
Submitted:
16 April 2024
Posted:
17 April 2024
You are already at the latest version
Abstract
Functional genomics, a multidisciplinary subject, investigates the functions of genes and their products in biological systems to better understand diseases and find new drugs. Drug repurposing is an economically efficient approach that entails discovering novel therapeutic applications for already-available medications. Genomics enables the identification of illness and therapeutic molecular characteristics and interactions, which in turn facilitates the process of drug repurposing. Techniques like gene expression profiling and Mendelian randomization are helpful in identifying possible medication candidates. Progress in computer science allows for the investigation and modelling of gene expression networks that involve large amounts of data. The integration of data from DNA, RNA, and protein activities has resemblance to pharmacogenomics, which is of utmost importance in the development of cancer drugs. Functional genomics in drug discovery, particularly for cancer, is still not thoroughly investigated, despite the existence of a significant amount of literature on the subject. Next-generation sequencing and proteomics present highly intriguing opportunities. Publicly available databases and mining techniques facilitate the development of cancer treatments based on functional genomics. Expanding the study and application of functional genomics has great promise to advance the process of discovering and repurposing drugs, especially in the field of oncology.
Keywords:
drug repurposing
; genomics
; Proteomics
; NGS
1. Introduction
1.1. Functional Genomics and Drug Repurposing
The field of functional genomics investigates the roles that genes and the products they produce play in biological systems, including tissues, cells, and organisms. Functional genomics can help identify the molecular mechanisms of diseases and potential targets for drug intervention.[1] Drug repurposing is the process of finding new therapeutic uses for existing drugs that have already been approved or tested for other indications [2]. Drug repurposing can save time and money compared to the traditional drug discovery process and can also provide novel treatments for unmet medical needs [3]. Genomics plays an important role in drug repurposing, as it can provide insights into the molecular signatures of diseases and drugs and reveal the potential interactions and effects of drugs on different biological pathways and networks[4]. One of the common strategies for drug repurposing based on genomics is to compare the gene expression profiles of diseases and drugs and identify drugs that can reverse or modulate the disease signatures[5]. Another strategy is to use Mendelian randomization, which is a method that uses genetic variants as natural experiments to infer causal relationships between exposures and outcomes, such as drugs and diseases [4,6]. moreover, this field of research that looks at the physiological, cellular, and/or biochemical properties of each gene product [7]. The aim is to determine the global effects of the genome on the phenotype. Thanks to these advancements, studying disease models and targeted medications has become a data-intensive field that can only be grasped by utilising concurrent advances in computer science, such as knowledge bases, big data mining techniques, machine learning techniques, and artificial intelligence. [8]. These techniques have been used in the research and development of cancer drugs.. The process of merging data from several processes related to DNA sequence, gene expression, and protein function is comparable to that of pharmacogenomics. These mechanisms encompass transcription, both coding and noncoding, translation of proteins, interactions between proteins and DNA and RNA, and protein-protein. Then, using these data, interactive and dynamic networks that control gene expression, cell differentiation, and the cell cycle's advancement are modelled [9]. We attempted searching on to obtain realistic scenes of the amount of info that was available. A search was conducted on PubMed at www.ncbi.nlm.nih.gov/pubmed on January 31, 2024, to find relevant literature for these things. In particular, the search query is 'functional AND (genomic OR genomics) AND (cancer OR carcinoma) AND pharmacol* AND (genome OR transcriptome OR proteome OR metabolome OR interactome) NOT review'. Overall A total of 584 hits were obtained, most of these had links to genetic association studies of small sets of genes with traits associated with disease. In this area, only a few important approaches have been tried to use functional genomics for the specific goal of drug discovery and repurposing, especially for cancer indications [10], instead of just talking about general findings that could lead to this outcome (Figure 1). These approaches include the use of next-generation sequencing (NGS) for cancer drug research purposes [11], functional proteomics-based approaches to cancer target identification, and knowledge discovery Table 1 lists many publicly accessible data bases and mining tools that are used in these primary scenarios of using functional genomics-based techniques for cancer treatment discovery. These scenarios will be briefly discussed and illustrated in the following.
Utilising genetic research in a variety of ways has made it possible to utilise in silico drug development and job repurposing [12]. All of the approaches share the analysis of data on drug interactions with molecular processes and the connection between this information and the molecular pathophysiology of the disease of interest. Additionally, computational molecular docking methods try to find the best places for small molecules to bind by looking at how well the chemical structures match up with each other[13]. Depending on the compound's uniqueness in the pharmacological setting, this is utilized for both drug discovery and repurposing [14]. To conduct virtual screens, a known drug is docked into a wide range of target structures, or an approved drug listed in a database is docked into the targeted protein. Therefore, the use of molecular docking is limited to research projects where a target's three-dimensional structure is craeted by nuclear magnetic resonance, crystallography, or comparative modelling [15]. MAPK1, also known as ERK2 (Extracellular Signal-Regulated Kinase 2), is a gene that encodes a protein belonging to the MAP kinase family. It plays a crucial role in various cellular processes, including cell proliferation, differentiation, and survival. MAPK1 is a key component, has been implicated in several diseases, including cancer.so, study with MAPK1 computational molecular docking was used successfully in an analgesic setting in a study that put drugs from the DrugBank database [16,17] into the 35 crystal structures of MAPK1[18]. This suggested that nilotinib, a Bcr Abl tyrosin kinase inhibitor, could be repurposed to treat inflammatory illnesses. The researchers used published experiment results that validated 31 of the most plausible interactions to support their computational conclusion. This study bears similarities to previous ones that employed computational functional genomics techniques.. Similarly, COX-2 inhibitor called celecoxib was also found to target the membrane protein cadherin-11, which has been linked to rheumatoid arthritis [19]. Also, to generate perturbation profiles of drug-treated versus untreated gene expressions, transcriptional responses are employed [20]. Comparing various gene expression patterns, such as those from GEO (Gene Expression Omnibus), is the foundation of other techniques [21], that are either caused by medicine or linked to disease. This necessitates information about the changes in gene expression brought about by drugs, which can be obtained by comparing a cell's expression profile before and after drug exposure. It also requires knowledge of the changes in gene expression linked to the disease of interest. specifically, phenomenon where the gene expression profile of a cell or tissue, which has been altered due to a particular condition or treatment and returns to a state similar to its original and genes or proteins are implicated in a biological process or function based on their co-expression or co-occurrence patterns with known genes or proteins associated with that process. In contrast to specific pharmacological targets or theories about how they work in the characteristic of interest [22], phenotypic drug discovery methods try to deal with the complicated nature of diseases that we don't fully understand.. [23]" molecular drug targets are merely a conduit between the drug and biological processes that are relevant to the disease. Diseases are viewed as the result of alterations in the activity of one or more biological processes that are involved in the pathophysiology of the disease. Listed biological processes that are included in the knowledge base of GeneOntology (GO) [24] In conclusion, the integration of genomics data and the exploration of biological processes play a pivotal role in the field of drug repurposing, offering a systematic approach to identify potential therapeutic candidates.
