
Submitted:
08 February 2024
Posted:
13 February 2024
You are already at the latest version
Abstract
This article is devoted to the problem of genetically coding of inherited cyclic structures in biological bodies, whose life activity is based on a great inherited set of mutually coordinated cyclic processes. The author puts forward and arguments the idea that the genetic coding system is capable of encoding inherited cyclic processes because it itself is a system of cyclic codes connected with Boolean algebra of logic. In other words, the physiological processes in question are cyclical because they are genetically encoded by cyclic codes. In support of this idea, the author presents a set of his results on the connection of the genetic coding system with cyclic Gray codes, which are one of many known types of cyclic codes. This opens up the possibility of using for modeling inherited cyclic biostructures those algebraic and logical theories and constructions that are associated with Gray codes and have long been used in engineering technologies: Karnaugh maps, Hilbert curve, Hadamard matrices, Walsh functions, dyadic analysis, etc. Additionally, the connections of these constructions with statistical rules of genomic DNAs and binary-genomic numbers are considered.
Keywords:
genetic code
; cycles
; Gray codes
; genomic DNAs
; binary oppositions
; binary-genomic numbers
; complementarity operation
; statistical analysis
; Karnaugh maps
; Hilbert curve
; Walsh functions
1. Introduction
A living organism is a huge chorus of genetically
inherited cyclic processes, the mutual coordination of which is maintained
throughout ontogenesis. For example, our body's inherited proteins are engaged
in continuous life-death cycles of assembling and disassembling them into amino
acids. For instance, the half-life of the hormone insulin is 6-9 minutes.
Somatic cells of the body divide cyclically (cell mitosis), which is
accompanied by a cyclic change in the cell stages of division. An important
role in this is played by proteins with the characteristic name “cyclins”, the
concentration of which in the cell changes cyclically. The energy costs for
these cyclic events are taken from the universal source of energy for all
biochemical processes of all living organisms on Earth: ATP (adenosine
triphosphoric acid). The lifetime of one ATP molecule in humans is less than
one minute. During the day, one ATP molecule goes through an average of
2000-3000 cycles of resynthesis (the human body synthesizes about 40 kg of ATP
per day).
Briefly speaking, genetically inherited parts of
our body are constantly dying and being reborn in a cyclical manner.
Considering such phenomena, the renowned physiologist A.G. Gurvich claimed:
"The main problem in biology is maintaining shape while constantly
renewing the substrate" [Gurvich, 1977]. These cyclic phenomena is closely
interrelated with the topic of internal biological clock, studying of molecular
cyclic bases of which was awarded by Nobel prize in 2017 (https://www.nobelprize.org/prizes/medicine/2017/press-release/).
It was shown that all multicellular organisms, including humans, utilize a
similar cyclic molecular mechanism of the internal clock to control circadian
biorhythms.
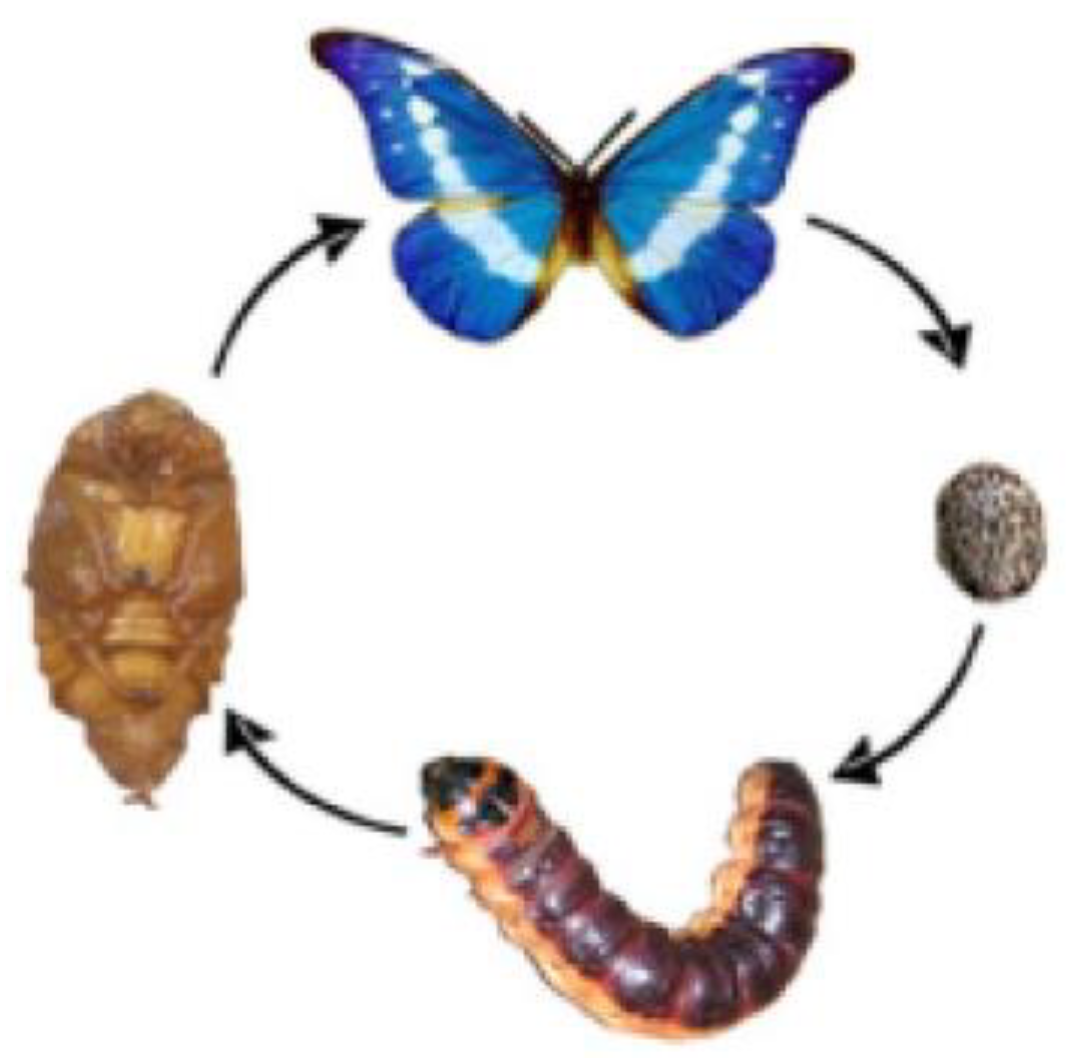
One of many inherited cyclic phenomena is the
cyclic metamorphosis of butterflies with the following stages:
butterfly-egg-caterpillar-pupa-butterfly (Figure
1.1). This metamorphosis of a butterfly demonstrates an example of the
work of cyclic genomic automata. Nobody teaches a butterfly how to get out of
its chrysalis and start flying. But she gets out and starts flying. Everything
necessary for these actions and the cyclic metamorphosis in the whole is
encoded in genomic informatics, capable of providing inheritance for multiple
cyclic processes. At the same time, at the pupal stage, the butterfly does not
feed on anything, that is, its atomic content is fixed from the beginning of
the formation of the pupae. But due to some genetically determined
rearrangements in this ensemble of atoms, a new organism ultimately arises - a
butterfly.
Figure 1.1.
The cycle of the metamorphosis of butterflies: butterfly-egg-caterpillar-chrysalis- butterfly.
Figure 1.1.
The cycle of the metamorphosis of butterflies: butterfly-egg-caterpillar-chrysalis- butterfly.
The neurons and muscle units of the butterfly work
in accordance with the fundamental physiological law of all-or-none, which
determines the binary principle of their functioning: a nerve cell or a muscle
fiber give only their answers “yes” or “no” under the action of different
stimulus by analogy with the Boolean variables. If a stimulus is above a
certain threshold, a nerve or muscle fiber will fire with full response.
Essentially, there will either be a full response or there will be no response
[Kaczmarek, Levitan, 1987; Martini, 2005;
https://en.wikipedia.org/wiki/All-or-none_law]. During the flight of a
butterfly, millions of its neurons and muscle units, each of which functions in
the named binary mode “yes” or “no”, act in mutual coordination as some kind of
genetically determined binary automata, the collective activity of whose
elements is based on their mutual logical coordination by analogy with
coordination of the operation of trigger ensembles in a computer based on
Boolean algebra logic.
Such facts led the author to the idea that the
genetic coding system is capable of encoding inherited cyclic processes because
it itself is a system of cyclic codes connected with Boolean algebra of logic.
In other words, the physiological processes in question are cyclical because
they are genetically encoded by cyclic codes. But in modern mathematics of
information coding there is a wide variety of types of cyclic codes. What kind
of cyclic codes, in their characteristics, corresponds to the structural
organization of the genetic code system and the known patterns of information
sequences of genomic DNAs? The author has obtained evidence in favor of the
important role of the family of cyclic Gray codes for the analysis and modeling
of the genetic coding system and genetic informatics in general.
The purpose of this article is to present the
author's results of using cyclic Gray codes for the analysis of structural
features of the genetic coding system, as well as for the analysis of the
general rules previously described by the author for the statistical
organization of information sequences of single-stranded DNAs in genomes of
higher and lower organisms [Petoukhov, 2022a,b, 2023a,b; Petoukhov, He, 2023].
Concerning to the mentioned general rules of
statistical organization of genomic DNAs, one should remind the following. P.
Jordan and E. Schrödinger, who were one of the creators of quantum mechanics,
noted the main difference between living and inanimate objects: inanimate
objects are controlled by the average random movement of their millions of
particles, whose individual influence is negligible, while in a living organism
selected – genetic - molecules have a dictatorial influence on the whole living
organism [McFadden, Al-Khalili, 2018]. In addition, P. Jordan, who was the
author of the first article on quantum biology, claimed that «life's missing
laws were the rules of chance and probability (the indeterminism) of the
quantum world that were somehow scaled up inside living organisms»
[McFadden, Al-Khalili, 2018]. According to Jordan’s thoughts, the mechanisms of
living organisms are associated with his ‘amplifier theory’, based on Bohr's
notion of the ‘irreversible act of amplification’, required to bring the fuzzy
quantum reality into sharp focus by ‘observing’ it. It is these hidden laws of
chance and probability, postulated by Jordan, that the author of this article
is looking for in the probabilistic characteristics of long DNA sequences of
hydrogen bonds and nitrogenous bases [Petoukhov, 2022a,b, 2023a,b]. In search
of these missing laws of probability, the author turned to the study of
statistical patterns in binary representations of single-stranded information
sequences of nucleotides in the DNAs of the genomes of higher and lower
organisms from the genetic data bank GenBank. As a result, the existence of
general statistical rules has been established on a wide variety of genomes,
which are candidates for the role of universal rules (laws) of the statistical
organization of genomic DNAs [Petoukhov, 2022a,b, 2023a,b].
2. Binary oppositions in genetic alphabets, Gray-type matrices, and Karnaugh maps
This section shows the usefulness of using Gray
codes in the structural analysis of the emergent properties of a genetic coding
system in the form of genetic Gray-type matrices, which are structurally
similar to Karnaugh maps widely used in combinational logic circuits for
simplifying Boolean algebra expressions.
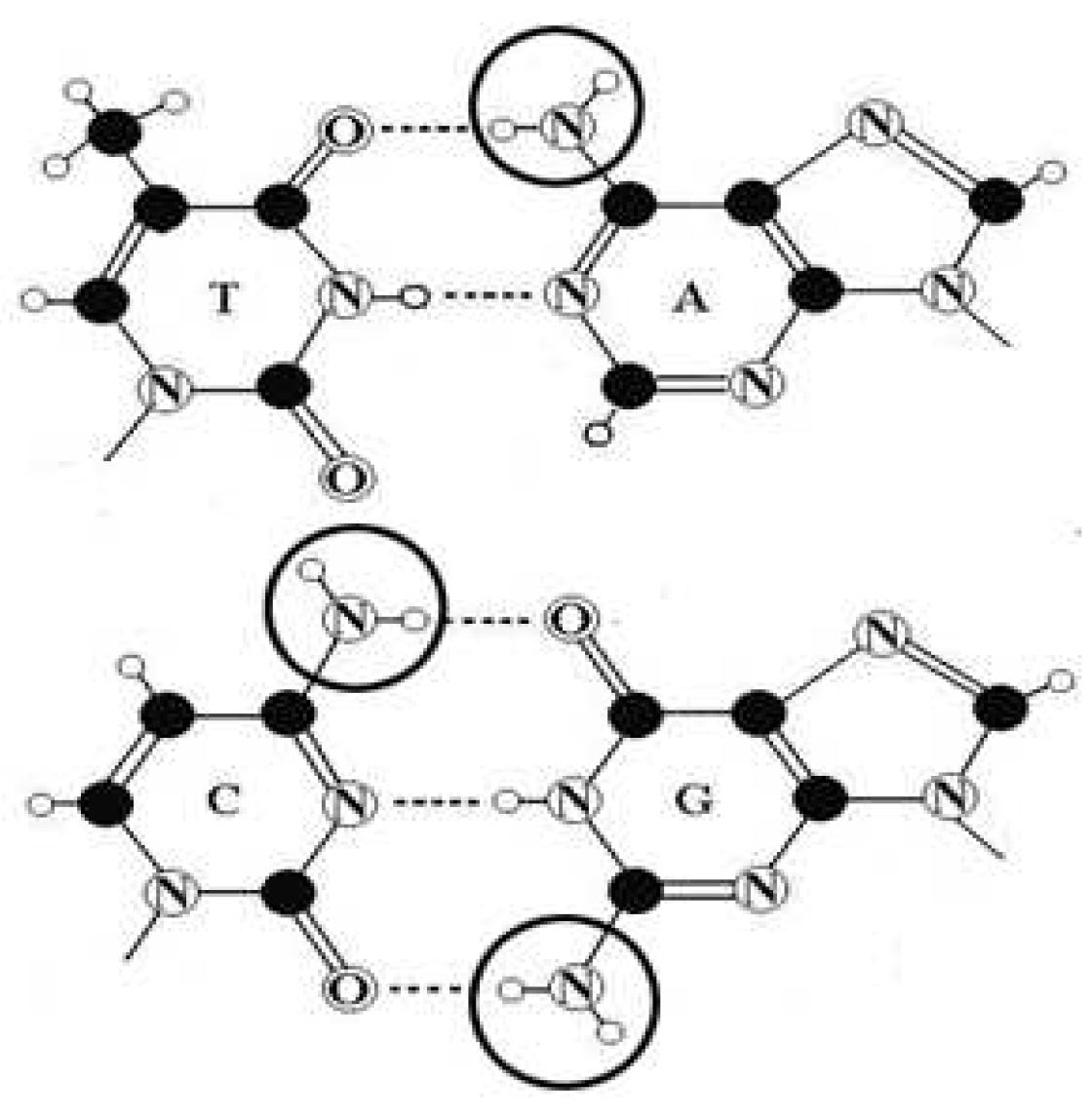
In DNA, the alphabet of 4 nucleotides – adenine A,
cytosine C, guanine G, and thymine T - is the carrier of a system of binary
oppositional characteristics:
- 1)
- two of these nucleotides are purines (A and G), and the other two (C and T) are pyrimidines, which gives the representation C = T = 0, A = G = 1;
- 2)
- two of these nucleotides are keto molecules (T and G), and the other two (C and A) are amino molecules, which gives the representation C = A = 0, T = G = 1.
Because of this, DNA alphabets of 4 nucleotides, 16
duplets and 64 triplets are represented in Figure
2.1 in the form of square matrices, the columns of which are numbered
with the opposition indicators “pyrimidine or purine” (C=T=0, A=G=1), and the rows with the opposition indicators
“amino or keto" (C=A=0, T=G=1). Column and row
binary numerations are arranged in the order of codewords of corresponding Gray
codes having n-bits. In such matrices with Gray code numerations, all
monoplets, duplets and triplets automatically occupy a strictly individual
place. Each cell in these matrices, as well as its n-plet, is numbered by
concatenation (connection) of the binary numbers of its row and column. For
example, the triplet CAG has 6-bit numeration 001011 because it is located at the intersection of
the row 001 and the column 011. The binary
Gray numbering order of all cells in three matrices in Figure 2.1 corresponds to 2-bit, 4-bit and
6-bit Gray codes. Genetic matrices with rows and columns ordered by Gray codes
will be briefly called Gray-type matrices. This type of numbering of rows and
columns based on Gray codes has long been used in Karnaugh maps associated with
Boolean functions of mathematical logic and presented below in connection with
the idea of genetically inherited logic in organization of living bodies and
their actions.
Figure 2.1.
The arrangement of 4 nucleotides, 16 duplets and 64 triplets in matrices whose rows and columns are ordered by the corresponding Gray codes. The decimal equivalents of codewords or numbers of Gray codes are indicated in parentheses.
Figure 2.1.
The arrangement of 4 nucleotides, 16 duplets and 64 triplets in matrices whose rows and columns are ordered by the corresponding Gray codes. The decimal equivalents of codewords or numbers of Gray codes are indicated in parentheses.
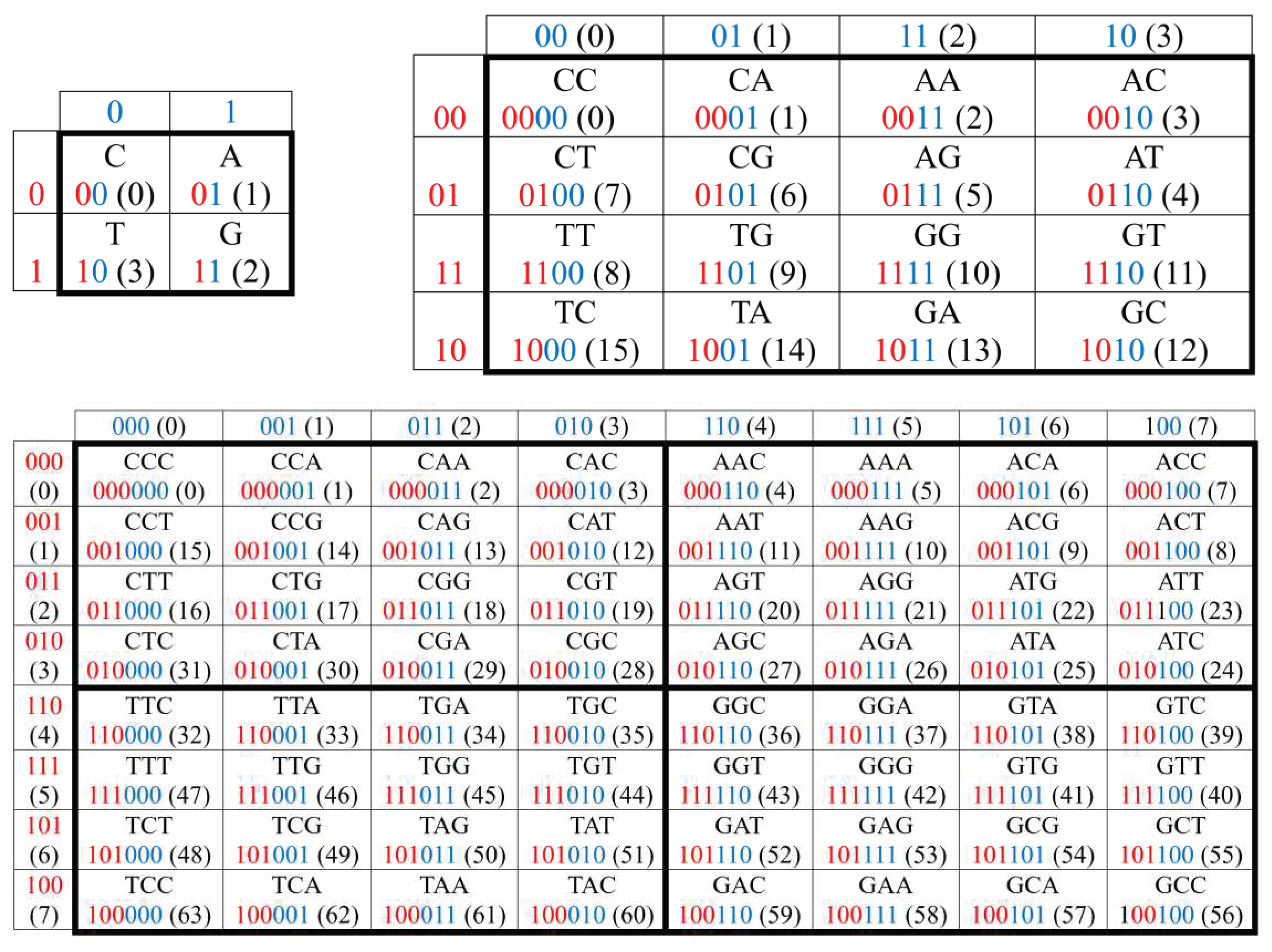
How are the amino acids and stop codons they encode
located in the shown matrix of 64 triplets constructed in this way? This
arrangement cannot be predicted, since the amino acids and nucleotides A, C, G,
T are completely different in structure. The number of options for the arrangement
of amino acids with their repetitions to fill the entire (8*8)-matrix is huge:
>>10100 (for comparison, in physics, the lifetime of the
Universe is estimated at 1017 seconds). Will this arrangement be
chaotic or will it suddenly turn out to be regular symmetrical? Figure 2.2 shows the case of the Vertebrate
Mitochondrial Code, which is considered to be the most ancient and symmetrical
among the genetic code dialects [Frank-Kamenetskii, 1988].
Figure 2.2.
The location of 64 triplets and the amino acids and stop codons they encode in the Gray-type matrix (from Figure 2.1) in the case of the Vertebrate Mitochondrial Code. Common abbreviations for amino acids and stop codons are used. Semicircular brackets on the sides of the Gray-type matrix show the directions of the codewords order of the 6-bit Gray code, which numerates 64 matrix cells and their 64 triplets.
Figure 2.2.
The location of 64 triplets and the amino acids and stop codons they encode in the Gray-type matrix (from Figure 2.1) in the case of the Vertebrate Mitochondrial Code. Common abbreviations for amino acids and stop codons are used. Semicircular brackets on the sides of the Gray-type matrix show the directions of the codewords order of the 6-bit Gray code, which numerates 64 matrix cells and their 64 triplets.
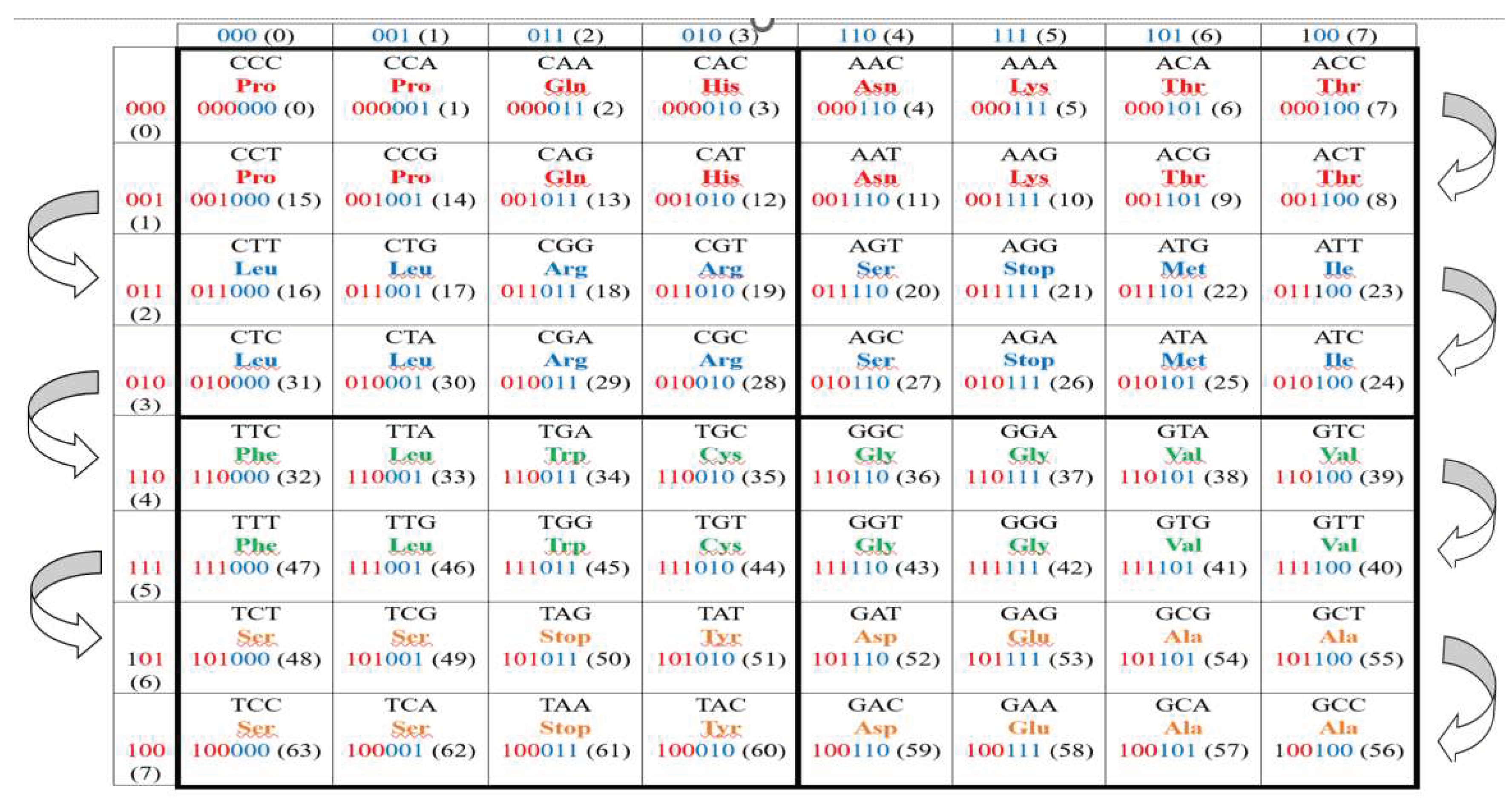
It turns out that from the ocean of possibilities, nature chose a symmetrically regular variant of the repetition and arrangement of amino acids and stop codons in the Gray-type matrix of 64 triplets. The shown matrix of encoded amino acids and stop codons consists of pairs of adjacent rows with decimal numbers 0-1, 2-3, 4-5, 6-7, identical in composition of amino acids and stop codons, shown in color. For example, lines 0 and 1 contain the same set of red amino acids Pro, Gln, His, Asn, Lys, Thr in composition and location.
