
Submitted:
15 April 2024
Posted:
17 April 2024
You are already at the latest version
Abstract
Non-neural Machine Learning (ML) and Deep Learning (DL) are used to predict system failures in industrial maintenance. However, only a few studies have assessed the effect of varying the amount of past data used to make a prediction and the extension in the future of the forecast. This study evaluates the impact of the size of the reading window and of the prediction window on the performances of models trained to forecast failures in three data sets of (1) an industrial wrapping machine working in discrete sessions, (2) an industrial blood refrigerator working continuously and (3) a nitrogen generator working continuously. A binary classification task assigns the positive label to the prediction window based on the probability of a failure to occur in such an interval. Six algorithms (logistic regression, random forest, support vector machine, LSTM, ConvLSTM and Transformers) are compared using multivariate time series. The dimension of the prediction windows plays a crucial role and the results highlight the effectiveness of DL approaches in classifying data with diverse time-dependent patterns preceding a failure and the effectiveness of ML approaches in classifying similar and repetitive patterns preceding a failure.
Keywords:
Failure prediction
; Machine Learning
; Deep Learning
; Predictive Maintenance
; Compressor
; Blood refrigerator
; Nitrogen generator
; Wrapping machine
1. Introduction
Predictive maintenance is a strategy that aims to reduce equipment degradation and prevent failures [1,2,3] by anticipating their occurrence. It differs from corrective maintenance (in which the components are used for their entire life span and replaced only when there is a fault) [4,5] and preventive maintenance (in which the replacement and reparation activities are scheduled periodically) [6,7].
Industrial data are often the result of monitoring several physical variables, which produces multivariate time series [8,9]. Predicting failures via manual inspection is time-consuming and costly, especially because the correlation among multiple variables can be difficult to appraise with manual approaches. Computer-aided methods can improve performance and reliability and are less onerous and error-prone [10,11,12].
Predicting machine failures requires the cycle of data collection, model identification, parameter estimation, and validation [13]. Alternative models are compared in terms of the effort needed to train them, the performances they deliver, and the relationship between such performances and the amount of input data used to make a prediction and the time horizon of the forecast.
In this paper, we compare alternative models trained for predicting malfunctions. The focus of the analysis is to study how performances, measured with the macro score metrics, are affected by the length of the input time series fragment used to make the prediction (reading window – RW) and by the extension in the future of the forecast (prediction window – PW).
As case studies, we consider the time series made of multiple telemetry variables collected with IoT sensors from three machines: (1) an industrial wrapper machine, (2) a blood refrigerator and (3) a nitrogen generator.
In the three data sets, IoT sensors collect physical quantities to monitor the system status. The emission of alert codes by the hardware of the machines signals the occurrence of anomalous conditions. The goal of the described data-driven predictive maintenance scenario is to anticipate the occurrence of a fault (i.e., a malfunctioning indicated by an alert code) within a future time interval (i.e., the prediction window) using historical data (i.e., the reading window). The presence of labeled data (i.e., the actual alert codes emitted by the machine in past work sessions) makes it possible to formulate the predictive maintenance problem as a binary classification task addressed with a fully supervised approach.
Our experimental setting contrasts non-neural Machine Learning (ML) and Deep Learning (DL), which are popular methods for addressing predictive maintenance tasks. ML methods have been widely used in diverse applications [12,14,15,16,17] and recent works also tested DL methods [18,19]. A few works have compared supervised ML and DL methods for failure prediction in time series data [19,20,21] and evaluated the influence of either the reading window (e.g., [16,17,22]) or of the prediction window (e.g., [15,20,23,24,25]). Only a few consider both parameters [12,26].
The contribution of the paper can be summarized as follows:
- We compare three ML methods (Logistic Regression, Random Forest, and Support Vector Machine) and three DL methods (LSTM, ConvLSTM, and Transformer) on three novel industrial data sets with multiple telemetry data.
- We study the effect of varying the size of both the reading window and the prediction window in the context of failure prediction and discuss the consequences of these choices on the performances.
- We evaluate the diversity of patterns preceding faults using the Euclidean distance between time series windows and the spectral entropy measured on whole data sets as a global complexity metrics, showing that DL approaches outperform ML approaches significantly only for complex data sets with more diverse patterns. In contrast, for simpler datasets where patterns exhibit greater uniformity, both DL and ML approaches produce comparable results, with DL algorithms not introducing substantial improvements.
- We show that all methods lose predictive power when the horizon enlarges because the temporal correlation between the input and the predicted event tends to vanish.
- We highlight that when patterns are diverse, the amount of historical data becomes influential. However, augmenting the amount of input is not beneficial in general.
- We publish the data sets and the compared algorithms to ensure reproducibility and allow the scientific community to extend the comparison to further ML and DL methods1. The published data sets are among the very few ones publicly accessible by researchers in the domain of fault prediction for industrial machines, as shown in [27].
2. Related Work
Anomaly detection and failure prediction are two related fields applied to diverse data, including time series [28,29,30,31,32] and images [33,34,35]. This research focuses on failure prediction applied to multivariate time series data acquired by multiple IoT sensors connected to an industrial machine. Several works have surveyed failure prediction on time series [31,36,37].
Failure prediction approaches belong to three categories, depending on the availability and use of data labels: supervised [12,18], semi-supervised [38] and unsupervised [39]. Predicting failures in a future interval given labeled past data can be considered a supervised binary classification task [12]. The data set used in this research is labeled, making supervised methods a viable option.
ML and DL are two popular approaches for failure prediction in time series data. For supervised failure prediction, ML methods include decision trees (DT) [14,15], Gradient Boosting (GB) [15,16], random forests (RF) [14,15,16,17], support vector machines (SVM) [14,15], and Logistic Regression (LR) [12,17]. DL methods include neural network architectures such as recurrent neural networks (RNN) [19] and convolutional neural networks (CNN) [19]. Some works have compared supervised ML and DL methods for failure prediction in time series data [19,20,21].
RF is one of the most used approaches [12,14,15,16,17,22,23,25,30,40,41,42,43,44,45]. The work in [25] compares RF with ML and DL approaches, including Neural Networks and SVM, and shows the superiority of RF in terms of accuracy for a prediction window not longer than 300 seconds for a case study of wind turbines. However, accuracy does not consider class unbalance and is not appropriate for evaluating the performance of failure prediction algorithms [31]. The work in [42] also considers the case of wind turbines and presents only the performances of RF using accuracy, sensitivity, and specificity for a prediction window of 1 hour. The work in [22] also uses RF on wind turbine data and measures performances using precision and recall for varying the reading windows up to 42 hours, showing rather poor performances. Other applications of RF in predictive maintenance range from refrigerator systems [45] to components of vending machines [43], vehicles [30], and chemical processes [16].
SVM is another approach commonly used in supervised failure prediction [12,14,15,25,26,43,46,47,48]. The work in [26] presents an application of SVM to railway systems and evaluates the performances using False Positive Rate (FPR) and recall. It is one of the few approaches considering variation in both PW and RW. However, the assessment of the contribution of each window is not performed because they were changed together. The work in [15] compares ML algorithms (DT, RF, GB, and SVM) and shows that GB outperforms the other approaches, followed by RF. The work in [14] compares the accuracy of six ML algorithms on industrial data, including SVM, RF, and DT. It shows that DT not only surpasses RF but is also more interpretable. However, precision and recall would be necessary to evaluate the quality of predictions, as the data set is likely unbalanced. The work in [17] also measures performances using accuracy (for a balanced data set), compares RF, LR, and Ctree, and shows that (1) RF outperforms the other algorithms, and (2) the reading window size does not have a significant impact on the performances.
A few works contrast ML and DL predictors. The work in [20] compares the performances using AUC and shows that a small fully-connected neural network outperforms Naïve Bayes. However, other popular methods (e.g., SVM, LR, LSTM) are not evaluated. The work in [19] is one of the few approaches considering a comparison between two DL approaches (a CNN and LSTM) and shows (1) the superiority of the convolutional network in terms of accuracy and (2) the decrease in accuracy as the prediction window increases. However, additional metrics would be necessary to evaluate performances on a likely unbalanced data set.
Considering alternative DL approaches, aside from the commonly employed LSTM-based architectures [49,50,51], there is noteworthy research interest on ConvLSTM models. The work in [52] finds that ConvLSTM exhibits comparable performance to Random Forest (RF) when predicting faults in wind turbine gearbox systems. The work in [53] shows the effectiveness of a ConvLSTM-based architecture for failure detection. Both works do not analyze the impact of the size of RW and PW nor compare alternative DL architectures. ConvLSTM has also proved effective in forecasting the value of telemetry variables, a preliminary step for fault prediction in diverse systems [54,55,56]. Transformer-based architectures have been applied to anomaly detection [57,58], and fault diagnosis [59,60]. The work in [61] shows the effectiveness of a Transformer-based architecture for the fault prediction task in an Electric Power Communication Network. In contrast to LSTM-based architectures, Transformers can capture long-range dependencies and offer parallel processing capabilities, which makes them suitable also for time series tasks over long intervals.
Several works investigate the failure prediction task by forecasting the occurrence of a failure within a pre-determined time frame [16,17,20,26]. Some studies evaluate the impact of either the reading window length [16,17,26] or the prediction window length [20,23,24]. Only a few [12,26] evaluate the impact of varying the reading and the prediction window. Considering the surveyed approaches, the work in [12] is the only one that proposes a comparison between different ML algorithms varying both the RW and PW and assessing the contribution of each. However, it does not consider DL algorithms in the comparison.
In summary, a few works on supervised failure prediction for multivariate time series evaluate the variation of both RW and PW. However, none compares ML and DL algorithms in this respect. Moreover, none of the surveyed papers considers the presence of discrete sessions in the telemetry time series, which is instead the case of the wrapping machine data set. Furthermore, the related works very rarely disclose the industrial data sets used in the experiments which hinders reproducibility of research and ultimately the progress of the status of the art.
Our work investigates the contribution of both the RW and PW variations and compares diverse ML and DL approaches on three novel industrial data sets featuring both discrete session-based and continuous time machines. The collected data sets, which derive from the telemetry of real machines and comprise hardware-produced failure alerts as ground truth, are made available in a public repository.
3. Materials and Methods
This section outlines the experimental design employed to evaluate the impact of the reading/prediction windows and of the hyperparameters on the performance of ML and DL approaches. It describes the data sets used and explains the data pre-processing procedures, the experimental methodology, and the performance metrics.
3.1. Data Sets
3.1.1. Wrapping Machine
Wrapping machines are systems used for packaging and comprise various components such as motors, sensors, and controllers. The monitored exemplars are semi-automatic machines that wrap objects carried on pallets with stretch film. Each machine comprises: the turntable, a central circular platform for loading objects; the lifter, a moving part that contains the wrapping film reel; the tower, a column on which the lifter moves; the platform motor, a gear motor controlling the movements of the turntable with a chain drive, and the lifting motor, an electric motor for lifting the carriage.
The functioning of the machine is cyclic. A cycle consists of five steps:
- Loading the products on a pallet at the center of the rotating platform.
- Tying the film’s trailing end to the pallet’s base.
- Starting the wrapping cycle, executed according to previously set parameters.
- Manually cutting the film (through the cutter or with an external tool) and making it adhere to the wrapped products.
- Removing the wrapped objects.
The data set contains records from sensors installed on a wrapping machine collected over one year (01-06-2021 to 31-05-2022). The machine is equipped with sensors attached to different components, such as the rotating platform and the electric motors. An acquisition system gathers data from sensors and sends them to a storage server. Sensors measure over 100 quantities (e.g., temperatures, motor frequencies, and platform speeds). Each data item records a timestamp, and the last value measured by a sensor. Data are transmitted only when at least one sensor registers a variation for saving energy, resulting in variable data acquisition frequency. Data are grouped into work sessions that represent periods in which the machine is operating. Each work session has a starting point, manually set by the operator, corresponding to the start of an interval during which the machine wraps at least one pallet. A work session ends when the machine finishes wrapping the pallets or when a fatal alert occurs. Session-level metrics are collected, too, such as the number of completed pallets and the quantity of consumed film. The data set contains information about alerts thrown by the machine during the power-on state (i.e., when the machine is powered on, which does not necessarily mean it is producing pallets). An alert is a numerical code that refers to a specific problem that impacts the functioning of the machine.
Depending on the changes detected by sensors, the irregular sampling time is addressed by resampling the time series with a frequency of 5 seconds, which gives a good trade-off between memory occupation and signal resolution. Missing values are filled in using the last available observation because the absence of new measurements indicates no change in the recorded value.
3.1.2. Blood Refrigerator
Blood refrigerators are systems designed for the safe storage of blood and its derivatives at specific temperatures. Each unit includes different components. Compressor: pumps the refrigerant, increasing its pressure and temperature. Condenser: cools down and condenses the refrigerant. Evaporator: causes the refrigerant to evaporate for cooling the inside of the unit. Expansion Valve: regulates the flow of refrigerant into the evaporator. Interconnecting Tubing: facilitates the movement of the refrigerant between the compressor, condenser, expansion valve and evaporator.
A refrigeration cycle comprises the following phases.
- Compression: The cycle begins with the compressor drawing in low-pressure, low-temperature refrigerant gas. The compressor then compresses the gas, which raises its pressure and temperature.
- Condensation: The high-pressure, high-temperature gas exits the compressor and enters the condenser coils. As the gas flows through these coils, it releases heat, cools down, and condenses into a high-pressure liquid.
- Expansion: This high-pressure liquid then flows through the capillary tube or expansion valve. As it does, its pressure drops, causing a significant drop in temperature. The refrigerant exits this stage as a low-pressure, cool liquid.
- Evaporation: The low-pressure, cool liquid refrigerant enters the evaporator coils inside the refrigerator. Here, it absorbs heat from the interior, causing it to evaporate and turn back into a low-pressure gas. This process cools the interior of the refrigerator.
- Return to Compressor: The low-pressure gas then returns to the compressor and the cycle starts over.
The data set includes information from IoT sensors that measure 58 variables (e.g., the status of the door of the refrigerator, its temperature, energy consumption, etc.). The series comprises data from 31-10-2022 to 30-12-2022 and records only when a variable changes value. This results in an irregular sampling period varying from a few seconds to one hour. For this reason, we resampled the data set using the median of the original sampling frequency (i.e., seconds).
3.1.3. Nitrogen Generator
Nitrogen generators separate the nitrogen from the other gasses, such as the oxygen, in compressed air. They include: an Air compressor, to supply the compressed air; Carbon Molecular Sieves (CMSs), to filter other gasses from the nitrogen; Absorption vessels, to take the nitrogen not filtered out by the CMS; Towers, to increase the nitrogen production. A tower comprises one CMS, two or more absorption vessels and the space where the division between nitrogen and oxygen takes place; Valves, to direct the flow of air and nitrogen and regulate the absorption of the nitrogen by the vessels; a Buffer Tank, to store the purified nitrogen.
