTI. All other transcripts from Actinia tenebrosa followed canonical order, even when they varied in the number (occurrence) of genes within the multidomain transcript.
2.2. Phylogenomics
We find Cono-Insulin genes distributed into four clades (Figure 4). Each clade includes genes from species belonging to multiple superfamilies, but in no clade does the gene tree match the expected species tree. The earliest branching clade, denoted Clade 3, is sister to the remaining three lineages and contains the fewest sequences, with genes from the hydrozoans Hydra and Clytia and four species of actiniarians: the metridioideans Diadumene lineata, Telmatactis australis, and Triactis producta and the actinioidean Condylactis gigantea (Figure 4). Clade 2 is the most species-rich clade, with sequences from 16 species; Clade 1A has sequences from 13 species and Clade 1B has sequences from 11 species. Clades 1 and 2 include only sequences from Anthozoans, with transcripts from the scleractinians Pocillopora damicornis and Stylophora pistillata recovered in Clades 1 and 2 (Clade 1B: S. pistillata; Clade 2: S. pistillata, P. damicornis). In general, there are more shared species between Clade 1 and 2 than between Clades 1A and 1B: Clades 1A and 1B share only two species; Clades 1A and 2 share nine species, and Clades 1B and 2 share six species. The metridioidean Metridium senile and the actinioidean Heterodactyla hemprichii are the only species with transcripts in Clades 1A, 1B, and 2. No species has sequences in all clades, or in Clade 1, 2, and 3.
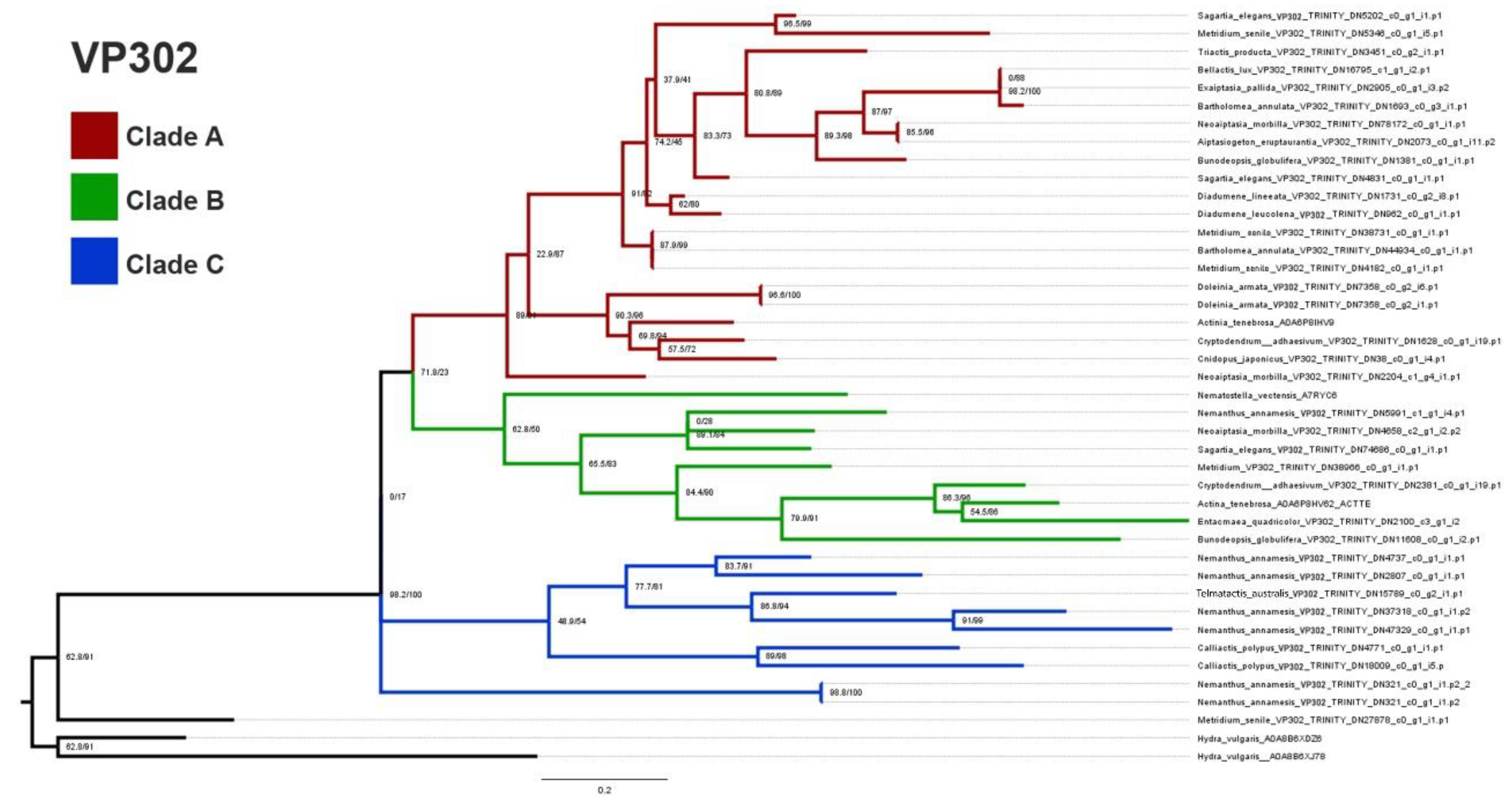
The gene tree from our phylogenomic analysis includes three clades of sequences for VP302 (Figure 5). Clades B and C are more closely related to each other than either is to Clade A, but precise relationships among the three clades are unclear. Clade A has the fewest number of sequences and the least diversity in terms of species, including only three species, all members of the metridioidean subclade Cuticulata: Nemanthus annamensis, Calliactis polypus and Telematics australis. Clades B and C both include representatives from Actinioidea and Metridioidea and in those clades, the gene trees largely reflected relationships expected based on the species phylogeny. Clade B has sequences from nine species and Clade C has sequences from 15 species. Overlap in terms of the species that contribute sequences to each clade is greatest between Clades B and C, which share six members; Clades A and B share one species, and Clades A and C share none. Reads which in Clade C only contained sequences that only coded for VP302 and not any multidomain proteins.
Figure 5.
Genes tree of VP302. Tree depicts each clade in a distinct color. Clade A and B are interpreted to have arisen via a duplication event, whereas Clade C implies and independent lineage of VP302.
Figure 5.
Genes tree of VP302. Tree depicts each clade in a distinct color. Clade A and B are interpreted to have arisen via a duplication event, whereas Clade C implies and independent lineage of VP302.
2.3. Predicted Protein Structure
Across the four clades of Cono-Insulins, the transcripts we used to predict structure did not converge on a single structural template (Table 3). Furthermore, no one clade had any specificity to any one template. We found that templates based on AlphaFold-predictions were used for transcripts belonging to Clade 1B from Nematostella vectensis and Oulactis sp. and for transcripts belonging to Clade 2 from Oulactis sp.
In general, predicted Cono-Inulin protein structures that did not use an AlphaFold template had low Global Model Quality Estimate (GMQE) scores (<.50). The three predicted Cono-Ins which used AlphaFold models have a GMQE score of (>.60) but (<.66). Sequence identity followed the same pattern, with non-AlphaFold sequences having a score of (<.40) and AlphaFold templates having (>.80). Coverages varied across all predicted proteins, but generally with scores (>60) see Table 3.
We found that predicted proteins structure for Cono-Insulins fell into two categories, those that used Swiss-Prot templates and those that use AlphaFold templates. The predictions that used a Swiss-Prot template all are inferred to have two canonical loops that form a large singular loop that folds back to itself and a 3-4 loop barrel. The proteins that were modeled on an AlphaFold template differed by not folding onto themselves, instead pointing away and forming a four-loop barrel (REF FIG 6).
VP302 showed less variation in shape, with all but two predicted proteins matching the template [3tjq.1.A Serine protease HTRA1]. The predicted protein of Cryptodendrum adhaesivum from Clade B used the template [A0A6P8IHV9.1.A Four-domain proteases inhibitor-like], whereas the predicted protein for Telmactis australis. in Clade C matched to [1wqj.1.A Insulin-like growth factor binding protein 4]. In general, for VP302, protein structure did not vary in any significant way: it comprised two larger adjacent loops and a third incomplete loop that in some cases included a smaller tight loop (Figure 6). All but the predicted protein for Telmatactis australis in clade C had a GMQE score >50. Coverage for VP302 predicted proteins was generally high (0.87-0.98) except for the predicted protein for Actinia tenebrosa (0.43) in Clade B (Table 3).
2.4. Sites under Selection
Based on the results of our gene trees for both of our venoms, we evaluated omega (dN/ dS) for the alignments for each independent clade and the across all clades (global). We used MEME to find sites that may have undergone episodic positive selection and the program FUBAR to infer sites under positive and negative selection. Additionally, for Cono-Insulin, we tested selection in functional chains A and B independently to determine whether the chains have distinct evolutionary pressures (Table 4). This allows us to determine whether there were clade-specific differences in the nature or strength of selection.
