Submitted:
19 February 2024
Posted:
20 February 2024
You are already at the latest version
Abstract
Water plays a vital role in the healthy growth of pears. Early detection of water stress can play a significant role in the timely management of water deficiency for pear yield. Most current methods are labour-intensive, time-consuming, only provide point measurements, and could be destructive. In this research, a real-time non-destructive method using a push-broom hyperspectral system (400-1000nm) was used to collect hyperspectral image data and detect the water stress of the pear seedling leaves. To build a reliable prediction model, machine learning techniques were used. The Successive Projections Algorithm (SPA) was applied for optimal wavelength selection. In particular, CNN was applied to obtain the features of key wavelengths. Both the CNN features and key wavelengths were put into RR-MLR, BLR and ENN for analysis. The training accuracy of the three modellings all reach the accuracy above 70% after about 100 epochs, while combination of CNN features outperformed the mere main spectra analysis. This research demonstrated that hyperspectral imaging coupled with machine learning techniques could be applied to predict the water content of pear leaves predict non-destructively.
Keywords:
hyperspectral imaging
; plant water stress
; machine learning
; optimal wavelengths
Introduction
Pear (Pyrus communis L.) is widely spread throughout temperate regions such as China, America and Australia (Silva et al., 2014). Pears are high in fibre, which can help to lower cholesterol. They are low GI, which makes them an excellent nutritious food (Amatya et al., 2012). China is a predominantly agricultural country, but compared with developed countries, the fertiliser and water utilisation rate is low (Han et al., 2018). Adjusting irrigation strategy is one of the essential tools for creating green and ecologically sustainable agriculture, which can also ensure the supply of agricultural products (He et al., 2022). Personal experience is still mainly used for watering. On the one hand, this can lead to over-irrigation and waste of water, as artificial experience cannot predict all situations. At the same time, excessive irrigation can also damage the pear tree itself, causing yield decline and other problems. On the other hand, since the pear is a regional plant, it is less extensive and widely planted than wheat and rice crops. Drought or water-deprivation can lead to serious issues. Therefore, the pear tree irrigation study needs more attention. In this paper, the main focus of the study is water stress detection.
Plant irrigation plays an important role in water stress. Water stress adversely impacts many aspects of plant physiology, particularly photosynthetic capacity (Osakabe et al., 2014). Once the stress is prolonged, the growth and productivity of plant is severely impacted. Moreover, water stress causes significant reductions in pear productivity. Water stress causes changes not only in leaf temperature and spectral emissivity but also in leaf and canopy water content, pigment content, and structure (Jones, 2004). LWC (leaf water content) reflects the absolute water content value (Li et al., 2018), which can be used to reflect the actual condition of plant growth more precisely. According to Jones (2004), stomatal conductance measured by a porometer is the most sensitive reference measurement of plant water stress induced by water deficit. However, this method is labour-intensive, time-consuming, and only provides point measurements (Wang, 2022).
In addition to emerging nondestructive techniques such as X-ray CT imaging (Costa et al., 2013) and Raman spectroscopy (Ahmed et al., 2018), near-infrared (NIR) spectroscopy (800-2500nm) is a method that is well-suited for characterising organic compounds, mainly in combination with multivariate mathematical techniques (Ambrose et al., 2016). When NIR light illuminates and transmits through an object, the energy of the incident electromagnetic wave changes because of the stretching and vibrations of chemical bonds such as O-H, N-H and C-H. Subsequently, the quality and quantity of an object can be evaluated indirectly, rapidly and without contact by analyzing the light reflectance and transmittance values (Ma et al., 2020). However, the conventional NIR approach collects spectral data from a single sample point; the simultaneous capturing of multiple targets remains a challenge. Hence, a time-efficient technique with high spatial resolution is required to apply NIR practically. NIR hyperspectral imaging (NIR-HSI) is such a technique: it provides a NIR spectral image at each wavelength (Li et al., 2019). It enables quality evaluation across an entire surface by indirectly analyzing the spatial distribution of molecular vibration information. In addition, many samples can be scanned and analyzed together by this advanced imaging technique. With such outstanding advantages, NIR-HSI has already been introduced to plant biotic and abiotic stress identification. Wei et al. (2021) conducted analysis of moisture content in tea leaves based on VNIR spectra. It was also used for orange spotting disease of oil palm (Golhani et al., 2019).
Plant leaves are the good medium for water stress detection. So far, many researchers have studied plant leaves in vitro using hyperspectral imaging. Liu et al. (2015) used hyperspectral imaging to predict nitrogen and phosphorus contents in citrus leaves. Liu et al. (2014) used hyperspectral imaging to simultaneously estimate Gannan navel orange leaves’ chlorophyll and water content. Wang et al. (2020) used hyperspectral imaging to rapidly detect the quality index of post-harvest fresh tea leaves. Also, Li et al. (2019) made use of an ASD Field Spec 4 spectrometer to determine the spectral reflectance of pear leaves in different periods to estimate the content of Fe in the leaves of pears. Li (2018) used hyperspectral data to estimate nutrient elements in the leaves and canopy of Pyrus sinkiangensis ‘Kuerlexiangli’. Liu et al. (2022) identified anthracnose and black spot of pear leaves on near-infrared hyper spectroscopy.
Machine learning and pattern recognition-based methods have succeeded in hyperspectral image analysis tasks. Many machine learning methods are well-suited for hyperspectral data (Gewali et al., 2018). They can automatically learn the relationship between the reflectance spectrum and the desired information while being robust against the noise and uncertainties in spectral and ground truth measurements (Giannoni et al., 2018). Wang (2022) did an inversion of nitrogen and chlorophyll content in crop leaves based on hyperspectral and Partial Least Squares Regression (PLSR). Ridge Regression Models was used to estimate grain yield from field spectral data in bread wheat (Triticum Aestivum L.) grown under three water regimes (Hernandez et al., 2015). Bayesian modelling of phosphorus content in wheat grain was conducted using hyperspectral reflectance data (Pacheco-Gil et al., 2023).
As there is no literature focusing on the plant leaf directly while the plants are growing, our study is significant because it can provide a timely and accurate monitoring system for farmers to take timely irrigation methods. Specifically, Poobalasubramanian et al. (2022) did a similar research to ours by using chlorophyll-fluorescence indices extracted via hyperspectral images; they tried to identify early heat and water stress in strawberry plants. However, unlike our study, which focuses on one leaf, their research considered all the canopies of leaves of one plant. Their research considered three water conditions: drought, normal and recovered state. In addition, the data analysis method they took was different from ours. In their study, eight chlorophyll-fluorescence indices were used to develop machine-learning models to determine the heat and water stress at the early stages of strawberries. The remote sensing analysis method was taken in their research. However, there are significant differences between species individuals at the leaf and canopy scales, which primarily affect the spectral characteristics of canopies composed of multiple leaves. Spatial variation of leaf water content is more challenging to measure using the presented method (Junttila et al.,2022). In order to overcome the challenge above-mentioned, our study decides to look at one leaf in the middle of the plant at one time instead of considering all the canopies of leaves of one plant, thus improving the accuracy and efficiency of plant water stress detection.
Also, our research makes an innovation by focusing on pear seedlings instead of the mature plant. Seedling is the most critical stage in the life history of plants, connecting intergenerational bonds in plants. The number of seedlings can reflect parent generations’ qualitative and quantitative characteristics and work as a prediction of group dynamics and evaluation trends for future species (Liu et al.,2017).
Convolution neural networks is popular for image feature extraction. Yalcin & Razavi (2016) proposed a Convolutional Neural Network (CNN) architecture to classify the type of plants from the image sequences collected from smart agro-stations. Ahmad et al. (2022) used CNN for feature extraction of plant leaf. CNN was also used for corn plant disease recognition (Guifen et al., 2019). This paper proposes a non-destructive real-time detection method using hyperspectral imaging to scan leaves from pear seedlings directly. Due to the fact that previous leaf water content detection methods can be destructive or costly, in addition, it would be tough for human eyes to identify the difference between regular leaves and leaves suffering from dryness before apparent wilting symptoms appear, therefore, the paper aims to combine hyperspectral imaging with machine learning models that can be used to identify pear seedling leaves under different water conditions in a real-time and non-destructive environment. We hypothesised that chemical changes in plant leaf cells during water stress generate changes in the reflectance profile in a particular spectral region. In our research, we use hyperspectral imaging (400nm-1000nm) to detect the difference in the water content in the leaf using machine learning methods.
Therefore, this study aims to demonstrate the effectiveness of hyperspectral imaging coupled with deep learning-based techniques Multiple Linear Regression Based on Ridge Regression, Bayesian linear regression and Elman Neural Network, and propose a practical plant-factory based model for detecting pear leaf water stress of young pear seedlings by focusing on one leaf directly from the plant at a time. Two types of information, main spectra selected using SPA and CNN features of main spectra were input into the neural networks. The overall classification accuracy of these three machine learning methods all reach an accuracy of over 70%. Hence, drought or oversaturated seedlings can be recovered in time without destroying the plant.
Materials and Methods
1. Material
QingzhenD3’ pear root-stocks with around 12 leaves per plant were grown in the National Agricultural and Forestry Science and Technology incubator seedling base in Zhucheng, China. Pear seedlings of similar growth were chosen. Pear seedlings were transported to greenhouses based at Qingdao Agricultural University. Two weeks after transplanting, all pear seedlings were treated with the complete nutrient solution and supplied with all the essential nutrients. A known amount of nutrient solution was provided to each plant using a trickle nozzle.
The temperature of the greenhouse was 25℃. The humidity of the greenhouse was around 95%. Each pot contained one seedling. The substrate was composed of peat and pastoral soil (1:1). The pastoral soil was procured from Qingdao Agricultural University and carefully sieved. The experiment took place between July and September 2021.
2. Experiment design
Treatment groups were established as the prediction models and simulate the differing water stress situations. There were three treatment groups: the excessive water treatment group, the drought group, and the control group-normal watering group. For each treatment, 30 pear seedlings were used for hyperspectral imaging collection. Specifically, there were 30 repetitions for each treatment group. A pre-experiment was conducted to conclude that the amount of water a pot of pear seedling needs was 10mL. The night before the experiment, the pear seedlings of the three treatment groups were watered thoroughly. Once the pear seedlings of the drought group were watered, no further watering was required during the experiment. The excessive water treatment group maintained water at a depth of 1.5cm, and the water was uniformly replenished at 6 pm. In addition, 10mL of water was added to pear seedlings in the regular watering group every day at 6 pm.
One leaf in the middle of each plant (usually the fourth leaf from the bottom) was employed for hyperspectral data collection (Figure 1). According to the research method requirement, the middle leaf is relatively stable and representative of the whole plant. The acquisition time was 0 days, one day, three days, five days, and seven days after water treatment before apparent symptoms such as wilting and yellowing appeared on pear leaves. Images were taken every other day to ensure the internal environment of the plant was recorded consistently and accurately. On day 0, the starting point of water treatment, only 30 hyperspectral images were collected (10 for each treatment). From day 0, day 1, day 3, day 5, day 7, 30 images were gathered for each treatment. The sample collection period was from 9:00 am to 11:00 am. Table 1 indicates the number of pictures collected. Three areas of interest were extracted from each hyperspectral cube, therefore, we have 765 areas of interest in total.
A workflow consisting of three phases was proposed, from data analysis to model development. In order to clearly demonstrate the experiment process, the workflow of this experiment is shown in Figure 1.
Figure 1.
Workflow of this research.
