Submitted:
21 March 2024
Posted:
26 March 2024
You are already at the latest version
Abstract
The concept of graphs with clique-width at most was first introduced by Courcelle et al.to be the graphs that can be characterized using -expressions derived from graph operations that use labels of vertices. If the clique-width for some graph is bounded then a grand number of algorithmic problems, in general NP-hard, can be solved in polynomial time when restricted to this graph. This important fact motivated the researchers to prove that the clique-width of certain graphs is bounded. Following this research direction, we prove in this paper that the clique-width of series-parallel digraphs is at most 6 and we present an time algorithm to construct a 6-expression for this class of digraphs. In another part, we present a linear time recognition algorithm for a similar class of series-parallel digraphs and prove that the clique-width of this class is at most 3.
Keywords:
Series parallel digraphs
; Clique-width
; Complexity
1. Introduction
Courcelle et al. in [1] characterized graphs with clique-width at most k as those graphs that can be generated through expressions involving graph operations utilizing vertex labels. Clique width generalizes another significant graph parameter, tree-width, in the sense that any graph has a bounded tree-width also has a bounded clique width [6]. The concept of clique width was established in 1993 [1], and since then a large number of studies concerning this concept have been published. The subjects in the literature that concern clique width have a theoretical or an algorithmic standpoint and can be summarized by one of the following questions:
- What is the complexity of computing the clique width?
- When the clique width of a graph is unbounded?
- Is there a general algorithm to recognize a graph of bounded clique width?
- Are there general algorithms to solve some optimization problems in a graph of bounded clique width?
- How to construct the clique width of a given graph?
The subject of complexity of computing the clique width has been resolved by Fellows et. al. in [14]. They proved that the problem of determining the clique width of a graph is NP-complete in general. The subject of determining the necessary and /or sufficient conditions to be the clique width of a graph unbounded is till now an open question. This question is motivated from the fact that the clique width for certain class of graphs can be unbounded, for example the class of -free graphs and not chordal [8]. The subject of recognizing a class of graphs of bounded clique width is resolved partially; for example, it is proved in [5] that any graph of clique width at most 3 can be recognized in time. The subject of solving some optimization problems in a graph of bounded clique width is the significance of these graph invariants. It stems from the fact that many problems that are NP-hard in general admit polynomial-time solutions when restricted to graphs with bounded clique width (see for example [2,3,15]). Among these problems are Hamiltonian path or Hamiltonian cycle problems, computing the minimum size of a maximal matching and several partition problems (partition into cliques or triangles or complete bipartite sub-graphs or perfect matching's or forests) [16], computing the chromatic number and computing the minimum size of a dominating set of vertices or edges [4], computing the maximum size of a cut [7], finding vertex-disjoint Paths [13]. The construction of the clique width for a given graph has been studied extensively. For example, in [9], it is proved that the clique width of Cactus graphs is at most 4 and the construction of 4-expression of these graphs can be done in polynomial time. Also in [10] it is proved that the clique width of polygonal tree graphs can be done by constructing a 5-expression in a polynomial time. Recently, the clique width for series parallel undirected graphs is studied in [12], where it is proved that the clique width of these graphs is at most 5 and an algorithm is presented to construct a 5-expression. Following this last direction of research, we prove that the clique width of the famous class of series parallel directed graphs (digraphs) is at most 6 and we propose an time algorithm to compute a 6-expression of this class. From other part, we introduce a new definition of a similar class of series parallel digraphs and present for which a linear time recognition algorithm. We prove that the clique width of this new class of digraphs is at most 3.
2. Preliminaries
A directed graph (or a digraph for short) is defined by two sets, or simply is the vertices set and or simply is the arcs set. Every arc of is an ordered pairs of vertices of . The number indicates to the number of vertices of and the number indicates to the number of edges of .If then is called a predecessor of and is called a successor of . The set of all predecessors of a vertex is denoted by , and the set of all successors of is denoted by ). The set of neighbors of is the set . The number is called the positive degree of and denoted by , and the number is called the negative degree of and denoted by , the degree of a vertex x is the number . A vertex is called a source if and is called a sink if . Given a subset of the vertices set , the sub-graph induced by will be denoted by . A path of length is a sequence of vertices such that any two consecutive vertices form an arc. A path is called a circuit if and . A directed acyclic graph denoted by DAG is a digraph with no circuit. A chain of length is a sequence of vertices such that or is an arc. If and the chain is called a cycle. An arc is called transitive arc if there is a path from to of length at least 2. A bipartite graph is given by a set of black vertices and a set of white vertices and a set of edges . A graph is called -free where is a set of graphs when does not contain an induced sub-graph isomorphic to a graph of .