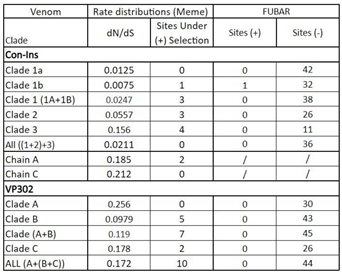
The global omega value (0.0211) for Cono-Insulins indicates strong negative selection as the prevailing mode of evolution. Omega ranged from 0.0075-0.156 in the constituent clades (Table 4). Despite finding no sites that inferred to have undergone episodic positive selection when all sequences are considered together, when considering each clade independently, MEME detected positive selection at one site in Clade 1B, three sites in Clade 1 (Clade 1A+ 1B), three sites in Clade 2, and four sites in Clade 3. Evaluating the sequences not by their clade but by their functional chain comes to a similar result: the overall value for omega is <1 for both Chain A and Chain B, with Chain A having have two sites inferred to be under positive selection and Chain B having none.
FUBAR found no sites under positive selection and 42 sites under negative selection when looking at all sequences in all clades for Cono-Insulin. No sites in Clade 1 (Clade 1A + Clade 1B), Clade 2, and Clade 3 were inferred to be under positive section, although one site within Clade 1B was inferred to be under positive selection when only those sequences were considered. FUBAR detected signatures of negative selection at 42 sites across the genes in the gene tree. Different sites were interpreted to be under negative selection in each lineage: 42 sites in Clade 1A, 32 sites in Clade 1B, 26 sites in Clade 2, and 11 sites in Clade 3. Although many of the sites are shared, the 42 sites interpreted to be under negative selection in Clade 1A and in the gene tree overall are not identical. In Clade 2, FUBAR found no sites under positive section and 26 sites under negative selection. For Clade 3, sister to both Clade 1 and 2, FUBAR found no sites under positive section and 11 sites under negative selection.
The overall omega value for VP302 was 0.172, indicating negative selection. MEME detected a total of 10 sites under positive selection when all sequences were considered. Clade A had the highest omega value (0.256) and no sites under positive selection. Clade B had the lowest omega value (0.0979), and MEME found 5 sites under positive selection. Clade A + Clade B had an omega value of 0.119 and seven sites inferred to be under positive selection. Clade C, sister to Clades A + B, had an omega value of 0.178 and two sites inferred to be under positive selection.
FUBAR identified no sites under positive selection when looking at all clades of sequences or when considering the sequences of each clade independently. It detected 30 sites under negative selection in Clade A, 43 sites in Clade B, and 26 in Clade C. Considering Clade B+C identified 45 sites under negative selection, including several sites not interpreted as under negative selection when the sequences of each of the constituent subclades were considered separately.
3. Discussion
3.1. ILPs in Sea Anemones
Most species included in this study had transcripts for both Cono-Insulins and VP302. A handful of actinioidean species had only transcripts for Cono-Insulins, but only one species, Dofleinia armata, had transcripts for VP302 but not Cono-Insulins. The absence of transcripts for any given species may reflect quality of the specific tissue assayed, transcriptome quality, sequencing depth, or the technology used for sequencing. Cono-Insulins likely have tissue-specific expression [46], so transcriptomes without any Cono-Insulins may be from tissue that does not natively express ILPs. Non-expression also might reflect biological factors, such as lack of transcriptomic activity for a specific gene at the instance of sampling or population-level loss of venom [12].
3.2. Phylogenetics
Cono-Insulin was the more phylogenetically widespread and commonly recovered type of ILP in the transcriptomes we studied. Contra the finding of Fu and colleagues[47], our findings indicate that Cono-Insulin has a single cnidarian-specific origin, rather than an actinarian specific origin. Within the Cnidarian clade of Cono-Insulins, there are multiple instances of duplication and loss (Ref To Figure 4). The gene tree for the various Cono-Insulin sequences we recovered indicates phylogenetically deep duplications in this gene, as Clades 1B, 2, and 3 include samples from across Cnidaria (Clade 3) and Anthozoa (Clade 2, 1B). Clades 1 and 2 are anthozoan-specific clades, which suggests a duplication in the common ancestor of actiniarians and scleractinians. Clade 1A appears to represent an actiniarian-specific duplication event, with the duplication either happening in the common ancestor of all Actiniaria (with loss of copies or of expression in Edwardsioidea) or in a common ancestor of Actinioidea + Metridioidea not also shared by Edwardsioidea. Our phylogenetic tree for each clade did not reflect the expected topology of the known species tree, suggesting loss or lower expression in some species. Generalizing from sea anemones to the other cnidarian lineages, we expect Cono-Insulins to be broadly present and to show intra-lineage gains and losses.
The phylogenetic evolutionary history of sea anemone venom VP302 gives us a clearer picture of its evolutionary history, compared to Cono-Insulins. The topology of the tree suggests one major duplication event, creating Clades A and B. The much more distantly related and phylogenetically restricted sequences of Clade C might represent an instance of secondary recruitment in the metridioidean subclade Cuticulata. Additionally, unlike in the Cono-Insulin tree, the topology of each clade within the VP302 tree largely reflects the expected species tree, at least at the level of superfamilies and major clades within them. We do not find VP302 sequences from other cnidarians interspersed in the phylogenetic tree of sea anemone VP302 sequences.
3.3. Alternative Splicing
Alternative splicing is a common genetic regulatory mechanism in Eukaryotes and is commonly part of the venom systems of many venomous species [54,55,56,57,58,59], where it has been suggested to increase the diversity of possible venoms in any one species. Alternative splicing has been identified in venom genes for sea anemones only for the sea anemone 8 (SA8) toxin gene family, which has alternative alternate splice isoforms derived from an inverted SA8 gene [60].
In contrast to these examples of a single transcript that encodes multiple copies of the same venom, our inference for VP302 is that it is part of multi-domain transcript, with multiple toxins encoded on it. The transcript that includes VP302 consists of the following known venoms and their PFAM annotations: signaling region > Insulin-like growth factor-binding protein VP302 (IGFBP)> Kazal domain protein> coagulation factor Xa/proclotting enzyme inhibitor (Antistasin) > serine protease inhibitor (Kunitz_BPTI). All four genes have been previously associated with venom in Cnidaria [5,7,9,50].
We recover the VP302-containing transcript with all four exons and in transcripts with one, two or three exons. Splicing-related isoform variation occurs only in Clade A+B, suggesting that this mechanism of generating diversity in venoms is unique to that lineage of VP302 genes. Clade C, which we infer to be an independent gain of venom function for VP302 or a related IGFBP, only contained single-domain VP302 transcripts. There was variation in the number of exons in any given transcripts but not in the order in which they were encoded. We only found transcripts that differed from the 3’ end with venom coding genes being spliced of 3’-5’. For each transcript we recovered that also had isoform variants the shared exons across these isoforms matched identically. We examined the genomic position of these transcripts in the genome of Exaiptasia daphnia and found that the reads were on a nonannotated scaffold of its genome. The multi-domain transcript followed the same positional arrangement in the genome. Alternative splicing seems to be the most likely transcriptional regulation mechanism contributing to the isoform variation we captured across Clades A and B.
3.4. Structural Predictions
SwissProt predictions of protein structure for ILPs from select actiniarians did not show substantially different structures. The most notable variation we found in the predicted protein structure was when Swiss-Prot used Alphafold derived templates for its protein prediction for Cono-Insulins. All the Cono-Insulins modeled on AlphaFold templates have a similar shape and differ from the non-AlphaFold models in not having the single loop fold onto itself (Ref to Figure 6). For both Cono-Insulins and VP302, the consistency in their predicted shape despite underlying diversity in sequence underscores the ability of venom coding genes to maintain consistent structure and, presumably, function across evolutionary divergences.
We found that most of our predicted proteins have a low GMQE score, implying a low confidence in the predicted structure created. Nonetheless, the shape of the predicted structure was consistent regardless of the scores, with the most substantive difference between the models derived from AlphaFold templates and those based only on Swiss-Prot models. This could be due to the variation in the sequence itself and the shapes being consistent due to the highly conserved cysteine frame works.
- Selection analysis
Our phylogenetic results demonstrate that each type of ILP inferred to be part of the venom of sea anemones consists of sequences with independent histories of duplication, gain, and loss. Not only do sequences for each ILP have their own evolutionary history, but each clade of sequences has a different signature of natural selection. Cono-Insulins as a whole (Clade (1+2) + 3) appear to be governed by strong negative selection, as predicted by previous work on the evolution of genes encoding venom in sea anemones [14,15]. However, we found variation across Cono-Insulins in dN/dS values (Table 4). For Cono-Insulins, the clades with greater phylogenetic breadth have the weakest negative selection: omega values were below zero but highest for Clade 3, which included scleractinian and hydrozoan sequences in addition to sequences from actiniarians. The two chains that comprise the mature Cono-Insulin both show patterns of substitution consistent with negative selection, but negative selection is stronger in Chain A than in Chain B (Table 4).
Like Cono-Insulin, VP302 is evolving under strong negative selection, although the overall omega value is relatively weaker (Table 4). However, this value may be skewed by the evolutionary history of VP302, where the sequences in Clade C, the sequences more recently and phylogenetically locally recruited into venom, show weaker negative section than the VP302 sequences more prevalent across the actiniarian tree. This clear indication of distinct evolutionary trajectories within each lineage of sequences may indicate specialization of function among the various ILPs and highlighting that inferences about mode and strength of selection may be in ways that overall (global) dN/dS values simply cannot capture.
