
Submitted:
07 May 2024
Posted:
08 May 2024
You are already at the latest version
Abstract
With the development of deep learning, the Super-Resolution (SR) reconstruction of microscopic images has improved significantly. However, the scarcity of microscopic images for training, the underutilization of hierarchical features in original Low Resolution (LR) images, and the high-frequency noise unrelated with the image structure generated during reconstruction process are still challenges in the Single Image Super-Resolution (SISR) field. Faced with these issues, we first collected sufficient microscopic images through Motic, a company engaged in the design and production of optical and digital microscopes, to establish a dataset. Secondly, we proposed a Residual Dense Attention Generative Adversarial Network (RDAGAN). The network comprises a generator, an image discriminator, and a feature discriminator. The generator includes a Residual Dense Block (RDB) and a Convolutional Block Attention Module (CBAM), focusing on extracting the hierarchical features of the original LR image. Simultaneously, the added feature discriminator enables the network to generate high-frequency features pertinent to the image’s structure. Finally, we conducted experimental analysis and compared our model with six classic models. Compared with the best model, our model improved PSNR and SSIM by about 1.5dB and 0.2, respectively.
Keywords:
single image super-resolution
; microscopic image
; generative adversarial network
; image processing
1. Introduction
Regardless of the magnification and numerical aperture of the objective lens used, the imaging throughput of current microscopes is typically only on the order of ten megapixels[1]. This leads to a compromise between high resolution and Field of View (FOV) when imaging. However, in biomedical research such as histopathology, hematology and neuroscience, there is a growing need for high-resolution imaging of large samples. In order to accurately resolve cellular-level life activities at the scale of the entire sample, a balance between global structure and microscale local details is required, along with quantitative analysis.Faced with this challenge, Super-Resolution(SR) imaging techniques were developed. Single Image Super-Resolution(SISR) reconstruction [2] aims to reconstruct a High-Resolution (HR) image from an input Low Resolution(LR) image.This technique is widely used in critical fields, including bright field micrographs[3], fluorescent imaging[4,5], remote sensing images[6,7], and surveillance videos[8]. Traditional SISR reconstruction algorithms can be divided into three categories: interpolation-based[9,10], reconstruction-based[11,12] and learning-based[13]. Interpolation-based algorithms have the advantages of simple principle and easy implementation. However, these methods are difficult to recover the detailed information of the image, and the reconstructed image is seriously distorted. Reconstruction-based algorithms first generate the constraints for SR reconstruction according to the imaging process of LR images, establish the corresponding mathematical model, and finally reconstruct HR images. However, when the magnification is high, it is still difficult to recover enough high-frequency information. The learning-based reconstruction algorithm mainly establishes the mapping relationship between LR and HR hyperspectral images, and then, reconstructs according to the mapping relationship.In recent years, with the rapid development of deep learning, the excellent learning ability of convolutional neural networks also brings new opportunities for the development of SR imaging technology.
Specifically, Dong et al.[14] used deep learning in image SR reconstruction by introducing Convolutional Neural Networks (CNN). This groundbreaking work paved the way for subsequent innovations. Kim et al.[15] introduced the Very Deep Super Resolution (VDSR) model, which leverages a deeply constructed neural network combined with residual learning for image reconstruction. This approach effectively addresses the issue of image size reduction caused by successive convolutions. Lai et al.[16] proposed the Laplacian Pyramid Super-Resolution Network (LapSRN) model, which employs a Laplacian pyramid to progressively reconstruct the image and perform feature extraction through a residual structure. Ledig et al.[17] advanced the field by incorporating residual blocks within the structure of a Generative Adversarial Network (GAN) to create the Super-Resolution Generative Adversarial Network (SRGAN) model. The use of GANs significantly improves the visual perception quality of the generated images, making them more closely resemble real images. Lim et al.[18] developed the Enhanced Deep Super-Resolution (EDSR) model, which refines the residual structure found in the SRGAN model for improved performance. Zhang et al.[19] contributed by introducing the Residual Dense Block (RDB) structure and the Residual Dense Network (RDN) model, further advancing the capabilities of SR reconstruction.
In terms of microscopic image reconstruction, Zhang et al.[20] proposed Registration-Free GAN Microscopy (RFGANM) workflow by combining SRGAN network with optical microscope and degradation model to achieve deep learning SR in large FOV, and improve the resolution of wide-field microscopy and light-sheet fluorescence microscopy images. Wang et al.[21] used a GAN network to develop SR techniques for cross-modal fluorescence microimaging by simulating the mapping relationships between different imaging techniques, such as wide-field fluorescence imaging, confocal to STED, and TIRF to TIRF-SIM, through deep learning. Van Sloun[22] applied deep learning to ultrasound microscopy SR study and proposed Deep-ULM model, which is based on U-Net network to reduce the effect of diffraction and obtain HR images in real time.Li et al.[23] achieved high-quality reconstruction of ordinary wide-field fluorescence images to SIM SR imaging results using a Deep Fourier Channel Attention (DCFA) network, greatly contributes to the development of super-resolution in microscopic images.
