
Submitted:
16 April 2024
Posted:
16 April 2024
You are already at the latest version
Abstract
Fast Field-Cycling (FFC) Nuclear Magnetic Resonance (NMR) relaxometry is a powerful non-destructive magnetic resonance technique that enables, among other things, the investigation of slow molecular dynamics at low magnetic field intensities. FFC-NMR relaxometry measurements provide insight into molecular motion across various timescales within a single experiment.
This study focuses on a \textit{model-free} approach, representing the NMRD profile $R_1$ as a linear combination of Lorentzian functions, thereby addressing the challenges of fitting data within an ill-conditioned linear least-squares framework.
Tackling this problem, we present a comprehensive review and experimental validation of three regularization approaches to implement the model-free approach to analysing NMRD profiles.
These include: (1) \nameUpe, utilizing locally adapted $L_2$ regularization; (2) \nameL, based on $L_1$ penalties; and (3) a hybrid approach combining locally adapted $L_2$ and global $L_1$ penalties. Each method's regularization parameters are determined automatically, according to the Balancing and Uniform Penalty principles.
%
Our contributions include the implementation and experimental validation of the \nameUpe{} and \nameUp{} algorithms, and the development of a "dispersion analysis" technique to assess the existence range of the estimated parameters. The objective of this work is to delineate the variance in fit quality and correlation time distribution yielded by each algorithm, thus broadening the set of software tools for the analysis of sample structures in FFC-NMR studies. The findings underline the efficacy and applicability of these algorithms in the analysis of NMRD profiles from samples representing different potential scenarios.
1
Keywords:
Fast Field-Cycling (FFC) NMR relaxometry
; Model-free approach to NMR Dispersion profiles
; MuPen and L1 regularization algorithms.
1. Introduction
Fast Field-Cycling (FFC) Nuclear Magnetic Resonance (NMR) relaxometry is a powerful non-destructive magnetic resonance technique that allows the exploration of slow molecular dynamics, accessible only at extremely low magnetic field intensities. By varying the strength of the relaxation magnetic fields, FFC enables the assessment of the frequency dispersion of the longitudinal relaxation rate () within a sample, consequently producing NMR Dispersion (NMRD) profiles. Consequently, FFC-NMR relaxometry measurements can detect molecular motion across a broad spectrum of timescales within a single experiment.
Under the proper constraints [1], spin relaxation theory characterizes relaxation rates as linear combinations of spectral density functions, which are the Fourier transforms of the time correlation functions. These functions capture the frequencies and their intensities present in the correlation function. Several models exist in the literature (see [2] for a survey) where the longitudinal relaxation rates are related to the parameters representing the physical phenomena occurring in the analyzed sample. Thus, all these approaches depend on the specific sample examined.
An approach that allows greater flexibility is known as model-free [3], where the NMRD profile is expressed as a linear combination of Lorentzian functions.
The model-free approach leads to a data fit problem consisting of an ill-conditioned linear least-squares problem whose stable solution requires appropriate regularization.
We propose a review of three potential approaches: MF-UPen, which employs locally adapted regularization; an algorithm based on the penalty, referred to as MF-L1; and finally, a method called MF-MUPen, that utilizes both locally adapted and global penalties. In all these approaches the regularization parameters are computed through automatic procedures founded on the Balancing Principle (BP) [4] and the Uniform Penalty principle [5].
All the algorithms are inspired by two-dimensional time-domain NMR relaxometry techniques. The locally adapted regularization was originally introduced by Bortolotti et al. in [5], where the regularization parameters are determined by applying the Uniform Penalty principle. The global regularization has been applied in [6] which addresses the more complex problem of data exhibiting spurious peaks caused by Quadrupolar Relaxation Enhancement. Finally, the coupling of locally adapted and global penalties was originally introduced by Bortolotti et al. in [7] for inverting two-dimensional NMR relaxation data and has been adapted to NMRD profiles.
The contributions of this work are the following:
- 1.
- The implementation and experimental testing of the MF-UPen algorithm, featuring a novel rule for automatically computing the threshold parameter .
- 2.
- The implementation and experimental testing of the MF-MUPen algorithm.
- 3.
- Development of a "dispersion analysis" procedure, enabling the determination of the existence range for estimated parameters.
Our aim is to illustrate the diversity of results achievable with different algorithms, focusing on fit quality and correlation time distribution. These insights will enrich the suite of software tools available for enhancing sample structure analysis in FFC-NMR studies.
2. The Parameter Identification Problem
In the following, we first describe the continuous model for NMRD profiles and then we derive its discretization.
