
Submitted:
07 May 2024
Posted:
08 May 2024
You are already at the latest version
Abstract
Understanding speech in noise is particularly difficult for individuals occupationally exposed to noise due to a to a mix between noise-induced auditory lesions and energetic masking of speech signal. For years, the monitoring of conventional audiometric thresholds has been the usual way to check and preserve the auditory function. But the highlighting of supra-threshold deficits, notably speech in noise understanding difficulties, has pointed out the need for new monitoring tools. The present study aims to identify the most important variables that predict speech in noise under-standing in order to suggest a new way of regular monitoring. Physiological (distortion products of otoacoustic emissions, electrocochleography) and behavioral (amplitude and frequency modula-tion detection thresholds, conventional and extended high frequency audiometric thresholds) variables were collected in a population of individuals presenting a relative homogeneous occu-pational noise exposure. Those variables were used as predictors in a statistical model (random forest) to predict scores of three different speech in noise tests and a self-report of speech in noise ability. The extended high frequency threshold appears to be the best predictor and therefore an interesting candidate for a new way of monitoring noise exposed professionals.
Keywords:
Extended high frequency
; speech in noise
; amplitude modulation detection
; frequency modulation detection
; distortion products of otoacoustic emissions
; electrocochleography
; speech spatial and hearing qualities questionnaire
1. Introduction
Understanding speech in noise is difficult. It is particularly difficult for individuals occupationally exposed to noise, e.g. motorcycle professional drivers. The difficulty arises because the background noise contains energy in the same frequency regions as the speech (energetic masking [1]). It also arises because noise exposure is an environmental stressor, and prolonged or excessive noise exposure can alter the auditory periphery structures, and may ultimately lead to noise-induced hearing loss (LePrell & Clavier, 2017; Henderson et al., 2006). However, individuals chronically exposed to noise, even with normal or near-normal audiometric thresholds, can exhibit difficulties understanding speech in noise (e.g. Hope et al., 2013; Alvord, 1983).
Recently, several research groups have explored the hypothesis that noise exposure can induce a selective synaptic loss at the synapses between the inner hair cells (IHC) and the low spontaneous rate auditory nerve fibers in the cochlea, often occurring with otherwise normal or near-to-normal audiograms (see the seminal paper by Kujawa & Liberman, 2009; for a review, see Kujawa & Liberman, 2016; Plack et al., 2014). This synaptopathy has also been called hidden hearing loss (term coined by Schaette & McAlpine, 2011), because its effect is supposed to be unrevealed by conventional audiometric measures. It is now widely assumed that clinical measures more sensitive than the conventional audiogram are needed (LePrell Brungart 2016). However, a gold standard of these new tests and best practices is still to be defined (LePrell & Brungart, 2016; Plack et al., 2016), in order to detect early signs of hearing deficits, and to implement better prevention programs.
These new tests should be defined in relation to the difficulties of speech understanding in noise. The evaluation of speech in noise performance in humans varies along a large variety of factors (type of target speech, type of masker, type of response, signal-to-noise ratio, type of paradigms, to name a few), each providing different insights into an individual's ability to process speech in noisy environments (review in LePrell & Clavier, 2017). An interesting way to differentiate them in the context of this study is by their lexical complexity (phoneme or syllable, words, and sentences). It has indeed been shown that this is one of the key factors to understand the relative influence of the cognitive processes underlying and correlated to the speech in noise tasks (review by Dryden et al., 2017). Classically, tests with phonemes are less sensitive to cognitive factors than sentence recognition tests. To understand the apparent discrepancy in the literature regarding the existence of noise-induced cochlear synaptopathy in humans, DiNino et al. (2022) showed that the choice of the target speech and the speech in noise task impact greatly on whether a relationship between the speech in noise performance and the assumed physiological proxies of synaptopathy ( Electrocochleography/Auditory Brainstem Response Wave I, Middle Ear Muscle Reflex) is observed. For instance, the tests with a low lexical complexity and which maximize the importance of fine temporal details were more likely to be correlated with proxy measures of synaptopathy in humans.
The list of statistically significant predictors of speech in noise performance is vast, especially for individuals exposed to noise. A systematic overview being largely beyond the scope of this paper, we chose to focus here instead on measures that would, in fine, be easily implemented in a prevention program – in addition to the conventional pure tone audiogram. Behaviorally, decline in auditory temporal abilities (e.g. amplitude- and frequency-modulation thresholds) has been linked to a decline in speech in noise performance (Strelcyk & Dau, 2009; Hopkins & Moore, 2011; Ruggles et al., 2011; Bharadwaj et al., 2015; Fullgrabe et al., 2015). There is also now ample evidence for an association between extended high-frequency (EHF) audiometry, defined as frequencies above 8 kHz, and speech perception difficulties (review by Lough & Plack, 2022). Interestingly here, noise exposure has been identified as one of the causes of EHF hearing loss (LePrell et al., 2013; Prendergast et al., 2017). To complement behavioral audiometric measures, electrophysiological measures of the cochlear function can be performed in individuals with normal hearing thresholds, and compared with speech-in-noise performance (e.g. Grant et al., 2020; Bramhall, 2021; Parker, 2020). These tests include the measure of the cochlear amplification function via the measure of distortion product otoacoustic emission (DPOAE), or the synaptic activity between the IHC and the auditory nerve via the measure of electrocochleography (EcochG). As explained before for the speech-in-noise tasks, the different and sometimes opposite results in the literature regarding the existence and the measure of noise-induced cochlear synaptopathy can also be linked to the very heterogenous methods used (see the recent reviews by Bharadwaj et al., 2019; Bramhall et al., 2019; Le Prell, 2019). The discrepancy in the literature could also highlight the fact that a variability in what we call normal thresholds or near-normal thresholds can be responsible for some of the so-called synaptopathy effects. In some of the studies in which noise exposure seems responsible for functional speech in noise differences in the absence of hearing loss, there is, of course, the possibility that differences in thresholds within the normal range can contribute nonetheless to the differences observed in the speech in noise performance (LePrell, Clavier, 2017; Plack et al, 2014). In addition, cochlear synaptopathy is indeed very hard to study in humans, and is generally mixed with other outer hair cells (OHC) dysfunctions (Parker, 2020).
Finally, when studying noise exposed individuals, the definition itself and the measure of what is called “exposure” is crucial. As pointed out by Parker (2020), one of the differences potentially explaining the discrepancies between noise-induced cochlear synaptopathy studies lies in the way noise exposure is measured. When noise exposure measure is based on self-reports, no link is found between proxy of cochlear synaptopathy and speech-in-noise performance [2,3,4]. When controlled and homogeneous groups of individuals exposed to noise are studied (young and professional musicians in Liberman et al., 2016; firearms users in Bramhall et al., 2017; train drivers, in Kumar et al., 2012), a correlation was found. Moreover, to investigate the effect of noise exposure, very often, groups of noise-exposed vs. control are compared. This could be in contradiction with the idea that the outcome of a noise exposure is possibly on a continuum from non-synaptopathy to synaptopathy with damage (LePrell and Brungart, 2016).
In the current study, we do not question the influence of different predictors on speech in noise performance, nor test the influence of one predictor on another (although it would be possible with this set of data). Instead, we investigate how to quantify and classify the various predictors of speech-in-noise performance in terms of importance. This approach has a direct clinical outcome as it allows us to establish which predictors are urgently needed for regular testing (LePrell & Clavier, 2017) in order to enhance existing hearing-loss prevention policies.
In fact, the choice of the statistical model and analysis are key to our study design as they influence the way we think about the design, as well as the conclusions we can draw from the data. To illustrate this point, Yeend et al (2017) recognized that one of the limitations of their study is the use of multiple comparisons, potentially resulting in falsely identified positive effects. More recently, Balan et al (2023) emphasized, with appropriate machine-learning techniques, the importance of EHF audiogram in predicting speech in noise performance.
In this paper, we use random forests - a machine-learning tool for classification and regression. The random forest tool is intuitive, and, more importantly, it has an inherent capacity of producing measures of “variable importance”. Kim et al. (2021) highlighted the usefulness of the random forest model, compared to other machine learning techniques, for predicting speech discrimination scores from pure tone audiometry thresholds.
In this study, we investigated the relative importance of several audiometric, auditory, physiological predictors on speech-in-noise performance. Speech-in-noise was assessed with 3 different speech audiometry in noise, with different degrees of lexical complexity (consonant identification; word in noise recognition; French sentence matrix test). Our listeners group consists of individuals exposed to occupational noise: professional motorcyclists. This allowed us to have a homogeneous subject group and an easy proxy measure of noise exposure (number of years of motorcycling). All participants had normal hearing thresholds (Pure Tone Average (PTA) : mean of thresholds at 500, 1000, 2000, and 4000 Hz, inferior to 20 dB HL according to the reference of the International Bureau for Audiophonologie [5]. For all participants, we measured EHF audiometry at 12.5 kHz; DPOAE to evaluate OHC function; and EcochG to assess auditory nerve function. Temporal processing was assessed using amplitude- (AM) and frequency-modulation (FM) detection thresholds. Finally, we evaluated the subjective auditory consequences of each subject’s noise exposure via the speech in noise pragmatic scale of the Speech, Spatial and Qualities of Hearing Scale (SSQ) questionnaire [6,7].
2. Materials and Methods
2.1. Overview
The experiment was conducted over a week during a span of 3 half-days, each dedicated to specific sets of experimental sessions. Two half-days were composed of a speech audiometry in noise test and a behavioral test (for instance, a session of consonants identification followed by a session of AM detection). The third one was composed of a speech audiometry in noise test, the recordings of DPOAE and EcochG, and the questionnaires (demographic and SSQ speech in noise pragmatic scale). The order of all tests was randomized with at least one speech-in-noise test during each half-day.
2.2. Participants
Seventy-three participants (72 men; mean and standard deviation age: 38 ±7.6 years (Figure 1) took part in the present study. All were professional bikers occupationally exposed to motorcycle noise (duration of exposure ranging between 1 year and 31 years, with a median duration of 8 years). Three participants were excluded because of their PTA above or equal to 20 dB HL. The 70 remaining participants had PTA considered normal in both ears according to Internation Bureau for Audiophonology calculation [5]. Maximal age was limited to 55 years to reduce the risk of presbycusis. Informed consent was obtained from all participants involved in the study. This study was approved by Comité de protection des personnes sud-ouest et outre-mer II (IDRCB 2017-A00859–44).
2.3. Mobile Laboratory
The tests were carried out in a mobile hearing laboratory (Figure 2 and Figure 3), consisting of four audiometric booths. Each booth is equipped with experimental instruments that can be remotely controlled from the control room. The four booths were used simultaneously to optimize the experimental time for a group of participants. An audio and video system enabled communication between the experimenter and each of the four participants individually or simultaneously, and was used to remind them of the instructions, maintain motivation and monitor their state of arousal.
2.4. Speech Audiometry in Noise
Each participant performed three different speech audiometry in noise tests: 1. the consonant identification test, 2. the word recognition test, and 3. the French matrix test (FrMatrix). The masking provided by the noise was an energetic one (no informational masking was used). A closed set paradigm was used for the consonant identification test whereas an open set paradigm was used for the word recognition and the FrMatrix tests.
2.5. Consonant Identification Test
The consonant identification test consists of the presentation of 48 nonsense vowel-consonant-vowel-consonant-vowels (VCVCVs) spoken by a French female talker presented in a spectro-temporally modulated noise at -10 dB SNR. The signal was presented monaurally on the right ear. The 48 presentations came from three recordings of 16 French consonants (C= /p, t, k, b, d, g, f, s, ∫, v, z,ᶚ , l, m, n, r/), systematically associated with the vowel /a/. The duration of each presentation was on average 1272 ±113 ms.
For each trial, the participant had to indicate the perceived consonant by clicking on a matrix of 16 different consonants presented visually in front of them. No feedback was provided. The identification score corresponded to the percentage of correct answers. The presentation level was 65 dB SPL.
2.6. Words in Noise Recognition
Ten different lists were presented in the right ear of each participant. Each list consisted of 25 monosyllabic French words. Four different SNR ratios were compared: -5, 0, 5, 10 dB in a speech shaped noise and in silence. For each SNR, two lists (i.e. 50 words) were presented. The order of presentations was randomized and the association between lists and SNR conditions were counterbalanced. Each participant had to write, using the keyboard, the word he/she heard. Participants were instructed to write the words as they heard them, even if only one phoneme was heard, and to respect phoneme to grapheme conversion in the French language, not minding spelling mistakes. Each correspondence between the written word and target word from the list was then manually checked by 2 independent observers.
2.7. French Sentence Matrix Test
The French version of the sentence matrix test [8] was used to determine the speech reception threshold of the participants. The sentences are all constructed using the same pattern: a firstname, a verb, a number, the name of an object and a color (for instance “Jean Luc ramène trois vélos rose”). There are 10 possible choices for each word categories. A test session consists of 20 sentences presented with an adaptative staircase procedure. The listener is seating one meter away facing the loudspeaker emitting the sentences and the noise. The participant’s task is to repeat aloud the words. The signal-to-noise ratio (fixed noise level at 65 dB SPL) varies from sentence to sentence depending on the number of correct words given by the participant in order to obtain the 50% speech reception threshold (SRT). Each participant performed three sessions. The final SRT of each participant (i.e. the dependent variable) is the best (i.e. lowest) value from the three sessions. The normative value is of -6 dB SNR (standard deviation 0.6 dB, [9]).
2.8. Speech Spatial and Quality of Hearing Questionnaire
In addition to the above-described behavioral measures of speech intelligibility in noise, the participant also completed a self-report measure.
The Speech, Spatial and Qualities of Hearing Scale (SSQ) questionnaire enables measurement of a participant's ability in various listening situations (Gatehouse & Noble, 2004) using a numerical gradation from 0 (no, not at all) to 10 (yes, perfectly). The questionnaire is divided in three subscales: speech comprehension (14 questions), spatial hearing (17 questions) and hearing quality (18 questions).
The closer the numerical value is to 10, the more the subject feels able to perform the task
described. We used a French version of the questionnaire, previously validated (Moulin et al., 2015; Moulin & Richard, 2016). The average of items 1, 4 and 6 of the speech comprehension subscale were combined into the “speech in noise” pragmatic scale [10].
2.9. Predictors of Speech in Noise Tests
In order to identify the best predictors of speech intelligibility in noise, several physiological and behavioral measurements were conducted. Altogether, when taking into account several markers (i.e. variables) for each measure type, a set of 48 variables was obtained. They are all described below. They were all expected to predict to a certain degree the speech-in-noise performance as measured by the four speech-in-noise tests described above (consonant identification, word recognition, FrMatrix and the speech in noise pragmatic scale of the SSQ).
2.9.1. Pure Tone Audiometry
The audiometric thresholds were recorded with an automatic procedure with the Echodia Elios® system (France) with Radiohear headphones DD45 at the left ear and at the right ear for the frequencies 125, 250, 500, 1000, 2000, 4000, 8000 and 12 500 Hz (Figure 4). The 12500 Hz was defined as the EHF threshold. The four frequencies pure tone average (PTA; 500, 1000, 2000, 4000) were computed in both ears, and best ear PTA was identified as the lower PTA across the two ears. Therefore, nineteen predictor values were obtained from the pure tone audiometry.
2.9.2. Amplitude and Frequency Modulation Detection Thresholds
A total of eight thresholds were obtained for each participant using a two-interval forced-choice procedure from the combination of modulation type (AM or FM), sinusoidal carrier signal frequency (500 or 4000 Hz) and stimulus intensity (10 or 60 dB SL). The standard signal was unmodulated, i.e., the modulation depth (Δ) was set to 0. The target signal was modulated and the value of the modulation depth, Δ was adaptively modified in order to determine the threshold. All stimuli were generated digitally using a sampling rate of 44.1 kHz, and presented to participants at a presentation level of 10 dB SL or 60 dB SL, using Beyer DT 770 headphones and an external AudioEngine D3 sound card. Stimuli were presented monaurally to the right ear. Each trial consisted of a target modulated signal and a standard unmodulated signal, presented in random order, and separated by a 600 ms silence interval. The participant was instructed to indicate the stimulus containing the modulation, and was informed of the accuracy of his/her response by a light signal (green if correct, otherwise red). Each stimulus duration was 1200 ms.