The lines in each of the indicated pairs 0-1, 2-3, 4-5, 6-7, having the repetition of amino acids and stop codons in them, differ in that the sequence of 6-bit numbers of their 16 cells forms a cyclic sequence with unit Hamming distance between adjacent cells, if you read the binary Gray numbers of the cells in the first of the two rows from left to right, and the cell numbers of the second row reversely from right to left.
Each type of amino acids in the Gray-type matrix (Figure 2.2) is grouped in such a way that it occupies only those cells whose 6-bit numbering forms a cyclic sequence with a unit Hamming distance between adjacent codewords. For example, the amino acid Pro is located in cells numbered 000000, 000001, 001001, 001000; the amino acid Arg is located in cells numbered 011011, 011010, 010010, 010011; and so on.
Below many other interconnections between Gray codes and the genetic code system are additionally represented to discover unknown emergent features of the genetic systems. But here the author would like to explain why he applies n-bit Gray codes for ordering of rows and columns in the genetic matrices in Figures 2.1 and 2.2. This application of Gray codes is not accidental at all. The main reason is that the similar Gray-type numeration of rows and columns are used long ago in Karnaugh maps, which is an effective method of simplifying Boolean algebra expressions to minimize number of logic gates in logic designs [Brown, 2012; Cook, 2017; Dodge, 2015; https://en.wikipedia.org/wiki/Karnaugh_map ]. Cells in Karnaugh maps are known as minterms, while each cell value represents the corresponding output value of the Boolean function. These analogies between the described genetic Gray-type matrices, having regular structural symmetries, and Karnaugh maps open interesting opportunities to interpret genetic n-plets (duplets, triplets, etc.) as appropriate output values of Boolean functions. This connection of the genetic coding system with mathematical logic through Karnaugh maps apparently reflects that genetically inherited logic, in accordance with which, for example, a butterfly emerges from its chrysalis and begins to fly with cyclic flapping of its wings. But an in-depth analysis of this interpretation, associated with the problems of genetic intelligence and its engineering analogues in the form of genomorphic intelligence, deserves a separate publication and is not the scope of this article. These studies of the connection between the genetic coding system and Gray's cyclic codes are associated with the thoughts of the founder of mathematical logic, G. Boole and his famous book «An Investigation of the Laws of Thought on Which are Founded the Mathematical Theories of Logic and Probabilities» [Boole, 2009]. One can add that digital logic designers widely use Gray codes to transfer multi-bit counter information in systems with synchronous logic that operate at different clock frequencies. In such cases, logic is considered to operate in different "clock regions". This is fundamental to the design of large chips that operate at many different clock speeds [https://ru.wikibrief.org/wiki/Gray_code].
Let us continue now the analysis of the genetic Gray-type matrices taking into account additional binary-oppositional features of the genetic code system.
3. Genetic code degeneracy and genetic Gray-type matrices
The genetic code is called degenerate because 64 triplets encode 20 amino acids and also protein synthesis termination signals (stop-codons). This degeneracy is associated with another well-known binary opposition, which is important to take into account when analyzing the connection of the molecular genetic system with Gray codes and cyclic structures. We are talking about binary-oppositional separation of the DNA alphabet of 64 triplets - according to their code properties - into two equal sub-alphabets: 32 triplets with strong roots (i.e. triplets starting with 8 strong duplets CC, CT, CG, AC, TC, GC, GT, GG) and 32 triplets with weak roots (i.e. triplets starting with other 8 duplets) [Rumer, 1968; Fimmel, Strüngmann, 2016]. We call this binary oppositional separation briefly as Rumer opposition. Coding value of triplets with strong roots is independent of a letter on their third position. For example, the four triplets with the same strong root CGC, CGA, CGT, CGC encode the same amino acid Arg, though they have different letters on their third position. By contrary, the coding value of triplets with weak roots depends on a letter on their third position. For example, in the grouping of the four triplets with the same weak root CAC, CAT, CAA, and CAG, two triplets (CAC, CAT) encode the amino acid His and the other two (CAA, CAG) encode another amino acid Gln. In Figure 3.1, which repeats Figure 2.1 in some detail, all strong duplets and triplets with strong roots are marked by black color in contrast to weak duplets and triplets with weak roots denoted by white color. One can see a symmetrical disposition of black and white duplets and triplets in these Gray-type matrices: any two cells located inversely symmetrically relative to the center of the matrix have the same color.
Figure 3.1.
Gray-type matrices of 16 duplets and 64 triplets from Figure 2.1 with black-and-white mosaics based on Rumer opposition. Strong duplets CC, CT, CG, AC, TC, GC, GT, GG and triplets with these strong roots are marked by black color.
Figure 3.1.
Gray-type matrices of 16 duplets and 64 triplets from Figure 2.1 with black-and-white mosaics based on Rumer opposition. Strong duplets CC, CT, CG, AC, TC, GC, GT, GG and triplets with these strong roots are marked by black color.
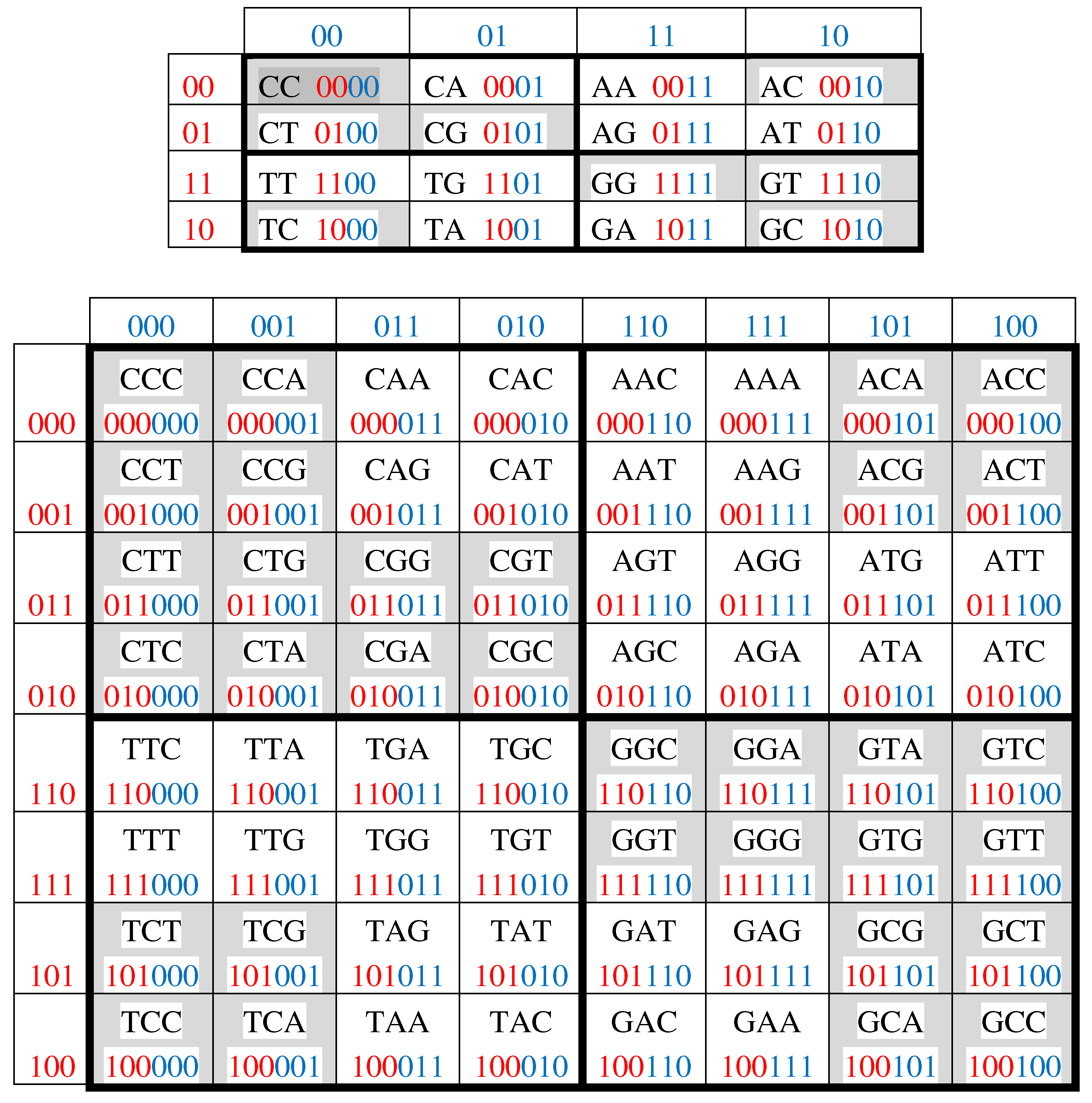
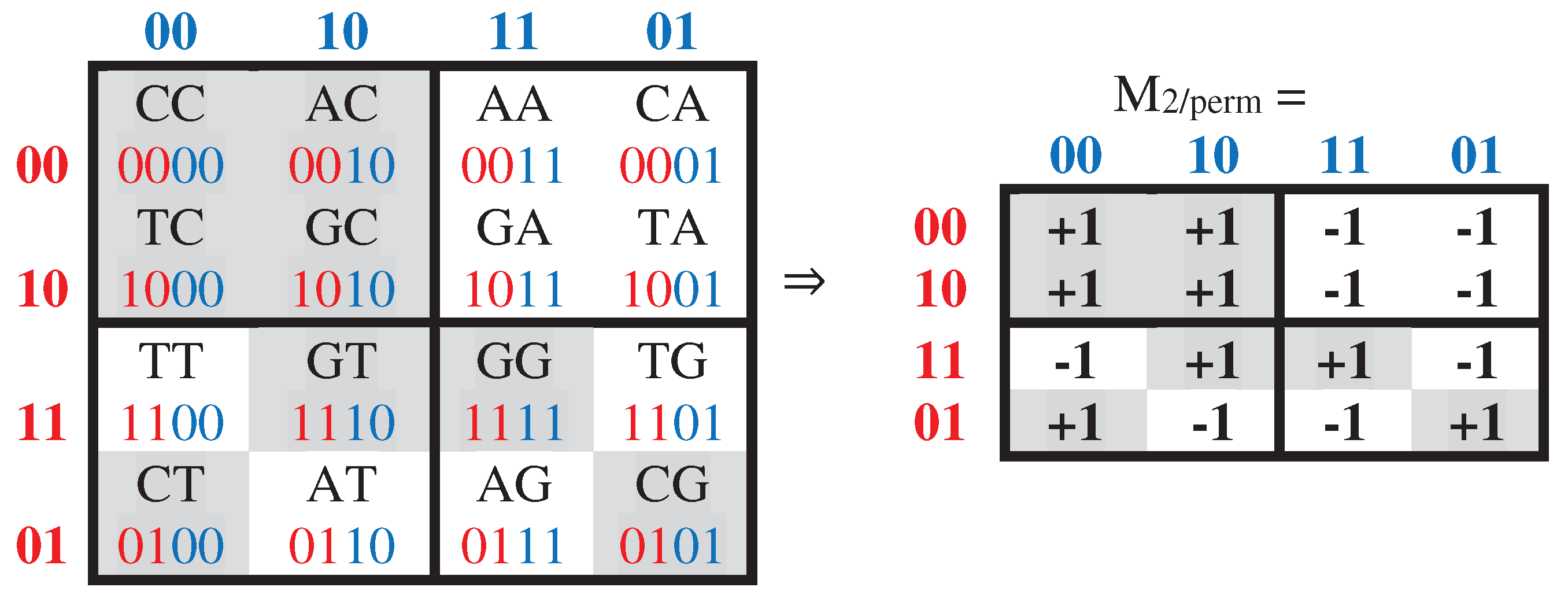
Black and white cells of the Gray-type matrices in Figure 3.1 reflect the binary opposition between strong and weak duplets, and also the binary opposition between triplets with strong and weak roots. For these reason, strong duplets and also triplets with strong roots can be represented by elements +1 in these matrices; on the contrary, weak duplets and triplets with weak roots are represented by elements -1. In this representation, the numeric Gray-type matrices M2 and M3 arise, which are shown in Figure 3.2.
Figure 3.2.
Representations of mosaic Gray-type matrices of 16 duplets and 64 triplets from Figure 3.1 in forms of numeric matrices M2 (at left) and M3. The indices n = 2, 3 in the notation of these matrices correspond to the n-bit Gray codes used in numbering their rows and columns. Each black cell contains entry +1 and each white cell contains entry -1.
Figure 3.2.
Representations of mosaic Gray-type matrices of 16 duplets and 64 triplets from Figure 3.1 in forms of numeric matrices M2 (at left) and M3. The indices n = 2, 3 in the notation of these matrices correspond to the n-bit Gray codes used in numbering their rows and columns. Each black cell contains entry +1 and each white cell contains entry -1.
Have these genetic Gray-type matrices M2 and M3, which reflect features of the genetic code degeneracy, any non-trivial algebraic meanings connected with the topic of cyclic changes? Yes, they have. It turns out that their algebraic properties are connected with hypercomplex numbers and cyclic shift transformations. Let us demonstrate this firstly for the matrix M2.
3.1. Analysis of the genetic Gray-type matrix for 16 duplets
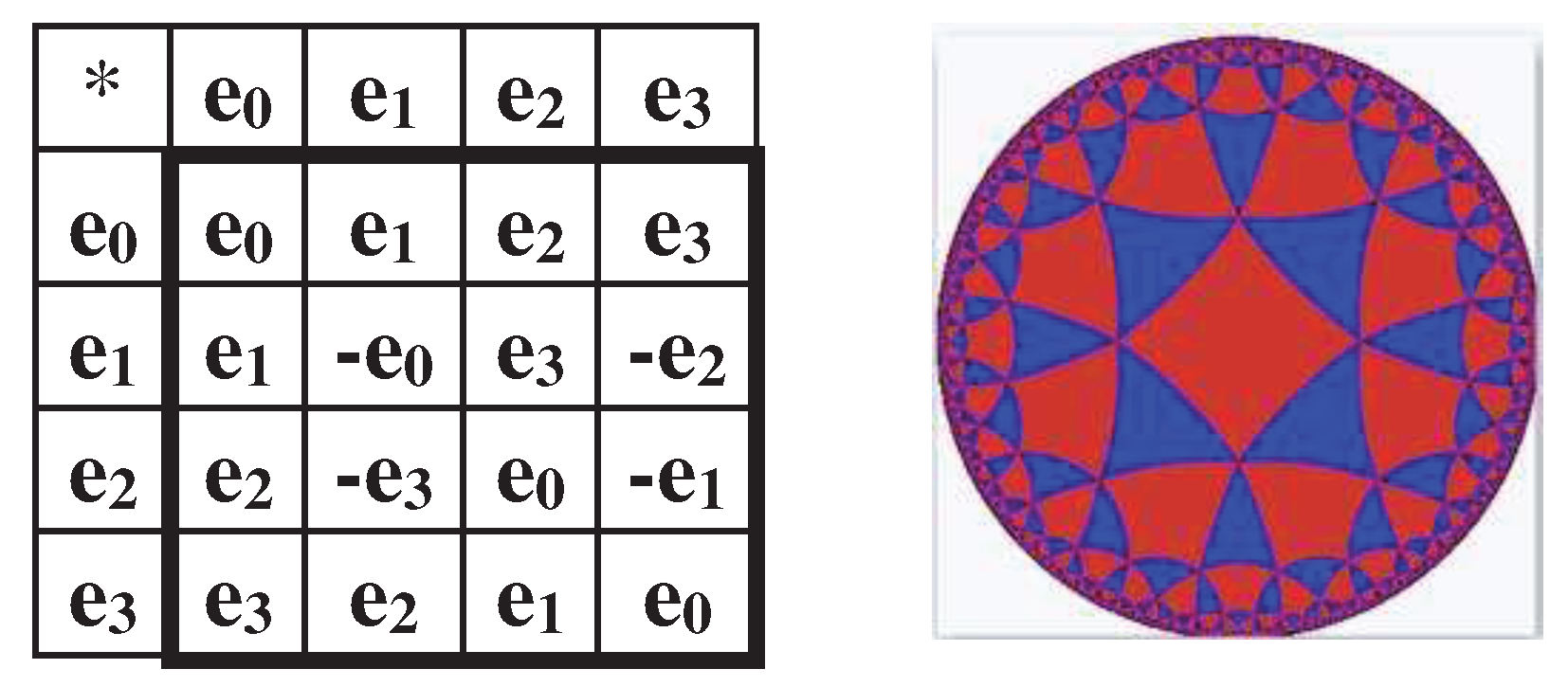
The dyadic-shift decomposition (described in Appendix B) of the matrix M2, whose mosaic is based on Rumer opposition, shows that this Gray-type matrix is a sum of 4 sparse matrices e0, e1, e2, and e3 (Figure 3.3). Each of these sparse matrices is orthogonal since e0e0T = E, e1e1T = E, e2e2T = E, e3e3T = E, where T means the transposition and E is the identity matrix. The set of these sparse matrices is closed relative to multiplication and corresponds to a certain multiplication table in Figure 3.3, at bottom. This table matches to the multiplication table of the 4-dimensional algebra of Cockle split-quaternions [https://en.wikipedia.org/wiki/Split-quaternion], which is used in the Poincare conformal disk model of hyperbolic geometry [Karzel, Kist, 1985].
Figure 3.3.
Dyadic-shift decomposition of the Gray-type matrix M2 from Figure 3.2 into 4 sparse matrices e0, e1, e2, and e3. Their set corresponds to the multiplication table of Cockle split-quaternions (at bottom), used in the Poincare conformal disk model of hyperbolic geometry. An artistic symbol of this model is shown at bottom; it is taken from https://commons.wikimedia.org/wiki/Category:Poincar%C3%A9_disk_models , where the right to use this symbol for any purpose is granted.
Figure 3.3.
Dyadic-shift decomposition of the Gray-type matrix M2 from Figure 3.2 into 4 sparse matrices e0, e1, e2, and e3. Their set corresponds to the multiplication table of Cockle split-quaternions (at bottom), used in the Poincare conformal disk model of hyperbolic geometry. An artistic symbol of this model is shown at bottom; it is taken from https://commons.wikimedia.org/wiki/Category:Poincar%C3%A9_disk_models , where the right to use this symbol for any purpose is granted.
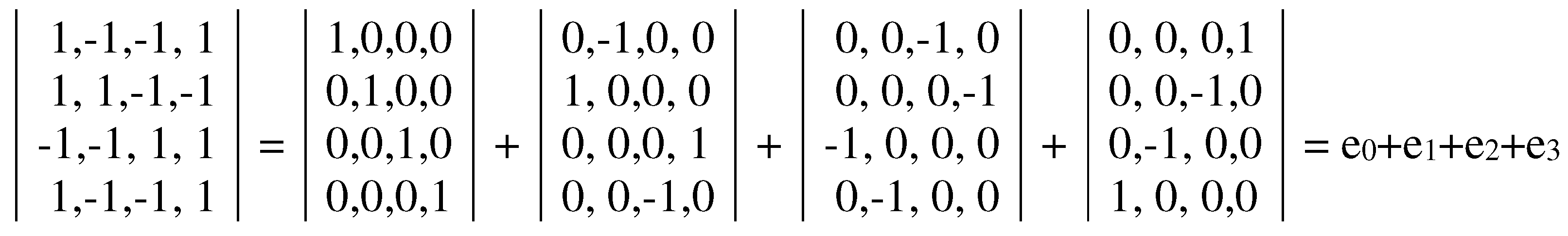
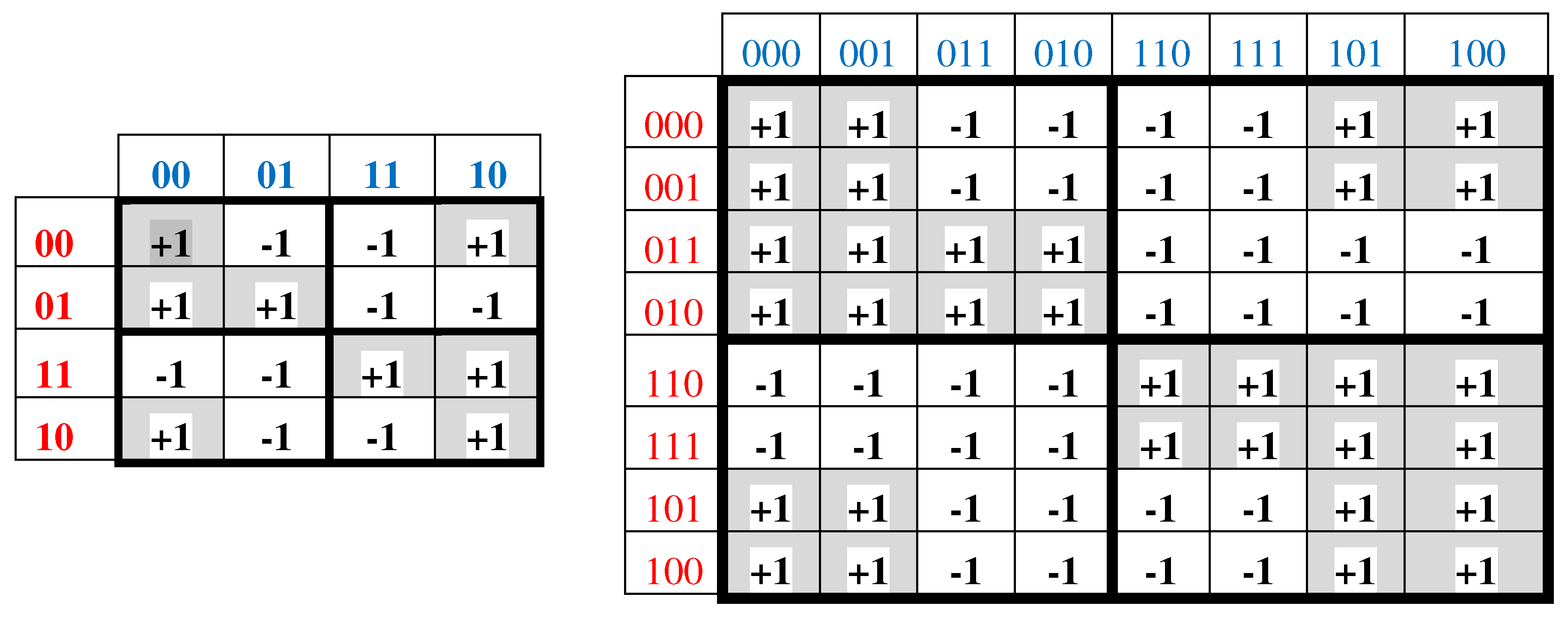
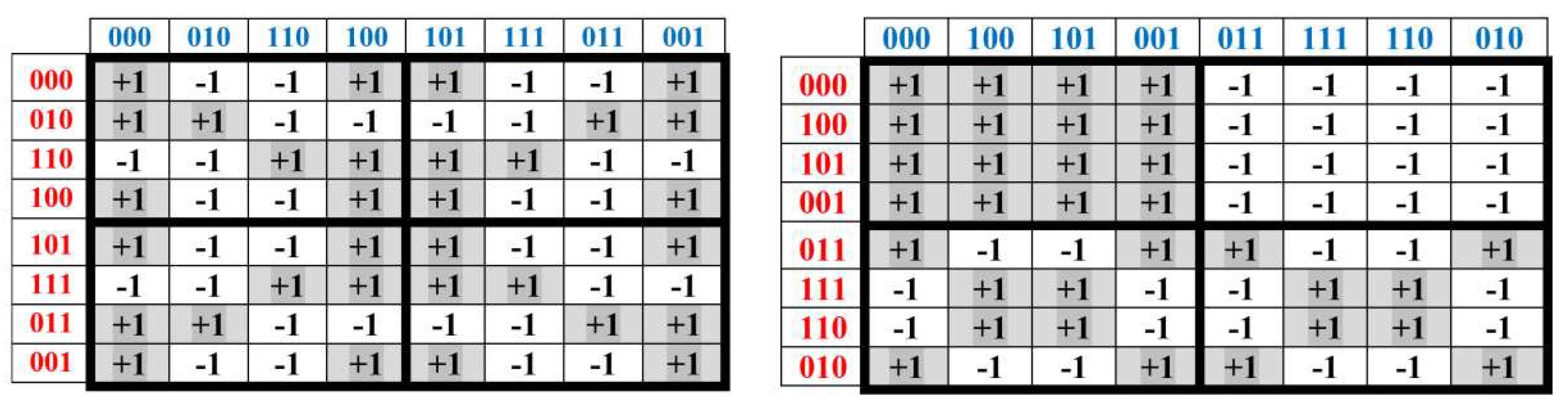
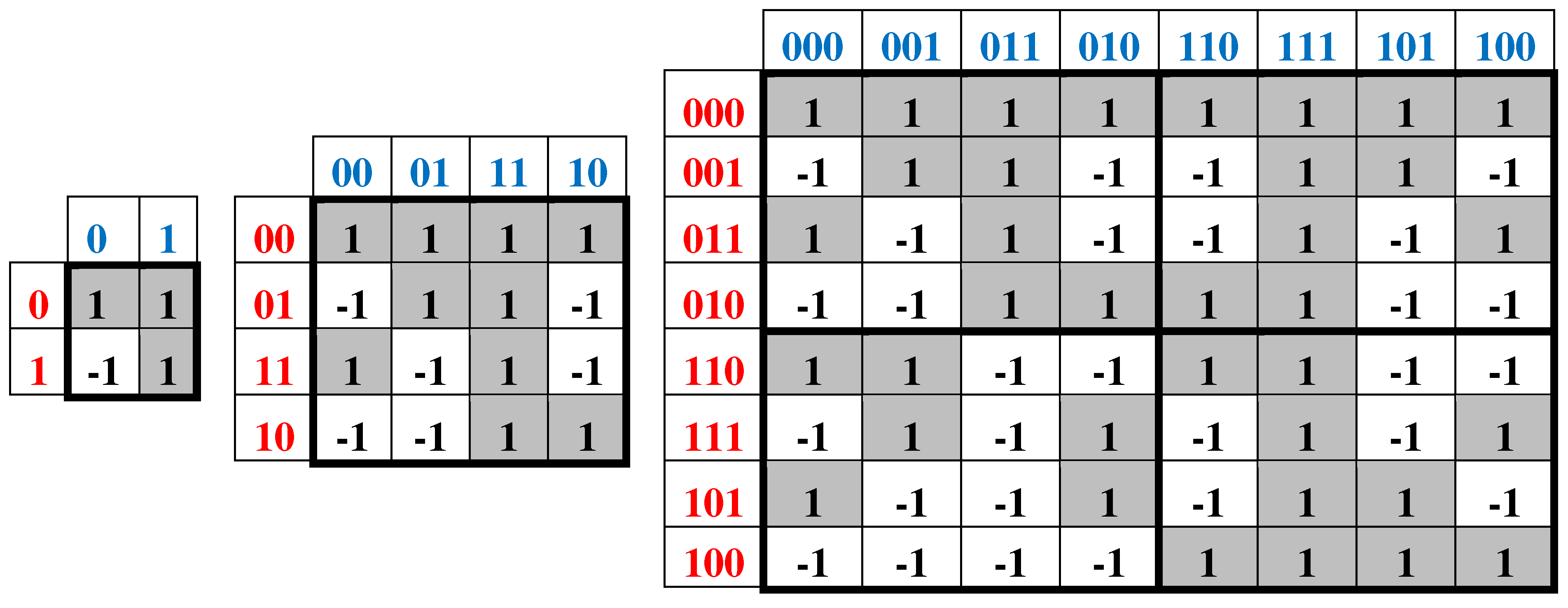
Concerning the topic of cyclic shifts, one can algorithmically transform the Gray-type matrix M2 by a cyclic shift inside each of its 2-bit codewords, which numerate matrix rows and columns. Under this shift transformation, the previous set of numberings 00, 01, 11, 10 becomes a new set of numberings 00, 10, 11, 01, whose using is accompanied by a permutation of matrix rows and columns. In the result, a new Gray-type matrix M2/perm arises with a completely different mosaic of arrangement of entries +1 and -1 (Figure 3.4).
