
Submitted:
15 March 2024
Posted:
18 March 2024
You are already at the latest version
Abstract
Nowadays the dynamism induced by the constant change of strategic decisions on the markets produces an extra difficulty in the management of an organization. The strategic decisions made by managers can become obsolete in a short period of time. One of the major difficulties in managing a commercial organization is to predict, with some precision degree, the impact some strategic decisions have on the financial results. Business Intelligence (BI) is an area widely used to help managers to make strategic decisions. But the methods used, behind the scenes, to achieve the conclusions are kept secret by BI company-based services. Modelling the environment can be a good option to study the impact of an action, provided by a strategic decision, in a real environment. A good model should give an approximate result of an action applied to a previous state of the environment. Artificial Neural Networks (ANNs) are proven to be excellent in modeling environments with some level of data noise. The same strategic action can have different results in different organizations. A tool that allows an evaluation of a strategic action applied to an environment should have a major importance in the management scope. Modeling the environment should save time and money for the organization to improve the performance of the strategic plan. If one evaluates the state of the environment after a strategic action being applied, it can be possible to mitigate the risk of failure of the strategic plan. As we will be able to verify, it is possible to use ANNs to model strategic environments that should allow the prediction of sales and operating results by the used strategies with some precision, although the level of success will be directly related with the user’s necessity.
Keywords:
Management
; Strategy
; modeling
; Risk Analysis
; Artificial Neural Networks
; Financial Results
1. Introduction
In recent years, artificial neural networks (ANNs) have gained prominence in various management domains due to their ability to model complex relationships and make predictions based on large datasets (Li et al., 2019; Bakir & Breitenecker, 2020; Zhang et al., 2020).
The focus of this research paper is to describe, analyze and evaluate a modeling method of strategic environment through ANNs and therefore evaluate the forecast of enterprise sales and operating results.
Strategic decisions and the performance of companies are a subject of enormous importance in all studies that target the organizations, due to the interest that exists in the analysis of the factors that affect the variations of the organizational performance (Hoopes et al., 2003; Mucharreira et al., 2019).
One of the major difficulties in managing a commercial organization is to predict, with some precision degree, the impact of some strategic decisions have on the financial results. Business Intelligence (BI) is an area widely used to help managers to make strategic decisions (Alcázar-Blanco et al., 2021; Han & Zhang, 2021).
With the mathematical model of the strategic environment, it should be possible to predict, with some precision, the impact of a strategic applied to the studied environment. The considered precision degree will be subject to a posteriori analysis.
The advantage of using mathematical models is to permit the forecast of results (Hoel, 1966). So deterministic mathematical models can be used to predict an action applied to an environment. The success of the model will be given through an evaluation of the results compared with what might happen in the real environment.
The supervised training concept associated with the ANNs should allow an easy evaluation of the forecasted results. There will be two data sets, one for training the ANNs and another to evaluate the performance of the achieved model.
Problems should be identified in advance using forecasting techniques, preparing the organization for future eventualities. Controlling, influencing, or acting on the sources of uncertainty can allow mitigation of the impacts caused. The increased flexibility and structural competitiveness reduce exposure to uncertainty.
Predictability is not the inverse of uncertainty, but rather the degree of "probabilistic certainty with which one can foresee certain events". There is an inverse relationship between predictability and uncertainty. The more dynamic and complex is the surrounding environment, the more difficult is to predict events by the organization.
So, in general the forecast of results can allow not only the mitigation of undesired situations but also the evaluation of a set of actions before they are executed. In a dynamic environment like the market, it can be a powerful tool if it has an adequate use.
The objective of the proposed study is to create, analyze and evaluate a modelling method that allows us to forecast the impact of strategies on sales and operating results. The platform chosen for modeling is based on an area of computer science, namely artificial intelligence, and neural networks, which has given known and motivating results in modeling non-linear environments that are susceptible to noise in the data.
The study focuses on the possibility of modeling and not on the construction of a model for the effect. The creation of the model is inherent to the need of measuring performance for the hypothesis. This innovative method consists in using artificial neural networks to model the behavior of sales and operating results according to the strategies applied in an organization.
The main contribution of the study is to evaluate the possibility of modelling strategic environments with a certain degree of precision. A positive evaluation of the modelling method allows a dynamic environment, such as the strategic environments to which organizations are subject, to be studied without expending resources or putting the organization at risk.
Predicting induced action in a strategic environment can enable organizations to conduct a prior study and whether the resources spent on this action should have the expected return. One method that should enable this evaluation is important as a support tool for managers.
The study of the impact of a certain action in the business can enable the survival of an organization that constantly strives to apply the right strategies to develop and expand.
A tool that allows one to evaluate the results of applying a strategy before it will be applied can lead to an important competitive advantage. This study evaluates the possibility and the precision of predicting the results of the strategic application.
In any case, it is an innovative study that allows other promising developments, such as the creation of behavioral models of managers of small and medium-sized companies. Another possibility to continue the study is to restrict the activity of the target organizations and the use of more specific strategies. This would give a more accurate picture of the impact of implementing certain strategies.
2. Framework of the Approach
Our approach consists of five steps, including hypothesis deals with the possibility of constructing a model, questionnaire, strategies considered, financial data and artificial neural networks, methodology me aiming to find a tool that allows to predict and adapt the strategies before they are implemented can lead to an outstanding advantage over its competitors.
2.1. Hypothesis Deals with the Possibility of Constructing a Model
This study is inherent to one hypothesis. The hypothesis will be the subject of a study on the possibility of being implemented. The hypothesis is associated, to the possibility of the model construction, being thus defined:
- The hypothesis deals with the possibility of constructing a model that allows results prediction through strategies. This model should have as input the results of the previous year and the strategies to be used in their respective year. The outputs are the expected results using the strategies defined in the input.
There are 2 (two) performance indicators of the modelling success:
- Training set performance: This will show if it is possible to model the environment with the given data.
- Test set performance: A good evaluation of the model with the test set will be a good indicator of the precision of the model.
The expected value of the indicators of the level of success will differ from environment to environment and the quality of the data provided to ANNs will have a significant importance.
Therefore, it should adapt the expected success to the market environment and data quality. One should not expect a good model if dynamism makes the environment unpredictable or if the provided data have bad quality.
2.2. Questionnaire
The object of the questionnaire was the strategies used in the organizations, the level of application of the strategies, that is, the importance that the organization gives to a certain strategy, as well as the level of success in the implementation of the strategy, that is, how the organization perspectives the impact of the application of the strategies in the results.
