Submitted:
15 February 2024
Posted:
16 February 2024
You are already at the latest version
Abstract
This dossier is aimed at individuals involved in the development, implementation, and application of AI-supported systems in the field of education, particularly those who are dealing with metadata in this context. The insights and recommendations described in this dossier are based on interviews with five experts from the USA and UK, research on metadata standards, and our personal experiences in the context of the INVITE competition. This dossier provides an overview of the current development of learning metadata and existing standards. It shows the efforts and obstacles to introducing those metadata standards from an international perspective based on interviews with five experts in the field. Furthermore, this dossier shows the international experiences in selecting and using metadata standards and how these findings can inspire discussions in the German-speaking discourse regarding the use of metadata in education.
Keywords:
Educational Metadata
; Learning Object Metadata
; Metadata standards
; Educational Metadata Standards
; Educational Technology
1. Introduction
Metadata play an important role in the consistent organization and description of educational resources for effective management, discoverability, and interoperability of learning content – both within and across digital learning environments. For example, metadata can be used to describe learning opportunities (e.g., a course, a video, a quiz), learners (e.g., knowledge, interests, subject), or digital credentials (e.g., date of issue, completed course, validity).
Even though metadata can facilitate the correct allocation of learning resources and the retrieval of available data, we observe some reluctance to thoroughly use metadata for digital learning contexts. First of all, filling, storing, and maintaining descriptive metadata for educational offers, competence requirements, and learner profiles as well as educational certificates is an awful lot of work. Second, one feels a bit lost when it comes to a generally accepted format for the respective metadata – there is simply no gold standard, but many different solutions (William and Barbosa 2020).
In the publishing business an international agreement on the use of specific metadata standards has been found and is familiar even to the general public, e.g., the existence of the ISBN, the “International Standard Book Number”. This number is related to exactly one publication and facilitates book finding processes worldwide. But why is defining and agreeing on a metadata standard in the educational context still out of reach – both within and across countries? The German research programme INVITE1 aims at developing different digital learning solutions for the field of vocational training, including e.g., adaptive learning platforms, conversational learning agents, and learning analytics dashboards. By their nature, these technologies require different data fields to describe, e.g., the learning resources and learners to successfully recommend matching learning resources or predict the learner’s behavior.
Three workshops were held in spring 2023 to discuss with selected INVITE projects which metadata standards they use for which work areas of their digital learning systems (Goertz, et al. 2023). It became apparent that there is no “one-size-fits-all” metadata standard for all learning situations. For each sub-process, different metadata standards are used. Among the standards used most frequently are ESCO, xAPI, and LOMS.
These results gave a good overview of which metadata standards are used within innovative German learning systems in the field of vocational training. However, since there remain manifold problems with the chosen standards, the wish to examine the international situation was expressed.
1.1. Why It Is Worthwhile to Look Abroad
Educational practices and systems vary widely across countries due to a combination of cultural, social, political, and technological factors. Each country may have its unique approach to organizing, describing, and sharing educational resources and offers through metadata. In other countries like USA or UK, some important progresses in this field have been made and there are new ways to tag resources with keywords or subject terms, or new approaches to represent the educational level or cultural context of resources. That is the reason that our study focusses on experts in these countries.
The use of metadata in digital learning systems in Germany presents several challenges, including the lack of standardized practices, integration complexities with legacy systems, and interoperability issues among various platforms. Addressing these challenges requires collaboration and an overview of how the international community is dealing with the issue of metadata. Our objective is to learn from the experts in the domain of education to identify good practices that can be used as examples in the INVITE competition projects. Metadata standards that are widely adopted and understood across countries can help to ensure that educational resources can be discovered, accessed, and used by learners and educators from different contexts. In addition, looking abroad for metadata implementations and standards can help to promote interoperability and sharing of educational resources among projects.
1.2. Research Questions
The goal of our study is to collect experiences and “best practices” from an international perspective. Mainly we want to know about experiences concerning choosing, implementing, and using metadata for learning courses or learning materials that are offered as part of the learning platform. For example, we are interested to know,
- what functions do experts seek to offer/fulfil with the help of metadata?
- how do they get the correct information to fill in the metadata fields?
- what problems do they encounter with their metadata system, and how they are seeking to solve these problems?
- did they use or consider metadata standards and for what reason?
To address these and other questions, an interview guideline is used. The questions are focused on collecting insight on the “practical implementations” as well as the use of “metadata standards” for learning resources in both the US and UK (see Appendix A).
