
Submitted:
09 April 2024
Posted:
15 April 2024
You are already at the latest version
Abstract
High-power laser facilities necessitate predicting incremental damage to final optics to identify evolving damage trends. In this study, we propose a surface damage detection method utilizing image segmentation employing ResNet-18, and a damage area estimation network employing U-Net++. Paired sets of online and offline images of optics obtained from a large laser facility is used to train the network. The trends of varying damage could be identified by incorporating additional experimental parameters. A key advantage of the proposed method is that the network can be trained end-to-end on small samples, eliminating the need for manual labeling or feature extraction. The software developed based on these models can facilitate the daily inspection and maintenance of optics in large laser facilities.
Keywords:
Optics image processing
; deep learning
; ResNet-18
; UNet++
1. Introduction
The final end of the inertial confinement fusion (ICF) [1–5] system, known as the final optics assembly (FOA), is subjected to the highest laser power load within the entire optical system. The damage-bearing capacity of optics in the FOA is severely limited by the nonlinear effects of high-power laser radiation, material defects, and other forms of contamination.
The load capacity of optics, often referred to as their damage-bearing capacity, is closely linked to the output laser power and energy stability of high-power laser facilities. Typically, initial damage to optics spans from dozens of micrometers to several millimeters. The earlier we detect and analyze such minor damage, the more likely we are to restore or replace the affected elements promptly, thereby effectively extending the longevity of the optics. Conversely, if the accumulating damage spirals out of control, it could result in significant economic losses and even induce laser beam modulation, leading to a catastrophic disaster for the entire facility.
The traditional method of detection involves the use of microscopes, which consumes a significant amount of time and manual labor, and its reliability is often unsatisfactory. Additionally, it is limited by environmental conditions, presenting significant drawbacks that are incompatible with the experimental requirements of high-power laser facilities. Consequently, we have turned to using imaging devices such as CCD, IR, X-ray, etc., to capture element images. Subsequently, we have integrated image processing technology with computer vision, specifically machine vision, to develop a more effective detection method.
The image processing algorithm based on morphology of graphics has found wide applications across various fields. However, it faces challenges when dealing with environments filled with unpredictable noise, leading to inefficiencies and inaccuracies in damage detection. Currently, a novel image processing algorithm based on deep learning is emerging as a promising alternative. Deep learning enables a closer approximation between complex input and output functions due to its self-learning capabilities and hierarchical structure. In comparison to morphology-based methods, deep learning has the potential to significantly enhance the algorithm for target detection.
In 2008, Adra Carr from LLNL was among the first to introduce machine learning technology into damage classification, focusing on the identification and characterization of damage occurrences [14]. Two years later, Ghaleb M. Abdulla, also from LLNL, applied a similar algorithm to recognize false damage caused by hardware reflections [15]. In 2014, Lu Li and her team from Zhejiang University utilized a classic machine learning algorithm, support vector machine, for offline detection in the SDES system, successfully distinguishing microscale damage and dust [16]. Subsequently, in 2019, Fupeng Wei from Harbin Institute of Technology conducted research on an intelligent inspection method for detecting weak feature damage in large aperture final optics using the K-ELM algorithm [17]. However, it's worth noting that the damage samples used in both the training and test sets were sourced from a single picture, indicating a need to enhance the generalizability of the research.
This study has outlined a predictive approach to incremental damage on optics. Initially, we introduce our proposed solution to the challenging engineering issues related to damage detection. Subsequently, we employ suitable algorithms to develop mathematical models for this purpose. Finally, we conclude by detailing the research progress and achievements in the field of predictive technology for damage prediction on optics.
2. Methods
The Final Optics Damage Inspection (FODI)[18] system is designed for imaging the overall aperture of optics using side illumination. However, the presence of stray light and other downstream optics can lead to the generation of false damage, which needs to be filtered out in the images. Figure 1 illustrates four main types of false damage: (1) damage reflection image, (2) hardware reflection, (3) damage from downstream optics , and (4) light spots. Hardware reflections, categorized as (2), are often observed at upstream optics such as continuous-contour phase plates (CPPs) and frequency conversion crystals (11-mm type-I KDP doubling crystals and 9-mm type-II deuterated-KDP tripling crystals). Given the diverse formation mechanisms of false damage, it becomes challenging to physically distinguish authentic damage from false ones.
To address this challenge, we adopt an offline approach instead of online inspection to meet practical demands during weekly maintenance of the facility. Before installation or after removal, optics are placed into a dark box and subjected to side-illumination to obtain offline dark-field images. This procedure helps eliminate the influence of background light or downstream optics. Consequently, any white dots observed in the offline image can be confidently identified as authentic damage, as shown in Figure 1.
Given the constraints of maintenance time and labor costs, the availability of offline images for analysis is limited. Recently, fewer than 10 offline images could be directly related to their online counterparts, a quantity insufficient for traditional machine learning applications. Furthermore, the scheduling of optics maintenance in routine operations is restrictive, limiting the opportunities to acquire new offline images. To address this, optics owning more than 1000 damages are prioritized for offline high-definition imaging, maximizing the collection of valuable damage samples within the constraints.
To overcome the challenge of limited data availability, we employ data augmentation[20] techniques. Data augmentation involves altering a limited dataset in various ways to create new, synthetic data points. This can include transformations such as rotation, scaling, and changes in lighting conditions, which help in simulating different scenarios that could lead to damage. By generating these new data points, we enhance the robustness and generalization capabilities of our machine learning models. This approach allows for more effective training of models to identify and classify damage, improving their accuracy and reliability in real-world applications despite the initial scarcity of offline images.
Braille marks [21] representing the last four digits of element numbers are engraved at the four corners of every optic, is depicted as Figure 2 below. These Braille marks serve as reference points for orientation during the processing of FODI images. By aligning the FODI image with these marked corners, we ensure that each image is standardized to have the same detection coordinates.
When referencing the offline image area, we locate the corresponding damage points on the matching online image and then calculate their coordinates. However, due to differences in position, light intensity, and contrast ratio between images taken at different times, adjustments are necessary. To achieve accurate adjustments, we utilize the information from the four corner images and the various Braille marks present on the optics. These references help calibrate the position, intensity, and contrast of the images, ensuring precise detection and measurement of damage points.
Utilizing a deep neural network is indeed a promising approach for estimating the damage area. By training the network on a dataset containing various trends of damage areas, it can learn to make predictions for specific damage areas occurring at different experiment times. This enables the network to perform three key functions: statistical analysis, tracing the origins of damage, and making predictions for future damage occurrences.
Additionally, by incorporating the time dimension into damage detection, we can define the regularity of the variation in both individual damage points and total damage area over time. This allows for the systematic management of damage, enabling us to track changes in damage patterns, identify potential causes, and implement preventive measures accordingly. By leveraging the capabilities of deep learning and time-series analysis, we can enhance our understanding of damage dynamics and improve our ability to manage and mitigate its impact effectively.
3. Implement
3.1. Pre-Process on Data
Taking FODI images once a week for maintenance purposes introduces variability in environmental conditions, leading to differences in light intensity and contrast ratio between images. This variation can indeed affect the accuracy of damage area calculations. Figure 3 illustrates a single damage point captured over different time intervals, showcasing the variability in damage appearance.
Furthermore, as depicted in the 7th picture of Figure 4 (taken on Sep. 7th, 2019), inconsistencies in light intensity and contrast ratio can result in discrepancies in pixel values for incremental damage. This deviation from the expected pattern contradicts the principle that incremental damage should not be irreversible.
To address these challenges and improve accuracy in damage area calculations, several measures can be taken:
- Normalization: Apply normalization techniques to standardize the pixel values across images, mitigating the impact of variations in light intensity and contrast ratio.
- Calibration: Implement calibration procedures to adjust for differences in environmental conditions and ensure consistency in image quality.
- Adaptive Algorithms: Develop adaptive algorithms capable of adjusting parameters based on image characteristics, allowing for accurate detection and measurement of damage areas despite variations in environmental conditions.
- Data Augmentation: Augment the dataset with images generated under various environmental conditions to improve the robustness of the deep learning models to different lighting and contrast scenarios.
By incorporating these strategies, we can enhance the accuracy and reliability of damage area calculations in FODI images, enabling more effective maintenance and management of structural integrity.