The clique width of a graph G is the smallest number of labels required to construct using the four operations listed below:
- The operation ) to create a new vertex has the label .
- The operation to make a union of two disjoint labeled graphs and .
- The operation to add in the labeled graph an edge (or an arc in case of digraphs) from each vertex with label to each vertex with label ().
- The operation to change in the labeled graph every label to label.
Using these four operations, any graph may be defined by an algebraic expression. For example, the graph where and can be defined by the following expression:
If an expression uses at most k different labels, it is referred to as a k-expression.
3. Clique Width of Series Parallel Digraphs (SP DAGs)
Series-parallel digraphs, or SP DAGs for short, are a class of directed graphs that play a significant role in graph theory and find extensive applications in various real-world scenarios. It has been defined by Tarjan et al. in [11] to be the digraph that can be constructed starting of the vertices set and recursively using two fundamental operations: series composition and parallel composition. More precisely:
Definition 1: A SP DAG is defined recursively as follows:
A DAG containing only one vertex is a SP DAG.
If and are two SP DAGs then the DAG constructed by each of the following operations is also a SP DAG :
Parallel composition: .
Series composition: where is the set of sink vertices of and is the set of source vertices of .
A SP DAG can be represented by a binary decomposition tree that reflects the construction of starting of its vertices using series and parallel operations as following:
- The leaves correspond to the vertices of .
- Let be An internal node and are respectively the left and right child of , then is labeled by (resp. ) if (resp. ) where is the sub-graph of induced by the set of vertices having as their least common ancestor.
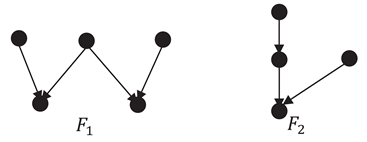
Figure 1 illustrates an example of a SP DAG and its binary decomposition tree. It is worthy mentioned that the two children of a -node are ordered according to the series operation of that node. Tarjan et. al. in [11] proved that the construction of when is a SP DAG can be done in time complexity. This binary decomposition tree of a SP DAG is the key of our computing to its clique width.
Theorem 1: The clique width of a SP DAG is at most 6.
Proof: Let be an internal node of and , are respectively the left and right child of . We will construct a 6-expression of starting of a similar 6-expression of and 6-expression of For , we can partition the vertices set of into at most four sets and , where is the set of non-isolated sources of , is the set of non-isolated sinks of , contains the set of isolated vertices of , and is the set of vertices that are not sources, not sinks, and not isolated in . We suppose that the label of every vertex of is 1, the label of every vertex of is 2, the label of every vertex of is 1, and the label of every vertex of is 5.We express this in notation by and . Similarly, we suppose that the label of every vertex of is 3, the label of every vertex of is 4, the label of every vertex of is also 4, and the label of every vertex of is 6. We can express the sub-graph by where:
Similarly, we can express the sub-graph by where:
Figure 2.a illustrates this decomposition of . Without loss of generality, and for simplification of reading, we represented in this Figure each set of and ,, by a single vertex. To construct a 6-expression for we distinguish two cases according to the type of :
Suppose that is a -node. In this case, the set is the set of non-isolated sources of , the set is the set of non-isolated sinks of , the set is the set of isolated vertices of , and the set is the set of vertices that are not sources, not sinks, and not isolated in . Hence, the expression constructs using 6 labels where:
Figure 2.b, illustrate the construction of using the expressions and . Suppose that is a -node. Since is connected, it does not contain isolated vertices. Since are respectively the left child and right child of then, every vertex of must be a sink in and every vertex of must be a source in , thus every vertex of would be a source in and every vertex of would be a sink in . Therefore, is the set of sources of , the set is the set of sinks of , and the set is the set of vertices that are not sources, not sinks, and not isolated in . Hence, the following ordered series of expressions constructs using 6 labels:
Figure 2.c illustrate the construction of using the expressions and . Now, by traversing in post order and calculating a 6-expression for every internal node of , we conclude that the whole digraph represented by the root of can be constructed by a 6-expression.