3.5. Sites under Selection—A Scaling Issue?
Inferences about the number of sites under selection (positive or negative) in any given alignment also change with the phylogenetic framing of the question and depend on the method of inference. Using MEME, we detected no individual AA sites in Cono-Insulins or in VP302 that had been under episodic or diversifying selection (Table 4). However, when we consider each clade within our sequence tree for Cono-Insulins or VP302, we find multiple sites under episodic or diversifying selection. Analyses using FUBAR drew the same broad picture. For Cono-Insulins, we found a single site under positive selection at AA position 41 for sequences belonging to Clade 1B. This site was not identified as under positive selection when sequences in Clade 1A and 1B were considered together. The pattern for individual sites within Cono-Insulins is highly variable across clades, with no sites inferred to be under positive selection in the sequences of Clades 1A, 2 and 3. The sequences of Clade 3 are generally the most different in terms of which sites are under selection, in both MEME and FUBAR analyses. VP302 shows a less varied and dynamic picture than Cono-Insulin, with no sites under episodic or positive selection. Unexpectedly, two sites in VP302 (AA 2, 56) are interpreted as under negative selection in each individual clade of sequences but neutral when lineages are aggregated into analyses of all sequences or sequences of Clade 1+2. Thus, we find that inferences about sites under selection is context dependent, relative to the framing of the analysis in terms of how inclusive it is of sublineages.
In cases where we see sites under selection in both branches of a clade (e.g., in Clades 1A and 1B, or Clades 1 and 2), we expect that the common ancestor sequence, prior to the gene duplication (Figure 7), would have been under selection, and that the site on the protein might be one that has potential to vary (if selection is positive) or requires constraint (if selection is negative). Instances where there are differences in the evolutionary circumstances of a site between sequences in sibling clades suggest independence of evolutionary pressures on those sequences, with these different pressures reflecting different interactions in terms of the absolute function (as determined by structure) or the relative function within distinct ecological/organismal interactions. In the specific instances of Cono-Insulin and VP302, we expect that the sequences (and thus products) of Clade 3 of Cono-Insulin are evolving independently of Clades 1 and 2, and that the sequences and products of Clade C of VP302 are evolving independently and under different pressures than the sequences belonging to Clades 1 and 2. In both of these cases, the phylogenetic distribution of the sequences align with these predictions, as Cono-Insulins of Clade 3 are much more broadly distributed, representing a pan-Cnidaria distribution, and as VP302 sequences of Clade C seem to represent an independent, secondary gain of sequence and function in cuticulate metridioideans.
Additionally, for Cono-Insulin, when examining both functional sites independently, Chain A has 2 sites inferred to be under positive selection, whereas no sites within Chain B are inferred to be under positive selection. Chain A may show a stronger signature of selection because it has more physical interactions in the molecular environments [16], and so is more directly under selection than the more internally-placed chain B.
4. Materials and Methods
4.1. Annotation/Identification
We sourced 29 transcriptomes from NCBI and collaborators using SRAtoolkit [61] and compiled unpublished transcriptomes from collaborators for two additional species, and sequenced the transcriptomes of three species, ultimately considering transcriptomes from 34 species (Supplemental Table S1). Transcriptome construction followed a Trinity v2.2 [62] de novo assembly using the Trimmomatic [63] option. Transcriptome annotation followed the pipeline from Delgado and colleagues[9], which uses Transdecoder v5.5.0 (https://transdecoder.github.io) with a changed min sequence length of 28. HMMMER[64] was used to predict protein family annotation (PFAM). From among these results, we retained for downstream analyses sequences in gene families tagged with the key word “insulin”.
Transcripts with “insulin” PFAM annotation were annotated by querying sequences against Swiss-Prot database (9/12/23) with BLAST [65]. We manually curated results to include only transcripts that closely matched other known venoms using an e-value cutoff of 0.001. To further confirm transcript identity, we sorted transcripts by their respective UNiPROT BLAST matches. For each distinct match type, we conducted a homology search for similar venom types on UNiPROT. Venoms have conserved cystine frameworks [66,67,68,69], and genetic alignments are used to confirm blast hit annotations. We used all the sourced transcripts which matched both in PFAM annotation and homologous genes from UNiPROT to conduct an alignment using CLUSTAL OMEGA [70]. We visualized the resulting alignment on Geneious Prime software 2023 V11.0.18[71]. We retained only transcripts that had matching cysteine residues.
We investigated the multi-domain transcript for VP302 by submitting all transcripts that included VP302 into InterPro 94.0 (https://www.ebi.ac.uk/interpro/ accessed 9/30/23) to identify signaling regions, protein domains, and total length of each protein. We examined the genomic positioning of VP302 in the genome of Exaiptasia diaphana (Baumgarten 2015[72]) by blasting the transcript to the reference genome [GCF_001417965.1 (Aiptasia genome 1.1)].
4.2. Phylogenomic Analyses
We removed signaling regions for both Cono-Insulins and VP302 prior to tree building. Because the C chain of Cono-Insulins are not part of the functional unit (Smit 1998), we followed previous studies [46] and used only chains A and B for our analyses. For VP302, we isolated the transcript for that peptide from the multi-domain transcript. For both Cono-Insulins and VP302, phylogenetic trees were created using IQtree[73] on the IQtree web server (http://iqtree.cibiv.univie.ac.at/), which both implements evolutionary model selection using Modelfinder [74].
4.3. Structural Predictions
We modeled the structure for three species per recovered clade in each of our gene trees. We chose individuals with possible overlap across clades, while considering phylogenetic representation of the species used. We used structural prediction modeling used the SWISS-MODEL workspace (https://swissmodel.expasy.org/)[75,76,77,78] which uses homology-based searches to find structural templates for protein modeling using the SWISS-MODEL repository[79]. All protein quality estimation was done within the SWISS-MODEL workspace. Proteins were viewed and annotated using Swiss-PdbViewer[80].
4.4. Mode of Selecetion
Assessment of the mode of evolution of each clade of ILP toxins and the assessment of sites under pervasive and or episodic positive selection was implemented in Mixed Effect Model of Evolution (MEME)[81]. The pervasive nature of selection was determined by using Fast Unconstrained Bayesian AppRoximation (FUBAR) [82] on the Datamonkey server [83,84,85]. All models used a 0.01 p-value cutoff.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org, Table S1: Data sources.
Author Contributions
Conceptualization, A.D. and M.D.; Data curation, A.D. and K.S; Formal analysis, A.D. and K.S.; Investigation, A.D.; Methodology, A.D. and M.D.; Writing—original draft, A.D. and M.D.; Writing—review & editing, A.D., K.S., and M.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We are grateful to Charlotte Benedict for discussions about the study.