In order to solve the problem mentioned above, we have tried to an amount of algorithm, yet no one works well. At last, we adopt braille marks as reference to adjust light intensity coefficient, which would be used for whole image. The adopted solution involves using braille marks as references to adjust light intensity coefficients for entire images:
a)Image Preprocessing: Identical areas marked by braille marks are extracted from all images.
b)Grayscale Normalization: Grayscale distributions within these areas are normalized to ensure consistency across images.
c)Criterion Selection: The image with the maximum grayscale value (piupper) is selected as the criterion.
d)Grayscale Adjustment: Grayscale intervals of other images are adjusted to match the criterion image.
e)Coefficient Calculation: Each image is assigned its adjustment coefficient (co(i)), likely based on its grayscale values relative to the criterion image.
f)Adjustment Application: Pixel values of each image are multiplied by their respective adjustment coefficients to achieve uniform brightness values across the image set.
Figure 5 and equation (1) illustrate the process of cutting identical areas marked by Braille marks from all images, obtaining the normalized distribution of pixel grayscale in these areas. Subsequently, the image with the maximum grayscale value is selected as a criterion, denoted as piupper. The grayscale intervals of other images are adjusted to match this criterion, and their adjustment coefficients, denoted as co(i), are calculated accordingly. Ultimately, the pixel values of the remaining complete images are multiplied by their corresponding adjustment coefficients to achieve a uniform set of brightness values across all images. Equation (1) defines the variables used in the adjustment process, where n represents the number of pictures, piadj denotes the pixel value after adjustment, piori represents the pixel value before adjustment, and piori signifies the total number of pixels in the i-th picture.
piupper(0) = max{piupper(1), piupper(2), piupper(3),..., piupper(n)}
co(i) = piupper(i) / piupper(0) (i∈[1,n])
piadj(i)(j) = piori(i)(j)·co(i) (j∈[1,mi])
co(i) = piupper(i) / piupper(0) (i∈[1,n])
piadj(i)(j) = piori(i)(j)·co(i) (j∈[1,mi])
To prevent issues such as abnormal damage area calculation arising from significant contrast differences, it's crucial to ensure that the contrast values between each image are similar. The contrast is computed using the equation(2):
c = ∑r(i, j)·r(i, j)·p(i, j)
r(i, j) = |i-j|
r(i, j) = |i-j|
The contrast value c is determined by the upper formula, where r(i,j) represents the gray difference between adjacent pixels, and p(i,j) denotes the pixel distribution probability of r for the gray difference between adjacent pixels.
The contrast values before and after the aforementioned image processing are c7ori=117.99 and c7adj=214.63, respectively. A comparison between the processed image and the previous one is depicted in Figure 7:
Each Braille mark can be conceptualized as a unique combination of a group of small circular points. Therefore, we employ a feature extraction technique for detecting circles, namely the Circle Hough Transform (CHT) [22]. This method is combined with the standard Braille pattern corresponding to the last four digits of its component number to identify and locate Braille marks. Figure 8 illustrates the Braille target pixel area detected before and after adjusting the brightness and contrast of the eight pictures. It is evident that the adjusted Braille target area values are similar, indicating that the eight pictures have essentially achieved normalization in terms of brightness and contrast.
To establish the mapping between online and offline images, we utilize Braille positioning to standardize their coordinate systems. Upon obtaining the coordinates of the four corner Braille marks, the original image is cropped to extract training set samples, as depicted in Figure 9.
3.2. Algorithm. and Model Training
To achieve more accurate discrimination between true and false damage, it's essential to replace cumbersome feature engineering with the nonlinear operations of deep neural networks. This allows for capturing richer target patterns and features, addressing classification challenges that may be difficult to discern at the surface level. However, excessively deep networks may lead to the degradation problem, where the accuracy on the training set plateaus or even deteriorates [23]. Residual Networks (ResNet) [24,25] offer a solution to this issue through their unique identity mapping structure, effectively avoiding degradation. Therefore, ResNet is chosen to tackle the problem of recognizing real damage targets.
Once real damage is identified, we employ a method to estimate the number of pixel grids, enabling quick and convenient determination of the area for each damage point. In scenarios with limited samples, the advanced U-Net++ algorithm [26,27,28], based on the U-shaped architecture of fully convolutional networks, is selected. It can capture features at various levels and integrate them through feature concatenation, resulting in higher accuracy in image segmentation. U-Net++ eliminates the need for manual feature extraction and efficiently utilizes limited training samples.
The idea framework are shown as Figure 10:
In this study, transfer learning and the feature pyramid network [29] are employed to pinpoint the real damage of elements. The deep learning model is pre-trained using a public dataset containing similar scenes, while the last several layers of the pre-trained model are fine-tuned using online-offline image sample data of elements after data augmentation. The deep learning model adopts the feature pyramid network structure based on ResNet-18, as illustrated in Figure 11.
The resolution of online and converted offline images, approximately 3000×3000, exceeds the neural network's input capacity. Consequently, the images are resized into smaller patches with a resolution of 32×32 pixels for inputting into the network. Subsequently, the LASNR[30] algorithm is employed to identify highlight positions and determine their full extent on the offline image. These marked points on the offline image represent actual damage instances and serve as input labels for training the network, as illustrated in Figure 12.
Following the filtration of images with a pure dark background, the dataset comprises 1650 paired images utilized for training the network, each with a resolution of 32×32 pixels for both online and offline samples. Subsequently, the dataset was randomly divided into training and validation sets at a ratio of 4:1, yielding 1320 samples for training and 330 samples for validation. The trained model is designed to identify and locate actual damage within the input online images. Upon acquiring the pixel coordinates of actual damage points, a deep neural network utilizing U-Net++ architecture will estimate the size of each damage point. The FODI image is grayscale, with pixel values ranging from 0 to 255. Next, the number of pixels with values ≥ 128 is counted within the 32×32 resolution offline image, with the additional criterion that the pixel values at the four corners are >0 (to mitigate noise), thereby estimating the area of damaged pixels. This area value serves as the label for the corresponding damage point in the online image and is incorporated into the training set of the U-Net++ neural network to derive the area estimation model, as illustrated in Figure 13. Thus, the pixel area of each damage point can be determined by inputting the online image annotated with actual damage into the model.
To detect multiple online images collected at different times after the same element is put online, we can establish a file for each damage point and associate each damage point with the time dimension. This will allow us to track the development of the damage area for each specific damage point over time, as illustrated in Figure 14.
To obtain the specific physical location and size of each damage, we utilize affine transformation to convert the detection result data (pixel coordinates) into physical coordinates. This allows us to determine the precise physical location and size of each damage. Figure 15(a) illustrates this process, where the damage area is represented on the ordinate axis, and the accumulated energy value from the experiment is represented on the abscissa axis, establishing a coordinate system.
We then perform a numerical fit on the damage situation and plot the damage development curve. By summing the areas of all damage points within the same element, we can examine the correlation between the overall damage development of the element and the experimental date (experimental energy). This analysis provides valuable insights into the relationship between damage accumulation and experimental energy.
With this information, we can read the parameters of future experimental plans and input the corresponding energy value to predict the damage area of the element during that specific time period. This predictive capability is depicted in Figure 15(b).
By establishing different damage thresholds for each component, we can determine the latest shelf removal date. This approach effectively prevents irreparable serious damage caused by component overload, ensuring the integrity and safety of the components.
To assess the accuracy of the predicted damage area, we selected five components and predicted their total damage areas for the upcoming period at each time node. Subsequently, we compared these predicted areas with the actual damage areas observed after completing the experiments in the next period, which spanned over a month. The results of this comparison are presented in Table 1 and Figure 16. Based on these preliminary findings, it can be concluded that the accuracy of the area prediction exceeds 90%.
In Figure 15, the gray dotted lines represent the historical daily output energy, while the blue lines depict the planned daily output energy. The fold lines illustrate the variation in the overall damage area over time. By defining a critical point for the damage area, we can determine the latest maintenance date by identifying the intersection point between the fold line and the corresponding energy output point. This approach enables us to establish a proactive maintenance schedule based on critical damage thresholds and energy output levels, ensuring optimal operational efficiency and component longevity.
4. Results
The research utilizing ResNet has successfully achieved online damage detection on optics of FOA, with a success ratio exceeding 95% and a failure ratio less than 5%. As depicted in Figure 17, the predicted damage for each element is highlighted and circled in red. Furthermore, this technology has been seamlessly integrated into relevant element management software and has been applied in practical settings for several years. This integration has undoubtedly enhanced the efficiency and effectiveness of damage detection and maintenance processes within the FOA system.
