
Submitted:
16 February 2024
Posted:
19 February 2024
You are already at the latest version
Abstract
In this article, we present two topics related to mathematical economics. We offer an intriguing proposal for securing cost and production functions in the face of uncertainty and risk. We discuss the relationship between individual and social preferences. This is important because traditional revealed preference theory does not account for such factors.
Keywords:
cost function
; group preferences
; individual preferences
; production function
MSC: 15B99; 91B38; 91B08; 91B10
1. Introduction
There is a common issue regarding data protection and privacy, such as costs or production factors, in enterprises. Of course, data can be computed and encrypted, but if an outsider gains access to encrypted data and the data functions for cost and production, it’s only a matter of time before the adversary reconstructs the real data. There are various published examples of encryption. In the article by [1] from 2017, authors present a general construction of functional encryption with inner product, which is resistant to chosen plaintext attacks (IND-FE-CCA), based on hash functions with homomorphic properties. Authors demonstrate specific implementations based on the assumptions of Decisional Composite Residuosity (DCR), Decisional Diffie-Hellman (DDH), and more generally, Matrix DDH. The article titled "Azure Functions security" [7] published on the Microsoft Learn website describes services and actions related to security that can be applied to Azure serverless functions. The article provides guidelines and resources to help develop secure code and deploy secure applications to the cloud. In the article [2] , the authors present a general scheme and syntax for functional encryption and demonstrate how existing encryption concepts, such as attribute-based encryption and many others, can be elegantly expressed as specific functionalities of functional encryption. Defining the security of abstract functional encryption proves to be very non-trivial. Authors present several definitions and challenges related to functional encryption.
The aim of the Section 2 is to ensure data security as well as the security of cost and production functions.The production function and the cost function are closely related because the cost of producing a certain quantity of a product depends on the inputs of production factors and their prices. The cost function shows the minimum cost of producing a given quantity of a product at given input prices. The cost function can be expressed as the sum of fixed costs F and variable costs , which depend on the production quantity Q:
The cost function can also be determined based on the production function if we know the prices of production factors: labor w and capital r. Then the cost function takes the form:
where L and K are the quantities of labor and capital needed to produce Q units of the product. To find these quantities, one must solve the cost minimization problem for a given production quantity:
subject to the condition , where is the production function.
In today’s times, a linear cost function may not be sufficient, as we may change prices at specified time intervals. Therefore, in the Section 2, we will consider a general cost function.
where the general cost function is a piecewise linear function.
In the Section 2, we also present three of the most well-known types of production functions and methods of their encryption. However, if a given enterprise were to use different production functions, one could infer from this section how to encrypt another type of function analogously. Specifically, we consider the traditional type of production function:
The Cobb-Douglas production function is frequently encountered:
Also the minimum function:
The revealed preference theory initiated by the American economist Paul Samuelson in [6], is a method of analyzing consumer choice, emphasizing the relationship between consumer behavior and preferences. It assumes that based on the decisions made by the consumer, their preferences can be determined, assuming that the consumer’s behavior is rational. Revealed preferences allow for the creation of a utility function for the consumer, which the consumer reveals through their consumption decisions (assuming that preferences remain unchanged). More details can be found in the book [3], where the authors present the foundations and development of revealed preference theory, discussing its assumptions, axioms, theorems, and applications. Authors also demonstrate how this theory can be used to study various economic issues such as demand, welfare, equilibrium, auctions, games, and social decisions. Unfortunately, this theory is heavily criticized by many economists. Raising many questions. In particular, the following questions arise: Are the assumptions about rationality, full information, and consistency of consumer preferences realistic and adequate for describing real behavior? Is the utility function a good tool for measuring and comparing satisfaction from different baskets of goods? Are consumer preferences stable and independent of external factors such as social, cultural, and marketing environments? Is the Equivalent Budgetary Consumption Model sufficient to account for the impact of income on consumer preferences? Is the consumer able to compare all available choice options and choose the best one for themselves? Is the consumer aware of their needs and preferences, or are they shaped by the decision-making process? Is the consumer always selfish and maximizing their utility, or do they consider the utility of other entities? Is consumer consistent in their time preferences, or do they succumb to impulses and temptations? In the article [4], published in 2014, Dryzek criticizes the theory of revealed preferences, arguing that it is too narrow and limited to capture the complexity and diversity of human rationality. Author proposes an alternative concept of rationality based on pluralism of values, norms, and goals, rather than a uniform utility function. It is also worth noting the article [5], where authors analyze the relationship between the theory of revealed preferences and behavioral economics, which deals with the influence of psychological, social, and emotional factors on economic decisions. Authors point out the limitations and challenges that revealed preference theory poses to behavioral economics, as well as the opportunities and benefits that arise from combining these two approaches.