It can be seen that although great progress has been made in the SR of microscopic images, most of them are focused on fluorescence images in a special way. We know that the features of fluorescence microscopy images are significantly different from those of cell images. Additionally, despite the above SR methods have achieved good results, there are some shortcomings in any of them. These include the absence of specialized datasets for microscopic images, which hampers model training; the inadequate use of hierarchical features in LR images by GAN-based SR models; insufficient utilization of information across convolutional layers due to varying receptive fields; a lack of prioritization in reconstructing feature map information, leading to suboptimal focus on critical details; and the reliance on pixel-level reconstruction errors as loss functions, which fails to capture high-frequency details and often results in overly smooth and potentially inaccurate images.
In order to response these challenges, this paper has carried out corresponding optimization work on cell microscopy images. The specific contributions are described as follows:
- (1)
- We produce a dataset of high and low resolution images of four cell types using microscope acquisition.You can find the dataset at here.
- (2)
- In order to fully utilize the hierarchical features of the original image, we propose a Residual Dense Attention Generative Adversarial Network (RDAGAN), whose generator uses RDABs with increased attention mechanisms.
- (3)
- To reconstruct the high-frequency features associated with HR images, we add a feature discriminator to the original discriminator and optimize the loss function.
- (4)
- Our proposed optimized model is compared with six classic models. Compared to the best performing model among them, PSNR and SSIM have improved by 1.5 db and 0.2, respectively.
2. Proposed Methodology
Our model is based on the aforementioned RFGANM[20] that have been used for microscopic cell image SR, constructing a generator network architecture composed of four main sections: the feature extraction part, the residual dense attention part, the dense feature fusion part, and the reconstruction part. The input LR image first passes through the feature extraction section, where initial features are extracted. These features are then processed by the residual dense attention section. Here, the RDB extracts rich local features through densely connected convolutional layers, fully leveraging the hierarchical features of the layers. The local feature fusion within the RDB allows for an adaptive and more effective integration of previous and current local features, thus stabilizing the training of broader network. An attention mechanism is added after each RDB, first applying a channel attention module to obtain a weighted result, followed by a spatial attention module to refine the weighting. This enables the network to concentrate on information that is most beneficial for image reconstruction. The RDB and the attention module together constitute the Residual Dense Attention Block (RDAB). After extracting dense local features through a series of residual dense attention modules, dense feature fusion is proposed to mine multi-level features from a global perspective. Additionally, a feature discriminator[24] is introduced to differentiate the detailed features of SR and HR images, encouraging the reconstructed image to generate more high-frequency features instead of noise.
2.1. Microscopic Cell Image Dataset
We used a microscope to capture cell images using both 40× and 20× objective lenses simultaneously to establish our dataset. Due to factors such as lens aberration and autofocus issues, the collected images were subject to center cropping. HR images were cropped to a resolution of 1024×1024 pixels, while LR images were cropped to 512×512 pixels, reflecting the 2× objective relationship. In constructing the dataset, we faced challenges in precisely matching HR and LR images. To address this, we employed Bicubic Downsampling (BD) to generate corresponding LR images from their HR counterparts. These LR images were then used for both reconstruction purposes and performance comparison. Finally, we created 800 pairs of images for training data and 200 pairs of image val data for reconstruction for each of four cell images.
2.2. Residual Dense Blocks for Fusion CBAM
The structure of our generator network is shown in Figure 1, consisting of four parts: a shallow feature extraction network, a RDAB, a Dense Feature Fusion (DFF) and an upsampling network. The input and output of the generator network are represented by and respectively . A convolutional layer is used to extract shallow features of the LR image and perform global residual learning, while also serves as an input to the RDAB. denotes the convolution operation on the LR image. Assuming that there are D RDABs in the generator, the Dth RDAB can be represented as:
where denotes the operation of the dth RDAB and is a composite function of operations such as convolution and Rectified Linear Unit(ReLU). Since is generated by the dth RDAB fully utilizing each convolutional layer within the block, can be considered as a local feature. The generator RDABs in this paper are 16 in total.
