
Submitted:
08 April 2024
Posted:
09 April 2024
You are already at the latest version
Abstract
Facial acne is a prevalent dermatological condition regularly observed in the general population. This study introduces a novel deep learning model for facial acne segmentation utilizing a semi-supervised learning method known as bidirectional copy-paste, which synthesizes images by interchanging foreground and background parts between labeled and unlabeled images during the training phase. To overcome the lower performance observed in the labeled image training part compared to the previous methods, a new framework was devised to directly compute the training loss based on labeled images. The effectiveness of the proposed method was evaluated against previous semi-supervised learning methods using images cropped from facial images at acne sites. The proposed method achieved a Dice score of 0.5205 in experiments utilizing only 3% of labels, marking an improvement of 0.0151 to 0.0473 Dice score over previous methods. The proposed semi-supervised learning approach for facial acne segmentation demonstrates improvement in performance, offering a novel direction for future acne analysis.
Keywords:
acne segmentation
; semi-supervised learning
; bidirectional copy-paste
; deep learning
; semantic segmentation
1. Introduction
Facial skin disorders commonly occur among people, which is why various studies are being conducted to detect them [1,2,3,4]. Out of these, acne is a prevalent skin disorder that frequently occurs in the general population. Untreated acne has the potential to deteriorate or result in scarring. Therefore, multiple research investigations are currently being conducted to detect and classify acne based on facial images.
Figure 1 displays cropped images around acne from facial images, highlighting the variety in color and shape of acne. To detect such varied presentations of acne, numerous studies have been proposed recently, using deep learning. Yadav et al. [5] identified candidate regions of acne presence on the face based on the HSV color space and then distinguished acne using classifiers trained with SVM or CNN. Rashataprucksa et al. [6] and Hyunh et al. [7] utilized object detection models such as faster-rcnn [8] and r-fcn [9] for acne detection. Min et al. [10] employed a dual encoder based on CNN and Transformer to detect face acne. Junayed et al. [11] also proposed a dual encoder based on CNN and Transformer, but they detected acne through a semantic segmentation approach. Kim et al. [12] enhanced the segmentation performance of acne by training on the positional information of acne in the final encoder.
Deep learning techniques fundamentally require labeled training data. However, labeling is time-consuming and costly, and securing even the original medical data, such as for acne, can be challenging. Recently, to partially address the difficulty of acquiring labeled data, much research has been conducted on semi-supervised learning, which utilizes both labeled and unlabeled data for training. Initially, various data augmentation techniques were applied to unlabeled data, employing consistency regularization [13]. Methods like Cutmix [14], which overlap parts of different images, have significantly aided in improving semi-supervised learning. Recently, a method that alternately bidirectional copy-paste (BCP) the foreground and background between labeled and unlabeled data has been proposed for medical image segmentation [15]. This proposed method performs semi-supervised learning while maintaining a bidirectional relationship between the two sets of data.
We conducted semi-supervised learning of the acne segmentation model using BCP. We aim to create an acne segmentation model based on semi-supervised learning using the BCP method. However, in BCP, training was conducted only with synthetic images created through copy-paste between labeled and unlabeled images. This approach made it challenging to fully reflect the characteristics of the labeled images. Although BCP performed well with CT images, we discovered shortcomings in segmenting acne across various shapes and skin tones. To address this issue, we propose adding a structure to the BCP framework that directly trains on input labeled images. Thus, our proposed method aims to maintain the BCP structure while enabling semi-supervised learning and improving acne segmentation performance by learning from input labeled images.
To verify the performance of our proposed method, we compared the acne segmentation performance with existing semi-supervised learning methods. For this purpose, we used images cropped primarily around acne from facial images, as illustrated in Figure 1. In our experiments, the proposed method, when utilizing 3% labeled data, exhibited a Dice score of 0.5205, demonstrating superior performance by 0.0151 to 0.0473 Dice score compared to previous methods. Additionally, when using 7% labeled data, it showed a Dice score of 0.5588, indicating an improvement of 0.0231 to 0.0426. Therefore, by directly training on input labeled images within the BCP structure, we confirmed an improvement in acne segmentation performance.
