
Submitted:
16 May 2024
Posted:
17 May 2024
You are already at the latest version
Abstract
Selecting road networks in cartographic generalization has consistently posed formidable challenges, driving research towards the application of intelligent models. Despite previous efforts, the accuracy and connectivity preservation in these studies, particularly when dealing with road types of similar sample sizes, still warrant improvement. To address these shortcomings, we introduce a Heterogeneous Graph Attention Network (HAN) for road selection, where feature masking method is initially utilized to assess the significance of road features. Concentrating on the most relevant features, two meta-paths are introduced within the HAN framework: one for aggregating features of the same road type within the first-order neighborhood, emphasizing local connectivity, and another extending this aggregation to the second-order neighborhood, capturing a broader spatial context. For a comprehensive evaluation, we introduce a set of metrics considering both quantitative and qualitative aspects of the road network. Compared to traditional neural networks, our HAN model demonstrates superior accuracy and F1-score, particularly for road types with comparable samples. Additionally, it enhances the overall connectivity of the selected network. In summary, our HAN-based method provides an advanced solution for road network selection, surpassing previous approaches in terms of accuracy and connectivity preservation.
Keywords:
cartographic generalization
; road network selection
; Heterogeneous Graph Attention Network
; meta path
; evaluation metrics
1. Introduction
Cartographic generalization, a fundamental technique in traditional cartography, remains a central focus in the realm of digital cartography, with automatic cartographic generalization standing out as a particularly challenging and innovative research frontier[1,2]. Within the cartographic generalization process, selection serves as the initial and pivotal step. Roads, as essential skeletal elements on maps, not only form a crucial component of maps but also command the attention and interest of both map users and cartographers. Given their significant roles in both social and military contexts, roads have become a focal point of extensive research and practical exploration worldwide, particularly in the realm of automatic road network selection[3,4,5].
Road network selection encompasses two key aspects: quantity selection and structure preservation. Quantity selection involves determining how many roads should be chosen, while structure preservation focuses on selecting which roads to include. Common methods for quantity selection include the square root model, correlation analysis, regression analysis, the map-suitable area-load method, and the geometric progression method[6]. The square root model and its variants are generally accepted as effective for quantity selection, shifting attention to the challenge of structure preservation.
In terms of structure preservation methods, constraint indicators are commonly considered based on semantics, geometry, and topology information. Structure preservation methods can be categorized into unsupervised and supervised approaches. Unsupervised selection methods include graph theory methods [7,8,9,10], block-based methods [11], stroke-based methods[12,13], and road grid density methods[14,15]. These methods primarily focus on the overall morphology of the road network using geometric and topological information. Among them, common improvement methods are based on the stroke-based approach [16]. Some scholars[17] have fused three algorithms (a stroke-based, a grid-based, and a combined stroke-mesh algorithm) with three selection methods and made corresponding improvements. In addition to geometric and topological considerations, road semantic information, such as POI (Point of Interest), Residential Areas, and Traffic Flow data, is also utilized for large-scale urban road network selection based on road functionality [18,19,20,21]. Unsupervised methods generally make better use of spatial and semantic information but require a deep understanding of the interactions between various road information and the formulation of selection rules. However, these methods are less automated due to their high subjectivity in determining constraint indicators and their weights.
The supervised selection methods of road networks have become a focal point of current discussions. With the rapid evolution of artificial intelligence, various techniques, including kernel machine learning [22], BP (back propagation) neural networks [23], Radial Basis Function [24], decision-tree-based (DT) models[25], and ontology knowledge reasoning [26], have been progressively applied to automate road network selection. And it has been demonstrated that road networks selected using machine learning models are extremely similar to the atlas maps [27],Despite these advancements, most supervised selection methods overlook the topological information inherent in road networks. Transforming the road network into a graph structure and employing graph theory in the automatic selection process has gained attention[28,29,30,31].
Leveraging the substantial achievements of deep convolutional neural networks in image recognition, Kipf and Welling [32] extended these networks to graph data, resulting in the development of Graph Convolutional Networks (GCN). While GCN effectively utilizes the topology information, its limited generalization ability, relying on the Laplacian operator, led scholars to introduce attention mechanisms into graph convolution, giving rise to Graph Attention Networks (GAT)[33].
The growing demand for graph convolution operations on large-scale graphs prompted the introduction of Graph Sampling Aggregation Networks (GraphSAGE)[34]. Unlike methods aggregating all neighboring nodes, GraphSAGE samples a subset of road neighboring nodes for aggregation, making it suitable for large-scale graphs. Scholarly study finds graph convolutional neural networks can learn spatial relationships[35]. Zhang et al. applied graph convolutional neural networks to automatic road network selection, comparing the performance of three homogeneous graph convolutional networks: GCN, GAT, and GraphSAGE [36]. Addressing the issue of gradient vanishing in deep graph neural networks, Zheng et al. incorporated architectures like JK-Nets, ResNet, and DenseNet into road network selection, resulting in significant performance improvements[37]. Additionally, Ma et al., Zhu et al., and Guo et al. utilized road stroke data to construct spectral domain graph convolution operators for road network selection[38,39,40]. Some scholars have also applied graph neural networks to the selection of rivers and achieved good results [41,42].
Despite the use of graph neural networks (GNNs) in previous studies for automatic road network selection, several shortcomings persist:
- Not exploring the importance of each feature of graph neural networks in the road network selection task;
- Performance Gaps in Intermediate-Grade Roads: Homogeneous graph selection algorithms exhibit poor performance, particularly concerning intermediate-grade roads. Additionally, there is a need to enhance the overall connectivity of the selected road network;
- Lack of Comparison in Transductive and Inductive Tasks: Previous studies have not adequately compared the selection performance of the model in both transductive and inductive tasks. Transductive tasks involve training a model on road data with a small number of known labels to infer the majority of the remaining labels. Inductive tasks, on the other hand, entail training a model on road data with numerous known labels to predict labels for nodes on a new road dataset. Such comparisons are essential for a comprehensive evaluation of the selection model, especially when considering road au-to-selection tasks in different spatial domains.
Addressing these shortcomings will contribute to the development of more robust and versatile graph neural network models for automatic road network selection.
2. Related Work
The classification of road types serves as a crucial constraint in road network selection, aiming to preserve high-grade roads while excluding low-grade ones. The complexity arises when dealing with intermediate-grade roads, where the challenge lies in achieving a balanced selection and removal ratio. Addressing these challenges is paramount for enhancing the precision and spatial coherence of road network selection models, especially in scenarios involving intermediate-grade roads.
Simultaneously, the exploration of heterogeneous graphs has gained prominence in graph neural network research, as highlighted by studies[43,44,45,46,47,48,49,50,51]. Unlike homogeneous graphs, heterogeneous graphs, or heterogeneous information networks, involve a graph data structure encompassing multiple node types or edge types. They serve to depict complex heterogeneous objects and their interactions, offering rich semantic information and an effective modeling tool for graph data mining.
In the context of road network selection, leveraging heterogeneous graph neural networks proves advantageous as they can harness the semantic information of roads. Through hierarchical training on the road network, these networks enhance the final selection outcomes. The key challenge in using heterogeneous graphs for road network selection lies in designing a method for road node aggregation that aligns with the characteristics of road selection, essentially, the establishment of a meta-path method. This methodological refinement is critical for optimizing the performance of road network selection models.
Certainly, it's recognized that roads of the same network type are typically designed to fulfill similar traffic demands during the planning and construction phases, serving comparable transportation purposes. For instance, highways are engineered for high-speed traffic, whereas urban arterial roads are constructed to accommodate urban traffic flow. Moreover, planning and design standards exert a pivotal influence on the correlation between different road types. The norms and standards established at the country, regional, or city level significantly shape the planning and design of roads. Similar planning and design standards often result in the creation of similar road types, thereby increasing their correlation.
Given this understanding, roads of the same type exhibit the highest correlation. To capture this correlation, two types of meta-paths have been devised based on the principle of road correlation. This principle facilitates the aggregation of the most pertinent road features. Specifically, each type of meta-path aggregates features from corresponding-order neighbors of the same road type. The rationale behind designing the second type of meta-path is that a single-layer convolution can effectively aggregate features from adjacent road nodes at a greater distance.
Leveraging the flexibility provided by the HAN (Heterogeneous graph attention network) model[52], which allows for the manual setting of meta-paths and employs a dual-layer attention mechanism for embedding road features, the HAN model is employed to embed road features for these two types of meta-paths. This approach enables a more nuanced representation of road characteristics based on their correlation and enhances the capabilities of the road network selection model.
In summary, recognizing the limitations of prior intelligent models in the road network selection task, our proposed approach addresses these shortcomings through a multi-step process. Initially, the dual graph is generated following data processing. Within the framework of a graph neural network, the significance of road features is evaluated using the feature masking method. Subsequently, the HAN model is introduced to refine the road network selection results. This is achieved by strategically designing two types of meta-paths, which capitalize on the road correlation principle. Finally, to validate the effectiveness of our proposed method, comprehensive comparisons are conducted against other classical intelligent models. The assessment encompasses both transductive and inductive tasks in the context of road selection. This rigorous evaluation serves to demonstrate the superiority and versatility of our proposed method in improving the precision and adaptability of road network selection processes. The detailed automatic road network selection process is illustrated in Figure 1.
3. Measurement of Road Feature Importance Based on Feature Masking Method
During the construction of graph data for road networks, the subjective nature of road feature selection introduces potential issues such as data redundancy, impacting model accuracy. Hence, it is imperative to delve into the significance of different road features in the road selection model. These features primarily stem from three dimensions: geometric, semantic, and topological.
Semantic features encompass road types, while geometric features comprise road length, the number of road vertices, road aspect ratio, mesh density, curvature ratio, and the coordinates of start and end points (X, Y). Topological features include degree, degree centrality, eigenvector centrality, betweenness centrality, and closeness centrality. For detailed information, please consult Table 1. Despite the ability of graph neural networks to capture road topology, the consideration of global topological features is currently absent. Consequently, this study also explores the significance of road topological features.
We used a relatively simple feature masking method to assess the importance of road features. Initially, all features slated for evaluation are fed into a two-layer Graph Attention Network (GAT)[33] model for training. The final trained model is determined by selecting the optimal Area Under the Curve (AUC) on the validation set. Subsequently, each feature under scrutiny is individually set to 0, and the ensuing change in the AUC metric on the validation set is observed. The evaluation of road feature importance is contingent upon the observed AUC variation. A higher decrease in the AUC value indicates greater importance for the corresponding road feature.
4. Construction of HAN Model for Road Network Selection
4.1. Meta-Path Design Method Based on Road Correlation
Before embarking on meta path design, it is crucial to establish the methodology for transforming the road network into graph data. In our proposed method, the road network type is designated as the node type in the graph data structure, leveraging the advantages of graph neural networks in embedding node features and aggregating features of neighboring nodes associated with them. In this context, intersections are treated as connecting edges, while roads are construed as nodes within the dual graph. Consequently, the original road network selection transforms into a question of node classification.
Figure 2 illustrates the transformation of a road network into a dual graph, using the U.S. 1M scale road network as an illustrative example. The four road types carry specific meanings:
These distinctions lay the foundation for a nuanced representation of the road network, enabling effective node classification and guiding subsequent meta path design.
(1) State Road: Highways constructed and maintained by state governments, facilitating connections between cities and regions within a state;
(2) US Road: Before the construction of the Highway System, US Roads served as the primary highway network. Nowadays, they continue to play a crucial role as major transportation corridors within states and between regions.
