
Submitted:
03 March 2024
Posted:
04 March 2024
You are already at the latest version
Abstract
Grasping the spatial and temporal patterns of forest fires, along with the key factors that drive them and the ability to forecast such events accurately, is essential for the successful management of forests. In China's southern region, forest fires significantly endanger the ecological system, public safety, and economic well-being. Through the application of Geographic Information Systems (GIS) and LightGBM (Light Gradient Boosting Machine) model, this study investigates the determinants of fire incidents and formulates a predictive model for forest fire occurrences, alongside a zoning strategy, within the Central-South area. The results indicate: (i) Spatially, fire points exhibit significant clustering and autocorrelation characteristics; (ii) The Central-South Forest Fire Prediction Model shows exceptional accuracy, reliability, and predictive power, with high performance metrics across training and validation sets, including over 85% accuracy, precision, recall, and F1 scores, along with AUC values above 89%, underscoring its efficacy in forecasting forest fires and distinguishing between fire events; (iii) Throughout the year, forest fire risks in the Central-South region of China vary by region and season, with risk spikes from March to May in Guangdong, Guangxi, Hunan, Hubei, and Hainan. From June to August, localized risks are observed in Heyuan and Huangshi, while from September to November, an increase in risk is noted in Guangdong (Meizhou, Heyuan, Shaoguan), Guangxi (Nanning, Hezhou, Yulin), and Hunan (Binzhou, Yongzhou, Hengyang) due to cooler, drier conditions and leaf litter accumulation. From December to February, the risk continues in specific areas across Guangdong, Guangxi, Hunan, and Hubei.
Keywords:
wildfire risk assessment
; Central-South China
; GIS application
; predictive modeling
; fire occurrence analytics
; seasonal fire patterns
; spatial clustering analysis
1. Introduction
Forests play a crucial role in mitigating climate change by absorbing carbon dioxide, thereby reducing greenhouse gas emissions [1,2,3]. Moreover, they are instrumental in the water cycle, regulating precipitation and maintaining the volumes of rivers and lakes [4,5]. Forests also provide essential resources for humans, such as timber, medicinal plants, and food, and form the basis of many cultures and communities. Thus, the protection and management of forests are vital for maintaining the ecological balance of the Earth and the well-being of humanity [6,7,8]. Forest fires have profound impacts on forests, including ecosystem destruction, biodiversity loss, increased greenhouse gas emissions in the atmosphere, soil degradation, and alterations in the water cycle. Effective forest management and fire prevention strategies are crucial for protecting forests and maintaining environmental balance [9]. Forest fire prediction is of paramount importance in forest management and environmental conservation. It enables early warning of fire risks, optimization of resource allocation, reduction of economic losses, protection of ecosystems and biodiversity, minimization of human casualties, and mitigation of climate change. Through effective prediction and response measures, the impact of forest fires on nature and humans can be significantly reduced [10,11].
Forest fire prediction is a significant research area within the domain of forest fire prevention. In recent years, technological advancements have led to notable progress in forest fire prediction techniques. The primary methods for predicting forest fires include those based on physical models and statistical analysis. (i) Physical model-based forest fire prediction involves inputting real-time meteorological data, vegetation parameters, and terrain information to predict the potential spread of fires under certain conditions [12,13]. Continuous optimization and refinement of physical models are undertaken to enhance prediction accuracy. This includes incorporating more detailed combustion mechanisms and chemical reaction models to more accurately simulate the dynamics of fire spread, as well as utilizing high-resolution terrain and vegetation data to more precisely simulate the impact of surface conditions on fire occurrence [14,15]. (ii) Statistical analysis-based fire prediction employs mathematical models to assess the risk of fire occurrences by analyzing historical fire data, meteorological data, human activities, and other related factors. These models typically rely on probabilistic statistical principles to reveal correlations between fire occurrences and various factors [16,17,18]. (iii) To improve the accuracy of forest fire prediction, researchers continually refine and optimize models. For instance, the application of artificial intelligence and machine learning technologies enables the training and optimization of forest fire prediction models, improving their adaptability and accuracy [19,20,21,22,23]. These intelligent algorithms can process large datasets, learning patterns and regularities hidden within the data to enhance prediction accuracy.
LightGBM (Light Gradient Boosting Machine) is an efficient gradient boosting decision tree algorithm widely applied in various machine learning tasks, including forest fire prediction [24,25,26]. Its advantages include efficient handling of large datasets, automatic processing of missing values and categorical features, and providing highly accurate predictions, making it particularly suitable for forest fire prediction tasks involving extensive environmental and meteorological data. LightGBM also supports parallel processing and GPU acceleration, offering high flexibility and adjustability [27,28]. Therefore, this study aims to conduct an in-depth analysis of forest fire data from 2001 to 2019 in the Central-South region of China, using Geographic Information System (GIS) technology to reveal trends, patterns, and seasonal variations in fire occurrences. The specific objectives include: (i) utilizing GIS technology to analyze historical fire data to identify and understand the geographical distribution, frequency, and severity of fires and their correlation with environmental factors; (ii) developing a LightGBM-based forest fire prediction model to accurately predict the likelihood of forest fires in future months, enhancing early warning and prevention capabilities; (iii) based on the analysis and prediction results, formulating effective forest fire prevention strategies, including risk area monitoring, early warning system establishment, emergency response plans, as well as public education and awareness raising. This research aims to provide comprehensive scientific guidance for reducing the occurrence and damage of forest fires in the Central-South region of China, protecting the natural environment and human society from the impacts of fire disasters.
2. Resources and Methods
2.1. The Study Area
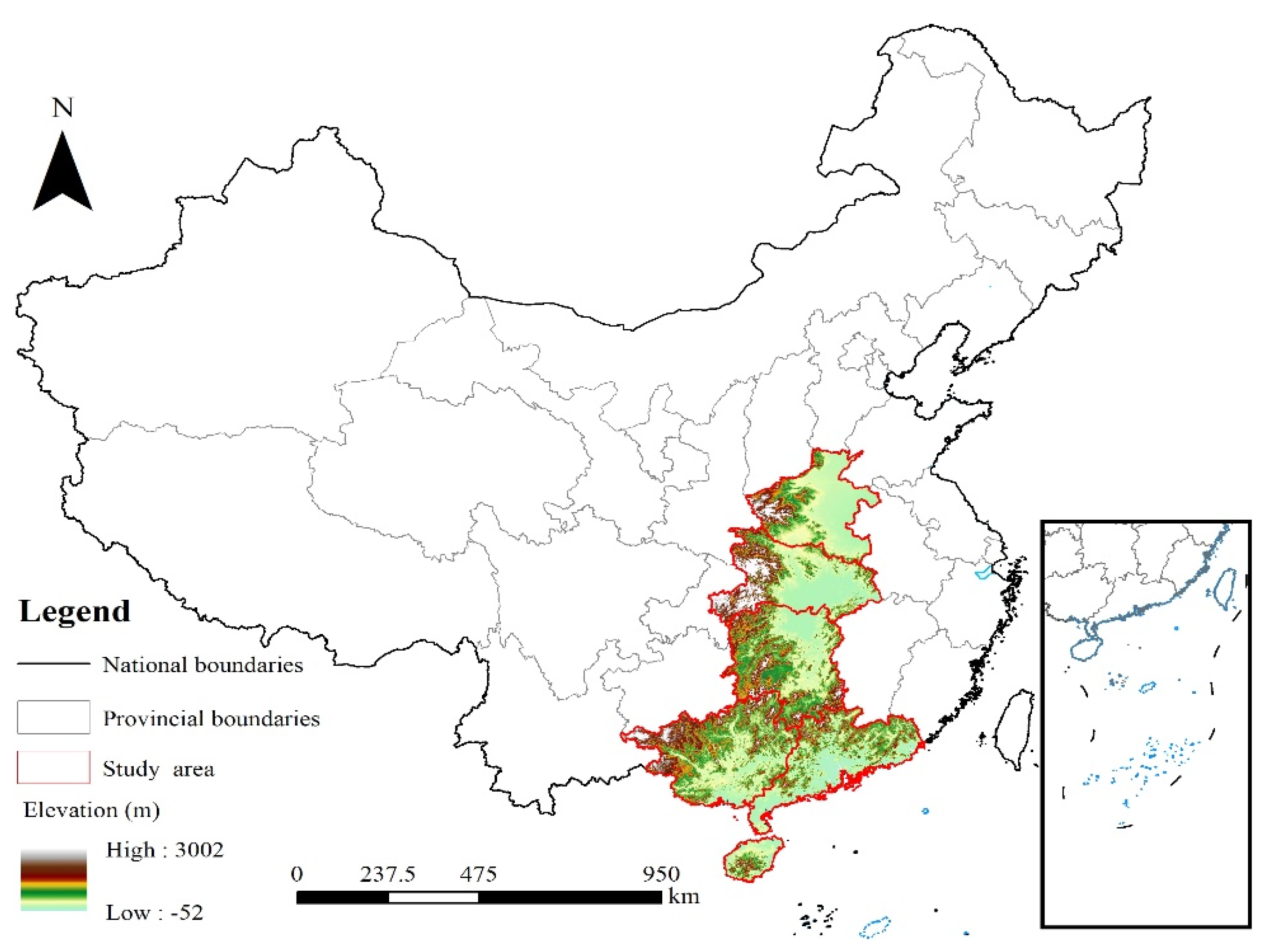
The Central-South region is a pivotal area in China, renowned for its abundant natural resources and advantageous geographical location. This region encompasses the provinces of Henan, Hubei, Hunan, Guangxi, Guangdong, and Hainan, featuring a complex and diverse topography that includes plains, hills, mountains, and plateaus. The climate is rich and distinct across seasons, with ample rainfall and sufficient sunlight, creating an ideal environment for the development of agriculture and forestry. The Central-South region also boasts rich water resources from major rivers such as the Yangtze, Yellow, and Pearl Rivers, which not only satisfy local demands for production and domestic use but also provide surplus resources for external allocation.
