
Submitted:
29 February 2024
Posted:
01 March 2024
You are already at the latest version
Abstract
Large datasets play a crucial role in the progression of surgical robotics, facilitating advancements in the fields of surgical task recognition and automation. Moreover, public datasets enable the comparative analysis of various algorithms and methodologies, thereby assessing their effectiveness and performance. The ROSMA (Robotics Surgical Maneuvers) dataset provides 206 trials of common surgical training tasks performed with the da Vinci Research Kit (dVRK). In this work, we extend ROSMA dataset with two annotated subsets: ROSMAT24, which contains bounding box annotations for instrument detection, and ROSMAG40, which contains high and low level gesture annotations. We propose an annotation method that provides independent labels for the right-handed tool and the left-handed tool. For instrument identification, we validate our proposal with a YOLOv4 model in two experimental scenarios. We demonstrate the generalization capabilities of the network to detect instruments in unseen scenarios. For gesture segmentation, we propose two label categories: high-level annotations that describe gestures at a maneuvers level, and low-level annotations that describe gestures at a fine-grain level. To validate this proposal, we have designed a recurrent neural network based on a bidirectional long-short term memory layer. We present results for four cross-validation experimental setups, reaching up to a 77.35% mAP.
Keywords:
robotic dataset
; instrument detection
; gesture segmentation
; surgical robotics
1. Introduction
Surgical data sciences is emerging as a novel domain within healthcare, particularly in the field of surgery. This discipline holds the promise of significant advancements in various areas such as virtual coaching, assessment of surgeon proficiency, and learning complex surgical tasks through robotic systems [1]. Additionally, it contributes to the field of gesture recognition [2], [3]. Understanding surgical scenes has become pivotal in the development of intelligent systems that can effectively collaborate with surgeons during live procedures [4]. The availability of extensive datasets related to the execution of surgical tasks using robotic systems would support these advancements forward, providing detailed information of the surgeon’s movements with both kinematics and dynamics data, complemented by video recordings. Furthermore, public datasets facilitate the comparison of different algorithms proposed in scientific literature. Rivas-Blanco et al. [5] provide a list of 13 publicly accessible datasets within the surgical domain, such as Cholec80 or M2CAI16.
While most of these datasets feature video data [6][7], only two of them incorporate kinematic data [8][9], which is fundamental in analyzing metrics associated with tool motion. Kinematic data is provided by research platforms such as the da Vinci Research Kit (dVRK). The dVRK is a robotic platform based on the first-generation commercial da Vinci Surgical System (by Intuitive Surgical, Inc., Sunnyvale, CA). This platform offers a software package that records kinematics and dynamics data of both the master tool and the patient side manipulators. The JIGSAWS dataset [8] and the UCL dVRK dataset [9] records were acquired using this platform. The first one stands out as one of the most renowned datasets in surgical robotics . It encompasses 76-dimensional kinematic data in conjunction with video data for 101 trials of three fundamental surgical tasks (suturing, knot-tying, and needle-passing) performed by six surgeons. The UCL dVRK dataset comprises 14 videos using the dVRK across five distinct types of animal tissue. Each video frame is associated with an image of the virtual tools produced using a dVRK simulator.
Common annotations in surgical robotics datasets are related to tool detection and gesture recognition. These annotations are the basis for developing new strategies to advance in the field of intelligent surgical robots and surgical scene understanding. One of the most studied applications in this field is surgical image analysis. There are many promising works for object recognition based on surgical images. Most works perform surgical instrument classification [10][11], instruments segmentation [12][13], and tools detection [7][14]. Al-Hajj et al. [15] propose a network that concatenates several CNNs layer to extract visual features of the images and RNNs for analyzing temporal dependencies. With this approach, they are able to classify seven different tools in cholecystectomy surgeries with a performance of around 98%. Sarikaya et al. [7] applied a region proposal network with a multimodal convolutional one for instrument detection, achieving a mean average precision of 90%. Besides surgical instruments, anatomical structures are an essential part of the surgical scene. Thus, organ segmentation provides rich information for understanding surgical procedures. Liver segmentation has been addressed by Nazir et al. [16] and Fu et al. [17] with promising results.
Another important application in surgical data sciences is surgical task analysis, as the basis for developing context-aware systems or autonomous surgical robots. In this domain, the recognition of surgical phases has been extensively studied, as it enables computer-assisted systems to track the progression of a procedure. This task involves breaking down a procedure into distinct phases and training the system to identify which phase corresponds to a given image. Petscharnig and Schöffmann [18] explored phase classification on gynecologic videos annotated with 14 semantic classes. Twinanda et al. [19] introduced a novel CNN architecture, EndoNet, which effectively performs phase recognition and tool presence detection concurrently, relying solely on visual information. They demonstrated the generalization of their work with two different datasets. Other researchers delve deeper into surgical tasks by analyzing surgical gestures instead of phases. Here, tasks such as suturing are decomposed into a series of gestures [20]. This entails a more challenging problem as gestures exhibit greater similarity to each other compared to broader phases. Gesture segmentation, so far, has primarily focused on the suturing task [21][22][23], with most attempts conducted in in-vitro environments yielding promising results. Only one study [24] has explored live suturing gesture segmentation. Trajectory segmentation offers another avenue for a detailed analysis of surgical instrument motion [25][26]. It involves breaking trajectories into sub-trajectories, facilitating learning from demonstrations, skill assessment, phase recognition, among other applications. Authors leverage kinematics information provided by surgical robots, which when combined with video data, yields improved accuracy results [27][28].
In a previous work [29], we presented the Robotic Surgical Maneuvers (ROSMA) dataset. This dataset contains kinematic and video data for 206 trials of three common training surgical tasks performed with the dVRK. In Rivas-Blanco et al. [29], we presented a detailed description of the data and the recording methodology, along with the protocol of the three tasks performed. This first version of ROSMA did not include annotations. In the present work, we incorporate manual annotations for surgical tool detection and gesture segmentation. The main novelty regarding the annotation methodology is that we have annotated independently the two instruments handled by the surgeon, i.e., we provide bounding box labels for the tool handled with the right master tool manipulator, and the one handled with the left one. We believe that this distinction would provide useful information for supervisory or autonomous systems, making it possible to pay attention to one particular tool, i.e., we may be interested in the position of the main tool or in the position of the support tool, even if they are both the same type of instrument.
In most works of the state of the art, phases, such as suturing, or gestures, such as pulling suture or needle orientation, are considered an action that involves both tools. However, the effectiveness of these methods relies heavily on achieving a consensus regarding the surgical procedure, thus limiting its applicability. Consequently, the generalization to other procedures remains poor. Thus, the approach of treating independently both tools is also followed for the gesture annotations presented in this work. We have annotated each video frame with a gesture label for the right-handed tool and a gesture label for the left-handed tool. This form of annotating gestures makes special sense for tasks that may be performed with either the right or the left hand, as is the case of ROSMA dataset, in which tasks are performed half of the trials with the right hand, and the other half with the left hand. Being able to detect the basic action each tool is performing would allow the identification of general gestures or phases either for dexterous or left-handed surgeons.
In summary, the main contributions of this letter are:
- This work completes the ROSMA dataset with surgical tools bounding box annotations on 24 videos, and gesture annotations on 40 videos.
- Unlike previous work, annotations are performed on the right tool and on the left tool independently.
- Annotations for gesture recognition have been evaluated using a recurrent neural network based on a bi-directional long-short term memory layer, using an experimental setup-up with four cross-validation schemes.
- Annotations for surgical tool detection have been evaluated with a YOLOV4 network using two cross-validation schemes.
2. Materials and Methods
2.1. Robotics Surgical Maneuvers dataset (ROSMA)
The Robotics Surgical Maneuvers (ROSMA) dataset is a large dataset collected using the dVRK, in collaboration between the University of Málaga (Spain) and The Biorobotics Insitute of the Scuola Superiore Sant’Anna (Italy), under a TERRINet (The European Robotics Research Infrastructure Network) project. The dVRK used to collect the ROSMA dataset (Figure 1) has a patient side with two Patient Side Manipulators (PSM), labeled as PSM1 and PSM2, and a master console consisting of two Master Tool Manipulators (MTM), labeled as MTML and MTMR. MTMR controls PSM1, while MTML controls PSM2. In this platform, stereo vision of the system is provided using two commercial webcams.
The ROSMA dataset contains 36 kinematic variables, divided into 154-dimensional data, recorded at 50 Hz for 206 trials of three common training surgical tasks. This data is complemented with the video recordings collected at 15 frames per second with 1024 x 768 pixel resolution. The dataset also includes task evaluation annotations based on time and task-specific errors, a synchronization data file between data and videos, the transformation matrix between the camera and the PSMs, and a questionnaire with personal data of the subjects (gender, age, dominant hand) and previous experience using teleoperated systems and visuo-motor skills (sport and musical instruments). This dataset is fully described in Rivas-Blanco et al. [29] and publicly available for download at Zenodo [30]. The code for using the data in Matlab and ROS can be found in Appendix A.
2.2. Gesture annotations
The ROSMA dataset contains the performance of three tasks of the Skill Building Task Set (from 3-D Techical Services, Franklin, OH): post and sleeve, pea on a peg, and Wire Chaser. These training platforms for clinical skill development provide challenges that require motions and skills used in laparoscopic surgery, such as hand-eye coordination, bimanual dexterity, depth perception or interaction between dominant and non-dominant hand. These exercises were born for clinical skill acquisition, but they are also commonly used in surgical research for different applications, such as clinical skills acquisition [31] or testing of new devices [32].