The construction a SP DAG by a 6-expression using the method described in the proof of Theorem 1 can be translated into the Algorithm Construction a 6-expression of a SP DAG. In this Algorithm, we define an empty expression, denoted by , to be an expression of an empty set of vertices. For any expression , we consider that, so and . Our Algorithm associates with every node of two expressions and , where represents the construction of the sub-graph induced by the non-isolated vertices of and represents the construction of isolated vertices of . It may be at most one of and empty. The labels in the end of computing or represent implicitly whether the corresponding vertices are non-isolated sources (labeled by 1), non-isolated sinks (labeled by 2), isolated vertices (labeled by 1), or vertices that are not sources, not sinks and not isolated in (labeled by 5). Initially, in step 1, every vertex is labeled by 1 since the sub-graph induced by a leaf consists only of one isolated vertex that consider as a source. Step 2 determines the left child and the right child of an internal node . Step 3 constructs the expression and for a -node to be respectively the disjoint union of and the disjoint union of . Steps 4 to 13 constructs the expressions and for a -node as following: Step 5 changes the label of non- isolated sources of from 1 to 3, the label of non-isolated sinks from 2 to 4, and the other non-isolated vertices from 5 to 6; Step 6, changes the label of isolated vertices of from 1 to 4 as these vertices are sinks in . Step 7 changes the label of isolated vertices of from 1 to 3. The steps from 8 to13 construct the expression in the same way as in Figure 2c. The expression must be empty because of is connected. Since the number of nodes in is and every step can be done in time, the total time complexity of this Algorithm is .

Figure 3 illustrates an example of the application of Algorithm Construction a 6-expression of a SP DAG for the digraph and its binary decomposition tree shown in Figure 1. The visited nodes according to post order traversal of is defined by the symbols , written near every internal node of . Every line in Figure 3 shows the executed steps for constructing . The vertices of left and right children of are represented respectively by a black color and a white color. The arrow and the number above it indicates the result of the corresponding step of the Algorithm. The absence of a result for a specific step means that this step has no effect on the construction.
