
Submitted:
05 April 2024
Posted:
08 April 2024
You are already at the latest version
Abstract
Algorithms, indispensable to understand Artificial Intelligence (AI), are omnipresent in social media but users’ understanding of these computational processes and the way they impact their consumption of information is often limited. There is a need for Media and Information Literacy (MIL) research investigating a) how MIL can support Algorithm Literacy (AL) as a subset of competences, and with what working definition, b) what competences users need in order to evaluate algorithms critically and interact with them effectively, and c) how to design learner-centred interventions that foster increased user understanding of algorithms and better response to disinformation spread by such processes. Based on Crossover project research, this paper looks at four scenarios of use by journalists, developers and MIL experts that mirror users’ daily interactions with social media. The results suggest several steps towards integrating AL within MIL goals, while providing a concrete definition of Algorithm-literacy that is experience-based. The competences and design considerations are organised in a conceptual framework thematically derived from the experimentation. This contribution can support AI developers and MIL educators in their co-design of algorithm-literacy interventions and guide future research on AL as part of a set of nested AI literacies within MIL.
Keywords:
Media and Information Literacy
; Algorithm-literacy
; Artificial Intelligence literacy
; competence framework
; course design
; information
; disinformation
1. Introduction
Algorithms, finite sequences of instructions fed to data flows, tend to organise content in order to rank (Google PageRank), to recommend (Facebook Newsfeed, Twitter feeds), to predict (Google auto-complete) and, increasingly, to generate information (via AI Generative systems with large language models trained chatbots like ChatGPT-4 or DALL-E). The providers and platforms use them to tailor content (news, search, advertising…) to their users’ habits, based on their individual and aggregated behavioural data. In doing so, they maximise traffic via engagement and generate revenue and benefits [1]. And users are increasingly perceiving the world online and offline via decisions made by algorithms, be it in their purchase of products, their search for friends and romance or their consumption of news. But they are not fully aware that such decisions may stomp their own agency [2,3].
This structural knowledge gap points to the need for practical solutions, to step up the challenge of algorithm opacity by looking at the end-user (not the producer) and empowering citizens to analyse algorithms critically and creatively, in the hope of bringing insights in their own information consumption [4]. It calls for a bottom-up approach, with more Media and Information Literacy (MIL) strategies adjusted to algorithmic savviness, to make citizens more competent in their uses of online social media and their capacity to fight disinformation [5]. Scaling up citizen’s agency is key to democratic societies capacity to harness the benefits of algorithms, useful as they may be, and downsize their negative effects on information quality, disinformation spread and platform transparency.
Shifting the focus on the end-user, the Crossover project [6], supported by EU funding, brought together developers, fact-checkers, journalists, and experts in MIL (crossover.social). The focus on MIL was conducted with an empirical research design to determine scenarios of use from which to derive competences and design orientations. We first discuss the fit of MIL for AL, by looking at how AL definitions reflect user-centred interests. Then, we describe four scenarios of use to determine the process of developing competences with a comprehensive analysis of their articulation to users’ online search and interactions. Finally, we present a comprehensive framework (via a toolkit) to build up teachers and educators’ confidence with using algorithm-literacy as a sub-field of Media and Information Literacy.
1.1. Algorithm Literacy: A Dimension of MIL Still in Its Infancy
When considering if and how AL can fit within a MIL framework, existing definitions need to be assessed for how they deal with the transdisciplinary dimension of algorithms, beyond maths and computing, towards social sciences, to understand how they affect and impact users’ decision-making processes and overall agency [7]. This perspective places the emphasis on societal issues, such as the attention economy, information quality, disinformation disorders and biases, and eventually, the ethics of it all.
Some definitions come from the field of computing and data management. Computation studies emphasise the users’ ability “to apply strategies that allow them to modify predefined settings in algorithmically curated environments, such as in their social media newsfeeds or search engines, to change algorithms’ outputs, compare the results of different algorithmic decisions, and protect their privacy” [8]. This definition is close to critical data literacy [9] and is more akin to privacy and consumer protection [10,11]. The definitions that emerge from the Artificial Intelligence field are derivative. There, AL consists in the ability “to organise and apply algorithmic curation, control and active practices relevant when managing one’s AI environment” [12]. This definition is attached to management and control.
Other definitions are closer to the field of Media and Information Literacy. One trend emanates from information literacy and library sciences. “Algorithmic literacy — a subset of information literacy, is a critical awareness of what algorithms are, how they interact with human behavioural data in information systems, and an understanding of the social and ethical issues related to their use.” [13]. Another definition, closer to media studies, considers algo-literacy as “the combination of users’ awareness, knowledge, imaginaries, and tactics around algorithms” [14]. This definition is the most user-centric and refers to the experiences of users with algorithms, including the representations in the users’ minds [15].
These definitions seem to be stemming from research on young people and their competences in the face of algorithms. Interviews of young people who played a game prototype designed by the Canadian MediaSmarts’ education team showed that “while youth understand and appreciate the benefits of recommendation algorithms, they are troubled by algorithmic data collection and data sharing practices.” [16]. The research conducted in the Netherlands interviewed young people and showed that they were unaware of the curation and personalization operated by algorithms on their social media uses; or - if aware - did not know what to do about it [14].
Among other researchers, Dogruel, Masur and Joeckel [8] have conducted tests on a competence-based approach, trying to answer the issue of verbalising and evaluating AL. They opted for two cognitive dimensions of algorithm literacy: awareness of algorithm uses and knowledge about algorithms. They found that “the two scales correlated positively with participants’ subjective coding skills and proved to be an appropriate predictor for participants’ handling of algorithmic curation in three test-scenarios.”