In terms of industrial structure, the region is dominated by the secondary and tertiary sectors, with manufacturing and tourism being the two pillar industries. Economically, Guangdong Province, particularly the Pearl River Delta area, plays a leading role in economic development as one of the most developed provinces in China [29]. Henan, Hubei, and Hunan are predominantly focused on agriculture and heavy industry, while Guangxi and Hainan exhibit unique advantages in tourism and tropical agriculture. The GDP total and per capita GDP of the Central-South region are both at a relatively high level, making it one of the significant engines of China’s economic growth. The population is substantial, primarily Han Chinese, but also includes various ethnic minorities.
Figure 1.
Study area (omitting Taiwan because of the absence of data).
2.2. Data Sources
As shown in Table 1, we adopted an extensive data collection and processing strategy to analyze forest fire occurrences effectively. The data were organized into four primary categories: topographic, climate, vegetation, and social and human factors, each playing a crucial role in understanding and predicting forest fires.
Fire Data Utilization: In this research, the Moderate Resolution Imaging Spectroradiometer (MODIS) dataset on forest fires was employed, which includes 18,705 identified fire occurrences. This dataset is made available by the National Aeronautics and Space Administration (NASA) and can be accessed via NASA’s Earth Data portal (https://earthdata.nasa.gov/) [19]. This comprehensive dataset enabled a detailed analysis of forest fire occurrences, facilitating the development of predictive models and strategies for effective fire management.
The dataset encompasses detailed information on forest fires, including occurrence dates, geographic coordinates (latitude and longitude) of the fire incidents, confidence levels, brightness measurements, among other pertinent attributes. Specifically focusing on the span from 2000 to 2019, this study pinpointed fires in the southwestern region with a confidence level above 80% from the years 2001 to 2019.
Topographic Data: This included details like terrain elevation and slopes, which are essential in understanding how the physical landscape influences the behavior and spread of forest fires. Topographic features significantly impact fire propagation patterns, making this data category vital for our analysis.
Climate Data: Meteorological records, such as temperature, humidity, and wind conditions, were meticulously analyzed. These climate factors are pivotal in understanding the environmental conditions that contribute to forest fires, as they directly influence both the likelihood and behavior of these events.
Vegetation Data: The type and extent of vegetation were catalogued, as they significantly affect fire vulnerability. Data on forest coverage and other vegetation types were gathered to identify areas that are more susceptible to fire incidents, due to the availability of burnable material.
Social and Human Factors: Socio-economic parameters, including demographic data, economic metrics, population density, and residential area information, were considered to assess how human activities might influence fire risks. Factors such as agricultural practices, unauthorized burnings, GDP, and special holidays were also taken into account. While lightning data, a natural trigger for wildfires, was excluded due to reliability concerns, human-related factors were incorporated indirectly through these proxies.
The methodology involved harmonizing these diverse data types into a unified, consistent dataset. This included rigorous data cleaning to resolve issues like missing values, outliers, and duplicates, ensuring data integrity and precision. The final step was data normalization, which standardized various data formats and units, making them comparable and suitable for integration into our predictive model. This step was essential in maintaining uniformity across datasets, enabling a comprehensive analysis of the multiple factors influencing forest fires.
2.3. Method
In this comprehensive study, Figure 2 serves as a pivotal illustration, mapping out the intricate technical journey undertaken to thoroughly explore the multifaceted issues surrounding forest fires. The roadmap delineates the sophisticated process of amalgamating a diverse array of datasets, each contributing a unique lens through which the phenomenon of forest fires is examined. These datasets span an extensive spectrum of information domains, including detailed records of fire incidents, land-use patterns, meteorological data, socioeconomic indicators, comprehensive vegetation characteristics, and nuanced terrain information. To harmonize these varied data sources and ensure their comparability and analyzability, the research employs advanced normalization techniques. These techniques adeptly minimize the amplitude disparities among the datasets, ensuring a harmonized data framework that facilitates consistency and equilibrium in the analysis.
Progressing beyond the initial phase of data preparation, the study ventures into an elaborate analysis employing a suite of sophisticated data examination methods. Through the utilization of kernel density analysis, the research identifies areas where fire incidents are notably concentrated, shedding light on the hotspots of forest fire occurrences. Spatial autocorrelation analysis is then applied to unravel the intricate spatial relationships between fire events, offering insights into the interconnectedness of these occurrences across the landscape. Furthermore, the deployment of standard deviation ellipses aids in delineating the directional trends and dispersion ranges of fire spread, enhancing our understanding of the dynamics of forest fire diffusion.
Building on these analytical insights, the study introduces the cutting-edge Light Gradient Boosting Model (LightGBM) algorithm, leveraging the power of machine learning to forecast potential forest fire risks with unprecedented precision. This predictive model integrates a comprehensive suite of factors, including historical fire incidents, meteorological conditions, land-use patterns, and socioeconomic indicators, weaving them into a predictive tapestry that forecasts the likelihood of future fire occurrences. By providing a scientifically grounded prediction of potential fire incidents, this model equips decision-makers with the critical information needed to devise targeted, proactive strategies for forest fire prevention and mitigation. Through this holistic approach, the study not only unveils the complex patterns and trends of forest fire occurrences but also contributes significantly to the domain of effective fire management, offering a robust foundation for informed decision-making and strategic planning in forest fire prevention efforts.
2.3.1. Kernel Density Estimation
Kernel Density Estimation (KDE) utilizes a smoothing technique to illustrate the distribution shape of data, making it exceptionally well-suited for continuous data analysis. Through this method, a kernel—often a Gaussian kernel—is positioned around each data point, with the data points being weighted according to the kernel’s bandwidth. This process effectively produces a comprehensive density estimate, offering a visual representation of data distribution [38,39]. Kernel density analysis in the context of forest fires transforms scattered incidents of forest fires into continuous density maps, offering an intuitive visualization of the spatial distribution of forest fires. This technique does not depend on prior distribution assumptions, which permits flexible adjustment of the analysis scale to accommodate various distribution patterns. In forest fire management, its application is instrumental in identifying high-risk areas, optimizing resource allocation, and uncovering potential factors contributing to forest fires. Consequently, it enhances the efficiency of forest fire prevention and response strategies [40].
The formula of kernel density analysis is as follows [41]:
The term f(x) denotes the kernel density estimate calculated within the specified threshold interval, indicating the estimated density of occurrences per unit area. The variable n stands for the total number of forest fires occurring within this interval, providing a quantitative measure of fire incidents. The parameter h represents the predetermined search radius or bandwidth for the kernel density estimation window, which determines the scale of smoothing applied to the data. Lastly, the symbol k refers to the kernel function employed in the analysis, which is a mathematical function used to weight the data points within the search radius, thereby influencing the shape of the resulting density estimate.
2.3.2. Spatial Autocorrelation Analysis
Spatial autocorrelation is a commonly used concept in geography and statistics, employed to describe the similarity or correlation between different locations in geographic space [42,43,44]. It refers to whether there is a connection or similarity between adjacent or distant locations in geographical space and is typically used to study the distribution, clustering, and variations of geographic phenomena [45].The advantages of spatial autocorrelation analysis in forest fire studies include revealing the geographical distribution patterns of fires, assisting in resource management and allocation, providing predictions and early warnings, optimizing monitoring networks, and supporting spatial decision-making to reduce fire risks and enhance fire response effectiveness. This analytical method plays a crucial role in forest fire research and control.
The formulas are as follows [46]:
Global autocorrelation:
In this equation, I represents the global Moran’s I index, stands for the total number of spatial units, denotes the spatial weights between units and , and represent the values of variable for units and , and signifies the average or mean of variable x.
Local autocorrelation:
In this formula, is the local Moran’s I index, is the number of spatial units, represents spatial weights between units and , is the value of variable for unit , is the mean of variable .