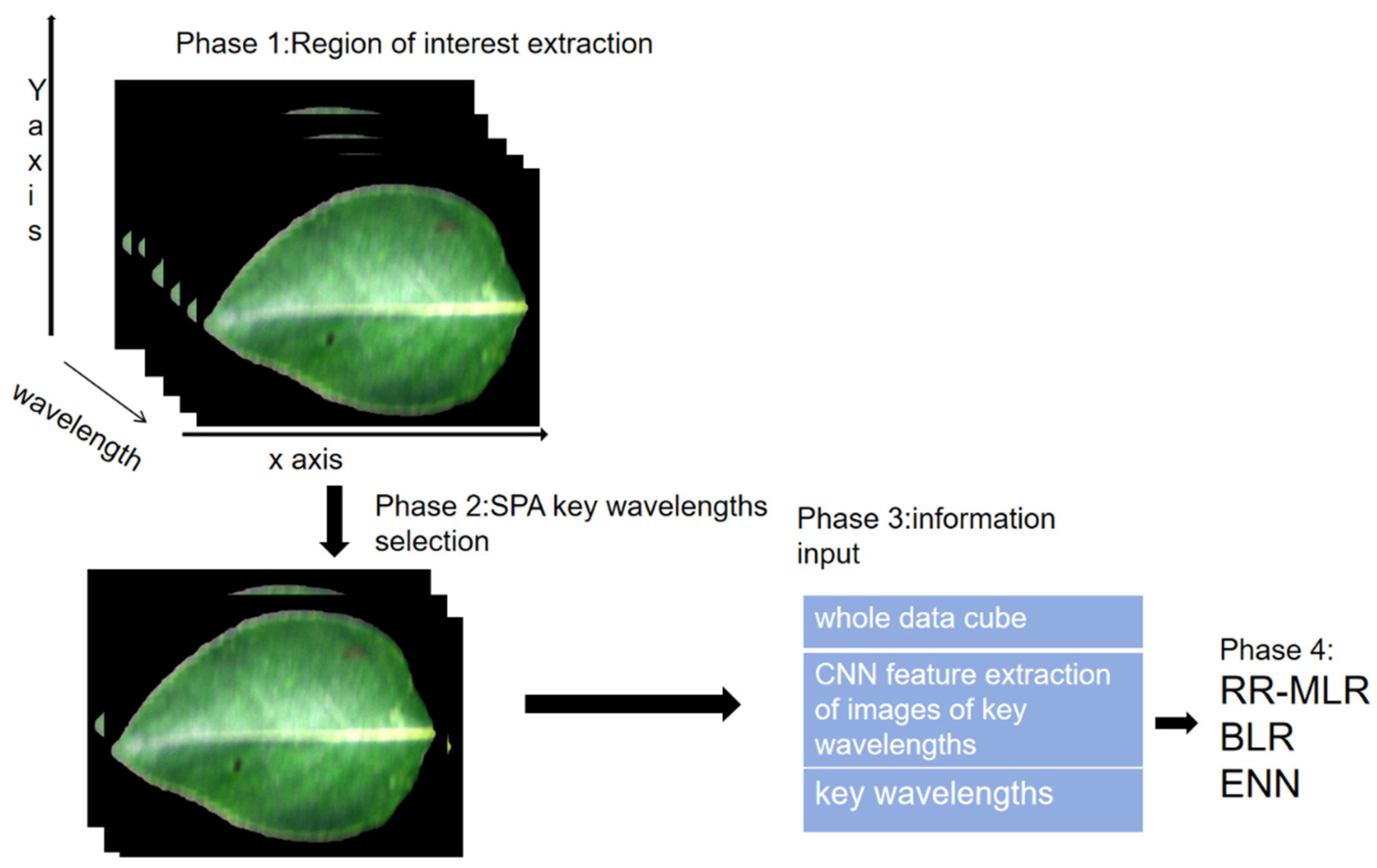
Phase1: region of interest procured from the acquired hyperspectral image (with leaf as an example); Phase 2: data cube acquired after performing dimension reduction (SPA key wavelengths selection); Phase 3: three types of information input into the neural network; Phase 4: machine learning analysis of the input
The proposed workflow has four phases: region-of-interest (ROI) extraction, feature selection, three types of information input into the neural network (whole data cube, main spectral, and CNN feature extraction of key wavelength images), and machine-learning analysis. Region of interest (ROI) selection is usually used in the study to remove the irrelevant target regions. Researchers usually use the application ENVI to extract pixel points in ROI or average spectra of hyperspectral images as pixel-level or object-level data for analysis and processing (Kang et al.,2022). In phase 1, the region-of-interest leaf area was chosen using ENVI. In phase 2, feature wavelengths were selected using a successive projections algorithm (SPA). In the third phase, we procured three types of information, whole data cubes, key wavelengths obtained using SPA, and CNN features of images of key wavelengths. In the fourth phase, three machine-learning models were employed and compared to model plant water stress detection. The final output provided results in the early detection of dry, normal and overwatering plants from the feature wavelengths selected.
2.1. Hyperspectral image acquisition
Resonon imager PIKA L was used for image acquisition (Figure 2). Resonon imaging spectrometers were line-scan imagers, meaning they collected data one line at a time. PIKA L covered the Visible and Near-Infrared (VNIR) spectral range of 400-1000nm. It had 281 spectral channels, with a spectral bandwidth of 2.1nm. The spectral resolution-FWHM was 3.3 nm, while the spatial pixels were 900. Its max frame rate (fps) was 249. The application SpectrononPro can collect data cubes with a Benchtop System. In addition, because the water condition of the live plants can be influenced by the outside environment, such as light, heat, etc., the water content of leaves is prone to change, which may affect the differentiation of leaves under different treatments. Therefore, the hyperspectral camera must be carefully calibrated as frequently as needed to obtain a valid data cube.
The lifting platform was placed on the moving stage. The vertical and horizontal directions were parallel to the corresponding sides of the moving stage. In the meantime, the height of the stage was adjusted so that the distance from the bottom edge of the light source to the whiteboard was about 35cm. The position of the stage was changed so that the inner side of the stage coincided with the longitudinal axis of the lens. And the horizontal axis of the lens was located at 1/3 of the whiteboard on the right. Next, the pear seedling was placed on the moving stage by adjusting the height and spatial orientation of the pear seedling. The target leaf was placed in the longitudinal centre of the whiteboard along the horizontal axis of the lens. It should be sure that the leaf was on the same horizontal plane as the whiteboard. During the entire experiment, the position of the lifting platform was kept fixed, to make sure of the clarity of the image.
The pear seedling leaf was kept on the black background of stiff paper and imaged to acquire the image. Image capture parameters used were 256 frames and 45 steps to get the best resolution image between 400 and 100nm. The exposure time used was 24ms-1. The parameters were kept consistent for all the photos. The resulting hyperspectral images was a particular block of 900×500×300 reflectance image, representing a 3-D image with X-axis and Y-axis coordinate information and the other representing the spectral information at 300 different wavelengths. This information was stored for subsequent analysis.
2.2. Image acquisition and image correction
The image acquisition was conducted in a dark room to avoid undesired light and at a controlled temperature and humidity of 20℃ and 65%, respectively. Hyperspectral datacubes were acquired in the 400-1000nm spectral range with 5nm intervals between contiguous bands. The acquired raw images were corrected with two reference images using the following Equation (1).
Where: R was the relative reflectance image of the sample, was the raw image of the sample, W was the white reference image acquired from a uniform, stable, and high reflectance ceramic tile (reflectance), and D was the current dark image acquired by completely covering the camera lens with its non-reflective opaque black cap (Wang et al., 2018).
2.3. Feature wavelength selection
Feature selection methods in HSI aim to reduce dimensionality while preserving relevant information for later classification (Wang et al., 2004). The selection of wavelength variables is integral to establishing a nondestructive testing model based on hyperspectral imaging. The model can be simplified by screening the characteristic wavelengths or wavelength ranges. Various feature selection techniques have been used to select important variables for spectroscopic data (Wang et al., 2018).
Feature extraction can reduce the dimension of spectral data and improve regression model performance. The successive projections algorithm (SPA) was used to obtain the optimum wavelength. The successive projection algorithm (SPA), a variable-selection technique, was proposed for constructing multivariate calibration models (Woldgiorgis et al., 2021). Later, it was extended to address classification problems (Kandpal et al., 2016). SPA is a one-way selection algorithm that mainly uses collinear minimisation to select the optimal variables (Arau ́jo et al., 2001). The advantage of this algorithm is that the variable group with the least redundant information can be chosen from more spectral variables. In addition, collinearity between variables within a variable group is minimised (Pontes et al., 2005). The SPA is executed in Matlab 2023 (The Math Works, Natick, USA) using a SPA toolbox (available at http://www.ele.ita.br/~kawakami/spa/). The test_size is 0.4, m_min is 2, m_max is 28.
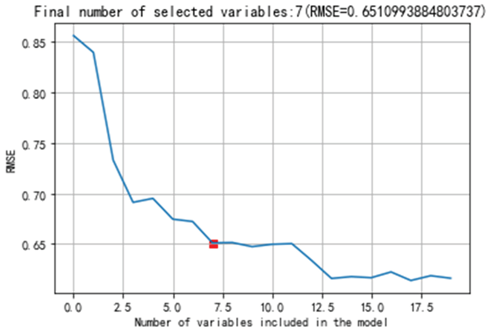
According to Figure 3 and Figure 7 wavelengths were chosen, substituting the 300 wavelengths of the original sample. The optimal wavelengths selected were listed in Table 2. Next, the eigenvectors of the image corresponding to the characteristic wavelength were extracted and put into neural networks for analysis. For these seven wavelengths, we obtain seven images. After applying CNN, for each image, we have 4096 features. After obtaining all features relevant to all the data points, we put into neural networks for analysis.
Different data input is shown in Table 3. In the data input part, the height of each hyperspectral imaging data is 300, the total treatment samples is 30+90×4=390, after SPA major wavelength selection, 7 spectra were selected to represent the original 300 wavelengths. Since we use AlexNet for feature selection, we procured 4096 features for each HSI data cube. Different parameters of neural networks are shown in Table 4.
According to Table 4, for the RR-MLR, the regularization parameter (gam) is 10, for the Bayesian Linear Regression, the covariance (sigma_squared) is 0.01, for the Elman Neural Network, the maximum number of iterations (epoch) is 2000, the target error (goal) is 1e-5, and the learning rate (lr) is 0.01.
3. Machine learning methods
The acquired hyperspectral data was analysed using machine learning methods. The data set was randomly divided into training dataset (80% of the hyperspectral data) and testing dataset (20% of the hyperspectral data).
Machine learning algorithms are effective for expressing complex relationships (Chang, 2007). Convolutional Neural Network (CNN) is used for feature extraction. Models such as Data Classification for Multiple Linear Regression Based on Ridge Regression, Bayesian Linear Regression, and Elman Neural Network are introduced in our research. These machine learning models are classic algorithms known for their relative high efficiency and accuracy, which can be used for image classification. In our research, we designed these three models under the same frame.
Multiple Linear Regression Based on Ridge Regression is a valuable technique for improving the performance and stability of Multiple Linear Regression models, particularly when dealing with multicollinearity and the risk of overfitting (Luo & Liu, 2017). It strikes a balance between bias and variance, making it a useful tool in many real-world regression problems (Matdoan et al., 2021). Regression models for predicting rice yield and protein content using unmanned aerial vehicle-based multispectral imagery was employed by Kang et al. (2021).
Bayesian Linear Regression offers several advantages over traditional frequentist linear regression methods: Bayesian Linear Regression allows to incorporate prior information or beliefs about the model parameters (Baldwin & Larson, 2017). Bayesian Linear Regression provides a full posterior distribution over the model parameters, not just point estimates (Kong et al., 2020). Bayesian methods can be effective when dealing with small datasets, as they naturally incorporate prior information, which becomes more influential when data is limited (Barbier et al., 2021). Bayesian model averaging was used to improve the yield prediction in wheat breeding trials (Fei et al., 2023).
Elman networks can be designed with varying degrees of complexity by adjusting the number of hidden units in the recurrent layer (Wang et al., 2021). This flexibility allows you to control the model’s capacity, making it suitable for both simple and complex tasks (Thilagaraj et al., 2021). Elman networks can handle input sequences of varying lengths (Sriram et al., 2018). This is advantageous when dealing with data where the number of time steps may change from one example to another. Elman neural network is used as a rapid prediction method of moisture content for green tea fixation (Lan et al., 2022).
3.1. Convolutional neural network (CNN) feature extraction
Convolutional neural networks, as a deep feedforward network, are commonly used to process multiple arrays of data, such as time series, images, and audio spectrograms (Chen et al.,2023). This application showed that CNN is capable of learning the features of the hyperspectral data well when properly trained. A typical convolutional neural network consists of a convolutional layer, a pooling layer, and a fully connected layer, each with a different function. The convolution layer convolves the input vector through the convolution kernel to generate a feature vector, and all units in the same feature value share the same filter. The pooling layer is located behind the convolutional layer and is divided into maximum pooling and average pooling, which compresses the input feature information and simplifies the computational complexity of the network (Gu et al.,2018).
The spectral information is calculated by the convolutional layer and the maximum pooling layer (Li et al.,2021). The network model effectively extracts the local and global features that cannot be directly obtained from the original spectral data and convert the extracted feature inputs into vectors by the global average pooling layer (Yamashita et al.,2018). The fully connected layer is used to convert the inputs into vectors and to realise the classification function (O’Shea & Nash, 2015).
The structural system of the convolutional neural network is mainly composed of two parts, namely, the feature extractor and the classifier (Albawi et al.,2017). The feature extractor usually consists of a stack of several convolutional layers and a maximum pooling layer, and the classifier is usually a fully connected softmax layer (Yang & Li,2017).
At a convolution layer, the previous layers’ feature maps are convolved with learnable kernels and put through the activation function to form the output feature map. Each output map may combine convolutions with multiple input maps. In general, we have that
Where represents a selection of input data, and the convolution is of the “valid” border handling type when implemented in MATLAB (Bouvrie,2006). Each output map is given an additive bias b, however for a particular output map, the input maps will be convolved with distrinct kernels. That is to say, if output map j and map k both sum over input map i, then the kernels applied to map i are different for output maps j and k.
3.2. Baseline model
3.2.1. Data Classification for Multiple Linear Regression Based on Ridge Regression
In Hoerl & Kennard (1970) it was shown that the optimal value of k, i.e., the value that minimizes the mean square error (MSE), is the following:
Based on the results obtained from the optimal value of k in that same article the authors sugested the following estimator of the ridge parameter:
Where = and are the residuals obtained from the OLS regression and is the maximum element of . Hence, for this estimator, and are simly replaced by their unbiased estimators. Further developments were then made by Kibria (2003) where the following estimators were proposed:
and
Where .
Khalaf and Shukur (2005) suggested a new method to estimate the ridge parameter k, as a modification of :
Where is the maximum eigenvalue of . Using the same idea as in Kibria (2003), Khalaf & Shukur (2005), and Alkhamisi et al. (2006) we have the following estimators for k:
and
Where
= .