Threshold was determined using a "2-down-1-up" method: Δf decreased when the participant responded correctly twice consecutively, and increased in the event of an error. The test stopped after 14 inversions, defined as an increase followed by a decrease in ∆ or vice versa. The detection threshold was calculated from the average ∆ over the last six inversions. Three threshold estimates were made for each intensity level condition (10 dB SL and 60 dB SL), and each type of modulation (AM and FM), and each carrier frequency (500 and 4000 Hz). The final value for each condition tested corresponded to the best performance obtained.
In our study, it appeared that some participants were not able to perform the task for three conditions of the FM detection task: 4000Hz carrier frequency at 10 dBSL; 4000 Hz carrier frequency at 60 dB SL; and 500 Hz carrier frequency at 10 dB SL. To take this into account, we created 3 two-levels categorical variables according to the ability of the participant to perform the task (able / not able). Therefore, 11 predictors were obtained from the AM and FM detection thresholds.
2.9.3. Distortion Products of Otoacoustic Emissions
Distorsion Products Otoacoustic Emissions (DPOAE) were collected with the Elios® system from Echodia (France). An f2/f1 ratio of 1.20 was used at intensity levels of f1=75 dB SPL and f2=65 dB SPL. The amplitude of DPOAE were recorded at frequencies of 1, 2, 3, 4 and 5 kHz at both ears (Recorded values of -10 dB SPL or lower were discarded) to obtain 10 predictors per participant.
2.9.4. Electrocochleography
The extratympanic electrocochleography (EcochG) was conducted with the Echodia Elios® system (France). Two electro-encephalogram electrodes were placed on the forehead of the participant (one centered and one off-center, the two on the hairline). The extratympanic electrode was a gold-coated soft Tiprode, positioned in the outer ear canal. The electric impedances of the electrodes were checked to be below 5 kΩ. Acoustic stimuli were short clicks delivered at a rate of 11/s. The recordings were collected at 90 dB nHL, then at 80 dB nHL. For each level, the procedure consisted of averaging 500 responses, repeated two or three times depending on the consistency of the waveforms across the 500 responses. For each waveform, the amplitude of the wave I was assessed by the difference in voltage between the first peak occurring between 1 and 2,5 ms and the next trough. Then, the amplitudes of the two most consistent waveforms were averaged. Furthermore, the slope of the input/output function obtained by linking the two stimulation levels (80 and 90 dB nHL) and the wave I amplitude was computed for each ear. Accordingly, six predictors (Wave I amplitude at 80 and 90 dB nHL at both ears plus Wave I slope at both ears) per participant were obtained.
2.9.5. Random Forest Analysis
In addition to the 48 predictor variables described above, 3 were added: the age; the number of years of motorcycling; and the history of hearing pathology (otitis media or acute acoustic trauma). 47 variables were continuous and 4 were categorical. The main goal here was to identify the most important predictors of speech-in-noise performance.
In order to perform this importance analysis, we used random forest algorithms. Recently, biomedical research in general has found an interest in this machine-learning paradigm, given its interpretability, its nonparametric approach with large use case, and the potential mix between continuous and categorical variables (REF). Random forests have already been identified as an interesting choice among machine learning algorithms in hearing sciences [11,12,13].
A random forest is a combination of 500 decision trees. Each decision tree is built from a random sample of the population and a random sample of the variables to reduce the risk of overfitting. Next, all 500 trees are combined to build a model and make a prediction. A prediction error is computed from the data excluded from the random samples (“error out of the box”). The difference between the observed value to predict and the actual prediction is represented by the mean square error (MSE). To assess the importance of a variable, the impact of random permutations of that variable is measured on the MSE. The more the MSE increases, the more important the variable is.
In order to have a reliable measure of each variable importance, the non-scaled importance measure was computed on 10 subsamples and then averaged across samples. The subsamples were built by randomly selecting 75% of the original data sample.
We used the randomForest R package Version: 4.7-1.1 with the hyperparameters set by default. Missing values were handled by the command “na.action==na.roughfix”.
In addition to the importance graph for each speech-in-noise test, we described the 9 most important variables and the correlations between the speech-in-noise performance and the variable (predictor). Hence, nine scatterplots graphs are plotted for each speech-in-noise audiometry. On each scatterplot, the Spearman coefficient of correlation, its p-value and the size sample are indicated. Spearman coefficient was chosen against Pearson coefficient because several variables were not normally distributed (e.g. speech in noise pragmatic scale, years of motorcycling), and for consistency with the nonparametric algorithm of the random forest.
2.9.6. Missing Values
The global sample size was 70 participants. However, due to various obstacles encountered during the experiment (mainly professional availability; hardware malfunctions; inability to record some of the measure for some participants, see explanations above), the sample size for each variable was less than 70 (see Table 1 for details).
3. Results
For the three speech audiometry in noise tests, large inter-individual differences were observed, as evidenced by the large interquartile ranges (Figure 5). The results for all other tests (i.e., the predictors) are represented in Appendix A.
3.1. Consonant Identification
3.1.1. Predictor Importance
3.1.2. Correlations between Predictors and Consonant Identification Scores
The EHF hearing threshold was the most important variable, by far (an importance value of 7.5 in increase of MSE, compared to 3.9 for the AMDT_60dB_500Hz; see Figure 6). For consonant identification scores, conventional audiometric values turned out to be important predictors too: the 8000Hz audiometric thresholds; the PTA for the left ear, the best ear PTA. Significant correlations were also observed for suprathreshold measures of the temporal coding namely the AM detection threshold and the FM detection threshold both measured at 60 dBSL for a 500Hz carrier frequency (Figure 7).
3.2. Words in Noise Recognition
3.2.1. Predictor Importance
3.2.2. Correlations between Predictors and Words in Noise Recognition Scores
For this speech-in-noise audiometry test as well, the EHF thresholds at both ears were among the most important variables (Figure 8), and their correlation with the words in noise recognition thresholds were among the highest (Figure 9). The FM detection threshold at 60 dB SL for a 500 Hz carrier frequency appears to be the most important but the correlation with the words in noise recognition results was non significant. This discrepancy could be due to the interaction between predictors not assessed here. Similarly, DPOAEs appeared important but the coefficient of correlation with the words in noise recognition results was not significant. The years of motorcycling practice were correlated with the words in noise recognition results. The history of hearing pathology was pointed out as an important variable. Indeed, participants with a history of otitis media had poorer words in noise recognition results.
3.3. French Matrix Test
3.3.1. Predictor Importance
3.3.2. Correlations between Predictors and French Matrix Test Scores
Again, the EHF thresholds was the most important predictor of the FrMatrix score (Figure 10). Two conventional audiometric thresholds were also among the important variables (4000Hz and 125 Hz measured at the right ear) but only the correlation with the 4000 Hz audiometric threshold was significant (Figure 11). AM detection threshold with a 500 Hz carrier frequency appeared important but the correlation was significant only at 60 dB SL (like with the consonant identification score) and not at 10 dB SL. Like with the words in noise recognition results, FrMatrix was related to the years of motorcycling practice. The DPOAEs appeared among the important variable, nevertheless the coefficient of correlation did not reach significance. The history of hearing pathology was also an important variable, and, similarly to the words in noise recognition, participants with a history of otitis media showed weaker scores.
3.4. Speech in noise Pragmatic Scale from the Speech Spatial and Quality of hearing Questionnaire
3.4.1. Predictor Importance
3.4.2. Correlations between Predictors and Speech in Noise Pragmatic Scale
The years of motorcycling practice was the most important variable as assessed by the model (Figure 12), and confirmed by the significant correlation with the speech in noise pragmatic scale (Figure 13). Similarly, the EHF was found to be significantly correlated to the speech in noise pragmatic scale. Several conventional audiometric thresholds were also present among the important variables: the right ear PTA, the right ear 8000 Hz threshold and the left ear 1000 Hz threshold. However, the correlation with left ear 1000 Hz threshold was not significant. Age also appeared as important. The DPOAE measured at 3000 Hz at the left ear appeared among the important variables but the correlation was non significant.
3.5. Relationship across the Speech in Noise Tests
3.5.1. Speech Audiometries in Noise
The consonants in noise score was correlated with the words in noise recognition which was correlated with the FrMatrix (Figure 14). However, the consonants in noise score was not correlated with the FrMatrix.
3.5.2. Speech in Noise Pragmatic Scale and Speech Audiometries in Noise
The self-reported speech in noise pragmatic scale was correlated with the consonant identification score and the words in noise recognition threshold but not with the FrMatrix score (Figure 15).
4. Discussion
The aim of the study was to identify the most relevant variables to monitor in a population of noise-exposed professionals. Different physiological and behavioral variables were assessed as predictors of three speech audiometries in noise and a self-report speech in noise ability. Despite the weak correlations between the speech in noise tests, the EHF threshold appeared as the variable the most often related to the speech in noise scores. However, among the behavioral variables, those related to temporal coding and conventional audiometric thresholds were also highlighted. Concerning the physiological variables, the DPOAE measured at 1000 and 3000 Hz appeared among the nine most important variables although the relationships were weaker as the behavioral variables quoted above.
4.1. Comparisons between Speech in Noise Tests
To the best of our knowledge, no previous study has looked into the relationship between speech audiometry in noise tests with normal or near-normal hearing listeners.
In the current study, weak correlations were observed between the three speech audiometry in noise tests. Those weak correlations could illustrate the fact that the speech audiometry in noise tests differed in their demand on auditory vs. non-auditory abilities (eg. linguistic abilities, working memory; [14]). Most probably, the consonant identification test has the lowest cognitive demand in comparison to the other tests. This is because of the use of non-words stimuli, which do not require linguistic skills, and the use of a closed-set paradigm that tap less into working memory skills [14]. The FrMatrix test probably has the highest cognitive demand with a sentence of five words and an open set paradigm - although the number of alternatives per word categories is limited to ten. The words in noise recognition test is assumed to have intermediate cognitive demand as it was designed to reduce cognitive demand by choosing frequent French words with phonological neighbors, while presented in an open set paradigm [15]. The hierarchy in cognitive demand across the three speech audiometry in noise tests could explain the pattern of observed correlation across the tests: consonant identification was correlated only with words in noise recognition, while the FrMatrix was correlated only with the words in noise recognition. This result emphasizes, within the same group of participants, the relative influence of sensory and cognitive factors on speech in noise task performance [14]. This is coherent with results reviewed by Dryden et al (2017). However, intra-individual variability due to learning effects[16] could have blurred the correlations across the tests. This learning-effect bias was controlled firstly by conducting three FrMatrix sessions, and secondly by providing a closed-set response choice in the consonant identification test. Finally, although learning effect cannot be excluded in the words in noise recognition test, that test was designed to reduce top down influences [17].
Moreover, the three speech audiometry in noise tests assessed in the current study, also presented weak correlations with the speech in noise pragmatic scale of the SSQ, a self-reported measure. This could emphasize the importance of using tests other than questionnaires in a prevention program. However, the lack of relationship could also reflect the low ecological aspect of the tests. None of the speech-in-noise tests used in the current study relied on semantic context or everyday sentences. In a large sample study (n=195 near-normal hearing listeners), Stenbäck and colleagues [18] found a correlation between the Speech SSQ scale and a speech in noise test using everyday sentences (HINT [19]), but not with a less ecologically valid test [20]. This point will still need to be reproduced and confirmed before being implemented in clinical prevention programs.
4.2. Speech in Noise Tests Predictors
4.2.1. Audiometric Thresholds
The importance of the EHF thresholds as a predictor for the 3 speech audiometry in noise tests is one of the most important result here.
Correlations between EHF threshold and speech in noise tests have been highlighted in many previous studies involving normal hearing listeners [21], including populations similar to ours (middle ages, near-normal hearing thresholds [22,23]. Two explanations at least have been suggested [22,24]. The first explanation is a direct causal relationship: the speech signal in the frequency region above 8 kHz could be useful to identify words presented in noisy background [25], especially consonants, like voiceless fricatives [26]. We have retrospectively explored this hypothesis by analyzing the signal spectrum of the speech from the three tests used here. Almost all of the acoustic energy was below 8 kHz (see results in Annex 2), suggesting that this explanation is not adapted to our study.
A second possible explanation is that chronic exposure to high-level noise could cause both cochlear synaptopathy which alters speech in noise performance, and damage to basal outer hair cells, which cause EHF threshold shift [21]. Indeed, extreme basal outer hair cells do not stand the oxidative stress produced by their over stimulation due to high noise levels because of their incapacity to maintain calcium homeostasis [27]. In the same way, high noise levels induce massive and toxic release of glutamate in the synapses of low spontaneous rate auditory fibers, leading to the destruction of the synapses [28].
A third explanation could be that the tuning curve of auditory fibers coding for EHF broadens when the acoustic stimulation reaches high levels. Thus, they could provide temporal information and improve the coding of lower frequencies as well [25]. Nevertheless, in our study, this explanation is unlikely given the relatively moderate levels used for stimulus presentation (around 65 dB SPL).
In addition, the EHF threshold was found to be correlated with several different cochlear aggressors beyond those suspected of inducing synaptopathy (age and noise), but also drugs (cisplatin), diabetes [29], or smoking [30]. Therefore, EHF threshold could be a kind of cochlear aggressor integrator, with each aggressor affecting speech understanding in various ways.
The high frequencies conventional audiometric thresholds and/or their combination represent several important variables for the consonant identification and the FrMatrix tests. Those results show that audiometric thresholds remain informative for normal or near-normal hearing listeners. Most of the studies involving normal hearing listeners explained individual differences in speech in noise performance by noise-induced synaptopathy, even if the mere existence of noise-induced cochlear synaptopathy in living humans is still questionable (Bramhall et al., 2019). Our results suggest that individual differences in conventional audiometric thresholds (EHF excluded), even if they remain in the “normal” range, are also interesting to explain individual differences in speech in noise performance for a noise-exposed population. Not dividing our participants in several groups, or comparing them with other non-exposed control group was one of the key points in our study design. Indeed, it is interesting to note here that conducting a study based on group comparisons, when the individuals within the group are very homogeneous in terms of conventional audiometric thresholds, might not be a relevant strategy to evaluate the predictors of speech-in-noise performance. Nevertheless, this strategy is often used to compare groups according to their noise exposure to search for noise-induced synaptopathy [2,3,21].
Finally, we think that focusing on a group of individuals exposed to one type of noise (motorcycle) in a very similar way (with one main variable link to the number of year motorcycling) was instrumental to limit the large variability inherent to this type of studies. The motorcycle noise could have caused both synaptopathy and audiometric threshold shift by outer hair damages, gradually and similarly among the population. In other studies exploring populations with normal hearing but different kinds of noise exposure, the correlation could have been blurred: some type of noise could have more impact on outer hair cells (impulse noise) and other types of noise more impact on the synapses (steady state noise) [31]
4.2.2. Amplitude and Frequency Modulation Detection
High permutation importance and significant correlations were observed between the consonant identification score and the AM and FM detection thresholds for low frequency carrier and high intensity. Measures of temporal coding appeared also important for the words in noise recognition and the FrMatrix.
Those results are consistent with an alteration of temporal coding abilities induced by the synaptopathy as suggested in humans [32] and in rodents [33]. The synaptopathy reduces the number of auditory fibers, hence the fidelity of the neural phase locking. Indeed, to obtain usable information, the activity of several fibers must be combined, due to their stochastic activity. However, temporal coding is thought to play a role in speech comprehension in noisy environments [34,35], by helping the segregation between noise and signal. Moreover, as temporal coding is crucial for segregation between speech streams, a higher importance of variables related to temporal coding would have been expected for speech in speech tasks [35] rather than speech in noise tasks as used in the current study. Furthermore, in our middle-age population, aging per se [36] or age-related synaptopathy [37] could have also altered the temporal coding abilities of the participants.