In the final Section 3, we will discuss the relationship between an individual consumer’s preference and the social influence on decision-making. We present a certain rigorous mathematical model as our proposal.
2. Protection of the cost and production functions
We will discuss the issue of encrypting cost function data. Encrypting cost function data is the process of transforming data containing information about the costs incurred by a company in the process of production or service provision using a secret key, so that it is incomprehensible to unauthorized individuals. Encrypting cost function data aims to ensure the confidentiality, integrity, and availability of this data, as well as to prevent manipulation and abuse by competitors, customers, suppliers, or other entities. Encrypting cost function data can also improve the efficiency and competitiveness of the company by optimizing decision-making processes and resource allocation. In this section, we will present a certain encryption method for various cases, which is easy to use and may give unauthorized individuals the illusion of the truthfulness of the data, as the method below does not change the form of the cost function.
Algorithm 2.1.
(1) We are given the cost function
where .
- (2)
- Let be the encrypting function, where .
- (3)
- We are looking for y such that .
- (4)
- The function is the new encrypted function C.
- (5)
- The function is the decrypting function.
Proposition 2.2.
The above algorithm is correct and resistant to attacks.
Proof.
Let and , where a, . Then
So the function is the decrypting function. The decrypting function arises from elementary transformations of the function h and the function g. The algorithm is correct.
Notice that the function h has the form of a linear function, the same as the function C. Therefore, it is a natural first defense where the function h can create the illusion of a true cost function.
If the function g is known, then the algorithm is also secure. Often, compositions of functions, functions , , and various combinations are used. Let’s compute:
As seen from the above calculations, classical decrypting operations fail. Any combination of functions g, , h, will not give us the function C. The algorithm is highly resistant to attacks. □
Remark 2.3.
In the above algorithm, we can use the derivative function to as a polynomial function of the form . Then, we can use the function instead of the function g in the algorithm. In this case, the algorithm’s resistance to attacks is even greater. Especially since in the worst case scenario, there may be an attempt to compute the integral of the new function g, where we then have an ambiguous general solution. And an additional problem arises, how many times to integrate.
Algorithm 2.4.
(1) We are given the cost function
where , and t is a new value from a certain moment in time.
- (2)
- Let be the encrypting function, where .
- (3)
- We are looking for y such that .
- (4)
- The function is the new encrypted function C.
- (5)
- The function is the decrypting function.
Proposition 2.5.
The above algorithm is correct and resistant to attacks.
Proof.
Notice that the function C can be expressed in the form of a piecewise linear function:
Similarly, the encrypting function g can be expressed in the form of a piecewise linear function:
Therefore, we can calculate the function h analogously for a given interval as in the previous algorithm and proof. We obtain:
We obtained the encrypting function h, which is piecewise linear on each interval. Thus, it perfectly masks the cost function C.
Now let’s check the correctness of decryption for the interval :
Similarly, we can confirm that for the interval .
Therefore, the function is the decrypting function. The decrypting function arises from elementary transformations of the function h and the function g. The algorithm is correct.
Notice that the function h is of the form of a piecewise linear function, the same as the function C. Therefore, it is a natural first defense where the function h can create the illusion of a true cost function.
If the function g is known, then the algorithm is also secure. Often, compositions of functions, functions , , and various combinations are used. Calculating for the interval we have:
Similarly, we can confirm that none of the above combinations will give us the function for the interval .
As seen from the above calculations, classical decrypting operations fail. Any combination of functions g, , h, will not give us the function C. The algorithm is highly resistant to attacks. □
Remark 2.6.
If we consider the cost function f over a general continuous time horizon, we will obtain a piecewise linear function for many time intervals, where , , …, are the individual values changing in subsequent time intervals. Therefore,
will be the given piecewise linear cost function. We can apply algorithm 2.1, but for n intervals. Of course, generating such a general algorithm is not difficult, but time-consuming. Personally, we recommend it anyway due to the smoothness of securing the entire cost function and also due to the increased level of difficulty in breaking the security.
Encrypting production functions involves securing information on how a company utilizes inputs of production factors: labor and capital, to achieve a certain level of production. Encryption can be applied to both general production functions and production functions of individual products or services. The purpose of encryption is to protect data from unauthorized access, theft, manipulation, or disclosure. In the following section, we will discuss a similar encryption method as for cost functions.