Figure 3.4.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of position in 2-bit numberings of rows and columns generates a matrix with new mosaic (at left). Numeric representation M2/perm of this new Gray-type matrix, when each black (white) cell contains entry +1 (-1), is shown at right.
Figure 3.4.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of position in 2-bit numberings of rows and columns generates a matrix with new mosaic (at left). Numeric representation M2/perm of this new Gray-type matrix, when each black (white) cell contains entry +1 (-1), is shown at right.
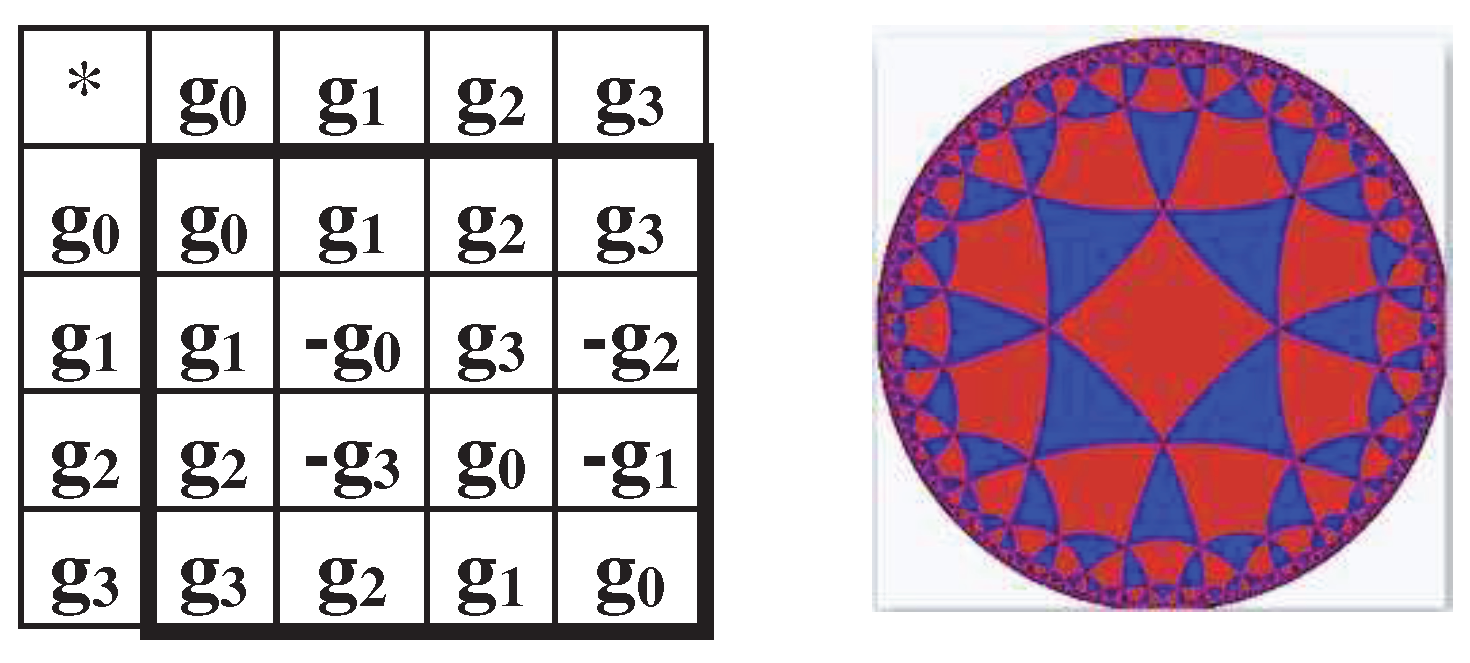
The dyadic-shift decomposition of this new matrix M2/perm shows that this Gray-type matrix is a sum of 4 sparse orthogonal matrices g0, g1, g2, and g3 (Figure 3.5). The set of these sparse matrices is again closed relative to multiplication and corresponds to the same multiplication table of the 4-dimensional algebra of Cockle split-quaternions, which was shown in Figure 3.3. In other words, Gray-type matrices M2 and M2/perm, which present structural features of the genetic code degeneracy, are two different matrix representations of 4-dimensional split-quaternions with unit coordinates.
Figure 3.5.
Dyadic-shift decomposition of the Gray-type matrix M2/perm from Figure 3.4 into 4 sparse matrices g0, g1, g2, and g3. Their set corresponds to the multiplication table of Cockle split-quaternions (at bottom), used in the Poincare conformal disk model of hyperbolic geometry. An artistic symbol of this model is shown at bottom.
Figure 3.5.
Dyadic-shift decomposition of the Gray-type matrix M2/perm from Figure 3.4 into 4 sparse matrices g0, g1, g2, and g3. Their set corresponds to the multiplication table of Cockle split-quaternions (at bottom), used in the Poincare conformal disk model of hyperbolic geometry. An artistic symbol of this model is shown at bottom.
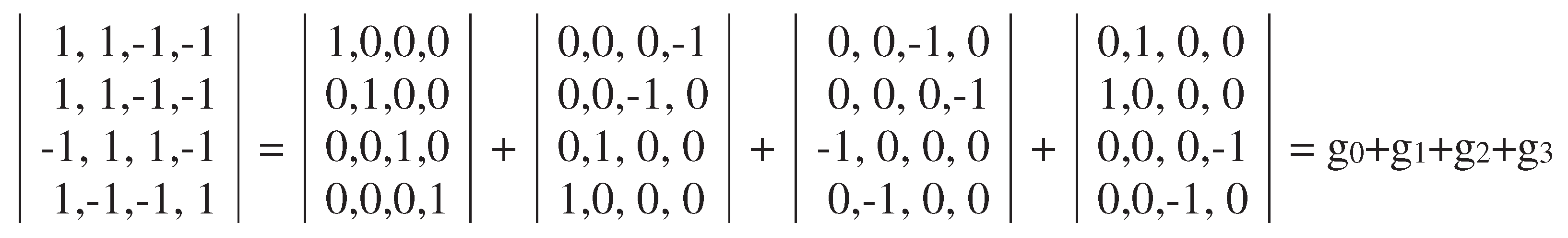
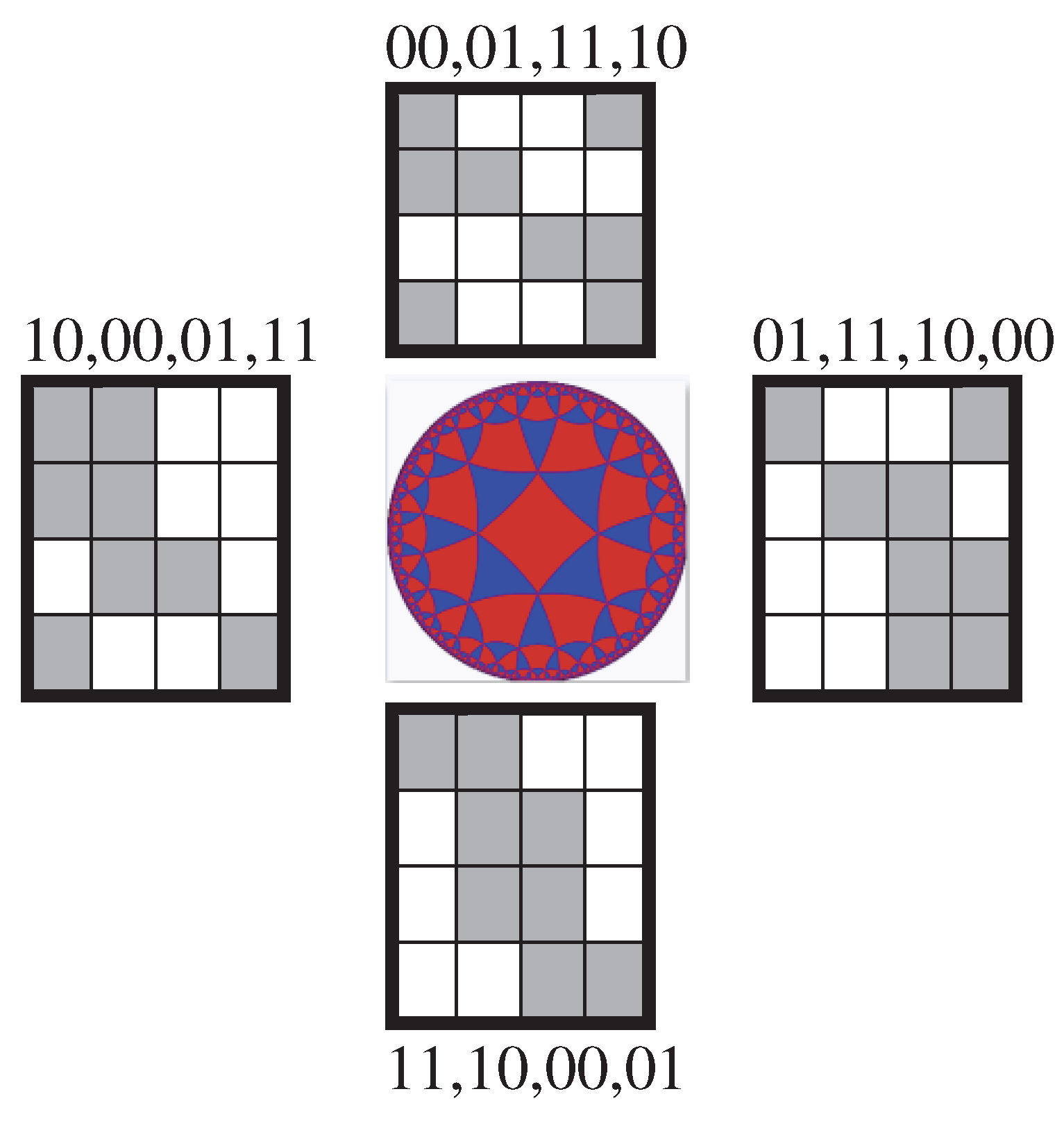
In addition, cyclic shifts in the set of 2-bit numberings 00, 01, 11, 10 of rows and columns in the initial Gray-type matrix M2 can be studied as well. More precisely, we mean the following tree possible orders of Gray-code members: 01, 11, 10, 00; 11, 10, 00, 01; 10, 00, 01, 11. Under using these three cyclic shift options for numberings of rows and columns of the genetic matrix of 16 duplets from Figure 3.1, matrix rows and columns are permutated and new Gray-type matrices arise with new arrangements of duplets and entries +1 and -1 (that is, with new black-and-white mosaics) (Figures 3.6–3.8). Numeric presentations of these three matrices are denoted as matrices P2/01, P2/11, P2/10. Dyadic-shift decompositions of these three matrices into appropriate 8 sparse orthogonal matrices (Figures 3.6–3.8) reveal that each of them is a matrix representation of the Cockle split-quaternions with unit coordinates as well (by analogy with matrices in Figures 3.2–3.5).
Figure 3.6.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 01, 11, 10, 00 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/01 gives 8 sparse orthogonal matrices s0, s1, s2, and s3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
Figure 3.6.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 01, 11, 10, 00 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/01 gives 8 sparse orthogonal matrices s0, s1, s2, and s3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
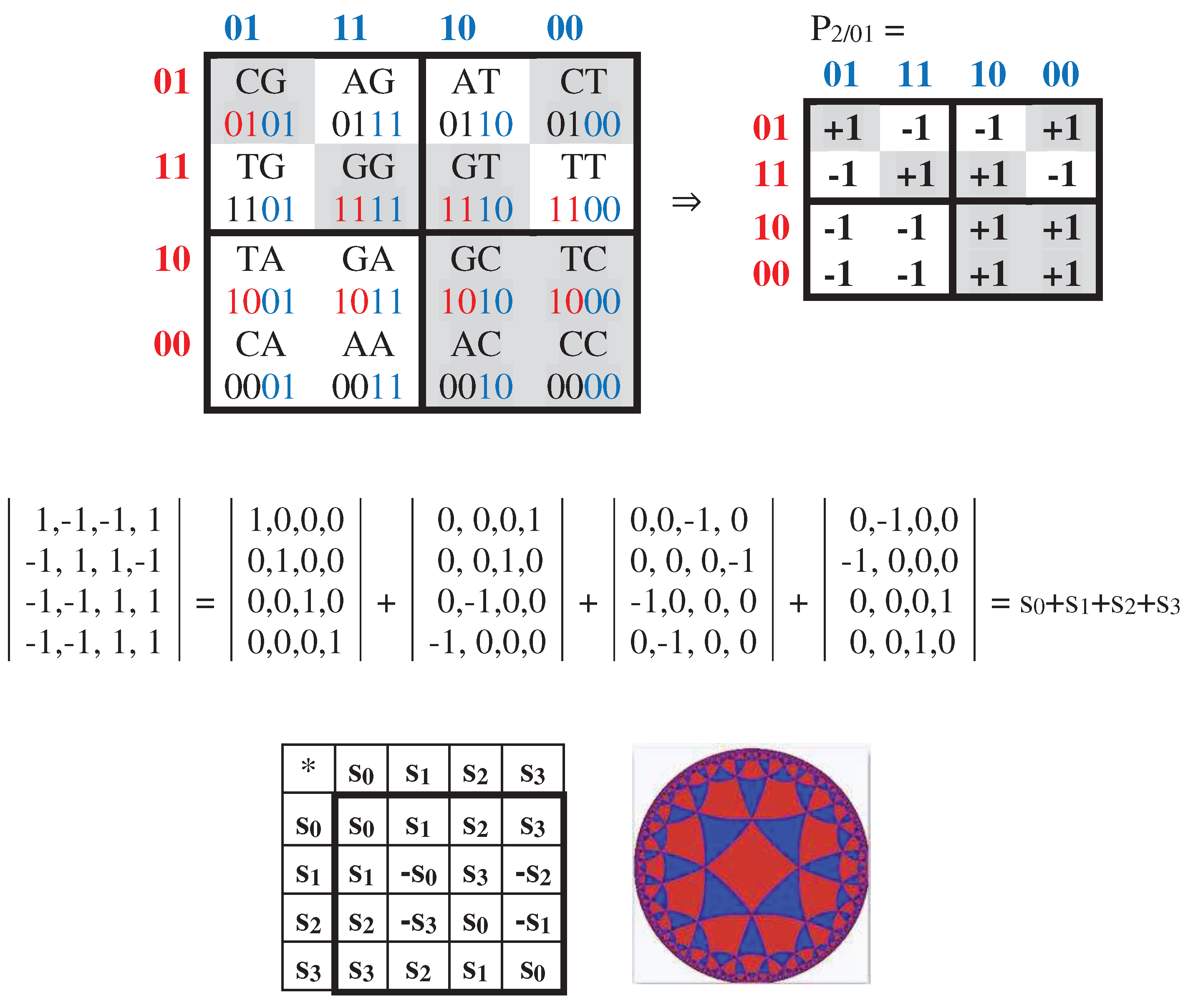
Figure 3.7.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 11, 10, 00, 01 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/11 gives 8 sparse orthogonal matrices r0, r1, r2, and r3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
Figure 3.7.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 11, 10, 00, 01 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/11 gives 8 sparse orthogonal matrices r0, r1, r2, and r3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
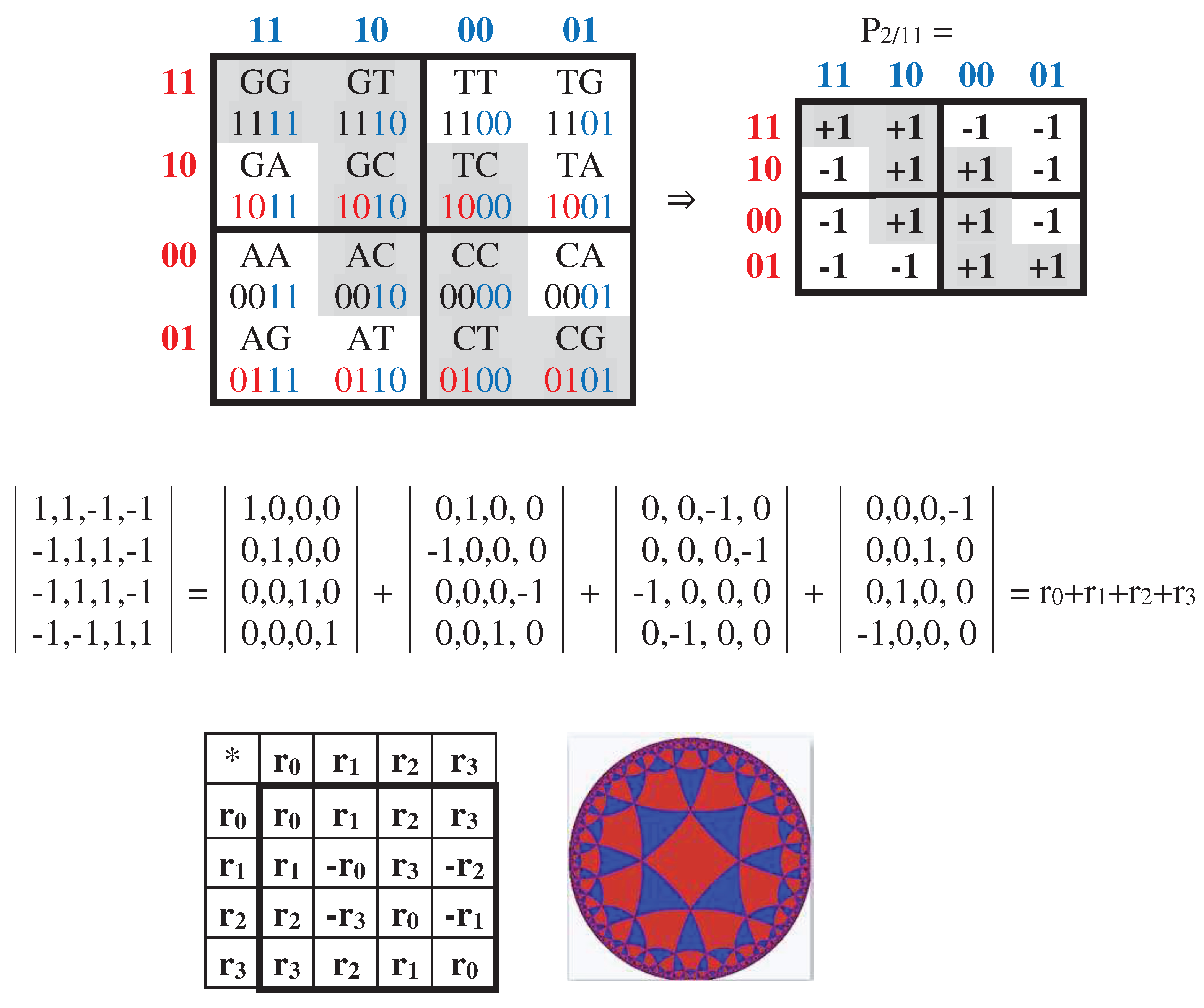
Figure 3.8.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 10, 00, 01, 11 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/10 gives 8 sparse orthogonal matrices q0, q1, q2, and q3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
Figure 3.8.
The transformation of the Gray-type matrix with 16 duplets from Figure 3.1 under the cyclic shift of numberings of rows and columns to the option 10, 00, 01, 11 generates a matrix with a new mosaic and an arrangement of duplets (at top). The dyadic-shift decomposition of the corresponding numeric matrix P2/10 gives 8 sparse orthogonal matrices q0, q1, q2, and q3 (shown at middle level), which defines a multiplication table of Cockle spit-quaternions used in the Poincare conformal disk model of hyperbolic geometry (shown at bottom jointly with the artistic symbol of this model).
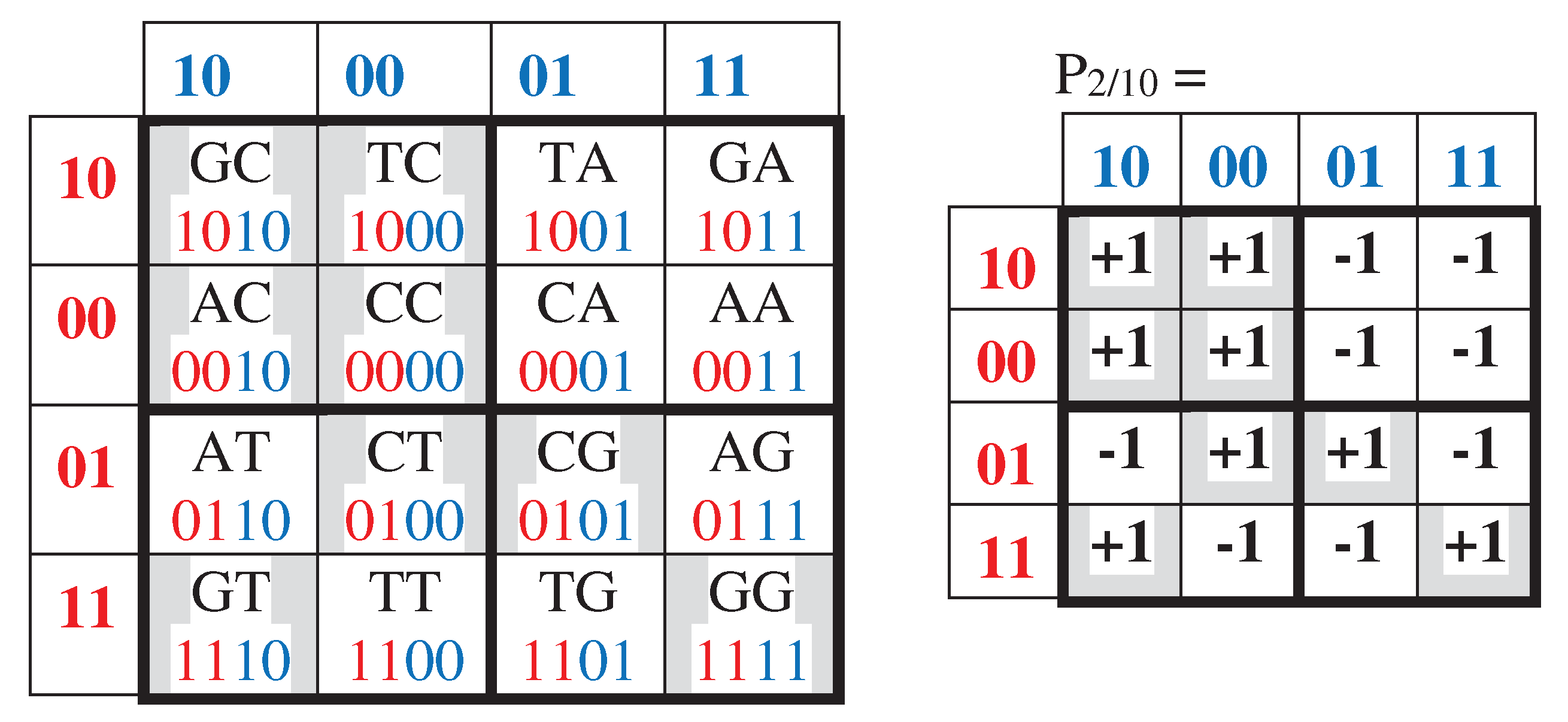
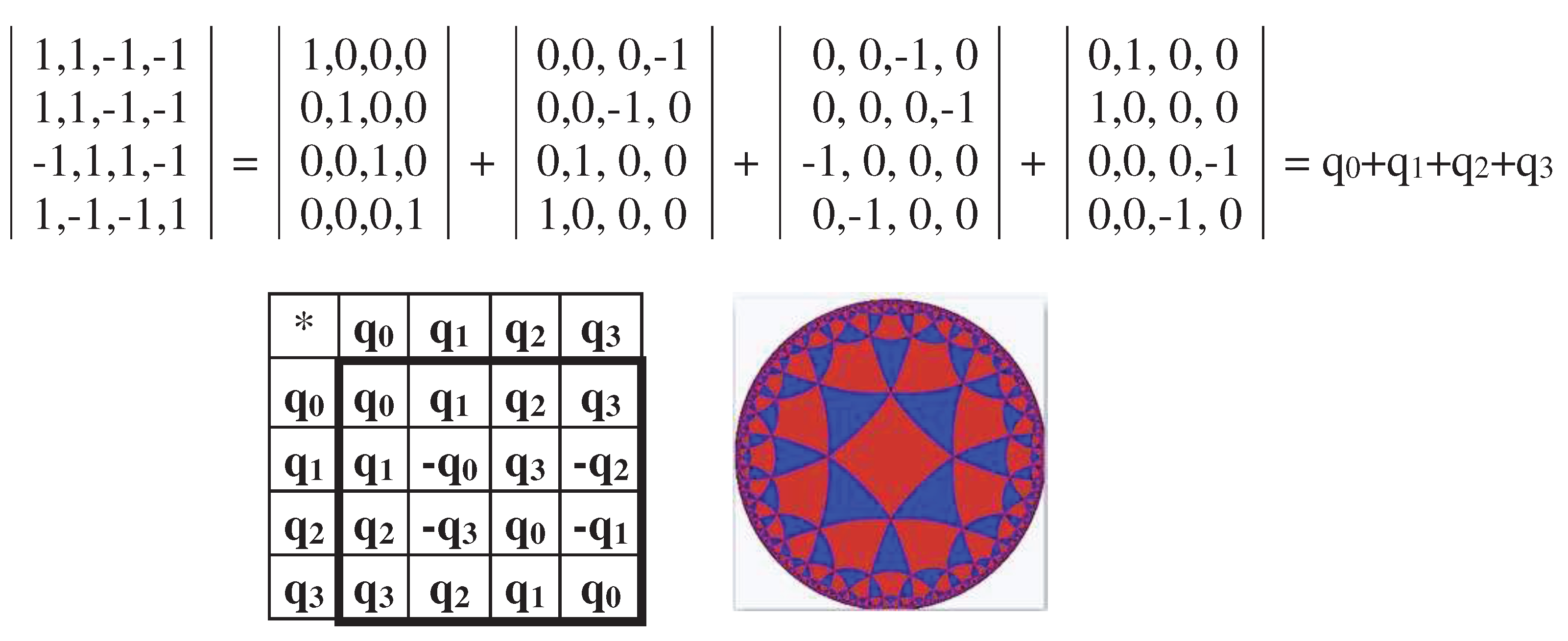
Figure 3.9 allows comparing - in a comfortable form - of mosaics of these 4 Gray-type matrices M2, P2/01, P2/11, and P2/10, in which cyclic changed sequences of Gray code members numerate rows and columns. Such cyclic changes of numberings transform matrices each into others.