Lo Meo et al. [8] developed a heuristic algorithm to model the NMRD profiles based on the model-free approach where the profiles are defined as a combination of two terms:
where is the Larmor angular frequency. The first term is an unknown offset keeping into account very fast molecular motions; the second term describes relaxation as
where represents the correlation time, i.e., the average time required by a molecule to rotate one radiant or to move for a distance as large as its radius of gyration, and f is the distribution to be recovered. Equation (1) identifies a parameter identification problem where the unknown parameters have to be estimated from NMRD profile values.
By discretizing equation (1), we obtain the following linear system:
where derives from the discretization of the integral for in (2):
with the vector representing the m Larmor angular frequency values (, with in ) at which the signal is evaluated. The unknown vector of the correlation times distribution is obtained by sampling in n logarithmically equispaced values . The vector represents the observations vector, i.e., , with . Generally, for a typical FFC-NMR experiment, .
Defining and we can reformulate (3) in a more compact form:
We underline that the model-free analysis provides a fingerprint of the possible motion regimes regardless of their physical-chemical interpretation. In fact, the integral form of the equation (2) unconstrainedly gives only the number of the possible correlation times describing the dynamics of the overall physical system. Instead, the typical approach used in FFC NMR relaxometry requests an ad-hoc mathematical model containing information about the number and meaning of the correlation times that describe a given system [6].
3. The Algorithms
From a mathematical point of view, the estimation of the parameters , and starting from the experimental observation represents an ill-conditioned linear inverse problem.
In this section, we describe the proposed algorithms based on locally adapted regularization (MF-UPen), -based regularization (MF-L1) and multi-penalty consisting of local- and penalties (MF-MUPen).
3.0.1. MF-UPen Algorithm
This algorithm, implementing the locally adapted regularization, solves the following constrained minimization problem:
with where is the discretization of the second derivative operator, according to central finite difference formulas, and is the components null column vector. Observe that the regularization is imposed only on the parameter since the sum in (6) ranges for indices i from 1 to n. The regularization parameters , are computed according to the following relaxed UPEN principle [5,9]:
where , and the are the indices subsets related to the neighborhood of the th entry, i.e. . The ’s are positive parameters. The parameter prevents division by zero and is a compliance floor, which should be small enough to prevent under-smoothing and large enough to avoid over-smoothing. The optimum value of ’s could substantially change with the nature of the measured sample.
The parameters are used to enhance or mitigate the local effects of slope/curvature. A preliminary trial value that often yields satisfactory results is . The parameter , however, is more critical; its value should not exceed the threshold defined by
while a too-small value, especially in cases where slope and curvature approach zero, would lead to an extremely ill-conditioned problem, hence causing computational challenges.
Therefore, we propose an automatic rule for determining based on the estimate of (8) obtained from a tentative solution computed by the Truncated Singular Value Decomposition [10] of the matrix :
where represent the singular values, and the vectors represent the i-th columns of U and V, respectively.
By setting:
where and , we calculate as follows:
The advantage of this approach is that it substitutes the parameter , which can range in , with the parameter , which is confined within the interval . This substitution ensures that remains lower than the highest values of V but higher than the lowest ones. This makes determining more intuitive, particularly when supported by a visual representation of V.
Summarizing, MF-UPen is an iterative scheme where, given an initial guess , , an approximate solution is computed by solving (6) for fixed , , and the regularization parameters values are updated according to (7). The minimization problem (6) is solved by the Newton projection method (NP) [5]. MF-UPen is sketched in Algorithm 1; the iterations are stopped when the following condition is satisfied
where Tol is a fixed tolerance.
| Algorithm 1 MF-UPen |
3.0.2. MF-L1 Algorithm
This algorithm employs an -norm based penalty, which is preferred for inducing sparsity in . This approach is based on the assumption that the distribution is a sparse function characterized by only a few non-zero terms.
The problem of parameter identification is reformulated as the following optimization problem:
where is the regularization parameter computed according to the Balancing Principle (BP) [4]. Following [6] we rewrite (11) as
In this new formulation (12) the last -based penalty term, , has been introduced only to ensure that is a definite positive matrix to ensure that (12) is well-posed. It is not a regularization term and a small positive value for is fixed.