In this article, we propose a modification of all of these estimators by multiplying them by the amount (10). The eigenvalues of the matrix of cross-products equal to one when the regressors are independent.
To investigate the performance of the RR and OLS, we calculate the MSE using the following equation:
Where is the estimator of β obtained from OLS or RR, and R equals 2000 which corresponds to the number of replicates used in the Monte Carlo simulation (Khalaf et al., 2013).
3.2.2. Bayesian linear regression
Provided a dataset
is the input variable, is the corresponding target value, N is the number of data samples (Kong et al., 2020).
Regression aims at providing a specific predictive value given the input variable . Form of linear regression mainly contains two types: standard linear model and kernelized model, which are given by Equations (12), (13), respectively (Bishop, 2006). The standard linear model is a linear combination of the elements of the input variable while the kernelized model is a linear combination of a set of nonlinear functions of the input variable.
where is the ith element of the weight vector w, is the ith element of the input variable , is the kernel function (Tipping, 2003).
The above two regression models can be uniformly expressed by:
where , is the ‘design’ matrix, =y()is referred to as ‘basis function’.
is the standard linear model under the conditions of M=d and .
is the kernelized model under the conditions of M=N and
3.2.3. Elman Neural Network
The network is a single recursive network that has a context layer as an inside self-reference layer, see Figure 6. During operation, both current input from the input layer and previous state of the hidden layer saved in the context layer activate the hidden layer. Note that there exists an energy function associated with the hidden layer, context layer, and input layer (Liou, 2006). With successive training, the connection weights can load the temporal relations in the training word sequences.
Figure 6.
the Elman network (Liou & Lin, 2006).
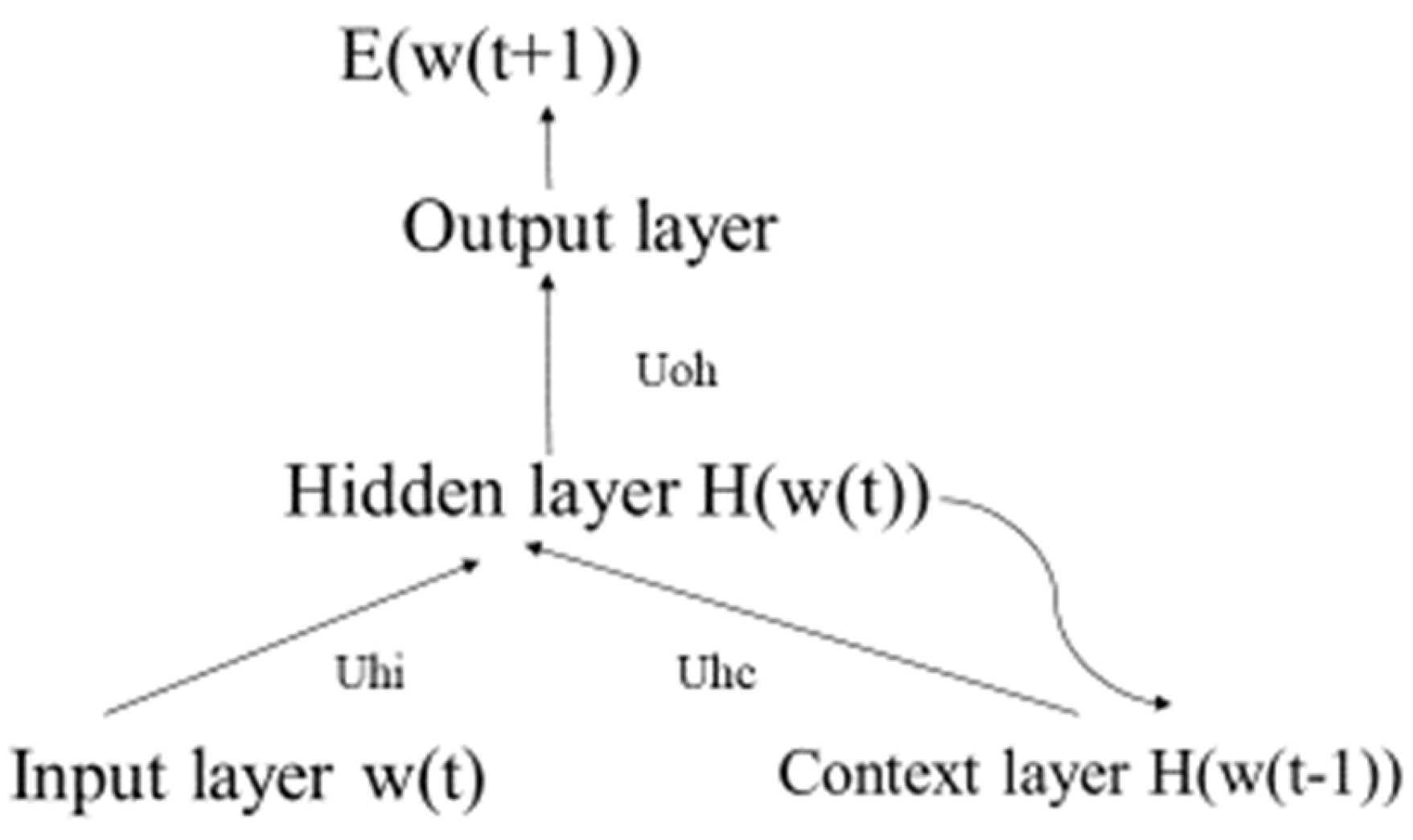
The context layer carries the memory. The hidden layer activates the output layer and refreshes the context layer with the current state of the hidden layer. The back-propagation learning algorithm (Rumelhart & McClelland,1986) is commonly employed to train the weights in order to reduce the difference between the output of the output layer and its desired output. In this study, the threshold value of every neuron in the network is set to zero. Let and be the number of neurons in the output layer, the hidden layer, the context layer, and the input layer, respectively. In the Elamn network, is equal to . In this study, the number of neurons in the input layer is equal to that in the output layer and is also equal to the number of total features, that is, R= (15)
Let
be the code set of different words in a corpus. The corpus, D, contains a collection of all given sentences. During training, a sentence is randomly selected from the corpus and fed to the network sequentially, word by word, starting from the first word of the sentence. Let |D| be the total length of all the sentences in the corpus, D. |D| is the total number of words in D. Usually, |D| is several times the number of different words in the corpus, so |D|>N. Initially, t=0, and all weights are set to small random numbers. Let w(t) be the current word in a selected sentence at time t, i.e.,
where is the last word of a training epoch. In this study, we set T=4|D| in one epoch. This means that in each epoch, we use all the sentences in the corpus to train the Elman network four times. Let the three weight matrices between layers be and , where is an by matrix, is an by matrix, and is an by matrix, as shown in Figure 6. The output vector of the hidden layer is denoted as when is fed to the input layer.
is an by 1 column vector with elements. Let be the output vector of the output layer when is fed to the input layer. is an by 1 column vector.
The function of the network is
Where is a sigmoid activation function that operates on each element of a vector (Rumelhart & McClelland,1986). We use the sigmoid fucntion for all neurons in the network. This function gives a value roughly between 1.7159 and 1.7159.
4. Performance metrics
4.1. Confusion matrix
Performance measurement is vital in defining the effectiveness of a program. Confusion matrixes are a common evaluation tool used in machine learning (An, 2020). Generally, they consist of a n n table plotting actual class against predicted class (n denoting the number of classes, so a binary classifier would utilize a 2 2 table), to which the true and false (determined by the actual classes) positives and negatives (determined by the predicted classes) fit within (Visa et al., 2011).
4.2. Accuracy
In practical applications, we should take the accuracy of the classifier into consideration. Because scientists and farmers are more concerned with the situations where the classifier sorts the drought pear seedling leaves as sound ones if the classifier makes the wrong decision, which will hinder the timely watering of the plants, leading to more significant potential economic losses than discarding the plants.
Accuracy (total correct divided by the total number of assessments), however, does not consider the significance of misidentified class (Halimu et al., 2019) and tends to be an overaly optimistic performance indicator.
4.3. evaluation metrics for classification algorithms
Commonly used evaluation metrics for classification algorithms include recall, precision, F1 score and mse-loss. Recall measures the ability to identify positive samples, precision measures the accuracy of positive sample predictions, and F1 score is a metric that combines recall and precision. MSE-loss is a criterion that measures the mean squared error between each element in the input and target.These metrics can be selected and weighted based on specific requirements. The formulas for these metrics are provided accordingly.
Where TP is true positive, TN is true negative, FP is false positive, FN is false negative, P is precision, and R is recall (Shu et al., 2023).
All hyperspectral data processing was conducted in ENVI and statistical analysis were executed in MATLAB 2023. All experiments were performed under a Windows 10 OS on a machine with CPU Intel Core i7-7820HK @ 2.90 GHz, GPU NVIDIA GeForce 1080 with Max-Q Design, and 8GB of RAM.
4. Result
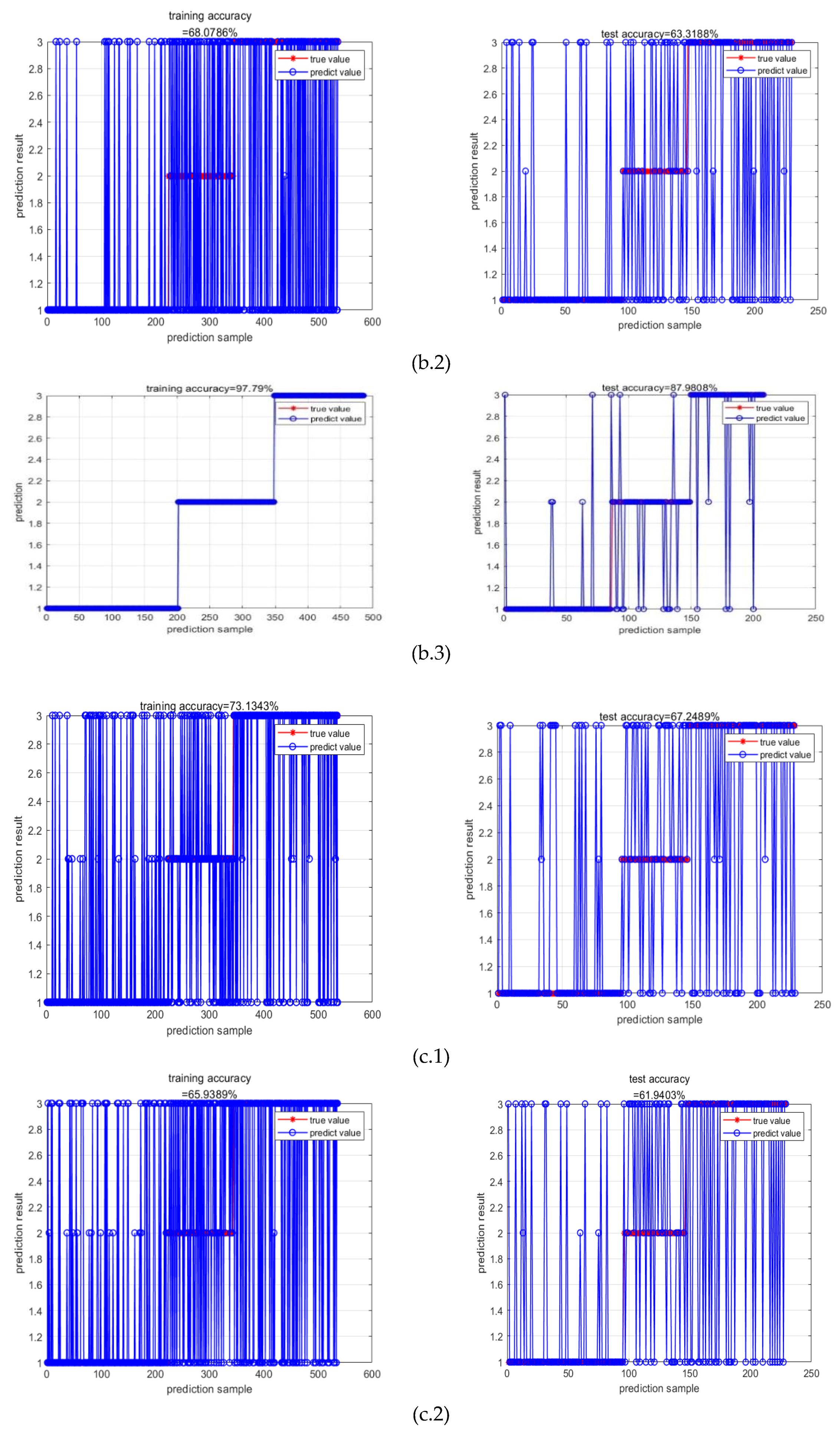
Three types of information, the whole data cubes, key wavelengths selected using SPA and CNN features of main spectra were input into the different neural networks. To avoid over-fitting problem, we obtained the accuracy using 10-fold cross validation which uses 9/10 of data as for training the algorithm and the remaining for testing puprpose and repeats the process 10 times and get the average result. 4096 features were extracted using CNN neural network for each main spectra. In the CNN features analysis, We compared the classification results of the Multiple Linear Regression based on Ridge Regression (a), Bayesian linear regression (b), and Elman Neural Network (c) (Figures 7–9).