Algorithm 2.7.
(1) We have a given production function
- (2)
- Let be the encrypting function, where for .
- (3)
- We are looking for such that .
- (4)
- We adopt in a secret way.
- (5)
- Let’s identify the function through the sum . This way, it becomes the function , which masks the function Q and is explicit.
- (5)
- The function is the decrypting function.
Proposition 2.8.
The above algorithm is correct and resistant to attacks.
Proof.
Let and , where for .
We are looking for such that . Since the solution is not unique, we can adopt the following solutions, which are obviously correct:
Then
Hence the function is the encrypted function of Q. Now let’s check the decryption:
Thus the function is the decrypting function. The decrypting function arises from elementary transformations of the function and the function g. The algorithm is correct.
Notice that the function has the same form as Q. Therefore, it is a natural first defense where can create the appearance of a real production function. Moreover, distinguishing between the explicit and secret versions of the function h can add an additional level of security.
If the function g is known, the algorithm is still secure. Often, compositions of functions are applied. Note that functions , , do not exist. Let’s calculate:
As seen from the above calculations, the classical decryption fails. There is a possibility of using with the knowledge of the function g. However, due to the strong ambiguity of the integer decomposition into the sum and the unknown function Q, it seems to have a low probability. □
The next production function is a Cobb-Douglas type function.
Algorithm 2.9.
(1) We have the production function
- (2)
- Let be the encrypting function, where for .
- (3)
- We are looking for such that and we can assume .
- (4)
- We assume in a secret way.
- (5)
- Let’s identify the function through the product . In this way, it is the explicit function that masks the function Q.
- (5)
- The function is the decrypting function.
Proposition 2.10.
The above algorithm is correct and resistant to attacks.
Proof.
Let and , where for .
We are looking for such that . Since the solution is not unique, we may adopt the following solutions, which are evidently true:
and we take .
Then
and
So the function is an encrypted function of Q. Now we will verify decryption:
Thus the function is the decrypting function. The decrypting function arises from elementary transformations of the function and the function g. The algorithm is correct.
Notice that the function is of the same form as Q. Therefore, it is a natural first defense, where the function h can create the appearance of a genuine production function. Moreover, distinguishing between the explicit and secret versions of the function h can add an additional level of security.
If the function g is known, then the algorithm is also secure. Composite functions are often used. Note that the functions , do not exist. Let’s calculate:
As seen from the above calculations, the classical decryption operation fails. Although the above calculations reveal the coefficient , the exponents are different. Due to the ambiguity of decomposing any number into the sum of two numbers, the probability of breaking the algorithm is low. □
We have one more production function left to discuss:
which is considered in enterprises, but unfortunately, the proposed methods in this paper are not practical for this function. Therefore, we leave it as an open question.
- Question:
- Let be a production function. Is it possible to encrypt and secure the function Q properly in a similar or different way?
3. Individual preferences versus social preferences
Let X be the space of choice products, and let Y be the space of preferences. For and , let’s define the function by the formula , where represents the consumer’s preference for the product . These are declarative responses as a random variable in a random experiment.
Furthermore, for n consumers, let’s define the social average preference as the function given by .
Let be a probabilistic measure such that .
Let’s also define the function , where , by the formulas:
The above formula combines individual preferences with social ones dependent on social factors. For , we speak of a positive influence of social factors on individual preferences, and for , we speak of a negative influence of social factors on individual preferences.
Proposition 3.1.
Functions and S are homotopic, denoted by
Proof.
Let’s consider two cases. Assuming there is a positive impact of social preferences on individual preferences, we have:
Now assume, there is a negative impact of social preferences on individual preferences. We have what is called symmetric homotopy :
S is homotopic with from the formula . Therefore, we have:
□
Proposition 3.2.
Equality holds then and only then if , this means if preferences without and with taking into account social factors are equal, individual preferences without taking into account social factors are eqal to social average preference.
Proof.
Let’s consider two cases. First consider, that .
Assume that . Then from it follows that . So
czyli .
Assume that . Then from it follows that , so .
Now consider the second case, where .
Assume that . Then from it follows that . So .
Assume that . Then from it follows that . So □
Proposition 3.3.
oraz .
Proof.
First we will show the first limit:
.
Now calculate the second one:
□
Proposition 3.4.
If , increases as grows. If , decreases as grows.
Proof.
To determine growth we must calculate derivate of the function relivate to . Let’s denote this derivative by d. Then from:
By assumption , so , where for .