The MF-L1 algorithm is an iterative procedure where, starting from an initial guess , at each iteration k, an estimate of the parameters is computed by solving the parameter estimation problem (12) for fixed , by the truncated Newton interior-point method [11] (see algorithm 2, step (4)). Then a new value is determined by using the BP (see [4] for a deep theoretical discussion). The BP selects the regularization parameter so that the data fidelity and the regularization terms are balanced up to a multiplicative factor , i.e.,:
We fix , and we obtain the following rule for the parameter selection:
The MF-L1 method is summarized in Algorithm 2.
| Algorithm 2 MF-L1 |
|
The Matlab implementation of this algorithm is part of the freeware Matlab tool, ModelFreeFFC, which addresses the more complex issue of data exhibiting spurious peaks caused by Quadrupolar Relaxation Enhancement. The software can be downloaded from https://site.unibo.it/softwaredicam/en/modelfree. For a detailed discussion, please refer to [6].
3.0.3. MF-MUPen Algorithm
This algorithm implements the multi-penalty approach, proposed in [7] for the two-dimensional NMR relaxometry data. MF-MUPen solves the following unconstrained minimization problem:
which incorporates both penalty functions from MF-UPen and MF-L1. The regularization parameters are then calculated using (7) for and (14) for .
Summarizing, MF-MUPen is an iterative scheme where, given an initial guess , , a parameter estimate is computed by solving (15) for fixed , . Problem (15) is solved by the FISTA method [12] which is one of the most popular methods for minimizing -penalized least squares functions.
MF-MUPenis stopped when the following condition is satisfied
MF-MUPen is sketched in Algorithm 3.
| Algorithm 3 MF-MUPen |
|
Algorithms 1,2 and 3 require an initial estimate for the regularization parameters. This can be obtained by computing a rough approximation to the following nonnegatively constrained least squares problem
and then by using the Balancing and Uniform Penalty principles to get the initial guess. More precisely,
in Algorithms 2, 3 and
in Algorithms 1 and 3.
4. Results and Discussion
In this section, we report and discuss the results obtained by the proposed algorithms on samples of two different materials well representing typical case tests.
In the first part Section 4.1, we present the metrics used to evaluate the results’ quality quantitatively and the experimental setting. In the last part, Section 4.2, we report and discuss the results obtained by the algorithms.
Numerical computations were carried out using Matlab R2022b on a laptop equipped with Apple M1 chip with 16 GB of RAM. Please observe that throughout the section, we refer to the frequencies instead of the angular frequencies , i.e., .
4.1. Experimental Setting
The fitted NMRD profiles, computed by algorithms 1, 2 and 3 are compared to the data by means of the value defined as follows:
where is the estimated data value, i.e.
with the computed parameters. We quantitatively compare the computed correlation time distributions given by the three algorithms determining the peak values and the area below in the neighbourhood of such peaks, defining such a value as SpecificWeight. Let us assume that f has local maxima at the correlation times , . Then we define the neighborhood of interest using the Full Width at Half Maximum parameter, i.e.
We compute the SpecificWeight value for each peak , i.e:
where is the number of correlation times belonging to , .
The value of the tolerance parameters used in the stopping criteria of all algorithms is . Moreover a maximum number of 10 iterations k has been set but never reached. The computational cost is evaluated in terms of execution time.
To test the algorithms’ robustness, we apply them to a set of artificial profiles obtained by adding to uniformly distributed noise within the experimental error intervals. With these tests, referred as dispersion analysis, we aim to explore the intervals containing the recovered parameter and how the calculated estimates scatter around the average value. Additionally, we want to examine how the position and value of the peaks change in the recovered correlation times distributions.
4.2. Numerical Results from FFC Measures
We present the results obtained by applying all the algorithms to NMRD profiles obtained from two experimental samples, Manganese and Poplar, respectively. These two samples show how the algorithms’ results can complement each other to improve the overall quality of the information provided. We evaluate the global quality of the examined methods in terms of , offset and computation time.
The data for the Manganese Sample is measured at 26 frequency values , ranging from to MHz. The error intervals for these measurements vary from to . These are illustrated by the black error bars in the left panel of Figure 1.
The Table 1 presents the estimated parameter , the goodness-of-fit measure , and the computation time in seconds obtained by the three algorithms. We observe that MF-L1 achieves a moderate value and the shortest computation time. In contrast, MF-UPen shows a slightly higher and takes longer to compute. Conversely, MF-MUPen achieves the best fit, as evidenced by the lowest . This suggests a superior model accuracy, with a modest increase in computation time.
The data for the Poplar Sample is measured at 21 frequency values , ranging from to MHz. The error intervals for these measurements vary from to . These are illustrated by the black error bar in the right panel of Figure 1.