Figures 7–9 illustrates the confusion matrix representing the classification results of the three neural networks in the context of main spectra analysis and CNN feature from images of key wavelengths, both for the training and test datasets. For the training dataset, all three neural networks have accurately categorized the samples into their respective groups.
Whole data cube (a.1), main spectra analysis (a.2) and CNN feature of main spectra analysis (a.3) in Multiple Linear Regression based on Ridge Regression (a); 1 stands for the normal group, 2 stands for the overwatering group and 3 stands for the drought group
According to Figure 4, in the whole data cube analysis, in the confusion matrix for train data in RR-MLR, 178 out of 247 normal samples were correctly identified; but 30 overwatering samples were wrongly treated as normal, 25 overwatering samples wrongly treated as drought (45.8%). In the confusion matrix for test data, 56 out of 83 drought samples were correctly identified as drought(67.5%). Whereas in the main spectra classification, 33 overwater samples were wrongly identified as normal, and 61 overwater samples wrongly treated as drought (78.3%). In the test data, 76 out of 95 samples were correctly identified as normal (80%). In the CNN feature analysis, during the testing phase of Multiple Linear Regression based on Ridge Regression, out of 81 samples, 68 were correctly identified as belonging to the normal treatment group. However, there were misclassifications, where 11 samples from the overwatering group and 2 samples from the drought group were wrongly categorized into the normal treatment group.
whole data cube (b.1), main spectra analysis (b.2) and CNN feature of main spectra analysis (b.3) in Multiple Linear Regression based on Bayesian linear regression (b); 1 stands for the normal group, 2 stands for the overwatering group and 3 stands for the drought group
In the whole data cube analysis (Figure 5), in the train data of Bayesian linear regression, 180 out of 261 samples were correctly identified as normal (69%), while 51 out of 120 samples were correctly identified as overwatering (57.5%). In the test data, out of 51 overwatering samples, 13 were correctly identified (25.5%). By comparison, in the main spectra analysis, 203 out of 223 normal water samples were correctly identified (91%), but 105 drought samples were wrongly taken as normal and 1 drought sample wrongly taken as overwatered (45.1%). In the test data, only 1 overwater sample was correctly pinpointed, but 33 overwater samples and 17 overwater samples were wrongly taken as normal and drought respectively (98%). In the CNN feature analysis, in the testing dataset of Bayesian linear regression, 50 out of 55 overwatering samples were correctly identified and classified as belonging to the overwatering group. However, misclassifications existed, where 3 samples from the normal group and 2 samples from the drought group were wrongly identified and categorized as belonging to the overwatering group.
Figure 5.
Confusion matrix of training and testing set of data.
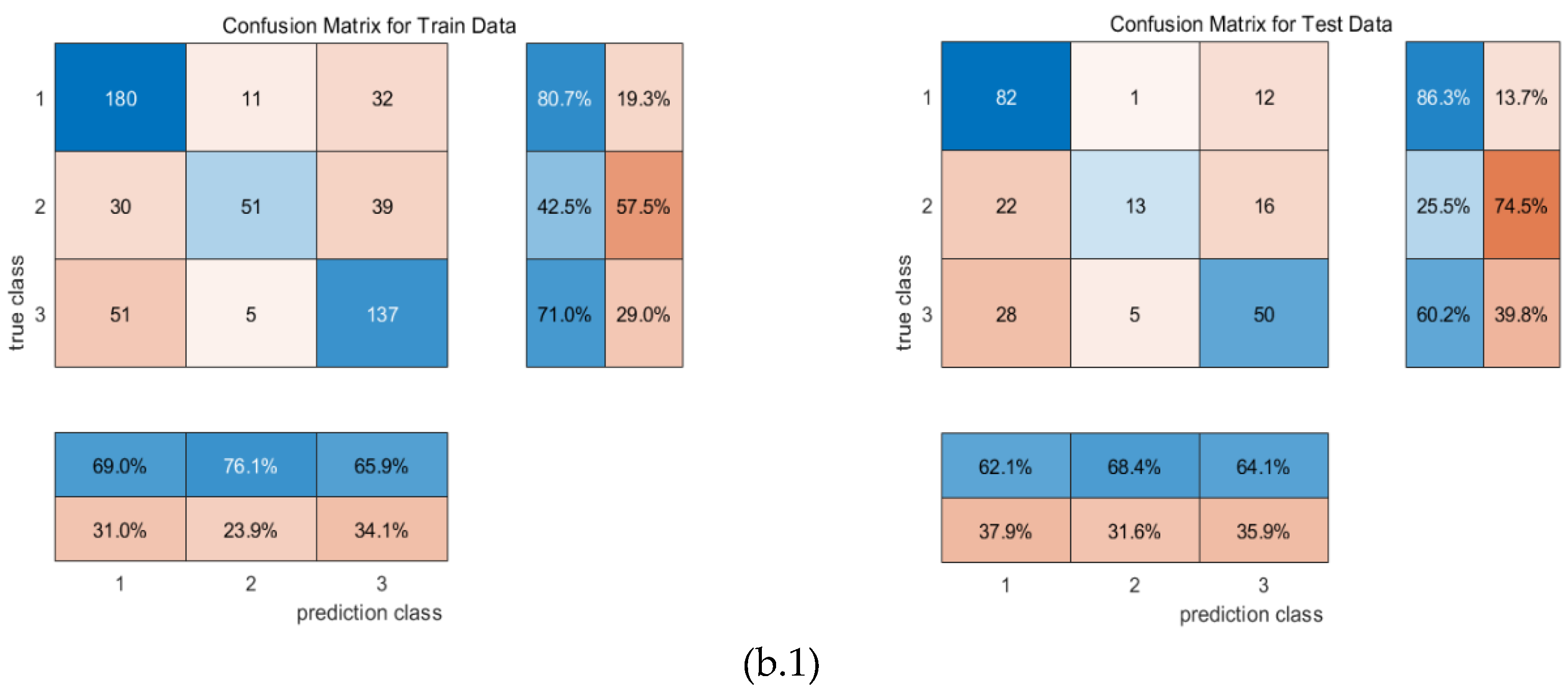
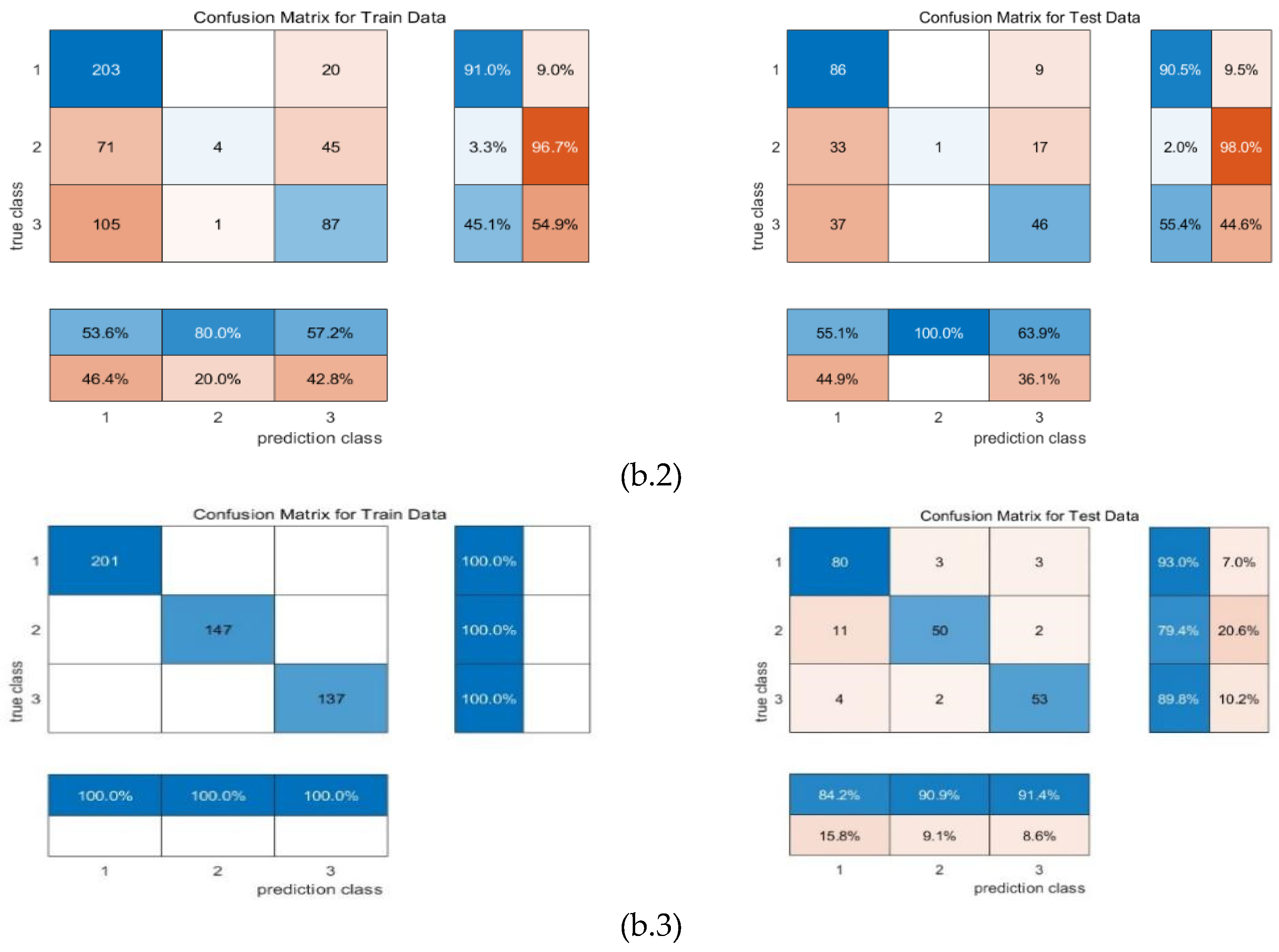
Figure 6.
Confusion matrix of training and testing set of data.
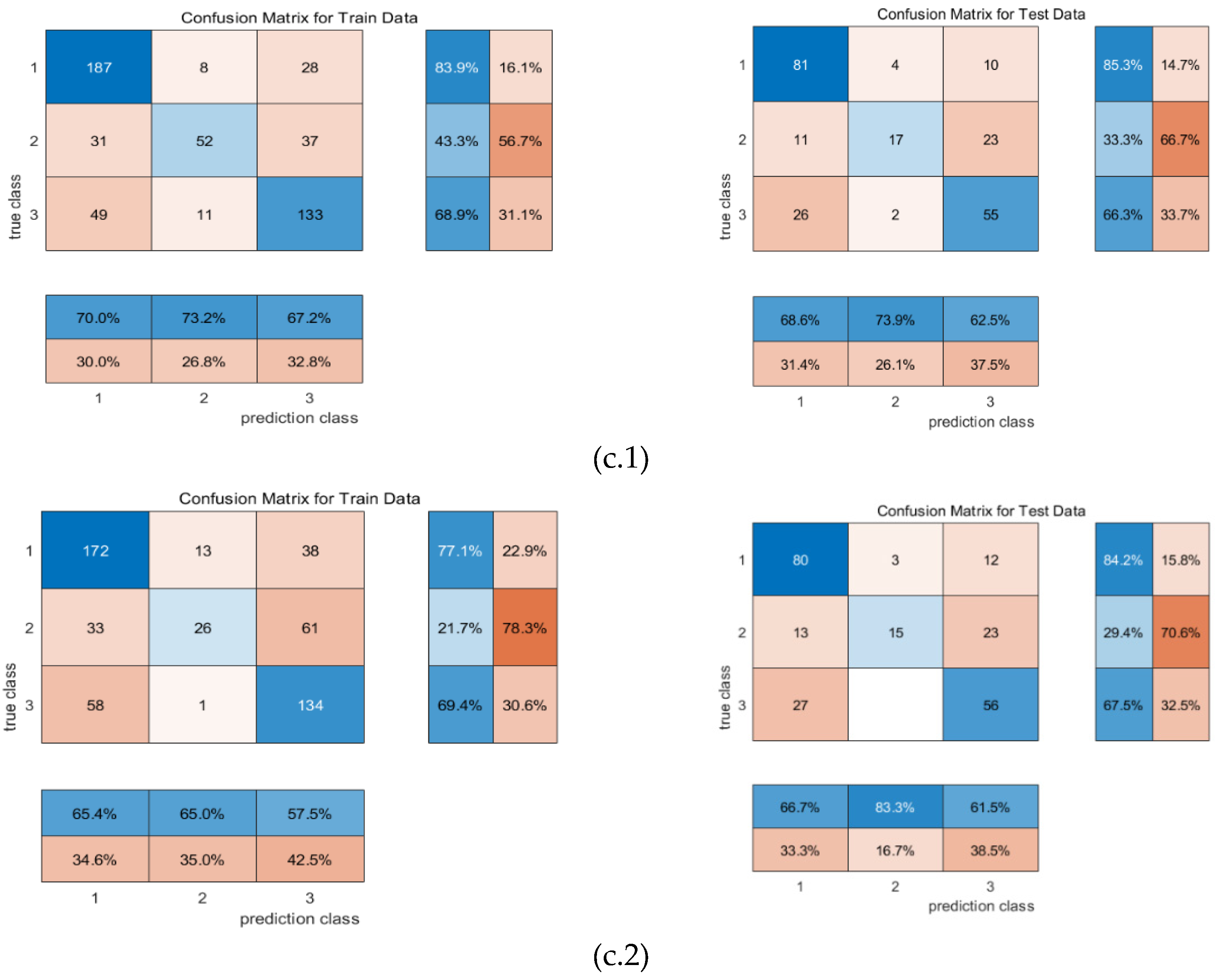
whole data cube (c.1), main spectra analysis (c.2) and CNN feature of main spectra analysis (c.3) in Multiple Linear Regression based on Elman Neural Network (c); 1 stands for the normal group, 2 stands for the overwatering group and 3 stands for the drought group
In the whole data cube analysis of Elman Neural Network (Figure 6), 187 out of 223 normal samples were correctly identified (83.9%), but 8 normal samples were wrongly identified as drought, and 28 wrongly identified as normal. By comparison, in the test data, 17 overwatering samples were correctly identified, but 11 overwatering samples were taken as normal and 23 overwatering samples were taken as drought (66.7%). In the confusion matrix of train data, 172 out of 223 samples were correctly identified as normal (77.1%), but 58 drought samples were wrongly taken as receiving normal treatment. In the test dataset, 80 out of 95 samples were correctly identified as normal (84.2%), whereas 13 overwater samples and 23 overwater samples were taken as normal and drought respectively (70.6%). In the CNN feature analysis, in the testing dataset of the Elman Neural Network, 54 out of 61 drought samples were correctly detected and classified as belonging to the drought group. However, there were misclassifications, where 4 samples from the normal group and 3 samples from the overwatering group were wrongly identified and categorized as belonging to the drought group.
