
Submitted:
08 May 2024
Posted:
09 May 2024
You are already at the latest version
Abstract
Recent advancements in deep learning have spurred the development of numerous novel semantic segmentation models for land cover mapping, showcasing exceptional performance in delineating precise boundaries and producing highly accurate land cover maps. However, to date, no systematic literature review has comprehensively examined semantic segmentation models in the context of land cover mapping. This paper addresses this gap by synthesizing recent advancements in semantic segmentation models for land cover mapping from 2017 to 2023, drawing insights on trends, data sources, model structures, and performance metrics based on a review of 106 extracted articles. Our analysis identifies top journals in the field, including MDPI Remote Sensing, IEEE Journal of Selected Topics in Earth Science, and IEEE Transactions on Geoscience and Remote Sensing, IEEE Geoscience and Remote Sensing Letters, ISPRS Journal Of Photogrammetry And Remote Sensing as the leading journals. We find that research predominantly focuses on land cover, urban areas, precision agriculture, environment, coastal areas, and forests. Geographically, 35.29% of the study areas are located in China, followed by USA (11.76%), France (5.88 %), Spain (4%) and others. Sentinel-2, Sentinel-1, and Landsat satellites emerge as the most commonly used data sources. Benchmark datasets such as ISPRS Vaihingen & Potsdam, LandCover.ai, DeepGlobe, and GID datasets are frequently employed. Model architectures predominantly utilize encoder-decoder, and hybrid convolutional neural network-based structures because of their impressive performances, with limited adoption of transformer-based architectures due to its computational complexity issue, and slow convergence speed. Lastly, this paper highlights existing key research gaps in the field to guide future research directions.
Keywords:
Remote Sensing
; Semantic Segmentation
; Land Use Land Cover
; Deep Learning
; Land Cover Classification
1. Introduction
Semantic segmentation models are crucial in land cover mapping especially in generating precise Land Cover (LC) maps [1]. LC maps show various types of land cover, such as forests, grasslands, wetlands, urban areas, and bodies of water. These maps are typically created using Remote Sensing (RS) data like satellite imagery or aerial photography [2]. Land cover maps serve for different purposes, including land use management [3], disaster management, urban planning [4], precision agriculture [5], forestry [6], building infrastructure development [7], climate changes problems [8] and others.
Due to advancements in Deep Convolutional Neural Network (DCNN) models, the domain of land cover mapping has progressively evolved [9]. DCNN are potentially successful for extracting information from high-resolution RS data [10]. They possess deep layers and hierarchical architectures, aiming to automatically identify high-level patterns in data [11]. Although DCNN have shown impressive performance in image classification task, the conventional models still struggle to capture comprehensive global information as well as long-range dependencies inherent RS data [12]. Consequently, they may not achieve precise image segmentation because could potentially overlook certain edge details of objects [13]. However, they have successfully contributed valuably to semantic segmentation methodologies.
Semantic segmentation model allocates every pixel in an image to a predefined class [14]. It’s effectiveness in landcover segmentation have established them as a mainstream method [15]. They have demonstrated enhanced performance leading to more accurate segmentation outcomes. A prominent example of a state-of-the-art (SOTA) semantic segmentation model is UNet [16]. Recently, many novel semantic segmentation models tailored for land cover mapping have been proposed, including DFFAN [12], MFANet [17], Sgformer [18], UNetFormer[19], and CSSwin-unet [20]. Accordingly, these models have demonstrated exceptional segmentation accuracy in this domain.
In recent years, literature reviews have predominantly explored Deep Learning (DL) semantic segmentation models. The review [21] presented significant methods, their origins, and contributions, including insights into datasets, performance metrics, execution time, and memory consumption relevant to DL-based segmentation projects. Similar reviews by [14] and [22] categorized existing semantic segmentation with DL methods based on criteria like supervision degree during training and architectural design). In addition, [23] summarized various semantic segmentation models for RS Imagery. These reviews offer comprehensive overviews of DL-based semantic segmentation models but have not specifically examined their application to land cover mapping. To address this gap, this literature review focuses on emerging semantic segmentation models in land cover mapping, aiming to answer predefined research questions quantitatively and qualitatively. Our objective is to identify knowledge gaps in semantic segmentation models applied to land cover mapping and understand the evolution of these models in relation to domain-specific studies, data sources, model structures, and performance metrics. Furthermore, this review offers insights for future research directions in land cover mapping.
The next sections of the review are structured as follows: Section II provides the research questions and method used in conducting the review. Section III delves into the results obtained from the performed systematic review, discusses the evolution and trends, the domain study, the data, semantic segmentation methodologies. Section IV challenges and provides future insights in land cover mapping. Finally, Section IV summarizes the highlights of the review.
2. Materials and Methods
The methodology used in conducting this comprehensive literature review follows the PRISMA framework as outlined by [24] of identification, eligibility, screening, and data extraction. A search strategy was developed to identify the literature for this review (Figure 1). Peer-reviewed papers published in relevant journals between 2017 and 2023 are reviewed. In this section, the research questions are formulated, thereafter, the search strategy was defined as used on Scopus database. The selection of the inclusion and exclusion criteria was explained as well as the eligibility criteria defined to assess articles utilized as final record for the bibliometric analysis.
2.1. Research Questions (RQs)
The objectives of the study are addressed based on 4 main research questions. These RQs are specifically selected to elicit trends, benchmark datasets, the state-of-the-art architecture, and performances of semantic segmentation in land cover mapping. This review is built around these RQs.
- RQ1. What are the emerging patterns in land cover mapping?
- RQ2. What are the domain studies of semantic segmentation models in land cover mapping?
- RQ3. What are the data used in semantic segmentation models for land cover mapping?
- RQ4. What are the architecture and performances of semantic segmentation methodologies used in Land cover mapping?
2.2. Search Strategy
The search strategy was carried out using Scopus (Elsevier) database (https://www.scopus.com/search). This database is renowned in the scientific community for its high-quality journals, extensive, multidisciplinary abstract collection, and it is an excellent fit for the purposes of review articles [25]. The search keywords used as search criteria to identify articles from the Scopus database are ‘'semantic AND segmentation', AND 'land AND use AND land AND cover', AND 'deep AND learning', AND 'land AND cover AND classification'. The search string is used to find relevant papers that links deep learning semantic segmentation to land use and land cover.
2.3. Study Selection Criteria
After the defined search strings are entered on Scopus, a total of 218 articles were initially retrieved from the scientific database. To further process the data retrieved, the papers are filtered between 2017 to 2023 excluding conference papers, conference reviews, data paper, books, and book chapters, articles in the press, conference proceedings, book series and articles that are not in English language. The stated period 2017 – 2023 is selected to provide us with the recent development in the field and during search, there were almost no notable articles published before 2017 on the subject matter. Consequently, the retrieved record was reduced to 121 articles.
2.4. Eligibility and Data Analysis
To determine eligibility and quality assessment of the extracted papers, we remove articles published in journals that are not Q1 or Q2. This is to ensure that the articles with rigorous peer review process and quality research output in this field are selected and synthesize for top quality review. After excluding Journals that are not ranking Q1 and Q2, 9 articles are excluded, and 112 records are retrieved. For further assessment, titles and abstracts are assessed regarding their relevance to the study. The relevant study focused on articles that implemented various deep learning semantic segmentation models focused on land use/land cover classification, and/or various satellite datasets extracted through semantic segmentation in different application. Furthermore, hybrid gold access and review paper are also excluded. This is to ensure that all articles are open access and 100% articles. At the end of this step, 6 articles are further excluded bringing down the record to a total number of 106 articles between the period of 2017 to 2023, which are eligible for bibliometric analysis.
2.5. Data Synthesis
In this section, the data synthesis is an important way to the answer the RQs. The data is visualized in such a way that it presents findings and synthesizing through quantitative and qualitative analysis. Categorization and visualization are done to draw important trends and findings of deep learning semantic segmentation models in land cover mapping in relation to datasets, applications, architecture, and performance. The study’s synthesizing themes were developed by full-text content analysis of the 106 articles. Vosviewer software is used to provide graphical visualizations of occurrence of key terms taking title, abstract, keywords as input.
3. Results and Discussion
This section looks into the results derived from the performed systematic literature review. Using 106 extracted articles, the results are presented and discussed based on the RQs.
3.1. RQ1. What Are the Emerging Patterns in Land Cover Mapping?
- Annual distribution of research studies
The annual distribution varies from 2017 to 2023. Figure 2 shows the number of research articles published annually from 2017 to 2023. The year 2017 saw a modest output of merely 3 articles. There is a surge in number of articles to 12 in 2020, 17 articles by the year 2021, 30 articles by 2022 and 40 articles by 2023. This observation aligns with the understanding that the adoption of deep learning semantic segmentation models on satellite imagery gained significant momentum in 2020 and subsequent years.
- Leading Journals
Figure 3 depicts number of articles published in academic journals of this domain. The top 13 journals produced over 81% of the number of research studies of semantic segmentation in land cover mapping. MDPI Remote Sensing (30) has the highest number of published articles in this domain, follow by IEEE Journal of selected topics in Earth Science (15), IEEE Transactions on Geoscience And Remote Sensing (12), IEEE Geoscience and Remote Sensing Letters (5), ISPRS Journal Of Photogrammetry And Remote Sensing (4) and so on, while 20 other journals have 1 article each published grouped as “other” category.
- Geographic distribution of studies
In terms of geographical distribution of studies extracted from Scopus database, 35 countries contributed to the study domain. Almost all continents have contributions except the African continent. Figure 4 shows that China published 63 articles of the total 106 articles, the second is the United States with 10 articles, followed by India (6), Italy (5), South Korea (4), United Kingdom(4), Canada, Finland and Germany (3), then Austria, Australia, Brazil, France, Greece, Turkey, Netherlands and Japan (2) while the rest countries have 1 each distributed.
- Leading Themes and Timelines
The significant keyword occurrences are obtained from the titles and abstracts of the extracted articles. The Figure 5 shows relevant and leading keywords. A threshold of 5 was set, which means the minimum number of occurrences of a keyword. Only 68 out of 897 keywords met the threshold. Bibliometric analysis reveals that keywords such as "high-resolution RS images", "Remote Sensing", "satellite imagery" and "very high resolution" exhibit prominence, showing strong associations with neural network-related terms including "Semantic Segmentation", "Deep Learning,", "Machine Learning", and "Neural Network". The Semantic Segmentation has “attention mechanisms” and “transformer” as different model’s architectural component. These learning models are further linked to various application domains, evident in their connections to terms like "Land Cover Classification", "Image Classification", "Image Segmentation", "Land Cover", "Land Use “, “Change Detection” and "Object Detection." In 2020, the research revolved around network architectures, object detection and image processing. In later part of 2021, there was a notable shift in research domains, predominantly towards image segmentation, image classification, and land cover segmentation. In 2022 and 2023, there were pronounced shift in research focusing more to semantic segmentation employing satellite high resolution images for change detection, land use, and land cover classification and segmentation.
3.2. RQ2. What Are Domain Studies of Semantic Segmentation Models in Land Cover Mapping?
In this section, each extracted paper is clustered based on similar study domains areas. Figure 6 shows the overall mind map of the domain studies. Land cover, urban, precision agriculture, environment, coastal areas and forest are mostly studied domain areas.
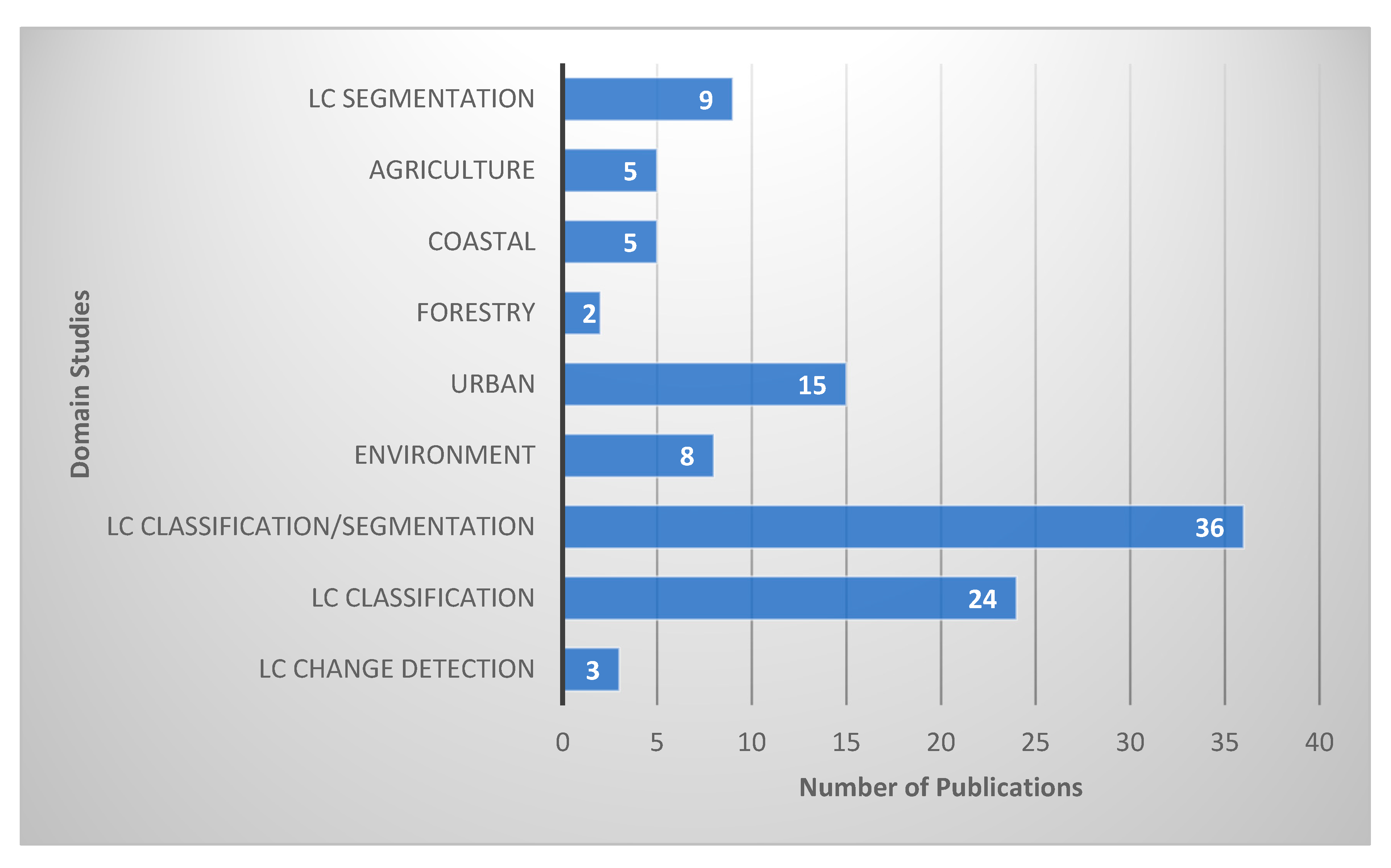
In Figure 7, it is evident that among the 106 articles, 36 studies cover both land cover (LC) classification and segmentation, 24 specifically focus on LC classification, 15 concentrate on urban applications, 9 address LC segmentation alone, 8 addresses environment issues, 5 center around precision agriculture, 5 are oriented toward coastal applications, with 3 articles addressing LC change detection and 2 focusing on forestry.