The survey consists in 11 (eleven) questions about strategies used by managers, in the target organizations. The strategies used to formulate the questions have a high level of abstraction as it makes it possible to increase the number of adherent organizations that respond to the survey. High level abstraction strategic questions allow organizations to identify similarities between the strategies used and the described ones.
The managers classified the application level of these strategies between 0 (zero) and 9 (nine), with 0 (zero) meaning that the organization didn’t apply that particular strategy and 9 (nine) when it was considered the highest priority strategy to be implemented.
2.3. Strategies Considered
For the empirical study inherent to this article, it was considered some generic strategies that can exist in almost all sectors of activity and in any organization, whether of small or significant size.
The strategies described below are not the subject of an intensive description. To simplify the questionnaire response process and the analysis of the results, the strategies were kept at low levels of detail. This makes it possible that the survey was conducted to as many organizations as possible within the scope of the study.
The strategies used for the survey were:
- Product Price Strategy
- Product Quality Strategy
- Cost Reduction Strategy
- Investment Strategy
- Financing Strategy
- Strategies of Product Specialization or Diversification
- Strategy to Increase or Reduce Markets
- Business Synergies Strategy
- Product Disclosure Strategy
- Structural Reorganization Strategy
- upplier Renegotiation Strategy
2.4. Financial Data and Artificial Neural Networks
The financial data was obtained through a specialized financial database service. After the survey, the financial results were obtained by a query where the organization identifier used was the tax identification number.
Organizations financial data analyzed, were collected from the SABI database (http://sabi.bdvinfo.com). The information considered relevant to the study were:
- Sales
- Operating Results
Neural networks aim to emulate human brain behavior. The human brain consists of about 1011 neurons, where each of these neurons is interconnected with several, about 104, other neurons. The information transitions from neuron to neuron through chemical and electromagnetic processes, enable both the propagation of information and the alteration of neuron states.
According to Marques (1999), neural networks are made up of simple, interconnected processing elements, capable of learning from the data and, despite the simplicity of each processing unit, the use of a large number of interconnected units allows the execution of complex, often surprising tasks.
Artificial neural networks are a robust solution for emulating real, discrete, and even vector-based functions. Neural networks are among the most effective learning methods for interpreting data of a complex nature (Mitchell, 1997).
Neural networks are known for learning from experimental data and in general they have a good performance dealing with and processing numerical data. One interesting fact of neural networks is to be able to approximate any nonlinear function defined on a compact set of data. (Siddique & Adeli, 2013; Alcázar-Blanco et al., 2021; Han & Zhang, 2021).
Neural networks can be used to process very noisy but redundant information collected from real world (Siddique & Adeli, 2013).
With the technological advancement in data processing by microprocessors, currently much faster and with the possibility of performing multiprocessing in real time, neural networks became a viable option for data analysis and provide results in a timely manner.
Badea (2014) refers in his article, dedicated to the study of behavioral prediction of consumers through neural networks, that although the training set is somewhat limited, the neural networks showed good results in modeling and therefore concludes that it is a good choice to improve marketing strategies and decision-making processes.
2.5. Methodology
The methodology followed consisted of the collection of data through a questionnaire placed on a web platform, available to the managers of the companies targeted for the study, developed for this purpose. After completing the questionnaire, the data on the strategies used were associated with data from the results. There was an analysis of the data, and it outlined an objective path to follow. This path was determined by the quantity and quality of the questionnaire responses.
After this first analysis, the data was collected and several eliminations were made, by using statistical methods, enabling the selection of data considered having good quality for the study.
After defining the adequate data for the study, it was created several multi-layered neural networks with different characteristics, allowing one to verify the best structure to model each of the models inherent to the hypothesis. Here the attempt and error were fundamental to analyze the behavior of the neural network with the data used.
2.6. Data Processing and Filtering
Data filtering is the process where unsuitable data is eliminated from the study. Data processing is the process where data is transformed so that it will become suitable to apply to ANNs.
The data processing and filtering follow the following steps:
- Filter organizations by the survey answers
- Filter organizations by the financial results
- Input and output data normalization
After data processing and filtering, data should be ready and optimized to be used to model the strategic environment.
2.7. Applying Data to ANNs
The inputs of the ANNs will be:
- The financial result from the first year
- The normalized answers to the survey given by the organization strategy manager.
Since there are 11 answers in the survey, the total number of inputs will be 12. Therefore, the ANNs will have 12 perceptrons in the first layer.
The output is only one and it will give the expected ratio Δ between the two years. The output simply gives the relation between the financial results of the two years. So, several ANNs will be trained and analyzed, one for each studied financial result.
The number of hidden layers and the number of perceptrons of each layer were chosen from several ANNs. Each ANNs was analyzed, and it was chosen as the one that showed the most promising results, though no advanced study was made for this analysis. To simplify the study the chosen ANNs topology was equal for all modelling analysis described further on and object of this study.
The chosen ANNs topology was 12-64-64-64-1. This means that there were 3 hidden layers, each one with 64 perceptrons.
3. Analysis of Results
The first set of results presented concerns the demonstration of modeling based on a set of random samples for both the training set and the test set. In this way, it is possible to independently evaluate the actual process of modeling the environment. That is, it allows us to evaluate the process without choosing the best NN for the modeling of the environment. If the best evaluation is chosen, it can present untrustworthy results. The second set of results presented is the average achieved in 100 experiences. In each of these experiments, there is a random choice, as in the first set of results, of the set of samples for the training set and test set. From these results, the modeling can be better evaluated.
3.1. Single Full Experiment
The results are expressed in 3 different ways: graphs, errors (MAE and RMSE) and a table with the number of samples categorized by relative error interval. The MAE is described as mean absolute error and is calculated as
RMSE is described as root mean square error and is calculated as
The RMSE gives more importance to the errors in which the forecast is farther from reality, since this distance is counted squared, together with the MAE it is possible to have an idea if the errors are many and small, or if they are few but significant.
Graphs are easy and quick for a first analysis. Each graphic represents the real output (y-axis) and the model prediction output (x-axis). Each graph has a diagonal line where the ratio is 1 (one) or x=y, the nearest is the point to this line the more accurate is the prediction. The other two lines from the graphs of test set represent an error of 20%, this means that every dot between these two lines has a prediction between 0.80 and 1.20 times the real.