Similarly, we prove that if , is . □
Proposition 3.5.
For some , if increases (other consumer preferences for product grows), grows faster for than for .
Proof.
Suppose that there are consumers i and j such that , and grows slower than when is increasing. This means that there is a value of such that for any given holds
Using the definitions of the functions and , we can simplify this inequality to
After moving all components from and to the left side and all components from , , and to the right side, we get
Now we can use the fact that and to simplify some expressions. We have
and
Now we can see that the left side of the inequality is positive because and . However, the right side of the inequality is negative because , , and are integers in the range , so their differences are at most equal to and . So we get a contradiction because it cannot be that a positive number is less than a negative number. Therefore, our assumption was wrong and it must hold that grows faster than as increases, for and . □
To better understand the reasoning presented, let’s give the following example.
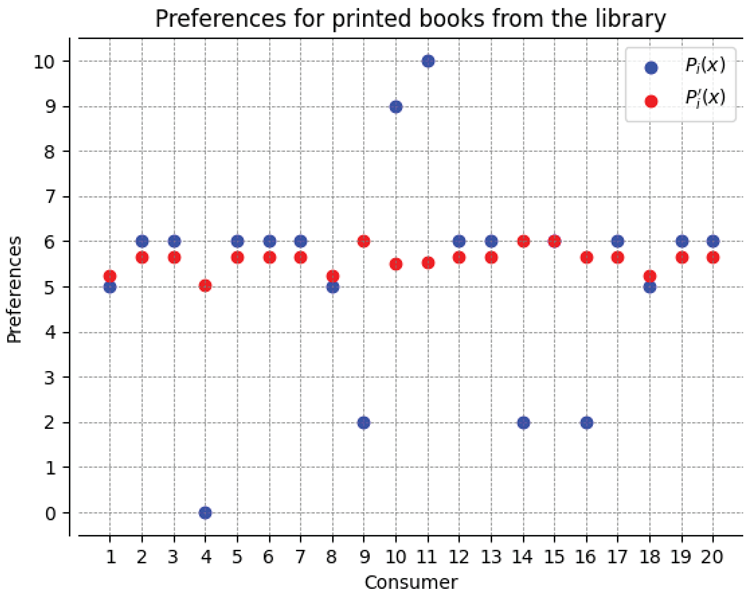
In the plot below (see Figure 1), we present declarations of 20 consumers, who have decided on the level of preferences for printed books from the library.
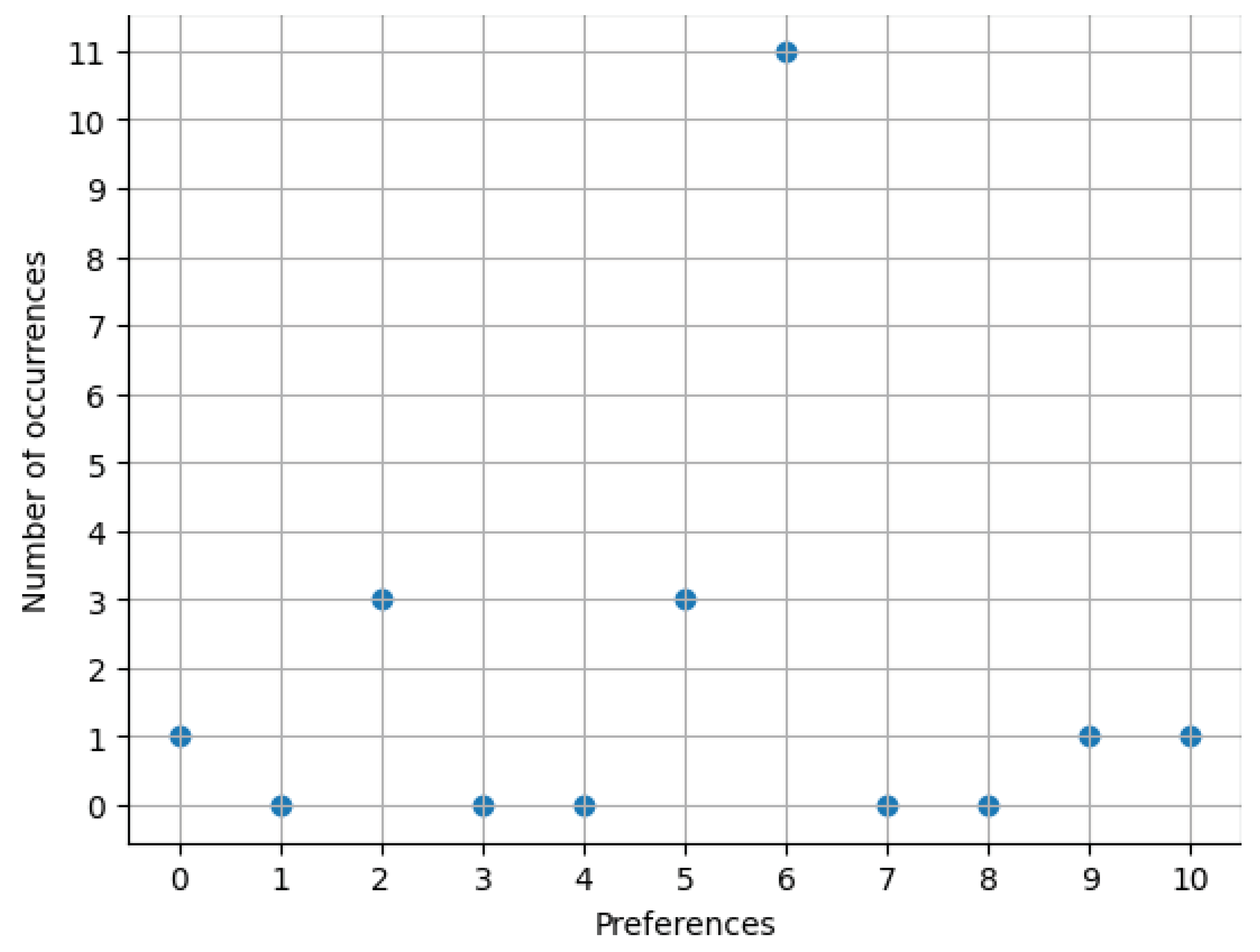
In the plot below (see Figure 2), we present the number of consumers based on their preference.
Indicating the values of preference weights based on the second plot (Figure 2): , , , , i .
Let’s determine the value of social weight:
.
Figure 3.
caption.
Let’s determine the value of individual preferences taking into account social preferences: , , , , i .
Now notice that the differences between individual preferences and preferences taking into account social factors:

In the analysis of differences between individual preferences and the combination of individual preferences with social ones dependent on social factors for various arguments, both positive and negative differences were observed. This suggests that the social influence on preferences is diverse and dependent on specific social context. This may be significant in decision-making contexts, especially when we want to understand which arguments are more susceptible to social influences. Analyzing cases with significant differences, for example for consumers 9, 10, 14, one may hypothesize that