4.2.3. Age
Age did not appear among the important variables for any of the speech audiometry in noise test. That was an unexpected result given that, even in the age span of our population, aging can alter speech in noise performance in many ways (alteration of outer hair cells, of synapses between inner hair cells and auditory fibers [37], decrease of temporal coding abilities [36,38]. The fact that age did not appear as a factor per se could mean that its effect was well captured by the measurements as well as the variable « years of motorcycling ». However, age is also related to a factor that we did not explore in our study, the working memory. The working memory is expected to play a role in the speech in noise intelligibility according to recent models (cognitive hearing science [39,40]. Working memory could be altered even within our population age span [41]. Nevertheless, the working memory was perhaps not relevant in our study to explain individual differences in speech in noise performance. First, a meta-analysis showed that working memory was not a relevant factor to explain individual differences among normal hearing listeners [42]. Second, although we did not explicitly measure it, the level of education which is related to working memory, was relatively homogeneous in our population. Moreover, in our study we used only speech in noise task. A speech in speech task would have shown a stronger relationship with age [43].
4.2.4. Physiological Measurements: Distortion Products of Otoacoustic Emissions and Electrocochleography
The amplitude of wave I was not related to speech in noise performance in our study. However, we had hypothesized that, their noise exposure should have caused synaptopathy. By definition, synaptopathy implies a decrease in the number of synapses, hence a lower amplitude of the wave I. However, many studies did not observe a correlation between wave I amplitude and speech in noise performance [2,44] in contrast to the findings of [21,45]. Methodological aspects have been proposed to explain this discrepancy [44]. The main difficulty is to target the low spontaneous rate fibers [28] in the recorded electrical signal. Different strategies have been used (Wave I growth function [46], summing potential / action potential ratio [21]). A promising technique would be to isolate the low spontaneous rate fibers thanks to an ipsilateral noise saturating the high spontaneous rate fibers [47]. In our study, the three tests relied on energetic masking. Nevertheless, informational masking with different intelligible speech streams would perhaps have been more efficient to reveal relationships with EcochG [14]. Indeed, the segregation of speech streams requires sufficient temporal coding abilities to identify the target speech based on voice cues or localization cues. As temporal coding of speech signal is supposed to be strongly linked to the number of functional low spontaneous rate fibers, synaptopathy would be particularly efficient to reduce speech in speech intelligibility.
Previous studies have suggested that the outer hair cells function could also be responsible for speech in noise performance [48]. Our results confirmed that by highlighting the DPOAE as an important predictor for words in noise recognition and FrMatrix. Interestingly, Parker (2020) found correlations between speech in noise tests and DPOAE in the same range of frequencies and magnitude of correlation coefficients but for lower intensity of stimulation (65/55 vs 75/65 dB SPL). Our parameters of DPOAE intensity stimulation were not classical [49]. Nevertheless they have probably improved the probability to obtain signals at satisfying the signal-to-noise ratio.
4.3. Clinical Implications
The importance of EHF thresholds to predict speech in noise performance suggests that it could be a relevant variable for screening a noise exposed population. With most commercial audiometers, it is now possible to measure EHF thresholds with the same equipment as the conventional frequencies, at least up to 12500 Hz. If an EHF threshold shift is detected, then further tests could be proposed in order to target in more details the auditory dysfunction. Tests could include speech audiometry in noise, physiological measurements (DPOAE, EcochG), and/or questionnaires (SSQ, tinnitus screening questionnaire). Finally, the early diagnostic of an auditory dysfunction would lead to appropriate and timely medical care (hearing aids, strategies for challenging listening situations, strategies to protect residual hearing) and prevent accompanying disabilities. Therefore, we approve that EHF testing should be performed standardly [24,50].
4.4. Limits of the Study
The interpretation of the results was complicated by the fact that some variables were identified as important although non significantly related to the speech in noise performance. That result could indicate potential complex interactions between the variables which could be explored in further studies implying a larger sample of participants. Another limitation of the study is the lack of gender diversity which is, unfortunately, inherent to the studied population. It represents a side effect of choosing a homogeneous exposed population.
5. Conclusion
A high number of behavioral or physiological measures are related to the speech intelligibility in noisy backgrounds. EHF threshold appears to be among the most important to predict different speech in noise tests among a noise exposed population. EHF threshold could reveal not only the impact of noise exposure but also to numerous auditory aggressors. Therefore, adding EHF thresholds in the monitoring of noise exposed population could help to prevent speech in noise understanding difficulties and an alteration of their professional and extra professional lives.
Author Contributions
Conceptualization, GA, CS, NP; methodology, GA, CS, NP, AM, FG, NW, VI.; software, NW, VI.; validation, GA.; formal analysis, GA, VI.; investigation, GA, CS, FG.; resources, GA, AM, FG, NW; data curation, GA., AM; writing—original draft preparation, GA, CS; writing—review and editing, GA, CS, NP, AM, FG, VI; visualization, GA, VI ; supervision, GA.; project administration, GA. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by Ethics Committee “Comité de protection des personnes” sud-ouest et outre-mer II (IDRCB 2017-A00859–44).)
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Acknowledgments
The authors warmly thank Christian Lorenzi for his helpful support and Jean Christophe Bouy for software development.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Amplitude Modulation and Frequency Modulation Detection Threshold
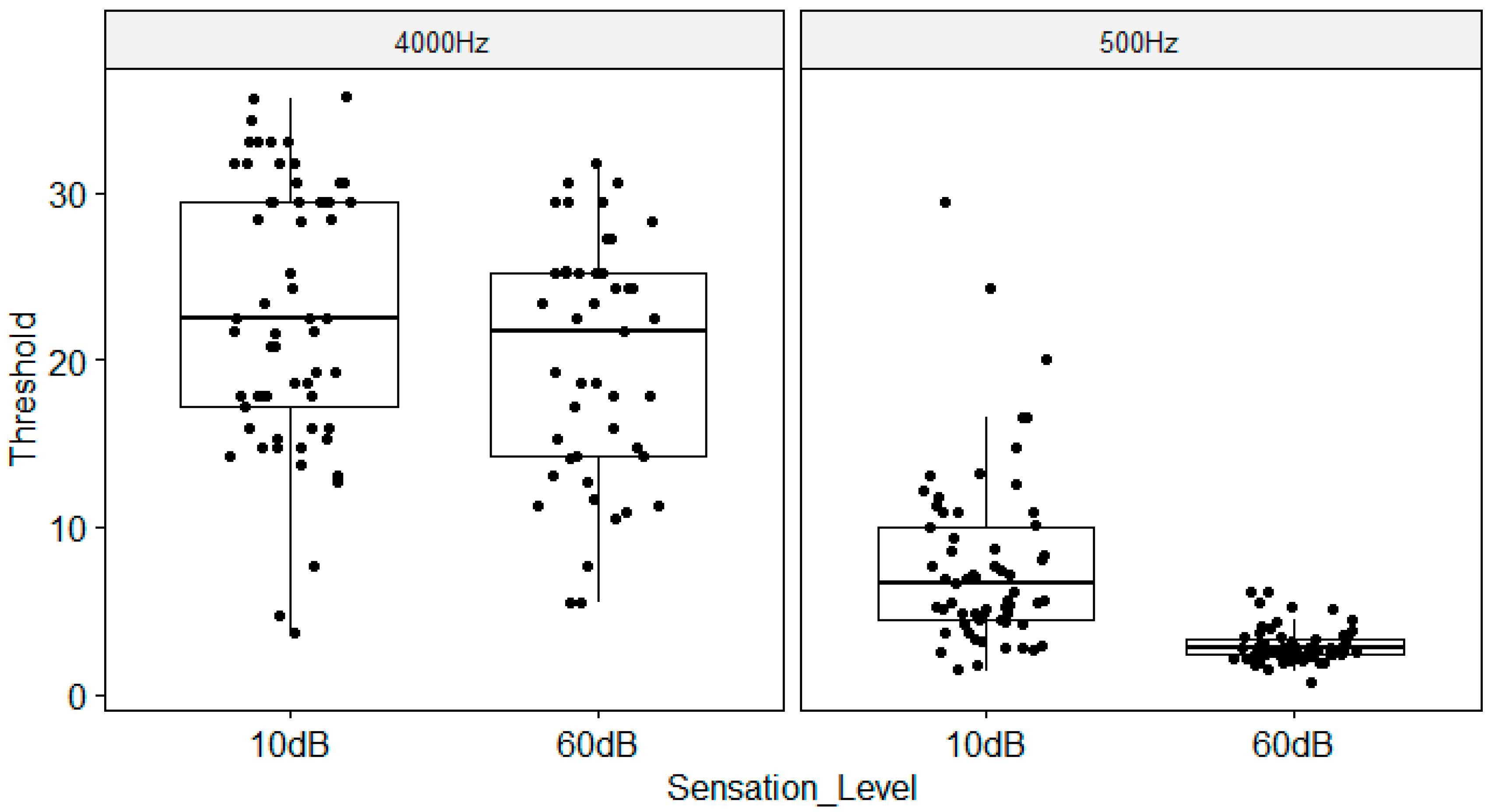
Figure A1.
Amplitude Modulation Detection Threshold as a function of Sensation Level and Carrier Frequency. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Figure A1.
Amplitude Modulation Detection Threshold as a function of Sensation Level and Carrier Frequency. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
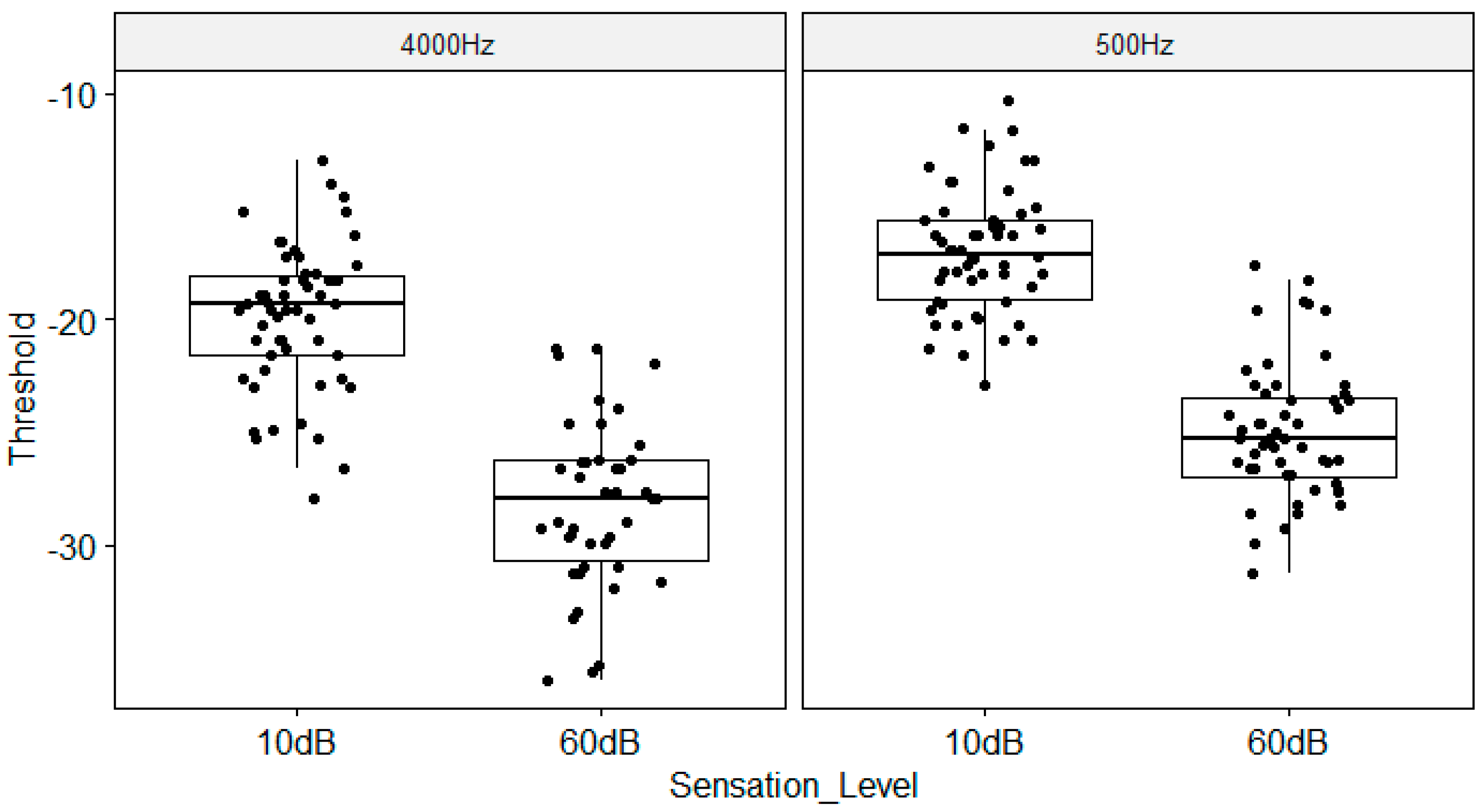
Figure A2.
Frequency Modulation Detection Threshold as a function of Sensation Level and Carrier Frequency. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Figure A2.
Frequency Modulation Detection Threshold as a function of Sensation Level and Carrier Frequency. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Electrocochleography
Figure A3.
Wave I Amplitude as a function of Click Level and Ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Figure A3.
Wave I Amplitude as a function of Click Level and Ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.

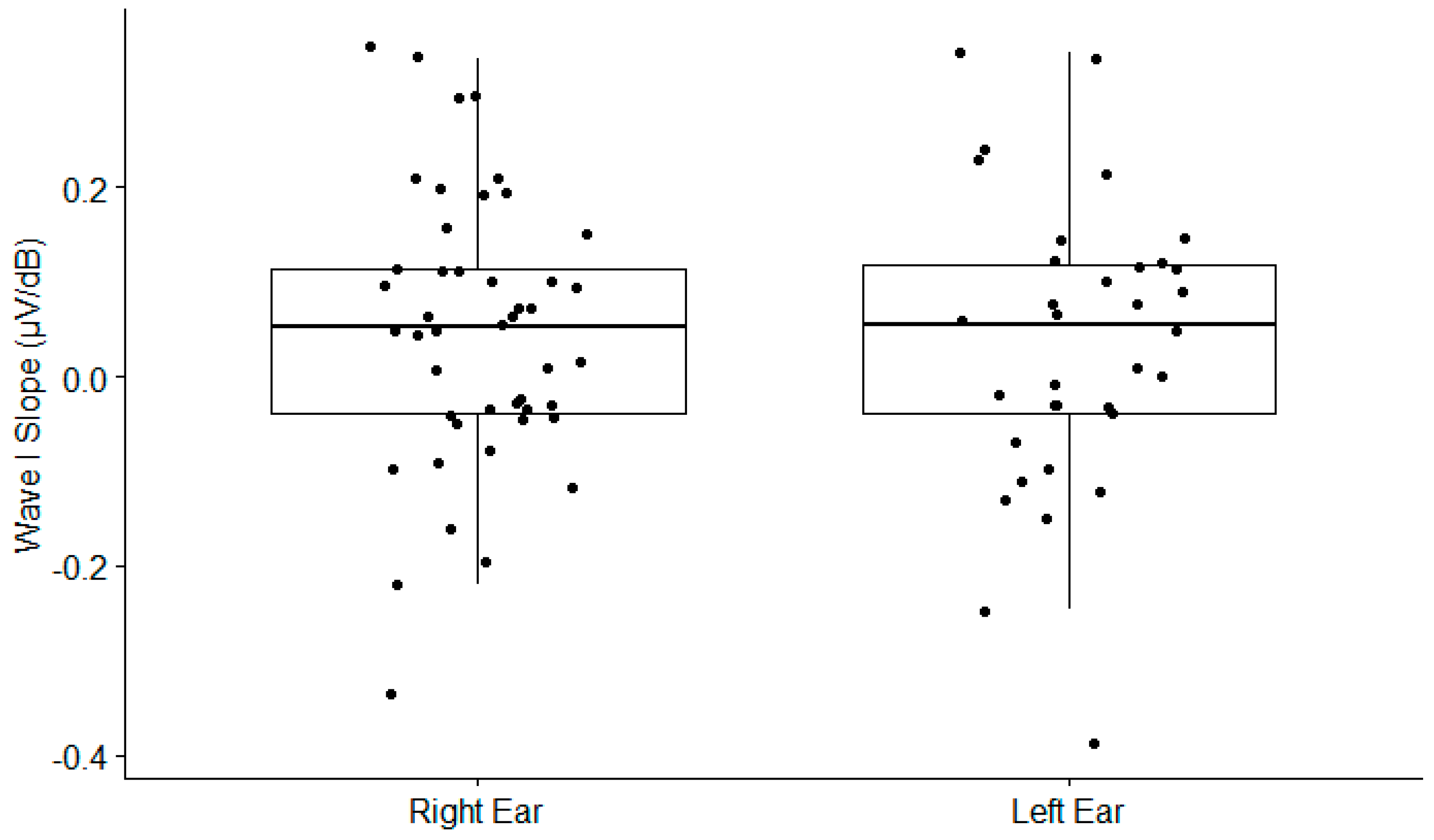
Figure A4.