The categorization table should give an idea where the errors will distance from the real. The 4 categories existent (in absolute percentage errors) are | ε | < 5%; 5%≤ | ε | < 10%; 10% ≤ | ε | < 20%; 20% ≤ | ε | < 25%; | ε | ≥ 25%. The relative error is calculated as
These values were defined evaluating the market dynamism, so it is considered that the forecasting of financial results based on the strategies with a margin of 25% of error is positive. But this margin should be defined based on the goal of the model and manager needs.
Three NN training algorithms were used to verify the behavior of the model. All achieved results will be presented so this behavior can be evaluated by the reader.
3.2. Sales
In this section it is possible to observe the graphs and performance indicators on the behavior of the ANNs with the different algorithms in relation to forecasting sales through the applied strategies. In this way, it is possible to understand, in an easy and intuitive way, the predictive performance of the target ANNs of the study. In the graphs, the central diagonal line indicates an identity relationship between what was calculated by the ANN and reality, which means that the closer the sample point (red dot) is to this line, the better the forecast. For the two extra lines in the test set model, if the sample point belongs to the interval between the two lines, then it indicates that the calculation of the sales forecast, in relation to reality, had an error of less than 20%.
3.3. Backpropagation Algorithm
The Backpropagation Algorithm is widely used for training ANNs. The simplicity of its concept makes it easy to understand how it works, which consists of adjusting the weights of each perceptron according to the gradient of the cost/error function. As usual in neural networks, ANN training is done by applying a set of data (training set) to the neural network and checking the output values with the expected values, to adapt the perceptron weights, which is designated by supervised learning. The test set is applied to the resulting ANN and the outputs are compared with the real data, but without adapting the weights of the ANN. With this method, it is possible to verify how good the ANN models the forecasting environment. It should be noted that if the training set is used to train the ANN, it means that the application of this training set to the resulting ANN itself, means that for these data there should be a good degree of performance, but that it is not useful to evaluate ANN's performance. By applying the test set then one can check if there is any relationship between the input data and the output data, as shown in Figure 1.
Table 1 shows information regarding what can be seen in the previous graphs. As can be seen the test model has 4 points outside the two lines that limits the error to 20%, although very close to this line.
With 60% of the samples with less than a 20% error and 80% of the sample considering an error below 25%, with a RMSE of 20.9% and a MAE of 18.9%, it can infer that the existing errors are not very distant from the “20%” line. One can consider a reasonable modelling for the sales with a backpropagation algorithm. With 31.2% of the model samples with an error greater than 5%, one can consider that the model of the training set was reasonable, but not excellent.
3.4. Positive Resilient Algorithm
The positive resilient algorithm is a variant of the Backpropagation Algorithm. This algorithm uses the gradient sign to choose the direction of weight adjustment. In this way one tends to eliminate the negative effects of the magnitude of the partial derivatives. In the case of the Positive Resilient Algorithm, the weights are only adapted if the sign of the partial derivatives are positive. The graphical evaluation and performance indicators are performed in the same way as described for the Backpropagation Algorithm (Figure 2).
Table 2 shows information regarding what can be seen in the previous graphs. As can be seen the test model has 3 points outside the two lines that limits the error at 20%, although very close to this line. This means that 70% of the samples have an error of less than 20% in the revenue forecast.
With positive resilient algorithm the results are somewhat better than the backpropagation algorithm, with a RMSE of 17%, a MAE of 13.5%, 30% of the samples model with an error less than 5% and 70% of the sample with an error less than 20%, one can consider a reasonable modelling performance.
3.5. Negative Resilient Algorithm
Analogously to the case of the Positive Resilient Algorithm, the Negative Resilient Algorithm is also a variant of the Backpropagation Algorithm. Only with the difference, in relation to the Positive Resilient Algorithm, that the weights are only adjusted if the partial derivatives are negative, as shown in Figure 3.
As can be seen the test model has 3 points outside the two lines that limits the error to 20%, although very close to this line. This means that 70% of the samples have an error of less than 20% in the revenue forecast (Table 3).
With 70% of the model samples with an error less than 20% and 30% of the model sample with an error greater than 25% makes the RProp- Algorithm a little less accurate than the RProp+ Algorithm, although one can consider a reasonable modeling performance.
3.6. Operating Results
As before, in which the data relating to the strategies used were applied to forecast sales, in this case the forecast focuses on operating results. It is expected that the forecast error is greater in this case than in sales. This expectation is related to the fact that operating results depend directly on sales, but not only. Therefore, the addition of some entropy to the system to be modeled is expected. The graphical evaluation can be done in the same way as it is done for sales, that is, checking the position of the Test Set samples in relation to the diagonal lines that allow the visualization of the admissible prediction zone in relation to reality.
3.7. Backpropagation Algorithm
Analogously to what was done with the sales data, it is now done with the operational results data. That is, the Backpropagation algorithm is applied to the Training Set to train the ANN and then the resulting ANN is applied to the Test Set without adapting the weights, just correlating the outputs with the real results, and thus quantifying the prediction error from the application of strategies to obtain operating results (Figure 4).
As can be seen in Table 4, the test model has 4 points outside the two lines that limits the error at 20%, although very close to this line. This means that 60% of the samples have an error of less than 20% in the revenue forecast.
With 60% of the samples with less than a 20% error and 80% of the sample with an error below 25%, with a RMSE of 18.9% and an MAE of 17.5%, one can infer that the existing errors are not very distant from the “20%” line. One can consider a reasonable modelling for the Operating Results with backpropagation algorithm. With 31.2% of the model samples with an error greater than 5%, one can consider that the model of the training set was reasonable, but not excellent.
3.8. Positive Resilient Algorithm
Also, with the data of the operational results, the performance of the ANN processed with the Positive Resilient Algorithm is verified and relating the values of the outputs with the expected values of the samples, the graphs and the corresponding performance indicators are obtained (Figure 5).
As can be seen in Table 5, the test model has 5 points outside the two lines that limits the error at 20%, although very close to this line. This means that 50% of the samples have an error of less than 20% in the revenue forecast.
Inversely to what happened in Operating Results modelling, with the RProp+ algorithm was worse than backpropagation algorithm to modelling operational results. With only 50% of model samples to have an error less than 20%, although 80% of the model samples have an error less than 25%. Both RMSE and MAE have a value less than 20%.
3.9. Negative Resilient Algorithm
Analogously to what was done previously, but now using the Negative Resilient Algorithm, to be able to evaluate the system's performance in predicting the operational results by applying the strategies to the ANN inputs (Figure 6).