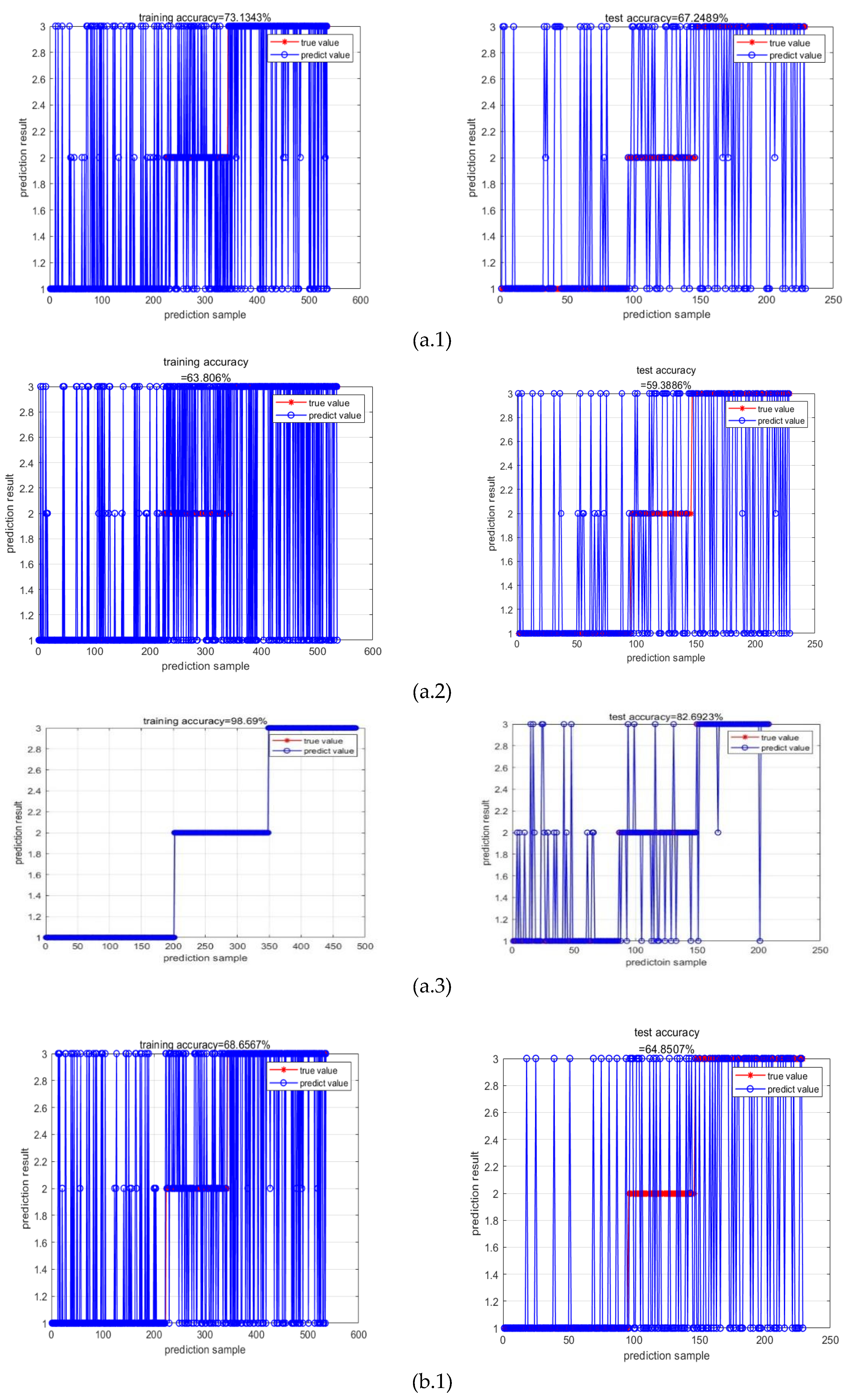
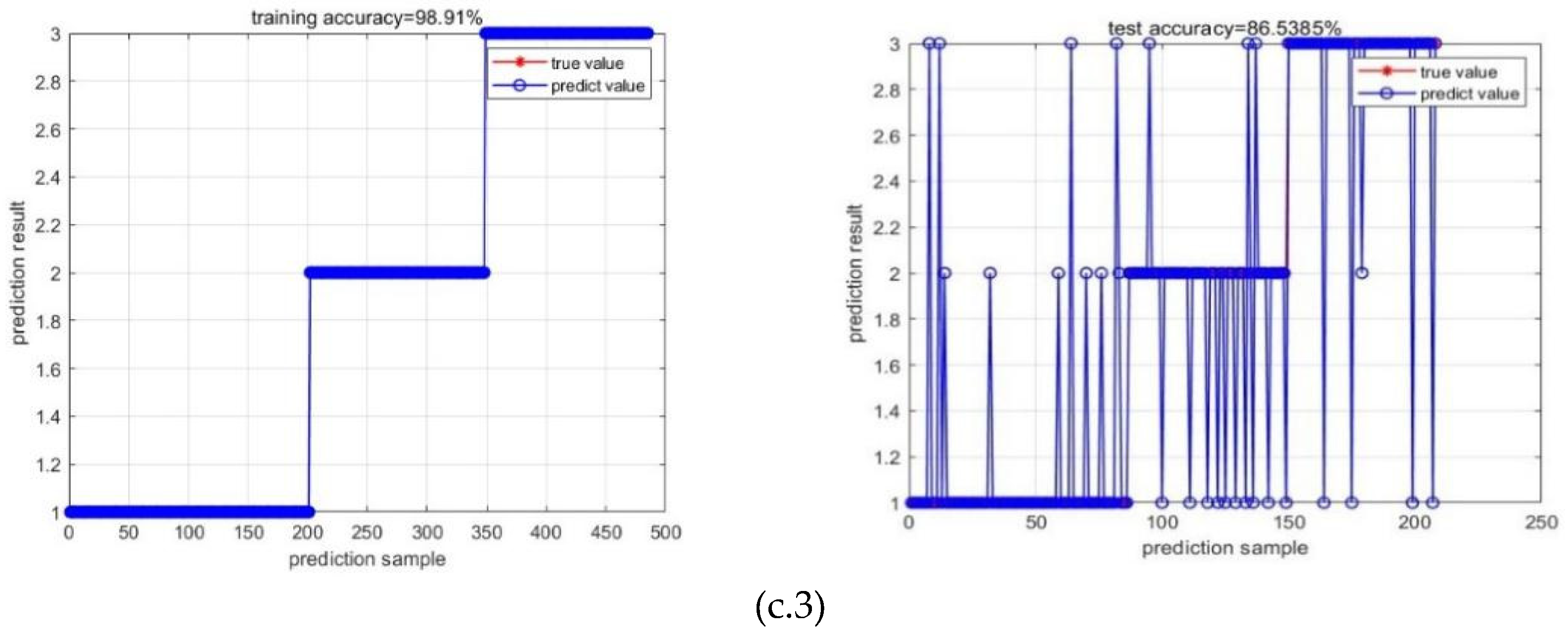
Table 5 shows the performance metrics of each machine learning methods and different inputs. According to the study, the performance of key wavelengths after SPA performed worse than the whole data cube, that is because the height of each hyperspectral cube is decreased drastically after the major wavelength selection. In the CNN feature of key wavelength image analysis, in the test dataset, Multiple Linear Regression based on Ridge Regression achieved the lowest accuracy at 82.69%, while Bayesian Linear Regression had the highest test accuracy at 87.98%. And the performance of CNN feature of key wavelength image analysis all outperformed the machine learning analysis of main spectra. In CNN feature analysis of Bayes and Elman, both F1 score is 0.87. Elman also has the precision of 0.87. Bayes has the highest recall rate of 0.91. Details of the training and test accuracy of the three neural networks used for hyperspectral imaging classification is shown in Figure 8 in Appendix A.
4. Conclusion and Discussion
As can be seen from the experiment result, the hyperspectral imaging classification result shows differences among groups under different water treatments. Therefore, the hyperspectral imaging tool with these three machine learning models can effectively differentiate leaves with various water stresses while the young seedlings are still growing. Timely measures can be taken to avoid irreparable loss.
We used hyperspectral imaging coupled with machine learning to identify pear seedling leaves under different water stresses because of its ability to automatically learn the spatiotemporal features without handcrafting and thus achieve high classification accuracy. RR-MLR, Bayes and Elman were used to classify the pear seeling hyperspectral images. According to our research, CNN features of main spectra outperformed mere spectral features in the machine learning algorithms.
Besides, our research confirms the findings of Zhao et al. (2020). Zhao et al. (2020) demonstrated the strong potential of using HSI technology for tomato leaf water status monitoring in plant factories. This experiment’s best leaf water content assessment model was attained using the normalised difference vegetation index (NDVI) with individual raw relative reflection (RAW) wavelengths and 1300 nm and 1310 nm wavelengths. Previous studies have shown that the NIR plateau between 800 nm and 1300 nm and water absorption bands above 1300 nm are common characteristics of reflectance spectra of all healthy green plants. The high reflectivity in the NIR region of 800 nm to 1300 nm is due to the porous plant leaf structure (tissues and cells) (Zhao et al., 2018). In addition, the reflectivity of the absorption band at 970 nm was significantly affected by factors such as water (Li et al.,2021).
Our study fills the gap by integrating hyperspectral imaging with machine learning models for differentiating plant leaves under water stress. This innovative approach offers the potential for enhanced accuracy and robustness in water stress detection, contributing to improved water management strategies and optimized plant growth in agricultural practices. The concept of employing Convolutional Neural Networks (CNNs) for the feature extraction from images of primary spectra represents an innovative and unexplored approach in the realm of image processing and spectral analysis. This method, pioneering in its application, leverages the advanced capabilities of CNNs to discern and extract key features from spectral images, a technique not previously attempted in this field.
In our research, a more significant number of hyperspectral cubes could be collected to improve the accuracy of our experiments. Furthermore, the methodology presented in this paper can be implemented in a plant water condition monitoring system. This plant water condition monitoring system will be tested in pots and field experiments, guiding farmers on irrigation problems. Overall, the outcomes of this research will play a crucial role in advancing precise water management practices. By accurately detecting water stress conditions and understanding the temporal dynamics of plant responses, we can implement more effective and sustainable water management approaches to optimize plant growth and yield while conserving water resources.
Funding
This study was financially supported by the Agriculture Science and Technology of Shandong Province (2019YO015) Breeding Plan of Shandong Provincial (2019LZG008).
Acknowledgments
I would love to appreciate the help provided by Jihong Tian, my mum.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Figure 8.
training and test accuracy of whole data cube (1), main spectra analysis (2) and CNN feature of main spectra analysis (3) in Multiple Linear Regression based on Ridge Regression (a), Bayesian linear regression (b), and Elman Neural Network (c).
Figure 8.
training and test accuracy of whole data cube (1), main spectra analysis (2) and CNN feature of main spectra analysis (3) in Multiple Linear Regression based on Ridge Regression (a), Bayesian linear regression (b), and Elman Neural Network (c).
