
Submitted:
24 April 2024
Posted:
28 April 2024
You are already at the latest version
Abstract
Degradation is an inevitable companion in the operation of solid oxide fuel cell (SOFC) systems since it directly deteriorates the reliability of the system’s operation and the system’s durability. Both are seen as barriers that limit the extensive commercial use of SOFC systems. Therefore diagnosis and prognosis are valuable tools that can contribute to raising the reliability of the system operation, efficient health management, increased durability and implementation of predictive maintenance techniques. Remaining useful life (RUL) prediction has been extensively studied in many areas like batteries and proton-exchange membrane fuel cell (PEM) systems, and a range of different approaches has been proposed. On the other hand, results available in the domain of SOFC systems are still relatively limited. Moreover, methods relying on detailed process models and models of degradation turned out to have limited applicability for in-field applications. Therefore, in this paper, we propose an effective, data-driven approach to predicting RUL where the trend of the health index is modelled by an adaptive linear model, which is updated at all times during the system operation. This allows for a closed-form solution of the probability distribution of the RUL, which is the main novelty of this paper. Such a solution requires no computational load and is as such very convenient for the application in ordinary low-cost control systems. The performance of the approach is demonstrated first on the simulated case studies and then on the data obtained from a long-term experiment on a laboratory SOFC system. From the tests conducted so far it turns out that, the quality of the RUL prediction is usually rather low at the beginning of the system operation, but then gradually improves while the system is approaching the end-of-life (EOL), making it a viable tool for prognosis.
Keywords:
prognosis
; linear trend modeling
; solid oxide fuel cells
; remaining useful life
1. Introduction
SOFC systems represent an attractive technology for the conversion of electrochemical energy into electrical power due to lower emissions, high efficiency, useful waste heat and fuel flexibility. They are being widely applied in auxiliary power unit (APU) and stationary power generators [1]. Yet, the most significant barriers to their broader commercialization and market deployment are insufficient durability, reliability and cost. Reliability and durability, in particular, are significantly impacted by the degradation phenomena that emerge during the operation at high temperatures.
Understanding the mechanisms that cause the deterioration is of paramount importance for the design, operation and management of the SOFC systems. Much of the research endeavour has been focused on modelling the multiphysics and multiscale processes from micro-structural to system level to understand the conditions that cause the degradation and its rate as well as the relationship with the reliability and the life span [2,3]. Due to the complexity of the underlying models and the required computational load, their use in online diagnosis and prognosis is not feasible.
Thanks to the increasing volume of historical data acquired from the rising number of SOFC systems under test in the laboratory and in-situ operation, room for the use of different machine learning approaches to either predict the degradation trend or estimate the RUL has become widely open. Particularly strong research and development of methods of prognosis have been conducted in the related areas of battery research and, to a lesser extent, in the domain of fuel cells. A comprehensive survey of prognostic methods for batteries can be found in [4]. For example in [5] over 20,000 electrochemical impedance spectroscopy (EIS) spectra of commercial Li-ion batteries, collected at different states of health, states of charge and temperatures were applied to a machine learning algorithm to automatically determine which spectral features predict degradation and the remaining life.
Although less intensive compared to the batteries, the amount of research in data-driven prognostics in PEM is still rather solid and a variety of machine learning techniques have been proposed. A good overview can be found in [6].
So far considerably less attention has been paid to the development of algorithms for online prediction of RUL in SOFC systems so the list of references is rather constrained. A brief address can be found in the review paper [7]. In an early attempt in [8] the authors adopt a neural network model in which time is used as an explicit independent variable to describe the decay of voltage as a function of time and operational parameters. The authors in [9] study the RUL prediction under two degradation modes, i.e. anode poisoning and cathode humidification. From a series of simulated life-long tests they learn the parameters of the transition model by the data-driven method (least squares – support vector machine). However, a change in the health metric, voltage in this case, can be directly affected by operating conditions imposed on the system. Therefore, it is difficult to distinguish whether it is caused by the degradation of the fuel cells, a change in load condition or if it is a response of the system due to a controller action.
Deriving the data-driven model of the stack voltage as a function of the process variables has been pursued in [10] by using a dynamic neural network model. The idea is to train the model in the nominal condition and then take the discrepancy between measured and reconstructed stack voltage as a health indicator and anticipate its trend.
In the paper [11] the health indicator is associated with the area specific resistance (ASR), which is largely affected by the stack degradation and can be made mostly invariant to the process variables. The idea is based on a simple premise that the degradation can be viewed as a hidden random walk process. To deconvolute the degradation dynamics from the available process data the authors developed a nonlinear lumped model of the process and the black-box model of the degradation dynamics. By using filtering techniques, the temporal evolution of the ASR is obtained. Based on that the RUL predictions are evaluated using Monte Carlo (MC) simulation. An attempt to include more prior knowledge in the degradation model, in [12] the authors showed that under proper conditions the quality of prognostics can be slightly improved compared to the pure black box model.
The hidden random walk models of the degradation might face two issues. First, it should be noted that a range of phenomenological models have been proposed in [13] based on a thorough investigation of the degradation phenomena under accelerated tests. The decision of which model to apply depends on the correct identification of the degradation mode. Incorrect diagnosis implicates the use of the incorrect degradation model, which might, in turn, lead to misleading results. Second, it can happen in practice that one degradation mode eventually unfolds other degradation modes so that such cascades are immensely difficult to identify.
Moreover, from past experimental runs, it seems the degradation progresses mainly as a monotone process [14] or even piecewise linear [15]. Once the health indicator is selected, the prediction of its future evaluation can be anticipated by using time series analysis tools. In quest of finding the optimum trade-off between the simplicity of the prognostic algorithm and the quality of the prognosis, in this paper, we apply a probabilistic linear trend analysis. The idea is to estimate the local trend using ordinary least squares (OLS) and then estimate the RUL as the time when the health indicator is anticipated to hit a limit value that marks the beginning of the failure state. A novelty of this approach is that the distribution of the first-hitting time (FHT) can be expressed in closed form meaning that the computational load is almost nil. Thus the algorithm can be easily applied to industrial controllers with limited computational power.
The paper is structured as follows. In section 2 the method of estimating a linear trend from the data is presented. Then the main idea that leads to the closed form solution of the probability distribution of the FHT from the linear trend model is presented. In section 3, the performance of the method is demonstrated on the different simulated time series scenarios. Finally, in section 4, the method is demonstrated on experimental data obtained from a long-term run of a SOFC system.
2. Methodology
2.1. Local Linear Trend Model
The observed degradation metric is taken as a time series. A rectangular window function of length M is used to select a part of the data - usually the latest M measurements. For each instance of windowed data, we propose the latent state of the health index, denoted as x, to behave as a linear function
while the observed state, denoted as y, is just the latent state with superimposed normally distributed white noise
Since we only get our measurements at discrete times , we can rewrite the upper equation to matrix form
From well-known OLS theory [16] follows that the most likely value of , denoted as , is
the uncertainty of , denoted as , is
and the noise level is
2.2. Distribution of the Ratio of Two Jointly Normal Variables
Again, the degradation with time, denoted as , is modelled as a linear function with slope k and intercept n. To account for the uncertainty of the said two parameters, we consider them probabilistic. Their joint distribution is taken to be multivariate-normal
where
The threshold, denoted as , is also considered uncertain, meaning
So if , then t, interpreted as the FHT, is
where The joint distribution of and k is then
where
It is clear that is a ratio distribution of two (possibly correlated) normal variables. Fortunately, the probability density function for such distributions is available in closed form [17]
where
The error is the complementary error function, defined as , where stands for the error function
Equation (14) can then be used to calculate the probability density function of the FHT distribution to obtain the estimates for RUL in a closed-form manner. A full derivation is available as supplementary material on this link.
The general idea of the method is showcased in Figure 1, highlighting the use of a data window to correctly predict the distribution of FHT.
It is important to stress that in this paper it is tacitly assumed that the indicator increases together with the degradation level, i.e. it should have a positive trend. In cases of a high noise level combined with a short time window, the slope of the estimated local trend model at time might turn negative. In that case the intersection (11) occurs at , which is not a feasible solution and is therefore discarded.
3. Performance Analysis on Simulated Time Series
To demonstrate the performance of the method above, four different simulation scenarios are analysed.
First, a noisy time series with a fixed linear trend in the latent variable is presented.
In the second case, the latent variable undergoes an abrupt change in the trend. This case serves to point out the impact of the window length on the adaptivity of the local linear trend model.
In the third case the latent variable suffers from oscillations, modelled by an autoregressive moving-average (ARMA) [18] process. This example aims to demonstrate the ability of the proposed method to account for the additional uncertainty in the FHT caused by the oscillations in the latent variable.
The fourth case is similar to the third one with one difference, that is, the parameters of the latent model are subjected to an abrupt change, once again illuminating the importance of window length.
3.1. Case 1: Time series with a fixed linear trend
In this simplest case the latent variable exhibits a fixed linear trend, while the measured health indicator is corrupted with noise
The parameters used in the simulation are given in Table 1.
The simulated time series with a fixed linear trend is plotted in Figure 2. The time between consecutive samples is h. At time h several local linear trend models are estimated over data windows and then used to evaluate the distribution of FHT. It is not surprising that utilisation of all the available data provides the most accurate prediction of FHT.
3.2. Case 2: Time Series with Linear Trend Subjected to Abrupt Changes
Like case 1, the latent variable follows a linear function, but its parameters undergo an abrupt change
where is the sigmoid function which changes the system from to . With the parameters and one defines the time of transition and the rate of transition respectively. Note that is not a free parameter to ensure a more natural-looking transition. The parameters used to simulate the second example are provided in Table 1.
In Figure 3 the simulated time series is presented along with the predicted distributions of the FHT obtained from local models estimated on three different windows. Shorter windows better adapt to the changes in the trend. In turn, the predicted FHT are more accurate compared to the models resulting from the longer time window, up to a point.
3.3. Case 3: Time Series Resulting from ARMA Process with Fixed Parameters
A more general case of a time series containing a linear trend and an oscillatory component is analyzed . For that purpose ARMA is utilized
Following the same steps as in Section 3.1 yields FHT distributions that are too narrow, since the oscillations of the latent variable are falsely regarded as white measurement noise. To circumvent this problem, we note that the scale of oscillations is approximately the same as the scale of the perceived white noise . We can now transfer this perceived uncertainty, caused by oscillations, to uncertainty of the threshold, so (see Eq. 10). Such adaptation of the problem statement rescales the distribution of FHT to a much better width, as shown in Figure 4. Note that this approximation is meaningful only under conditions of relatively high signal-to-noise ratios. Otherwise, the uncertainty of the resulting FHT distributions may be overestimated. Alternatively, if the actual noise level is known, one can subtract the actual noise level from the perceived white noise level, so
To adequately test the algorithm, three different ARMA models are employed to simulate oscillating latent variable. Their parameters are presented in Table 3.
Their typical behavior is showcased in Figure 5.
In Figure 6, the algorithm was tested using three data windows of different sizes. For a meaningful comparison to the resulting distributions, the ground-truth FHT distribution was approximated by MC sampling of the known ARMA process and compared to the results.
Examining the same situation from a different standpoint, Figure 7 features the same latent processes as Figure 6, but instead the quantiles of the resulting FHT distributions from various sizes of the data-windows are presented.
It turns out that with enough data and far enough away from the threshold the algorithm stands as a viable alternative to a full regression of an ARMA model for FHT prediction. It is also worth noting that in this case, where the time series has a constant trend, retaining as much information as possible leads to more accurate predictions.