For the forecast of operating results with negative resilient algorithm, as we can see in Table 6, the test model has 3 points outside the two lines that limits the error to 20%, although very close to this line. This means that 70% of the samples have an error of less than 20% in the revenue forecast.
One can consider that RProp- algorithm have a reasonable performance, once 70% of the sample model had an error less than 20%. The RMSE is 20.5% and the MAE is 16.9%.
3.10. Set of 100 Experiments
The following results were obtained by evaluating 600 modeling experiments, 100 experiments for each par (Financial Result; Algorithm). Table 7 shows the average result for the samples which are within a certain error margin (5%, 10%, 20% and 25%). This should demonstrate the stability of the method when considering the performance evaluation.
Table 7 can help to evaluate the performance of the modeling through ANNs. As can be verified, the model achieves an average performance of about 90% for the Sales and more than 80% for Operating Results, if considering an error lower than 25%. Even if one considering an error within 20%, for these financial results, the performance is more than reasonable.
4. Conclusions
Although a successful modeling grade was adopted for the results previously demonstrated, it is the reader responsibility to make his/her own conclusions about the success or failure grade. The success or failure grades depend on the necessity. This means if the user necessity is to have 95% of the samples within a 5% error, it is different of when is sufficient to have 70% of the samples with less than 25% in error. Before the further development of the conclusion for the modeling method proposed, it is necessary to understand the possible problems associated with the data used. It is necessary to understand that a better quality in the data used should have better results in the final model.
The first issue that should be taken into consideration is although the financial results were obtained through a specialized database, it uses the official results presented to the governmental institutions. It is possible and it should be remembered that the survey had as target small and medium enterprises and that the real results could differ from the presented ones, although it is believed that differences, if any, should be small. The second issue is that the survey was responded by different persons for different organizations and although the data was processed to minimize the different values adjacent to the behavior and beliefs between management, there is always the possibility that some answers have induced some noise in the model.
Sales model results shows more than 90% of the samples with an error within 20% and about 96% of the samples if one considered an error less than 25%, for both RProp Algorithms. It is believed that this is a good indicator of the possibility of modeling the environment with a good level of precision.
Operating Results Model have from 62.4% to 77.1% of the samples with an error margin less than 20%. 74.1% to 87.1% of the samples had less than 25% error. These results indicate an acceptable level of success.
Although the results are promising, managers should not forget that the dynamism of the market presents numerous challenges to strategic managers. It is important to understand this dynamism and how it is influenced before strategic plans are developed (Parnell, 2014).
There are limitations, such as variables extrinsic to the application of strategies that can have a significant impact. For example, a strategic action in an environment of economic growth, will have a different impact from the same strategic action applied to an environment of economic recession. So, modeling must be in accordance with the economic environment in which organizations operate.
Another limitation is associated with neural networks. The modeling through the neural networks only allows that the results to be modeled are in the interval to which the data of the training set belongs. In this way, the further the training data from the data that is intended to be predicted, the higher the error rate should be.
The fact that the strategies used in the study are generic does not imply a specific knowledge about the implementation process, that is, of the resources spent to implement it. Therefore, it is not possible to know exactly the return of the implementation of such strategy.
References
- Alcázar-Blanco, A.C., Paule-Vianez, J., Prado-Román, M. & Coca-Pérez, J.L. (2021). Generalized regression neuronal networks to predict the value of numismatic assets. Evidence for the walking liberty half dollar. European Research on Management and Business Economics, 27(3), 100167. [CrossRef]
- Badea, L. (2014). Predicting Consumer Behavior with Artificial Neural Networks. Procedia Economics and Finance, 15, 238-246. [CrossRef]
- Bakir, S. & Breitenecker, R. (2020). Artificial neural networks in operations management: A survey. Journal of Intelligent Manufacturing, 31(3), 543-564.
- Han, C. & Zhang, S. (2021). Multiple strategic orientations and strategic flexibility in product innovation. European Research on Management and Business Economics, 27(1), 100136. [CrossRef]
- Hoel, P. G. (1966). Introduction to Mathematical Statistics (3rd ed.). Jonh Wiley & Sons.
- Hoopes, D., Madsen, T. & Walker, G. (2003). Why is there a resource-based view? Toward a theory of competitive heterogeneity. Strategic Management Journal, 24(10), 889-902.
- Li, Y., Wang, X. & Tan, K.C. (2019). Artificial neural networks in finance and accounting: A state-of-the-art review. Intelligent Systems in Accounting, Finance and Management, 27(1), 16-30.
- Marques, J. (1999). Reconhecimentos de Padrões: Métodos Estatísticos e Neuronais. IST Press.
- Mitchell, T. M. (1997). Machine Learning, McGraw-Hill.
- Mucharreira, P. R., Antunes, M. G., Abranja, N., Justino, M. R., & Texeira Quirós, J. (2019). The relevance of tourism in financial sustainability of hotels. European Research on Management and Business Economics, 25(3), 165-174. [CrossRef]
- Parnell, J. A. (2014). Strategic Management: Theory an Pratice (4th ed.). SAGE.
- Siddique, N. & Adeli, H. (2013). Computational Intelligence: Synergies of Fuzzy Logic, Neural Networks and Evolutionary. John Wiley and Sons.
- Zhang, Y., Velez, J.L. & Lassila, D.A. (2020). A review of artificial neural networks in strategic management research: Big data, big decisions. Strategic Management Journal, 41(3), 472-491.
Figure 1.
Graphic results for Sales - Backpropagation Algorithm.
