Submitted:
04 June 2024
Posted:
05 June 2024
You are already at the latest version
Abstract
We propose a neural-network-based watermarking method that introduces the quantized activation function that approximates the quantization of JPEG compression. Many neural-network-based watermarking methods have been proposed. Conventional methods have acquired robustness against various attacks by introducing an attack simulation layer between the embedding network and the extraction network. The quantization process of JPEG compression was replaced by the noise addition process in the attack layer of the conventional methods. In this paper, we propose a quantized activation function that can simulate the JPEG quantization standard as it is in order to improve the robustness against the JPEG compression. Our quantized activation function consists of several hyperbolic tangent functions and is applied as an activation function for neural networks. Our network was introduced in the attack layer of ReDMark proposed by Ahmadi et al. to compare it with their method. That is, the embedding and extraction networks had the same structure. We compared the usual JPEG compressed images and the images applying the quantized activation function. The results showed that a network with quantized activation functions can approximate JPEG compression with high accuracy. We also compared the bit error rate (BER) of estimated watermarks generated by our network with those generated by ReDMark. We found that our network was able to produce estimated watermarks with lower BERs than those of ReDMark. Therefore, our network outperformed the conventional method with respect to image quality and BER.
Keywords:
Watermarking method
; Neural network
; Activation function
; JPEG compression
1. Introduction
People are now easily able to upload photos and illustrations to the Internet, owing to smartphones and personal computers. To protect content creators, we need to prevent unauthorized copying and other abuses because digital content is not degraded by copying or transmissions. Digital watermarking is effective against such unauthorized use.
In digital watermarking, secret information is embedded in digital content by making slight changes to the content. In the case of an image, the image in which the information is embedded is called a stego-image, and the embedded information is called a digital watermark. There are two types of digital watermarking: blind and non-blind. The blind method does not require the original image to extract the watermark from the stego-image. However, the non-blind method requires the original image when extracting a watermark from a stego-image. Therefore, the blind method is more practical. In addition, because stego-images may be attacked by various kinds of image processing, watermarking methods must have the ability to extract watermarks from degraded stego-images. Two types of attacks on stego-images can occur: geometric attacks such as rotation, scaling, and cropping and non-geometric attacks such as noise addition and JPEG compression [1].
Neural-network-based methods have been proposed. In single-stage-training, where the embedding and extraction are performed in a single network, the network has been trained to output a watermark from an input image [2,3]. The overall performance of the network is low because the relationship between the image and the watermark is trained individually. To improve performance, watermarking methods using autoencoders (AE) have been proposed [4,5,6]. The input layer to the middle layer is called the embedding network, and the middle to the output layer is called the extraction network. Both the original image and the watermark are input into the input layer of the AE, and the identity mapping is learned to retrieve them in the output layer. The stego-image is extracted from the middle layer [6]. Since the original image is unnecessary during extraction, it is often omitted to output only the watermark. Furthermore, AE with convolutional neural networks has been proposed [7]. An adversarial network has also been added to improve image quality [8]. DARI-Mark [9] is a DNN-based watermarking method using attention to determine the embedding regions. It can find non-significant regions that are insensitive to the human eye and increases robustness by embedding the watermark with larger intensities. Thus, end-to-end models were proposed [6,7,8,9,10,11]. However, a huge training dataset was needed to train the connections as the network became more complex. Although data augmentation was sometimes introduced, a model with internal networks mimicking attacks was proposed in order to train on a relatively small training dataset [8,10,11].
The HiDDeN [8] proposed by Zhu et al. has an attack layer that simulates attacks such as Gaussian blur, per-pixel dropout, cropping, and JPEG compression attacks on images during training. Here, the implementation of JPEG compression is approximated by JPEG-Mask, which sets the high-frequency components of the discrete cosine transform (DCT) coefficients to zero, and JPEG-Drop, which uses progressive dropout to eliminate the high-frequency components of the DCT coefficients. Therefore, this implementation does not meet the standard for quantization in the JPEG compression process. It has also been noted that the JPEG-Mask and JPEG-Drop layers of HiDDeN do not provide sufficient performance for the robustness of the JPEG compression [12,13]. JPEGdiff is a method of approximating around the quantized values in JPEG compression by a cubic function. Hamamoto and Kawamura’s method [10] also introduces a layer of additive white Gaussian noise as an attack layer to improve robustness against JPEG compression. Moreover, ReDMark proposed by Ahmadi et al. [11] has attack layers implementing salt-and-pepper noise, Gaussian noise, JPEG compression, and mean smoothing filters. The quantization of the JPEG compression is approximated by adding uniform noise. As described, the quantization process has been replaced by the process of adding noise, and the quantization process as per the JPEG standard has not been introduced.
Adversarial samples are a problem in the field of pattern recognition. They are generated by adding distortions to images to misclassify it. To avoid misclassification, a pattern recognition method using JPEG compressed images has been proposed [15]. JPEG compression is expected to effectively reduce noise while preserving the information needed for pattern recognition. However, JPEGdiff has been proposed as a way to break this technique [12]. By approximating the JPEG quantization with a differentiable function, a JPEG-resistant adversarial image can be generated. Therefore, approximating the JPEG quantization with a smooth function may affect the performance of the model.
In our previous work [14], we proposed a quantization activation function (QAF) that can simulate the quantization of JPEG compression according to a standard. That model consists of a network that introduces the QAF into the AE-based model proposed by Hamamoto and Kawamura [6]. Better performance was obtained in terms of JPEG compression robustness than the AE-based model [6]. The effectiveness of the QAF has been demonstrated in our previous work. However, in that model, QAF with a constant quantization width were used instead of the quantization table. In this paper, we apply the QAF to the attack layer of the ReDMark [11], which is a CNN-based model, rather than an AE-based model. Furthermore, the proposed method uses the quantization table-based QAF. The robustness against the JPEG compression is expected to be improved using the QAF. The effectiveness of our method is evaluated by comparing JPEG-compressed images with QAF-applied images. The image quality of the stego-image was also evaluated.
The rest of the paper is organized as follows. In Section 2, the process of JPEG quantisation is explained. In Section 3, we describe the ReDMark and, in addition, we address our previous work. In Section 4, we define the quantized activation function and describe the structure of the proposed network. In Section 5, we show the effectiveness of the function and demonstrate the performance of our network in computer simulations. The last section concludes the paper.
Figure 1.
JPEG compression quantization for luminance components. 1) Creation of the quantization table , 2) The quantization process, 3) The dequantization process.
Figure 1.
JPEG compression quantization for luminance components. 1) Creation of the quantization table , 2) The quantization process, 3) The dequantization process.
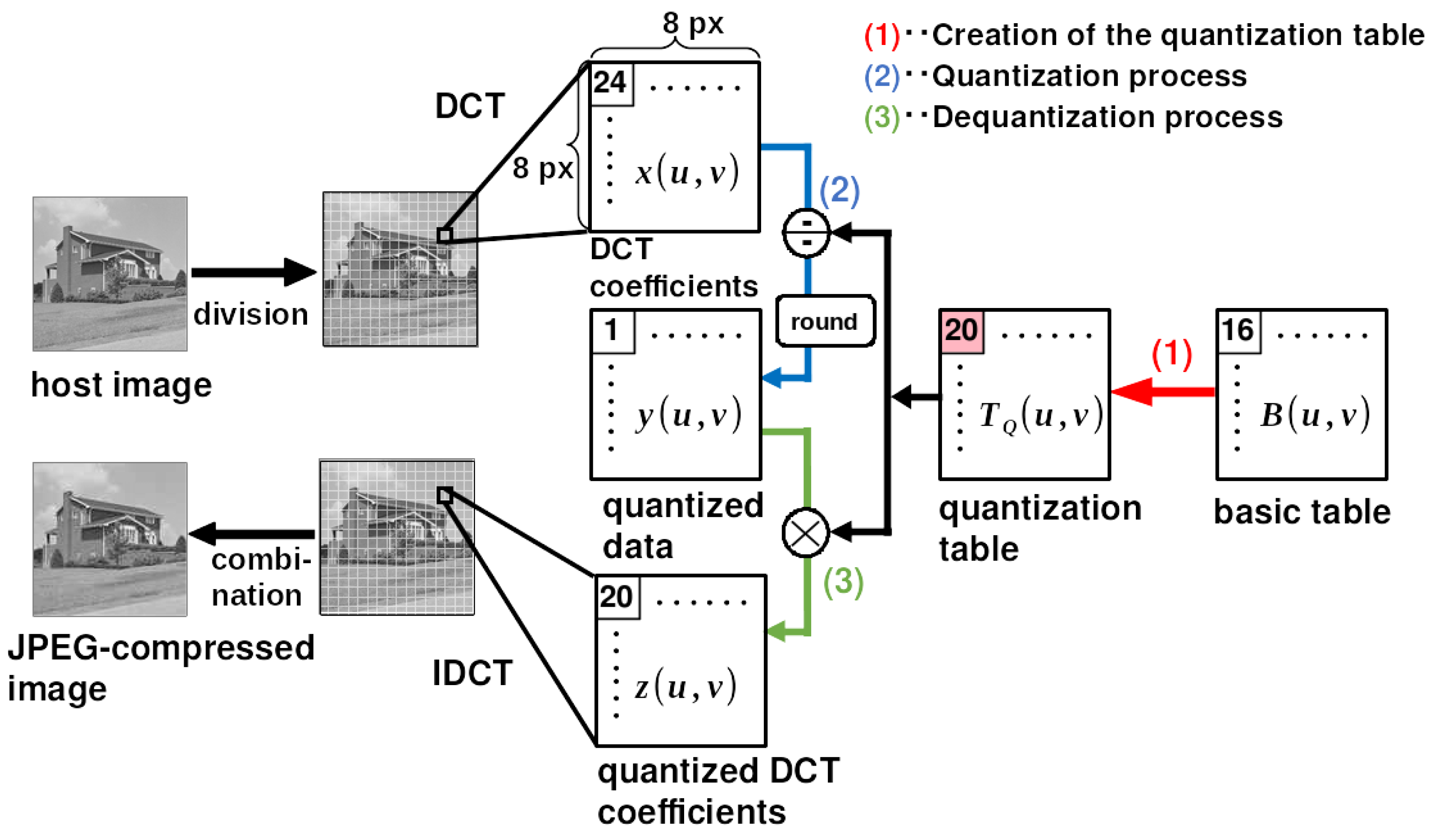
2. Preliminary: JPEG Quantization
JPEG compression is a lossy compression that reduces the amount of information in an image to reduce the file size. In this kind of compression, an image is divided into -pixel blocks. Then, in each block, the processes of the DCT, quantization, and entropy coding are sequentially performed. In JPEG compression, the process of reducing the amount of information is the quantization process of the DCT coefficients. We focus on the quantization of the DCT coefficients of the luminance component in an image because the watermark is embedded in these coefficients of the image. Figure 1 shows the quantization process in JPEG compression for DCT coefficients [16]. The process consists of three steps: 1) creation of the quantization table , 2) the quantization process, and 3) the dequantization process.