The generator works as follows:
- The air compressor compresses the air to a high pressure and supplies it to the machine.
- In the towers the CMS adsorbs smaller gas molecules such as oxygen while allowing larger nitrogen molecules to pass through the sieve and go into the vessels.
- The buffer tank receives the nitrogen gas from the vessels through the valves.
- The valves reduce the pressure in the current working tower to release the residual gasses, while in the other towers the pressure is increased to restart the process.
The data set includes information from IoT sensors installed in the generator. A set of 64 variables measure the essential work parameters (e.g., the nitrogen pressure, CMS air pressure, etc.). The series comprises data from 01-08-2023 to 29-09-2023 and contains values recorded when a change in a variable occurs. This results in an irregular sampling period varying from a few seconds to four hours. For this reason, we resampled the data set using 1 minute as frequency.
3.2. Data Processing
Data processing is an essential step in the analysis of each dataset, involving the selection of pertinent variables associated with physical quantities and of the resampling period. To characterize the diversity of the data sets, the anomalous patterns preceding faults can be considered. To this end, the data set is first normalized using min-max normalization and then a set of fixed-size windows preceding each fault is defined. For every pair of such windows, denoted as and , the Euclidean distance, , is calculated between pairs of data points at corresponding positions, indexed by k, for each variable, represented as v. The distance is computed between the points and . The diversity of patterns is quantified as the mean value scaled in the range :
To characterize the complexity of a data set as a whole, we compute the mean of the spectral entropies of the considered time series [62], as implemented in the antropy library2, normalized between 0 and 1 and using the fft method [63]. Higher entropy values correspond to a higher time series complexity.
3.2.1. Wrapping Machine
The first phase is feature selection. Since not all the quantities are equally relevant, only 13 are kept based on the data description provided by the manufacturer and are summarized in Table 1. Most removed features were redundant or had constant values. For example, such features as the employed recipe and the firmware version are excluded because they do not describe the system dynamics, whereas such features as the variation of a variable value during the session are eliminated because they can be derived from the initial and final values.
The second phase is selecting relevant alert codes for the anticipation of machine malfunction. Figure 1 presents the distribution of the alert codes most relevant according to the manufacturer. Most of them are rare (i.e., are observed less than 10 times), and alerts 11 (platform motor inverter protection) and 34 (machine in emergency condition) are the most common ones. Alert 34 is thrown when the operator presses an emergency button. However, this occurrence heavily depends on human behavior because the operators often use the emergency button as a quick way to turn the machine off, as confirmed by the plant manager. For this reason, alert 34 is discarded, and the prediction task focuses only on alert 11. This alert is fundamental for the correct functioning of the machine, because the inverter controls the frequency or power supplied to the motor and thus controls its rotation speed. The improper control of the rotation speed hinders the wrapping operation.
In the examined data set, alert 11 is preceded by diverse time-dependent patterns, and the mean Euclidean distance defined in Equation (1) is for a window of 15 minutes. Figure 2 shows two examples of patterns preceding faults. The spectral entropy is .
The work session boundaries provided in the data set also depend on human intervention. Some inconsistent session-level metrics and a large number of sessions that do not produce any pallets are observed. A more reliable definition of a work session can be inferred from the telemetry variables. Intuitively, a session start time is introduced when at least one motion variable increases its value, and a session end time is created when all motion variables have decreased their value in the last ten minutes. Algorithm 1 specifies how sessions are defined.
| Algorithm 1: Computation of session boundaries. |
|
Figure 3 shows the distribution of the work session duration computed from the telemetry data. The idle time intervals between sessions are neglected in further processing.
After pre-processing, it is possible to compute the distance of each data sample within a work session to the successive alert, i.e., the Time To Failure (TTF).
3.2.2. Blood Refrigerator
The data comprise variables directly measured by sensors (base variables) and variables derived from the base ones. For instance, the base variable “Door status” represents the status of the refrigerator door and has an associated derived variable “Door opening daily counter”, which counts every day when the door is open. We keep the 12 most significant variables, shown in Table 2.
The data set also contains alarms (e.g., High-Temperature Compartment, Blackout, Defrost Timeout Failure, etc.). Specifically, the data set originally contained 15 types of alarms, but those described as critical by the manufacturer are the ones presented in Table 3. After an analysis of such two alarms, we have selected “alarm 5” as the prediction target because “alarm 1” has too few occurrences, making the analysis of performances unfeasible. Storing blood at low temperature is crucial, as higher temperature can lead to bacterial growth [64], hemolysis [65] and increased risk of adverse reactions, including life-threatening conditions [66]. Figure 4 presents the typical anomalous pattern preceding a fault for three variables. In this case, the mean Euclidean distance defined in Equation (1) is for a window of 15 minutes, less than the one of the wrapping machine data set. The spectral entropy is , indicating a lower complexity with respect to the wrapper machines data set.
3.2.3. Nitrogen Generator
The data are collected by IoT sensors over two months (01-08-2023 to 29-09-2023). We have considered only the variables that are directly measured from the sensors and discarded the derived ones. Table 4 shows the relevant variables, which record the changes of the physical status of the system.
The nitrogen generator can produce different alarms, including “Air pressure too high”, and “Oxygen failure - Second threshold reached”. However, only one type of alarm is present in the data set: “CMS pressurization fail”, whose frequency is shown in Table 5. A fail in CMS pressurization can hinder the separation of oxygen and nitrogen, as mentioned in [67]. Figure 5 presents the typical anomalous pattern of three variables preceding a fault. The mean Euclidean distance defined in Equation (1) is for a window of 15 minutes, less than the one of the wrapping machine data set, and less than the one of the blood refrigerator data set. The spectral entropy is , indicating a lower complexity with respect to both the wrapper machines and the blood refrigerator data sets.
3.3. Definition of the Reading and Prediction Windows
The task for comparing ML and DL methods is predicting the occurrence of alerts within a future time interval (i.e., a prediction window PW) given historical data (i.e., a reading window RW). This task is formulated as a binary classification, which assigns a label (failure/no failure) to each RW [31]. Failures were provided by the manufacturer, which has measured them using sensors installed in the considered machines. A failure label associated with an RW is assigned when the corresponding PW contains at least an alert code. Itis interpreted as a high probability of an alert occurring in the PW next to it. Given a session of length N and an RW size , reading windows are extracted. Each RW starts at timestamp , with . For an RW , the corresponding PW starts at time stamp . The proposed approach can be applied in absence of sessions without loss of generality, because the entire interval of the data set can be considered as one session.
3.4. Class Unbalance
Alerts are anomalies and thus, by definition, rarer than normal behaviors [68]. For this reason, the number of RWs with label no failure is significantly greater than that of RWs with label failure, leading to a heavily imbalanced data set. For all the data sets, Random UnderSampling (RUS) [69,70] is applied to balance the class distribution by making the cardinality of the majority class comparable to that of the minority class. The algorithm randomly selects and removes observations from the majority class until it achieves the desired equilibrium between the two classes. In the case of the wrapping machine, RUS is applied separately on each train set (comprising 4 folds) and test set (1 fold) for each combination of RW and PW sizes. To prevent the presence of similar data in the train and test sets (i.e., partially overlapping data), after the definition of the test set, the partially overlapping windows in the train set are neglected by RUS. The RUS step is applied 10 times, as proposed in [12]. In the blood refrigerator and nitrogen generator data sets, RUS is applied on the train and validation sets during the training phase, but not on the test set, where the test score is evaluated assigning a different weight to the failure and no failure classes in order to account for the unbalance.
3.5. Algorithms and Hyperparameter Tuning
The algorithms for which the influence of the RW and PW size is assessed include Logistic Regression (LR), as a representative of the Generalized Linear Models family [71], Random Forest (RF), as a representative of the Ensemble Methods family [72], Support Vector Machine (SVM), as a representative of the Kernel Methods family [73], Long Short-Term Memory (LSTM) [74], Transformers [75] and ConvLSTM [76], as representatives of DL methods.
For SVM, RF, and LR, the implementation used in this work is from the Python library scikit-learn3, while DL models use TensorFlow4. The tested network architectures of the DL models and the hyperparameters resulting from the hyperparameter search of all models can be found in the project repository.
For LR, C is the inverse of the regularization strength, and smaller values indicate a stronger regularization.
In the case of RF, the search varies the number of internal estimators (i.e., the number of decision trees) and the maximum number of features that can be selected at each split (in this context, a feature is defined as the value of a variable at a specific timestamp).
In the case of SVM, the C coefficient is the regularization hyperparameter multiplied by the squared penalty and is inversely proportional to the strength of the regularization. Small values of C lead to a low penalty for misclassified points, while if C is large, SVM tries to minimize the number of misclassified examples.
Considering LSTM, in the case of the wrapping machine the only hyperparameters that vary are the type of LSTM layer, Unidirectional or Bidirectional, and the loss function. For the latter, we compare the sigmoid loss with and (from now on referred to as loss) [77] and the Binary Cross-Entropy (BCE) loss. The use of BiLSTM has been shown to be effective in the works [74,78], which focus on forecasting problems. The two compared loss functions have been proven to deliver the top performances in [77]. Each loss function serves a distinct purpose and offers advantages and disadvantages. The loss considers precision and recall, thus providing a balanced model performance evaluation. In this case, minimizing the loss means maximizing the score for the “Failure” class (i.e., reducing the missed “Failure” occurrences). The BCE loss is a widely used loss function for binary classification tasks and is symmetric with respect to the two classes. It measures the dissimilarity between predicted probabilities and target labels, encouraging the model to improve its probability estimations. BCE loss encourages the model to output probabilities for each class, providing richer information about the model’s confidence in its prediction. However, it does not inherently consider the interplay between precision and recall and is not the most suitable choice for tasks where a balance between precision and recall is essential.
In the case of Transformers, the Binary Cross-Entropy (BCE) loss function is employed [79], and two hyperparameters are relevant: the number of attention heads and the number of transformer blocks. The former affects the capacity of the model to capture diverse patterns and relationships in the data, with higher values improving the ability to discern patterns. The latter increases the complexity of the model, thus allowing it to capture more complex patterns but also augmenting the risk of overfitting.
In the case of ConvLSTM [76], BCE is chosen as the loss function and the hyperparameter search (described in the project repository) has varied both the kernel size and the number of filters. Increasing the kernel size extends the receptive field and augmenting the number of filters allows capturing more diverse and complex spatiotemporal features.
3.6. Training and Evaluation
Results are assessed using the macro score, which extends the score, defined in Equation
(2). The score depends on precision and recall, defined respectively in Equations (3) and (4), where TP stands for the number of true positives, FP for the number of false positives, TN for the number of true negatives, and FN for the number of false negatives.
The macro score is the average of the scores computed for each class independently. To compute the score for each class, the model treats that class as the positive class and the other class as the negative class. Let be the score computed when class “Failure” is the positive one and be the score computed when class “No failure” is the positive one. Then, the macro score is given by Equation (5).
The range of RW and PW sizes is adapted to the dynamics of the machines (a slow varying behavior requires testing less window sizes than a fast changing one). For the wrapping machine data set, we use 9 values for the PW (0.25, 0.5, 1, 1.5, 2, 2.5, 3, 3.5, and 4 hours) and 6 values for the RW (10, 15, 20, 25, 30, and 35 minutes). For the blood refrigerator, we use 4 values for the PW (0.5, 1, 1.5, and 2 hours) and 5 values for the RW (10, 15, 20, 25, and 30 minutes). For the nitrogen generator data set, we use 6 values for the PW (0.5, 1, 1.5, 2, 3 and 5 hours) and 5 values for the RW (10, 15, 20, 25, and 30 minutes). For all the data sets, the minimum PW size is set to the smallest time span necessary for avoiding an unrecoverable machine failure, so that the operator can intervene.
The validation procedure is also adapted to the characteristics of the different use cases. In the wrapping machine data set there are only 13 alarms, which yield failure RWs in the whole time series. Thus the number of failure RWs in the test set would be too small to test adequately the performances. Thus we adopt a training and evaluation procedure based on k-fold cross-validation (with ). Each fold is identified by with . The procedure also relies on 10 RUS instances for the test set and 10 RUS instances for the train set, 6 algorithms , with RF, LR, SVM, LSTM, ConvLSTM, Transformer}, and the hyperparameter settings for each algorithm (). Each combination of RW and PW sizes is used to compare the models with a procedure consisting of six steps:
- For each k-fold split, the data are divided into a train set , comprising the folds with , and a test set , corresponding to .
- For each and , RUS is applied to balance the classes, obtaining 10 RUS instances for the test set and 10 RUS instances for the train set.
- For each , the four presented algorithms , with their hyperparameters , are trained on the train folds and evaluated on the RUS instance on the test fold, obtaining macro scores on the test set, denoted as .
- For each algorithm and hyperparameter setting, the mean of the results is computed as
- Then, the maximum macro score for each algorithm is computed as
- Finally, the best macro score is computed as , and the best algorithm as
For the blood refrigerator and nitrogen generator data sets, a higher number of failure RWs is available and thus k-fold cross validation is unnecessary. Each data set is first divided into a train, validation and test set. The model is trained on the training set and the best combination of hyperparameters is determined as the one with the best macro score on the validation set using Bayesian Optimization. Finally, the best configuration of each algorithm is evaluated on the test set.
4. Results
This section reports the macro scores (from now on referred to as scores) and the macro average precision and recall of the compared algorithms computed with the abovementioned procedure. It discusses the effect of RW and PW selection on SVM, RF, LR, LSTM, ConvLSTM and Transformers prediction performances.
4.1. Wrapping Machine
In the wrapping machine case, the cardinality of the minority class samples is significantly influenced by both the PW and the RW, as reading windows spanning across multiple sessions are neglected. Figure 6 shows the number of RWs with class “Failure” (i.e., the support) as RW and PW sizes vary. Note that a longer PW is more likely to contain a failure, resulting in a higher probability of the RW being classified as “Failure”. Consequently, the number of RWs classified as “Failure” increases for larger PWs (i.e., the support increases). The support also increases with the decrease in RW size because more RWs are paired to a PW of class “Failure”.
Table 6 compares the scores of each algorithm as PW and RW vary (i.e., the values), and Figure 7 shows the best algorithms for each reading and prediction window size (i.e., the values) and their scores (i.e., the values). In both cases, lighter backgrounds indicate better performances. Missing results correspond to cases in which at least one fold does not contain RWs of class “Failure”.
Table 6, Figure 7 and Figure 8 show that the score, on average, increases as the RW size increases until a peak at 20 minutes and decreases afterward. Smaller train sets and the lesser relevance of past information can explain this behavior [80,81]. For example, considering a PW of 15 minutes, the support increases of a factor from an RW of 30 minutes to an RW of 10 minutes. The work in [81] reports that decreasing the number of train set samples (in this case, the number of RWs in the train set) can reduce performances and that the best results are achieved for the greatest number of training samples. The work in [80] finds that increasing the amount of historical data (in this case, the RW length) does not necessarily lead to better performance, as irrelevant information may be provided to the predictor. Similarly to [12], the performances tend to decrease as the PW size increases, with the best performances observed for the smallest PW size. This pattern depends on the fact that the predictions for smaller PWs exploit more recent data than for larger PWs.