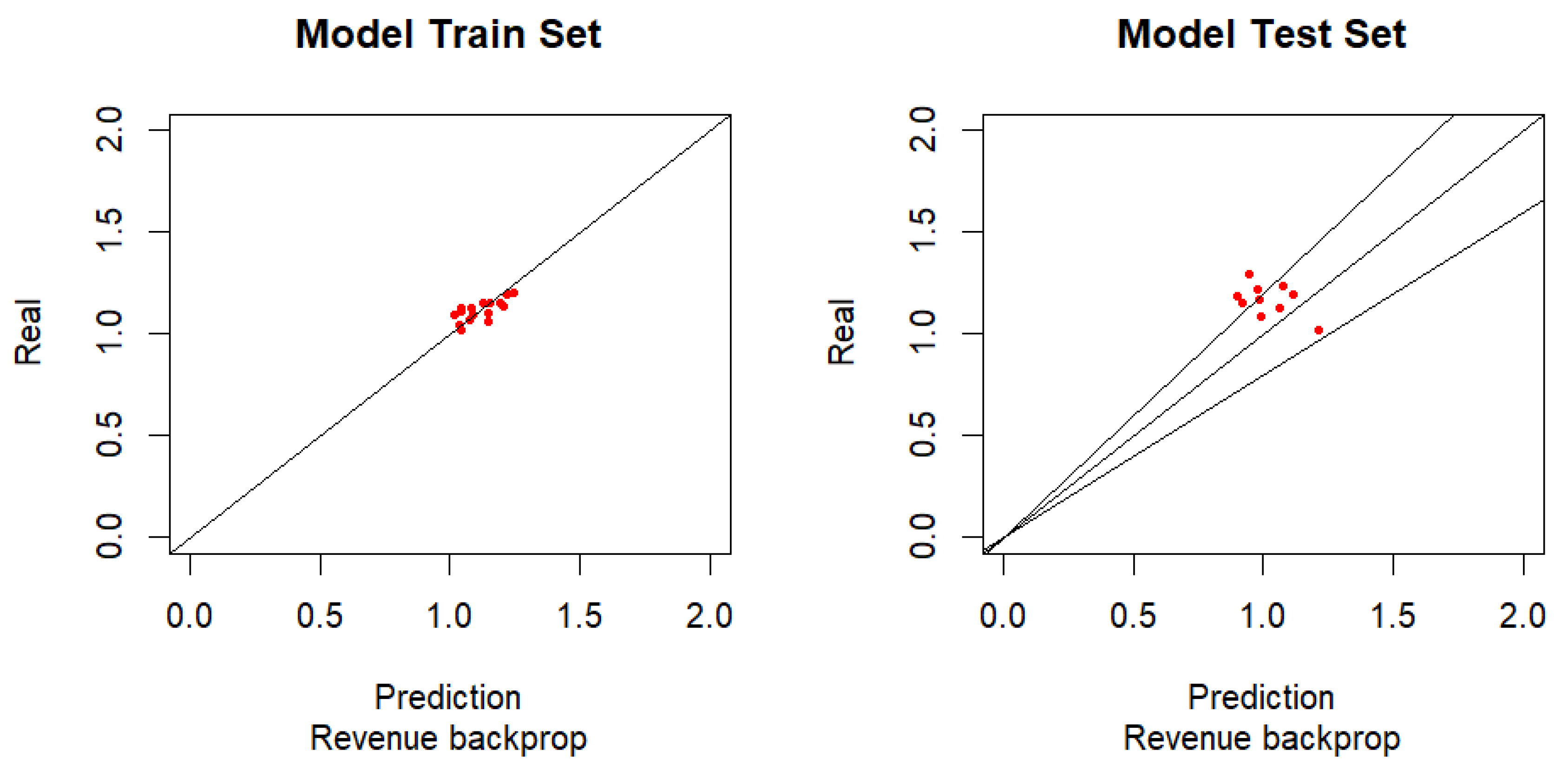
Figure 2.
Graphic results for Sales - RProp+ Algorithm.
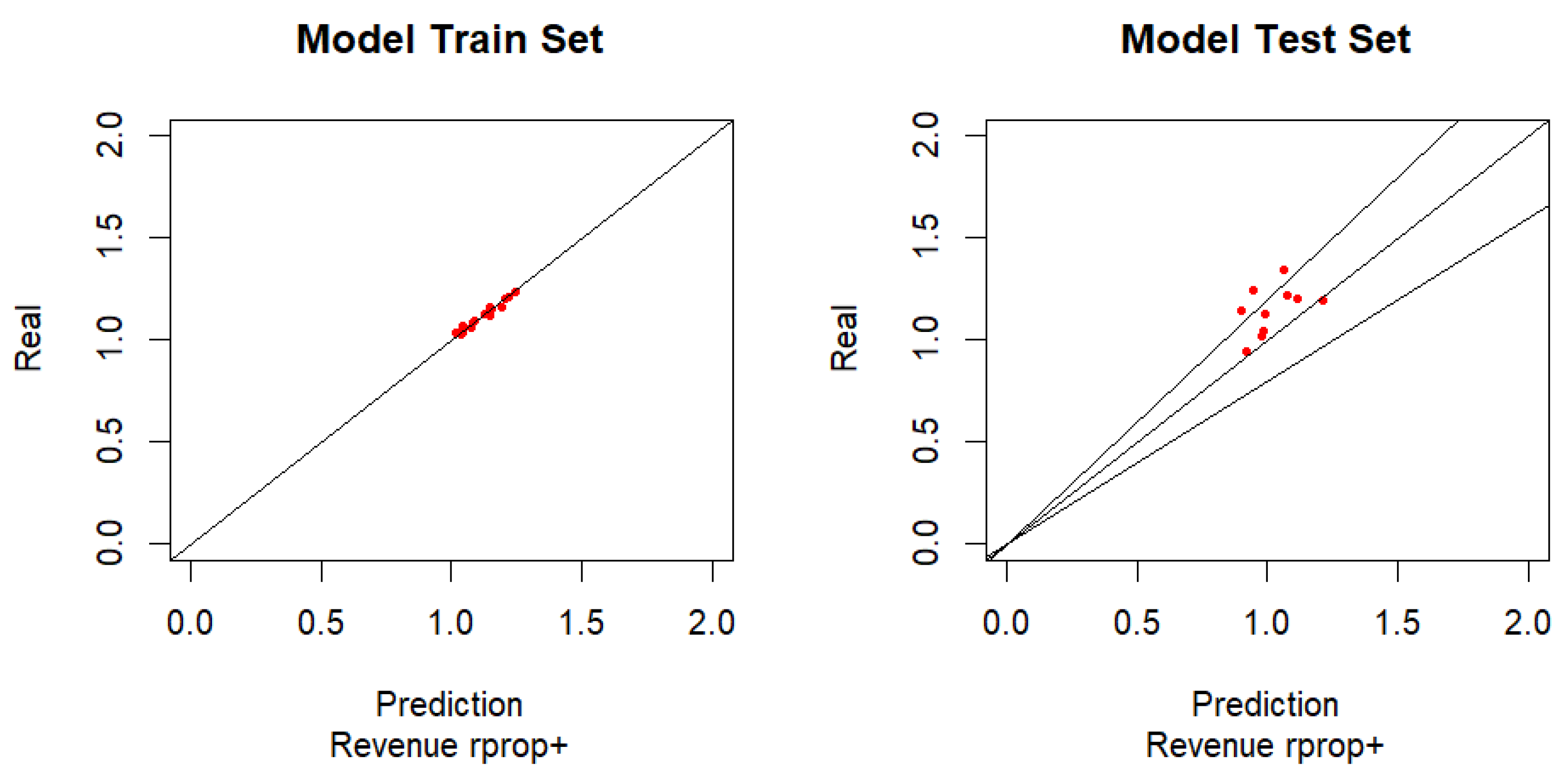
Figure 3.