The examination reveals that the prediction of each incremental damage trend and the overall growth of damage areas on optics can be visually represented. Moreover, this technology has been successfully implemented in the high-power laser facility of CAEP. It allows for the examination of multiple online images of a single element captured at various times. By selecting any damage point in Figure 17, the software will display the evolving trend of that specific damage, as illustrated in Figure 18.
Figure 18(b) presents similar content to Figure 15(b), depicting the prediction for overall damage trend variations. By combining future experiment plans and relevant experimental parameters with the predictions, the system can effectively manage all elements in optimal condition. When the damage area approaches a critical point, maintenance warnings are issued to prevent catastrophic damage. Experimental results have demonstrated an accurate prediction ratio for damage area exceeding 90%. This robust predictive capability ensures proactive maintenance and enhances the overall operational efficiency and safety of the system.
5. Conclusions
This study proposes a vision-based approach for detecting and predicting damages on optics using image segmentation. The deep learning system outlined in this essay accurately identifies laser-induced damages on optics in real-time and predicts their area based on future experiment parameters. Due to the limited number of available samples, it is challenging to precisely define the size and shape of damages using traditional deep learning methods. However, this essay presents a method that achieves element damage detection with a small number of samples by combining key algorithms from ResNet and UNet, along with data augmentation, transfer learning, and image processing techniques.
To ensure consistency in studying area growth, the brightness and contrast of all samples are normalized based on the highest brightness Braille label in each sample. Braille markers located at the four corners are used to localize and crop the samples, thus unifying the coordinate system and accurately locating damages in different samples.
Unlike typical classification models that assign a single label to an entire image, the ResNet model employed in this approach assigns a class label to each pixel, enabling better localization of damages. Moreover, this detection model can be trained end-to-end with small samples without the need for manual labeling or feature extraction. This method also exhibits advantages over other detection methods when dealing with samples containing multiple adjacent objects. It effectively identifies false damages caused by reflections through spatial and intensity information, which improves efficiency and accuracy compared to previous studies using typical classification models.
The experimental results demonstrate the effectiveness of the proposed method. The success ratio for damage detection in each image exceeds 97%, with a failure ratio of less than 7% (mostly due to pixel loss). Additionally, the predicted damage area meets the required accuracy, with an average relative error below 10%. This method holds promise for online detection and maintenance in large laser facilities with limited available samples, offering wide-ranging applications in the field.
The proposed online optics damage detection system described above holds promise for improving the efficiency and longevity of optics in large laser facilities. However, there are some limitations to consider.
Firstly, the predictive ability of the system relies heavily on the quality of the imaging system. If one of the Braille marks used for localization cannot be detected, it may result in the unavailability of an online FODI (focused optical damage inspection) image, thus affecting the accuracy of damage detection and prediction.
Secondly, the current method does not utilize successive online images taken per week to discriminate tiny defects from backgrounds effectively. There is potential for improvement by employing deep learning techniques to track and predict the growth of each damage in successive online images instead of relying solely on numerical simulations.
Addressing these limitations could further enhance the capabilities and reliability of the online optics damage detection system, ultimately leading to improved experimental efficiency and optics longevity in laser facilities. Future research could focus on improving the robustness of the imaging system and integrating successive online images into the analysis pipeline to better distinguish between defects and background noise.
Author Contributions
Conceptualization, XY.H. and Z.C.; methodology, Wei Zhou; software, H.G.; validation, Wei Zhou; formal analysis, Z.C.; investigation, Wei Zhong; resources, B.Z.; data curation, B.Z.; writing—original draft preparation, XY.H.; writing—review and editing, Z.C.; visualization, Wei Zhou; supervision, Q.Z.; project administration, Q.Z.; funding acquisition, XX.H.; Formal analysis, XY.H. and Z.C..
Funding
This research was funded by the NATURAL NATIONAL SCIENCE FOUNDATION OF CHINA (NSFC) , grant number 62105310.
Acknowledgments
The authors would like to gratefully acknowledge the auspices of the colleagues in the Laser Engineering Division of Laser Fusion Research Center.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang Ganchang. Overview of the latest progress in laser inertial confinement fusion (ICF)[J]. Nuclear Science and Engineering 1997, 017(003), 266-269.
- Howard Lowdermilk W. Inertial Confinement Fusion Program at Lawrence Livermore National Laboratory: The National Ignition Facility, Inertial Fusion Energy, 100–1000 TW Lasers, and the Fast Igniter Concept[J]. Journal of Nonlinear Optical Physics & Materials 1997, 06(04), 507-533. [CrossRef]
- Tabak M.; Hammer J.; Glinsky M. E., et al. Ignition and high gain with ultrapowerful lasers*[J].Physics of Plasmas 1998, 1(5), 1626-1634. [CrossRef]
- Hirsch; Robert L. Inertial-Electrostatic Confinement of Ionized Fusion Gases[J].Journal of Applied Physics 1967, 38(11), 4522-4534. [CrossRef]
- Zhu Q; Zheng W; Wei X, et al. Research and construction progress of the SG III laser facility[C]. SPIE/SIOM Pacific Rim Laser Damage: Optical Materials for High-Power Lasers, Shanghai, P. R. China, 19th May 2013. [CrossRef]
- Spaeth M. L.; Wegner P. J.; Suratwala T. I., et al. Optics Recycle Loop Strategy for NIF Operations Above UV Laser-Induced Damage Threshold[J]. Fusion Science & Technology 2016, 69(1), 265-294. [CrossRef]
- Baisden P. A.; Atherton L. J.; Hawley R. A., et al. Large Optics for the National Ignition Facility[J]. Fusion Science & Technology 2016, 69(1), 614-620. [CrossRef]
- Schwartz, S.; Feit M. D.; Kozlowski M. R. & Mouser R. P. Current 3-ω large optic test procedures and data analysis for the quality assurance of national ignition facility optics[J]. Proceedings of SPIE - The International Society for Optical Engineering 1999, 3578. [CrossRef]
- Sheehan L. M.; Hendrix J. L.; Battersby C. L., et al. National Ignition Facility small optics laser-induced damage and photometry measurements program[C]. Spies International Symposium on Optical Science.International Society for Optics and Photonics, 1999. [CrossRef]
- Nalwa H. S. Organometallic materials for nonlinear optics[J]. Applied Organometallic Chemistry 1991, 5(5), 349-377. [CrossRef]
- Liao Z. M.; Nostrand M.; Whitman P., et al. Analysis of optics damage growth at the National Ignition Facility[C]. SPIE Laser Damage, Boulder, Colorado, United States, October 2015. [CrossRef]
- Zheng Wanguo. Load Capacity of High Power Laser Device and Related Physical Problems [M]. Science Press: Beijing, China, 2014.
- Sasaki T.; Yokotani A. Growth of large KDP crystals for laser fusion experiments[J]. Journal of Crystal Growth 1990, 99(1, Part 2), 820-826. [CrossRef]
- Carr A.; Kegelmeyer L.; Liao Z. M., et al. Defect classification using machine learning[C]. Proceedings of SPIE - The International Society for Optical Engineeringaser, Boulder, CO, United States, September 22th, 2008 through September 24th, 2008. [CrossRef]
- Abdulla G. M.; Kegelmeyer L. M.; Liao Z. M., et al. Effective and efficient optics inspection approach using machine learning algorithms[C]. Laser Damage Symposium XLII: Annual Symposium, Boulder, Colorado, United States, 26th September 2010. [CrossRef]
- Li L.; Liu D.; Cao P., et al. Automated discrimination between digs and dust particles on optical surfaces with dark-field scattering microscopy[J]. Applied Optics 2014, 53(23), 5131-5140. [CrossRef]
- Wei Fupeng. Research on Intelligent Detection Method of Weak Feature Damage of Large Aperture optics [D]. Harbin Institute of Technology, Harbin, 2019.