Figure 3.9.
Comparison of Gray-type matrices M2, P2/01, P2/11, and P2/10 (from Figures 3.3, 3.6–3.8), in which cyclic changed sequences of Gray codewords numerate rows and columns (the corresponding sequence is shown next to each matrix). In matrices, each black (white) cell contains entry +1 (-1). All 4 matrices are different matrix representations of Cockle split-quaternions used in the Poincare conformal disk model of hyperbolic geometry, whose symbol is shown in the center.
Figure 3.9.
Comparison of Gray-type matrices M2, P2/01, P2/11, and P2/10 (from Figures 3.3, 3.6–3.8), in which cyclic changed sequences of Gray codewords numerate rows and columns (the corresponding sequence is shown next to each matrix). In matrices, each black (white) cell contains entry +1 (-1). All 4 matrices are different matrix representations of Cockle split-quaternions used in the Poincare conformal disk model of hyperbolic geometry, whose symbol is shown in the center.
Squaring each of these Gray-type matrices M2, P2/01, P2/11, and P2/10 results in doubling it:
Each of these Gray-type matrices M2, P2/01, P2/11, and P2/10, when divided by two, is a projector, since its squaring results the same matrix, which is the criterion of projector operators:
M22 = 2M2 , P2/012 = 2P2/01, P2/11 = 2P2/11, P2/102 = P2/10
(M2/2)2 = M2/2 , (P2/01/2)2 = P2/01/2, (P2/11/2)2 = P2/11/2, (P2/10 /2)2 = P2/10/2
The presented data (Figures 3.3–3.9) raise the question of why the genetic coding system is associated with the Poincare conformal disk model of Lobachevsky’s hyperbolic geometry? The author believes that this may be due to the theory of automorphic functions and the fundamental importance of cyclic organization for living bodies. The fact is that it was on the basis of the properties of Lobachevsky’s hyperbolic geometry that A. Poincaré developed the theory of automorphic functions, which are a generalization of periodic functions and are associated with the ideology of cycles. This algebraic theory uses actions of discrete groups of transformations on functions. Many inherited biological symmetries are connected with appropriate non-Euclidean symmetries of conform-geometrical types (cyclomeries, etc.), which expand similarity bio-symmetries by A.V. Shubnikov [Petoukhov, 1989].
All the genetic Gray-type matrices M2, M2/perm, P2/01, P2/11, and P2/10 (Figures 3.3–3.9) have a general property associated with the operation of mutual replacement 0↔1 in the binary numbering of columns (this mutual replacement is called the complementarity operation): any two columns, whose numberings are complementary each to another relative to the replacement of 0↔1, have sets of entries, which differ only by their opposite signs (that is, these sets are also complementary each to another relative to the replacement operation of signs “+ ↔ -“ ). For example, in matrix M2 (Figure 3.2), two complementary columns with complementarity numberings 00 and 11 contain correspondingly entries “1,1,-1,1” and “-1,-1,1,-1”, which differ only by their opposite signs. Two other columns with complementarity numberings 01 and 10 contain correspondingly entries “-1,1,-1,-1” and “1,-1,1,1”, which also differ only by their opposite signs. This general property of the considered Gray-type matrices can be conditionally called as the property of the double complementarity.
This double complementarity provides that the matrix operators M2, P2/01, P2/11, and P2/10 (Figures 3.3–3.9) are cyclic operators in the following sense. Let's consider an arbitrary 4-parameter system, the behavior of which in time is described by the vector Y=[f0(t), f1(t), f2(t), f3(t)], whose coordinates are voluntary periodic functions fi(t) independent of each other. The action of any of the named genetic Gray-type matrices on this vector generates a vector whose coordinates are not only mutually dependent, but also consist of pairs equal in magnitude and opposite in signs. The expression (3.3) shows an example of the action of the Gray-type matrix M2 (Figure 3.2) on such vector:
In the generated vector (3.3), the cyclic behavior of coordinates X0(t) and X2(t), denoted by yellow, is synchronized: at each value of t, these coordinates are equal in amplitude and opposite in sign (the complementarity relative to signs), that is, their periodic behavior occurs in antiphase. The same holds for relations between the coordinates X1(t) and X3(t) denoted by green. It means that the action of genetic Gray-type matrices M2, P2/01, P2/11, and P2/10 on arbitrary 4-dimensional vectors with periodic coordinates introduces a cyclic ordering into the coordinates of the generated vector. Figuratively speaking, cycles beget cycles.
Similar properties exist in the case of the action of the Gray-type matrix M3 (Figure 3.2) on arbitrary 8-dimensional vectors with periodic coordinates. In this direction, an algebraic theory of code hypercycles based on cyclic Gray codes is developed by the author in some distant analogy with the biochemical theory of hypercycles of Nobel laureate M. Eigen modeling life origin via the scheme of combining self-replicating macromolecules into closed autocatalytic chemical cycles [Eigen, Schuster, 1977].
One more kind of interconnections of genetic Gray-type matrices M2, M2/perm, P2/01, P2/11, and P2/10 (Figures 3.3–3.9) with the complementarity operation 0↔1 is revealed due to a special decomposition of each of these matrices into the sum of two sparse matrices, whose example in the case of the matrix M2 is shown in Figure 3.10. Each of these two sparse matrices contains only those non-zero columns whose 2-bit numberings are complementarity: more precisely, these columns numberings are 00 and 11, and also 01 and 10 (one can remind that these numberings are based on the molecular binary opposition “purines-vs-pyrimidines”).
Figure 3.10.
The decomposition of the genetic Gray-type matrix M2 from Figure 3.2 into the sum of two sparse matrices, having only those two non-zero columns, whose 2-bit numberings are complementarity each to another.
Figure 3.10.
The decomposition of the genetic Gray-type matrix M2 from Figure 3.2 into the sum of two sparse matrices, having only those two non-zero columns, whose 2-bit numberings are complementarity each to another.

Each of these two sparse matrices in Figure 3.10 occurs to be a matrix representation of 2-dimensional hyperbolic numbers with unit coordinates. It is revealed by a decomposition of each of these sparse matrices into the sum of two other sparse matrices shown in Figure 3.11. The set of these two new sparse matrices is closed relative to multiplication and defines the multiplication table of the algebra of 2-dimensional split-complex or hyperbolic numbers [https://en.wikipedia.org/wiki/Split-complex_number].
Figure 3.11.
Decompositions of the two sparse matrices from Figure 3.10 into sums of other two sparse matrices v0, v1 and v2, v3. The set of the matrices v0 and v1 is closed relative to multiplication and defines the shown multiplication table of the algebra of 2-dimensional split-complex numbers (at top). The same holds for the set of the matrices v2 and v3 (at bottom).
Figure 3.11.
Decompositions of the two sparse matrices from Figure 3.10 into sums of other two sparse matrices v0, v1 and v2, v3. The set of the matrices v0 and v1 is closed relative to multiplication and defines the shown multiplication table of the algebra of 2-dimensional split-complex numbers (at top). The same holds for the set of the matrices v2 and v3 (at bottom).
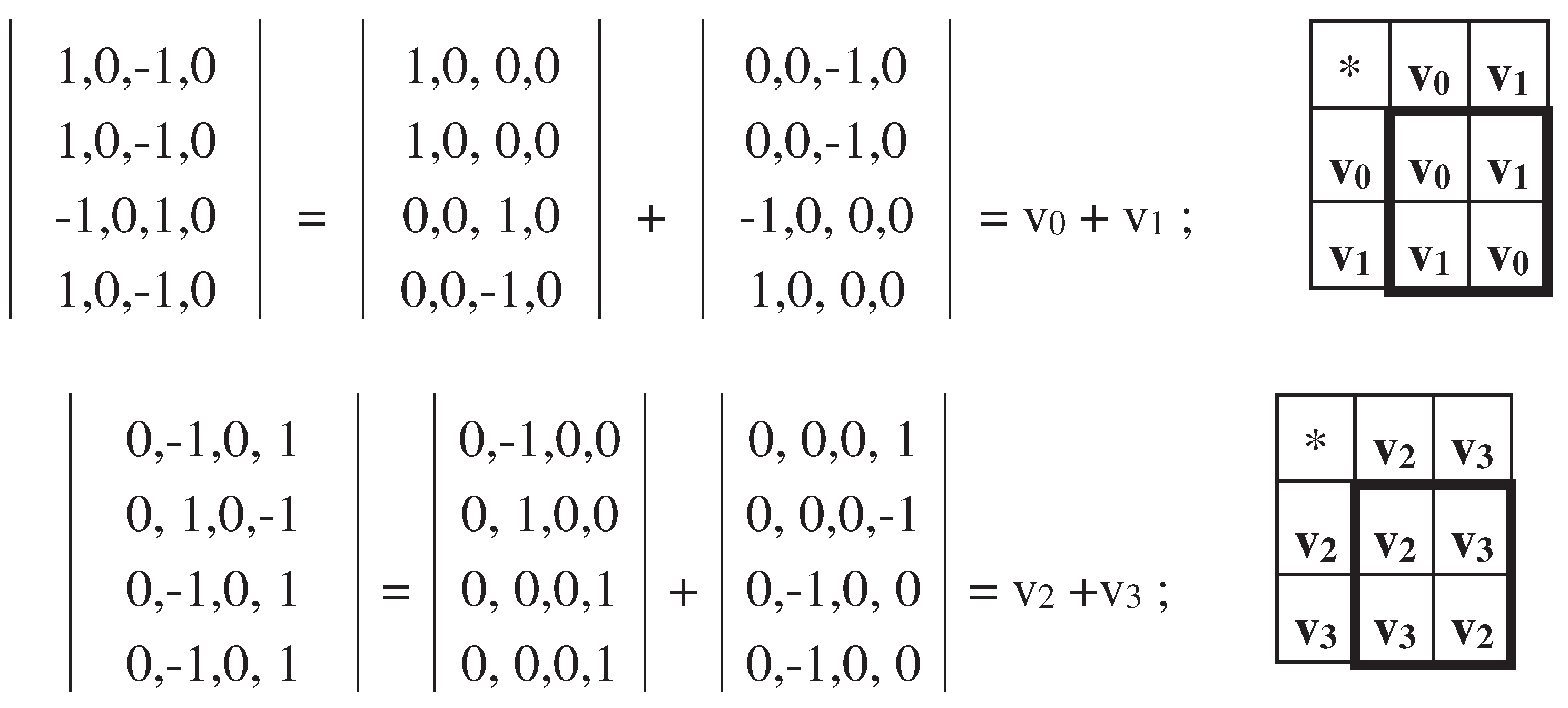
3.2. Analysis of the genetic Gray-type matrix for 64 triplets
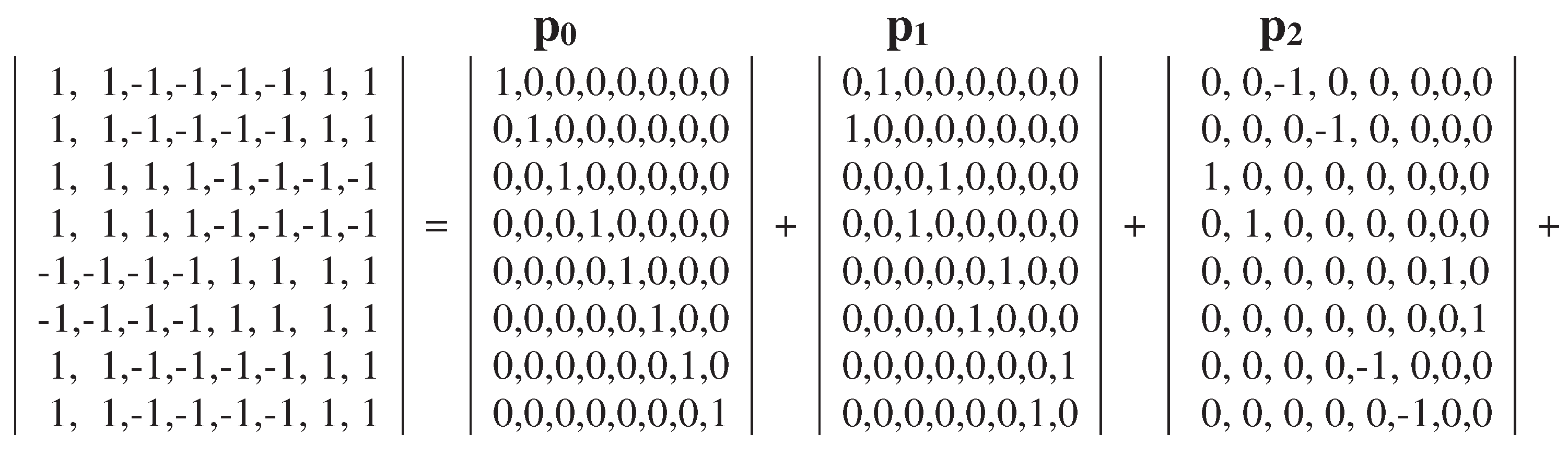
Now let us turn to a similar analysis of the genetic Gray-type matrix M3 for 64 triplets, which reflects the genetic code degeneracy for the alphabet of 64 triplets by means of the black-and-white mosaic based on Rumer opposition (Figures 3.1 and 3.2). The dyadic-shift decomposition of the matrix M3 shows that this matrix is a sum of 8 sparse orthogonal matrices p0, p1, p2, p3, p4, p5, p6, p7 (Figure 3.12). The set of these 8 sparse matrices is closed relative to multiplication and defines a multiplication table of 8-dimensional algebra of hypercomplex numbers (Figure 3.12, at bottom), which can be considered as associated with the multiplication table of 4-dimensional algebra of Cockle split-quaternions in Figures 3.3, 3.5–3.9.
Figure 3.12.
The dyadic-shift decomposition of the genetic Gray-type matrix M3 of 64 triplets (from Figure 3.2) into the sum of 8 sparse orthogonal matrices p0, p1, p2, p3, p4, p5, p6, p7, whose set is closed relative to multiplication and defines the shown multiplication table of 8-dimensional algebra of hypercomplex numbers (at bottom).
Figure 3.12.
The dyadic-shift decomposition of the genetic Gray-type matrix M3 of 64 triplets (from Figure 3.2) into the sum of 8 sparse orthogonal matrices p0, p1, p2, p3, p4, p5, p6, p7, whose set is closed relative to multiplication and defines the shown multiplication table of 8-dimensional algebra of hypercomplex numbers (at bottom).
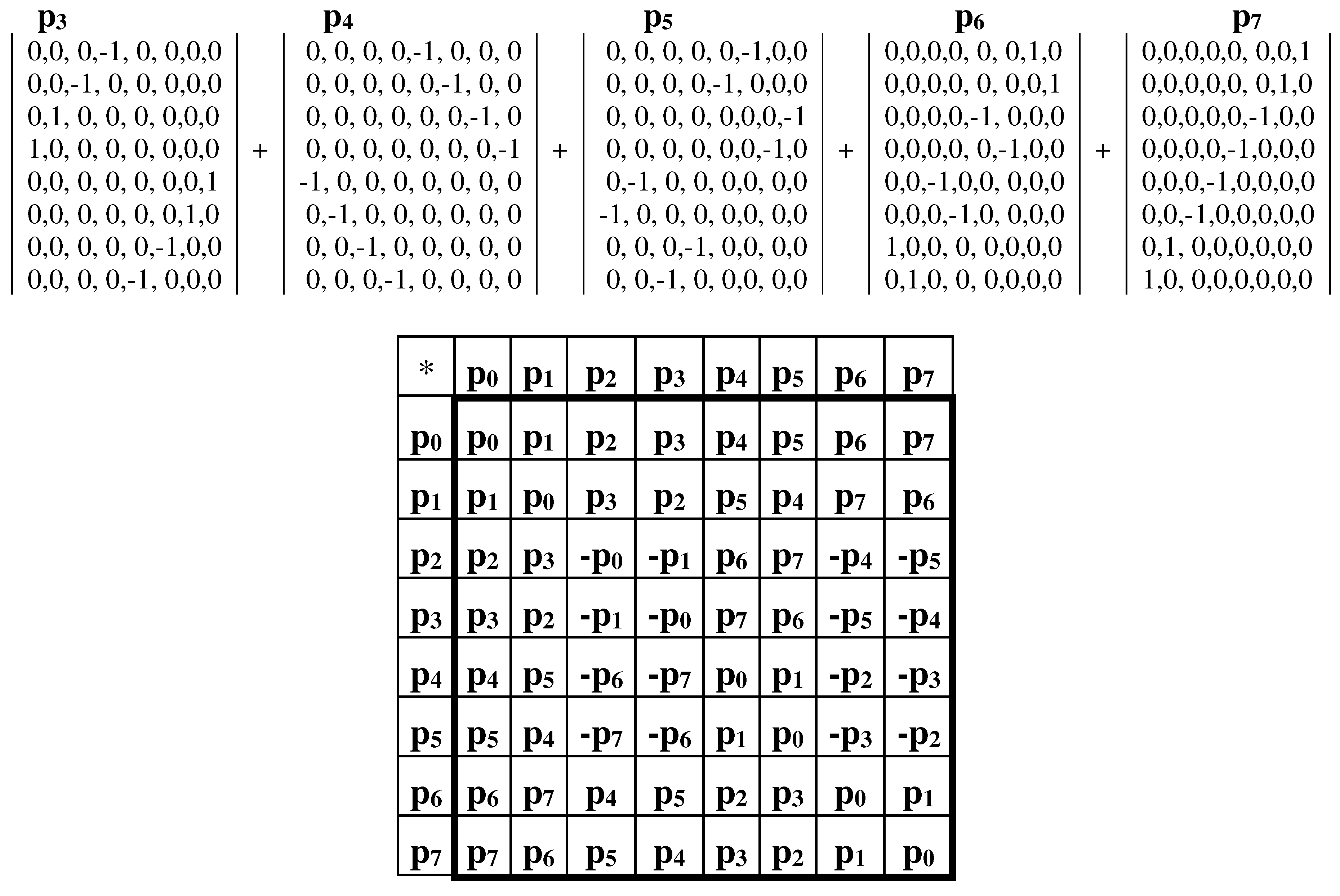
Concerning the topic of cyclic shifts, one can algorithmically transform the Gray-type matrix M3 by a cyclic shift inside each of its 3-bit codewords, which numerate matrix rows and columns. Under this shift transformation, the previous set of numberings 000, 001, 011, 010, 110, 111, 101, 100 becomes two net set of numberings. Under the cyclic shift for 1 position, the following set arises: 000, 010, 110, 100, 101, 111, 011, 001. Under the cyclic shift for 2 positions, the following set arises: 000, 100, 101, 001, 011, 111, 110, 010. These new sets of numberings of rows and columns are accompanied with a permutation of matrix rows and columns. In the result, new Gray-type matrices M3/perm1 and M3/perm2 arise with a completely different mosaic of arrangements of entries +1 and -1 (Figure 3.13).
Figure 3.13.
Transformations of the genetic Gray-type matrix M3 from Figure 3.2 under the cyclic shifts - on 1 and 2 positions - in 3-bit numberings of its rows and columns generate corresponding matrices M3/perm1 (at left) and M3/perm2 (at right) with new mosaic of arrangements of +1 and -1.
Figure 3.13.
Transformations of the genetic Gray-type matrix M3 from Figure 3.2 under the cyclic shifts - on 1 and 2 positions - in 3-bit numberings of its rows and columns generate corresponding matrices M3/perm1 (at left) and M3/perm2 (at right) with new mosaic of arrangements of +1 and -1.
The same dyadic-shift decomposition of each of these Gray-type matrices M3/perm1 and M3/perm2 represents it as a sum of 8 sparse orthogonal matrices, whose set is closed relative to multiplication and corresponds to the same multiplication table of 8-dimensional algebra of hypercomplex numbers shown in Figure 3.12 (with accuracy up to reindexing of these 8 sparse matrices).
Possible cyclic shifts of members in the set of Gray 3-bit codewords 000, 001, 011, 010, 110, 111, 101, 100 produce 7 new sequences of Gray codewords (3.4):
Under using these seven cyclic shift options for numberings of rows and columns of the Gray-type matrix of 64 triplets from Figure 3.1, matrix rows and columns are permutated and new seven Gray-type matrices arise with new arrangements of triplets and entries +1 and -1 (that is, with new black-and-white mosaics) (Figure 3.14).
001, 011, 010, 110, 111, 101, 100, 000;
011, 010, 110, 111, 101, 100, 000, 001;
010, 110, 111, 101, 100, 000, 001, 011;
110, 111, 101, 100, 000, 001, 011, 010;
111, 101, 100, 000, 001, 011, 010, 110;
101, 100, 000, 001, 011, 010, 110, 111;
100, 000, 001, 011, 010, 110, 111, 101
011, 010, 110, 111, 101, 100, 000, 001;
010, 110, 111, 101, 100, 000, 001, 011;
110, 111, 101, 100, 000, 001, 011, 010;
111, 101, 100, 000, 001, 011, 010, 110;
101, 100, 000, 001, 011, 010, 110, 111;
100, 000, 001, 011, 010, 110, 111, 101
Figure 3.14.
Seven additional Gray-type matrices, which arise under cyclic shifts in sets of Gray codewords numberings of rows and columns (3.4) in the initial Gray-type matrix from Figure 3.1. This family of 8 Gray-type matrices represents the genetic code degeneracy.
Figure 3.14.
Seven additional Gray-type matrices, which arise under cyclic shifts in sets of Gray codewords numberings of rows and columns (3.4) in the initial Gray-type matrix from Figure 3.1. This family of 8 Gray-type matrices represents the genetic code degeneracy.