- Land Cover Studies
In the 72 studies out of 106 related to land cover, research activities encompass land cover classification (33.3%), land cover segmentation (12.5%), change detection (4.2%), and the combined application of land cover classification and segmentation (50%). These areas of study are extensively documented and represent the most widely researched applications within land cover studies. Land cover classification involves assigning an image to one of several classes of land use and land cover (LULC), while land cover segmentation entails assigning a semantic label to each pixel within an image [26]. Land cover refers to various classes of biophysical earth cover, while land use describes how human activities modify land cover. On the other hand, change detection plays a crucial role in monitoring LULC changes by identifying changes over time periods, which can help predict future events or environmental impacts. Change detection methods employing DL have attained remarkable achievements [27] across various domains, including urban change detection [4], agriculture, forestry, wildfire management, and vegetation monitoring [28].
Figure 6.
Land cover mapping domain studies.
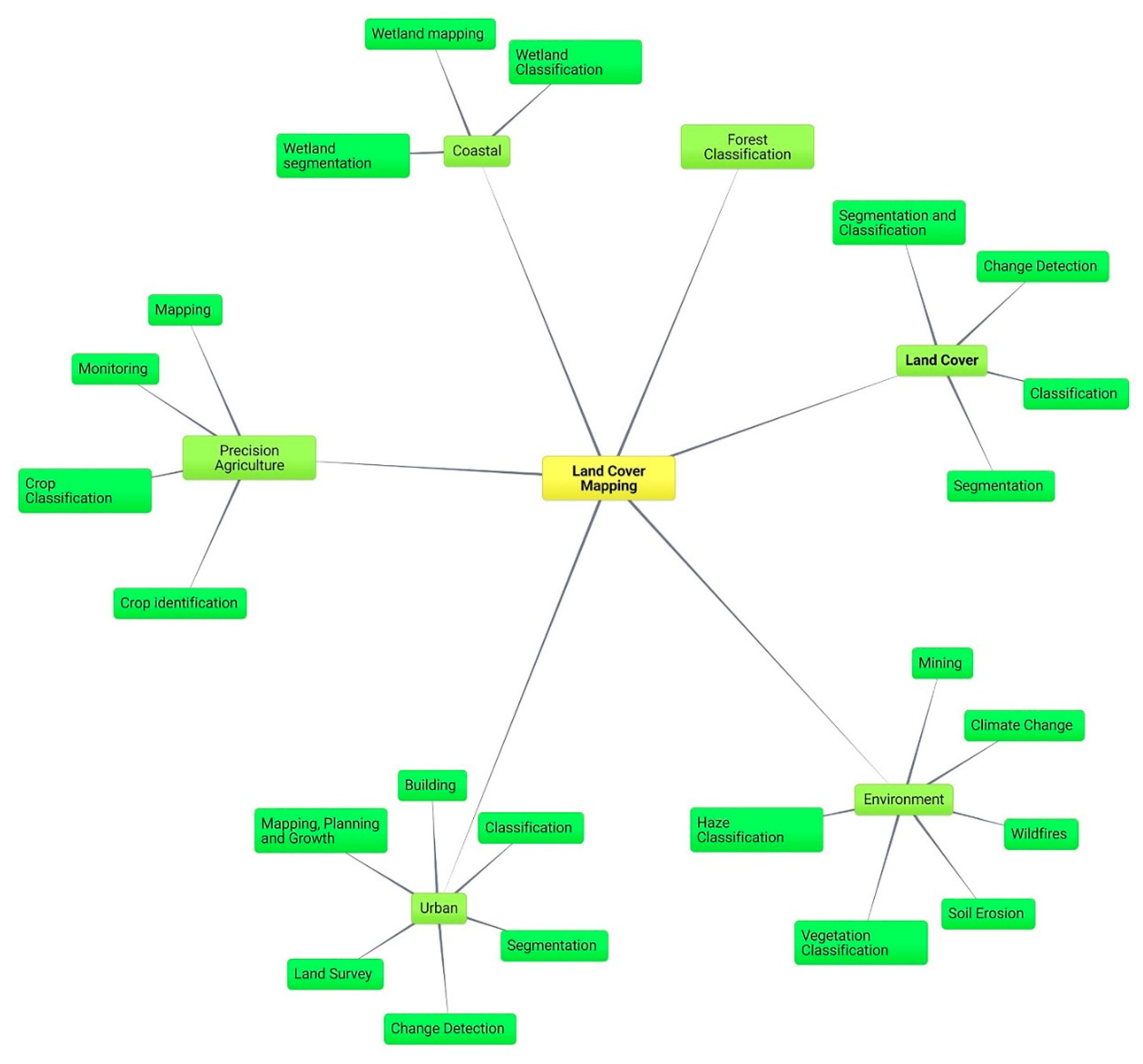
Figure 7.
Number of publications per domain studies.
- Urban
Among the 15 publications related to urban studies, 38% focus on segmentation applications, including urban scene segmentation [19,29,30], while 31% address urban change detection for mapping, planning, and growth [31,32]. For instance, change detection techniques provide insights into urban dynamics by identifying changes from remote sensing imagery [7], including changes in settlement areas. Additionally, these studies involve predicting urban trends and growth over time, managing land use [3], monitoring urban densification [33] as well as mapping built-up areas to assess human activities across large regions [34].
Publications in urban studies also cover 6% in land survey management [35] and 25% in urban classification and detection [36,37,38,39,40] particularly in building applications and for Urban Land-Use Classification [41].
- Precision Agriculture
Out of the 5 publications concerning precision agriculture studies, the research focuses on various aspects such as crop mapping [42], identification, [43,44], classification [45], and monitoring [46]. For example, mapping large-scale rice farms [5] monitoring crops to analyze different growth stages [43], and classifying Sentinel data for creating an oil palm land cover map [47].
- Environment
Among the 8 environmental studies analyzed, the research spans various applications. These include 25% focusing on soil erosion applications [48,49], which involves rapid monitoring of ground covers to mitigate soil erosion risks. Additionally, 12.5% of the studies center around wildfire applications [50] encompassing burned area mapping, wildfire detection [51], and smoke monitoring [52], along with initiatives for preventing wildfires through sustainable land planning [8]. Another 12.5% of the studies involve haze classification [53] specifically cloud classification using Sentinel-2 imagery. Climate change research [54] accounts for another 12.5% of the studies, focusing on aspects such as the urban thermal environment. Furthermore, 12.5% of the studies are dedicated to vegetation classification [55] and an additional 25% address mining applications [56] including the detection of changes in mining areas [57].
- Forest
Research in this domain encompasses forest classification, including the classification of landscapes affected by deforestation [58]. Moreso, change detection in vegetation and forest areas enables decision-makers, conservationists, and policymakers to make informed decisions through forest monitoring initiatives [6] and mapping strategies tailored to tropical forests [59].
- Coastal Areas
Within this field, 5 studies out of the 106 articles focus on wetland mapping, classification, and segmentation [10,60,61,62,63]. Although, the exploration and study of coastal area remote sensing image segmentation remains a relatively underexplored research area, as noted by [61]. This challenge is primarily attributed to the significant complexities associated with coastal land categories, including issues such as homogeneity, multiscale features, and class imbalance, as highlighted [64].
3.3. RQ3. What Are the Data Used in Semantic Segmentation Models for Land Cover Mapping?
In this section, the paper synthesizes extensively employed, particularly the study location, data source and benchmark datasets used for land cover mapping.
- Study Locations
Figure 8 illustrates the countries where the study areas were located and where in-depth research was conducted among the extracted articles. Among the 22 countries represented in 51 studies, 35.29% of the study areas are located in China, with 11.76% in the USA, 5.88% in France, and 3.92% in Spain, Italy, Brazil, South Korea, and Finland each. Other countries in the chart each account for 1.96% of the study areas.
- Data Sources:
Table 1 presents the identified data sources along with the number of articles and their corresponding references. The data sources identified in literatures include RS satellites, RS Unmanned Aerial Vehicles (UAVs) and Unmanned Aircraft Systems (UAS), mobile phones, Google Earth, Synthetic Aperture Radar (SAR), and LiDAR sources. Among these, Sentinel-2, Sentinel-1, and Landsat satellites are the most frequently utilized data sources. It is important to recognize that the primary remote sensing (RS) technologies include RS satellite imagery, Synthetic Aperture Radar (SAR), and Light Detection and Ranging (LiDAR).
RS Imagery: RS data are the most extensively utilized in land cover mapping. In RS, data are collected from satellite sources such as sentinel-1, Landsat, sentinel-2, WorldView-2 and QuickBird at certain time step intervals for a period. The data capture products of these satellite include Panchromatic (1 Channel – 2D), Multispectral or Hyperspectral images [1]. RSI can be represented as aerial images [2], these are taken using Drone or UAVs. These data usually possess spatial resolution and spectral resolution of certain image sizes.
Synthetic Aperture Radars Among the radar systems used in Land Cover Mapping, SAR stands out as a notable data source [83]. SAR utilizes radio detection technology and constitutes an essential tool in this field. SAR data carries distinct advantages, especially in scenarios where optical imagery faces limitations such as cloud cover or limited visibility. SAR can penetrate through cloud cover and offer earth surface imaging even in the presence of clouds or unfavorable weather conditions. This is one of the key advantages of SAR technology. Unlike electromagnetic spectrum which are obstructed by clouds [84].
There are various types of SAR data harnessed for the purpose of land cover mapping, such as polarimetric synthetic aperture radar (PolSAR) images [82], E-SAR, AIRSAR, Gaofen-3, RADARSAT-2 datasets [85], GaoFen-2 data [86], GF-2 images[87] and Interferometric Synthetic Aperture Radar [6]. At present, semantic segmentation of PolSAR images holds significant utility in the interpretation of SAR imagery, particularly within agricultural contexts [88]. Similarly, the High-Resolution GaoFen-3 SAR Dataset is useful for the Semantic Segmentation of Building [34,89,90]. The benchmark dataset Gaofen-3 (GF-3), comprised of single-polarization SAR images, holds significant importance [91]. This dataset is derived from China's pioneering civilian C-band polarimetric SAR satellite, designed for high-resolution RS. Notably, FUSAR-Maps are generated from extensive semantic segmentation efforts utilizing high-resolution GF-3 single-polarization SAR images [92], while GID dataset is collected from the Gaofen-2 satellite.
Light Detection and Ranging data (LiDAR): LiDAR holds a significant role within the sphere of land cover mapping and climate change [93]. LiDAR involves the emission of laser pulses and the measurement of their return times to precisely gauge distances, creating highly accurate and detailed elevation models of the Earth's surface. It provides detailed information, including topographic features, terrain variations, and the vertical structure of vegetation. It stands as an indispensable data source for land cover mapping endeavors. Notable examples include the utilization of multispectral LiDAR [55], an advanced RS technology merging conventional LiDAR principles with the capacity to concurrently capture multiple spectral bands. There's the Follo 2014 LiDAR data, a dataset that specifically captures Light Detection and Ranging (LiDAR) data in the Follo region during 2014. Additionally, the NIBIO AR5 (Norwegian Institute of Bioeconomy Research - Assessment Report 5) Land Resources dataset, developed by the Norwegian Institute of Bioeconomy Research, represents a comprehensive evaluation of land resources. This dataset encompasses a range of attributes including land cover, land use, and pertinent environmental factors [94].
- Benchmark datasets
The benchmark datasets used for evaluation in this domain as identified in the review are shown in Figure 9. ISPR Vaihingen and Potsdam are the widely used benchmark datasets, followed by GID, Landcover.ai, DeepGlobe and WHDLD.
The ISPRS Vaihingen comprises 33 aerial image patches in IRRGB format along with their associated digital surface model (DEM) data, each with a size of around 2500 × 2500 pixels at 9 cm spatial resolution [95,96]. Similarly, the publicly accessible ISPRS Potsdam dataset encompasses Potsdam city, Germany. It is composed of 38 aerial IRRGB images measuring 6000 × 6000 pixels each at a spatial resolution of 5 centimeters [97].
The Global Imperviousness Dataset, GID dataset [98] contains 150 images of GaoFen-2 data [86], GF-2 images [87]. The GaoFen-2 data and GF-2 images collectively form an integral component of the benchmark GID dataset, offering valuable insights into global imperviousness patterns and land cover characteristics. Every image is composed of pixels measuring 6908 × 7300 and compose of the R, G, and B bands, each with a spatial resolution of 4 meters. The GID dataset consist of 5 land-use categories: farmland, meadow, forest, waters, built-up [99].