The Table 1 outlines the computational results obtained for the Poplar sample by the three algorithms. MF-UPen and MF-L1 both report nearly identical values for , with minimal and very short computation times, indicating efficient and effective performance. However, MF-MUPen, while yielding a similar to the other two algorithms, shows a higher value, suggesting a slightly poorer fit. Additionally, MF-MUPen requires longer computation time.
The outcomes for the Manganese and Poplar samples represent two scenarios, each indicative of the potential variability in sample analysis. This diversity highlights the importance of utilizing multiple methods to fully understand sample characteristics under varying conditions.
The peak analysis for both the Manganese and Poplar samples across the three methods is performed by plotting the correlation times amplitudes computed by each method in Figure 2 and reporting in the Table 3, Table 4 peaks positions amplitudes, half-width and SpecificWeights for each sample.
In Table 3 we observe a perfect agreement among the three methods in locating the peak at longest correlation time . While MF-UPen and MF-L1 have a quite good agreement at the intermediate times: and respectively. The distribution pattern in Figure 2, left panel, shows similarity features between MF-UPen and MF-MUPen and reveals a tendency of MF-L1 to resolve multiple components at the shortest times.
In the case of the Poplar sample, as shown in the right panel of Figure 2 and Table 4, we observe a tighter clustering of peaks across the methods, particularly at the highest amplitude peak around . This suggests that all three methods are in agreement concerning the main features of the Poplar sample’s distribution.
4.3. Dispersion Analysis
The robustness of the methods is investigated through the dispersion analysis, described in Section 4.1. The boxplots in Figure 3 offer a comparative view of algorithmic performance on the two samples. Each boxplot outlines the algorithms’ interquartile range (IQR) and median of values.
We observe uniformity in medians for the Manganese sample, with outliers highlighted by red plus symbols, suggesting occasional significant deviations for MF-UPen. The symmetry of the data is evident from the whiskers’ lengths.
Conversely, the Poplar sample exhibits a tighter IQR for each algorithm, denoting less variability. Despite the close median values indicating consistent algorithmic performance, outliers for MF-L1 reveal notable deviations in some cases.
Table 5 compares the confidence intervals, mean , and medians for both Manganese and Poplar samples across the three algorithms.
The confidence intervals and mean values suggest a wider range of estimates for the Manganese sample, indicating a less uniform agreement among the algorithms. The median values, while closer, still reflect a notable variation between the algorithms, suggesting that the model fit depends on the algorithm applied.
Conversely, the Poplar sample demonstrates remarkable consistency, with both confidence intervals and mean values being nearly identical across all three algorithms. The median values also closely align, reinforcing the observation of uniform performance. This indicates that for the Poplar sample, the choice of algorithm does not significantly influence the outcome, and all three algorithms provide equivalent information.
Table 5 represents two distinct scenarios that may emerge when these algorithms are applied to samples with varying characteristics. In the case of the Poplar sample, the outcome from all three algorithms is congruent, implying that the algorithms are robust and interchangeable for this type of sample. Conversely, the Manganese sample demonstrates less consistency across the algorithms, suggesting that additional insights from alternative investigative methods are necessary to supplement the analysis.
Concerning the distribution intensities, we computed the mean distribution obtained by each method and analyzed the peak positions and amplitudes analogously to Table 1 and Table 4 for the single samples.
From both Table 6 and Table 7 we notice that MF-L1 tends to identify a greater number of peaks compared to the other two methods, suggesting a higher algorithm’s sensitivity.
In the case of the Manganese sample, the data reported in Table 6 show that there is a perfect correspondence in peak position at the longest correlation time among the three algorithms. While the peaks at shortest and intermediate times are split into multiple components.
Concerning the poplar sample (Table 7), we observe that all algorithms show identical peak positioning corresponding to the largest amplitude, reached at the shortest correlation time . At longest correlation times, MF-UPen finds a single peak around while MF-L1 and MF-MUPen split the amplitudes in two peaks at and respectively.
However, despite the differences in the number of peaks identified, Figure 4 shows that all three algorithms exhibit a fundamental robustness in the localization of the positions of the highest peaks.
5. Conclusion
This study reviews three algorithms designed for the analysis of NMRD profiles from experimental data, showing their efficacy in two different datasets representative of possible applicative scenarios. The comparative analysis of the three algorithms, while revealing a general consistency in identifying the primary peak positions, shows that MF-MUPen exhibits higher robustness in the presence of data noise.
In conclusion, the proposed algorithms have the potential to significantly improve the quality of NMRD profile analysis and enrich the toolkit available to researchers for investigating the molecular dynamics of various samples.
