
Submitted:
25 March 2024
Posted:
26 March 2024
Read the latest preprint version here
Abstract
In this work, several random Boolean networks (RBN) are generated and analyzed from two characteristics: their time evolution diagram and their transition diagram. To do this, its randomness is estimated using three metrics, of which algorithmic complexity is the only one capable of revealing both transitions towards the chaotic regime and the algorithmic contribution of certain states to the transition diagram and their relationship with the order they occupy in the temporal evolution of the respective RBN.
Keywords:
Random boolean networks
; entropy
; algorithmic complexity
; compressibility
1. Introduction
Discrete-time models are applied in biology to capture the dynamic nature of biological systems. In particular, Boolean networks are models that also assume discrete values for their variables, and allow us to have a qualitative view of the dynamics of a system. The origin of Boolean networks can be traced in the work where Kauffman[1] introduces random genetic nets to test the hypothesis that modern organisms are randomly assembled molecular automata. Later works, such as that of Kauffman[2] where maps continuous biochemical control networks to their discrete analogue, and that of Thomas[3] who attempts to formalize genetic situations through models of complex control circuits, established the usefulness of Boolean network models to study biological regulatory systems.
Many studies highlight the usefulness of models of Boolean networks to analyze regulatory networks. Some examples are: a) the dynamic properties of the core network that controls the mammalian cell cycle[4], b) simulation of the stomatal response in plants with a signal transduction network model[5], c) virulence and response to pathogens resulting from the interactions between bacteria and the immune components of an infected host[6], d) the modeling of the lac operon in Escherichia coli[7], and e) the modeling of the network of regulatory interactions that occur through various stages of embrionic development of the Drosophila[8]. Most importantly, such type of models of regulation and signalling serves to study a multitude of factors in an integrated way, rather than studying them in isolation.
In this paper, we present and compare various methodologies for analyzing the dynamics of some Boolean networks under the simplest of assumptions. First, we analyze the regimes of certain Boolean networks; then, we study the transitions between states in some simple Boolean networks applying perturbations. This work intends to introduce some useful tools for potential applications in the modeling and analysis of regulatory networks in biology.
2. Background
Boolean networks, also known as N-k networks, are characterized by two parameters: the number of nodes N and the in-degree k. The state that each node can acquire is only one of two possible states -0 and 1, and is determined by a set of rules called boolean functions,
where the states of the nodes at time are determined by the Boolean functions that depend on certain nodes at time t (in this work, we make the assumption of synchronous update; but there exist more flexible modeling frameworks that incorporate randomness in the duration of processes, see [9]). The arguments of Boolean functions, as well as their order, are specified by a connectivity graph and a connectivity matrix. Boolean functions are represented by a truth table. A Boolean network has a transition diagram between all possible states (see Figure 1).
2.1. Random Boolean Networks
When Boolean functions are extracted from a random sample of 0s and 1s they become random boolean functions, and the network becomes a random boolean network (RBN)[10]. Boolean functions can be constructed with a uniform probability distribution. Or they can be constructed from a binomial probability distribution with parameter p, this parameter being therefore the probability that each of the Boolean functions returns a “1” as output. This parameter will also determine the type of system:
- Chaotic, if
- Ordered, if
- At the edge of chaos, if
In the last case, is known as critical in-degree. Since these are probabilities, this is only true when the number of nodes N is very large. Figure 2 shows time evolution diagrams for three RBNs with 500 nodes and in-degree ; two of them are in the ordered regime ( and ) and the other one () is in the chaotic regime. For the RBN with there is a 90 percent probability that the Boolean functions deactivate their respective node; this can be confirmed in its time evolution diagram where there are many more deactivated nodes and in the rapid fall in a limit cycle attractor. Similarly, for the RBN with there is a 90 percent probability that the Boolean functions activate their respective node, and a rapid fall in a limit cycle attractor is observed. On the other hand, it can be seen that the RBN with is a chaotic system.
The time evolution and transition diagrams such as in Figure 2 allow us to analyze qualitatively the regimes in RBNs; for a more quantitative approach, we need a measure that is capable of capturing such regimes and the transitions between them. In the next section, we introduce some methods of measure as candidates for the task at hand.
3. Methodology
The act of explaining what our eyes see has always been a human need. The act of trying to understand reality, which some have called science, common sense, etc., is nothing more than classifying randomness. That is, when one discovers the mechanism of operation of a phenomenon, what we have done is to find that this phenomenon is not random, that it has a cause and we have found it. To do this, a phenomenon can be abstracted to a chain of symbols and we call that “the object”. However, measuring randomness is a challenge, and there are several measures at our disposal. In the next subsections, we review some of these measures.
3.1. Information Theory and Entropy
Information theory[11] is a branch of mathematics that deals with the quantification and communication of information. One of the fundamental concepts in information theory is the concept of entropy. In particular, the Shannon entropy is a measure of the amount of uncertainty or information content in a random variable.
The Shannon entropy of a discrete random variable X with probability mass function is defined as
where is the set of all possible values of X. The logarithm is usually taken to base 2, so the entropy is measured in bits.
The Shannon entropy has a number of important properties, including:
- It is always non-negative, .
- It is maximized when all the possible values of X are equally likely, i.e., when for all . In this case, the entropy is .
- It is minimized when X is a deterministic function of another random variable Y, i.e., when there exists a function f such that with probability 1.
In the last case, the entropy is 0, since there is no uncertainty or information content in X beyond what is already contained in Y.