In this equation, represents the local Moran’s I index, stands for the total number of spatial units, denotes the spatial weights between units and , signifies the value of variable for unit i, and represents the mean or average of variable .
Global and local autocorrelation analyses offer a nuanced lens for exploring spatial patterns across vast geographic expanses and within specific regions, respectively. These analyses classify spatial relationships into four distinct patterns: H-H (where high-value areas cluster together), H-L (where high-value areas are surrounded by low-value ones), L-H (where low-value areas are encircled by high-value ones), and L-L (where low-value areas cluster together). This framework facilitates a deeper understanding of how similar or dissimilar value areas associate with each other, revealing patterns of aggregation or dispersion. Such insights are crucial for devising targeted strategies in spatial planning and analysis, allowing for a more informed approach to managing geographical spaces and their inherent characteristics.
2.3.3. Standard Deviation Ellipse
The standard deviation ellipse is a visualization tool used in multivariate statistical data analysis [47,48]. It constructs an ellipse with a specific shape and orientation by considering the standard deviation and covariance matrix of the data, reflecting the dispersion and correlation of data points [49]. This visualization tool is commonly employed for displaying data distributions, detecting outliers, and performing data clustering analysis. By examining the shape and orientation of the ellipse, it helps researchers gain a better understanding of the characteristics and structure of the dataset [50]. In the context of forest fires, the advantage of using standard deviation ellipses lies in their ability to visually depict the distribution of forest fire data, identify clusters of fire sources and anomalies, and provide valuable support for spatial planning and data analysis, ultimately enhancing our understanding of the spatial features of forest fires and improving risk management and response strategies.
The formula is as follows [51]:
In this equation, and represent the standard deviations of the variables and , while stands for the number of observations. Additionally, and denote the averages or means of variables and , respectively.
Within this mathematical expression, represents the tangent of the angle of rotation, whereas and signify the transformed or rotated coordinates of individual points within the updated coordinate system.
In this equation, and represent the standard deviations of the transformed coordinates, while and denote the coordinates of individual points i after rotation within the updated coordinate system.
2.3.4. Light Gradient Boosting Model
The Light Gradient Boosting Machine (LightGBM) is an efficient gradient boosting framework that utilizes tree-based learning algorithms, specially optimized for handling large datasets while maintaining high training speed and accuracy [52].LightGBM introduces two key innovations: Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB), both designed to reduce computational and memory usage during training without compromising model performance. GOSS retains data points with larger gradients while downsampling others, thus reducing computational load while ensuring training accuracy. EFB reduces the dimensionality of features by bundling exclusive features (i.e., features that do not take on values simultaneously). These innovations allow LightGBM to achieve faster training speeds and lower memory consumption when processing large-scale datasets, compared to other gradient boosting methods, while maintaining or enhancing model performance [54,55,56].
2.3.5. Evaluation Indicators
In the realm of machine learning and statistical analysis, a suite of metrics including Accuracy, Precision, Recall, F1 score, and AUC (Area Under the Curve) are pivotal for evaluating the efficacy of classification models. These metrics act as benchmarks to determine the effectiveness of a model in accurately segregating data into respective categories. They offer a comprehensive view of model performance by assessing different aspects of classification accuracy. The formulas for these metrics are as follows [19,57]:
In a binary classification context, such as assessing a forest fire prediction model, True Positives (TP) are cases accurately predicted as fire incidents, while True Negatives (TN) are non-incidents correctly identified. Conversely, False Positives (FP) refer to non-incidents erroneously classified as fires, and False Negatives (FN) are actual fire incidents that the model fails to detect. These parameters are crucial in evaluating the precision and effectiveness of the forest fire prediction model, as they measure the accuracy of the model in distinguishing between actual and non-existent forest fires.
3. Results
3.1. Forest Fire Kernel Density Analysis in the Central and Southern Regions
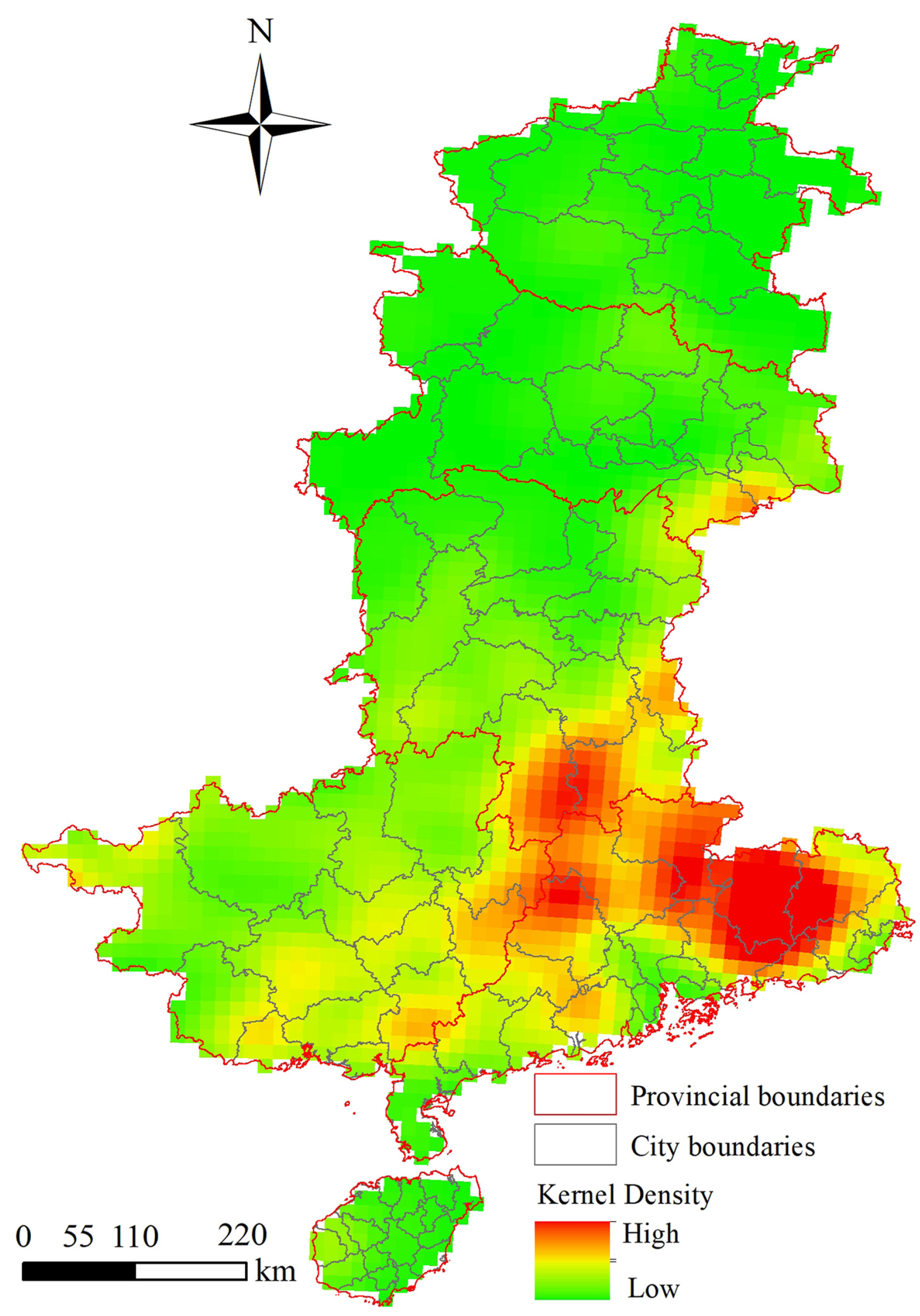
Regions with high forest fire kernel density in the Central-South area are primarily concentrated in Guangdong Province (including Heyuan, Meizhou, Shaoguan, etc.), and Hunan Province (Yongzhou, Binzhou, Hezhou, etc.). This concentration is largely attributed to a combination of factors including variable climate, dense vegetation, complex geographical conditions, and human activities. The monsoon climate, characterized by humid summers and dry winters, can lead to vegetation drought, thereby increasing the risk of forest fires. Dense vegetation provides ample fuel for fires, while mountainous and hilly terrains offer pathways for fire spread. Additionally, inappropriate human activities, such as trash burning and open fire use, can also trigger forest fires. To mitigate the threat of wildfires, it is necessary to implement preventive measures, enhance monitoring and early warning systems, and raise public awareness to more effectively manage and control the potential risk of forest fires.
Figure 3.
Kernel Density Analysis of Forest Fires in the Central South Region.