units with similar preferences characterized by higher social weight exert a greater influence on social preferences. For different arguments, the influence of social weight may vary, suggesting differences in how strongly social preferences depend on individual preferences depending on the social context. Differences between individual and social preferences may be more pronounced when the social average significantly differs from individual preferences. In cases where social preferences are more aligned with individual ones, it can be assumed that the social average reflects more dominant and accepted preferences in society.
- Generalization
Let and , where for all .
By analyzing the integral, where f represents the weight density function, with , we can observe how different values of social weight W contribute to the overall influence mass. This can provide information about whether there is a certain range of social weights that dominates in shaping social preferences. If is close to , we can interpret this as a limit of differentiation, indicating that we are analyzing the function f in the context of very small changes in W. This situation focuses on analyzing local changes in social weight and their impact on social preferences. It may be important to understand how small changes in social weight translate into the total social mass. This kind of approach can be used to find extrema of the function, where we analyze how very small changes in social weight affect changes in social preferences.
Author Contributions
Julia Fidler – Sections 1, 3. Łukasz Matysiak – Sections 1, 2.
Funding
This paper was not funded.
Conflicts of Interest
On behalf of all authors, the corresponding author declares that there is no conflict of interest.
References
- Benhamouda, F., Bourse, F., Lipmaa, H., CCA-Secure Inner-Product Functional Encryption from Projective Hash Functions in: Lecture Notes in Computer Science. (s. 36-66). Cham: Springer International Publishing (2017). ISBN 978-3-319-70694-8.
- Boneh, D., Sahai, A., Waters, B., Functional Encryption: Definitions and Challenges, IACR, (2011), https://eprint.iacr.org/2011/543.pdf.
- Chambers, C., Echenique, F., Revealed Preference Theory, Cambridge: Cambridge University Press, (2016), ISBN 978-1-107-11971-9.
- Dryzek, J. S., Revealed Preference and the Pluralism of Rationality, Economics and Philosophy, 30 (3), (2014) 383-403.