The structure of this paper is as follows: Chapter 2 provides a brief introduction to acne segmentation research and semi-supervised learning. Chapter 3 describes the semi-supervised learning method proposed in this paper, and Chapter 4 presents the experimental results of the proposed method. Chapter 5 shows an ablation study required when adding the training loss from input labeled images to the total loss, and Chapter 6 summarizes the conclusions of this paper.
2. Related Works
2.1. Acne Detection
Rashataprucksa et al. [6] employed object detection models, Faster-RCNN [8] and R-FCN [9], to detect acne in facial images, comparing these two models to evaluate their respective acne detection capabilities. Min et al. [10] utilized a dual encoder composed of CNN and Transformer to extract features, which were then processed through dynamic context enhancement and mask-aware multi-attention for final acne detection. Similarly, Junayed et al. [11] approached acne detection through semantic segmentation, employing a dual encoder setup with CNN and Transformer. This method involved extracting both local and global information, which were then integrated through a feature versatile block to the decoder. Kim et al. [12] segmented acne using a U-Net [16,17] structure and applied a center point loss to train the last encoder on acne location information. Acne detection has primarily been conducted through either object detection or semantic segmentation. However, since the shape of acne can help differentiate the severity of the condition and assist in treatment [18], our paper aims to detect acne based on semantic segmentation.
2.2. Semi-Supervised Learning
Semi-supervised learning primarily applies various data augmentations to unlabeled images, focusing on consistency-based learning. FixMatch [19] extracts prediction probabilities by applying different levels of data augmentation to unlabeled data. Then, it ensures that the predictions from strongly augmented data maintain consistency based on the prediction probabilities of weakly augmented data. However, in FixMatch, only unlabeled data with predicted probabilities above a certain threshold were used for training, leading to the exclusion of many unlabeled data instances. To overcome this limitation, Full-Match [20] introduced adaptive negative learning to improve training performance. Furthermore, Wu et al. [21] applied pixel smoothness and inter-class separation in semi-supervised learning to address the blurring of pixels in edge or low-contrast areas. UniMatch [22] improved semi-supervised performance by applying stronger data augmentation in a dual structure. Notably, for strong data augmentation, Cutmix [14] was applied, which involves inserting specific parts of an image into another image. Recently, a method similar to Cutmix, bidirectional copy-paste (BCP) [15], was proposed for medical image segmentation. This method pairs labeled and unlabeled data, overlapping specific parts of their images in a manner similar to Cutmix. Semi-supervised learning is then performed using a teacher and student network structure. Loss is calculated by comparing the labeled data region with the actual ground truth, while the loss for the unlabeled data region is determined using the pseudo ground truth from the teacher network. Given BCP’s proven effectiveness in medical image segmentation, this paper aims to leverage BCP to improve facial acne segmentation performance.
3. Method
3.1. Overall Structure
Figure 2 illustrates the overall structure proposed in this paper. It is fundamentally composed of a teacher network T and a student network S, similarly to bidirectional copy-paste (BCP) method [15]. Both T and S are constructed with U-Net-BN [16], where the channel count of the first encoder is 16. Initially, T and S utilize the same pre-trained weights , which are trained through supervised learning using only labeled images. However, unlike previous approaches that trained with synthetic images created by applying BCP among labeled images, this study employs labeled images. This is because using labeled images to generate resulted in better performance than using BCP for acne segmentation.
3.2. Bidirectional Copy-Paste for Synthetic images
The method of generating synthetic images using BCP is as follows. First, a mask M of the same size as the images is created. M consists of zeros and ones, where the area of ones becomes the region to be copied. Then, M is applied to equations 1 and 2 to generate and .
where and are the i-th and j-th labeled images, respectively (i≠j), ⊙ represents element-wise multiplication. and are the p-th and q-th unlabeled images, respectively (). 1 represents a matrix of the same size as M, with all elements being 1. Figure 3 provides a detailed example of a sample image generated through BCP.