References
- Casewell, N.R.; Wüster, W.; Vonk, F.J.; Harrison, R.A.; Fry, B.G. Complex cocktails: the evolutionary novelty of venoms. Trends Ecol. Evol. 2013, 28, 219–229. [Google Scholar] [CrossRef]
- Muscatine, L. Coelenterate Biology: Reviews and New Perspectives; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Chintiroglou, C.C.; Doumenc, D.; Zamponi, M. Commented list of the Mediterranean Actiniaria and Corallimorpharia (Anthozoa). Acta Adriat. 1997, 38, 65–70. [Google Scholar]
- Daly, M. Functional and genetic diversity of toxins in sea anemones. In Evolution of Venomous Animals and Their Toxins; Malhotra, A., Gopalakrishnakone, P., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 87–104. [Google Scholar] [CrossRef]
- Madio, B.; Undheim, E.A.; King, G.F. Revisiting venom of the sea anemone Stichodactyla haddoni: Omics techniques reveal the complete toxin arsenal of a well-studied sea anemone genus. J. Proteom. 2017, 166, 83–92. [Google Scholar] [CrossRef]
- Macrander, J.; Broe, M.; Daly, M. Tissue-specific venom composition and differential gene expression in sea anemones. Genome Biol. Evol. 2016, 8, 2358–2375. [Google Scholar] [CrossRef] [PubMed]
- Ashwood, L.M.; Norton, R.S.; Undheim, E.A.B.; Hurwood, D.A.; Prentis, P.J. Characterising functional venom profiles of anthozoans and medusozoans within their ecological context. Mar. Drugs 2020, 18, 202. [Google Scholar] [CrossRef]
- Ashwood, L.M.; Undheim, E.A.B.; Madio, B.; Hamilton, B.R.; Daly, M.; Hurwood, D.A.; King, G.F.; Prentis, P.J. Venoms for all occasions: The functional toxin profiles of different anatomical regions in sea anemones are related to their ecological function. Mol. Ecol. 2021, 31, 866–883. [Google Scholar] [CrossRef] [PubMed]
- Delgado, A.; Benedict, C.; Macrander, J.; Daly, M. Never, ever make an enemy… out of an anemone: transcriptomic comparison of clownfish hosting sea anemone venoms. Mar. Drugs 2022, 20, 730. [Google Scholar] [CrossRef]
- Frazão, B.; Vasconcelos, V.; Antunes, A. Sea Anemone (Cnidaria, Anthozoa, Actiniaria) toxins: An overview. Mar. Drugs 2012, 10, 1812–1851. [Google Scholar] [CrossRef]
- Menezes, C.; Thakur, N.L. Sea anemone venom: Ecological interactions and bioactive potential. Toxicon 2022, 208, 31–46. [Google Scholar] [CrossRef]
- Smith, E.G.; Surm, J.M.; Macrander, J.; Simhi, A.; Amir, G.; Sachkova, M.Y.; Lewandowska, M.; Reitzel, A.M.; Moran, Y. Micro and macroevolution of sea anemone venom phenotype. Nat. Commun. 2023, 14, 249. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.-C.; Konaté, M.M.; Chen, L.; Das, B.; Karlovich, C.; Williams, P.M.; Evrard, Y.A.; Doroshow, J.H.; McShane, L.M. TPM, FPKM, or normalized counts? a comparative study of quantification measures for the analysis of RNA-seq data from the NCI patient-derived models repository. J. Transl. Med. 2021, 19, 269. [Google Scholar] [CrossRef]
- Sunagar, K.; Moran, Y. The rise and fall of an evolutionary innovation: Contrasting strategies of venom evolution in ancient and young animals. PLoS Genet. 2015, 11, e1005596. [Google Scholar] [CrossRef]
- Jouiaei, M.; Sunagar, K.; Gross, A.F.; Scheib, H.; Alewood, P.F.; Moran, Y.; Fry, B.G. Evolution of an ancient venom: Recognition of a novel family of cnidarian toxins and the common evolutionary origin of sodium and potassium neurotoxins in sea anemone. Mol. Biol. Evol. 2015, 32, 1598–1610. [Google Scholar] [CrossRef]
- Gibbs, H.L.; Rossiter, W. Rapid evolution by positive selection and gene gain and loss: PLA2 venom genes in closely related SISTRURUS rattlesnakes with divergent diets. J. Mol. Evol. 2008, 66, 151–166. [Google Scholar] [CrossRef]
- Modica, M.V.; Gorson, J.; E Fedosov, A.; Malcolm, G.; Terryn, Y.; Puillandre, N.; Holford, M. Macroevolutionary analyses suggest that environmental factors, not venom apparatus, play key role in terebridae marine snail diversification. Syst. Biol. 2020, 69, 413–430. [Google Scholar] [CrossRef]
- Binford, G.; Wells, M. The phylogenetic distribution of sphingomyelinase D activity in venoms of Haplogyne spiders. Comp. Biochem. Physiol. Part B Biochem. Mol. Biol. 2003, 135, 25–33. [Google Scholar] [CrossRef]
- Quattrini, A.M.; Rodríguez, E.; Faircloth, B.C.; Cowman, P.F.; Brugler, M.R.; Farfan, G.A.; Hellberg, M.E.; Kitahara, M.V.; Morrison, C.L.; Paz-García, D.A.; et al. Palaeoclimate ocean conditions shaped the evolution of corals and their skeletons through deep time. Nat. Ecol. Evol. 2020, 4, 1531–1538. [Google Scholar] [CrossRef]
- Sachkova, M.Y.; Macrander, J.; Surm, J.M.; Aharoni, R.; Menard-Harvey, S.S.; Klock, A.; Leach, W.B.; Reitzel, A.M.; Moran, Y. Some like it hot: population-specific adaptations in venom production to abiotic stressors in a widely distributed cnidarian. BMC Biol. 2020, 18, 121. [Google Scholar] [CrossRef]
- Sachkova, M.Y.; A Singer, S.; Macrander, J.; Reitzel, A.M.; Peigneur, S.; Tytgat, J.; Moran, Y. The birth and death of toxins with distinct functions: A case study in the sea anemone Nematostella. Mol. Biol. Evol. 2019, 36, 2001–2012. [Google Scholar] [CrossRef]
- J. Prentis, P.; Pavasovic, A.; S. Norton, R. Sea Anemones: Quiet Achievers in the Field of Peptide Toxins. Toxins 2018, 10, 36. [Google Scholar] [CrossRef]
- Escoubas, P.; King, G.F. Venomics as a drug discovery platform. Expert Rev. Proteom. 2009, 6, 221–224. [Google Scholar] [CrossRef]
- Beeton, C.; W. Pennington, M.; SNorton, R. Analogs of the sea anemone potassium channel blocker ShK for the treatment of autoimmune diseases. Inflamm. Allergy Drug Targets (Former. Curr. Drug Targets Inflamm. Allergy) 2011, 10, 313–321. [Google Scholar]
- Pennington, M.W.; Lanigan, M.D.; Kalman, K.; Mahnir, V.M.; Rauer, H.; McVaugh, C.T.; Behm, D.; Donaldson, D.; Chandy, K.G.; Kem, W.R.; et al. Role of disulfide bonds in the structure and potassium channel blocking activity of ShK toxin. Biochemistry 1999, 38, 14549–14558. [Google Scholar] [CrossRef]
- Macrander, J.; Broe, M.; Daly, M. Tissue-specific venom composition and differential gene expression in sea anemones. Genome Biol. Evol. 2016, 8, 2358–2375. [Google Scholar] [CrossRef]
- Tysoe, C.; Withers, S.G. Structural dissection of Helianthamide reveals the basis of its potent inhibition of human pancreatic α-Amylase. Biochemistry 2018, 57, 5384–5387. [Google Scholar] [CrossRef]
- Sintsova, O.; Gladkikh, I.; Kalinovskii, A.; Zelepuga, E.; Monastyrnaya, M.; Kim, N.; Shevchenko, L.; Peigneur, S.; Tytgat, J.; Kozlovskaya, E.; et al. Magnificamide, a β-Defensin-Like Peptide from the Mucus of the Sea Anemone Heteractis magnifica, Is a Strong Inhibitor of Mammalian α-Amylases. Mar. Drugs 2019, 17, 542. [Google Scholar] [CrossRef]
- D’ambra, I.; Lauritano, C. A review of toxins from Cnidaria. Mar. Drugs 2020, 18, 507. [Google Scholar] [CrossRef]
- Irwin, D.M. Evolution of the mammalian insulin (Ins) gene; changes in proteolytic processing. Peptides 2021, 135, 170435. [Google Scholar] [CrossRef]
- Rotwein, P. Diversification of the insulin-like growth factor 1 gene in mammals. PLoS ONE 2017, 12, e0189642. [Google Scholar] [CrossRef]