After extracting the hierarchical features with a set of D RDABs, further DFF is performed, including Global Feature Fusion (GFF) and Global Residual Learning (GRL). DFF fully utilizes the features of all previous layers, is the output feature mapping of the composite function of the DFF module, which can be expressed as:
Local and global features are extracted and fused in the LR space to obtain , which is used as an input to the up-sampling network. The upsampling network used in this invention is the same as SRGAN. The entire network of the generator as a whole can be represented as:
The structure of the RDAB is shown below in Figure 2. Our RDAB contains a dense connectivity layer, local feature fusion (LFF), Local Residual Learning (LRL), and CBAM, thus forming a Continuous Memory (CM) mechanism.
Denote the input and output of the dth RDAB by and , respectively. The outputs of the previous RDAB and each convolutional layer of that RDAB are directly connected to all subsequent layers, which not only preserves the feed-forward properties but also extracts the local dense features. denotes the output of the cth convolutional layer in that RDAB, and denotes the output of the last convolutional layer of the densely connected layers in that RDAB. The purpose of LRL is to further improve the information flow, and the final output of the dth RDAB is denoted as:
where denotes the fusion of all layer feature information in the dth RDAB. DFF is feature fusion and residual learning for each RDAB feature obtained to utilize hierarchical features in a global manner. DFF includes GFF and GRL. The global features are extracted by fusing the features of all RDABs.
The RDAB introduces a continuous memory mechanism that allows previous RDABs to directly access each layer of the current RDAB. By using LFF, it is possible to train the deep network stably, while LRL can further optimize the information flow and gradient. In addition the RDAB uses GFF and GRL to further extract global features.
Convolutional Block Attention Module (CBAM)[25] is a simple and efficient forward convolutional neural attention module. Given a feature map, CBAM sequentially infers the attention map along two separate dimensions, channel and spatial, and then multiplies the attention map with the input feature map for adaptive feature refinement.CBAM is a lightweight and general-purpose module that can be seamlessly integrated into network architectures. The diagram of the attention module is shown in Figure 3.
2.3. Discriminator and Loss function
In order to make the reconstructed image generate real high-frequency information, we add a feature discriminator under the original image discriminator[21], which takes the image in the pixel domain as input, just like the previous method. On the other hand, the feature discriminator inputs images into a VGG network and extracts intermediate feature maps. The feature discriminator then attempts to distinguish between SR images and true HR images based on the extracted feature maps. Since the feature maps encode structural information, the feature discriminator distinguishes between SR images and true HR images based not only on high-frequency components but also on structural components. Ultimately, the generator is trained to synthesize real structural features instead of arbitrary high-frequency noise.The structure of our discriminator is shown in Figure 4.
Image discriminator and feature discriminator . Image discriminator distinguishes between real HR images and spurious SR images by examining the pixel values. Feature discriminator distinguishes between real HR images and spurious SR images by examining their feature maps so that the generator can be trained to synthesize more meaningful high-frequency details. The generator loss function is:
is the perceptual loss[20]. is the generator’s image GAN loss for synthesizing high-frequency details in the pixel domain. is the generator’s feature GAN loss for synthesizing structural details in the feature domain. is the weights of the GAN loss terms. To train the discriminators and , we minimize the losses and , which correspond to and , respectively. the generator and the discriminator are trained by alternately minimizing , and .The image GAN loss and image discriminator loss of the generator are defined as follows:
where is the output of the image discriminator . The feature GAN loss and feature discriminator loss of the generator are defined as follows:
where is the output of the feature discriminator . During training, the generator can be made to produce realistic structural high-frequency details instead of noise artifacts.
3. Experimental Results And Discussion
3.1. Experimental Settings
We used cell images obtained from a 40× microscope as HR images and downsampled them using BD to obtain the corresponding LR images. Each of the four cells has 800 pairs of training datasets and 5 test datasets. The test datasets are each named Cell A, Cell B, Cell C, and Cell D.We use the Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity index (SSIM) on the Y channel in YCbCr space as metrics. At the same time, we also calculated Learned Perceptual Image Patch Similarity (LPIPS), model parameters and single cell image reconstruction time.
The LR images are blur downsampled corresponding images with downscaling factors ×2. The batch size is set to 16, and the input size is 192×192 patches randomly cropped from HR images. We used BD downsampling on HR images to obtain 96×96 LR images to be used as training. We add random horizontal flips and , , rotations to the input. We set the weight in Equation (8) as . For in Equation (11), Equation (12) we use the Conv5 layer of the VGG-19. We train our model using ADAM optimizer with , . The learning rate is initialized to and multiplied with 0.5 after 200-th epoch. Our model is implemented using the PyTorch framework and trained on an NVIDIA 3090 GPU.
3.2. Comparison With Classic Models
We conducted ablation experiments on our proposed model. We trained it using the collected microscope image dataset and evaluated it on the Cell A dataset. As can be seen from the results in Table 1, the CBAM, RDB and feature discriminator that we have added to the model have better PSNR value and SSIM value.