3.3. Pseudo Synthetic GT for Supervisory Signals
The Pseudo GT for unlabeled images is generated through the teacher network T. First, the prediction values for the unlabeled images and are extracted using the equation below.
Then, as in Equation (3), a binarized Pseudo GT is generated using the equation below.
where i and j are coordinates.
Next, apply the formula below to the ground truths and of and , respectively, to generate and that are synthetic ground truths.
3.4. Loss Computation
To calculate the training loss for the student network S, the labeled images (, ) and synthetic images (, ) are each inferred through the student network S as , , , and , respectively.
Then the training loss for each corresponding GT is calculated using equations (8) through (10). is the linear combination of Dice loss and Cross-entropy.
where represents the weight of the unlabeled images. The final training loss is calculated using Equation (11).
where is a parameter that adjusts the weight of the purely supervised loss. Using the above loss, the student network S is ultimately updated. Subsequently, an Exponential Moving Average (EMA) update is performed on the Teacher network T using Equation (12).
where and represent the parameters of the teacher network T and the student network S, respectively.
4. Experimental Results
4.1. Experimental Setup
To validate the performance of our proposed acne segmentation method, we acquired images of acne from facial images taken with skin diagnostic equipment [23]. Each acne image is cropped around the acne as shown in Figure 1 and scaled to 256 x 256. We collected a total of 2,000 acne images, of which 1,600 were designated as the training set and the remaining 400 as the evaluation set. The optimizer used for network training was SGD, with a learning rate of 0.01, momentum of 0.9, and weight decay set to 0.0001. The batch size was set to 24, comprising 12 labeled and 12 unlabeled data. Based on BCP [15], alpha was set to 0.5, and lambda was set to 0.99. The size of the area for mask 1 was set to 2/3 of the input image. Gamma was set to 0.5 according to our ablation study. Pre-training iterations were set to 10k, and semi-supervised learning iterations were set to 30k. The training evaluation was compared using Dice Score and Jaccard Index. All experiments were conducted on an RTX 4090, Ubuntu 20.04, Pytorch 2.1.1.
4.2. Comparison of Results
4.2.1. Comparison between Synthetic Images and Labeled Images for Pre-Trained Weight
Pre-trained weights are trained through supervised learning. In the conventional approach, bidirectional copy-paste (BCP) was applied to labeled images to create synthetic images for training pre-trained weights. Our method, however, utilizes labeled images directly without applying BCP for training pre-trained weights. Thus, a comparison between these two approaches was initially conducted.
Table 1 presents the results of training with different proportions of labeled data at 3% and 7%. As shown in Table 1, generating pre-trained weights with labeled images demonstrated superiority in three metrics over using synthetic images. Therefore, we opted to train with labeled images, which overall provided better performance, for generating pre-trained weights .
4.2.2. Semi-Supervised Learning Comparison
We compared the semi-supervised learning performance of our proposed method with existing methods. Table 2 lists the performance of our proposed method against comparison methods across various metrics. As shown in Table 2, our proposed method exhibited the highest performance. This suggests that training with both BCP-based synthetic images and labeled images simultaneously provided mutual benefits, leading to the superior performance of our proposed method. Figure 4 presents examples of results from each method when using 7% labeled images.
5. Ablation study
In this section, we present the results of acne segmentation according to different values used in Equation (11) for combining synthetic image loss +) and labeled image loss +). We tested three scenarios with values of 0.1, 0.5, and 1.0. Generally, using resulted in superior overall performance in Table 3. While there were differences in some scores, high performance was demonstrated in the Dice and Jaccard indexes, which consider overall performance. Therefore, in our experiments, we used .
Next, we experimented with increasing the number of channels in the first encoder of the UNet-BN used in our experiments. While BCP set the number of channels at 16, we conducted comparative experiments with increased numbers at 32 and 64. Table 4 shows the acne segmentation performance when the number of channels was increased. As the number of channels increased, performance metrics also improved. Therefore, based on using 7% labeled images for acne segmentation, compared to using BCP, the Dice score increased by 0.0424 and the Jaccard Index by 0.0359.