3.2. Results of Autocorrelation Analysis on Forest Fire Occurrences in Central and Southern China region
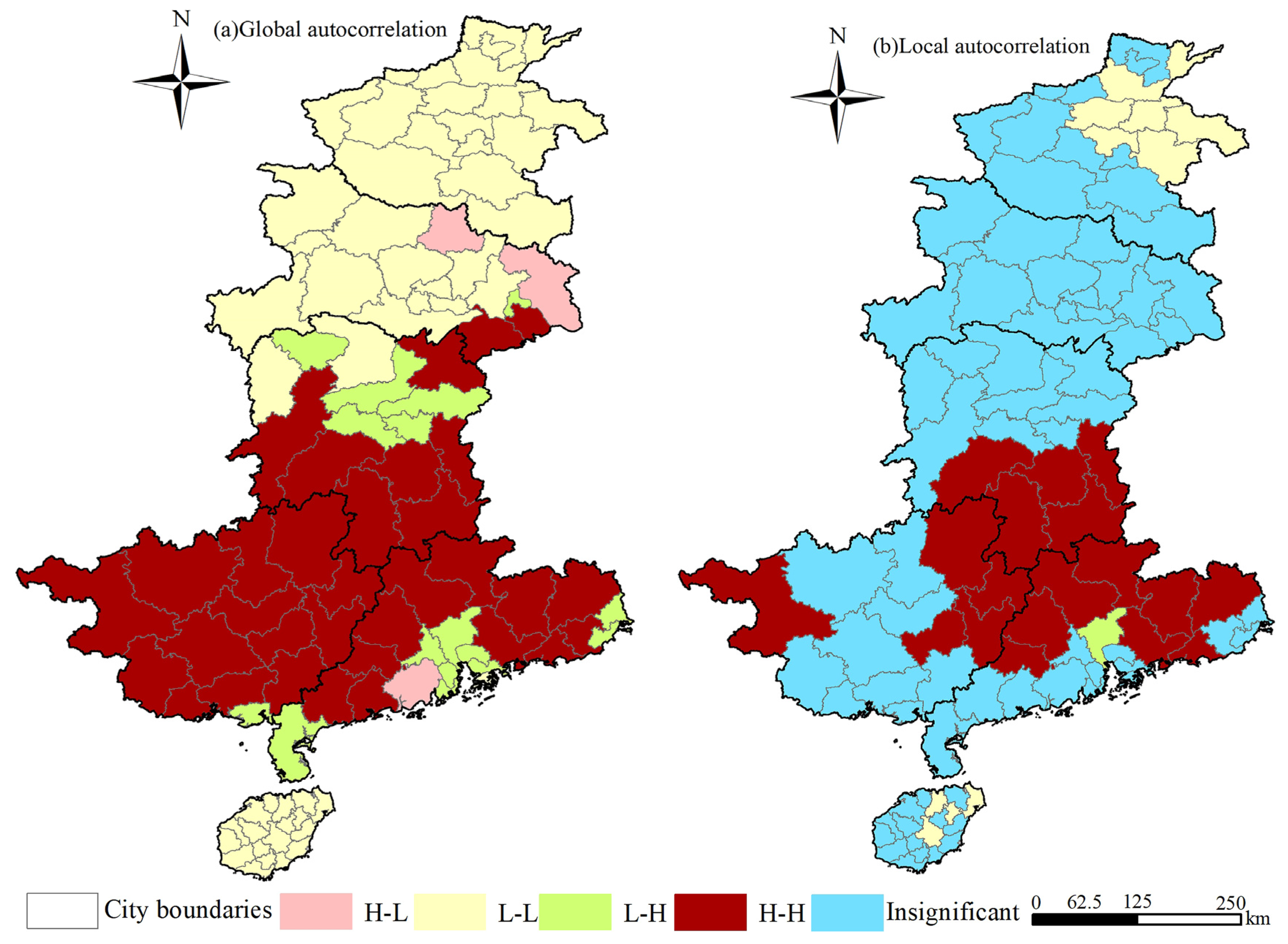
As illustrated in Figure 4, within the Central-South region cities experiencing forest fires, there are 33 cities identified with global autocorrelation characteristics of High-High (H_H), predominantly distributed in Hunan Province (e.g., Shaoyang, Hengyang, Yongzhou), Guangxi Zhuang Autonomous Region (e.g., Guilin, Liuzhou, Hechi), and Guangdong Province (e.g., Heyuan, Qingyuan, Zhaoqing). Additionally, four cities exhibit local autocorrelation features of High-Low (H_L), located in Hubei Province (Suizhou and Huanggang) and Guangdong Province (Jiangmen and Zhongshan). Furthermore, 12 cities are characterized by Low-High (L-H) features, including cities in Hunan Province (Yiyang, Changsha, Loudi) and Guangdong Province (Guangzhou, Foshan). The remaining cities are either classified as Low-Low (L_L) or fall into nonsignificant areas. Among these, 18 cities experiencing local autocorrelation of H_H are mainly found in Hunan Province (Hengyang, Shaoyang, Yongzhou), Guangdong Province (Shaoguan, Heyuan, Meizhou), and Guangxi Zhuang Autonomous Region (Hezhou, Guilin, Wuzhou). Additionally, only Guangzhou exhibits an L-H characteristic, with the rest being categorized as L_L or in nonsignificant regions.
The cities in the Central-South region that have been affected by forest fires exhibit varying degrees of global and local autocorrelation characteristics. This phenomenon can be attributed to the combined effects of climate, geographical conditions, human activities, forest management, and emergency response capabilities. Climate conditions and geographical factors play a crucial role in the spread and occurrence of fires, while urban human activities, forest management strategies, and fire response capabilities also influence the autocorrelation characteristics of fires. These factors together shape the unique patterns of fire characteristics across different cities. Understanding these factors is crucial for effectively preventing and mitigating the impact of fires in the region.
Figure 3.
Plots for Autocorrelation Analysis; with (a) depicting Global Autocorrelation and (b) illustrating Local Autocorrelation.
Figure 3.
Plots for Autocorrelation Analysis; with (a) depicting Global Autocorrelation and (b) illustrating Local Autocorrelation.
3.3. The Results of Standard Deviation Ellipse for the forest fires
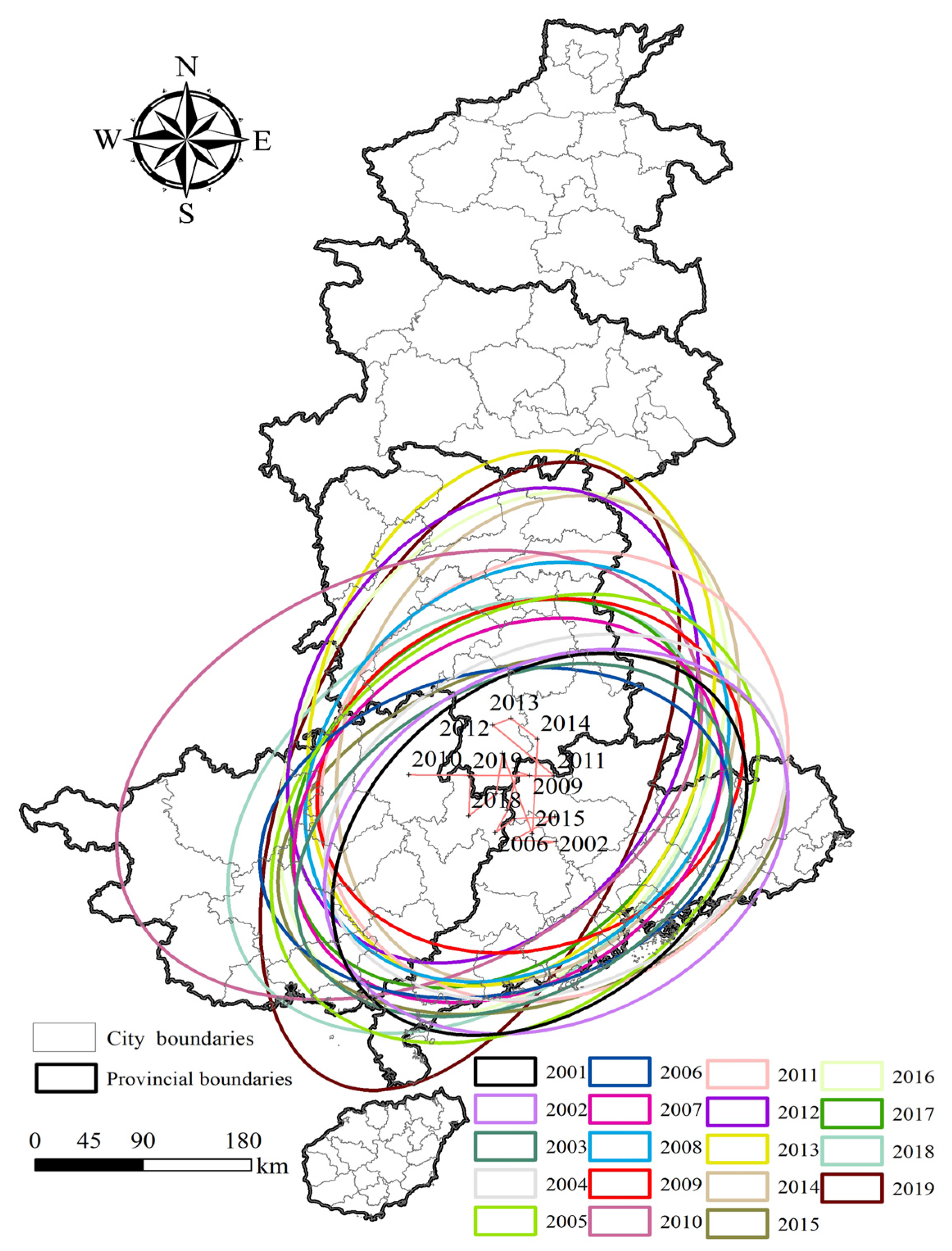
Illustrated in Figure 4 and detailed in Table 2, the analysis covering the years 2001 to 2019 reveals that the central point representing the location of forest fire incidents in the Central-South region has gradually shifted towards the north. During this period, the focal point of fires primarily shifted within the intersection of Hunan, Guangdong, and Guangxi provinces, specifically in Zhaoqing and Qingyuan cities in Guangdong, Yongzhou and Chenzhou cities in Hunan, and Guilin and Hezhou cities in Guangxi. Between 2001 and 2009, the centroid was predominantly located in Guangdong province, likely reflecting the high incidence of forest fires there during this time and suggesting that Guangdong faced significant fire risks and challenges. Since 2009, the position of the fire centroid has shown fluctuating changes. Except for the years 2011 and 2015, when the centroid was mainly in Guangdong, in other years, it constantly moved between the borders of Hunan and Guangxi provinces. This indicates that the risk and patterns of forest fires might be influenced by a variety of factors, including changes in climate conditions, topographical variations, forest cover, and human activities.