- Chowański, S.; Walkowiak-Nowicka, K.; Winkiel, M.; Marciniak, P.; Urbański, A.; Pacholska-Bogalska, J. Insulin-like peptides and cross-talk with other factors in the regulation of insect metabolism. Front. Physiol. 2021, 12, 701203. [Google Scholar] [CrossRef]
- Semaniuk, U.; Piskovatska, V.; Strilbytska, O.; Strutynska, T.; Burdyliuk, N.; Vaiserman, A.; Bubalo, V.; Storey, K.B.; Lushchak, O. Drosophila insulin-like peptides: from expression to functions—A review. Entomol. Exp. Appl. 2021, 169, 195–208. [Google Scholar] [CrossRef]
- Wu, Q.; Brown, M.R. Signaling and function of insulin-like peptides in insects. Annu. Rev. Èntomol. 2006, 51, 1–24. [Google Scholar] [CrossRef]
- Zheng, S.; Chiu, H.; Boudreau, J.; Papanicolaou, T.; Bendena, W.; Chin-Sang, I. A functional study of all 40 Caenorhabditis elegans insulin-like peptides. J. Biol. Chem. 2018, 293, 16912–16922. [Google Scholar] [CrossRef]
- Smit, A.; VAN Kesteren, R.; Li, K.; VAN Minnen, J.; Spijker, S.; VAN Heerikhuizen, H.; Geraerts, W. Towards Understanding the Role of Insulin in the Brain: Lessons from Insulin-related Signaling Systems in the Invertebrate Brain. Prog. Neurobiol. 1998, 54, 35–54. [Google Scholar] [CrossRef]
- Hassan, A.K.; El-Kotby, D.A.; Tawfik, M.M.; Badr, R.E.; Bahgat, I.M. Antidiabetic effect of the Egyptian honey bee (Apis mellifera) venom in alloxan-induced diabetic rats. J. Basic Appl. Zoöl. 2019, 80, 58. [Google Scholar] [CrossRef]
- Wong, E.S.W.; Morgenstern, D.; Mofiz, E.; Gombert, S.; Morris, K.M.; Temple-Smith, P.; Renfree, M.B.; Whittington, C.M.; King, G.F.; Warren, W.C.; et al. Proteomics and deep sequencing comparison of seasonally active venom glands in the platypus reveals novel venom peptides and distinct expression profiles. Mol. Cell. Proteom. 2012, 11, 1354–1364. [Google Scholar] [CrossRef]
- Wong, E.S.W.; Nicol, S.; Warren, W.C.; Belov, K. Echidna Venom gland transcriptome provides insights into the evolution of monotreme venom. PLoS ONE 2013, 8, e79092. [Google Scholar] [CrossRef]
- Conlon, J.; Attoub, S.; Musale, V.; Leprince, J.; Casewell, N.R.; Sanz, L.; Calvete, J.J. Isolation and characterization of cytotoxic and insulin-releasing components from the venom of the black-necked spitting cobra Naja nigricollis (Elapidae). Toxicon X 2020, 6, 100030. [Google Scholar] [CrossRef]
- HR Fagundes, F.; Aparicio, R.; L dos Santos, M.; BSDiz Filho, E.; CBOliveira, S.; OToyama, D.; HToyama, M. A Catalytically Inactive Lys49 PLA2 Isoform from Bothrops jararacussu venom that Stimulates Insulin Secretion in Pancreatic Beta Cells. Protein Pept. Lett. 2011, 18, 1133–1139. [Google Scholar] [CrossRef]
- Furman, B.L. The development of Byetta (exenatide) from the venom of the Gila monster as an anti-diabetic agent. Toxicon 2012, 59, 464–471. [Google Scholar] [CrossRef]
- Safavi-Hemami, H.; Gajewiak, J.; Karanth, S.; Robinson, S.D.; Ueberheide, B.; Douglass, A.D.; Schlegel, A.; Imperial, J.S.; Watkins, M.; Bandyopadhyay, P.K.; et al. Specialized insulin is used for chemical warfare by fish-hunting cone snails. Proc. Natl. Acad. Sci. USA 2015, 112, 1743–1748. [Google Scholar] [CrossRef]
- Safavi-Hemami, H.; Hu, H.; Gorasia, D.G.; Bandyopadhyay, P.K.; Veith, P.D.; Young, N.D.; Reynolds, E.C.; Yandell, M.; Olivera, B.M.; Purcell, A.W. Combined Proteomic and Transcriptomic Interrogation of the Venom Gland of Conus geographus Uncovers Novel Components and Functional Compartmentalization. Mol. Cell. Proteom. 2014, 13, 938–953. [Google Scholar] [CrossRef]
- Robinson, S.D.; Safavi-Hemami, H. Insulin as a weapon. Toxicon 2016, 123, 56–61. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, M.L.; Hossain, M.A.; Lin, F.; Pinheiro-Junior, E.L.; Peigneur, S.; Wai, D.C.C.; Delaine, C.; Blyth, A.J.; Forbes, B.E.; Tytgat, J.; et al. Identification, Synthesis, Conformation and Activity of an Insulin-like Peptide from a Sea Anemone. Biomolecules 2021, 11, 1785. [Google Scholar] [CrossRef]
- Fu, J.; He, Y.; Peng, C.; Tang, T.; Jin, A.; Liao, Y.; Shi, Q.; Gao, B. Transcriptome Sequencing of the pale anemone (Exaiptasia diaphana) Revealed functional peptide gene resources of sea anemon. Front. Mar. Sci. 2022, 9. [Google Scholar] [CrossRef]
- Darling, J.A.; Reitzel, A.R.; Burton, P.M.; Mazza, M.E.; Ryan, J.F.; Sullivan, J.C.; Finnerty, J.R. Rising starlet: the starlet sea anemone, Nematostella vectensis. BioEssays 2005, 27, 211–221. [Google Scholar] [CrossRef]
- Ruiming, Z.; Yibao, M.; Yawen, H.; Zhiyong, D.; Yingliang, W.; Zhijian, C.; Wenxin, L. Comparative venom gland transcriptome analysis of the scorpion Lychas mucronatus reveals intraspecific toxic gene diversity and new venomous components. BMC Genom. 2010, 11, 452. [Google Scholar] [CrossRef]
- Klompen, A.M.L.; Macrander, J.; Reitzel, A.M.; Stampar, S.N. Transcriptomic Analysis of Four Cerianthid (Cnidaria, Ceriantharia) Venoms. Mar. Drugs 2020, 18, 413. [Google Scholar] [CrossRef]
- Chapman, J.A.; Kirkness, E.F.; Simakov, O.; Hampson, S.E.; Mitros, T.; Weinmaier, T.; Rattei, T.; Balasubramanian, P.G.; Borman, J.; Busam, D.; et al. The dynamic genome of Hydra. Nature 2010, 464, 592–596. [Google Scholar] [CrossRef]
- Jin, A.-H.; Muttenthaler, M.; Dutertre, S.; Himaya, S.; Kaas, Q.; Craik, D.J.; Lewis, R.J.; Alewood, P.F. Conotoxins: Chemistry and Biology. Chem. Rev. 2019, 119, 11510–11549. [Google Scholar] [CrossRef] [PubMed]
- Norton, R.S.; Olivera, B.M. Conotoxins down under. Toxicon 2006, 48, 780–798. [Google Scholar] [CrossRef] [PubMed]
- Ogawa, T.; Oda-Ueda, N.; Hisata, K.; Nakamura, H.; Chijiwa, T.; Hattori, S.; Isomoto, A.; Yugeta, H.; Yamasaki, S.; Fukumaki, Y.; et al. Alternative mRNA Splicing in Three Venom Families Underlying a Possible Production of Divergent Venom Proteins of the Habu Snake, Protobothrops flavoviridis. Toxins 2019, 11, 581. [Google Scholar] [CrossRef]
- Ye, X.; He, C.; Yang, Y.; Sun, Y.H.; Xiong, S.; Chan, K.C.; Si, Y.; Xiao, S.; Zhao, X.; Lin, H.; et al. Comprehensive isoform-level analysis reveals the contribution of alternative isoforms to venom evolution and repertoire diversity. Genome Res. 2023, 33, 1554–1567. [Google Scholar] [CrossRef] [PubMed]
- Haney, R.A.; Matte, T.; Forsyth, F.S.; Garb, J.E. Alternative Transcription at Venom Genes and Its Role as a Complementary Mechanism for the Generation of Venom Complexity in the Common House Spider. Front. Ecol. Evol. 2019, 7. [Google Scholar] [CrossRef] [PubMed]
- Chalmers, I.W.; McArdle, A.J.; Coulson, R.M.; A Wagner, M.; Schmid, R.; Hirai, H.; Hoffmann, K.F. Developmentally regulated expression, alternative splicing and distinct sub-groupings in members of the Schistosoma mansoni venom allergen-like (SmVAL) gene family. BMC Genom. 2008, 9, 89. [Google Scholar] [CrossRef] [PubMed]
- Zhijian, C.; Feng, L.; Yingliang, W.; Xin, M.; Wenxin, L. Genetic mechanisms of scorpion venom peptide diversification. Toxicon 2006, 47, 348–355. [Google Scholar] [CrossRef] [PubMed]
- Viala, V.L.; Hildebrand, D.; Trusch, M.; Fucase, T.M.; Sciani, J.M.; Pimenta, D.C.; Arni, R.K.; Schlüter, H.; Betzel, C.; Mirtschin, P.; et al. Venomics of the Australian eastern brown snake (Pseudonaja textilis): Detection of new venom proteins and splicing variants. Toxicon 2015, 107, 252–265. [Google Scholar] [CrossRef] [PubMed]