1.2. GWAS & Drug Repurposing
In the grand quest for novel therapeutic avenues, Genome-wide Association Studies (GWAS) unfurl their molecular sails to navigate the genomic seas [25]. These studies meticulously scan the vast expanse of our genetic landscape, revealing cryptic variants intricately tied to various diseases [26]. This genetic treasure map marks the first step in the intricate dance of drug discovery and repurposing, as these variants become beacons guiding researchers towards uncharted territories of potential treatments [27]. So, genome-wide association studies (GWAS) play a crucial role in drug repurposing by uncovering genetic variants associated with diseases and providing insights into potential therapeutic targets[28]. Here are two case studies illustrating the impact of GWAS in the drug repurposing process [29]. An unbiased method of genomewide association studies (GWAS) is used to find correlations between genotype and phenotype in genotyping arrays or sequencing data [30]. GWAS has been carried out for thousands of features, improving our knowledge of human genetics and advancing the creation of treatments and diagnostics[31]. 2, 3: Genotype-phenotype association analysis (GWAS) has become a crucial method for comprehending how genotype shapes phenotype due to the increasing quantity of genetic information[32]. investigations of genome-wide associations [33]. Over the past years, there has been a significant rise in the number of genome-wide association studies (GWAS) due to advancements in genotyping technology, the completion of the Human Genome Project, and declining genotyping prices. The goal of GWAS is to find genetic variants linked to common diseases, which will shed light on the biology of diseases. The information gathered might also help find new targets [34]. It's possible that some of these targets are common to both GWAS-studied disease phenotypes and drug-treated diseases. This could lead to drugs being moved to different positions. 44. The pharmaceutical industry's targets were 2.7 times more enriched in the GWAS gene set [35]. Sanseau and colleagues 44 improved the list of published GWAS traits from the US National Human Genome Research Institute (NHGRI). Researchers discovered that genes related to a disease trait were more likely than genes in other parts of the genome to code for proteins that can be potential for developing pharmaceutical interventions to treat a specific condition or developing new ones to influence the target for therapeutic purposes. They also found 92 different genes with a GWAS phenotype different from the initial therapeutic indication. This means that treatments targeting the products of these 92 genes may be tested for a new illness indication . Grover and colleagues 45 did a different study that used bioinformatics to look for possible repositioning opportunities[36]. They did this by matching gene targets found for coronary artery disease with drug information gathered by combining three drug-target databases (DrugBank [37], Therapeutic Target Database, and PharmGKB [38]). GWAS data can be difficult to use for medication repositioning(), and it is currently uncertain how useful it is. It might be hard to find the causal gene and/or gene variants when GWAS signals are present in areas with a lot of genes and a lot of linkage disequilibrium [39]. A further problem is the lack of knowledge regarding the gene variant's direction of action; functional investigations must be carried out to determine this before determining whether an activator or a suppressor is needed to manage the disease() [44]. When predicting repurposing targets, it is recommended to use GWAS data intuitively, as they do not provide precise pathophysiological information [40]. It should be highlighted that there may be many more novel genes found and that our current understanding of the human genome is not final. Genome-wide Association Studies (GWAS) are a strong tool in the complex game of genetic discovery [29,41]; they comb through the vast expanse of our genetic code to reveal the secrets woven into our DNA strands. By expertly charting the landscape of diseases and locating elusive variants that may hold the key to unlocking individualised treatment plans, these investigations serve as genetic cartographers. As the notes of genetic symphonies are decoded, GWAS orchestrates a shocking discovery by bringing to light specific groups of patients with unique molecular stories. Patient stratification enables us to create homogeneous groups that are suited for individualised, targeted therapies. It is the art of extracting accuracy from complexity. This method is also considered an alchemist of drug development, opening doors into the mysterious worlds of genes and pathways involved in the development of illnesses. These findings suggest that there may be drug targets out there just waiting to be found or used again, like old scrolls. The master of links, GWAS, creates a tapestry connecting genetic variants linked to disease and currently available medications, providing access to therapeutic options catered to certain genetic subtypes. The combination of pharmacology and genetics is what makes drug development such a focused and fast-moving endeavor. The wisdom of genomics gives rise to precision medicine, which uses a patient's unique genetic composition to create a personalised treatment plan. Each genetic note in the symphony determines how a certain medicine will respond to it, resulting in a personalised, efficacious tune. When it comes to clinical trials, GWAS shines as a beacon that points the way towards patient populations most likely to benefit from a certain medication. With this focused strategy, clinical trials become well-executed productions where success and efficiency go hand in hand. GWAS acts as a sorcerer, unravelling the secrets of specific genes and pathways intricately woven into the fabric of diseases. These genetic insights metamorphose into potential drug targets, offering a trove of opportunities for both novel drug development and the repurposing of existing medications. The flow of meachisam of action shown in Figure 2.
So, The integration of drug repurposing into this GWAS sharpens our focus on the intricate genetic basis of diseases. By unravelling specific genetic alterations highlighted by GWAS, researchers gain insights essential for drug repurposing ndeavors. With information about disease subtypes, researchers can search through the huge field of pharmacology to find drugs that have already been made for other uses but may work against certain disease subtypes that were identified through GWAS. In the realm of precision medicine, this approach transcends conventional treatment paradigms. Repurposed drugs, tailored to specific disease subtypes identified through GWAS, align with the principles of precision medicine. This personalised strategy considers the unique genetic makeup of individual patients or specific subgroups, offering a nuanced and effective approach to treatment. Validation is based on clinical data from repurposing trials, which shows that certain drugs are effective at treating certain types of disease. This iterative process refines and validates disease subtype classifications based on genetic markers, fostering confidence in the precision medicine approach. Furthermore, drug repurposing emerges as a potent catalyst for expediting the drug development process. By bypassing the need to start from scratch, researchers capitalise on the existing safety profiles and pharmacological data of repurposed drugs. This accelerates the translation of genetic insights into actionable treatment options for specific disease subtypes, paving the way for more efficient and targeted interventions. The culmination of GWAS-guided disease subtype mapping and drug repurposing heralds a new era of personalised treatment strategies. Patients within a particular disease subtype stand to benefit from treatments finely tailored to their specific genetic vulnerabilities, promising improved therapeutic outcomes. Basically, the combination of GWAS and drug repurposing is a big step towards a future where complex genomic landscapes guide therapeutic efforts. This could lead to a more accurate, effective, and resource-efficient healthcare system. or rediscovery, laying the foundation for more streamlined drug development pipelines. Drug repurposing using single nucleotide polymorphism (SNP) analysis is a promising approach for identifying new indications for existing drugs. Several studies have utilised genomic analysis and functional annotations to identify drug-repurposing candidates for various diseases, including metabolic disease. To come up with new hypotheses for cancer and rare diseases [42] , computational methods have been created that combine different types of chemical and genomic data, such as chemical structures, drugtarget interactions, pathways, and disease-gene associations.