In most of the works on gesture segmentation in surgical procedures, gestures are considered an action or maneuver that involves the motion of two surgical instruments, such as suturing, knot-tying, inserting the needle in the tissue, etc. Usually, these kinds of maneuvers are performed following a similar protocol, where actions are always performed by the same tool, i.e., complex tasks that require high precision are usually performed with the right-handed tool, while the left-handed one is usually employed for support tasks. However, left-handed surgeons may not follow this convention, as their dexterous hand is the left. Thus, we believe that being able to recognize gestures that are defined by an adjective instead of by an action would facilitate the generalization of the gesture segmentation algorithms to different protocols of the same task, as well as the generalization to different ways of performing a particular task, for example in the case of left-handed surgeons.
Two of the tasks used in the ROSMA dataset represent suitable scenarios to explore this idea. Post and sleeve task (Figure 2a) consists of moving the colored sleeves from one side of the board to the other. Each user performs 6 trials: three starting from the right side and the other three starting from the left side. On the other hand, pea on a peg (Figure 2b) consists of picking six beads from the cup and placing them on top of the pegs. As in the previous task, each user performs six trials: three placing the beads on the left-side pegs, and the other three on the opposite pegs. The detailed protocol of these tasks is described in Table 1. Although these two tasks have different procedures, they follow the same philosophy: picking an object and placing it on a peg. Hence, the idea behind the gesture annotation methodology of this work is being able to recognize the gesture or actions regardless of whether the user is performing pea on a peg or post and sleeve.
2.2.1. ROSMAG40 annotations
ROSMAG40 is a subset of ROSMA dataset that includes gesture annotations for 40 videos (72.843 frames). The distribution of the annotated videos according to the user, the task, and the dominant hand of each trial is described in Table 2. ROSMAG40 includes videos from 5 different users: users X01, X02, and X07 are dexterous, while users X06, and X08 are ambidextrous. For each user, we have annotated 8 video, 4 for the pea on a peg task, and 4 for post and sleeve. For each task, we have annotated 2 trials performed using PSM1 as the dominant tool and other 2 trials using PSM2 as the dominant tool (for pea on a peg, the dominant tool is the one in charge of picking and placing the peas, while for post and sleeve, the dominant tool is considered the one that picks the sleeves). This dataset is available for download at the Zenodo website [33].
For the annotations, we have followed the previous idea of defining the gestures to facilitate their generalization to other tasks. In this sense, we define a descriptive gesture as a gesture or action characterized by an action adjective. For example, we can define a descriptive gesture as a precision action, irrespective of whether we are inserting the needle in a particular point, putting a staple, or dissecting a duct. This work defines two classes of descriptive gestures: maneuver descriptors (MD) and fine-grain descriptors (FGD). Maneuver descriptors represent high-level actions that are common to all surgical tasks, such as precision or collaborative actions. On the other hand, fine-grain descriptors represent low-level actions that are specifically performed in the ROSMA training tasks, such as picking or placing, but which are not generalizable for other types of tasks. ROSMAG40 provides manual annotations for these two classes of gestures.
2.2.2. Maneuver descriptor (MD) gestures
MD gestures describe the gestures at a higher level than FGD and represent gestures that are common to most surgical tasks. We have defined 4 MD gestures:
- Idle (G1): the instrument is in a resting position.
- Precision (G2): this gesture is characterized by actions that require an accurate motion of the tool, such as picking or placing objects.
- Displacement (G3): this gesture is characterized by motions that do not require high accuracy, i.e., displacement of the tools either to carry an object or to position the tip in a particular area of the scenario.
- Collaboration (G4): both instruments are collaborating on the same task. For pea on a peg, collaboration occurs when the dominant tool needs support, usually to release peas held together by static friction, so it is an intermittent and unpredictable action. For post and sleeve, collaboration is a mandatory step between picking and placing an object, in which the sleeve is passed from one tool to another.
Table 3 summarizes the gestures’ description, along with their ID, labels, and the presence (number of frames) of each gesture in the dataset for PSM1 and PSM2.
Figure 3 shows six snapshots characteristic of each MD gesture, three for pea on a top (top) and three for post and sleeve (bottom images). Figure 4 shows a box chart for the MD gestures occurrence for the 40 videos of the dataset. These plots clearly show the dispersion of the data for different trials of the tasks, which was otherwise expected due to the non-uniform nature of the different trials (half of the trials were performed with PSM1 as the dominant tool, and the other half with PSM2). Besides this fact, there is a non-uniform workflow between both tasks:
- Pea on a peg is mostly performed with the dominant tool, which follows the flow of picking a pea and placing it on top of a peg. The other tool mostly performs collaborative actions to supply support for releasing peas from the tool. Thus, the dominant tool gestures follow mostly the following flow: displacement (G3) - precision (G2) - displacement (G3) - precision (G2), with short interruptions for collaboration (G4). While the other tool is mostly in an idle (G1) position, with some interruptions for collaboration (G4). This workflow is shown in Figure 5, which represents the sequential distribution of the gestures along a complete trial of the task.
- Post and sleeve tasks follow a more sequential workflow between the tools: one tool picks a sleeve and transfers it to the other tool, which places it over a peg on the opposite side of the board. Thus, the workflow is more similar for both tools, as it can be seen in Figure 6.
2.2.3. Fine-grain descriptor (FGD) gestures
FGD gestures describe the gestures at lower level, i.e., the adjectives used to define the gesture are linked to specific actions of the tools. We have defined 6 FGD gestures, which are common for the two tasks of the dataset. Table 4 presents the ID, label and description of each gesture, along with the number of frames annotated for PSM1 and PSM2. These 6 FGD gestures are:
- Idle (F1): this is the same gesture as for MD gestures described in the previous section (G1).
- Picking (F2): the instrument is picking an object, either a pea on the pea on a peg task or a colored sleeve on the post and sleeve task. This gesture is a particularity of G2 of MD descriptors.
- Placing (F3): the instrument is placing an object, either a pea on top of a peg or a sleeve over a peg. This gesture is also a particularity of G2.
- Free motion (F4): the instrument is moving without carrying anything at the tip. This gesture corresponds with actions of approaching the objective to pick, and it is a particularity of G3 of MD descriptors.
- Load motion (F5): the instrument is moving holding an object. This gesture corresponds with actions of approaching the objective to place, and therefore it is also a particularity of G3.
- Collaboration (F6): equivalent to gesture G4 of maneuver descriptors.
Figure 7 shows six snapshots characteristic of each FGD gesture, three for pea on a peg (top) and three for post and sleeve (bottom images). Figure 8 shows the gesture occurrence distribution for FGD gestures. As expected, this box chart reveals the same conclusions of MD gestures regarding the dispersion of the data for different trials of the tasks. This can also be seen in Figure 9 and Figure 10, which show the sequential workflow of the gestures for a pea on a peg task and a post and sleeve task, respectively:
- The workflow of pea on a peg task for FGD gesture is mostly as follows: free motion (F4) - picking (F2) - load motion (F5) - placing (F3), with short interruptions for collaboration (G6). While the other tool is mostly in an idle (F1) position, with some interruptions for collaboration (F6).
- As we stated previously, post and sleeve tasks follow a more sequential workflow between the tools. In the trial represented in Figure 10, PSM1 was the dominant tool, so the comparison between the gestures sequential distribution for PSM1 and PSM2 reflects that picking is a more time-consuming task than placing.
2.3. Instruments annotations (ROSMAT24)
In this work, we extend the usability of ROSMA dataset incorporating manual annotations for instrument detection. Hence, we present the ROSMAT24 dataset, a subset of ROSMA that includes bounding box annotations for instruments detection on 24 videos, 22 videos of pea on a peg instances, and 2 videos of post and sleeve. Unlike most of the previous work on instrument detection, we provide separate labeled bounding boxes for the tip of PSM1 and PMS2. This way, we can model a network able to distinguish between both tools. We have annotated a total of 48.919 images, 45.018 images (92%) of pea on a peg trials, and 3.901 (8%) of post and sleeve. The idea of this non-uniform distribution of the annotations between the tasks is to validate the robustness of the recognition method for different scenarios. Table 5 shows the specific trials that have been manually annotated and the overall number of labeled frames. Figure 11 shows two examples of the instruments bounding boxes annotations. This dataset is available for download at the Zenodo website [34].
2.4. Evaluation method
In this section, we describe the evaluation methodology for the instruments and the gesture annotations.
2.4.1. Gesture segmentation
To validate the gesture annotations presented in Section 2.2, we propose the recurrent neural network (RNN) model of Figure 12. Input data of the network is a sequence of kinematic data collected with the dVRK during the experiments. ROSMA dataset includes 154 kinematics variables from the dVRK platform (both master and slave sides). To isolate the gesture segmentation methodology from the particular robotic system employed to carry out the experiments, we have only considered PSMs kinematics for gesture segmentation. To be able to replicate the model proposed in this work in a different scenario, we have also obviated cartesian position of the manipulators. Thus, the kinematic variables input to the network are shown in Table 6. Tools orientation, linear and angular velocity, and wrench force and torque are raw data collected from the dVRK. To these data, we have added two hand-crafted variables that provide useful information on the relation between the tools: distance and angle between PSM1 and PSM2. As gesture annotations on ROSMAG40 dataset have been defined to be as generalizable as possible, we have not added images to the input of the network, as they would condition the learning process to a particular experimental scenario.
These 34 features are input to the network of Figure 12. The sequence layer extracts the input from the given sequence. Then a Bi-directional Long-Short Term Memory (Bi-LSTM) layer with 50 hidden units learns long-term dependencies between time steps of the sequential data. This layer is followed by a dropout layer of 0.5 dropout rate to reduce overfitting. The network concludes with a 50-fully connected layer, a softmax layer, and a classification layer, that infers the output predicted gesture. LSTM layers are effective classifiers for time series sequence data, as they employ three control units, namely the input gate, the output gate, and the forget gate, to keep long-term and short-term dependencies. A bi-LSTM layer is a model with two LSTM networks that work in two directions: one LSMT layer takes the input in a forward direction, and the other in a backward direction. This model allows increasing the amount of information available to the network and improving the model performance [35].