3.4. Case 4: Time Series Resulting from ARMA Process with Abruptly Changing Parameters
In dynamical situations, an important feature of the prediction algorithm is the flexibility to quickly adapt to changes in trends. For that purpose we again utilize limited-size time windows. Similarly to Section 3.2, the algorithm is tested on data generated by ARMA process featuring a change in the trend. The model parameters used for simulation are shown in Table 4.
In Figure 8 and Figure 9 the simulated ARMA process with a change in trend is depicted for two examples. The first example has the data from h available and for the second one we use h. The change in trend is initiated around h for both examples. For the data interval up to about h the slope of the trend is , which changes to afterwards. Resulting FHT distributions derived from different data windows are illustrated in Figure 8 and Figure 9. An obvious improvement in the quality of prognosis can be observed after incorporating only the data after the trend change.
In Figure 10 and Figure 11 we show quantiles of FHT distributions from local trend models obtained from differently sized windows on the data. For example, a window h includes of the data up to 1000h. The consequence of such flexibility can be seen in frequent changes in the mean of the FHT distribution acquired from the most recent data, where the trend is not yet obvious. For comparison, ground-truth FHT distribution (dark blue curve) is also provided.
We notice that up to the point, adding data improves precision and accuracy. If we also include data before the trend change, the precision of the predictions does not suffer as much as the accuracy. This highlights a potential limitation in assessing the reliability of the prediction. Without the variance of the prediction ballooning, this could lead to a false sense of confidence in the prediction by the operator.
We also notice a slight bias in predictions, when the time of prediction is somewhat close to the EOL, see Figure 9. Due to the limited time available, any large enough oscillation significantly impacts the point of threshold crossing. The latent variable is therefore unable to regress to the mean before the crossing, which significantly alters the ground truth distribution.
4. Application to the Prognosis of a Laboratory SOFC System
4.1. System Description
The study was done on a 10kW SOFC system, which consists of two interconnected modules, the balance of plant (BoP) and the stack. The latter consists of 80 fuel cells and is fuelled by methane. Water-gas shift (WGS), steam methane reforming (SMR) and hydrogen-oxidation reactions take place inside to produce heat, water and electrical power. Air is fed by the blower to the cathode inlet of the stack. Methane is passed through a reformer in order to get hydrogen, which is then delivered to the anode inlet. The remaining fuel in the cathode output is recycled. During the test, various operational parameters were manipulated for a complete characterization of the system.
4.2. Lumped Model of the Stack
The model of the stack is based on its energy balance [3]
where and are the outlet and inlet gas temperatures, and denote energy flows in and out of the stack, denotes lumped heat capacity of the stack, U is stack voltage and I is load current.
The inlet/outlet energy flows are defined as [3]
where denotes the molar flow of the gas component, H2, H2O, CH4, CO, CO2, O2, N2}, at corresponding locations where i.e. stack inlet/outlet, and corresponding temperatures . is the enthalpy of the gas.
For the purpose of constructing such a simple model, SMR, WGS and hydrogen oxidation reactions are considered to be in thermodynamic equilibrium. This assumption is often employed in SOFC systems and can be justified [3,19,20,21,22]. Assuming total methane reforming and using the WGS equilibrium constant from [23], the reforming equilibrium can be solved [24], yielding the concentration of each outlet gas component, which we take to be proportional to its flow rates.
The stack voltage U can be expressed as
where A is the active area of a single cell, is the number of cells and is the Nerst voltage [25]
where R is the universal gas constant.
For an approximation of the partial pressure of gases inside the stack, the average of input and output molar flows is used
where and are total anode or cathode inlet/outlet molar flows.
The temperature variation of lumped Ohmic ASR of a single cell can be expressed by the second-order Steinhart–Hart equation [20,25]
where is ASR at reference temperature . It is we are actually after, since we are in a need of temperature-invariant health index.
Putting all the necessary parts together, we arrive at the full lumped dynamic model of the stack
Since it was only possible to measure indirectly and (31) is non-linear, an unscented Kalman filter [26], highly suitable to such problems, was used to filter out as much noise from the measurements as possible.
Lastly, an adequate criterion for the EOL for the stack is needed. While we will be using some rather arbitrary value of that signals the EOL, to get a physically meaningful value, one needs to define the lowest appropriate stack voltage at the same typical operating point. This minimum voltage can be easily converted to an value using (27).
4.3. Prognostics of the Remaining Useful Life Based on ASR as a Health Indicator
In Figure 12 operational data of almost 1850h is presented. The system was operated in a non-stationary regime during which there were frequent changes in the load. Therefore, the stack voltage is not the best candidate for the health indicator. Instead, ASR was chosen as the health metric since it is invariant to changes in process variables (technically, we have chosen ASR0 as the metric according to (31)). For validation of the algorithm the threshold of ASR was set to mm2 (a red horizontal line in Figure 12).
Validation of the Proposed Method by Comparison to an Alternative Prognostic Algorithm
To assess the new algorithm on experimental data, where the latent model is unknown, we decided to compare it to an ARMA process whose parameters were obtained by the maximum-likelihood method. Specifically, we have used statsmodels v0.14.1 [27], a Python package for inference for statistical models. After comparing several different variations of the model via the Akaike information criterion, we have landed on ARMA with a deterministic linear function as an exogenous variable (same framework as in (21)).
4.4. Results
Results for the experimental data can be seen in Figure 13. The improvement in the quality of resulting FHT distribution is proportional to the number of data points included in the prognosis, which is expected since the ASR time signal includes no obvious trend changes. The alternative FHT distribution, sampled from fitted ARMA model, can be seen in Figure 13 as well. It was smoothed using kernel density estimation (KDE) [28] for easier comparison.
To further compare the quality of the derived algorithm to an ARMA model, Figure 14 shows the evolution of variance and mean of both predictive distributions over the amount of data taken into account. The time of perceived EOL is shown with a horizontal red line.
Again, the presented algorithm shows comparable results to the alternative. The larger variance at the start can be attributed to the lack of sufficient data. Such uncertainty in the prediction can be valuable for the operator, as it suggests a need for caution when interpreting the prognosis. Over time we can observe a slow regression of the mean to the ground truth FHT, together with the variance shrinking to a useful level.
On the other hand, the alternative prediction from an ARMA model suffers from overconfidence issues in the beginning, since only a point-wise fit is considered for the parameters. Other than that, it also slowly converges to the vicinity of the actual FHT.
Similarly to Figure 14, Figure 15 shows quantiles of FHT distributions derived throughout the experiment. Abrupt changes in the mean of the FHT distributions can be observed, which indicate volatile oscillations of ASR during the measurement process. In the magnified inset of the Figure we again compare the actual FHT to the prediction. Upon closer examination, we conclude that the predicted FHT distributions successfully encompass the eventual EOL as early as h.
5. Conclusion
In this paper, a novel algorithm for predicting the remaining useful life for SOFC systems based on adaptive trend estimation of the time-evolving health indicator is proposed. A distinctive feature of the algorithm is that the predicted distribution of the remaining useful life is provided in a closed form. Hence the computational time is insignificant, thus rendering the algorithm appropriate for implementation in industrial low-cost platforms with limited computational resources.
The performance of the algorithm is first demonstrated on four different artificial types of time series that are intended to mimic the potential evolutions of the health indicators met in practice.
The study shows that in the simple case of a constant trend time series larger size data windows deliver more accurate predictions of FHT. If on the other hand time series exhibit variable trends, shorter data windows offer better flexibility to account for the variations.
Tests on time series that depart from the strongly monotone features due to internal dynamics modelled by ARMA process show that the proposed algorithm consistently captures the distribution of FHT without the need for inferring the coefficients of the ARMA process.
Finally, the performance of the proposed algorithm is compared with a more elaborated algorithm ARMA on experimental data. Specifically, ASR measurements from a laboratory SOFC stack were modelled as a time series. It turns out that the proposed algorithm consistently delivers the same level of quality of prognosis throughout the experiment even though estimation of ARMA model parameters is computationally more demanding than operating with linear local trend.
To sum up, the proposed prognostic algorithm is usable as a plug-and-play tool appropriate for SOFC applications lacking specific prognostic models and without prior knowledge of the degradation. In the follow up it would be of interest to explore adaptive strategies to dynamically adjust the threshold values based on evolving system conditions. This adaptability could enhance the algorithm’s performance in handling varying degradation patterns and unexpected changes in the health indicator.
Author Contributions
Conceptualization, L. Ž. and Ž. G.; methodology, L.Ž. and Ž.G.; software, L.Ž. and Ž. G.; validation L.Ž., Ž.G. and Đ.J.; formal analysis, L.Ž. and Ž.G.; data curation, L.Ž. and Ž.G.; writing—original draft preparation, L.Ž.; writing—review and editing, L.Ž., Ž.G. and Đ.J.; supervision, Đ.J.; funding acquisition, Đ.J. All authors have read and agreed to the published version of the manuscript.
Funding
The projects leading to the results presented in this paper have received funding from the Fuel Cells and Hydrogen 2 Joint Undertaking (now Clean Hydrogen Partnership) under Grant Agreements No 101007175 and No 875047. This Joint Undertaking receives support from the European Union’s Horizon 2020 Research and Innovation programme, Hydrogen Europe and Hydrogen Europe Research. The authors are also grateful to the Slovenian Research Agency for support through the Research Programme P2-0001.