GWAS charts a course through the perilous waters of pharmaceutical treatments, revealing the possible storm clouds of adverse reactions in search of safe havens. The guardian angel of precision medicine, precision medicine employs genetic findings as a compass to steer treatment decisions away from dangerous areas and towards calmer waters. The incorporation of GWAS data becomes the compass steering the ship towards better therapeutic results as the genetic symphony continues, promising optimised drug selection and dose catered to each patient's distinct genetic melody. Drug repurposing, when coupled with genome-wide association studies, introduces a paradigm shift in the understanding and treatment of diseases. Therefore, GWAS heralds the era of personalised precision in drug repurposing , where every genetic strand contributes to a well-balanced and efficient healthcare symphony.
2. Gene Expression Signatures and Drug Repurposing
Gene expression signatures can be used in drug repurposing to identify new therapeutic applications for existing drugs. Potential therapeutic candidates can be found for repurposing by evaluating the overall transcriptome effects of medications and comparing them to illness gene expression characteristics [43].Drug repurposing for different types of cancer has made use of the idea of [44] , which entails finding medications that can restore gene expression changes brought on by a disease to healthy levels. A computational system based on gene expression signatures and connection scores has been created to find possible repurposable medicines. These methods have demonstrated potential for locating therapeutic candidates for conditions like low-survival malignancies and psoriasis. Overall, gene expression signatures play a crucial role in the field of drug repurposing by providing insights into the molecular effects of drugs and their potential therapeutic applications [45].
Another, imporatant area in gene expresion study refere as Transcriptome signature reversion. Its aa concept at the forefront of genomic research, unravels the dynamic intricacies of gene expression patterns within biological systems[46]. As interventions, treatments, or environmental stimuli induce alterations in the transcriptome, the study of signature reversion[47] delves into the intriguing phenomenon of whether the gene expression profile returns to its original state over time[48]. This process is paramount in deciphering the long-term impacts of therapeutic interventions[49], guiding researchers to discern the resilience and adaptability of cellular responses. The investigation of transcriptome signature reversion holds immense significance, particularly in drug development and precision medicine. It offers a nuanced understanding of how biological systems respond to external influences[50] and whether the induced changes are reversible, providing crucial insights[51] for tailoring interventions and optimizing treatment strategies. In unveiling the dynamics of gene regulation, transcriptome signature reversion emerges as a pivotal concept shaping the landscape of genomic exploration, promising advancements in our comprehension of cellular behavior and potential avenues for therapeutic discovery[52]. it has been used a lot to find new uses for drugs that have already been approved, is the main benefit of genomic signatures in oncology-based drug repurposing for different types of cancer.
The standard protocol for a Transcriptome Signature Reversion (TSR) drug repositioning study typically involves employing differential gene expression analysis to elucidate the specific genes that exhibit altered expression patterns in tumor tissue compared to adjacent healthy normal tissue. This foundational step is crucial for identifying potential therapeutic candidates and understanding the molecular underpinnings of the disease. By pinpointing genes that are either upregulated or downregulated in the tumor context, researchers gain valuable insights into the unique transcriptomic signature associated with the pathological state. This differential gene expression analysis serves as the basis for subsequent investigations, guiding the selection of candidate drugs for repositioning. The approach not only illuminates the molecular landscape of the disease but also provides a rational framework for exploring existing drugs with the potential to modulate the identified gene expression changes, thereby advancing drug repositioning efforts in the realm of cancer therapeutics. Also, The Connectivity Map (CMap) database and the Library of Integrated Network-Based Cellular Signatures (LINCS) L1000 database are two prominent resources used for mapping altered gene expression patterns observed in the disease context. Moreover,numerous studies that have employed this process have produced drugs with anticancer effectiveness against particular tumour types, indicating that TSR has a good predictive capacity for ranking potential medicines for repurposing. The concept of TSR in oncology has the strongest available systematic evidence. A study showed that the compounds tested in a single cell line of that tumour type had an associated median half maximal inhibitory concentration (IC50) that could be used to reverse the gene expression signatures of breast, liver, and colorectal tumours. Nevertheless, rather than focusing on the upstream "cause" of the proliferative phenotype that distinguishes a particular cancer type, medications identified using TSR may instead address the downstream proliferative "effect." It has been shown that drugs that decrease cell viability have similar disruption profiles of gene expression, which are linked to transcription factors regulating cell death, proliferation, and division time. Stated differently, a larger anticipated inversion of a cancer gene expression profile based on the pharmacological signature may reflect the treatment's overall efficacy to limit cell proliferation rather than its specificity to the specific type of tumour being studied. As a result, TSR as it is currently applied is not as useful for drug repurposing as previously believed since it is not specific enough to determine which drugs are most likely to be effective against a particular type of cancer[53]. The drug signatures that indicate downstream gene expression effects that result in fewer cells surviving may be removed in order to improve the accuracy of TSR.

Table 2.