LSTM performs better than the other algorithms (on average, ). ConvLSTM is, on average, the second-best algorithm (on average, ), followed by LR (on average, ), Transformers (on average, ), SVM (on average, ), and RF (on average, ). Related studies on time series forecasting also show the effectiveness of LSTM over simpler non-DL approaches [74,82,83]. Figure 9 shows that the improvement in performance introduced by LSTM (the best DL algorithm) with respect to LR (the best ML algorithm) is, on average, higher for smaller PWs, and lower for larger PWs. The work in [84] also observes that LSTM forecasting performances decrease for a longer prediction horizon. This pattern can be explained by the decrease in the relevance of past information for predicting behaviors far in the future. In addition, [78] observes that the performance improvement between different models tends to decrease as the forecasting horizon enlarges, suggesting that more complex approaches are as effective as less complex ones when the historical data are far in the past. Overall, our findings show that in the case study, LSTM can capture temporal dependencies effectively and behave better for small PWs (i.e., the observed temporal patterns have a noticeable influence on the predicted class). As observed in [85], LR can exploit time-independent patterns since it does not consider any temporal dependency. This explains why the difference between LSTM and LR performances decreases as the PW increases.
Considering LSTM-based networks, the choice of the loss function also has an impact. As the RW and PW vary, the difficulty of predicting failures changes. In particular, predicting errors becomes harder when the PW increases, especially when less historical information is available (i.e., for small RWs and large PWs). In such cases, the loss is ineffective, as it maximizes the score for the “Failure” class. However, a relatively high score () corresponds to the trivial case in which only the “Failure” class is predicted, and it becomes more challenging to surpass this result in the most difficult instances of the prediction problem. Instead, the BCE loss does not privilege one of the two classes and is more suitable for the more challenging cases, leading to better macro scores.

Table 7.
Comparison of the and BCE loss functions for LSTM. loss becomes less effective as the classification problem becomes more difficult (i.e. when the PW increases and the RW decreases).
Table 7.
Comparison of the and BCE loss functions for LSTM. loss becomes less effective as the classification problem becomes more difficult (i.e. when the PW increases and the RW decreases).
| Reading Window (RW) | Prediction Window (PW) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.25h | 0.5h | 1.0h | 1.5h | 2.0h | 2.5h | 3.0h | 3.5h | 4.0h | |
| 10 minutes | BCE | BCE | BCE | BCE | BCE | BCE | BCE | ||
| 15 minutes | BCE | BCE | BCE | BCE | BCE | BCE | |||
| 20 minutes | BCE | BCE | BCE | BCE | BCE | ||||
| 25 minutes | BCE | BCE | BCE | ||||||
| 30 minutes | |||||||||
| 35 minutes | |||||||||
Focusing on the ML approaches, RF and SVM show poorer performances. SVM, similarly to LR, is not able to capture time dependencies. However, LR is expected to perform better than SVM, especially when the number of features exceeds the number of samples, as SVM with RBF is prone to overfitting [86], while LR is a simpler model. In this case, the number of features for both algorithms is given by the number of samples in the reading windows multiplied by the number of time series variables. On average, there are more features than training windows ( features per training sample), which justifies the better performances of LR over SVM ( times better in terms of score, on average).
RF is the worst approach because each decision tree considers a limited number of features selected randomly, neglecting temporal dependencies, and the number of trees is much smaller than the number of input features ( to ). For these reasons, the random forest ensembles weak estimators that cannot capture complex patterns. Increasing the number of estimators or the maximum number of features does not necessarily yield better results. For the combination of PW and RW leading to the best result for RF (i.e., 0.25 hours and 25 minutes, respectively), the best number of trees is 150, and the best number of maximum features is 33% of all the features. Increasing the number of trees to 200 yields a -0.01% variation in the macro score, and increasing the maximum number of features to 100% yields a -0.1% variation in the macro score. On average across all the RW-PW combinations, the best ML algorithm has an of , while the best DL algorithm (LSTM) has an of . In this data set, DL algorithms result the best choice for the specified fault prediction task.
In summary, the best results are obtained using a PW of 0.25 hours and an RW of 20 minutes, which is considered suitable in the industrial setting of the case study. A moderate amount of historical data is sufficient to predict an alert enough in advance to allow the operator to intervene. For these RW and PW values, SVM, LR, LSTM, and ConvLSTM reach their highest scores (respectively 0.783, 0.789, 0.861, and 0.807). However, LSTM obtains the best score, which is better than LR and SVM, better than ConvLSTM, and better than RF. The difference between LSTM and the other approaches is justified by considering that it can consider temporal dependencies explicitly, and benefits are especially significant when recent historical data are used for predicting. Regarding the other DL algorithms, Transformers focus on non-sequential patterns and ConvLSTM on spatial patterns, which makes them less effective for the specified time series fault prediction task.
4.2. Blood Refrigerator
Table 8 shows the scores of each algorithm as PW and RW vary, similarly to Table 6. DL algorithms outperform ML algorithms in less cases than in the wrapping machine time series. Such difference can be explained by considering the different nature of the data sets. While the wrapping machine faults are not associated with clearly identifiable short patterns and are caused by a longer wearing of the machine components, in the blood refrigerator, the high product temperature is often observed as a consequence of some short easily identifiable patterns, exemplified in Figure 4. Such patterns can be found by simpler algorithms (i.e., ML algorithms), and more complex architectures do not lead to significant benefits.
Table 8.
Classification results on the metrics for the blood refrigerator case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, Transformer, and ConvLSTM. Lighter background corresponds to better results.
Table 8.
Classification results on the metrics for the blood refrigerator case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, Transformer, and ConvLSTM. Lighter background corresponds to better results.
| Reading Window (RW) | Algorithm | Prediction Window (PW) | |||
|---|---|---|---|---|---|
| 0.5h | 1.0h | 1.5h | 2.0h | ||
| 10 minutes | ConvLSTM | 0.750 | 0.612 | 0.634 | 0.575 |
| LR | 0.729 | 0.602 | 0.610 | 0.602 | |
| LSTM | 0.735 | 0.615 | 0.633 | 0.633 | |
| RF | 0.765 | 0.568 | 0.524 | 0.546 | |
| SVM | 0.748 | 0.635 | 0.634 | 0.612 | |
| Transformer | 0.794 | 0.621 | 0.558 | 0.659 | |
| 15 minutes | ConvLSTM | 0.727 | 0.615 | 0.633 | 0.615 |
| LR | 0.727 | 0.599 | 0.608 | 0.608 | |
| LSTM | 0.782 | 0.657 | 0.599 | 0.563 | |
| RF | 0.773 | 0.624 | 0.569 | 0.548 | |
| SVM | 0.742 | 0.650 | 0.640 | 0.609 | |
| Transformer | 0.787 | 0.551 | 0.556 | 0.603 | |
| 20 minutes | ConvLSTM | 0.680 | 0.624 | 0.617 | 0.576 |
| LR | 0.712 | 0.605 | 0.598 | 0.608 | |
| LSTM | 0.760 | 0.643 | 0.607 | 0.568 | |
| RF | 0.814 | 0.619 | 0.574 | 0.550 | |
| SVM | 0.744 | 0.648 | 0.636 | 0.614 | |
| Transformer | 0.795 | 0.633 | 0.670 | 0.659 | |
| 25 minutes | ConvLSTM | 0.725 | 0.634 | 0.627 | 0.542 |
| LR | 0.721 | 0.605 | 0.599 | 0.599 | |
| LSTM | 0.779 | 0.665 | 0.520 | 0.489 | |
| RF | 0.822 | 0.599 | 0.578 | 0.586 | |
| SVM | 0.738 | 0.651 | 0.634 | 0.613 | |
| Transformer | 0.758 | 0.658 | 0.607 | 0.670 | |
| 30 minutes | ConvLSTM | 0.730 | 0.544 | 0.601 | 0.588 |
| LR | 0.724 | 0.598 | 0.603 | 0.587 | |
| LSTM | 0.804 | 0.633 | 0.577 | 0.477 | |
| RF | 0.835 | 0.606 | 0.571 | 0.555 | |
| SVM | 0.742 | 0.635 | 0.632 | 0.606 | |
| Transformer | 0.728 | 0.646 | 0.613 | 0.519 | |
Figure 10 presents the algorithm with the best score for each RW and PW pair. The results highlight the small variation of performances across the algorithms. On average, the best ML algorithm for each RW-PW combination has an of , while the best DL algorithm for each RW-PW combination has an of .
In the case of the blood refrigerator, the absence of sessions leads to negligible differences in the support, and does not affect results significantly. In this case, the average score for different RWs varies between and , a small variation () compared to the one of the wrapping machine data set (). This result also suggests that the amount of historical data has, for this data set, a negligible effect, and that short RWs already lead to high scores.
4.3. Nitrogen Generator
Table 9 compares the scores of each algorithm as PW and RW vary. Also in this case, the performances of ML and DL algorithms are similar, suggesting that as the data set becomes simpler, more complex algorithms become less effective and often worse than simple ones. In particular, the best DL algorithms for each RW-PW combination reach, on average, an score of , while the best ML algorithms for each RW-PW combination reach an average of . As in the blood refrigerators case, this result can be explained considering the easily identifiable and similar anomalous patterns preceding faults, as visible in Figure 5.
Table 9.
Classification results on the metrics for the nitrogen generator case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, Transformer, and ConvLSTM. Lighter background corresponds to better results.
Table 9.
Classification results on the metrics for the nitrogen generator case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, Transformer, and ConvLSTM. Lighter background corresponds to better results.
| Reading Window (RW) | Algorithm | Prediction Window (PW) | |||||
|---|---|---|---|---|---|---|---|
| 0.5h | 1.0h | 1.5h | 2.0h | 3.0h | 5.0h | ||
| 10 minutes | ConvLSTM | 0.875 | 0.900 | 0.873 | 0.879 | 0.810 | 0.792 |
| LR | 0.812 | 0.824 | 0.841 | 0.835 | 0.660 | 0.674 | |
| LSTM | 0.874 | 0.872 | 0.869 | 0.856 | 0.865 | 0.806 | |
| RF | 0.931 | 0.885 | 0.883 | 0.883 | 0.844 | 0.838 | |
| SVM | 0.903 | 0.882 | 0.885 | 0.871 | 0.807 | 0.771 | |
| Transformer | 0.874 | 0.879 | 0.871 | 0.890 | 0.828 | 0.811 | |
| 15 minutes | ConvLSTM | 0.830 | 0.904 | 0.798 | 0.868 | 0.830 | 0.848 |
| LR | 0.837 | 0.837 | 0.840 | 0.828 | 0.663 | 0.676 | |
| LSTM | 0.818 | 0.892 | 0.887 | 0.879 | 0.830 | 0.807 | |
| RF | 0.919 | 0.892 | 0.876 | 0.878 | 0.834 | 0.838 | |
| SVM | 0.894 | 0.879 | 0.875 | 0.874 | 0.810 | 0.784 | |
| Transformer | 0.892 | 0.888 | 0.893 | 0.883 | 0.839 | 0.821 | |
| 20 minutes | ConvLSTM | 0.888 | 0.893 | 0.882 | 0.876 | 0.856 | 0.812 |
| LR | 0.832 | 0.837 | 0.841 | 0.826 | 0.670 | 0.678 | |
| LSTM | 0.834 | 0.885 | 0.906 | 0.878 | 0.813 | 0.814 | |
| RF | 0.902 | 0.890 | 0.873 | 0.882 | 0.843 | 0.834 | |
| SVM | 0.882 | 0.877 | 0.873 | 0.881 | 0.815 | 0.795 | |
| Transformer | 0.896 | 0.891 | 0.896 | 0.888 | 0.813 | 0.825 | |
| 25 minutes | ConvLSTM | 0.842 | 0.872 | 0.887 | 0.890 | 0.809 | 0.823 |
| LR | 0.845 | 0.838 | 0.854 | 0.827 | 0.675 | 0.680 | |
| LSTM | 0.814 | 0.893 | 0.888 | 0.879 | 0.832 | 0.811 | |
| RF | 0.914 | 0.883 | 0.873 | 0.880 | 0.857 | 0.836 | |
| SVM | 0.872 | 0.882 | 0.873 | 0.887 | 0.829 | 0.803 | |
| Transformer | 0.877 | 0.861 | 0.905 | 0.898 | 0.838 | 0.836 | |
| 30 minutes | ConvLSTM | 0.752 | 0.881 | 0.887 | 0.882 | 0.850 | 0.796 |
| LR | 0.863 | 0.848 | 0.864 | 0.825 | 0.691 | 0.687 | |
| LSTM | 0.848 | 0.865 | 0.910 | 0.885 | 0.852 | 0.812 | |
| RF | 0.892 | 0.880 | 0.873 | 0.871 | 0.868 | 0.839 | |
| SVM | 0.863 | 0.878 | 0.879 | 0.889 | 0.837 | 0.817 | |
| Transformer | 0.868 | 0.879 | 0.912 | 0.898 | 0.821 | 0.820 | |
Figure 11 presents the algorithm with the best score for each RW and PW pair. The results highlight the similar performances of different algorithms on all the RWs and PWs. In particular, the average score of the best algorithm varies between and as the RW changes, a smaller difference () compared to the other data sets.
In this case, RF is, on average, the best algorithm (with an score of ). It benefits from simple and repetitive patterns in the data, that it is able to capture effectively. Other algorithms have similar performances. Transformers have an average of , LSTM has an average of , SVM has an average of , ConvLSTM has an average of , and LR has an average of .
5. Conclusions
Failure prediction on industrial multivariate data is crucial for implementing effective predictive maintenance strategies to reduce downtime and increase productivity and operational time. However, achieving this goal with non-neural machine learning and deep learning models is challenging and requires a deep understanding of the input data.
The illustrated case studies show the importance of setting meaningful prediction and reading windows consistent with domain-specific requirements. Experimental results demonstrate that basic, general purpose algorithms, such as Logistic Regression already achieve acceptable performances in complex cases. In the wrapping machine case study, Logistic Regression attains a macro score of 0.789 with a prediction window of 15 minutes and a reading window of 20 minutes. In the same case study, LR is outperformed by LSTM, a complex model that exploits temporal dependencies, with a margin of more than 7% on average on all RW-PW pairs. In the best-case scenario of a prediction window of 15 minutes and a reading window of 20 minutes, the LSTM model achieves a notable macro score of 0.861. However, the performance gap declines as the prediction horizon enlarges because the relevance of the temporal dependencies between the RW and the PW fades out. Ultimately, an LSTM model is maximally effective for short PWs, when the influence of the reading window historical data is expected to be more critical and becomes less effective as the prediction window increases.