3. Similar Series Parallel Digraphs (SSP DAGs)
Definition 1: A SSPDA G is defined recursively as follows:
A DAG having a single vertex is a SSP.
If and are two SSP DAGs then the DAG constructed by each of the following operations is also a SSP:
Parallel composition: .
Series composition: where is the set of source vertices of .
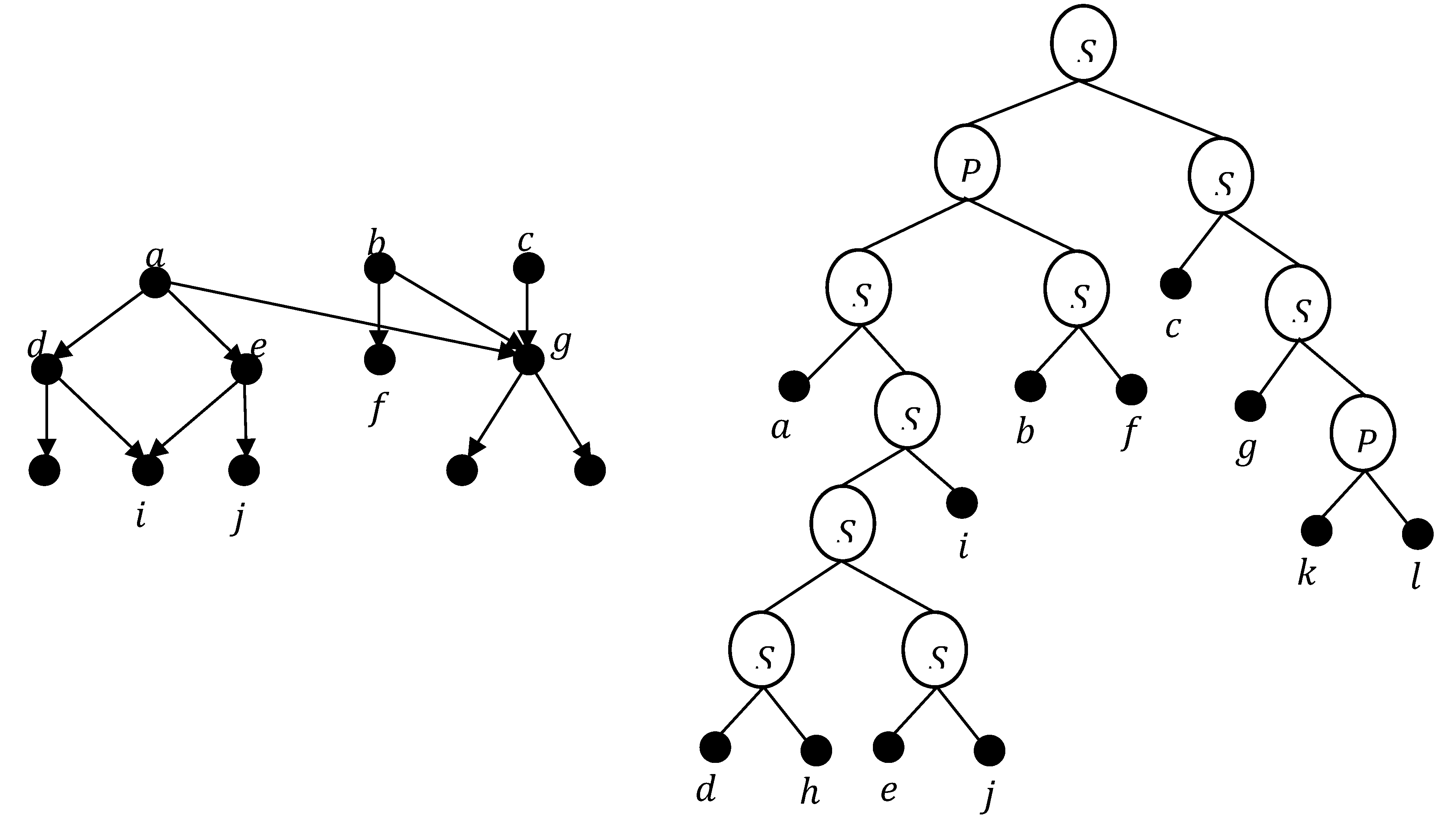
It is obvious that a SSP DAG is without transitive arcs. In the same way as in the class of SP DAGs, a SSP DAG can be represented by a binary decomposition tree that reflects the construction of starting of its vertices using series and parallel operations. Also as in the binary decomposition tree of a SP DAG, the two children of a -node are ordered according to the series operation of that node. Figure 4 represents a SSP DAG and its binary decomposition tree .
The following theorem is the key of our recognition algorithm of SSP DAGs.
Theorem 2: Let G be a connected DAG without transitive arcs. is a SSP if and only is -free.
Proof: Suppose that is a SSPDAG and let’s show that is -free.
Claim 1: Let such that then or .
Proof: Since is a SSP, every arc in is created by a series operation. According to the series operation, for any vertex , all the arcs are created by the same series operation. So, if there is two vertices such that then if the two sets of arcs and are created by the same series operation then .Suppose that the set of arcs is created by a series operation and the set of arcs is created by a series operation where precedes . Since , the vertex was a source during the operation , so . If precedes then . ■
By Claim 1, is -free.
Claim 2: Let, for every
Proof: Let . By the definition of the series operation, the arc has been created by a series operation that precedes the series operation for which the arc has been created. Since the arcs have been created by the same series operation then during the series operation there was as sources and , therefore , this implies that . ■
By Claim 2, is -free suppose now is a connected DAG without transitive arcs and -free. Let’s show that is SSP DAG. Let be the set of all sources of and .
Claim 3: Every vertex ofthat is a successor of a vertex of is a source of .