References
- Kimmich, R.; Anoardo, E. Field-cycling NMR relaxometry. Progress in Nuclear Magnetic Resonance Spectroscopy 2004, 44, 257–320. [Google Scholar] [CrossRef]
- Bortolotti, V.; Brizi, L.; Landi, G.; Testa, C.; Zama, F. Introduction to FFC NMR Theory and Models for Complex and Confined Fluids 2024.
- Halle, B.; Jóhannesson, H.; Venu, K. Model-Free Analysis of Stretched Relaxation Dispersions. Journal of Magnetic Resonance 1998, 135, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Ito, K.; Jin, B.; Takeuchi, T. A Regularization Parameter for Nonsmooth Tikhonov Regularization. SIAM Journal on Scientific Computing 2011, 33, 1415–1438. [Google Scholar] [CrossRef]
- Bortolotti, V.; Brown, R.J.S.; Fantazzini, P.; Landi, G.; Zama, F. Uniform Penalty Inversion of two-dimensional NMR relaxation data. Inverse Problems 2016, 33, 19. [Google Scholar] [CrossRef]
- Landi, G.; Spinelli, G.; Zama, F.; Martino, D.C.; Conte, P.; Lo Meo, P.; Bortolotti, V. An automatic L1-based regularization method for the analysis of FFC dispersion profiles with quadrupolar peaks. Applied Mathematics and Computation 2023, 444, 127809. [Google Scholar] [CrossRef]
- Bortolotti, V.; Landi, G.; Zama, F. 2DNMR data inversion using locally adapted multi-penalty regularization. Computational Geosciences 2020, 25, 1215–1228. [Google Scholar] [CrossRef]
- Lo Meo, P.; Terranova, S.; Di Vincenzo, A.; Chillura Martino, D.; Conte, P. Heuristic Algorithm for the Analysis of Fast Field Cycling (FFC) NMR Dispersion Curves. Analytical Chemistry 2021. [Google Scholar] [CrossRef] [PubMed]