Graphic results for Sales - RProp- Algorithm.
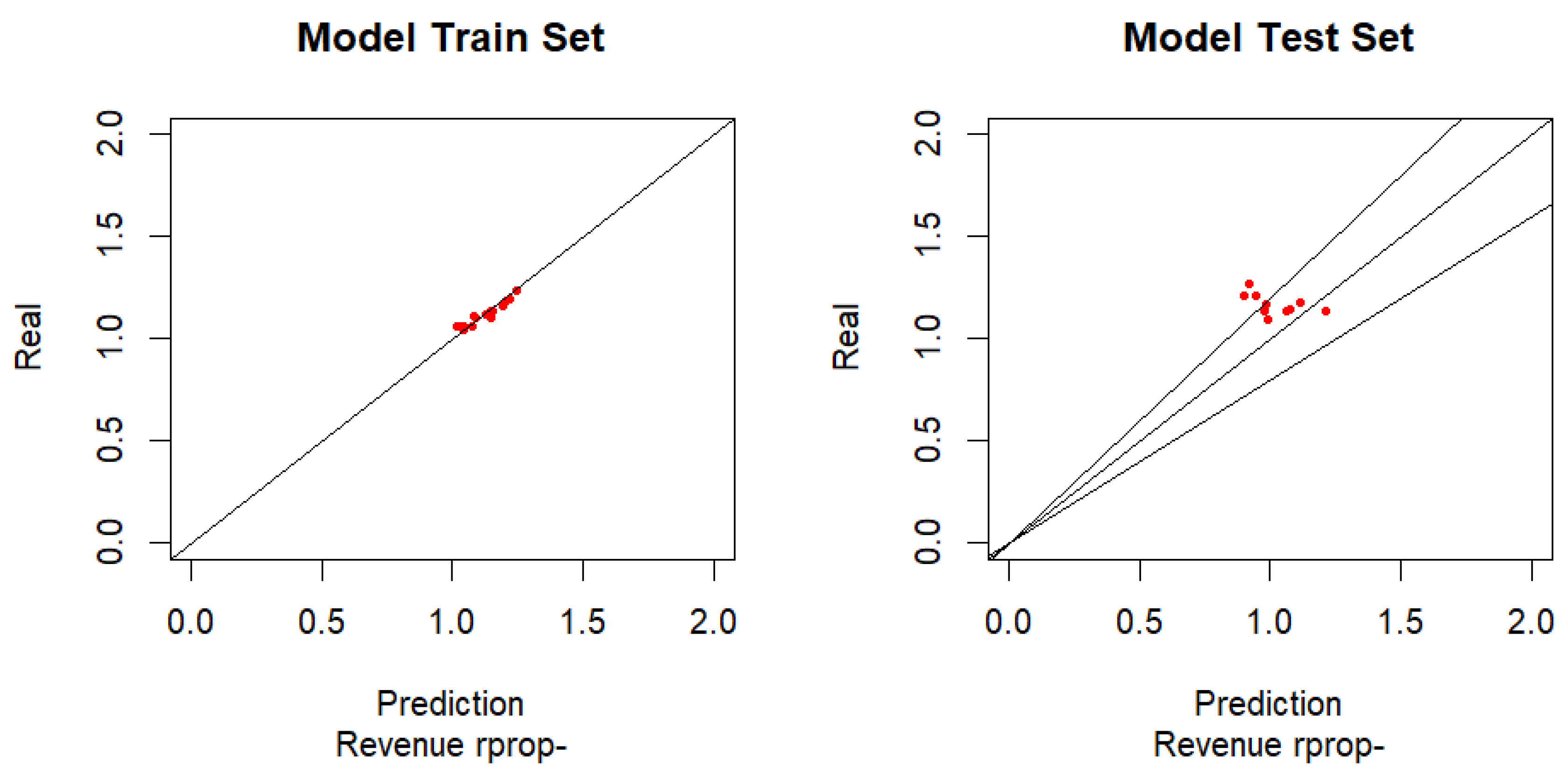
Figure 4.
Graphic results for Operating Results - Backpropagation Algorithm.
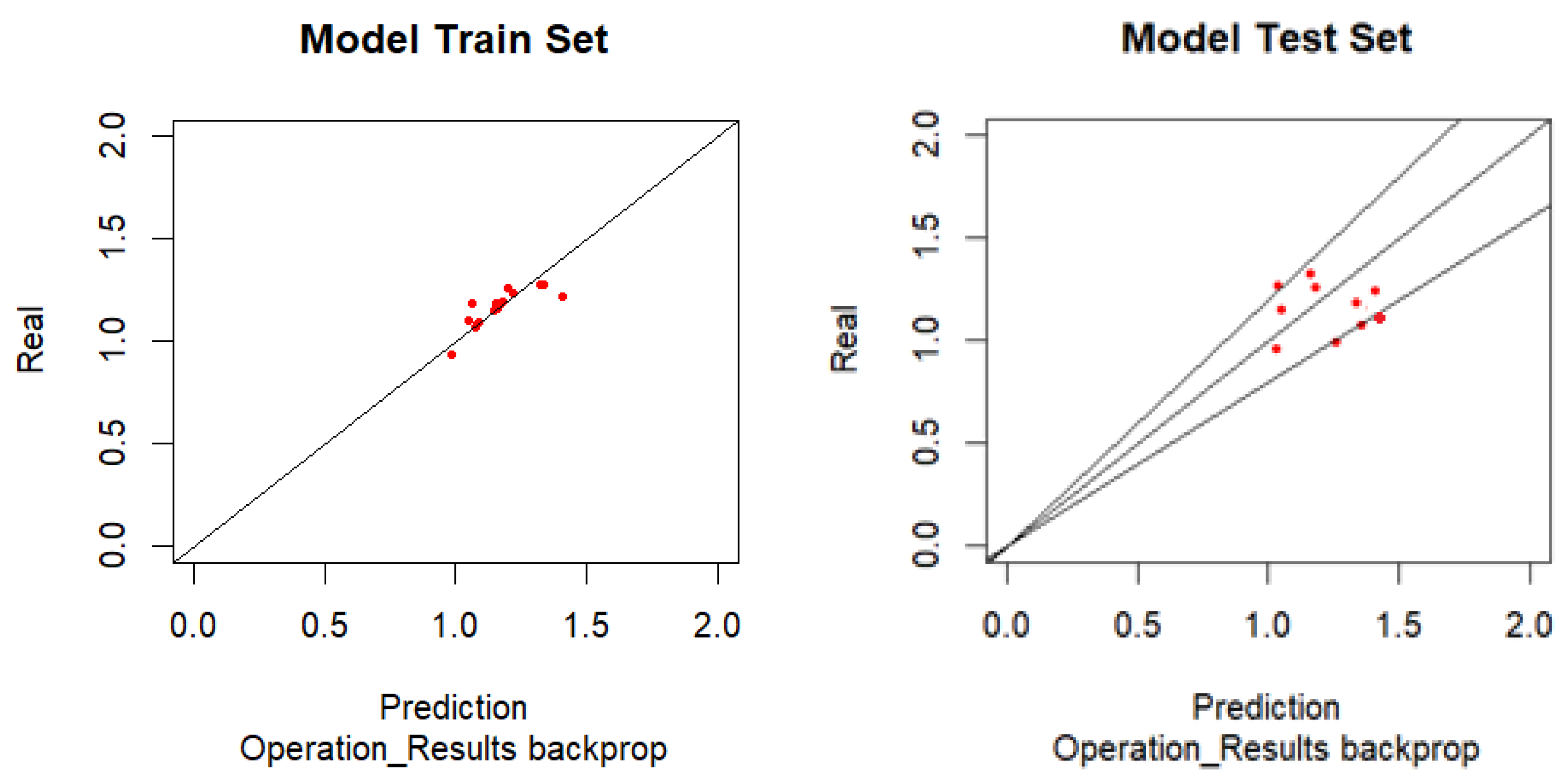
Figure 5.