During the quantization process, the DCT coefficients are quantized based on a default basic table or a self-defined basic table. The default basic table is defined as
The quantization table is then determined using the quality factor (Q) and the basic table . The quantization table for the quantization level Q at coordinates is defined as
where is the floor function and where is the component of the basic table . Also, the scaling factor is given by
The quantization process is performed using the quantization table . Let be the quantized data, and let be the DCT coefficients in an -pixel block. The quantization process is performed as
where
Let be the quantized DCT coefficients; then, the dequantization process is performed as
3. Related Works
3.1. ReDMark
Figure 2 shows the overall structure of ReDMark [11], which consists of an embedding network, an extraction network, and an attack layer. The h and w are the height and width of the 2D watermark, and H and W are the height and width of the original and stego-images. The images are divided into -pixel blocks, where as it is in ReDMark.
The process flow during training is illustrated by the red arrows in Figure 2. The host image and watermark are fed to the embedding network, and the attack layer degrades the generated stego-image. By feeding the degraded image to the extraction network, the extraction network learns to extract the watermark from the degraded image. After training, the embedding and extraction networks are used individually. The process flow during testing is illustrated by the blue arrows in Figure 2. A stego-image is generated by the embedding network. This image is published and attacked. Let us assume that the attack is to compress the image by some JPEG tool. When the attacked image is obtained, the watermark is extracted from the image in the extraction network.
In ReDMark [11], normalization and reshaping are performed on the input image in preprocessing. For the input image , the normalized image is given by
Figure 3.
Embedding network of ReDMark [11]
Figure 3.
Embedding network of ReDMark [11]
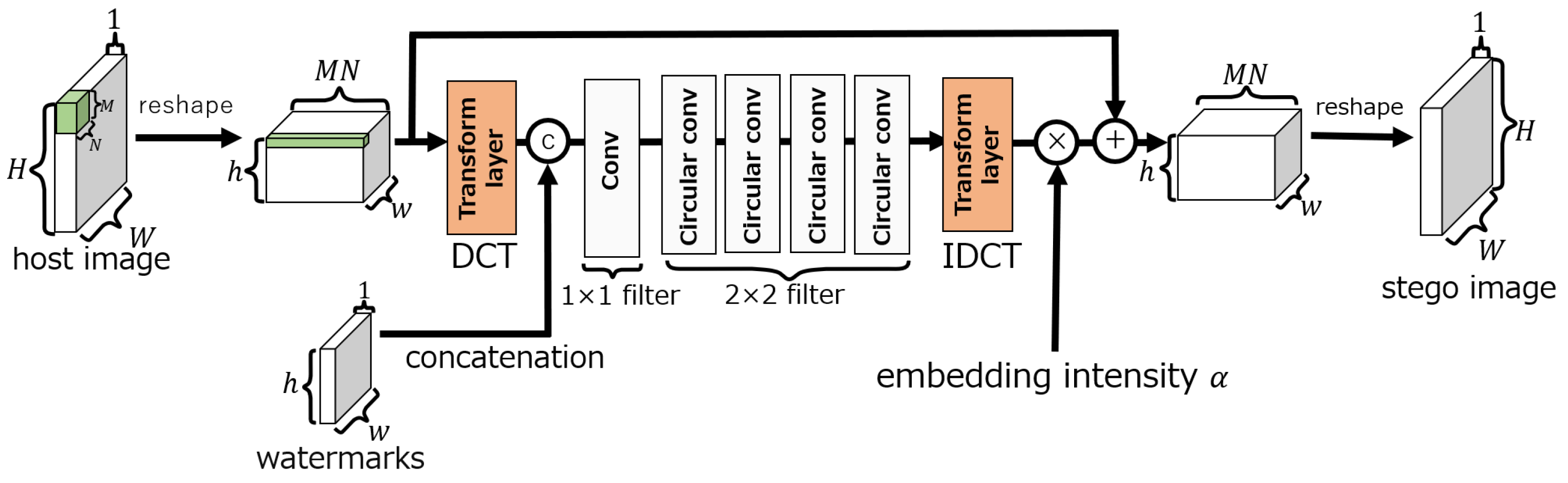
Reshape is an operation that divides an image into -pixel blocks and transforms them into a 3D tensor representation. The image size is assumed to satisfy . The reshaped image is represented by a 3-dimensional tensor of . This image is called the image tensor of size . If necessary, the tensor is inverse transformed back to its original dimension.
3.1.1. Embedding Network
The embedding network, as shown in Figure 3, consists of three layers: convolution, circular convolution, and transform. The transform layer can perform lossless linear transforms using convolutional layers, e.g., the DCT, wavelet transform, and Hadamard transform. In our method, the DCT is selected as the transform layer as it is in ReDMark. The circular convolution layer extends the input to make it cyclic before the convolution is performed. Figure 4 shows an example of applying a circular convolution layer with a filter when the input is pixels. When a circular convolution layer is used, the dimension of the output after convolution is the same as the dimension of the input.
In the embedding network, the convolution and circular convolution layers use and filters, respectively, and both have 64 filters. In each layer, an exponential linear unit (ELU) [17] activation function is used. The output of the embedding network is obtained by summing the output of the transform layer performing the inverse DCT (IDCT) (for the IDCT layer) with the input image tensor of size and then by performing the inverse process of reshaping. Here, the output of the IDCT layer can be adjusted by the embedding intensity . The intensity is fixed as during training and can be changed during an evaluation.
3.1.2. Extraction network
The extraction network consists of a convolution layer, a circular convolution layer, and a transform layer, as shown in Figure 5. The transform layer of the extraction network also performs the DCT. The filter sizes of the convolutional and circular convolutional layers are and , respectively. The number of filters is 64 for the fourth layer and 1 for the fifth layer. The activation function up to the fourth layer is ELU [17], and a sigmoid function is used in the fifth layer. Let be the output of the extraction network, and the estimated watermark is given by
3.1.3. Attack Layer
The attack layer lies between the embedding and the extraction networks and operates when ReDMark is trained. The attack layer itself is not trained. By simulating possible attacks on the stego-image and feeding the attacked image to the extraction network, the network can be trained to extract the watermark from the degraded image. Various attacks can be simulated in the attack layer. In the attack layer of ReDMark [11], three networks were implemented according to the type of attacks: a GT-Net (Gaussian-trained network), a JT-Net (JPEG-trained network), and a MT-Net (multi-attack-trained network).
In ReDMark, the quantization process is approximated using the quantization table and uniform noise . Let represent the DCT coefficients of an -pixel block of a stego-image, and the quantized DCT coefficients are given as
where represents noise subject to a uniform distribution in the interval . In other words, the quantization process is equivalent to adding a uniform noise proportional to the quantization table .
3.2. JPEGdiff
In the quantization of JPEG compression, the DCT coefficient values are converted to integers. This causes a problem that the activation function cannot be differentiated when training a neural network. For example, the JPEG-Mask and JPEG-Drop layers of HiDDeN do not provide sufficient performance against robustness for JPEG compression. Therefore, the JPEGdiff, which approximates the activation function to a cubic function around the quantized value, has been proposed [12,13]. This approximation could reduce the number of non-differentiable points and reduce the number of regions with zero gradient. As a result, performance was improved by training. The JPEGdiff is given by
Note that this function still has non-differentiable points on the boundaries of the intervals.
3.3. Previous work
In our previous work [14], we proposed a quantized activation function (QAF). This function was a functional representation of the quantization process of JPEG compression. Specifically, the function consists of several hyperbolic tangent functions and returns the quantized value of the argument x. The proposed QAF was applied to the attack layer of the AE-based model proposed by Hamamoto and Kawamura [6]. Moreover, all DCT coefficients were quantized with the same intensity. In other words, the value of the quantization table was constant, as given by
where is a constant. Even with a constant quantization table, the previous method had a certain level of tolerance to JPEG compression. However, if the original values of the quantization table could be applied, the tolerance could be enhanced.