Very little research focuses on teachers and their perception of AL. It confirms their urgent need for training and points to major gaps among the teaching body. Educators are very reluctant to include sessions on AL because they lack knowledge and confidence on the topic, because it is not present in curricular design and because they lack teaching guidelines and support from their hierarchy [17,18]. Researchers call for more algorithmic literacy tools and resources to help youth acquire the knowledge they need to protect themselves and their information in digital spaces. Some alert to three methodological challenges for algo-literacy research: “first, the lack of an established baseline about how algorithms operate; second, the opacity of algorithms within everyday media use; and third, limitations in technological vocabularies that hinder young people in articulating their algorithmic encounters.” [14].
The examination of the research on definitions and their implementation points to the fact that research and education on AL is still in its infancy, with knowledge gaps [19] without a consistent set of competences that deal with skills, knowledge, attitudes, and values. It also confirms that AL can be part of MIL, to inform users in their non-technical daily interactions with social media as they affect information consumption and circulation. To address the lack of curricular design, MIL can use the familiarity principle, with true and tried methods to make it less daunting for educators and learners to tackle algorithms since using MIL strategies does not require as huge an effort in training and upskilling as starting from scratch or from STEM —where AL is sometimes part of computing [20].
Accordingly, the working definition adopted for the Crossover project was derived from the key MIL elements of the review of literature. It posited that AL recombined 1/ the users’ awareness and knowledge of representations and tactics around algorithms, with 2/ the users’ explicit and implicit actions to curate content with algorithms and adjust browsing behaviour and ethics. This two-tiered user-centric definition encompassed algorithmic functions and the cultural practices and imaginaries around them. Tying it to actual real-life test-scenarios of use was crucial to identify sense-making practices that incorporated key algorithmic concepts such as ranking, recommending, predicting as well as issues of filtering, curating and attention engineering. The focus was on MIL practitioners (educators and journalists), as being the most likely to apply AL in their interventions and the neediest in terms of competence frameworks and design guidance.
1.2. MIL Methodology, Research Design and Data Collection
To bring together users’ algorithmic awareness and users’ curating behaviour, the MIL theory used was transliteracy as it considers the multi-level understanding of information as news, documents and data [21]. Transliteracy theory takes into account the “1) the multi-media dimensions of current literacy —being able to read, write, count and compute with print and digital tools and via all sorts of formats from book to blog; 2) the trans-domain requirements for digitally sustainable literacy —being able to code and to search, test, validate, modify information as understood in computation (data), in communication (news) and in library science (documents)” [15,21,22].
Based on transliteracy theory, the Crossover project looked both at the multi-media dimension (across social media channels, mass media and print) and the trans-domain dimension (from data to news to documents). It was based on several steps: real life inquiries conducted by two fact-checking entities, Checkfirst and Disinfolab.eu; news stories derived from the inquiries and printed by one newspaper, Apache.be; debriefing podcasts dissected with MIL experts. It involved the appropriation by developers, fact-checkers, journalists and MIL experts of a smart innovative tool, the Dashboard, and its attendant “user-meters” since an autonomous system of mini-computers was placed in the homes of 9 users (dispersed over Belgium) to simulate their online behaviour.
The Dashboard was designed to understand the functioning of algorithms, from a user perspective. Hence the double approach conducted by Checkfirst: using the APIs that were made available by the platforms, to query and monitor different search engines and social media (Google, YouTube, Facebook, Twitter, Odysee, Reddit and Mastodon), and placing an autonomous robot that made requests on the platforms from the homes of various users (see Figure 1). This double approach made it possible not to be dependent on the platforms to provide data, but also to compare the data they officially provided with the concrete experience of the users. Thus, the influence of algorithms on users’ consumption of news was made apparent, especially as specific topics were investigated by journalists trained to use the Dashboard.
The Crossover Dashboard tool 1/ afforded measures in real time about the influence of recommendation algorithms on social media and search engines, 2/ detected potential disinformation campaigns, 3/ was used for online and field investigations, and 4/ took into account users with a unique system of at-home monitoring (see Figure 2).
For the data collection, the method adopted was by scenario of use [23]. Scenarios of use are especially efficient in an empirical and experimental approach because they enable descriptions of users’ interactions with a system (here the online platforms) while achieving a goal (here algorithmic trends in news) under specified conditions (the dashboard and its constraints and affordances). They thus provide insights into their process and yield information about the context in which the system operates, from the perspective of the user, in a task-oriented way as close to their practice as possible [24].
This method made it possible to mimic the two levels of interaction with algorithms: what the platforms provide the users and the concrete experience of the users. It also allowed all participants in the project to gather evidence of algorithmic activity (almost as forensics) and then use it to make real life investigations. The fact-checking and journalistic activity was then processed to fit a needs-based approach for teachers and educators. A comprehensive MIL framework, the MIL “Debunking kit” to tackle AL, was produced to build on this empirical approach, as the four scenarios of use for journalists mimicked and mirrored the algorithmic uses of a larger audience.
Four inquests and attendant news stories were followed, from beginning to end, and they were “debriefed” in four podcasts that involved all actors (developers, fact-checkers, journalists and MIL experts). The podcast editorial lines for the four inquests followed a similar pattern, to drive the sense of the digital factory of evidence-based actions of algorithms on the access, search and curation of information (and, incidentally, disinformation).
- (1)
- The initial inquest: the online “trending” information of the moment
- (2)
- The Apache.be investigation and new story
- (3)
- A zoom on a search scenario of use with the Dashboard
- (4)
- An explanation of a key algorithmic notion
- (5)
- The resolution: the disinformation risk avoided/dealt with
- (6)
- The MIL solutions and competences called for.