Electrocochleography Wave I slope as a function of the ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Figure A4.
Electrocochleography Wave I slope as a function of the ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Distorsion Products of OtoAcoustic Emissions
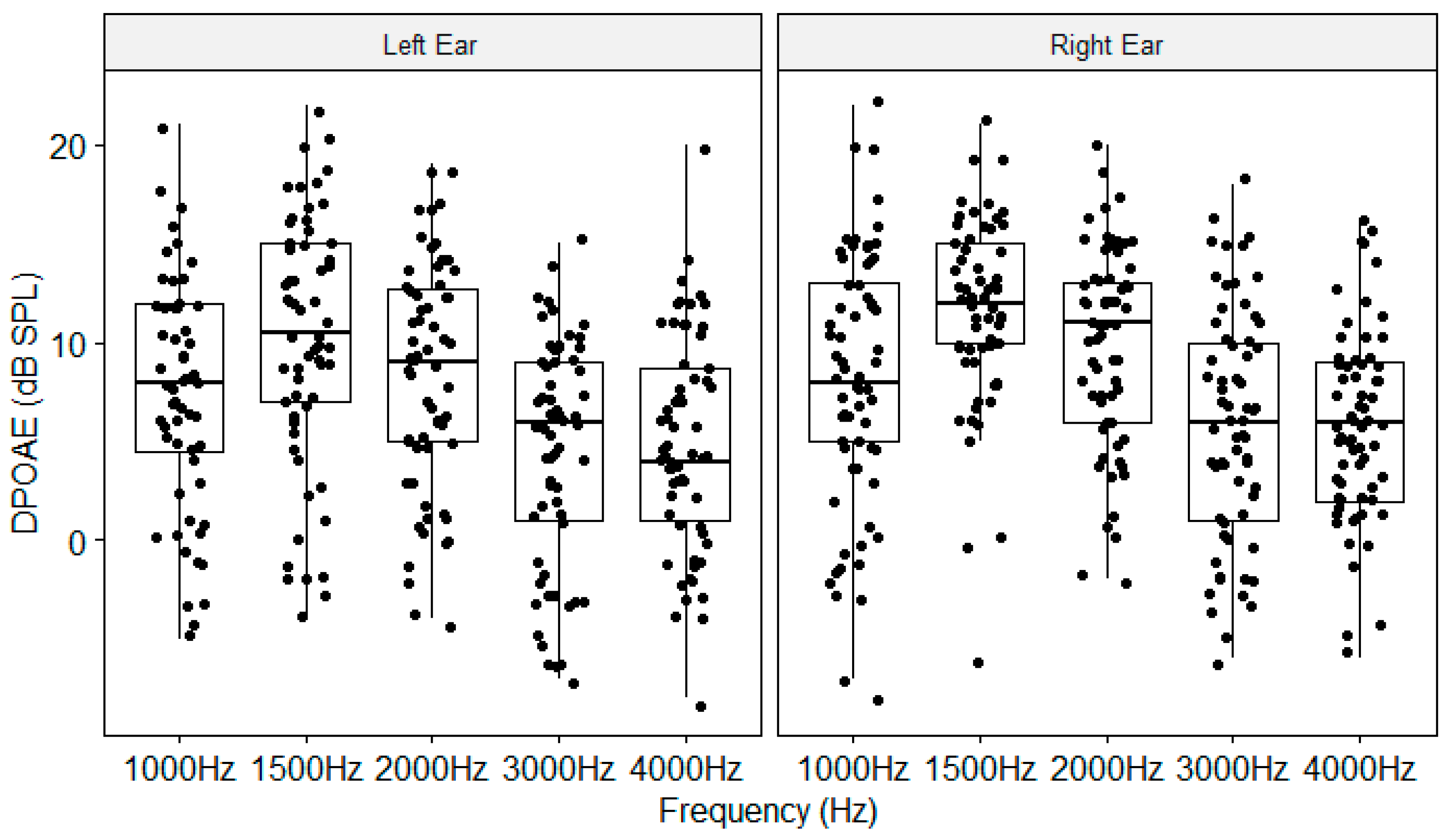
Figure A5.
DPOAE as a function of frequency and Ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Figure A5.
DPOAE as a function of frequency and Ear. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Dots show individual points.
Appendix B
Acoustical Analyses of the Three Speech Corpora
For these analyses, the ‘consonant’ and ‘words’ corpora contain all 48 and 291 sound files respectively, while the ‘FrMatrix’ corpus contains the recording of 100 random sentences.
Upper Frequency Bound Comprising 99% of the Total Power of the Spectrum
Figure B1.
Upper frequency bounds under which 99% of the total power of the spectrum of the speech signals are comprised, for the three speech corpora. Medians (red bars), 25th and 75th percentiles are represented as boxes, while the whiskers extend to the most extreme data points not considered outliers (‘+’ symbols).
Figure B1.
Upper frequency bounds under which 99% of the total power of the spectrum of the speech signals are comprised, for the three speech corpora. Medians (red bars), 25th and 75th percentiles are represented as boxes, while the whiskers extend to the most extreme data points not considered outliers (‘+’ symbols).
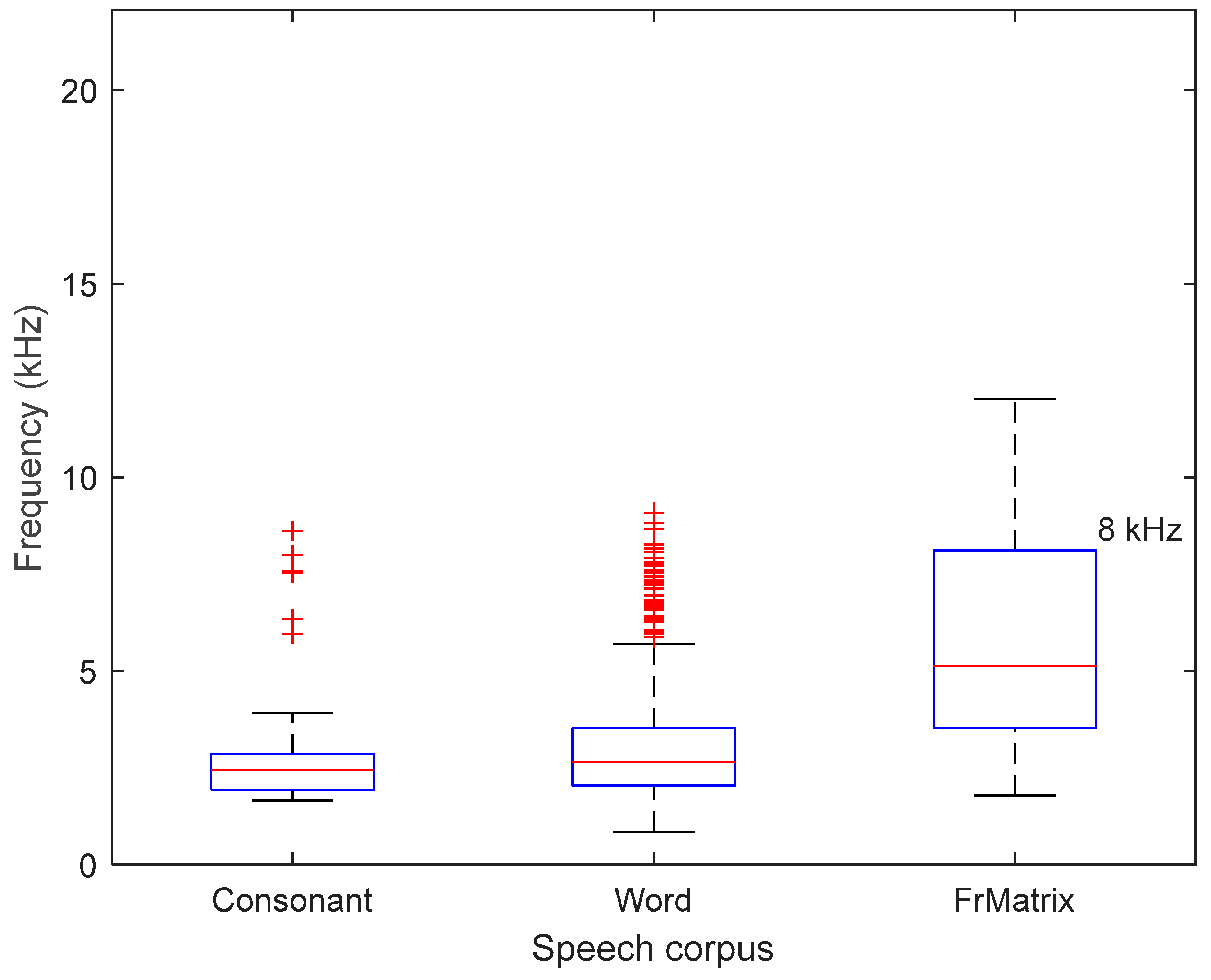
Ratio of Acoustical power in High vs. Low Frequencies
Figure B2.
Ratio of acoustical power contained in high vs. in low frequencies, with a cutoff frequency of 8 kHz, for the three speech corpora. The majority of speech sounds present at least 20 dB more energy in low (below 8 kHz) vs. in high frequencies.
Figure B2.
Ratio of acoustical power contained in high vs. in low frequencies, with a cutoff frequency of 8 kHz, for the three speech corpora. The majority of speech sounds present at least 20 dB more energy in low (below 8 kHz) vs. in high frequencies.
References
- Moore BCJ. An introduction to the psychology of hearing, 5th ed. San Diego, CA, US: Academic Press; 2003.
- Prendergast G, Guest H, Munro KJ, Kluk K, Léger A, Hall DA, et al. Effects of noise exposure on young adults with normal audiograms I: Electrophysiology. Hear Res 2017;344:68–81. [CrossRef]
- Prendergast G, Millman RE, Guest H, Munro KJ, Kluk K, Dewey RS, et al. Effects of noise exposure on young adults with normal audiograms II: Behavioral measures. Hear Res 2017;356:74–86. [CrossRef]
- Guest H, Dewey RS, Plack CJ, Couth S, Prendergast G, Bakay W, et al. The Noise Exposure Structured Interview (NESI): An Instrument for the Comprehensive Estimation of Lifetime Noise Exposure. Trends Hear 2018;22:2331216518803213. [CrossRef]
- International Bureau for Audiophonology. Audiometric classification of hearing impairments. International Bureau for Audiophonology recommendation 02/1 1997.
- Gatehouse S, Noble W. The Speech, Spatial and Qualities of Hearing Scale (SSQ). Int J Audiol 2004;43:85–99. [CrossRef]
- Moulin A, Pauzie A, Richard C. Validation of a French translation of the Speech, Spatial, and Qualities of Hearing Scale (SSQ) and comparison with other language versions. Int J Audiol 2015;54:889–98. [CrossRef]
- Jansen S, Luts H, Wagener KC, Kollmeier B, Del Rio M, Dauman R, et al. Comparison of three types of French speech-in-noise tests: a multi-center study. Int J Audiol 2012;51:164–73. [CrossRef]
- HörTech gGmbH. Instruction manual “French Matrix Test” FRAMATRIX for Oldenburg Measurement Applications from release 1.5.4.0 2014.
- Akeroyd MA, Guy FH, Harrison DL, Suller SL. A factor analysis of the SSQ (Speech, Spatial, and Qualities of Hearing Scale). Int J Audiol 2014;53:101–14. [CrossRef]
- Kim H, Park J, Choung Y-H, Jang JH, Ko J. Predicting speech discrimination scores from pure-tone thresholds—A machine learning-based approach using data from 12,697 subjects. PLOS ONE 2021;16:e0261433. [CrossRef]
- Lenatti M, Moreno -Sánchez Pedro A., Polo EM, Mollura M, Barbieri R, Paglialonga A. Evaluation of Machine Learning Algorithms and Explainability Techniques to Detect Hearing Loss From a Speech-in-Noise Screening Test. Am J Audiol 2022;31:961–79. [CrossRef]
- Balan JR, Rodrigo H, Saxena U, Mishra SK. Explainable machine learning reveals the relationship between hearing thresholds and speech-in-noise recognition in listeners with normal audiograms. J Acoust Soc Am 2023;154:2278–88. [CrossRef]
- DiNino M, Holt LL, Shinn-Cunningham BG. Cutting Through the Noise: Noise-Induced Cochlear Synaptopathy and Individual Differences in Speech Understanding Among Listeners With Normal Audiograms. Ear Hear 2022;43:9–22. [CrossRef]
- Moulin A, Bernard A, Tordella L, Vergne J, Gisbert A, Martin C, et al. Variability of word discrimination scores in clinical practice and consequences on their sensitivity to hearing loss. Eur Arch Otorhinolaryngol 2017;274:2117–24. [CrossRef]
- Le Prell CG, Brungart DS. Speech-in-Noise Tests and Supra-threshold Auditory Evoked Potentials as Metrics for Noise Damage and Clinical Trial Outcome Measures. Otol Neurotol 2016;37:e295. [CrossRef]
- Moulin A, Richard C. Lexical Influences on Spoken Spondaic Word Recognition in Hearing-Impaired Patients. Front Neurosci 2015;9. [CrossRef]
- Stenbäck V, Marsja E, Ellis R, Rönnberg J. Relationships between behavioural and self-report measures in speech recognition in noise. Int J Audiol 2023;62:101–9. [CrossRef]
- Hällgren M, Larsby B, Arlinger S. A Swedish version of the Hearing In Noise Test (HINT) for measurement of speech recognition: Una versión sueca de la Prueba de Audición en Ruido (HINT) para evaluar el reconocimiento del lenguaje. Int J Audiol 2006;45:227–37. [CrossRef]
- Hagerman B. Sentences for Testing Speech Intelligibility in Noise. Scand Audiol 1982;11:79–87. [CrossRef]
- Liberman MC, Epstein MJ, Cleveland SS, Wang H, Maison SF. Toward a Differential Diagnosis of Hidden Hearing Loss in Humans. PloS One 2016;11:e0162726. [CrossRef]
- Yeend I, Beach EF, Sharma M. Working Memory and Extended High-Frequency Hearing in Adults: Diagnostic Predictors of Speech-in-Noise Perception. Ear Hear 2019;40:458–67. [CrossRef]
- Yeend I, Beach EF, Sharma M, Dillon H. The effects of noise exposure and musical training on suprathreshold auditory processing and speech perception in noise. Hear Res 2017;353:224–36. [CrossRef]
- Lough M, Plack CJ. Extended high-frequency audiometry in research and clinical practice. J Acoust Soc Am 2022;151:1944. [CrossRef]
- Motlagh Zadeh L, Silbert NH, Sternasty K, Swanepoel DW, Hunter LL, Moore DR. Extended high-frequency hearing enhances speech perception in noise. Proc Natl Acad Sci 2019;116:23753–9. [CrossRef]
- Monson BB, Hunter EJ, Lotto AJ, Story BH. The perceptual significance of high-frequency energy in the human voice. Front Psychol 2014;5. [CrossRef]
- Fettiplace R, Nam J-H. Tonotopy in calcium homeostasis and vulnerability of cochlear hair cells. Hear Res 2019;376:11–21. [CrossRef]
- Furman AC, Kujawa SG, Liberman MC. Noise-induced cochlear neuropathy is selective for fibers with low spontaneous rates. J Neurophysiol 2013;110:577–86. [CrossRef]
- Gülseven Güven S, Binay Ç. The Importance of Extended High Frequencies in Hearing Evaluation of Pediatric Patients with Type 1 Diabetes. J Clin Res Pediatr Endocrinol 2023;15:127–37. [CrossRef]
- Cunningham DR, Vise LK, Jones LA. Influence of Cigarette Smoking on Extra-High-Frequency Auditory Thresholds. Ear Hear 1983;4:162.