4. Proposed Method
We propose a quantization table-based QAF, and apply it to the attack layer of the ReDMark [11], which is a CNN-based model rather than an AE-based model. To demonstrate the effectiveness of the QAF, we compare the proposed layer using the QAF with the JT-Net of ReDMark [11] . The embedding and extraction networks of the proposed method is the same as those of ReDMark.
4.1. Quantized Activation Function
We propose a quantization table-based QAF for neural networks to implement the quantization process of the JPEG compression according to the standard. The QAF consists of n hyperbolic tangent (tanh) functions and is defined as
where is the value of the quantization table when the quantization level is Q. The parameters n and denote the number and slope of the functions, respectively. The red dashed line in Figure 6 represents when the slope and the value of the quantization table . In addition, the values of the DCT coefficients after JPEG quantization are plotted with a black line. We can see that they are almost the same.
Quantization is essentially a rounding operation to integer values. It should therefore be represented by a discontinuous, step-like function. In other words, a sign function should be used for the representation of JPEG quantization (13). However, the function was used in the proposed method. When training a neural network, the differentiable function works better for training. Therefore, we chose the function, which is a continuous function. Figure 7 (a) shows the functions for different slopes . We can see that the slope becomes steeper and asymptotically closer to the sign function as increases. When the slope of tanh is set to , it asymptotically approaches the sign function. For practical use, a large value of can approximate the quantization with sufficient accuracy.
Let us see how the quantization with QAF differs from the quantization with JPEGdiff. Figure 7 (b) shows comparison of JPEGdiff (11) with QAF functions. The green curve represents the JPEGdiff, and the blue and orange curves represent the QAF at slopes . We can see that the JPEGdiff has discontinuities, while the QAF is smooth. Since the QAF has no discontinuities, the network may be better trained.
Finally, we consider the number n of tanh functions. The number n depends on the value of . If the minimum value of , because the maximum value of the DCT coefficients is 2040, then at most 2039 tanh functions are required. A sufficiently large constant n was chosen, because it did not matter if the possible values of the QAF exceed the maximum value of the DCT coefficients.
4.2. Proposed Attack Layer
The proposed attack layer consists of three sub-layers: a DCT layer, a layer introducing QAF (QAF layer), and an IDCT layer. Note that in our network, the DCT coefficients are quantized as in the JPEG compression. Figure 8 shows the structure of the network. The embedding and extraction networks have the same structure as that of ReDMark [11]. The output of the DCT layer is processed by the QAF (13) at the QAF layer. The output of this layer is calculated by
Note that the quantization table is divided by 255 because it is normalized by (7). The quantization table values in (14) are determined according to because the quantization table values are different for each of the coordinates of the DCT coefficients. The coordinates are defined by
The attack layer [11] in ReDMark performs noise addition to the coefficients, while the one in our network performs the quantization with the QAF.
4.3. Training Method
The embedding and extraction networks are trained in the same way as they were in ReDMark [11], respectively. The loss function of the embedding network is defined as
where SSIM represents the structural similarity function (SSIM) [18], which measures the structural similarity between two images. The closer to 1.0, the larger the similarity between the two images [18]. It is defined in
where is the original image given as a teacher and where is the output of the embedding network. and are the means of and , respectively. and are the variances of each image, and represents the covariance between the two images. Let and be constants, and let . Because the output of the embedding network takes a real number, the stego-image is obtained by converting it back to 256 levels of the pixel value. That is, it is given by
The loss function of the extraction network is defined as
where is the watermark used as a teacher for the extraction network. is the output of the sigmoid function of the extraction network. That is, the value of the element takes a value between 0 and 1. The total loss function L of our network is defined as
where the parameter determines the balance between the two loss functions. The embedding and extraction network are trained by the back propagation [19] using stochastic gradient descent (SGD) as the optimization method.
5. Computer Simulations
5.1. Evaluation of the QAF
First, the ability that the QAF function can approximate the quantization process of JPEG compression was assessed, using computer simulations. Because the DCT and quantization were applied to -pixel blocks in the JPEG compression, the QAF was also applied to -pixel blocks. The evaluation images were taken from a dataset provided by the University of Granada [20]. They consist of 49 images of pixels. Each image was normalized by (7). The -pixel image is divided into blocks of pixels, resulting in blocks. These blocks were indexed in raster scan order as . The DCT was performed on each block. Let be the DCT coefficients of the -th block. The QAF was applied to the -th block as
where the quantization level of the JPEG compression was set to . The parameters of the QAF in (13) were set as gradient and the number of the hyperbolic tangent functions . For all the QAF-applied blocks, an IDCT was performed, and the luminance values were inversely normalized using (18). Next, all blocks were combined. The combined image was converted back to the original image size. Then, the QAF-applied image was given by
In general, the peak signal to noise ratio (PSNR) of an evaluated image against a reference image is defined by
where
To see the difference between the QAF and JPEG-compressed images shown in Figure 6, the difference could be evaluated by PSNR rather than MSE. The accuracy of the QAF could be measured by the PSNR of a QAF-applied image against a JPEG-compressed image, that is, , where was the JPEG-compressed image. Note that the PSNR was measured against the JPEG-compressed image, not the original image. Similarly, we evaluated the approximation ability of JT-Net using PSNR and compared it with QAF. Figure 9 showed a histogram of PSNRs for JT-Net-applied images by using (9) and QAF-applied images given by (21) and (22), where the quantization level was . The PSNRs for QAF-applied images were clearly greater than those for JT-Net-applied images. Figure 10 showed three examples of QAF-applied images and their PSNRs. Thus, we found that the QAF more adequately represents the quantization of the JPEG compression.
5.2. Evaluation of the Proposed Attack Layer
We compared the JT-Net in the ReDMark, our previous model and the proposed quantization table-based QAF network (QT-QAF-Net) based on the image quality of stego-images and the BER of watermarks extracted from stego-images after the JPEG compression. Note that our previous model [14] was the AE-based model with the quantization table quantized by constant intensity. For comparison, we use an improved model of the CNN-based QAF network with a constant intensity quantisation table (constant QAF-Net). The only difference between the QT-QAF-Net and the constant QAF-Net are the values of the quantisation table.
5.2.1. Experimental Conditions
The training and test images were selected as they were in ReDMark [11]. The training images were 50,000 images of pixels from CIFAR10 [21] (). An -bit watermark was embedded, where . The watermark was randomly generated. Therefore, the amount of watermark embedded per pixel was approximately bits per pixel. In the parameters used for training, the block height and width sizes were set to and , respectively. The parameter of the loss function (20) was set to , the number of learning epochs was set to 100, and the mini-batch size was set to 32. For the parameters of SGD, the training rate was set to , and the moment was set to . For training the proposed attack layer, the gradient of the QAF (13) was set to and the number of the hyperbolic tangent functions was set to . In the attack layer of JT-Net and the proposed method, the quantization level was set to , and the quantization table was used. The embedding, attack, and extraction networks were all connected, and the network was trained using the training images and watermarks. Here, the embedding intensity was fixed at .
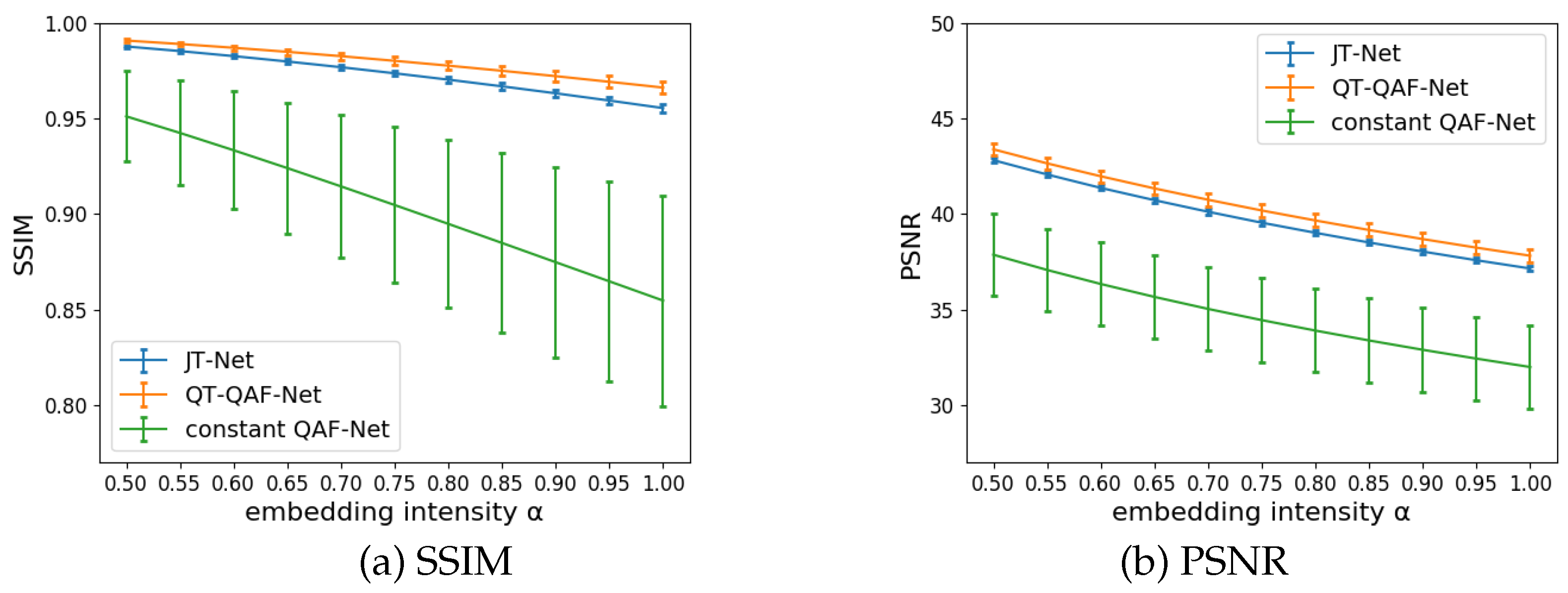
Figure 11.