- Bortolotti, V.; Brown, R.; Fantazzini, P.; Landi, G.; Zama, F. I2DUPEN: Improved 2DUPEN algorithm for inversion of two-dimensional NMR data. Microporous and Mesoporous Materials 2018, 269, 195–198. [Google Scholar] [CrossRef]
- Hansen, P.C. Truncated singular value decomposition solutions to discrete ill-posed problems with ill-determined numerical rank. SIAM Journal on Scientific and Statistical Computing 1990, 11, 503–518. [Google Scholar] [CrossRef]
- Kim, S.J.; Koh, K.; Lustig, M.; Boyd, S.; Gorinevsky, D. An Interior-Point Method for Large-Scale ℓ1-Regularized Least Squares. IEEE Journal of Selected Topics in Signal Processing 2007, 1, 606–617. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences 2009, 2, 183–202. [Google Scholar] [CrossRef]
Figure 1.
Comparison of relaxation rates for the Manganese and Poplar samples. The plots show the comparative analysis between the actual data and the results from the MF-UPen, MF-L1, and MF-MUPen algorithms.
Figure 1.
Comparison of relaxation rates for the Manganese and Poplar samples. The plots show the comparative analysis between the actual data and the results from the MF-UPen, MF-L1, and MF-MUPen algorithms.
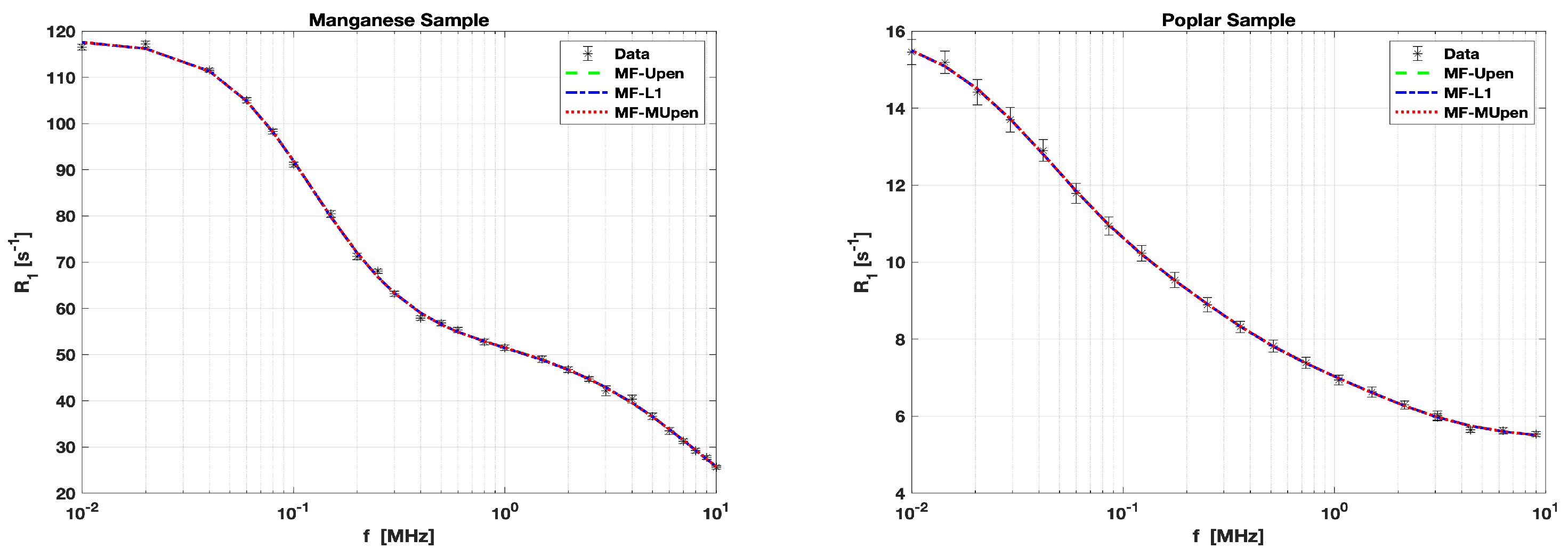
Figure 2.
Distribution intensity as a function of for the Manganese and Poplar samples. The plots show the results from the MF-UPen, MF-L1, and MF-MUPen algorithms.
Figure 2.
Distribution intensity as a function of for the Manganese and Poplar samples. The plots show the results from the MF-UPen, MF-L1, and MF-MUPen algorithms.
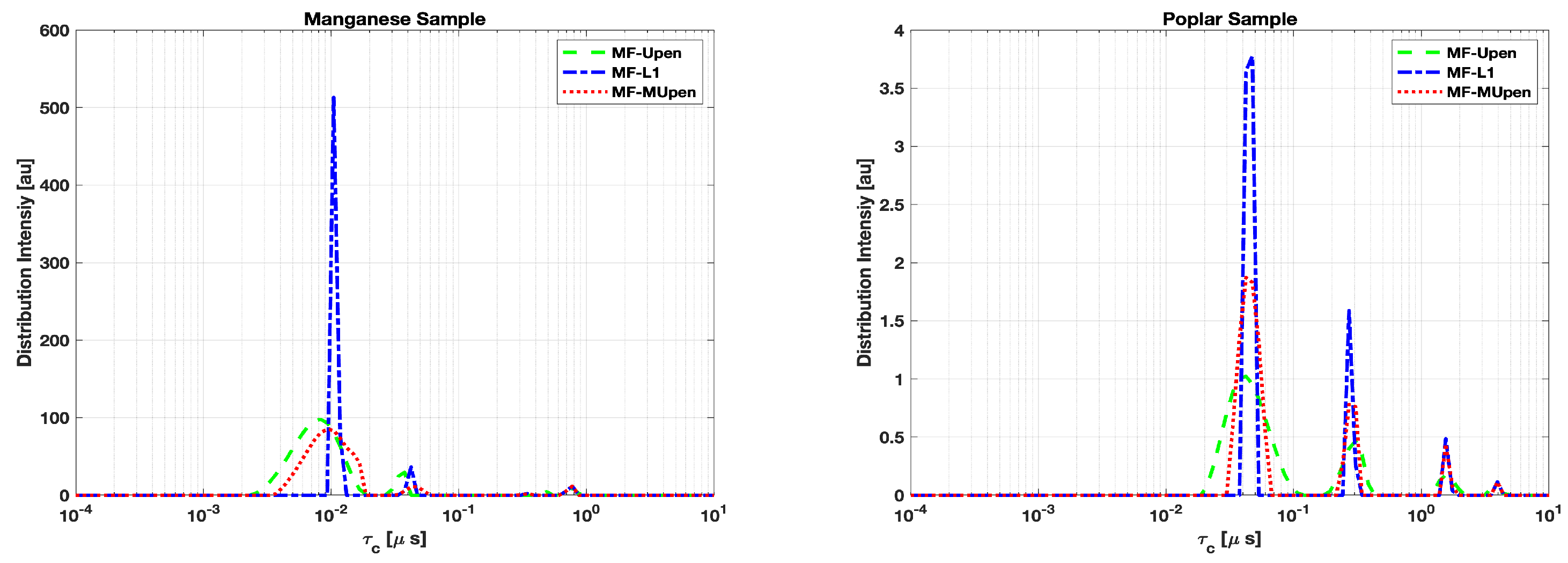
Figure 3.