- Le Prell CG, Hammill TL, Murphy WJ. Noise-induced hearing loss and its prevention: Integration of data from animal models and human clinical trials. J Acoust Soc Am 2019;146:4051–74. [CrossRef]
- Bharadwaj HM, Verhulst S, Shaheen L, Liberman MC, Shinn-Cunningham BG. Cochlear neuropathy and the coding of supra-threshold sound. Front Syst Neurosci 2014;8:26. [CrossRef]
- Parthasarathy A, Kujawa SG. Synaptopathy in the aging cochlea: Characterizing early-neural deficits in auditory temporal envelope processing. J Neurosci 2018;38:7108–19.
- Lorenzi C, Gilbert G, Carn H, Garnier S, Moore BCJ. Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proc Natl Acad Sci U S A 2006;103:18866–9. [CrossRef]
- Füllgrabe C, Moore BCJ, Stone MA. Age-group differences in speech identification despite matched audiometrically normal hearing: contributions from auditory temporal processing and cognition. Front Aging Neurosci 2014;6:347. [CrossRef]
- Grose JH, Mamo SK. Processing of temporal fine structure as a function of age. Ear Hear 2010;31:755–60. [CrossRef]
- Wu PZ, Liberman LD, Bennett K, de Gruttola V, O’Malley JT, Liberman MC. Primary Neural Degeneration in the Human Cochlea: Evidence for Hidden Hearing Loss in the Aging Ear. Neuroscience 2019;407:8–20. [CrossRef]
- Paraouty N, Ewert SD, Wallaert N, Lorenzi C. Interactions between amplitude modulation and frequency modulation processing: Effects of age and hearing loss. J Acoust Soc Am 2016;140:121. [CrossRef]
- Arlinger S, Lunner T, Lyxell B, Pichora-Fuller MK. The emergence of cognitive hearing science. Scand J Psychol 2009;50:371–84. [CrossRef]
- Rönnberg J, Signoret C, Andin J, Holmer E. The cognitive hearing science perspective on perceiving, understanding, and remembering language: The ELU model. Front Psychol 2022;13:967260. [CrossRef]
- Klaassen EB, Evers EAT, de Groot RHM, Backes WH, Veltman DJ, Jolles J. Working memory in middle-aged males: Age-related brain activation changes and cognitive fatigue effects. Biol Psychol 2014;96:134–43. [CrossRef]
- Füllgrabe C, Rosen S. On The (Un)importance of Working Memory in Speech-in-Noise Processing for Listeners with Normal Hearing Thresholds. Front Psychol 2016;7:1268. [CrossRef]
- Helfer KS, Merchant GR, Wasiuk PA. Age-Related Changes in Objective and Subjective Speech Perception in Complex Listening Environments. J Speech Lang Hear Res JSLHR 2017;60:3009–18. [CrossRef]
- Bramhall N, Beach EF, Epp B, Le Prell CG, Lopez-Poveda EA, Plack CJ, et al. The search for noise-induced cochlear synaptopathy in humans: Mission impossible? Hear Res 2019;377:88–103. [CrossRef]
- Bramhall N, Ong B, Ko J, Parker M. Speech Perception Ability in Noise is Correlated with Auditory Brainstem Response Wave I Amplitude. J Am Acad Audiol 2015;26:509–17. [CrossRef]
- Johannesen PT, Buzo BC, Lopez-Poveda EA. Evidence for age-related cochlear synaptopathy in humans unconnected to speech-in-noise intelligibility deficits. Hear Res 2019;374:35–48. [CrossRef]
- Giraudet F, Labanca L, Souchal M, Avan P. Decreased Reemerging Auditory Brainstem Responses Under Ipsilateral Broadband Masking as a Marker of Noise-Induced Cochlear Synaptopathy. Ear Hear 2021;42:1062–71. [CrossRef]
- Parker MA. Identifying three otopathologies in humans. Hear Res 2020;398:108079. [CrossRef]
- Gorga MP, Neely ST, Ohlrich B, Hoover B, Redner J, Peters J. From laboratory to clinic: a large scale study of distortion product otoacoustic emissions in ears with normal hearing and ears with hearing loss. Ear Hear 1997;18:440–55. [CrossRef]
- Moore D, Hunter L, Munro K. Benefits of Extended High-Frequency Audiometry for Everyone. Hear J 2017;70:50. [CrossRef]
Figure 1.
Distribution of the age of participants. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Each dot show the age of one participant.
Figure 1.
Distribution of the age of participants. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range. Each dot show the age of one participant.
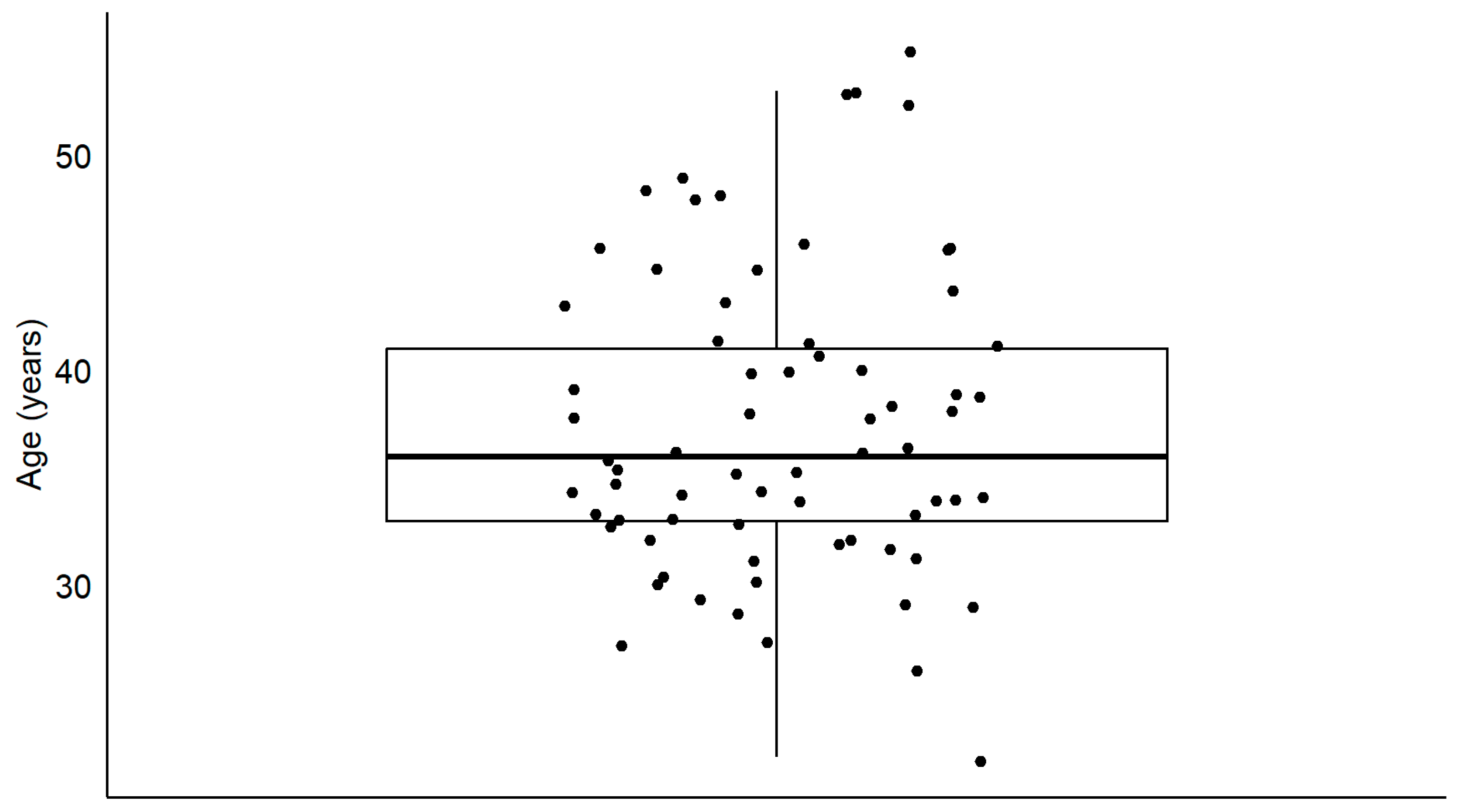
Figure 2.
Exterior view of the Mobile Hearing Laboratory.

Figure 3.
Interior view of the Mobile Hearing Laboratory. In the center right of the setup, a video screen displays images of participants situated in the four booths. Positioned in the center left are four portable "followers" computers equipped with fold-down screens, to which the screens, keyboards, and mice of each booth are connected. Beneath these computers, there is the "leader" computer, positioned at the bottom center, with its screen visible. Additionally, the screens corresponding to the "follower" computers are also visible.
Figure 3.
Interior view of the Mobile Hearing Laboratory. In the center right of the setup, a video screen displays images of participants situated in the four booths. Positioned in the center left are four portable "followers" computers equipped with fold-down screens, to which the screens, keyboards, and mice of each booth are connected. Beneath these computers, there is the "leader" computer, positioned at the bottom center, with its screen visible. Additionally, the screens corresponding to the "follower" computers are also visible.

Figure 4.
Audiometric thresholds as a function of frequency for left and right ear (N = 70). The black line shows the median, the grey area show the interquartile range.
Figure 4.
Audiometric thresholds as a function of frequency for left and right ear (N = 70). The black line shows the median, the grey area show the interquartile range.
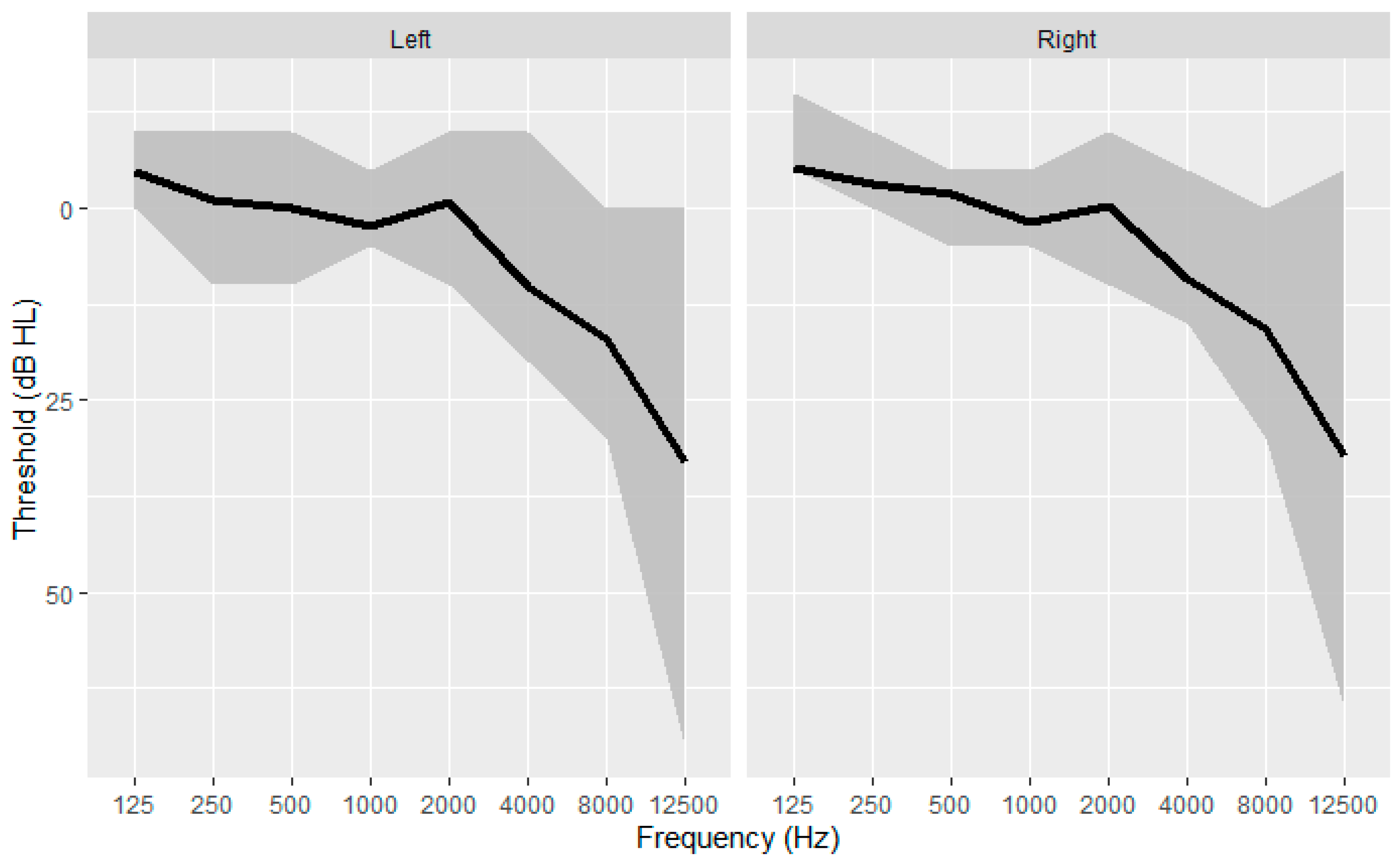
Figure 5.
The performance for each speech audiometry in noise; each dot show the result of one participant. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range.
Figure 5.
The performance for each speech audiometry in noise; each dot show the result of one participant. The boxplots show the medial (horizontal bar) and the interquartile range (box). The whiskers reach from the lowest to the highest observed value within 1.5 times the interquartile range.
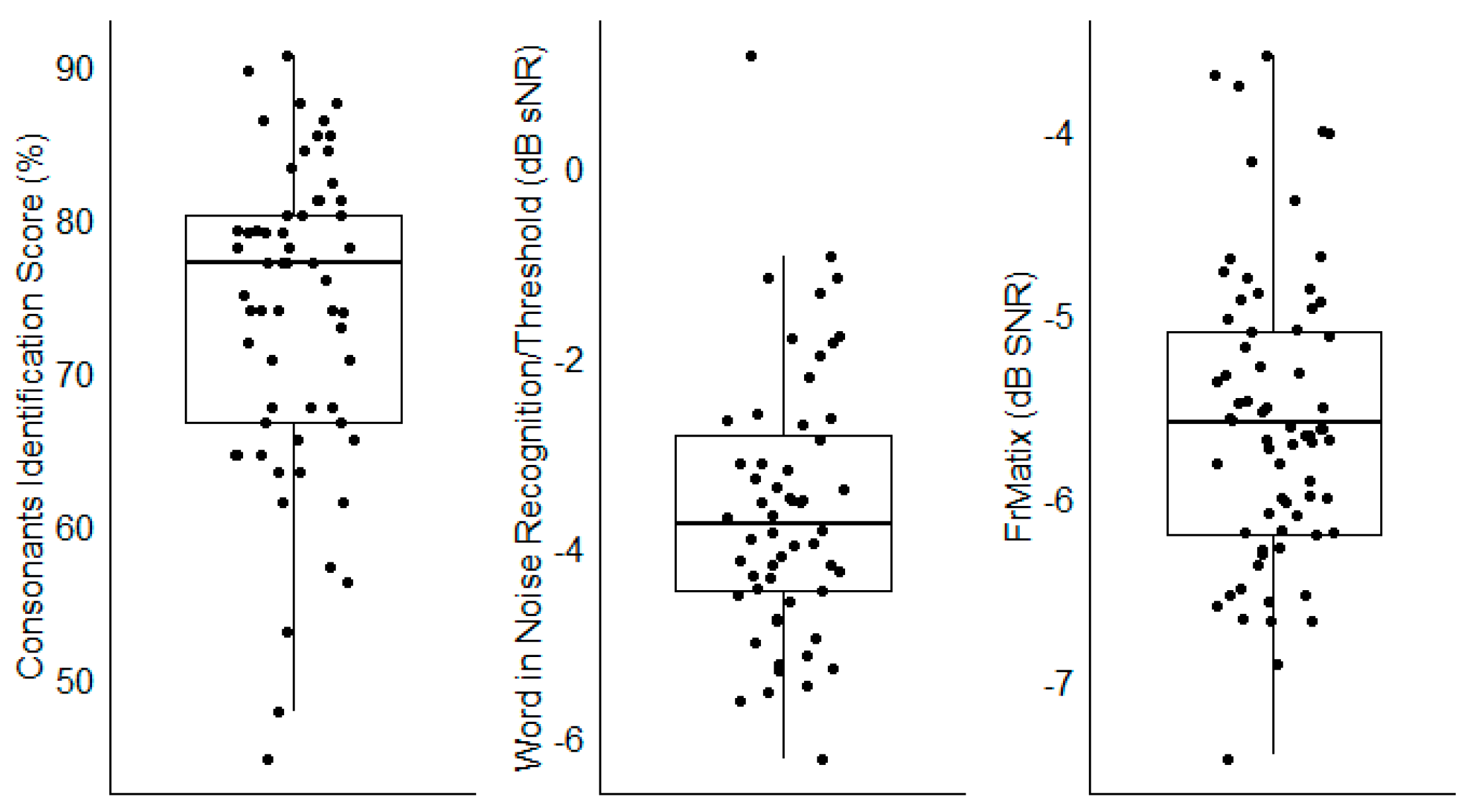
Figure 6.