(3) Interstate Road: The primary objective of an Interstate Road is to enhance the safety and efficiency of automotive travel. Generally, Interstate Roads permit the fastest speeds compared to any other roadways in the vicinity.
(4) CR: County roads constructed and maintained by local governments, serve as vital conduits linking cities and regions within a county.
In the HAN model, the construction of the adjacency matrix deviates from the homogeneous graph convolution algorithm. Specific meta paths need to be devised for each category of road nodes, enabling the generation of distinct adjacency matrices to capture various semantics. A meta path, an abstract path pattern delineating node relationships in intricate networks, aids computer models in comprehending network structures. We explain the role of meta path in terms of movie, director, and actor as shown in Figure 3 below:
Since there is no direct edge connection between movies, the homomorphic graph neural network model is difficult to apply to the node embedding of heteromorphic graphs. to establish edge connections between movies, the actors, and the director are used as a bridge to establish connections. For example, if the actors in two movies are the same person, then the two movies can be connected. meta path will search for the corresponding neighbor nodes with which the node is semantically connected, so as to aggregate the features of the neighbor nodes for better embedding of its own features. So, meta paths contribute to a deeper understanding of information flow within complex networks, thereby improving model performance.
Graph neural networks outperform traditional neural networks in node classification by aggregating neighboring node features to create more robust node embeddings. The core principle involves aggregating node features closely linked to the target node, incorporating the features of neighboring nodes with strong connections. Following this methodology, meta paths for road networks can be crafted to aggregate features of closely related road nodes.
Given that roads of the same type generally adhere to similar design standards, functions, and purposes, they are inherently more closely related. Consequently, the connectivity and coherence of roads are typically considered during the planning and construction processes.
Two distinct types of meta paths were formulated for each road type. The first type consolidates node features of the same road type within the first-order neighbors, while the second type encompasses node features of the same road type within the second-order neighbors. In the case of N road types, N+1 meta paths are established. In instances where there is no road type attribute, the road network can be hierarchically divided using the back-propagation method based on semantic levels (He et al., 2015). Subsequently, the corresponding adjacency matrix can be generated following the design principles of meta paths outlined in the previous section.
Taking the example of roads labeled as 'State' in Figure 2, five meta paths are identified: ① State-State, ②State-State-State, ③ State-US-State, ④ State-Interstate-State, and ⑤ State-CR-State. In summary, two primary categories of meta paths are developed. The first type aggregates features of the same road type within the first-order neighbors, exemplified by ①. The second type aggregates features of the same road type within the second-order neighbors, illustrated by ②, ③, ④, and ⑤. Consequently, the four road types yield five distinct adjacency matrices. Using the node labeled '1' in Figure 2 as an illustration, the surrounding neighboring nodes aggregated under each meta path are detailed in Table 2.
4.2. Heterogeneous Graph Attention Network Embedding Road Features
The Heterogeneous Graph Attention Network is a deep learning model designed to handle heterogeneous graph data, characterized by diverse node and edge types. In the context of transforming road networks into graph data, the heterogeneity is manifested in the varied types of roads. Unlike traditional road selection models that typically focus on homogeneous graphs with nodes and edges of the same type, the HAN model autonomously configures meta-paths and employs both node-level and semantic-level attention mechanisms. To further explain node-level attention and semantic-level attention, Figure 4 shows how the node-level and semantic-level attention mechanisms are aggregated after the road network is transformed into a dual graph.
The HAN model is particularly adept at aggregating road neighboring features under two types of meta-paths. The semantic-level attention in road networks is influenced by road types, leading to varying attention coefficients as road features are embedded and aggregated along different meta-paths. Simultaneously, the node-level attention takes into account the attention weights of different road features from neighboring roads when aggregating features within the same meta-path. The node-level attention[52] coefficient is calculated as outlined by Wang et al.:
Where the notation represents the concatenation operation, and denote the features of its road and the features of the neighboring roads under this meta path, respectively. Additionally, represents the shared attention weights for the meta path Φ. The notation denotes the activation function, and the attention coefficients are normalized through a SoftMax layer.
represents the set of all road nodes; is the semantic level attention vector, is the weight matrix, and is the bias vector, which are the three trainable parameters shared for all meta paths. denotes the node level embedding vector of the ith node under that meta path. As shown in Eq. (3), , which is obtained under all meta paths, is normalized to finally obtain the semantic level attention coefficients.
In the proposed model, the initial step involves converting the road network into a dual graph. Subsequently, the spatial geometry features, semantic features, and topological features of the roads are amalgamated to construct a feature matrix. In this matrix, each row corresponds to a road, and each column represents a numericalized feature derived from the three types of features. Node-level attention coefficients play a pivotal role in aggregating neighboring road network features for each meta path, facilitating the generation of node-level embeddings for the road network.
Following this, semantic-level attention coefficients are employed to aggregate the node-level embedding features obtained from each meta path. This process culminates in the creation of semantic-level embeddings for the road network. It is important to note that the proposed model undergoes training using backpropagation and gradient descent, allowing for iterative refinement of the model parameters to enhance its performance.
4.3. The Framework of HAN Model
The framework of the HAN model is depicted in Figure 5. The model is composed of an input layer, a block of graph convolution layers, a fully connected layer, a prediction probability result layer, and a prediction result layer.
Taking the U.S. 1M scale road network as an example, the input layer represents five adjacency node graphs denoted by (1)-(5), each requiring aggregation under five distinct meta-paths. The HAN model's graph convolution module primarily involves aggregating node-level features using computed node-level attention coefficients and semantic-level features using semantic-level attention coefficients. The graph convolution block comprises two convolution layers, utilizing the ReLU function as a non-linear activation function, and applying Dropout for regularization.
The fully connected layer compresses the feature matrix into a prediction result matrix of size CR*RR. CR refers to the row number of the matrix, indicating a specific road for prediction purposes, while RR represents the number of columns in the matrix, which corresponds to the respective probabilities of selecting or not selecting a particular road.). The prediction probability result layer indicates the likelihood of selecting or not selecting each road segment. The prediction result layer determines the selection status of a road segment based on a selection threshold, where 1 indicates selection and 0 indicates non-selection.
The model is trained using the backpropagation gradient descent algorithm, with cross-entropy loss serving as the training objective, and the Adam optimizer employed for the training process.
5. Evaluation Metrics for the HAN Model
The assessment of road network selection quality is primarily centered on validating the preservation of spatial distribution characteristics, ensuring an appropriate density, and scrutinizing potential disruptions to road connectivity, among other considerations. Spatial distribution characteristics encapsulate the overall features of the road network, providing a comprehensive overview of its structure and layout. In contrast, density characteristics emphasize local attributes, focusing on the density and compactness of roadways within specific areas. Preserving these characteristics necessitates subjective qualitative evaluation, enabling a thorough understanding of the road network's layout and functionality.
The evaluation of road network selection results in this paper predominantly encompasses quantitative metrics and an assessment of spatial distribution. The AUC, ACC, and f1-score indicators serve as the primary metrics for evaluating the quantitative aspects of road network selection results. The AUC metric identifies the optimal model from the validation set, while the ACC and f1-score metrics gauge the model's proficiency in automatically selecting road networks. Furthermore, the evaluation includes road network density, as well as the number of isolated roads and their total length, to appraise the spatial distribution quality of the selection result.
5.1. Evaluation Metrics for Quantity Assessment of the HAN Model
AUC, ACC, and f1-score stand as widely employed evaluation metrics for binary classification models. ACC signifies the proportion of correctly predicted labels to the total number of samples. The ACC value serves as an indicator of the model's quality. Its calculation formula is expressed as follows [37]:
Where True Positive (TP) denotes the instances where both predicted and true values are positive, indicating true positive cases. False Positive (FP) represents instances where the predicted value is positive while the true value is negative, indicating false positive cases. False Negative (FN) signifies instances where the predicted value is negative while the true value is positive, indicating false negative cases. True Negative (TN) denotes instances where both predicted and true values are negative, indicating true negative cases.
The calculation principle of AUC involves determining the area under the Receiver Operating Characteristic (ROC) curve. This curve is formed by adjusting the probability threshold from 0 to 1, with the False Positive Rate (FPR) on the X-axis and the True Positive Rate (TPR) on the Y-axis. The calculation formulas are as follows [37]:
Furthermore, given the imbalanced distribution of positive and negative labels in road network data, AUC is employed as the evaluation metric for the road selection model on the validation set.
The f1-score, as the harmonic mean of recall and precision, provides an assessment of the model's performance on positive samples. In this study, the f1-score is utilized to evaluate the model's performance specifically on positive samples. The formula for calculating the f1-score is expressed as [37]:
The calculation formulas for recall and precision are defined as follows:
5.2. Road Network Density
Road network density is characterized as the ratio of the total length of roads within a specific area to the total area of that region, providing a measure of road density within the designated area. The calculation for road network density is described by Zheng et al. (2021) as:
Where represents the sum of the lengths of all roads within the specific area. In this study, road network density is selected as an evaluation metric for the model to assess its performance. The primary objective is to compare the road network density chosen by experts with that of the automatically selected road model.
5.3. Metrics Related to Isolated Road
To assess the connectivity of the chosen road network, both the total number and length of isolated roads are taken into account. The following method is employed to derive these metrics: Initially, the road network selected by the automatic selection model is transformed into graph data, focusing on road intersections. Subsequently, the largest connected subgraph within this graph data is extracted. Finally, roads within this largest connected subgraph lacking road intersections are identified as isolated roads. Utilizing GIS software, the total length and count of isolated roads are computed. Lower values for the total length and number of isolated roads indicate enhanced connectivity of the selected roads.
6. Experimental Process and Results
6.1. Experimental Data and Data Preprocessing
The experimental data utilized in this study comprises road network data of the United States, sourced from USGS and encompassing both 1M and 2M scale datasets. The experimental area chosen for analysis consists of nine eastern states of the United States, characterized by intricate road networks. These states include Illinois, Indiana, Kentucky, Ohio, West Virginia, Virginia, Pennsylvania, North Carolina, and parts of Maryland, as illustrated in Figure 6. The road network at scales of 1M and 2M within the study area is visualized in Figure 7.
To investigate the significance of road features, this study employed data from the first seven states and portions of Maryland. Employing an 8:2 ratio, positive and negative samples of various road types were randomly stratified and divided into training and validation sets. The count of positive and negative samples for each road type is presented in Table 3, while the spatial distribution of the two datasets is visualized in Figure 8.
For the transductive road selection task, the division of training, validation, and testing sets was performed through stratified random sampling of positive and negative samples in a ratio of 2:1:7. The spatial distribution of these three datasets is illustrated in Figure 9, and the corresponding quantitative statistics are presented in Table 4.
For the inductive road network selection model, the training and validation sets consist of positive and negative samples divided using stratified random sampling in an 8:2 ratio. The testing set is exclusively from North Carolina. The spatial distribution of the three datasets is depicted in Figure 10, and the quantity distribution is outlined in Table 5.
Data preprocessing encompasses the removal of isolated road segments and the execution of topological construction. For 1M road types, missing road types are imputed based on the road types connected to them in the 2M road data. Label construction for the training data primarily involves generating buffers at two different scales and then assigning labels based on the coverage area ratio of these buffers. The road network data slated for selection is assigned a label attribute of 1, indicating positive samples, while the remaining road network data receives a label attribute of 0, denoting negative samples. Following manual verification and adjustment of data labels, intersecting lines are segmented. Subsequently, the geometric and topological features of each road segment are computed, and ultimately, adjacency and feature matrices are constructed.