The experimental setup includes four cross-validation schemes based on [8]:
- Leave-one-user-out (LOUO): in the LOUO setup, we created five folds, each one consisting of data from one of the five users. This setup can be used to evaluate the robustness of the model when a subject is not seen by the model.
- Leave-one-supertrial-out (LOSO): a supertrial is defined as in Gao et al. [8] as the set of trials from all subjects for a given surgical task. Thus, we created two folds, each comprising data from one of the two tasks. This setup can be used to evaluate the robustness of the method for a new task.
- Leave-one-psm-out (LOPO): as half of the trials of the dataset are performed with PSM1 as the dominant tool while the other half are performed with PSM2 as the dominant tool, we have created two folds, one for trials of each dominant tool. This setup can be used to evaluate the robustness of the model when tasks are not performed following a predefined order.
-
Leave-one-trial-out (LOTO): a trial is defined as the performance of one subject of one instance of a specific task. For this cross-validation scheme, we have considered the following test data partitions:
- −
- Test data 1: test data includes 2 trials per user as follows: one of each task, and performed with a different PSM as dominant. Thus, we have left out 10 trials: 2 per user, 5 from each task, and 5 with one PSM as dominant. This setup allows us to train the model with the widest variety possible.
- −
- Test data 2: this test folder includes 10 trials of pea on a peg task, 2 trials per user with different PSM as dominant. This setup allows evaluating the robustness of the method when the network has significantly more observations of one task.
- −
- Test data 3: same philosophy of test data 2, but leaving for testing just post and sleeve data for testing.
- −
- Test data 4: this test folder includes 10 trials performed with PSM1 as the dominant tool, 2 trials per user and task. This setup allows evaluating the robustness of the method when the network has significantly more observations with a particular workflow of the task performance.
- −
- Test data 5: same philosophy of test data 4, but leaving for testing just performance with PSM2 as the dominant tool.
2.4.2. Instruments detection
In this work, YOLOv4 was used to detect the instruments in the images. YOLO (You only Look Once) is a popular single-shot object detector known for its speed and accuracy. This model is an end-to-end neural network that makes predictions of bounding boxes and class probabilities all at once. This model is composed of three parts: backbone, neck, and head. The backbone is a pretrained CNN that computes feature maps from the input images. The neck connects the backbone and the head. It consists of a spatial pyramid pooling module and a path aggregation network, which merges the feature maps from various layers of the backbone network and forwards them as inputs to the head. The head processes the aggregated features and makes predictions for bounding boxes, objectness scores, and classification scores. Yolov4 has already proven to provide good results for surgical instrument detection [36].
The experimental setup for instrument detection includes two scenarios:
- Leave-One-Supertrial-Out (LOSO): for this setup, we only used images of videos performing pea on a peg for training the network, and then we incorporated images of videos performing post and leave for testing. This setup can be used to evaluate the robustness of the method for different experimental scenarios.
- Leave-One-Trial-Out (LOTO): for this setup, we used images of videos performing pea on a peg and post and sleeve for training and testing the network.
3. Results
This section presents the experimental results for the gesture segmentation network described in Section 2.4.1 and the instruments detection method presented in Section 2.4.2. All the experiments have been conducted on Intel(R) Xeon(R) Gold 5317 CPU @ 3.00GHz with GA120GL (RTX A6000) GPU running Ubuntu 20.04.5 LTS. The code used to generate the experimental results, along with video demonstrations of the gesture segmentation network and the instrument detection model can be found in the Appendix A.
3.1. Results for gesture segmentation
This section presents the results of the gesture segmentation network described in Section 2.4.1. We present the results for the two categories of annotations of ROSGMAG40 dataset and the four experimental setups: leave-one-user-out (LOUO), leave-one-supertrial-out (LOSO), leave-one-psm-out (LOPO) and leave-one-trial-out (LOTO). Matlab 2023b software was used to implement the RNN model. Training of the network was performed with the Adam optimization algorithm with an initial learning rate of 0.001. We used a batch size of 8 for 60 epochs (240 iterations). A higher number of training epochs resulted in worse metrics due to overfitting of the network. The total number of observations of the network is 72.843. The size of the test data varies depending on the cross-validation method evaluated, ranging from 15.347 to 36.215. The detection time of the network ranges from 0.0021 to 0.0035 seconds.
Table 7 shows the results for LOUO cross-validation scheme. Observing these results we can deduce that the model suffers from a lack of generalization when a user is left out of the training. We can observe that the mean average precision varies from 39% for user X01 to 64.9% for X02. Though the experimental protocol is the same for all users, these results suggest that the performance is highly dependent on the skill of each user. Moreover, we left freedom to complete the tasks in a random order, i.e., each user had to place six peas on top of the pegs and transfer the six colored sleeves from one side to the other of the pegboard, but the order in which they had to complete the task was not predefined.
Table 8 shows the results for the LOSO cross-validation scheme. As in the previous case, the model has difficulties extrapolating the features learned by the network to a task that has not been seen before. Table 9 shows the results for the LOPO cross-validation scheme. In this case, we can observe how the network has poor results for the low-level FGD annotations, but good results for high-level MD annotations, reaching a maximum mAP of 67.5%.
Table 10 shows the results for the LOTO cross-validation scheme. This is the experimental setup with more variety of the training data, thus it has the best results of the four cross-validation schemes. Using the test folds of test data 1, which offers the most variety of observations to the network, we reach a 64.65% and 71.39% mAP for the segmentation of PSM1 and PSM2 gestures, respectively, using MD annotations. However, for the segmentation of PSM1 gesture, we reach a maximum precision of 71.39% using test data 5 folds and FGD annotations.
3.2. Results for instruments detection
We present experimental results for two architectures of the YOLOv4 network: a CSPDarkNet53 backbone pretrained on COCO dataset, and the compressed version YOLOv4-tiny. We trained both networks for 40 epochs with the sgdm optimizer with momentum of 0.9, a batch size of 16, and an initial learning rate of 0.001. The learning rate is divided by a factor of 10 every 10 epochs.
Table 11 shows the experimental results for the LOSO experimental setup. Both models have high-precision results for the detection of both tools, reaching over 80% mAP. This reveals the generalization capabilities of the YOLOv4 network to detect the instruments in a scenario the network has not seen before. On the other hand, Table 12 presents the experimental results for the LOTO experimental setup. As expected, results when the network has seen both task scenarios during the training are higher, reaching values of 97.06% and 95.22% mAP for PSM1 and PSM2, respectively. Comparison between the performance using CSPDarket53 and YOLOv4-tiny shows that the tiny version provides similar accuracy results but the performance is 2/3 times faster. Figure 13 shows the precision-recall curves for this model, showing both high recall and high precision for the PSMs detection.
Figure 14 shows different examples of correct (top images) and incorrect (bottom images) tools detection. In this figure, we can observe two examples of how the model is able to detect and distinguish the instruments even when they cross and there is an overlap of their bounding boxes. This figure also shows the more representative situations of incorrect detections, i.e., when the network detects more than two instruments in the image, and incorrect detection when the instruments cross.
4. Discussion
This work explores the approach of studying the motion of the surgical instruments separately one from each other. In this sense, instead of considering a gesture or maneuver as a part of an action that involves the coordinated motion of the two tools the surgeon is managing, we define gestures as actions each tool is performing independently, whether they are interacting with the other tool or not. We consider that this approach would facilitate the generalization of the recognition methods for procedures that do not follow rigid protocols. To train the recurrent neural network proposed we have used kinematic data without cartesian position to allow the reproduction of the experiments with different robotic platforms. We have decided not to use images as input to the network to be able to extrapolate the results to different scenarios, i.e., the idea is that the network learns behavioral patterns of the motion of the tools, whether they are picking colored sleeves, peas, rings or any other object.
Results reveal a high dependency of the model on the user skills, with a wide range of precision from 39% to 64.9% mAP depending on the user left out for the LOUO cross-validation scheme. In future works, we will investigate the model performance when it is trained with a higher variety of users. The model also has a high dependency on the task used for training but shows high robustness for changes in the tool. The mean accuracy of the model is over the 65% when the model has been trained using a particular tool as the dominant one to complete the task, but tested with trials with a different dominant tool. These are promising results to generalize the recognition method for dexterous or left-handed surgeons.
When the system is trained with a wide variety of trials, comprising different users, tasks, and dominant tools, the performance of the gestures prediction reaches 77.3% mAP. This result is comparable to other works that perform gesture segmentation using kinematics data. Luongo et al. [37] achieve 71% mAP using only kinematic data as input to an RNN on the JIGSAWS dataset. Other works that include images as input data report results of 70.6% mAP [26] and 79.1% mAP [27]. Thus, we consider that we achieved a good result, especially taking into account that recognition is performed on tasks that do not follow a specific order in any of the attempts. We believe that the annotations provided on ROSMAG40 are a good base to advance in the generalization of the gesture and phase recognition methodologies for procedures with a non-rigid protocol. Moreover, the annotations presented in this work could be merged with the traditional way of annotating surgical phases to provide low-level information on the performance of each tool, which could improve the high-level phase recognition with additional information.
The annotations provided in ROSMAT24 for tool detection can be used as complementary to the gesture segmentation methods to focus the attention on a particular tool. This is important because surgeons usually perform the accuracy tasks with their dexterous hand and the support tasks with the non-dexterous one. Thus, being able to detect each one independently can provide useful information. We have demonstrated that YOLOv4 network provides high precision in the instrument’s detection, reaching 97% mAP. This result is comparable to other works on surgical instruments detection, such as Kurman et. al [7], who reported a 90% mAP or Zhao et al. [38] with 91.6% mAP. We also demonstrated the capabilities of the network to detect the instruments in an unseen scenario through the LOSO experimental setup.