The experiment used a mixed method of competences and experiences, to tap directly on the participants’ everyday experiences with algorithms, building on their shock and surprise with faulty results and predictions. The podcasts were a way of eliciting conversations and insights on how algorithms work behind the scenes, without accepting the “black box” metaphor [10,25,26]. The themes that emerged (war, disinformation…) were likely to act at two levels: arousing curiosity (or shock) about algorithms and their hidden role AND motivating users to change behaviour and take action. From these authentic experiences, awareness of mechanisms at work and competences, interactive quizzes were derived to build a knowledge base and modular pedagogical pathways were suggested for the MIL educators.
This method was construed in accordance with MIL pedagogical design principles [27,28]. The general objective was to facilitate the appropriation of a holistic pedagogical strategy by practitioners, which implied:
- -
- A modular approach (stories, podcasts, quizzes) to allow for a variety of entries for practitioners and educators,
- -
- Authentic documents and examples to remain as close as possible to users’ experiences and societal issues,
- -
- A competence-based framework with verbalised notions and actions to stimulate critical thinking and foster civic actions,
- -
- A multi-stakeholder strategy that shows the perspectives of the different actors involved in understanding algorithms and in the co-design of MIL interventions (developers, journalists, experts).
3. Results
3.1. The MIL Algorithm-Literacy Matrix of Scenarios of Use
Overall, the scenarios of use, as reflected in the podcasts, mimicked four major information search strategies: by notional keywords, by communities of affinity, by influencer accounts, by tool affordances, as the Dashboard became more and more agile as its database increased (see Table 1). This implied being able to navigate across social media, mass media and print channels and to validate and modify information across domains (from data to news to documents), as suggested by transliteracy theory. It was thus possible to develop a trajectory for users, from online source to data traces to evidence-building in real life circumstances.
In the process, the scenarios of use provided insights on three major roles of algorithms (ranking, recommending and predicting), in a task-oriented way. This did not so much increase the transparency of algorithms than transparency in their uses, eliciting the notion that if they cannot be modified, it is nonetheless possible to modify their uses and practices. The initial focus on information (rather than disinformation) was equally rewarding, as it became apparent that the point was not to stop algorithms but to stop the amplification of disinformation, thus raising ethical issues among the users.
The revelations of the inquests showed the actual workings of the algorithms, at the users’ end (not the API end of the platforms) and as a consequence, the competences mobilised, and the societal issues addressed. The first two podcasts laid the stress on the investigative and search dimensions of the strategies while the last two podcasts also added a reflexive dimension, as journalists, fact-checkers, developers and MIL experts objectified their practices.
- Scenario 1, “the keyboard fighters”, showed the mismatch between the online calls for action and real-life mobilisations as the “liberty convoy” threats, that seemed threatening online, turned out to be insubstantial in real life. The role of algorithmic ranking was thus debunked in relation to user search. The MIL lesson drawn was that disinformation did not always work and had to be verified by facts (See podcast 1).
- Scenario 2, “algorithms and propaganda: dangerous liaisons”, revealed how algorithms tended to promote state propaganda: as Russia Today was banned by the European decision (due to the war in Ukraine), algorithms recommended a new state-controlled media, CGTN, the state channel of the Chinese Communist Party, that relayed Russian propaganda. The role of algorithmic recommendation was thus exposed in relation to user engagement. The MIL lesson drawn was that disinformation was amplified along polarised lines (See podcast 2).
- Scenario 3, “how algorithms changed my life”, unveiled how conspiracy theories circulated on influential accounts, in “censorship free” and unmoderated networks like Odysee. It followed an influencer, the extreme right political personality Dries Van Langenhove, who called for racism, violence and anti-covid stances. The role of algorithmic recommendation was thus unveiled in relation to user echo chambers. The MIL lesson drawn was that information diversity was key to avoid being caught in the rabbit holes of the attention economy (See podcast 3).
- Scenario 4, “the algorithm watchers”, demonstrated how Google auto-complete systematically offered users the Donbass Insider recommendation when they typed Donbass in their search bar, across all people user-meters. Donbass Insider relayed Russian false messages about the war in Ukraine and was linked to Christelle Néant, a Franco-Russian pro-Kremlin blogger and self-styled journalist. The role of algorithmic prediction was revealed in relation to user interactions with the tool affordances. The MIL lesson drawn was that queries and prompts can lead to automated bias and manipulation (See podcast 4).
The scenarios of use method confirmed its efficiency in describing user interactions with the various social media and online platforms and in unveiling the role of algorithms in their interplay with information and user engagement. They provided insights on the workings of such systems, yielding some surprises and undermining some “faulty” early hypotheses and predictions, as the developers, fact-checkers and journalists followed through with their real-life inquests. This task-oriented perspective, close to their everyday practice, was further elicited in the conversations held in the podcasts, with the MIL experts, especially the last two that were focused on how algorithms changed their working strategies.
The scenarios of use also indicated a shift in the modes of conducting information search, in particular in relation to sources and evidence-building. The users are no longer dealing with secret or opaque sources but with contingent, voluminous amounts of data that require interpretation, with the help of specific tools and with an awareness of how algorithms work. This shift was made visible by the journalists involved in project Crossover, who equated it to a form of “forensics”, that required a different way of conceptualising inquiry (podcast 4). They saw a positive use of algorithms as an “early signal” of phenomena that might develop and that are worth monitoring and pursuing (podcast 3). They described a kind of algo-journalism, focused on demand, riding the algorithms with a two-step process: online trends detection followed by selection of topics that are worth delving into. This algo-journalism “includes sorting information, reviewing it, presenting it visually or even using robots to write articles… And we almost systematically use algorithms with artificial intelligence to process all that” (podcast 3).
To a larger extent, the scenarios of use also made visible the engineering of attention, via algorithms. The topics that were chosen for inquiry, pushed by algorithms, revealed how much this attention is based on emotions, especially fear, that generates traffic, even if this traffic is based on propaganda, bias or manipulation (podcast 2). The intricate patterns between engagement and recommendation are particularly telling about how participation, presented as a positive attitude online, can be weaponized to bend offline attitudes (podcast 2), though not always meeting with success (podcast 1).