- Ongena J.; Ogawa Y. Nuclear fusion: Statusreport and future prospects[J]. Energy Policy 2016, 96, 770–778. [CrossRef]
- Pryatel J. A.; Gourdin W. H. Clean assembly practices to prevent contamination and damage to optics[C]. Boulder Damage Symposium XXXVII: Annual Symposium on Optical Materials for High Power Lasers, Boulder, Colorado, United States, 19th September 2006. [CrossRef]
- Valente, J.; António, J.; Mora, C.; Jardim, S. Developments in Image Processing Using Deep Learning and Reinforcement Learning[J]. J. Imaging 2023, 9, 207. [CrossRef]
- Mennens J , Van Tichelen L , Francois G ,et al. Optical recognition of Braille writing using standard equipment[J].IEEE Trans on Rehabilitation Engineering 1994, 2(4), 207-212. [CrossRef]
- Ballard D. H. Generalizing the hough transform to detect arbitrary shapes[J]. Pattern Recognition 1981, 13(2), 111-122. [CrossRef]
- Pennada, S.; Perry, M.; McAlorum, J.; Dow, H.; Dobie, G. Threshold-Based BRISQUE-Assisted Deep Learning for Enhancing Crack Detection in Concrete Structures. J. Imaging 2023, 9, 218. [CrossRef]
- Veit A.; Wilber M.; Belongie S. Residual Networks Behave Like Ensembles of Relatively Shallow Networks[J]. Advances in Neural Information Processing Systems, 2016. [CrossRef]
- Tai Y.; Yang J.; Liu X. Image Super-Resolution via Deep Recursive Residual Network[J]. IEEE, 2017. [CrossRef]
- van der Schot, A.; Sikkel, E.; Niekolaas, M.; Spaanderman, M.; de Jong, G. Placental Vessel Segmentation Using Pix2pix Compared to U-Net. J. Imaging 2023, 9, 226. [CrossRef]
- T. Falk D. Mai; R. Bensch; O. Cicek; A. Abdulkadir; Y. Marrakchi; A. Bohm; J. Deubner; Z. Jackel; K. Seiwald et al. U-net: deep learning for cell counting, detection, and morphometry. Nature methods 2018, 1. [CrossRef]
- K. He; X. Zhang; S. Ren; J. Sun. Deep residual learning for image recognition. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, 770–778.
- Cumbajin, E.; Rodrigues, N.; Costa, P.; Miragaia, R.; Frazão, L.; Costa, N.; Fernández-Caballero, A.; Carneiro, J.; Buruberri, L.H.; Pereira, A. A Systematic Review on Deep Learning with CNNs Applied to Surface Defect Detection. J. Imaging 2023, 9, 193. [CrossRef]
- Kegelmeyer L.; Fong P.; Glenn S. ,et al. Local area signal-to-noise ratio (LASNR) algorithm for image segmentation[J]. Proceedings of SPIE - The International Society for Optical Engineering 2007, 6696. [CrossRef]
Figure 1.
Different types of false damage in online FODI images. (a) is an offline image, and all the damage can be regarded as real damage; (b) is an online image.
Figure 1.
Different types of false damage in online FODI images. (a) is an offline image, and all the damage can be regarded as real damage; (b) is an online image.

Figure 2.
Braille marks representing the last four digits of element numbers are carved at 4 corners of every optical element.
Figure 2.
Braille marks representing the last four digits of element numbers are carved at 4 corners of every optical element.

Figure 3.
The inconformity of brightness&contrast between photographs taken on different dates.

Figure 4.
The abnormal growth of damage area caused by the inconsistency of image brightness & contrast.
Figure 4.
The abnormal growth of damage area caused by the inconsistency of image brightness & contrast.
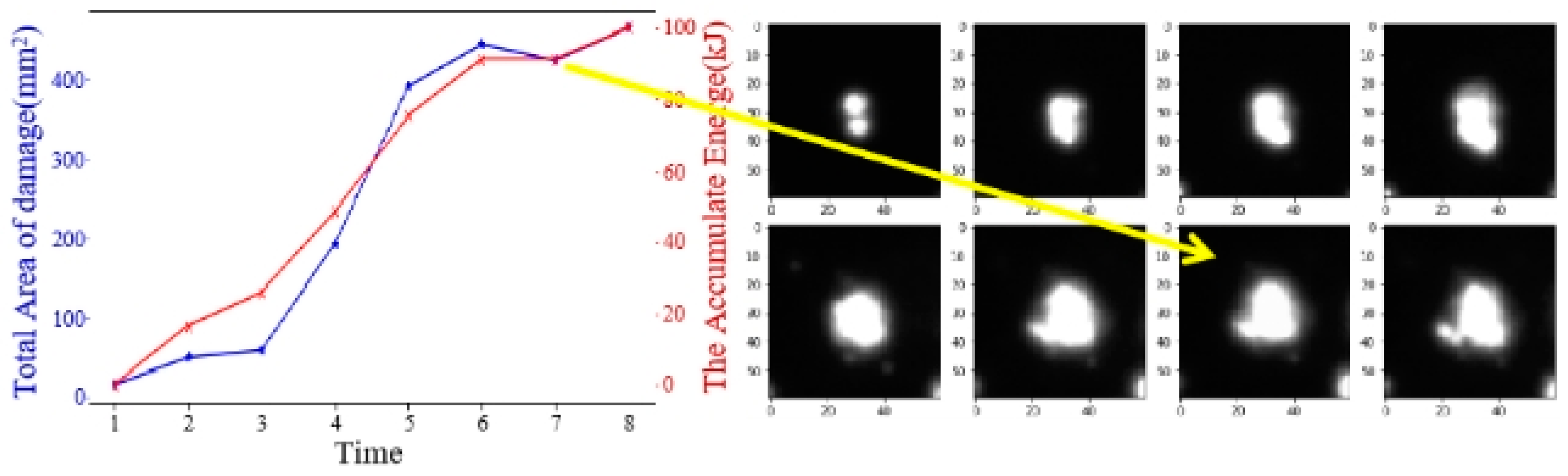
Figure 5.
Choose one graph as the standard and unify the brightness&contrast of other braille marks, calculate the adjustment coefficient and use it to adjust the whole graph.
Figure 5.
Choose one graph as the standard and unify the brightness&contrast of other braille marks, calculate the adjustment coefficient and use it to adjust the whole graph.

Figure 6.
Pixel gray scale histogram. (a) Before adjustment; (b) After adjustment.
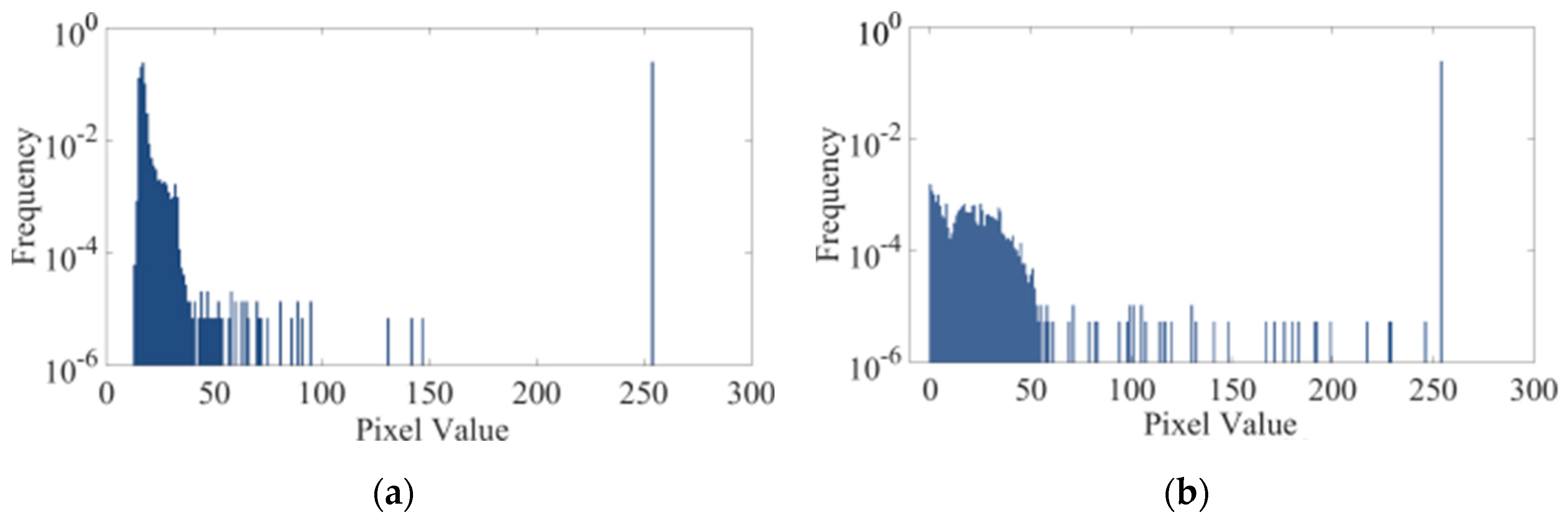
Figure 7.