List of drug repurposed for cancer target.
| Drug | Discovered | Repurposed | Ref. |
|---|---|---|---|
| Anastrazole | Ovulation induction | Breast cancer | [54] |
| Capecitabine | Colon cancer | Breast cancer | |
| Cyclophosphamide | As immuno-modulator in autoimmune | Breast cancer | |
| Everolimus (Votubia, Evertor) | Immunosuppressants during organ | Breast cancer | |
| Exemestane | Ovulation induction | Breast cancer | |
| Fluorouracil | Keratoacanthomas, actinic kerato- | Breast cancer | |
| Fulvestrant | Antiestrogen | Breast cancer | |
| Gemcitabine | Anti-viral drug | Breast cancer | |
| Goserelin | Prostate cancer, uterine fibroids, precursor cleavage | Breast cancer, a variety of cancers | |
| Methotrexate | Leukemia | Breast cancer | |
| Paclitaxel | Ovarian cancer, atrial restenosis | Breast cancer | |
| Raloxifene | Osteoporosis in postmenopausal | Breast cancer | |
| Thiotepa | Immunosuppressant | Breast cancer | |
| Letrozole | Ovulation induction | Breast cancer | |
| Toremifene | Infertility with an ovulatory disorder | Breast cancer | |
| Vinblastine | Hodgkin lymphoma, non-Hod- | Breast cancer | |
| Docetaxel | Hormone-refractory prostate cancer | Breast cancer and active against fungal biofilms | |
| Clarithromycin, pioglitazone, | Antibiotic | Non-small cell lung cancer | [55] |
| Digoxin | Treatment for cardiac diseases | Anticancer | |
| Disulfiram (Antabuse) | Reduces ethanol tolerance in alco- | Metastatic breast cancer & Alzheimer’s | [56] , |
| Mibefradil (Posicor) | Antihypertensive, calcium channel | Short term use as an adjuvant in cancer | |
| Metformin | Diabetes | Anti-nonsmall cell lung cancer, and aug- cancer | |
| Itraconazole | Antifungal | Anticancer | [57] |
| Mebendazole | Antiparasitic/Helminthiasis/Anti- infective | Brain cancer (i.e., medulloblastoma and | |
| Mycophenolic acid | Immunosuppressant | Anticancer |
One of case studies on Dexamethasone resistance,which is a bottleneck in the treatment of Acute Lymphoid Leukemia (ALL), was found to be overturned when treated with Sirolimus. The gene signatures of dexamethasone resistance and sensitivity in both control and diseased patients were constructed from bone marrow leukemic cells and used as query signatures in CMap. The query signatures of dexamethasone sensitivity exhibited a high correlation with sirolimus (a mTOR inhibitor). Further, Gene Set Enrichment Analysis (GSEA) [58]revealed a high degree of correlation between the down-regulated genes of the Sirolimus-treated lymphoid cells and the up-regulated genes of glucocorticoid-resistant cells. Also, in vitro analysis using the lymphoid cell line CEM-c1 revealed that pretreatment with 10 nM sirolimus increased the sensitivity of dexamethasone in dexamethasone-resistant ALL cells and non-resistant ALL cells . Based on promising results from computational and in vitro analysis, proof-of-concept was established to support the current status of siroliums in phase I trials in combination with dexamethasone for relapsed ALL (NCT01403415) [59].
Figure 3.
Stages of Gene expression signatures and drug repurposing.
Another, studies shows using publicly available molecular data reporting gene expression in inflammatory bowel disease (IBD) samples, the authors searched a database of small-molecule drug compounds. Gene expression signatures were compared across a range of known drug compounds to a gene expression signature of IBD from the National Centre for Biotechnology Information's Gene Expression Omnibus (GEO) GEO is an international public database that archives microarrays, next-generation sequencing, and other forms of high-throughput functional genomics data. generated predictions for drug-disease relationships based on the hypothesis that if a drug has a gene expression profile that is opposite of the disease expression profile, then that drug represents a potential treatment for that disease. Different studied model predicts the corticosteroid drug prednisolone to show the opposite gene expression profile of Crohn's disease; prednisolone is indeed a well-known treatment approach for managing the symptoms of Crohn's disease. When tested on the gene expression profile for ulcerative colitis, the drug topiramate was shown to have the opposite pattern. This means that it could be used as a therapeutic agent topiramate is a safe, FDA-approved drug for the treatment of epilepsy and migraine headaches and, therefore, was identified as a promising candidate for repurposing to treat IBD. As a retrospective administrative claims study did not provide evidence to support this indication of topiramate as an alternative strategy, if two drugs have a similar gene expression impact, then the two drugs could share a therapeutic application, regardless of their chemical structure or direct drug target. The rationale is that finding another drug with a similar genetic mechanism of action could result in a new therapy with improved efficacy or safety. Many researcher developed an automated approach that exploits similarity in transcriptional response in human cell lines following drug treatment (across multiple cell lines and dosages) to predict similarities in drug effect and mechanism of action. The result is a publicly available Mode of Action by Network Analysis (MANTRA; http://mantra.tigem.it/) tool for the analysis of the mode of action of novel drugs and the identification of candidates for drug repositioning. In addition, expression quantitative trait loci analysis, which melds genomics approaches with transcriptomic approaches, has proven useful for mapping genetic variants with tissue-specific gene expression. Together, these tools, in combination with in vitro reporter assays and functional in vivo assays, can help identify genes associated with disease for further exploration. Combining various omics to generate more holistic hypotheses and approaches represents an important advancement in the use of existing data and is a strategy that should continue to be employed and improved. Similarly. Comparing the expression profile before and after drug exposure can elucidate the changes brought about by drugs on the transcriptional programme. Several computational approaches have been proposed for drug repurposing based on transcriptional data. The signature of differential gene expression reflects the impact of a drug on gene expression. Drug-induced transcriptional changes can then be compared with disease-associated gene expression. If there is a negative correlation between the disease-induced transcriptional changes and the drug-induced transcriptional changes, then the drug may have efficacy in treating the disease. The drug may be able to reverse the disease-induced gene expression and mitigate the disease phenotype.
Author Contributions
“Conceptualization, K.D. and M.S.; methodology, K.D.; software, M.S..; validation, M.S.., K.D and M.J.; formal analysis, D.P.; investigation, P.S.D.; resources, A.Y.; data curation, M.J.; writing—original draft preparation, K.D, D.P.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- 1. Zheng, W., N. Thorne and J. C. McKew. "Phenotypic screens as a renewed approach for drug discovery." Drug Discovery Today 18 (2013): 1067-73. https://www.sciencedirect.com/science/article/pii/S135964461300202X. [CrossRef]
- Schroeder, H. W., Jr. "Mixing the old with the new: Drug repurposing for immune deficiency in the era of precision medicine and pediatric genomics." J Allergy Clin Immunol Pract 6 (2018): 2168-69. http://www.ncbi.nlm.nih.gov/pubmed/30390908. [CrossRef]
- Dudley, J. "The promise of genomics-based drug repurposing." Clin Adv Hematol Oncol 12 (2014): 601-3. http://www.ncbi.nlm.nih.gov/pubmed/25654481.