The better performances obtained with DL algorithms, however, are negligible in the case of simpler data sets, where easily identifiable repetitive patterns can be found. The blood refrigerator data set is a simpler data set, with a few relevant anomalous patterns leading to failures. In that case, ML algorithms perform similar to DL algorithms, often surpassing the latter. A similar result is obtained for the nitrogen generator data set. In this case, Random Forest, which has the worst performances on the wrapping machine data set, can effectively find simple rule-based repetitive patterns anticipating failures, achieving the best performances.
The results presented in this paper are valid for the industrial scenario and data sets employed in the experiments. Larger data sets would likely contain more occurrences of multiple alert codes enabling the study of different types of anomalies.
Our future work will focus on fine-tuning the LSTM model and exploring different architectures (e.g., CNN-based models [87] and Gaussian Processes [88]) and hybrid models that combine multiple machine learning and deep learning techniques [89]. Such a comparison can help identify the most effective approach for different industrial scenarios and enable a better understanding of how different network structures and learning algorithms impact failure prediction accuracy. Another fundamental research direction for the practical application of LSTM as predictors is the interpretability of their output [90]. As DL models are often used as black boxes, understanding the reasons behind their predictions is crucial in industrial settings where the model’s output is used to take preventive maintenance action.
Author Contributions
Conceptualization, N.O.P.V., F.F. and P.F.; methodology, N.O.P.V., F.F. and P.F.; software, N.O.P.V., F.F. and P.F.; validation, N.O.P.V., F.F. and P.F.; formal analysis, N.O.P.V., F.F. and P.F.; investigation, N.O.P.V., F.F. and P.F.; resources, N.O.P.V., F.F. and P.F.; data curation, N.O.P.V., F.F. and P.F.; writing—original draft preparation, N.O.P.V., F.F. and P.F.; writing—review and editing, N.O.P.V., F.F. and P.F.; visualization, N.O.P.V., F.F. and P.F.; supervision, P.F.; project administration, P.F.; funding acquisition, P.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union’s Horizon 2020 project PRECEPT, grant number 958284.
Data Availability Statement
Data sets and code have been made available at https://github.com/nicolopinci/polimi_failure_prediction.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bousdekis, A.; Apostolou, D.; Mentzas, G. Predictive Maintenance in the 4th Industrial Revolution: Benefits, Business Opportunities, and Managerial Implications. IEEE Engineering Management Review 2020, 48, 57–62. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Computers & Industrial Engineering 2020, 150, 106889. [Google Scholar] [CrossRef]
- Dalzochio, J.; Kunst, R.; Pignaton, E.; Binotto, A.; Sanyal, S.; Favilla, J.; Barbosa, J. Machine learning and reasoning for predictive maintenance in Industry 4.0: Current status and challenges. Computers in Industry 2020, 123, 103298. [Google Scholar] [CrossRef]
- Sheut, C.; Krajewski, L.J. A decision model for corrective maintenance management. International Journal of Production Research 1994, 32, 1365–1382. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, C.; Wu, J.; Wang, Y.; Xiong, Y. A corrective maintenance scheme for engineering equipment. Engineering Failure Analysis 2014, 36, 269–283. [Google Scholar] [CrossRef]
- Meller, R.D.; Kim, D.S. The impact of preventive maintenance on system cost and buffer size. European Journal of Operational Research 1996, 95, 577–591. [Google Scholar] [CrossRef]
- Wu, S.; Zuo, M. Linear and Nonlinear Preventive Maintenance Models. IEEE Transactions on Reliability 2010, 59, 242–249. [Google Scholar] [CrossRef]
- Liang, H.; Song, L.; Wang, J.; Guo, L.; Li, X.; Liang, J. Robust unsupervised anomaly detection via multi-time scale DCGANs with forgetting mechanism for industrial multivariate time series. Neurocomputing 2021, 423, 444–462. [Google Scholar] [CrossRef]
- Tian, Z.; Zhuo, M.; Liu, L.; Chen, J.; Zhou, S. Anomaly detection using spatial and temporal information in multivariate time series. Scientific Reports 2023, 13. [Google Scholar] [CrossRef]
- Salfner, F.; Lenk, M.; Malek, M. A survey of online failure prediction methods. ACM Computing Surveys 2010, 42, 1–42. [Google Scholar] [CrossRef]
- García, F.P.; Pedregal, D.J.; Roberts, C. Time series methods applied to failure prediction and detection. Reliability Engineering & System Safety 2010, 95, 698–703. [Google Scholar] [CrossRef]
- Leukel, J.; González, J.; Riekert, M. Machine learning-based failure prediction in industrial maintenance: Improving performance by sliding window selection. International Journal of Quality & Reliability Management 2022. [Google Scholar] [CrossRef]
- Box, G.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Wiley, 2016.
- Pertselakis, M.; Lampathaki, F.; Petrali, P. Predictive Maintenance in a Digital Factory Shop-Floor: Data Mining on Historical and Operational Data Coming from Manufacturers’ Information Systems. In Lecture Notes in Business Information Processing; Springer International Publishing, 2019; pp. 120–131. [CrossRef]
- Khorsheed, R.M.; Beyca, O.F. An integrated machine learning: Utility theory framework for real-time predictive maintenance in pumping systems. Proceedings of the Institution of Mechanical Engineers, Part B: Journal of Engineering Manufacture 2020, 235, 887–901. [Google Scholar] [CrossRef]
- Proto, S.; Ventura, F.; Apiletti, D.; Cerquitelli, T.; Baralis, E.; Macii, E.; Macii, A. PREMISES, a Scalable Data-Driven Service to Predict Alarms in Slowly-Degrading Multi-Cycle Industrial Processes. In Proceedings of the 2019 IEEE International Congress on Big Data (BigDataCongress). IEEE, July 2019. [CrossRef]
- Kaparthi, S.; Bumblauskas, D. Designing predictive maintenance systems using decision tree-based machine learning techniques. International Journal of Quality & Reliability Management 2020, 37, 659–686. [Google Scholar] [CrossRef]
- Alves, F.; Badikyan, H.; Moreira, H.A.; Azevedo, J.; Moreira, P.M.; Romero, L.; Leitao, P. Deployment of a Smart and Predictive Maintenance System in an Industrial Case Study. In Proceedings of the 2020 IEEE 29th International Symposium on Industrial Electronics (ISIE). IEEE, June 2020. [CrossRef]
- Dix, M.; Chouhan, A.; Sinha, M.; Singh, A.; Bhattarai, S.; Narkhede, S.; Prabhune, A. An AI-based Alarm Prediction in Industrial Process Control Systems. In Proceedings of the 2022 IEEE International Conference on Big Data and Smart Computing (BigComp). IEEE, January 2022. [CrossRef]
- Colone, L.; Dimitrov, N.; Straub, D. Predictive repair scheduling of wind turbine drive-train components based on machine learning. Wind Energy 2019. [Google Scholar] [CrossRef]
- Javeed, A.; Khan, S.U.; Ali, L.; Ali, S.; Imrana, Y.; Rahman, A. Machine Learning-Based Automated Diagnostic Systems Developed for Heart Failure Prediction Using Different Types of Data Modalities: A Systematic Review and Future Directions. Computational and Mathematical Methods in Medicine 2022, 2022, 1–30. [Google Scholar] [CrossRef]
- Leahy, K.; Gallagher, C.; O’Donovan, P.; Bruton, K.; O’Sullivan, D. A Robust Prescriptive Framework and Performance Metric for Diagnosing and Predicting Wind Turbine Faults Based on SCADA and Alarms Data with Case Study. Energies 2018, 11, 1738. [Google Scholar] [CrossRef]
- Bonnevay, S.; Cugliari, J.; Granger, V. Predictive Maintenance from Event Logs Using Wavelet-Based Features: An Industrial Application. In Advances in Intelligent Systems and Computing; Springer International Publishing, 2019; pp. 132–141. [CrossRef]
- Barraza, J.F.; Bräuning, L.G.; Perez, R.B.; Morais, C.B.; Martins, M.R.; Droguett, E.L. Deep learning health state prognostics of physical assets in the Oil and Gas industry. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability 2020, 236, 598–616. [Google Scholar] [CrossRef]
- Kusiak, A.; Verma, A. A Data-Mining Approach to Monitoring Wind Turbines. IEEE Transactions on Sustainable Energy 2012, 3, 150–157. [Google Scholar] [CrossRef]
- Li, H.; Parikh, D.; He, Q.; Qian, B.; Li, Z.; Fang, D.; Hampapur, A. Improving rail network velocity: A machine learning approach to predictive maintenance. Transportation Research Part C: Emerging Technologies 2014, 45, 17–26. [Google Scholar] [CrossRef]
- Forbicini, F.; Pinciroli Vago, N.O.; Fraternali, P. Time Series Analysis in Compressor-Based Machines: A Survey, 2024. [CrossRef]
- Laptev, N.; Amizadeh, S.; Flint, I. Generic and Scalable Framework for Automated Time-series Anomaly Detection. In Proceedings of the Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; p. 2015. [CrossRef]
- Ren, H.; Xu, B.; Wang, Y.; Yi, C.; Huang, C.; Kou, X.; Xing, T.; Yang, M.; Tong, J.; Zhang, Q. Time-Series Anomaly Detection Service at Microsoft. In Proceedings of the Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, July 2019. [CrossRef]
- Chen, K.; Pashami, S.; Fan, Y.; Nowaczyk, S. Predicting Air Compressor Failures Using Long Short Term Memory Networks. In Progress in Artificial Intelligence; Springer International Publishing, 2019; pp. 596–609. [CrossRef]
- Leukel, J.; González, J.; Riekert, M. Adoption of machine learning technology for failure prediction in industrial maintenance: A systematic review. Journal of Manufacturing Systems 2021, 61, 87–96. [Google Scholar] [CrossRef]
- Zangrando, N.; Fraternali, P.; Petri, M.; Vago, N.O.P.; González, S.L.H. Anomaly detection in quasi-periodic energy consumption data series: A comparison of algorithms. Energy Informatics 2022, 5. [Google Scholar] [CrossRef]
- Carrera, D.; Manganini, F.; Boracchi, G.; Lanzarone, E. Defect Detection in SEM Images of Nanofibrous Materials. IEEE Transactions on Industrial Informatics 2017, 13, 551–561. [Google Scholar] [CrossRef]
- Si, W.; Yang, Q.; Wu, X. Material Degradation Modeling and Failure Prediction Using Microstructure Images. Technometrics 2018, 61, 246–258. [Google Scholar] [CrossRef]
- Bionda, A.; Frittoli, L.; Boracchi, G. Deep Autoencoders for Anomaly Detection in Textured Images Using CW-SSIM. In Image Analysis and Processing – ICIAP 2022; Springer International Publishing, 2022; pp. 669–680. [CrossRef]
- Xue, Z.; Dong, X.; Ma, S.; Dong, W. A Survey on Failure Prediction of Large-Scale Server Clusters. In Proceedings of the Eighth ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD 2007). IEEE, July 2007. [CrossRef]
- Ramezani, S.B.; Killen, B.; Cummins, L.; Rahimi, S.; Amirlatifi, A.; Seale, M. A Survey of HMM-based Algorithms in Machinery Fault Prediction. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI). IEEE, December 2021. [CrossRef]
- Yoon, A.S.; Lee, T.; Lim, Y.; Jung, D.; Kang, P.; Kim, D.; Park, K.; Choi, Y. Semi-supervised Learning with Deep Generative Models for Asset Failure Prediction, 2017. [CrossRef]
- Zhao, M.; Furuhata, R.; Agung, M.; Takizawa, H.; Soma, T. Failure Prediction in Datacenters Using Unsupervised Multimodal Anomaly Detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data). IEEE, December 2020. [CrossRef]
- Nowaczyk, S.; Prytz, R.; Rögnvaldsson, T.; Byttner, S. Towards a machine learning algorithm for predicting truck compressor failures using logged vehicle data. In Proceedings of the 12th Scandinavian Conference on Artificial Intelligence, Aalborg, Denmark, November 20–22, 2013; IOS Press, 2013; pp. 205–214. [Google Scholar]
- Prytz, R.; Nowaczyk, S.; Rögnvaldsson, T.; Byttner, S. Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data. Engineering Applications of Artificial Intelligence 2015, 41, 139–150. [Google Scholar] [CrossRef]
- Canizo, M.; Onieva, E.; Conde, A.; Charramendieta, S.; Trujillo, S. Real-time predictive maintenance for wind turbines using Big Data frameworks. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM). IEEE, June 2017. [CrossRef]
- Xiang, S.; Huang, D.; Li, X. A Generalized Predictive Framework for Data Driven Prognostics and Diagnostics using Machine Logs. In Proceedings of the TENCON 2018 - 2018 IEEE Region 10 Conference. IEEE, October 2018. [CrossRef]
- Mishra, K.; Manjhi, S.K. Failure Prediction Model for Predictive Maintenance. In Proceedings of the 2018 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM). IEEE, November 2018. [CrossRef]
- Kulkarni, K.; Devi, U.; Sirighee, A.; Hazra, J.; Rao, P. Predictive Maintenance for Supermarket Refrigeration Systems Using Only Case Temperature Data. In Proceedings of the 2018 Annual American Control Conference (ACC). IEEE, June 2018. [CrossRef]
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine Learning for Predictive Maintenance: A Multiple Classifier Approach. IEEE Transactions on Industrial Informatics 2015, 11, 812–820. [Google Scholar] [CrossRef]
- Hamaide, V.; Glineur, F. Predictive Maintenance of a Rotating Condenser Inside a Synchrocyclotron. In Proceedings of the BNAIC/BENELEARN; 2019. [Google Scholar]
- Orrù, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability 2020, 12, 4776. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Computation 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Fagerström, J.; Bång, M.; Wilhelms, D.; Chew, M.S. LiSep LSTM: A Machine Learning Algorithm for Early Detection of Septic Shock. Scientific Reports 2019, 9. [Google Scholar] [CrossRef]
- Aung, N.N.; Pang, J.; Chua, M.C.H.; Tan, H.X. A novel bidirectional LSTM deep learning approach for COVID-19 forecasting. Scientific Reports 2023, 13. [Google Scholar] [CrossRef]
- Jin, L.; Wenbo, H.; You, J.; Lei, W.; Fei, J. A ConvLSTM-Based Approach to Wind Turbine Gearbox Condition Prediction. In Proceedings of the 7th PURPLE MOUNTAIN FORUM on Smart Grid Protection and Control (PMF2022); Springer Nature: Singapore, 2023; pp. 529–545. [Google Scholar] [CrossRef]
- Alos, A.; Dahrouj, Z. Using MLSTM and Multioutput Convolutional LSTM Algorithms for Detecting Anomalous Patterns in Streamed Data of Unmanned Aerial Vehicles. IEEE Aerospace and Electronic Systems Magazine 2022, 37, 6–15. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting, 2015. [CrossRef]
- Szarek, D.; Jabłoński, I.; Zimroz, R.; Wyłomańska, A. Non-Gaussian feature distribution forecasting based on ConvLSTM neural network and its application to robust machine condition prognosis. Expert Systems with Applications 2023, 230, 120588. [Google Scholar] [CrossRef]
- Wu, X.; Geng, J.; Liu, M.; Song, Z.; Song, H. Prediction of Node Importance of Power System Based on ConvLSTM. Energies 2022, 15, 3678. [Google Scholar] [CrossRef]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data, 2022. [CrossRef]
- Huang, S.; Liu, Y.; Fung, C.; He, R.; Zhao, Y.; Yang, H.; Luan, Z. HitAnomaly: Hierarchical Transformers for Anomaly Detection in System Log. IEEE Transactions on Network and Service Management 2020, 17, 2064–2076. [Google Scholar] [CrossRef]
- Jin, Y.; Hou, L.; Chen, Y. A Time Series Transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Wu, B.; Cai, W.; Cheng, F.; Chen, H. Simultaneous-fault diagnosis considering time series with a deep learning transformer architecture for air handling units. Energy and Buildings 2022, 257, 111608. [Google Scholar] [CrossRef]
- Gao, P.; Guan, L.; Hao, J.; Chen, Q.; Yang, Y.; Qu, Z.; Jin, M. Fault Prediction in Electric Power Communication Network Based on Improved DenseNet. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB). IEEE, June 2023. [CrossRef]
- Tang, L.; Lv, H.; Yang, F.; Yu, L. Complexity testing techniques for time series data: A comprehensive literature review. Chaos, Solitons & Fractals 2015, 81, 117–135. [Google Scholar] [CrossRef]
- Inouye, T.; Shinosaki, K.; Sakamoto, H.; Toi, S.; Ukai, S.; Iyama, A.; Katsuda, Y.; Hirano, M. Quantification of EEG irregularity by use of the entropy of the power spectrum. Electroencephalography and Clinical Neurophysiology 1991, 79, 204–210. [Google Scholar] [CrossRef] [PubMed]
- Saxena, S.; Odono, V.; Uba, J.; Nelson, J.M.; Lewis, W.L.; Shulman, I.A. The Risk of Bacterial Growth in Units of Blood that Have Warmed to More Than 10 °C. American Journal of Clinical Pathology 1990, 94, 80–83. [Google Scholar] [CrossRef] [PubMed]
- Blaine, K.P.; Cortés-Puch, I.; Sun, J.; Wang, D.; Solomon, S.B.; Feng, J.; Gladwin, M.T.; Kim-Shapiro, D.B.; Basu, S.; Perlegas, A.; et al. Impact of different standard red blood cell storage temperatures on human and canine RBC hemolysis and chromium survival. Transfusion 2018, 59, 347–358. [Google Scholar] [CrossRef]
- Aalaei, S.; Amini, S.; Keramati, M.R.; Shahraki, H.; Abu-Hanna, A.; Eslami, S. Blood bag temperature monitoring system. In e-Health–For Continuity of Care; IOS Press, 2014; pp. 730–734.