6. Conclusion
In this paper, we proposed a semi-supervised learning method for training an acne segmentation model. We identified that bidirectional copy-paste (BCP) based semi-supervised learning methods did not incorporate learning from labeled images, and we sought to address this by including labeled images in the training process, thereby improving the overall acne segmentation performance. The proposed method was compared with existing semi-supervised learning approaches on actual acne images and demonstrated superior performance based on evaluation metrics such as the Dice score and Jaccard index. Our future research aims to apply the proposed method to the broader field of medical imaging to enhance performance.
Author Contributions
Conceptualization, S.K., H.Y. and J.L.; methodology, S.K.; software, H.Y.; validation, S.K., H.Y. and J.L.; formal analysis, J.L.; investigation, S.K. and H.Y.; resources, J.L.; data curation, H.Y.; writing—original draft preparation, S.K.; writing—review and editing, S.K., H.Y., and J.H.; visualization, S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Review Board of Severance Hospital (2022-31-1043).
Informed Consent Statement
Facial images were collected with informed consent from all subjects, in accordance with all relevant national regulations and institutional policies, and approved by the authors’ institutional committees.
Data Availability Statement
Data sharing not applicable
Conflicts of Interest
The authors declare no conflict of interest..
References
- Mekonnen, B. , Hsieh, T., Tsai, D., Liaw, S., Yang, F. & Huang, S. Generation of Augmented Capillary Network Optical Coherence Tomography Image Data of Human Skin for Deep Learning and Capillary Segmentation. Diagnostics. 11 (2021), https://www.mdpi.com/2075-4418/11/4/685.
- Bekmirzaev, S. , Oh, S. & Yo, S. RethNet: Object-by-Object Learning for Detecting Facial Skin Problems. Proceedings Of The IEEE/CVF International Conference On Computer Vision Workshops. pp. 0-0 (2019).
- Yoon, H. , Kim, S., Lee, J. & Yoo, S. Deep-Learning-Based Morphological Feature Segmentation for Facial Skin Image Analysis. Diagnostics. 13 (2023), https://www.mdpi.com/2075-4418/13/11/1894.
- Lee, J. , Yoon, H., Kim, S., Lee, C., Lee, J. & Yoo, S. Deep learning-based skin care product recommendation: A focus on cosmetic ingredient analysis and facial skin conditions. Journal Of Cosmetic Dermatology. (2024).
- Yadav, N. , Alfayeed, S., Khamparia, A., Pandey, B., Thanh, D. & Pande, S. HSV model-based segmentation driven facial acne detection using deep learning. Expert Systems. 39, e12760 (2022).
- Rashataprucksa, K. , Chuangchaichatchavarn, C., Triukose, S., Nitinawarat, S., Pongprutthipan, M. & Piromsopa, K. Acne Detection with Deep Neural Networks. Proceedings Of The 2020 2nd International Conference On Image Processing And Machine Vision. pp. 53-56, 2020. [Google Scholar] [CrossRef]
- Huynh, Q. , Nguyen, P., Le, H., Ngo, L., Trinh, N., Tran, M., Nguyen, H., Vu, N., Nguyen, A., Suda, K., Tsuji, K., Ishii, T., Ngo, T. & Ngo, H. Automatic Acne Object Detection and Acne Severity Grading Using Smartphone Images and Artificial Intelligence. Diagnostics. 12 (2022), https://www.mdpi.com/2075-4418/12/8/1879.
- Ren, S. , He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions On Pattern Analysis And Machine Intelligence. 39, 1137-1149 (2017).
- Dai, J. , Li, Y., He, K. & Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Advances In Neural Information Processing Systems. 29 (2016).
- Min, K. , Lee, G. & Lee, S. ACNet: Mask-Aware Attention with Dynamic Context Enhancement for Robust Acne Detection. 2021 IEEE International Conference On Systems, Man, And Cybernetics (SMC). pp. 2724-2729 (2021).