Proof:Let be a vertex of that is not a source and a successor to a vertex . Let be a source in such that is an ancestor of . Since does not contain transitive arcs, for every vertex located on the path going from to . Suppose that is a predecessor of . Since is the set of all sources of , there is a source such that . Since does not contain transitive arcs, the set induces the configuration , a contradiction. Suppose that is not a predecessor of , let be a predecessor of in and is a predecessor of . Since does not contain transitive arcs then induces the configuration , a contradiction. ■
Let be the connected components of and is the set of sources of .
Claim 4: If a source is a predecessor to a source of some connected component then is a predecessor to every source of .
Proof: Suppose the contrary, then there a source in such that . Since and are sources in and is connected there is a chain in that connects and . Without loss of generality, let such that . Now the set induces the configuration , a contradiction. ■
If then by Claim 4, is a bipartite complete. It is clear that admit a series decomposition into and .
Suppose and is not abipartite complete. Since is connected, must be also connected. We claim that there is a vertex ' such that for every , Suppose the contrary, then for every vertex ' there is avertex such that . Let and such that and . Since is connected, there is a chain in that connects and . Without loss of generality, let such that , then induces the configuration , a contradiction. Let and be the connected components of that contain the vertices of . It is proved in Claim 4 that every source of every connected component is a successor of every source in . Therefore admit a series decomposition into and . It follows that we can always reduce to its vertices set by a parallel decomposition and a series decomposition, this implies that is a SSP DAG.
4. Recognition of SSP DAGs
We present in this section a linear Algorithm to recognize if an arbitrary DAG is SSP or not. We will take into account the following sort of the vertex set for a DAG .
Definition 3: Letbe a DAG andis the set of sources of, let. The sort is called a topologically sort of .
Our Algorithm uses the following result:
Lemma 4: Let be a DAG and let be the topologically sort of. Then is a SSP DAG if and only if the following conditions are verified:
- a)
- For everythere issuch that;
- b)
- For everyis a bipartite-free graph;
- c)
- Letbe a connected component of,then for every.
Proof: We can remark that if and only if contains a transitive arc or contains the configuration . The conditions a and b assure that is -free, the conditions a and c assure that is -free.
The following Lemma provides a simple method for verifying the condition b of Lemma 4.
Lemma 5: Let be a bipartite DAG of depth one. is -free if and only if for every or .
Proof: Obviously if is -free then the conditions of Lemma must be verified. On the contrary, if one of these conditions is verified then every connected component of contains an isolated vertex or a universal vertex. Therefore we can reduce to its vertices set by a parallel and series decomposition.
The following Algorithm contains the procedures for detecting the conditions of Lemma 4. Step 1 tests whether contains a transitive arc or the configuration . Step 2 tests whether contains the configuration or not. Step 3 tests whether contains between two consecutive levels of the configuration or not. Let’s show that the time complexity of this algorithm is . The determination of and testing whether every arc of is located between two consecutive levels of requires time. The success of first step guarantees that the sets of edges , constitute a partition of . Therefore, testing the inclusion relation of the vertices for every , using the mark procedure described in step 2, can be executed in time , so the second step also requires time. The non-empty sets produced in step 2 are the input of step 3 for every . Indeed are the connected components of . Now, to test the condition c of Lemma 4, it is enough to compare for every , the set with where is an arbitrary vertex of . This can be done in time. Hence the total time complexity of this Algorithm is .


5. Clique Width of SSP DAGs
The computation of clique width of SSP DAGs can be done in a similar way to the one we did for computing the clique width of SP DAGs. The following theorem shows this computation.
Theorem 1: The clique width of a SSP DAGis at most 3.