1.3. The Method – Guided Interviews with International Experts
1.3.1. Procedure
This study is based on guided expert interviews, reviews of metadata standards, and best practices established internationally in education and vocational training. The focus of the interviews is to gain an overview of what metadata is assigned to learning opportunities in the US and UK to understand the issues that arise when using and populating metadata fields and to investigate to what extent standards for metadata are already being used.
To account for the exploratory and multidimensional character of our questions, we have chosen expert interviews as the main method of our study. For this study it is important to collect in-depth reasoning for decisions around the topic of metadata from people with different characteristics and opinions. The respondents should have the opportunity to address as many aspects as possible.
Experts were searched by looking at various educational service platforms, technology firms, LinkedIn profiles, and educational standard development organizations. The experts were contacted with a request for an interview study. Five interviews were finalized from twenty experts contacted for the interview.
Interviews were conducted in English and online via Microsoft Teams. The audio data was transcribed for further analysis. Transcripts were analyzed by identifying common themes or key points. Extracted information was then categorized, and discrepancies between experts were noted for contrasting points of views.
1.3.2. Sample: Five Experts
We interviewed five experts (3 males and 2 females). Four experts were from the USA and one from the UK. The experts have either experience in developing educational and learning technologies or are affiliated with organizations dealing with primary to higher education and corporate training sectors. All experts have advanced international experience with different types of learning technologies and standards. The experts have been involved with the topic of metadata for educational resources both from a technical and research point of view. They have a focus on how metadata can be used for the discovery and recommendation of educational resources more efficiently and accurately. The experts from the USA will be referred to as E-USA1 to E-USA4, and the expert from the UK will be referred to as E-UK in the document.
2. Interview Results
This section discusses how experts are using metadata in their educational applications. We use the opportunity to introduce some basic knowledge about learning metadata, partly derived from the interviews in the form of questions – illustrated by quotes from the interviewed experts.
The interview questions are divided into four sections: Section 1 collects information about the experts and the learning platforms, Section 2 captures practical implementation or usage of metadata in the educational context, and Section 3 wraps up the discussion while getting the general opinion of the experts.
2.1. Practical Usage of Metadata - Why Experts Use Metadata and How
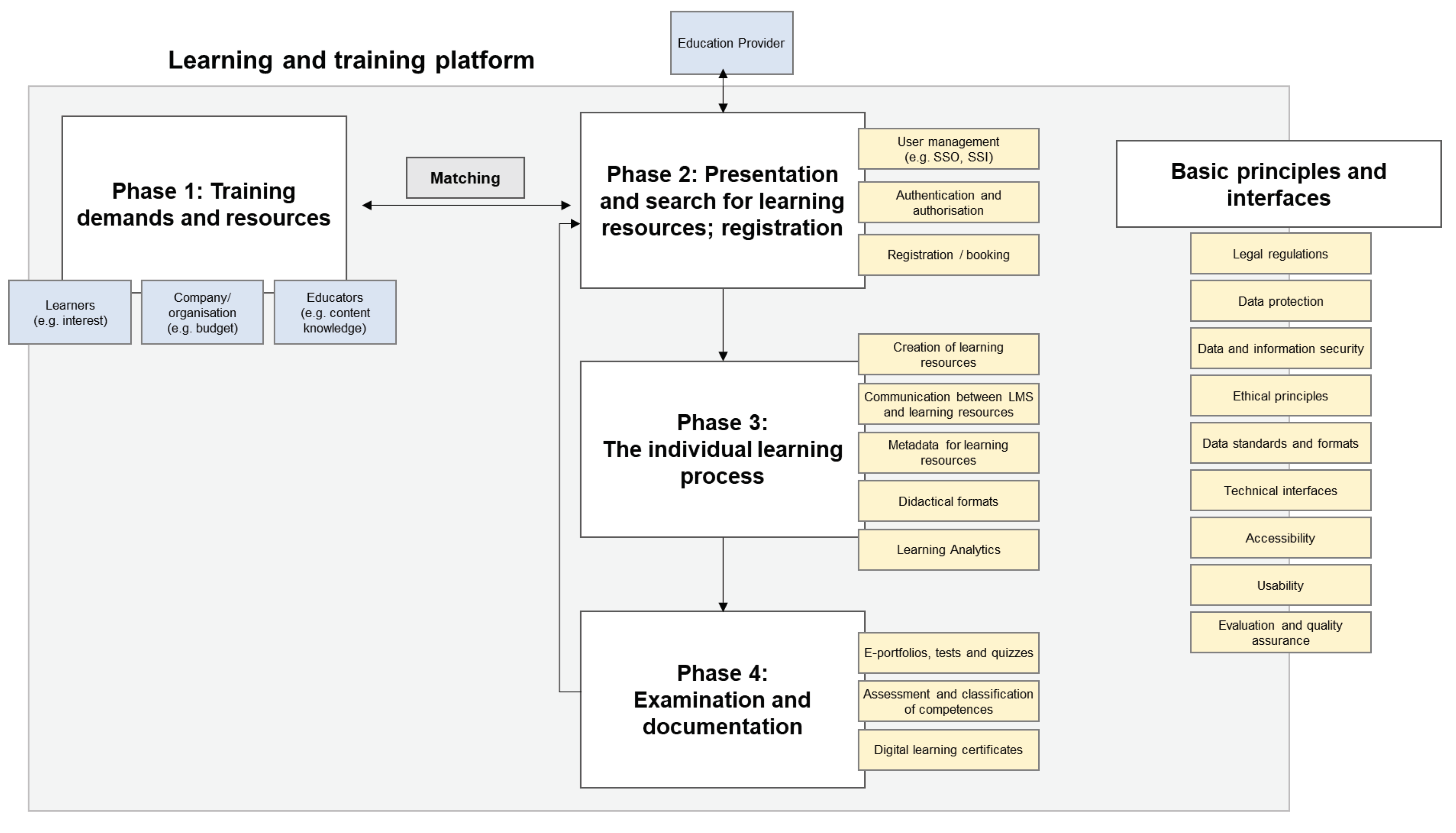
The digital learning process can be divided into four phases (Reichow et al. 2021) as shown in Figure 1. We asked experts in which phase they used the metadata and for what purpose? All experts agreed that metadata is eventually required for all these phases, however, four experts specifically used metadata for phase 2, three experts mentioned using metadata in phases 1 and 4, and two experts used metadata in phase 3.
What functions do the experts seek to fulfill with the help of metadata?
Experts mentioned the following uses of metadata in the educational context:
- Searching the educational content or offers
- Recommendation of educational content or offers
- Describing competencies or learning objectives