Shannon entropy is a useful tool in a variety of applications, including coding theory, data compression, and cryptography[12]. The Shannon entropy indicates how much “surprise” or “unexpectedness” there is in the outcomes of a random variable. The higher the entropy, the more uncertain or unpredictable the random variable is, and the more information is needed to describe or communicate its outcomes. Conversely, the lower the entropy, the more certain or predictable the random variable is, and the less information is needed to describe or communicate its outcomes.
3.2. Compression Algorithms and Compressibility
A lossless compression algorithm is any encoding procedure that aims to represent a certain amount of information using or occupying a smaller space, making an exact reconstruction of the original data possible. An example is the Lempel-Ziv-Welch (LZW) algorithm[13], a dictionary-based lossless compressor. The algorithm uses a dictionary to map the sequence of symbols to codes that take up less space. The LZW algorithm performs well, especially with files that have repetitive sequences. Another example of a lossless compression algorithm is the free and open-source file compression program called BZip2, which uses the Burrows-Wheeler algorithm[14], which only compresses individual files; It relies on standalone external utilities for tasks such as handling multiple files, encryption, and file splitting.
From the lossless compression of a piece of data we can define its compressibility rate as the length of the codified data divided by the length of the original data. This is an intuitive measure of randomness because we expect that the more random a piece of data or string is, the more difficult to compress it.
3.3. Algorithmic Complexity and BDM
Program size complexity, also known as algorithmic complexity, is a measure that quantifies algorithmic randomness. The algorithmic complexity (AC) of a string s is defined as the length of the shortest computer program p that is executed in a prefix-free Universal Turing Machine and generates s as an output[15,16]:
The difference between the original length and the minimum program size determines the complexity of data s. A string s is said to be random if (in bits) .
A technical drawback is that K is not computable due to the Halting problem[17], since we can’t always find the shortest programs in a finite time without having to run all the computer programs, which means having to wait forever in case they never stop. Nevertheless, it is possible to randomly produce programs that produce a specific result to estimate its AC from above; for this purpose, the algorithmic probability of a binary string s is defined as the sum over all (prefix-free) programs with which a (prefix-free) Universal Turing Machine generates s and stops:
The Coding Theorem Method (CTM)[18,19] further establishes the connection between and ,
where c is a fixed constant, independent from s. This theorem implies [20] that the output frequency distribution of random computer programs to approximate can be converted to estimates of using
Finally, the Block Decomposition Method (BDM)[21] is a powerful tool to estimate algorithmic complexity. This method allows the decomposition of a large system in smaller and more manageable pieces, facilitating the estimation of its total complexity. By dividing the data into fragments and precomputing CTM calculations on these fragments[22,23], BDM provides a measure that lies between entropy and algorithmic complexity, allowing a better understanding of the structure and behavior of the system under study. In general, for w-dimensional objects, BDM is defined as
where is an element from the decomposition of X (specified by the partition ) and is the multiplicity of each .
4. Results and Discussion
In this section we present and discuss some results about time evolution of RBNs. We used the randomness measures of Section 3 (for the estimation of AC by BDM we used the pybdm library [24])
4.1. RBNs with nodes
At the top of Figure 3 there are randomness estimates, for both the Boolean functions and the time evolution diagrams, of RBNs with nodes and in-degree . The results concerning the Boolean functions show “causality gaps” between the entropy/LZW estimates and the AC estimates using the BDM, and could be anticipated since the Boolean functions were constructed from a binomial probability distribution with parameter p (see [21]). Regarding the randomness estimates of the time evolution diagrams, the causality gaps are more noticeable; it can even be seen that the AC estimation is capable of revealing the transition to the chaotic regime on both sides of the ordered regime, while both entropy and LZW are insensitive to such transition (beyond some small fluctuations) and give results from which it can only be suggested that the evolution diagrams arise from a binomial probability distribution. For greater statistical rigor, estimates of average algorithmic complexity from samples of size 10 of RBNs generated with a fixed value of p are shown at the bottom of Figure 3; as in the upper part, we can see the transitions to the chaotic regime.
Finally, Figure 4 shows some parametric series of BDM (evolution diagram) vs BDM (Boolean functions), obtained for each specific value of in-degree k. In this case, the parameter is p and takes on discrete values in the interval . Each series of values is normalized to the maximum value. In each of the series, we can notice a sudden growth of the time evolution diagram’s BDM starting from a certain p value (marked with vertical lines). Such p values are the critical p values that point out the transition to the critical regime in each series, as can be confirmed by comparison with the theoretical p values obtained from the chaos condition in RBNs (see Table 1). We can also notice that the critical p value increases when going from one series to another with k lower, following the chaos condition in RBNs. Furthermore, as expected, in each series it is observed that an increase in BDM of the evolution diagrams goes hand in hand with an increase in BDM of the Boolean functions; It can also be observed that the series with greater k have greater BDM values in the time evolution diagrams.
4.2. RBNs with nodes and
In this subsection, some RBNs with 10 nodes and in-degree of 5 are analyzed from their complete transition diagram - which have possible states. In Figure 5 there are three transition diagrams, two for RBNs with extreme values of p and one for an RBN with a value of . The internal eigenvector centrality measure or prestige of the nodes[25] in each diagram was calculated. In the transition diagram of the RBN with a single fixed point attractor is observed, in which all states fall after a few time steps. In the transition diagram of the RBN with a similar behavior is observed with two limit cycle attractors. On the other hand, in the RBN with several attractors with more time steps are observed. It can be noted that the attractors have the greatest prestige in each transition diagram.