- Junayed, M. , Islam, M. & Anjum, N. A Transformer-Based Versatile Network for Acne Vulgaris Segmentation. 2022 Innovations In Intelligent Systems And Applications Conference (ASYU). pp. 1-6, 2022. [Google Scholar]
- Kim, S. , Lee, C., Jung, G., Yoon, H., Lee, J. & Yoo, S. Facial Acne Segmentation based on Deep Learning with Center Point Loss. 2023 IEEE 36th International Symposium On Computer-Based Medical Systems (CBMS). pp. 678-683, 2023. [Google Scholar]
- Laine, S. & Aila, T. Temporal ensembling for semi-supervised learning. ArXiv Preprint ArXiv:1610.02242. (2016).
- Yun, S. , Han, D., Oh, S., Chun, S., Choe, J. & Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. Proceedings Of The IEEE/CVF International Conference On Computer Vision (ICCV). (2019,10).
- Bai, Y. , Chen, D., Li, Q., Shen, W. & Wang, Y. Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation. Proceedings Of The IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR), pp. 11514-11524 (2023,6). [Google Scholar]
- Kim, S. , Yoon, H., Lee, J. & Yoo, S. Semi-automatic Labeling and Training Strategy for Deep Learning-based Facial Wrinkle Detection. 2022 IEEE 35th International Symposium On Computer-Based Medical Systems (CBMS), pp. 383-388 (2022). [Google Scholar]
- Kim, S. , Yoon, H., Lee, J. & Yoo, S. Facial wrinkle segmentation using weighted deep supervision and semi-automatic labeling. Artificial Intelligence In Medicine. 145 pp. 102679 (2023), https://www.sciencedirect.com/science/article/pii/S0933365723001938.
- Kang, S. , Lozada, V., Bettoli, V., Tan, J., Rueda, M., Layton, A., Petit, L. & Dréno, B. New Atrophic Acne Scar Classification: Reliability of Assessments Based on Size, Shape, and Number. Journal Of Drugs In Dermatology : JDD. 15, 693-702 (2016,6), http://europepmc.org/abstract/MED/27272075. [Google Scholar]
- Sohn, K. , Berthelot, D., Carlini, N., Zhang, Z., Zhang, H., Raffel, C., Cubuk, E., Kurakin, A. & Li, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Advances In Neural Information Processing Systems, 33 pp. 596-608 (2020). [Google Scholar]
- Chen, Y. , Tan, X., Zhao, B., Chen, Z., Song, R., Liang, J. & Lu, X. Boosting Semi-Supervised Learning by Exploiting All Unlabeled Data. Proceedings Of The IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR), pp. 7548-7557 (2023,6). [Google Scholar]
- Wu, Y. , Wu, Z., Wu, Q., Ge, Z. & Cai, J. Exploring smoothness and class-separation for semi-supervised medical image segmentation. International Conference On Medical Image Computing And Computer-assisted Intervention, pp. 34-43 (2022). [Google Scholar]
- Yang, L. , Qi, L., Feng, L., Zhang, W. & Shi, Y. Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation. Proceedings Of The IEEE/CVF Conference On Computer Vision And Pattern Recognition (CVPR), pp. 7236-7246 (2023,6). [Google Scholar]
- Lumini. (2020). Lumini KIOSK V2 Home Page. [Online]. Available: https://www.lulu-lab.com/bbs/write. php?bo_table=product_en&sca=LUMINI+KIOSK. [Accessed: July 9, 2020].
Figure 1.
Various acne samples. The shape and skin color of acne are considerably diverse.