The movement and distribution pattern of this fire centroid provides crucial insights into the dynamic changes of forest fires within the region. It reflects not only the spatial distribution trends of forest fires but also might be closely related to changes in the ecological environment, adjustments in forest management strategies, and the capabilities and measures to respond to forest fires. Therefore, a thorough analysis of these changes is vital for developing effective forest fire prevention and management strategies, reducing the losses caused by fires, and protecting and restoring the ecological environment.
Figure 4.
The results of the standard deviation ellipse analysis in Central and Southern China region.
Figure 4.
The results of the standard deviation ellipse analysis in Central and Southern China region.
3.4. Evaluation of Forecast Precision for Forest Fires in Southern China
Figure 5 illustrates the exceptional performance of the Central-South Forest Fire Prediction Model across both training and validation sets, underscoring its high accuracy, reliability, and robust predictive capabilities. On the training set, the model showcased an impressive accuracy rate of 85.71%, precision of 87.5%, recall of 86.67%, and an F1 score of 87.08%, demonstrating a well-balanced and accurate approach in forecasting forest fires. Furthermore, an AUC value of 90.21% highlights its superior proficiency in distinguishing between positive and negative instances. The model’s performance on the validation set further affirmed its strengths, achieving an accuracy of 84.38%, precision of 86.25%, recall of 85.71%, F1 score of 86.02%, and an AUC of 89.79%. These indicators collectively reflect the model’s excellent generalization capability and stability, ensuring reliable forest fire predictions across different scenarios.
In summary, Figure 6 encapsulates the Central-South Forest Fire Prediction Model’s efficiency and reliability in predicting forest fires, underpinning its significant contribution to the effective prevention and management of forest fires. This performance not only showcases the model’s adeptness in addressing forest fire risks but also emphasizes its pivotal role in enhancing forest management strategies and safeguarding ecosystems.
3.5. Predicting Monthly Forest Fires in the Central and Southern Regions of China
As Figure 6 illustrates the fluctuating patterns of fire hazard zones within Central and Southern China across different months, highlighting the influence of seasonal shifts and climatic conditions on wildfire risks. Here’s a revised description of the temporal distribution of these high-risk zones:
(i) March-May: During this period, the risk of forest fires is high in certain areas of Guangdong Province (Meizhou, Chaozhou, Jieyang), Guangxi Zhuang Autonomous Region (Wuzhou, Guilin, Baise), Hunan Province (Hengyang, Loudi, Yongzhou), Hubei Province (Huangshi, Xianning), and Dongfang City in Hainan Province. The climate becomes warmer but remains relatively dry, with low rainfall. The accumulation of withered plants from winter provides ample fuel for fires. Additionally, agricultural activities such as burning crop residue and clearing land, along with increased tourism and improper outdoor fire use, significantly raise the risk of forest fires.
(ii) June-August: Most of the Central South region experiences low forest fire risk due to the rainy season, which increases humidity. However, some areas in Guangdong’s Heyuan and Hubei’s Huangshi face high risks, potentially due to uneven rainfall distribution or localized drought conditions.
(iii) September-November: The risk of forest fires increases again in areas like Meizhou, Heyuan, and Shaoguan in Guangdong Province; Nanning, Hezhou, and Yulin in the Guangxi Zhuang Autonomous Region; and Binzhou, Yongzhou, and Hengyang in Hunan Province. As autumn progresses, temperatures drop and humidity decreases, while fallen leaves provide new fuel for fires.
(iv)December-February: High-risk areas include Shaoguan, Qingyuan, and Zhaoqing in Guangdong Province; regions within the Guangxi Zhuang Autonomous Region; and Hengyang, Binzhou, and Yongzhou in Hunan Province, along with Huangshi in Hubei Province. Despite lower temperatures, the low humidity and dry conditions increase the risk of forest fires. Dry vegetation and the accumulation of flammable materials, coupled with human activities like agricultural clearing, further heighten the likelihood of fires.
4. Discussion and Conclusions
4.1. Discussion
This study, employing advanced integrated learning models and multifaceted data, has developed a predictive model for forest fire occurrences, aiming to provide a scientific basis for forest fire management in the Central-South region. By analyzing fire risks across different months and regions, our model reveals the comprehensive impact of climate change, human activities, and geographical factors on the risk of forest fires. Future efforts will enhance integrated forest fire monitoring and early warning systems through state-of-the-art technologies such as satellite-based remote sensing, BeiDou navigation, multi-network communications, and mobile command systems, combined with big data and high-performance computing technologies [58].
This will enable comprehensive monitoring and real-time response to forest fires, including critical information such as temperature, humidity, wind direction and speed, and vegetation conditions, along with precise fire location positioning and rapid communication and coordination capabilities, allowing command centers and rescue teams to respond swiftly to emergencies.For effective management of forest fire risks in the Central-South region, this research delves into the spatiotemporal distribution characteristics and patterns of forest fires in the area. We find that focusing on high-incidence and moderate-to-high incidence areas and formulating targeted fire prevention strategies, zoning measures, and key prevention and control measures are crucial. Such targeted strategies not only effectively reduce the risk of fires but also help protect China’s rich and diverse forest resources, maintain ecological balance, and ensure the safety of people’s property.
Future research on forest fire prediction is actively exploring the integration of information related to extreme climate phenomena like ENSO to further enhance the accuracy of fire predictions. The periodic occurrence of ENSO events and their significant impact on climate play a crucial role in the occurrence and spread of forest fires. This provides a deeper understanding and hopes to optimize fire management strategies through improved prediction models [59,60,61]. While this study has made progress in developing a forest fire prediction model, we recognize that obtaining long time series, high-precision, and consistent spatial and temporal resolution data sources remains a challenge for large-scale study areas, potentially affecting the accuracy of the research. In the future, we plan to use higher resolution VIIRS fire detection data to improve the precision of the analysis [62].
Additionally, considering different types of forest fires (e.g., lightning-induced fires, human-caused fires) may be influenced by different factors, future research will explore using longer time series, higher resolution, and more comprehensive fire description indicators to provide more realistic simulation effects, thereby more accurately predicting and understanding different types of forest fires [63,64,65,66].
Therefore, utilizing fire data with longer time series, higher resolution, and more comprehensive fire description indicators can offer more realistic simulation effects, thereby better predicting and understanding different types of forest fires. In summary, although this study has achieved certain results, forest fire occurrence prediction remains a complex and variable field, requiring interdisciplinary cooperation and continuous research efforts. By continually optimizing prediction models and combining them with field validation, we can more effectively mitigate the impacts of forest fires, protecting the natural environment and human welfare.
4.2. Conclusions
In summary, this research provides an in-depth investigation into the spatial and temporal patterns of forest fires in China’s Central-South region, utilizing the combined strengths of Geographic Information Systems (GIS), and sophisticated machine learning approaches. Our results uncover the complex behaviors of forest fire incidences, emphasizing the notable concentration and spatial interconnectivity of fire locations, essential for grasping how fires distribute and potentially propagate in this area.
(i) Technological Fusion: This research effectively combines the use of Geographic Information Systems (GIS) and machine learning techniques to examine the spatial and temporal patterns of forest fires and identify their causative factors in China’s Central-South region, showcasing the efficacy of combining various technological approaches in the study of environmental sciences.