References
- Ahmat, R.; Hasan, U.; Abliz, A.; Kasim, J. Hyperspectral estimate of Spring wheat leaf water content based on machine learning. Journal of Triticeae Crops 2021, 42, 640–648. [Google Scholar]
- Ahmed, M.; Yasmin, J.; Collins, W.; Cho, B. X-ray CT image analysis for the morphology of muskmelon seed in relation to germination. Biosyst. Eng 2018, 175, 183–193. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In 2017 international conference on Engineering and Technology (ICET). IEEE. 2017; pp. 1-6. [CrossRef]
- Alkhamisi, M.A.; Khalaf, G.; Shukur, G. Some modifications for Choosing ridge parameter. Commun. Statist. Theor. Meth 2006, 35, 1–16. [Google Scholar] [CrossRef]
- Amatya, S.; Karkee, M.; Alva, A.; Larbi, P.; Adhikari, B. (2012). Hyperspectral Imaging for Detecting Water Stress in Potatoes. ASABE. Dallas, Texas, July 29 - August 1, 2012. St. Joseph, MI. [CrossRef]
- Ambrose, A.; Lohumi, S.; Lee, W.; Cho, B. Comparative nondestructive measurement of corn seed viability using Fourier transform near-infrared (FT-NIR) and Raman spectroscopy. Sens. Actuators, B Chem 2016, 224, 500–506. [Google Scholar] [CrossRef]
- Arau ́jo, M.; Saldanha, T.; Galva ̃o, R.; Yoneyama, T.; Chame, H.; Visani, V. Chemom. Intell. Lab. Syst 2001, 57.
- Baldwin, S.A.; Larson, M.J. An introduction to using Bayesian linear regression with clinical data. Behaviour research and therapy 2017, 98, 58–75. [Google Scholar] [CrossRef] [PubMed]
- Barbier, J.; Chen, W.K.; Panchenko, D.; Sáenz, M. Performance of Bayesian linear regression in a model with mismatch. arXiv arXiv:2107.06936, 2021.
- Barrs, H.; Weatherly, P.A. re-examination of the relative turgidity technique for estimating water deficits in leaves. Aus. J. Biol. Sci 1962, 15, 413–428. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern recognition and machine learning (Vol. 4, No. 4, p. 738). New York: springer. 2006. [CrossRef]
- Bouvrie, J. (2006). Notes on convolutional neural networks.
- Canny, M.J.; Huang, C.X. Leaf water content and palisade cell size. New phytologist 2006, 170, 75–85. [Google Scholar] [CrossRef]
- Chang, C. (2007). Hyperspectral data exploitation: Theory and Applications. John Wiley; Sons. [CrossRef]
- Chen, Q.; Tang, B.; Long, Z.; Miao, J.; Huang, Z.; Dai, R.; Shi, S.; Zhao, M.; Zhong, N. Water quality classification using convolutional neural network based on UV-Vis Spectroscopy. Spectroscopy and Spectral Analysis 2022, 43. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc.IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Cifre, J.; Bota, J.; Escalona, J.; Medrano, H.; Flexas, J. Physiological tools for irrigation scheduling in grapevine (vitis vinifera l. ): an open gate to improve water-use efficiency? Agriculture Ecosystems & Environment 2005, 106, 159–170. [Google Scholar] [CrossRef]
- Costa, J.; Grant, O.; Chaves, M. Thermography to explore plant-environment interactions. J. Exp. Bot. 2013, 64, 3937–3949. [Google Scholar] [CrossRef] [PubMed]
- Fei, S.; Chen, Z.; Li, L.; Ma, Y.; Xiao, Y. Bayesian model averaging to improve the yield prediction in wheat breeding trials. Agricultural and Forest Meteorology 2023, 328, 109237. [Google Scholar] [CrossRef]
- Ferentinos, K.P. Deep learning models for plant disease detection and diagnosis. Computers and Electronics in Agriculture 2018, 145, 311–318. [Google Scholar] [CrossRef]
- Ge, Y.; Bai, G.; Stoerger, V.; Schnable, J.C. Temporal dynamics of maize plant growth, water use, and leaf water content using automated high throughput RGB and hyperspectral imaging. Computers and Electronics in Agriculture 2016, 127, 625–632. [Google Scholar] [CrossRef]
- Gewali, U.; Monteiro, S.; Saber, E. (2018). Machine learning based hyperspectral image analysis: A survey. ArXiv abs/1802.08701.
- Giannoni, L.; Lang, F.; Tachtsidis, L. Hyperspectral imaging solutions for brain tissue metabolic and hemodynamic monitoring: past, current and future developments. Journal of Optics 2018, 20, 044009. [Google Scholar] [CrossRef] [PubMed]
- Golhani, K.; Balasundram, S.K.; Vadamalai, G.; Pradhan, B. Selection of a spectral index for detection of orange spotting disease in oil palm (Elaeis guineensis Jacq.) using red edge and neural network techniques. Journal of the Indian Society of Remote Sensing 2019, 47, 639–646. [Google Scholar] [CrossRef]
- Govender, M.; Govender, P.J.; Weiersbye, I.M.; Witkowski, E.T.F.; Ahmed, F. Review of commonly used remote sensing and ground-based technologies to measure plant water stress. Water Sa 2009, 35. [Google Scholar] [CrossRef]
- Govindjree, W.; Fork, D.; Armond, P. Chlorophyll a fluorescence transient as an indicator of water potential of leaves. Plant Sci. Letter 1981, 20. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; Chen, T. Recent advances in convolutional neural networks. Pattern recognition 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Guifen, C.; Shan, Z.; Liying, C.; Siwei, F.; Jiaxin, Z. Corn plant disease recognition based on migration learning and convolutional neural network. Smart Agriculture 2019, 1, 34. [Google Scholar]
- Guretzki, S.; Papenbrock, J. Comparative analysis of methods analyzing effects of drought on the herbaceous plant Lablab purpureas. Journal of Applied Botany and Food Quality 2013, 86, 47–54. [Google Scholar]
- Halimu, C.; Kasem, A.; Newaz, S.H.S. (2019). Empirical Comparison of Area under ROC curve (AUC) and Mathew Correlation Coefficient (MCC) for Evaluating Machine Learning Algorithms on Imbalanced Datasets for Binary Classification Proceedings of the 3rd International Conference on Machine Learning and Soft Computing, Da Lat, Viet Nam. [CrossRef]
- Han, X.; Gui, X.; Yang, L. Introduction to the application and promotion of water and fertiliser integration technology in poor mountainous areas in poor mountainous regions of the north. Modern Horticulture 2018, 2, 232–233. [Google Scholar]
- He, B.; Han, Li.; Zhu, N.; Yu, J.; Qi, C.; Cai, L.; Gu, X. Effects of different irrigation strategies on growth and fruit trains of cherry and tomato. Vegetables 2022, 7. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identify mappings in deep residual networks. Computer Vision and Pattern Recognition. arXiv arXiv:1603.05027, 2016.
- Hernandez, J.; Lobos, G.; Matus, I.; del Pozo, A.; Silva, P.; Galleguillos, M. Using Ridge Regression Models to Estimate Grain Yield from Field Spectral Data in Bread Wheat (Triticum Aestivum L.) Grown under Three Water Regimes. Remote Sensing 2015, 7, 2109–2126. [Google Scholar] [CrossRef]
- How to use Pear. (2023). Chinese Medical Information Platform.
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for non-orthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L. Deep Convolutional Neural Networks for Hyperspectral Image Classification[J]. Journal of Sensors 2015, 2, 1–12. [Google Scholar] [CrossRef]
- Jones, H.G. Irrigation scheduling: advantages and pitfalls of plant-based methods. J. Exp. Bot. 2004, 55, 2427–2436. [Google Scholar] [CrossRef]
- Junttila, S.; Hölttä, T.; Saarinen, N.; Kankare, V.; Yrttimaa, T.; Hyyppä, J.; Vastaranta, M. Close-range hyperspectral spectroscopy reveals leaf water content dynamics. Remote Sensing of Environment 2022, 277, 113071. [Google Scholar] [CrossRef]
- Kandpal, L.; Lohumi, S.; Kim, M.; Kang, J.; Cho, B. Near-infrared hyperspectral imaging system coupled with multivariate methods to predict viability and vigour in muskmelon seeds. Sensors and Actuators B: Chemical 2016, 229, 534–544. [Google Scholar] [CrossRef]
- Kang, Z.; Zhao, Y.; Chen, L.; Guo, Y.; Mu, Q.; Wang, S. Advances in Machine Learning and Hyperspectral Imaging in the Food Supply Chain. Food Eng Rev 2022, 14, 596–616. [Google Scholar] [CrossRef]
- Kang, Y.; Nam, J.; Kim, Y.; Lee, S.; Seong, D.; Jang, S.; Ryu, C. Assessment of regression models for predicting rice yield and protein content using unmanned aerial vehicle-based multispectral imagery. Remote Sensing 2021, 13, 1508. [Google Scholar] [CrossRef]
- Katsoulas, N.; Elvanidi, A.; Ferentinos, K.; Bartzanas, T.; Kittas, C. A hyperspectral imaging system for plant water stress detection: Calibration and Preliminary Results. Agricongress 2014.
- Khalaf, G.; Månsson, K.; Shukur, G. Modified ridge regression estimators. Communications in Statistics-Theory and Methods 2013, 42, 1476–1487. [Google Scholar] [CrossRef]
- Khalaf, G.; Shukur, G. Choosing ridge parameters for regression problems. Commun. Statist. Theor. Meth 2005, 34, 1177–1182. [Google Scholar] [CrossRef]
- Kibria, B. Performance of some new ridge regression estimators. Commun. Statist. Theor. Meth 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Kong, D.; Zhu, J.; Duan, C.; Lu, L.; Chen, D. Bayesian linear regression for surface roughness prediction. Mechanical Systems and Signal Processing 2020, 142, 106770. [Google Scholar] [CrossRef]
- Lan, T.; Shen, S.; Yuan, H.; Jiang, Y.; Tong, H.; Ye, Y.A. Rapid Prediction Method of Moisture Content for Green Tea Fixation Based on WOA-Elman. Foods 2022, 11, 2928. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: analysis, applications, and prospects. IEEE transactions on neural networks and learning systems 2021. [CrossRef] [PubMed]
- Li, H.; Yang, W.; Lei, J.; She, J.; Zhou, X. Estimation of leaf water content from hyperspectral data of different plant species by using three new spectral absorption indices. PLoS ONE 2021, 16, e0249351. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Li, S.; Su, J.A. Multi-Category Brain Tumor Classification Method Bases on Improved ResNet50. CMC-Computers, Materials; Continua 2021, 69, 2355–2366. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Z.; Liu, Y.; Li, Q.; Ding, Y.; Wang, Y.; Liu, M. Hyperspectral Estimation Model of Foliar Fe Concentration of Pyrus brestsschneideri Rehd. in Different Periods. Southwest China Journal of Agricultural Sciences 2019, 32, 1. [Google Scholar]
- Li, Y. Models of estimating nutrient elements in leaves and canopy of Pyrus sinkiangensis ‘Kuerlexiangli’ using hyperspectral data.Xin Jiang Agricultural University. 2018. [CrossRef]
- Li, M.; Chu, R.; Yu, Q.; Abu, I.; Shuren, C.; Shen, S. Evaluating structural, chlorophyll-based and photochemical indices to detect summer maize responses to continuous water stress. Water 2018, 10, 500. [Google Scholar] [CrossRef]
- Liou, C.Y.; Lin, S.L. Finite memory loading in hairy neurons. Natural Computing 2006, 5, 15–42. [Google Scholar] [CrossRef]
- Liou, C.Y. (2006). Backbone structure of hairy memory. In Artificial Neural Networks–ICANN 2006: In 16th International Conference, Athens, Greece, September 10-14, 2006. Proceedings, Part I 16 (pp. 688-697). Springer Berlin Heidelberg. [CrossRef]
- Liu, Y.; Lyu, Q.; He, S.; Yi, S.; Liu, X.; Xie, R.; Zheng, Y.; Deng, L. Prediction of nitrogen and phosphorus contents in citrus leaves based on hyperspectral imaging. International Journal of Agricultural and Biological Engineering 2015, 8, 80–88. [Google Scholar]
- Liu, Y.; Zhang, G.; Liu, D. Simultaneous Chlorophyll and Water Content Measurement in Navel Orange Leaves Based on Hyperspectral Imaging. Spectroscopy 2014, 29. [Google Scholar]
- Liu, L.; Tao, H.; Fang, J.; Zheng, W.; Wang, L.; Jin, X. Identifying anthracnose and black spot pear leaves on near-infrared hyper spectroscopy. Journal of Agricultural Machinery 2022, 53, 2. [Google Scholar]
- Luo, Y.; Zou, J.; Yao, C.; Zhao, X.; Li, T.; Bai, G. (2018). HSI-CNN: A novel convolution neural network for hyperspectral image. In 2018 International Conference on Audio, Language and Image Processing (ICALIP) (pp. 464-469). IEEE. [CrossRef]
- Luo, H.; Liu, Y. (2017, November). A prediction method based on improved ridge regression. In 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS) (pp. 596-599). IEEE. [CrossRef]
- Ma, T.; Tsuchikawa, S.; Inagaki, T. Rapid and non-destructive seed viability prediction using near-infrared hyperspectral imaging coupled with a deep learning approach. Computers and Electronics in Agriculture 2020, 177, 105683. [Google Scholar] [CrossRef]
- Matdoan, M.Y.; Wance, M.; Balami, A.M. (2021, September). Ridge regression modeling in overcoming multicollinearity problems in multiple linear regression models (case study: Life expectancy in Maluku Province). In AIP Conference Proceedings (Vol. 2360, No. 1). AIP Publishing.
- Mirjalili, S.; Mirjalili, S.; Lewis, A. Grey wolf optimizer[J]. Advances in engineering software 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. (2010). Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10) (pp. 807-814).