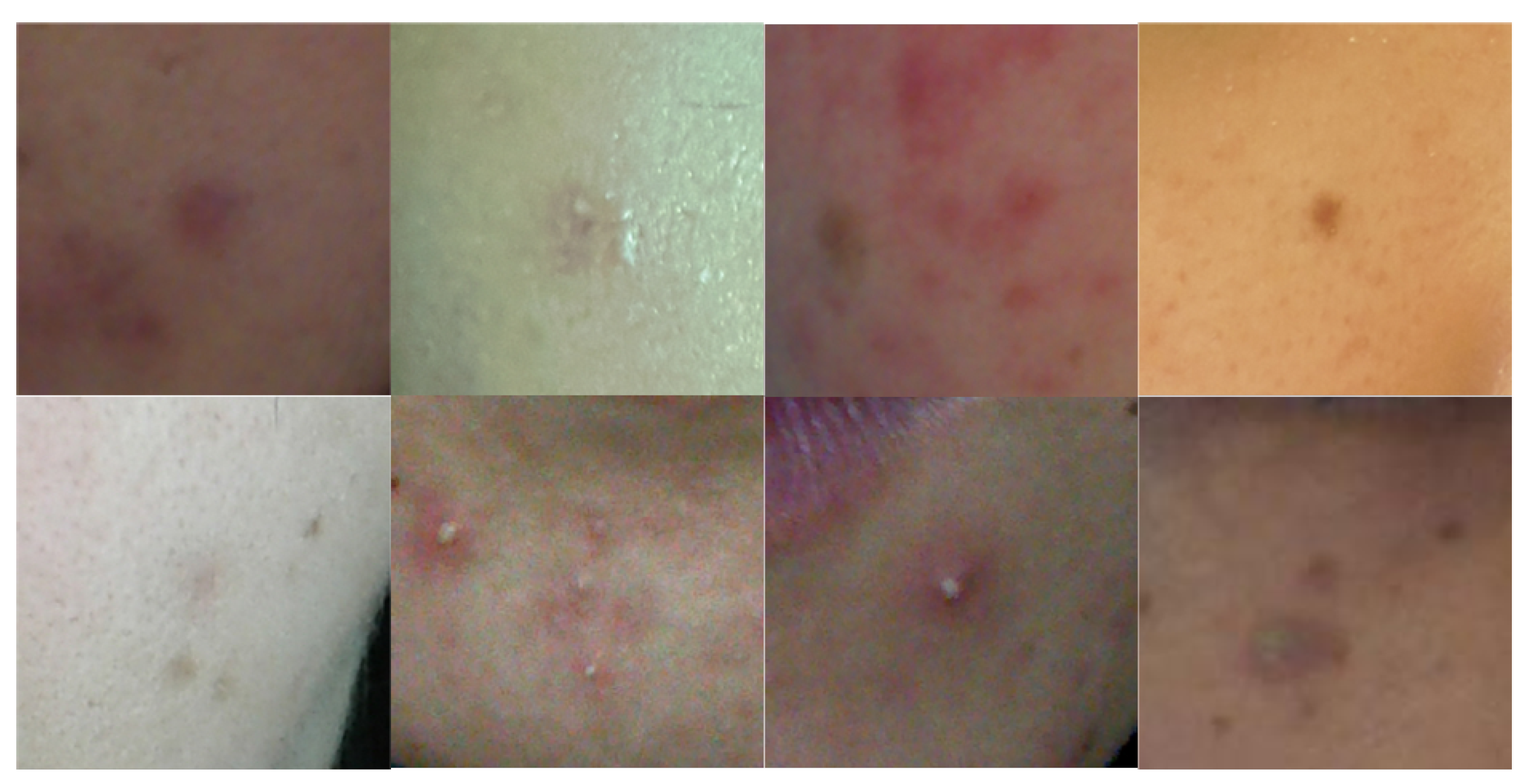
Figure 2.
Overall structure of the proposed method. Synthetic images are generated using the bidirectional copy-paste method. The labeled image and synthetic image are each inferred for prediction values through the student network. Then, synthetic GT is generated using ground truth (GT) and pseudo GT. The training loss is calculated by sending a supervisory signal to the student network through each GT. Once the student network is trained, an ema update is applied to the teacher network.
Figure 2.