Main predictors of the consonant Identification score. The importance is measured as the MSE increase for the nine first most important variables. The larger the value, the more important the variable. See Table 1 for abbreviations.
Figure 6.
Main predictors of the consonant Identification score. The importance is measured as the MSE increase for the nine first most important variables. The larger the value, the more important the variable. See Table 1 for abbreviations.
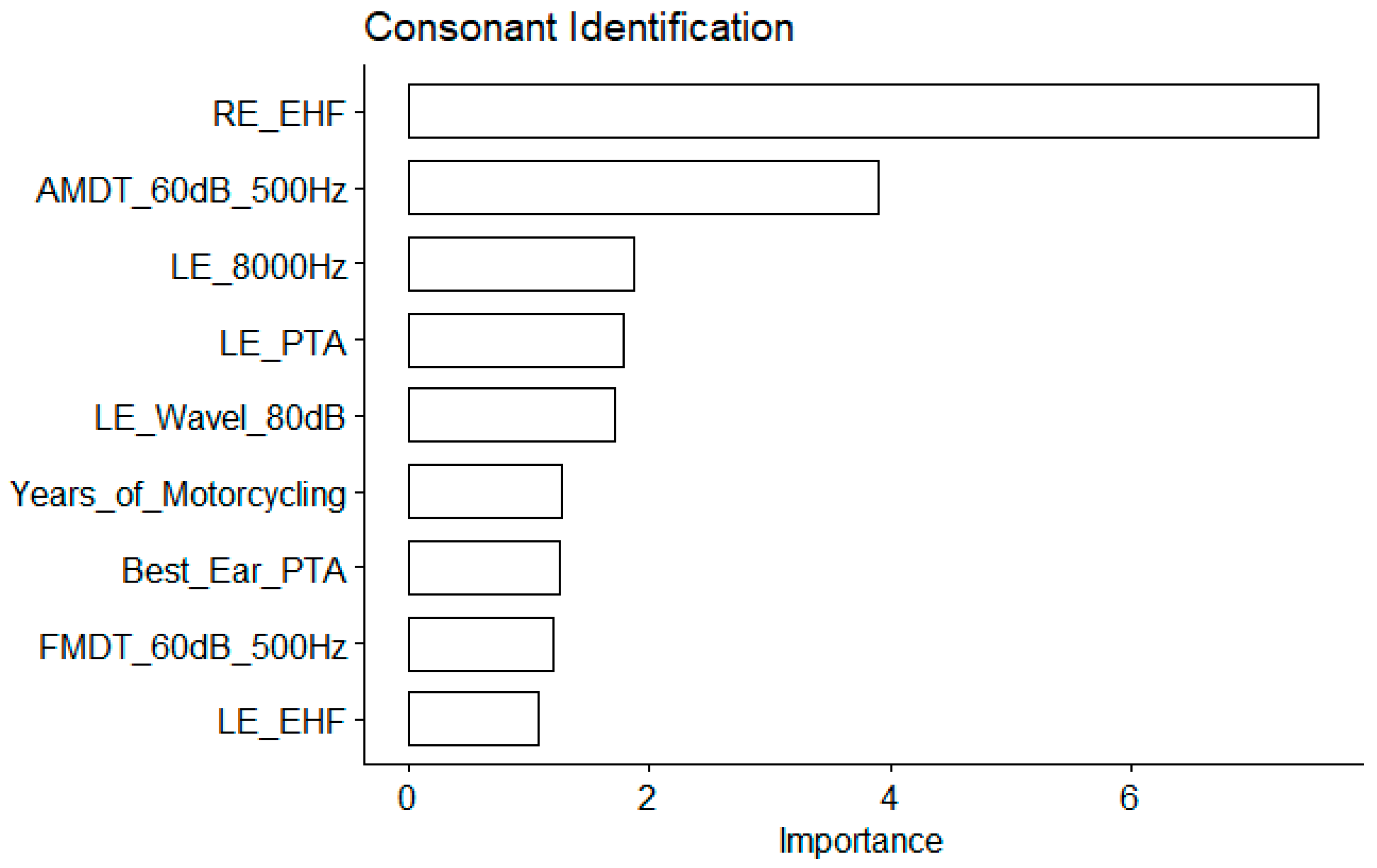
Figure 7.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Right ear EHF Threshold. B. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. C. Left Ear 8000Hz Threshold. D. Left Ear Pure Tone Average. E. Left Ear Wave I Amplitude at 80 dB nHL. F. Years of Motorcycling. G. Best Ear Pure Tone Average. H. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz. I. Left ear EHF Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 7.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Right ear EHF Threshold. B. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. C. Left Ear 8000Hz Threshold. D. Left Ear Pure Tone Average. E. Left Ear Wave I Amplitude at 80 dB nHL. F. Years of Motorcycling. G. Best Ear Pure Tone Average. H. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz. I. Left ear EHF Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
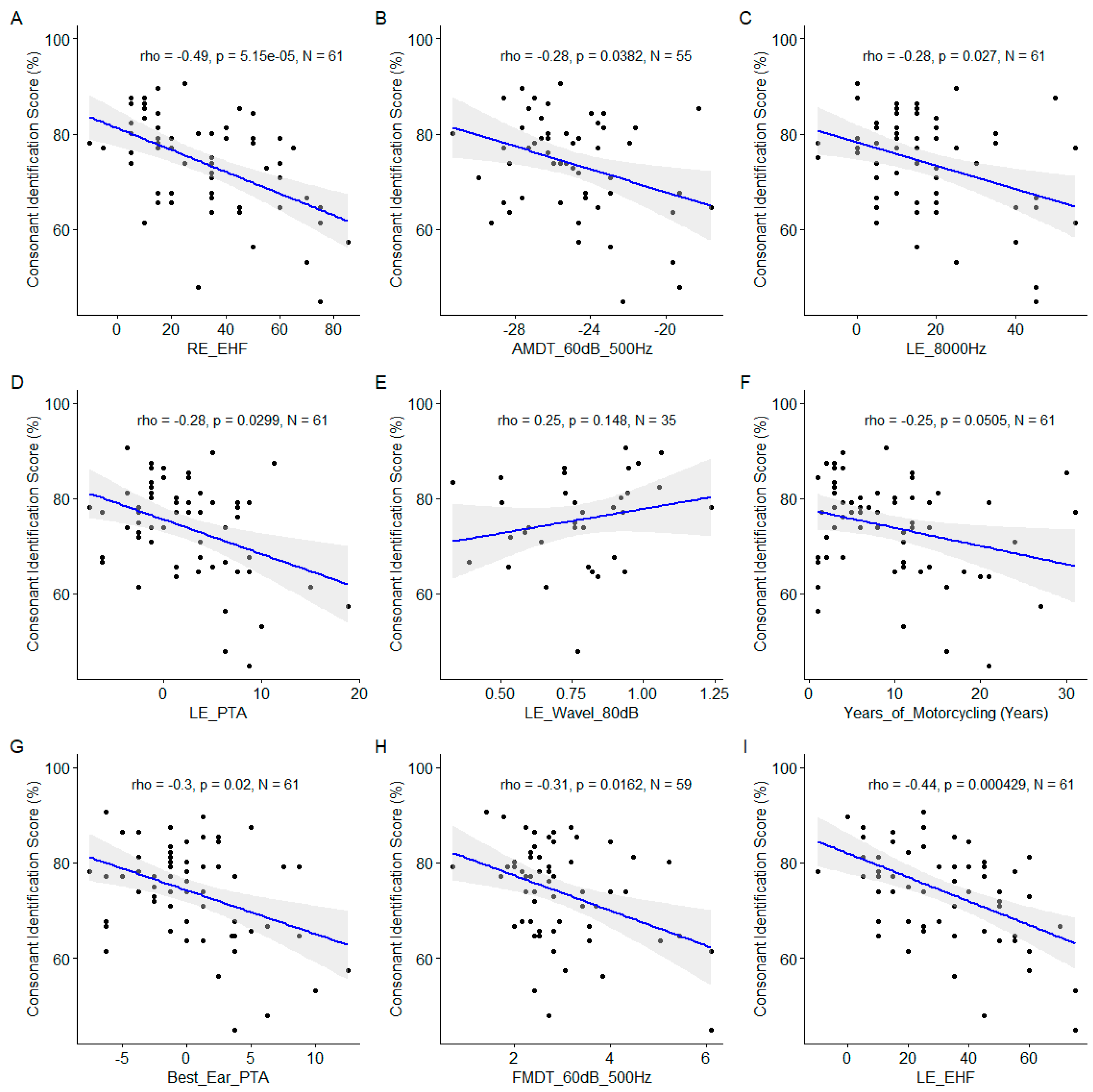
Figure 8.
Word in Noise Recognition. Importance measured as the increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model. See Table 1 for abbreviations.
Figure 8.
Word in Noise Recognition. Importance measured as the increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model. See Table 1 for abbreviations.
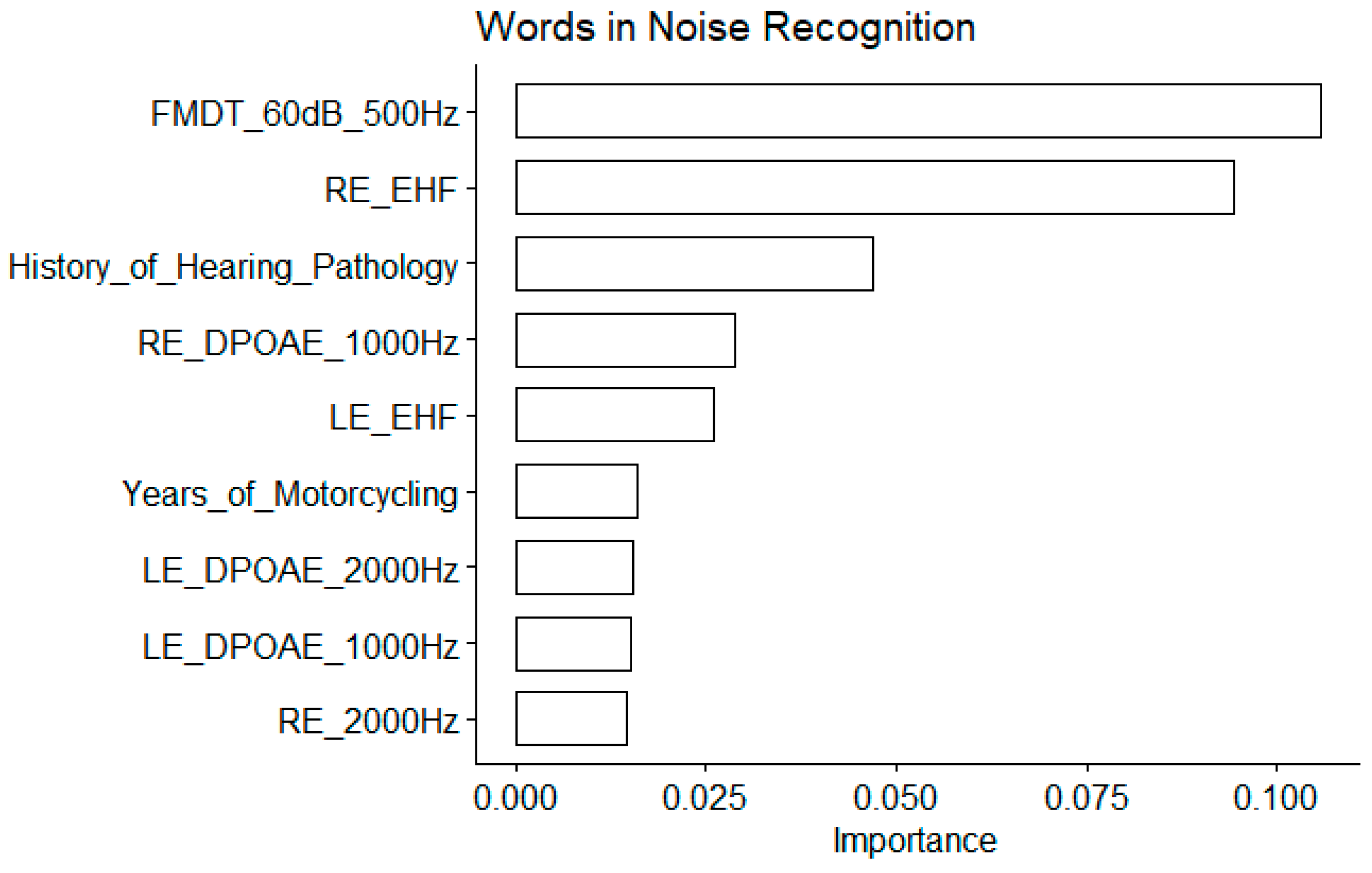
Figure 9.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz B. Right ear EHF Threshold. C. History of Hearing Pathology. D. Left Ear 1000 Hz Threshold. Pure Tone Average. E. Left Ear EHF Threshold. F. Years of Motorcycling. G. Left Ear DPOAE at 2000 Hz. H. Left Ear DPOAE at 1000 Hz. I. Left Ear 2000 Hz Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 9.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz B. Right ear EHF Threshold. C. History of Hearing Pathology. D. Left Ear 1000 Hz Threshold. Pure Tone Average. E. Left Ear EHF Threshold. F. Years of Motorcycling. G. Left Ear DPOAE at 2000 Hz. H. Left Ear DPOAE at 1000 Hz. I. Left Ear 2000 Hz Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
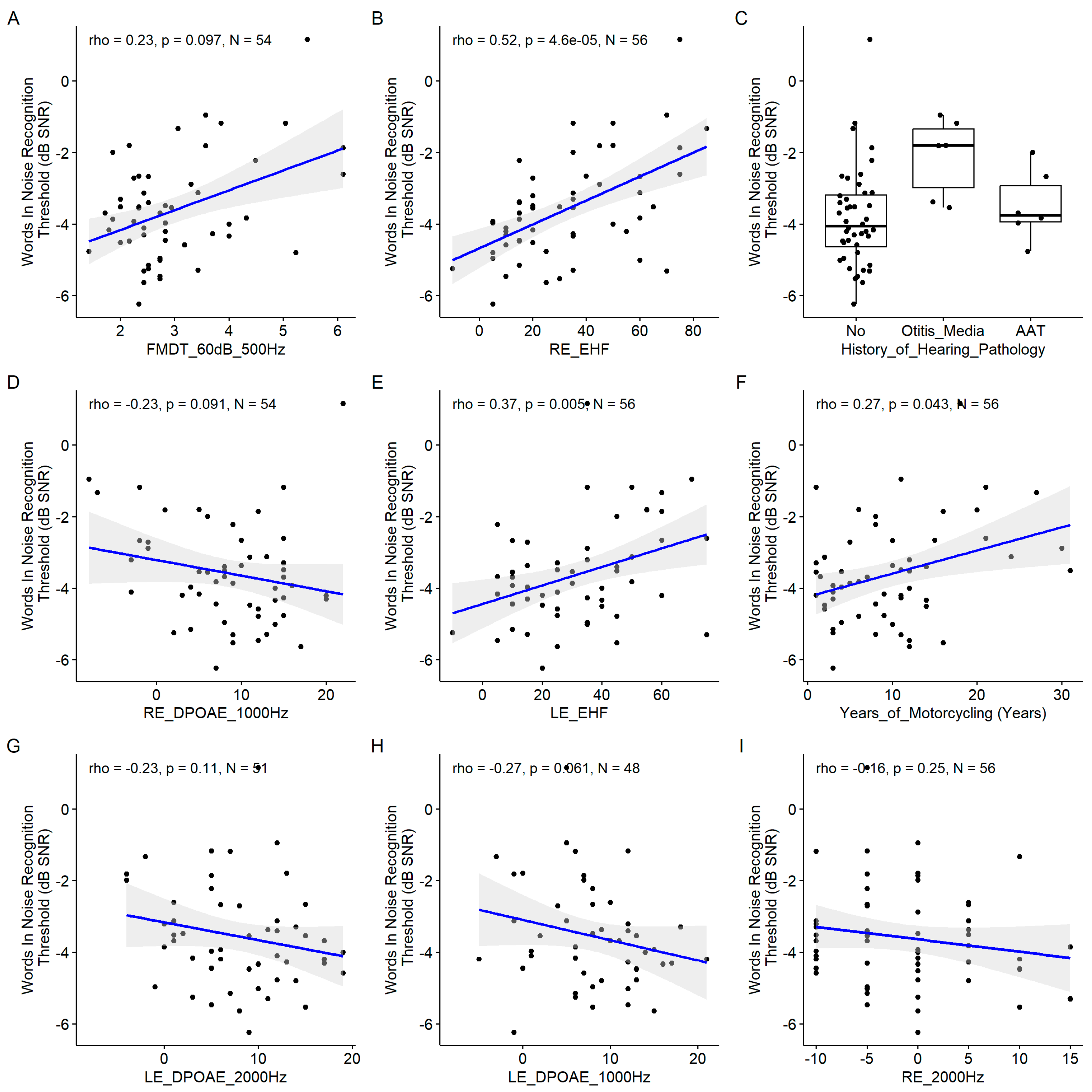
Figure 10.