Proof: Let be a binary decomposition tree of a SSP DAG . Let be an internal node of and , are respectively the left and right children of . We will construct a 3-expression of starting of a similar 3-expression of and 3-expression of For , we can partition the vertices set of into at most two sets and , where is the set of sources of and is the set of remaining vertices of . We must point out here that if contains an isolated vertex then this vertex is considered as a source in . We suppose that the label of every vertex of is 1 and the label of every vertex of is 2. Similarly, we suppose that the label of every vertex of is 3 and the label of every vertex of is 2. So we can express the sub-graph and as:
Suppose that is a -node. The set is the set of sources of , and the set is the set of remaining vertices of . Hence, the expression constructs using 3 labels where:
Suppose that is a -node. By the definition of series operation, the set of sources of is the set , and the set of remaining vertices of is the set . Hence the expression constructs using 3 labels where:
6. Conclusion
We show in this paper that the clique width of a SP DAG is at most 6 and the construction of a 6-expression of can be done in time complexity using a binary decomposition tree. On other hand, we defined the class of digraphs SSP as a similar class of SP DAGs and proved that this new class can be recognized in linear time complexity. We proved that the clique width of a SSP DAG is at most 3. The construction of a 3-expression of a SSP DAG requires to construct a binary decomposition tree that we believe to be done in linear time.
References
- Courcelle, B.; Engelfriet, J. Rozenberg. Handle-rewriting hypergraph grammars. Journal of Computer and System Sciences 1993, 46, 218–270. [Google Scholar] [CrossRef]
- Courcelle, B.; Makowsky, J.A.; Rotics, U. Linear time solvable optimization problems on graphs of bounded clique width. Theory of Computing Systems 2000, 33, 125–150. [Google Scholar] [CrossRef]
- Courcelle, B. The expression of graph properties and graph transformations in monadic second-order logic, in: Handbook of Graph Grammars and Computing by Graph Transformation, vol. 1, World Sci. Publishing, River Edge, NJ, 1997, pp. 313_400.
- Kobler, D.; Rotics, U. Edge dominating set and colorings on graphs with fixed clique width. Discrete Applied Mathematics 2003, 126, 197–221. [Google Scholar] [CrossRef]
- Corneil, D.G.; Habibb, M.; Lanlignel, J.M.; Reedd, B.; Rotics, U. Polynomial-time recognition of clique width ≤ 3 graphs. Discrete Applied Mathematics 2012, 160, 834–865. [Google Scholar] [CrossRef]
- Corneil, D.G.; Rotics, U. On the relationship between clique-width and treewidth. SIAM Journal on Computing 2005, 34, 825_847. [Google Scholar] [CrossRef]
- Wanke, E. k-NLC graphs and polynomial algorithms. Discrete Applied Mathematics 1994, 54, 251–266. [Google Scholar] [CrossRef]
- Penev, I. On the clique width of (4k1,C4,C5,C7)-free graphs. Discrete Applied Mathematics 2020, 285, 688–690. [Google Scholar] [CrossRef]
- Gonzalez-Ruiz, J.L.; Marcial-Romero, J.R.; Hernandez-Servın, J. Computing the clique width of cactus graphs. Electronic Notes in Theoretical Computer Science 2016, 328, 47–57. [Google Scholar] [CrossRef]
- Gonzalez-Ruiz, J.L.; Marcial-Romero, J.R.; Hernandez, J.A.; De Ita, G. Computing the clique width of polygonal tree graphs, Advances in Soft Computing, Springer International Publishing, Cham, (2017) pp. 449–459.
- Valdes, J.; Tarjan, R.E.; Lawler, E.L. The Recognition of Series Parallel Digraphs. SIAM Journal on Computing 1982, 2, 298–313. [Google Scholar] [CrossRef]
- López-Medina, M.A.; González-Ruiz, J.L.; Marcial-Romero, J.R.; Hernández, J.A. Computing the Clique-Width on Series-Parallel Graphs. Computación y Sistemas 2022, 26. [Google Scholar] [CrossRef]
- Kurt, M.; Berberler, M.; Ugurlu, O. A New Algorithm for Finding Vertex-Disjoint Paths. The International Arab Journal of Information Technology 2015, 12. [Google Scholar]
- Fellows, M.R.; Rosamond, F.A.; Rotics, U.; Szeider, S. Clique-width is NP-complete. SIAM Journal on Discrete Mathematics 2009, 23, 909–939. [Google Scholar] [CrossRef]
- Oum, S.I.; Seymour, P. Approximating clique width and branch-width. Journal of Combinatorial Theory Series B 2006, 94, 514–528. [Google Scholar] [CrossRef]
- Espelage, W.; Gurski, F.; Wanke, E. How to solve NP-hard graph problems on clique width bounded graphs in polynomial time. Lecture Notes in Computer Science 2001, 2204, 117–128. [Google Scholar]
Figure 1.