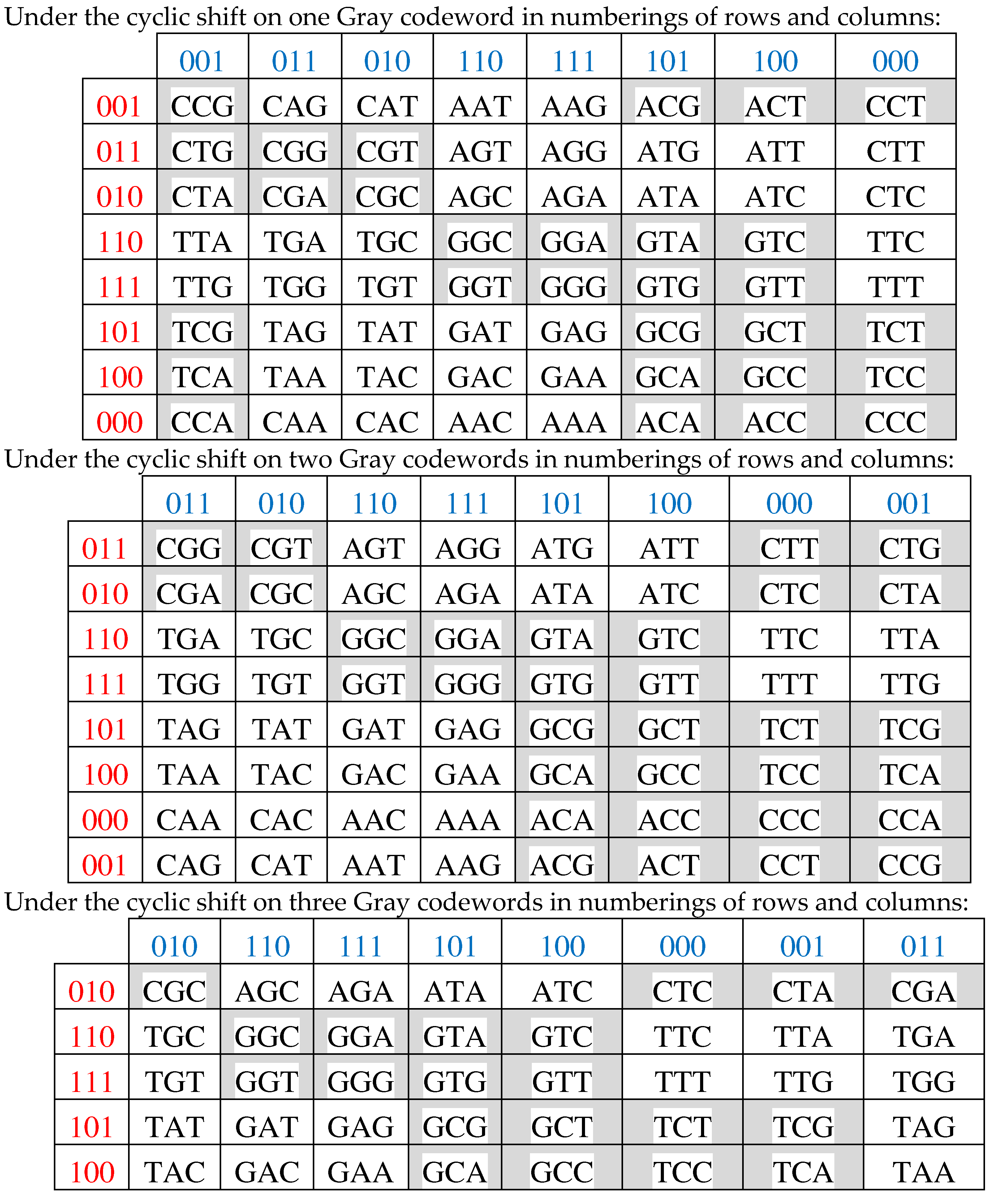
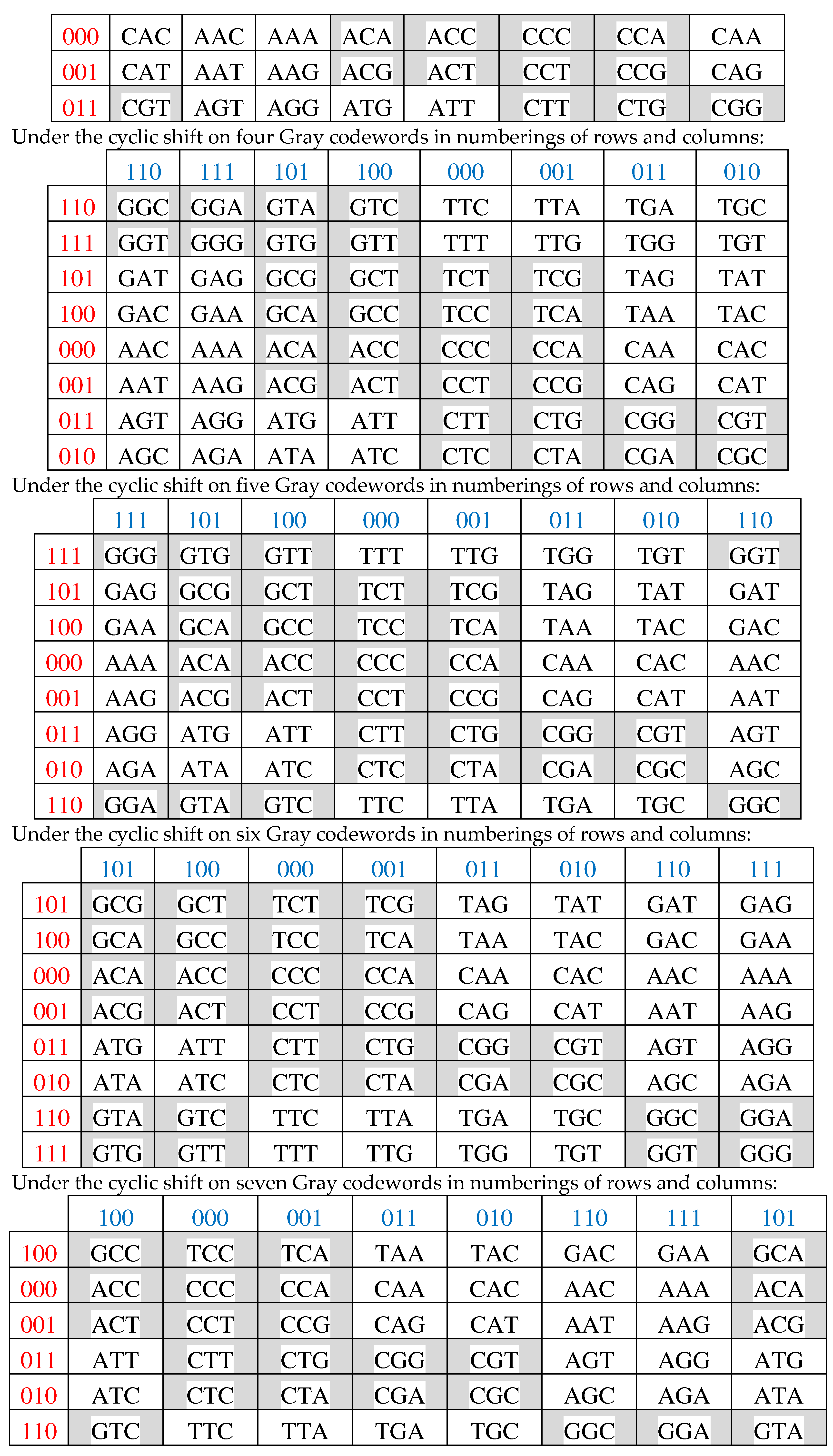
Figure 3.15 shows all these 8 Gray-type matrices of 64 triplets from Figures 3.1 and 3.14 in their numeric forms, where each black (white) cell contains +1 (-1). These matrices are transformed one into another by appropriate cyclic shifts of numberings of its rows and columns.
Figure 3.15.
A comparison of black-and-white mosaic of 8 Gray-type matrices Gi (i = 0, 1, 2, …, 7) of 64 triplets from Figures 3.1, 3.2 and 3.14. Each black (white) cell in matrices contains +1 (-1).
Figure 3.15.
A comparison of black-and-white mosaic of 8 Gray-type matrices Gi (i = 0, 1, 2, …, 7) of 64 triplets from Figures 3.1, 3.2 and 3.14. Each black (white) cell in matrices contains +1 (-1).
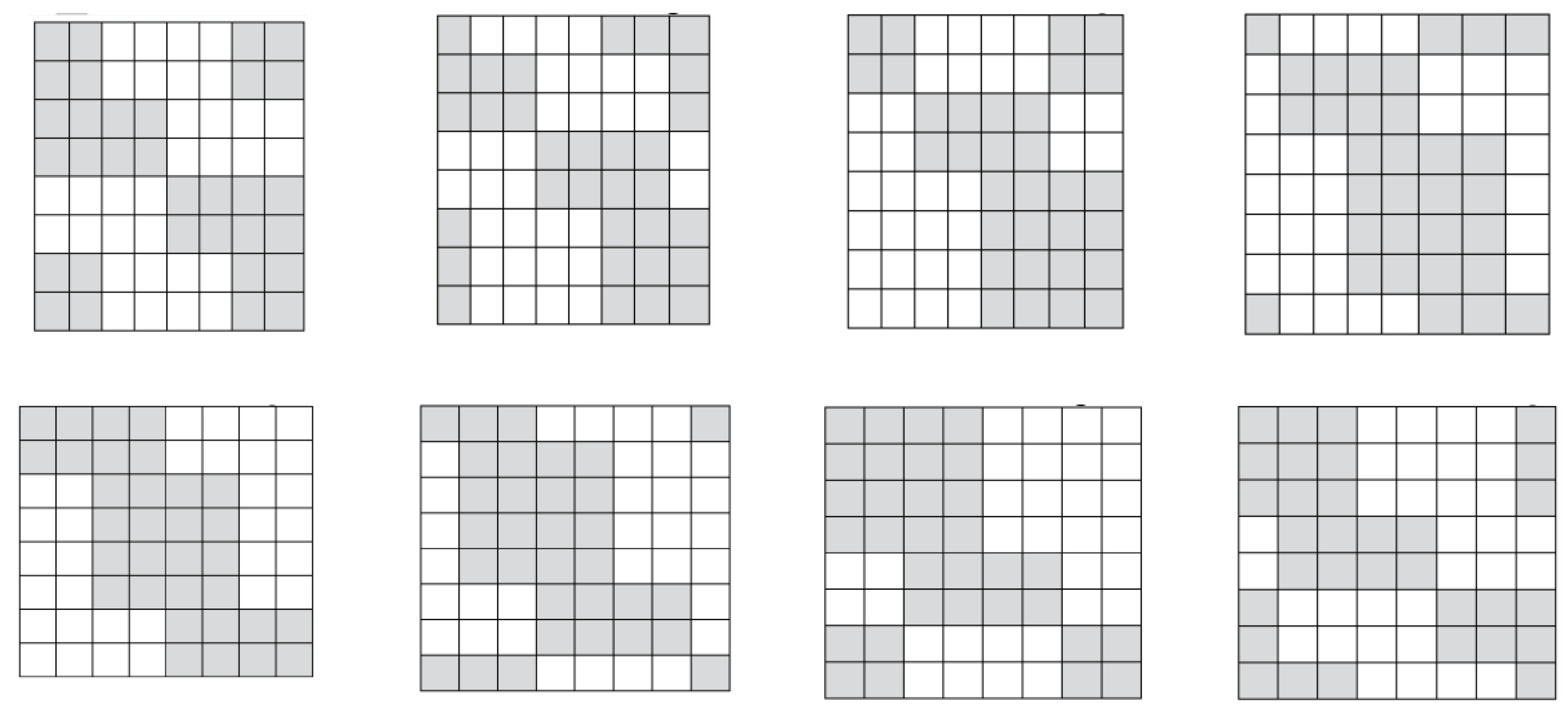
All 8 Gray-type matrices Gi of 64 triplets in Figure 3.15, which represent the genetic code degeneracy in connection with cyclic changes in the sets of 3-bit numberings of their rows and columns, possess general algebraic properties: raising each matrix to the fourth power generates its quadrupling; each matrix, when divided by four, is a projector operator (3.5):
Gi2 = 4Gi ; (Gi/4)2 = Gi
All 8 genetic Gray-type matrices in Figure 3.15 have a general property associated with the complementarity operation of the replacement 0↔1 in the 3-bit numberings of their columns: any two columns, whose numberings are complementary each to another relative to the replacement of 0↔1, have sets of entries, which differ only by their opposite signs (that is, these sets are also complementary each to another relative to the replacement operation of signs “+ ↔ -“). For example, in the matrix M3 from Figure 3.2, the column with numbering 000 contains the set of entries +1, +1, +1, +1, -1, -1, +1, +1, and the complementary column with numbering 111 contains the same set of entries but with opposite signs: -1, -1, -1, -1, +1, +1, -1, -1. This general property of the considered Gray-type matrices of triplets can be also conditionally called as the property of the double complementarity.
This double complementarity provides that the Gray-type matrix operators Gi (Figure 3.15) are cyclic operators in the following sense. Let's consider an arbitrary 8-parameter system, the behavior of which in time is described by the vector =[f0(t), f1(t), f2(t), f3(t), f4(t), f5(t), f6(t), f7(t)], whose coordinates are voluntary periodic functions fi(t) independent of each other. The action of any of the named genetic Gray-type matrices Gi on this vector generates a vector whose coordinates become mutually dependent and synchronized in cyclic behaviors of its separate coordinates (3.6). In other words, instead of a random set of oscillations fi(t) in a multi-parameter system, order arises in the form of strictly ordered relationships of cyclic processes occurring in different subspaces of the system configuration space, due to which this system acquires the features of a whole entity. For example, the action of the Gray-code matrix M3 (from Figure 3.2) on the vector =[f0(t), f1(t), f2(t), f3(t), f4(t), f5(t), f6(t), f7(t)] generates the following vector = [X0, X1, X2, X3, X4, X5, X6, X7], where cyclic coordinates with identical amplitudes at any fixed t are marked by identical colors:
According to (3.6), X0(t) =X1(t) = -X4(t) = -X5(t) and X2(t) = X3(t) = -X6(t) = -X7(t). It means that 4 yellow coordinates X0, X1, X4, and X5 are identical in their amplitudes at any t, but coordinates X4 and X5 are cyclically changed in opposite phases in comparison with coordinates X0 and X1. Analogically, 4 green coordinates X2, X3, X6, and X7 are identical in their amplitudes at any t, but coordinates X6 and X7 are cyclically changes in opposite phases in comparison with coordinates X2 and X3.
4. Interrelation between the Hilbert curve and Gray codes for using in genetic studies
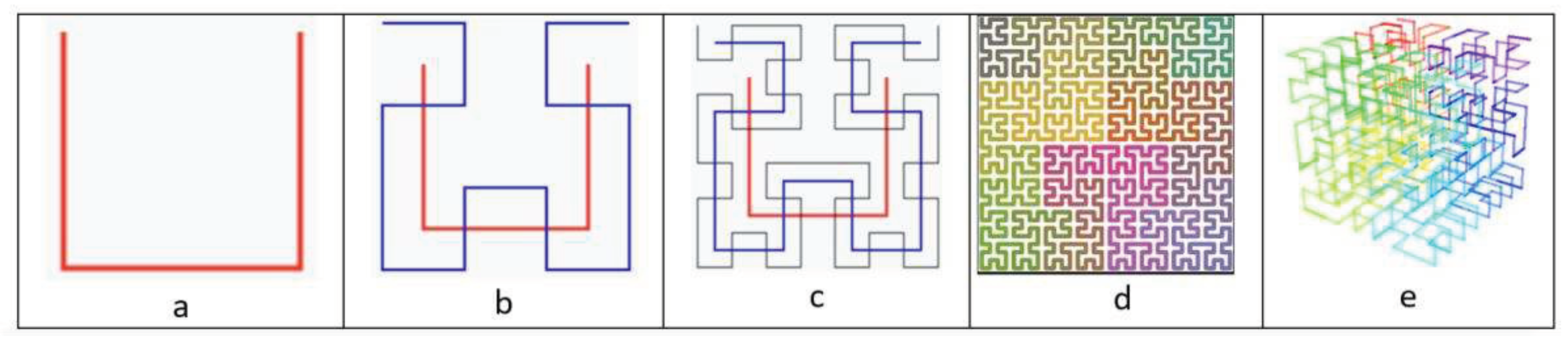
Gray codes are closely related to the Hilbert curve [https://en.wikipedia.org/wiki/Hilbert_curve ; Zzeng, 2020]. First described by David Hilbert in 1891, the Hilbert curve is a one-dimensional fractal trajectory that densely fills higher-dimensional space without crossing itself (Figure 4.1). The main property due to which the Hilbert curve is used is that the distance between any two adjacent points on the curve is equal to one. This is analogous with the property of the Gray code, in which the Hamming distance between two adjacent codewords is equal to one. The basic element of the Hilbert curve is the U-shaped element (Figure 4.1).
Figure 4.1.
Examples of the Hibert curve: a – Hilbert curve, the first order; b – Hilbert curve, first and second orders; c – Hilbert curve, first to third orders; d – Hilbert curve of a higher order; e - 3-D Hilbert curve with color showing progression (taken from https://en.wikipedia.org/wiki/Hilbert_curve , permission is granted to copy, distribute and adapt these images under the Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic, 1.0 Generic license and also under the Creative Commons Attribution-Share Alike 4.0 International license).
Figure 4.1.
Examples of the Hibert curve: a – Hilbert curve, the first order; b – Hilbert curve, first and second orders; c – Hilbert curve, first to third orders; d – Hilbert curve of a higher order; e - 3-D Hilbert curve with color showing progression (taken from https://en.wikipedia.org/wiki/Hilbert_curve , permission is granted to copy, distribute and adapt these images under the Creative Commons Attribution-Share Alike 3.0 Unported, 2.5 Generic, 2.0 Generic, 1.0 Generic license and also under the Creative Commons Attribution-Share Alike 4.0 International license).
The Hilbert curve allows you to “discretize” any space, creating a convenient coordinate system in it (the curve is continuous, and, therefore, the resolution of such a coordinate system is arbitrarily large). Thus, we can map any point in three-dimensional space with coordinates (x,y,z) to a point on the Hilbert curve with coordinate d, which is only equal to the distance to this point from the beginning of the line. This is associated with the biological problem of how genetic information recorded on one-dimensional DNA filaments determines the three-dimensional morphology of living bodies. The dimensionality reduction problem is the cornerstone of many Big Data processing problems. In addition, we can “pave” a space of any dimension with a Hilbert curve. Due to its properties, the Hilbert curve is used in many areas, including database table clustering, multidimensional object indexing, color palette management, antenna design, etc.
Regarding genomes, it is important to note that the spatial packaging of chromatin in the genome turns out to correspond to the Hilbert curve, representing its polymer fractal 3D-globule, free of nodes [Lieberman-Aiden ey al., 2009]. Emphasizing the importance of this fact, the journal Science featured on the cover of its issue, containing this article, an image of the Hilbert curve similar to its image in Figure 4.1d [https://www.science.org/toc/science/326/5950]. This fact that the three-dimensional architecture of the genome is a polymer analogue of the Hilbert curve additionally supports our declaration about close connections between the genetic code system and cyclic Gray codes related to the Hilbert curve. One should note that the author does not consider in this article the spatial 3D-packaging of the genome, but completely different issues relating, first of all, to the binary-oppositional features of DNA alphabets and also information binary sequences in genomic DNAs, which are analyzed from the viewpoint of properties of cyclic Cray codes.
The most effective methods for constructing fractal structures of arbitrary size in a volume are considered to be algorithms for generating Hilbert curves that fill space [Nazarov, 2017]. The main idea of the algorithm is the recursive construction of the Hilbert curve: in an elementary cubic volume, a continuous Hilbert curve connects all the vertices of the cube, after this each of the vertices of the cube is represented as a separate cube, inside which, in a similar way, the curve connects all the vertices, and so on, resulting in a curve consisting of 8n points, where n is the number of hierarchical levels in the structure (or the number of approximations, when each point in space is transformed into a separate cube, as shown in Figure 4.2).
Figure 4.2.
Recursive construction of the fractal Hilbert curve of the first, second, and third orders to fill space (taken from https://en.wikipedia.org/wiki/Moore_curve, permission is granted to copy, distribute and adapt the work under the Creative Commons Attribution-Share Alike 4.0 International license).
Figure 4.2.
Recursive construction of the fractal Hilbert curve of the first, second, and third orders to fill space (taken from https://en.wikipedia.org/wiki/Moore_curve, permission is granted to copy, distribute and adapt the work under the Creative Commons Attribution-Share Alike 4.0 International license).
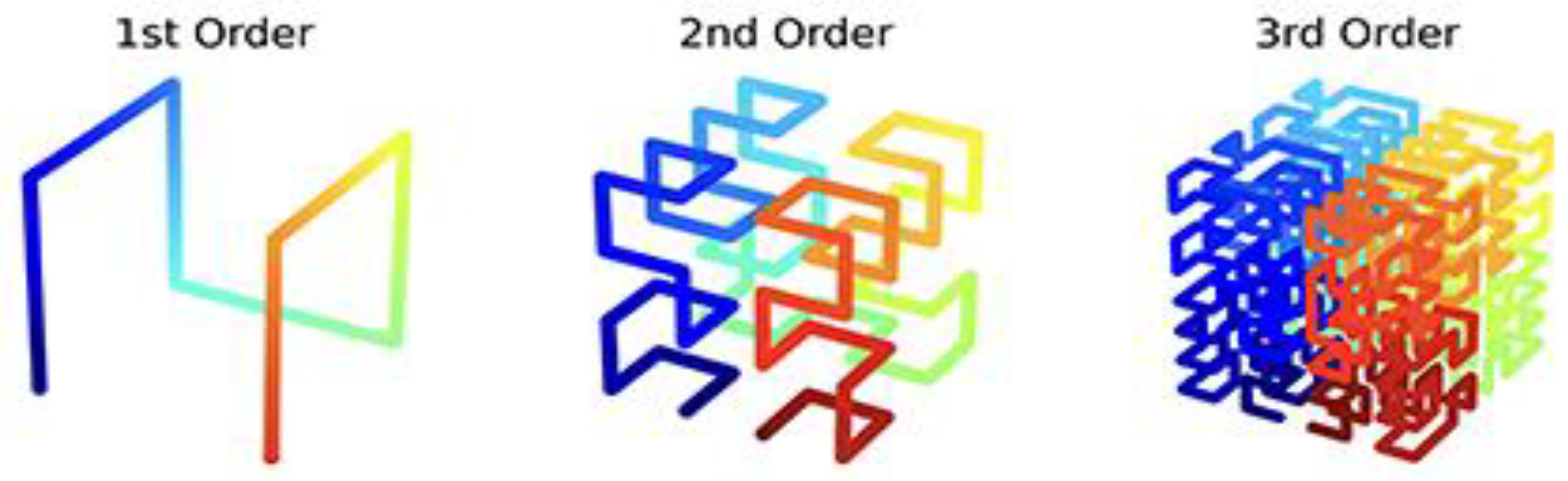
Below we will use a similar recursive algorithm of fractal generations for modeling emergent properties of fractal hypercycle biosystems by means of fractal Gray code families when each of codewords of an initial Gray code is represented as a new Gray code, having appropriate number of codewords, with repetition of such complicating representation again and again.
5. Gray codes for modeling genetic structures and inherited cyclic phenomena. Cyclic biocomputing
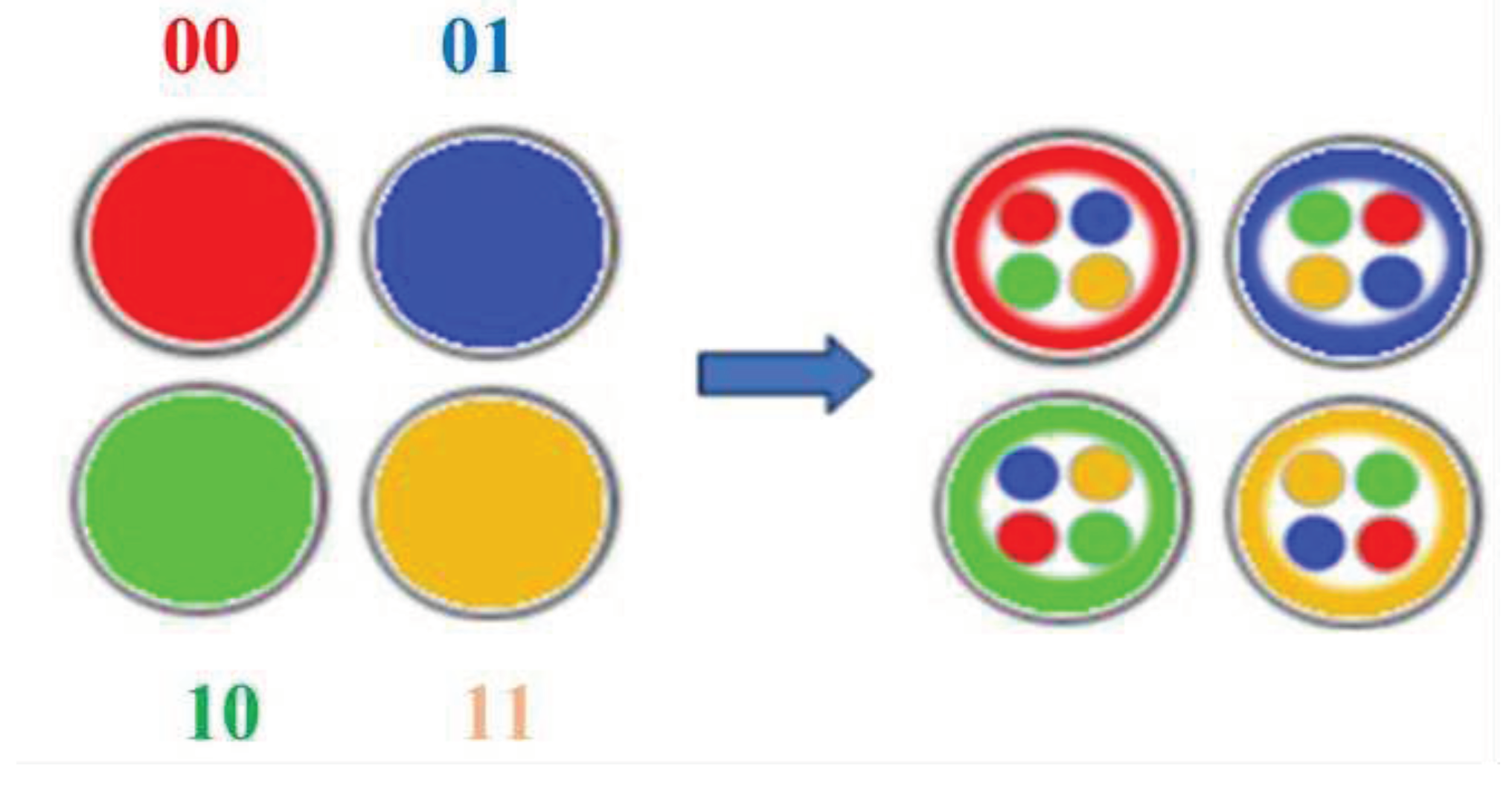
In this article, we consider Gray codes in an expanded sense as sequences of n-bit codewords (or binary strings), in which any two adjacent codewords differ by exactly one digit including the same difference between its last and its first codewords, which are interpreted as adjacent codewords as well (the Hamming distance between them is 1). In this approach, cyclic sequences in Gray codes can be considered in many cases as code hypercycles, which contain inside them cyclic subsequences of Gray codewords or cropped cyclic Gray codes (see detail in Appendix A). Let us firstly note a transformation of any Gray codes into another Gray code under the complementarity operation 0↔1 in its set of binary codewords (Figure 5.1). Applying this complementarity operation to a new Gray code generates the original Gray code, associated with the property of self-duplication and multiplication of DNA.
Figure 5.1.
Example of a transformation of one 3-bit Gray code into another 3-bit Gray code under the complementarity operation 0↔1 in its set of binary codewords.
Figure 5.1.
Example of a transformation of one 3-bit Gray code into another 3-bit Gray code under the complementarity operation 0↔1 in its set of binary codewords.