Author Contributions
I.R.B.: methodology, writing—original draft preparation, software, validation; C.L.C: software,writing—review and editing, validation; J.M.H.L.: formal analysis, software; J.C.V: software, data curation and C.P.P: supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Spanish Ministry of Science and Innovation, under grant number PID2021-125050OA-I00..
Institutional Review Board Statement
Not applicable
Informed Consent Statement
Not applicable
Data Availability Statement
The code supporting the reported results can be found at https://github.com/irivas-uma/rosma, and the data is publicly available at Zenodo website for both ROSMAT24 and ROSMAG40 datasets.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ROSMA | Robotics Surgical Maneuvers |
| dVRK | da Vinci Research Kit |
| MD | Maneuver Descriptor |
| FGD | Fine-Grained Descriptor |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| Bi-LSTM | Bidirectional Long-short Term Memory |
| MT | Master Tool Manipulator |
| PSM | Patient Sided Manipulator |
| YOLO | You only Look Once |
Appendix A
The code used to generate the results presented in this work is provided on GitHub: https://github.com/irivas-uma/rosma. Beside the code, this repository also contains video demonstrations of the instrument detection and the gesture segmentation algorithms presented in this work.
References
- Vedula, S.S.; Hager, G.D. Surgical data science: The new knowledge domain. Innovative Surgical Sciences 2020, 2, 109–121. [CrossRef]
- Pérez-del Pulgar, C.J.; Smisek, J.; Rivas-Blanco, I.; Schiele, A.; Muñoz, V.F. Using Gaussian Mixture Models for Gesture Recognition During Haptically Guided Telemanipulation. Electronics 2019, 8, 772. [CrossRef]
- Ahmidi, N.; Tao, L.; Sefati, S.; Gao, Y.; Lea, C.; Haro, B.B.; Zappella, L.; Khudanpur, S.; Vidal, R.; Hager, G.D. A Dataset and Benchmarks for Segmentation and Recognition of Gestures in Robotic Surgery. IEEE Transactions on Biomedical Engineering 2017, 64, 2025–2041. [CrossRef]
- Setti, F.; Oleari, E.; Leporini, A.; Trojaniello, D.; Sanna, A.; Capitanio, U.; Montorsi, F.; Salonia, A.; Muradore, R. A Multirobots Teleoperated Platform for Artificial Intelligence Training Data Collection in Minimally Invasive Surgery. 2019 International Symposium on Medical Robotics, ISMR 2019. Institute of Electrical and Electronics Engineers Inc., 2019. [CrossRef]
- Rivas-Blanco, I.; Perez-Del-Pulgar, C.J.; Garcia-Morales, I.; Munoz, V.F.; Rivas-Blanco, I. A Review on Deep Learning in Minimally Invasive Surgery. IEEE Access 2021, 9, 48658–48678. [CrossRef]
- Attanasio, A.; Scaglioni, B.; Leonetti, M.; Frangi, A.F.; Cross, W.; Biyani, C.S.; Valdastri, P. Autonomous Tissue Retraction in Robotic Assisted Minimally Invasive Surgery - A Feasibility Study. IEEE Robotics and Automation Letters 2020, 5, 6528–6535. [CrossRef]
- Sarikaya, D.; Corso, J.J.; Guru, K.A. Detection and Localization of Robotic Tools in Robot-Assisted Surgery Videos Using Deep Neural Networks for Region Proposal and Detection. IEEE Transactions on Medical Imaging 2017, 36, 1542–1549. [CrossRef]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; Chen, C.C.G.; Vidal, R.; Khudanpur, S.; Hager, G.D. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling. Modeling and Monitoring of Computer Assisted Interventions (M2CAI) – MICCAI Workshop 2014, pp. 1–10.
- Colleoni, E.; Edwards, P.; Stoyanov, D. Synthetic and Real Inputs for Tool Segmentation in Robotic Surgery. International Conference on Medical Image Computing and Computer-Assisted Intervention - MICCAI 2020; Springer, Cham: Lima, Peru, 2020; pp. 700–710. [CrossRef]
- Wang, S.; Raju, A.; Huang, J. Deep learning based multi-label classification for surgical tool presence detection in laparoscopic videos. Proceedings - International Symposium on Biomedical Imaging 2017, pp. 620–623. [CrossRef]
- Mishra, K.; Sathish, R.; Sheet, D. Learning Latent Temporal Connectionism of Deep Residual Visual Abstractions for Identifying Surgical Tools in Laparoscopy Procedures. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. IEEE Computer Society, 2017, Vol. 2017-July, pp. 2233–2240. [CrossRef]
- Islam, M.; Atputharuban, D.A.; Ramesh, R.; Ren, H. Real-time instrument segmentation in robotic surgery using auxiliary supervised deep adversarial learning. IEEE Robotics and Automation Letters 2019, 4, 2188–2195. [CrossRef]
- Kurmann, T.; Marquez Neila, P.; Du, X.; Fua, P.; Stoyanov, D.; Wolf, S.; Sznitman, R. Simultaneous recognition and pose estimation of instruments in minimally invasive surgery. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer Verlag, 2017, Vol. 10434 LNCS, pp. 505–513. [CrossRef]
- Chen, Z.; Zhao, Z.; Cheng, X. Surgical instruments tracking based on deep learning with lines detection and spatio-temporal context. Proceedings - 2017 Chinese Automation Congress, CAC 2017. Institute of Electrical and Electronics Engineers Inc., 2017, Vol. 2017-Janua, pp. 2711–2714. [CrossRef]
- Al Hajj, H.; Lamard, M.; Conze, P.H.; Cochener, B.; Quellec, G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Medical Image Analysis 2018, 47, 203–218. [CrossRef]
- Nazir, A.; Cheema, M.N.; Sheng, B.; Li, P.; Li, H.; Yang, P.; Jung, Y.; Qin, J.; Feng, D.D. SPST-CNN: Spatial pyramid based searching and tagging of liver’s intraoperative live views via CNN for minimal invasive surgery. Journal of biomedical informatics 2020, 106, 103430. [CrossRef]
- Fu, Y.; Robu, M.R.; Koo, B.; Schneider, C.; van Laarhoven, S.; Stoyanov, D.; Davidson, B.; Clarkson, M.J.; Hu, Y. More unlabelled data or label more data? a study on semi-supervised laparoscopic image segmentation. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer, 2019, Vol. 11795 LNCS, pp. 173–180. [CrossRef]
- Petscharnig, S.; Schöffmann, K. Deep learning for shot classification in gynecologic surgery videos. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer Verlag, 2017, Vol. 10132 LNCS, pp. 702–713. [CrossRef]
- Twinanda, A.P.; Shehata, S.; Mutter, D.; Marescaux, J.; De Mathelin, M.; Padoy, N. EndoNet: A Deep Architecture for Recognition Tasks on Laparoscopic Videos. IEEE Transactions on Medical Imaging 2017, 36, 86–97. [CrossRef]
- Gao, Y.; Swaroop Vedula, S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; Chiung, C.; Chen, G.; Vidal, R.; Khudanpur, S.; Hager, G.D. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A Surgical Activity Dataset for Human Motion Modeling. MICCAI Workshop: Modeling and Monitoring of Computer Assisted Interventions (M2CAI); , 2014.