The transition diagrams obtained are conducive to performing perturbation analysis. In this work, perturbations were carried out on our RBNs according to the following procedure:
- Perform randomness measurements of the unperturbed transition diagram.
- Create a list of nodes with the highest prestige.
- Perturbation: locate the node with the highest prestige in the list, disconnect it from the transition diagram, and perform randomness measurements.
- Remove the most prestigious node from the list.
- Restore disconnected node to transition diagram.
- Repeat steps 3, 4, and 5 until the list of most prestigious nodes is exhausted.
Let’s call this perturbation method perturbation of most relevant nodes. Similarly, let’s call perturbation of less relevant nodes the perturbation method where nodes with lower prestige are disconnected (modifying step 2).
Figure 6 shows the results of performing the aforementioned perturbations. The 20 most relevant-prestigious nodes and the 20 least relevant-prestigious nodes in each transition diagram in Figure 5 were perturbed. In each perturbation, the randomness of the respective transition diagram was calculated from its adjacency matrix. The perturbations series obtained were normalized to the maximum value, and show that the compressibility by LZW is blind to the perturbations, as is the entropy (except for a few perturbations), while the algorithmic complexity - estimated by BDM - is sensitive in the face of these perturbations. For the transition diagram with we can observe that perturbations of less relevant nodes induce a sudden increase in algorithmic complexity before descending to values close to the initial value, indicating that the first least relevant node makes a relatively high causal contribution to the transition diagram since it moves it more towards randomness when disturbed. This is to be expected since the least relevant-prestigious nodes are found on the periphery of the transition diagram to which they belong, which makes them more preceding nodes in the temporal evolution of the respective RBN. Regarding the perturbation of more relevant nodes, we see a slight increase in algorithmic complexity in the first perturbation, followed by a few complexity peaks over a constant value; This tells us that the majority of less relevant nodes, by not moving the transition diagram to randomness or simplicity, are not essential in the explanation of the system, so it is likely that they are elements produced by the natural course of evolution of the system. The latter is to be expected since the most relevant-prestigious nodes are usually close to the attractors. A similar analysis follows for the results for the transition diagram with , although the perturbation of the first least relevant node moves the system towards simplicity, which in turn indicates that the first least relevant node does not take part in the algorithmic content of the system. Finally, for the transition diagram with it is observed that one of the first least relevant nodes induces a sudden change in the algorithmic complexity, followed by oscillations below a constant maximum value, while the perturbation of the first most relevant node is neutral to a certain point, where the system moves towards simplicity by perturbing nodes with low causal contribution.
5. Conclusions
We used three measures of randomness to analyze the dynamics of RBNs with synchronous updates. We showed that CA is capable of both detecting regime changes and revealing the causal contribution of certain states according to the order they occupy in the temporal evolution of an RBN. The latter indicates that “algorithmic perturbations” are capable of indicating the temporal direction of RBNs.
A future work may be the extension of the analysis to RBN models with asynchronous updates[9], or the application of perturbation analysis on connectivity graphs in regulatory network models to help simplify such graphs and their Boolean rules/functions.
Funding
This research received no external funding.
Acknowledgments
(Pendiente).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RBN | Random Boolean Networks |
| AC | Algorithmic Complexity |
| CTM | Coding Theorem Method |
| BDM | Block Decomposition Method |
References
- Kauffman, S. Metabolic stability and epigenesis in randomly constructed genetic nets. Journal of Theoretical Biology 1969, 22, 437–467. [Google Scholar] [CrossRef] [PubMed]
- Glass, L.; Kauffman, S.A. The logical analysis of continuous, non-linear biochemical control networks. Journal of Theoretical Biology 1973, 39, 103–129. [Google Scholar] [CrossRef] [PubMed]
- Thomas, R. Boolean formalization of genetic control circuits. Journal of Theoretical Biology 1973, 42, 563–585. [Google Scholar] [CrossRef] [PubMed]
- Fauré, A.; Naldi, A.; Chaouiya, C.; Thieffry, D. Dynamical analysis of a generic Boolean model for the control of the mammalian cell cycle. Bioinformatics 2006, 22, e124–e131, [https://academic.oup.com/bioinformatics/article-pdf/22/14/e124/48839020/bioinformatics_22_14_e124.pdf]. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Assmann, S.; Albert, R. Predicting essential components of signal transduction networks: A dynamic model of guard cell abscisic acid signaling. PLoS biology 2006, 4, 1732–1748. [Google Scholar] [CrossRef] [PubMed]
- Thakar, J.; Parette, M.; Kirimanjeswara, G.; Harvill, E.; Albert, R. Modeling Systems-Level Regulation of Host Immune Responses. PLoS computational biology 2007, 3, e109. [Google Scholar] [CrossRef] [PubMed]
- Veliz-Cuba, A.; Stigler, B. Boolean models can explain bistability in the lac operon. Journal of computational biology : a journal of computational molecular cell biology 2011, 18, 783–794. [Google Scholar] [CrossRef] [PubMed]
- Albert, R.; Othmer, H.G. The topology of the regulatory interactions predicts the expression pattern of the segment polarity genes in Drosophila melanogaster. Journal of Theoretical Biology 2003, 223, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Chaves, M.; Albert, R.; Sontag, E.D. Robustness and fragility of Boolean models for genetic regulatory networks. Journal of Theoretical Biology 2005, 235, 431–449. [Google Scholar] [CrossRef] [PubMed]
- Shmulevich, I.; Dougherty, E.R. Probabilistic Boolean Networks; Society for Industrial and Applied Mathematics, 2010; [https://epubs.siam.org/doi/pdf/10.1137/1.9780898717631]. [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. The Bell System Technical Journal 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Stone, J.V. Information Theory: A Tutorial Introduction, 1st ed.; Sebtel Press, 2015.