Then, we compare our model with six classic image SR models, including EDSR, Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN)[26], very deep Residual Channel Attention Networks (RCAN)[27], RDN, SRResnet[17](less a discriminator compared to SRGAN), RFGANM. And from Table 2, it can see that compared to other SR models, our model achieves the highest PSNR and SSIM, and good LPIPS, model parameters, and reconstruction times.
In addition, Figure 5 shows the reconstruction detail views of our proposed model and two classic models. It can be observed that the cell detail textures and edge parts reconstructed by our model are closer to the HR images. In summary, these results demonstrate that our network model has achieved excellent performance.
4. Conclusion
In this paper, we provide a microscopic images dataset. And the SRGAN model is improved by modifying the residual block of the generator to an RDB and combining the attention mechanism. Additionally, a feature discriminator is introduced to ensure that the reconstruction avoids generating artifacts and instead produces high-frequency features pertinent to the image. The loss function is also enhanced. Finally, the experimental results demonstrate that our model outperforms the classical models and is hopeful to meet the demand for high-resolution imaging of large volume samples.
Author Contributions
Conceptualization, S.L. and X.W.; methodology, S.L.; software, S.L.; validation, X.W. and S.L.; formal analysis, S.L.; investigation, S.L. and X.W.; resources, M.C.; data curation, X.W.; writing—original draft preparation, S.L. and X.W.; writing—review and editing, S.L., X.W., X.G. and X.X.; visualization, X.W.; supervision, S.L. and L.Z.; project administration, S.L.; funding acquisition, S.L. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Fundamental Research Funds for the Central Universities (Grant No. ZQN-1005) and the Scientific Research Funds of Huaqiao University (Grant No. 21BS118).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
Many thanks Muwang Chen’s contribution to the analysis method proposed and strong support in this article.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FOV | Field of View |
| SR | Super-Resolution |
| LR | Low Resolution |
| HR | High-Resolution |
| SISR | Single Image Super-Resolution Reconstruction |
| RDAGAN | Residual Dense Attention Generative Adversarial Network |
| CNN | Convolutional Neural Networks |
| VDSR | Very Deep Super Resolution |
| LapSRN | Three letter acronym |
| GAN | Generative Adversarial Network |
| SRGAN | Super-Resolution Generative Adversarial Network |
| EDSR | Enhanced Deep Super Resolution |
| RDB | Residual Dense Block |
| RDN | Residual Dense Network |
| RF-GANM | Registration-Free GAN |
| DCFA | Deep Fourier Channel Attention |
| RDAB | Residual Dense Attention Block |
| BD | Bicubic Downsampling |
| DFF | Dense Feature Fusion |
| ReLU | Rectified Linear Unit |
| GFF | Global Feature Fusion |
| GRL | Global Residual Learning |
| LFF | Local Feature Fusion |
| LRL | Local Residual Learning |
| CBAM | Convolutional Block Attention Module |
| CM | Continuous Memory |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural SIMilarity index |
| LPIPS | Learned Perceptual Image Patch Similarity |
| ESRGAN | Enhanced Super Resolution Generative Adversarial Networks |
| RCAN | Residual Channel Attention Networks |
References
- Sanderson, J. Multi-Photon Microscopy. Current Protocols 2023, 3. [Google Scholar] [CrossRef] [PubMed]
- Tsai, R.; Huang, T.S. Multiframe Image Restoration and Registration. Advances in Computer Vision and Image Processing 1984, 1, 317–339. [Google Scholar]
- Rivenson, Y.; Koydemir, H.C.; Wang, H.; Wei, Z.; Ren, Z.; Günaydın, H.; Zhang, Y.; Göröcs, Z.; Liang, K.; Tseng, D.; Ozcan, A. Deep Learning Enhanced Mobile-Phone Microscopy. ACS Photonics 2018, 5, 2354–2364. [Google Scholar] [CrossRef]
- Wei, O.; Andrey, A.; Mickaël, L.; Xian, H.; Christophe, Z. Deep Learning Massively Accelerates Super-Resolution Localization Microscopy. Nature Biotechnology 2018, 36, 460–468. [Google Scholar]
- Nehme, E.; Weiss, L.E.; Michaeli, T.; Shechtman, Y. Deep-STORM: Super-Resolution Single-Molecule Microscopy by Deep Learning. Optics 2018, 5, 458–464. [Google Scholar] [CrossRef]
- Xiao, Y.; Yuan, Q.; Jiang, K.; He, J.; Wang, Y.; Zhang, L. From Degrade to Upgrade: Learning a Self-Supervised Degradation Guided Adaptive Network for Blind Remote Sensing Image Super-Resolution. Information Fusion 2023, 96, 297–311. [Google Scholar] [CrossRef]
- Y. Xiao, X. Su, Q. Yuan, D. Liu, H. Shen, and L. Zhang, “Satellite Video Super-Resolution via Multiscale Deformable Convolution Alignment and Temporal Grouping Projection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–19, 2021.