- Gao, X.; Jin, Y.; Dou, Q.; Heng, P.A. Automatic Gesture Recognition in Robot-assisted Surgery with Reinforcement Learning and Tree Search. 2020 IEEE International Conference on Robotics and Automation (ICRA); Institute of Electrical and Electronics Engineers (IEEE): IE63, 2020; pp. 8440–8446. [CrossRef]
- Qin, Y.; Pedram, S.A.; Feyzabadi, S.; Allan, M.; McLeod, A.J.; Burdick, J.W.; Azizian, M. Temporal Segmentation of Surgical Sub-tasks through Deep Learning with Multiple Data Sources. 2020 IEEE International Conference on Robotics and Automation (ICRA). Institute of Electrical and Electronics Engineers (IEEE), 2020, pp. 371–377. [CrossRef]
- Funke, I.; Bodenstedt, S.; Oehme, F.; von Bechtolsheim, F.; Weitz, J.; Speidel, S. Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer, 2019, Vol. 11768 LNCS, pp. 467–475. [CrossRef]
- Luongo, F.; Hakim, R.; Nguyen, J.H.; Anandkumar, A.; Hung, A.J. Deep learning-based computer vision to recognize and classify suturing gestures in robot-assisted surgery. Surgery 2020. [CrossRef]
- Murali, A.; Garg, A.; Krishnan, S.; Pokorny, F.T.; Abbeel, P.; Darrell, T.; Goldberg, K. TSC-DL: Unsupervised trajectory segmentation of multi-modal surgical demonstrations with Deep Learning. Proceedings - IEEE International Conference on Robotics and Automation 2016, 2016-June, 4150–4157. [CrossRef]
- Zhao, H.; Xie, J.; Shao, Z.; Qu, Y.; Guan, Y.; Tan, J. A fast unsupervised approach for multi-modality surgical trajectory segmentation. IEEE Access 2018, 6, 56411–56422. [CrossRef]
- Shao, Z.; Zhao, H.; Xie, J.; Qu, Y.; Guan, Y.; Tan, J. Unsupervised Trajectory Segmentation and Promoting of Multi-Modal Surgical Demonstrations. IEEE International Conference on Intelligent Robots and Systems. Institute of Electrical and Electronics Engineers Inc., 2018, pp. 777–782. [CrossRef]
- Marban, A.; Srinivasan, V.; Samek, W.; Fernández, J.; Casals, A. Estimating Position & Velocity in 3D Space from Monocular Video Sequences Using a Deep Neural Network. Proceedings - 2017 IEEE International Conference on Computer Vision Workshops, ICCVW 2017. Institute of Electrical and Electronics Engineers Inc., 2017, Vol. 2018-Janua, pp. 1460–1469. [CrossRef]
- Rivas-Blanco, I.; Del-Pulgar, C.J.; Mariani, A.; Tortora, G.; Reina, A.J. A surgical dataset from the da Vinci Research Kit for task automation and recognition. International Conference on Electrical, Computer, Communications and Mechatronics Engineering, ICECCME 2023 2023. [CrossRef]
- Rivas-Blanco, I.; Pérez-del Pulgar, C.; Mariani, A.; Tortora, G. Training dataset from the Da Vinci Research Kit, 2020. [CrossRef]
- Hardon, S.F.; Horeman, T.; Bonjer, H.J.; Meijerink, W.J. Force-based learning curve tracking in fundamental laparoscopic skills training. Surgical Endoscopy 2018, 32, 3609–3621. [CrossRef]
- Velasquez, C.A.; Navkar, N.V.; Alsaied, A.; Balakrishnan, S.; Abinahed, J.; Al-Ansari, A.A.; Jong Yoon, W. Preliminary design of an actuated imaging probe for generation of additional visual cues in a robotic surgery. Surgical Endoscopy 2016, 30, 2641–2648. [CrossRef]
- Rivas-Blanco, I.; Carmen, L.C.; Herrera Lopez, J.M.; Cabrera-Villa, J.; Pérez-del Pulgar, C. ROSMAG40: a subset of ROSMA dataset with gesture annotations. [CrossRef]
- Rivas-Blanco, I.; Carmen, L.C.; Herrera Lopez, J.M.; Cabrera-Villa, J.; Pérez-del Pulgar, C. ROSMAT24: a subset of ROSMA dataset with instruments detection annotations. [CrossRef]
- Joshi, V.M.; Ghongade, R.B.; Joshi, A.M.; Kulkarni, R.V. Deep BiLSTM neural network model for emotion detection using cross-dataset approach. Biomedical Signal Processing and Control 2022, 73. [CrossRef]
- Wang, Y.; Sun, Q.; Sun, G.; Gu, L.; Liu, Z. Object detection of surgical instruments based on Yolov4. 2021 6th IEEE International Conference on Advanced Robotics and Mechatronics, ICARM 2021, 2021. [CrossRef]
- Itzkovich, D.; Sharon, Y.; Jarc, A.; Refaely, Y.; Nisky, I. Using augmentation to improve the robustness to rotation of deep learning segmentation in robotic-assisted surgical data. Proceedings - IEEE International Conference on Robotics and Automation. Institute of Electrical and Electronics Engineers Inc., 2019, Vol. 2019-May, pp. 5068–5075. [CrossRef]
- Zhao, Z.; Cai, T.; Chang, F.; Cheng, X. Real-time surgical instrument detection in robot-assisted surgery using a convolutional neural network cascade. Healthcare Technology Letters 2019, 6, 275–279. [CrossRef]
Figure 1.
da Vinci Research Kit (dVRK) platform used to collect the ROSMA dataset. (a) The slave side has two Patient Side Manipulators (PSM1 and PSM2), two commercial webcams to provide stereo vision and to record the images, and the training task board. (b) The master console has two Master Tool Manipulators (MTML and MTMR) and a stereo vision system.
Figure 1.
da Vinci Research Kit (dVRK) platform used to collect the ROSMA dataset. (a) The slave side has two Patient Side Manipulators (PSM1 and PSM2), two commercial webcams to provide stereo vision and to record the images, and the training task board. (b) The master console has two Master Tool Manipulators (MTML and MTMR) and a stereo vision system.

Figure 2.
Experimental board scenario for the ROSMA datasets tasks: (a) Post and sleeve and (b) Pea on a peg
Figure 2.
Experimental board scenario for the ROSMA datasets tasks: (a) Post and sleeve and (b) Pea on a peg

Figure 3.
Examples of MD gesture annotations

Figure 4.
Distribution of the gestures occurrence for the MD gestures for (a) PSM1 and (b) PSM2.
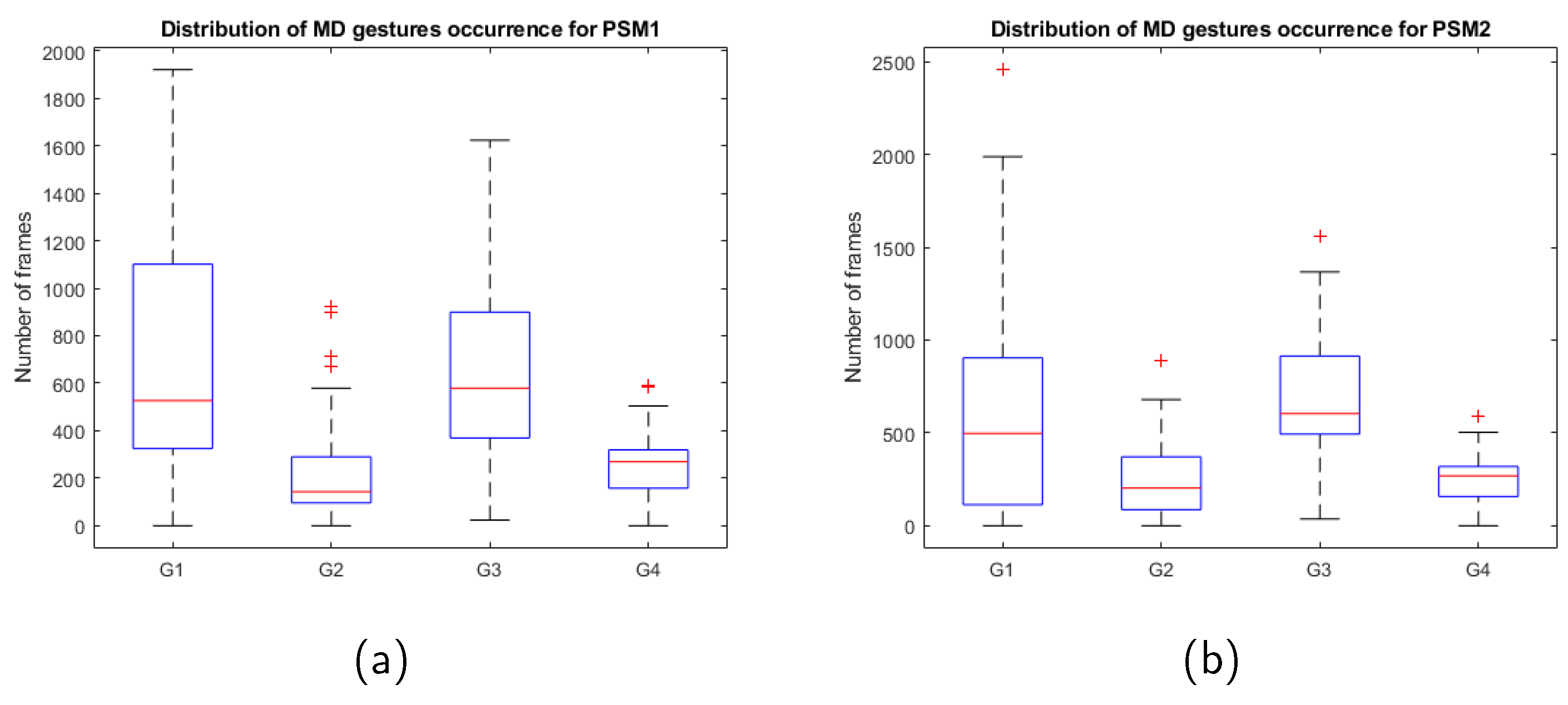
Figure 5.
Sequential distribution of the MD gestures along a complete trial of a pea on a peg task for PSM1 (left) and PSM2 (right)
Figure 5.