- Manifesting features for AI based educational technologies like intelligent tutoring or personalized learning
One of the crucial functions of metadata is providing descriptive information that helps users find relevant resources more efficiently. It also helps in the reuse of learning resources. To find things more easily, some experts mentioned the importance of “context”.


The context can be added to metadata with the help of ontologies2 by providing a structured framework for representing and organizing knowledge about a specific domain. Ontologies define concepts, relationships, and properties within a domain, allowing for more precise and meaningful metadata representation.
Another important use of metadata is in recommending learning content to provide personalized and relevant suggestions to learners based on their interests, preferences, and learning goals (Reichow et al. 2022; Drachsler et al. 2015). Metadata associated with user profiles, course attributes, learner feedback and ratings, and contextual factors, can be used to recommend learning content at the time of need. For example, metadata related to learning pathways can be used to suggest a structured learning path to learners, ensuring their progress through courses in a meaningful and cohesive manner, e.g., from beginner to advanced levels. By utilizing metadata, the course recommendation system can generate personalized and relevant suggestions to learners, helping them discover courses that match their interests, level of expertise, and learning objectives.
In the mature phase of recommendation, one of the experts (E-USA2) envisioned the implicit recommendation of educational content at the point of need. This can be achieved based on the learning experience and with the help of a lot of metadata as suggested by the expert.

Another direction where we need metadata is to describe “competencies”, also called “competency frameworks”. These are the “expectations” or “learning objectives” (the taxonomy of what one should learn). For example, if developing a curriculum or course, a student should show these “competencies” or “master these skills” after the course. Associating competency metadata with learning resources enables learners and organizations to identify the most relevant resources for developing and accessing specific competencies (competency-based search). E-USA3 mentioned the use of competencies from “Open Competency Framework Collaboration OCFC”3, which is a domestically focused organization, but the standards defined can be used internationally. The expert also emphasised the use of metadata for manifesting the features to develop AI based educational systems like intelligent tutoring systems or personalized learning systems.
Which metadata fields do experts use for the description of learning materials or course offers on their platform?
Various metadata fields are collectively used to describe learning contents or course offerings like title, subject, and author information, etc. These fields provide a set of information to help learners, educators, and administrators organize and utilize learning materials effectively. However, finding an optimal set of metadata fields catering to the diverse usage of metadata in the educational setting is a challenging task.
E-USA1 described using the fields proposed by the IEEE-P2881 Learning metadata standard. A brief description of the standard is provided in Appendix B. The standard is recently available with an open-source license. Further details and description of the metadata schema are available as an open-source standard by IEEE4.
E-USA3 and E-UK mentioned using the LRMI standard for the description of learning material and course offers. E-UK also spoke about the CTDL standard for describing competencies and skills.