Finally, the scenarios of use also pointed to the possibility of new mediations: journalists, developers, and MIL experts came together in engaging collaborative work. The dashboard was improved in an agile method as the various inquests led to new strategies, akin to pre-bunking, befitting their fact-checking mission (podcasts 3 and 4). The dashboard introduced a tooled mediation as well, that could offer a counter-balance to the algorithmic mediation as captured by the major online platforms (Google and Meta in particular).
3.2. MIL AL-Competence Framework
The scenarios of use enabled the MIL experts to derive a number of valuable “lessons learnt”. They made it possible to understand how the actions online (such as queries and prompts) were algorithmically conditioned to shape access to information and individualisation of results and outcomes (as verified by the user-meters vs the APIs analysis). They made it possible to combine awareness of processes and knowledge about functions, in particular ranking, recommending and predicting. They could thus derive the competences required for users to deal with algorithms in their daily practices.
More importantly, some meta-competences appeared together with specific micro-competences. They could point to strategies and solutions at the individual and collective level. The interest of considering developments in journalism (media), with the description of platform algorithmic applications (data) in order to consider the results yielded (documents) confirmed the usefulness of transliteracy theory for embedding Algorithm literacy in Media and Information Literacy (see last section in podcasts 1, 2, 3 and 4).
For media, the meta competence was related to the understanding of the context of production and distribution of algorithms and the cultural and societal implications. The ensuing micro-competences were distributed along areas related to knowledge, skills, attitudes and values:
- -
- Know the new context of news production and amplification via algorithms
- -
- Pay attention to emotions and how they are stirred by sensationalist contents and take a step back from “hot” news,
- -
- Be suspicious and aware of “weak signals” for disinformation (lack of traffic on some accounts, except for some divisive topics; very little activity among and across followers on a so-called popular website or community, …)
- -
- Fight confirmation biases and other cognitive biases
For documents, the meta competence was related to the mastery of information search and platform navigation, in particular the controlled and diversified use of sources as pushed by algorithms. The ensuing micro-competences were distributed along areas related to knowledge, skills, attitudes and values:
- -
- Vary sources of information
- -
- Be vigilant about divisive issues where opinion dominates and facts and sources are not presented
- -
- Modify social media uses to avoid filter bubbles and (unsolicited) echo chambers
- -
- Set limits to tracking so as to reduce targeting (as less data are collected from your devices)
- -
- Deactivate some functionalities regularly and set the parameters of your accounts
- -
- Browse anonymously (use VPNs)
For data, the meta competence was related to the control or oversight of algorithmic patterns, in particular for the sake of transparency and accountability. The ensuing micro-competences were distributed along areas related to knowledge, skills, attitudes and values:
- -
- Decipher algorithms, their biases and platform responsibility
- -
- “Ride” algorithms for specific purposes
- -
- Pay attention to RGPD and platform loyalty to data protection
- -
- Mobilise for more transparency and accountability about their impact
- -
- Require social networks to delete fake news accounts, to ban toxic personalities, to moderate contents
- -
- Encourage the creation of information verification sites and use them
- -
- Use technical fact checking tools like the Dashboard or InVID-Weverify
- -
- Signal or report to platforms or web managers if misuses are detected
- -
- Comment and/or rectify “fake news”, whenever possible
- -
- Alert fact checkers, journalists or the community of affinity
The MIL experts deemed it important to emphasise user agency and reactivity by adding explicit and implicit actions to curate algorithms and adjust browsing behaviour, as evidenced in Crossover project. They were intent on elucidating the mechanics of algorithms as well as the processes at stake to make it possible to prevent algorithmic risks as well as empower users to ride algorithms for their own information consumption.
3.3. The Knowledge Base with Pedagogical Pathways and Design Considerations
The competences domains and attendant micro-competences were picked up in the interactive quizzes and their accompanying documents. The four interactive quizzes offered many options like “drag and drop”, “fill in the blanks”, etc. They could be played as standalone (by youth and adults) or associated with the podcasts (see Table 3 and Table 4).
Quiz 1 was derived from the scenario of use 1 and podcast 1.
Apart from understanding how algorithms work, understanding the economic and geopolitical models behind them, and using your critical thinking skills wisely (without becoming paranoid), you can build some strategies to control your information better. Here is a list of reasonable goals if you want to reduce the influence of algorithms on your information. It's up to you to find the solution that goes with it!
Quiz 2 was derived from the scenario of use 2 and podcast 2.
The four pedagogical pathways showed educators how to use the quizzes in class while reinforcing their knowledge base. They suggested activities and workshops for interactions with young people, including how to use the Dashboard (pedagogical document 4). The full “Algo-literacy Prebunking toolkit” [29] also summarized the whole experiment with a poster, downloadable for educators and the general public, to be used in all kinds of workshops, entitled “Algo-literacy for all in 10 key points” (https://savoirdevenir.net/crossover/).
Figure 3.
Algo-literacy for all in 10 key points. (https://crossover.social/algo-literacy-for-all-in-10-points/).
Figure 3.
Algo-literacy for all in 10 key points. (https://crossover.social/algo-literacy-for-all-in-10-points/).

The full “prebunking toolkit” was put together according to MIL design principles, in particular modularity, authenticity of documents, competence-based framework and tool embedded in multi-stakeholder activity in order to understand information and disinformation [27]. The accompanying document, with teaching guidelines, were meant to entice educators in engaging with MIL literacy, so that they could overcome their lack of knowledge and confidence on the topic [17]. The prebunking notion [30,31] seemed fit to be introduced at the end of the process, in terms of helping users anticipate the role of algorithms by preparation and education as the best filter against disinformation. The point was to create new heuristics and a kind of educational preparedness that could be pedagogically sustainable, especially if taken in a larger MIL design that encompassed the societal and cultural context [32].