- Bisson, W. H. "Drug repurposing in chemical genomics: Can we learn from the past to improve the future?" Curr Top Med Chem 12 (2012): 1883-8. http://www.ncbi.nlm.nih.gov/pubmed/23116467. [CrossRef]
- Mirza, N., G. J. Sills, M. Pirmohamed and A. G. Marson. "Identifying new antiepileptic drugs through genomics-based drug repurposing." Hum Mol Genet 26 (2017): 527-37. http://www.ncbi.nlm.nih.gov/pubmed/28053048. [CrossRef]
- Power, A., A. C. Berger and G. S. Ginsburg. "Genomics-enabled drug repositioning and repurposing: Insights from an iom roundtable activity." JAMA 311 (2014): 2063-4. http://www.ncbi.nlm.nih.gov/pubmed/24867009. [CrossRef]
- Bateman, J. R. and C. T. Wu. "A genomewide survey argues that every zygotic gene product is dispensable for the initiation of somatic homolog pairing in drosophila." Genetics 180 (2008): 1329-42. http://www.ncbi.nlm.nih.gov/pubmed/18791221. [CrossRef]
- Ultsch, A., D. Kringel, E. Kalso, J. S. Mogil and J. Lotsch. "A data science approach to candidate gene selection of pain regarded as a process of learning and neural plasticity." Pain 157 (2016): 2747-57. http://www.ncbi.nlm.nih.gov/pubmed/27548044. [CrossRef]
- Moffat, J. G., F. Vincent, J. A. Lee, J. Eder and M. Prunotto. "Opportunities and challenges in phenotypic drug discovery: An industry perspective." Nat Rev Drug Discov 16 (2017): 531-43. http://www.ncbi.nlm.nih.gov/pubmed/28685762. [CrossRef]
- Kulkarni, V. S., V. Alagarsamy, V. R. Solomon, P. A. Jose and S. Murugesan. "Drug repurposing: An effective tool in modern drug discovery." Russ J Bioorg Chem 49 (2023): 157-66. http://www.ncbi.nlm.nih.gov/pubmed/36852389. [CrossRef]
- Giridhara Prema, S., J. Chandrasekaran, S. Kanekar, M. George, T. S. K. Prasad, R. Raju, S. Dagamajalu and R. D. A. Balaya. "Cisplatin and procaterol combination in gastric cancer? Targeting checkpoint kinase 1 for cancer drug discovery and repurposing by an integrated computational and experimental approach." OMICS 28 (2024): 8-23. http://www.ncbi.nlm.nih.gov/pubmed/38190280. [CrossRef]
- Botella, L. M. "Drug repurposing as a current strategy in medicine discovery." Semergen 48 (2022): 101790. http://www.ncbi.nlm.nih.gov/pubmed/35545490. [CrossRef]
- Yang, H. T., J. H. Ju, Y. T. Wong, I. Shmulevich and J. H. Chiang. "Literature-based discovery of new candidates for drug repurposing." Brief Bioinform 18 (2017): 488-97. http://www.ncbi.nlm.nih.gov/pubmed/27113728. [CrossRef]
- Deplanque, D., C. Fetro, A. Ferry, P. Lechat, T. Beghyn, C. Bernard, A. Bernasconi, H. Bienayme, C. Cougoule, J. Del Bano, et al. "Drug repurposing: From the discovery of a useful pharmacological effect to making the treatment available to the patient." Therapie 78 (2023): 10-18. http://www.ncbi.nlm.nih.gov/pubmed/36528417. [CrossRef]
- Boguski, M. S., K. D. Mandl and V. P. Sukhatme. "Drug discovery. Repurposing with a difference." Science 324 (2009): 1394-5. 10.1126/science.1169920. http://www.ncbi.nlm.nih.gov/pubmed/19520944. [CrossRef]
- Wishart, D. S., Y. D. Feunang, A. C. Guo, E. J. Lo, A. Marcu, J. R. Grant, T. Sajed, D. Johnson, C. Li, Z. Sayeeda, et al. "Drugbank 5.0: A major update to the drugbank database for 2018." Nucleic Acids Res 46 (2018): D1074-D82. http://www.ncbi.nlm.nih.gov/pubmed/29126136. [CrossRef]
- Southan, C., M. Sitzmann and S. Muresan. "Comparing the chemical structure and protein content of chembl, drugbank, human metabolome database and the therapeutic target database." Mol Inform 32 (2013): 881-97. http://www.ncbi.nlm.nih.gov/pubmed/24533037. [CrossRef]
- Tao, X. and L. Tong. "Crystal structure of the map kinase binding domain and the catalytic domain of human mkp5." Protein Sci 16 (2007): 880-6. http://www.ncbi.nlm.nih.gov/pubmed/17400920. [CrossRef]
- Fan, H. W., G. Y. Liu, C. F. Zhao, X. F. Li and X. Y. Yang. "Differential expression of cox-2 in osteoarthritis and rheumatoid arthritis." Genet Mol Res 14 (2015): 12872-9. [CrossRef]
- Bai, J. P., A. V. Alekseyenko, A. Statnikov, I. M. Wang and P. H. Wong. "Strategic applications of gene expression: From drug discovery/development to bedside." AAPS J 15 (2013): 427-37. http://www.ncbi.nlm.nih.gov/pubmed/23319288. [CrossRef]
- Clough, E. and T. Barrett. "The gene expression omnibus database." Methods Mol Biol 1418 (2016): 93-110. http://www.ncbi.nlm.nih.gov/pubmed/27008011. [CrossRef]
- Barrett, T. and R. Edgar. "Mining microarray data at ncbi's gene expression omnibus (geo)*." Methods Mol Biol 338 (2006): 175-90. http://www.ncbi.nlm.nih.gov/pubmed/16888359. [CrossRef]
- Ortega, S. S., L. C. Cara and M. K. Salvador. "In silico pharmacology for a multidisciplinary drug discovery process." Drug Metabol Drug Interact 27 (2012): 199-207. http://www.ncbi.nlm.nih.gov/pubmed/23152402. [CrossRef]