- Ashwood, L.M.; Elnahriry, K.A.; Stewart, Z.K.; Shafee, T.; Naseem, M.U.; Szanto, T.G.; van der Burg, C.A.; Smith, H.L.; Surm, J.M.; Undheim, E.A.B.; et al. Genomic, functional and structural analyses elucidate evolutionary innovation within the sea anemone 8 toxin family. BMC Biol. 2023, 21, 121. [Google Scholar] [CrossRef] [PubMed]
- Heldenbrand, J.; Ren, Y.; Asmann, Y.; Mainzer, L.S. Step-by-step guide for downloading very large datasets to a supercomputer using the SRA Toolkit. 2017. [Google Scholar]
- Grabherr, M.G. Trinity: reconstructing a full-length transcriptome without a genome from RNA-Seq data. Nat. Biotechnol. 2011, 29, 644–652. [Google Scholar] [CrossRef]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef]
- Finn, R.D.; Clements, J.; Eddy, S.R. HMMER web server: Interactive sequence similarity searching. Nucleic Acids Res. 2011, 39, W29–W37. [Google Scholar] [CrossRef]
- Mahram, A.; Herbordt, M.C. NCBI BLASTP on High-Performance Reconfigurable Computing Systems. ACM Trans. Reconfigurable Technol. Syst. 2015, 7, 33:1–33:20. [Google Scholar] [CrossRef]
- Reeks, T.A.; Fry, B.G.; Alewood, P.F. Privileged frameworks from snake venom. Cell. Mol. Life Sci. 2015, 72, 1939–1958. [Google Scholar] [CrossRef]
- Tamaoki, H.; Miura, R.; Kusunoki, M.; Kyogoku, Y.; Kobayashi, Y.; Moroder, L. Folding motifs induced and stabilized by distinct cystine frameworks. Protein Eng. Des. Sel. 1998, 11, 649–659. [Google Scholar] [CrossRef]
- Chen, Z.; Cao, Z.; Li, W.; Wu, Y. Cloning and characterization of a novel Kunitz-type inhibitor from scorpion with unique cysteine framework. Toxicon 2013, 72, 5–10. [Google Scholar] [CrossRef]
- Fainzilber, M.; Nakamura, T.; Gaathon, A.; Lodder, J.C.; Kits, K.S.; Burlingame, A.L.; Zlotkin, E. A new cysteine framework in sodium channel blocking conotoxins. Biochemistry 1995, 34, 8649–8656. [Google Scholar] [CrossRef]
- Sievers, F.; Higgins, D.G. Clustal Omega. Current Protocols in Bioinformatics 2014, 48, 3.13.1–3.13.16. [Google Scholar]
- Kearse, M.; Moir, R.; Wilson, A.; Stones-Havas, S.; Cheung, M.; Sturrock, S.; Buxton, S.; Cooper, A.; Markowitz, S.; Duran, C.; et al. Geneious Basic: An integrated and extendable desktop software platform for the organization and analysis of sequence data. Bioinformatics 2012, 28, 1647–1649. [Google Scholar] [CrossRef]
- Baumgarten, S.; Simakov, O.; Esherick, L.Y.; Liew, Y.J.; Lehnert, E.M.; Michell, C.T.; Li, Y.; Hambleton, E.A.; Guse, A.; Oates, M.E.; et al. The genome of Aiptasia, a sea anemone model for coral symbiosis. Proc. Natl. Acad. Sci. 2015, 112, 11893–11898. [Google Scholar] [CrossRef]
- Nguyen, L.-T.; Schmidt, H.A.; Von Haeseler, A.; Minh, B.Q. IQ-TREE: A Fast and Effective Stochastic Algorithm for Estimating Maximum-Likelihood Phylogenies. Mol. Biol. Evol. 2015, 32, 268–274. [Google Scholar] [CrossRef]
- Kalyaanamoorthy, S.; Minh, B.Q.; Wong, T.K.F.; Von Haeseler, A.; Jermiin, L.S. ModelFinder: Fast model selection for accurate phylogenetic estimates. Nat. Methods 2017, 14, 587–589. [Google Scholar] [CrossRef]
- Kiefer, F.; Arnold, K.; Künzli, M.; Bordoli, L.; Schwede, T. The SWISS-MODEL Repository and associated resources. Nucleic Acids Res. 2009, 37, D387–D392. [Google Scholar] [CrossRef]
- Schwede, T.; Kopp, J.; Guex, N.; Peitsch, M.C. SWISS-MODEL: an automated protein homology-modeling server. Nucleic Acids Res. 2003, 31, 3381–3385. [Google Scholar] [CrossRef]
- Waterhouse, A.; Bertoni, M.; Bienert, S.; Studer, G.; Tauriello, G.; Gumienny, R.; Heer, F.T.; De Beer, T.A.P.; Rempfer, C.; Bordoli, L.; et al. SWISS-MODEL: Homology modelling of protein structures and complexes. Nucleic Acids Res. 2018, 46, W296–W303. [Google Scholar] [CrossRef]
- Biasini, M.; Bienert, S.; Waterhouse, A.; Arnold, K.; Studer, G.; Schmidt, T.; Kiefer, F.; Cassarino, T.G.; Bertoni, M.; Bordoli, L.; et al. SWISS-MODEL: modelling protein tertiary and quaternary structure using evolutionary information. Nucleic Acids Res. 2014, 42, W252–W258. [Google Scholar] [CrossRef]
- Bienert, S.; Waterhouse, A.; de Beer, T.A.P.; Tauriello, G.; Studer, G.; Bordoli, L.; Schwede, T. The SWISS-MODEL Repository—New features and functionality. Nucleic Acids Res. 2017, 45, D313–D319. [Google Scholar] [CrossRef]
- Guex, N.; Peitsch, M.C.; Schwede, T. Automated comparative protein structure modeling with SWISS-MODEL and Swiss-PdbViewer: A historical perspective. Electrophoresis 2009, 30, S162–S173. [Google Scholar] [CrossRef]
- Murrell, B.; Wertheim, J.O.; Moola, S.; Weighill, T.; Scheffler, K.; Pond, S.L.K. Detecting Individual Sites Subject to Episodic Diversifying Selection. PLoS Genet. 2012, 8, e1002764. [Google Scholar] [CrossRef]
- Murrell, B.; Moola, S.; Mabona, A.; Weighill, T.; Sheward, D.; Pond, S.L.K.; Scheffler, K. FUBAR: A Fast, Unconstrained Bayesian AppRoximation for Inferring Selection. Mol. Biol. Evol. 2013, 30, 1196–1205. [Google Scholar] [CrossRef]
- Weaver, S.; Shank, S.D.; Spielman, S.J.; Li, M.; Muse, S.V.; Kosakovsky Pond, S.L. Datamonkey 2.0: A Modern Web Application for Characterizing Selective and Other Evolutionary Processes. Mol. Biol. Evol. 2018, 35, 773–777. [Google Scholar] [CrossRef]
- Delport, W.; Poon, A.F.Y.; Frost, S.D.W.; Pond, S.L.K. Datamonkey 2010: a suite of phylogenetic analysis tools for evolutionary biology. Bioinformatics 2010, 26, 2455–2457. [Google Scholar] [CrossRef] [PubMed]
- Kosakovsky Pond, S.L.; Frost, S.D.W. Not So Different After All: A Comparison of Methods for Detecting Amino Acid Sites Under Selection. Mol. Biol. Evol. 2005, 22, 1208–1222. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Alignment of recovered metazoan Cono-Insulins sequences from UNiPROT. The alignment is comprised of the functional A and B chain for Cono-Insulin. Both chain positions are designated above. Highlighting of amino acids shows a 75% threshold identity consensus.
Figure 1.
Alignment of recovered metazoan Cono-Insulins sequences from UNiPROT. The alignment is comprised of the functional A and B chain for Cono-Insulin. Both chain positions are designated above. Highlighting of amino acids shows a 75% threshold identity consensus.

Figure 2.
Top image shows the genomic expression of the multidomain transcript, based on the size and order of exons in transcripts from Exaiptasia diaphana. VP302 is followed by a Kazal domain protein > Antistasin protein > Kunitz_BPTI protein. The bottom image is a schematic of the gene tree showing isoform variation across distinct clades of VP302. See Figure 5 for the full gene tree for VP302.
Figure 2.
Top image shows the genomic expression of the multidomain transcript, based on the size and order of exons in transcripts from Exaiptasia diaphana. VP302 is followed by a Kazal domain protein > Antistasin protein > Kunitz_BPTI protein. The bottom image is a schematic of the gene tree showing isoform variation across distinct clades of VP302. See Figure 5 for the full gene tree for VP302.
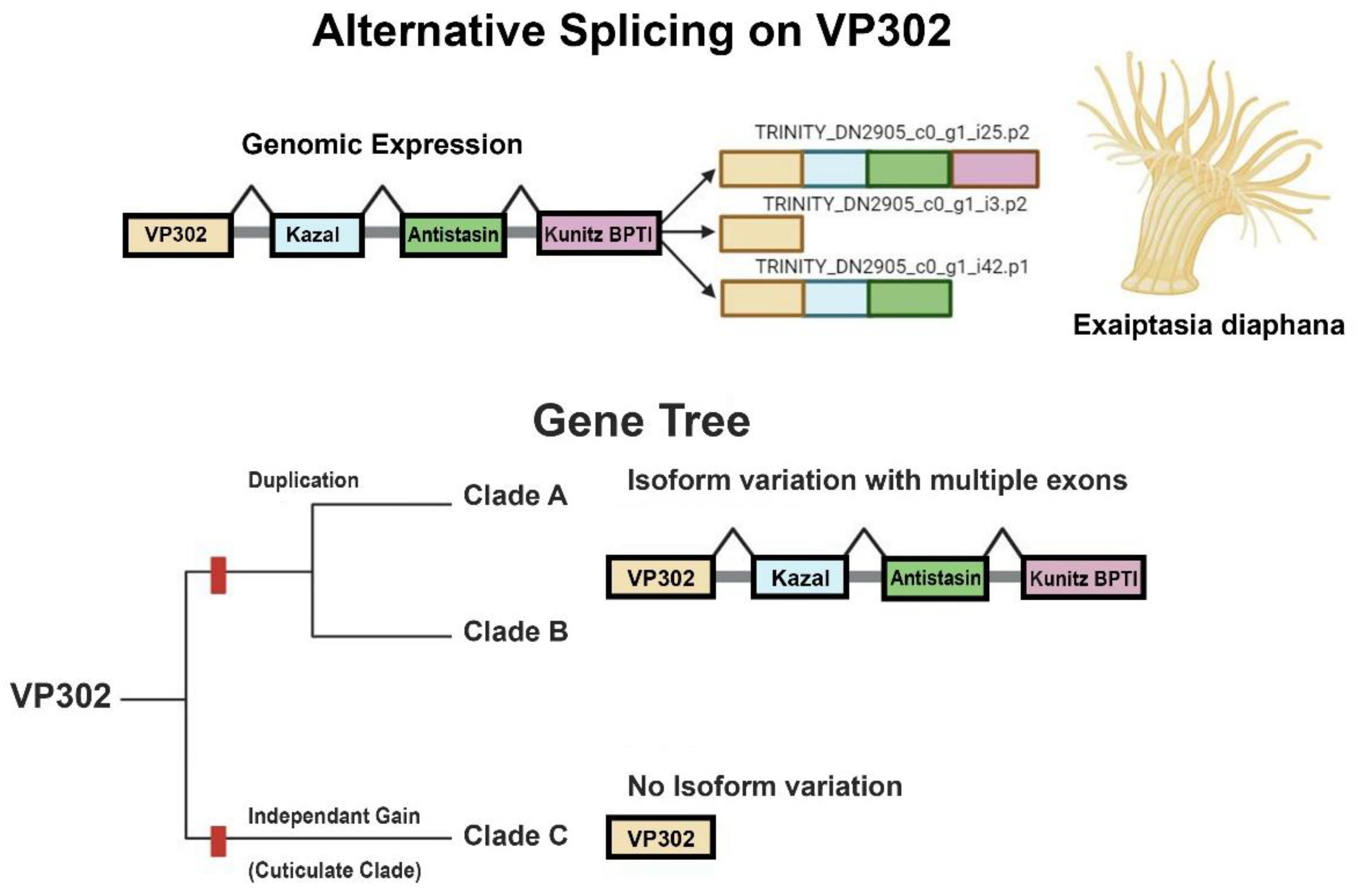
Figure 3.