Image quality of stego-images (tained by )
For testing, 49 images of pixels from the University of Granada were used. These images were divided into pixel subimages, and the embedding process was performed on each of them. The 256 subimages were given to the network as test images. Meanwhile, a -bit watermark was randomly generated. One watermark was embedded four times in one image. That is, the watermark was divided into -bit subwatermarks, and finally each subwatermark was embedded in one subimage. An estimated watermark was determined by bit-by-bit majority voting because the same watermark was embedded four times in one image.
As stated in Section 3.1, the attack layer was not used during testing. The test images and the watermarks were used to output stego-images in the embedding network. Here, the embedding intensity was set to values from to . The stego-image is published. Subsequently, we assume that it was JPEG compressed by some JPEG tool with quantization levels . The compressed stego-images were input to the extraction network, and the estimated watermarks were output. These networks were trained 10 times with different initial weights for the comparison of our network with the JT-Net on image quality and BER. The mean and standard deviation of structural similarity index measures (SSIMs), PSNRs, and BERs were calculated.
5.2.2. Evaluation of the Image Quality
The image quality of the stego-images obtained from the JT-Net, the constant QAF-Net and QT-QAF-Net was evaluated using the SSIMs and PSNRs. The image quality of the stego-image against the original image can be expressed as by (17) and by (23). Figure 11 shows the SSIM and PSNR. The horizontal and vertical axes represent the embedding intensity and SSIM or PSNR, respectively. The error bars represent the standard deviation of the SSIMs and PSNRs. Embedding the watermark strongly causes degradation in the image quality. Therefore, the SSIM and PSNR decreased as the intensity increased. The image quality of the proposed QT-QAF-Net was higher than that of the other two networks. In other words, our network can reduce the degradation of image quality even with the same embedding intensity.
As the images were processed block by block, they were visually checked for block artefacts. Three images selected from the dataset were cropped to -pixel size as shown in the Figure 12. These images were generated from the proposed network trained with embedding intensity . The images were not reduced in size when displayed. Few noticeable artifacts were observed.
Figure 12.
Images cropped to pixels.

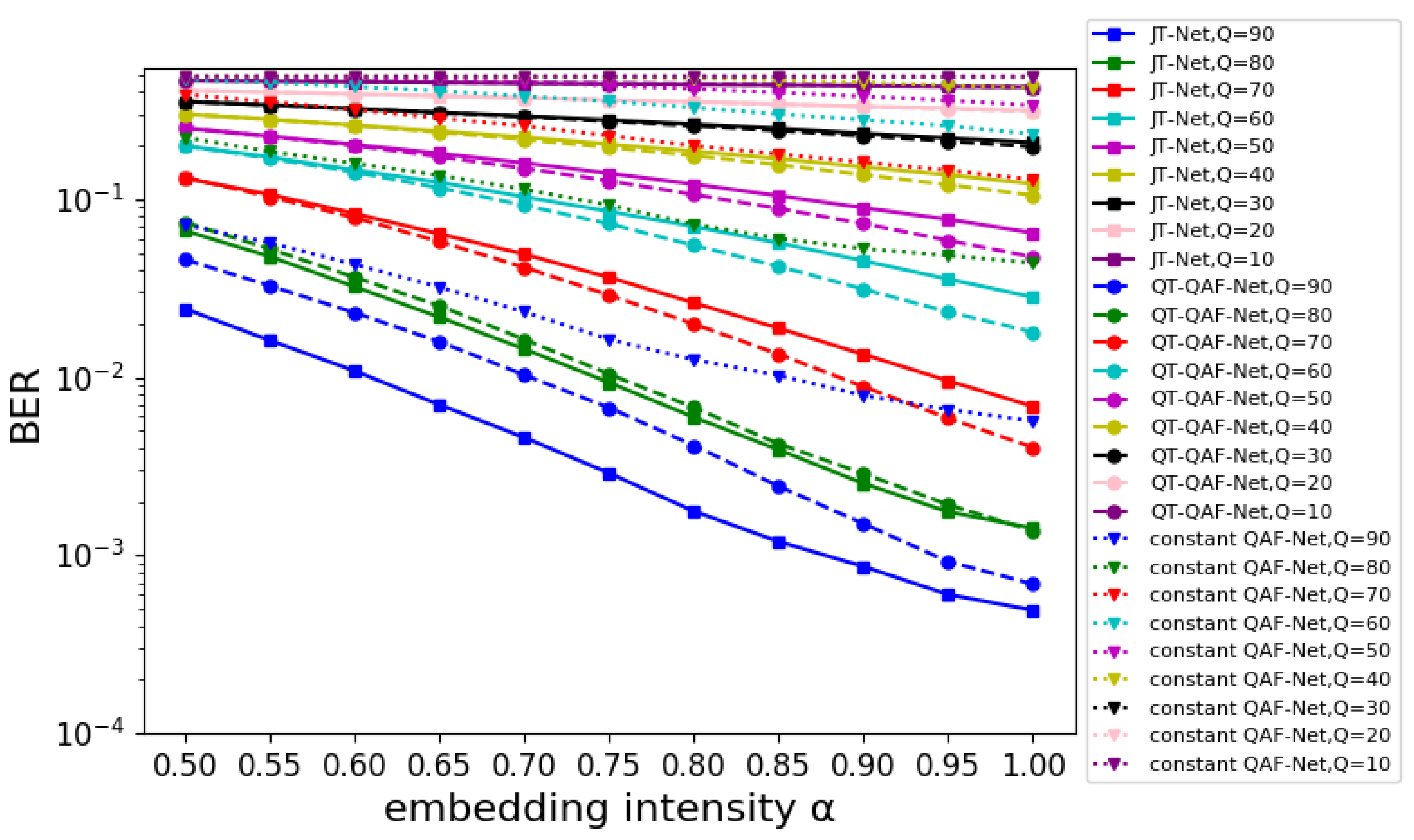
Figure 13.
BER for embedding intensity
5.2.3. Evaluation of the BER
The robustness of our network against the JPEG compression was evaluated. The estimated watermark obtained by (8) was evaluated by using the BER. The BER of the estimated watermark can be defined by
where is the original watermark, and ⊕ represents the exclusive OR.
First, we compared the robustness of our network with that of the JT-Net and constant QAF-Net using the same embedding intensity . Figure 13 shows the BER of the estimated watermark for the embedding intensity . The horizontal and vertical axes represent the intensity and BER, respectively. For different compression levels Q, the dashed lines with circles represent the BER for the QT-QAF-Net, the solid lines with squares represent the BER for the JT-Net and the dotted lines with triangles represent the BER for the constant QAF-Net. When the watermark was strongly embedded, it was extracted correctly. Therefore, the BER decreased as the intensity increased. The lowest BER was obtained when . At compression level , the BER of the proposed network was lower than that of the JT-Net. Also, at , they had almost the same BER. Furthermore, at , the BER of our network was larger than that of the JT-Net. The BER of the constant QAF-Net was always larger than that of the other two networks.