The contrast of the adjusted graph with its pre-date graph.

Figure 8.
Braille pattern detection area before and after adjustment.
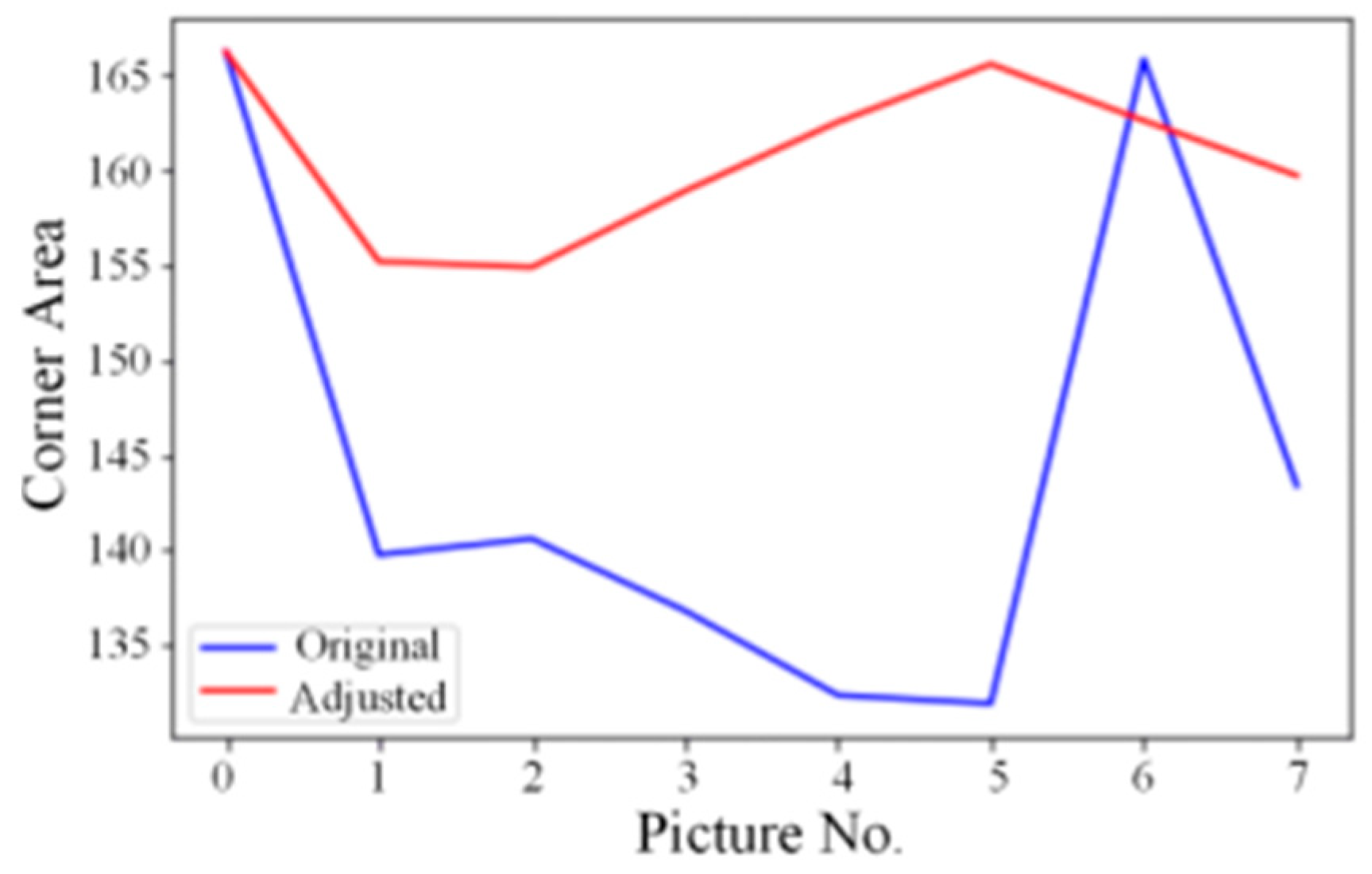
Figure 9.
Crop Braille marks after positioning.
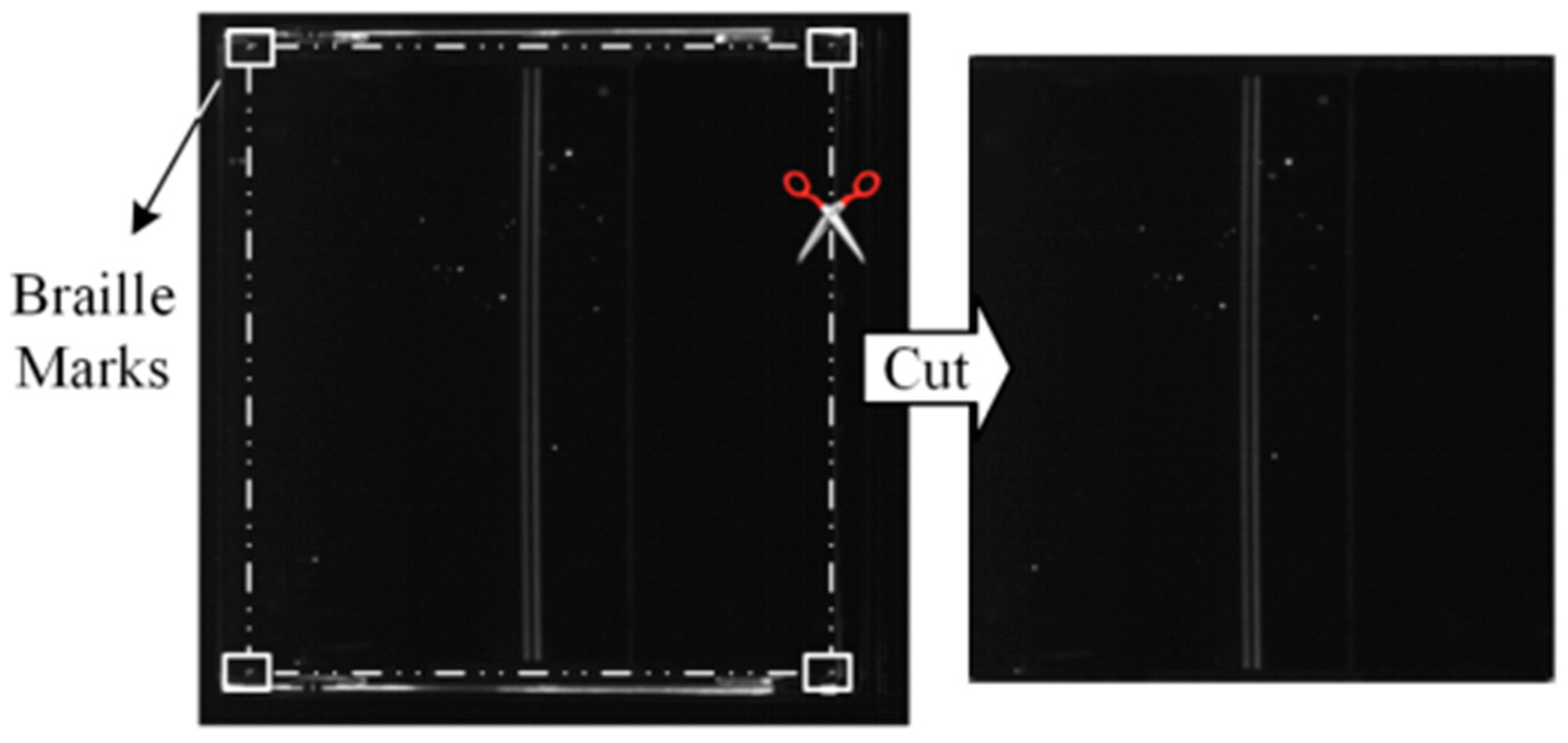
Figure 10.
The algorithm framework of damage detection.