- Manzini, P., Mariotti, M., Revealed Preference and Behavioral Economics, in Zamir, E., Teichman, D. (red.). The Oxford Handbook of Behavioral Economics and the Law, (2014), s. 3-21. Oxford: Oxford University Press. ISBN 978-0-19-994547-4.
- Samuelson, P. A., A note on the pure theory of consumers’ behaviour, Economica. New Series.5 (17): 61–71, 1938.
- Azure Functions security, Microsoft Learn, (2022), https://docs.microsoft.com/en-us/learn/modules/secure-azure-functions/.
Figure 1.
preference values.
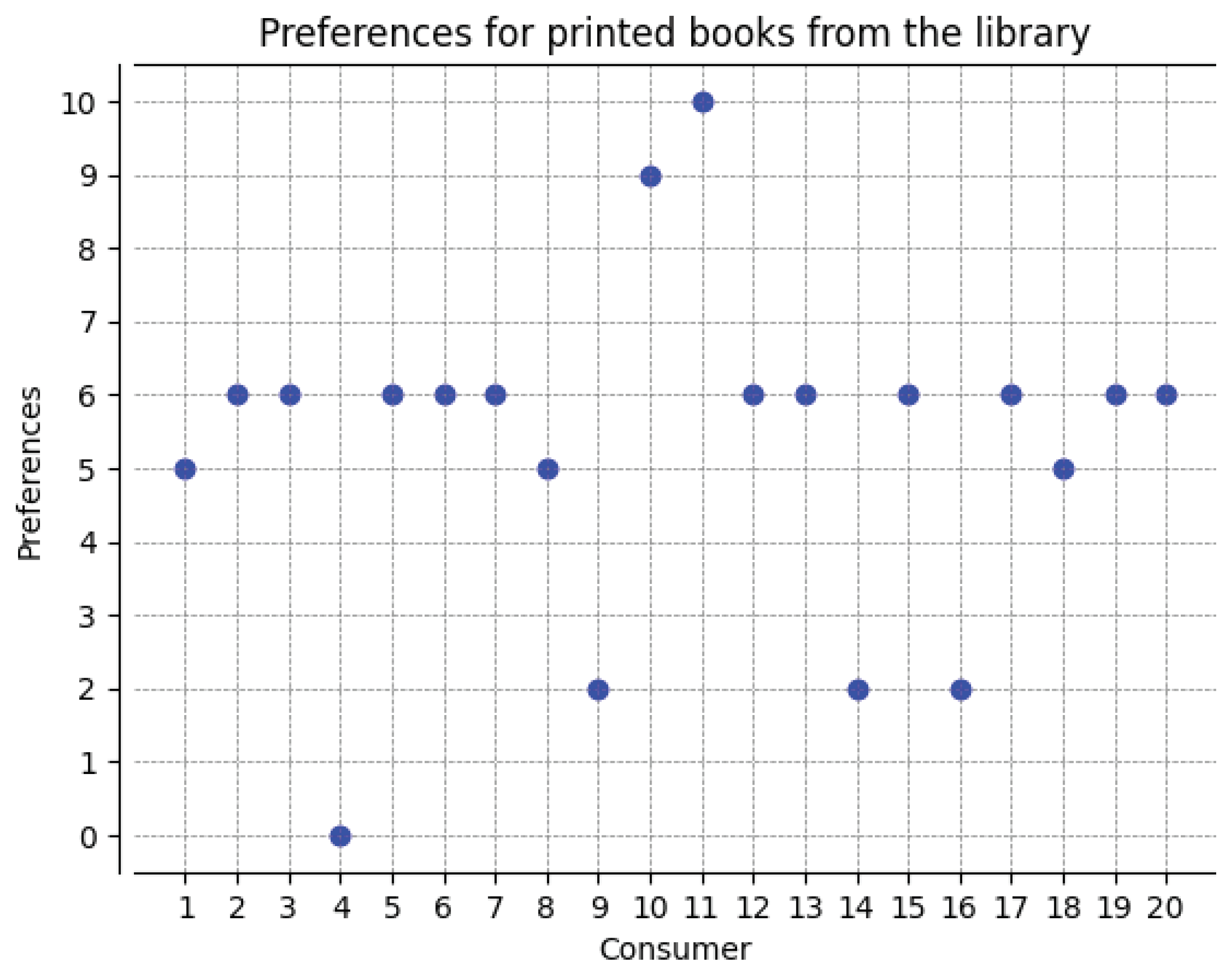
Figure 2.
number of given preference values.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