E-USA4 discussed the use of some metadata fields such as “study type”, “subject matter”, “course level”, “discipline”, “subject” (in a discipline), “topic”, and “learning outcome”. In addition, the expert also used tags to describe “language”, “accessibility level”, “authoring information”, “course number”, and “additional keywords” (if additional information needs to be added that can help like Bloom’s level for the resource).
E-USA2 mentioned to use fields like “topic”, “format”, “organization”, “source” etc. Additionally, the expert emphasized to include fields to capture the following information:
- Type of the learning object (a PowerPoint presentation, an eLearning module, a manual, or a procedure for the headset display, etc.).
- Compliance-related aspects of the object e.g., Google compliance.
- Access rights and privacy, who has the right to see it?
- Ownership, lifecycle, and maintenance: who is the owner of the things, what is the approval process, and who approves it? What is the retention policy? When will the resource expire? How often do we maintain it, and who is responsible for the maintenance?
- Sequences, if there is a particular sequence. Where is the object positioned in the sequence? Should the user have seen another object before seeing this object?
- Geography, important in some cases where different legal requirements may arise for different geographical locations.
- Version/Change, helpful in the search for a finished product that is changed, there may be a need to reference back to the base product.
- Tracking Information, metadata after publishing the objects for tracking.
Metadata recording formats and authoring tools
We also asked experts about how they get the correct information for the metadata fields, their preferred tools/languages to store that information, and whether are they using any metadata authoring tool. Mostly the metadata fields are filled manually by content providers and here lots of problems can occur. Therefore, experts were also seeking to fill the metadata fields automatically with the help of artificial intelligence or other techniques. Mostly the metadata are being stored using XML5, RDF6, JSON7, and JSON-LD8 machine readable formats. Some of the experts provided information about metadata authoring tools which are listed below.
- LearningMate Frost: https://learningmate.com/frost/
- Xyleme: https://xyleme.com/
- Dominknow: https://www.dominknow.com/
Coping with problems in using metadata
As we can see using metadata provides a lot of benefits when implemented in a learning platform. However, there are a few challenges that were mentioned by the experts.
One major problem is how to get complete and accurate information for the metadata fields, Mostly, this is done manually where people fill in the metadata fields using existing information/domain knowledge of the learning resource. However, this manual effort is not favorable as mentioned by experts. First, it is required to equip people with a certain level of knowledge about the learning resources so that they can provide relevant and correct data to the metadata fields. In most cases, the data also needs to be consistent.
Second, the process is very time-consuming. Motivating people to fill all the relevant fields is a difficult task. E.g. “even though the expert thought that a metadata framework like SCORM is very robust and easy to adopt, individuals assigned to fill the fields do it with only minimal effort such that the results are not very useful.” Third, how to verify that the provided content is of high data quality? Has it been tagged accurately? To overcome these issues, experts stated that we need to train people to understand the importance and content of a taxonomy or a metadata field. Alternately, it is better employing the subject matter experts or teachers to tag their own resources to avoid inaccurate entries. Another approach could be to write metadata before the development of the actual learning resource including all the required information.
Automation techniques such as natural language processing (NLP) or AI algorithms can also help to streamline the process. Machine learning (ML) algorithms can be used to develop fully automated or semi-automated solutions for generating “data” for metadata fields from the learning resources. However, this could be challenging to ensure the quality of the tagging. AI may be good in extracting data but interpreting the meaning or context could be problematic. The problem can be solved using a human-machine collaborative form, where machines should suggest tags for the fields and humans just need to validate or interpret it if required. The AI-system has the role of an assistant service. Alternatively, aside from relying on AI or ML for metadata enrichment, an alternative approach is facilitating direct communication between two databases.
Another issue faced by the experts in their application scenarios is the use of non-standard metadata that causes the issue of interoperability of the system to another learning domain or partners, as people may use different metadata schemas for recording metadata. Ideally, common metadata fields should prevail, ensuring seamless transformation. However, executing such transformations can pose significant challenges. A solution lies in using standardized metadata schemas as well as standards to fill the metadata fields. Sometimes there is a problem in using fixed metadata schemas when switching from one domain to another. For example, one might not have a “level of organization” for middle school, but it may exist for higher education, so it needs to be added into the system at some point.
User Interface is another issue. What user interface on the screen is good to fill the metadata fields efficiently? There are various options, e. g. free text, fixed list items to the excel worksheets. If a lot of free text to be filled which is difficult, and people did not fill it out most of the time. A fixed list is also problematic, it is not dynamic and cannot be changed and if you change you need to retag everything.