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Transactions on Information Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Snyder, D. bzip2. https://gitlab.com/bzip2/bzip2/, 2023. Accessed: (, 2023). 21 November.
- Kolmogorov, A.N. Three approaches to the quantitative definition of information *. International Journal of Computer Mathematics 1968, 2, 157–168. [Google Scholar] [CrossRef]
- Chaitin, G.J. On the Length of Programs for Computing Finite Binary Sequences. J. ACM 1966, 13, 547–569. [Google Scholar] [CrossRef]
- Copeland, B. The Essential Turing; Clarendon Press, 2004.
- Solomonoff, R. A formal theory of inductive inference. Part I. Information and Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Levin, L.A. Laws of information conservation and problems of foundation of probability theory. Probl. Peredachi Inf. 1974, 10, 30–35. [Google Scholar]
- Calude, C.; Chaitin, G.; Salomaa, A. Information and Randomness: An Algorithmic Perspective; Monographs in Theoretical Computer Science. An EATCS Series, Springer Berlin Heidelberg, 2013.
- Zenil, H.; Hernández-Orozco, S.; Kiani, N.A.; Soler-Toscano, F.; Rueda-Toicen, A.; Tegnér, J. A Decomposition Method for Global Evaluation of Shannon Entropy and Local Estimations of Algorithmic Complexity. Entropy 2018, 20. [Google Scholar] [CrossRef] [PubMed]
- Delahaye, J.P.; Zenil, H. Numerical evaluation of algorithmic complexity for short strings: A glance into the innermost structure of randomness. Applied Mathematics and Computation 2012, 219, 63–77. [Google Scholar] [CrossRef]
- Soler-Toscano, F.; Zenil, H.; Delahaye, J.P.; Gauvrit, N. Calculating Kolmogorov complexity from the output frequency distributions of small Turing machines. PloS one 2014, 9, e96223. [Google Scholar] [CrossRef] [PubMed]
- Talaga, S. PyBDM: Python interface to the Block Decomposition Method. https://pybdm-docs.readthedocs.io/en/latest/, 2019. Accessed: (February 04, 2024).
- Newman, M. Networks; OUP Oxford, 2018.
Figure 1.
A specific boolean network. Left: connectivity graph with and . Medium: connectivity matrix and truth table. Right: transition diagram between all possible states, constructed from the connectivity matrix and truth table; steady states or atractors are depicted in black.
Figure 1.
A specific boolean network. Left: connectivity graph with and . Medium: connectivity matrix and truth table. Right: transition diagram between all possible states, constructed from the connectivity matrix and truth table; steady states or atractors are depicted in black.
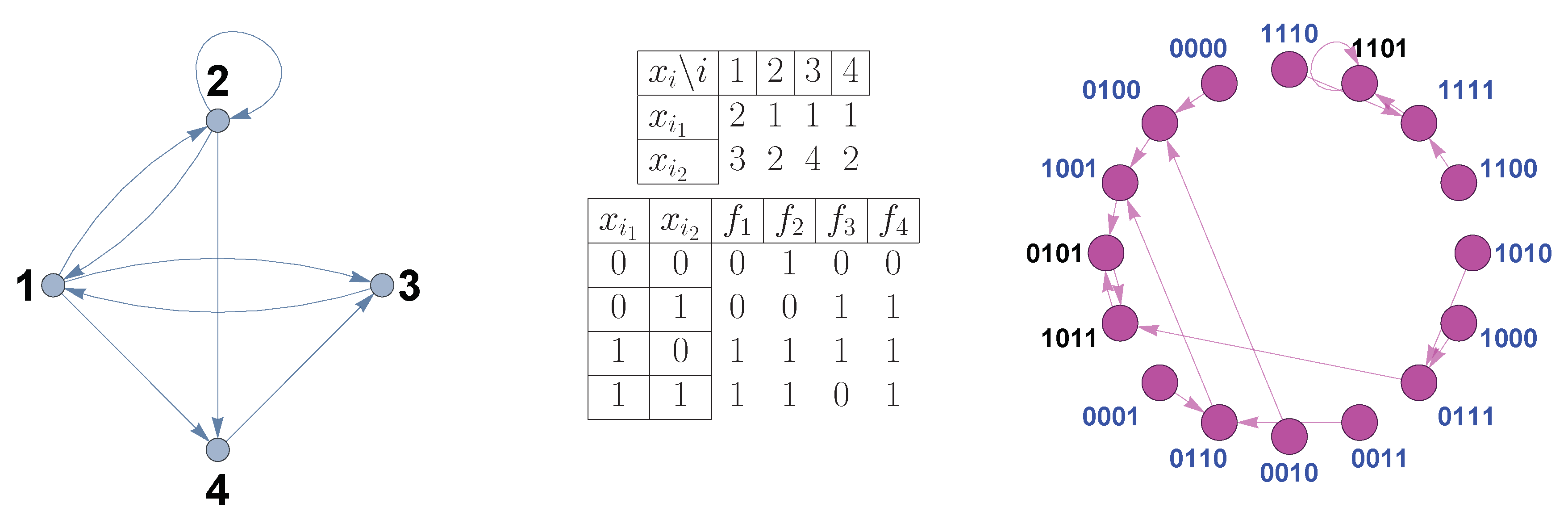
Figure 2.