- Chang, B., R. Kustra and W. Tian. "Functional-network-based gene set analysis using gene-ontology." PLoS One 8 (2013): e55635. http://www.ncbi.nlm.nih.gov/pubmed/23418449. [CrossRef]
- Kang, H., S. Pan, S. Lin, Y. Y. Wang, N. Yuan and P. Jia. "Pharmgwas: A gwas-based knowledgebase for drug repurposing." Nucleic Acids Res 52 (2024): D972-D79. http://www.ncbi.nlm.nih.gov/pubmed/37831083. [CrossRef]
- Khosravi, A., B. Jayaram, B. Goliaei and A. Masoudi-Nejad. "Active repurposing of drug candidates for melanoma based on gwas, phewas and a wide range of omics data." Mol Med 25 (2019): 30. http://www.ncbi.nlm.nih.gov/pubmed/31221082. [CrossRef]
- Lin, W. Z., Y. C. Liu, M. C. Lee, C. T. Tang, G. J. Wu, Y. T. Chang, C. M. Chu and C. Y. Shiau. "From gwas to drug screening: Repurposing antipsychotics for glioblastoma." J Transl Med 20 (2022): 70. http://www.ncbi.nlm.nih.gov/pubmed/35120529. [CrossRef]
- Sabik, O. L. and C. R. Farber. "Using gwas to identify novel therapeutic targets for osteoporosis." Transl Res 181 (2017): 15-26. http://www.ncbi.nlm.nih.gov/pubmed/27837649. [CrossRef]
- Nanda, H., N. Ponnusamy, R. Odumpatta, J. Jeyakanthan and A. Mohanapriya. "Exploring genetic targets of psoriasis using genome wide association studies (gwas) for drug repurposing." 3 Biotech 10 (2020): 43. http://www.ncbi.nlm.nih.gov/pubmed/31988837. [CrossRef]
- Kaya, S., C. A. Schurman, N. S. Dole, D. S. Evans and T. Alliston. "Prioritization of genes relevant to bone fragility through the unbiased integration of aging mouse bone transcriptomics and human gwas analyses." J Bone Miner Res 37 (2022): 804-17. http://www.ncbi.nlm.nih.gov/pubmed/35094432. [CrossRef]
- Dand, N., P. E. Stuart, J. Bowes, D. Ellinghaus, J. Nititham, J. R. Saklatvala, M. Teder-Laving, L. F. Thomas, T. Traks, S. Uebe, et al. "Gwas meta-analysis of psoriasis identifies new susceptibility alleles impacting disease mechanisms and therapeutic targets." medRxiv (2023): 10.1101/2023.10.04.23296543. http://www.ncbi.nlm.nih.gov/pubmed/37873414.
- Shu, L., M. Blencowe and X. Yang. "Translating gwas findings to novel therapeutic targets for coronary artery disease." Front Cardiovasc Med 5 (2018): 56. http://www.ncbi.nlm.nih.gov/pubmed/29900175. [CrossRef]
- Xu, Y., J. Kong and P. Hu. "Computational drug repurposing for alzheimer's disease using risk genes from gwas and single-cell rna sequencing studies." Front Pharmacol 12 (2021): 617537. http://www.ncbi.nlm.nih.gov/pubmed/34276354. [CrossRef]
- Lippmann, C., D. Kringel, A. Ultsch and J. Lotsch. "Computational functional genomics-based approaches in analgesic drug discovery and repurposing." Pharmacogenomics 19 (2018): 783-97. http://www.ncbi.nlm.nih.gov/pubmed/29792109. [CrossRef]
- Breen, G., Q. Li, B. L. Roth, P. O'Donnell, M. Didriksen, R. Dolmetsch, P. F. O'Reilly, H. A. Gaspar, H. Manji, C. Huebel, et al. "Translating genome-wide association findings into new therapeutics for psychiatry." Nat Neurosci 19 (2016): 1392-96. [CrossRef]
- Uffelmann, E., Q. Q. Huang, N. S. Munung, J. de Vries, Y. Okada, A. R. Martin, H. C. Martin, T. Lappalainen and D. Posthuma. "Genome-wide association studies." Nature Reviews Methods Primers 1 (2021): 59. https://doi.org/10.1038/s43586-021-00056-9. [CrossRef]
- Wishart, D. S., C. Knox, A. C. Guo, D. Cheng, S. Shrivastava, D. Tzur, B. Gautam and M. Hassanali. "Drugbank: A knowledgebase for drugs, drug actions and drug targets." Nucleic Acids Res 36 (2008): D901-6. [CrossRef]
- Klein, T. E. and R. B. Altman. "Pharmgkb: The pharmacogenetics and pharmacogenomics knowledge base." The Pharmacogenomics Journal 4 (2004): 1-1. 10.1038/sj.tpj.6500230. [CrossRef]
- Bovijn, J., J. C. Censin, C. M. Lindgren and M. V. Holmes. "Commentary: Using human genetics to guide the repurposing of medicines." Int J Epidemiol 49 (2020): 1140-46. http://www.ncbi.nlm.nih.gov/pubmed/32097451. [CrossRef]
- Truong, V. Q., J. A. Woerner, T. A. Cherlin, Y. Bradford, A. M. Lucas, C. C. Okeh, M. K. Shivakumar, D. H. Hui, R. Kumar, M. Pividori, et al. "Quality control procedures for genome-wide association studies." Curr Protoc 2 (2022): e603. http://www.ncbi.nlm.nih.gov/pubmed/36441943. [CrossRef]
- Reay, W. R. and M. J. Cairns. "Advancing the use of genome-wide association studies for drug repurposing." Nat Rev Genet 22 (2021): 658-71. http://www.ncbi.nlm.nih.gov/pubmed/34302145. [CrossRef]
- Satish, M., K. Sandhya, K. Nitin, N. Yashas Kiran, B. Aleena, A. Satish Kumar, K. G and E. Rajakumara. "Computational, biochemical and ex vivo evaluation of xanthine derivatives against phosphodiesterases to enhance the sperm motility." J Biomol Struct Dyn 41 (2023): 5317-27. http://www.ncbi.nlm.nih.gov/pubmed/35696450. [CrossRef]