- Netto, A.; Campostrini, E.; De Oliveira, J.; Bressansmith, R. Photosynthetic pigments, nitrogen, chlorophyll a fluorescence and SPAD-502 readings in coffee leaves. Sci. Hortic 2005, 104, 199–209. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv arXiv:1511.08458, 2015.
- Pandey, P.; Ge, Y.; Stoerger, V.; Schnable, J.C. High throughput in vivo analysis of plant leaf chemical properties using hyperspectral imaging. Frontiers in plant science 2017, 8, 1348 https://doi org/103389/fpls201701348. [Google Scholar] [CrossRef]
- Pacheco-Gil, R.A.; Velasco-Cruz, C.; Pérez-Rodríguez, P.; Burgueño, J.; Pérez-Elizalde, S.; Rodrigues, F.; Ortiz-Monasterio, I.; del Valle-Paniagua, D.H.; Toledo, F. Bayesian modelling of phosphorus content in wheat grain using hyperspectral reflectance data. Plant Methods 2023, 19, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Pear. (2023). Encyclopedia of China Publishing House.
- Pinkard, E.; Patel, V.; Mohammed, C. Chlorophyll and nitrogen determination for plantation-grown Eucalyptus nitens and Eucalyptus globules using a non-destructive meter. For. Ecol. Manage 2006, 223, 211–217. [Google Scholar] [CrossRef]
- Pontes, M.; Galva ̃o, R.; Arau ́jo, M.; Moreira, P.; Neto, O.; Jos(e) ́, G.; Saldanha, T. Chemom. Intell. Lab. Syst. 2005, 78. [Google Scholar]
- Poobalasubramanian, M.; Park, E.-S.; Faqeerzada, M.A.; Kim, T.; Kim, M.S.; Baek, I.; Cho, B.-K. Identification of Early Heat and Water Stress in Strawberry Plants Using Chlorophyll-Fluorescence Indices Extracted via Hyperspectral Images. Sensors 2022, 22, 8706 MDPI AG Retrieved from. [Google Scholar] [CrossRef]
- Rayapudi, S.R.; Lakshmi, N.; Manyala, R.R.; Srinivasa, R.A. Optimal Network Reconfiguration of Large-Scale Distribution System Using Harmony Search Algorithm. IEEE Transactions on Power Systems 2011, 26, 1080–1088. [Google Scholar] [CrossRef]
- Renzullo, L.A. method of wavelength selection and spectral discrimination of hyperspectral reflectance spectrometry. IEEE Trans. Geosci. Remote Sens 2006, 44, 1986–1994. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L.; PDP Research Group, C.O.R.P.O.R.A.T.E. (Eds.). (1986). Parallel distributed processing: Explorations in the microstructure of cognition, Vol. 1: Foundations. MIT press.
- Sabour, S.; Frosst, N.; Hinton, G.E. (2017). Dynamic routing between capsules. In Advances in neural information processing systems (pp. 3856-3866). 3856–3866.
- Sak, H.; Senior, A.; Beaufays, F. Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition. Neural and Evolutionary Computing. arXiv arXiv:1402.1128, 2014.
- Santos, L.; Barreto, W.O.; Silva, E.F. (2016). Araújo. Wilson, S.
- Shu, Z.; Li, X.; Liu, Y. Detection of Chili Foreign Objects Using Hyperspectral Imaging Combined with Chemometric and Target Detection Algorithms. Foods 2023, 12, 2618. [Google Scholar] [CrossRef] [PubMed]
- Silva, G.; Medeiros, T.; Lia, B.; Antonio, C. Origin, Domestication, and dispersing of pear (Pyrus spp.). Advances in Agriculture 2014, 1–8. [Google Scholar] [CrossRef]
- Sriram, L.M.K.; Gilanifar, M.; Zhou, Y.; Ozguven, E.E.; Arghandeh, R. Causal Markov Elman network for load forecasting in multinetwork systems. IEEE Transactions on Industrial Electronics 2018, 66, 1434–1442. [Google Scholar] [CrossRef]
- Suhandono, N.; Mulyono, S.; Maspiyanti, F.; Fanany, M.I. (2013). An extreme leaning machine model for growth stages classification of rice plants from hyperspectral images subdistrict indramayu. In The Second Indonesia-Japanese Conference on Knowledge Creation; Intelligent Computing. [CrossRef]
- Thilagaraj, M.; Arunkumar, N.; Ramkumar, S.; Hariharasitaraman, S. Electrooculogram signal identification for elderly disabled using Elman network. Microprocessors and Microsystems 2021, 82, 103811. [Google Scholar] [CrossRef]
- Tipping, M.E. (2003). Bayesian inference: An introduction to principles and practice in machine learning. In Summer School on Machine Learning (pp. 41-62). Berlin, Heidelberg: Springer Berlin Heidelberg. [CrossRef]
- Verrelst, J.; Alonso, L.; Caicedo, J.; Moreno, J.; Camps-Valls, G. Gaussian Process Retrieval of Chlorophyll Content From Imaging Spectroscopy Data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2013, 6, 867–874. [Google Scholar] [CrossRef]
- Visa, S.; Ramsay, B.; Ralescu, A.; Knaap, E. (2011). Confusion Matrix-based Feature Selection (Vol. 710).
- Wang, Y.; Li, L.; Shen, S.; Liu, Y.; Ning, J.; Zhang, Z. Rapid detection of the quality index of postharvest fresh tea leaves using hyperspectral imaging. Journal of the Science of Food and Agriculture 2020, 100, 3803–3811. [Google Scholar] [CrossRef] [PubMed]
- Wang, T. (2022). Inversion of nitrogen and chlorophyll content in crop leaves based on hyperspectral and machine learning. Jilin University. [CrossRef]
- Wang, Y.; Wang, L.; Yang, F.; Di, W.; Chang, Q. Advantages of direct input-to-output connections in neural networks: The Elman network for stock index forecasting. Information Sciences 2021, 547, 1066–1079. [Google Scholar] [CrossRef]
- Wang, Y.; Li, L.; Shen, S.; Liu, Y.; Ning, J.; Zhang, Z. Rapid detection of the quality index of postharvest fresh tea leaves using hyperspectral imaging. Journal of the Science of Food and Agriculture 2020, 100, 3803–3811. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, M.; Zhai, G. Application of deep learning architectures for accurate and rapid detection of internal mechanical damage of blueberry using hyperspectral transmittance data. Sensors 2018, 18, 1126. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Shi, G.; Xu, Q. Toxic effects of lanthanum, cerium, chromium and zinc on potamogeton malaianus[J]. Journal of The Chinese Rare Earth Society 2004, 22, 682–686. [Google Scholar]
- Wei, Y.; Li, X.; He, Y. Generalisation of tea moisture content models based on VNIR spectra subjected to fractional differential treatment. Biosystems Engineering 2021, 205, 174–186. [Google Scholar] [CrossRef]
- Wen, L.J.; Asaari, M.S.M.; Dhondt, S. Spectral Correction and Dimensionality Reduction of Hyperspectral Images for Plant Water Stress Assessment. Science; Technology 2023. [CrossRef]
- Weng, S.; Ma, J.; Tao, W.; Tan, Y.; Pan, M.; Zhang, Z.; Huang, L.; Zheng, L.; Zhao, J. Drought stress identification of tomato plant using multi-features of hyperspectral imaging and subsample fusion. Frontiers in plant science 2023, 14, 1073530. [Google Scholar] [CrossRef] [PubMed]
- Woldegiorgis, S.; Enqvist, A.; Baciak, J. ResNet and CycleGAN for pulse shape discrimination of He-4 detector pulse: Recovering pulses conventional algorithms fail to label unanimously[J]. Applied Radiation and Isotopes 2021, 6, 109819. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Zhao, X.; Chen, R.; Liu, P.; Liang, W.; Wang, J.; Teng, M.; Wang, X.; Gao, S. Wastewater treatment plants act as essential sources of microplastic formation in aquatic environments: A critical review. Water Research 2022, 221, 118825. [Google Scholar] [CrossRef] [PubMed]
- Yalcin, H.; Razavi, S. (2016, July). Plant classification using convolutional neural networks. In 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics) (pp. 1-5). IEEE. [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: an overview and application in radiology. Insights into imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Yang, W. (2020). Ningxia Lingwu Horticultural Experimental Field (Lingwu Forest Farm). Atlas of Fruit Tree Germplasm Resources of Ningxia Lingwu Horticultural Experimental Field[M].
- Yang, J.; Li, J. (2017). Application of deep convolution neural network. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 229-232). IEEE. [CrossRef]
- Zhao, D.; Li, Z.; Feng, G.; Wang, F.; Hao, C.; He, Y.; Dong, S. Using swarm intelligence optimization algorithms to predict the height of fractured water-conducting zone. Energy Exploration; Exploitation 2023, 01445987231178938. [CrossRef]
- Zhao, T.; Nakano, A. Agricultural Product Authenticity and Geographical Origin Traceability. Jpn. Agric. Res. Q. JARQ 2018, 52, 115–122. [Google Scholar] [CrossRef]
- Zhao, T.; Nakano, A.; Iwaski, Y.; Umeda, H. Application of hyperspectral imaging for assessment of tomato leaf water status in plant factories. Applied Sciences 2020, 10, 4665, doi 103390/app10134665. [Google Scholar] [CrossRef]
- Zhu, H.; Chu, B.; Zhang, C.; Liu, F.; Jiang, L.; He, Y. Hyperspectral imaging for presymptomatic detection of tobacco disease with successive projections algorithm and machine-learning classifiers. Scientific reports 2017, 7, 4125. [Google Scholar] [CrossRef]
- Zhu, Q.; Guan, J.; Huang, M.; Lu, R.; Mendoza, F. Predicting bruise susceptibility of ‘Golden Delicious’ apples using hyperspectral scattering technique. Postharvest Biology and Technology 2016, 114, 86–94. [Google Scholar] [CrossRef]
Figure 1.
Using the leaf in the middle for data collection.
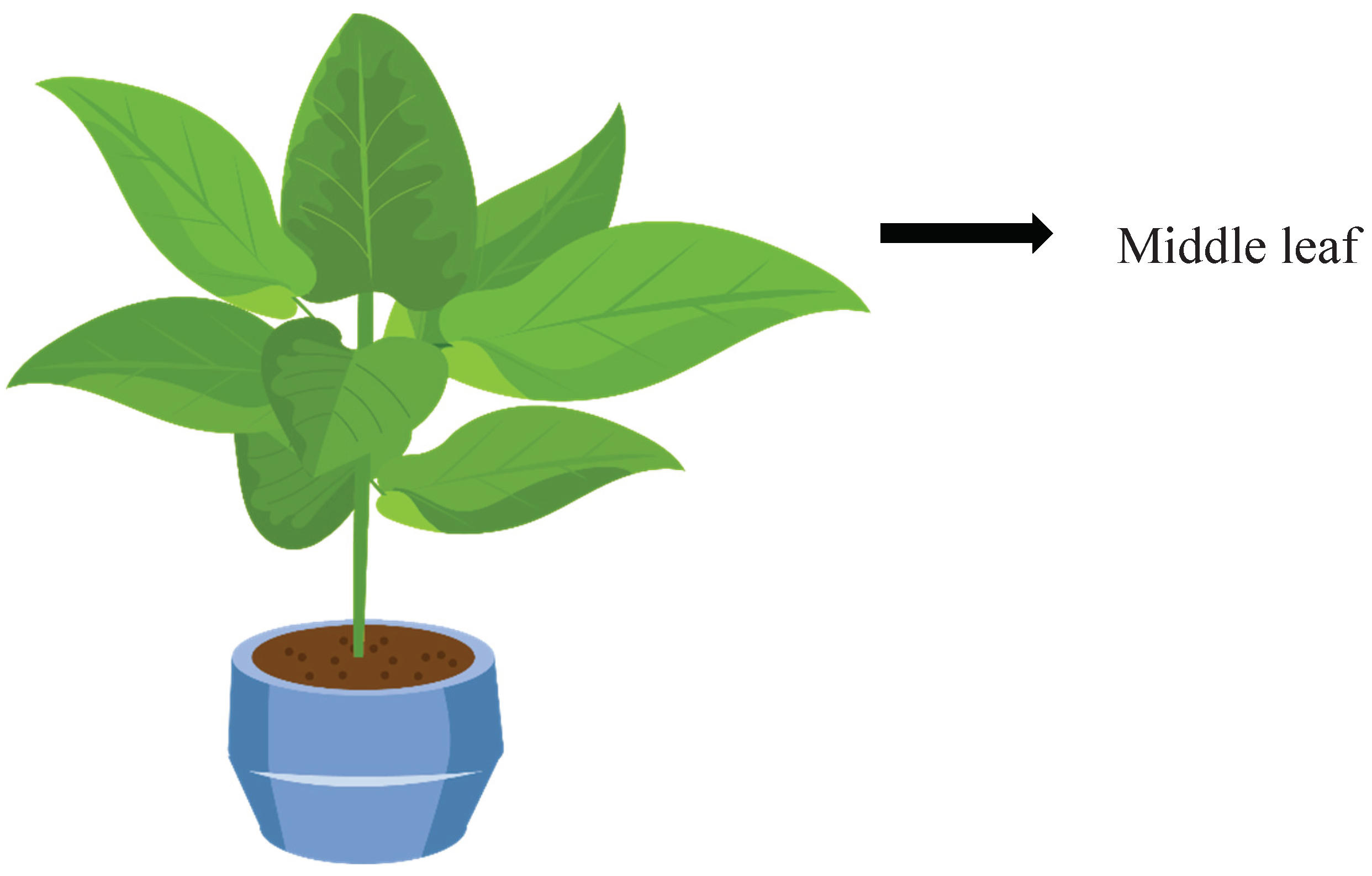
Figure 2.
lab setup-use of HSI imaging.