4. Discussion
Implementing scenarios of use was an effective method for addressing the main goals of project Crossover in terms of Media and Information Literacy. It made it possible to make visible some of the workings of algorithms, to clarify the interconnections between AL and MIL, and to test the working definition. It allowed the construction of a competence framework based on the felt experience of users and provided modular elements to design MIL interventions derived from experimentation.
4.1. Understanding Opacity
The four inquests yielded insights on algorithms that went beyond the “black box” metaphor [19,33],providing an “understanding of opacity” [34]. The analysis of traces left during the search process made it possible to infer a number of actions by algorithms that confirmed the initial hypotheses made by the developers and journalists. These authentic inquests participated in the empowerment of users by revealing and providing “evidence” of the action of algorithms in everyday life, in the sense of making visible and providing proof [35]. This also emphasised the multi-stakeholder benefits of editorial collaboration and technical experimentation with a tool that was co-designed by all actors.
Using the experiences of developers and journalists has proved useful, as their everyday encounters with algorithms elicited unexpected outputs around real life cases and enquiries [15]. Creating surprise or concern with faulty results and predictions can invite conversations and reflections on how algorithms work behind the scenes. Creating situations that elicit exchanges and co-learning can be achieved around themes that are likely to bring out the hidden role of algorithms, arousing curiosity or concern, and motivating users to change behaviour and take measures to counteract them. This approach goes beyond “coping” [8], to encourage users to be critically aware of their online surroundings and to be active in their responses against disinformation as conveyed by algorithms.
In terms of transliteracy theory, the added insight was that what happens inside the system “black box” does not determine the whole of the process, especially when it comes to information search and curation [25]. The users do not need to know the full architecture of algorithms as developed by the platforms to understand its mechanics, especially in terms of outputs and services in their everyday life. However, the users do need to know how some basic functions (ranking, recommending, predicting) can affect their actions and the consequences algorithms might have in real life, for their civic engagement and consumption of news for instance. This is where interacting with the affordances of a tool like the Dashboard can provide some computational thinking that makes sense of the technology, its affordances, and its dependencies.
4.2. Confirming the Definition of Algorithm Literacy
The initial two-tiered user-centric definition encompassed algorithmic functions and the cultural practices and imaginaries around them, which was confirmed throughout the experimentation. The distinction between awareness and knowledge [8] established in the first tier of the definition was validated by confronting representations with tactical real-life results. The actions of curation and engagement established in the second tier were also validated by a pragmatic, task-driven posture, in a logic of prevention and prebunking [30].
This definition proposed a functional and operational algorithm literacy for societal and cultural engagement [7]. As such, it incorporated the complex imbrication of transliteracy [21,22]: it fostered critical thinking about the level of multi-media services provided by algorithms (their functionalities, their finalities) and about the level of transdomain reach of algorithms (their impact on information access, search and curation).
This definition also addressed the old MIL conundrum about “the technicist trap” [36], eschewing the tool dependency bias that comes from using media and other smart devices like the Dashboard. The trap was avoided by incorporating design principles from MIL and information and communications sciences, like verification processes or disinformation detection [17,37], with authentic cases where the tool is embedded in a larger contextual setting. The engineering dimension of algorithms was made explicit and explainable, the Dashboard becoming a kind of pedagogical tool that enabled demonstrations of how to get specific results from the codes and data [38]. Understanding the mechanics of algorithms makes it possible to embrace all the stakes of information circulation and consumption, not just the disinformation risks and biases. The four scenarios of use evinced the need for a modicum of technical skills, as journalists and developers had to revisit their professional practices, including their experiences of algorithms, towards “algo-journalism” (podcasts 3 and 4).
4.3. Fine-Tuning the Competence Framework with MIL Design
Developing algorithmic literacy implied to mesh tactical experiences and active competences to deal with curated online environments. The competence framework articulated explicitly the transliteracy domains for algorithm literacy. It mixed cultural and communication competences (media literacy), organisational and search competences (information literacy) and operational and problem-solving competences (data literacy). The final framework showed the overlaps with Media and Information Literacy and the specificities of algorithm-literacy was key (see Table 5). This competence-based approach indicated how algorithmic literacy could be integrated within a MIL design and curriculum, rather than seen as a separate literacy, following the familiarity principle that could bring adoption and implementation among teachers and educators [20].
Becoming savvy in algorithm-literacy can encompass different types of behaviours: detecting disinformation; verifying content; disclosing/exposing the results of search; responding/refuting the outcomes; asking for transparency and accountability from platforms and services. It implies supporting a certain number of values, traditionally fostered by MIL, such as information integrity, quality data, freedom of expression and media pluralism and diversity. It also suggests solutions that are personal (building resilience) and collective (building resistance). Beyond coping, users need to engage actively with their online surroundings, in particular to address platform developers and policy makers [1,39].
The development of algorithmic literacy thus enlarges the users' understanding of the digital culture in which they are immersed, as a technical culture and a culture based on the economy of attention, —a misnomer for systemic inattention. Such a literacy needs to be part of basic literacy curricula for citizens’ empowerment, as they need to acquire the individual capacities and collective processes to resist algorithmic logics and mechanics when they pose a threat to information and weaponize disinformation. Confronting issues such as “transparency” and “accountability” cannot be achieved without a critical citizenship force [40,41].
5. Conclusions
The research finally provided insights on how algorithm literacy, embedded in MIL, could open new perspectives on user agency. The four scenarios of use showed the workings of algorithms from the inside of the black box, to expose the processes that lead to specific search results in real life. Such scenarios could be extended to other fields than media, that are structuring our relations to reality via digital platforms, such as the algorithms of tax administration, of dating services, of streaming movie recommendation, etc. They imply the rise in competences of a number of societal actors, like journalists, developers, fact-checkers, MIL experts and researchers, in order to forestall the platform infomediaries interests in maintaining algorithm opacity over their commercial services. This connects algorithm literacy to crucial democratic goals, as the stakes ultimately are to preserve the citizens’ rights to access information and make decisions away from bias, disinformation and manipulation.