Sequential distribution of the MD gestures along a complete trial of a pea on a peg task for PSM1 (left) and PSM2 (right)
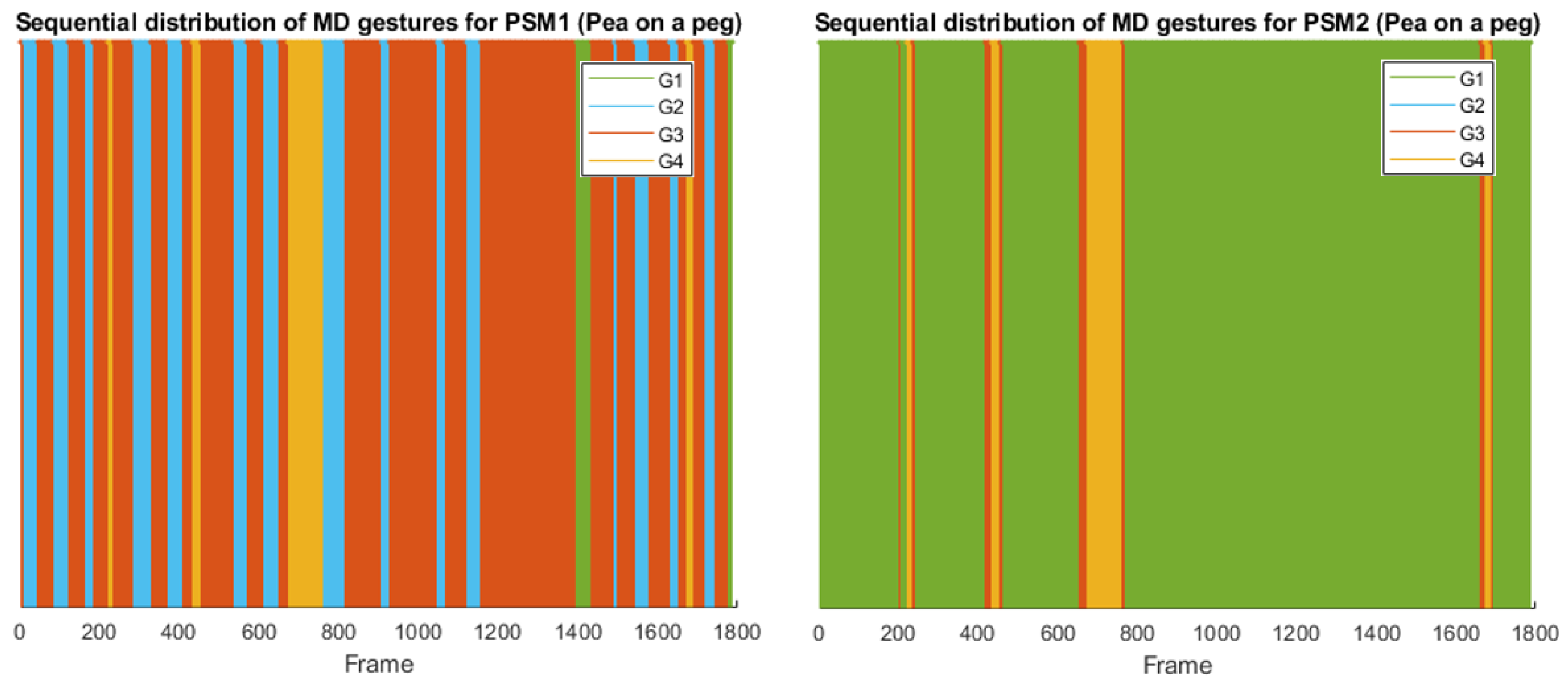
Figure 6.
Sequential distribution of the MD gestures along a complete trial of post and sleeve task for PSM1 (left) and PSM2 (right)
Figure 6.
Sequential distribution of the MD gestures along a complete trial of post and sleeve task for PSM1 (left) and PSM2 (right)
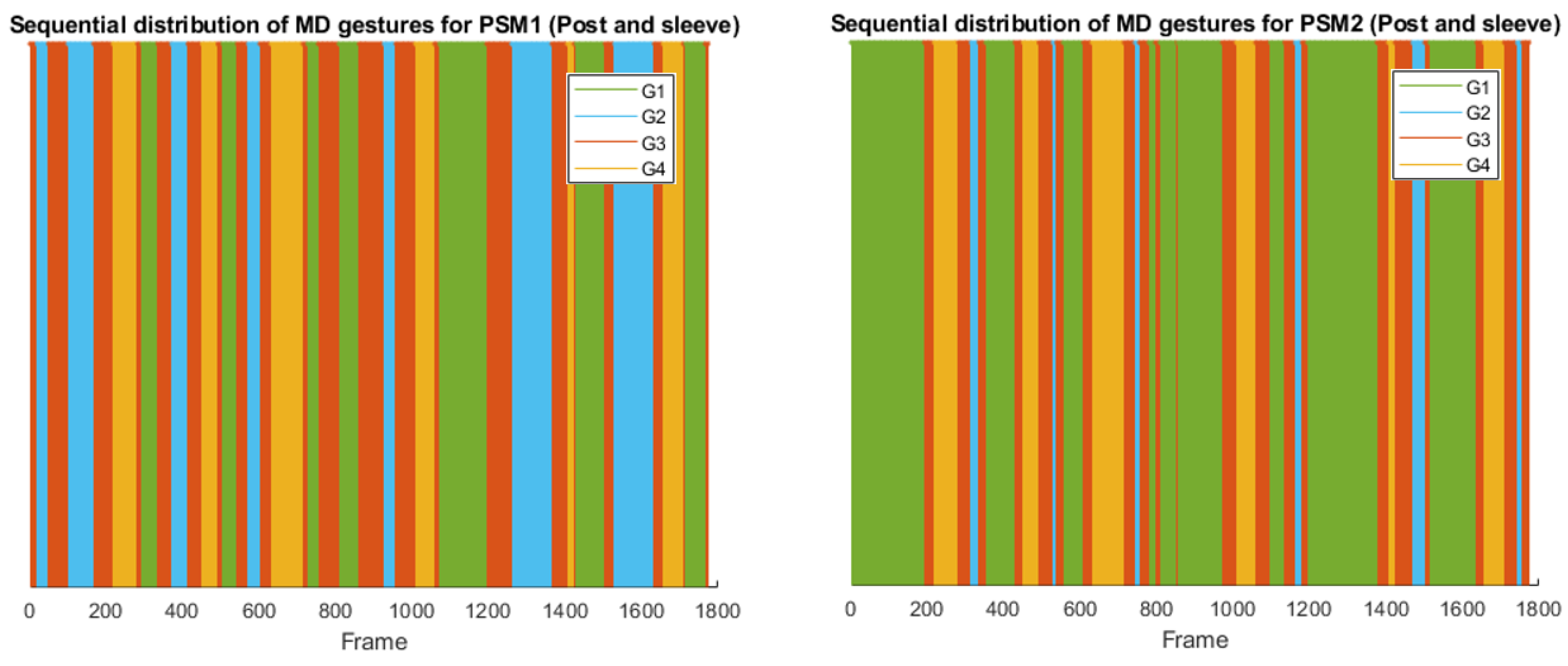
Figure 7.
Examples of FGD gesture annotations

Figure 8.
Distribution of the occurrence for the FGD gestures for (a) PSM1 and (b) PSM2.
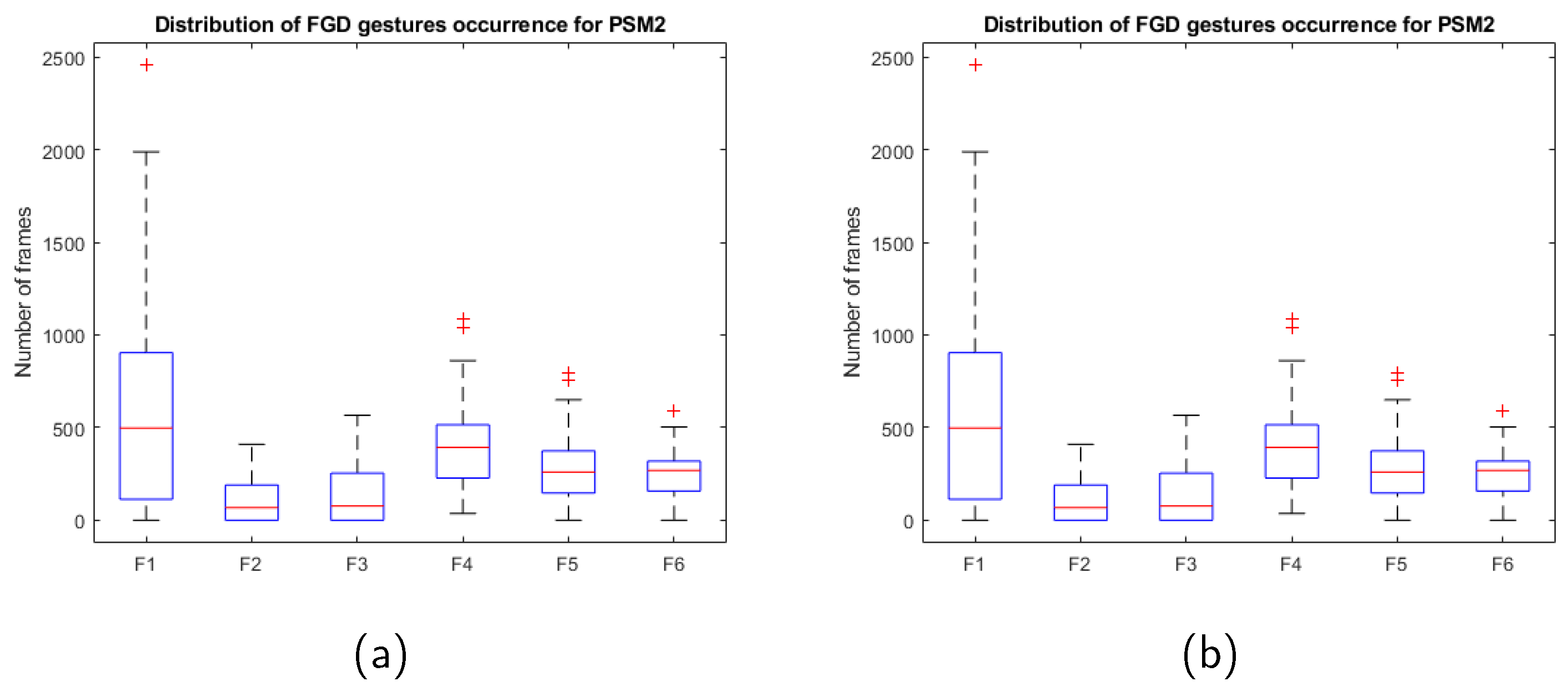
Figure 9.
Sequential distribution of the FGD gestures along a complete trial of a pea on a peg task for PSM1 (left) and PSM2 (right)
Figure 9.