- Wu, P., Q. Feng, V. E. Kerchberger, S. D. Nelson, Q. Chen, B. Li, T. L. Edwards, N. J. Cox, E. J. Phillips, C. M. Stein, et al. "Integrating gene expression and clinical data to identify drug repurposing candidates for hyperlipidemia and hypertension." Nat Commun 13 (2022): 46. [CrossRef]
- Koudijs, K. K. M., S. Böhringer and H. J. Guchelaar. "Validation of transcriptome signature reversion for drug repurposing in oncology." Brief Bioinform 24 (2023). [CrossRef]
- Jha, A., M. Quesnel-Vallières, D. Wang, A. Thomas-Tikhonenko, K. W. Lynch and Y. Barash. "Identifying common transcriptome signatures of cancer by interpreting deep learning models." Genome Biology 23 (2022): 117. [CrossRef]
- Abdelhafiz, A. S., M. A. Fouda, N. A. Elzefzafy, Taha, II, O. M. Mohemmed, N. H. Alieldin, I. Toony, A. A. Abdel Wahab and I. G. Farahat. "Gene expression analysis of invasive breast carcinoma yields differential patterns in luminal subtypes of breast cancer." Ann Diagn Pathol 55 (2021): 151814. http://www.ncbi.nlm.nih.gov/pubmed/34517157. [CrossRef]
- Nguyen, H. T. N., H. Xue, V. Firlej, Y. Ponty, M. Gallopin and D. Gautheret. "Reference-free transcriptome signatures for prostate cancer prognosis." BMC Cancer 21 (2021): 394. http://www.ncbi.nlm.nih.gov/pubmed/33845808. [CrossRef]
- Slebioda, T. J., M. Stanislawowski, M. Cyman, P. M. Wierzbicki, D. Zurawa-Janicka, J. Kobiela, W. Makarewicz, M. Guzek and Z. Kmiec. "Distinct expression patterns of two tumor necrosis factor superfamily member 15 gene isoforms in human colon cancer." Dig Dis Sci 64 (2019): 1857-67. http://www.ncbi.nlm.nih.gov/pubmed/30788683. [CrossRef]
- Koufos, N., J. Syrios, D. Michailidou, I. D. Xynos, A. Lazaris, N. Kavantzas, P. Tomos, S. Kakaris, C. Kosmas and N. Tsavaris. "Distinct patterns of angiogenic factor expression as a predictive factor of response to chemotherapy in stage iiia non-small-cell lung cancer patients." Mol Clin Oncol 5 (2016): 440-46. http://www.ncbi.nlm.nih.gov/pubmed/27699040. [CrossRef]
- Kutay, M., D. Gozuacik and T. Cakir. "Cancer recurrence and omics: Metabolic signatures of cancer dormancy revealed by transcriptome mapping of genome-scale networks." OMICS 26 (2022): 270-79. http://www.ncbi.nlm.nih.gov/pubmed/35394340. [CrossRef]
- Li, H. R., J. Wang-Rodriguez, T. M. Nair, J. M. Yeakley, Y. S. Kwon, M. Bibikova, C. Zheng, L. Zhou, K. Zhang, T. Downs, et al. "Two-dimensional transcriptome profiling: Identification of messenger rna isoform signatures in prostate cancer from archived paraffin-embedded cancer specimens." Cancer Res 66 (2006): 4079-88. http://www.ncbi.nlm.nih.gov/pubmed/16618727. [CrossRef]
- Deng, Z., T. Guo, J. Bi, G. Wang, Y. Hu, H. Du, Y. Zhou, S. Jia, X. Xing and J. Ji. "Transcriptome profiling of patient-derived tumor xenografts suggests novel extracellular matrix-related signatures for gastric cancer prognosis prediction." J Transl Med 21 (2023): 638. http://www.ncbi.nlm.nih.gov/pubmed/37726803. [CrossRef]
- Koudijs, K. K. M., A. G. T. Terwisscha van Scheltinga, S. Böhringer, K. J. M. Schimmel and H. J. Guchelaar. "Transcriptome signature reversion as a method to reposition drugs against cancer for precision oncology." Cancer J 25 (2019): 116-20. [CrossRef]
- Aggarwal, S., S. S. Verma and S. C. Gupta. "Drug repurposing for breast cancer therapy: Old weapon for new battle." Semin Cancer Biol 68 (2021): 8-20. [CrossRef]
- Hernandez, J. J., M. Pryszlak, L. Smith, C. Yanchus, N. Kurji, V. M. Shahani and S. V. Molinski. "Giving drugs a second chance: Overcoming regulatory and financial hurdles in repurposing approved drugs as cancer therapeutics." Front Oncol 7 (2017): 273. 10.3389/fonc.2017.00273.
- Schein, C. H. "Repurposing approved drugs on the pathway to novel therapies." Med Res Rev 40 (2020): 586-605. [CrossRef]
- Shim, J. S. and J. O. Liu. "Recent advances in drug repositioning for the discovery of new anticancer drugs." Int J Biol Sci 10 (2014): 654-63. [CrossRef]
- Wang, B., F. van der Kloet, M. Kes, J. Luirink and L. W. Hamoen. "Improving gene set enrichment analysis (gsea) by using regulation directionality." Microbiol Spectr (2024): e0345623. http://www.ncbi.nlm.nih.gov/pubmed/38294221. [CrossRef]
- Gns, H. S., S. Gr, M. Murahari and M. Krishnamurthy. "An update on drug repurposing: Re-written saga of the drug’s fate." Biomedicine & Pharmacotherapy 110 (2019): 700-16. https://www.sciencedirect.com/science/article/pii/S0753332218372871. [CrossRef]
Figure 1.
Overview of computational functional genomics techniques chosen for application in medication research.
Figure 1.
Overview of computational functional genomics techniques chosen for application in medication research.
Figure 2.
Flowchart of GWAS & drug repurposing.