Overall structure of the proposed method. Synthetic images are generated using the bidirectional copy-paste method. The labeled image and synthetic image are each inferred for prediction values through the student network. Then, synthetic GT is generated using ground truth (GT) and pseudo GT. The training loss is calculated by sending a supervisory signal to the student network through each GT. Once the student network is trained, an ema update is applied to the teacher network.
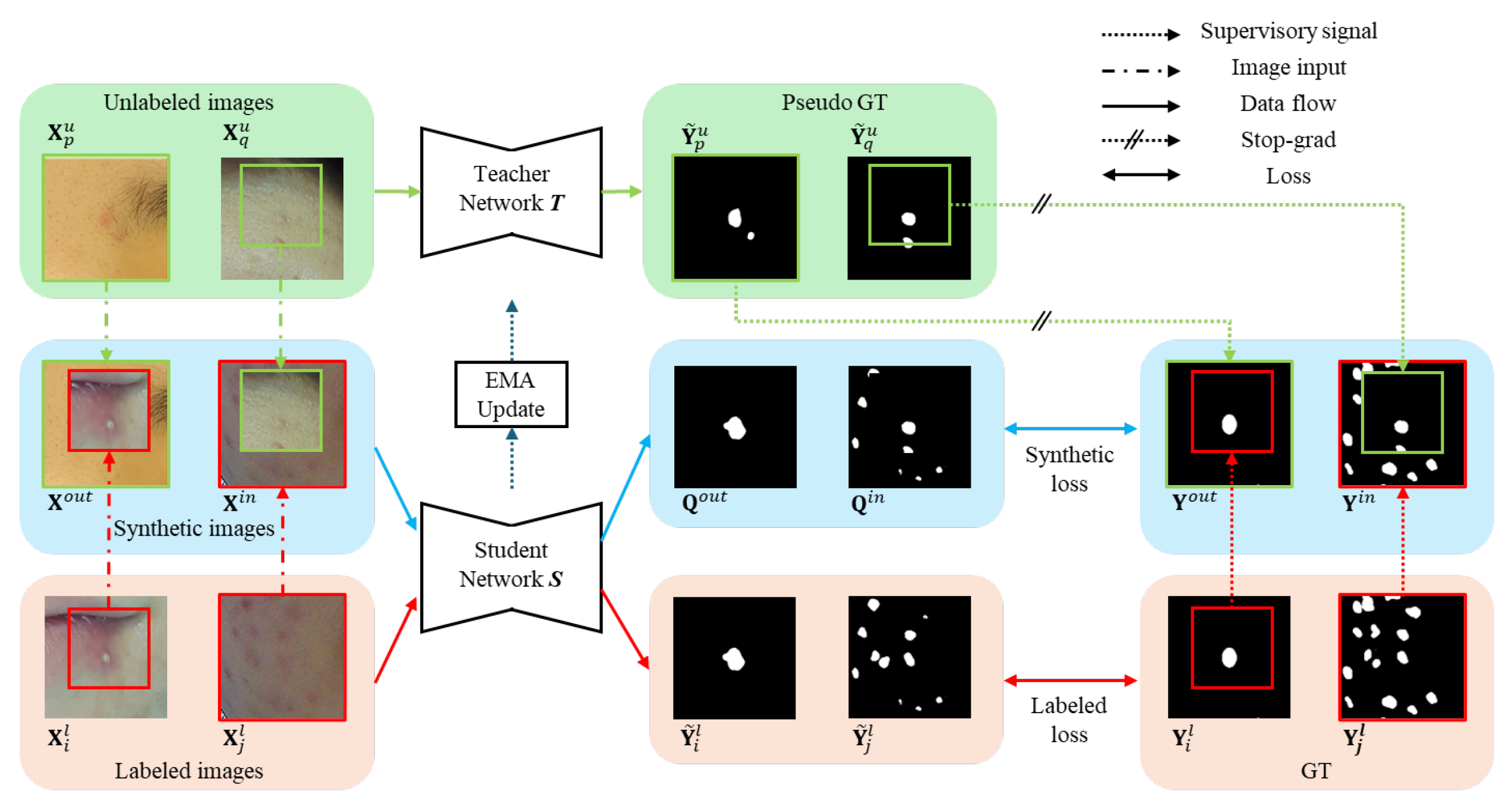
Figure 3.