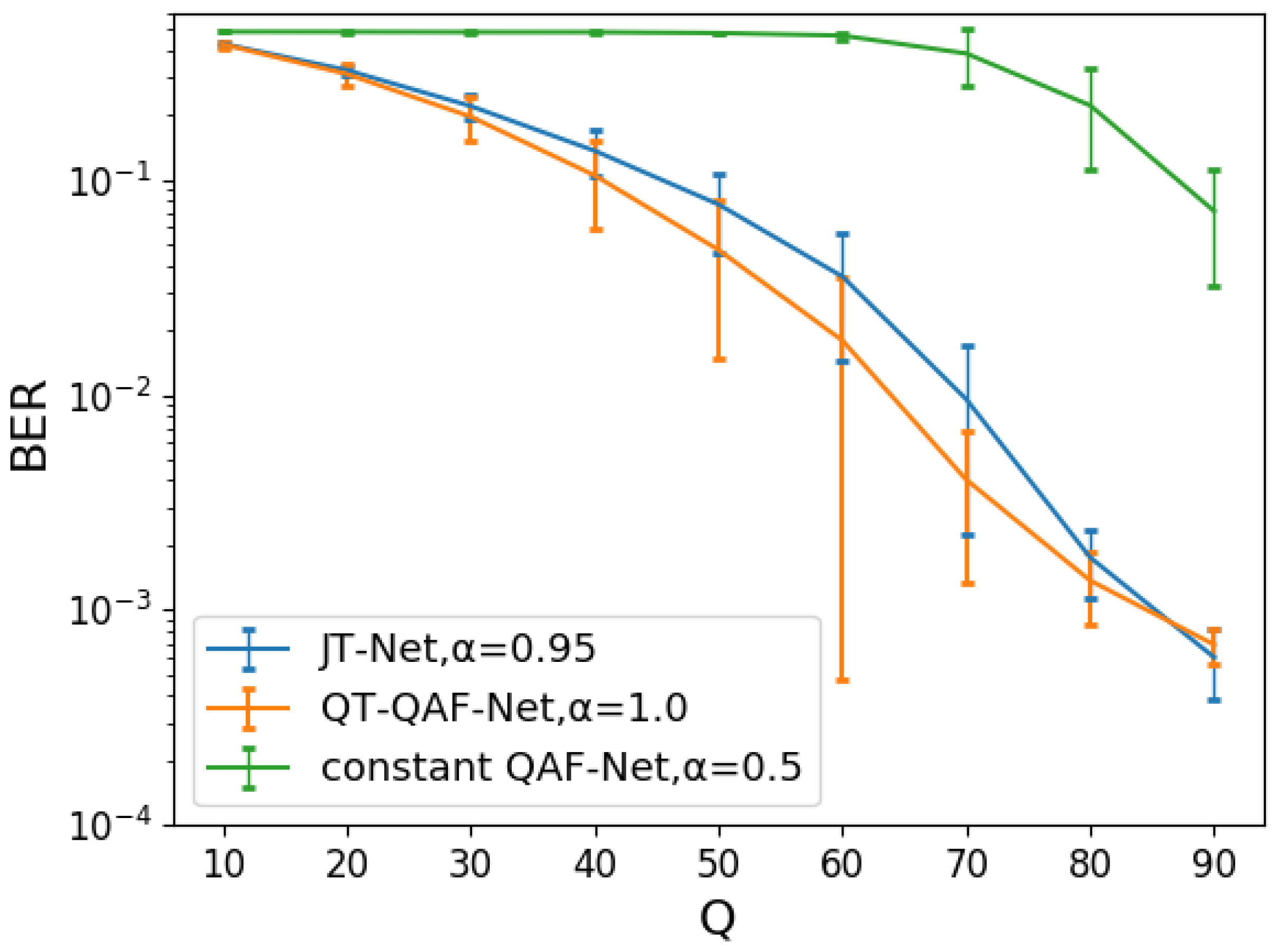
Even with the same embedding intensity, the image quality of our network differs from that of the JT-Net and the constant QAF-Net. Therefore, we next adjusted the embedding intensity so that the PSNRs of these three networks were approximately the same, and we compared the BERs of the networks under this condition. Figure 14 shows the histograms of PSNRs for the QT-QAF-Net with embedding intensity . (a) shows the histograms for the embedding intensity for the JT-Net and for the constant QAF-Net, respectively. (b) shows histograms for these embedding intensities and , respectively. The intensities of the three networks were chosen so that the histograms shown in (b) look similar. To measure the robustness against JPEG compression, we set the intensity to ensure that the PSNR obtained from these networks is approximately the same. Specifically, we set the intensity for the JT-Net and QT-QAF-Net to (average PSNR dB) and (average PSNR dB), respectively. Figure 15 is the BER for the compression level Q. The error bars are the standard deviation of the BERs. The BER of the estimated watermark for QT-QAF-Net was lower than that for the JT-Net and constant QAF-Net. Thus, we can say that our network can generate watermarks with fewer errors under the given PSNR.
6. Conclusion
The JT-Net in ReDMark [11] is a network that simulates JPEG compression. This network substituted the quantization process with a process that adds noise proportional to the value of the quantization table. In previous work [14], a quantised activation function (QAF) quantised by constant intensity (constant QAF-Net) was proposed. In this paper, we proposed the quantization table-based QAF network (QT-QAF-Net), which can approximate the quantization process of the JPEG compression according to the standard. By approximating the quantization of the JPEG compression using the QAF, we expected to improve the robustness against the JPEG compression. The results of computer simulations showed that the QAF represented quantization with sufficient accuracy. Also, we found that the network trained with the QAF was more robust against the JPEG compression than those trained with the JT-Net. Because the embedding and extraction networks were more robust against the JPEG compression when trained with the QAF, we conclude that our method is more suitable for simulating JPEG compression than conventional methods applying additive noise.
Further studies with QAF are expected. For example, since QAF is differentiable over the whole interval, it may produce better adversarial images compared to JPEGdiff [12]. Furthermore, there is a study on the estimation of the sign bit of DCT coefficients [22]. The non-linearity of the quantized DCT coefficients made the estimation difficult. The solution could be simplified by using QAF.
Author Contributions
Conceptualization, M.K. ; methodology, M.K. and S.Y.; software, S.Y.; investigation, S.Y.; resources, M.K.; data curation, M.K. and S.Y.; writing—original draft preparation, S.Y.; writing—review and editing, M.K.; visualization, S.Y.; supervision, M.K.; project administration, M.K.; funding acquisition, M.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JSPS KAKENHI Grant Number 20K11973 and Support Center for Advanced Telecommunications Technology (SCAT) research grant. The computations were performed using the supercomputer facilities at the Research Institute for Information Technology of Kyushu University.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: CIFAR-10 dataset https://www.cs.toronto.edu/ kriz/cifar.html and Computer Vision Group. University of Granada https://ccia.ugr.es/cvg/CG/base.htm
Acknowledgments
This work was supported by JSPS KAKENHI Grant Number 20K11973 and Support Center for Advanced Telecommunications Technology (SCAT) research grant. The computations were performed using the supercomputer facilities at the Research Institute for Information Technology of Kyushu University.
Conflicts of Interest
The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; in the decision to publish the results.
References
- Wan, W.; Wang, J.; Zhang, Y.; Li, J.; Yu, H.; Sun, J. A comprehensive survey on robust image watermarking. Neurocomputing 2022, 488, 226–247, . [CrossRef]
- M. Vafaei, H. M.-Nasab and H. Pourghassem, “A new robust blind watermarking method based on neural networks in wavelet transform domain,”World Applied Sciences Journal, vol. 22, no. 11, pp. 1572–1580, 2013.
- Sy, N.C.; Kha, H.H.; Hoang, N.M. An Efficient Robust Blind Watermarking Method Based on Convolution Neural Networks in Wavelet Transform Domain. Int. J. Mach. Learn. Comput. 2020, 10, 675–684, . [CrossRef]
- He, D.; Xu, K.; Wang, D. Design of multi-scale receptive field convolutional neural network for surface inspection of hot rolled steels. Image Vis. Comput. 2019, 89, 12–20, . [CrossRef]
- Singh, H.K.; Singh, A.K. Digital image watermarking using deep learning. Multimedia Tools Appl. 2023, 83, 2979–2994, . [CrossRef]
- Hamamoto, I.; Kawamura, M. Image Watermarking Technique Using Embedder and Extractor Neural Networks. IEICE Trans. Inf. Syst. 2019, E102.D, 19–30, . [CrossRef]
- M. Jamali , N. Karimi, P. Khadivi, S. Shirani, S. Samavi “Robust watermarking using diffusion of logo into auto-encoder feature maps,” Multimedia Tools and Applications, vol. 82, pp.45175–45201, 2023.
- J. Zhu, R. Kaplan, J. Johnson, L. Fei-Fei, “HiDDeN: hiding data with deep networks,” European Conference on Computer Vision, 2018.
- Zhao, Y.; Wang, C.; Zhou, X.; Qin, Z. DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking. Mathematics 2022, 11, 209, . [CrossRef]
- Hamamoto, I.; Kawamura, M. Neural Watermarking Method Including an Attack Simulator against Rotation and Compression Attacks. IEICE Trans. Inf. Syst. 2020, E103.D, 33–41, . [CrossRef]
- Ahmadi, M.; Norouzi, A.; Karimi, N.; Samavi, S.; Emami, A. ReDMark: Framework for residual diffusion watermarking based on deep networks. Expert Syst. Appl. 2019, 146, 113157, . [CrossRef]
- R. Shin, D. Song, “Jpeg-resistant adversarial images,” NIPS 2017 workshop on machine learning and computer security, vol. 1, pp. 8–13, 2017.
- Mareen, H.; Antchougov, L.; Van Wallendael, G.; Lambert, P. Blind deep-learning-based image watermarking robust against geometric transformations, 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 2024, pp. 1-2, 2024.
- S. Yamauchi, M. Kawamura, “Neural network based watermarking trained with quantized activation function,” Asia Pacific Signal and Information Processing Association Annual Summit and Conference 2022, pp. 1608–1613, 2022.
- C. Guo, M. Rana, M. Cisse, L. van der Maaten, “Countering adversarial images using input transformations,” International Conference on Learning Representations, 2018.
- Independent JPEG group, http://www.ijg.org/, (Accessed 2023-05-21).
- D. Clevert, T. Unterthiner, S. Hochreiter, “Fast and accurate deep network learning by exponential linear units (ELUs),” arXiv preprint arXiv:1511.07289, 2015.
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612, . [CrossRef]
- D. E. Rumelhart, G. E. Hinton, R. J.Williams, “Learning representations by back-propagating errors,” Nature, vol. 323, no. 6, pp. 533–536, 1986.
- Computer vision group at the University of Granada, dataset of standard 512 × 512 grayscale test images, http://decsai.ugr.es/cvg/CG/base.htm, (Accessed 2023-06-09).
- A. Krizhevsky, V. Nair, G. Hinton, The CIFAR-10 dataset, https://www.cs.toronto.edu/ kriz/cifar.html, (Accessed 2023-06-09).
- Lin, R.; Liu, S.; Jiang, J.; Li, S.; Li, C.; Kuo, C.-C.J. Recovering sign bits of DCT coefficients in digital images as an optimization problem. J. Vis. Commun. Image Represent. 2024, 98, . [CrossRef]
Figure 2.