(ii) Predictive Model Performance: The Central-South Forest Fire Prediction Model demonstrates outstanding performance. This showcases the model’s high reliability and efficacy in forecasting forest fires and distinguishing between different fire events.
(iii) Seasonal and Regional Risk Variations: The analysis reveals significant seasonal and regional variations in forest fire risk, identifying specific periods and locations with heightened risk. This nuanced understanding aids in the targeted allocation of resources and implementation of fire prevention measures.
(iv) Implications for Forest Fire Management: The findings underscore the importance of an integrated approach to forest fire management, combining advanced technologies with a deep understanding of the environmental and seasonal factors that influence fire risks. This approach enables the development of more effective strategies for mitigating the impact of forest fires.
Author Contributions
In this research paper, each author made significant contributions: Q.H. led the conceptualization and design, and was heavily involved in data analysis and manuscript drafting. X.H., as the corresponding author, oversaw the project coordination and supervision, and played a key role in shaping the research framework. B.V., B.G., S.B., and N.C. were instrumental in data acquisition and fieldwork, providing valuable insights for data analysis. Y.B. and H.S. brought expertise in remote sensing and GIS, crucial for the processing and interpretation of satellite data. Collectively, their diverse skills and expertise were essential for the successful completion of this study.
Funding
This research was supported by the International Cooperation and Exchange Program of the National Natural Science Foundation of China, under the project titled "Forest-Grassland Fire Risk Warning and Information Sharing on the Mongolian Plateau under the Background of Climate Change" (Grant No. 41961144019).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
Our appreciation goes to the editors and reviewers whose valuable feedback and suggestions enhanced the quality of this research.
Conflicts of Interest
No conflicts of interest are reported by the authors.
References
- Baldocchi, D.; Penuelas, J. The physics and ecology of mining carbon dioxide from the atmosphere by ecosystems. Global Change Biology 2019, 254, 1191–1197. [Google Scholar] [CrossRef]
- Malhi, Y.; Meir, P.; Brown, S. Forests, carbon and global climate. Philosophical Transactions of the Royal Society of London. Series A: Mathematical, Physical Engineering Sciences 2002, 360, 1567–1591. [Google Scholar] [CrossRef]
- Pawłowski, A.; Pawłowska, M.; Pawłowski, L. Mitigation of greenhouse gases emissions by management of terrestrial ecosystem. Ecological Chemistry Engineering 2017, 242, 213–221. [Google Scholar] [CrossRef]
- Keleş, S. An assessment of hydrological functions of forest ecosystems to support sustainable forest management. Journal of Sustainable Forestry 2019, 384, 305–326. [Google Scholar] [CrossRef]
- Ellison, D.; Morris, C.E.; Locatelli, B.; Sheil, D.; Cohen, J.; Murdiyarso, D.; Gutierrez, V.; Van Noordwijk, M.; Creed, I.F.; Pokorny, J. Trees, forests and water: Cool insights for a hot world. Global environmental change 2017, 43, 51–61. [Google Scholar] [CrossRef]
- Ritter, E.; Dauksta, D. Human–forest relationships: ancient values in modern perspectives. Environment, development sustainability 2013, 15, 645–662. [Google Scholar] [CrossRef]
- Melese, S.M. Importance of non-timber forest production in sustainable forest management, and its implication on carbon storage and biodiversity conservation in Ethiopia. International Journal of Biodiversity Conservatio 2016, 811, 269–277. [Google Scholar]
- Ramachandra, T.; Soman, D.; Naik, A. D.; Chandran, M. S. Appraisal of forest ecosystems goods and services: Challenges and opportunities for conservation. Journal of Biodiversity 2017, 81, 12–33. [Google Scholar] [CrossRef]
- Dhar, T.; Bhatta, B.; Aravindan, S. Forest fire occurrence, distribution and risk mapping using geoinformation technology: A case study in the sub-tropical forest of the Meghalaya, India. Remote Sensing Applications: Society Environment 2023, 29, 100883. [Google Scholar] [CrossRef]
- Shao, Y.; Fan, G.; Feng, Z.; Sun, L.; Yang, X.; Ma, T.; Li, X.; Fu, H.; Wang, A. Prediction of forest fire occurrence in China under climate change scenarios. Journal of Forestry Research 2023, 1–12. [Google Scholar] [CrossRef]
- Wu, Z.; He, H. S.; Keane, R. E.; Zhu, Z.; Wang, Y.; Shan, Y. Current and future patterns of forest fire occurrence in China. International journal of wildland fire 2019, 292, 104–119. [Google Scholar] [CrossRef]
- Zigner, K.; Carvalho, L.; Peterson, S.; Fujioka, F.; Duine, G.; Jones, C.; Roberts, D.; Moritz, M. Evaluating the ability of FARSITE to simulate wildfires influenced by extreme, downslope winds in Santa Barbara, California. Fire 2020. [Google Scholar] [CrossRef]
- Dong, X.-m.; Li, Y.; Pan, Y.-l.; Huang, Y.-j.; Cheng, X.-d. Study on urban fire station planning based on fire risk assessment and GIS technology. Procedia engineering 2018, 211, 124–130. [Google Scholar] [CrossRef]
- Zhou, T.; Ding, L.; Ji, J.; Yu, L.; Wang, Z. Combined estimation of fire perimeters and fuel adjustment factors in FARSITE for forecasting wildland fire propagation. Fire safety journal 2020, 116, 103167. [Google Scholar] [CrossRef]
- Phelps, N.; Woolford, D. G. Guidelines for effective evaluation and comparison of wildland fire occurrence prediction models. International journal of wildland fire 2021, 304, 225–240. [Google Scholar] [CrossRef]
- Su, Z.; Zeng, A.; Cai, Q.; Hu, H. Study on prediction model and driving factors of forest fire in Da Hinggan Mountains using Gompit regression method. Journal of Forestry Engineering 2019, 44, 135–142. [Google Scholar]
- D’este, M.; Ganga, A.; Elia, M.; Lovreglio, R.; Giannico, V.; Spano, G.; Colangelo, G.; Lafortezza, R.; Sanesi, G. Modeling fire ignition probability and frequency using Hurdle models: A cross-regional study in Southern Europe. Ecological Processes 2020, 91, 1–14. [Google Scholar] [CrossRef]
- Boubeta, M.; Lombardía, M. J.; Marey-Pérez, M.; Morales, D. Poisson mixed models for predicting number of fires. International journal of wildland fire 2019, 283, 237–253. [Google Scholar] [CrossRef]
- Shao, Y.; Wang, Z.; Feng, Z.; Sun, L.; Yang, X.; Zheng, J.; Ma, T. Assessment of China’s forest fire occurrence with deep learning, geographic information and multisource data. Journal of Forestry Research 2023, 344, 963–976. [Google Scholar] [CrossRef]
- Arif, M.; Alghamdi, K.; Sahel, S.; Alosaimi, S.; Alsahaft, M.; Alharthi, M.; Arif, M. Role of machine learning algorithms in forest fire management: A literature review. Robot. Autom 2021, 5, 212–226. [Google Scholar]
- Mohajane, M.; Costache, R.; Karimi, F.; Pham, Q. B.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of remote sensing and machine learning algorithms for forest fire mapping in a Mediterranean area. Ecological Indicators 2021, 129, 107869. [Google Scholar] [CrossRef]
- Eslami, R.; Azarnoush, M.; Kialashki, A.; Kazemzadeh, F. GIS-based forest fire susceptibility assessment by random forest, artificial neural network and logistic regression methods. Journal of Tropical Forest Science 2021, 332, 173–184. [Google Scholar] [CrossRef]
- Tang, X.; Machimura, T.; Li, J.; Liu, W.; Hong, H. A novel optimized repeatedly random undersampling for selecting negative samples: A case study in an SVM-based forest fire susceptibility assessment. Journal of Environmental Management 2020, 271, 111014. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, T. Application of improved LightGBM model in blood glucose prediction. Applied Sciences 2020, 109, 3227. [Google Scholar] [CrossRef]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M. U. A model combining convolutional neural network and LightGBM algorithm for ultra-short-term wind power forecasting. Ieee Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, K.; Li, Y.; Li, G. Research on forest fire prediction in Yunnan province based on LightGBM and SHAP. Fire Science and Technology 2023, 4211, 1567–1571. [Google Scholar]
- Tian, L.; Feng, L.; Yang, L.; Guo, Y. Stock price prediction based on LSTM and LightGBM hybrid model. The Journal of Supercomputing 2022, 789, 11768–11793. [Google Scholar] [CrossRef]
- Yang, H.; Chen, Z.; Yang, H.; Tian, M. Predicting Coronary Heart Disease Using an Improved LightGBM Model: Performance Analysis and Comparison. IEEE Access 2023, 11, 23366–23380. [Google Scholar] [CrossRef]