Here one can remind about the importance of complementarity operations in genetics. The DNA double helix model created by J.D. Watson and F. Crick in 1953 showed to the world a recursive algorithm for the complementary replication of DNA strands, which ensures the replication of the genetic information recorded on these strands. Before the complementary replication, DNA is separated in two complementary strands. Each strand of the original DNA molecule serves as a template for the production of its new complementary counterpart. This seminal work by Watson and Crick was perceived as the discovery of a key secret of life, corresponding to the ancient notions that "like begets like". Scientists were struck by how simple and beautiful this explanation of the replication and preservation of genetic information based on the mechanism of complementarity turned out to be. It was emphasized that it is this complementarity that provides the most important properties of DNA as a carrier of hereditary information [Chapeville, Haenni, 1974].
Based on analogies between the structural properties of the genetic coding system and Gray codes, the author is developing a family of models of cyclic genetic biomechanics, including the following models:
- -
- chromosome crossing over;
- -
- biological colonies based on cyclic n-bit Gray codes using concatenation operations,
- -
- complementary replication, fragmentation, etc.;
- -
- amino acid sequences of proteins and their “life-death” cycles, including the breakdown of proteins into amino acids and their rebirth; and etc.
The family of these models additionally uses the above-described connection of Gray codes with the Hilbert curve, as well as the connection of Gray codes with orthogonal Walsh functions and sequency theory by Harmuth [Harmuth, 1977, 1989]. This model approach is based on the postulate introduced by the author: living organisms are cyclically coded cyclic entities, the properties of which can be modeled based on the idea of hypercycles of Gray codes.
In this approach, the author models the emergent properties of living bodies considered as cyclic systems consisting of cyclic subsystems, the states of which change in a mutually coordinated manner due to relay race-like processes of state change. These emergent properties are associated with information ensembles of long polymer molecules of the genetic code system, the states of which within the ensemble can change in a coordinated manner. Hypercycles of Gray codes are used by the author as an effective tool for modeling emergent phenomenological properties of biomolecular systems of a cyclic nature. Each of the codewords of modeling Gray codes matches to a subsystem state of a corresponding biomolecular system having abilities of cyclic changes of its states. The effectiveness of the proposed biomathematical modeling based on cyclic Gray codes indicates the existence and important physiological significance of biomolecular systems characterized by the present of appropriate cyclically and coordinately changes of states of their subsystems.
The author focuses on cyclic biosystems, consisting of subsystems whose states are interconnected and can change cyclically in a coordinated manner; the sequence of cyclically alternating states in each of these subsystems is denoted by a sequence of code words of one or another Gray code in the extended sense (see Appendix A). When modeling such biosystems based on hypercycles on Gray codes, the author uses the following main points:
- Point 1. We consider the emergent properties of model biological systems, consisting of a sequence of subsystems, the mutually related initial states of which form a sequence, denoted by a sequence of codewords in one or another Gray code. For example, we consider a system of four mutually connected subsystems a, b, c, d, the initial states of which are designated by 4 codewords 00, 01, 11, 10 of the 2-bit Gray code);
- Point 2. Among these subsystems there is a subsystem that acts as a "pacemaker" to define a rhythm of changes: its initial state, denoted by one of the codewords of the Gray code, is transformed into a state denoted by the adjacent codeword of the Gray code. This shift change in the state of the first subsystem (pacemaker) causes a shift change in the state of the neighboring subsystem, denoted by the next codeword of the Gray code. Such a transformation is accompanied by a relay race-like process of similar shift changes in the states of subsequent subsystems with the cyclic passage of the entire set of code words denoting these states. For example, a subsystem with an initial state denoted by codeword 00 is transformed into a state denoted by a neighboring codeword 01, and the neighboring subsystem at the same time moves from the initial state 01 to state 11, etc. The concept of a pacemaker is borrowed from cardiology, which has discovered that just the cyclic action of pacemaker cells of the heart sets the rhythmic work of the heart without the influence of nerves;
- Point 3. The cyclic biosystems under consideration have the ability to fractal-like complication due to the recursive algorithm applied to their cyclic subsystems, similar to that described above for the fractal Hilbert curve (Figure 4.2): under this fractal-generating algorithm, each of the cyclic subsystems is represented as a set of new cyclic subsystems, again denoted by codewords of a Gray code of correspondingly increased bit depth. This model property of the biosystems under consideration reminds the ability of living organisms to develop fractal complexity during development; it also resembles the vegetative reproduction of multicellular organisms, in which a complex organism grows from a piece of a biological body.
Let us consider illustrative examples of such model cyclic biosystems. Figure 5.2 presents an example of a model system of two sets of subsystems, the states of which are mutually related and can change cyclically. These sets are indicated in the figure by two squares of 4 subsystems. Each subsystem can be in one of four states, designated by codewords 00, 01, 11, 10 of the 2-bit Gray code. For visual comfort, each of these 4 code words is represented by one of 4 colors. Figure 5.2a shows the initial states of the subsystems. The role of a pacemaker is, for example, the subsystem located in Figure 5.2a in the left square and in the state indicated in red. Figure 5.2b–e show the relay race-like process of cyclic change in the states of all subsystems when the state of this pacemaker cyclically changes.
Figure 5.2.
An example of a cyclic system with 8 subsystems, each of which can be in one of 4 states, denoted by codewords 00, 01, 11, 10 of the 2-bit Gray code. The top row shows a color representation of each of these codewords and states. Figures 5.2a-e illustrate the relay race-like process of cyclic change in the states of all 8 subsystems (see text for details).
Figure 5.2.
An example of a cyclic system with 8 subsystems, each of which can be in one of 4 states, denoted by codewords 00, 01, 11, 10 of the 2-bit Gray code. The top row shows a color representation of each of these codewords and states. Figures 5.2a-e illustrate the relay race-like process of cyclic change in the states of all 8 subsystems (see text for details).
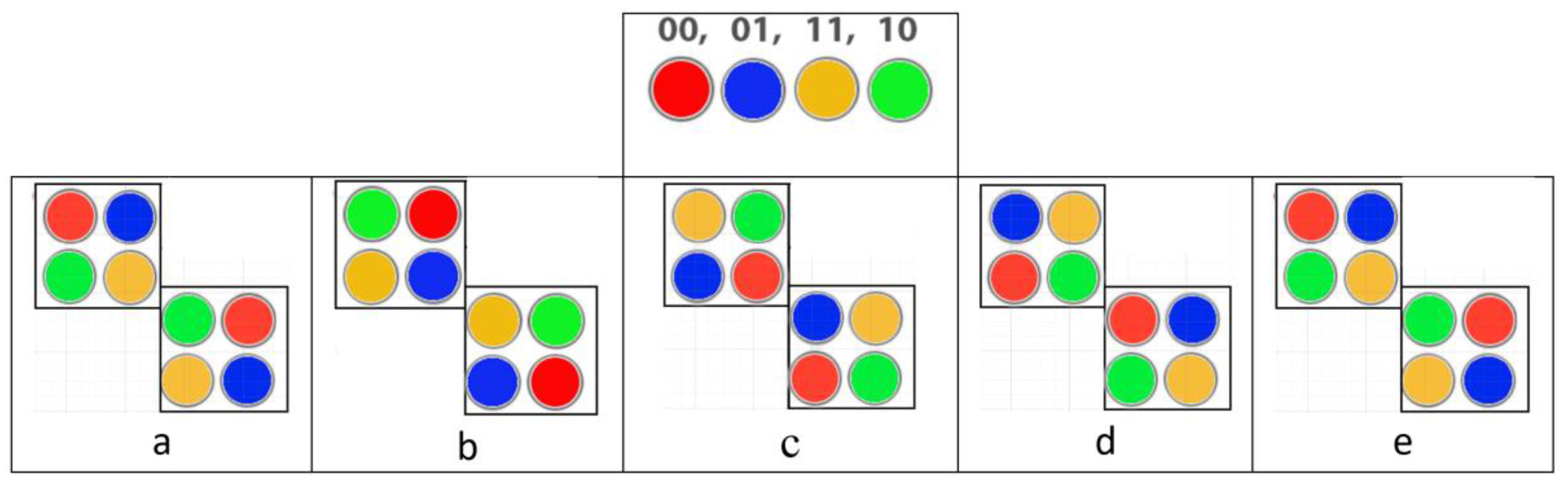
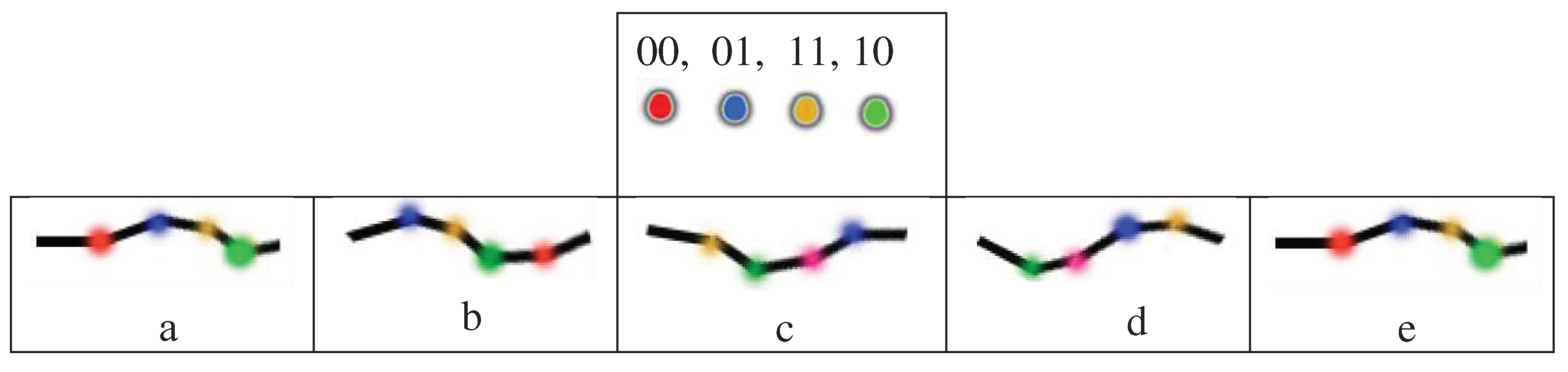
Figure 5.3 presents an example of the cyclic kinematics of a model system of 5 successive rods. This system consists of 4 mutually connected cyclic subsystems, the state of each of which is characterized by the corresponding angle between adjacent rods. Each of the subsystems can be in 4 angular states, corresponding to the angles -200, +300, +250, -450 between adjacent rods and designated by code words 00, 01, 11, 10 of the 2-bit Gray code. In this sequence of 4 subsystems, their initial states form a sequence corresponding to code words 00, 01, 11, 10. A cyclic shift in the angular state of one of the subsystems is accompanied by a cyclic shift in the angular state in the adjacent subsystem. For example, when the first subsystem changes state 00 to state 10 the state of the neighboring subsystem is cyclically shifted to state 11, followed by a relay race-like process of cyclic shift of angular states in the entire sequence of subsystems. This cyclic change in the angular states of the subsystems is accompanied by the shown kinematics of the entire cyclic system.
Figure 5.3.
An example of cyclic kinematics of a system of 5 rods, consisting of 4 mutually connected cyclic subsystems of angular types. Each of these subsystems can be in 4 angular states, characterized by the angle between adjacent rods and denoted by the code words 00, 01, 11, 10 (for clarity, these angular states are assigned color labels, as shown at the top). The initial angular states in the sequence of 4 subsystems correspond to the sequence of code words 00, 01, 11, 10. The kinematics of the rod system is shown during a relay race-like process of cyclic shift of the angular states of the subsystems (for details, see the text).
Figure 5.3.
An example of cyclic kinematics of a system of 5 rods, consisting of 4 mutually connected cyclic subsystems of angular types. Each of these subsystems can be in 4 angular states, characterized by the angle between adjacent rods and denoted by the code words 00, 01, 11, 10 (for clarity, these angular states are assigned color labels, as shown at the top). The initial angular states in the sequence of 4 subsystems correspond to the sequence of code words 00, 01, 11, 10. The kinematics of the rod system is shown during a relay race-like process of cyclic shift of the angular states of the subsystems (for details, see the text).
Now let's move on to the illustration of the above-mentioned Point 3 about the fractal-generating algorithm for complicating the cyclic systems under consideration. Figure 5.4 shows an example of such a fractal-like complication of the original cyclic system, consisting of 4 mutually interconnected cyclic subsystems, designated by code words 00, 01, 11, 10, as well as four different colors for clarity. Each of the subsystems can be in one of 4 states, cyclically replacing each other. In this case, a change of state in one subsystem (playing the role of a pacemaker) causes a relay race-like cyclic change of state1 in other subsystems, as described above in connection with Figure 5.2, 5.3. In the example under consideration, the action of the fractal-generating algorithm transforms each of the 4 original subsystems into 4 new cyclic subsystems, which results in the emergence of a new cyclic system with 16 cyclic subsystems, which are interconnected with each other by the same principle of relay race-like change of states in neighboring subsystems.
Figure 5.4.
An example of algorithmic fractal-like growth of a cyclic system, initially consisting of 4 mutually connected cyclic subsystems. In the presented system, each of the 4 subsystems can be in 4 states. These states cyclically replace each other in a relay race manner and are designated by Gray codewords 00,01,11,10, which are additionally marked with 4 colors for clarity. As a result of the algorithm, according to which each subsystem is transformed into 4 new cyclic subsystems, an enlarged cyclic system with 16 cyclic subsystems is formed (see text for details).
Figure 5.4.
An example of algorithmic fractal-like growth of a cyclic system, initially consisting of 4 mutually connected cyclic subsystems. In the presented system, each of the 4 subsystems can be in 4 states. These states cyclically replace each other in a relay race manner and are designated by Gray codewords 00,01,11,10, which are additionally marked with 4 colors for clarity. As a result of the algorithm, according to which each subsystem is transformed into 4 new cyclic subsystems, an enlarged cyclic system with 16 cyclic subsystems is formed (see text for details).
As shown in Figure 5.4, as a result of applying this fractal-generating algorithm, the original system of 4 cyclic subsystems, which are denoted by codewords of a 2-bit Gray code, turns into a system of 16 cyclic subsystems, denoted by codewords of a 4-bit Gray code: 0000, 0001, 0011, 0010, 0110, 0100, 0101, 0111, 1111, 1110, 1100, 1101, 1001, 1011, 1010, 1000.
Many authors supposed that living beings are molecular quantum computers (biocomputers) and that natural laws are embedded in molecular texts of DNA for molecular controlling systems (see, for example, [Liberman, Minina, 1996; Liberman, Minina, Shklovskii-Kordi, 2001]. This article on the genetic cyclic coding of inherited cyclic physiological structures opens a new direction of thoughts about living beings as cyclic biocomputers using advantages of cyclic Gray codes. It should be explained additionally.
Each subsystem of cyclic behavior within the considered cyclic biosystems can serve as a memory cell, the state of which changes cyclically in relay race-like coordination with the states of other memory cells of the considered cyclic system (a cooperative cyclic change of states in the sets of biocomputer memory cells). In the cooperative updating of states in sets of such memory cells, pacemakers play an important role, setting the rhythm of cyclic rearrangements of cell states. Under the fractal-like growth of a cyclic system with an increase in the number of subsystems in it (see example in Figure 5.4), the number of cooperative memory cells that cyclically change their state in such a model cyclic biocomputer increases accordingly. In accordance with the multilayered features of the organization of genomic DNAs informatics [Petoukhov, 2022a,b, 2023a,b; Petoukhov, He, 2023], cyclic biocomputing can be functionally organized as a multilayer (n-layer) constructure. For example, one layer of cooperative circular memory cells is tied to cells whose memory changes according to sequences of 2-bit Gray code words. Another layer of cooperative cyclic memory cells is represented by cells whose memory changes in accordance with the sequences of codewords of the 3-bit Gray code, etc. The development of the theory of such cyclic biocomputers, whose organization is built in accordance with principles of the genetic informatics, can serve to progress in artificial intelligence systems.
6. Genetic Hadamard matrices, Walsh functions, and Gray codes
This section focuses on one more kind of the binary oppositions in the DNA nucleotide alphabet A, C. G. T. We are talking about the phenomenological opposition of the properties of thymine T to properties of three other nucleotides A, C, G:
- -
- Firstly, at the transition from DNA to RNA only one letter T is replaced by U (uracil), and the other three letters are not changed;
- -
- Secondly, in the genetic alphabet, only the molecule T (and also the molecule U in RNA) has not the important amino-group NH2 in contrast to the molecules A, C, and G (Figure 6.1).
Figure 6.1.
Schematic images of nucleotides T, A, C, and G. Big circles denote amino groups NH2 in nucleotides A, C, and G. Small black circles represent carbon atoms and small white circles represent hydrogen atoms. The letter N stands for nitrogen atom.
Figure 6.1.
Schematic images of nucleotides T, A, C, and G. Big circles denote amino groups NH2 in nucleotides A, C, and G. Small black circles represent carbon atoms and small white circles represent hydrogen atoms. The letter N stands for nitrogen atom.
This phenomenological opposition can be represented by the binary numeric opposition:
In accordance with the expression (6.1) each of the duplets, triplets, and in general n-plets can be represented as the product of these numerical expressions of its constituent nucleotides. For example, a duplet AT is represented by the product (+1)∙(-1) = -1; triplet CTG – by the product (+1)∙(-1)∙(+1)= -1; triplet TAT - by the product (-1)∙(+1)∙(-1)= +1; etc. When substituting these numerical representations of nucleotides, duplets, and triplets into algorithmically constructed genetic matrices (Figure 2.1), in which the rows and columns are ordered in accordance with cyclic Gray codes (by analogy with the above-mentioned Karnaugh maps from the topic of Boolean functions), numerical matrices are formed, shown in Figure 6.2. These three numeric matrices are called H2, H4, and H8.
A = C= G= +1, T = -1
Figure 6.2.
Matrices H2, H4, and H8, which are numerical representations of symbolic genetic matrices of nucleotides, duplets, and triplets from Figure 2.1. Cells with entries +1 are shown in black, and cells with entries -1 are shown in white. Rows and columns of matrices are ordered according to appropriate sequences of codewords of cyclic Gray codes, similar to Karnaugh maps (see explanation in the text).
Figure 6.2.
Matrices H2, H4, and H8, which are numerical representations of symbolic genetic matrices of nucleotides, duplets, and triplets from Figure 2.1. Cells with entries +1 are shown in black, and cells with entries -1 are shown in white. Rows and columns of matrices are ordered according to appropriate sequences of codewords of cyclic Gray codes, similar to Karnaugh maps (see explanation in the text).
These matrices H2, H4, and H8 are Hadamard matrices because they satisfy the Hadamard matrix criterion:
where the symbol T means matrix transposition, and E is the identity matrix.
H2∙H2T = 2E, H4*H4T = 4E, H8*H8T = 8E,
Hadamard matrices play an important role in quantum mechanics (the evolution of a closed quantum system is described by the Hadamard operator), quantum information science (Hadamard gates), multi-channels spectrometers with Hadamard transformations, and a number of other fields. Cyclic permutations of rows and columns of Hadamard matrices always generate new Hadamard matrices.
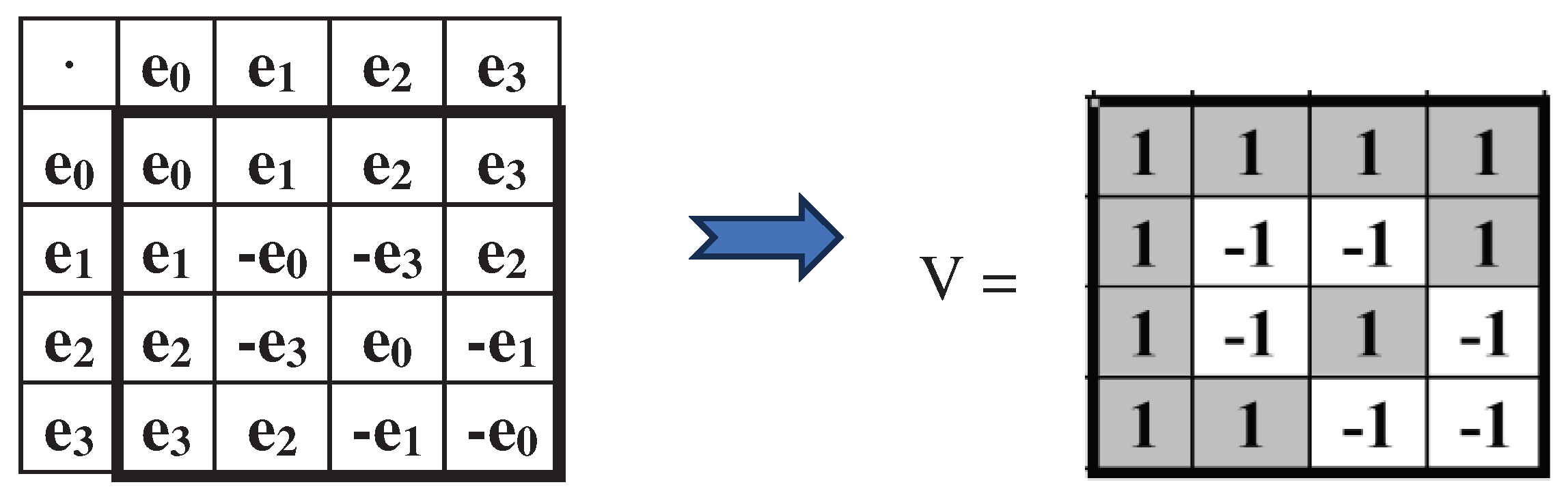
Matrix H2 is the sum of two sparse matrices [1, 0; 0, 1] and [0, 1; -1, 0], the set of which is closed under multiplication and defines the multiplication table of the algebra of complex numbers (in other words, matrix H2 is the matrix representation of complex number with unit coordinates). The dyadic-shift decomposition of the matrix H4 represents it as the sum of 4 sparse matrices e0, e1, e2, e3, the set of which is closed under multiplication and defines a symmetric multiplication table of the basic elements of some commutative algebra (Figure 6.3). This multiplication table is different in that the location of + and – signs in it corresponds to their location in matrix V shown in the figure, which is also the Hadamard matrix: V4∙V4T = 4E. This algebra deserves special study in the future due to its connection with the genetic system and the Gray code.
Figure 6.3.
Dyadic-shift decomposition of the Hadamard genetic matrix H4 (from Figure 6.2) represents it as the sum of 4 sparse matrices, the set of which is closed under multiplication and defines the symmetric multiplication table shown. The location of the + and – signs in this multiplication table is similar to their location in the shown Hadamard matrix V.
Figure 6.3.
Dyadic-shift decomposition of the Hadamard genetic matrix H4 (from Figure 6.2) represents it as the sum of 4 sparse matrices, the set of which is closed under multiplication and defines the symmetric multiplication table shown. The location of the + and – signs in this multiplication table is similar to their location in the shown Hadamard matrix V.
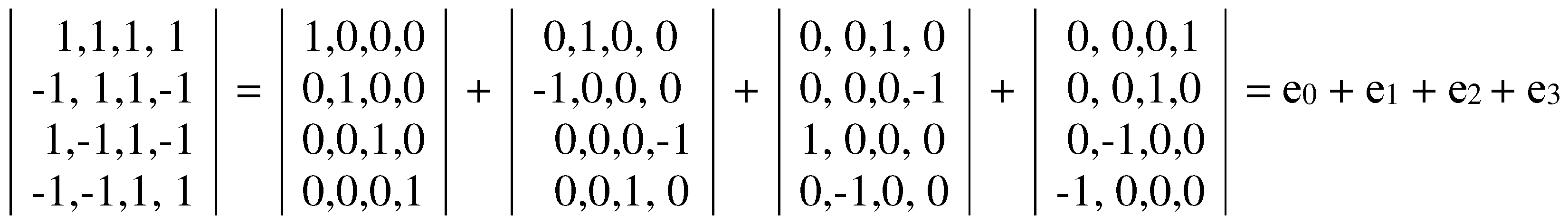
With a simultaneous cyclic shift in numbering sequence of rows and columns in matrix H4 by 1 position, we obtain matrix H4/1, with a shift by 2 positions - matrix H4/2, with a shift by 3 positions - matrix H4/3, which are shown in Figure 64. All of these matrices, whose rows and columns are ordered by 2-bit Gray code, have a different mosaic of +1 and -1 elements, and the diad-shift decomposition of each of them gives different quadruples of sparse matrices. But each of the sets of these sparse matrices turns out to be closed under multiplication and defines the same multiplication table from Figure 6.3.
Figure 6.4.
The family of Hadamard matrices, which arise from matrix H4 (Figure 6.2) under a simultaneous cyclic shift in its number sequence of rows and columns by 1 position, by 2 positions, and by 3 positions.
Figure 6.4.
The family of Hadamard matrices, which arise from matrix H4 (Figure 6.2) under a simultaneous cyclic shift in its number sequence of rows and columns by 1 position, by 2 positions, and by 3 positions.
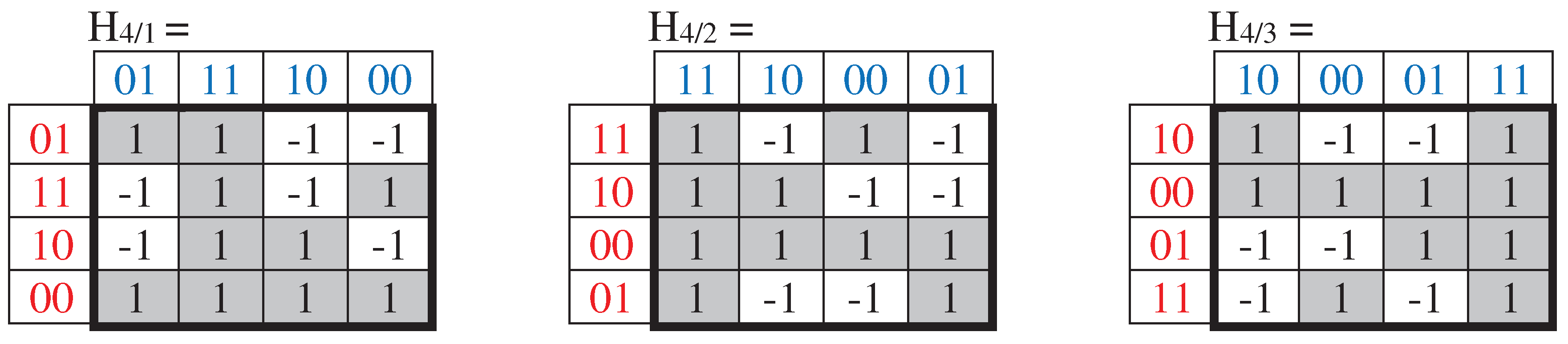
When these genetic Hadamard matrices H2, H4, and H8 (Figure 6.2), taken with appropriate weighting coefficients, are raised to the power, then cyclic groups are formed. For example, the matrix 0.5∙H4, when raised to a power, forms a cyclic group with a period of 4: (0,5∙H4)n = (0,5∙H4)n+4.