Data Availability Statement
The implementation of the prognosis algorithm in Python and the necessary simulation framework can be found on this link. The experimental data is currently unavailable due to the manufacturer opting to keep this data confidential.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FHT | First-hitting time |
| OLS | Ordinary least squares |
| MC | Monte Carlo |
| SOFC | Solid oxide fuel cell |
| BoP | Balance of plant |
| RUL | Remaining useful life |
| EECD | Electrochemical energy conversion devices |
| ASR | Area specific resistance |
| SMR | Steam methane reforming |
| WGS | Water-gas shift |
| EOL | End-of-life |
| ARMA | Autoregressive moving-average |
| KDE | Kernel density estimation |
| DIAMOND | Diagnosis aided control for SOFC power systems |
| PEM | Proton-exchange membrane fuel cell |
| APU | Auxilary power unit |
References
- Peng, J.; Huang, J.; long Wu, X.; wu Xu, Y.; Chen, H.; Li, X. Solid oxide fuel cell (SOFC) performance evaluation, fault diagnosis and health control: A review. Journal of Power Sources 2021, 505, 230058. [Google Scholar] [CrossRef]
- Nakajo, A.; Tanasini, P.; Diethelm, S.; herle, J.V.; Favrat, D. Electrochemical model of solid oxide fuel cell for simulation at the stack scale II: Implementation of degradation processes. J. Electrochem. Soc. 2011, 158, B1102–B1118. [Google Scholar] [CrossRef]
- Marra, D.; Sorrentino, M.; Pohjoranta, A.; Pianese, C.; Kiviaho, J. A Lumped Dynamic Modelling Approach for Model-Based Control and Diagnosis of Solid Oxide Fuel Cell System with Anode Off-Gas Recycling. ECS Transactions 2015, 68, 3095. [Google Scholar] [CrossRef]
- Zhao, J.; Feng, X.; Pang, Q.; Wang, J.; Lian, Y.; Ouyang, M.; Burke, A.F. Battery prognostics and health management from a machine learning perspective. Journal of Power Sources 2023, 581, 233474. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, Q.; Zhang, Y.; Wang, J.; Stimming, U.; Lee, A.A. Identifying degradation patterns of lithium ion batteries from impedance spectroscopy using machine learning. Nature Communications 2020, 11, 1706. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Chen, J.; Hissel, D.; Lu, J.; Hou, M.; Shao, Z. Prognostics methods and degradation indexes of proton exchange membrane fuel cells: A review. Renewable and Sustainable Energy Reviews 2020, 123, 109721. [Google Scholar] [CrossRef]
- Ming, W.; Sun, P.; Zhang, Z.; Qiu, W.; Du, J.; Li, X.; Zhang, Y.; Zhang, G.; Liu, K.; Wang, Y.; Guo, X. A systematic review of machine learning methods applied to fuel cells in performance evaluation, durability prediction, and application monitoring. International Journal of Hydrogen Energy 2023, 48, 5197–5228. [Google Scholar] [CrossRef]
- Marra, D.; Sorrentino, M.; Pianese, C.; Iwanschitz, B. A neural network estimator of solid oxide fuel cell performance for on-field diagnostics and prognostics applications. J. Power Sources 2013, 241, 320–329. [Google Scholar] [CrossRef]
- Wu, X.; Ye, Q. Fault diagnosis and prognostic of solid oxide fuel cells. Journal of Power Sources 2016, 321, 47–56. [Google Scholar] [CrossRef]
- Cheng, S.J.; Li, W.K.; Chang, T.J.; Hsu, C.H. Data-Driven Prognostics of the SOFC System Based on Dynamic Neural Network Models. Energies 2021, 14. [Google Scholar] [CrossRef]
- Dolenc, B.; Boškoski, P.; Pohjoranta, A.; Noponen, M.; Đani Juričić. Hybrid Approach to Remaining Useful Life Prediction of Solid Oxide Fuel Cell Stack. ECS Transactions 2017, 78, 2251. [Google Scholar] [CrossRef]
- Dolenc, B.; Juričić, D.; Boškoski, P. Identification of the coupling functions between the process and the degradation dynamics by means of the variational Bayesian inference: an application to the solid-oxide fuel cells. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2019, 377, 20190086, [https://royalsocietypublishing.org/doi/pdf/10.1098/rsta.2019.0086]. [Google Scholar] [CrossRef]
- Polverino, P.; Gallo, M.; Pianese, C. Development of mathematical transfer functions correlating Solid Oxide Fuel Cell degradation to operating conditions for Accelerated Stress Test protocols design. Journal of Power Sources 2021, 491, 229521. [Google Scholar] [CrossRef]
- Guida, M.; Postiglione, F.; Pulcini, G. A random-effects model for long-term degradation analysis of solid oxide fuel cells. Reliability Engineering & System Safety 2015, 140, 88–98. [Google Scholar] [CrossRef]
- Naeini, M.; Cotton, J.S.; Adams, T.A. An eco-technoeconomic analysis of hydrogen production using solid oxide electrolysis cells that accounts for long-term degradation. Frontiers in Energy Research 2022, 10. [Google Scholar] [CrossRef]
- Goldberger, A.; Shenhart, W.; Wilks, S. Econometric Theory; WILEY SERIES in PROBABILITY and STATISTICS: APPLIED PROBABILITY and STATIST ICS SECTION Series, J. Wiley, 1964.
- Simon, M.K. Probability Distributions Involving Gaussian Random Variables: A Handbook for Engineers and Scientists; International series in engineering and computer science, Springer US, 2007.
- Shumway, R.H.; Stoffer, D.S. ARIMA Models. In Time Series Analysis and Its Applications: With R Examples; Springer International Publishing: Cham, 2017; pp. 75–163. [Google Scholar] [CrossRef]
- Aguiar, P.; Adjiman, C.S.; Brandon, N.P. Anode-supported intermediate temperature direct internal reforming solid oxide fuel cell. I: model-based steady-state performance. Journal of Power Sources 2004, 138, 120–136. [Google Scholar] [CrossRef]
- Marra, D.; Pianese, C.; Polverino, P.; Sorrentino, M. Models Hierarchy, 2016. [CrossRef]
- Sorrentino, M.; Pianese, C.; Guezennec, Y.G. A hierarchical modeling approach to the simulation and control of planar solid oxide fuel cells. Journal of Power Sources 2008, 180, 380–392. [Google Scholar] [CrossRef]
- Wahl, S.; Segarra, A.G.; Horstmann, P.; Carré, M.; Bessler, W.G.; Lapicque, F.; Friedrich, K.A. Modeling of a thermally integrated 10 kWe planar solid oxide fuel cell system with anode offgas recycling and internal reforming by discretization in flow direction. Journal of Power Sources 2015, 279, 656–666, 9th International Conference on Lead-Acid Batteries – LABAT 2014. [Google Scholar] [CrossRef]
- Massardo, A.F.; Lubelli, F. Internal Reforming Solid Oxide Fuel Cell-Gas Turbine Combined Cycles (IRSOFC-GT): Part A—Cell Model and Cycle Thermodynamic Analysis. Journal of Engineering for Gas Turbines and Power 1999, 122, 27–35, [https://asmedigitalcollection.asme.org/gasturbinespower/articlepdf/122/1/27/5548041/27_1.pdf]. [Google Scholar] [CrossRef]
- Dolenc, B.; Vrečko, D.; Đani Juričić. ; Pohjoranta, A.; Pianese, C. Online gas composition estimation in solid oxide fuel cell systems with anode off-gas recycle configuration. Journal of Power Sources 2017, 343, 246–253. [Google Scholar] [CrossRef]
- Huang, B.; Qi, Y.; Murshed, A.M. Dynamic Modelling and Predictive Control in Solid Oxide Fuel Cells: First Principle and Data-Based Approaches, 2013. [CrossRef]
- Wan, E.; Van Der Merwe, R. The unscented Kalman filter for nonlinear estimation. Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No.00EX373), 2000, pp. 153–158. [CrossRef]
- Seabold, S.; Perktold, J. statsmodels: Econometric and statistical modeling with python. 9th Python in Science Conference, 2010.
- Härdle, W.K.; Müller, M.; Sperlich, S.; Werwatz, A. Nonparametric and Semiparametric Models; Springer Berlin, Heidelberg, 2006; pp. 68–69. [CrossRef]
Figure 1.
Example of the general inner workings of the proposed method. Since a change in the trend of the observed health metric is present, not all of the available data should be taken into account. A (blue rectangle) data window chooses the most recent data, from which a prediction of the FHT distribution (blue curve) is calculated.
Figure 1.
Example of the general inner workings of the proposed method. Since a change in the trend of the observed health metric is present, not all of the available data should be taken into account. A (blue rectangle) data window chooses the most recent data, from which a prediction of the FHT distribution (blue curve) is calculated.
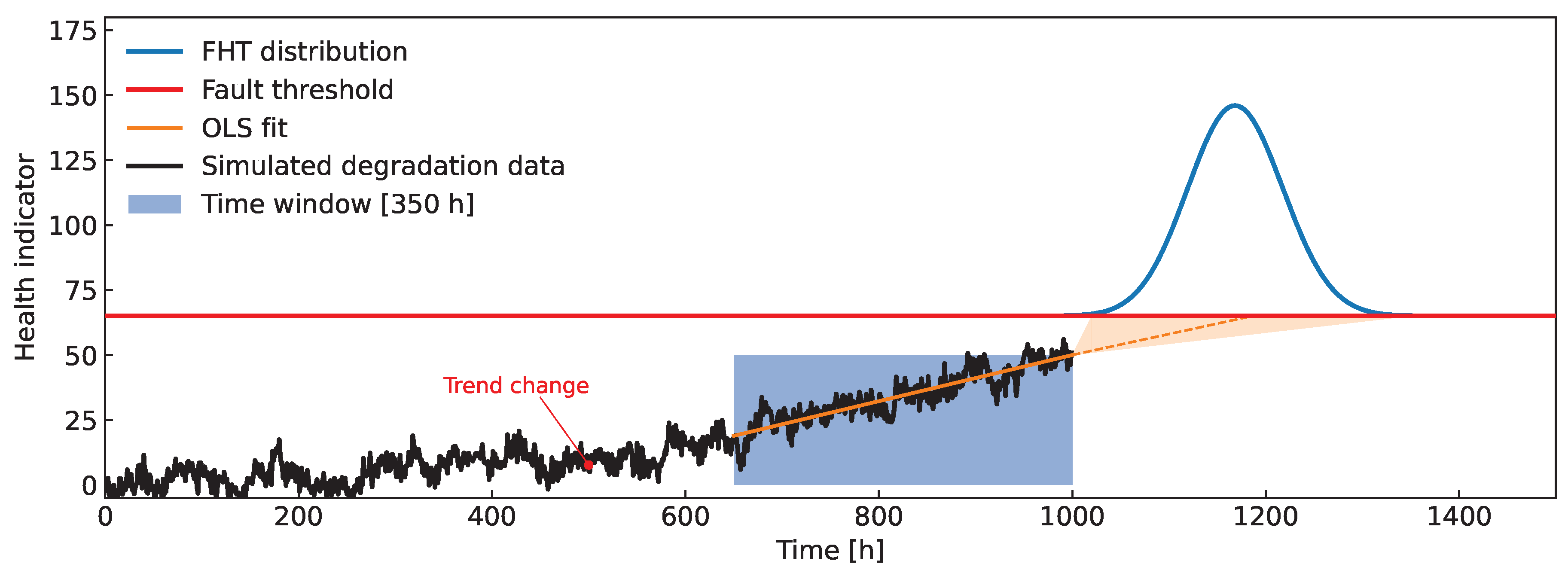
Figure 2.
Simulated time series with a fixed linear trend. The measured are collected for 0h h and the distributions of FHT are evaluated at t=400h for three different windows. The shortest window is [340h,400h], which means the last of the available data, while the longest window [0h,400h] utilizes all of the available data.
Figure 2.
Simulated time series with a fixed linear trend. The measured are collected for 0h h and the distributions of FHT are evaluated at t=400h for three different windows. The shortest window is [340h,400h], which means the last of the available data, while the longest window [0h,400h] utilizes all of the available data.