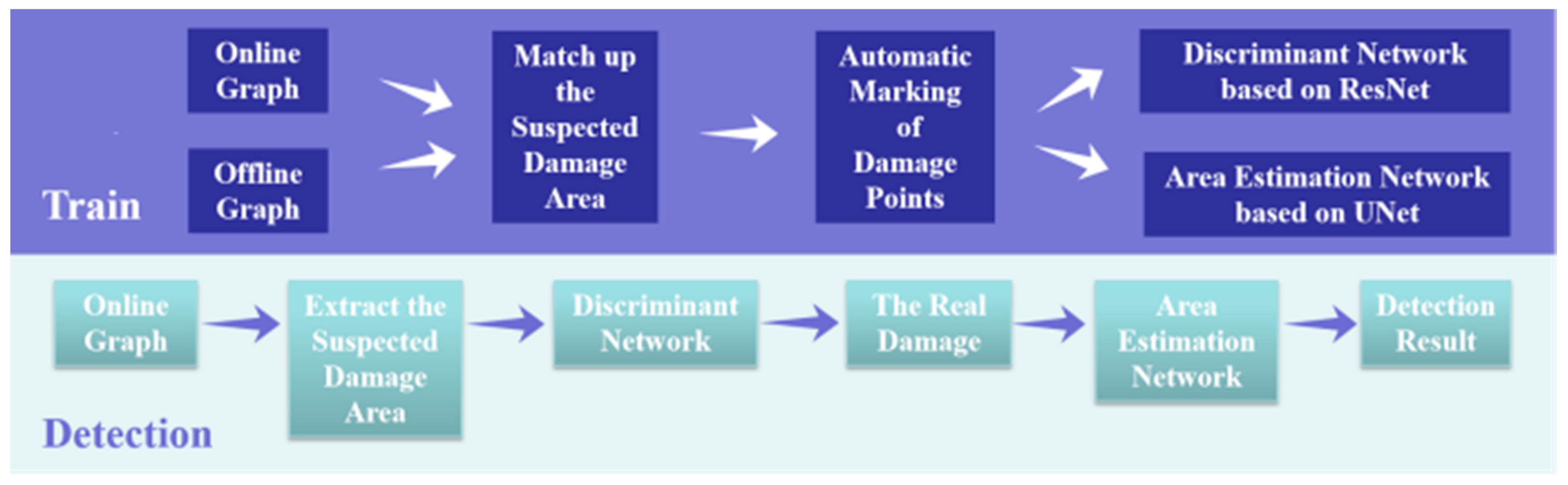
Figure 11.
This figure illustrates ResNet-18 based model proposed for real damage target recognition. These boxes correspond to the multi-channel feature map, and the side length of the box represents the pixel resolution.
Figure 11.
This figure illustrates ResNet-18 based model proposed for real damage target recognition. These boxes correspond to the multi-channel feature map, and the side length of the box represents the pixel resolution.
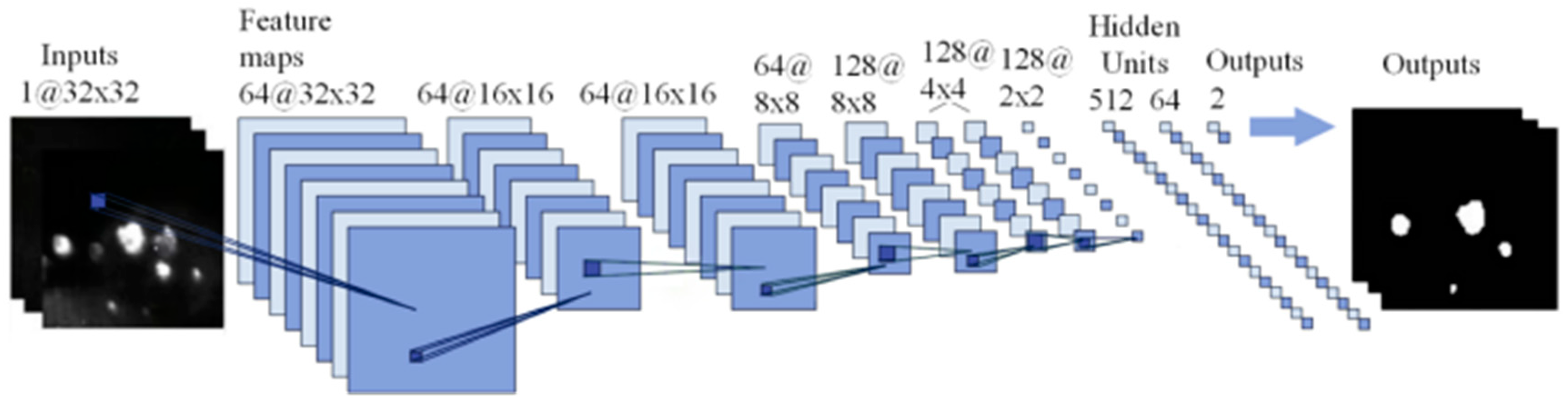
Figure 12.
The overall architecture to train the model for detection of optical defects in real time.
Figure 12.
The overall architecture to train the model for detection of optical defects in real time.
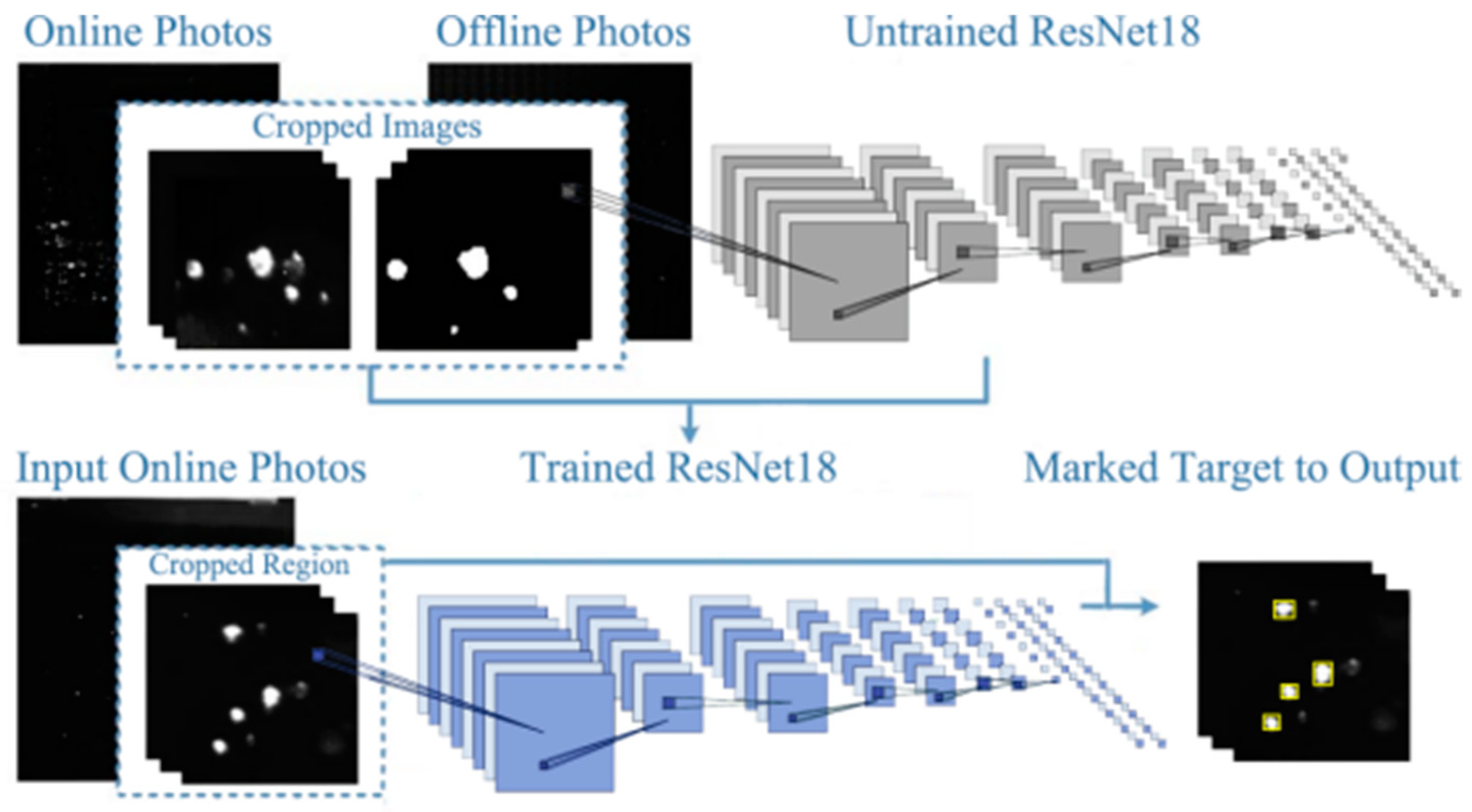
Figure 13.