Boxplot of the values for the Manganese and Poplar samples, comparing the results of the different algorithms on 500 data realizations.
Figure 3.
Boxplot of the values for the Manganese and Poplar samples, comparing the results of the different algorithms on 500 data realizations.
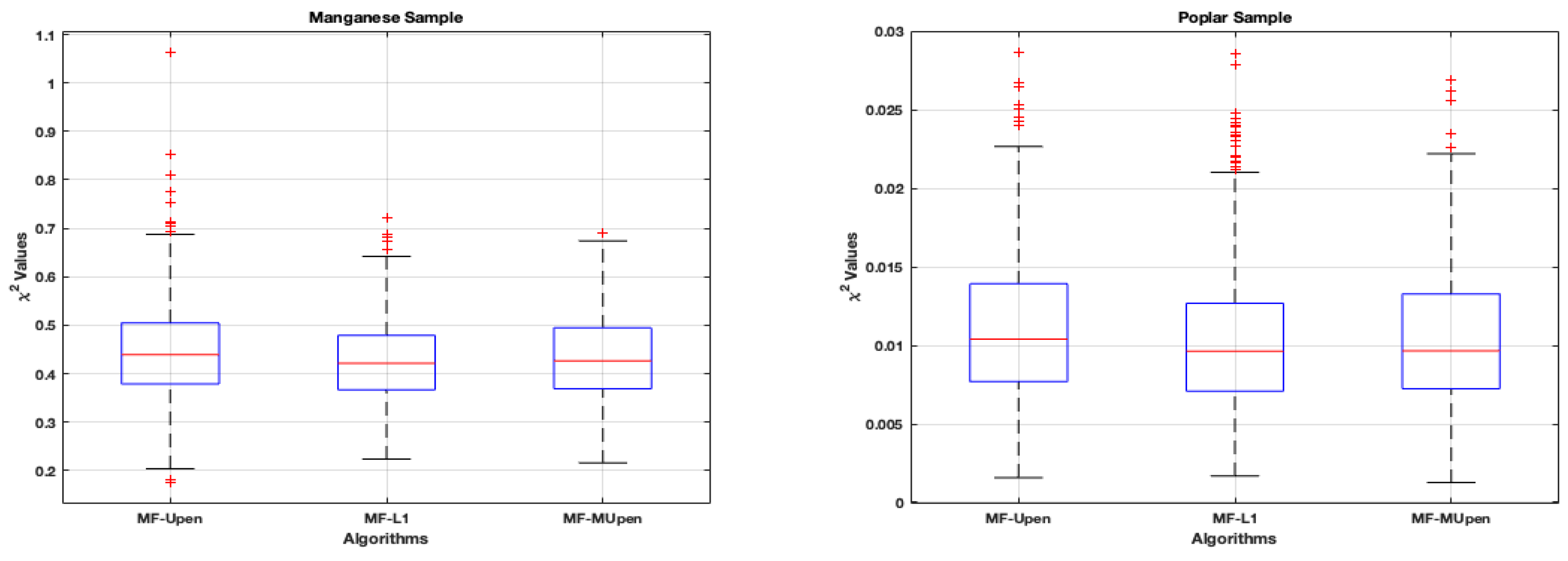
Figure 4.
Mean distribution amplitude over 500 data realizations for Manganese and Poplar samples.