- Xiao, Y.; Yuan, Q.; Jiang, K.; Jin, X.; He, J.; Zhang, L.; Lin, C.W. Local-Global Temporal Difference Learning for Satellite Video Super-Resolution. IEEE Transactions on Circuits and Systems for Video Technology, 2023.
- Blu, T.; Thévenaz, P.; Unser, M. Linear Interpolation Revitalized. IEEE Transactions on Image Processing 2004, 13, 710–719. [Google Scholar] [CrossRef] [PubMed]
- Meijering, E.; Unser, M. A Note on Cubic Convolution Interpolation. IEEE Transactions on Image Processing 2003, 12, 477–479. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.; Wu, C.; Li, G.; Ma, J. Projections onto Convex Sets Super-Resolution Reconstruction Based on Point Spread Function Estimation of Low-Resolution Remote Sensing Images. Sensors 2017, 17, 362. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; He, X.; Wei, Z.; Mu, Z.; Li, M. Super-Resolution Image Reconstruction Based on an Improved Maximum a Posteriori Algorithm. Journal of Beijing Institute of Technology 2018, 27, 237–240. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image Super-Resolution Via Sparse Representation. IEEE Transactions on Image Processing 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. in European Conference on Computer Vision (ECCV), pp. 184-199, 2014.
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1646-1654, 2016.
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5835-5843, 2017.
- C. Ledig, L. C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang and W. S, "Photo-Realistic Single Image Super Resolution Using a Generative Adversarial Network," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4681–4690, 2017.
- B. Lim, S. B. Lim, S. Son, H. Kim, S. Nah and K. M. Lee, "Enhanced Deep Residual Networks for Single Image Super-Resolution," in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 1132-1140, 2017.
- Y. Zhang, Y. Tian, Y. Kong, B. Zhong and Y. R. Fu, "Residual Dense Network for Image Super-Resolution," in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2472-2481, 2018.
- Zhang, H.; Fang, C.; Xie, X.; Yang, Y.; Mei, W.; Jin, D.; Fei, P. High-Throughput, High-Resolution Deep Learning Microscopy Based on Registration-Free Generative Adversarial Network. Biomedical optics express 2019, 10, 1044–1063. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Rivenson, Y.; Jin, Y.; Wei, Z.; Gao, R.; Günaydın, H.; Bentolila, L.A.; Kural, C.; Ozcan, A. Deep Learning Enables Cross-Modality Super-Resolution in Fluorescence Microscopy. Nature Methods 2019, 16, 103–110. [Google Scholar] [CrossRef] [PubMed]
- van Sloun, R.J.G.; Solomon, O.; Bruce, M.; Khaing, Z.Z.; Wijkstra, H.; Eldar, Y.C.; Mischi, M. Super-Resolution Ultrasound Localization Microscopy Through Deep Learning. IEEE Transactions on Medical Imaging 2021, 40, 829–839. [Google Scholar] [CrossRef] [PubMed]
- Qiao, C.; Li, D.; Guo, Y.; Liu, C.; Jiang, T.; Dai, Q.; Li, D. Evaluation and Development of Deep Neural Networks for Image Super-Resolution in Optical Microscopy. Nature Methods 2021, 18, 194–202. [Google Scholar] [CrossRef] [PubMed]
- S. J. Park, H. Son, S. Cho, K. S. Hong, and S. Lee, "SRFeat: Single Image Super-Resolution with Feature Discrimination," in European Conference on Computer Vision (ECCV), pp. 439-455, 2018.
- S. Woo, J. Park, J. Y. Lee, and I. S. Kweon, "CBAM: Convolutional Block Attention Module," in European Conference on Computer Vision, pp. 3-19, 2018.
- X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao and C. C. Loy, "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks," in European Conference on Computer Vision (ECCV) Workshops, 2018.
- Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong and Y. R. Fu, "Image Super-Resolution Using Very Deep Residual Channel Attention Networks," in European Conference on Computer Vision (ECCV), pp. 286-301, 2018.
Figure 1.