- Tanco, M.L.; Tanaka, D.P. Recent Advances on Carbon Molecular Sieve Membranes (CMSMs) and Reactors. Processes 2016, 4, 29. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection. ACM Computing Surveys 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Prusa, J.; Khoshgoftaar, T.M.; Dittman, D.J.; Napolitano, A. Using Random Undersampling to Alleviate Class Imbalance on Tweet Sentiment Data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration. IEEE, August 2015. [CrossRef]
- Zuech, R.; Hancock, J.; Khoshgoftaar, T.M. Detecting web attacks using random undersampling and ensemble learners. Journal of Big Data 2021, 8. [Google Scholar] [CrossRef]
- Stefanski, L.A.; Carroll, R.J.; Ruppert, D. Optimally hounded score functions for generalized linear models with applications to logistic regression. Biometrika 1986, 73, 413–424. [Google Scholar] [CrossRef]
- Breiman, L. Machine Learning 2001, 45, 5–32. 45. [CrossRef]
- A, V.S. Advanced support vector machines and kernel methods. Neurocomputing 2003, 55, 5–20. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The Performance of LSTM and BiLSTM in Forecasting Time Series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data). IEEE, December 2019. [CrossRef]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? Proceedings of the AAAI Conference on Artificial Intelligence 2023, 37, 11121–11128. [Google Scholar] [CrossRef]
- SHI, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.k.; WOO, W.c. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems; Cortes, C.; Lawrence, N.; Lee, D.; Sugiyama, M.; Garnett, R., Eds. Curran Associates, Inc., 2015, Vol. 2.
- Bénédict, G.; Koops, V.; Odijk, D.; de Rijke, M. sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification, 2021. [CrossRef]
- Abduljabbar, R.L.; Dia, H.; Tsai, P.W. Unidirectional and Bidirectional LSTM Models for Short-Term Traffic Prediction. Journal of Advanced Transportation 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Tang, Z.; Wu, B.; Wu, W.; Ma, D. Fault Detection via 2.5D Transformer U-Net with Seismic Data Pre-Processing. Remote Sensing 2023, 15, 1039. [Google Scholar] [CrossRef]
- Zargoush, M.; Sameh, A.; Javadi, M.; Shabani, S.; Ghazalbash, S.; Perri, D. The impact of recency and adequacy of historical information on sepsis predictions using machine learning. Scientific Reports 2021, 11. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.B.; Ho, L.S.; Al-Ansari, N.; Le, H.V.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Mathematical Problems in Engineering 2021, 2021, 1–15. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A Comparison of ARIMA and LSTM in Forecasting Time Series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, December 2018. [CrossRef]
- Rahimzad, M.; Nia, A.M.; Zolfonoon, H.; Soltani, J.; Mehr, A.D.; Kwon, H.H. Performance Comparison of an LSTM-based Deep Learning Model versus Conventional Machine Learning Algorithms for Streamflow Forecasting. Water Resources Management 2021, 35, 4167–4187. [Google Scholar] [CrossRef]
- Malakar, S.; Goswami, S.; Ganguli, B.; Chakrabarti, A.; Roy, S.S.; Boopathi, K.; Rangaraj, A.G. Designing a long short-term network for short-term forecasting of global horizontal irradiance. SN Applied Sciences 2021, 3. [Google Scholar] [CrossRef]
- Allam, A.; Nagy, M.; Thoma, G.; Krauthammer, M. Neural networks versus Logistic regression for 30days all-cause readmission prediction. Scientific Reports 2019, 9. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Chan, L.; Zhu, N. Flood forecasting using support vector machines. Journal of Hydroinformatics 2007, 9, 267–276. [Google Scholar] [CrossRef]
- Sherly, S.I.; Mathivanan, G. An efficient honey badger based Faster region CNN for chronc heart Failure prediction. Biomedical Signal Processing and Control 2023, 79, 104165. [Google Scholar] [CrossRef]
- Lee, W.J.; Sutherland, J.W. Time to Failure Prediction of Rotating Machinery using Dynamic Feature Extraction and Gaussian Process Regression. 2023. [Google Scholar] [CrossRef]
- Wahid, A.; Breslin, J.G.; Intizar, M.A. Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework. Applied Sciences 2022, 12, 4221. [Google Scholar] [CrossRef]
- Guo, T.; Lin, T.; Antulov-Fantulin, N. Exploring interpretable LSTM neural networks over multi-variable data. In Proceedings of the 36th International Conference on Machine Learning; Chaudhuri, K.; Salakhutdinov, R., Eds. PMLR, 09–15 Jun 2019, Vol. 97, Proceedings of Machine Learning Research, pp. 2494–2504.
| 1 | Available at https://github.com/nicolopinci/polimi_failure_prediction (as of April 2024) |
| 2 | |
| 3 |
https://scikit-learn.org/stable/ (as of April 2024) |
| 4 |
https://www.tensorflow.org/ (as of April 2024) |
Figure 1.
Distribution of the alert codes on a logarithmic scale. Alert 34 is the most frequent but must be discarded because it is unreliable. Alert 11 is the second most frequent. The remaining alerts have less than ten occurrences in the entire data set.
Figure 1.
Distribution of the alert codes on a logarithmic scale. Alert 34 is the most frequent but must be discarded because it is unreliable. Alert 11 is the second most frequent. The remaining alerts have less than ten occurrences in the entire data set.
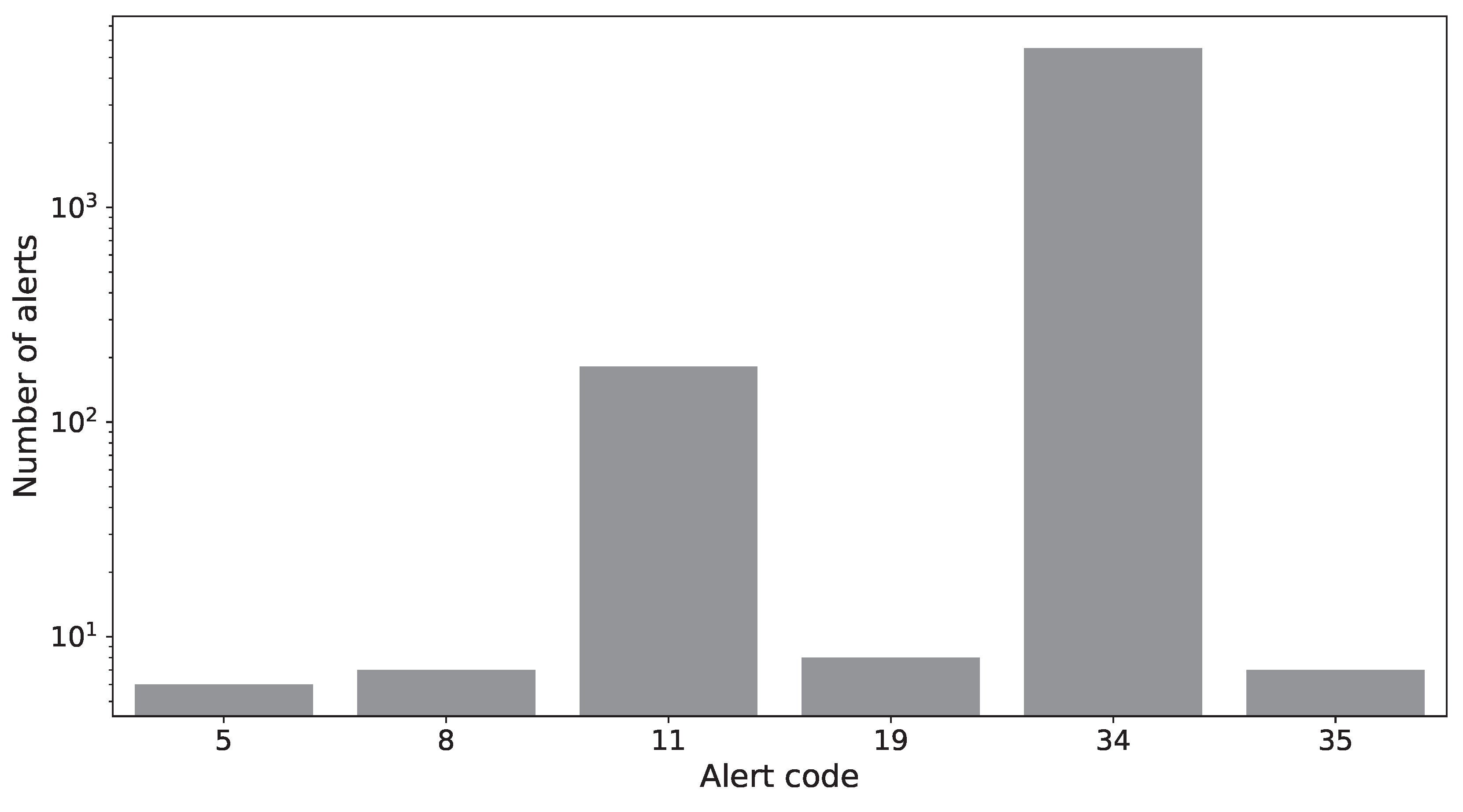
Figure 2.
Examples of diverse patterns preceding faults in the wrapping machine data set. The patterns involve three variables and the faults are displayed as dashed vertical lines. The example on the left shows two faults observed on 15-06-2021. They are preceded by a slow decrease in the film tension and after the second fault the slave motor has a speed of zero. On the right, the fault observed on 30-06-2021 is preceded by a sudden acceleration of the platform rotation speed, while the slave motor does not move, but the film tension remains constant.
Figure 2.
Examples of diverse patterns preceding faults in the wrapping machine data set. The patterns involve three variables and the faults are displayed as dashed vertical lines. The example on the left shows two faults observed on 15-06-2021. They are preceded by a slow decrease in the film tension and after the second fault the slave motor has a speed of zero. On the right, the fault observed on 30-06-2021 is preceded by a sudden acceleration of the platform rotation speed, while the slave motor does not move, but the film tension remains constant.
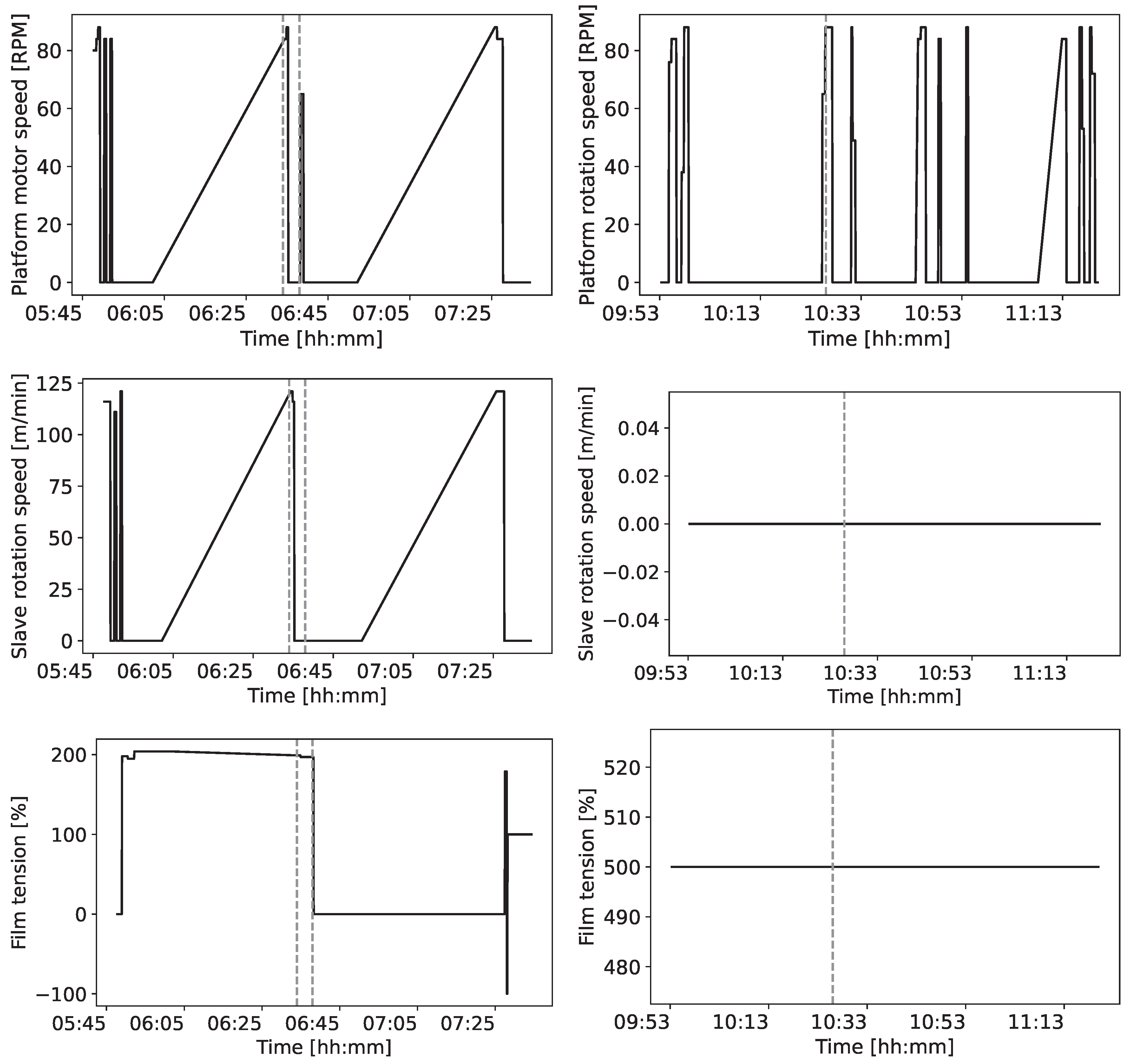
Figure 3.