French Matrix test. Importance measured as the Increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model.
Figure 10.
French Matrix test. Importance measured as the Increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model.
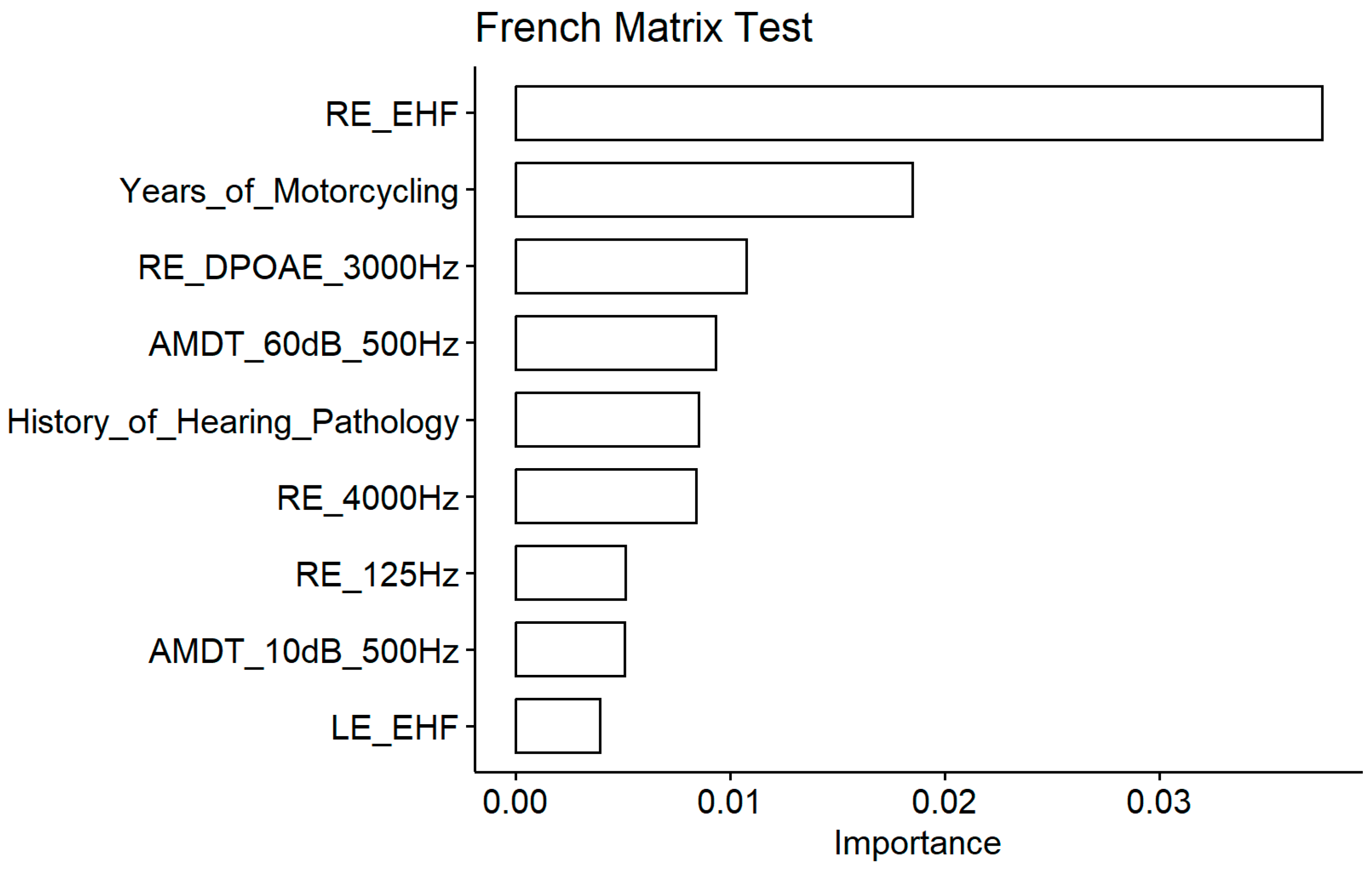
Figure 11.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Right ear EHF Threshold. B. Years of Motorcycling. C. Right Ear DPOAE at 3000 Hz. D. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. E. History of Hearing Pathology. F. Right Ear 4000 Hz Threshold. G. Right Ear 125 Hz Threshold. H. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. I. Left Ear EHF Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 11.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Right ear EHF Threshold. B. Years of Motorcycling. C. Right Ear DPOAE at 3000 Hz. D. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. E. History of Hearing Pathology. F. Right Ear 4000 Hz Threshold. G. Right Ear 125 Hz Threshold. H. Amplitude Modulation Detection Threshold at 60 dB SL at 500 Hz. I. Left Ear EHF Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
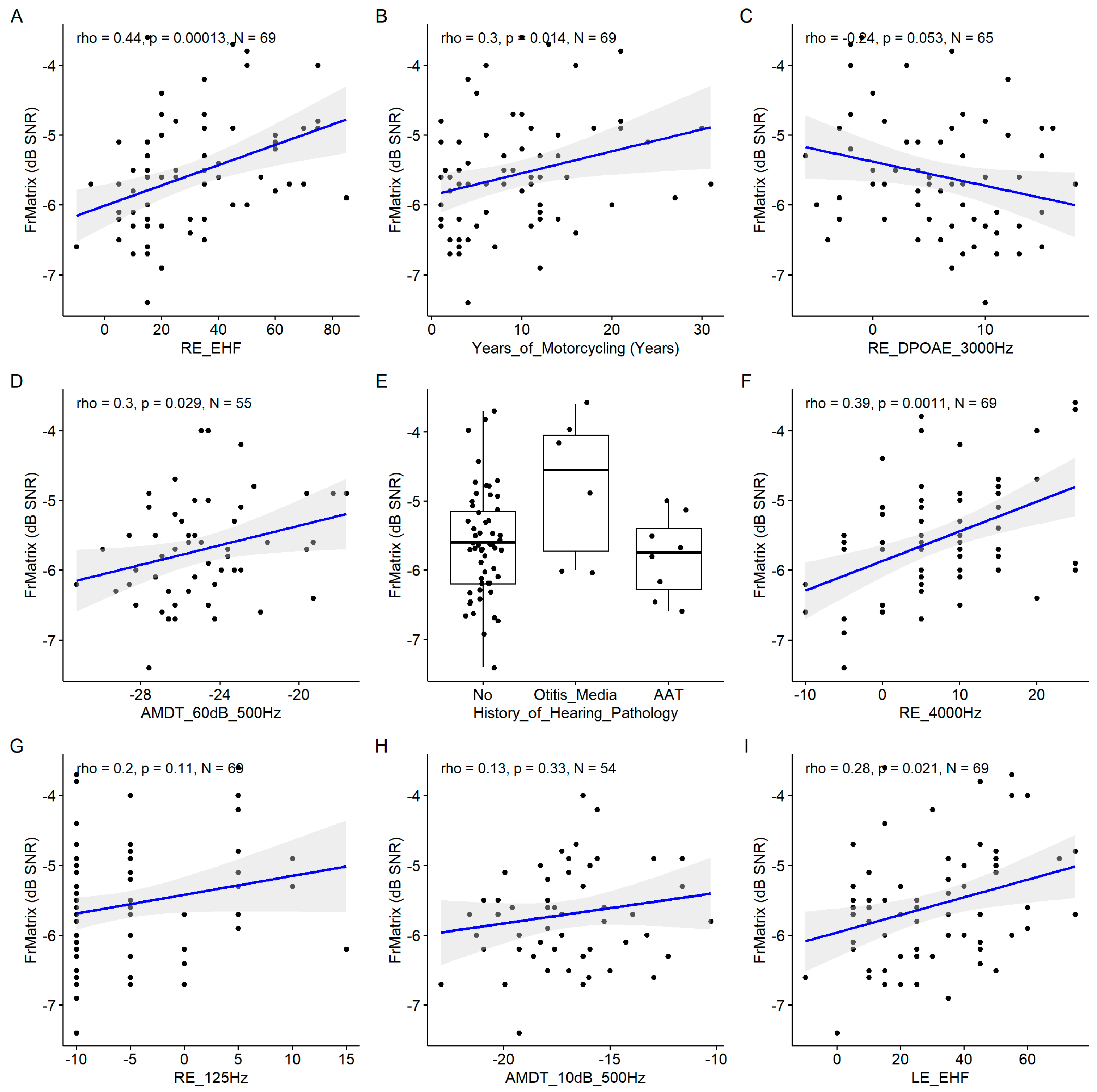
Figure 12.
Speech in Noise Pragmatic Scale. Importance measured as the Increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model.
Figure 12.
Speech in Noise Pragmatic Scale. Importance measured as the Increase of the mean square error for the nine most important variables. The larger the value is, the more important the variable in the model.
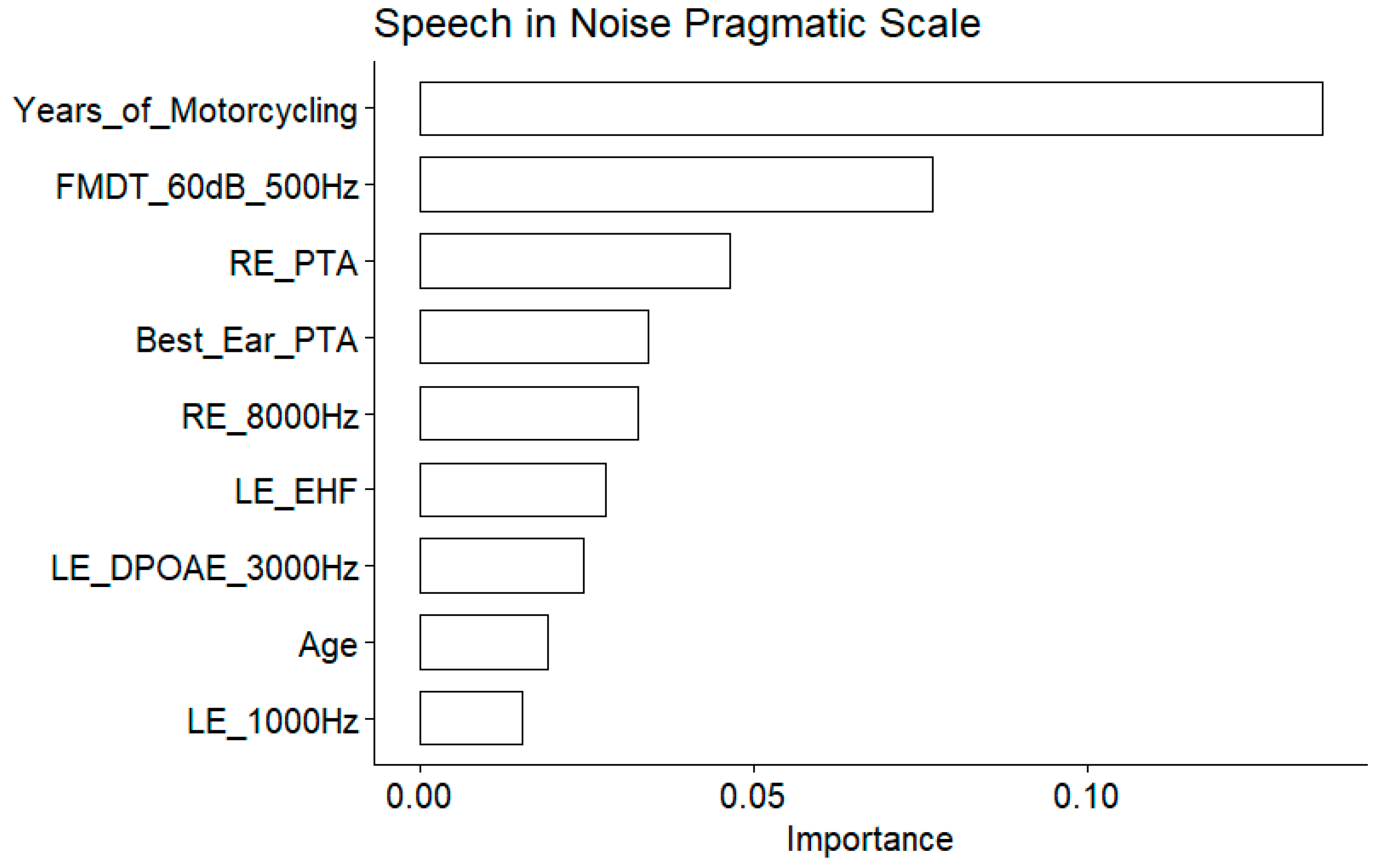
Figure 13.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Years of Motorcycling. B. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz. C. Right Ear Pure Tone Average. D. Best Ear Pure Tone Average. E. Right Ear 8000 Hz Threshold. F. Left Ear EHF Threshold. G. Left Ear DPOAE at 3000 Hz. H. Age. I. Right Ear 1000 Hz Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 13.