A SP DAG and its decomposition binary tree.
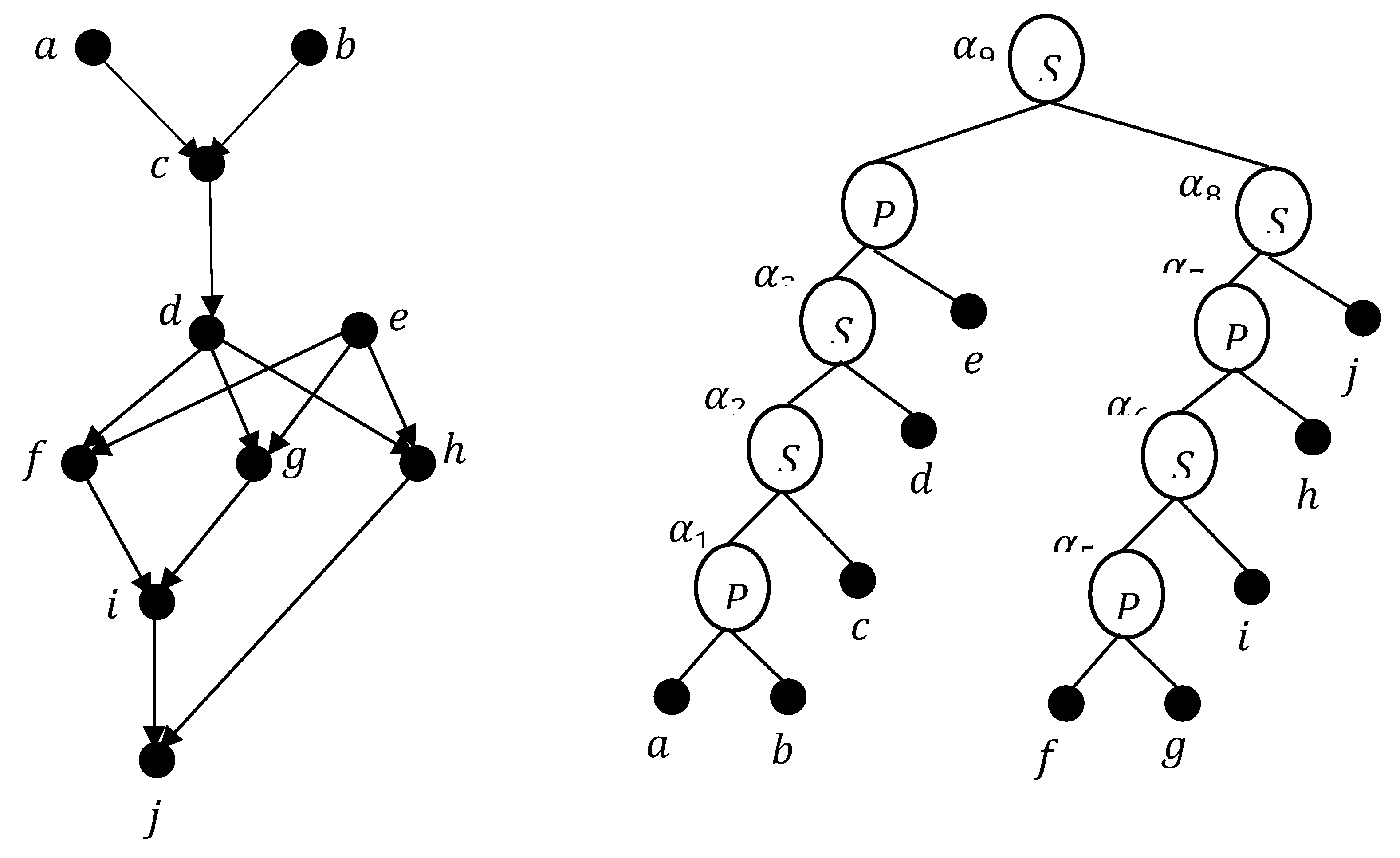
Figure 2.
a) The sub-graphs and , b) the construction of , c) the construction of .