An example of creating by applying BCP to an unlabeled image and a labeled image . In Mask M, 1 represents the white area, and 0 represents the black area. 1 represents a matrix of the same size as M, with all elements being 1. ⊙ is element-wise multiplication, and ⊕ is element-wise addition.
Figure 3.
An example of creating by applying BCP to an unlabeled image and a labeled image . In Mask M, 1 represents the white area, and 0 represents the black area. 1 represents a matrix of the same size as M, with all elements being 1. ⊙ is element-wise multiplication, and ⊕ is element-wise addition.

Figure 4.
Examples of acne segmentation results from the compared semi-supervised methods.


Table 1.
Comparison between synthetic images and labeled images for generating pre-trained weights .
Table 1.
Comparison between synthetic images and labeled images for generating pre-trained weights .
| Method | Ratio | Metrics | ||
|---|---|---|---|---|
| Labeled | Unlabeled | Dice Score | Jaccard Index | |
| Synthetic images | 3% | 0% | 0.4423 | 0.3108 |
| Labeled images | 3% | 0% | 0.4570 | 0.3203 |
| Synthetic images | 7% | 0% | 0.4784 | 0.3425 |
| Labeled images | 7% | 0% | 0.4951 | 0.3517 |
Table 2.
Comparison between synthetic images and labeled images for generating pre-trained weights .
Table 2.
Comparison between synthetic images and labeled images for generating pre-trained weights .
| Method | Ratio | Metrics | ||
|---|---|---|---|---|
| Labeled | Unlabeled | Dice Score | Jaccard Index | |
| Pre-trained | 3% | 97% | 0.4570 | 0.3203 |
| SS-Net [21] | 3% | 97% | 0.4732 | 0.3333 |
| BCP [15] | 3% | 97% | 0.5054 | 0.3617 |
| Ours | 3% | 97% | 0.5251 | 0.3777 |
| Pre-trained | 7% | 93% | 0.4951 | 0.3517 |
| SS-Net [21] | 7% | 93% | 0.5162 | 0.3750 |
| BCP [15] | 7% | 93% | 0.5357 | 0.3912 |
| Ours | 7% | 93% | 0.5603 | 0.4117 |
Table 3.
Comparison of acne segmentation performance based on .
| Method | Ratio | Metrics | ||
|---|---|---|---|---|
| Labeled | Unlabeled | Dice Score | Jaccard Index | |
| 0.1 | 3% | 97% | 0.5177 | 0.3693 |
| 0.5 | 3% | 97% | 0.5251 | 0.3777 |
| 1.0 | 3% | 97% | 0.5205 | 0.3753 |
| 0.1 | 7% | 93% | 0.5522 | 0.4060 |
| 0.5 | 7% | 93% | 0.5603 | 0.4122 |
| 1.0 | 7% | 93% | 0.5588 | 0.4117 |
Table 4.
Comparison of acne segmentation performance based on changes in the number of channels in the first encoder.
Table 4.
Comparison of acne segmentation performance based on changes in the number of channels in the first encoder.
| Method | Ratio | Metrics | ||
|---|---|---|---|---|
| Labeled | Unlabeled | Dice Score | Jaccard Index | |
| 16 (BCP[15]) | 3% | 97% | 0.5054 | 0.3617 |
| 16 (ours) | 3% | 97% | 0.5251 | 0.3777 |
| 32 (ours) | 3% | 97% | 0.5394 | 0.3912 |
| 64 (ours) | 3% | 97% | 0.5458 | 0.3965 |
| 16 (BCP[15]) | 7% | 93% | 0.5357 | 0.3912 |
| 16 (ours) | 7% | 93% | 0.5603 | 0.4117 |
| 32 (ours) | 7% | 93% | 0.5709 | 0.4233 |
| 64 (ours) | 7% | 93% | 0.5781 | 0.4271 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