Graphic results for Operational Results - RProp+ Algorithm.
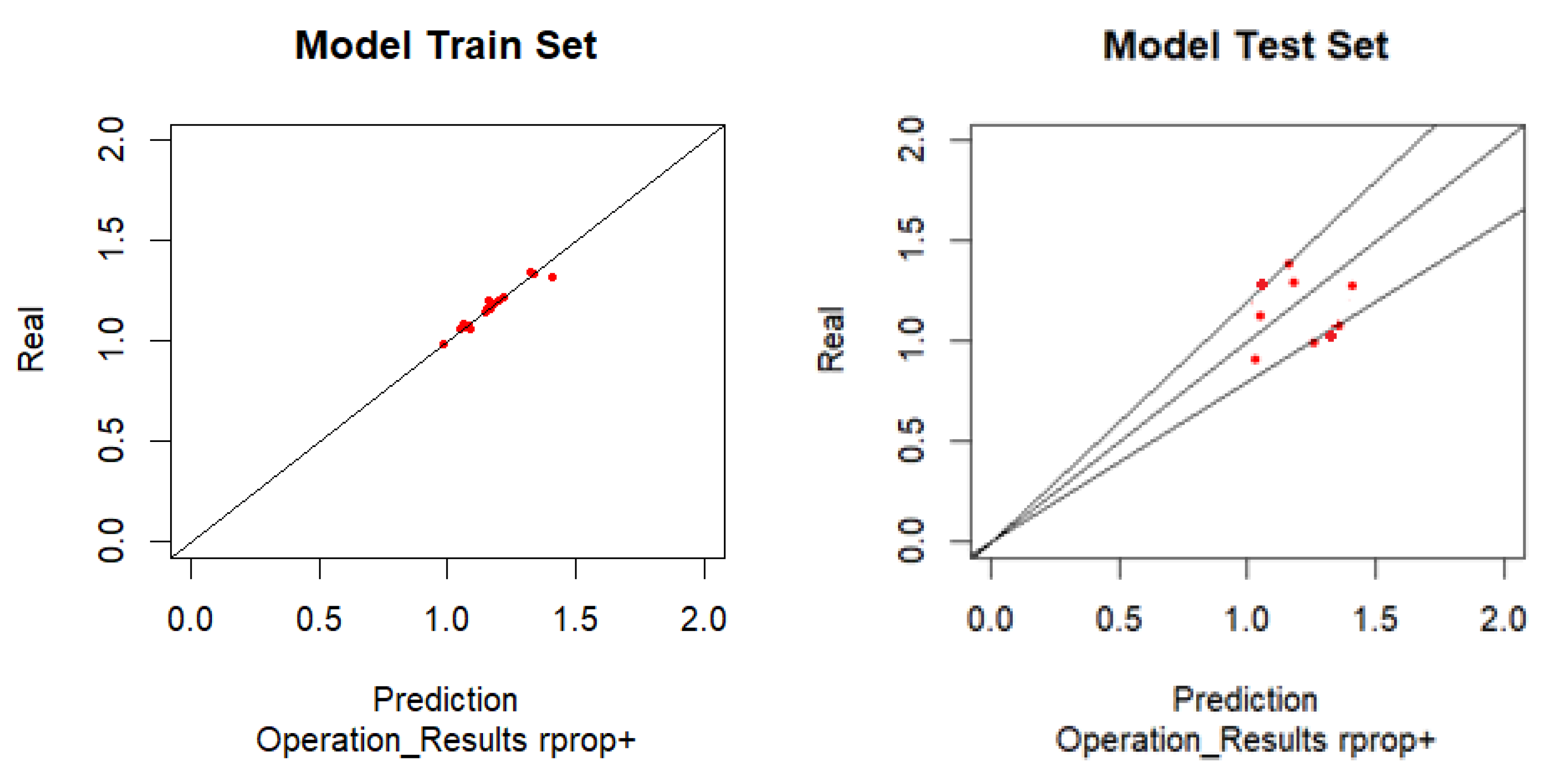
Figure 6.
Graphic results for Operating Results - RProp- Algorithm.