References
- European commission, DG-Connect (2018). A multi-dimensional approach to disinformation - Report of the independent High level Group on fake news and online disinformation. Publications Office of the European Union. https://digital-strategy.ec.europa.eu/en/library/final-report-high-level-expert-group-fake-news-and-online-disinformation.
- Seaver, N. (2019). Captivating Algorithms: Recommender Systems as Traps. Journal of Material Culture, 24(4), 421-436. [CrossRef]
- Dogruel, L., Facciorusso, D., & Stark, B. (2020). ‘I’m still the master of the machine.’ Internet users’ awareness of algorithmic decision-making and their perception of its effect on their autonomy. Special Issue of Digital Communication Research. Information, Communication & Society, 25:9, 1311-1332. [CrossRef]
- boyd, d. , Crawford, K. (2012). Critical questions for big data: provocations for a cultural, technological, and scholarly phenomenon, Information, Communication & Society, 15 (5), 662-679. [CrossRef]
- Hill, J. (2022), "Policy responses to false and misleading digital content : A snapshot of children’s media literacy", Documents de travail de l'OCDE sur l'éducation, 275, Éditions OCDE. [CrossRef]
- Crossover Project (2021-22). https://crossover.social.
- Beer, D. (2017). The social power of algorithms. Information, Communication & Society, 20(1), 1-13. [CrossRef]
- Dogruel, L. Masur, P. and Joeckel, S. (2022) Development and Validation of an Algorithm Literacy Scale for Internet Users, Communication Methods and Measures, 16 (2), 115-133. [CrossRef]
- Cotter, K. M. (2020). Critical algorithmic literacy: Power, epistemology, and platforms [Dissertation]. Michigan State University, Michigan. https://search.proquest.com/openview/3d5766d511ea8a1ffe54c53011acf4f2/1?pq-origsite=gscholar&cbl=18750&diss=y.
- Nguyen, D. and Beijnon, B. (2023): The data subject and the myth of the ‘black box’ data communication and critical data literacy as a resistant practice to platform exploitation, Information, Communication & Society, 27 (2), 333-349. [CrossRef]
- Matthews, P. (2016) Data literacy conceptions, community capabilities. The Journal of Community Informatics, 12 (3). [CrossRef]
- Shin, D. Rasul, A. and Fotiadis, A. (2022), "Why am I seeing this? Deconstructing algorithm literacy through the lens of users", Internet Research, Vol. 32 No. 4, pp. 1214-1234. [CrossRef]
- Head, A. Fister, B. and MacMillan, M. (2020). Information literacy in the age of algorithms. https://projectinfolit.org/pubs/algorithm-study/pil_algorithm-study_2020-01-15.pdf.
- Swart, J. (2021). Experiencing Algorithms: How Young People Understand, Feel About, and Engage With Algorithmic News Selection on Social Media. Social Media + Society, 7(2). [CrossRef]
- Bucher, T. (2017). The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1), 30-44. [CrossRef]
- Brisson-Boivin, Kara and Samantha McAleese. (2021). Algorithmic Awareness: Conversations with Young Canadians about Artificial Intelligence and Privacy. MediaSmarts. Ottawa. https://mediasmarts.ca/sites/default/files/publication-report/full/report_algorithmic_awareness.pdf.
- Nygren, T. Frau-Meigs, D, Corbu, N and Santoval, S. (2022). Teachers’ views on disinformation and media literacy supported by a tool designed for professional fact-checkers: perspectives from France, Romania, Spain and Sweden, SN Soc Sci 2:40. [CrossRef]
- Moylan, R. and Code J. (2023) Algorithmic futures: an analysis of teacher professional digital competence frameworks through an algorithm literacy lens, Teachers and Teaching, Theory and practice. [CrossRef]
- Cotter, K. et Reisdorf, B. C. (2020). Algorithmic Knowledge Gaps: A New Horizon of (Digital) Inequality. International Journal of Communication, 14, 745-765. https://ijoc.org/index.php/ijoc/article/view/12450.
- Frau-Meigs, D. (2024). User empowerment through media and information literacy responses to the evolution of generative artificial intelligence (GAI). UNESCO. https://unesdoc.unesco.org/ark:/48223/pf0000388547.
- Frau-Meigs, Divina (2012). Transliteracy as the new research horizon for media and information literacy. Media Studies, 3(6). https://hrcak.srce.hr/ojs/index.php/medijske-studije/article/view/6064.
- Frau-Meigs, D. (2022a). Transliteracy and the digital media: Theorizing Media and Information Literacy, In: International Encyclopedia of Education (4th Edition) Robert Tierney, Fazal Rizvi and Kadriye Ercikan (eds). Elsevier.
- Carroll, J. M. (2000). Making use: Scenario-based design of human-computer interactions. The MIT Press.
- Alexander, I. F. , & Maiden, N., (Eds.) (2004). Scenarios, stories, use cases through the systems development life cycle. Wiley.
- Hargittai, E. , Gruber, J., Djukaric, T., Fuchs, J. et Brombach, L. (2020). Black box measures? How to study people’s algorithm skills. Information, Communication & Society, 23(5), 764-775. [CrossRef]
- Lloyd, A. (2019). Chasing Frankenstein’s Monster: Information literacy in the black box society. Journal of Documentation, 75(6), 1475-1485. [CrossRef]
- Frau-Meigs, D. and Corbu, N. (eds.) (2024). Disinformation Debunked: MIL to build online resilience. Routledge.