The LandCover.ai dataset [100] comprises images chosen from aerial photographs encompassing 216.27 square kilometers of Poland, a country in central Europe. The dataset includes 41 RS images, with 33 images having an approximate resolution of 25 cm, measuring around 9000 × 9000 pixels, and 8 images with a resolution of approximately 50 cm, spanning about 4200 × 4700 pixels [12,17,101]. The dataset was manually categorised into 4 types of objects such as buildings, woodland, water as well as background.
DeepGlobe Data [102] is another important dataset in land cover mapping. The dataset stands out as the inaugural publicly available collection of high-resolution satellite imagery primarily emphasizing urban and rural regions. This dataset comprises a total of 1146 satellite images, each with dimensions of 20448 × 20448." [103]. It is of great important to Land Cover Classification Challenge. Likewise, the Inria dataset [104] consist of aerial visual images encompassing 10 regions in the United States and Austria, collected at a 30 cm resolution, with RGB bands [105]. It is organised by 5 cities in both in training and test data. Every city includes 36 image tiles, each sized at 5000 × 5000 pixels, and these tiles are divided into two semantic categories: buildings and non-building classes.
In addition, Disaster Reduction and Emergency Management Building dataset exhibits a notable similarity to the Inria dataset. It has image tiles size of 5000 × 5000 with a spatial resolution of 30 cm, all the tiles contain R, G, and B bands [99]. The building dataset from Wuhan University comprises an aerial dataset encompassing 8189 image patches captured at a 30 cm resolution. These images are in RGB format, with each patch measuring 512 × 512 pixels [106]. The Aerial Imagery for Roof Segmentation dataset [107] is composed of aerial images that encompass the Christchurch city area in New Zealand. These images are captured at a resolution of 7.5 cm and include RGB bands [105]. It was captured following the seismic event that impacted the town of Christchurch in New Zealand. Four images, each with dimensions of 5000 × 4000 pixels, were labeled to include the following categories: buildings, cars and vegetation [108]. Other benchmark datasets include the Massachusetts building and road datasets [109], Dense labeling RS dataset [110], VEhicle Detection in Aerial Imagery (VEDAI) dataset and LoveDA dataset [111].
3.4. RQ4. What Are the Architecture and Performances of Semantic Segmentation Methodologies Used in Land Cover Mapping?
This section investigates the design and effectiveness of recent advancements in novel semantic segmentation methodologies applied to land cover mapping. In this paper, the methodologies employed in land cover mapping are classified based on similarities in their structural components. We have identified three primary architectural structures: encoder-decoder structures, transformer structures, and hybrid structures. Hybrid structures involve the integration of various architectural elements, including deep learning components, encoder-decoder models, transformers, module fusion techniques, and other parameters. Among 80 articles employing different model structures, 59% utilized hybrid structures, 36% utilized encoder-decoder structures, and 5% utilized transformer-based structures.
- Encoder-Decoder based structure
Encoder-decoder structures consist of two main parts: an encoder that processes the input data and extracts high-level features, and a decoder that generates the output (e.g., segmentation map) based on the encoder's representations [16]. The authors [112] suggested an innovative encoding-to-decoding technique known as the Full Receptive Field network, which utilizes two varieties of attention mechanisms, with ResNet-101 serving as the fundamental backbone. Similarly, a different DL segmentation framework known as the DGFNET Dual-gate fusion network. [113] adopts an encoder-decoder architecture design. Typically, encoder-decoder architectures encounter difficulties with the semantic gap. To address this, the DGFNET framework comprises two modules: the Feature Enhancement Module as well as the Dual Gate Fusion Module mitigate the impact of semantic gaps in deep convolutional neural networks, leading to improved performance in land cover classification. The model underwent evaluation using both the landcover dataset and the Potsdam dataset, achieving MIoU scores of 88.87% and 72.25%, respectively.
The article [114] proposed U-Net incorporating asymmetry and fusion coordination. It is an encoder and decoder architecture with an integrated coordinated attention mechanism, a non-symmetric convolution block refinement fusion block that gets long term dependencies and intricate information from RS data. It was reported that the method was evaluated on DeepGlobe datasets and performed best MIoU of 85.54% as reported compared to other models like UNet, MAResU-Net, PSPNet, DeepLab v3+ etc. However, the model has low network efficiency and not recommended for mobile applications. Also, [115] suggested the Attention dilation-LinkNet neural network, which contains an encoder-decoder structure. It takes advantage of serial-parallel combination dilated convolution and 2 channel-wise attention mechanisms, as well as pretrained encoder to be useful for satellite image segmentation particularly road extraction. The best performance of an ensemble of the model achieved an IoU of 64.49% on DeepGlobe road extraction dataset. Table 2 tabulates some semantic segmentation models using encoder decoder structure. It shows that these models have relatively impressive generalization performances on different data, however, accuracy can be further enhanced through parameter optimization.
- Transformer-based structure
Transformer-based architectures are neural network structures originally designed for natural language processing (NLP), utilizing transformer modules as their fundamental building components. In the context of land cover mapping tasks, transformer-based architectures such as the Swin-S-GF [120], BANet [121], DWin-HRFormer [29], spectral spatial transformer [122], Sgformer [18], and Parallel Swin Transformer have been developed. Table 9 presents various transformer-based structures alongside their performance metrics and limitations. Researchers have noted that while these architectures achieve effective segmentation accuracy with an average OA of approximately 89%, transformers can exhibit slow convergence and computationally expensive, particularly in land cover mapping tasks. This limitation contributes to their relatively low adoption in land cover segmentation applications.

Table 3.
Transformer-based semantic segmentation models for land cover segmentation.
| Models | Data | Performance | Limitation |
|---|---|---|---|
| Swin-S-GF [120], | GID | OA = 0.89 MIoU=80.14 |
Computational complexity issue, and Slow convergence speed |
| BANet [121] | Vaihingen, Potsdam, UAVid dataset |
MIoU=81.35, MIoU=86.25, MIoU=64.6 |
Combine convolution and Transformer as a hybrid structure to improve performance. |
| Spectral spatial transformer [122] | Indian dataset | OA=0.94 | Computational complexity issue |
| Sgformer [18] | Landcover dataset | MIOU=0.85 | Computational complexity issue, and Slow convergence speed |
| Parallel Swin Transformer [123] | Postdam, GID WHDLD |
OA=89.44, OA = 84.67, OA=84.86 |
Performance can improve. |
- Hybrid based-structure
A hybrid-based structure combines elements from different neural network architectures or techniques to create a unified model for semantic segmentation. Traditional convolutional neural network methods face limitations in accurately capturing boundary details and small ground objects, potentially leading to the loss of crucial information. While deep convolutional neural networks are applied for classifying land use covers results often show suboptimal performance in land cover segmentation task [75]. However, this result can be tackled by hybrid through introduction of encoder-decoder style semantic segmentation models, leverage existing deep learning backbone [70], and explore diverse data settings and parameters in their experimentation [124]. Other methods of structure’s enhancement include architectural modifications through the integration of attention mechanisms, transformer architecture, module fusion, and multi-scale feature fusion[125,126]. Example is the SCOCNN framework [127], which addresses the limitation faced by CNN through module integration: A module for semantic segmentation, a module for superpixel optimization, and a module for fusion. While the evaluated performance of the framework demonstrated improvement, further enhancement in boundary retrieval can be achieved by incorporating superior boundary adhesion and integrating it into the boundary optimization module.
Moreso, [128] proposed multi-level context-guided classification method Object-based CNN. It involves high level feature-fusing and employed a Conditional Random Field for better classification performance. The model attained a comparable overall accuracy with DeepLabV3+ at various segmentation scale parameter on Vaihingen dataset and suboptimal overall accuracy to DeepLabV3+ on Potsdam dataset. Another approach identified is utilizing a Generative Adversarial Network-based approach for domain adaptation, such as Full Space Domain Adaptation Network [106] as well as leveraging domain adaptation and transfer learning [129]. It has proven to enhance accuracy in scenarios where source and target images originate from distinct domains. Although the domain adaption segmentation using RS images remains largely underexplored [130]. The authors [97] presented a CNN based SegNet model that classifies terrain features using 3D geospatial data, the model did well on building classification than other natural objects. The model was validated on Vaihingen dataset and tested on Potsdam dataset, achieved IoU of 84.90%.
In addition, [131] proposed SBANet, stands for Semantic Boundary Awareness Network used to extract sharp boundaries, ResNet was employed as the backbone. Subsequently, it was enhanced by introducing a boundary attention module and applying adaptive weights in multitask learning to incorporating both low and high-level features, with the goals of improving land-cover boundary precision and expediting network convergence. The method was evaluated on Potsdam and Vaihingen semantic labelling datasets, they reported that SBANet performed best compared to models like UNet, FCN, SegNet, PSPNet, Deeplab3+ and others. DenseNet-Based model [132], a proposed method modified one of the DL backbones DenseNet by adding 2 novel fusions that is the unit fusion and cross-level fusion. The unit fusion is well detailed-oriented fusion and the other integrates different information levels. This model with both fusions performed best on the DeepGlobe dataset.
Furthermore, [98] Suggested a bidirectional grid fusion network, a 2-way fusion architecture for classifying land in very high-resolution RS data. It encourages bidirectional information flow with mutual benefits of feature propagation, a grid fusion architecture is attached for further improvement. The best refined model was tested on ISPR and GID datasets achieved MIoU performances of 68.88% and 64.01%, respectively. Table 4 shows some identified hybrid semantic segmentation models and performance metric in land cover mapping. These models have demonstrated effective performances with an average overall accuracy of 91.3% across presented datasets.
4. Land Cover Mapping Challenges, Future Insights and Directions
The challenges highlighted in land cover mapping, as revealed through an extensive review of existing literature, underscore persistent gaps requiring targeted attention and innovative solutions in forthcoming research efforts. This section examines these challenges and outlines potential avenues for future investigation. Key challenges identified include:
- Extracting boundary information
The precise delineation of sharp and well-defined boundaries [138], the refinement of object edges [139], the extraction of boundary details [131], and the acquisition of content details [140] from RS Imagery, all aimed at achieving accurate land cover segmentation. This research gap remains area that needs further exploration.
Defining clear land cover boundaries is a crucial aspect of RS and geospatial analysis. It involves precisely delineating the borders that divide distinct land cover categories on the Earth's surface. Semantic segmentation encounters performance degradation due to the loss of crucial boundary information [127]. The challenge of delineating precise boundaries in land cover maps is exacerbated by the heightened probability of prediction errors occurring at borders and within smaller segments [19,141]. This holds particularly true in scenarios like the segmentation and classification of vegetation land covers [55]. An illustrative example of this complexity is encountered when attempting to segment the boundaries among ecosystems characterized by a combination of both forest and grassland in regions with semi-arid to semi-humid climates [142].
Unclear boundaries, loss of essential and detailed information at boundaries decreases the chance of producing fine segmentation results [131,143]. The task of effectively capturing entire and well-defined boundaries in intricate RS images of very high resolution remains open for further research and improvement.
- Generating Precise Land Cover Maps
The demand for accurate and timely high-resolution land cover maps is high and are of immediate importance to various sectors and communities [128]. The creation of precise land cover maps holds significant value for subsequent applications. These applications encompass a diverse range of tasks, including vehicle detection [108], the extraction of building footprints [144], building segmentation [134], road extraction, surface classification [115], determining optimal seamlines for orthoimage mosaicking within settlements [145] and land consumption [146]. This offers valuable assistance in the monitoring and reporting of data within rapidly changing urban regions. However, it has been reported that generating and automating of accurate land cover maps still present a formidable challenge [147,148].
- Enhancing Deep learning model performance
Improving deep learning semantic segmentation architecture is a notable research gap in land cover mapping. This gap is characterized by the ongoing need to advance the capabilities of these models to address complex challenges emanating from producing land cover maps. Various studies have critically compared the accuracy assessment and effectiveness of models, both on natural images and RS imagery, aiming to enhance their generalization performance [10]. Moreover, multiple studies such as [149] have modified semantic segmentation model to improve generalization performance for land cover mapping.
- Analysis of RS images
In terms of RS data, extracting information from RS imagery data remains a challenge. The following factors contributes to inaccurate RS classification, namely the complexities inherent in deciphering intricate spatial and spectral patterns within RS Imagery [13,150], the challenge of handling diverse distributions of ground objects with variations within the same class [26] and significant intra-class and limited inter-class pixel differences[151,152,153]. Other contributing factors include data complexity, geographical time difference [154], foggy conditions[155] and data acquisition errors [147]. Moreso, several studies have implemented works for very high RS resolution images. However, only few studies have focused on low and medium-resolution images [70,80,117,156]. As future insight, it is recommended to conduct more research using fast and efficient DL methods for low and medium resolution RS.
Another area is the analysis of SAR Images. SAR images is extremely important for many applications especially in Agriculture. Researchers find it very challenging classifying SAR data and the segmentation is poorly understood [88]. Some studies have undertaken land cover classification and segmentation tasks across diverse categories of SAR data [91], including polarimetric SAR imagery[78,88,90], single-polarization SAR images [92], and multi-temporal SAR data [83]. As consideration, we recommend a roadmap for simplified and automated semantic segmentation of SAR images should be investigated.
In LiDAR data analysis, [94] pioneered novel deep learning architectures designed specifically for land cover classification and segmentation, which were extensively validated using airborne LiDAR data. Additionally, [157] developed DL models that synergistically leverage airborne LiDAR data and high-resolution RS Imagery to achieve enhanced generalization performance. Beyond RS Imagery and LiDAR, semantic segmentation is applied to high-resolution Synthetic Aperture Radar (SAR) images [85,89] and aerial images of high resolution [2,158].