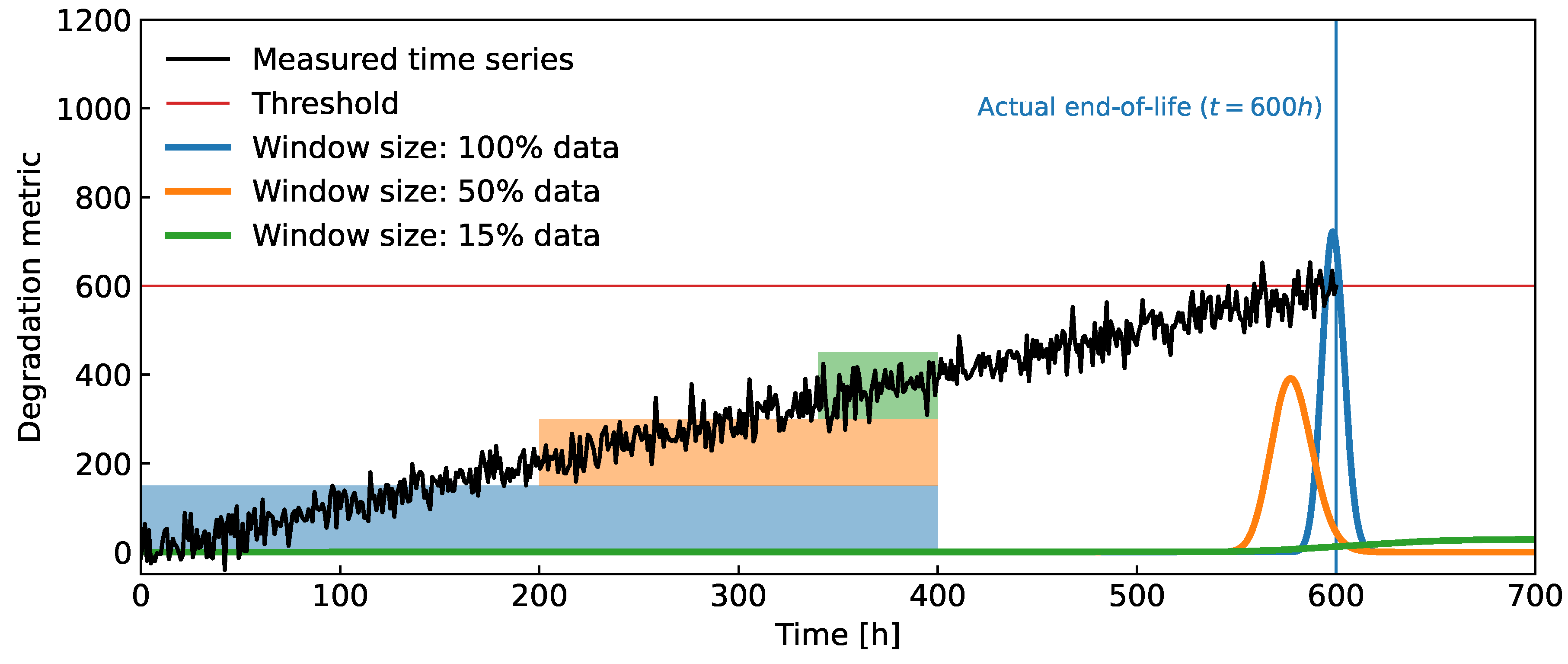
Figure 3.
(Top) Time series with an abrupt change in the linear trend and the distributions of the FHT obtained from local models evaluated over different data windows. Note that the trend model evaluated from the most recent data provides the most accurate prediction of the FHT. More specifically, in this case, utilizing only of the latest data yields the best result. (Bottom) The sigmoid function that switches between two linear trend models with different parameters.
Figure 3.
(Top) Time series with an abrupt change in the linear trend and the distributions of the FHT obtained from local models evaluated over different data windows. Note that the trend model evaluated from the most recent data provides the most accurate prediction of the FHT. More specifically, in this case, utilizing only of the latest data yields the best result. (Bottom) The sigmoid function that switches between two linear trend models with different parameters.
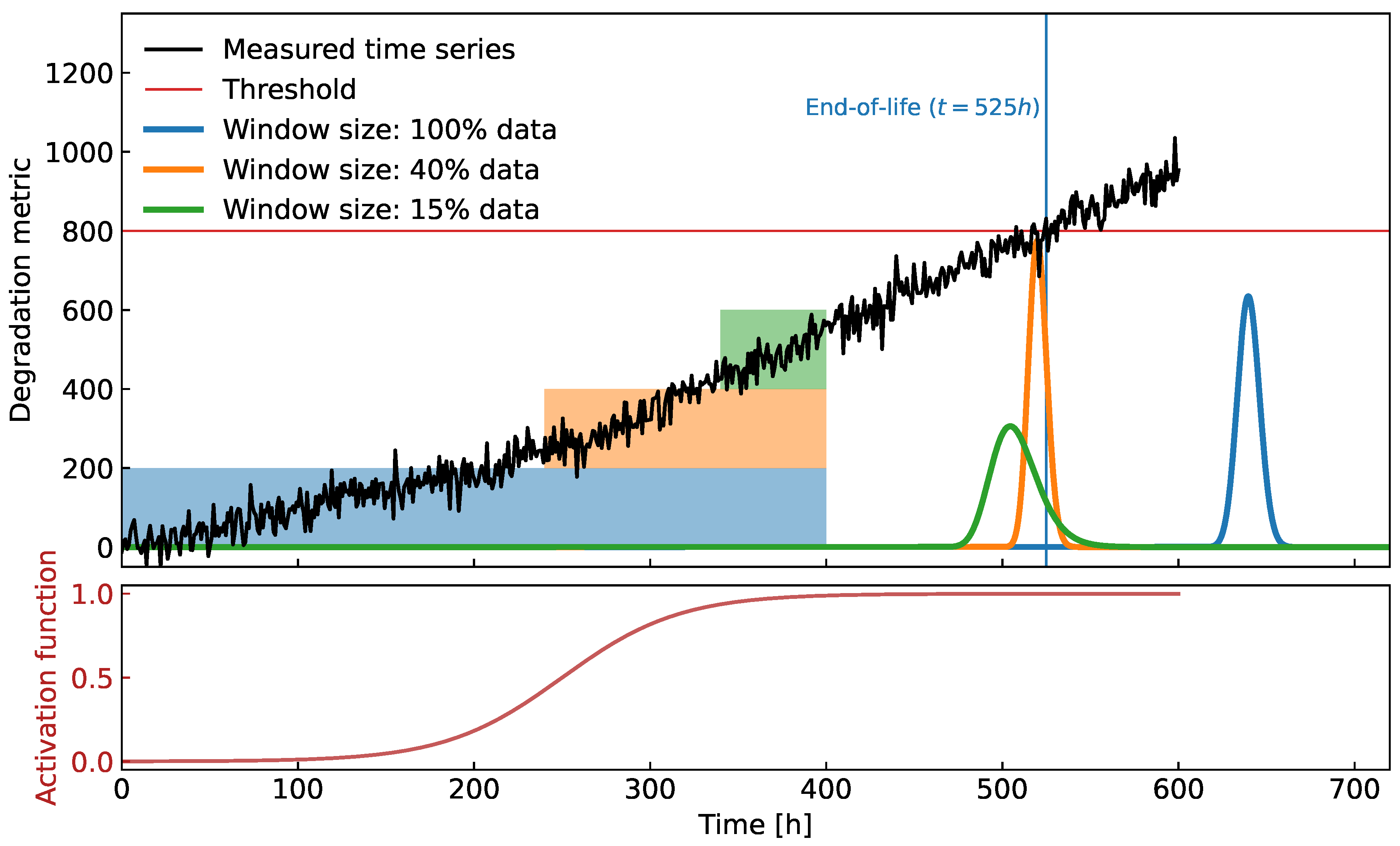
Figure 4.
Accounting for the variability in the internal variable by using the distribution of . The predictions rely on time series resulting from an ARMA process. The blue curve shows the ground truth, i.e. the prediction obtained with MC sampling of the latent model composed of a deterministic linear trend with ARMA oscillations, see Eq. 21.
Figure 4.
Accounting for the variability in the internal variable by using the distribution of . The predictions rely on time series resulting from an ARMA process. The blue curve shows the ground truth, i.e. the prediction obtained with MC sampling of the latent model composed of a deterministic linear trend with ARMA oscillations, see Eq. 21.
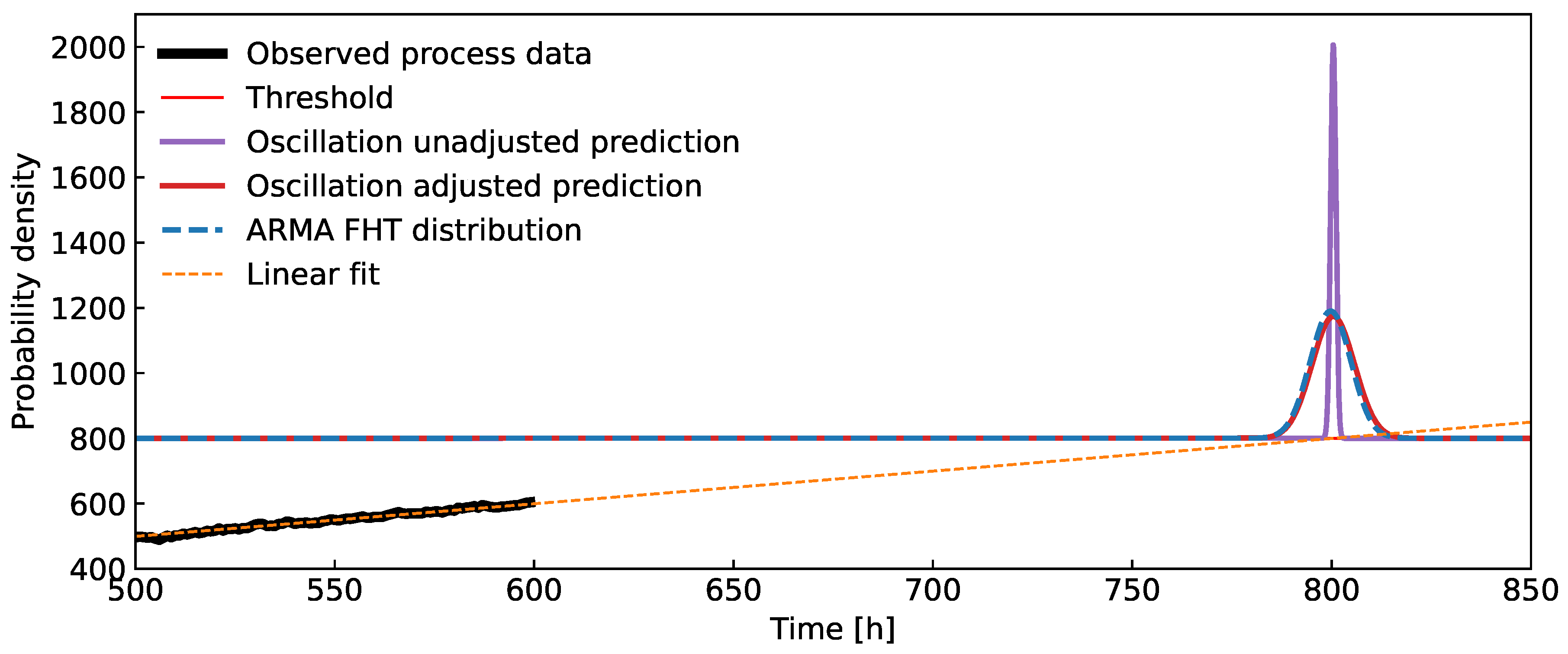
Figure 5.
Time series generated by three different ARMA processes with the parameters given in Table 3.
Figure 5.
Time series generated by three different ARMA processes with the parameters given in Table 3.