Time evolution diagrams (top) and their respective state transition graphs (bottom) for some RBNs with nodes and . The RBNs share the same initial state and the same connectivity matrix, both generated randomly from uniform probability distributions.
Figure 2.
Time evolution diagrams (top) and their respective state transition graphs (bottom) for some RBNs with nodes and . The RBNs share the same initial state and the same connectivity matrix, both generated randomly from uniform probability distributions.
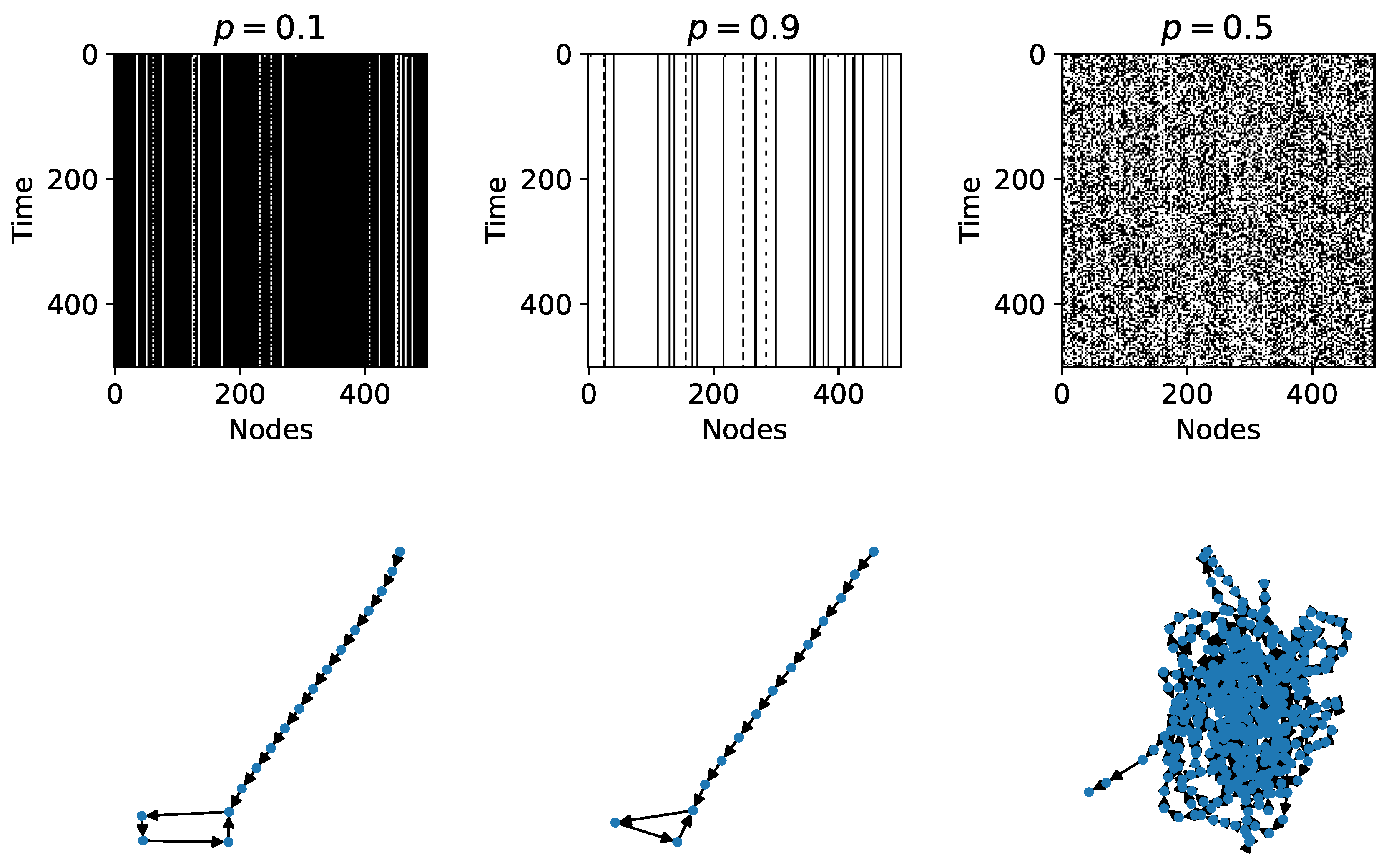
Figure 3.
Top: randomness estimates of RBNs with and as a function of the parameter p. Bottom: estimates of average algorithmic complexity from samples of size 10. Horizontal dotted lines represent the critical values of and at the edge of chaos. All RBNs share the same initial state and the same connectivity matrix, both generated randomly from uniform probability distributions.
Figure 3.
Top: randomness estimates of RBNs with and as a function of the parameter p. Bottom: estimates of average algorithmic complexity from samples of size 10. Horizontal dotted lines represent the critical values of and at the edge of chaos. All RBNs share the same initial state and the same connectivity matrix, both generated randomly from uniform probability distributions.