6.2. Results of Road Feature Importance Measurement
To assess the significance of road features in the divided dataset, a two-layer Graph Attention Network (GAT) road network auto-extraction model is employed, aligning with the framework of the HAN model. In the construction of the feature matrix for the GAT model, road types are encoded using one-hot encoding. Initially, all features are fed into the GAT model, featuring a hidden layer with 64 neurons, 4 attention heads, and a dropout rate of 0.1. The training steps and weight decay coefficient are manually adjusted. The model undergoes training for 1000 epochs, and the model exhibiting the highest AUC on the validation set is chosen as the final benchmark model, achieving an optimal AUC of 0.8413. Subsequently, the evaluated features are set to 0 in the feature matrix, and the trained model is employed to observe the change in AUC, thus gauging the contribution of each feature to the model. The experimental results are presented in Table 6.
The AUC changes of road features that positively impact the GAT model are consolidated and the proportion of each feature in the total sum is calculated. The results are visually represented in Figure 11.
The results indicate that road type holds the highest importance, followed by start and end points (X, Y), closeness centrality, degree centrality, road length, degree, curvature ratio, and betweenness centrality. Table 7 showcases the selection outcomes of the GAT model on the validation dataset, utilizing the partition threshold established by the total count selected by experts.
The GAT model exhibits insufficient performance for the State and CR road types, with limited discussion on the CR road type due to its constrained data volume. Particularly for the State Road type, characterized by a relatively balanced distribution of positive and negative samples, the GAT model's performance falls short of expectations. Consequently, there arises a need to develop dedicated automatic selection models tailored to specific road types within the road network. In response, the HAN model is introduced for the automatic selection of roads, enabling classification-based selection. The subsequent automatic road network selection model selects start and end points X, Y; clessness centrality; degree centrality; road length; degree, and curvature ratio as features for model training.
6.3. Analysis of the Road Selection Results in the Transductive Task
The transductive task involves training a model on the same graph data with a small number of known labels to infer the majority of the remaining labels. This task requires the model to generalize beyond the training samples, especially when dealing with limited labeled data. The application of this task to road selection occurs when only a few road segments are known, and the objective is to predict the selection of the remaining road segments within the same road network.
To evaluate the selection performance of the HAN model, it is compared with Multilayer Perceptron (MLP), the homogeneous graph neural network GAT, and the Fast Graph Transformer Networks (FastGTN). Notably, the FastGTN [50] model possesses the ability to automatically generate meta paths.
The parameters for different models are configured as follows: The MLP model has 512 hidden layers, while the HAN and GAT models both have hidden layers with 64 neurons, 4 attention heads, and a dropout rate of 0.1. Conversely, the FastGTN model features hidden layer neurons set to 128 with 4 channels. In the FastGTN model, the initial matrix takes into account the adjacency of all road types, resulting in a total of N^2 initial matrices, where each road type is adjacent to N other road types.
The weight decay coefficients and training step lengths are manually adjusted, and training is conducted for 1000 epochs. Optimal AUC on the validation set, being suitable for imbalanced binary classification problems, is selected as the final model, and performance metrics are compared on the test set. Since the model output represents selection probabilities when aggregated from 1M to 2M, the threshold for the selection quantity is determined based on road data of two different scales.
The HAN model selects roads based on road types individually, and all models in this study use expert-selected quantities for various road types to establish selection thresholds. Given the limited quantity of CR-type roads, the HAN model cannot be adequately trained for this specific road type. Consequently, individual comparisons for CR roads are not conducted, and the overall selection results for CR roads in the HAN model are computed based on the GAT model's selection results. To standardize variables, CR-type roads in other models are also based on the GAT model's selection results.
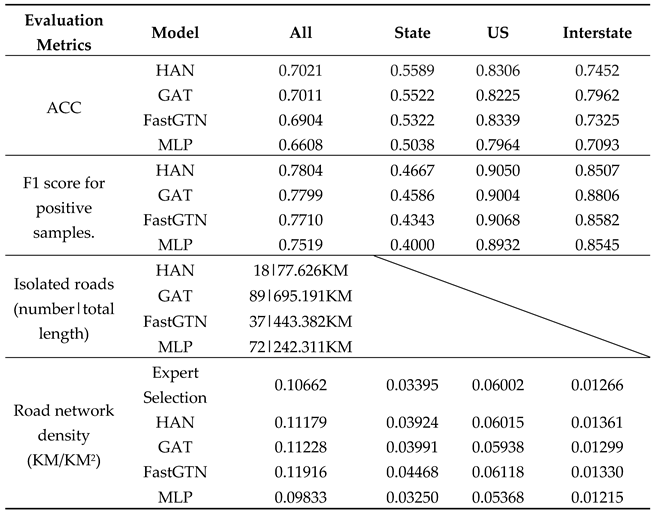
In the experimental road network data, the number of positive and negative samples for state roads is relatively balanced. Table 8 illustrates that the HAN model's selection for State-type roads surpasses other models in terms of ACC and f1-score. Specifically, ACC and f1-score are 1.62% and 1.43% higher, respectively, compared to other models. Overall, for the selection by the HAN model, ACC and f1-score are 1.02% and 1.01% higher, respectively, than other models. In terms of the quantity and total length of isolated roads, the HAN model records 158 fewer roads and 1414.441KM less than other optimal models.
The comparison of the selection results of the four models with the expert selection results is depicted in Figure 12. The four models tend to under-select the middle of the road network, although the HAN model and the GAT model show improvement. Additionally, the HAN model exhibits the lowest number of isolated roads among the four models.The main reason why most of the isolated roads appear at the edges of the road network is because the cropping operation of the road network destroys the original topological features of the roads at the margins, so it produces many isolated roads appearing at the margins of the road network.
To assess the spatial equilibrium of road network density, this study partitions the road network into 5-kilometer grids aligned with the study area. The standard deviation of road network density across these grids is computed to determine the evenness of the selected road density distribution. The experts' selected 5-km grid exhibits a road network density standard deviation of 0.059187, whereas the HAN model exhibits a standard deviation of 0.069638, the GAT model has a standard deviation of 0.069483, the FastGTN model has a standard deviation of 0.069356, and the MLP model exhibits a standard deviation of 0.073987.
To examine the spatial distribution of selection and deletion outcomes from selection models, Figure 13 compares the spatial distribution of the selection results from the four models with the expert selection results. Notably, all four selection models exhibit a significant number of erroneous deletions in the central region of the road network and a notable number of erroneous selections in the upper right corner.
6.4. Analysis of the Road Selection Results in the Inductive Task
The inductive task involves training a model on a graph dataset with numerous known labels to predict the labels of nodes in a new graph. This task is particularly suitable for road auto-selection tasks in different spatial domains. The parameters for different models are configured as follows: The HAN model features 512 hidden layers, 4 attentional heads, and a dropout rate of 0.1, while the GAT model has 64 hidden layers, 4 attentional heads, and a dropout rate of 0.1. On the other hand, the MLP has 512 hidden layers, and the FastGTN has 512 hidden layers and 4 channels. The training step size and weight decay rate are manually adjusted. A total of 1000 epochs are trained, and the model with the highest AUC on the validation set is selected as the final model for testing on the test set. Due to the limited number of CR road types, they were not analyzed separately.
Table 9 indicates that the HAN model outperforms other models in selecting State-type roads, achieving higher accuracy (ACC) and f1-score. Specifically, the HAN model surpasses other optimal models by 0.67% and 0.81% in terms of ACC and f1-score, respectively. In terms of the quantity and total length of isolated roads, the HAN model falls short of other optimal models, with 19 fewer roads and 365.756 KM less than other models.
Figure 14 compares the selection results of the four models with the expert selection. The spatial distribution of the road network selected by the MLP model is highly fragmented, and numerous isolated roads are present in both the FastGTN and GAT models. Overall, the HAN model performs better than the other models, exhibiting the minimum number of isolated roads. The density standard deviation of the 5KM grid selected by the experts is 0.06117, while that of the HAN model is 0.058875, GAT model is 0.059803, FastGTN model is 0.06099, and MLP model is 0.072805.
To examine the spatial distribution of the selection and deletion results of the four models, Figure 15 compares their selection outcomes with the expert's selection. The comparison reveals that the MLP model exhibits numerous mistakenly deleted roads concentrated in the middle of the road network, while the FastGTN model shows more mistaken selections in the road network. In contrast, the HAN and GAT models display more evenly distributed patterns of mistakenly deleted roads. These findings suggest that the HAN and GAT models exhibit more balanced and consistent selection results compared to the other models.
7. Conclusion and Discussion
Our objective is to tackle the challenges encountered by homogeneous graph neural networks in accurately selecting road types within a road network, especially when dealing with similar numbers of selections and deletions. Additionally, we aim to enhance the spatial distribution of the selected road network. To achieve this, we have devised two distinct meta-paths for each road type, adhering to the principle of aggregating the most pertinent features from neighboring nodes. This approach allows us to construct a heterogeneous graph attention network specifically designed for intelligent road network selection.
In addition, we have applied the feature masking method to explore the significance of three key road features in automatic road network selection models based on graph neural networks: geometric features, semantic features, and topological features. Our findings uncover that road type stands out as the most crucial feature, closely followed by start and end points (X, Y), closeness centrality, degree centrality, length, degree, curvature ratio, and betweenness centrality. Conversely, mesh density, the number of road vertices, and eigenvector centrality exhibit a negative influence on the model's performance.
For the transductive road network selection task, the HAN model demonstrates superior performance compared to other optimal models. It achieves a 1.62% higher accuracy and a 1.43% higher F1-score in the selection and deletion of a similar number of State Road types. When considering the overall selection results, the HAN model further outperforms the remaining optimal models by increasing accuracy metrics and F1-Score by 1.02% and 1.01%, respectively. Additionally, the HAN model significantly reduces the number of isolated road networks and the total length of the selection results by 79.78% and 63.60%, respectively, compared to the other models.
In the inductive road network selection task, the HAN model also excels, achieving a 0.67% higher accuracy index and a 0.81% higher F1-Score than the remaining optimal models for State Road types. Furthermore, the HAN model reduces the number and length of isolated road networks by 51.35% and 67.96%, respectively, compared to the other models. This improved performance can be attributed to the second-layer convolution of the HAN model, which effectively extracts a wider range of peripheral node features, as four out of its five mating paths are second-order neighbors.
It is worth emphasizing that while FastGTN can indeed automatically generate a range of meta-paths, it falls short in effectively incorporating the background knowledge specific to road network selection. Experimental results underscore the superiority of the HAN model presented in this article, which is explicitly designed based on road correlation. When compared to the FastGTN model, the HAN model demonstrates superior efficiency and accuracy in road network selection tasks. This advantage can be attributed to the HAN model's ability to leverage domain-specific knowledge, enabling it to make more informed and precise decisions during the selection process.
The primary contribution of this paper lies in quantifying the significance of road features within graph neural network models, developing a refined set of evaluation metrics for road network selection, and innovatively designing two distinct meta-paths for road network aggregation based on neighboring node features. By applying a heterogeneous graph neural network to the automated selection of road networks, we have achieved the establishment of individual, automated selection models tailored for each road type.
Across two road network selection tasks, our approach enhances the precision of selecting road types with a comparable number of deletions and significantly mitigates the issue of excessive isolated roads within the selected network. Notably, our current research has not delved into the model's performance for road network selection using existing methods to generate road types in scenarios where road type attributes are absent.