- Unlabelled and Imbalance RS data
A large majority of RS images lack high-quality or are largely unlabeled [159], weak and missing annotations that reduce the model’s performances. The efforts to obtain well-annotated RS data are expensive, laborious, and highly time-consuming. This affects generating accurate land use maps, thereby impacting the generation of precise land cover maps negatively. To mitigate this challenge, exploration into study areas like domain adaptation techniques [160] and the application of DL models can be considered to facilitate the creation of accurate land cover maps [161]. Another suggested approach for addressing the shortage of well-annotated data is to utilize networks capable of utilizing training labels derived from lower resolution land cover data [162]. Furthermore, it is advisable to harness the benefits of multi-modal RS data, as its potential to enhance model performance particularly in situations with limited training samples has not been fully realized [163]. To overcome the laborious and time-consuming process of manually labeling data, certain studies such as [155,164] introduced DL models that addressed this issue. The authors [140] proposed the effectiveness of semi-supervised adversarial learning methods for handling limited and unannotated high-resolution satellite images. Furthermore, the investigations by [39,156,165,166] sought remedies for challenges stemming from the scarcity of well-annotated pixel-level data and as well as other studies proposed steps on how to tackle instances of class imbalance[65,161,167].
5. Conclusions
This study conducted an analysis of emerging patterns, performance, applications, and data sources related to semantic segmentation in land cover mapping. The objective was to identify knowledge gaps within this domain and offer readers a roadmap and detailed insights into semantic segmentation for land use/land cover mapping. Employing the PRISMA methodology, a comprehensive review was undertaken to address predefined research questions.
The results reveal a substantial increase in publications between 2020 and 2023, with 81% appearing in the top 13 journals. These studies originate from diverse global institutions, with over 59% attributed to Chinese institutions, followed by the USA and India. Research focuses primarily on land cover, urban areas, precision agriculture, environment, coastal areas, and forests, particularly in tasks such as land use change detection, land cover classification, and segmentation of forests, buildings, roads, agriculture, and urban areas. Remote sensing (RS) satellites, RS unmanned aerial vehicles (UAVs) and unmanned aircraft systems (UAS), mobile phones, Google Earth, Synthetic Aperture Radar (SAR), and LiDAR sources are the major data sources, with Sentinel-2, Sentinel-1, and Landsat satellites being the most utilized. Many studies use publicly available benchmark datasets for semantic segmentation model evaluation. ISPRS Vaihingen and Potsdam being widely employed, followed by GID, Landcover.ai, DeepGlobe, and WHDLD datasets.
In terms of semantic segmentation models, three primary architectural structures are identified and grouped as encoder-decoder structures, transformer structures, and hybrid structures. While all models demonstrate effective performance, hybrid and encoder-decoder structures are most popular due to their impressive generalization capabilities and speed. Transformer-based structures show good generalization but slower convergence. Current research directions and expanding frontiers in land cover mapping emphasize the introduction and implementation of innovative semantic segmentation techniques for satellite imagery in remote sensing. Furthermore, key research gaps identified include the need to enhance model accuracy on RS data, improve existing model architectures, extract precise boundaries in land cover maps, address scarcity of well-labeled datasets, and tackle challenges associated with low and medium-resolution RS data. This study provides useful domain specific information. However, there are some threats to review validity, which include database choice, searched keywords, and classification bias.
Supplementary Materials
The following supporting information can be downloaded at: Preprints.org: Extracted Records
Author Contributions
Conceptualization, S.A.; methodology, S.A.; software, S.A.; validation, S.A., and P.C.; investigation, S.A.; data curation, S.A.; writing—original draft preparation, S.A.; writing—review and editing, S.A and P.C..; visualization, S.A.; supervision, P.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie-RISE, Project SUSTAINABLE (https://www.projectsustainable.eu) with grant number 101007702”
Data Availability Statement
The full list of the reviewed publications is provided in a Supplementary File.
Acknowledgments
The authors thank Marco Painho, professor at NOVA IMS Information Management School for his valuable comments and suggestions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens (Basel) 2020, 12. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sens (Basel) 2020, 12. [Google Scholar] [CrossRef]
- Pourmohammadi, P.; Adjeroh, D.A.; Strager, M.P.; Farid, Y.Z. Predicting Developed Land Expansion Using Deep Convolutional Neural Networks. Environmental Modelling and Software 2020, 134. [Google Scholar] [CrossRef]
- Di Pilato, A.; Taggio, N.; Pompili, A.; Iacobellis, M.; Di Florio, A.; Passarelli, D.; Samarelli, S. Deep Learning Approaches to Earth Observation Change Detection. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Wei, P.; Chai, D.; Lin, T.; Tang, C.; Du, M.; Huang, J. Large-Scale Rice Mapping under Different Years Based on Time-Series Sentinel-1 Images Using Deep Semantic Segmentation Model. ISPRS Journal of Photogrammetry and Remote Sensing 2021, 174, 198–214. [Google Scholar] [CrossRef]
- Dal Molin Jr., R.; Rizzoli, P. Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X.; Huang, J.; Wang, H.; Xin, Q. Fine-Grained Building Change Detection from Very High-Spatial-Resolution Remote Sensing Images Based on Deep Multitask Learning. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Trenčanová, B.; Proença, V.; Bernardino, A. Development of Semantic Maps of Vegetation Cover from UAV Images to Support Planning and Management in Fine-Grained Fire-Prone Landscapes. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Z.; Zhang, J.; Wei, A. MSANet: An Improved Semantic Segmentation Method Using Multi-Scale Attention for Remote Sensing Images. Remote Sensing Letters 2022, 13, 1249–1259. [Google Scholar] [CrossRef]
- Scepanovic, S.; Antropov, O.; Laurila, P.; Rauste, Y.; Ignatenko, V.; Praks, J. Wide-Area Land Cover Mapping with Sentinel-1 Imagery Using Deep Learning Semantic Segmentation Models. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 10357–10374. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep Learning for Visual Understanding: A Review. Neurocomputing 2016, 187. [Google Scholar] [CrossRef]
- Huang, J.; Weng, L.; Chen, B.; Xia, M. DFFAN: Dual Function Feature Aggregation Network for Semantic Segmentation of Land Cover. ISPRS Int J Geoinf 2021, 10. [Google Scholar] [CrossRef]
- Chen, S.; Wu, C.; Mukherjee, M.; Zheng, Y. Ha-Mppnet: Height Aware-Multi Path Parallel Network for High Spatial Resolution Remote Sensing Image Semantic Seg-Mentation. ISPRS Int J Geoinf 2021, 10. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A Brief Survey on Semantic Segmentation with Deep Learning. Neurocomputing 2020, 406. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical Dense-Shortcut Deep Fully Convolutional Networks for Semantic Segmentation of Very-High-Resolution Remote Sensing Images. IEEE J Sel Top Appl Earth Obs Remote Sens 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); 2015; Vol. 9351. [Google Scholar]
- Chen, B.; Xia, M.; Huang, J. Mfanet: A Multi-Level Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens (Basel) 2021, 13, 1–20. [Google Scholar] [CrossRef]
- Weng, L.; Pang, K.; Xia, M.; Lin, H.; Qian, M.; Zhu, C. Sgformer: A Local and Global Features Coupling Network for Semantic Segmentation of Land Cover. IEEE J Sel Top Appl Earth Obs Remote Sens 2023, 16, 6812–6824. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS Journal of Photogrammetry and Remote Sensing 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Xiao, D.; Kang, Z.; Fu, Y.; Li, Z.; Ran, M. Csswin-Unet: A Swin-Unet Network for Semantic Segmentation of Remote Sensing Images by Aggregating Contextual Information and Extracting Spatial Information. Int J Remote Sens 2023, 44, 7598–7625. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A Survey on Deep Learning Techniques for Image and Video Semantic Segmentation. Applied Soft Computing Journal 2018, 70. [Google Scholar] [CrossRef]
- Lateef, F.; Ruichek, Y. Survey on Semantic Segmentation Using Deep Learning Techniques. Neurocomputing 2019, 338. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A Review of Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery. Expert Syst Appl 2021, 169. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. The BMJ 2021, 372. [Google Scholar]
- Manley, K.; Nyelele, C.; Egoh, B.N. A Review of Machine Learning and Big Data Applications in Addressing Ecosystem Service Research Gaps. Ecosyst Serv 2022, 57. [Google Scholar] [CrossRef]
- Tian, T.; Chu, Z.; Hu, Q.; Ma, L. Class-Wise Fully Convolutional Network for Semantic Segmentation of Remote Sensing Images. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Wan, L.; Tian, Y.; Kang, W.; Ma, L. D-TNet: Category-Awareness Based Difference-Threshold Alternative Learning Network for Remote Sensing Image Change Detection. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Picon, A.; Bereciartua-Perez, A.; Eguskiza, I.; Romero-Rodriguez, J.; Jimenez-Ruiz, C.J.; Eggers, T.; Klukas, C.; Navarra-Mestre, R. Deep Convolutional Neural Network for Damaged Vegetation Segmentation from RGB Images Based on Virtual NIR-Channel Estimation. Artificial Intelligence in Agriculture 2022, 6, 199–210. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, X.; Li, J. DWin-HRFormer: A High-Resolution Transformer Model With Directional Windows for Semantic Segmentation of Urban Construction Land. IEEE Transactions on Geoscience and Remote Sensing 2023, 61. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Akcay, O.; Kinaci, A.C.; Avsar, E.O.; Aydar, U. Semantic Segmentation of High-Resolution Airborne Images with Dual-Stream DeepLabV3+. ISPRS Int J Geoinf 2022, 11. [Google Scholar] [CrossRef]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int J Geoinf 2022, 11. [Google Scholar] [CrossRef]
- Chen, T.-H.K.; Qiu, C.; Schmitt, M.; Zhu, X.X.; Sabel, C.E.; Prishchepov, A.V. Mapping Horizontal and Vertical Urban Densification in Denmark with Landsat Time-Series from 1985 to 2018: A Semantic Segmentation Solution. Remote Sens Environ 2020, 251. [Google Scholar] [CrossRef]
- Wu, F.; Wang, C.; Zhang, H.; Li, J.; Li, L.; Chen, W.; Zhang, B. Built-up Area Mapping in China from GF-3 SAR Imagery Based on the Framework of Deep Learning. Remote Sens Environ 2021, 262. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, S.; Zeng, J.; Li, T.; Guo, Q.; Jin, S. A Framework for Land Use Scenes Classification Based on Landscape Photos. IEEE J Sel Top Appl Earth Obs Remote Sens 2020, 13, 6124–6141. [Google Scholar] [CrossRef]
- Xu, L.; Shi, S.; Liu, Y.; Zhang, H.; Wang, D.; Zhang, L.; Liang, W.; Chen, H. A Large-Scale Remote Sensing Scene Dataset Construction for Semantic Segmentation. Int J Image Data Fusion 2023, 14, 299–323. [Google Scholar] [CrossRef]
- Sirous, A.; Satari, M.; Shahraki, M.M.; Pashayi, M. A Conditional Generative Adversarial Network for Urban Area Classification Using Multi-Source Data. Earth Sci Inform 2023, 16, 2529–2543. [Google Scholar] [CrossRef]
- Vasavi, S.; Sri Somagani, H.; Sai, Y. Classification of Buildings from VHR Satellite Images Using Ensemble of U-Net and ResNet. Egyptian Journal of Remote Sensing and Space Science 2023, 26, 937–953. [Google Scholar] [CrossRef]
- Kang, J.; Fernandez-Beltran, R.; Sun, X.; Ni, J.; Plaza, A. Deep Learning-Based Building Footprint Extraction with Missing Annotations. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Yu, J.; Zeng, P.; Yu, Y.; Yu, H.; Huang, L.; Zhou, D. A Combined Convolutional Neural Network for Urban Land-Use Classification with GIS Data. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Yu, J.; Zeng, P.; Yu, Y.; Yu, H.; Huang, L.; Zhou, D. A Combined Convolutional Neural Network for Urban Land-Use Classification with GIS Data. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Wei, P.; Chai, D.; Huang, R.; Peng, D.; Lin, T.; Sha, J.; Sun, W.; Huang, J. Rice Mapping Based on Sentinel-1 Images Using the Coupling of Prior Knowledge and Deep Semantic Segmentation Network: A Case Study in Northeast China from 2019 to 2021. International Journal of Applied Earth Observation and Geoinformation 2022, 112. [Google Scholar] [CrossRef]
- Liu, S.; Peng, D.; Zhang, B.; Chen, Z.; Yu, L.; Chen, J.; Pan, Y.; Zheng, S.; Hu, J.; Lou, Z.; et al. The Accuracy of Winter Wheat Identification at Different Growth Stages Using Remote Sensing. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Bem, P.P.D.; de Carvalho Júnior, O.A.; Carvalho, O.L.F.D.; Gomes, R.A.T.; Guimarāes, R.F.; Pimentel, C.M.M. Irrigated Rice Crop Identification in Southern Brazil Using Convolutional Neural Networks and Sentinel-1 Time Series. Remote Sens Appl 2021, 24. [Google Scholar] [CrossRef]