Residual Dense Attention Generative Adversarial Network (RDAGAN) framework
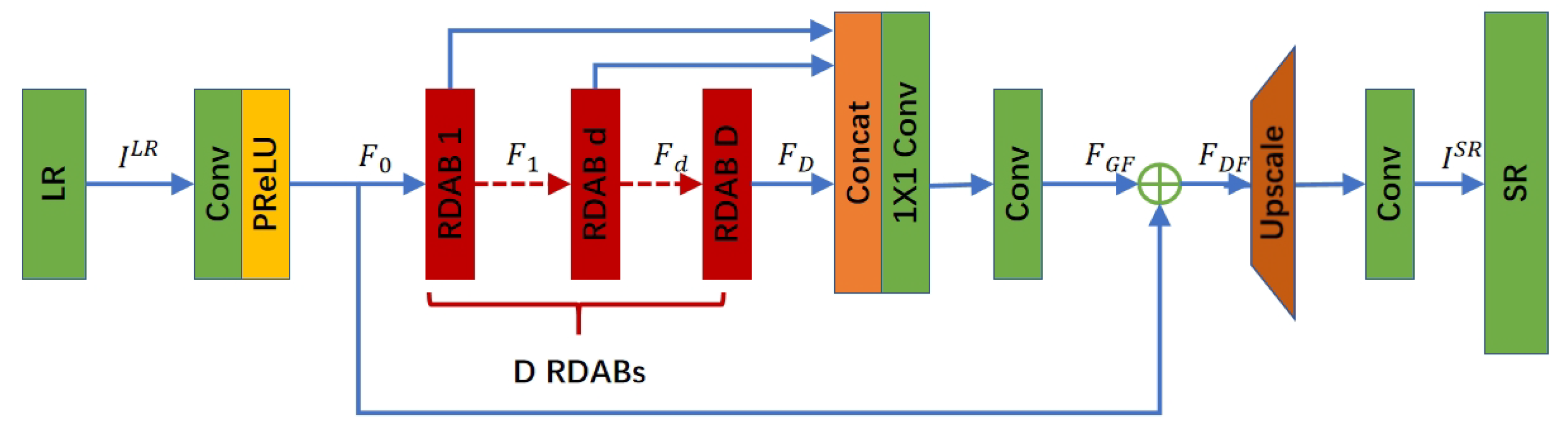
Figure 2.
Residual Dense Attention Blocks (RDAB)
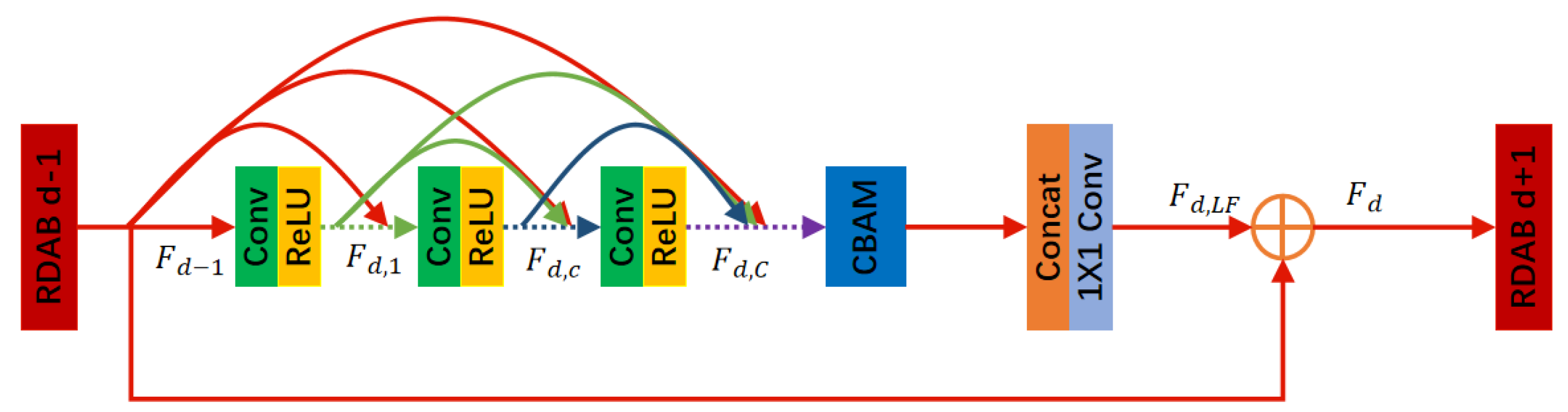
Figure 3.