Overall structure of ReDMark [11]
Figure 2.
Overall structure of ReDMark [11]
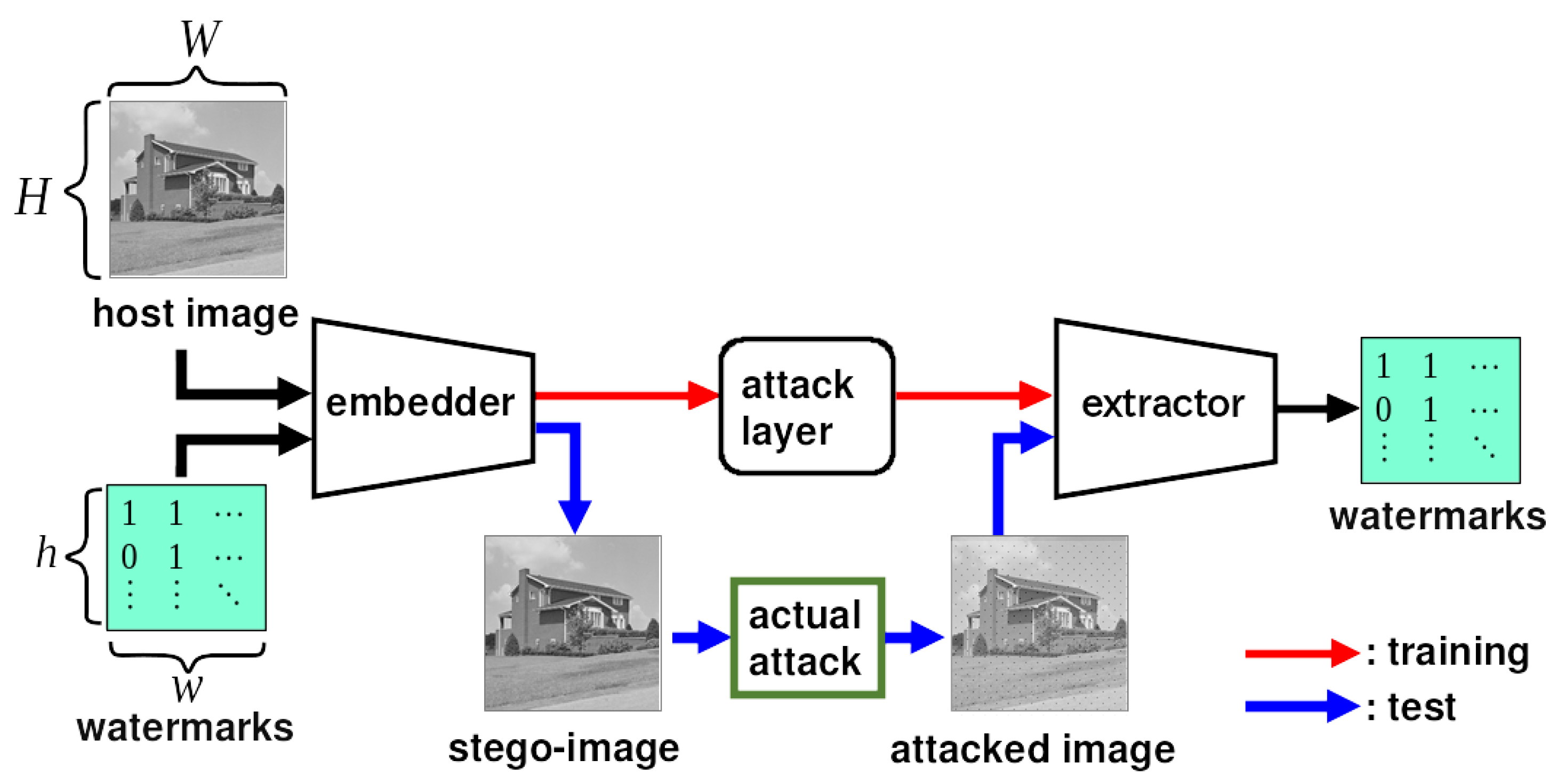
Figure 4.
Extended input in a circular convolution layer. ➀ Extended in the column direction. ➁ Extended in the row direction.
Figure 4.
Extended input in a circular convolution layer. ➀ Extended in the column direction. ➁ Extended in the row direction.
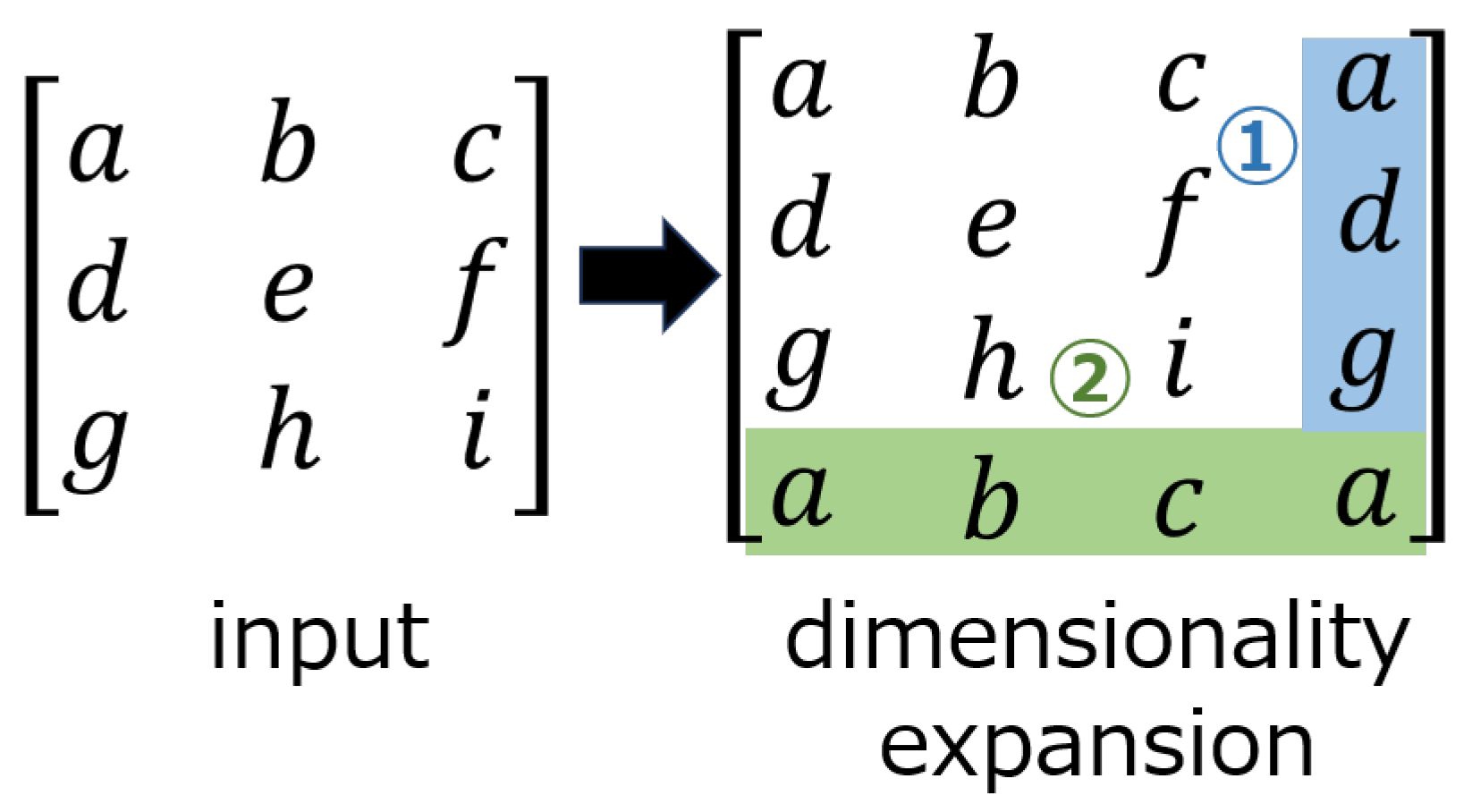
Figure 5.
Extraction network of ReDMark [11]
Figure 5.
Extraction network of ReDMark [11]
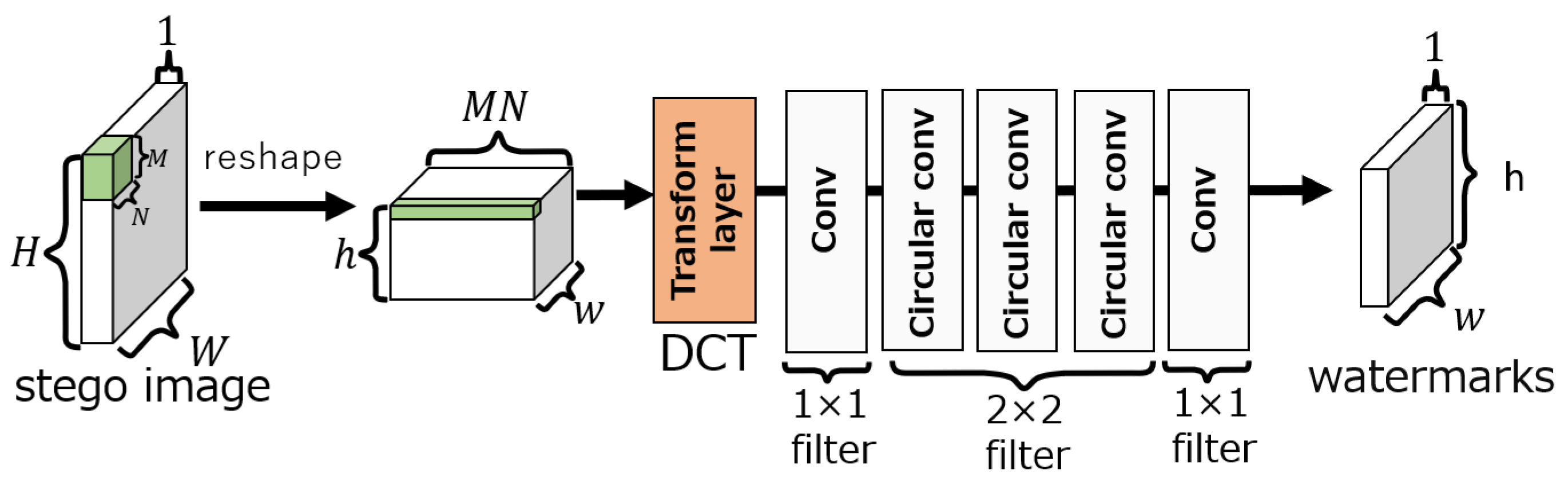
Figure 6.