2.2. Metadata Standards – for What Purposes do Experts Use Them
To date, several learning metadata standards exist that can facilitate educational institutions, content creators, and learners in various phases of digital learning or education process. For example, IEEE Standard for Learning Object Metadata (LOM) and Dublin Core metadata standards have been in practice from the last few decades for the description and presentation of learning resources (Barker and Campbell 2010). A brief description of metadata standards discussed by experts is given in Appendix B.
E-USA1 discussed the use of Dublin Core and LOM standards as well as others in the development of new IEEE standard P2881-Learning Metadata Terms (LTM). LTM is extensively derived from Dublin Core, Learning Resource Metadata Initiative (LRMI), Credential Transparency Description Language (CTDL), and Schema.org with an objective to bridge different communities and standards, to serve as a common, shared vocabulary for describing various digital objects related to learning and teaching.
E-USA3 also talked about LRMI, Dublin Core, Schema.org as the same family of standards. The expert mentioned the use of SCORM for content management and the use of xAPI for the representation of learning activities. The major weakness of xAPI is that it offers a standard for communicating activities but does not provide a schema for describing these activities.
E-UK revealed the use of LRMI and CTDL standards. The LRMI allows us to describe the educationally significant characteristics and relationships of a resource. E.g. it allows us to describe the relationship of resources to competencies (teaches a particular competency or assesses a particular competency), the nature of resources such as whether it is an instructional video or a textbook, etc. It also encompasses details like the typical learning time, and target audience (which may differ from the ultimate beneficiaries). The LRMI can be used in recommender systems, allowing for more personalized and effective resource recommendations based on specific user preferences and needs.
The CTDL serves a multifaceted purpose. It enables the recording of skills required for a degree, details on how these skills are assessed, the relevance of the degree to specific occupations, the institution where the degree was pursued, and the duration of the study. Additionally, it is employed for describing the credentials themselves, the organizations offering the competencies, the assessment procedures, available programs and courses, pathways within a program, and aspects like micro-credentialing and badges. This allows for the development of pathways from one credential or badge to another, including stackable credentials that lead to larger qualifications, and considerations such as credit accumulation and credit transfer.
In addition, experts also talked about various learning standards and international standard development activities. Notable resources include:
-
IEEE Learning Technology Standards Committee: https://sagroups.ieee.org/ltsc/
- ○
- The work includes SCORM, xAPI, Competency Data Standards, and more.
- ○
- P2881 Standard for Learning Metadata working group. This is the continuing work from the original LOM: https://sagroups.ieee.org/2881/
- T3 Innovation Network Open Competency Framework Collaborative (OCFC) https://www.t3networkhub.org/networks/ocn
- 1EdTech (formerly IMS Global) CASE Network: https://www.imsglobal.org/casenetwork
- Achievement Standards Network (ASN): http://www.achievementstandards.org/
- Common Education Data Standards (CEDS): https://ceds.ed.gov/
- EdMatrix directory of learning data standards: https://EdMatrix.org
2.3. What Experts Think about Metadata Standards in General
In general metadata standards in education and learning ensure a wide range of benefits. They provide a consistent and structured way to describe and organize educational resources that make searching the relevant educational resources easier and quicker for educators and learners. Adopting standardized metadata ensures that different learning systems, platforms, and tools can communicate and exchange data seamlessly.
However, finding relevant standards that enable the integration of diverse resources and technologies, creating a cohesive learning experience is still problematic. There are several standards and selecting a specific standard may require a significant effort. Experts have different opinions about why there are so many metadata standards. According to experts, the reason for having so many standards could be:
- Different application scenarios have different requirements for metadata, which can lead to the development of multiple standards that are tailored to specific needs.
- Another reason for the proliferation of metadata standards is that different organizations working simultaneously come in similar time frame but slightly different priorities and goals without any coordination. For example, ISO and IEEE created a lot of standards but there was no ability to somehow work together and that is the reason they try to re-create things.
- A different group of people with slightly different perspectives worked on developing standards. People think of objects differently, e.g., people from library science or people from the learning domain think another way, and this can also lead to different standards being developed that are optimized for different goals.
- Varying regulations and governmental influences on educational metadata, which can differ across countries.
Despite having a lot of standards, very few of them are widely accepted by the community and most of them failed or they are outdated. This can happen for a variety of reasons, such as lack of awareness, lack of incentives to adopt, or lack of support from key stakeholders. One reason for failure may be that most individuals lack a clear understanding of metadata standards – what they are, their purpose, and their benefits. Also, a lot of work is done by volunteers and there are many opportunities for errors during the standard development process. Another reason could be that past experiences with metadata standards may not have been effective, leading to a perception of limited value. This could be due to inadequate delivery, perhaps excelling in one aspect like search but falling short in others.