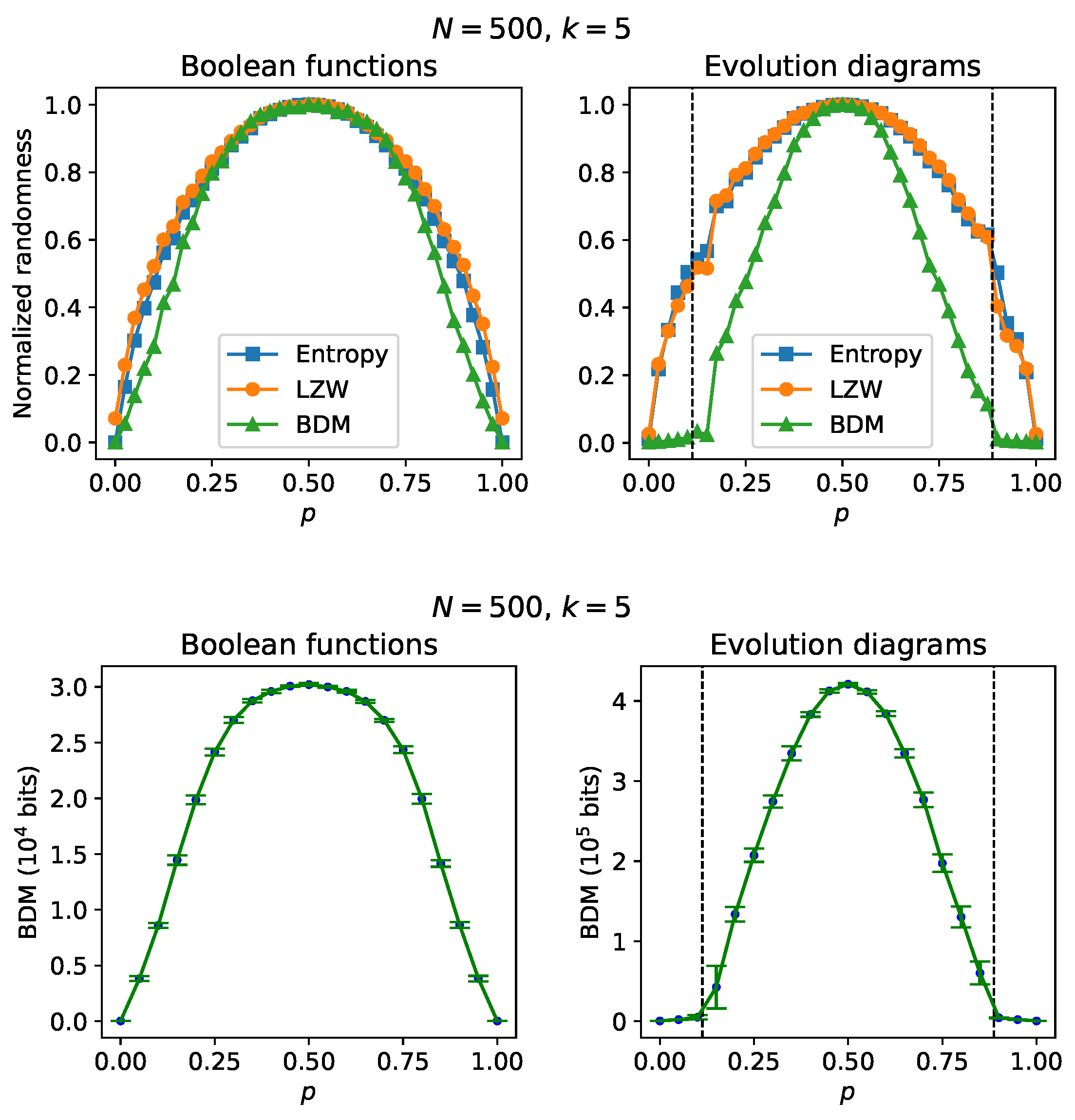
Figure 4.
Parametric plots of time evolution diagram’s BDM vs boolean functions’ BDM. Vertical dotted lines mark the critical p values in each series. All RBNs share the same initial state, and all RBNs for a given in-degree k share the same connectivity matrix; both types of objects were generated randomly from uniform probability distributions.
Figure 4.
Parametric plots of time evolution diagram’s BDM vs boolean functions’ BDM. Vertical dotted lines mark the critical p values in each series. All RBNs share the same initial state, and all RBNs for a given in-degree k share the same connectivity matrix; both types of objects were generated randomly from uniform probability distributions.