Alignment of VP302 sequences across sea anemones. Highlighting of ammino acids shows a 75% threshold identity consensus.
Figure 3.
Alignment of VP302 sequences across sea anemones. Highlighting of ammino acids shows a 75% threshold identity consensus.
Figure 4.
Gene Tree for Cono-Insulin. This tree uses all recovered sea anemone Cono-Insulin sequences and is rooted with recovered cone snail sequences. On the top right a key indicates colors for each of the four recovered clades.
Figure 4.
Gene Tree for Cono-Insulin. This tree uses all recovered sea anemone Cono-Insulin sequences and is rooted with recovered cone snail sequences. On the top right a key indicates colors for each of the four recovered clades.
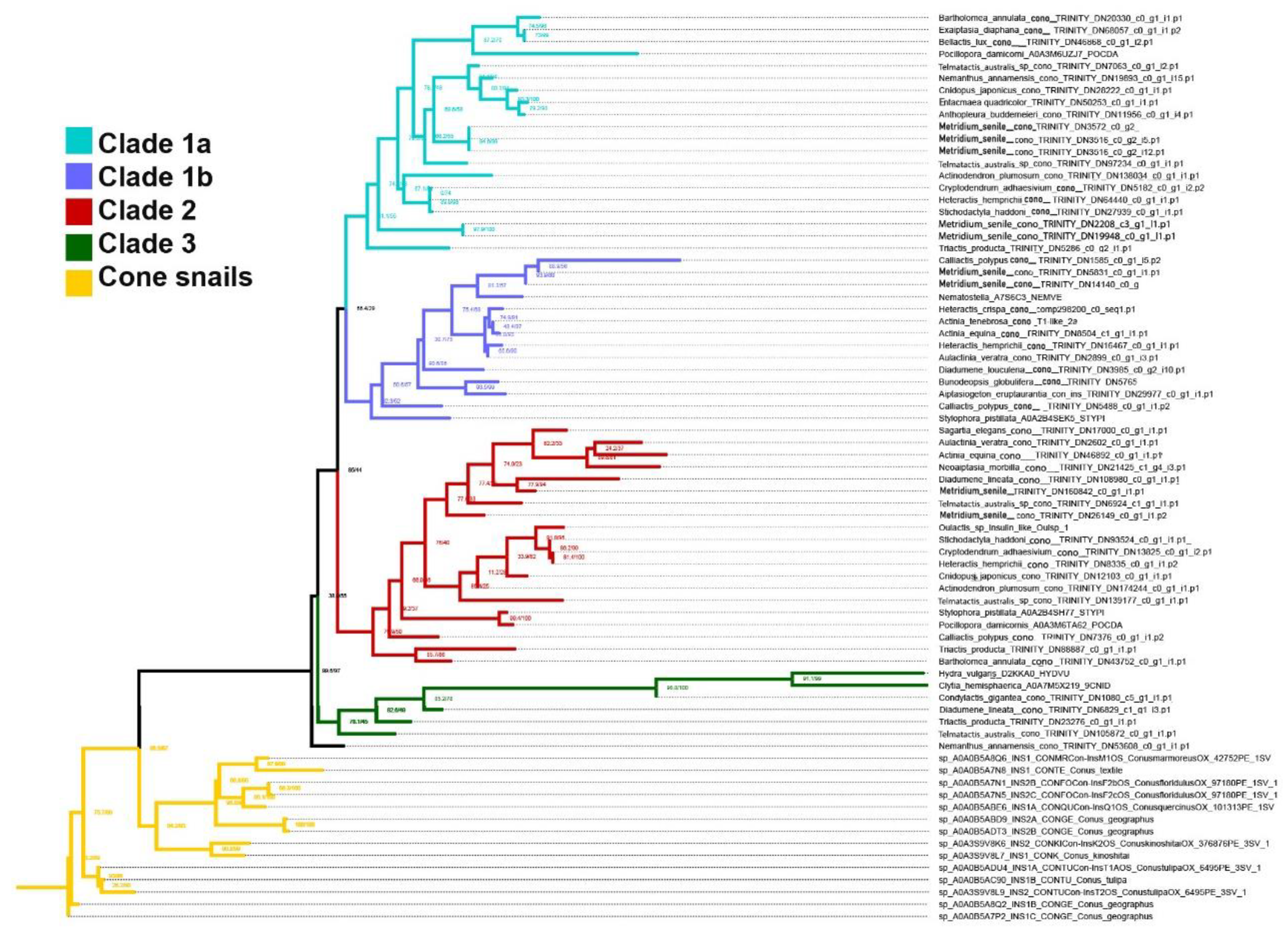
Figure 6.
A. Simplified Cono-Insulin gene tree with Swiss-Prot models at each tip. Protein structures within a box were modeled via AlphaFold templates. B. Simplified VP302 gene tree with Swiss-Prot models at each tip.
Figure 6.
A. Simplified Cono-Insulin gene tree with Swiss-Prot models at each tip. Protein structures within a box were modeled via AlphaFold templates. B. Simplified VP302 gene tree with Swiss-Prot models at each tip.
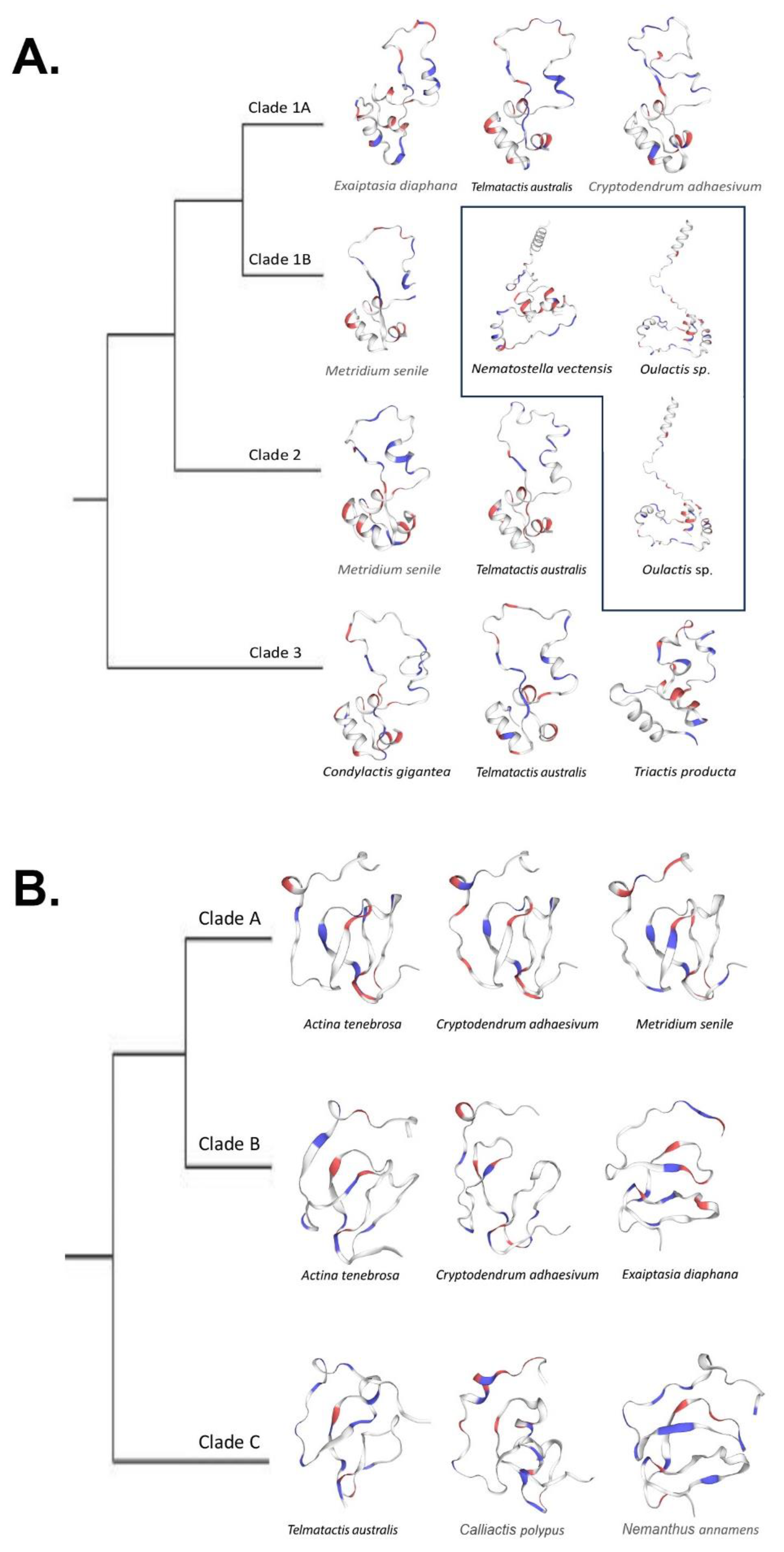
Figure 7.