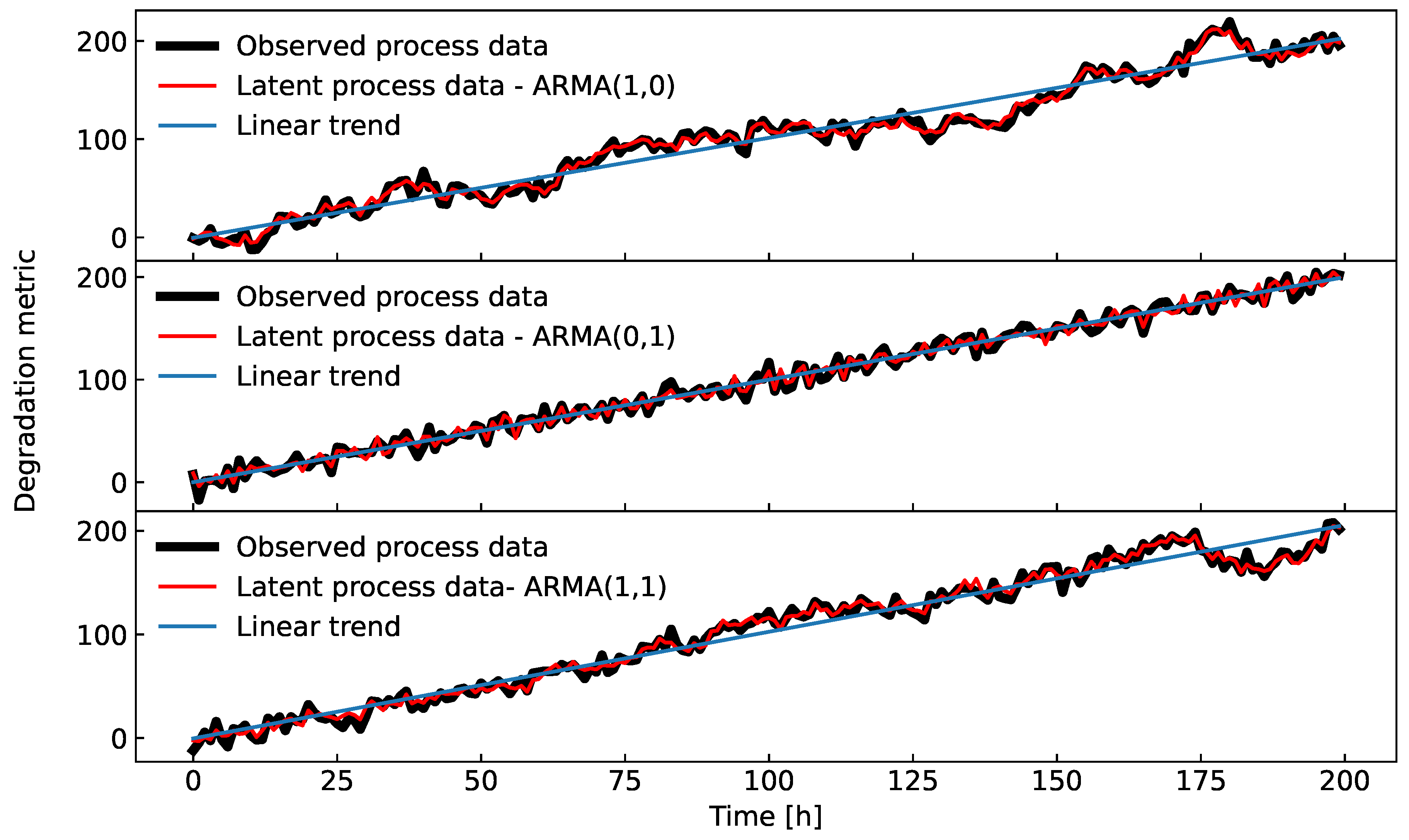
Figure 6.
The distributions of FHT evaluated at time for three different ARMA models. Additionally, three different windows for estimation of the local trends are used: or the last , or the last and or of the available data.
Figure 6.
The distributions of FHT evaluated at time for three different ARMA models. Additionally, three different windows for estimation of the local trends are used: or the last , or the last and or of the available data.
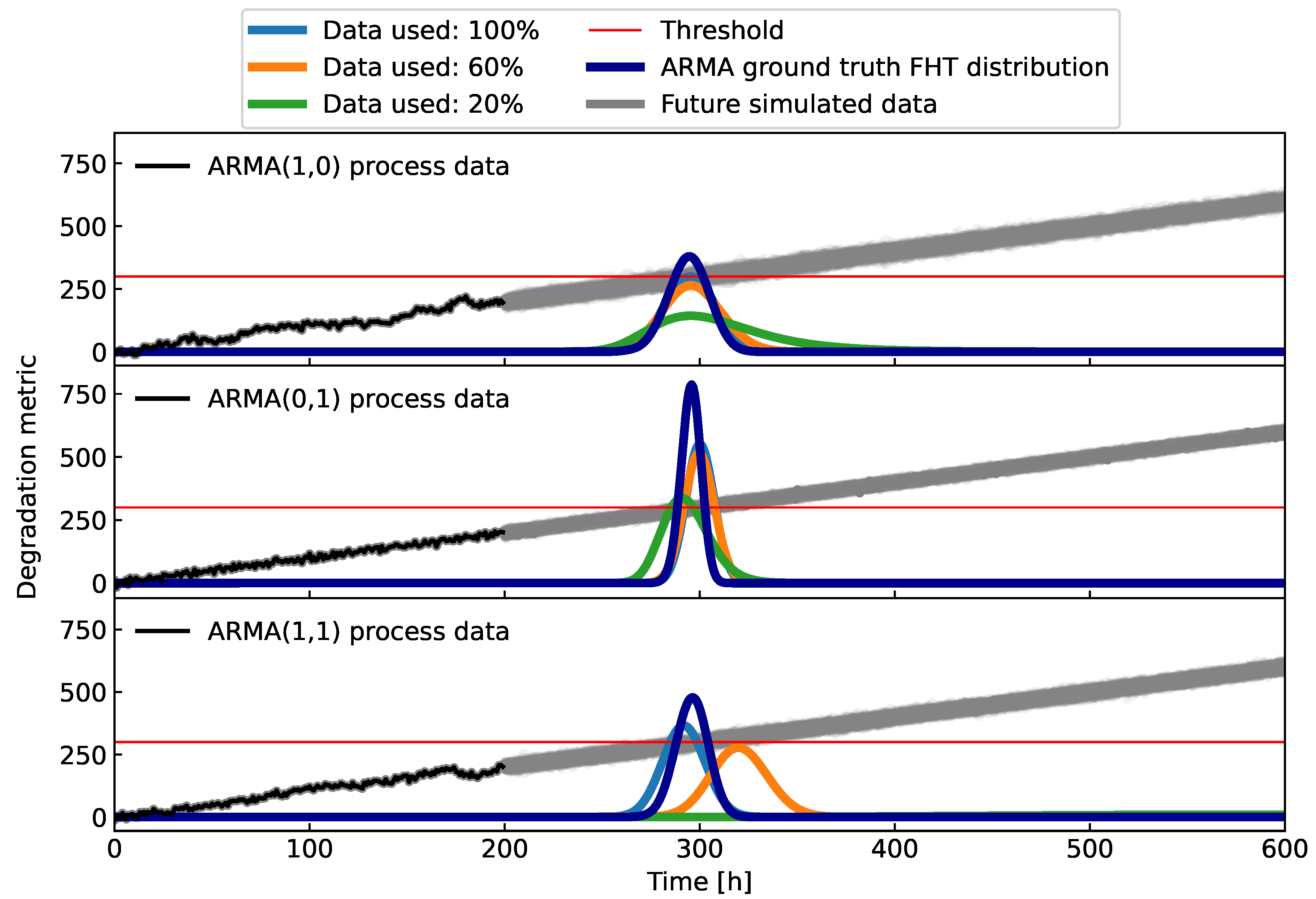
Figure 7.
Quantile plots over time for three different simulated processes (see Figure 6 for their time-signals). The predicted FHT distributions calculated by the proposed algorithm stay in-line with the ground truth when at least (from the start) of the data are taken into account. When data are taken at the begining of the process (far from the FHT, e.g. the first of the dataset), the variance of the predicted distributions grows significantly, thus signaling unreliable prognosis.
Figure 7.
Quantile plots over time for three different simulated processes (see Figure 6 for their time-signals). The predicted FHT distributions calculated by the proposed algorithm stay in-line with the ground truth when at least (from the start) of the data are taken into account. When data are taken at the begining of the process (far from the FHT, e.g. the first of the dataset), the variance of the predicted distributions grows significantly, thus signaling unreliable prognosis.
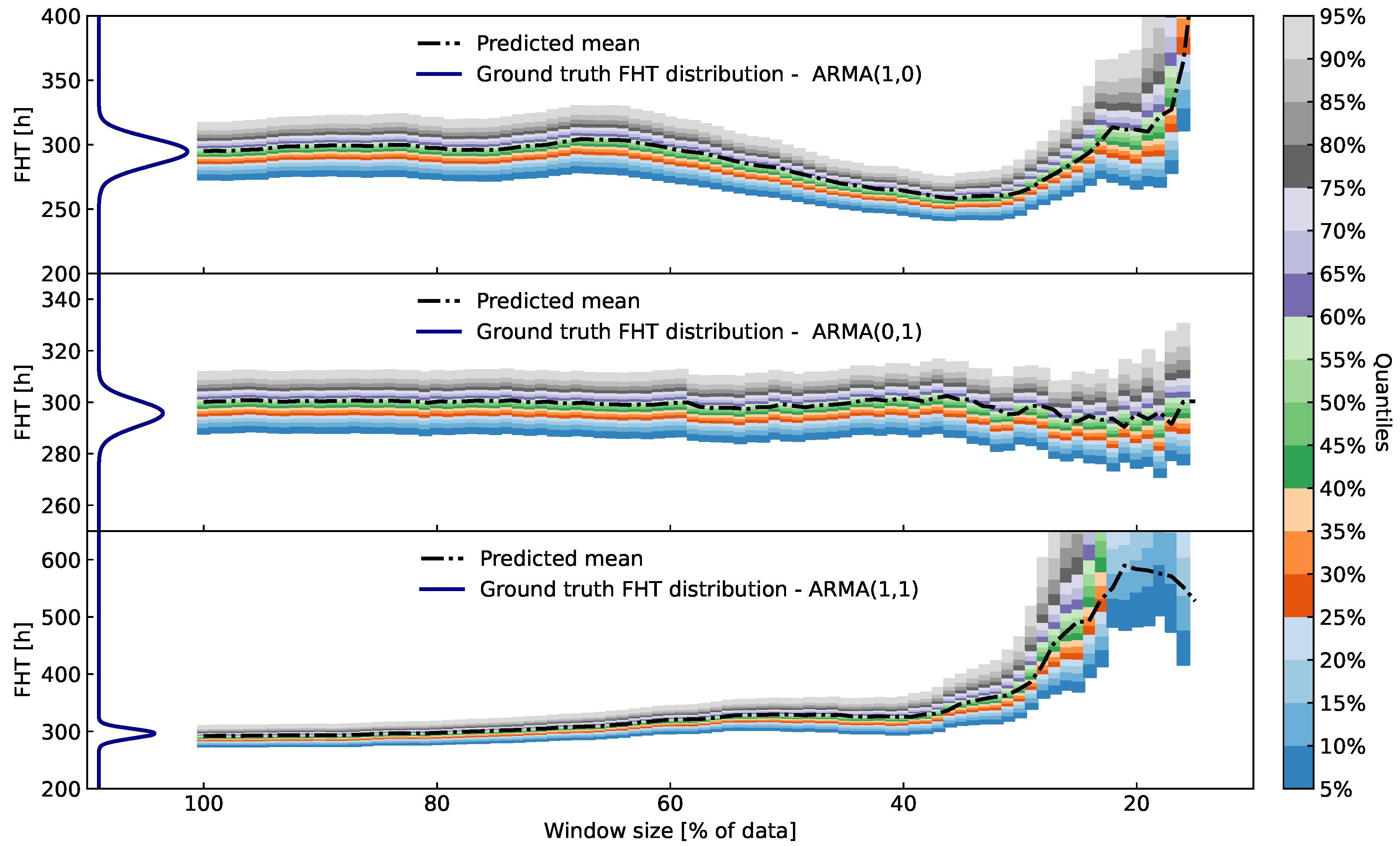
Figure 8.