Scatter plots of the linear regression of the nine most important predictors of the consonant identification score. A. Years of Motorcycling. B. Frequency Modulation Detection Threshold at 60 dB SL at 500 Hz. C. Right Ear Pure Tone Average. D. Best Ear Pure Tone Average. E. Right Ear 8000 Hz Threshold. F. Left Ear EHF Threshold. G. Left Ear DPOAE at 3000 Hz. H. Age. I. Right Ear 1000 Hz Threshold. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
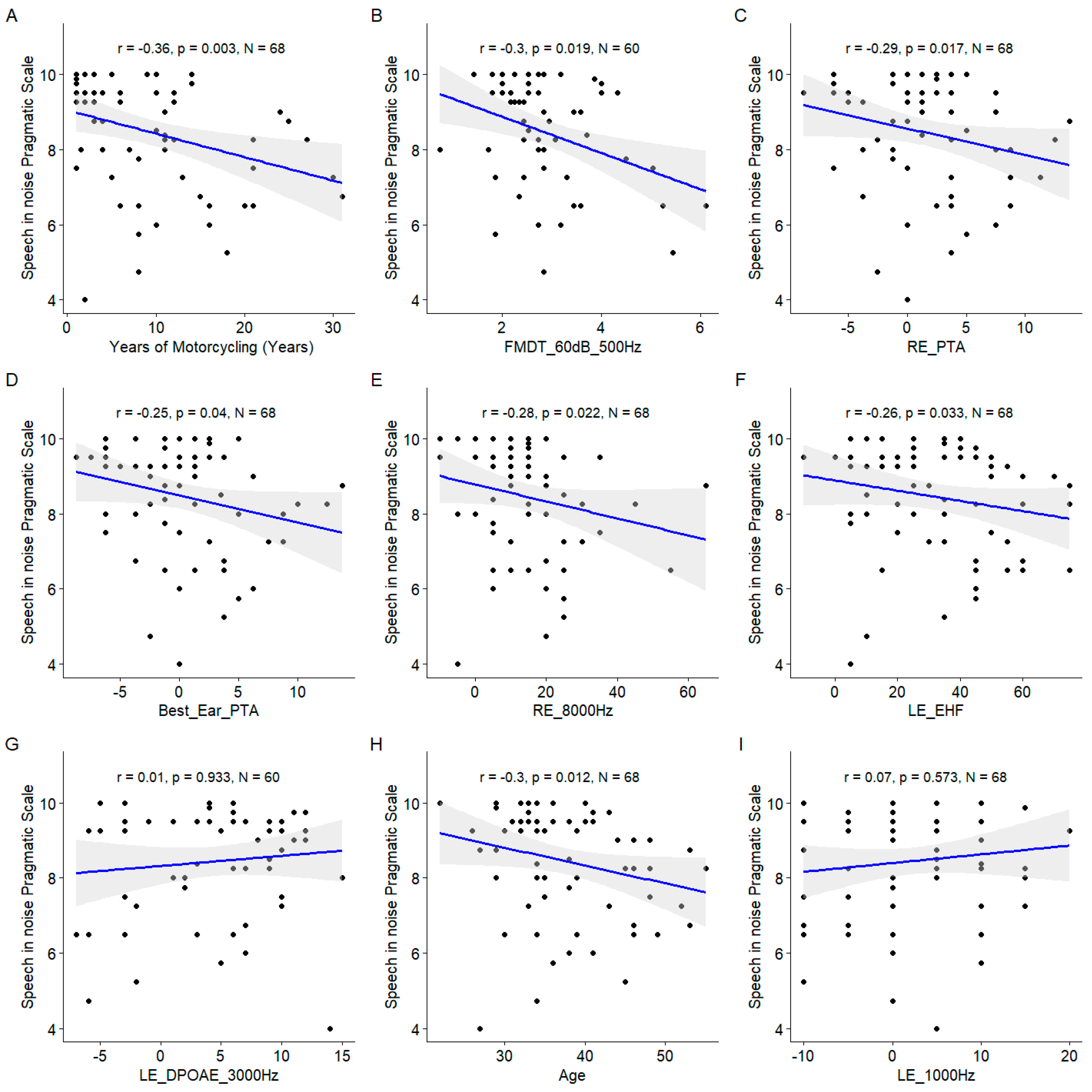
Figure 14.
Scatter plots showing the correlations between the three speech audiometries in noise: A. Consonant Identification vs. French Matrix Test. B. Words in Noise Recognition vs. French Matrix Test. C. Consonant Identification vs Words in Noise Recognition. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 14.
Scatter plots showing the correlations between the three speech audiometries in noise: A. Consonant Identification vs. French Matrix Test. B. Words in Noise Recognition vs. French Matrix Test. C. Consonant Identification vs Words in Noise Recognition. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
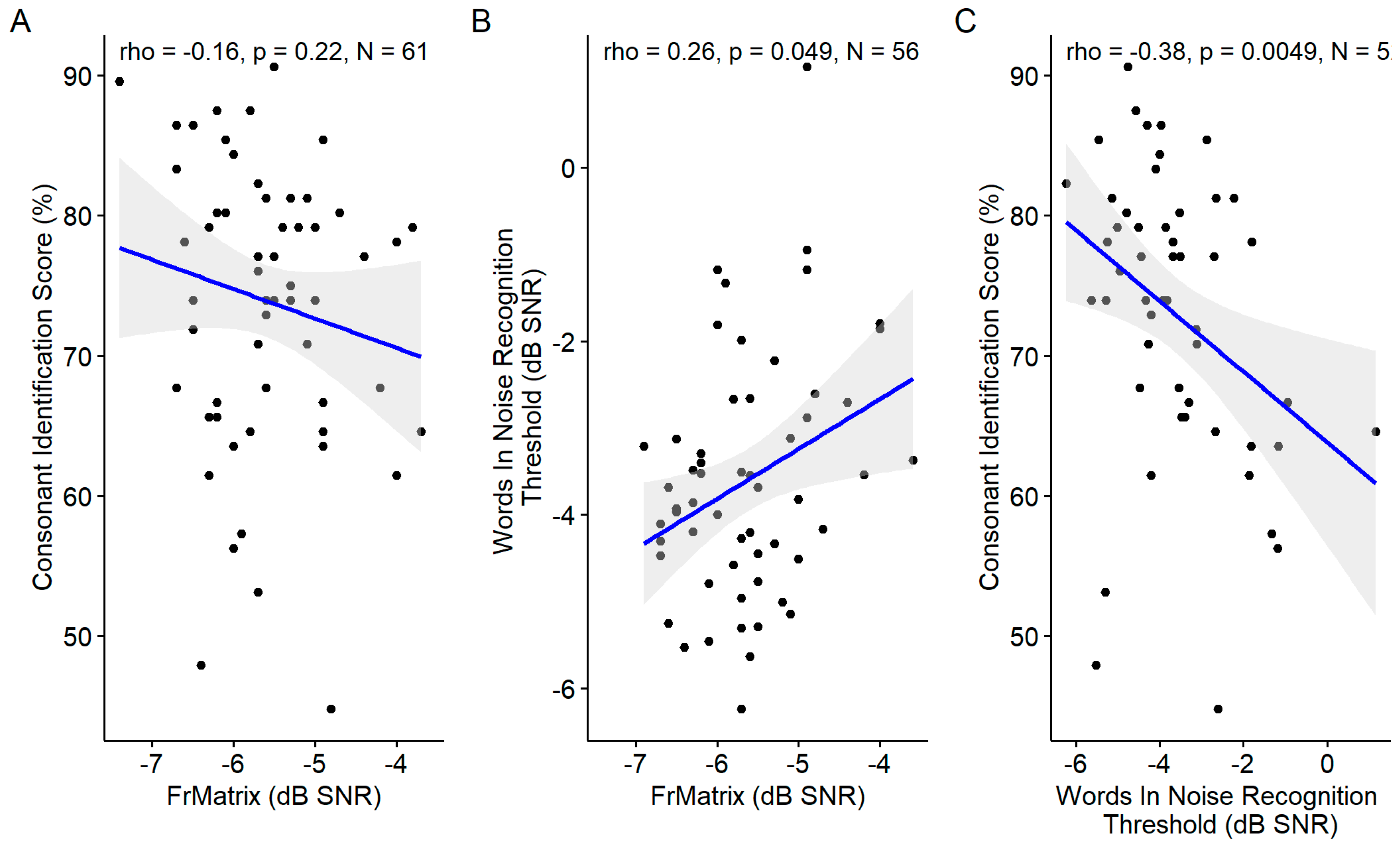
Figure 15.
Scatter plots showing the correlations between the speech in noise pragmatic scale and the three speech audiometries in noise. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
Figure 15.
Scatter plots showing the correlations between the speech in noise pragmatic scale and the three speech audiometries in noise. The blue line indicates the linear fit. The gray region indicates the 95% confidence interval of the regression line. In each panel, the Spearman coefficient of correlation, its p-value and the sample size are shown.
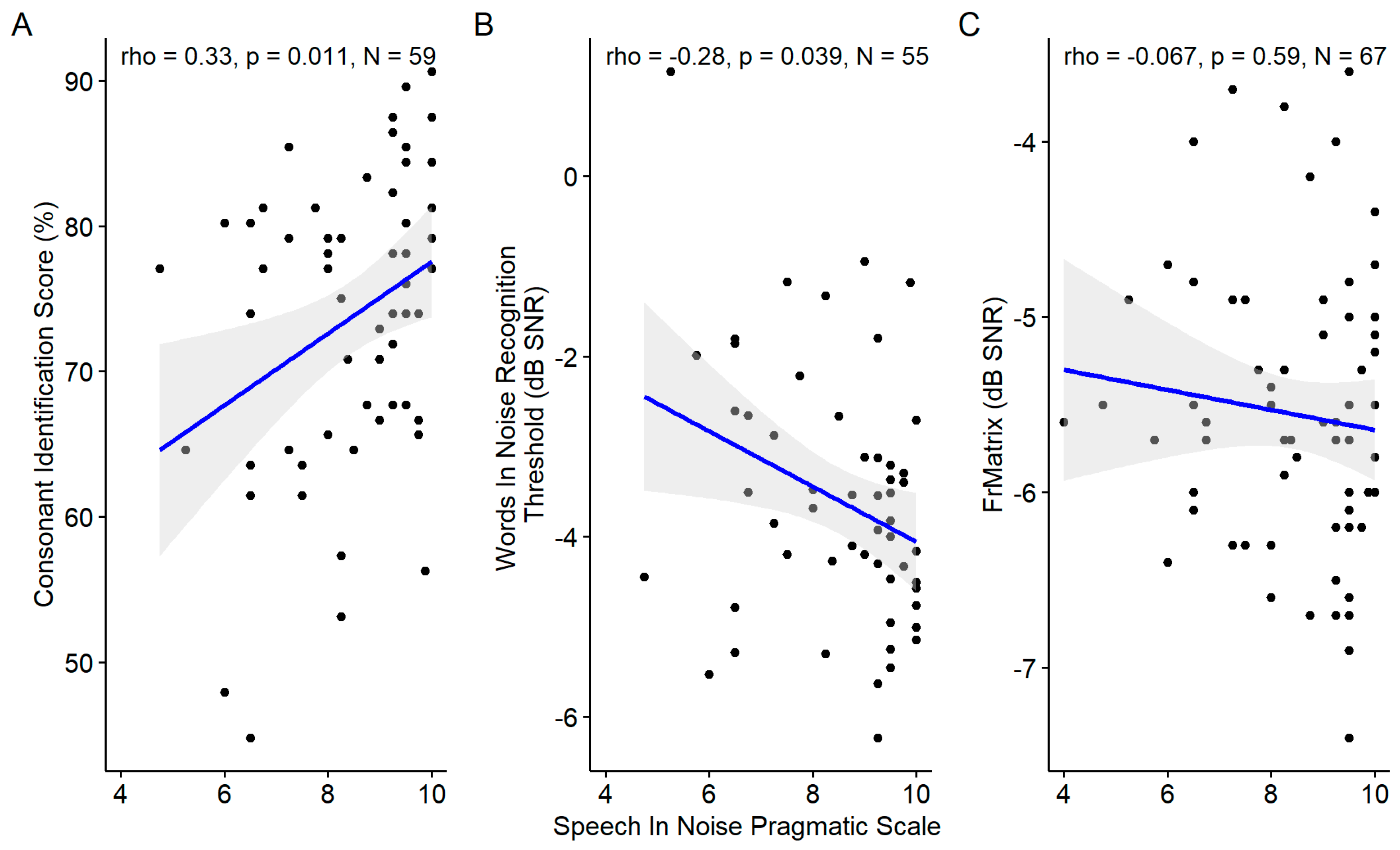

Table 1.
Sample size of each combination of variable and conditions of the dataset. AMDT: Detection threshold of AM, FMDT: Detection threshold of FM, DPOAE: Distortion Products of OtoAcoustic Emission.
Table 1.
Sample size of each combination of variable and conditions of the dataset. AMDT: Detection threshold of AM, FMDT: Detection threshold of FM, DPOAE: Distortion Products of OtoAcoustic Emission.
| Test | Conditions | N | Abbreviation |
|---|---|---|---|
| Consonant Identification | 61 | ||
| Word in Noise Recognition | 56 | ||
| French Matrix Test | 69 | FrMatrix | |
| Age | 70 | Age | |
| History of Hearing Pathology | 70 | History_of_Hearing_Pathology | |
| Years of Motocycling | 70 | Years_of_Motocycling | |
| AMDT | 60 dB SL 4000 Hz | 42 | AMDT_60dB_4000Hz |
| 60 dB SL 500 Hz | 55 | AMDT_60dB_500Hz | |
| 10 dB SL 4000 Hz | 55 | AMDT_10dB_4000Hz | |
| 10 dB SL 500 Hz | 55 | AMDT_10dB_500Hz | |
| FMDT | 60 dB SL 4000 Hz | 22 | FMDT_60dB_4000Hz |
| 60 dB SL 500 Hz | 61 | FMDT_60dB_500Hz | |
| 10 dB SL 4000 Hz | 23 | FMDT_10dB_4000Hz | |
| 10 dB SL 500 Hz | 45 | FMDT_10dB_500Hz | |
| 60 dB SL 4000 Hz Ability | 60 | FMDT_60dB_4000Hz_Ab | |
| 10 dB SL 4000 Hz Ability | 61 | FMDT_10dB_4000Hz_Ab | |
| 10 dB SL 500 Hz Ability | 61 | FMDT_10dB_500Hz_Ab | |
| DPOAE | Left Ear 1000 Hz | 59 | LE_DPOAE_1000Hz |
| Left Ear 1500 Hz | 62 | LE_DPOAE_1500Hz | |
| Left Ear 2000 Hz | 62 | LE_DPOAE_2000Hz | |
| Left Ear 3000 Hz | 62 | LE_DPOAE_3000Hz | |
| Left Ear 4000 Hz | 62 | LE_DPOAE_4000Hz | |
| Left Ear 5000 Hz | 58 | LE_DPOAE_5000Hz | |
| Right Ear 1000 Hz | 65 | RE_DPOAE_1000Hz | |
| Right Ear 1500 Hz | 63 | RE_DPOAE_1500Hz | |
| Right Ear 2000 Hz | 65 | RE_DPOAE_2000Hz | |
| Right Ear 3000 Hz | 65 | RE_DPOAE_3000Hz | |
| Right Ear 4000 Hz | 65 | RE_DPOAE_4000Hz | |
| Right Ear 5000 Hz | 61 | RE_DPOAE_5000Hz | |
| Tonal Audiometry | Left Ear 125 Hz | 70 | LE_125Hz |
| Left Ear 250 Hz | 70 | LE_250Hz | |
| Left Ear 500 Hz | 70 | LE_500Hz | |
| Left Ear 1000 Hz | 70 | LE_1000Hz | |
| Left Ear 2000 Hz | 70 | LE_2000Hz | |
| Left Ear 4000 Hz | 70 | LE_4000Hz | |
| Left Ear 8000 Hz | 70 | LE_8000Hz | |
| Left Ear EHF | 70 | LE_EHF | |
| Left Ear PTA | 70 | LE_PTA | |
| Right Ear 125 Hz | 70 | RE_125Hz | |
| Right Ear 250 Hz | 70 | RE_250Hz | |
| Right Ear 500 Hz | 70 | RE_500Hz | |
| Right Ear 1000 Hz | 70 | RE_1000Hz | |
| Right Ear 2000 Hz | 70 | RE_2000Hz | |
| Right Ear 4000 Hz | 70 | RE_4000Hz | |
| Right Ear 8000 Hz | 70 | RE_8000Hz | |
| Right Ear EHF | 70 | RE_EHF | |
| Right Ear PTA | 70 | RE_PTA | |
| Best Ear PTA | 70 | Best_Ear_PTA | |
| Electrocochleography | Left Ear Wave I 80 dB HL | 37 | LE_WaveI_80dB |
| Left Ear Wave I 90 dB HL | 38 | LE_WaveI_90dB | |
| Right Ear Wave I 80 dB HL | 49 | RE_WaveI_80dB | |
| Right Ear Wave I 90 dB HL | 52 | LE_WaveI_90dB | |
| Left Ear Wave I Slope | 34 | LE_Slope | |
| Right Ear Wave I Slope | 46 | RE_Slope |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