Distribution of the duration of work sessions.
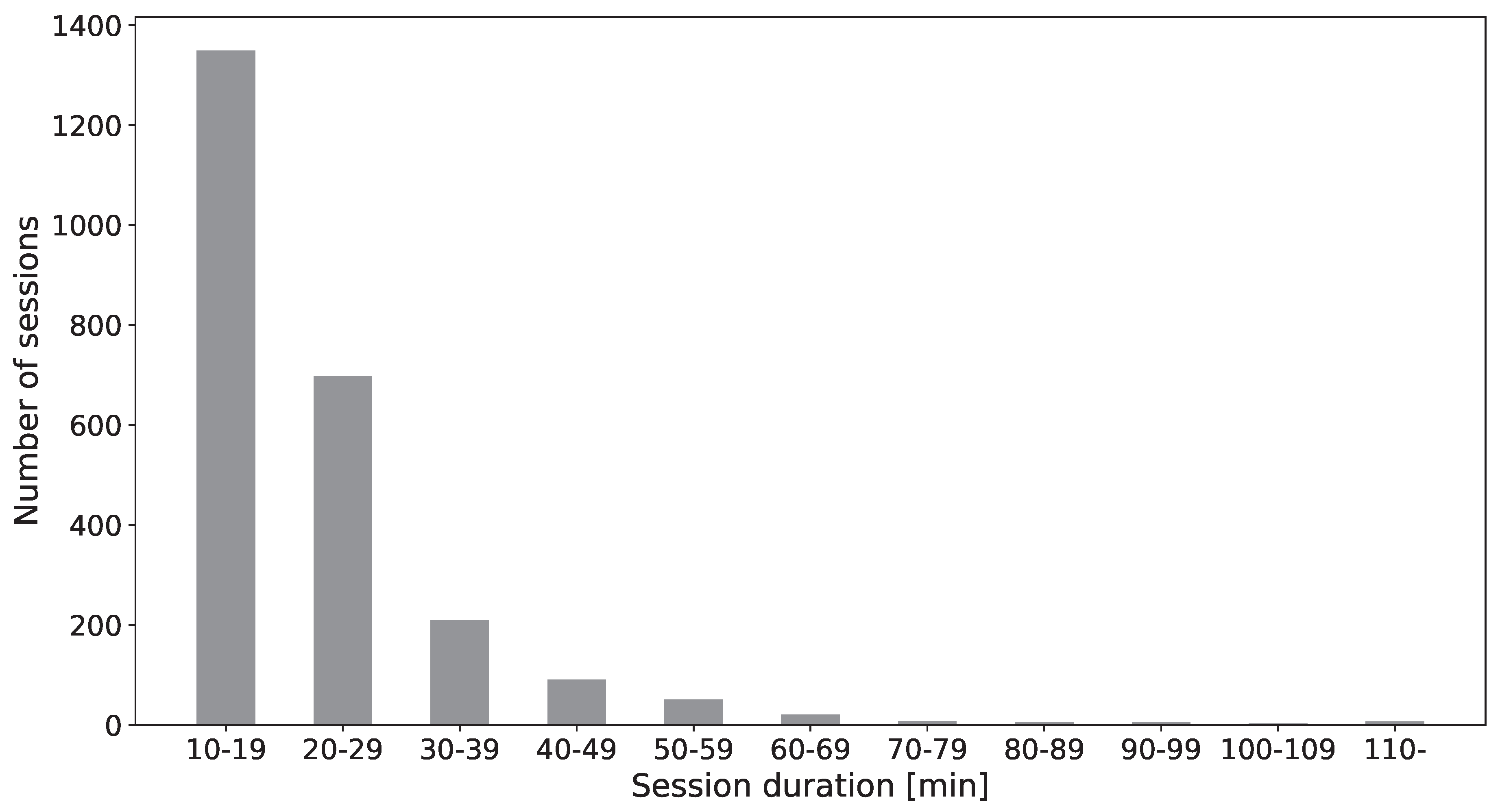
Figure 4.
Examples of patterns preceding a fault in a blood refrigerator, observed on 22-11-2022. Before the fault (shown by a dashed line), the instant power consumption increases and then decreases after a short time, the evaporator temperature decreases of after a sudden increase, and the product temperature has an increase.
Figure 4.
Examples of patterns preceding a fault in a blood refrigerator, observed on 22-11-2022. Before the fault (shown by a dashed line), the instant power consumption increases and then decreases after a short time, the evaporator temperature decreases of after a sudden increase, and the product temperature has an increase.
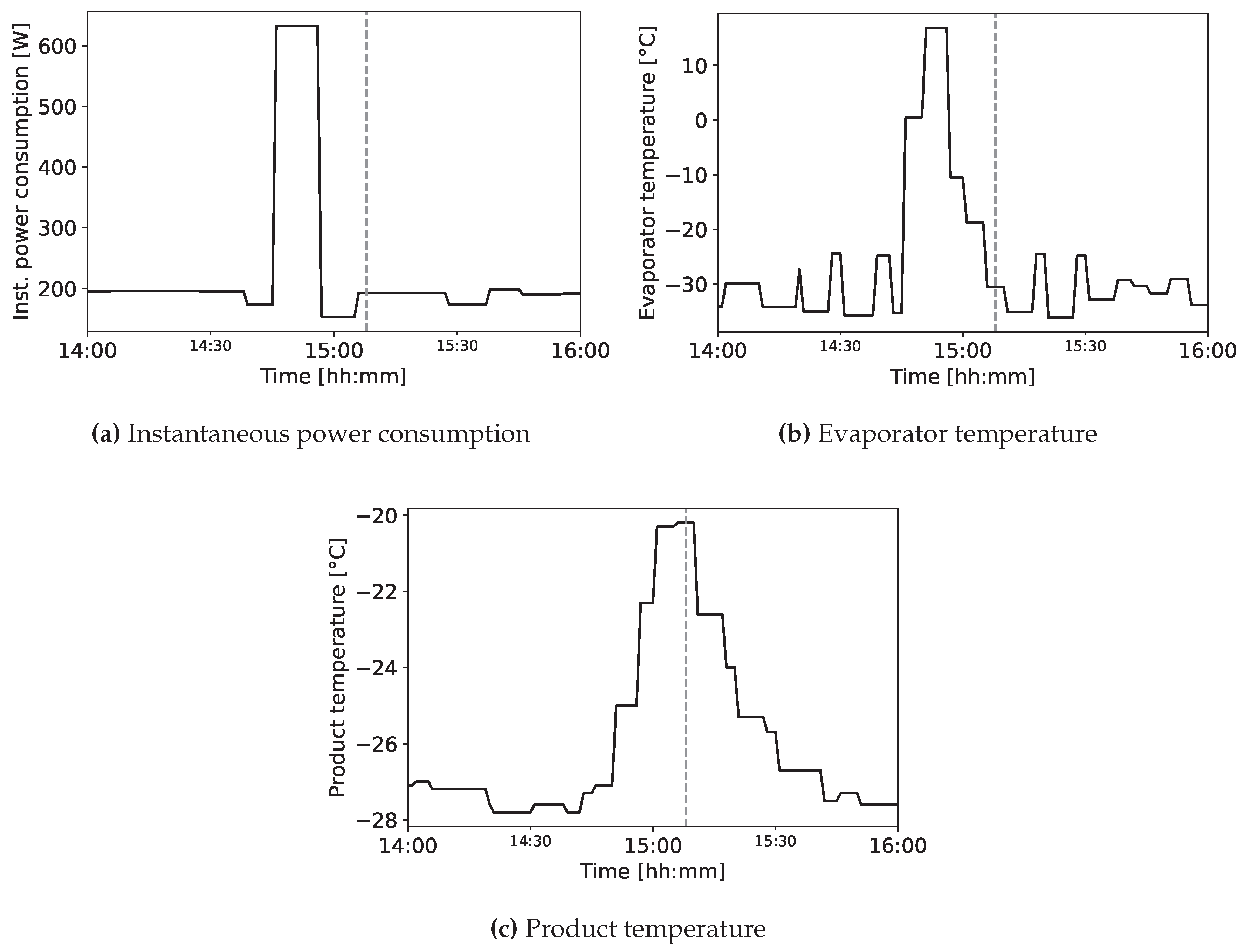
Figure 5.
A typical pattern in a nitrogen generator, observed on 01-08-2023. In this case, before a fault (indicated with a gray dashed line), the oxygen concentration drops, the CMS air pressure decreases of of bar, and the nitrogen pressure decreases of bar, making the generation of nitrogen impossible.
Figure 5.
A typical pattern in a nitrogen generator, observed on 01-08-2023. In this case, before a fault (indicated with a gray dashed line), the oxygen concentration drops, the CMS air pressure decreases of of bar, and the nitrogen pressure decreases of bar, making the generation of nitrogen impossible.
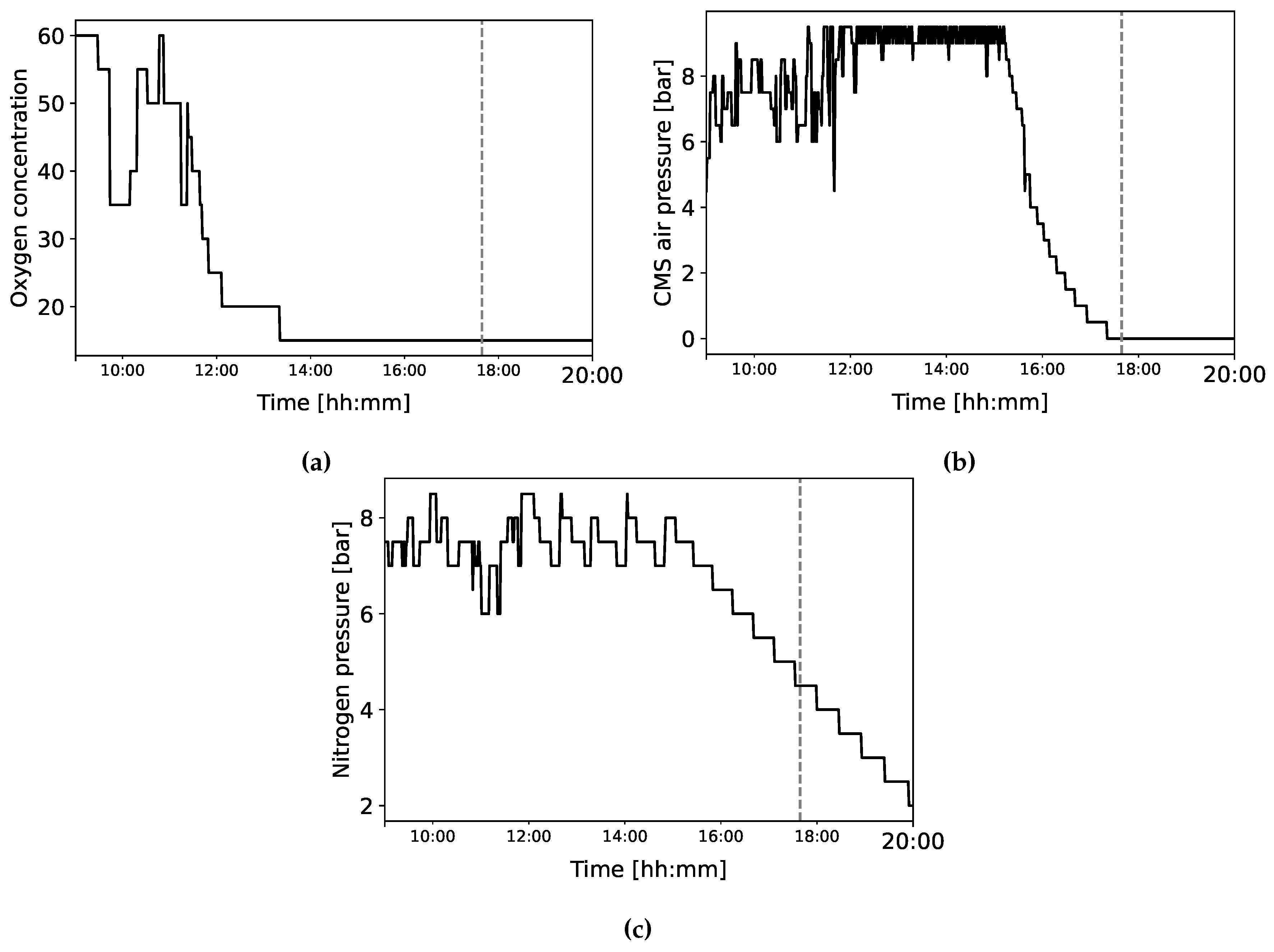
Figure 6.
The number of RWs with class “Failure” as RW and PW sizes vary. The highest number of “Failure” labels is observed for short RWs and long PWs. Darker colors indicate a higher number of “Failure” RWs.
Figure 6.
The number of RWs with class “Failure” as RW and PW sizes vary. The highest number of “Failure” labels is observed for short RWs and long PWs. Darker colors indicate a higher number of “Failure” RWs.