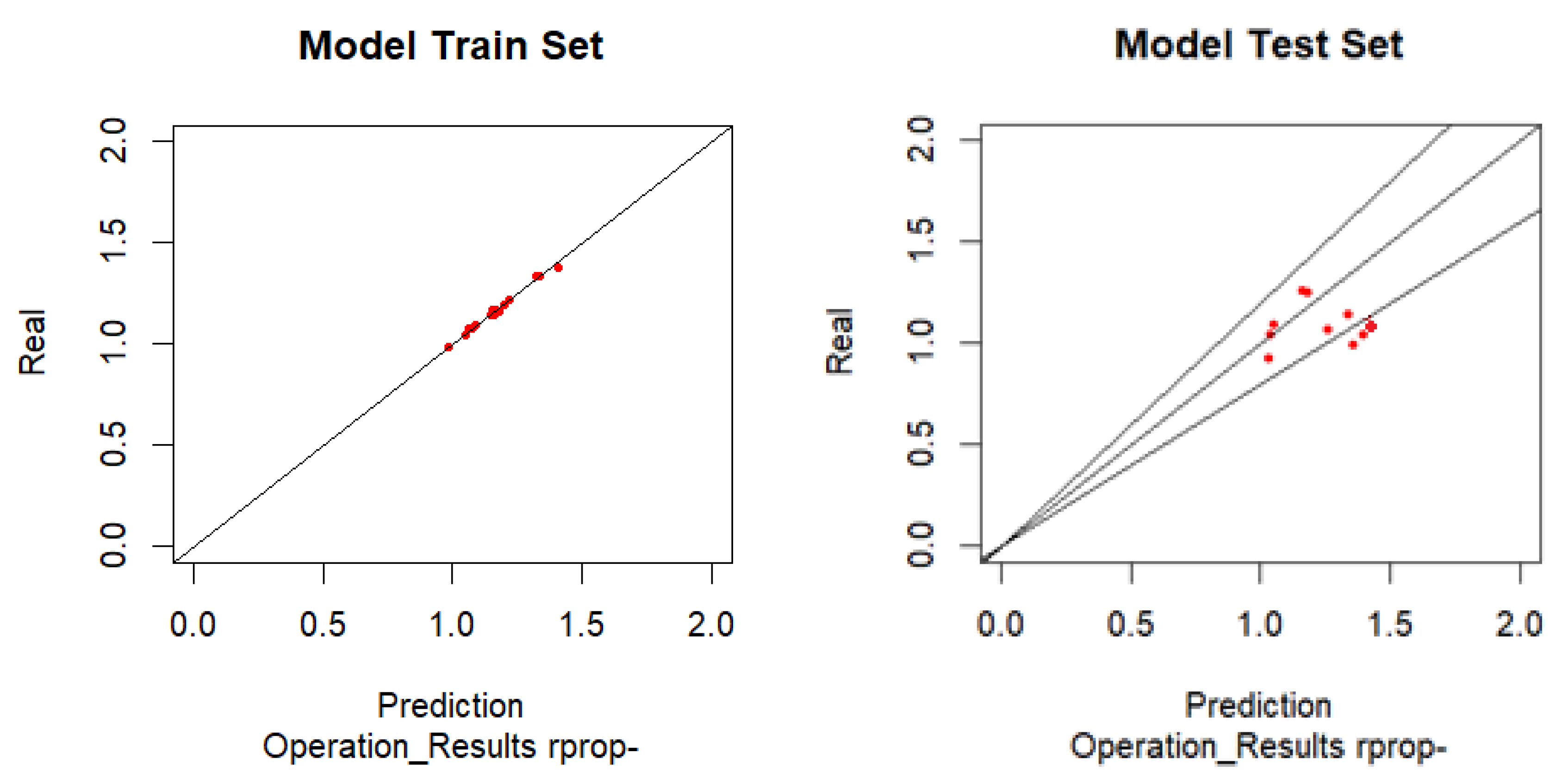

Table 1.
Data Error Information for Sales - Backpropagation Algorithm.
| Backpropagation | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 0 | 0.0% | 3 | 30.0% | 3 | 60.0% | 2 | 80.0% | 2 | 20.9% | 18.9% |
| Training Set | 16 | 11 | 68.8% | 5 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 5.0% | 4.1% |
Table 2.
Data Error Information for Sales - RProp+ Algorithm.
| RProp+ | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 3 | 30.0% | 2 | 50.0% | 2 | 70.0% | 1 | 80.0% | 2 | 17.0% | 13.5% |
| Training Set | 16 | 16 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 1.5% | 1.2% |
Table 3.
Data Error Information for Sales - RProp- Algorithm.
| RProp- | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 0 | 0.0% | 4 | 40.0% | 3 | 70.0% | 0 | 70.0% | 3 | 19.6% | 16.6% |
| Training Set | 16 | 16 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 2.4% | 1.9% |
Table 4.
Data Error Information for Operating Results - Backpropagation Algorithm.
| Backpropagation | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 0 | 0.0% | 2 | 20.0% | 4 | 60.0% | 2 | 80.0% | 2 | 18.9% | 17.5% |
| Training Set | 16 | 11 | 68.8% | 3 | 87.5% | 2 | 100.0% | 0 | 100.0% | 0 | 6.4% | 4.3% |
Table 5.
Data Error Information for Operating Results - Prop+ Algorithm.
| RProp+ | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 0 | 0.0% | 1 | 10.0% | 4 | 50.0% | 3 | 80.0% | 2 | 19.5% | 18.4% |
| Training Set | 16 | 15 | 93.8% | 1 | 100.0% | 0 | 100.0% | 0 | 100.0% | 2.6% | 1.6% |
Table 6.
Data Error Information for Operating Results - RProp- Algorithm.
| RProp- | # | | ε | < 5% | (%) | ε | < 5% | 5%≤ | ε | < 10% | (%) | ε | < 10% | 10% ≤ | ε | < 20% | (%) | ε | < 20% | 20% ≤ | ε | < 25% | (%) | ε | < 25% | | ε | ≥ 25% | RMSE | MAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test Set | 10 | 1 | 10.0% | 2 | 30.0% | 4 | 70.0% | 0 | 70.0% | 3 | 20.5% | 16.9% |
| Training Set | 16 | 16 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 100.0% | 0 | 1.1% | 0.9% |
Table 7.
Table of Average Samples within errors vs results and algorithms.
| Financial Result | Algorithm | ε <5% | ε <10% | ε <20% | ε <25% |
| Sales | backprop | 24.40% | 48.30% | 82.00% | 89.80% |
| Sales | rprop+ | 27.90% | 55.50% | 91.70% | 96.40% |
| Sales | rprop- | 29.50% | 55.70% | 90.80% | 96.30% |
| Operating Results | backprop | 20.20% | 39.10% | 72.90% | 82.30% |
| Operating Results | rprop+ | 19.90% | 38.30% | 71.30% | 83.40% |
| Operating Results | rprop- | 20.80% | 39.40% | 74.20% | 85.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