Synthetic experiment on ARMA time signal with an abrupt change in the trend (around h). Data, available for the prognosis, was limited up to h. Actual EOL is compared to results from the developed algorithm with various amounts of data taken into account.
Figure 8.
Synthetic experiment on ARMA time signal with an abrupt change in the trend (around h). Data, available for the prognosis, was limited up to h. Actual EOL is compared to results from the developed algorithm with various amounts of data taken into account.
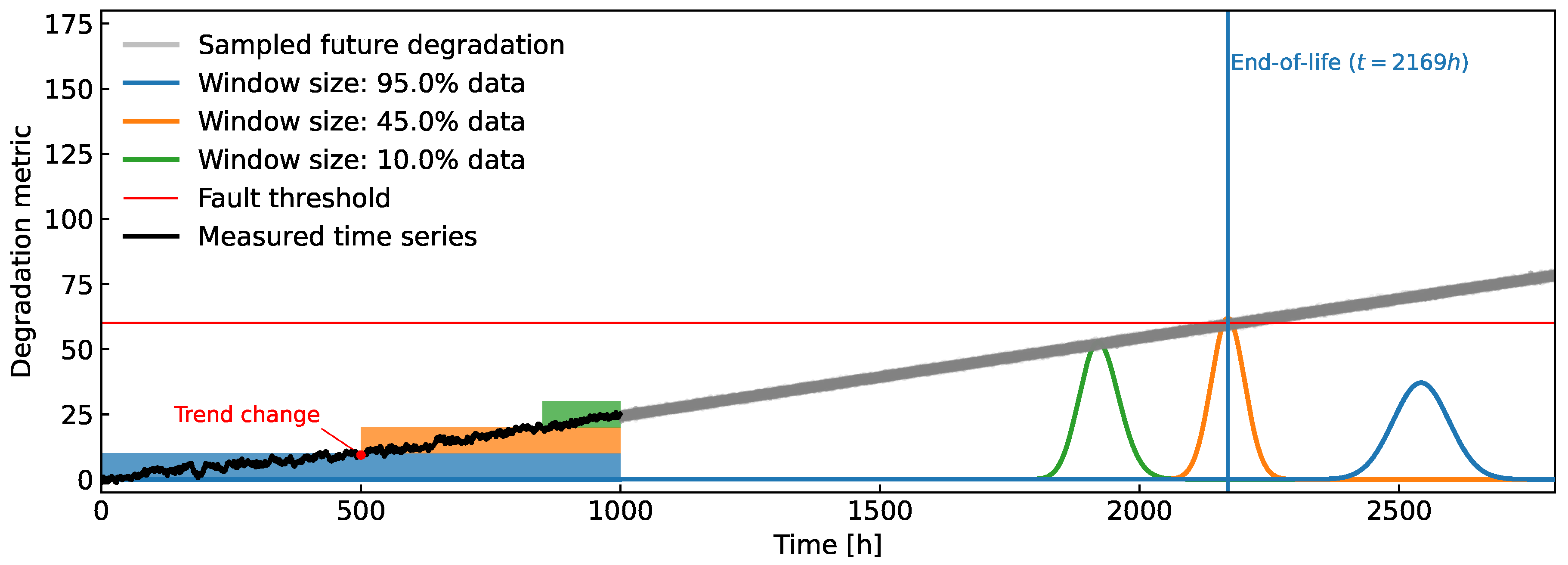
Figure 9.
Second example of synthetic time signals of the ARMA process with an abrupt change in the trend (around h). The FHT distributions are derived with various amounts of data taken into account. Relating to Figure 8, there were more available data for the prognostic algorithm here, up to h. But on the other hand, EOL is now much closer and any large oscillations in time signal will importantly affect the actual breach of the threshold.
Figure 9.
Second example of synthetic time signals of the ARMA process with an abrupt change in the trend (around h). The FHT distributions are derived with various amounts of data taken into account. Relating to Figure 8, there were more available data for the prognostic algorithm here, up to h. But on the other hand, EOL is now much closer and any large oscillations in time signal will importantly affect the actual breach of the threshold.
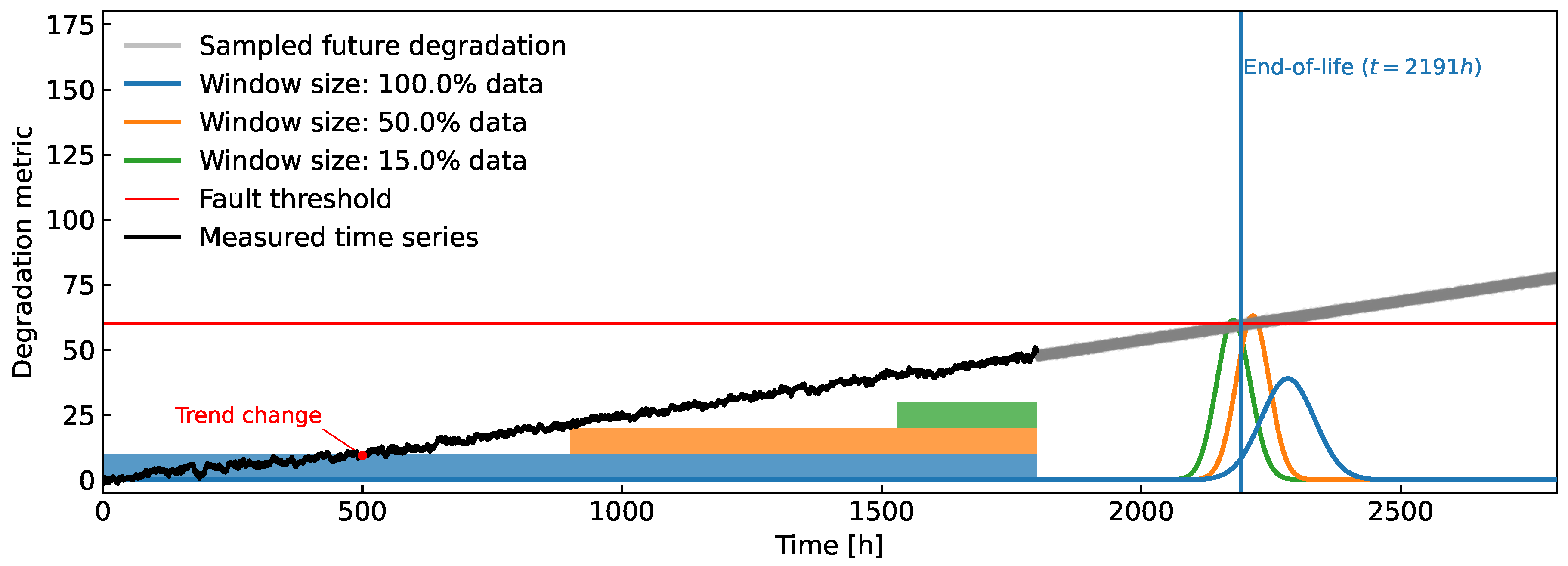
Figure 10.
Quantiles of FHT distributions over various percentages of available data at h taken into account. The artificial data is from an ARMA process with a change in the trend. On the left, ground-truth FHT is presented (dark blue curve). The prediction is best when taking at most of the recent data since that is when the trend change has occurred.
Figure 10.
Quantiles of FHT distributions over various percentages of available data at h taken into account. The artificial data is from an ARMA process with a change in the trend. On the left, ground-truth FHT is presented (dark blue curve). The prediction is best when taking at most of the recent data since that is when the trend change has occurred.
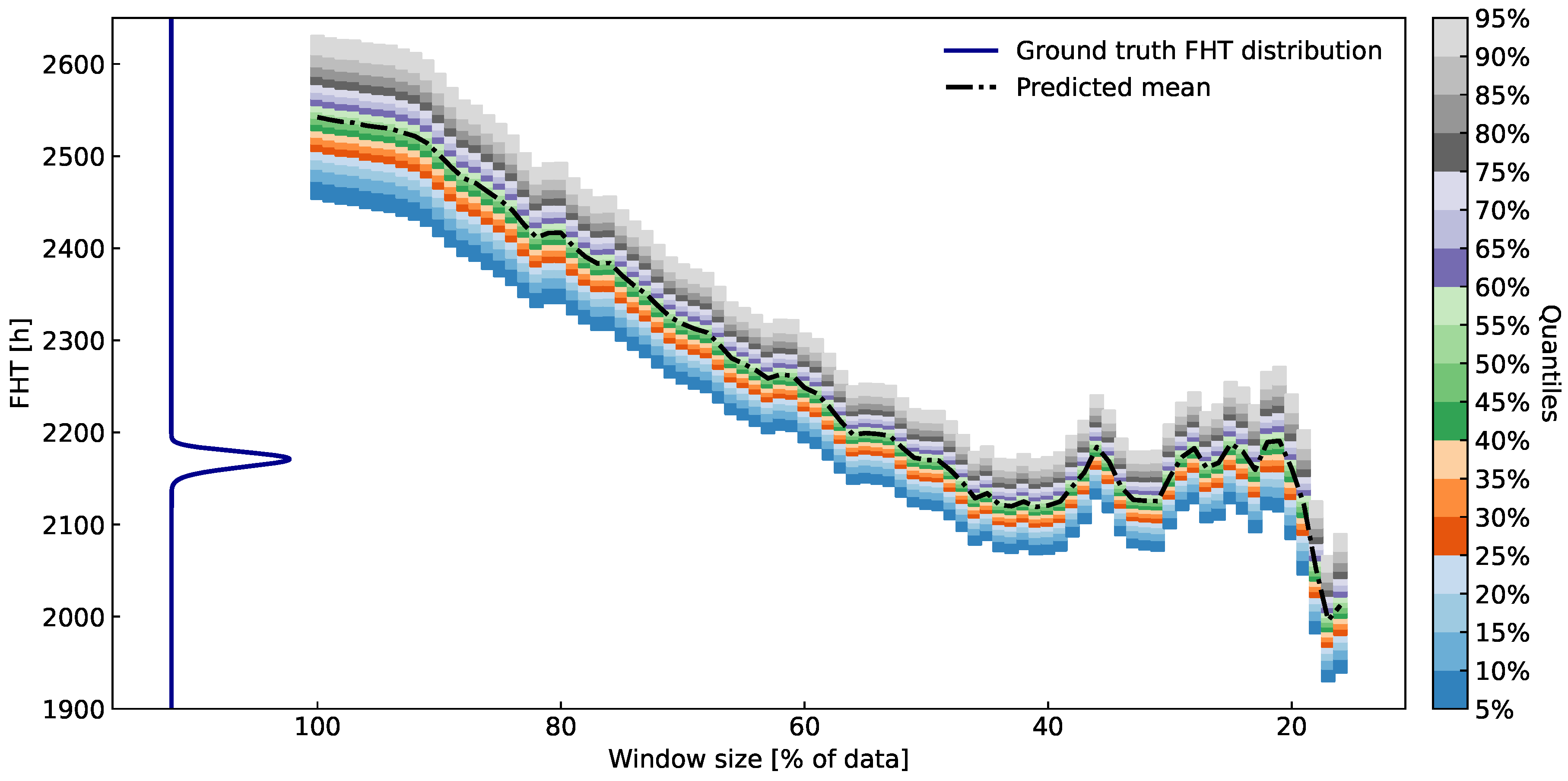
Figure 11.