Figure 3.
Operation process of SPA.
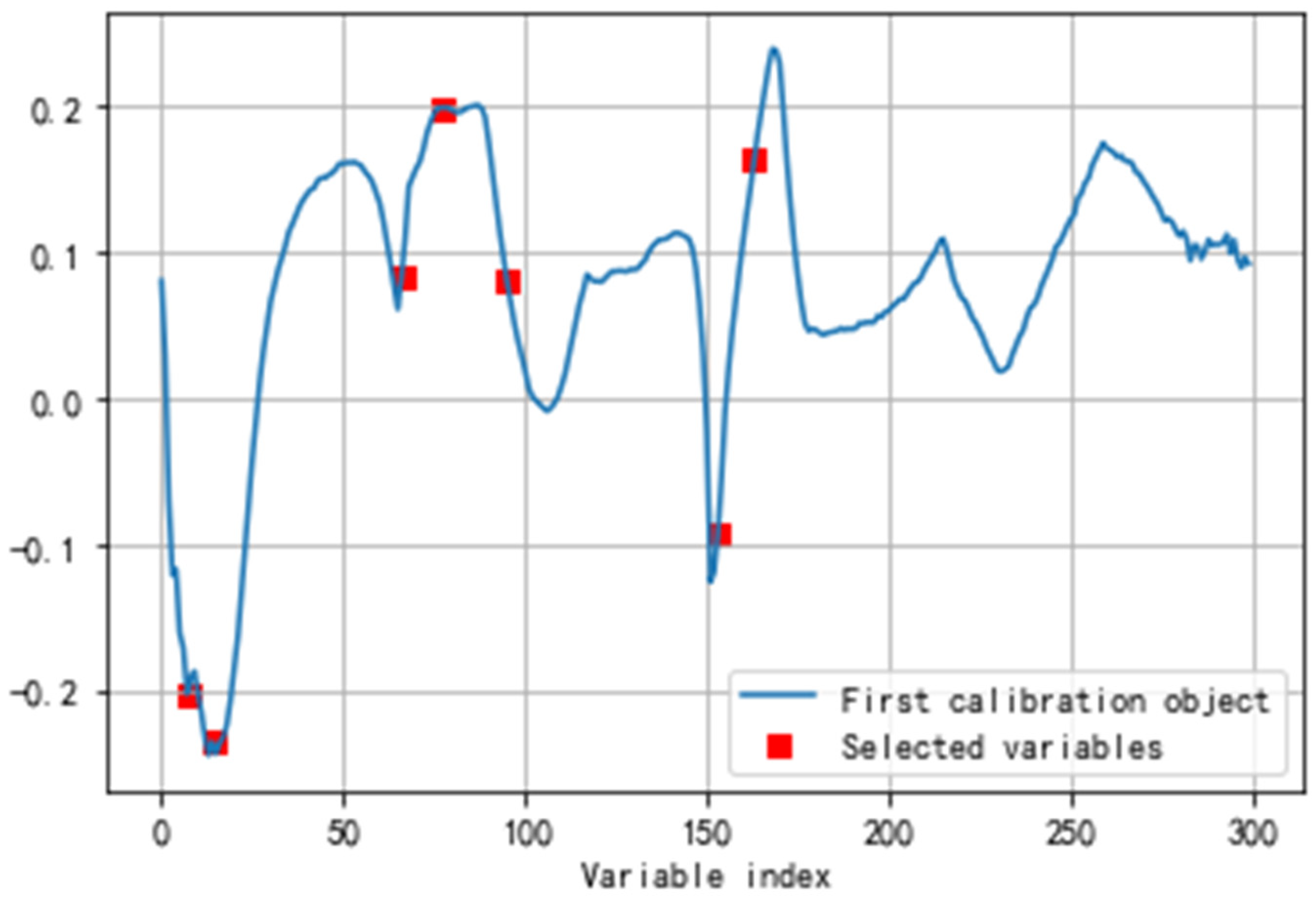
Figure 4.
Confusion matrix of training and testing data.
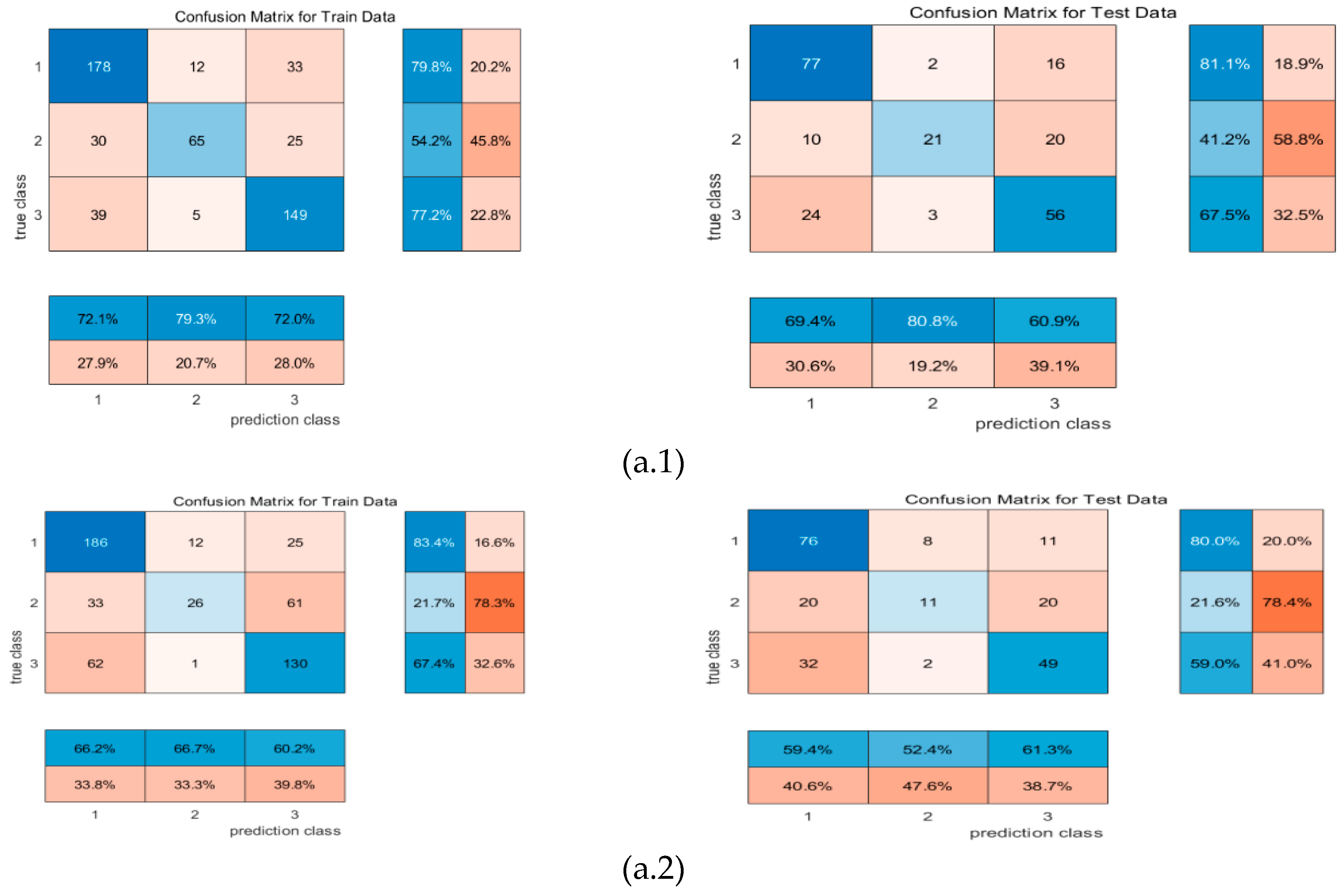
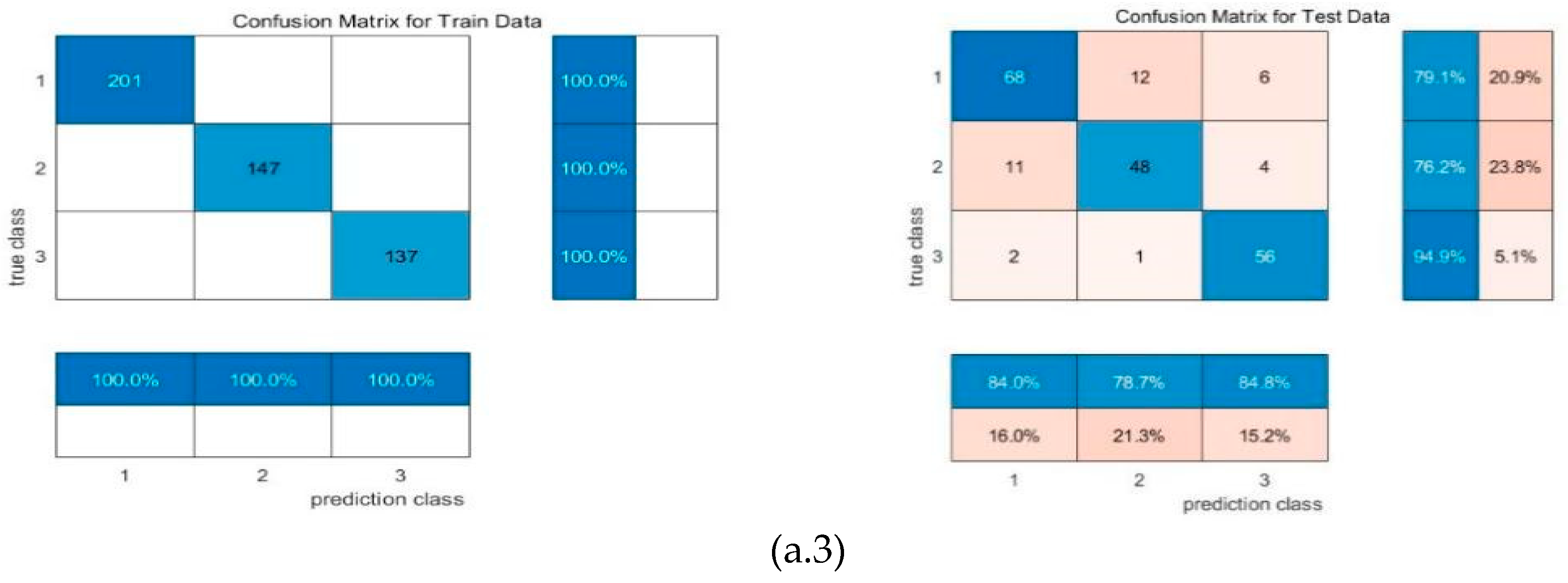

Table 1.
Datacubes collected from pear seedling leaves.
| Date | July 25 (day 0) |
July 27 (day 1) |
July 29 (day 3) |
July 31 (day 5) | August 1 (day 7) |
| Number of images collected | 30 for normal treatment | 90 (30 normal, 30 overwater, 30 drought) per day |
|||
Table 2.
Optimal wavelengths selection.
| Band8 | Band15 | Band54 | Band64 | Band67 | Band78 | Band96 |
| 395.55nm | 409.75nm | 489.53nm | 510.19nm | 516.40nm | 539.23nm | 576.81nm |
Table 3.
Data input.
| Input data | HSI whole data cube 300×(30+90×4) |
| Main spectra 7×(30+90×4) | |
| CNN features of main spectra 4096×(30+90×4) |
Table 4.
Parameters of different neural networks.
| Neural network | parameters |
| RR-MLR | gam = 10 |
| Bayesian Linear Regression | sigma_squared=0.01 |
| Elman Neural Network | epochs = 2000 goal = 1e-5 lr = 0.01 |
Table 5.
Performance metrics.
| Machine learning | input | F1 | precision | recall | mse_loss | test accuracy |
| RR-MLR | Whole datacube | 0.65 | 0.66 | 0.64 | 0.80 | 67.25% |
| Key wavelengths | 0.60 | 0.67 | 0.60 | 0.80 | 59.39% | |
| CNN feature | 0.86 | 0.86 | 0.86 | 0.19 | 82.69% | |
| Bayes | Whole datacube | 0.72 | 0.68 | 0.77 | 0.91 | 64.85% |
| Key wavelengths | 0.59 | 0.51 | 0.69 | 1.39 | 63.32% | |
| CNN feature | 0.87 | 0.84 | 0.91 | 0.23 | 87.98% | |
| Elman | Whole datacube | 0.65 | 0.66 | 0.65 | 0.16 | 67.25% |
| Key wavelengths | 0.57 | 0.66 | 0.57 | 0.17 | 61.94% | |
| CNN feature | 0.87 | 0.87 | 0.87 | 0.08 | 86.54% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