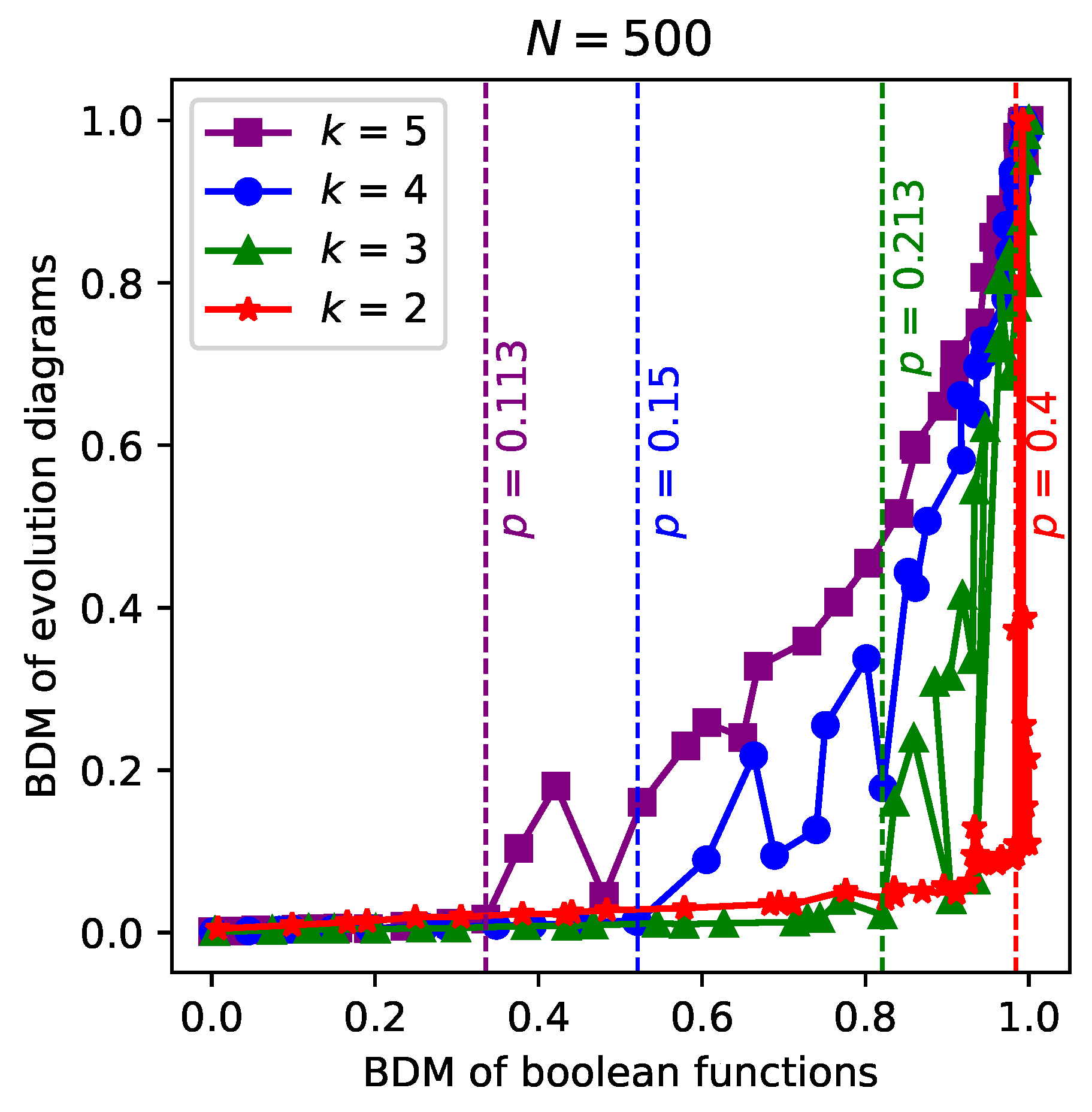
Figure 5.
Transition diagrams for three RBNs with , and , respectively. The color of the nodes denotes their inner eigenvector centrality.
Figure 5.
Transition diagrams for three RBNs with , and , respectively. The color of the nodes denotes their inner eigenvector centrality.
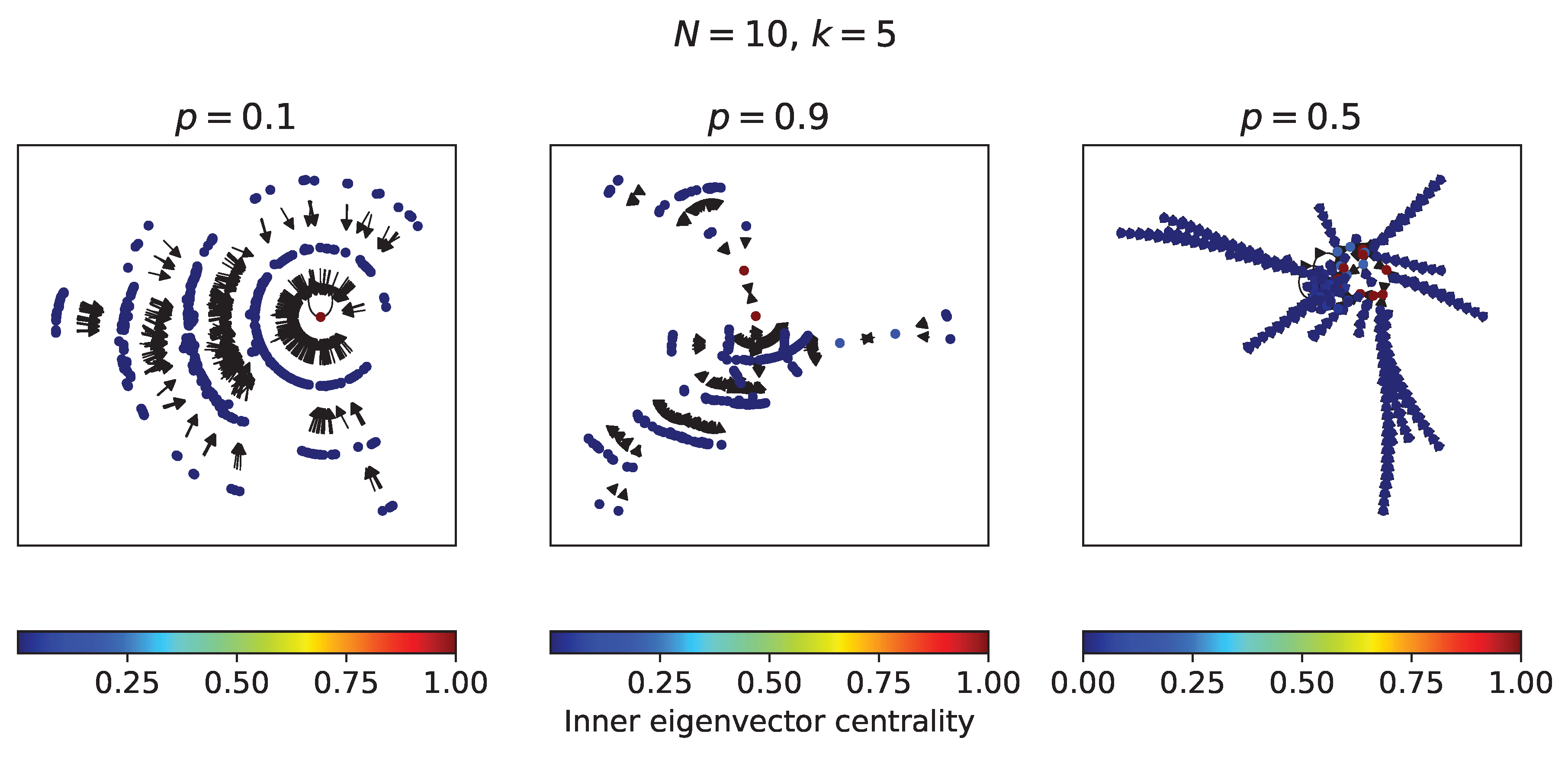
Figure 6.