An interpretation of selection across Cono-Insulins in Cnidaria. The taxonomic breadth of membership within each clade is indicated with the clade labels and pictograms. representation of the the ansestral state of selection across Cono-Insulin gene tree. Each clade is labeled to indicate the taxonomic breadth it encompasses. The green plus sigh inducates linages in which we found positive selection for a specific amino acid. The red “X” represents a loss in the positve selective singnal for that perticular amino acid.
Figure 7.
An interpretation of selection across Cono-Insulins in Cnidaria. The taxonomic breadth of membership within each clade is indicated with the clade labels and pictograms. representation of the the ansestral state of selection across Cono-Insulin gene tree. Each clade is labeled to indicate the taxonomic breadth it encompasses. The green plus sigh inducates linages in which we found positive selection for a specific amino acid. The red “X” represents a loss in the positve selective singnal for that perticular amino acid.
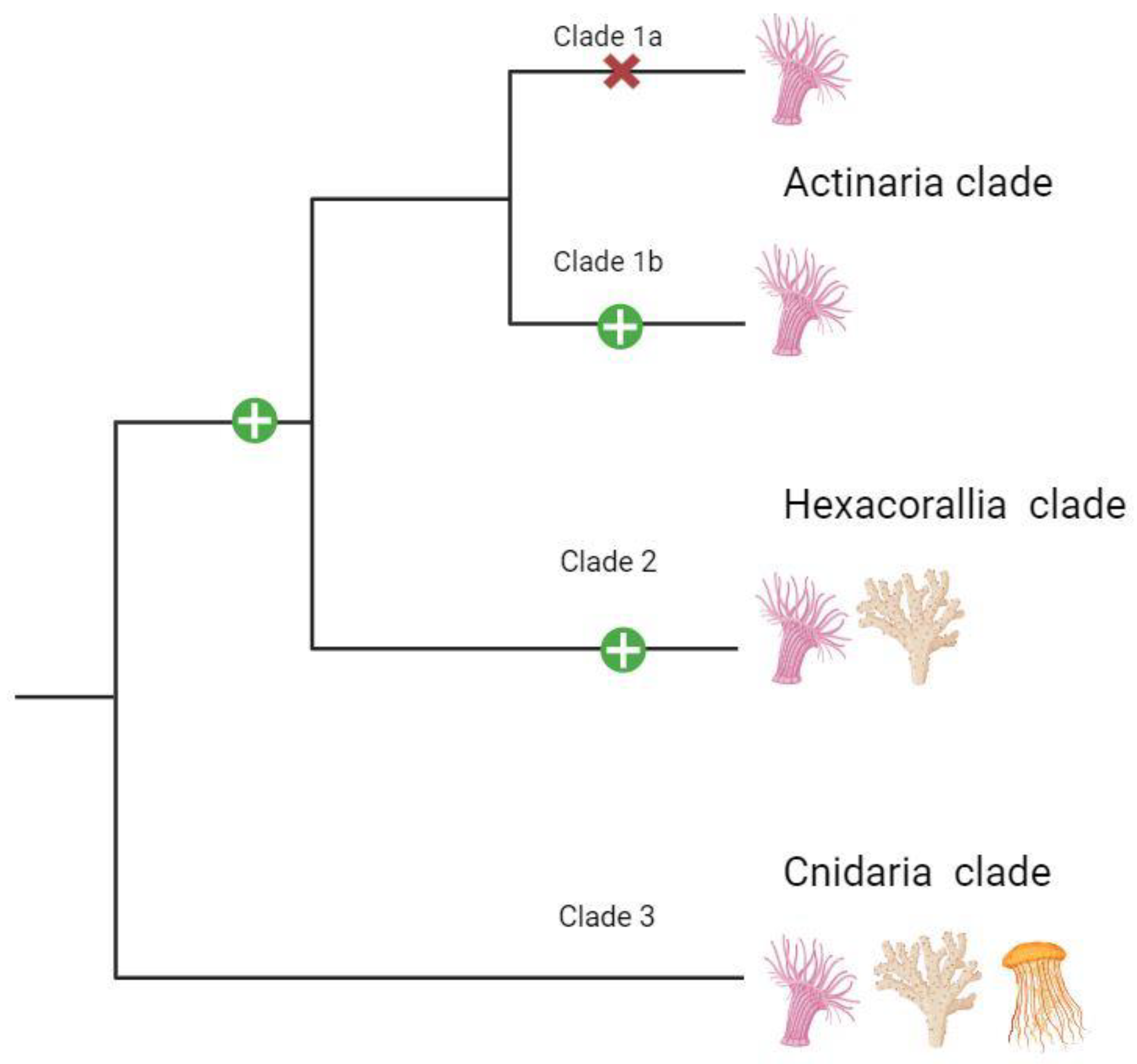

Table 1.
Recovery table showing both taxanomy of 34 speceis of sea anemomens whos transcriptomes were used in this study. Table also shows the recovery of clade spesifc transcripts for Cono-Insulins and VP302 transcripts.
Table 1.
Recovery table showing both taxanomy of 34 speceis of sea anemomens whos transcriptomes were used in this study. Table also shows the recovery of clade spesifc transcripts for Cono-Insulins and VP302 transcripts.
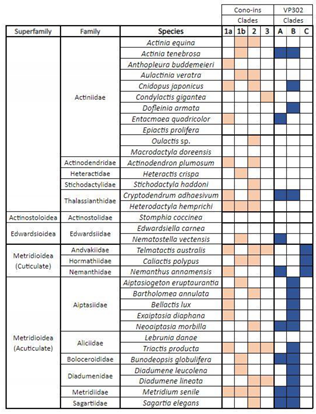
Table 2.
Variation of isoforms of VP302 transcripts, indicating the the venom coding genes recovered within transcripts from each species. The clade of VP302 sequences to which the sequences recovered belong are indicated Species are organized taxonomically and across each clade from our gene tree.
Table 2.
Variation of isoforms of VP302 transcripts, indicating the the venom coding genes recovered within transcripts from each species. The clade of VP302 sequences to which the sequences recovered belong are indicated Species are organized taxonomically and across each clade from our gene tree.
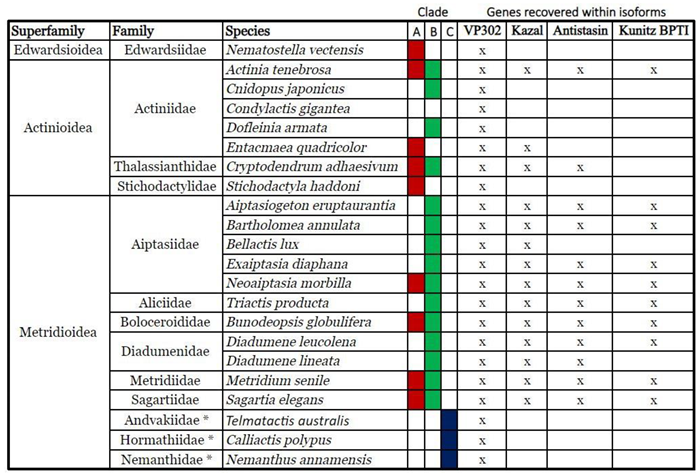
Table 3.
Swissprot statistical results for both Con-Ins and VP302 across each phylogenetic clade that we examined. The table gives us the GMQE (Global Model Quality Estimate) shows the accuracy of the model built with the given alignment and template, normalized by the coverage of the target sequence. The template used for the structural model. Sequence identity for the use of sequence relative to the sequence of the template and the coverage of the sequence relative to the template sequence.
Table 3.
Swissprot statistical results for both Con-Ins and VP302 across each phylogenetic clade that we examined. The table gives us the GMQE (Global Model Quality Estimate) shows the accuracy of the model built with the given alignment and template, normalized by the coverage of the target sequence. The template used for the structural model. Sequence identity for the use of sequence relative to the sequence of the template and the coverage of the sequence relative to the template sequence.
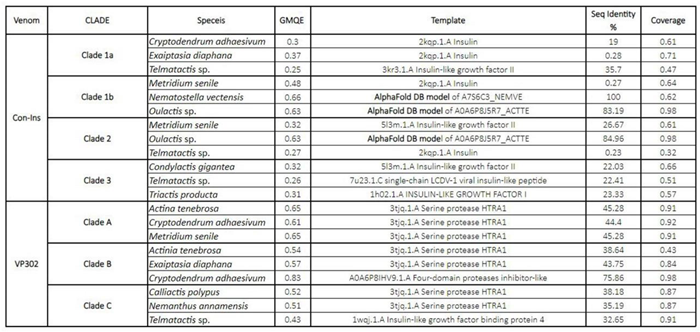
Table 4.
Results of both MEME and FUBAR. MEME results give dN/dS values and the number of sites under selection. FUBAR results indicate the number of sites found under positive and negative selection.
Table 4.
Results of both MEME and FUBAR. MEME results give dN/dS values and the number of sites under selection. FUBAR results indicate the number of sites found under positive and negative selection.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