- Potter, W. J., & Thai, C. L. (2019). Reviewing media literacy intervention studies for validity. Review of Communication Research, 7, 38–66. [CrossRef]
- Savoir Devenir, Algo-literacy Prebunking kit (2022). https://savoirdevenir.net/wp-content/uploads/2023/03/PREBUNKING-KIT-ENG.pdf.
- Kahne, J., Hodgin, E., & Eidman-Aadahl, E. (2016). Redesigning civic education for the digital age: Participatory politics and the pursuit of democratic engagement. Theory & Research in Social Education, 44 (1), 1-35. [CrossRef]
- McGrew, S., Breakstone, J., Ortega, T., Smith M. and Wineburg, S. (2018). Can Students Evaluate Online Sources? Learning From Assessments of Civic Online Reasoning. Theory & Research in Social Education, 46(2), 165-193. [CrossRef]
- Frau-Meigs, D. (2022b). How Disinformation Reshaped the Relationship between Journalism and Media and Information Literacy (MIL): Old and New Perspectives Revisited, Digital Journalism, 10 (5), 912-922. [CrossRef]
- Pasquale, F. (2015). The Black Box Society. The Secret Algorithms That Control Money and Information. Harvard UP.
- Burrell, J. (2016). How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data & Society, 3(1). [CrossRef]
- Le Deuff, O. and Roumanos, R (2021). Enjeux définitionnels et scientifiques de la littératie algorithmique : entre mécanologie et rétro-ingénierie documentaire », tic&société 15 (2-3). [CrossRef]
- Masterman, L. (1985). Teaching the media. Routledge. [CrossRef]
- Wineburg S, and McGrew, S. ( 2019). Lateral Reading and the Nature of Expertise: Reading Less and Learning More When Evaluating Digital Information. Teachers college Record 121 (22), 1-40. [CrossRef]
- Rieder, B. (2020). Engines of Order: A Mechanology of Algorithmic Techniques. Amsterdam University Press.
- European Commission, DG-EAC (2022). Guidelines for teachers and educators on tackling disinformation and promoting digital literacy through education and training. Publications Office of the European Union.
- Kemper, J., & Kolkman, D. (2018). Transparent to whom? No algorithmic accountability without a critical audience. Information, Communication & Society, 19(4), 1–16. [CrossRef]
- Kitchin, R. (2017). Thinking critically about and researching algorithms. Information, Communication & Society, 20(1), 14–29. [CrossRef]
Figure 1.
Data collection strategy, using two types of sources (API and user-meter). https://crossover.social/methodology/.
Figure 1.
Data collection strategy, using two types of sources (API and user-meter). https://crossover.social/methodology/.
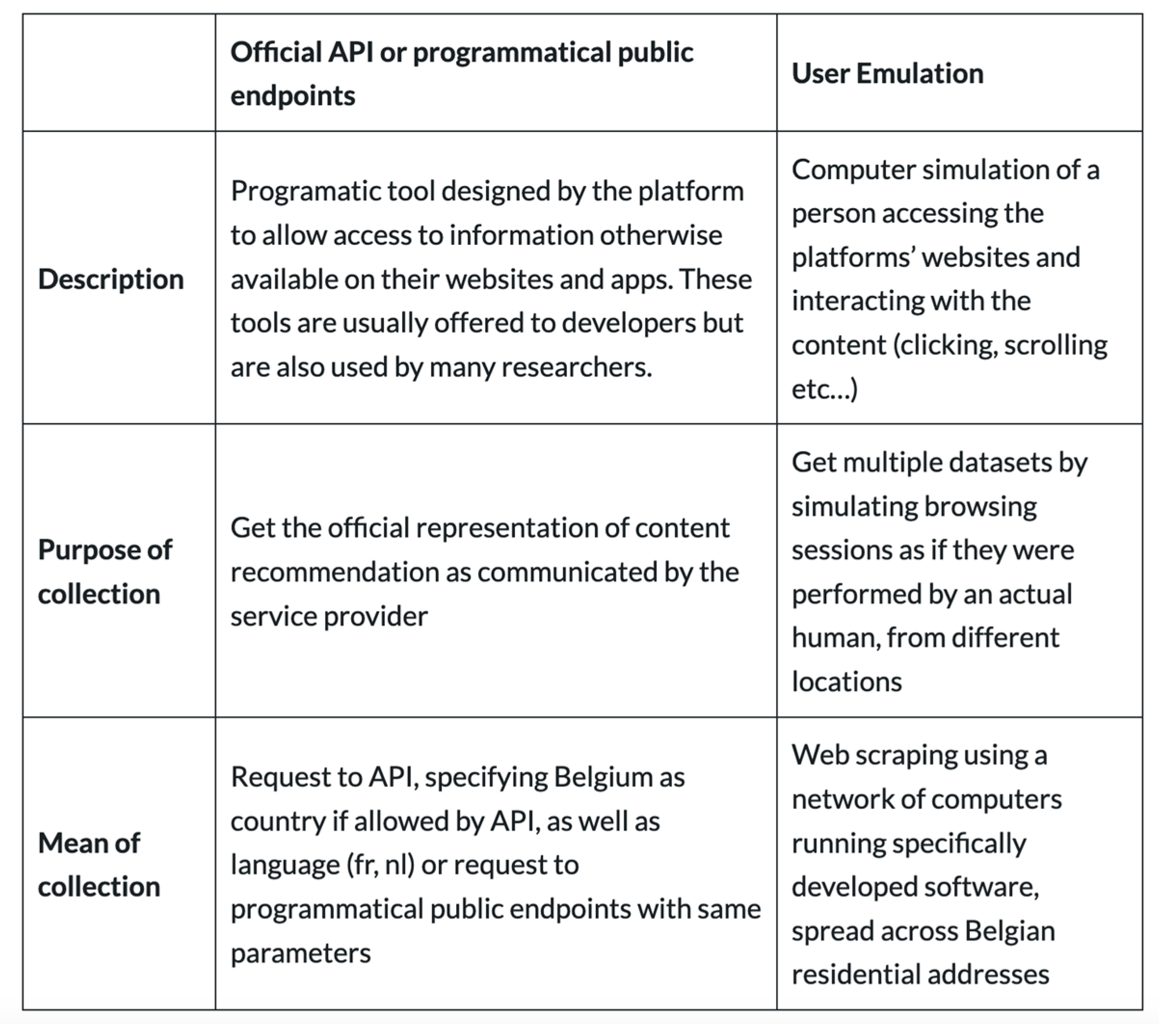
Figure 2.