Sequential distribution of the FGD gestures along a complete trial of a pea on a peg task for PSM1 (left) and PSM2 (right)
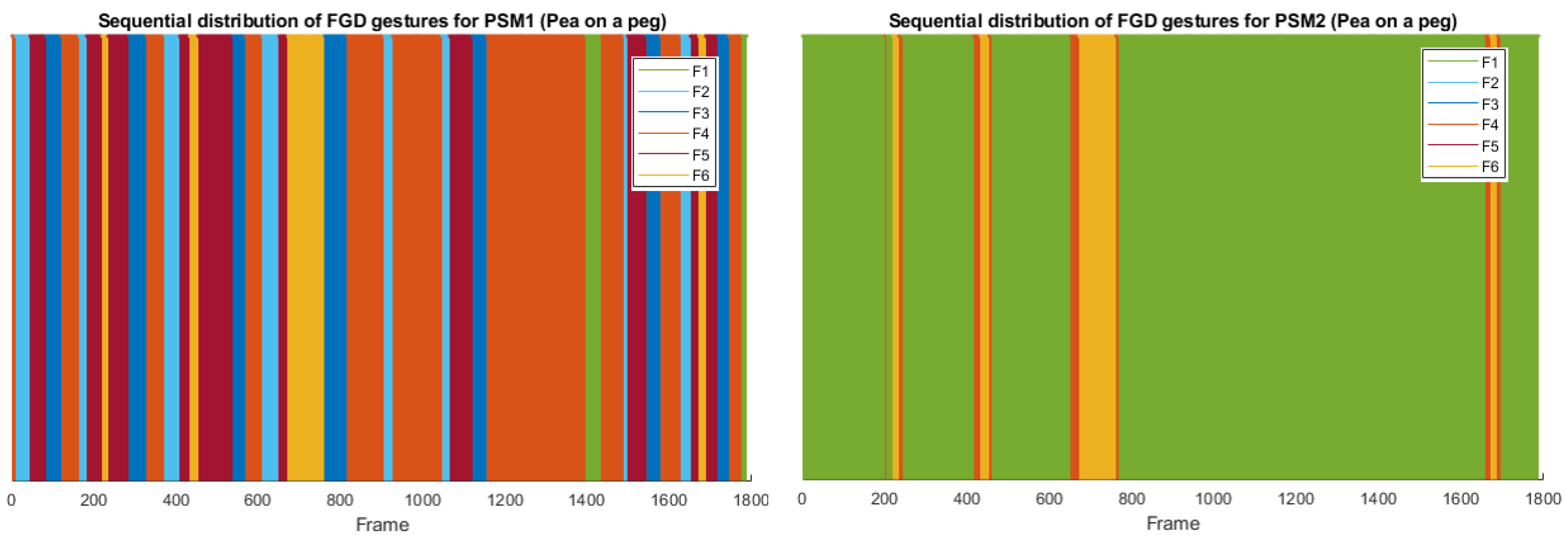
Figure 10.
Sequential distribution of the FGD gestures along a complete trial of post and sleeve task for PSM1 (left) and PSM2 (right)
Figure 10.
Sequential distribution of the FGD gestures along a complete trial of post and sleeve task for PSM1 (left) and PSM2 (right)
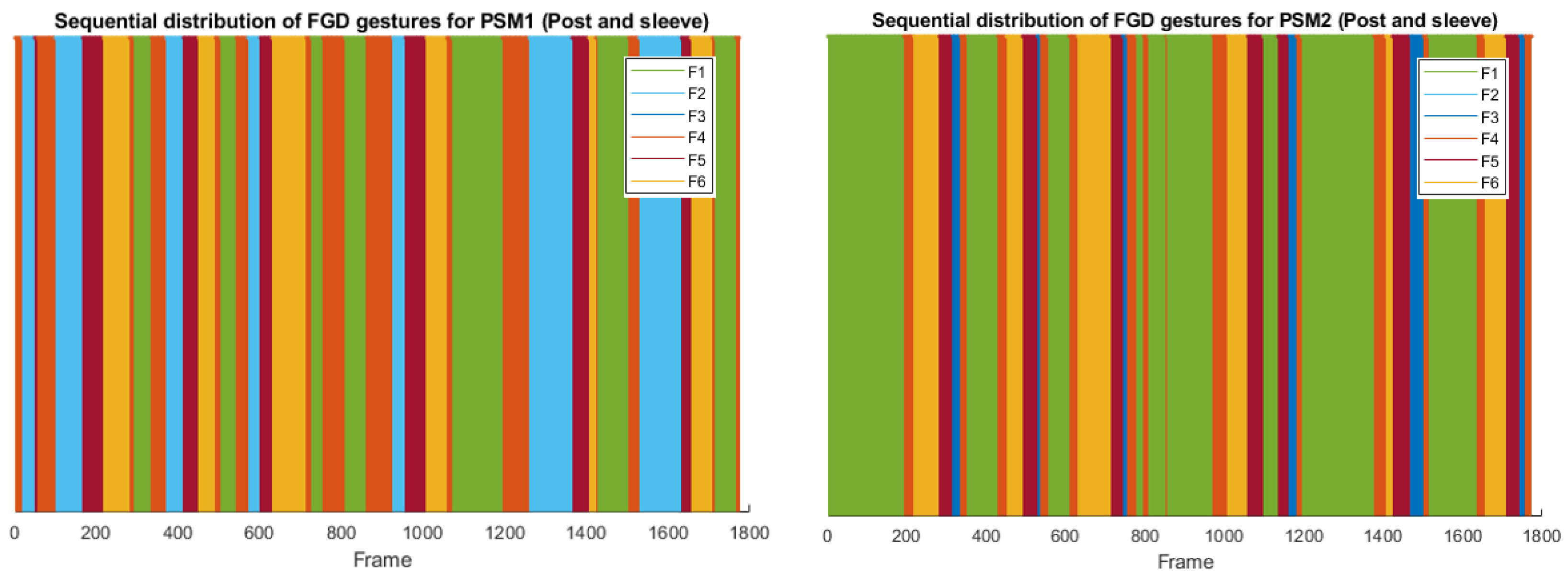
Figure 11.
Examples of the instruments bounding boxes annotations of ROSMAT24.

Figure 12.
RRN model based on a bi-directional LSTM network for gesture segmentation
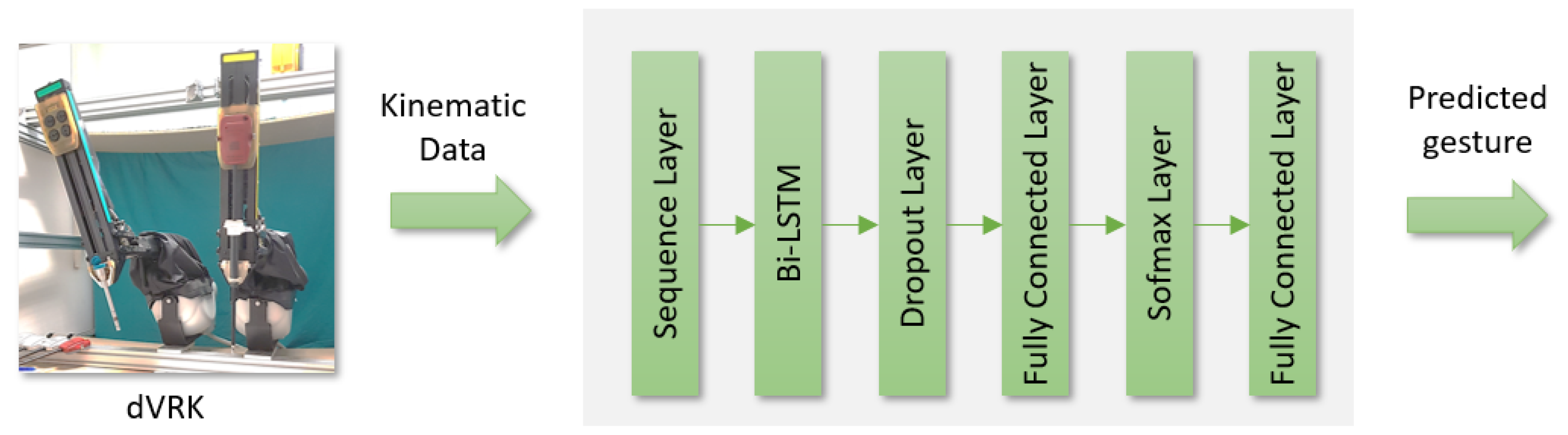
Figure 13.
Precision-recall curve for the LOTO cross-validation scheme using CSPDarknet53 architecture
Figure 13.