Overview of the quantized activation function: with slope and number of hyperbolic tangent functions, .
Figure 6.
Overview of the quantized activation function: with slope and number of hyperbolic tangent functions, .
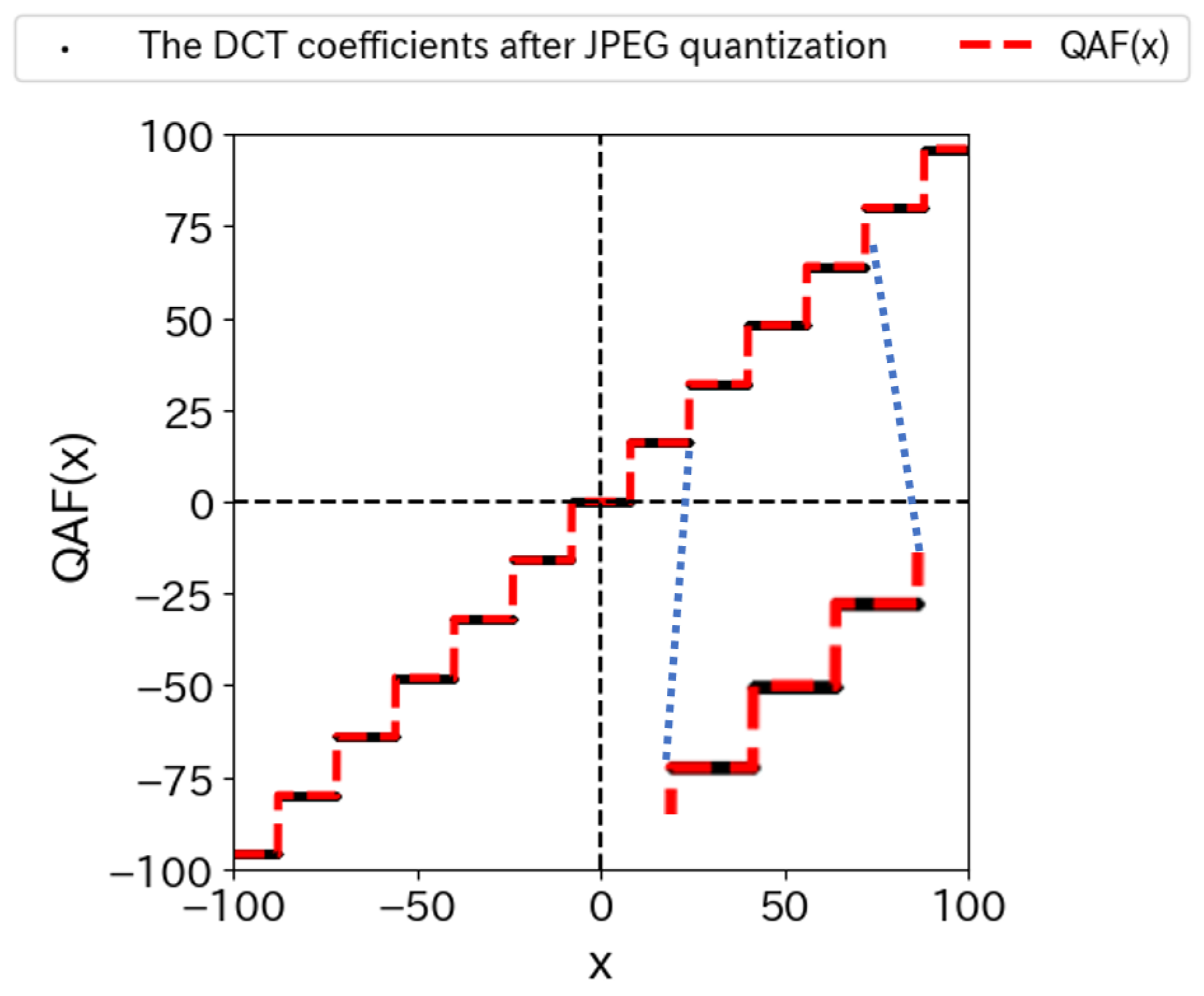
Figure 7.
Activation functions: (a) the hyperbolic tangent functions for slopes . (b) JPEGdiff vs QAF.
Figure 7.
Activation functions: (a) the hyperbolic tangent functions for slopes . (b) JPEGdiff vs QAF.
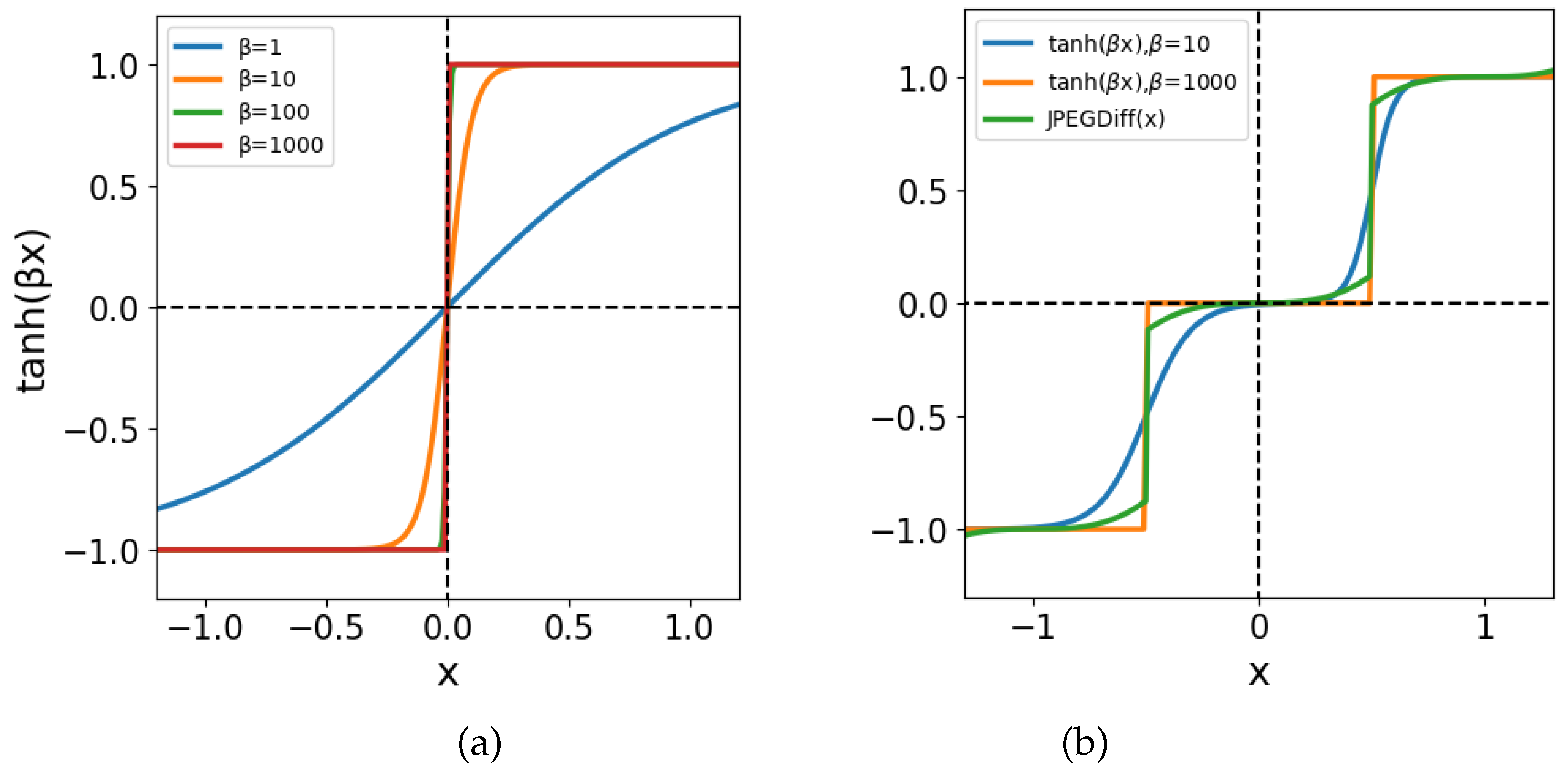
Figure 8.