- Niu, B.; Feng, Q.; Su, S.; Yang, Z.; Zhang, S.; Liu, S.; Wang, J.; Yang, J.; Gong, J. Semantic Segmentation for Plastic-Covered Greenhouses and Plastic-Mulched Farmlands from VHR Imagery. Int J Digit Earth 2023, 16, 4553–4572. [Google Scholar] [CrossRef]
- Sykas, D.; Sdraka, M.; Zografakis, D.; Papoutsis, I. A Sentinel-2 Multiyear, Multicountry Benchmark Dataset for Crop Classification and Segmentation With Deep Learning. IEEE J Sel Top Appl Earth Obs Remote Sens 2022, 15, 3323–3339. [Google Scholar] [CrossRef]
- Descals, A.; Wich, S.; Meijaard, E.; Gaveau, D.L.A.; Peedell, S.; Szantoi, Z. High-Resolution Global Map of Smallholder and Industrial Closed-Canopy Oil Palm Plantations. Earth Syst Sci Data 2021, 13, 1211–1231. [Google Scholar] [CrossRef]
- He, J.; Lyu, D.; He, L.; Zhang, Y.; Xu, X.; Yi, H.; Tian, Q.; Liu, B.; Zhang, X. Combining Object-Oriented and Deep Learning Methods to Estimate Photosynthetic and Non-Photosynthetic Vegetation Cover in the Desert from Unmanned Aerial Vehicle Images with Consideration of Shadows. Remote Sens (Basel) 2023, 15. [Google Scholar] [CrossRef]
- Wan, L.; Li, S.; Chen, Y.; He, Z.; Shi, Y. Application of Deep Learning in Land Use Classification for Soil Erosion Using Remote Sensing. Front Earth Sci (Lausanne) 2022, 10. [Google Scholar] [CrossRef]
- Cho, A.Y.; Park, S.-E.; Kim, D.-J.; Kim, J.; Li, C.; Song, J. Burned Area Mapping Using Unitemporal PlanetScope Imagery With a Deep Learning Based Approach. IEEE J Sel Top Appl Earth Obs Remote Sens 2023, 16, 242–253. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Reinke, K.; Stein, A. Predicting Wildfire Burns from Big Geodata Using Deep Learning. Saf Sci 2021, 140. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, P.; Liang, H.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. Semantic Segmentation and Analysis on Sensitive Parameters of Forest Fire Smoke Using Smoke-Unet and Landsat-8 Imagery. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Liu, C.-C.; Zhang, Y.-C.; Chen, P.-Y.; Lai, C.-C.; Chen, Y.-H.; Cheng, J.-H.; Ko, M.-H. Clouds Classification from Sentinel-2 Imagery with Deep Residual Learning and Semantic Image Segmentation. Remote Sens (Basel) 2019, 11. [Google Scholar] [CrossRef]
- Ji, W.; Chen, Y.; Li, K.; Dai, X. Multicascaded Feature Fusion-Based Deep Learning Network for Local Climate Zone Classification Based on the So2Sat LCZ42 Benchmark Dataset. IEEE J Sel Top Appl Earth Obs Remote Sens 2023, 16, 449–467. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, Shrub, and Grass Classification Using Only RGB Images. Remote Sens (Basel) 2020, 12. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Bester, M.S.; Guillen, L.A.; Ramezan, C.A.; Carpinello, D.J.; Fan, Y.; Hartley, F.M.; Maynard, S.M.; Pyron, J.L. Semantic Segmentation Deep Learning for Extracting Surface Mine Extents from Historic Topographic Maps. Remote Sens (Basel) 2020, 12, 1–25. [Google Scholar] [CrossRef]
- Zhou, G.; Xu, J.; Chen, W.; Li, X.; Li, J.; Wang, L. Deep Feature Enhancement Method for Land Cover With Irregular and Sparse Spatial Distribution Features: A Case Study on Open-Pit Mining. IEEE Transactions on Geoscience and Remote Sensing 2023, 61. [Google Scholar] [CrossRef]
- Lee, S.-H.; Han, K.-J.; Lee, K.; Lee, K.-J.; Oh, K.-Y.; Lee, M.-J. Classification of Landscape Affected by Deforestation Using High-resolution Remote Sensing Data and Deep-learning Techniques. Remote Sens (Basel) 2020, 12, 1–16. [Google Scholar] [CrossRef]
- Yu, T.; Wu, W.; Gong, C.; Li, X. Residual Multi-Attention Classification Network for a Forest Dominated Tropical Landscape Using High-Resolution Remote Sensing Imagery. ISPRS Int J Geoinf 2021, 10. [Google Scholar] [CrossRef]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study over a Wetland. Remote Sens (Basel) 2020, 12. [Google Scholar] [CrossRef]
- Fang, B.; Chen, G.; Chen, J.; Ouyang, G.; Kou, R.; Wang, L. Cct: Conditional Co-Training for Truly Unsupervised Remote Sensing Image Segmentation in Coastal Areas. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Buchsteiner, C.; Baur, P.A.; Glatzel, S. Spatial Analysis of Intra-Annual Reed Ecosystem Dynamics at Lake Neusiedl Using RGB Drone Imagery and Deep Learning. Remote Sens (Basel) 2023, 15. [Google Scholar] [CrossRef]
- Wang, Z.; Mahmoudian, N. Aerial Fluvial Image Dataset for Deep Semantic Segmentation Neural Networks and Its Benchmarks. IEEE J Sel Top Appl Earth Obs Remote Sens 2023, 16, 4755–4766. [Google Scholar] [CrossRef]
- Chen, J.; Chen, G.; Wang, L.; Fang, B.; Zhou, P.; Zhu, M. Coastal Land Cover Classification of High-Resolution Remote Sensing Images Using Attention-Driven Context Encoding Network. Sensors (Switzerland) 2020, 20, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain Knowledge-Guided Deep Collaborative Fusion Network for Multimodal Unitemporal Remote Sensing Land Cover Classification. ISPRS Journal of Photogrammetry and Remote Sensing 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Liu, S.; Peng, D.; Zhang, B.; Chen, Z.; Yu, L.; Chen, J.; Pan, Y.; Zheng, S.; Hu, J.; Lou, Z.; et al. The Accuracy of Winter Wheat Identification at Different Growth Stages Using Remote Sensing. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Tzepkenlis, A.; Marthoglou, K.; Grammalidis, N. Efficient Deep Semantic Segmentation for Land Cover Classification Using Sentinel Imagery. Remote Sens (Basel) 2023, 15. [Google Scholar] [CrossRef]
- Billson, J.; Islam, M.D.S.; Sun, X.; Cheng, I. Water Body Extraction from Sentinel-2 Imagery with Deep Convolutional Networks and Pixelwise Category Transplantation. Remote Sens (Basel) 2023, 15. [Google Scholar] [CrossRef]
- Bergamasco, L.; Bovolo, F.; Bruzzone, L. A Dual-Branch Deep Learning Architecture for Multisensor and Multitemporal Remote Sensing Semantic Segmentation. IEEE J Sel Top Appl Earth Obs Remote Sens 2023, 16, 2147–2162. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, B.; Chen, Z.; Bai, Y.; Chen, P. A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Yang, X.; Chen, Z.; Zhang, B.; Li, B.; Bai, Y.; Chen, P. A Block Shuffle Network with Superpixel Optimization for Landsat Image Semantic Segmentation. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Boonpook, W.; Tan, Y.; Nardkulpat, A.; Torsri, K.; Torteeka, P.; Kamsing, P.; Sawangwit, U.; Pena, J.; Jainaen, M. Deep Learning Semantic Segmentation for Land Use and Land Cover Types Using Landsat 8 Imagery. ISPRS Int J Geoinf 2023, 12. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Stein, A. Recurrent Multiresolution Convolutional Networks for VHR Image Classification. IEEE Transactions on Geoscience and Remote Sensing 2018, 56, 6361–6374. [Google Scholar] [CrossRef]
- Karila, K.; Matikainen, L.; Karjalainen, M.; Puttonen, E.; Chen, Y.; Hyyppä, J. Automatic Labelling for Semantic Segmentation of VHR Satellite Images: Application of Airborne Laser Scanner Data and Object-Based Image Analysis. ISPRS Open Journal of Photogrammetry and Remote Sensing 2023, 9. [Google Scholar] [CrossRef]
- Zhang, X.; Du, L.; Tan, S.; Wu, F.; Zhu, L.; Zeng, Y.; Wu, B. Land Use and Land Cover Mapping Using Rapideye Imagery Based on a Novel Band Attention Deep Learning Method in the Three Gorges Reservoir Area. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Zhu, Y.; Geis, C.; So, E.; Jin, Y. Multitemporal Relearning with Convolutional LSTM Models for Land Use Classification. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 3251–3265. [Google Scholar] [CrossRef]
- Clark, A.; Phinn, S.; Scarth, P. Pre-Processing Training Data Improves Accuracy and Generalisability of Convolutional Neural Network Based Landscape Semantic Segmentation. Land (Basel) 2023, 12. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A New Fully Convolutional Neural Network for Semantic Segmentation of Polarimetric SAR Imagery in Complex Land Cover Ecosystem. ISPRS Journal of Photogrammetry and Remote Sensing 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Wenger, R.; Puissant, A.; Weber, J.; Idoumghar, L.; Forestier, G. Multimodal and Multitemporal Land Use/Land Cover Semantic Segmentation on Sentinel-1 and Sentinel-2 Imagery: An Application on a MultiSenGE Dataset. Remote Sens (Basel) 2023, 15. [Google Scholar] [CrossRef]
- Fan, Z.; Zhan, T.; Gao, Z.; Li, R.; Liu, Y.; Zhang, L.; Jin, Z.; Xu, S. Land Cover Classification of Resources Survey Remote Sensing Images Based on Segmentation Model. IEEE Access 2022, 10, 56267–56281. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Adriano, B.; Zhang, L.; Li, G.; Wang, Z. A Benchmark High-Resolution GaoFen-3 SAR Dataset for Building Semantic Segmentation. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 5950–5963. [Google Scholar] [CrossRef]
- Kotru, R.; Turkar, V.; Simu, S.; De, S.; Shaikh, M.; Banerjee, S.; Singh, G.; Das, A. Development of a Generalized Model to Classify Various Land Covers for ALOS-2 L-Band Images Using Semantic Segmentation. Advances in Space Research 2022, 70, 3811–3821. [Google Scholar] [CrossRef]
- Mehra, A.; Jain, N.; Srivastava, H.S. A Novel Approach to Use Semantic Segmentation Based Deep Learning Networks to Classify Multi-Temporal SAR Data. Geocarto Int 2022, 37, 163–178. [Google Scholar] [CrossRef]
- Pešek, O.; Segal-Rozenhaimer, M.; Karnieli, A. Using Convolutional Neural Networks for Cloud Detection on VENμS Images over Multiple Land-Cover Types. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Jing, H.; Wang, Z.; Sun, X.; Xiao, D.; Fu, K. PSRN: Polarimetric Space Reconstruction Network for PolSAR Image Semantic Segmentation. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 10716–10732. [Google Scholar] [CrossRef]
- Shi, H.; Fan, J.; Wang, Y.; Chen, L. Dual Attention Feature Fusion and Adaptive Context for Accurate Segmentation of Very High-Resolution Remote Sensing Images. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- He, S.; Lu, X.; Gu, J.; Tang, H.; Yu, Q.; Liu, K.; Ding, H.; Chang, C.; Wang, N. RSI-Net: Two-Stream Deep Neural Network for Remote Sensing Images-Based Semantic Segmentation. IEEE Access 2022, 10, 34858–34871. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, J.; Feng, L.; Li, S.; Yang, W.; Guo, D. A Refined Pyramid Scene Parsing Network for Polarimetric SAR Image Semantic Segmentation in Agricultural Areas. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Adriano, B.; Zhang, L.; Li, G.; Wang, Z. A Benchmark High-Resolution GaoFen-3 SAR Dataset for Building Semantic Segmentation. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 5950–5963. [Google Scholar] [CrossRef]
- Garg, R.; Kumar, A.; Bansal, N.; Prateek, M.; Kumar, S. Semantic Segmentation of PolSAR Image Data Using Advanced Deep Learning Model. Sci Rep 2021, 11. [Google Scholar] [CrossRef]
- Zheng, N.-R.; Yang, Z.-A.; Shi, X.-Z.; Zhou, R.-Y.; Wang, F. Land Cover Classification of Synthetic Aperture Radar Images Based on Encoder - Decoder Network with an Attention Mechanism. J Appl Remote Sens 2022, 16. [Google Scholar] [CrossRef]
- Shi, X.; Fu, S.; Chen, J.; Wang, F.; Xu, F. Object-Level Semantic Segmentation on the High-Resolution Gaofen-3 FUSAR-Map Dataset. IEEE J Sel Top Appl Earth Obs Remote Sens 2021, 14, 3107–3119. [Google Scholar] [CrossRef]
- Yoshida, K.; Pan, S.; Taniguchi, J.; Nishiyama, S.; Kojima, T.; Islam, M.T. Airborne LiDAR-Assisted Deep Learning Methodology for Riparian Land Cover Classification Using Aerial Photographs and Its Application for Flood Modelling. Journal of Hydroinformatics 2022, 24, 179–201. [Google Scholar] [CrossRef]
- Arief, H.A.; Strand, G.-H.; Tveite, H.; Indahl, U.G. Land Cover Segmentation of Airborne LiDAR Data Using Stochastic Atrous Network. Remote Sens (Basel) 2018, 10. [Google Scholar] [CrossRef]
- Xu, Z.; Su, C.; Zhang, X. A Semantic Segmentation Method with Category Boundary for Land Use and Land Cover (LULC) Mapping of Very-High Resolution (VHR) Remote Sensing Image. Int J Remote Sens 2021, 42, 3146–3165. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, P.; Shi, Q.; Liu, M. An Adversarial Domain Adaptation Framework with KL-Constraint for Remote Sensing Land Cover Classification. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Lee, D.G.; Shin, Y.H.; Lee, D.C. Land Cover Classification Using SegNet with Slope, Aspect, and Multidirectional Shaded Relief Images Derived from Digital Surface Model. J Sens 2020, 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, H.; Zhuang, Y.; Sang, Q.; Chen, L. Bidirectional Grid Fusion Network for Accurate Land Cover Classification of High-Resolution Remote Sensing Images. IEEE J Sel Top Appl Earth Obs Remote Sens 2020, 13, 5508–5517. [Google Scholar] [CrossRef]
- Yang, N.; Tang, H. Semantic Segmentation of Satellite Images: A Deep Learning Approach Integrated with Geospatial Hash Codes. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover. Ai: Dataset for Automatic Mapping of Buildings, Woodlands, Water and Roads from Aerial Imagery. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops; 2021. [Google Scholar]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel Feature Fusion Lozenge Network for Land Segmentation. J Appl Remote Sens 2022, 16. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops; 2018; Vol. 2018-June. [Google Scholar]