Future work will focus on exploring which methods generate road types that yield optimal performance within this model. Additionally, we aim to investigate the model's effectiveness in selection tasks across varying scales, thus broadening its applicability and further validating its utility in real-world scenarios.
Author Contributions
Conceptualization, Haohua Zheng and Jianchen Zhang; methodology, Haohua Zheng and Jianchen Zhang; software, Haohua Zheng; resources, Jiayao Wang and Jianzhong Guo; writing—original draft preparation, Haohua Zheng and Jianchen Zhang; writing—review and editing, Heying Li and Guangxia Wang. All authors have read and agreed to the published version of the manuscript.
Funding
The Project Supported was by Henan Provincial Natural Science Foundation (grant number 232300420436, 242300420589), Science and Technology Development Project of Henan Province (grant number: 242102210175), the National Natural Science Foundation of China (grant number U21A2014), Henan Collaborative Innovation Center of Geo-Information Technology for Smart Central Plains (grant number 2023C001), and the Open Fund of Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Natural Resources (grant number KF-2022-07-020).
Data Availability Statement
The current study’s data are available from the corresponding author based on a reasonable request.
Acknowledgments
We would like to thank the anonymous reviewers for their insightful comments and substantial help in improving this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, Zhilin, Wanzeng Liu, Zhu Xu, Peng Ti, Peichao Gao, Chaode Yan, Yan Lin, Ran Li, and Chenni Liu. "Cartographic Representation of Spatio-Temporal Data : Fundamental Issues and Research Progress." Acta Geodaetica et Cartographica Sinica 50, no. 8 (2021): 1033-48. [CrossRef]
- Wang, Jiayao, Fang Wu, and Haowen Yan. "Cartography:Its Past,Present and Future." Acta Geodaetica et Cartographica Sinica 51, no. 6 (2022): 829-42. [CrossRef]
- Reichstein, M., G. Camps-Valls, B. Stevens, M. Jung, J. Denzler, N. Carvalhais, and Prabhat. "Deep Learning and Process Understanding for Data-Driven Earth System Science." Nature 566, no. 7743 (2019): 195-204. [CrossRef]
- Kronenfeld, Barry J., Barbara P. Buttenfield, and Lawrence V. Stanislawski. "Map Generalization for the Future: Editorial Comments on the Special Issue." ISPRS International Journal of Geo-Information 9, no. 8 (2020). [CrossRef]
- Li, Zhilin, Tian Lan, Peng Ti, and Zhu Xu. "Advances in Cartography from the Perspective of Maslow's Hierarchy of Needs." Acta Geodaetica et Cartographica Sinica 51, no. 7 (2022): 1536-43. [CrossRef]
- Wu, Fang, Xianyong Gong, and Jiawei Du. "Overview of the Research Progress in Automated Map Generalization." Acta Geodaetica et Cartographica Sinica 46, no. 10 (2017): 1645-64. [CrossRef]
- Jiang, B., and C. Claramunt. "A Structural Approach to the Model Generalization of an Urban Street Network*." GeoInformatica 8, no. 2 (2004): 157-71. [CrossRef]
- Touya, Guillaume. "A Road Network Selection Process Based on Data Enrichment and Structure Detection." Transactions in GIS 14, no. 5 (2010): 595-614. [CrossRef]
- Weiss, Roy, and Robert Weibel. "Road Network Selection for Small-Scale Maps Using an Improved Centrality-Based Algorithm." Journal of Spatial Information Science, no. 9 (2014). [CrossRef]
- Shoman, Wasim, and Fatih Gülgen. "Centrality-Based Hierarchy for Street Network Generalization in Multi-Resolution Maps." Geocarto International 32, no. 12 (2016): 1352-66. [CrossRef]
- Gülgen, F., and T. Gökgöz. "A Block-Based Selection Method for Road Network Generalization." International Journal of Digital Earth 4, no. 2 (2011): 133-53. [CrossRef]
- Thomson, Robert C. "The’ Stroke’ Concept in Geographic Network Generalization and Analysis." In Progress in Spatial Data Handling: 12th International Symposium on Spatial Data Handling, edited by Andreas Riedl, Wolfgang Kainz and Gregory A. Elmes, 681-97. Berlin, Heidelberg: Springer Berlin Heidelberg, 2006.
- Zhou, Qi, and Zhilin Li. "A Comparative Study of Various Strategies to Concatenate Road Segments into Strokes for Map Generalization." International Journal of Geographical Information Science 26, no. 4 (2012): 691-715. [CrossRef]
- Chen, Jun, Yungang Hu, Zhilin Li, Renliang Zhao, and Liqiu Meng. "Selective Omission of Road Features Based on Mesh Density for Automatic Map Generalization." International Journal of Geographical Information Science 23, no. 8 (2009): 1013-32. [CrossRef]
- Zhou, Qi, and Zhilin Li. "Empirical Determination of Geometric Parameters for Selective Omission in a Road Network." International Journal of Geographical Information Science 30, no. 2 (2015): 263-99. [CrossRef]
- Liu, and Li. "A New Algorithms of Stroke Generation Considering Geometric and Structural Properties of Road Network." ISPRS International Journal of Geo-Information 8, no. 7 (2019). [CrossRef]
- Benz, Stefan A., and Robert Weibel. "Road Network Selection for Medium Scales Using an Extended Stroke-Mesh Combination Algorithm." Cartography and Geographic Information Science 41, no. 4 (2014): 323-39. [CrossRef]
- Xu, Zhibang, Zhonghui Wang, Hanwen Yan, Fang Wu, Xiaoqi Duan, and Li Sun. "A Method for Automatic Road Selection Combined with Poi Data." Journal of Geo-information Science 20, no. 2 (2018): 159-66.
- Deng, Min, Xueying Chen, Jianbo Tang, Huimin Liu, and Jinqiang He. "A Method for Road Network Selection Considering the Traffic Flowsemantic Information." Geomatics and Information Science of Wuhan University 45, no. 9 (2020). [CrossRef]
- Yu, Wenhao, Yifan Zhang, Tinghua Ai, Qingfeng Guan, Zhanlong Chen, and Haixia Li. "Road Network Generalization Considering Traffic Flow Patterns." International Journal of Geographical Information Science 34, no. 1 (2020): 119-49. [CrossRef]
- Lyu, Zheng, Qun Sun, Jingzhen Ma, Qing Xu, Yuanfu Li, and Fubing Zhang. "Road Network Generalization Method Constrained by Residential Areas." ISPRS International Journal of Geo-Information 11, no. 3 (2022). [CrossRef]
- Liu, K, and J.S Ma. "Research on Intelligent Selection Ofroad Network Automatic Generalization Based on Kernel-Based Machine Learning." Nanjing University: Nanjing, China (2017).
- Liu, Kai, Jin Li, Jie Shen, and jinsong Ma. "Selection of Road Network Using Bp Neural Networkand Topological Parameters." Journal of Geomatics Science and Technology 33, no. 3 (2016): 325-30.
- Liu, Pei, Linhui Yuan, Kang Zhang, Jie Shen, and Jinsong Ma. "Intelligent Selection of Osm Road Network Based on Rbf Neural Network." Geomatics World 26, no. 3 (2019): 8-13.
- Karsznia, Izabela, Karolina Wereszczyńska, and Robert Weibel. "Make It Simple: Effective Road Selection for Small-Scale Map Design Using Decision-Tree-Based Models." ISPRS International Journal of Geo-Information 11, no. 8 (2022). [CrossRef]
- Guo, Xuan, Haizhong Qian, Xiao Wang, Junnan Liu, Yan Ren, Yuzhe Zhao, and Guoqing Chen. "Ontology Knowledge Reasonin Method for Multi-Source Intelligent Road Selection." Acta Geodaetica et Cartographica Sinica 51, no. 2 (2022): 279-89. [CrossRef]
- Karsznia, Izabela, Albert Adolf, Stefan Leyk, and Robert Weibel. "Using Machine Learning and Data Enrichment in the Selection of Roads for Small-Scale Maps." Cartography and Geographic Information Science 51, no. 1 (2023): 60-78. [CrossRef]
- Wang, Jiayao, Tiejun Cui, and Guangxia Wang. "Application of Graph Theory in Automatic Selection of Road Network." Journal of Geomatics Science and Technology 1 (1985).
- Liu, Gang, YongShu Li, Jun Yang, and Xiping Zhang. "Auto-Selection Method of Road Networks Based on Evaluation of Node Importance for Dual Graph." Acta Geodaetica et Cartographica Sinica 43, no. 1 (2014): 97-104.
- Cao, Weiwei, Hong Zhang, Jing He, and Tian Lan. "Road Selection Considering Structural and Geometric Properties." Geomatics and Information Science of Wuhan University 42, no. 4 (2017): 520-24. [CrossRef]
- 31. Ma, Chao, Qun Sun, Huanxin Chen, Qing Xu, and Bowei Wen. "Application of Weighted Pagerank Algorithm in Road Network Auto-Selection." Geomatics and Information Science of Wuhan University 43, no. 8 (2018): 1159-65. [CrossRef]
- Kipf, Thomas N., and Max Welling. "Semi-Supervised Classification with Graph Convolutional Networks." (2016). [CrossRef]
- Velikovi, Petar, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. "Graph Attention Networks." (2017).
- Hamilton, William L, Rex Ying, and Jure Leskovec. "Inductive Representation Learning on Large Graphs." (2017).
- Courtial, Azelle, Guillaume Touya, and Xiang Zhang. "Can Graph Convolution Networks Learn Spatial Relations?" Abstracts of the ICA 3 (2021): 1-2. [CrossRef]
- Zhang, Kang, Jing Zheng, Jie Shen, and Jinsong Ma. "Application of the Graph Convolution Network in the Selection of Road Network." Science of Surveying and Mapping 46, no. 2 (2021): 165-70+77.
- Zheng, J., Z. R. Gao, J. S. Ma, J. Shen, and K. Zhang. "Deep Graph Convolutional Networks for Accurate Automatic Road Network Selection." ISPRS International Journal of Geo-Information 10, no. 11 (2021): 22. [CrossRef]
- Ma, Chao, Shun Xiong, and Danni Jiang. "Application of the Graph Convolution Network in the Road Network Auto-Selection." Science of Surveying and Mapping 47, no. 12 (2022): 200-05+15.
- Zhu, Yude, Min Yang, and Xiongfeng Yan. "A Road Network Selection Method Using Graph Convolutional Network." Beijing Surveying and Mapping 36, no. 11 (2022): 1455-59.