Sets of rows and columns of genetic matrices H2, H4, and H8 (Figure 6.2) represent complete orthonormal systems of Walsh functions of appropriate order, widely used in the theory of noise-resistant information coding, radio communications, and spectral analysis (they can be used to represent any discrete function), etc. [https://en.wikipedia.org/wiki/Walsh_function, https://mathworld.wolfram.com/WalshFunction.html ]. In particular, the sequency theory based on Walsh functions provides valuable advantages when used in aerospace photo and video study [Kostrov, 2012]. The Walsh functions consist of trains of square pulses (with the allowed states being -1 and 1) such that transitions may only occur at fixed intervals of a unit time step, the initial state is always +1. The 2n Walsh functions of order n are given by the rows of the Hadamard matrix of order (2n∙2n). The even Walsh functions Cal(k) and the odd Walsh functions Sal(k) exist:
where k is the sequency defined below. The Walsh function is defined on the interval [0, T]; outside this interval the function repeats periodically and for this reason belongs to the topic of cyclic structures.
Cal(k,θ) = W(2k,θ), Sal(k,θ) = W(2k-1, θ)
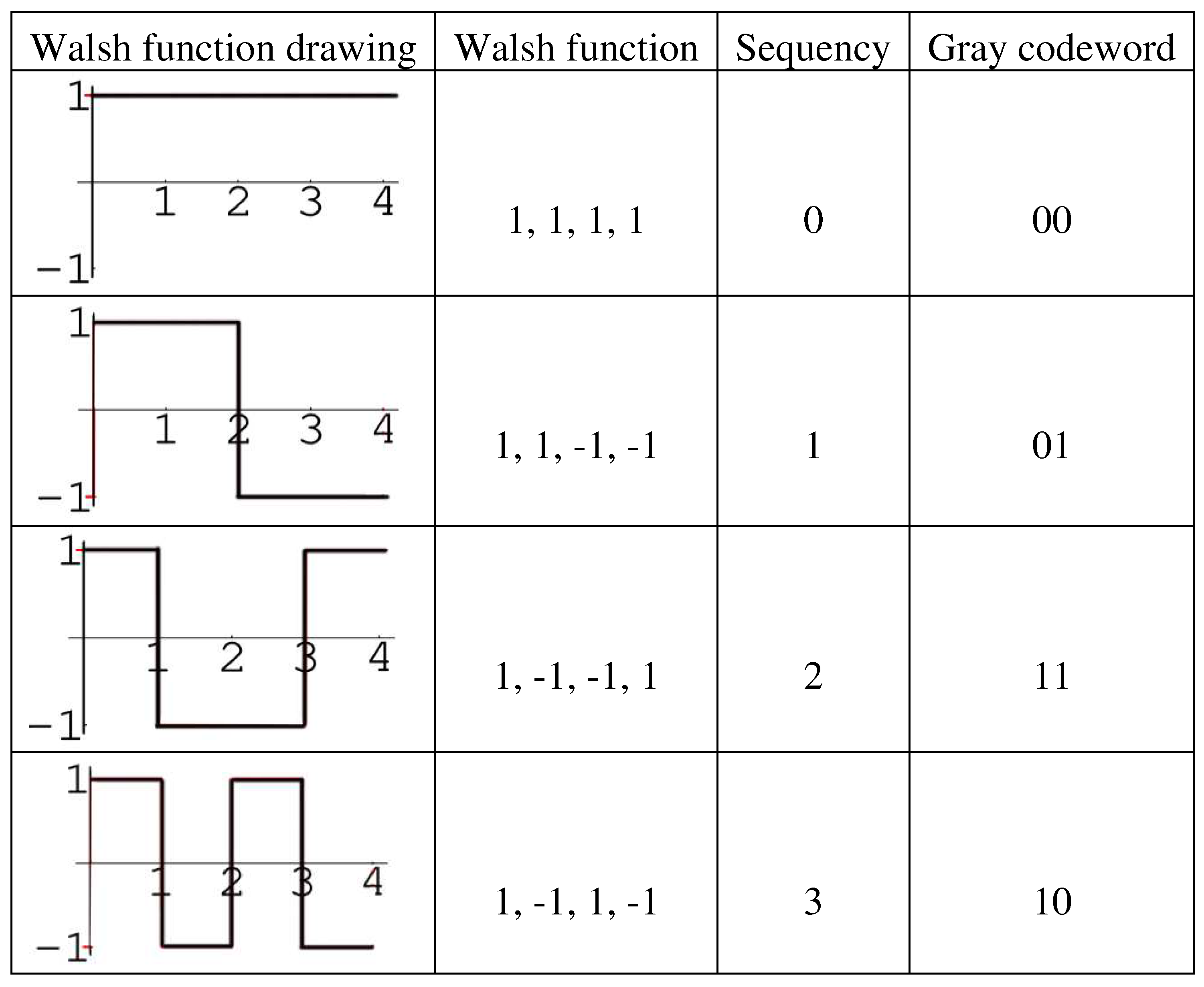
In the theory of Walsh functions, the notion of “sequency” is important. It means the number of changes in the value of the Walsh function and serves as an analogue of the normalized frequency of a sinusoidal oscillation [Harmuth, 1972, 1977, 1989]. Through this notion, each complete system of 2n orthonormal Walsh functions is one-to-one mapped to an n-bit Gray code containing the same number - 2n - codewords (as it is described in Appendix A for Gray codes in a narrow sense): each of the Walsh functions mathes one of the codewords of the corresponding Gray code (see example in Figure 6.5). Interrelation between Gray codes and complete orthonormal systems of Walsh functions is considered, for example, in [Yuen, 1971; Cohn M, 1971; Doran, 2007; Beletsky, 2003].
Figure 6.5.
A complete orthonormal system of 4 Walsh functions, whose set of sequency 0, 1, 2, 3 are in one-to-one correspondence with the 4 codewords of the 2-bit Gray code. Here these 4 Walsh functions are ordered in the ascending sequency order.
Figure 6.5.
A complete orthonormal system of 4 Walsh functions, whose set of sequency 0, 1, 2, 3 are in one-to-one correspondence with the 4 codewords of the 2-bit Gray code. Here these 4 Walsh functions are ordered in the ascending sequency order.
This one-to-one correspondence between Gray codes and Walsh functions is used in complex engineering control systems for autonomous objects that use sensors based on Gray codes and for which special devices are developed to automatically convert Gray codes into Walsh functions (see, for example, [Lega et al., 2004]).
Within the framework of the presented concept of genetic coding of heritable cyclic structures based on cyclic Gray codes, we accept that this unambiguous relationship between Gray codes and Walsh functions, which is used in engineering, is also important for the phenomenology of genetic inheritance. More precisely, we assume in our model approach that, in a genetic coding system, cyclic Gray codes encode orthonormal Walsh functions. It was shown above (Figure 2.1) that - due to the binary-oppositional structure of the genetic coding system - each nucleotide, doublet, triplet and, in general, n-plet can be designated (or coded) by one of the codewords of the corresponding n-bit Gray code, which automatically a specific Walsh function, having appropriate sequency, is mapped. Thus, from this cyclic-coding point of view, the entire genetic coding system with its multiple alphabets of DNA and RNA n-plets appears as a set of complete orthonormal systems of Walsh functions of order n. Accordingly, a new starting point appears for the analysis of hidden interrelations in genetic structures and the development of algebraic biology; it is associated with complete orthonormal systems of Walsh functions, which play an important role in computer science, technology, mathematics and physics, about which we will additionally recall below.
7. Gray codes, dyadic clock, and the sequency theory by Harmuth
The model approach to cyclic coding of a genetically inherited set of biological cycles concerns the problems of biological clock, which is needed for their coordination in time. The genetic coding system is discrete in nature, since it is built on discrete alphabets of nucleotides, amino acids, etc. In addition, its structures, as noted above, are closely related to binary oppositions and dyadic groups of binary numbers (codewords of Gray codes belong to these dyadic groups). Consideration of cyclic bioprocesses modeled on the basis of Gray codes and dyadic calculus assumes the existence of corresponding dyadic clocks. Let us pay special attention to this.
Such dyadic clocks, associated with Gray codes and used to describe movements, were introduced and described in detail in the book [Harmuth, 1989]. This book analyzes the transition to discrete space and time instead of their continuum representations. At the same time, an algebraic apparatus for working with discrete space and time was developed based on dyadic calculus and Walsh functions with using Gray codes. This apparatus uses difference equations instead of differential equations. The effectiveness of this apparatus is demonstrated by examples of the derivation of difference equations of physics, for example, the Schrödinger, Klein-Gordon and Dirac difference equations in a Coulomb field.
The concepts of dyadic time and dyadic space considered by Harmuth are associated with his theory of sequency analysis [Harmuth, 1977], which gave rise to many technical applications (see, for example, [Soroko, 1973, 1979]. Let us list some of them, since it can be assumed that they have analogues in living bodies, the genetic coding system of which is structurally related to Gray codes and Walsh functions. This theory has long penetrated into radio engineering, television, computer technology, acoustics, seismography, aerospace photography and videography, optics and physics. Based on sequential analysis, fundamentally new communication systems have been created, instant image processing devices, and underwater acoustic cinema devices with a high frame rate have been built. Logical holography systems based on Walsh functions have been constructed [Morita, Sakurai,1973]. Thanks to sequency analysis, it was possible to circumvent the problem of absorption of radio waves and acoustic waves at high frequencies. Harmuth himself created in the USA a fundamentally new system for generating acoustic film images with a frame rate of up to 105 per second. Based on sequential analysis, high-speed filters and processors of spatial and temporal signals have been developed. Walsh functions provide fast and efficient data compression without losing useful information.
In the field of antenna technology, a Walsh antenna has emerged, in which the time dependence of the excitation current is specified by Walsh functions and which has unique functional features. For example, the generated electromagnetic wave acquires a range mark. Therefore, to estimate the distance between the Walsh antenna and the observer, it is enough to register the signal shape at only one point in space (the classical electromagnetic field emitted by a Hertz dipole does not have this property). Circularly polarized electromagnetic Walsh waves make it possible to distinguish a scatterer object from a reflector object. Non-sinusoidal electromagnetic waves, asymmetrical in polarity, make it possible to distinguish a conducting object from a non-conducting one. The Walsh antenna also differs from the Hertz dipole in that the Walsh electromagnetic field has Doppler invariance; this property of Walsh waves, as Harmuth noted, gives astronomers hope for the possibility of establishing communication with extraterrestrial civilizations, since for such communication these civilizations must use electromagnetic waves, which are invariant with respect to the Doppler frequency shift. The features of the Walsh antenna are associated with some biological phenomena described in the author’s doctrine of energy-information evolution based on bio-antenna arrays [Petoukhov, 2022b]. When developing future models of heritable cyclic bioprocesses involving electromagnetic waves, it is necessary to take into account the possibility of the participation of cyclically operating Walsh antennas in the bio-antenna arrays of organisms.
8. Universal stochastic rules of genomic DNAs, binary-genomic numbers, and complementarity operation
This article has already mentioned more than once the operation of complementarity, which consists in the mutual replacement of 0⇔1 in families of binary numbers representing different features of genetic subsystems. This operation can be repeated and therefore should be considered one of the cyclic operations associated with genetic informatics. The binary numbers 0 and 1 are codewords of a 1-bit Gray code. This section highlights data on the participation of the complementarity operation in the universal rules of statistical (probabilistic) organization of information sequences of single-stranded DNAs in the genomes of higher and lower organisms.
P. Jordan, the author of the first article on quantum biology in 1932, argued that the laws of life missed by science are the laws of probability of the quantum world. In search of these overlooked laws of life, the author turned to the study of statistical patterns in the binary “purine-pyrimidine” sequences of single-stranded DNAs of genomes of higher and lower organisms from the GenBank. As a result, general biological rules for the statistical organization of genomic DNAs were discovered. Let's turn to them.
As mentioned above, two of the 4 nucleotides of DNA are purines (A and G), and the other two (C and T) are pyrimidines. Any single-stranded DNA can be represented as a binary sequence of purines and pyrimidines. Let's look at the example of single-stranded DNA of human chromosome No. 1, containing about 250 million nucleotides (https://www.ncbi.nlm.nih.gov/nuccore/NC_000001.11). By denoting the purines (A and G) with the symbol 0, and the pyrimidines (C and T) with the symbol 1, we get a representation of this genomic DNA in the form of a super-huge binary number with about 250 million bits (the decimal equivalents of this number go up to 2250000000). The author called these numbers “binary-genomic” (BG-numbers). They apparently reflect the laws of quantum biophysics and quantum information science, genetic memory, etc. Mathematical science has not previously worked with systems of such huge numbers (as far as the author knows).
It turned out that these binary-genomic numbers constitute a special subset of the entire set of binary numbers with such multi-million bits. A distinctive feature of BG-numbers is the presence in their statistical organization of certain patterns of hierarchical, symmetric, dichotomous and fractal-like types.
To detect statistical patterns hidden in BG-numbers, they were analyzed by the author’s “method of hierarchical binary statistics" or briefly HBS-method considering their structure as an analogue of the structure of Russian nesting dolls.
This method includes the following stages of analysis of the percentage composition of the binary-genomic number:
- -
- first, a studied BG-number is represented as a sequence of single characters 0-1-1-1-0-0-... and the percentages %0 and %1 are calculated in it;
- -
- second, it is represented as a sequence of duplets 01-11-00-10-... and the percentages of each type of binary duplets %00, %01, %10, %11 are calculated;
- -
- after this, similarly, the same BG-number is represented as a sequence of binary triplets, tetraplets, pentaplets, ..., with calculation of the percentages of the corresponding types of n-plets each time.
Thus, the binary-genomic number is represented as a multilayer number, each layer of which is written in the alphabet of the corresponding dyadic group of n-bit numbers. As a result, we obtain a table of probabilities of each type of n-plets in the corresponding n-plet layer of the BG-number. We present the calculated probabilities (percentages) of members of n-bit alphabets in these n-bit layers of the BG-number of any analyzed genomic DNA in the form of coordinates of the corresponding 2n-dimensional vectors n (Table 8.1). In each such vector, the sum of its coordinates is equal to 1. In each vector n, the order of percentages of n-plets, as its coordinates, corresponds to the order of ascending members of dyadic groups of binary numbers.

Table 8.1.
A unified vector representation of families of probabilities (percentages) of n-bit numbers characterizing the statistical structure of binary sequences of single-stranded DNAs (that is, their binary-genomic numbers), which are analyzed using the HBS method described in the text. The percentages of n-plets starting with 0 are shown in red and those starting with 1 are shown in blue.
Table 8.1.
A unified vector representation of families of probabilities (percentages) of n-bit numbers characterizing the statistical structure of binary sequences of single-stranded DNAs (that is, their binary-genomic numbers), which are analyzed using the HBS method described in the text. The percentages of n-plets starting with 0 are shown in red and those starting with 1 are shown in blue.

For example, for the binary-genomic number of purines and pyrimidines in the DNA of human chromosome No. 1, the data shown in Table 8.2 were obtained.8.2.
Table 8.2.
Phenomenological percent values of each of the n-plets of purines (symbol 0) and pyrimidines (symbol 1) in binary-genomic number corresponding to the single-stranded DNA of human chromosome № 1 (n = 1, 2, 3, 4, 5). This binary-genomic number contains about 250 million purines and pyrimidines. Initial data on this chromosome were taken from the GenBank: https://www.ncbi.nlm.nih.gov/nuccore/NC_000001.11. Percentages are given in fractions of one and are shown as the coordinates of the vectors n from Table 8.1.
Table 8.2.
Phenomenological percent values of each of the n-plets of purines (symbol 0) and pyrimidines (symbol 1) in binary-genomic number corresponding to the single-stranded DNA of human chromosome № 1 (n = 1, 2, 3, 4, 5). This binary-genomic number contains about 250 million purines and pyrimidines. Initial data on this chromosome were taken from the GenBank: https://www.ncbi.nlm.nih.gov/nuccore/NC_000001.11. Percentages are given in fractions of one and are shown as the coordinates of the vectors n from Table 8.1.
The data in this Table 8.2 shows the unexpected existence in the BG-number of a given chromosomal DNA of a very strict numerical pattern (in the form of a rule of approximate equality of percentages) in all considered families of n-plets: any two “complementary” n-plets, i.e. n-plets, distinguished by the mutual replacement of purines and pyrimidines in them (0 ⇔ 1), have almost equal percentage values in it. For example, %011 = 0.116037…, and %100 = 0.115959…. Figure 8.1 illustrates this pattern of statistical organization of a given chromosomal DNA and its BG-number in the form of diagrams, the left and right halves of each of which are almost mirror-symmetrical to each other. This symmetry is preserved under cyclically repeating the complementarity operation 0 ⇔ 1.
Figure 8.1.
Diagrams of the percentages of binary n-plets of purines and pyrimidines in the 4-duplet, 8-triplet, 16-tetraplet, and 32-pentaplet families taken from Table 8.2. The order of the columns corresponds to the order of the coordinates in the corresponding vectors n of Table 8.1. The numbers of these coordinates n are plotted along the abscissa axis, and the values of these coordinates are plotted along the ordinate axis, that is, the percentages of binary n-plets of DNA of the first human chromosome in its binary representation as a sequence of purines and pyrimidines (in the form of its BG-number for the sequence of purines and pyrimidines).
Figure 8.1.
Diagrams of the percentages of binary n-plets of purines and pyrimidines in the 4-duplet, 8-triplet, 16-tetraplet, and 32-pentaplet families taken from Table 8.2. The order of the columns corresponds to the order of the coordinates in the corresponding vectors n of Table 8.1. The numbers of these coordinates n are plotted along the abscissa axis, and the values of these coordinates are plotted along the ordinate axis, that is, the percentages of binary n-plets of DNA of the first human chromosome in its binary representation as a sequence of purines and pyrimidines (in the form of its BG-number for the sequence of purines and pyrimidines).
In addition, between the families of percentages of binary n-plets of purines and pyrimidines, presented in Table 1.1 for different n, there is another unexpected regular connection (the rule of dichotomy or twinning of probabilities). It consists in high-precision cascade twinning or dichotomy (with the studied values of n = 1, 2, 3, 4, 5): the percentage of any binary n-plet is practically equal to the sum of the percentages of such two binary (n+1)-plets that differ from it the presence of suffixes “0” or “1” (equality accurate to the 4th or 5th decimal place). This phenomenological connection leads to the existence of a fractal dichotomous tree of percentages (Figure 8.2), in which each node is the beginning of its own fractal dichotomous tree [Petoukhov, 2023a,b].
Figure 8.2.
Diagram comparing the percentages of binary n-plets of purines and pyrimidines from Table 8.2 at different values of n and also the corresponding fractal tree of probability dichotomies (right). At each level of the diagram, the lengths of the intervals are proportional to the percentage values of the corresponding n-plets from Table 8.2. The relationships of dichotomy (or twinning) between the lengths of the corresponding intervals at adjacent levels are visible.
Figure 8.2.
Diagram comparing the percentages of binary n-plets of purines and pyrimidines from Table 8.2 at different values of n and also the corresponding fractal tree of probability dichotomies (right). At each level of the diagram, the lengths of the intervals are proportional to the percentage values of the corresponding n-plets from Table 8.2. The relationships of dichotomy (or twinning) between the lengths of the corresponding intervals at adjacent levels are visible.

In addition to the diagram in Figure 8.2, Table 8.3 - based on the analysis of numerical percentage data from Table 8.2. - shows high accuracy of equalities between the percentage of each of the considered n-plets with the sum of the percentages of two (n+1)-plets, differing from it by the presence of suffixes 0 and 1.
Table 8.3.
Comparison of the percentage X of each n-plet from Table 8.2 with the sum ∑ percent of two (n+1)-plets, differing from it by the presence of suffixes 0 and 1. Numbers are rounded to the fourth decimal place. The right column shows virtually no ∑-X difference between these quantities.
Table 8.3.
Comparison of the percentage X of each n-plet from Table 8.2 with the sum ∑ percent of two (n+1)-plets, differing from it by the presence of suffixes 0 and 1. Numbers are rounded to the fourth decimal place. The right column shows virtually no ∑-X difference between these quantities.
| % | X | СУММА | ∑ | ∑-X |
| %0 = | 0,4997 | %00+%01= | 0,4998 | 0,0001 |
| %1 = | 0,5003 | %10+%11= | 0,5002 | -0,0001 |
| %00 = | 0,2807 | %000+%001= | 0,2807 | 0,0000 |
| %01= | 0,2191 | %010+%011= | 0,2191 | 0,0000 |
| %10 = | 0,219 | %100+%101= | 0,219 | 0,0001 |
| %11= | 0,2812 | %110+%111= | 0,2812 | -0,0001 |
| %000 = | 0,1646 | %0000+%0001= | 0,1646 | 0,0000 |
| %001 = | 0,1161 | %0010+%0011= | 0,116 | -0,0001 |
| %010 = | 0,1031 | %0100+%0101= | 0,1031 | 0,0000 |
| %011= | 0,116 | %0110+%0111= | 0,116 | 0,0000 |
| %100 = | 0,116 | %1000+%1001= | 0,1159 | -0,0001 |
| %101= | 0,1031 | %1010+%1011= | 0,1031 | 0,0000 |
| %110 = | 0,1159 | %1100+%1101= | 0,116 | 0,0001 |
| %111= | 0,1652 | %1110+%1111= | 0,1651 | -0,0001 |
| %0000 = | 0,0977 | %00000+%00001= | 0,0977 | 0,0000 |
| %0001= | 0,0669 | %00010+%00011= | 0,0669 | 0,0000 |
| %0010= | 0,0556 | %00100+%00101= | 0,0556 | 0,0000 |
| %0011= | 0,0604 | %00110+%00111= | 0,0604 | 0,0000 |
| %0100 = | 0,0555 | %01000+%01001= | 0,0555 | 0,0000 |
| %0101= | 0,0476 | %01010+%01011= | 0,0476 | 0,0000 |
| %0110 = | 0,049 | %01100+%01101= | 0,049 | 0,0000 |
| %0111= | 0,067 | %01110+%01111= | 0,067 | 0,0000 |
| %1000 = | 0,0669 | %10000+%10001= | 0,0669 | 0,0000 |
| %1001= | 0,049 | %10010+%10011= | 0,0491 | 0,0001 |
| %1010 = | 0,0475 | %10100+%10101= | 0,0475 | 0,0000 |
| %1011= | 0,0556 | %10110+10111= | 0,0556 | 0,0000 |
| %1100 = | 0,0605 | %11000+%11001= | 0,0606 | 0,0001 |
| %1101= | 0,0555 | %11010+%11011= | 0,0555 | 0,0000 |
| %1110 = | 0,0669 | %11100+%11101= | 0,0669 | 0,0000 |
| %1111= | 0,0982 | %11110+%11111= | 0,0982 | 0,0000 |
These rules for the statistical organization of binary sequences (BG-numbers) of purines and pyrimidines of DNA, described using the example of the DNA of the first human chromosome, are also valid for all other binary sequences of purines and pyrimidines studied by the author in the genomic DNAs of higher and lower organisms: all 24 human chromosomes; all chromosomes of Drosophila, mouse, worm, many plants; 19 genomes of bacteria and archaea; many extremophiles, which lives in extreme conditions, such as radiation levels 1000 times lethal to humans [Petoukhov, 2023a,b; Petoukhov, He, 2023].
Thus, Jordan’s prediction about the existence of laws of life missed by science, which are the laws of probabilities of the quantum world, is confirmed. It also correlates with the statement by Schrödinger in his book “What is life? The physical aspect of the living cell”: “New laws to be expected in the organism. What I wish to make clear in this last chapter is, in short, that from all we have learned about the structure of living matter, we must be prepared to find it working in a manner that cannot be reduced to the ordinary laws of physics" [Schrodinger, 1955, Chapter 7]. The general genomic rules of probabilities in information sequences of genomic DNAs, presented in this article and other publications by the author, are candidates for the role of such laws [Petoukhov, 2022a,b, 2023a,b].
If, instead of the binary sequences of purines and pyrimidines, we turn to the binary sequences of keto-nucleotides (G, T) and amino-nucleotides (A, C) in genomic single-stranded DNAs, then they correspond to their own binary-genomic numbers, the statistical organization of which, as it turns out, subject to similar rules [Petoukhov, 2023b].
Let us show the connection of genomic probability vectors n from Table 8.2 with complete orthonormal systems of Walsh functions and with Hadamard matrices, which, as discussed above, are associated with the genetic coding system and Gray codes. We will talk about spectral (sequency) analysis of genomic probability vectors from Table 8.2. The action of the Hadamard matrices Hn on n-dimensional vectors, called the Hadamard transform, decomposes an arbitrary input vector into a superposition of Walsh functions, defining a vector Sn called the Hadamard spectrum of the input vector. In this spectrum, each Walsh function from the applied Hadamard matrix receives its own spectral coefficient. Using the condition Hn∙HnT = n∙E (here n is the order of the Hadamard matrix, T is the sign of transposition, E is the identity matrix), which is satisfied by the Hadamard matrices Hn, it is possible - by means of the action of the transposed matrix HnT on the spectrum vector - to obtain a vector which, when divided by n, exactly reproduces the original vector.