The overall architecture to train the model for estimation of damage area.
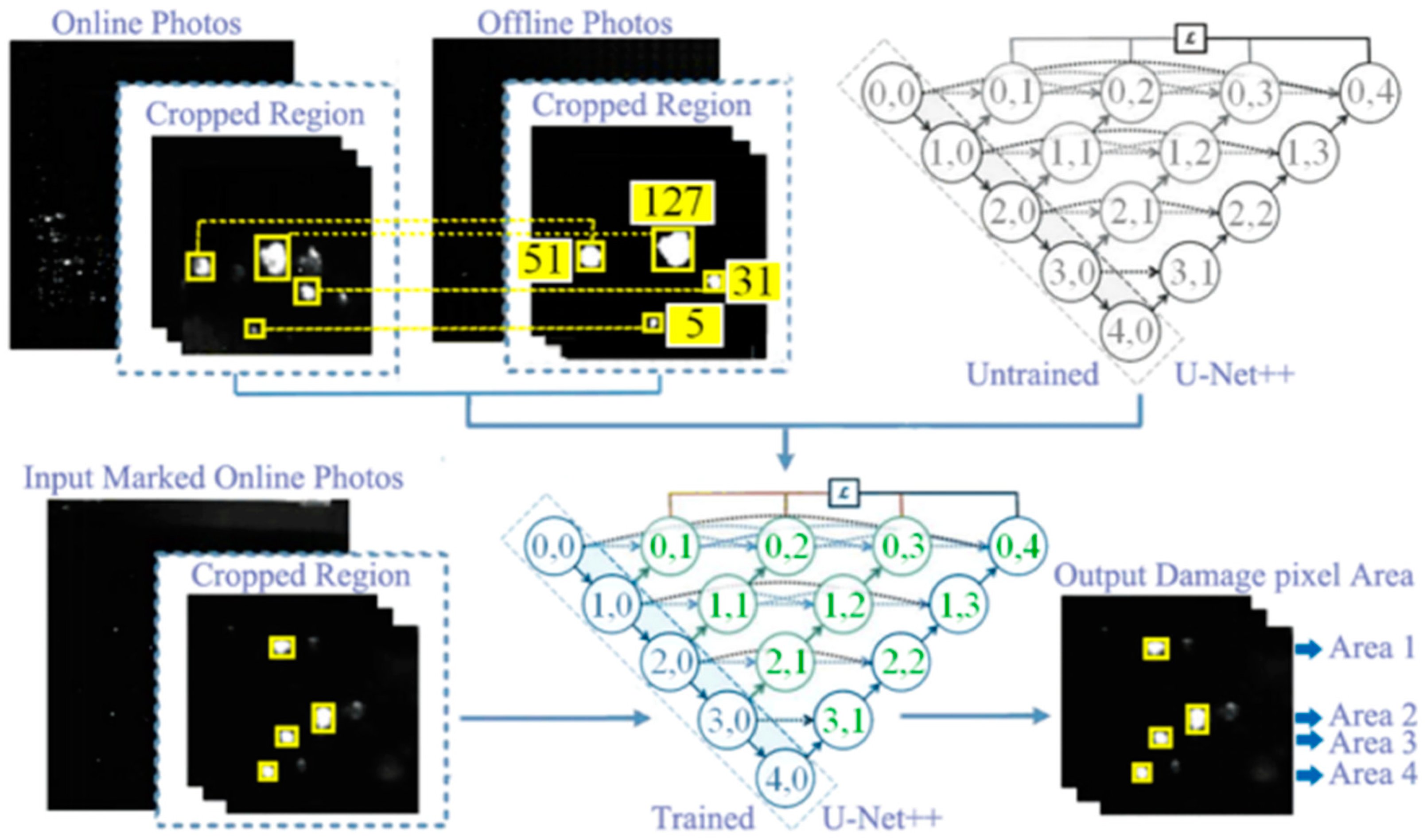
Figure 14.
The development law of single damage with the number of experiments.

Figure 15.
(a) Numerical simulation of the relationship between a single damage area and the energy; (b) The development and prediction of total damages.
Figure 15.
(a) Numerical simulation of the relationship between a single damage area and the energy; (b) The development and prediction of total damages.
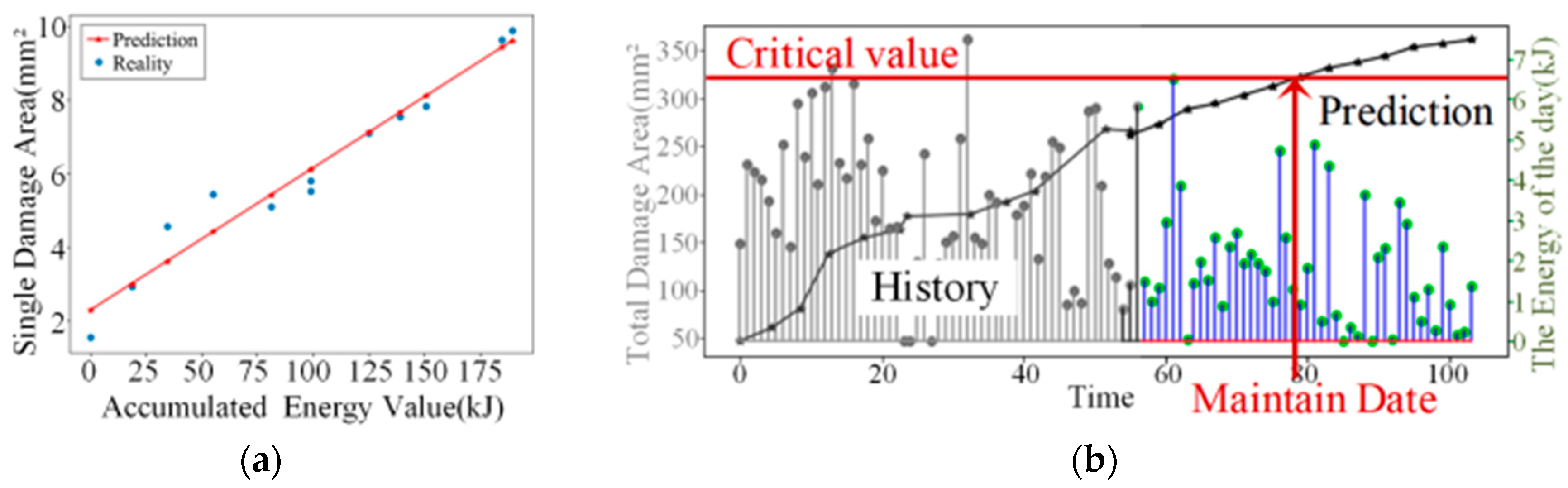
Figure 16.
Comparison between predicted value and actual value of damage area.