While there are many standards that have failed, there are also many that have been successful and continue to be widely used today. For example, LRMI is widely employed internally by publishers. Overall, the development of learning metadata standards is a complex and ongoing process that is influenced by a variety of factors. The field is still in the early stages of understanding the relationships among various elements, individuals, and their functionalities, as well as delineating boundaries and distinctions.
3. What Can We Learn from International Experiences on Metadata?
The use of metadata resembles a “Chicken and Egg” scenario. High-quality metadata are a prerequisite for effective functions and applications and only effective outcomes or new functions provide a strong motivation to accomplish the tedious work of tagging metadata fields.
Previously, a lack of awareness led to the proliferation of many standards, as people were unaware of others’ efforts. But in recent years, there has been a positive shift. People now have knowledge about each other’s work, leading to coordination among different endeavors. There is now better communication between each other and between the different standards groups to see which standard for which target group and for which topic. For example, currently, there’s a significant increase in communication among communities, and they are beginning to play their roles effectively. One notable development is the T3 innovation networks, which include the OCFC. Their focus is on achieving interoperability among competency frameworks, specifically targeting three key areas: achievement standards networks, IMS case network and credential engine.
Looking ahead, there will be a focus on demand-driven use of metadata. Such as AI-based personalized learning systems or intelligent tutoring systems, which necessitate demand-driven metadata. There already some AI specific standards exist to support ethical and efficient implementation of AI algorithms in learning domain (Rashid, Reichow and Blanc 2023). It is crucial to validate the algorithms driving personalized learning to determine the effectiveness of the metadata and resources utilized. Moreover, it is not just standards for metadata that are necessary, but also standards for the content itself.
Regarding the ongoing standard development, the current focus is on creating a context-aware system. While not specifically targeting recommenders, our ecosystem envisions a machine being conscious not only of available opportunities but also of the individual’s credentials and history. This enables the system to better understand the learner’s context, resulting in a recommender system that relieves users from the exhaustive task of searching for opportunities on their own. Instead, it comprehends the vast pool of options available and incorporates the learner’s unique background.
Funding
This paper was written as part of the German funding program “Innovationswettbewerb INVITE” in the “INVITE-Meta” project. INVITE-Meta is a joint project of the mmb Institute and the German Research Center for Artificial Intelligence (DFKI) with a duration of 2021-2025.
Acknowledgments
We would like to express our sincere thanks to the experts who have participated in this interview study. We would also like to thank all the people who participated in the preparation and commenting on this dossier, especially our colleagues from the INVITE-Meta project. A dossier in the context of the German Research program on AI in vocational training “INVITE”.
Appendix A. Information on the Interview
| Date: | |
| Participant (Name, Institution): | |
| Background information: | |
| Interviewer: | |
| Duration: | |
| Comment: |
 |
Appendix B. Metadata Standards
This section briefly provides background information about some existing metadata standards for learning resources discussed by experts during interviews.
IEEE 1484.12.1 Standard for Learning Object Metadata (LOM)
IEEE LOM was developed by the IEEE Learning Technology Standards Committee (LTSC) and is widely used in North America (IEEE 2020). It covers a broad range of information about resources, including technical details, educational information, and rights. It is more complex and detailed than Dublin Core and provides more information about resources and mapping to other standards.
IEEE P2881 – Learning Metadata Terms (LTM)
IEEE P2881 is an open-source standard by the IEEE Computer Society/ Learning Technology Standards Committee (C/LTSC) (IEEE 2024). It intentionally builds on the IEEE LOM 1484.12.1 standard but is explorative to new learning paradigms and modern technology practices. This standard aims to reconcile LOM with the emerging open-world design by replacing and integrating it with new metadata standards.
In a closed world design, data is tightly controlled with specific formats and controlled vocabularies for optimized applications (such as in LOM). In contrast, open world thinking assumes that information may be incomplete and can be expanded to provide additional meaning9. The standard will specify a conceptual data schema that defines the structure of a metadata instance. The conceptual data schema specifies the data elements that compose a metadata instance for multiple learning types. The objective of the standard is to create a data model using a resource description framework (RDF) that can be expressed in or mapped to any serialization format, ensuring strong interoperability and long-term viability.