- Guo, X., J. N. Liu, F. Wu, and H. Z. Qian. "A Method for Intelligent Road Network Selection Based on Graph Neural Network." ISPRS International Journal of Geo-Information 12, no. 8 (2023). [CrossRef]
- Wang, Di, and Haizhong Qian. "Graph Neural Network Method for the Intelligent Selection of River System." Geocarto International 38, no. 1 (2023). [CrossRef]
- Yu, Huafei, Tinghua Ai, Min Yang, Jingzhong Li, Lu Wang, Aji Gao, Tianyuan Xiao, and Zhe Zhou. "Integrating Domain Knowledge and Graph Convolutional Neural Networks to Support River Network Selection." Transactions in GIS 27, no. 7 (2023): 1898-927. [CrossRef]
- Sun, Yizhou, and Jiawei Han. "Mining Heterogeneous Information Networks: A Structural Analysis Approach." SIGKDD Explor. Newsl. 14, no. 2 (2013): 20–28. [CrossRef]
- Zhang, J., C. T. Lu, M. Zhou, S. Xie, Y. Chang, and P. S. Yu. "Heer: Heterogeneous Graph Embedding for Emerging Relation Detection from News." Paper presented at the 2016 IEEE International Conference on Big Data (Big Data), 5-8 Dec. 2016 2016. [CrossRef]
- Dong, Yuxiao, Nitesh V. Chawla, and Ananthram Swami. "Metapath2vec: Scalable Representation Learning for Heterogeneous Networks." In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 135–44. Halifax, NS, Canada: Association for Computing Machinery, 2017. [CrossRef]
- Sankar, A., X. Zhang, and K. C. C. Chang. "Meta-Gnn: Metagraph Neural Network for Semi-Supervised Learning in Attributed Heterogeneous Information Networks." Paper presented at the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), 27-30 Aug. 2019 2019. [CrossRef]
- Yun, Seongjun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. "Graph Transformer Networks." (2019).
- Zhou, Sheng, Jiajun Bu, Xin Wang, Jiawei Chen, Bingbing Hu, Defang Chen, and Can Wang. "Hahe: Hierarchical Attentive Heterogeneous Information Network Embedding." (2019). [CrossRef]
- Jia, Xiangen, Yihong Dong, Feng Zhu, and Jiangbo Qian. "Research Progress of Heterogeneous Graph Convolutional Networks." Computer Engineering and Applications 57, no. 9 (2021): 36-49.
- Yun, Seongjun, Minbyul Jeong, Sungdong Yoo, Seunghun Lee, Sean S. Yi, Raehyun Kim, Jaewoo Kang, and Hyunwoo J. Kim. "Graph Transformer Networks: Learning Meta-Path Graphs to Improve Gnns." Neural Networks 153 (2022): 104-19. [CrossRef]
- Bing, R., G. Yuan, M. Zhu, F. R. Meng, H. F. Ma, and S. J. Qiao. "Heterogeneous Graph Neural Networks Analysis: A Survey of Techniques, Evaluations and Applications." Artificial Intelligence Review 56, no. 8 (2023): 8003-42. [CrossRef]
- Wang, Xiao, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. "Heterogeneous Graph Attention Network." Paper presented at the The world wide web conference 2019. [CrossRef]
Figure 1.
Flowchart of road network selection.
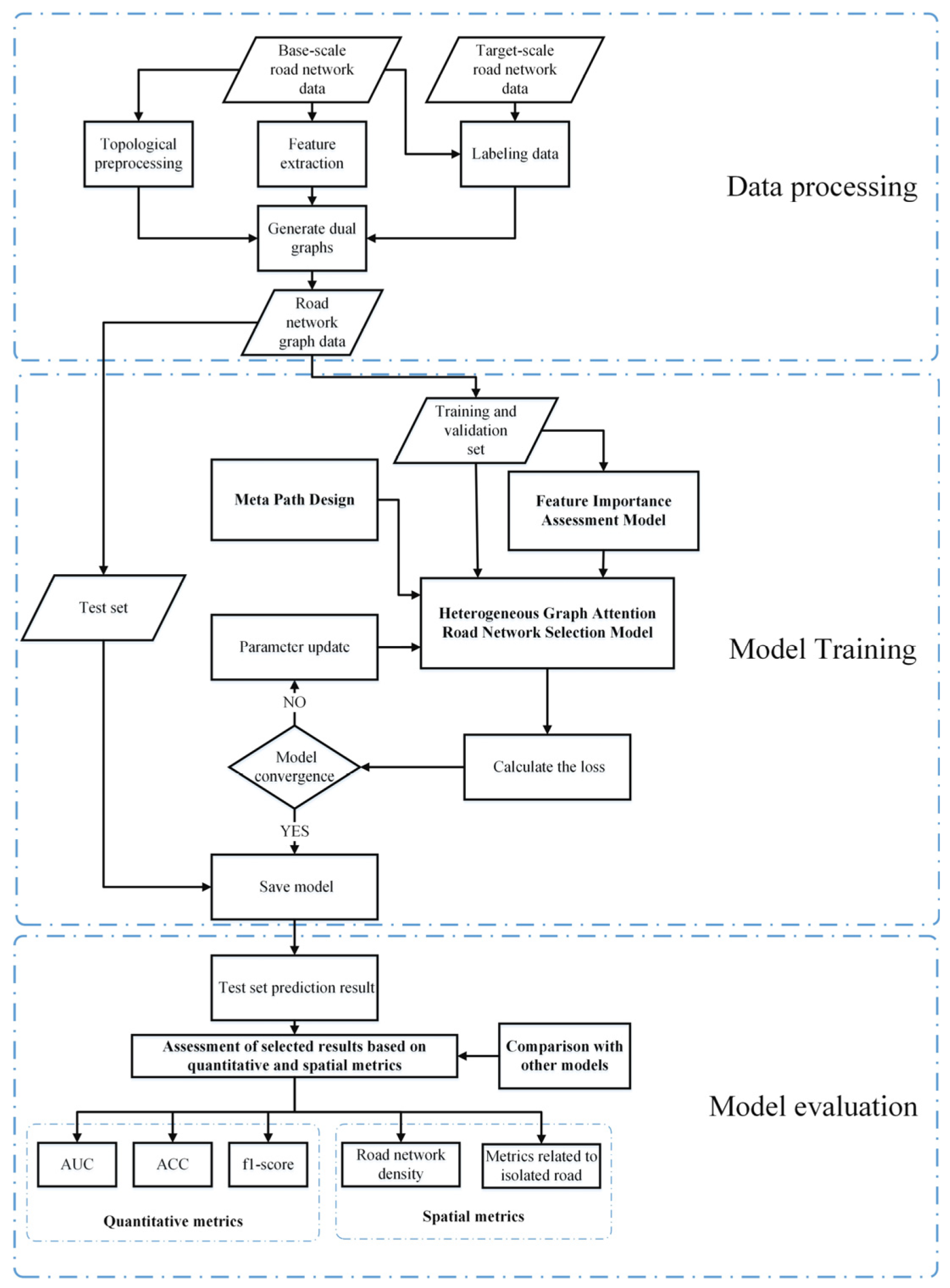
Figure 2.
Constructing dual graph data based on road network intersections.
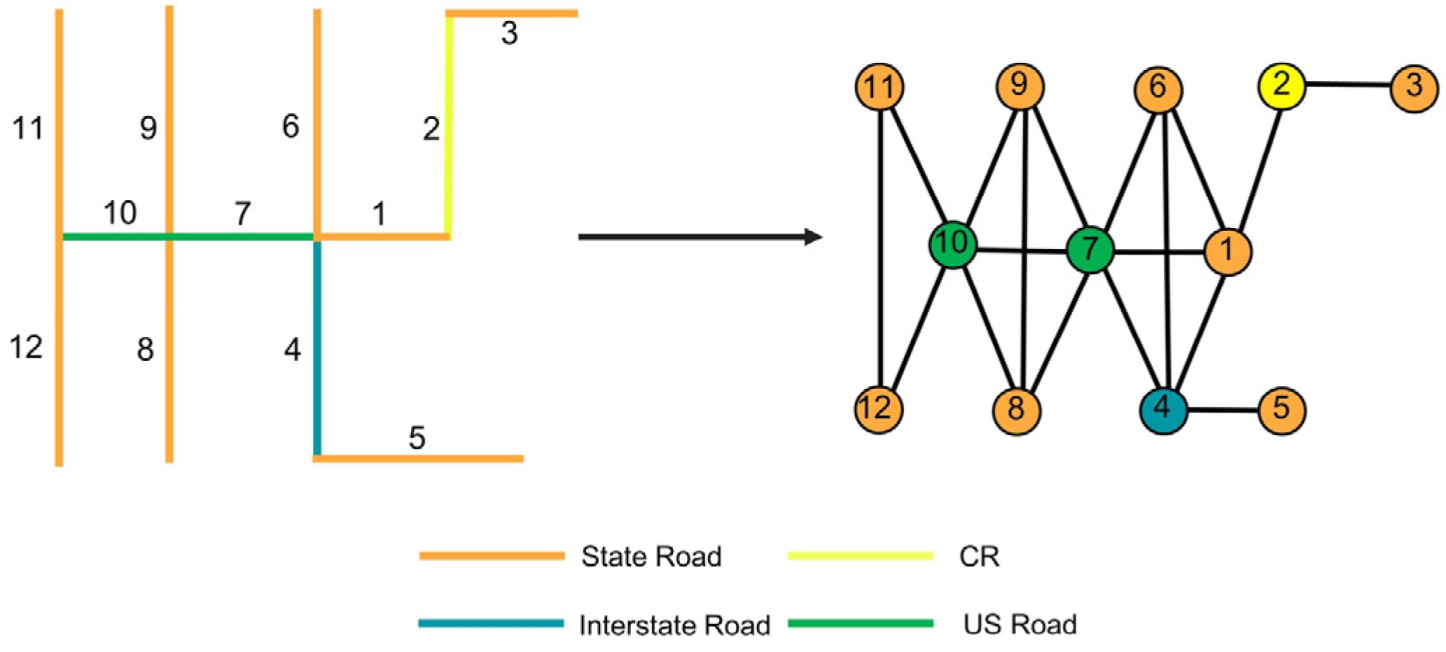
Figure 3.
An illustrative example of a meta path.
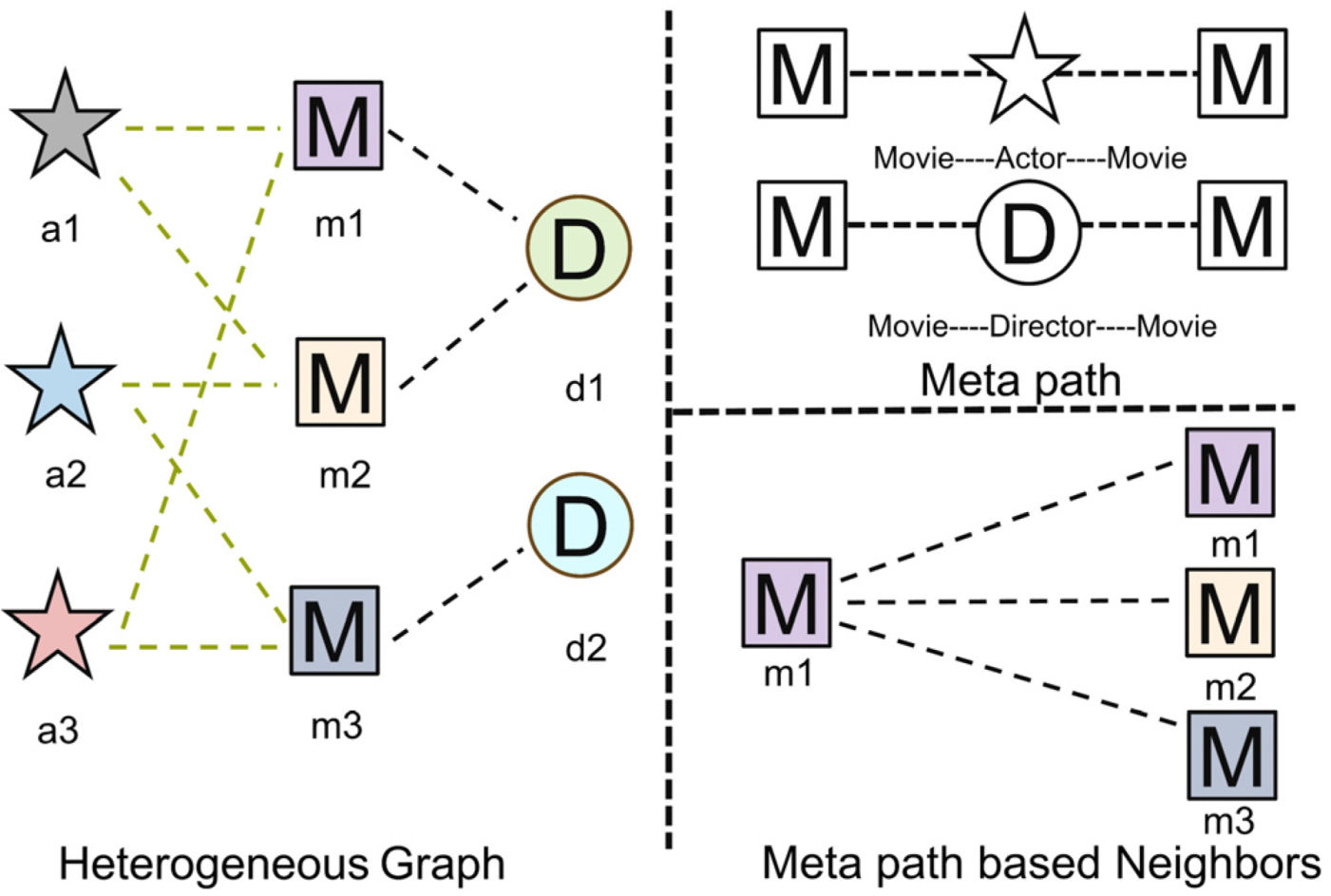
Figure 4.