- Wei, H.; Xu, X.; Ou, N.; Zhang, X.; Dai, Y. Deanet: Dual Encoder with Attention Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? The Inria Aerial Image Labeling Benchmark. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS); 2017; Vol. 2017-July. [Google Scholar]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data. Remote Sens (Basel) 2019, 11. [Google Scholar] [CrossRef]
- Ji, S.; Wang, D.; Luo, M. Generative Adversarial Network-Based Full-Space Domain Adaptation for Land Cover Classification from Multiple-Source Remote Sensing Images. IEEE Transactions on Geoscience and Remote Sensing 2021, 59, 3816–3828. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S.L. Aerial Imagery for Roof Segmentation: A Large-Scale Dataset towards Automatic Mapping of Buildings. ISPRS Journal of Photogrammetry and Remote Sensing 2019, 147. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens (Basel) 2017, 9. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Khan, S.D.; Alarabi, L.; Basalamah, S. Deep Hybrid Network for Land Cover Semantic Segmentation in High-Spatial Resolution Satellite Images. Information (Switzerland) 2021, 12. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Sang, Q.; Zhuang, Y.; Dong, S.; Wang, G.; Chen, H. FRF-Net: Land Cover Classification from Large-Scale VHR Optical Remote Sensing Images. IEEE Geoscience and Remote Sensing Letters 2020, 17, 1057–1061. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, F.; Xiang, Y.; You, H. Article Dgfnet: Dual Gate Fusion Network for Land Cover Classification in Very High-Resolution Images. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Niu, X.; Zeng, Q.; Luo, X.; Chen, L. FCAU-Net for the Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Wu, M.; Zhang, C.; Liu, J.; Zhou, L.; Li, X. Towards Accurate High Resolution Satellite Image Semantic Segmentation. IEEE Access 2019, 7, 55609–55619. [Google Scholar] [CrossRef]
- Li, J.; Wang, H.; Zhang, A.; Liu, Y. Semantic Segmentation of Hyperspectral Remote Sensing Images Based on PSE-UNet Model. Sensors 2022, 22. [Google Scholar] [CrossRef] [PubMed]
- Salgueiro, L.; Marcello, J.; Vilaplana, V. SEG-ESRGAN: A Multi-Task Network for Super-Resolution and Semantic Segmentation of Remote Sensing Images. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Marsocci, V.; Scardapane, S.; Komodakis, N. MARE: Self-Supervised Multi-Attention REsu-Net for Semantic Segmentation in Remote Sensing. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Attention Guided Encoder-Decoder Network with Multi-Scale Context Aggregation for Land Cover Segmentation. IEEE Access 2020, 8, 215299–215309. [Google Scholar] [CrossRef]
- Feng, D.; Zhang, Z.; Yan, K. A Semantic Segmentation Method for Remote Sensing Images Based on the Swin Transformer Fusion Gabor Filter. IEEE Access 2022, 10, 77432–77451. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Bai, J.; Wen, Z.; Xiao, Z.; Ye, F.; Zhu, Y.; Alazab, M.; Jiao, L. Hyperspectral Image Classification Based on Multibranch Attention Transformer Networks. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Wang, D.; Yang, R.; Zhang, Z.; Liu, H.; Tan, J.; Li, S.; Yang, X.; Wang, X.; Tang, K.; Qiao, Y.; et al. P-Swin: Parallel Swin Transformer Multi-Scale Semantic Segmentation Network for Land Cover Classification. Comput Geosci 2023, 175. [Google Scholar] [CrossRef]
- Dong, R.; Fang, W.; Fu, H.; Gan, L.; Wang, J.; Gong, P. High-Resolution Land Cover Mapping through Learning with Noise Correction. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Shen, X.; Weng, L.; Xia, M.; Lin, H. Multi-Scale Feature Aggregation Network for Semantic Segmentation of Land Cover. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, J.; Yang, X.; Yu, Z.; Tan, Z. Pixel Representation Augmented through Cross-Attention for High-Resolution Remote Sensing Imagery Segmentation. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, Z.; Chen, N.; Gong, J. Land Cover Classification Based on the PSPNet and Superpixel Segmentation Methods with High Spatial Resolution Multispectral Remote Sensing Imagery. J Appl Remote Sens 2021, 15. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Shangguan, B.; Wang, M.; Wu, Z. A Multi-Level Context-Guided Classification Method with Object-Based Convolutional Neural Network for Land Cover Classification Using Very High Resolution Remote Sensing Images. International Journal of Applied Earth Observation and Geoinformation 2020, 88. [Google Scholar] [CrossRef]
- Van den Broeck, W.A.J.; Goedemé, T.; Loopmans, M. Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, T.; Wang, B. Curriculum-Style Local-to-Global Adaptation for Cross-Domain Remote Sensing Image Segmentation. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Li, A.; Jiao, L.; Zhu, H.; Li, L.; Liu, F. Multitask Semantic Boundary Awareness Network for Remote Sensing Image Segmentation. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Shan, L.; Wang, W. DenseNet-Based Land Cover Classification Network with Deep Fusion. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Meng, X.; Yang, Y.; Wang, L.; Wang, T.; Li, R.; Zhang, C. Class-Guided Swin Transformer for Semantic Segmentation of Remote Sensing Imagery. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int J Geoinf 2022, 11. [Google Scholar] [CrossRef]
- Safarov, F.; Temurbek, K.; Jamoljon, D.; Temur, O.; Chedjou, J.C.; Abdusalomov, A.B.; Cho, Y.-I. Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture. Sensors 2022, 22. [Google Scholar] [CrossRef]
- Liu, Z.-Q.; Tang, P.; Zhang, W.; Zhang, Z. CNN-Enhanced Heterogeneous Graph Convolutional Network: Inferring Land Use from Land Cover with a Case Study of Park Segmentation. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Wang, D.; Yang, R.; Liu, H.; He, H.; Tan, J.; Li, S.; Qiao, Y.; Tang, K.; Wang, X. HFENet: Hierarchical Feature Extraction Network for Accurate Landcover Classification. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, M.; Wang, Y.; Shang, J.; Liu, X.; Li, B.; Song, A.; Li, Q. Automated Delineation of Agricultural Field Boundaries from Sentinel-2 Images Using Recurrent Residual U-Net. International Journal of Applied Earth Observation and Geoinformation 2021, 105. [Google Scholar] [CrossRef]
- Maggiolo, L.; Marcos, D.; Moser, G.; Serpico, S.B.; Tuia, D. A Semisupervised CRF Model for CNN-Based Semantic Segmentation with Sparse Ground Truth. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Barthakur, M.; Sarma, K.K.; Mastorakis, N. Modified Semi-Supervised Adversarial Deep Network and Classifier Combination for Segmentation of Satellite Images. IEEE Access 2020, 8, 117972–117985. [Google Scholar] [CrossRef]
- Wang, Q.; Luo, X.; Feng, J.; Li, S.; Yin, J. CCENet: Cascade Class-Aware Enhanced Network for High-Resolution Aerial Imagery Semantic Segmentation. IEEE J Sel Top Appl Earth Obs Remote Sens 2022, 15, 6943–6956. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, L.; Zhang, B.Y.J.; Sun, J.; Dong, S.; Wang, X.; Li, Y.; Xu, J.; Chu, W.; Dong, Y.; et al. Land Cover Classification in a Mixed Forest-Grassland Ecosystem Using LResU-Net and UAV Imagery. J For Res (Harbin) 2022, 33, 923–936. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, Z.; Chen, N.; Gong, J. Land Cover Classification Based on the PSPNet and Superpixel Segmentation Methods with High Spatial Resolution Multispectral Remote Sensing Imagery. J Appl Remote Sens 2021, 15. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens (Basel) 2018, 10. [Google Scholar] [CrossRef]
- Li, L.; Yao, J.; Liu, Y.; Yuan, W.; Shi, S.; Yuan, S. Optimal Seamline Detection for Orthoimage Mosaicking by Combining Deep Convolutional Neural Network and Graph Cuts. Remote Sens (Basel) 2017, 9. [Google Scholar] [CrossRef]
- Cecili, G.; De Fioravante, P.; Congedo, L.; Marchetti, M.; Munafò, M. Land Consumption Mapping with Convolutional Neural Network: Case Study in Italy. Land (Basel) 2022, 11. [Google Scholar] [CrossRef]
- Abadal, S.; Salgueiro, L.; Marcello, J.; Vilaplana, V. A Dual Network for Super-Resolution and Semantic Segmentation of Sentinel-2 Imagery. Remote Sens (Basel) 2021, 13. [Google Scholar] [CrossRef]
- Henry, C.J.; Storie, C.D.; Palaniappan, M.; Alhassan, V.; Swamy, M.; Aleshinloye, D.; Curtis, A.; Kim, D. Automated LULC Map Production Using Deep Neural Networks. Int J Remote Sens 2019, 40, 4416–4440. [Google Scholar] [CrossRef]
- Shojaei, H.; Nadi, S.; Shafizadeh-Moghadam, H.; Tayyebi, A.; Van Genderen, J. An Efficient Built-up Land Expansion Model Using a Modified U-Net. Int J Digit Earth 2022, 15, 148–163. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Shangguan, B.; Wang, M.; Wu, Z. A Multi-Level Context-Guided Classification Method with Object-Based Convolutional Neural Network for Land Cover Classification Using Very High Resolution Remote Sensing Images. International Journal of Applied Earth Observation and Geoinformation 2020, 88. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, C.; Fang, L.; Yan, Y. A Deep Learning Based Framework for Remote Sensing Image Ground Object Segmentation. Appl Soft Comput 2022, 130. [Google Scholar] [CrossRef]
- Guo, X.; Chen, Z.; Wang, C. Fully Convolutional Densenet with Adversarial Training for Semantic Segmentation of High-Resolution Remote Sensing Images. J Appl Remote Sens 2021, 15. [Google Scholar] [CrossRef]
- Zhang, B.; Wan, Y.; Zhang, Y.; Li, Y. JSH-Net: Joint Semantic Segmentation and Height Estimation Using Deep Convolutional Networks from Single High-Resolution Remote Sensing Imagery. Int J Remote Sens 2022, 43, 6307–6332. [Google Scholar] [CrossRef]
- Li, W.; Chen, K.; Shi, Z. Geographical Supervision Correction for Remote Sensing Representation Learning. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Shi, W.; Qin, W.; Chen, A. Towards Robust Semantic Segmentation of Land Covers in Foggy Conditions. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Fast and Accurate Land Cover Classification on Medium Resolution Remote Sensing Images Using Segmentation Models. Int J Remote Sens 2021, 42, 3277–3301. [Google Scholar] [CrossRef]
- Dechesne, C.; Mallet, C.; Le Bris, A.; Gouet-Brunet, V. Semantic Segmentation of Forest Stands of Pure Species Combining Airborne Lidar Data and Very High Resolution Multispectral Imagery. ISPRS Journal of Photogrammetry and Remote Sensing 2017, 126, 129–145. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, W.; Cao, J.; Xie, G. MKANet: An Efficient Network with Sobel Boundary Loss for Land-Cover Classification of Satellite Remote Sensing Imagery. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical Knowledge-Driven Representation Learning for Remote Sensing Images. IEEE Transactions on Geoscience and Remote Sensing 2022, 60. [Google Scholar] [CrossRef]
- Liu, W.; Liu, J.; Luo, Z.; Zhang, H.; Gao, K.; Li, J. Weakly Supervised High Spatial Resolution Land Cover Mapping Based on Self-Training with Weighted Pseudo-Labels. International Journal of Applied Earth Observation and Geoinformation 2022, 112. [Google Scholar] [CrossRef]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A.-B. Dense Dilated Convolutions Merging Network for Land Cover Classification. IEEE Transactions on Geoscience and Remote Sensing 2020, 58, 6309–6320. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Lu, F.; Xue, R.; Yang, G.; Zhang, L. Breaking the Resolution Barrier: A Low-to-High Network for Large-Scale High-Resolution Land-Cover Mapping Using Low-Resolution Labels. ISPRS Journal of Photogrammetry and Remote Sensing 2022, 192, 244–267. [Google Scholar] [CrossRef]
- Yuan, Q.; Mohd Shafri, H.Z. Multi-Modal Feature Fusion Network with Adaptive Center Point Detector for Building Instance Extraction. Remote Sens (Basel) 2022, 14. [Google Scholar] [CrossRef]
- Mboga, N.; D’aronco, S.; Grippa, T.; Pelletier, C.; Georganos, S.; Vanhuysse, S.; Wolff, E.; Smets, B.; Dewitte, O.; Lennert, M.; et al. Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa. ISPRS Int J Geoinf 2021, 10. [Google Scholar] [CrossRef]
- Zhang, Z.; Doi, K.; Iwasaki, A.; Xu, G. Unsupervised Domain Adaptation of High-Resolution Aerial Images via Correlation Alignment and Self Training. IEEE Geoscience and Remote Sensing Letters 2021, 18, 746–750. [Google Scholar] [CrossRef]
- Simms, D.M. Fully Convolutional Neural Nets In-the-Wild. Remote Sensing Letters 2020, 11, 1080–1089. [Google Scholar] [CrossRef]
- Liu, C.; Du, S.; Lu, H.; Li, D.; Cao, Z. Multispectral Semantic Land Cover Segmentation from Aerial Imagery with Deep Encoder-Decoder Network. IEEE Geoscience and Remote Sensing Letters 2022, 19. [Google Scholar] [CrossRef]
- Sun, P.; Lu, Y.; Zhai, J. Mapping Land Cover Using a Developed U-Net Model with Weighted Cross Entropy. Geocarto Int 2022, 37, 9355–9368. [Google Scholar] [CrossRef]
- Chen, J.; Sun, B.; Wang, L.; Fang, B.; Chang, Y.; Li, Y.; Zhang, J.; Lyu, X.; Chen, G. Semi-Supervised Semantic Segmentation Framework with Pseudo Supervisions for Land-Use/Land-Cover Mapping in Coastal Areas. International Journal of Applied Earth Observation and Geoinformation 2022, 112. [Google Scholar] [CrossRef]
Figure 1.
Flow chart of peer-review procedure.