Dublin Core: Dublin Core (DC) is one of the oldest and most widely used metadata standards that was developed in 1995 for describing all kinds of web-based resources (Dublin Core 1995). The European Committee for Standardization (CEN) published the Dublin Core Metadata Element Set as CWA 13874 (NEN 2000). The element set was then published as an international standard, ISO 15836-2003. The most recent updates of these standards are ISO 15836-1:2017 (ISO 2017) and ISO 15836-2:2019 (ISO 2019), covering several dozen properties and classes. To date, the “DCMI metadata terms” (“Dublin Core terms” for short) are an authoritative specification of all metadata terms that include the fifteen terms of the Dublin Core Metadata Element Set (also known as “the Dublin Core”) plus several dozen properties, classes, datatypes, and vocabulary encoding schemes which are maintained by the Dublin Core Metadata Initiative (Dublin Core 2020).
Learning Resource Metadata Initiative (LRMI)
The Learning Resource Metadata Initiative (LRMI) specification provides a collection of classes, properties and concept schemes for markup and description of educational resources (Dublin Core 2014). It provides a lightweight data model and vocabulary (complementing existing resource description vocabularies like those from DCMI, Schema.org10, and other established standards) to describe educational characteristics such as learning objectives, educational level, intended audience etc. of a learning resource11.
Credential Transparency Description Language (CTDL)
The Credential Transparency Description Language (CTDL) is the family of standards for providing descriptions of credentials and other resources available as data for search and discovery and cross-system interoperability (Credential Engine 2024). CTDL schemas are available in three categories,
- CTDL: Large schema for all types of credentials and a wide range of adjacent resources such as learning opportunities, assessments, pathways, and transfer value, etc.
- CTDL Achievement Standards Network (ASN): The schema for descriptions of competencies. Competency is broadly defined to include assertions of academic, professional, occupational, vocational and life goals, outcomes, and standards, however labeled such as knowledge, skills and abilities, capabilities, dispositions, habits of mind, or habits of practice.
- Quantitative Data (QData): The schema for numeric and statistical data such as aggregated completion rates or employment and earnings.
The CTDL specifications are based on semantic web, where each CTDL term possesses a semantic meaning and incorporates linked data structures. This linked data structure within CTDL allows for comprehensive narratives, addressing inquiries such as credential costs, duration of attainment, enrollment prerequisites, mandatory courses, alignment with other credentials, potential job opportunities, available pathways, outcomes, and other relevant information.
ADL SCORM (Sharable Content Object Reference Model)
The Sharable Content Object Reference Model - SCORM was created by the ADL Initiative in 2000 to address e-learning interoperability, reusability, and durability challenges (ADL 2000). SCORM comprises a collection of standards and specifications used in web-based educational technology that allow e-learning content and learning management system (LMS) to work together. It is composed of three sub-specifications. Content packaging specifies how content should be packaged and described. Run-Time specifies how content should be launched, how data communicates with the LMS and includes the specification for the data model of that communication. Lastly, Sequencing specifies how a learner navigates between parts of a course, i.e., the learner’s path through the training material, bookmarking progress, and ensuring valid test scores. There are currently four different implementable versions of SCORM available. The most recent release is SCORM 2004 4th edition released in 2009.
ADL xAPI (Experience Application Programming Interface)
xAPI, or Experience API, is another initiative by ADL that provides a data and interface standard and enables software applications to capture and share extensive data on human performance, including relevant context information (ADL 2024). The ‘x’ stands for experience, because xAPI enables detailed recording and transfer of “learning experience” data, whether those data come from an e-learning experience, a simulation-based training experience, a tablet-based educational experience, or even an operational (on-the-job) experience.
1EdTech/IMS Learning standards
1EdTech, formally IMS Global Learning Consortium, brings together educational institutions, technology providers, and other stakeholders to collaborate on the creation of open standards that facilitate the integration and effective use of technology in education (1EdTech 2024). Some of its well-known standards include:
Common Cartridge: A format for packaging and exchanging digital learning content and assessments across different learning management systems (LMS) and platforms.
Learning Tools Interoperability (LTI): A standard that allows educational applications (tools) to seamlessly integrate with LMS platforms, enabling instructors and students to access external tools without leaving the LMS environment.
Caliper Analytics: A framework for capturing and exchanging learning analytics data, helping institutions gather insights into student engagement and performance.
Competency and Academic Standards Exchange (CASE): A standard for representing academic standards and competencies, facilitating the alignment of learning resources with specific learning objectives.
| 1 | The German Federal Ministry of Education and Research (BMBF) is funding 35 projects with a total of 88 million euros between 2021 and 2025 with the programme “Innovationswettbewerb INVITE”. The aim is the connection and further developing of platforms for vocational education and continuing training and the common use of standards. The German Federal Institute for Vocational Education and Training (BIBB) has been commissioned to provide technical and administrative support for the programme, supported by an accompanying digital research, the “Digitalbegleitung” (VDI/VDE-IT) and scientific support "INVITE-Meta" (mmb Institute and DFKI). |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | The formal definition LRMI uses for a learning resource: a persistent resource that has one or more physical or digital representations, and that explicitly involves, specifies, or entails a learning activity or learning experience. |
References
- 1EdTech. 2024. 1EdTech Interoperability Standards. Accessed 01 10, 2024. https://www.1edtech.org/specifications.