Explanation of aggregating process in both node-level and semantic-level.
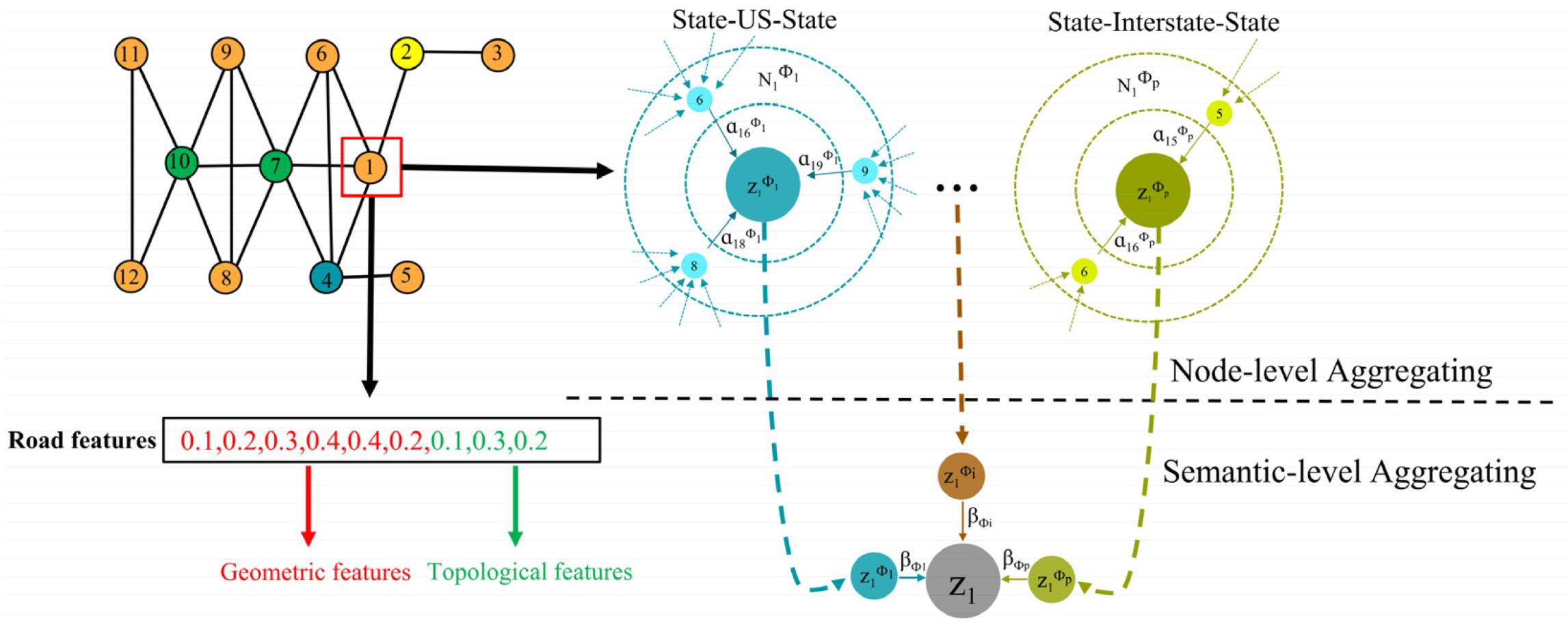
Figure 5.
The framework of the HAN road network automatic selection model.
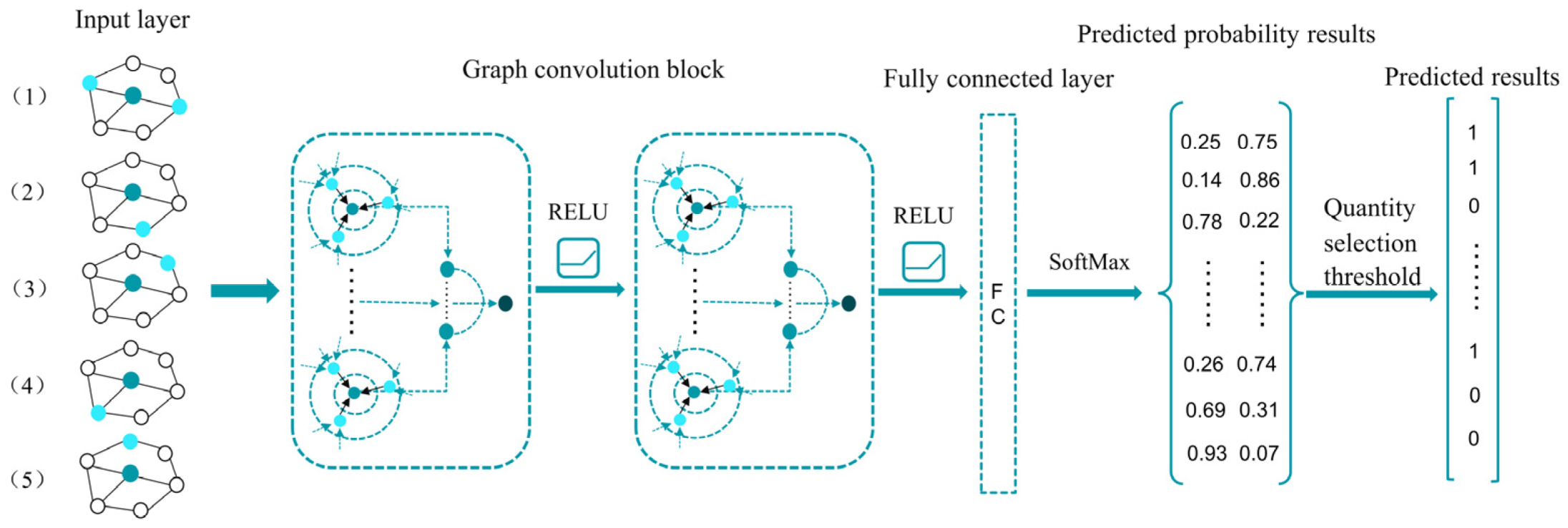
Figure 6.
Study area.
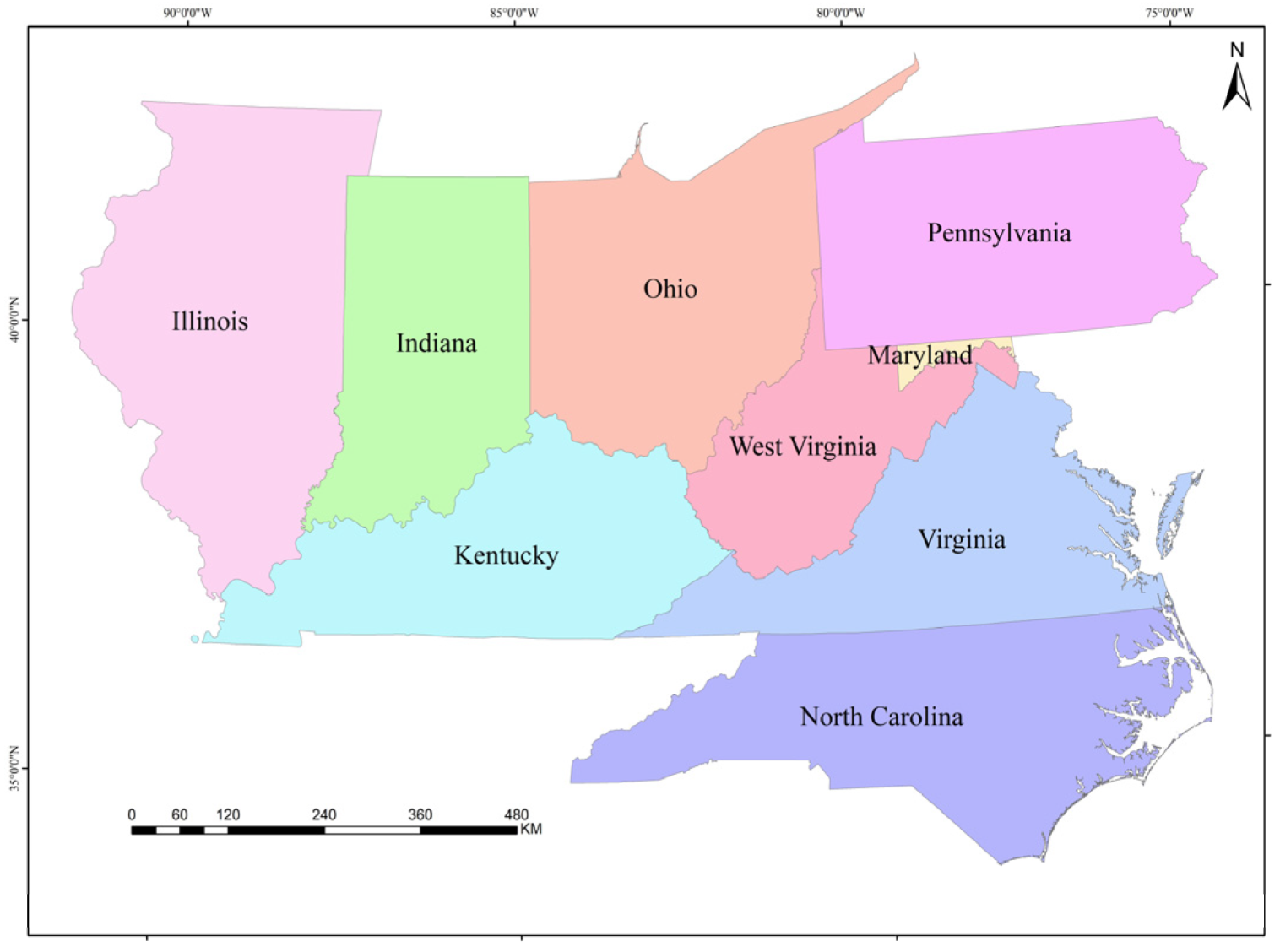
Figure 7.