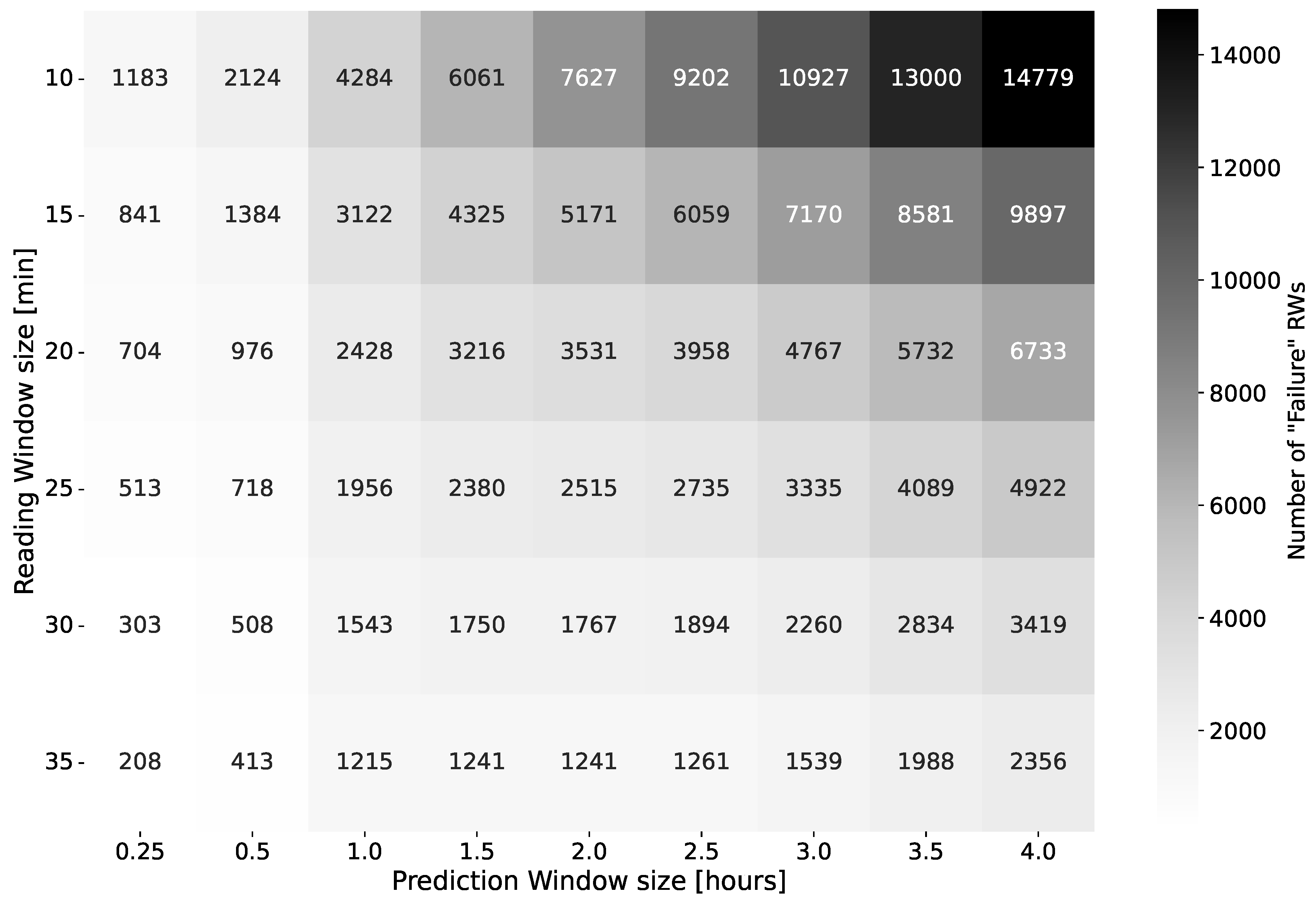
Figure 7.
Comparison of the best scores for each combination of RW and PW sizes for the wrapping machine case study. The heatmap shows each combination’s best method and the corresponding score. Lighter background colors correspond to better results.
Figure 7.
Comparison of the best scores for each combination of RW and PW sizes for the wrapping machine case study. The heatmap shows each combination’s best method and the corresponding score. Lighter background colors correspond to better results.

Figure 8.
The score varies depending on the RW and, on average, reaches its peak for an RW of 20 minutes. This pattern is particularly noticeable for a PW of 0.25 hours.
Figure 8.
The score varies depending on the RW and, on average, reaches its peak for an RW of 20 minutes. This pattern is particularly noticeable for a PW of 0.25 hours.
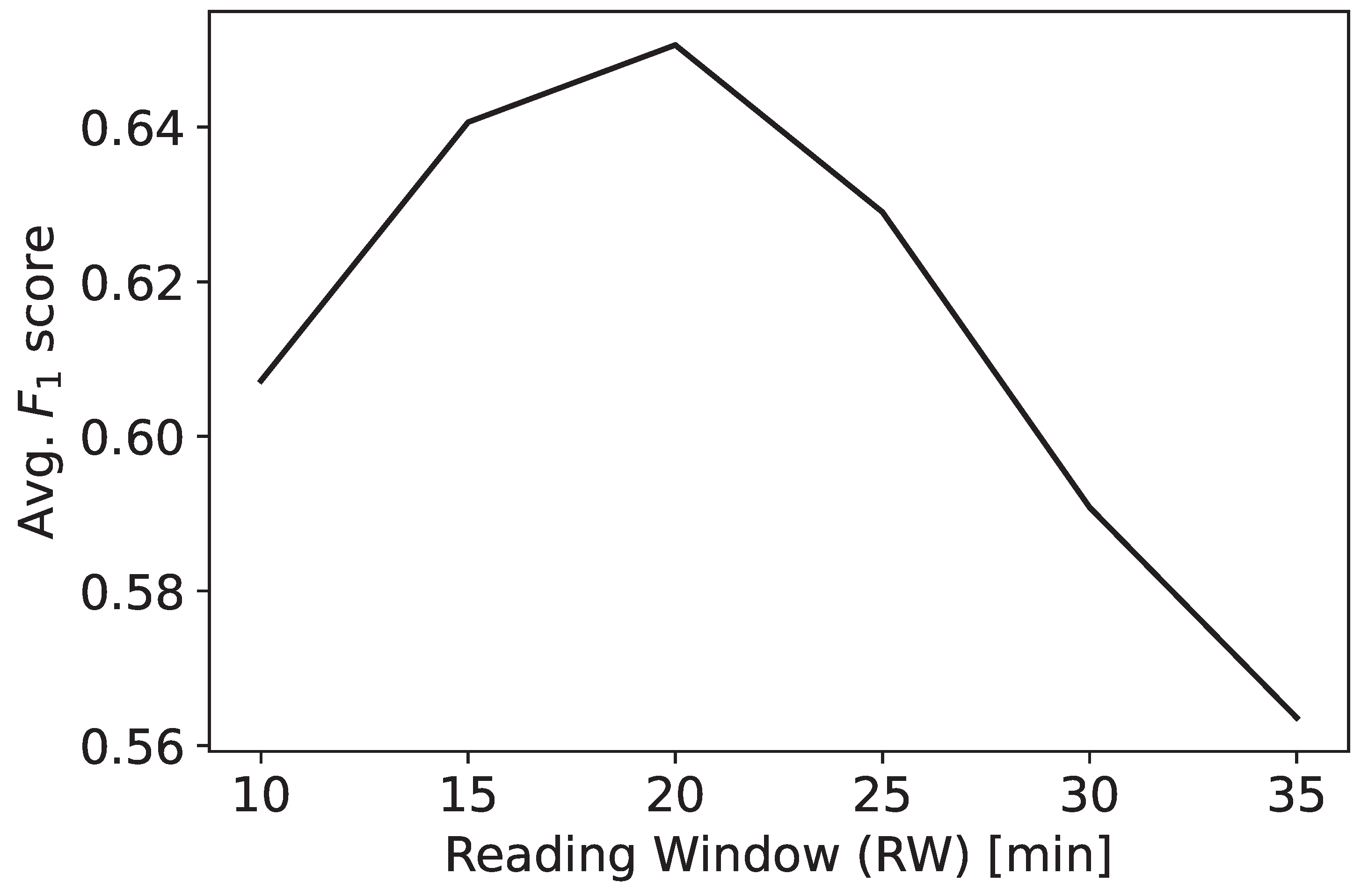
Figure 9.
The average improvement of LSTM with respect to LR shows that LSTM benefits more from short PWs since it can capture relevant time-dependent patterns. Note that the values for the two smallest PWs (0.25 and 0.5 hours) are not entirely comparable with the others because they do not consider the longest RWs, for which the prediction could not be computed.
Figure 9.
The average improvement of LSTM with respect to LR shows that LSTM benefits more from short PWs since it can capture relevant time-dependent patterns. Note that the values for the two smallest PWs (0.25 and 0.5 hours) are not entirely comparable with the others because they do not consider the longest RWs, for which the prediction could not be computed.
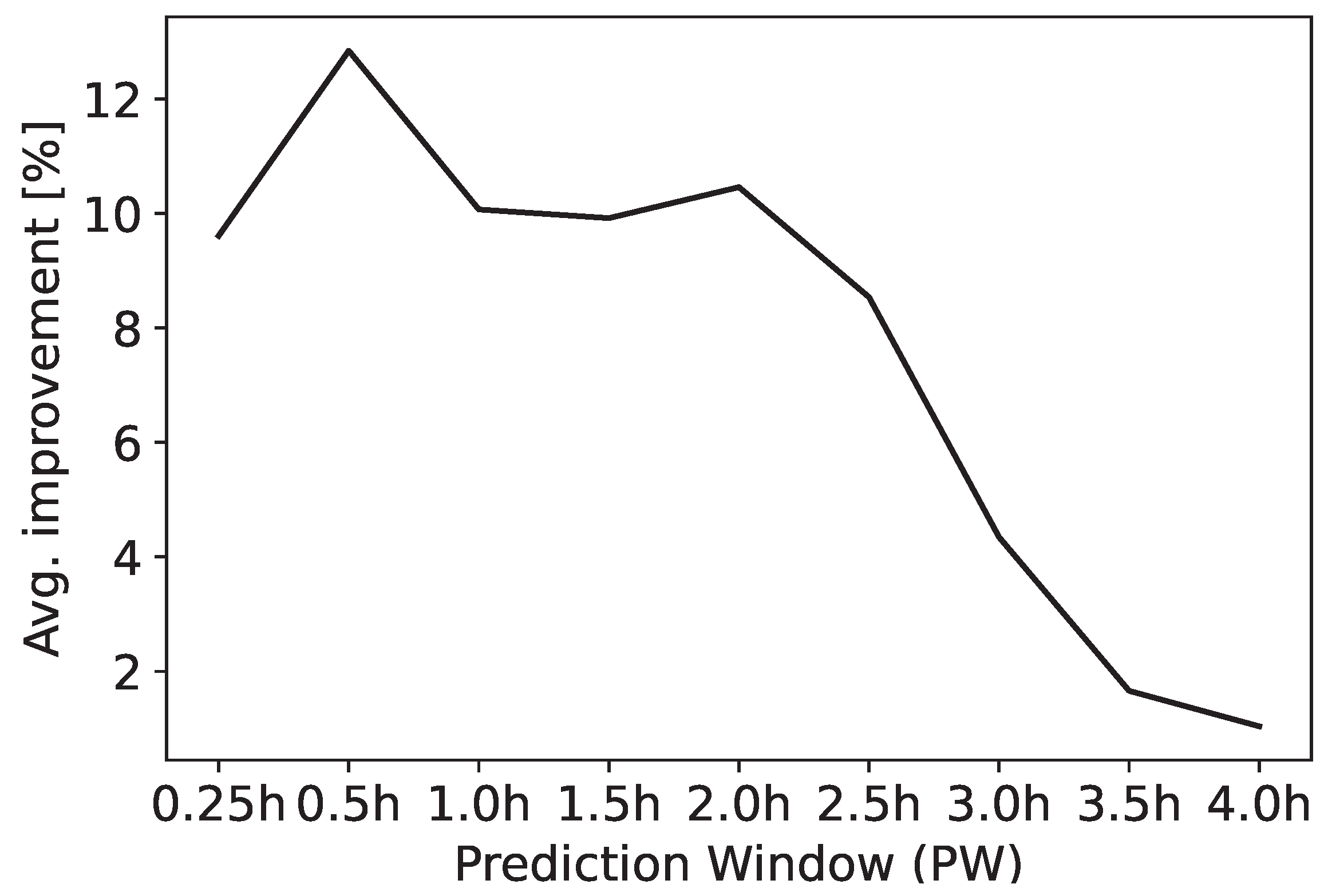
Figure 10.
Comparison of the best scores for each combination of RW and PW sizes for the blood refrigerator case study. The heatmap shows each combination’s best method and the corresponding score. Lighter background colors correspond to better results.
Figure 10.
Comparison of the best scores for each combination of RW and PW sizes for the blood refrigerator case study. The heatmap shows each combination’s best method and the corresponding score. Lighter background colors correspond to better results.
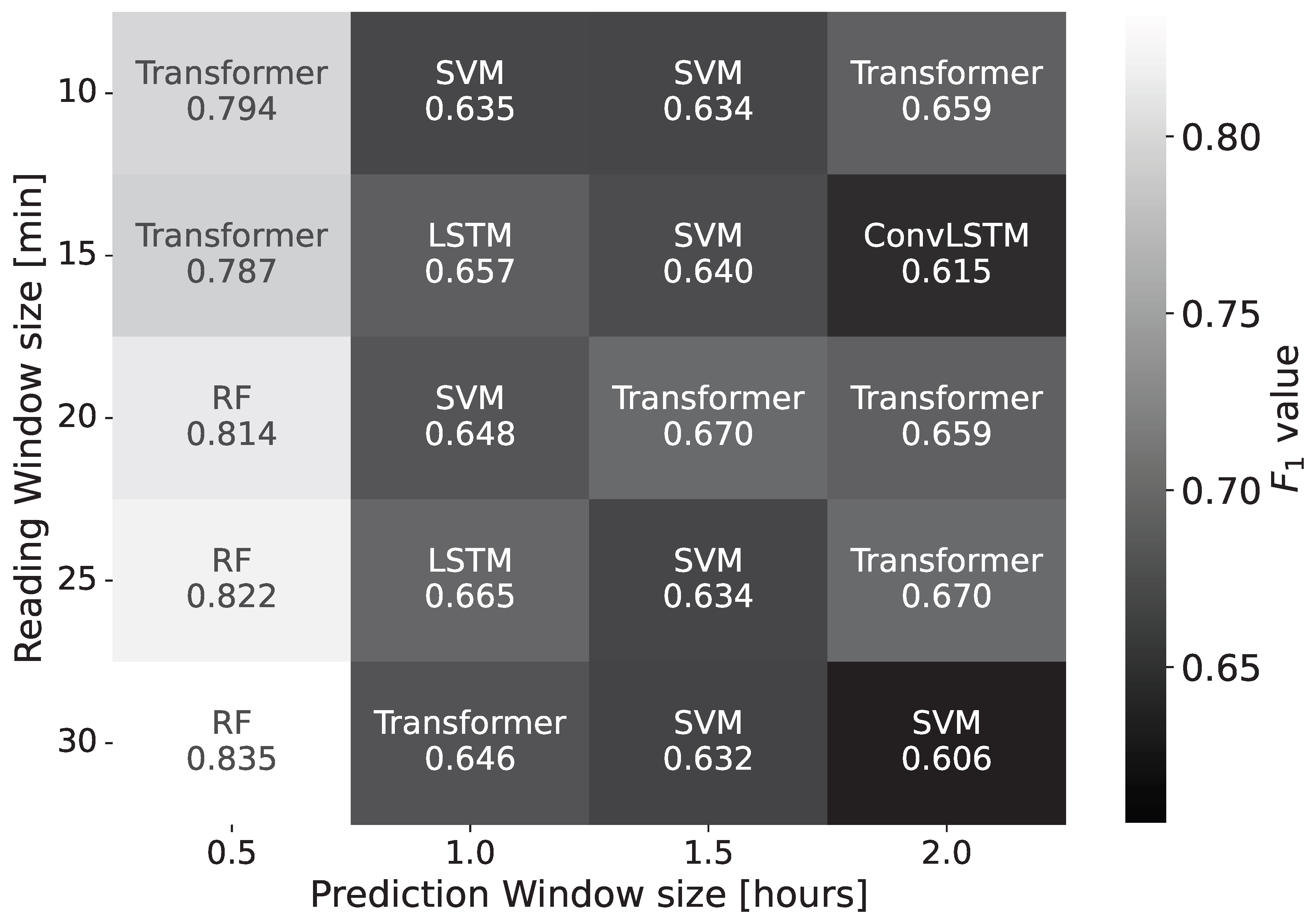
Figure 11.