In some cases, the initial vector characterizing the system under study turns out to be such that its spectral vector contains a number of small, and therefore insignificant, spectral coefficients of some of the Walsh functions. Neglecting these small spectral coefficients (i.e., setting them to zero), a filtered Sn/f Hadamard spectrum is obtained, from which the original vector can be restored using the described procedure with a slight error. This slightly coarsened vector turns out to be sufficient in a number of cases for the analysis of the system under study. This procedure is called Walsh filtering or Walsh filter. For a genetic informatics, Walsh filters can be important.
Figure 8.3 shows the Hadamard matrices H2, H4, H8, H16, which we will use to show the connection between the genomic probability vectors n from Table 8.2 with the Walsh filters. The Walsh functions in shown matrices are ordered in ascending order of their sequency parameters. In the notation used here for each Walsh function w(k,n) that makes up a row of the Hadamard matrix, the value of the sequent k and the order n of the Walsh function are indicated in parentheses. For example, the notation w(3,8) refers to a Walsh function whose sequency parameter is 3 and whose order is 8 (the same as the order of the corresponding Hadamard matrix). Odd Walsh functions have an odd number in their sequency parameters in contrast to even Walsh functions having an even number in their sequency parameters.
Figure 8.3.
Hadamard matrices H2, H4, H8, H16, whose Walsh functions w(k,n) are ordered in ascending order of their sequency parameters. To the right of the matrices, indicated by bold boundaries, the Walsh functions corresponding to their rows are shown, indicating the sequency parameter k and the order n.
Figure 8.3.
Hadamard matrices H2, H4, H8, H16, whose Walsh functions w(k,n) are ordered in ascending order of their sequency parameters. To the right of the matrices, indicated by bold boundaries, the Walsh functions corresponding to their rows are shown, indicating the sequency parameter k and the order n.
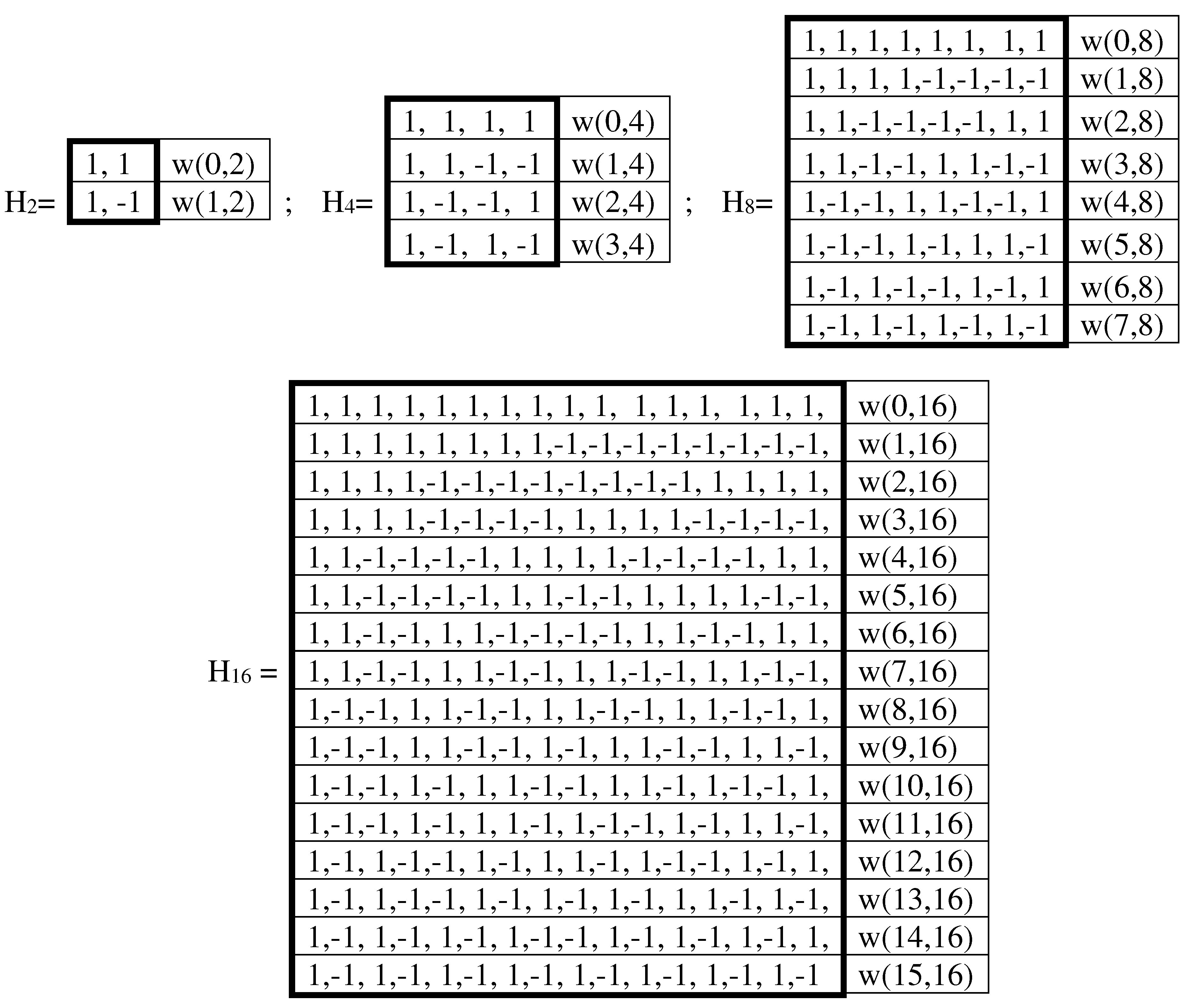
Let's take the first genomic probability vector 1 = [0.4997,0.5003] from Table 8.2 and act on it with the Hadamard matrix H2 from Figure 8.3. As a result, we obtain the Hadamard spectrum (8.1) of this vector 1:
In this spectrum, the coefficient -0.0006 of the Walsh function w(1,2), i.e. function with an odd sequency parameter, is practically equal to zero and can be neglected when forming the filtered Hadamard spectrum [1.0000, 0] for the vector . Thus, here the Walsh filter emphasizes the overwhelming significance of the even Walsh function w(0,2) with the even sequency parameter.
Let's take the second genomic probability vector 2 = [0.2807, 0.2191, 0.2190, 0.2812] from Table 8.2 and act on it with the Hadamard matrix H4 from Figure 8.3. As a result, we obtain the Hadamard spectrum of this vector 2:
In this spectrum, the coefficients -0.0004 and -0.0006 for the Walsh functions w(1,4) and w(3,4) with odd sequency parameters are practically equal to zero and can be neglected. Thus, here the Walsh filter again emphasizes the overwhelming significance of the Walsh functions precisely with the even sequency parameters w(0,1) and w(2,4) for the vector 2.
Let us take from Table 8.2 the third genomic probability vector 3= [0.1646, 0.1161, 0.1031, 0.1160, 0.1160, 0.1031, 0.1159, 0.1652] and act on it with the Hadamard matrix H8 from Figure 8.3. As a result, we obtain the Hadamard spectrum (8.3) of this vector 3:
The resulting Hadamard spectrum (8.3) of the vector 3 again shows the overwhelming significance of only even Walsh functions with even sequency parameters: w(0,8), w(2,8), w(4,8), and w(6,8).
Let us take from Table 8.2 the fourth genomic probability vector 4 = [0.0977, 0.0669, 0.0556, 0.0604, 0.0555, 0.0476, 0.0490, 0.0670 and act on it with the Hadamard matrix H16 from Figure 8.3. As a result, we obtain the Hadamard spectrum (8.4) of this vector 4:
The resulting Hadamard spectrum (8.4) of the vector 4 again shows the overwhelming significance of only even Walsh functions with even sequency parameters: w(0,16), w(2,16), w(4,16), w(6,16), w(8,16), w(10,16), w(12,16), w(14,16).
Thus, the statistical organization of super huge binary-genomic numbers is characterized not only by symmetries and dichotomous fractality, but also by conjugation with Walsh-Hadamard filters. Such translation of phenomenological data into the language of mathematical theories is an important part of mathematical natural science.
Some concluding remarks.
Many fundamental and applied problems of biology and medicine are associated with cyclical and biorhythmic phenomena characteristic of living matter at all levels of its organization. Cyclic changes and biorhythms have been given great importance since ancient times. One example is the ancient Chinese book “I-Ching” or “Book of Cyclic Changes,” written several thousand years ago and which had a strong influence on the medicine, worldview and culture of Ancient China and neighboring countries [Adler, 2022; https://en.wikipedia.org/wiki/I_Ching]. Nowadays, knowledge about biological cycles and rhythms is additionally in demand due to the emergence of new medical methods and the emergence of occupational diseases (for example, vibration disease), the development of biotechnology, etc. Knowledge of the principles of coding and operation of many interconnected cycles in the body can be useful for the development of biocomputing and new approaches to artificial intelligence.
According to the author, knowledge of these principles is also useful for understanding the deep structural and mathematical connection between objects from different fields of science and art, which is the subject of the famous book by Nobel laureate G. Hesse “The Glass Bead Game” [Hesse, 1975]. This book talks about the art of composing metatext, the synthesis of all branches of art into one, universal art. We are talking, first of all, about the connection between music and mathematics and about the time when musical processes began to be expressed by physical and mathematical formulas. The algebraic-logical theory of genetic coding of ensembles of biological cycles, whose elements are presented in this article, seems to be useful for developing the ideas of Hesse’s book on the search for metatexts for the analysis and synthesis of musical and other works in connection with the conviction of many musicians and thinkers about the connection between music and mathematics.
It should be added that since the philosophical works of Martin Heidegger, there exists an idea that language is smarter than us. A rich language has an extensive history of development and effective application to reality. Using this or that language, we indirectly use all experience of its formation and applications to reality. As soon as the language is smarter than us, then a good language can guide us, suggesting new solutions and directions of search. In his study of coded cyclic bioprocesses, the author of this article uses for such guide of the well-developed and widely used scientific language of the theories of Gray codes, Karnaugh maps and mathematical constructions, interconnected with them. In other words, the author translates genetic structures and cyclic bio-phenomena into this algebraic-logical language with final receiving new meanings and regularities to which this language guide.
Appendix A. Regarding Gray codes
A binary Gray code of order n in its narrow sense, which is frequently used, is a sequence of 2n n-bit numbers in which any two adjacent numbers differ by exactly one digit including the same difference between its last and its first numbers, which are interpreted as adjacent numbers as well (the Hamming distance between them is 1). A Gray code of order n represents each number in the sequence of decimal integers {0...2n-1} as a binary string (or a binary word) of length n in an order such that adjacent integers have Gray code representations that differ in only one bit position. Marching through the integer sequence therefore requires flipping just one bit at a time. Some call this defining property of Gray codes the "adjacency property" [Goldberg, 1989]. Numbers in the Gray code are fundamentally different from binary numbers, although they also consist of a sequence of 0 and 1. For example, the decimal number 3 in binary notation is 011, but in Gray code it is 010 (Figure A1). Binary numbers and Gray code numbers can be converted algorithmically to each other. Figure A1 shows a comparison of binary representations of decimal numbers in cases of 3-bit binary numbers and members of the 3-bit Gray code.
Figure A1.
The comparison of representations of decimal numbers 0, 1, …, 7 in forms of 3-bit binary numbers and of Gray code numbers.
Figure A1.
The comparison of representations of decimal numbers 0, 1, …, 7 in forms of 3-bit binary numbers and of Gray code numbers.
A Gray code is a cyclic code since the circular shifts of each codeword gives another word that belongs to the code. Gray codes for 4 or more bits are not unique, even allowing for permutation or inversion of bits. The most typical kind of Gray code utilized in digital systems is the symmetrically reflected Gray code. This name is due to the following algorithm for constructing a hierarchy of such reflected n-bit Gray codes. Let Gn be the sequence of members of the n-bit Gray code, and the sequence GnR has the reverse order of the sequence Gn. Then the sequence Gn+1 of reflected (n+1)-bit Gray code is obtained by assigning 0 on the left to each member in the sequence Gn and 1 on the left to each member of the sequence GnR with combining them in a final step. For example, for n = 2 we have Gn: 00, 01, 11, 10; GnR: 10, 11, 01, 00. After the indicated assignment of 0 on the left to the members of Gn and 1 on the left to the members of GnR, we obtain 3-bit sequences 000, 001, 011, 010 and 110, 111, 101, 100. Combining these two sequences we obtain the reflected 3-bit Gray code G3: 000, 001, 011, 010, 110, 111, 101, 100. If you do not pay attention to the first bit in members of the resulting 3-bit Gray code, then its left and right halves are mirror symmetrical each to another. There is an online calculator of reflected n-bit Gray codes up to the value n=16 on the Internet (https://planetcalc.ru/8648/). An n-bit Gray code corresponds to a Hamiltonian cycle on an n-dimensional hypercube.
Gray codes are widely used in engineering technologies: rotary and optical encoders including encoding of track numbers on hard drives; error detection; Karnaugh maps connecting with Boolean functions and logic operations; theory of genetic algorithms; etc. Many literary sources, conferences, and Internet web-sites are devoted to Gray codes and their applications.
In this article, we consider Gray codes in an expanded sense as sequences of n-bit codewords (or binary strings), in which any two adjacent codewords differ by exactly one digit including the same difference between its last and its first codewords, which are interpreted as adjacent codewords as well (the Hamming distance between them is 1). In this approach, cyclic sequences in Gray codes can be considered in many cases as hypercycles, which contain inside them cyclic subsequences of Gray codewords (or cropped cyclic Gray codes). For example, the 3-bit Gray code 000, 001, 011, 010, 110, 111, 101, 100 contains cyclic subsequences, each of which can be considered as cyclic Gray code in the wide sense:
- -
- any pair of adjacent codewords in this cyclic sequence of 8 codewords is a separate cyclic subsequence (for example, 000, 001 or 010, 110);
- -
- the first quadruple of codewords (000, 001, 011, 010) is a cyclic subsequence with unit Hamming distance between adjacent terms. The same is true for the subsequence of final four codewords (110, 111, 101, 100);
- -
- symmetrical cropping of the same number of codewords from both ends of a Gray codeword sequence generates a cyclic subsequence (for example, by removing one term from both ends of the sequence under consideration, we obtain a cyclic subsequence 001, 011, 010, 110, 111, 101, and by removing 2 terms from both ends, we obtain another cyclic subsequence 011, 010, 110, 111).
Each of these subsequences, being a cyclic Gray code in the extended sense, can serve as the basis for generating Gray codes of increased bit depth using the algorithm described above concerning a construction of symmetrically reflected Gray code. For example, by means of this algorithm, the cyclic subsequence of 3-bit codewords 000, 001 generates the cyclic sequence of 4-bit codewords 0000, 0001, 1001, 1000 which produces by the same algorithm the cyclic sequence of 5-bit codewords 00000, 00001, 01001, 01000, 11000, 11001, 10001, 10000, and so on. This property of cyclic Gray codes, which are considered in a broad sense, can be called the property of regenerating multi-bit families of Gray codes from cropped (fragmented) Gray codes. The regeneration property of Gray code families evokes associations with the well-known regenerative and holographic properties of living organisms, described, for example, in the works of [Belousov, 2015; Pribram, 1998; Petoukhov, 2022a]. For example, as is known in embryology, by separating the blastomeres of sea urchin eggs from each other, it is possible to grow normal (albeit reduced) larvae with all their organs from one embryonic cell (blastomere). Such “holographic” phenomena of distributed information have been repeatedly confirmed in many taxonomic groups of multicellular organisms - from sponges to mammals.
Appendix B. Regarding dyadic-shift decompositions of matrices
For special decompositions of genetic matrices we will use structures of matrices of dyadic shifts long known in theory of discrete signal processing, sequency theory by Harmuth, etc. [Ahmed, Rao, 1975; Harmuth, 1977, §1.2.6]. These matrices are constructed on the basis of mathematical operation of modulo-2 addition for binary numbers (see example in Figure A2). Modulo-2 addition is utilized broadly in the theory of discrete signal processing as a fundamental operation for binary variables. By definition, the modulo-2 addition of two numbers written in binary notation is made in a bitwise manner in accordance with the following rules: 0 + 0 = 0, 0 + 1 = 1, 1+ 0 = 1, 1+ 1 = 0 (1) For example, modulo-2 addition of two binary numbers 110 and 101, which are equal to 6 and 5 respectively in decimal notation, gives the result 110 ⊕ 101 = 011, which is equal to 3 in decimal notation (⊕ is the symbol for modulo-2 addition). The set of binary numbers 000, 001, 010, 011, 100, 101, 110, 111 (2) forms a dyadic group, in which modulo-2 addition serves as the group operation [Harmuth, 1989]. The distance in this symmetry group is known as the Hamming distance. Since the Hamming distance satisfies the conditions of a metric group, the diadic group is a metric group. The modulo-2 addition of any two binary numbers from (2) always results in a new number from the same series. The number 000 serves as the unit element of this group: for example, 010 ⊕ 000 = 010. The reverse element for any number in this group is the number itself: for example, 010 ⊕ 010 = 000. The series (2) is transformed by modulo-2 addition with the binary number 001 into a new series of the same numbers: 001, 000, 011, 010, 101, 100, 111, 110 (3) Such changes in the initial binary sequence, produced by modulo-2 addition of its members with any binary numbers (2), are termed dyadic shifts [Ahmed and Rao, 1975; Harmuth, 1989]. If any system of elements demonstrates its connection with dyadic shifts, it indicates that the structural organization of its system is related to the logic of modulo-2 addition. The article shows that the structural organization of genetic systems is related to logic of modulo-2 addition.
Figure A2 shows an example of a (4x4)-matrix of dyadic shifts whose rows and columns are numerated in accordance with sequence of codewords of the 2-bit Gray code. Each matrix cell contains a result of modulo-2 addition of numberings of its row and column. One can see that all 16 cells of such matrix bear only 4 kinds of binary numbers 00, 01, 11, 10 (four pieces each), which serve in 2-bit Gray code as its codewords. Dyadic shift decompositions of dyadic shift matrices, which are used in this article (Figures 3.3, 3.5–3.8, 3.12 and 6.3), are constructed in accordance with arrangement of such identical codewords inside the considered matrix.
Figure A2.
An example of a matrix of dyadic shifts.
Acknowledgments
Some results of this paper have been possible due to long-term cooperation between Russian and Hungarian Academies of Sciences on the theme “Non-linear models and symmetrologic analysis in biomechanics, bioinformatics, and the theory of self-organizing systems”, where the author was a scientific chief from the Russian Academy of Sciences. The author is grateful to G. Darvas, E. Fimmel, A.A. Koblyakov, S.Ya. Kotkovsky, M. He, Z.B. Hu, Yu.I. Manin, V. Rosenfeld, I.V. Stepanyan, V.I. Svirin, and G.K. Tolokonnikov for their collaboration. The work was carried out within the framework of the State assignment, scientific topic code FFGU-2024-0019.
References
- Adler J.A. The Yijing: A Guide. New York: Oxford University Press. 2022.
- Ahmed N., Rao K. Orthogonal transforms for digital signal processing. - New-York: Springer-Verlag Inc., 1975.
- Beletsky A.Ya. Combinatorics of Gray codes. − K.: KVITs, 2003. 506 p. (in Russian).
- Beloussov L.V. Morphomechanics of Development. - Springer International Publishing Switzerland, New York, USA, 2015.
- Boole G. An Investigation of the Laws of Thought on Which are Founded the Mathematical Theories of Logic and Probabilities. Macmillan. Dover Publications, New York, NY (reissued by Cambridge University Press, 2009, ISBN 978-1-108-00153-3).
- Brown F.M. Boolean Reasoning - The Logic of Boolean Equations (reissue of 2nd ed.). Mineola, New York, 2012: Dover Publications Inc., ISBN 978-0-486-42785-0.
- Chapeville F., Haenni A.L. Biosynthese des proteins. - Hermann Collection, Paris Methodes, 1974 (in French).
- Cohn M. Walsh Functions, Sequency, and Gray Codes. - SIAM Journal on Applied Mathematics, vol. 21, no. 3, 1971, pp. 442–47. JSTOR, http://www.jstor.org/stable/2099589. Accessed 28 Jan. 2024.
- Dodge N.B. (September 2015). Simplifying Logic Circuits with Karnaugh maps. – The University of Texas at Dallas, Erik Jonsson School of Engineering and Computer Science. September 2015.
- Doran R.W. The Gray code. - Journal of Universal Computer Science, vol. 13, no. 11, 2007, pp.1573-1597, https://www.jucs.org/jucs_13_11/the_gray_code/jucs_13_11_1573_1597_doran.pdf.
- Eigen M., Schuster P. The hypercycle. A principle of natural self-organization. Part A: Emergence of the hypercycle. - Naturwissenschaften, 1977, Vol. 64, pp. 541–565. [CrossRef]
- Fimmel E., Strüngmann L. Yury Borisovich Rumer and his ‘biological papers’ on the genetic code. Phil. Trans. R. Soc. A, 374: 20150228 (2016). [CrossRef]
- Frank-Kamenetskii M. D. The most important molecule. // Moscow, Nauka, 1988 (in Russian).
- Goldberg D.E. Genetic Algorithms in Search, Optimization, and Machine Learning (Addison-Wesley, Reading, MA, 1989.
- Gurvich A.G. Selected works. Moscow, Medicine, 1977.
- Harmuth H.F. Transmission of Information by Orthogonal Functions . 2nd ed. Berlin, Springer-Verlag, 1972, XXII + 392 p.
- Harmuth H.F. Sequency Theory: Foundations and Applications, Academic Press, 1977. Harmuth H.F. Information theory applied to space-time physics.- Washington: The Catholic University of America, D. C., 1989.
- Hesse H. The Glass Bead Game. – Penguin, Hammondsworth, 1975.
- Kaczmarek L.K., Levitan I.B. Neuromodulation: The Biochemical Control of Neuronal. – Oxford University Press, 1987.
- Karzel H., Kist G. Kinematic Algebras and their Geometries. In: Rings and Geometry, eds. R. Kaya, P. Plaumann, and K. Strambach, pp. 437–509, 1985.
- Kostrov B.V.Theory and methodology of applying sequency analysis for aerospace image processing. - Dissertation of doctor of technical sciences. Ryazan. Ryazan State Radio Engineering University, 2012 (in Russian).
- Lega Yu.G., Lukashenko V.M., Lukashenko A.G. , Lukashenko M.G. , Korpan Y.V. Gray code to Walsh function converter. - Proceedings of the Sixteenth International scientific and technical conference “Sensor-2004”, Sudak, January 2004, p. 199, file:///C:/Users/User/Downloads/Korpan_1.pdf. [CrossRef]
- Lieberman-Aiden E., van Berkum N.L., Williams L., Imakaev M., Ragoczy T., Telling A., Amit I., Lajoie B.R., Sabo P.J., Dorschner M.O., et al. Comprehensive mapping of longrange interactions reveals folding principles of the human genome, Science, 326, 289, 2009. [CrossRef]
- Liberman E.A., Minina S.V. Cell molecular computers and biological information as the foundation of nature’s laws. - Biosystems, 38, p. 173-177, 1996. [CrossRef]
- Liberman E.A., Minina S.V., Shklovskii-Kordi N.E. Problems combining biology, physics, and mathematics. Ideas of the new science. - Biophysics, v. 46, № 4. С. 767 (2001)].
- Martini F.H. Anatomy and Physiology. - New York: Prentice Hall, 2005. https://en.wikipedia.org/wiki/All-or-none_law.
- McFadden J., Al-Khalili J. The origins of quantum biology. - Proceedings of the Royal Society A, 2018, Vol. 474, Issue 2220, pp. 1-13. [CrossRef]
- Morita Y., Sakurai Y. Holography by Walsh Waves. – Proceedings of the Symposium (4th) Held at the Catholic University of America, Washington, D. C. on 16-18 April, 1973, pp. 122-126.
- Nazarov L.I. Statistical theory of chromatin structure. Dissertation of a candidate of physical and mathematical sciences. Faculty of Physics, Moscow State University, 2017, 107 p. file:///C:/Users/User/Downloads/DissertatsiyaNazarov.PDF.
- Petoukhov S.V. Non-Euclidean geometries and algorithms of living bodies, Computers & Mathematics with Applications, 1989, v.17, № 4-6, pp. 505-534. [CrossRef]
- Petoukhov S.V. Binary oppositions, algebraic holography, and stochastic rules in genetic informatics. – Biosystems, vol. 221, 104760, 2022a. [CrossRef]
- Petoukhov S.V. The stochastic organization of genomes and the doctrine of energy-information evolution based on bio-antenna arrays. - Biosystems, 2022b, 104712, ISSN 0303-2647. [CrossRef]
- Petoukhov S.V. The principle “like begets like” in algebra-matrix genetics and code biology. Biosystems, 2023a, 233 105019. [CrossRef]
- Petoukhov S.V. The Principle “Like Begets Like” in Molecular and Algebraic-Matrix Genetics. Preprints 2022, 2022110528. Version 3, 2023b. [CrossRef]
- Petoukhov S.V., He M. Algebraic biology, matrix genetics, and genetic intelligence. - Singapore, World Scientific, 2023, 616 p. [CrossRef]
- Pribram K. The holographic brain. – 1998, https://web.archive.org/web/20060518075852/http://homepages.ihug.co.nz/~sai/pribram.htm.
- Rumer Yu.B. Codon systematization in the genetic code. Doklady Akademii Nauk SSSR, 183(1), p. 225-226, 1968.
- Schrodinger E. What is life? The physical aspect of the living cell, (Cambridge University Press), 1955.
- Soroko L.M. Walsh functions in physics and engineering. - Uspekhi Fizicheskih Nauk, 1973, v.111, issue 3, pp. 561-563.
- Soroko L.M. The sequency analysis in engineering and physics. - Uspekhi Fizicheskih Nauk, 1979, v. 129, issue 10, pp. 355-357.
- Yuen C. Walsh Functions and Gray Code. - in IEEE Transactions on Electromagnetic Compatibility, vol. EMC-13, no. 3, pp. 68-73, Aug. 1971. [CrossRef]
- Zzeng. About the geometric meaning of Gray codes. 2020. https://habr.com/ru/articles/484532/.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