Quantiles of FHT distributions over various percentages of available data at h taken into account. The artificial data is from an ARMA process with a change in the trend. On the left, ground-truth FHT is presented (dark blue curve). The prediction gets better when taking up at most of the recent data. Since the time of prediction is relatively close to the EOL, there is a noticeable difference between the bias and the variance in the ground truth and the predictive FHT distribution.
Figure 11.
Quantiles of FHT distributions over various percentages of available data at h taken into account. The artificial data is from an ARMA process with a change in the trend. On the left, ground-truth FHT is presented (dark blue curve). The prediction gets better when taking up at most of the recent data. Since the time of prediction is relatively close to the EOL, there is a noticeable difference between the bias and the variance in the ground truth and the predictive FHT distribution.
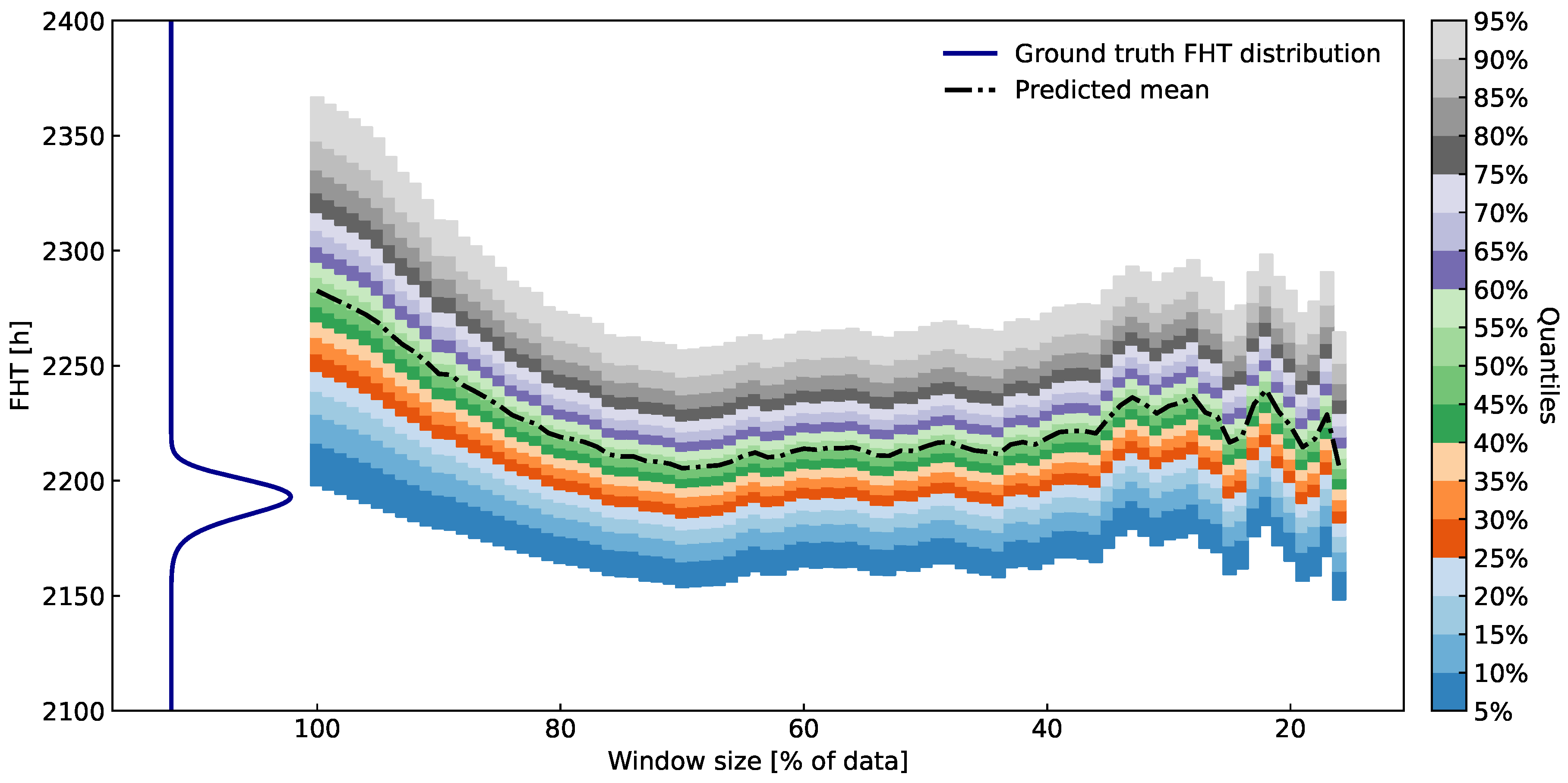
Figure 12.
Data from SOFC stack experiment in [11]. From top to bottom: ASR, stack voltage, current and outlet temperature.
Figure 12.
Data from SOFC stack experiment in [11]. From top to bottom: ASR, stack voltage, current and outlet temperature.
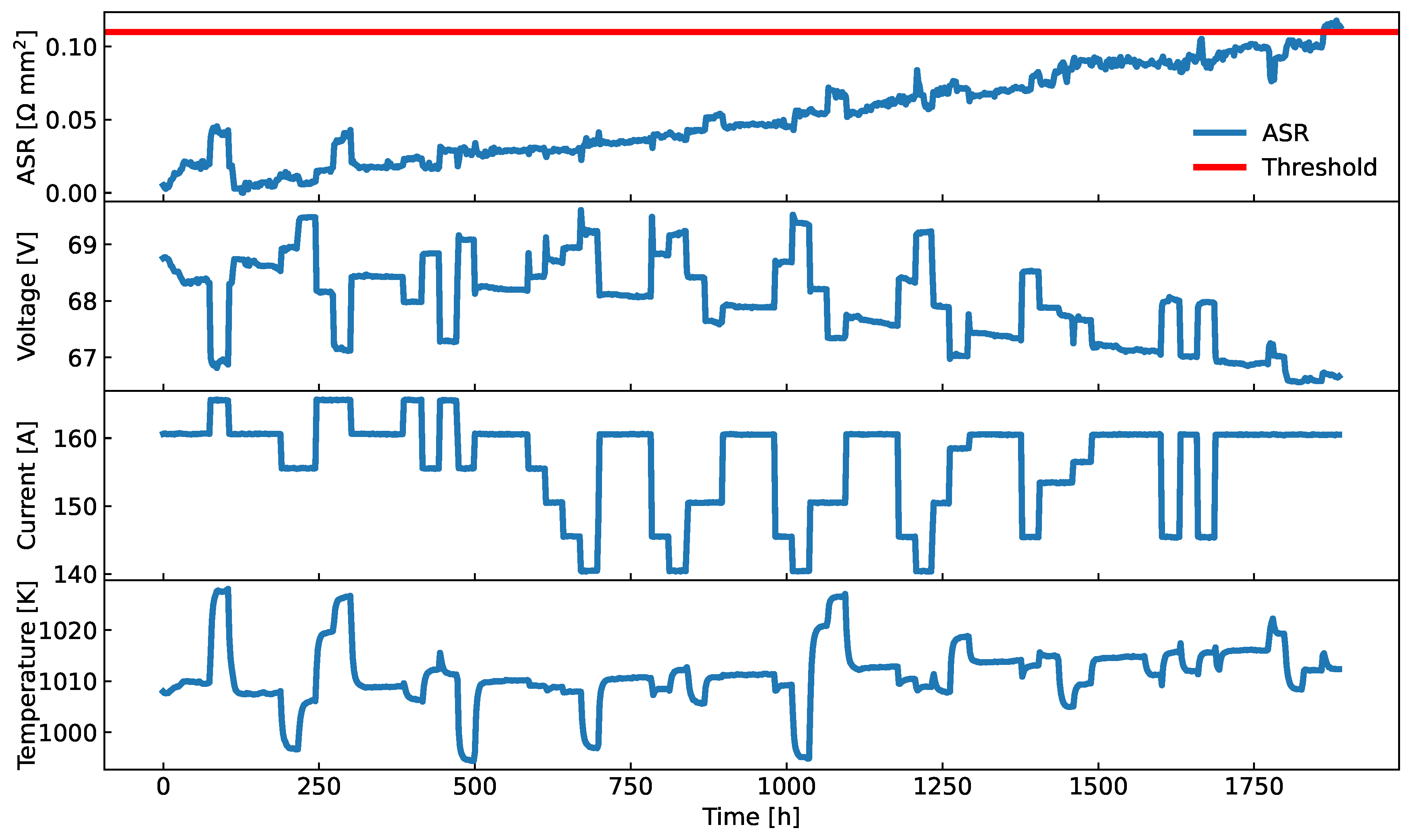
Figure 13.
A demonstration of the application of the new algorithm on real-life ASR measurements. A major chunk of the data is used for learning (black curve), while the minor chunk is used for validation (dark blue curve). Few data windows, shown as rectangular coloured windows, were used on the learning part of the data to derive FHT predictions. The figure includes a comparison to an alternative prognostic algorithm, an ARMA process, fitted on the whole learning part of the data, which obtains similar results.
Figure 13.
A demonstration of the application of the new algorithm on real-life ASR measurements. A major chunk of the data is used for learning (black curve), while the minor chunk is used for validation (dark blue curve). Few data windows, shown as rectangular coloured windows, were used on the learning part of the data to derive FHT predictions. The figure includes a comparison to an alternative prognostic algorithm, an ARMA process, fitted on the whole learning part of the data, which obtains similar results.