Comparison of the best scores for each combination of RW and PW sizes for the nitrogen generator case study. The heatmap shows each combination’s best method and the corresponding score, where “Trans.” indicates the Transformer. Lighter background colors correspond to better results.
Figure 11.
Comparison of the best scores for each combination of RW and PW sizes for the nitrogen generator case study. The heatmap shows each combination’s best method and the corresponding score, where “Trans.” indicates the Transformer. Lighter background colors correspond to better results.
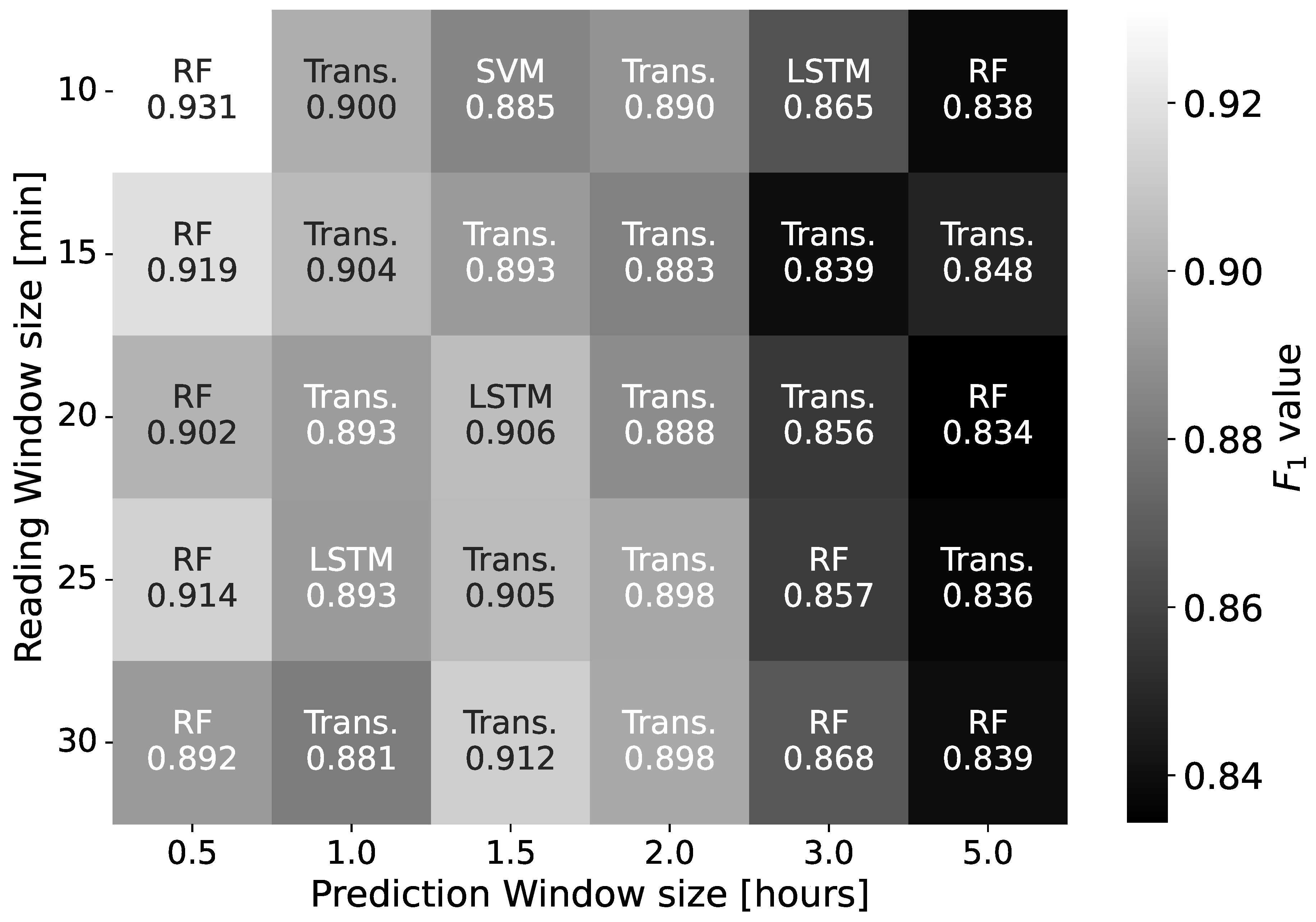
Table 1.
The 13 variables obtained after pre-processing. The minimum and maximum values are reported for each variable and the measurement unit. The “Movement” column indicates whether the variable is used to determine whether any motors are moving.
Table 1.
The 13 variables obtained after pre-processing. The minimum and maximum values are reported for each variable and the measurement unit. The “Movement” column indicates whether the variable is used to determine whether any motors are moving.
| Variable name | Minimum | Maximum | Unit | Movement |
|---|---|---|---|---|
| Platform Motor frequency | 0 | 5200 | Hz | ✓ |
| Current speed cart | 0 | 100 | % | ✓ |
| Platform motor speed | 0 | 100 | % | ✓ |
| Lifting motor speed | 0 | 88 | RPM | ✓ |
| Platform rotation speed | 0 | 184 | RPM | ✓ |
| Slave rotation speed | 0 | 184 | m/min | ✓ |
| Lifting speed rotation | 0 | 73 | m/min | ✓ |
| Flag roping | 0 | 31 | ||
| Platform Position | 0 | 359 | ° | |
| Temperature hoist drive | 0 | 55 | °C | |
| Temperature platform drive | 0 | 61 | °C | |
| Temperature slave drive | 0 | 55 | °C | |
| Total film tension | -100 | 9900 | % |
Table 2.
The 12 variables of the blood refrigerator.
| Variable Name | Minimum | Maximum | unit |
|---|---|---|---|
| Product Temperature Base | -30.8 | 5.7 | °C |
| Evaporator temperature base | -37.8 | 18.2 | °C |
| Condenser temperature base | 15.8 | 36.7 | °C |
| Power supply | 134.0 | 146.0 | V |
| Instant power consumption | 0.0 | 661.0 | W |
| Signal | -113.0 | 85.0 | dBm |
| Door alert | 0 | 1 | |
| Door close | 0 | 1 | |
| Door open | 0 | 1 | |
| Machine cooling | 0 | 1 | |
| Machine defrost | 0 | 1 | |
| Machine pause | 0 | 1 |
Table 3.
The alarms of the blood refrigerator.
| Name of the alarm | Description | Number of data points |
|---|---|---|
| alarm 1 | High-Temperature Compartment | 2 |
| alarm 5 | High Product Temperature | 188 |
Table 4.
The 4 variables of the nitrogen generator.
| Variable Name | Minimum | Maximum | unit |
|---|---|---|---|
| CMS air pressure | 0.0 | 9.5 | bar |
| Oxygen base concentration | 5.0 | 500.0 | |
| Nitrogen pressure | 0.0 | 9.0 | bar |
| Oxygen over threshold | 0 | 1 |
Table 5.
The alarm of the nitrogen generator.
| Name of the alarm | Description | Number of data points |
|---|---|---|
| CMS pressurization fail | Pressurization of nitrogen sieve failed | 54 |
Table 6.
Classification results on the metrics for the wrapping machine case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, ConvLSTM, and Transformers. Lighter background corresponds to better results. Empty cells indicate that the results cannot be computed due to the lack of “Failure” labels in some folds.
Table 6.
Classification results on the metrics for the wrapping machine case study, varying both the reading and prediction window, for SVM, RF, LR, LSTM, ConvLSTM, and Transformers. Lighter background corresponds to better results. Empty cells indicate that the results cannot be computed due to the lack of “Failure” labels in some folds.
| Reading Window (RW) | Algorithm | Prediction Window (PW) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.25h | 0.5h | 1.0h | 1.5h | 2.0h | 2.5h | 3.0h | 3.5h | 4.0h | ||
| 10 minutes | ConvLSTM | 0.684 | 0.691 | 0.577 | 0.554 | 0.533 | 0.517 | 0.524 | 0.506 | 0.483 |
| LR | 0.604 | 0.598 | 0.549 | 0.518 | 0.503 | 0.498 | 0.532 | 0.514 | 0.516 | |
| LSTM | 0.758 | 0.743 | 0.634 | 0.599 | 0.583 | 0.536 | 0.550 | 0.540 | 0.512 | |
| RF | 0.577 | 0.571 | 0.429 | 0.417 | 0.402 | 0.388 | 0.382 | 0.381 | 0.391 | |
| SVM | 0.697 | 0.654 | 0.590 | 0.543 | 0.521 | 0.517 | 0.520 | 0.485 | 0.476 | |
| Transformer | 0.714 | 0.646 | 0.585 | 0.584 | 0.540 | 0.486 | 0.498 | 0.482 | 0.452 | |
| 15 minutes | ConvLSTM | 0.787 | 0.683 | 0.554 | 0.530 | 0.547 | 0.532 | 0.558 | 0.514 | 0.498 |
| LR | 0.742 | 0.548 | 0.516 | 0.530 | 0.513 | 0.483 | 0.526 | 0.539 | 0.540 | |
| LSTM | 0.846 | 0.753 | 0.671 | 0.590 | 0.612 | 0.593 | 0.593 | 0.547 | 0.562 | |
| RF | 0.565 | 0.391 | 0.410 | 0.363 | 0.361 | 0.376 | 0.365 | 0.349 | 0.367 | |
| SVM | 0.753 | 0.659 | 0.532 | 0.524 | 0.513 | 0.518 | 0.505 | 0.471 | 0.477 | |
| Transformer | 0.818 | 0.677 | 0.613 | 0.567 | 0.563 | 0.506 | 0.513 | 0.503 | 0.477 | |
| 20 minutes | ConvLSTM | 0.807 | 0.699 | 0.567 | 0.559 | 0.531 | 0.546 | 0.551 | 0.537 | 0.489 |
| LR | 0.789 | 0.696 | 0.587 | 0.554 | 0.517 | 0.518 | 0.555 | 0.585 | 0.563 | |
| LSTM | 0.861 | 0.798 | 0.665 | 0.614 | 0.559 | 0.599 | 0.611 | 0.557 | 0.557 | |
| RF | 0.538 | 0.448 | 0.404 | 0.393 | 0.381 | 0.389 | 0.379 | 0.417 | 0.384 | |
| SVM | 0.783 | 0.568 | 0.499 | 0.468 | 0.486 | 0.485 | 0.481 | 0.443 | 0.468 | |
| Transformer | 0.799 | 0.649 | 0.584 | 0.559 | 0.543 | 0.513 | 0.516 | 0.478 | 0.438 | |
| 25 minutes | ConvLSTM | 0.744 | 0.635 | 0.527 | 0.541 | 0.512 | 0.557 | 0.523 | 0.561 | 0.524 |
| LR | 0.735 | 0.620 | 0.552 | 0.531 | 0.519 | 0.530 | 0.580 | 0.608 | 0.575 | |
| LSTM | 0.783 | 0.686 | 0.623 | 0.612 | 0.618 | 0.577 | 0.579 | 0.568 | 0.538 | |
| RF | 0.641 | 0.433 | 0.395 | 0.379 | 0.401 | 0.433 | 0.410 | 0.401 | 0.378 | |
| SVM | 0.613 | 0.512 | 0.436 | 0.411 | 0.416 | 0.436 | 0.482 | 0.413 | 0.435 | |
| Transformer | 0.772 | 0.660 | 0.517 | 0.529 | 0.504 | 0.493 | 0.492 | 0.449 | 0.450 | |
| 30 minutes | ConvLSTM | 0.426 | 0.490 | 0.464 | 0.437 | 0.470 | 0.569 | 0.569 | 0.528 | |
| LR | 0.456 | 0.510 | 0.474 | 0.471 | 0.495 | 0.542 | 0.574 | 0.532 | ||
| LSTM | 0.579 | 0.588 | 0.616 | 0.612 | 0.596 | 0.598 | 0.585 | 0.553 | ||
| RF | 0.367 | 0.360 | 0.353 | 0.353 | 0.352 | 0.349 | 0.353 | 0.347 | ||
| SVM | 0.332 | 0.348 | 0.339 | 0.338 | 0.343 | 0.438 | 0.406 | 0.405 | ||
| Transformer | 0.473 | 0.505 | 0.489 | 0.474 | 0.464 | 0.443 | 0.475 | 0.443 | ||
| 35 minutes | ConvLSTM | 0.396 | 0.405 | 0.409 | 0.419 | 0.461 | 0.597 | 0.492 | ||
| LR | 0.410 | 0.393 | 0.393 | 0.395 | 0.473 | 0.526 | 0.492 | |||
| LSTM | 0.547 | 0.563 | 0.558 | 0.531 | 0.538 | 0.649 | 0.558 | |||
| RF | 0.333 | 0.333 | 0.333 | 0.333 | 0.332 | 0.351 | 0.343 | |||
| SVM | 0.328 | 0.328 | 0.328 | 0.329 | 0.375 | 0.428 | 0.338 | |||
| Transformer | 0.516 | 0.471 | 0.490 | 0.464 | 0.433 | 0.492 | 0.464 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