Two scales of road network in the study area.
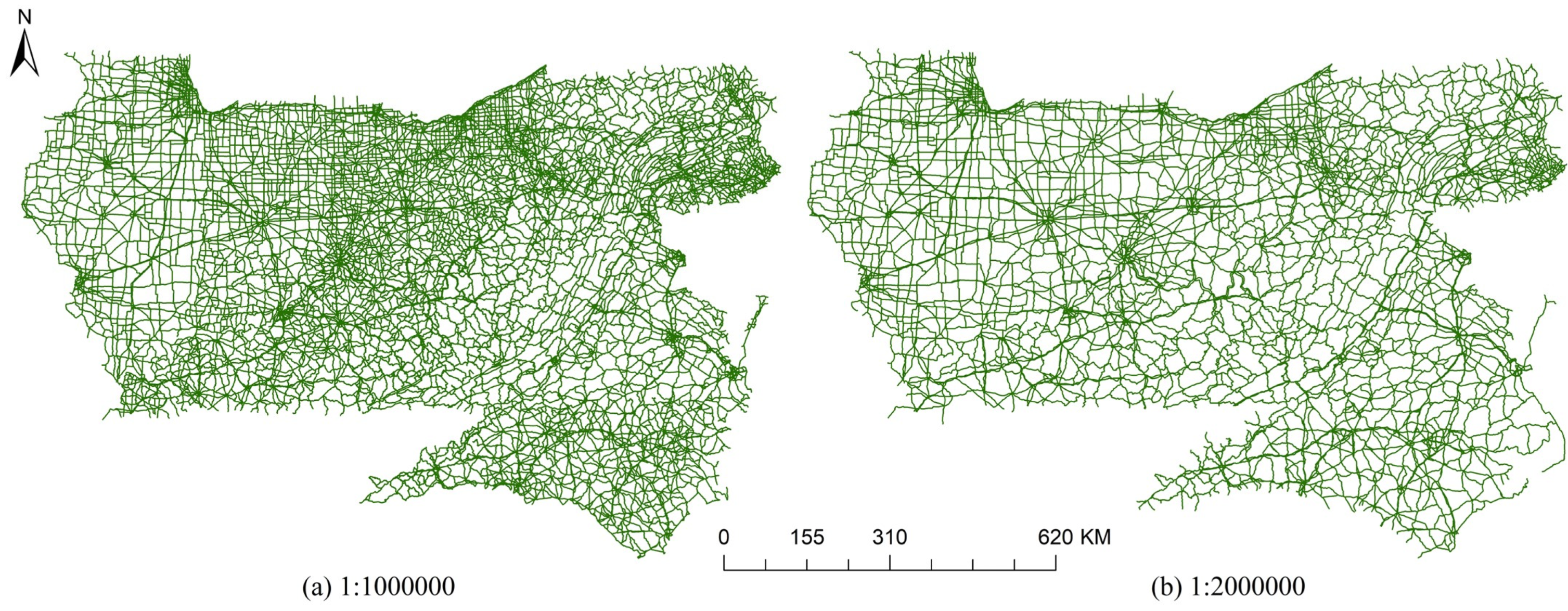
Figure 8.
Spatial distribution of road data for feature importance exploration.
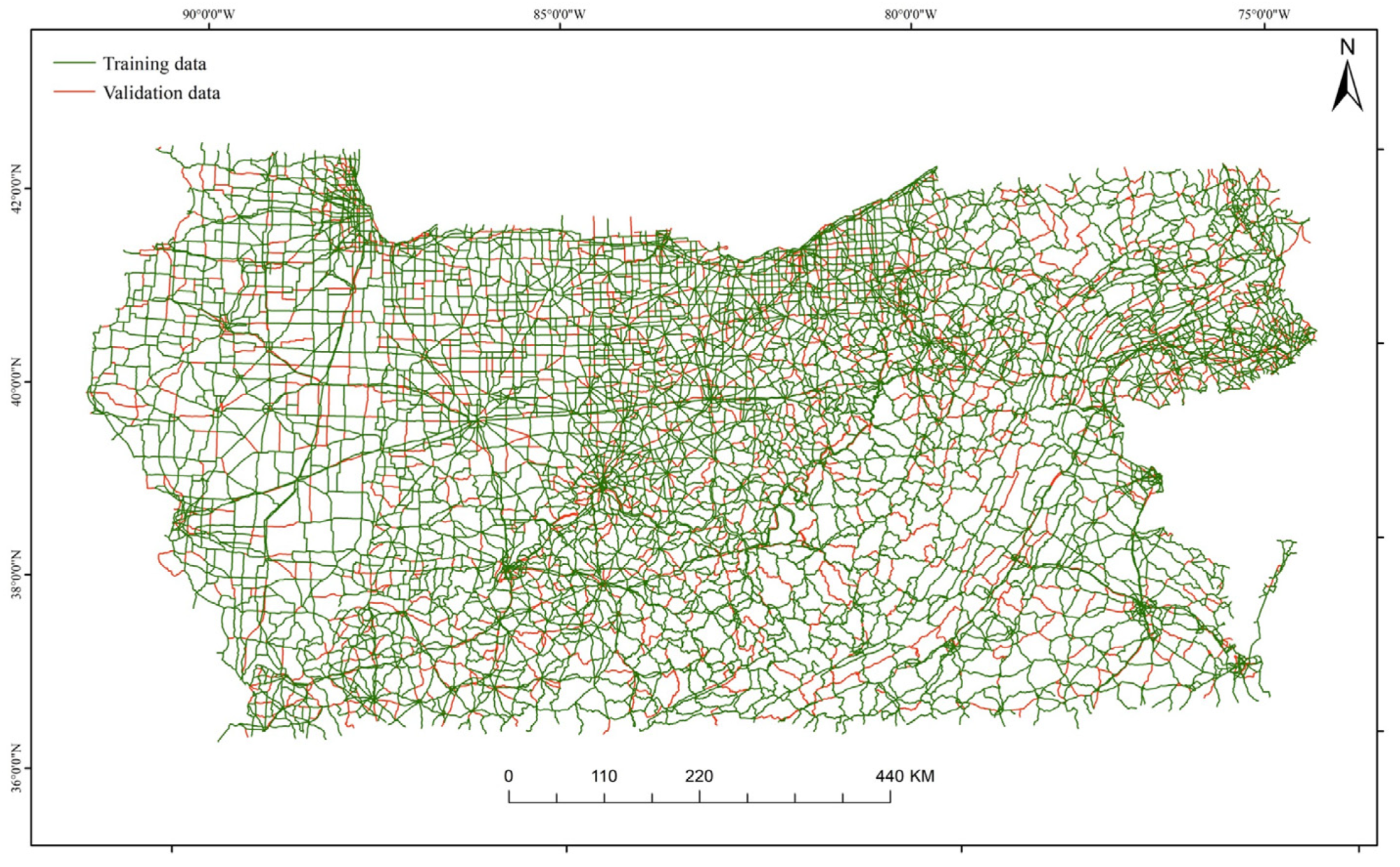
Figure 9.
Spatial Distribution of road data for the transductive road network selection model.
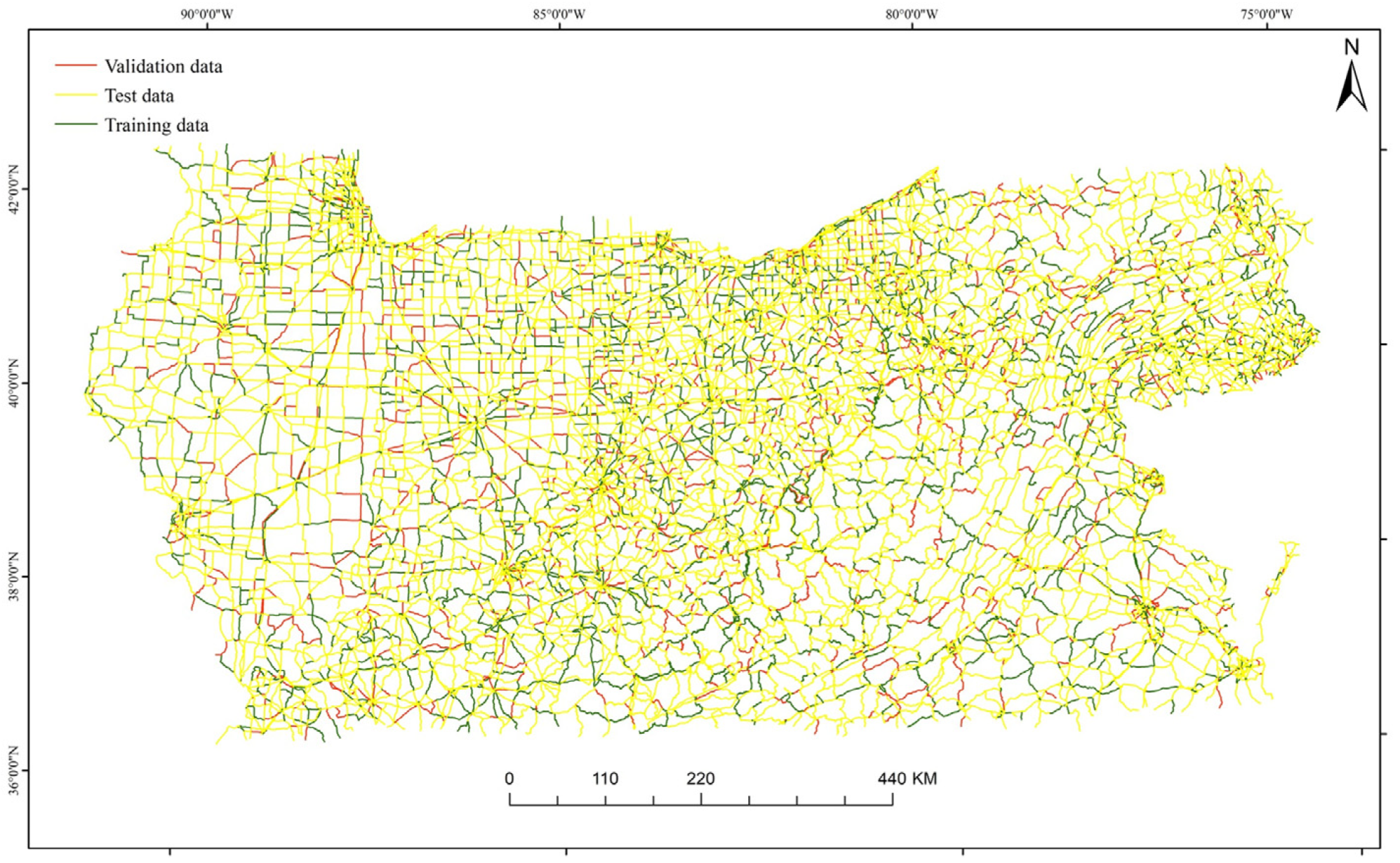
Figure 10.
Spatial distribution of road data for the inductive road network selection model.