- Wang, H. GDP of 31 provinces in the first half of the year: Guangdong pulls ahead, Anhui continues to overtake Shanghai. China Economic Weekly (newspaper) 2021, 15, 54–57. [Google Scholar]
- Ciesielski, M.; Balazy, R.; Borkowski, B.; Szczesny, W.; Zasada, M.; Kaczmarowski, J.; Kwiatkowski, M.; Szczygiel, R.; Milanovic, S. Contribution of anthropogenic, vegetation, and topographic features to forest fire occurrence in Poland. iForest-Biogeosciences Forestry 2022, 15, 307. [Google Scholar] [CrossRef]
- Flannigan, M. D.; Amiro, B. D.; Logan, K. A.; Stocks, B. J.; Wotton, B. M. Forest fires and climate change in the 21 st century. Mitigation adaptation strategies for global change 2006, 11, 847–859. [Google Scholar] [CrossRef]
- De Rigo, D.; Libertà, G.; Durrant, T. H.; Vivancos, T. A.; San-Miguel-Ayanz, J. Forest fire danger extremes in Europe under climate change: variability and uncertainty; Publications Office of the European Union, 2017. [Google Scholar]
- Tian, X.-r.; Shu, L.-f.; Zhao, F.-j.; Wang, M.-y.; Mcrae, D. Future impacts of climate change on forest fire danger in northeastern China. Journal of Forestry Research 2011, 223, 437–446. [Google Scholar] [CrossRef]
- Chéret, V.; Denux, J.-P. Analysis of MODIS NDVI time series to calculate indicators of Mediterranean forest fire susceptibility. GIScience Remote Sensing 2011, 482, 171–194. [Google Scholar] [CrossRef]
- Hardy, C. C.; Burgan, R. E. Evaluation of NDVI for monitoring live moisture in three vegetation types of the western US. Photogrammetric Engineering Remote Sensing 1999, 65, 603–610. [Google Scholar]
- Laschi, A.; Foderi, C.; Fabiano, F.; Neri, F.; Cambi, M.; Mariotti, B.; Marchi, E. Forest road planning, construction and maintenance to improve forest fire fighting: a review. Croatian Journal of Forest Engineering: Journal for Theory Application of Forestry Engineering 2019, 40, 207–219. [Google Scholar]
- Kim, S. J.; Lim, C.-H.; Kim, G. S.; Lee, J.; Geiger, T.; Rahmati, O.; Son, Y.; Lee, W.-K. Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sensing 2019, 111, 86. [Google Scholar] [CrossRef]
- Liu, M.; Jiang, B.; Zhao, Z. Study on the layout method of coal mine ventilation monitoring points under linear constrained kernel density. Science of Surveying and Mapping 2023, 48, 63-71+93. [Google Scholar]
- Jiang, H.; Li, C.; Feng, M.; Luo, M.; Ma, X. Analysis on probabilistic seismic damage characteristics of dry joint prefabricated bridge pier based on kernel density estimation. Journal of Southeast University (Natural Science Edition) 2021, 51, 566–574. [Google Scholar]
- Zhou, Q. Spatial Patterns and Drivers of Forest Fire Occurrence in the Daxing’an Mountains of Inner Mongolia. 2023.
- Zhang, W.; Wang, J.; Wang, Q.; Zhang, X.; Cao, H.; Long, T. Analyses on spatial and temporal characteristies of forest fires in YunnanProvince based on MODIS from 2001 to 2020. Journal of Nanjing Forestry University( Natural Sciences Edition) 2023, 47, 73–79. [Google Scholar]
- Getis, A. A history of the concept of spatial autocorrelation: A geographer’s perspective. Geographical analysis 2008, 403, 297–309. [Google Scholar] [CrossRef]
- Lv, M.; Zhang, H.; He, G.; Zhang, X.; Liu, Y. Dynamic evolution and driving factors of water conservation service function in the Yellow River Basin. ACTA ECOLOGICA SINICA 2024, 07, 1–11. [Google Scholar]
- Gou, A.; Li, W.; Wang, J. Spatiotemporal Correlation Between Green Space Landscape Pattern and PM2.5 Concentration in Chongqing City, China. Journal of Earth Sciences and Environment 2024, 46, 25–37. [Google Scholar]
- Yu, W.; Chen, Y.; Fang, F.; Zhang, J.; Li, Z.; Zhao, L. An analysis of grassland spatial distribution and driving forces of patterns of change in grassland distribution in Guizhou Province from 1980 to 2020. ACTA PRATACULTURAE SINICA 2024, 3301, 1–18. [Google Scholar]
- Sun, Y.; Xu, M.; Wang, X. Spatial-temporal Evolution of Carbon Storage and Spatial Autocorrelation Analysis in Zhengzhou City Based on InVEST-PLUS Model. Bulletin of Soil and Water Conservation 2023, 4305, 374–384. [Google Scholar]
- Moore, T. W.; Mcguire, M. P. Using the standard deviational ellipse to document changes to the spatial dispersion of seasonal tornado activity in the United States. NPJ Climate Atmospheric Science 2019, 21, 21. [Google Scholar] [CrossRef]
- Cheng, Y.; Yang, L. Spatial evolution and differences in driving factors of China’s tourism dual circulation market efficiency. Arid Land Geography 2024, 1–12. [Google Scholar]
- Hu, J.; Yu, J.; Zhang, C. A study on the spatial distribution of China’s aid to Africa based on Standard Deviational Ellipse. World Regional Studies 2024, 1–13. [Google Scholar]
- Li, Y.; Peng, S. Characterisation of industrial agglomeration in the Yangtze River Delta region based on standard deviation ellipses. Statistics and Decision 2024, 4001, 136–141. [Google Scholar]
- Cheng, Y.; Yang, L. Spatial evolution and differences in driving factors of China’s tourism dual circulation market efficiency. Arid Land Geography 2024, 1–12. [Google Scholar]
- Fan, J.; Ma, X.; Wu, L.; Zhang, F.; Yu, X.; Zeng, W. Light Gradient Boosting Machine: An efficient soft computing model for estimating daily reference evapotranspiration with local and external meteorological data. Agricultural water management 2019, 225, 105758. [Google Scholar] [CrossRef]
- Xu, K.; Han, Z.; Xu, H.; Bin, L. Rapid prediction model for urban floods based on a light gradient boosting machine approach and hydrological–hydraulic model. International Journal of Disaster Risk Science 2023, 141, 79–97. [Google Scholar] [CrossRef]
- Guo, J.; Yun, S.; Meng, Y.; He, N.; Ye, D.; Zhao, Z.; Jia, L.; Yang, L. Prediction of heating and cooling loads based on light gradient boosting machine algorithms. Building Environment 2023, 236, 110252. [Google Scholar] [CrossRef]
- Chen, T.; Xu, J.; Ying, H.; Chen, X.; Feng, R.; Fang, X.; Gao, H.; Wu, J. Prediction of extubation failure for intensive care unit patients using light gradient boosting machine. IEEE Access 2019, 7, 150960–150968. [Google Scholar] [CrossRef]
- Cui, Z.; Qing, X.; Chai, H.; Yang, S.; Zhu, Y.; Wang, F. Real-time rainfall-runoff prediction using light gradient boosting machine coupled with singular spectrum analysis. Journal of Hydrology 2021, 603, 127124. [Google Scholar] [CrossRef]
- He, R.; Lu, H.; Jin, Z.; Qin, Y.; Yang, H.; Liu, Z.; Yang, G.; Xu, J.; Gong, X.; Zhang, Q. Construction of forest fire prediction model and driving factors analysis based on random forests algorithm in Southwest China. Acta Ecol. Sin 2023, 4322, 9356–9370. [Google Scholar]
- Yuan, J.; Cao, J.; He, S.; Hu, J. The Design and Research of Air-space-ground Forest Fire Monitoring and Warning System. CHINA EMERGENCY RESCUE 2023, 6, 32-35+53. [Google Scholar]
- Farfán, M.; Dominguez, C.; Espinoza, A.; Jaramillo, A.; Alcántara, C.; Maldonado, V.; Tovar, I.; Flamenco, A. Forest fire probability under ENSO conditions in a semi-arid region: a case study in Guanajuato. Environmental monitoring assessment 2021, 19310, 684. [Google Scholar] [CrossRef]
- Bai, M.; Wang, X.; Yao, Q.; Fang, K. ENSO modulates interaction between forest insect and fire disturbances in China. Natural Hazards Research 2022, 22, 138–146. [Google Scholar] [CrossRef]
- Cordero, R. R.; Feron, S.; Damiani, A.; Carrasco, J.; Karas, C.; Wang, C.; Kraamwinkel, C. T.; Beaulieu, A. Extreme fire weather in Chile driven by climate change and El Niño–Southern Oscillation (ENSO). Scientific reports 2024, 141, 1974. [Google Scholar] [CrossRef] [PubMed]
- Oliva, P.; Schroeder, W. Assessment of VIIRS 375 m active fire detection product for direct burned area mapping. Remote Sensing of Environment 2015, 160, 144–155. [Google Scholar] [CrossRef]
- Veraverbeke, S.; Rogers, B. M.; Goulden, M. L.; Jandt, R. R.; Miller, C. E.; Wiggins, E. B.; Randerson, J. T. Lightning as a major driver of recent large fire years in North American boreal forests. Nature Climate Change 2017, 77, 529–534. [Google Scholar] [CrossRef]
- Krider, E.; Noggle, R.; Pifer, A.; Vance, D. Lightning direction-finding systems for forest fire detection. Bulletin of the American Meteorological Society 1980, 619, 980–986. [Google Scholar] [CrossRef]
- Arndt, N.; Vacik, H.; Koch, V.; Arpaci, A.; Gossow, H. Modeling human-caused forest fire ignition for assessing forest fire danger in Austria. iForest-Biogeosciences Forestry 2013, 6, 315. [Google Scholar] [CrossRef]
- Xiong, Q.; Luo, X.; Liang, P.; Xiao, Y.; Xiao, Q.; Sun, H.; Pan, K.; Wang, L.; Li, L.; Pang, X. Fire from policy, human interventions, or biophysical factors? Temporal–spatial patterns of forest fire in southwestern China. Forest Ecology Management 2020, 474, 118381. [Google Scholar] [CrossRef]
Figure 2.