- ADL. 2024. Experience API (xAPI) Standard. Accessed 01 10, 2024. https://adlnet.gov/projects/xapi/.
- —. 2000. Sharable Content Object Reference Model (SCORM®). Accessed 01 10, 2024. https://adlnet.gov/past-projects/scorm/.
- Barker, Philip Andrew, and Lorna M. Campbell. 2010. “Metadata for learning materials: an overview of existing standards and current developments.” Cognition and Learning 7: 225-243.
- Credential Engine. 2024. Credential Transparency Description Language (CTDL). Accessed 01 10, 2024. https://credentialengine.org/credential-transparency/ctdl/.
- Drachsler, Hendrik, Katrien Verbert, Olga C. Santos, and Nikos Manouselis. 2015. “Panorama of Recommender Systems to Support Learning.” In Recommender Systems Handbook, by Lior Rokach und Bracha Shapira Francesco Ricci, 421 - 451. Boston, MA: Springer US. [CrossRef]
- Dublin Core. 2020. DCMI Metadata Terms. Accessed 01 10, 2024. https://www.dublincore.org/specifications/dublin-core/dcmi-terms/.
- —. 1995. Dublin Core™. Accessed 01 10, 2024. https://www.dublincore.org/specifications/dublin-core/.
- —. 2014. LRMI. Accessed 01 10, 2024. https://www.dublincore.org/specifications/lrmi/.
- Goertz, L., S. F. Rashid, E. Vogel-Adham, A. Vogt, and A. Wilhelm-Weidner. 2023. Metadatenstandards im Innovationswettbewerb INVITE. Essen: peDOCS. [CrossRef]
- IEEE. 2020. 1484.12.1-2020 - IEEE Standard for Learning Object Metadata. Accessed 01 10, 2024. https://ieeexplore.ieee.org/document/9262118.
- —. 2024. P2881 - Standard for Learning Metadata. Accessed 01 10, 2024. https://standards.ieee.org/ieee/2881/10248/.
- ISO. 2017. ISO 15836-1:2017 The Dublin Core metadata element set. Accessed 01 10, 2024. https://www.iso.org/standard/71339.html.
- —. 2019. ISO 15836-2:2019. Accessed 01 10, 2024. https://www.iso.org/standard/71341.html.
- NEN. 2000. CWA 13874:2000. Accessed 01 10, 2024. https://www.nen.nl/en/cwa-13874-2000-en-58057.
- Rashid, Sheikh Faisal, Insa Reichow, and Berit Blanc. 2023. Standards für Künstliche Intelligenz im Bildungsbereich. Ein Dossier im Rahmen des INVITE-Wettbewerbs. Berlin: PeDOCS. [CrossRef]
- Reichow, Insa, and Monica Hochbauer. 2021. Standards und Empfehlungen zur Umsetzung digitaler Weiterbildungsplattformen in der beruflichen Bildung. Ein Dossier im Rahmen des des INVITE-Wettbewerbs. Bonn: Bundesinstitut für Berufsbildung (BiBB). Online: https://res.bibb.de/vet-repository_779586.
- Reichow, Insa, Katja Buntins, Benjamin Paaßen, Hasan Abu-Rasheed, Christian Weber, and Mareike Dornhöfer. 2022. Recommendersysteme in der beruflichen Weiterbildung. Grundlagen, Herausforderungen und Handlungsempfehlungen. Ein Dossier im Rahmen des des INVITE-Wettbewerbs. Berlin: PeDOCS. [CrossRef]
- Schema.org. 2024. Schema.org. Accessed 01 10, 2024. https://schema.org/.
- William, Simão de Deus, and Ellen Francine Barbosa. 2020. “The Use of Metadata in Open Educational Resources Repositories: An Exploratory Study.” 44th Annual Computers, Software, and Applications Conference (COMPSAC). Madrid, Spain: IEEE. 123-132. [CrossRef]
Figure 1.
Phases of the continuing education process in the digital education system, adopted from: https://res.bibb.de/vet-repository_779586.
Figure 1.
Phases of the continuing education process in the digital education system, adopted from: https://res.bibb.de/vet-repository_779586.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