Dashboard of YouTube. https://crossover.social/methodology/.
Figure 2.
Dashboard of YouTube. https://crossover.social/methodology/.


Table 1.
matrix of scenarios of use.
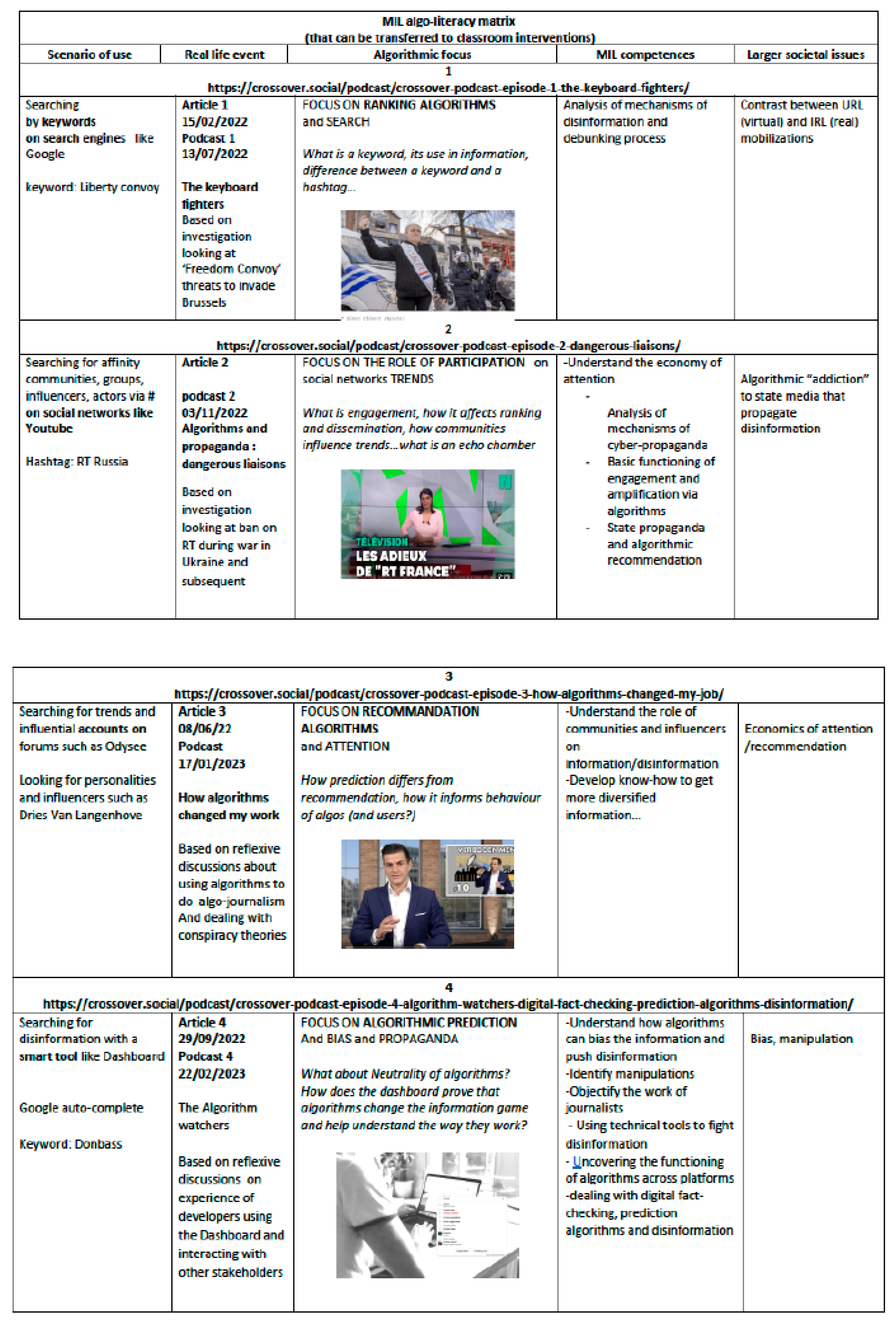 |
Table 3.
Quiz 1 associated with podcast 1.
| GOALS | SOLUTIONS |
|---|---|
| Limiting the amount of data collected from your devices to reduce targeting | Setting your cookies to limit tracking |
| Browsing anonymously | Using a VPN |
| Not falling for sensationalist news | Watching out for information that arouses a lot of emotion and verify it |
| Going beyond the beaten path, varying your sources of information | Opening your community to people with different profiles. Snooping elsewhere than in the first page of Google or searching on other sites |
| Making sure that informing yourself is a voluntary act, that respects clear rules | Mobilising for an increased regulation of algorithms, for more transparency about their impact. |
Table 4.
Quiz 2 associated with podcast 2.
| Fake accounts and bots are created by the millions every day and are often the basis of raging debates. What are the signs that should make you suspicious? |
|
| Answer: the correct answers (in bold) are only clues. The more of them that converge, the higher the probability that you are dealing with a bot. |
Table 5.
algorithm literacy framework.
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