Technology roadmap.
Figure 5.
Assessment of the Model’s Performance.
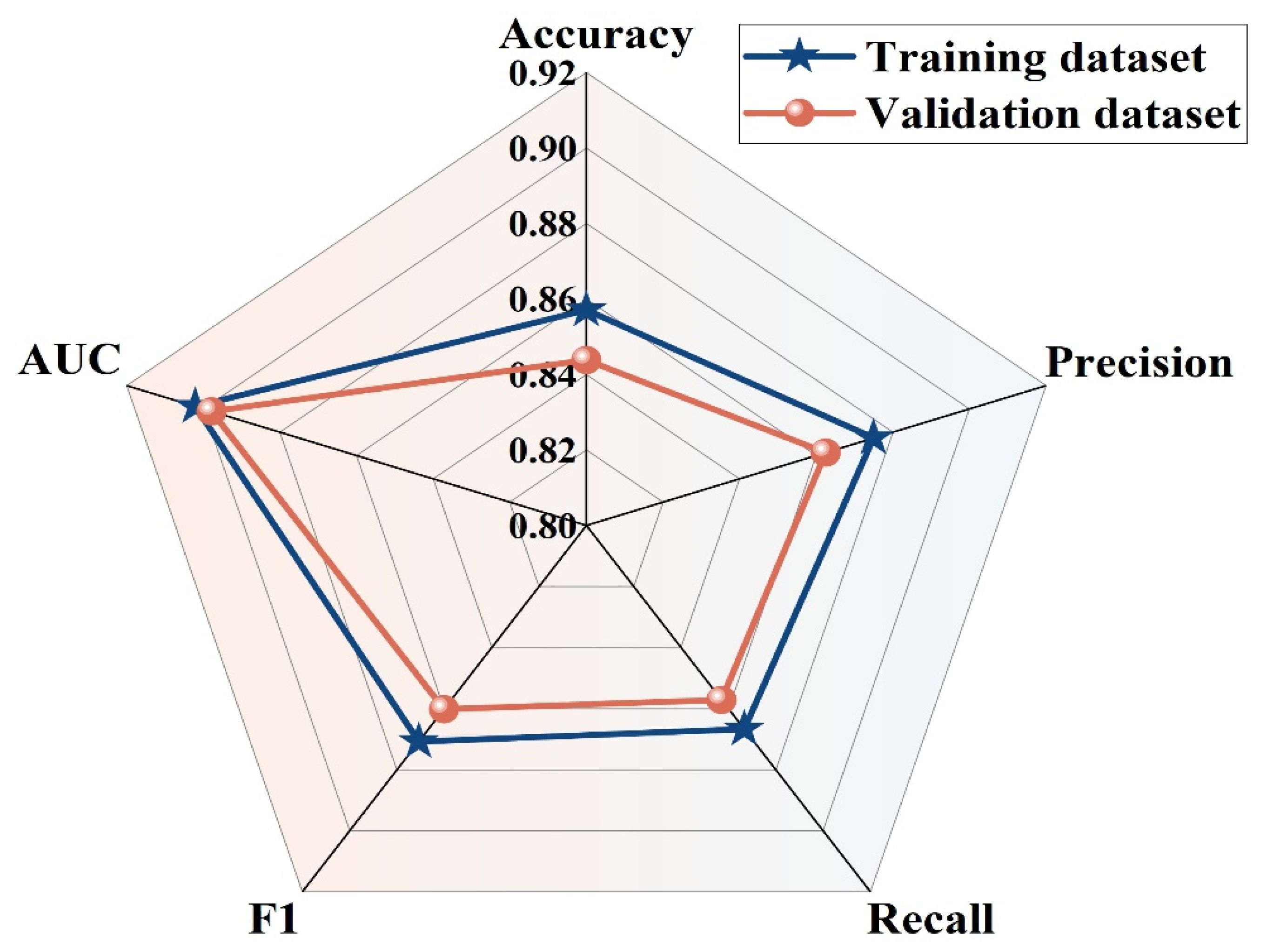
Figure 6.
Zoning for forest fire predictions on a monthly basis across Southern China, where Categories I through V denote the spectrum of forest fire occurrences from scarcely minimal to critically high levels.
Figure 6.
Zoning for forest fire predictions on a monthly basis across Southern China, where Categories I through V denote the spectrum of forest fire occurrences from scarcely minimal to critically high levels.

Table 1.
Overview of Data Sources Employed in the Research.
| Classification | Data | Resolution | Source | References |
|---|---|---|---|---|
| Topographic | Slope/Elevation/Slope direction | 1 km | https://www.resdc.cn(Accessed on 5 May 2023) | [19,30] |
| Climate | Average daily surface temperature/ average daily relative humidity/ daily maximum surface temperature, etc. | - | https://data.cma.cn(Accessed on 1 May 2023) | [10,31,32,33] |
| Vegetation | Fractional vegetation cover | - | https://www.resdc.cn(Accessed on 2 May 2023) | [34,35] |
| Social and human factors | Distance from road / Distance from residential area/Gross Domestic Product/ Population | 1:100,000,1:100,000, 1 km, 1 km, | https://www.resdc.cn(Accessed on 8 May 2023) | [19,36,37] |
Table 2.
The standard deviation parameters of forest fire occurrence ellipses in the Central and Southern China region.
Table 2.
The standard deviation parameters of forest fire occurrence ellipses in the Central and Southern China region.
| Year | XStdDist(km) | YstdDist(km) | Shape_Leng(km) | Shape_Area(km2) | Oblateness | Rotation |
|---|---|---|---|---|---|---|
| 2001 | 372.534 | 268.997 | 2028.542 | 314802.413 | 1.385 | 45.072 |
| 2002 | 388.413 | 296.779 | 2162.196 | 362120.052 | 1.309 | 56.898 |
| 2003 | 373.526 | 258.979 | 2003.366 | 303885.299 | 1.442 | 55.733 |
| 2004 | 381.818 | 285.181 | 2106.417 | 342059.692 | 1.339 | 60.849 |
| 2005 | 436.113 | 317.943 | 2383.464 | 435584.544 | 1.372 | 45.146 |
| 2006 | 376.658 | 271.229 | 2048.857 | 320927.371 | 1.389 | 73.757 |
| 2007 | 370.653 | 286.349 | 2072.507 | 333418.207 | 1.294 | 48.246 |
| 2008 | 303.707 | 380.991 | 2157.867 | 363492.458 | 0.797 | 35.858 |
| 2009 | 345.373 | 287.833 | 1993.357 | 312288.287 | 1.200 | 62.898 |
| 2010 | 491.176 | 339.273 | 2630.753 | 523491.125 | 1.448 | 60.522 |
| 2011 | 348.712 | 398.867 | 2351.203 | 436941.327 | 0.874 | 35.829 |
| 2012 | 297.208 | 422.206 | 2277.155 | 394192.353 | 0.704 | 24.360 |
| 2013 | 308.922 | 461.787 | 2445.076 | 448137.993 | 0.669 | 13.721 |
| 2014 | 300.586 | 424.630 | 2294.988 | 400961.846 | 0.708 | 18.729 |
| 2015 | 415.751 | 283.334 | 2215.941 | 370044.820 | 1.467 | 67.391 |
| 2016 | 317.519 | 470.922 | 2500.411 | 469722.244 | 0.674 | 25.864 |
| 2017 | 275.339 | 369.203 | 2035.607 | 319343.775 | 0.746 | 42.487 |
| 2018 | 431.219 | 305.251 | 2330.600 | 413502.468 | 1.413 | 46.869 |
| 2019 | 276.814 | 562.527 | 2713.722 | 489146.723 | 0.492 | 21.242 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