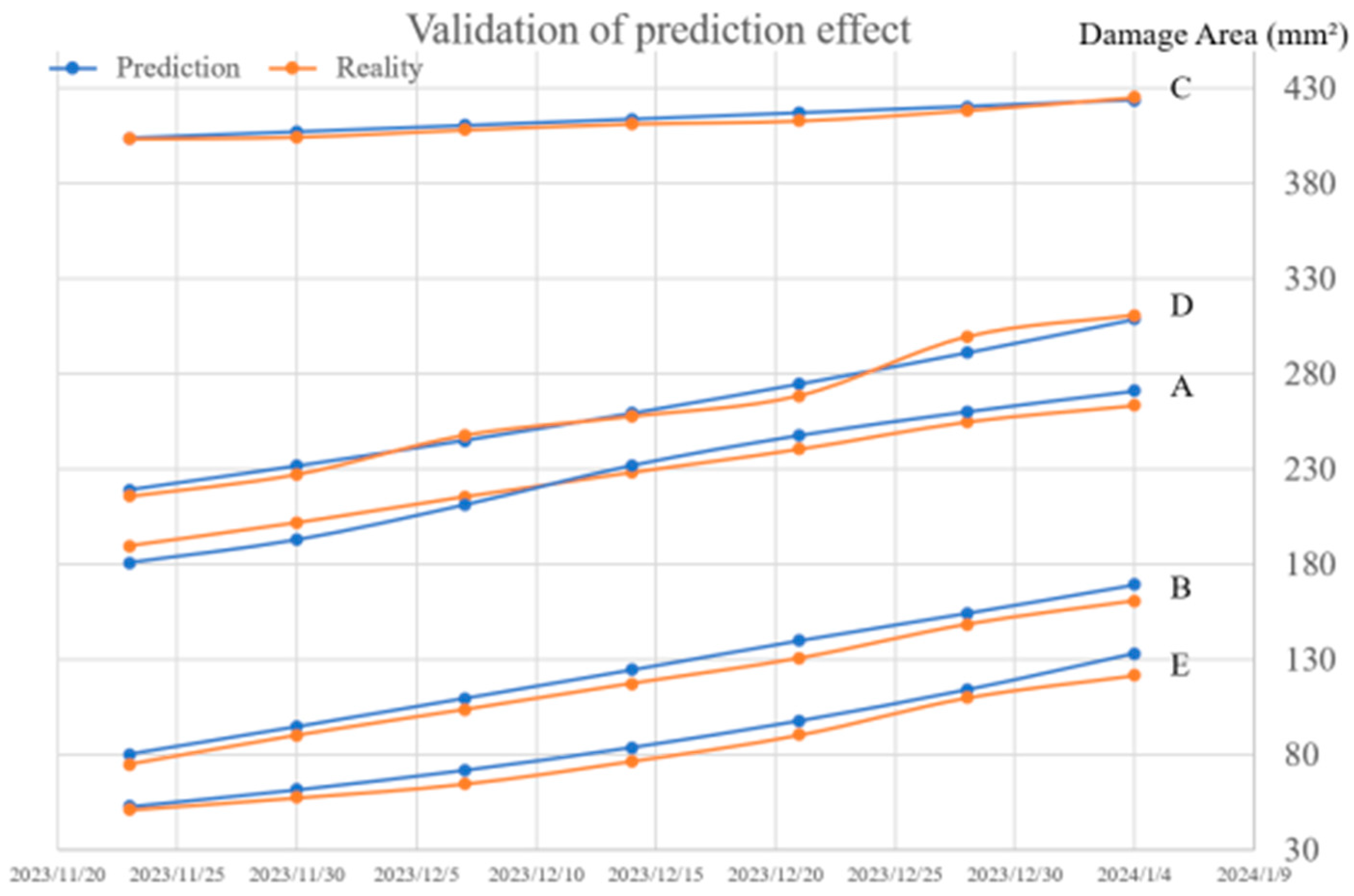
Figure 17.
An example of the result: The online damage image detection of a shield window.

Figure 18.
(a) Prediction of the growth of a single damage; (b) Prediction of the development of the total damages.
Figure 18.
(a) Prediction of the growth of a single damage; (b) Prediction of the development of the total damages.
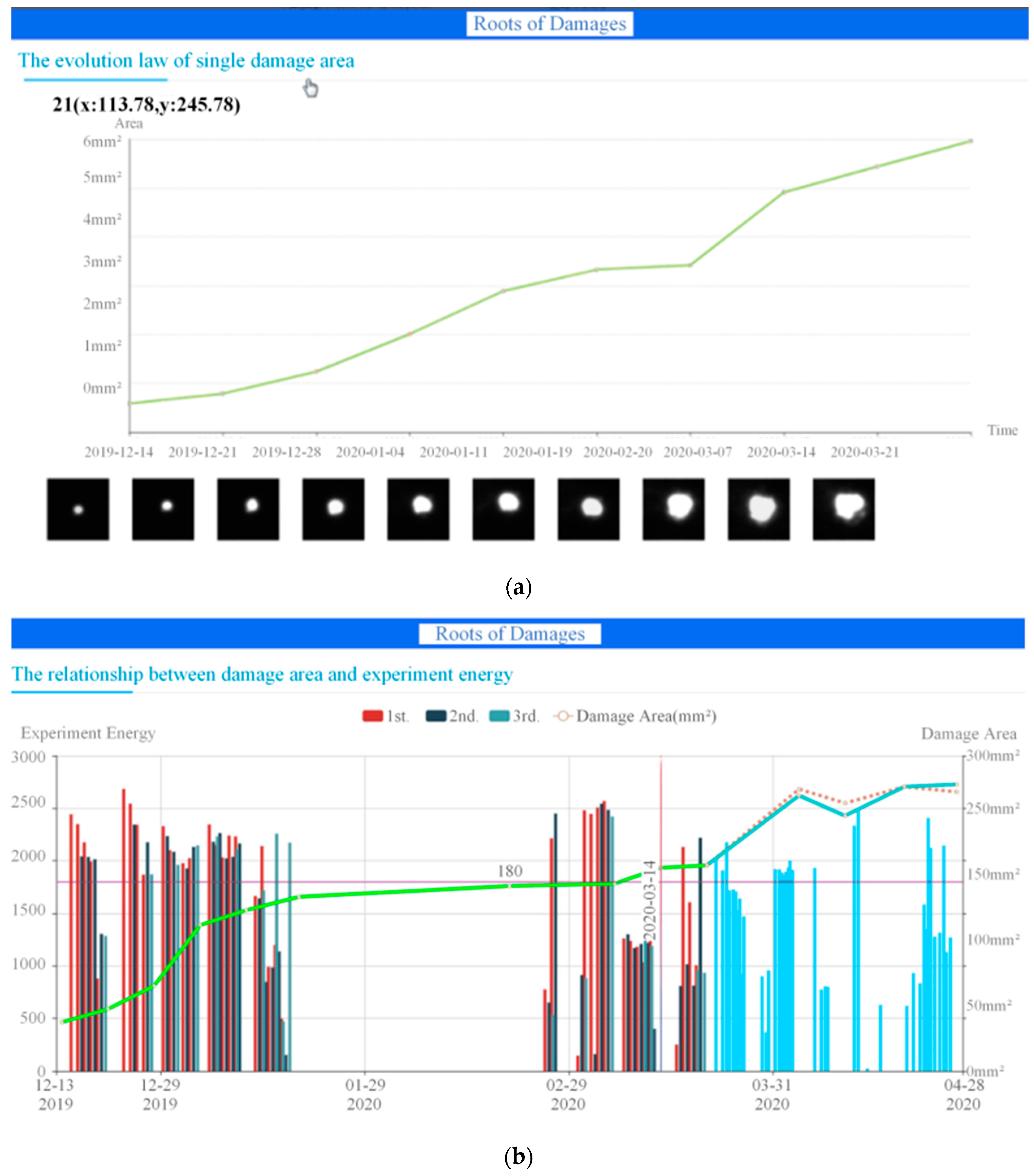

Table 1.
Comparison between predicted value and actual value of damage area.
| Object | Date | 11-23 | 11-30 | 12-07 | 12-14 | 12-21 | 12-28 | 01-04 |
|---|---|---|---|---|---|---|---|---|
| Area of Optics A (mm2) | Prediction | 189.50 | 201.75 | 215.41 | 228.32 | 240.57 | 254.97 | 263.62 |
| Reality | 180.74 | 192.81 | 211.21 | 232.04 | 247.89 | 260.38 | 271.29 | |
| Area of Optics B (mm2) | Prediction | 80.07 | 94.54 | 109.41 | 124.41 | 139.81 | 154.2 | 169.17 |
| Reality | 74.63 | 89.92 | 103.45 | 117.23 | 130.53 | 148.36 | 160.72 | |
| Area of Optics C (mm2) | Prediction | 404.07 | 407.31 | 410.57 | 413.85 | 417.17 | 420.51 | 423.87 |
| Reality | 403.54 | 404.46 | 408.22 | 411.38 | 412.98 | 418.44 | 425.34 | |
| Area of Optics D (mm2) | Prediction | 179.00 | 191.56 | 204.99 | 219.37 | 234.76 | 251.23 | 268.85 |
| Reality | 175.76 | 187.23 | 207.79 | 217.67 | 228.61 | 259.52 | 270.87 | |
| Area of Optics E (mm2) | Prediction | 52.64 | 61.43 | 71.69 | 83.67 | 97.64 | 113.95 | 132.98 |
| Reality | 50.97 | 57.27 | 64.53 | 76.49 | 90.26 | 109.75 | 121.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