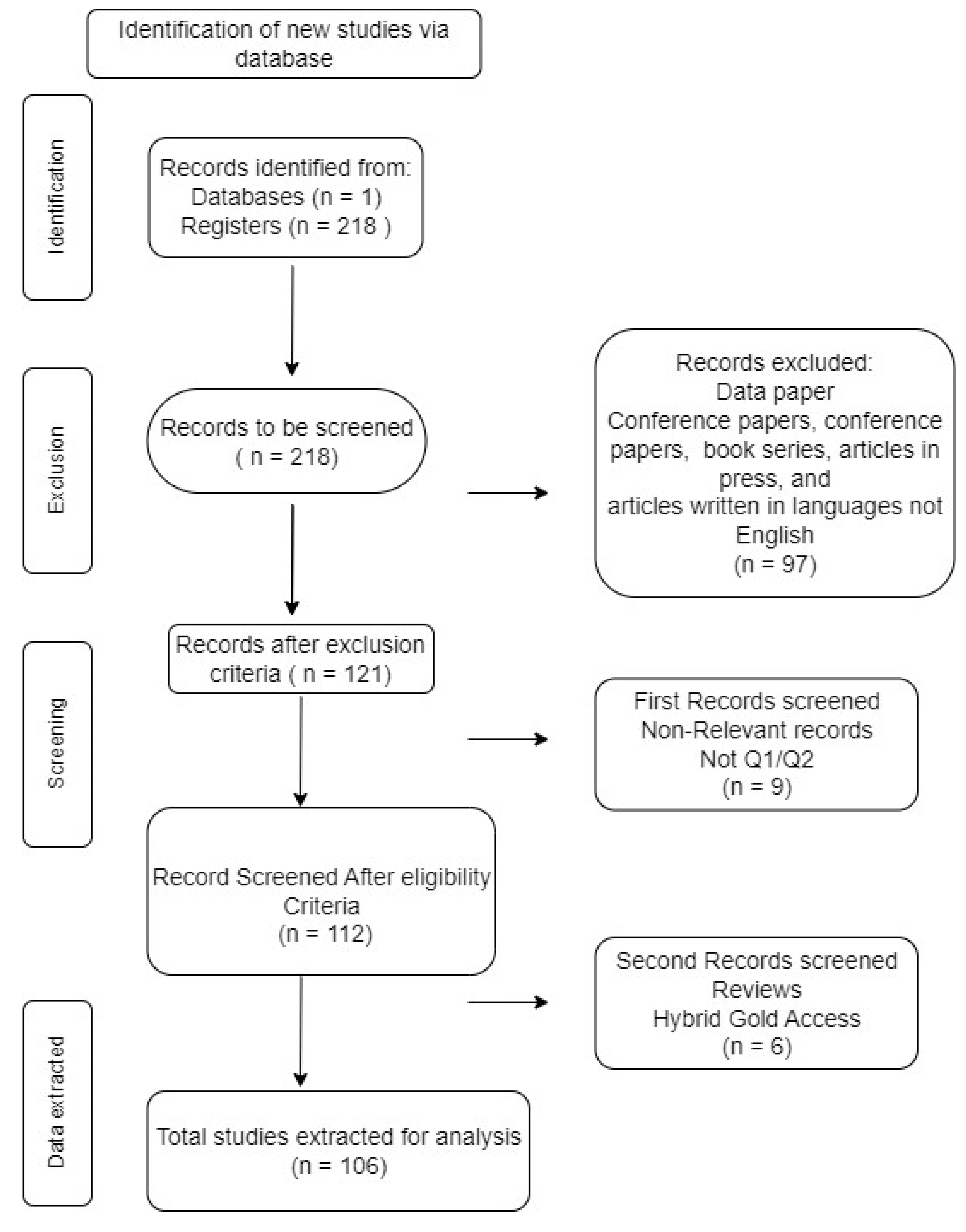
Figure 2.
Annual distribution of research studies.
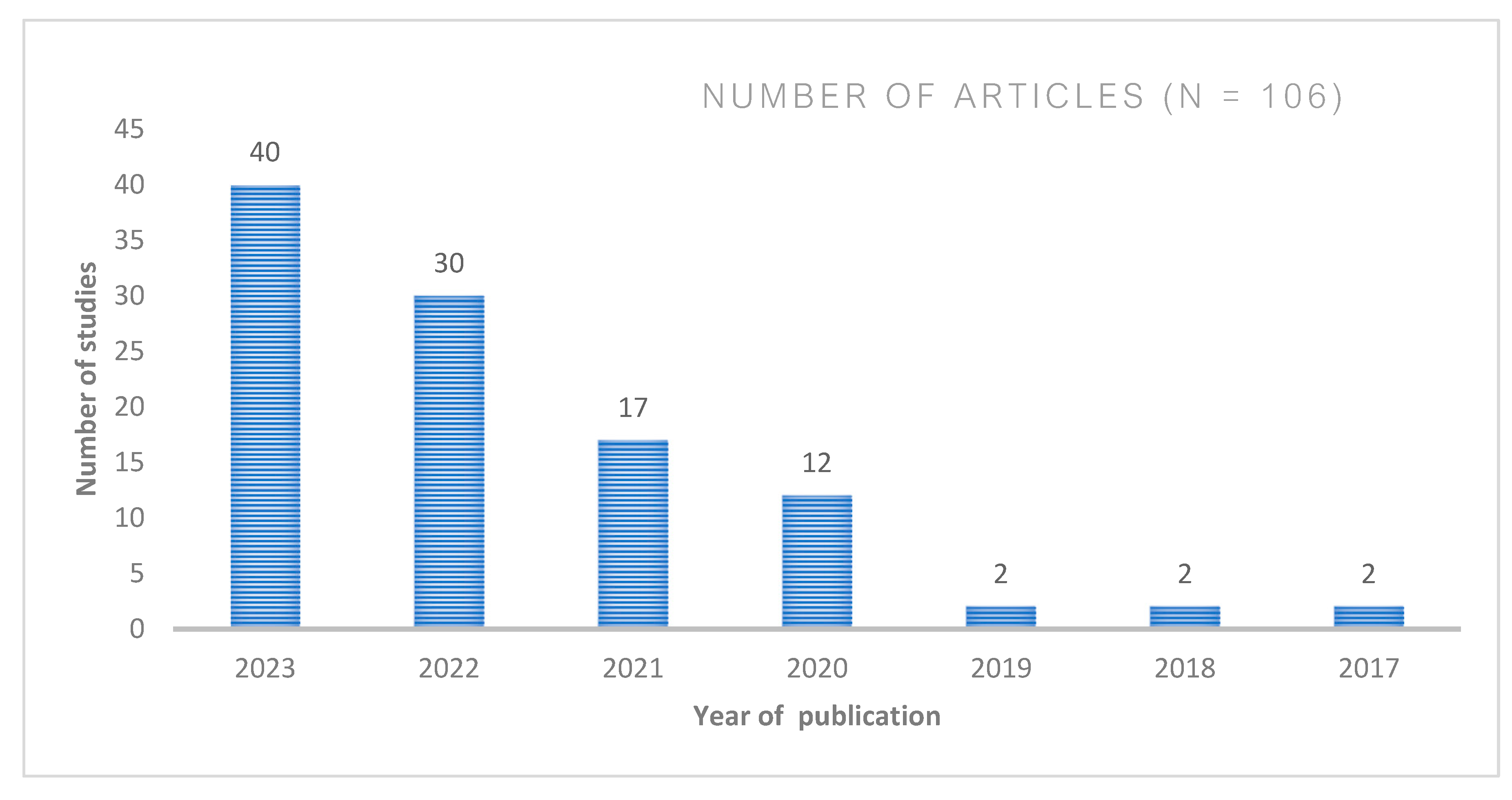
Figure 3.
Number of relevant publications in this field distributed per Journals.
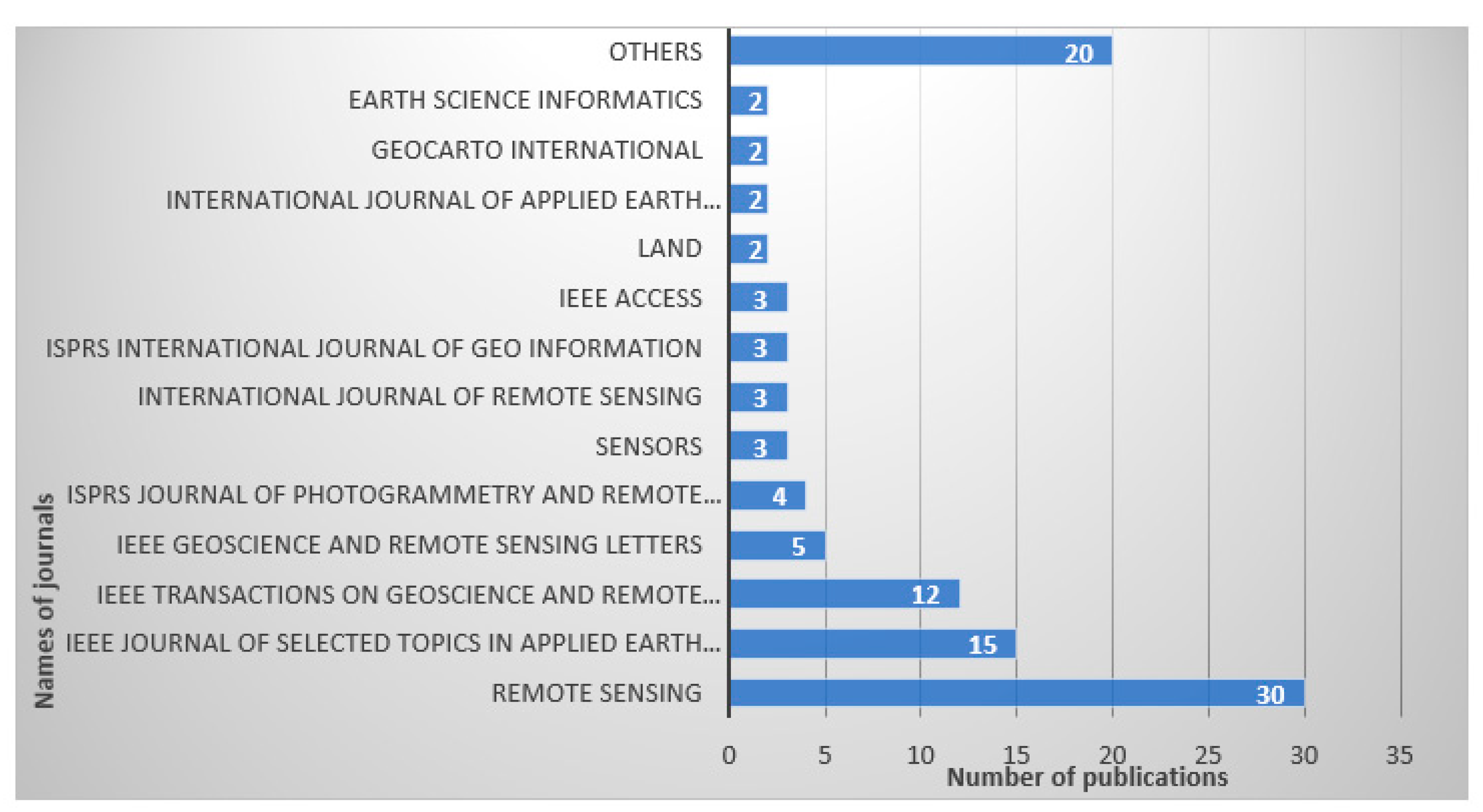
Figure 4.
Geographic distribution of studies per country.
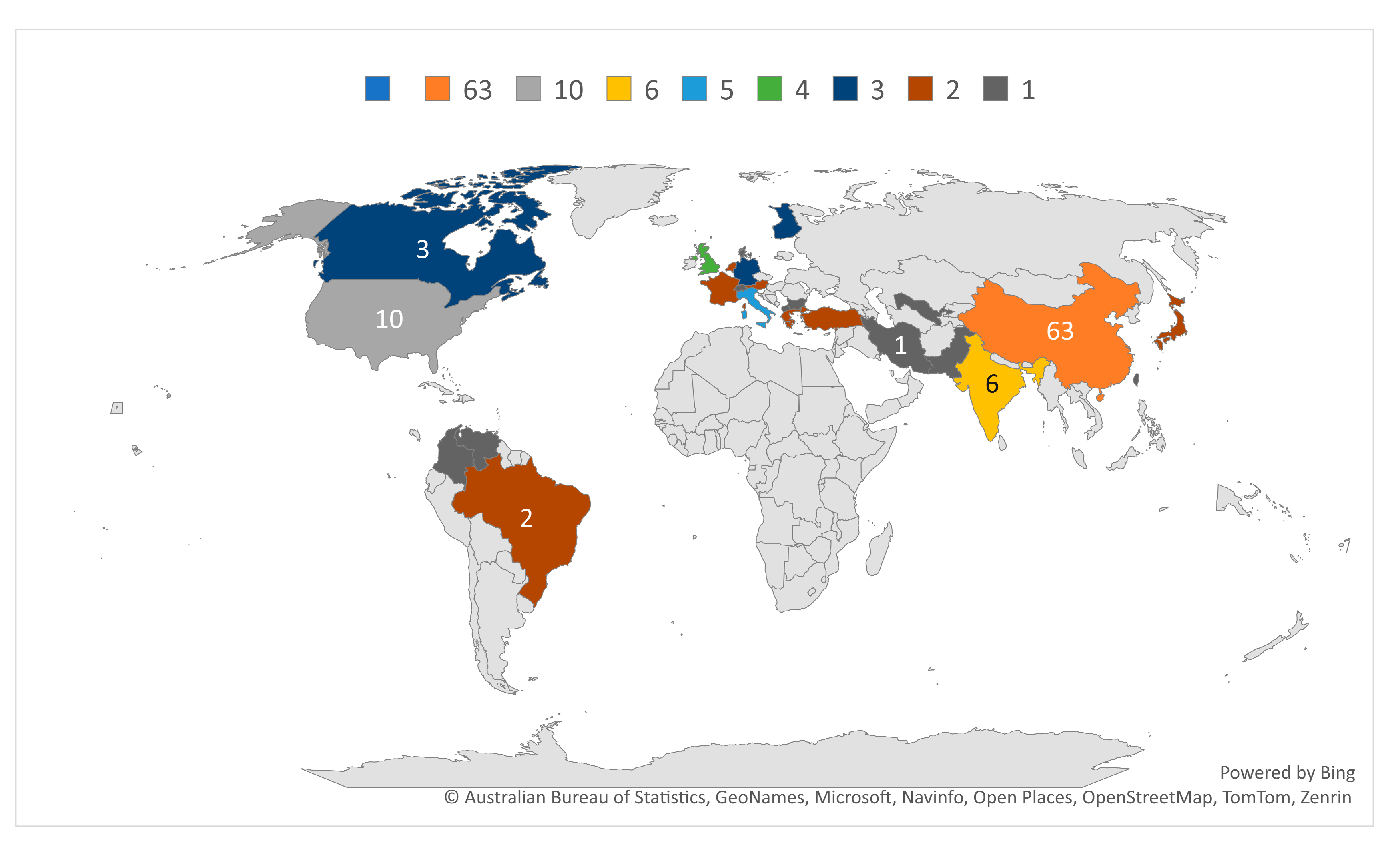
Figure 5.