Proposed attack layer
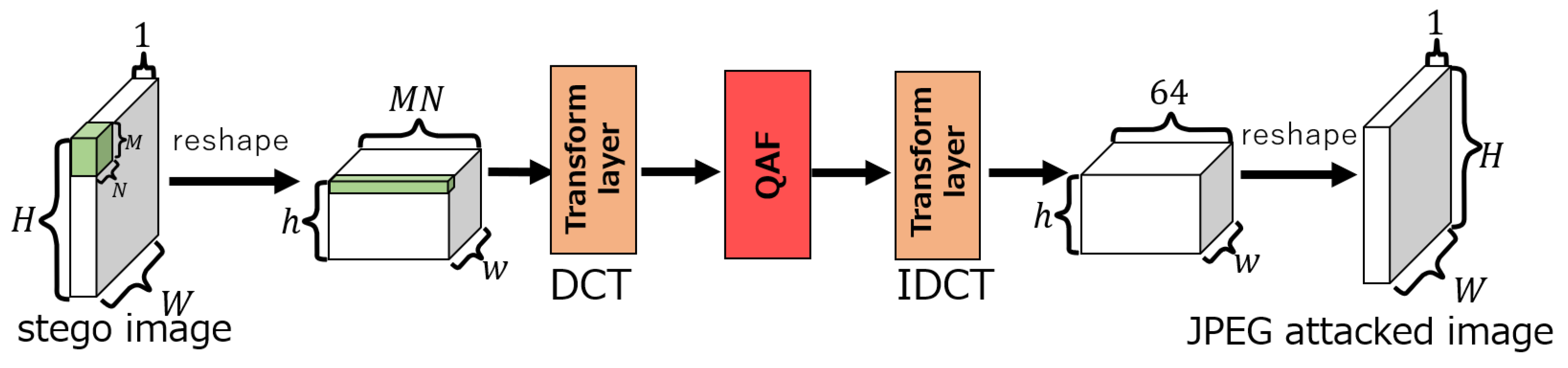
Figure 9.
Histogram of PSNRs for JT-Net-applied images and QAF-applied images
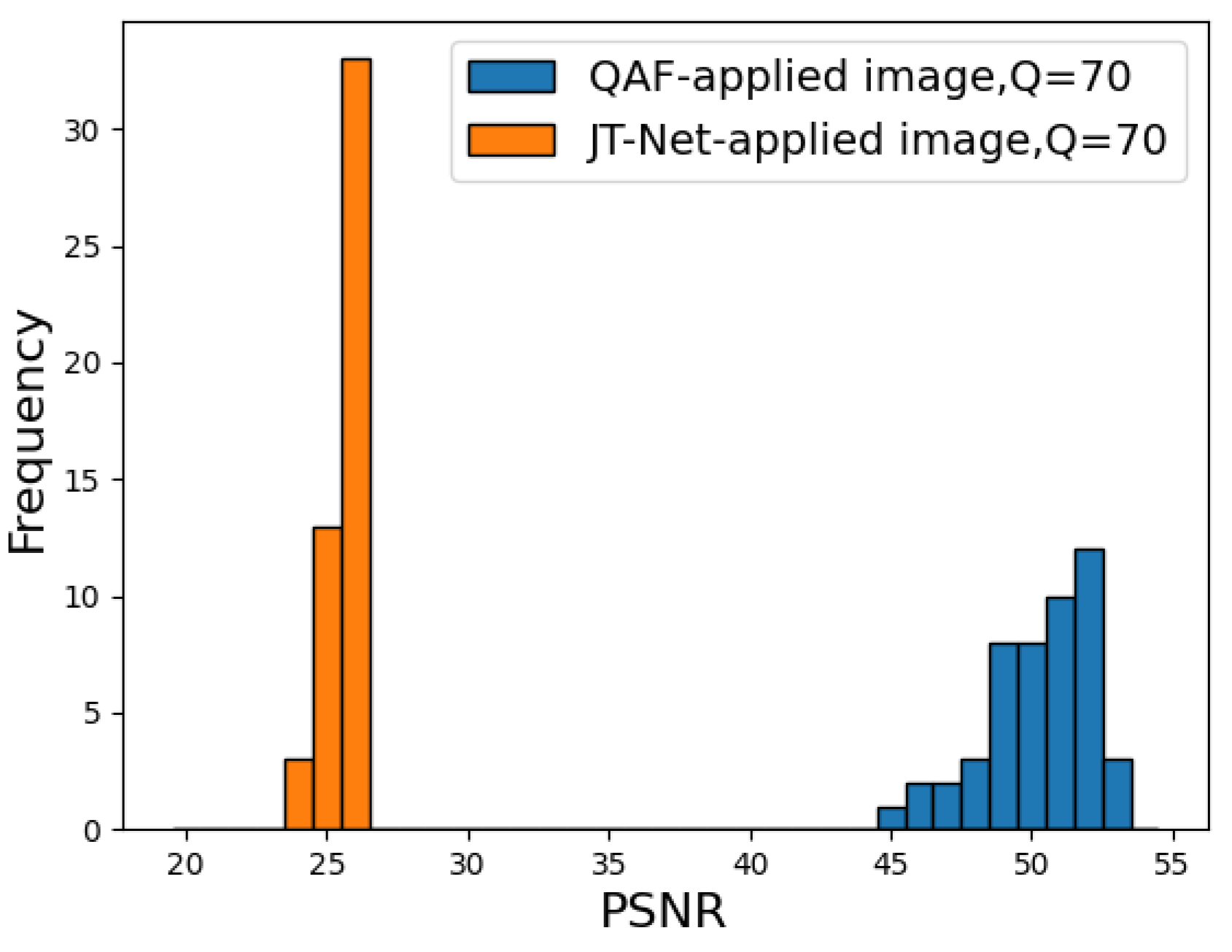
Figure 10.
QAF-applied images and their PSNRs

Figure 14.
Histogram of PSNR for embedding intensity for QT-QAF-Net: (a) intensity for JT-Net and for constant QAF-Net and (b) intensity for JT-Net and intensity for constant QAF-Net .
Figure 14.
Histogram of PSNR for embedding intensity for QT-QAF-Net: (a) intensity for JT-Net and for constant QAF-Net and (b) intensity for JT-Net and intensity for constant QAF-Net .
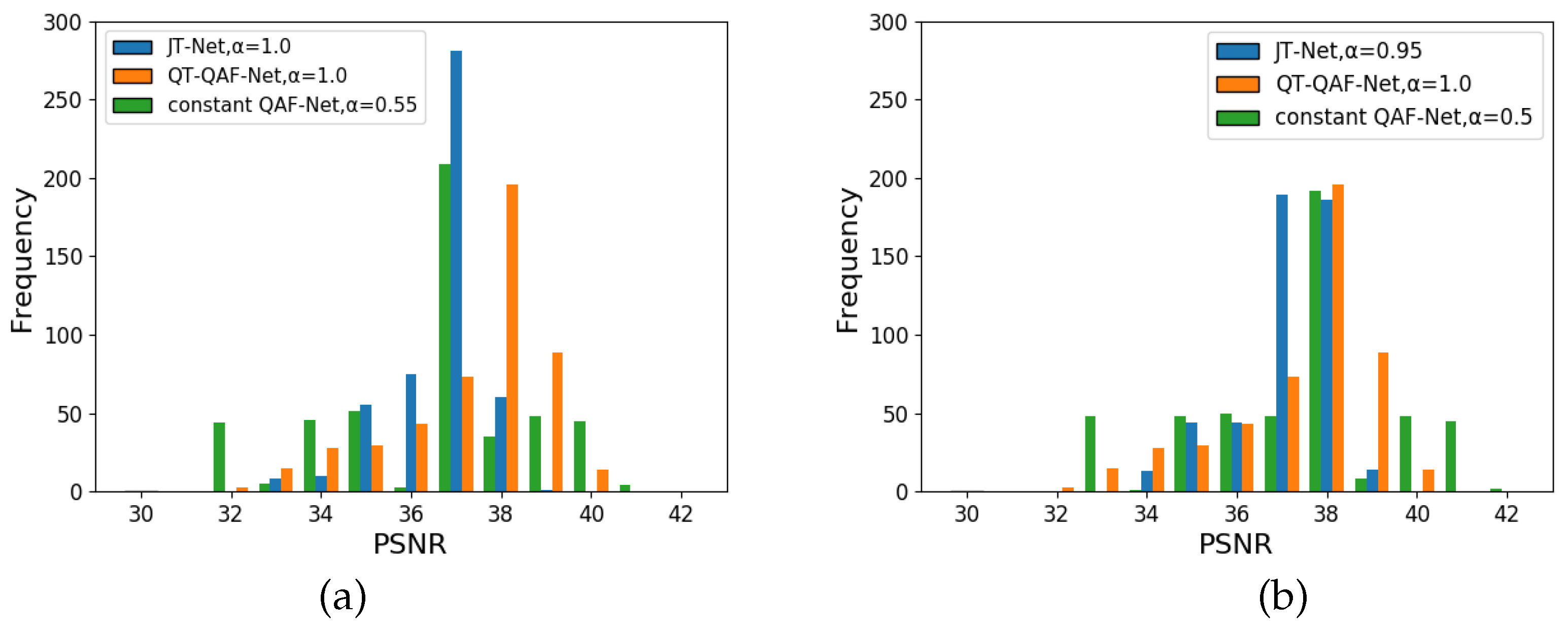
Figure 15.
BER for the JPEG compression level Q
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