Convolutional Block Attention Module (CBAM)
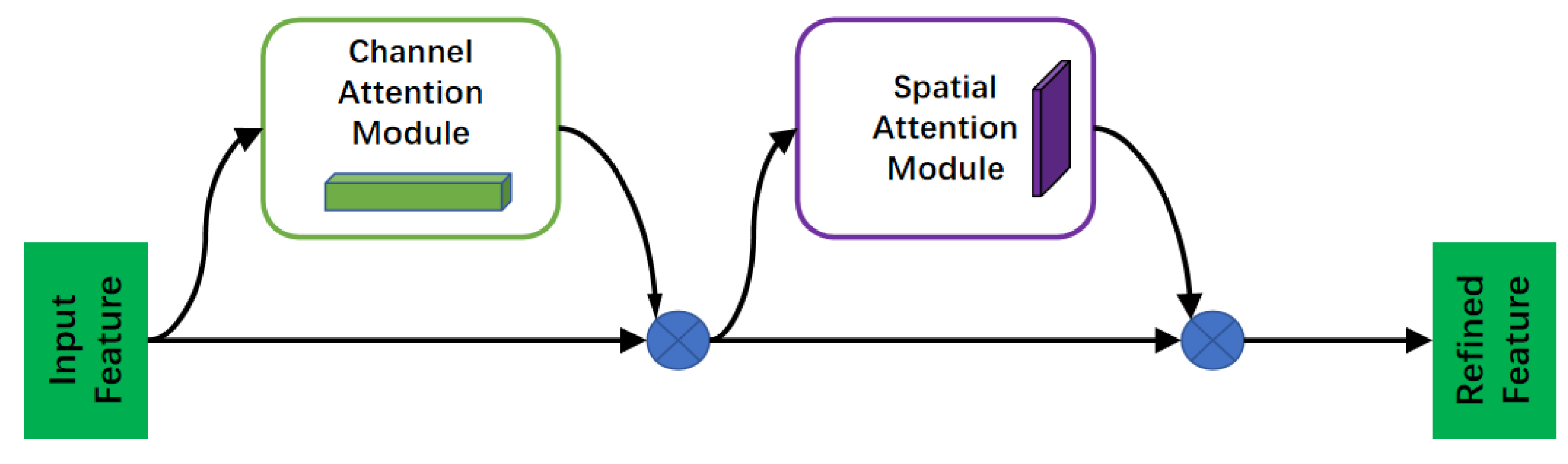
Figure 4.
Architecture of our discriminator network

Figure 5.
Comparison of reconstructed detail views for Cell A, Cell B, Cell C, and Cell D using our proposed model and two classical models
Figure 5.
Comparison of reconstructed detail views for Cell A, Cell B, Cell C, and Cell D using our proposed model and two classical models
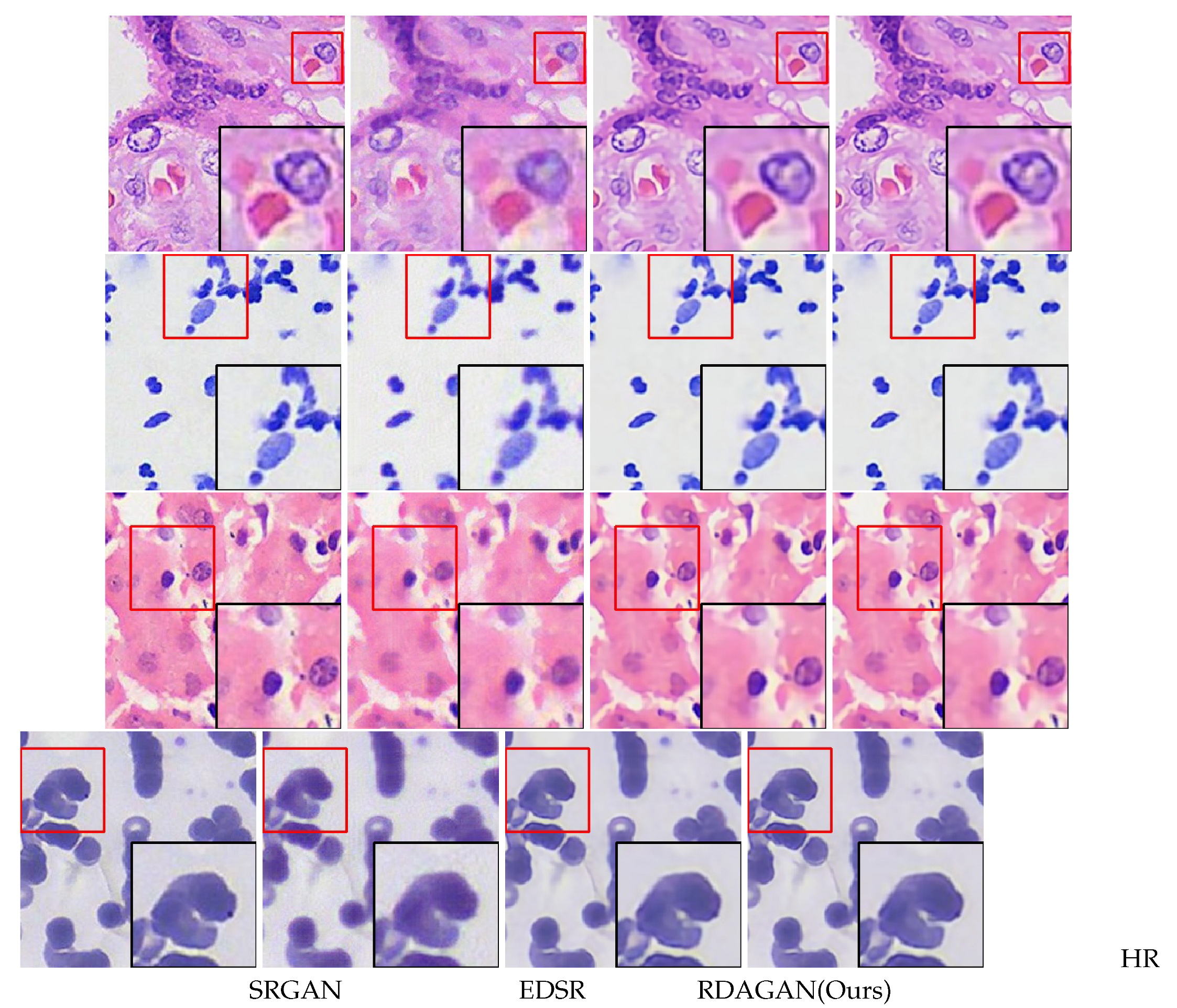

Table 1.