Precision-recall curve for the LOTO cross-validation scheme using CSPDarknet53 architecture
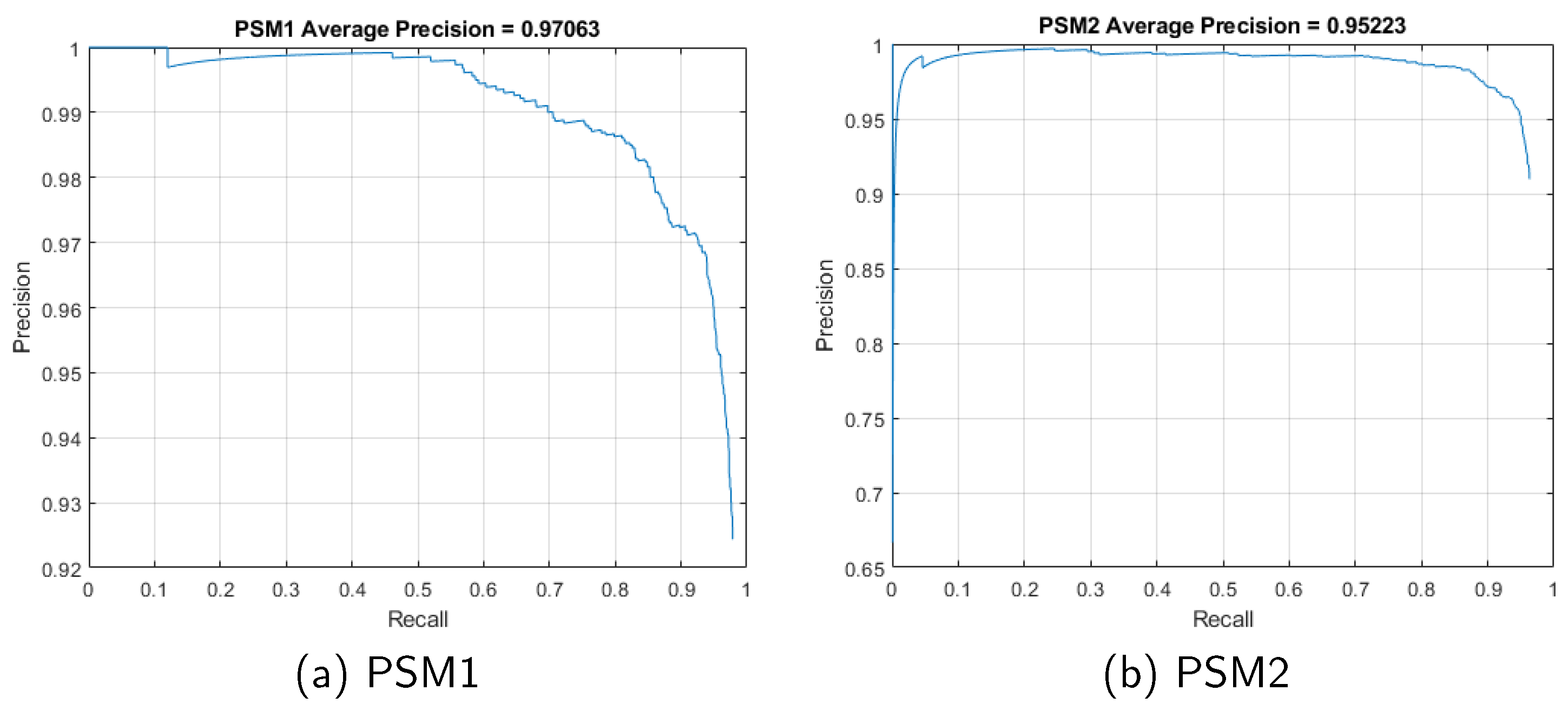
Figure 14.
Example of correct detections (top images) and incorrect detection (bottom images)


Table 1.
Protocol of the task pea on a peg and post and sleeve of the ROSMA dataset
| Post and sleeve | Pea on a peg | |
|---|---|---|
| Goal | To move the colored sleeves from side to side of the board. | To put the beads on the 14 pegs of the board. |
| Starting position | The board is placed with the peg rows in a vertical position (from left to right: 4-2-2-4). The six sleeves are positioned over the 6 pegs on one of the sides of the board. | All beads are on the cup. |
| Procedure | The subject has to take a sleeve with one hand, pass it to the other hand, and place it over a peg on the opposite side of the board. If a sleeve is dropped, it is considered a penalty and it cannot be taken back. | The subject has to take the beads one by one out of the cup and place them on top of the pegs. For the trials performed with the right hand, the beads are placed on the right side of the board, and vice versa. If a bead is dropped, it is considered a penalty and it cannot be taken back. |
| Repetitions | Six trials: three from right to left, and other three from left to right. | Six trials: three placing the beads on the pegs of the right side of the board, and other three on the left side2. |
Table 2.
Description of the ROSMAG40 dataset distribution
| User ID | Task | Dominant tool | Annotated videos |
|---|---|---|---|
| X01 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X02 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X06 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X07 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 | ||
| X08 | Pea on a Peg | PSM1 | 2 |
| PSM2 | 2 | ||
| Post and sleeve | PSM1 | 2 | |
| PSM2 | 2 |
Table 3.
Description of ROSMAG40 annotations for MD gestures
| Gesture ID | Gesture label | Gesture description | No. frames PSM1 | No. frames PSM2 |
|---|---|---|---|---|
| G1 | Idle | The instrument is in a resting position | 28395 (38.98%) | 2583 (35.46%) |
| G2 | Precision | The instrument is performing an action that requires an accurate motion of the tip. | 9062 (12.43%) | 9630 (13.1%) |
| G3 | Displacement | The instrument is moving with or without an object on the tip | 24871 (34.14%) | 26865 (36.42%) |
| G4 | Collaboration | Both instruments are collaborating on the same task. | 10515 (14.53%) | 10515 (14.53%) |
Table 4.
ROSMAG40 annotations for maneuver descriptor gestures
| Gesture ID | Gesture label | Gesture description | Number of frames PSM1 | Number of frames PSM2 |
|---|---|---|---|---|
| F1 | Idle | The instrument is in a resting position | 28395 (38.98%) | 2583 (35.46%) |
| F2 | Picking | The instrument is picking an object. | 3499 (4.8%) | 4287 (5.8%) |
| F3 | Placing | The instrument is placing an object on a peg. | 5563 (7.63%) | 5343 (7.3%) |
| F4 | Free motion | The instrument is moving without carrying anything at the tool tip. | 15813 (21.71%) | 16019 (21.99%) |
| F5 | Load motion | The instrument is moving holding an object. | 9058 (12.43%) | 10846 (14.43%) |
| F6 | Collaboration | Both instruments are collaborating on the same task. | 10515 (14.53%) | 10515 (14.53%) |
Table 5.
Description of the ROSMAT24 dataset annotations
| Video | No. frames | Video | No. frames |
|---|---|---|---|
| X01 Pea on a Peg 01 | 1856 | X03 Pea on a Peg 01 | 1909 |
| X01 Pea on a Peg 02 | 1532 | X03 Pea on a Peg 02 | 1691 |
| X01 Pea on a Peg 03 | 1748 | X03 Pea on a Peg 03 | 1899 |
| X01 Pea on a Peg 04 | 1407 | X03 Pea on a Peg 04 | 2631 |
| X01 Pea on a Peg 05 | 1778 | X03 Pea on a Peg 05 | 1587 |
| X01 Pea on a Peg 06 | 2040 | X03 Pea on a Peg 06 | 2303 |
| X02 Pea on a Peg 01 | 2250 | X04 Pea on a Peg 01 | 2892 |
| X02 Pea on a Peg 02 | 2151 | X04 Pea on a Peg 02 | 1858 |
| X02 Pea on a Peg 03 | 1733 | X04 Pea on a Peg 03 | 2905 |
| X02 Pea on a Peg 04 | 2640 | X04 Pea on a Peg 04 | 2265 |
| X02 Pea on a Peg 05 | 1615 | X01 Post and Sleeve 01 | 1911 |
| X02 Pea on a Peg 06 | 2328 | X11 Post and Sleeve 04 | 1990 |
Table 6.
Kinematic data variables from the dVRK used as input to the RNN for gesture segmentation
| Kinematic variable | PSM | No. features |
|---|---|---|
| Tool orientation (x,y,z,w) | PSM1 | 4 |
| PSM2 | 4 | |
| Linear velocity (x,y,z,) | PSM1 | 3 |
| PSM2 | 3 | |
| Angular velocity (x,y,z,) | PSM1 | 3 |
| PSM2 | 3 | |
| Wrench force (x,y,z,) | PSM1 | 3 |
| PSM2 | 3 | |
| Wrench torque (x,y,z,) | PSM1 | 3 |
| PSM2 | 3 | |
| Distance between tools | - | 1 |
| Angle between tools | - | 1 |
| Total number of input features | - | 34 |
Table 7.
Results for Leave-One-User-Out (LOUO) cross-validation scheme
| User left out Id | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| X1 | 48.9% | 39% | 46.26% | 23.36% |
| X2 | 58.8% | 64.9% | 48.16% | 51.39% |
| X3 | 50.4% | 64.2% | 39.71% | 51.24% |
| X4 | 63.0% | 61.2% | 54.05% | 49.08% |
| X5 | 54.6% | 53.6% | 52.34% | 52.7% |
| Mean | 55.14% | 56.58 | 48.01% | 45.55% |
Table 8.
Results for Leave-One-Supertrial-Out (LOSO) cross-validation scheme
| Supertrial left out | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| Pea on a peg | 56.15% | 56% | 46.36% | 46.67% |
| Post and sleeve | 52.2% | 51.9% | 39.06% | 43.38% |
1 Tables may have a footer.
Table 9.
Results for Leave-One-Psm-Out (LOPO) cross-validation scheme
| Dominant PSM | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| PSM1 | 56.53% | 67% | 24.11% | 37.33%% |
| PSM2 | 65.7% | 67.5% | 52.47% | 54.68% |
1 Tables may have a footer.
Table 10.
Results for Leave-One-Trial-Out (LOTO) cross-validation scheme
| Dominant PSM | PSM1 mAP (MD) | PSM2 mAP (MD) | PSM1 mAP (FGD) | PSM2 mAP (FGD) |
|---|---|---|---|---|
| Test data 1 | 64.65% | 77.35% | 56.46% | 58.99% |
| Test data 2 | 63.8% | 62.8% | 30.43% | 70.58% |
| Test data 3 | 53.26% | 55.58% | 53.26% | 61.6% |
| Test data 4 | 48.72% | 60.62% | 58.3% | 55.58% |
| Test data 5 | 60.51% | 66.84% | 71.39% | 46.67% |
Table 11.
Results for LOSO experimental setup
| Architecture | Test data | PSM1 mAP | PSM2 mAP |
|---|---|---|---|
| CSPDarknet53 | Post and sleeve | 70.92% | 84.66% |
| YOLOv4-tiny | Post and sleeve | 83.64% | 73.45% |
Table 12.
Results for LOTO experimental setup
| Architecture | Left tool mAP | Right tool mAP | Detection time |
|---|---|---|---|
| CSPDarknet53 | 97.06% | 95.22% | 0.0335 s (30 fps) |
| YOLOv4-tiny | 93.63% | 95.8% | 0.02 s (50 fps) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