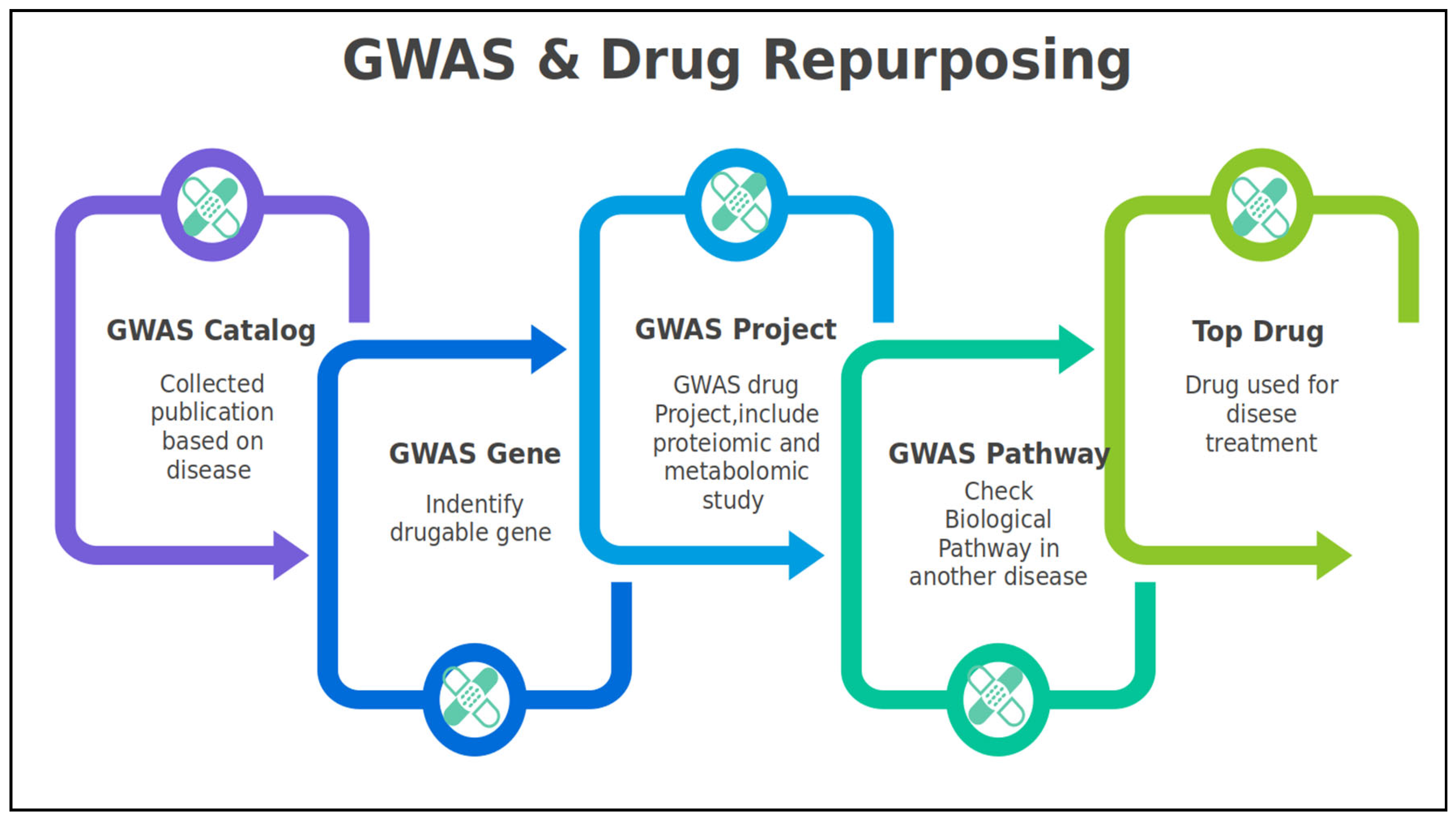
Table 1.
Examples of information sources and computer programs that are utilized in the data science approach to medication repurposing based on knowledge from functional genomics.
Table 1.
Examples of information sources and computer programs that are utilized in the data science approach to medication repurposing based on knowledge from functional genomics.
| Gene names and functions | ||
|---|---|---|
| AmiGO (search utility for GO) | Search utility for Gene Ontology (GO) | http://amigo.geneontology.org/ |
| Gene Ontology (GO) | A standardized classification system for gene functions and products. | www.geneontology.org/ |
| HUGO Gene Nomenclature Committee | Assigns standardized nomenclature to human genes. | www.genenames.org/ |
| Database for Annotation, Visualization, and Integrated Discovery (DAVID) | Provides tools for functional annotation and enrichment analysis of gene sets. | https://david.ncifcrf.gov |
| NCBI gene index database | National Center for Biotechnology Information's database for gene information. | www.ncbi.nlm.nih.gov/gene/ |
| GeneCards | Comprehensive database for human genes, their products, and their associations. | www.genecards.org |
| Human diseases | ||
| Online Mendelian Inheritance in Man (OMIM) database | Catalogs human genes and genetic disorders with a focus on the relationships between phenotype and genotype. | www.ncbi.nlm.nih.gov/omim |
| MalaCards: The human disease database | Database providing comprehensive information on human diseases. | www.malacards.org |
| DiseaseGenes database | A database cataloging genes associated with various diseases. | www.jbldesign.com/jmogil/enter.html |
| The Human Disease Genetics Database (HPGDB) | Database focused on the genetics of human diseases. | https://humandiseasegenetics.org/hpgdb/ |
| Comparative Toxicogenomics Database (CTD) | Integrates toxicology and genomics to advance understanding of the effects of environmental exposures on human health | http://ctd.mdibl.org |
| Biological pathways | ||
| Pathway Commons | A resource for biological pathway analysis and integration. | www.pathwaycommons.org |
| Kyoto Encyclopedia of Genes and Genomes (KEGG) | Provides information on biological pathways, diseases, and drugs. | www.genome.jp/kegg/ |
| Drugs, small molecules, and/or (potential) targets | ||
| DrugBank database | Database containing information on drugs, their targets, and mechanisms of action. | www.drugbank.ca |
| Connectivity map (CMap) | Analyzes the effects of small molecules on gene expression and cellular phenotypes. | https://clue.io/cmap |
| DrugSig | Identifies gene expression signatures related to drug response. | http://biotechlab.fundan.edu.cn/database/drugsig/ |
| Thomson Reuters Integrity database (non-free) | Database providing information on drugs and their properties. | https://integrity.thomson-pharma.com |
| ChEMBL | Database of bioactive molecules with drug-like properties. | www.ebi.ac.uk/chembl/ |
| UniProtKB/Swiss-Prot | Comprehensive resource for protein information. | www.uniprot.org |
| Gene Expression Omnibus (GEO) | Repository for high-throughput gene expression and functional genomics data. | www.ncbi.nlm.nih.gov/geo |
| Software | ||
| R software | Programming language and software environment for statistical computing and graphics. | http://CRAN.R-project.org/ |
| Drug versus disease (DvD) | Analytical approach comparing drug and disease-related data. | www.ebi.ac.uk/saezrodriguez/DVD/ |
| GeneTrail | Software for the statistical evaluation of biological pathways. | http://genetrail.bioinf.uni-sb.de/ |
| Bioconductor | Open-source software for the analysis and comprehension of high-throughput genomic data. | http://bioconductor.org/ |
| R package ‘org.Hs.eg.db’ | R package providing gene annotation for the human genome. | https://bioconductor.org/packages/org.Hs.eg.db/ |
| R package ‘GO.db’ | R package providing Gene Ontology annotations. | http://bioconductor.org/packages/GO.db/ |
| R package ‘dbtORA’ | R package for over-representation analysis in genomics. | https://github.com/IME-TMP-FFM/dbtORA |
| Graphviz | Open-source graph visualization software. | www.graphviz.org |
| Literature | ||
| PubMed | A comprehensive database of biomedical literature, providing access to a vast collection of articles, research papers, and other scholarly materials. | www.ncbi.nlm.nih.gov/pubmed/ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