The ablation experiments results ("✓" denotes the corresponding operation)
| CBAM | RDB | feature discriminator | PSNR/dB ↑ | SSIM ↑ | |
|---|---|---|---|---|---|
| 1 | 28.12 | 0.72 | |||
| 2 | ✓ | 28.75 | 0.75 | ||
| 3 | ✓ | ✓ | 32.83 | 0.85 | |
| 4 | ✓ | ✓ | ✓ | 33.13 | 0.87 |
Table 2.
Comparison of PSNR, SSIM, LPIPS, model parameters, and reconstruction times for Cell A, B, C, and D using our proposed model and six classic image SR models ( the red indicates the best result)
Table 2.
Comparison of PSNR, SSIM, LPIPS, model parameters, and reconstruction times for Cell A, B, C, and D using our proposed model and six classic image SR models ( the red indicates the best result)
| Model | Dataset | PSNR/dB↑ | SSIM↑ | LPIPS↓ | Parameters/M | Time/s |
|---|---|---|---|---|---|---|
| RFGANM[20] | Cell A | 28.12 | 0.72 | 0.2048 | 5.92 | 2.27 |
| Cell B | 27.45 | 0.85 | 0.1108 | |||
| Cell C | 28.86 | 0.77 | 0.1645 | |||
| Cell D | 29.62 | 0.84 | 0.1513 | |||
| ESRGAN[26] | Cell A | 28.74 | 0.75 | 0.1089 | 102.16 | 2.70 |
| Cell B | 31.71 | 0.90 | 0.0292 | |||
| Cell C | 30.49 | 0.79 | 0.0775 | |||
| Cell D | 33.50 | 0.89 | 0.0414 | |||
| SRResnet[17] | Cell A | 30.98 | 0.82 | 0.1616 | 5.34 | 2.33 |
| Cell B | 33.53 | 0.93 | 0.0385 | |||
| Cell C | 32.62 | 0.86 | 0.1356 | |||
| Cell D | 35.92 | 0.93 | 0.0572 | |||
| RCAN[27] | Cell A | 31.06 | 0.82 | 0.1689 | 58.92 | 2.17 |
| Cell B | 33.54 | 0.93 | 0.0412 | |||
| Cell C | 32.66 | 0.86 | 0.1466 | |||
| Cell D | 35.68 | 0.93 | 0.0590 | |||
| EDSR[18] | Cell A | 31.63 | 0.84 | 0.1542 | 155.30 | 2.05 |
| Cell B | 34.07 | 0.94 | 0.0362 | |||
| Cell C | 32.73 | 0.86 | 0.1414 | |||
| Cell D | 36.45 | 0.93 | 0.0606 | |||
| RDN[19] | Cell A | 31.68 | 0.84 | 0.1531 | 50.14 | 3.23 |
| Cell B | 34.13 | 0.94 | 0.0365 | |||
| Cell C | 32.81 | 0.86 | 0.1401 | |||
| Cell D | 36.89 | 0.94 | 0.0609 | |||
| RDAGAN | Cell A | 33.13 | 0.87 | 0.1364 | 11.25 | 2.56 |
| Cell B | 36.09 | 0.96 | 0.0259 | |||
| Cell C | 34.29 | 0.89 | 0.1272 | |||
| Cell D | 38.31 | 0.96 | 0.0550 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