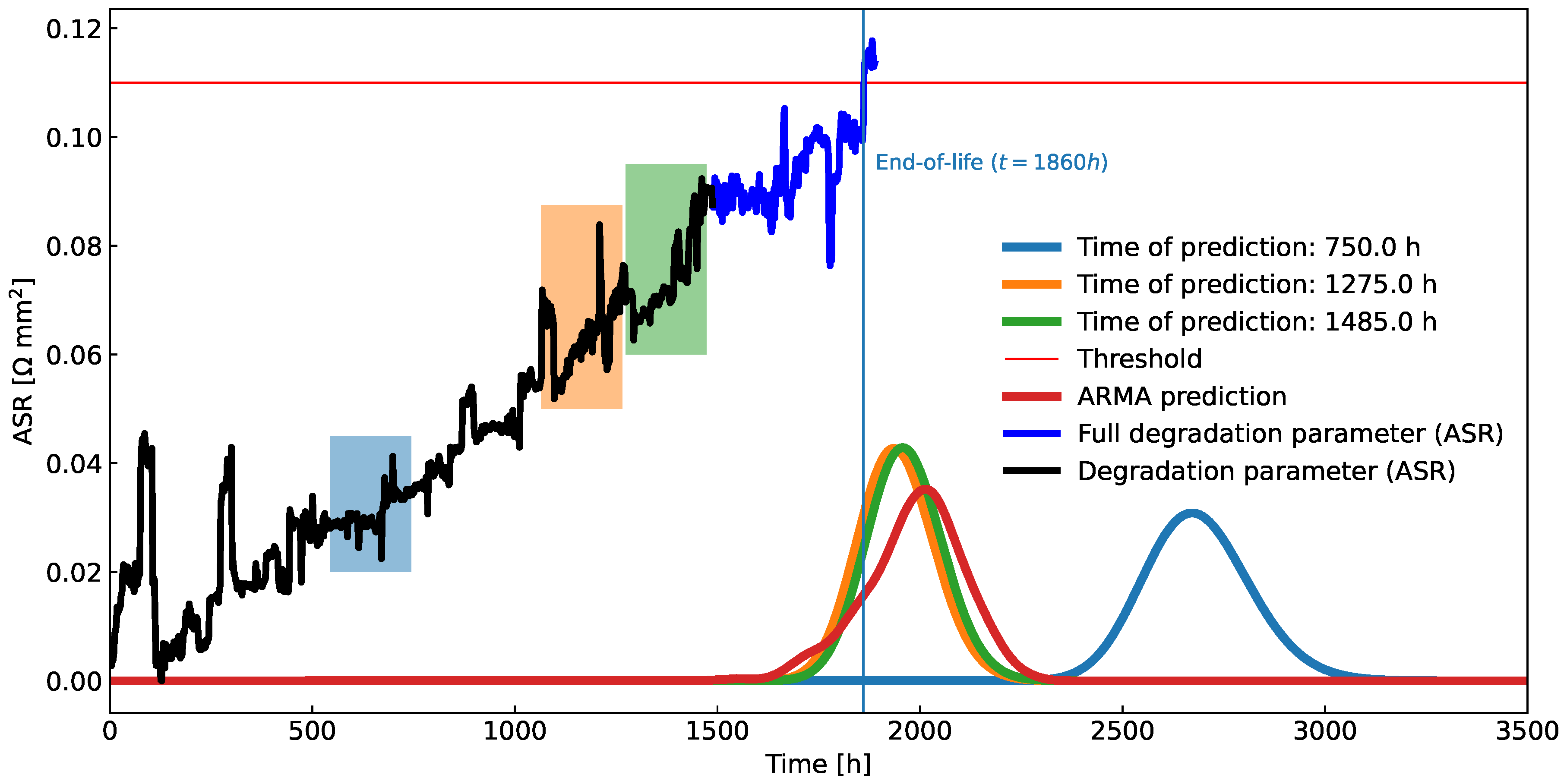
Figure 14.
Comparison of ARMA and the derived prognostic algorithm on the experimental data. The x-axis represents the percentage of the full set of data used, simulating the real-life scenario of data accumulating over time. The horizontal red line denotes EOL for the stack. While both models converge to a similar solution, that is in line with the actual ASR’s breach of threshold, when at least of data is available, they both experience major deviations from the correct result when the data is insufficient. The major difference between the methods is that the new prognostic algorithm undergoes variance explosion when data is scarce, while ARMA stays overconfident.
Figure 14.
Comparison of ARMA and the derived prognostic algorithm on the experimental data. The x-axis represents the percentage of the full set of data used, simulating the real-life scenario of data accumulating over time. The horizontal red line denotes EOL for the stack. While both models converge to a similar solution, that is in line with the actual ASR’s breach of threshold, when at least of data is available, they both experience major deviations from the correct result when the data is insufficient. The major difference between the methods is that the new prognostic algorithm undergoes variance explosion when data is scarce, while ARMA stays overconfident.
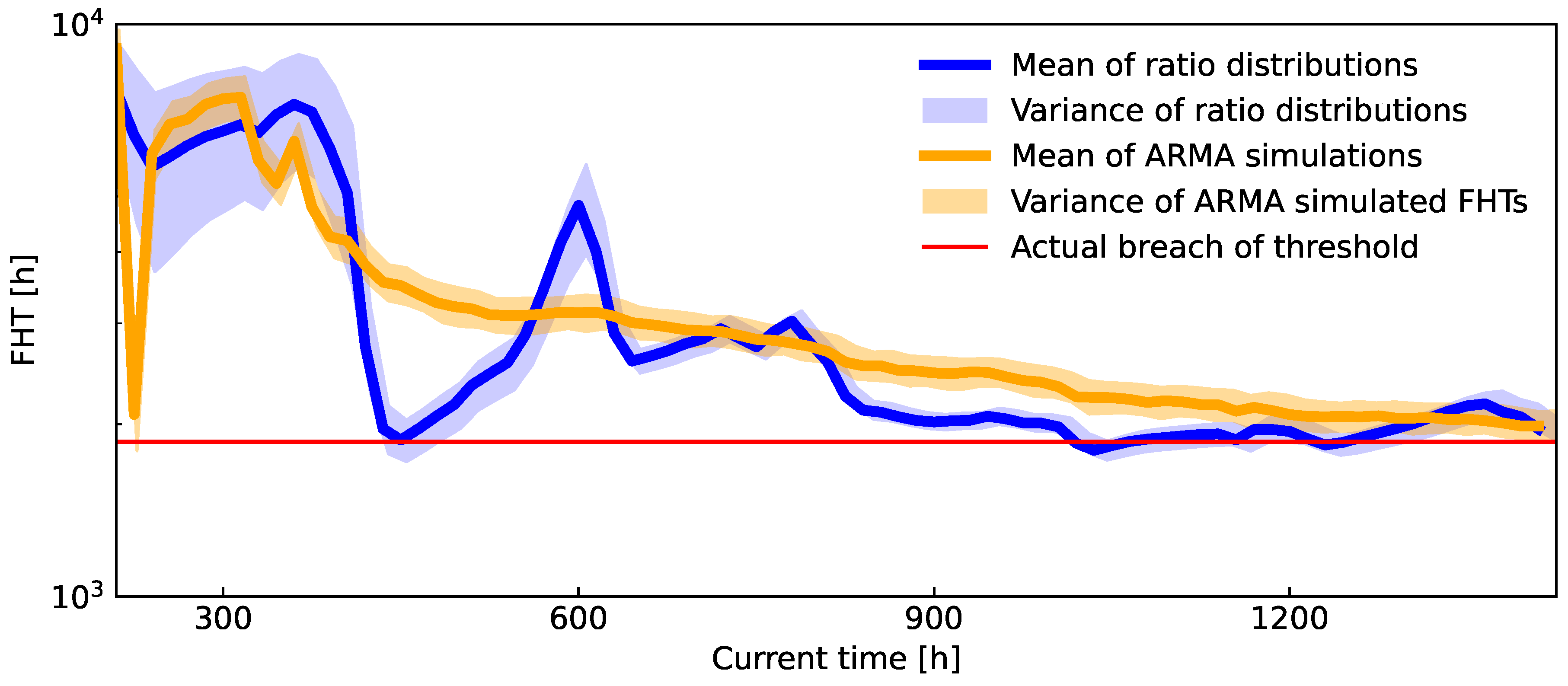
Figure 15.
Quantile plot over time for ASR. The figure depicts the evolution of the FHT distribution over time, starting at 15% of the data and progressing to the full dataset. It simulates a real-life application where data comes in over time and the prognostic capabilities improve. The inset highlights the latter part of the measurement process, where the predicted FHT distribution can be trusted to assess the probable EOL.
Figure 15.
Quantile plot over time for ASR. The figure depicts the evolution of the FHT distribution over time, starting at 15% of the data and progressing to the full dataset. It simulates a real-life application where data comes in over time and the prognostic capabilities improve. The inset highlights the latter part of the measurement process, where the predicted FHT distribution can be trusted to assess the probable EOL.
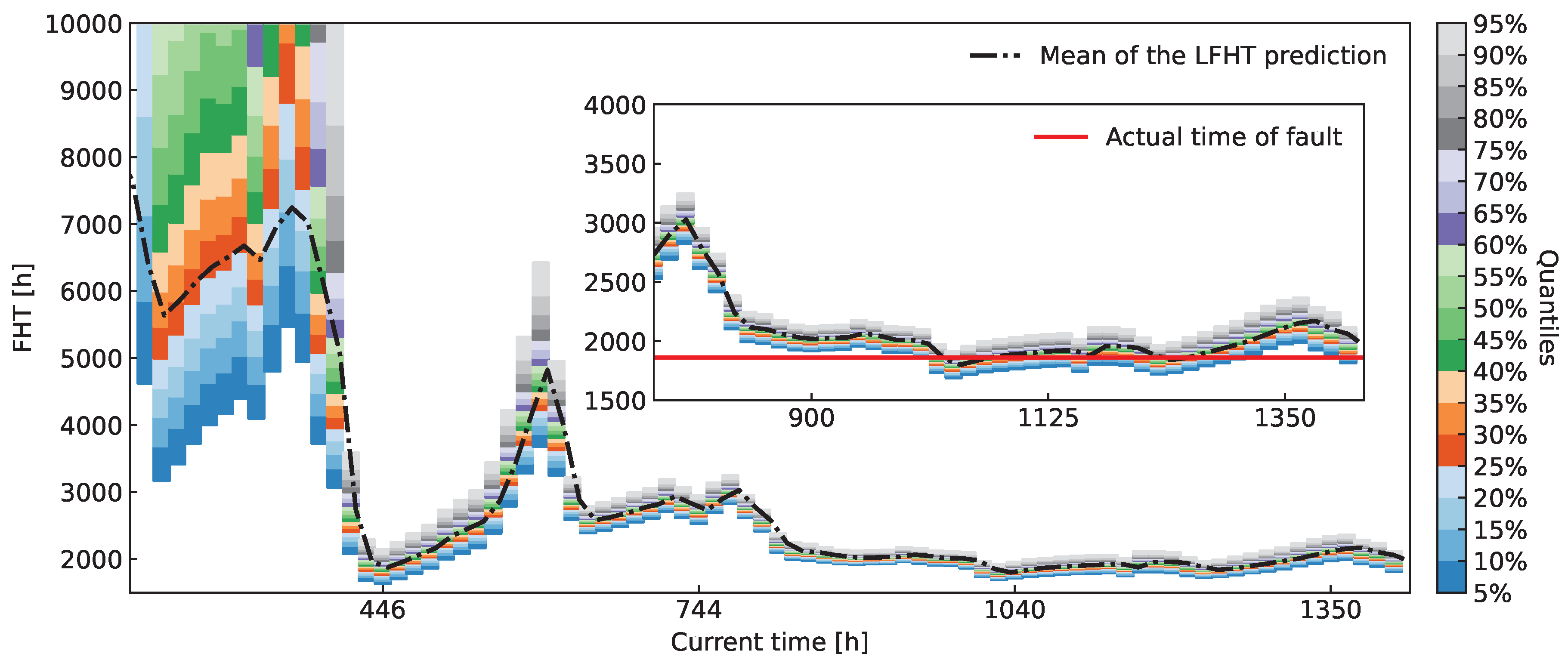

Table 1.
Parameters of the linear trend model with fixed parameters (case 1)
| Simulated scenario | n | k | ||
|---|---|---|---|---|
| Case 1 | 0 | 1 | 30 | 600 |
Table 2.
Parameters of the linear trend model with switching parameters (case 2)
| Simulated scenario | n | k | [h] | [h−1] | |||
|---|---|---|---|---|---|---|---|
| Case 2 | 30 | 250 | 800 | ||||
| (calculated by ()) = | 30 |
Table 3.
Parameters of ARMA models used to generate the time series.
| Simulated scenario | n | k | ||||
|---|---|---|---|---|---|---|
| ARMA | 0 | 1 | 5 | 5 | 0 | |
| ARMA | 0 | 1 | 5 | 5 | 0 | |
| ARMA | 0 | 1 | 5 | 5 |
Table 4.
Parameters of the ARMA model with switching parameters
| Simulated scenario | n | k | Time of change [h] | |||
|---|---|---|---|---|---|---|
| Case 4 | 500 | 60 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