Effect of perturbations of the transition diagrams from Figure 5 on their randomness measures.
Figure 6.
Effect of perturbations of the transition diagrams from Figure 5 on their randomness measures.
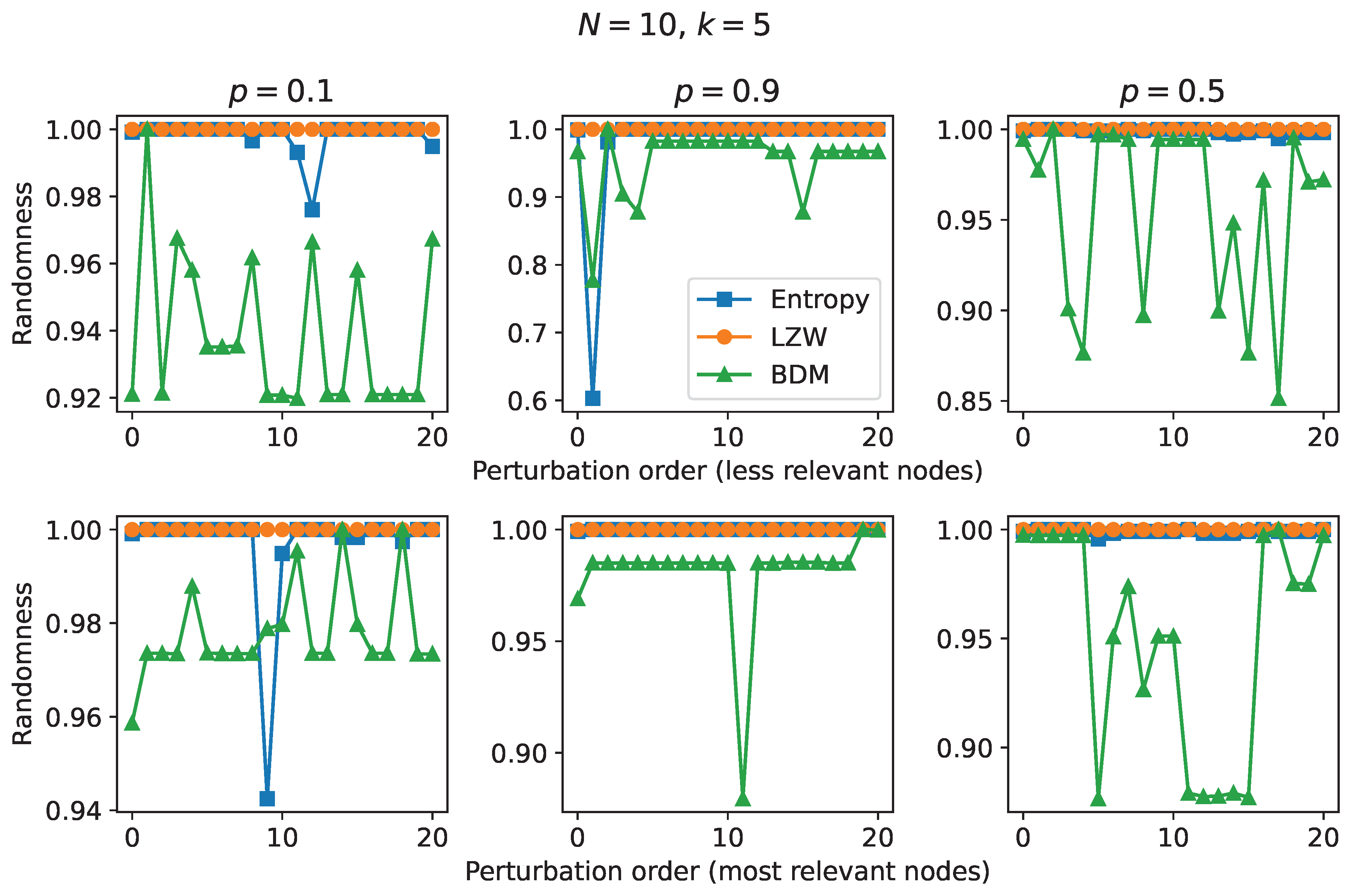

Table 1.
Comparison of critical p values for the RBNs simulated in Figure 4.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