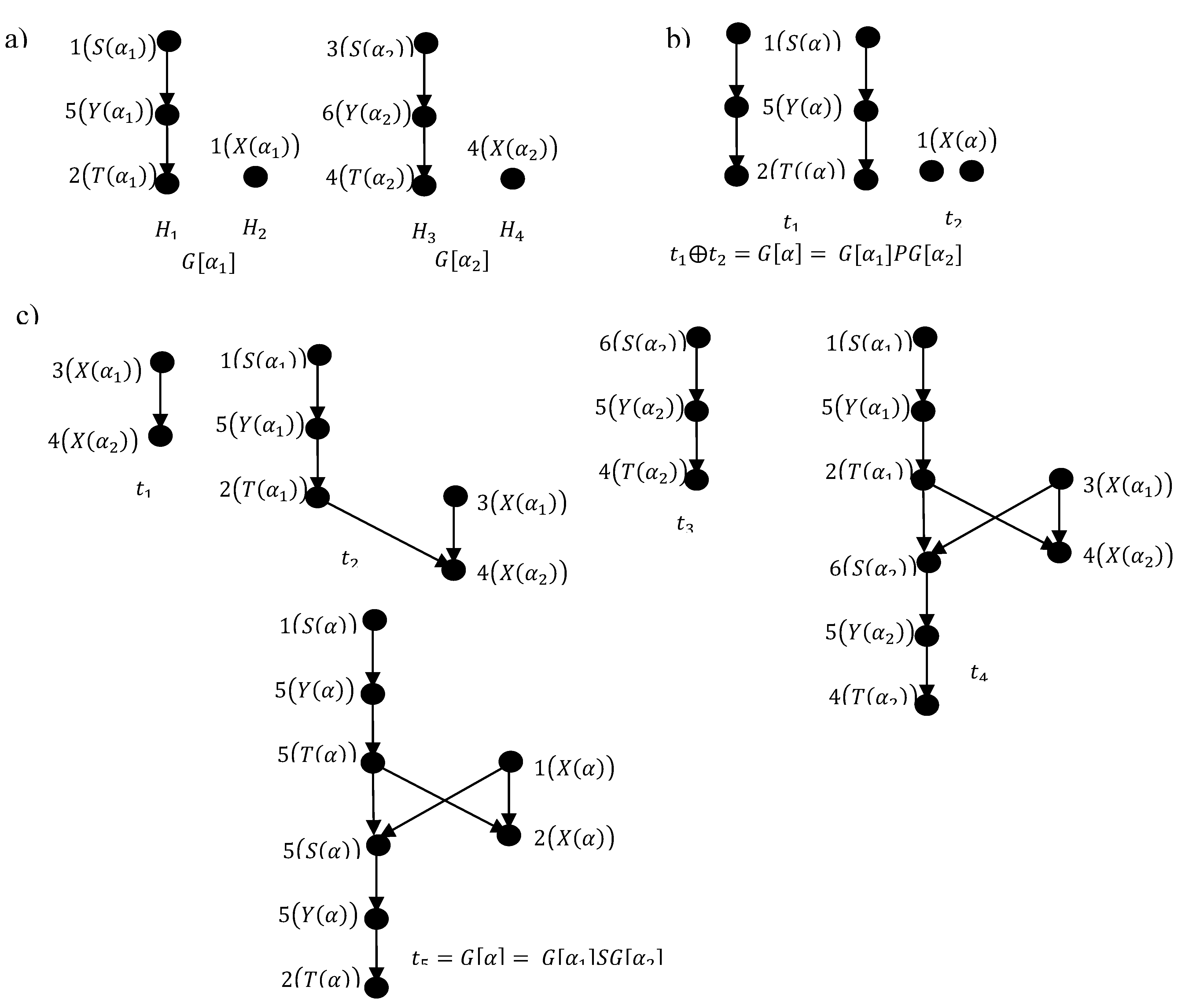
Figure 3.
application of Algorithm Construction a 6-expression of a SP DAG for the digraph in Figure 1.
Figure 3.
application of Algorithm Construction a 6-expression of a SP DAG for the digraph in Figure 1.

Figure 4.
A SSP DAG and its binary decomposition tree.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