Significant keywords occurrence driving domain theme.
Figure 8.
Number of publications per study location.
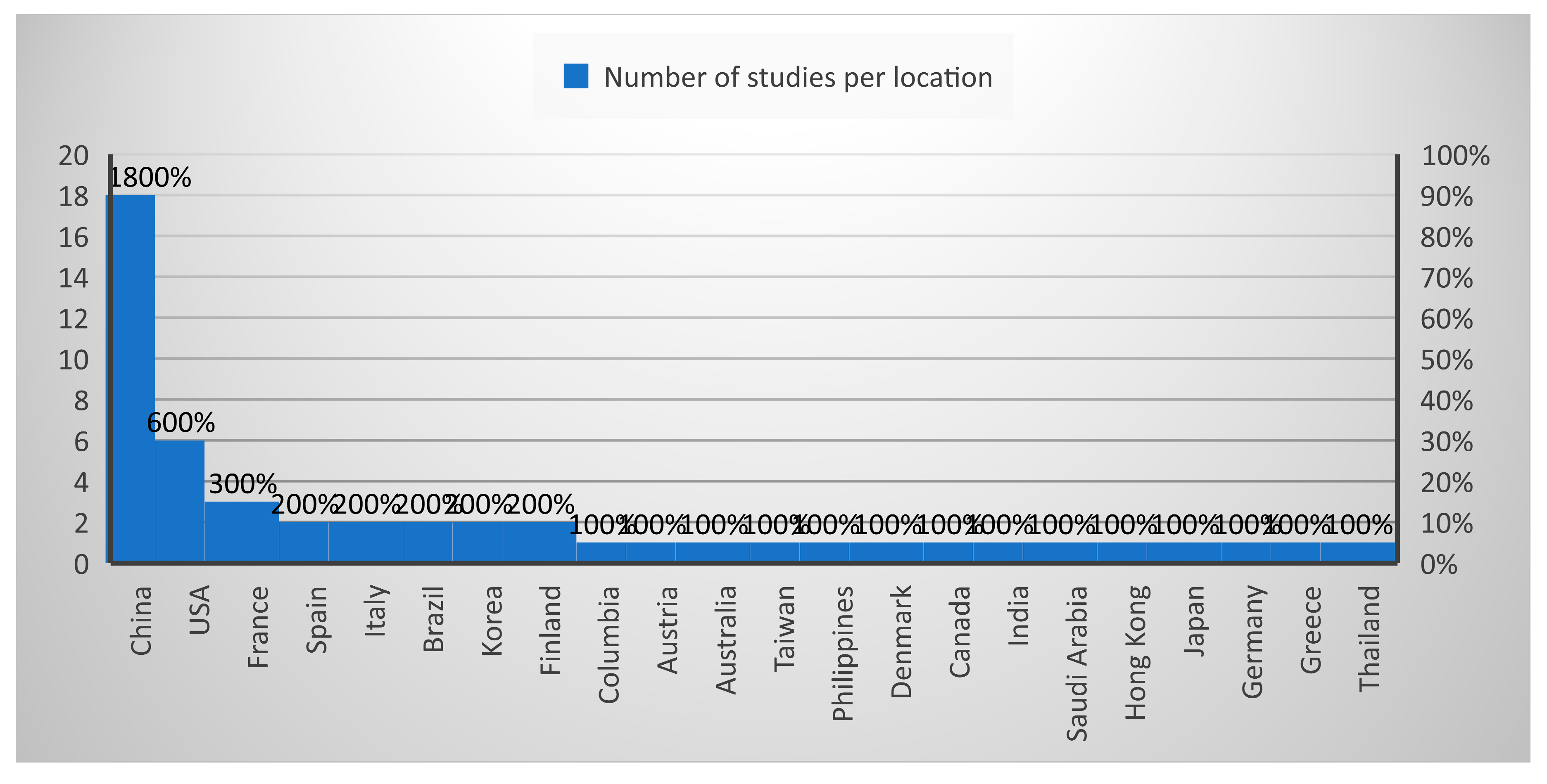
Figure 9.
Benchmark datasets identified in literatures.
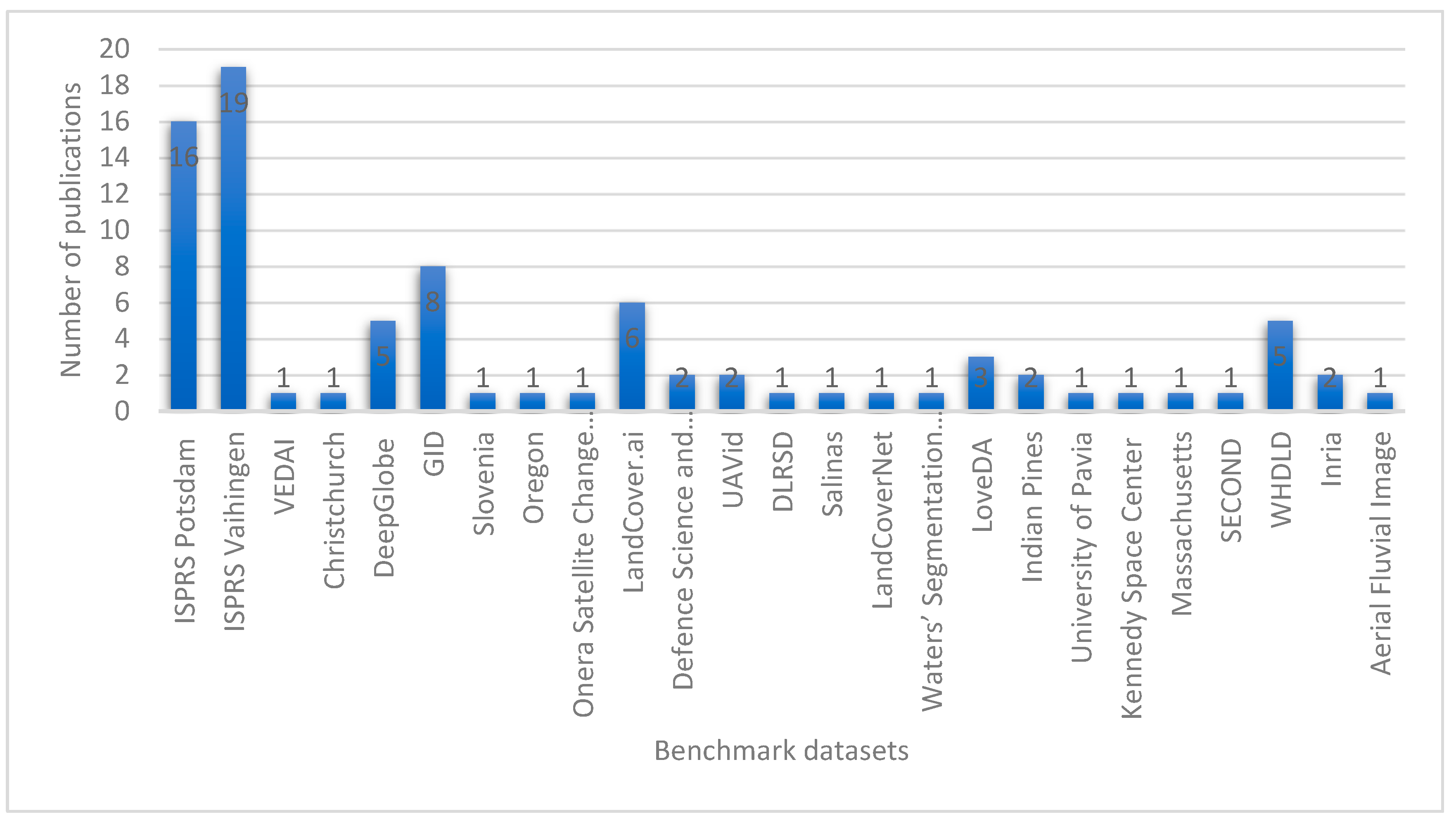
Table 1.
Data Sources identified in Review.
| Datasources | Number of articles | References |
|---|---|---|
| RS Satellites | ||
| Sentinel -2 | 7 | [46,65,66,67,68,69] |
| Landsat | 5 | [33,70,71,72] |
| Worldview-03 | 2 | [73,74] |
| Rapid eye | 1 | [75] |
| Worldview-02 | 1 | [76] |
| Quickbird | 1 | [76] |
| ZY-3 | 1 | [49] |
| PlanetScope | 1 | [50] |
| Aerial images | ||
| Phantom m multi-rotor AUS | 1 | [60] |
| Quadcopter drone | 1 | [62] |
| Vexcel Ultracam Eagle Camera | 1 | [77] |
| DJI-Phantom 4 pro UAV | 1 | [48] |
| SAR SAT | ||
| RADARSAT-2 | 1 | [78] |
| Sentinel -1 | 6 | [10,42,44,65,67,79] |
| GF-2 | 2 | [49,80] |
| GF-3 | 1 | [81] |
| ALOS-2 | 1 | [82] |
| Others | ||
| Earth digitalglobe | 2 | ,[45,61] |
| Mobile phone | 1 | [35] |
| Lidar Sources | 1 | [37] |
Table 2.
Encoder-Decoder based semantic segmentation models for land cover segmentation.
| Models | Datasets | Performance metrics | Limitation/future work |
|---|---|---|---|
| RAANet [111] | LoveDA, ISPRS Vaihingen |
MIoU=77.28, MIoU=73.47 |
Accuracy can be improved with Optimization. |
| PSE-UNet Model[116] | Salinas Dataset | MIoU=88.50 | Inaccurate segmentation of land cover features with low frequencies, superfluous parameter redundancy, and unvalidated generalization capabilities. |
| SEG-ESRGAN [117] | Sentinel-2 and WorldView-2 image pairs. | MIoU = 62.78 | The assessment of utilizing medium-resolution images has not been tested |
| Class-wise FCN [26] | Vaihingen, Potsdam | MIoU=72.35, MIoU=76.88 |
Enhancements in performance can be achieved through class-wise considerations for multiple classes, along with improved and more efficient implementations. |
| MARE [118] |
Vaihingen | MIoU=81.76 | Improve performance through parameter optimization and extend approach incorporating other self-supervised algorithms. |
| Feature fusion with dual attention and flexible contextual adaptation. [86] | Vaihingen, GaoFen-2 |
MIoU =70.51, MIoU =56.98 |
Computational complexity issue. |
| Deanet [103] | LandCover.ai, DSTL dataset, DeepGlobe |
MIoU=90.28, MIoU=52.70, MIoU=71.80 |
Suboptimal performance. Future efforts involve incorporating the spatial attention module into a single unified backbone network. |
| An encoder-decoder framework featuring attention-guided multi-scale context integration [119] | GF-2 images | MIoU= 62.3% | Reduced accuracy on imbalance data. |
Table 4.
Hybrid-based semantic segmentation models for land cover segmentation.
| Models | Datasets | Performance metrics | Limitation |
|---|---|---|---|
| RSI-Net [87] | Vaihingen, Potsdam, GID |
OA=91.83, OA=93.31, OA=93.67 |
Limitation in segmentation of pixel-wise semantics. Enhanced feature map fusion decoders can lead to performance improvements |
| CG-Swin [133] | Vaihingen, Potsdam |
OA = 91.68 MIoU=83.39, OA = 91.93 MIoU=87.61 |
Extending CG-Swin to accommodate multi-modal data sources for more comprehensive and robust classification. |
| HMRT [134] | Potsdam | OA = 85.99 MIoU=74.14 |
Parameter complexity issue, decrease in segmentation accuracy due to a lot of noise. Optimization is required. |
| UNetFormer [19] | UAVid v, Vaihingen, Potsdam, LoveDA |
MIoU=67.8, OA=91.0 MIoU=82.7, OA=91.3 MIoU=86.8, MIoU=52.4 |
Investigate the Transformer's potential and practicality in addressing geospatial vision tasks is open for research. |
| (TL-ResUNet) model [135] | DeepGlobe | IoU=0.81 | Improve classification performance is open for research, and developing real time and automated solution for land use land cover |
| CNN-enhanced heterogeneous GCN [136] | Beijing dataset, Shenzhen dataset. |
MIou= 70.48, MIoU= 62.45 |
Future endeavour is to optimize the utilization of pretrained deep CNN features and GCN features across various segmentation scales. |
| HFENet [137] | MZData, LandCover Dataset, WHU Building Dataset |
MioU= 87.19, MIoU= 89.69, MioU= 92.12 |
Time and Space complexity issues. Future work can be to automatically fine-tune the parameters to attain the optimal performance of the model. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