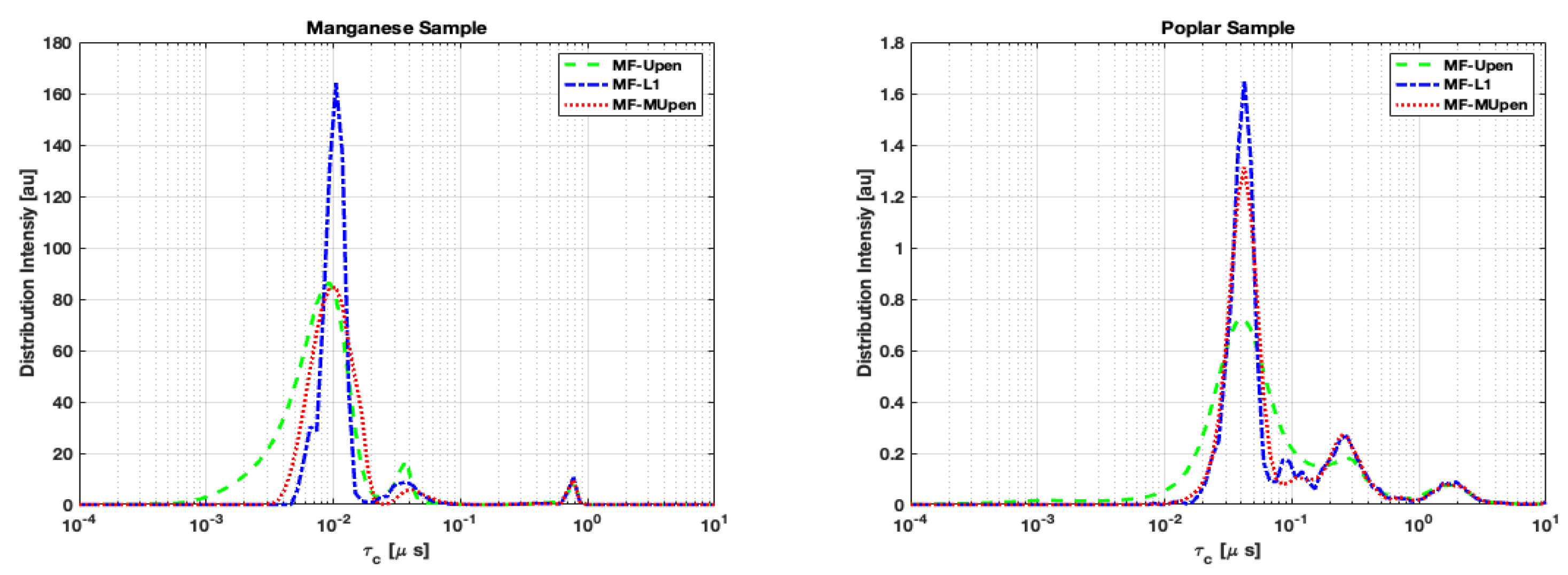

Table 1.
Manganese Sample. Computational results of the proposed methods.
| Algorithm | Computation Time [s] | ||
|---|---|---|---|
| MF-UPen | |||
| MF-L1 | |||
| MF-MUPen |
Table 2.
Poplar Sample. Computational results of the proposed methods.
| Algorithm | Computation Time [s] | ||
|---|---|---|---|
| MF-UPen | |||
| MF-L1 | |||
| MF-MUPen |
Table 3.
Manganese Sample Analysis. Position () and amplitude of the distribution peaks sorted by .
| Algorithm | Half-width | SpecificWeight | ||
|---|---|---|---|---|
| MF-UPen | ||||
| MF-L1 | ||||
| MF-MUPen | ||||
Table 4.
Poplar Sample Analysis. Position () and amplitude of the distribution peaks sorted by .
| Algorithm | Half-width | SpecificWeight | ||
|---|---|---|---|---|
| MF-UPen | ||||
| MF-L1 | ||||
| MF-MUPen | ||||
Table 5.
Comparison of R0 Confidence Intervals, Mean R0, and Median for Manganese and Poplar samples.
Table 5.
Comparison of R0 Confidence Intervals, Mean R0, and Median for Manganese and Poplar samples.
| Sample | Algorithm | R0 Confidence Interval | R0 Mean | Median |
|---|---|---|---|---|
| Manganese | MF-UPen | [5.240, 9.253] | ||
| MF-L1 | [9.251, 12.12] | |||
| MF-MUPen | [9.652, 11.38] | |||
| Poplar | MF-UPen | [5.363, 5.406] | ||
| MF-L1 | [5.370, 5.413] | |||
| MF-MUPen | [5.370, 5.416] |
Table 6.
Manganese Sample. Analysis of mean distribution over 500 realizations. Position () and amplitude of the distribution peaks sorted by .
Table 6.
Manganese Sample. Analysis of mean distribution over 500 realizations. Position () and amplitude of the distribution peaks sorted by .
| Algorithm | Half-width | SpecificWeight | ||
|---|---|---|---|---|
| MF-UPen | ||||
| MF-L1 | ||||
| MF-MUPen | ||||
Table 7.
Poplar Sample. Analysis of mean distribution over 500 realizations. Position () and amplitude of the distribution peaks sorted by .
Table 7.
Poplar Sample. Analysis of mean distribution over 500 realizations. Position () and amplitude of the distribution peaks sorted by .
| Algorithm | Half-width | SpecificWeight | ||
|---|---|---|---|---|
| MF-UPen | ||||
| MF-L1 | ||||
| MF-MUPen | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