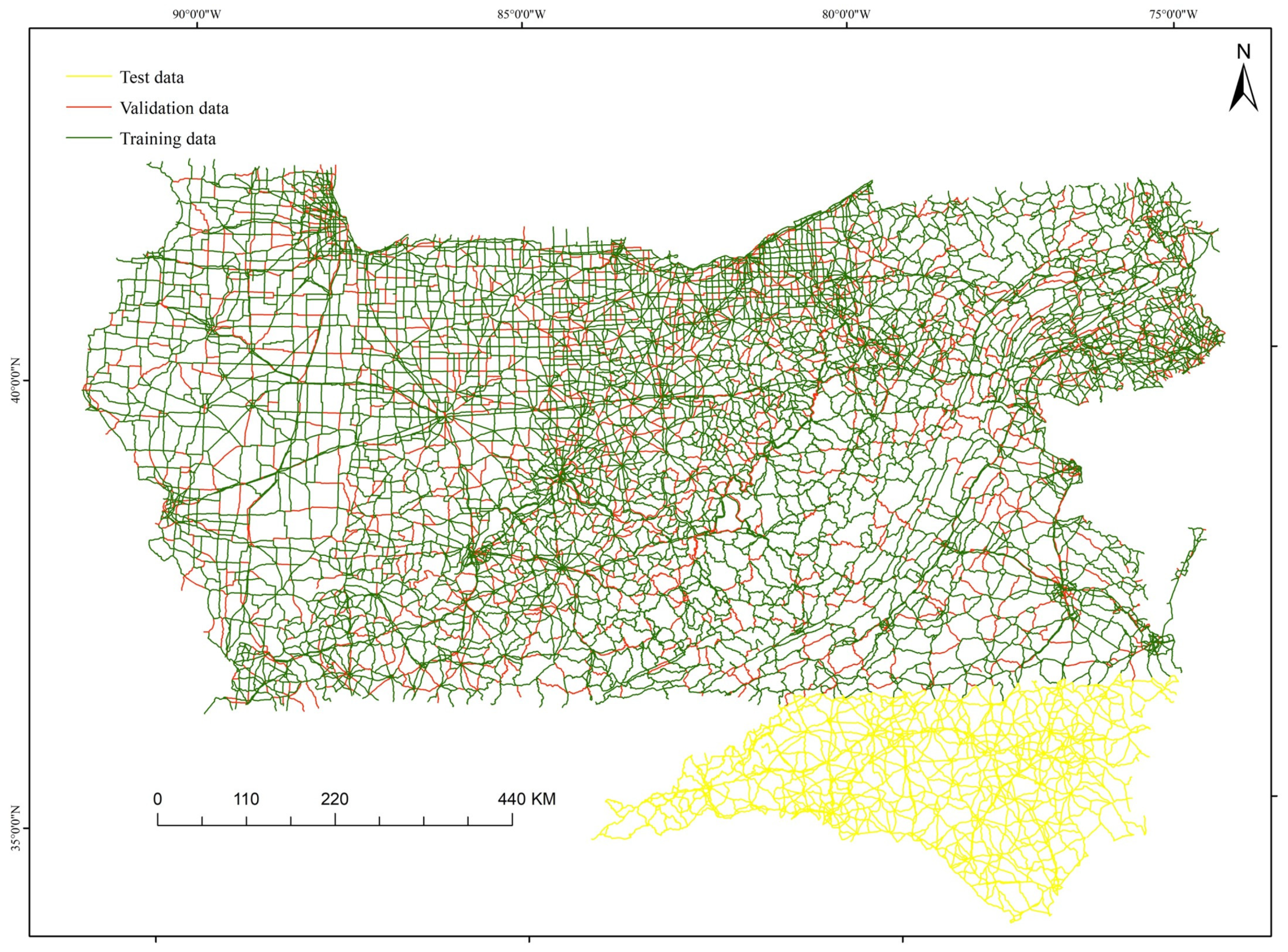
Figure 11.
Ranking of road features with positive impact importance.
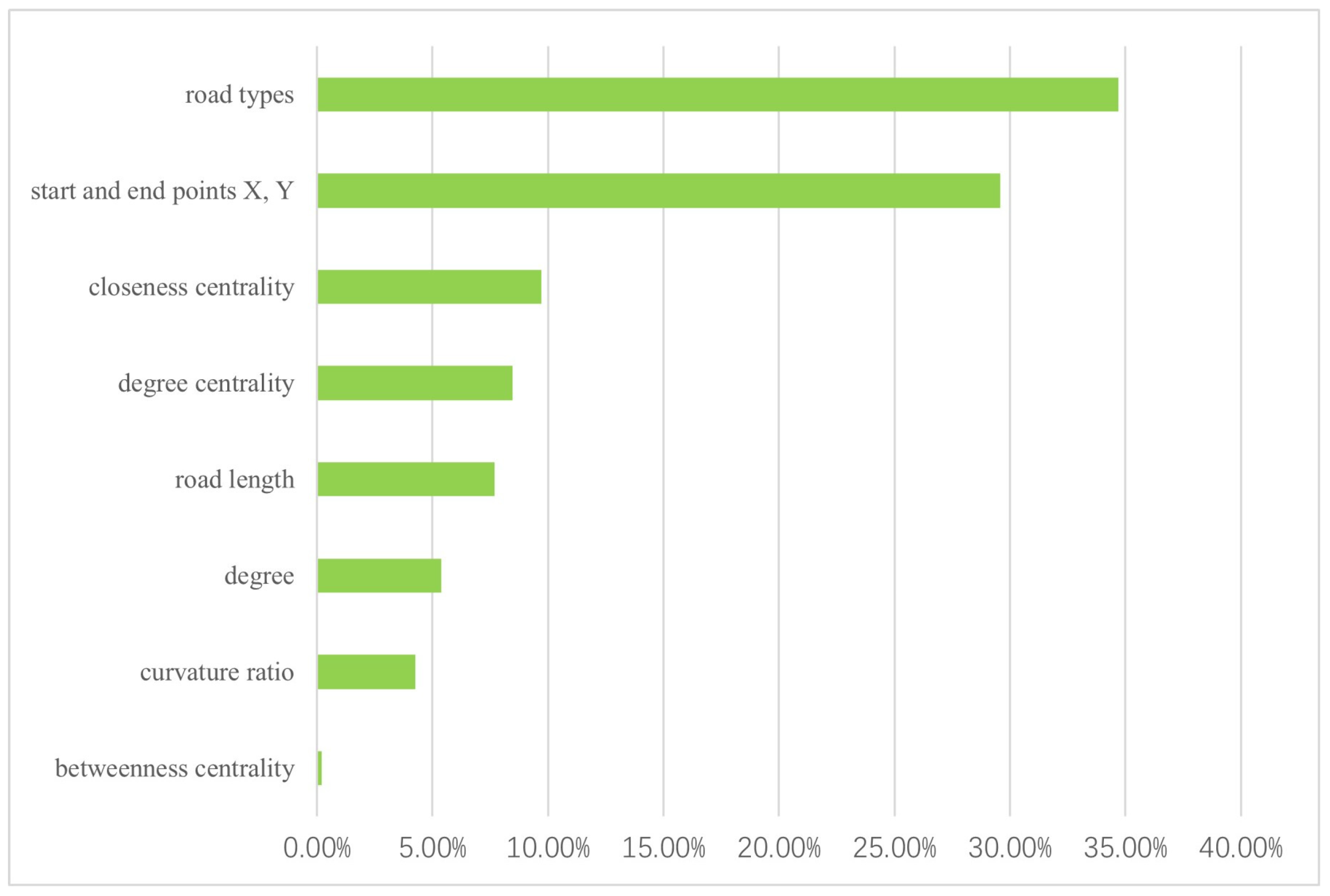
Figure 12.
The isolated roads of the HAN and other models in the transductive task.
Figure 13.
The spatial distribution of the selection results from different method in the inductive task.
Figure 13.
The spatial distribution of the selection results from different method in the inductive task.
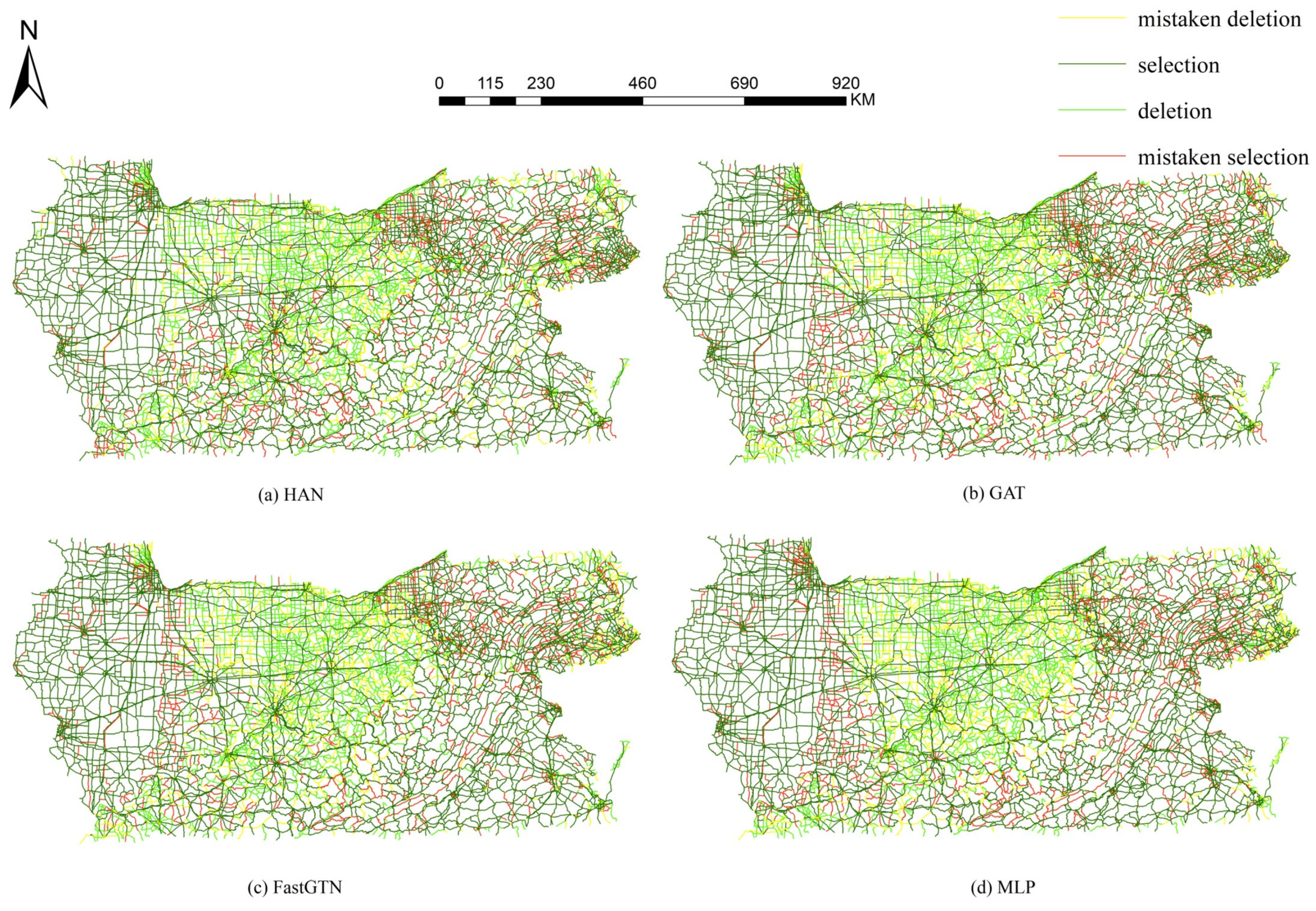
Figure 14.
The isolated roads of the HAN and other models in the inductive task.
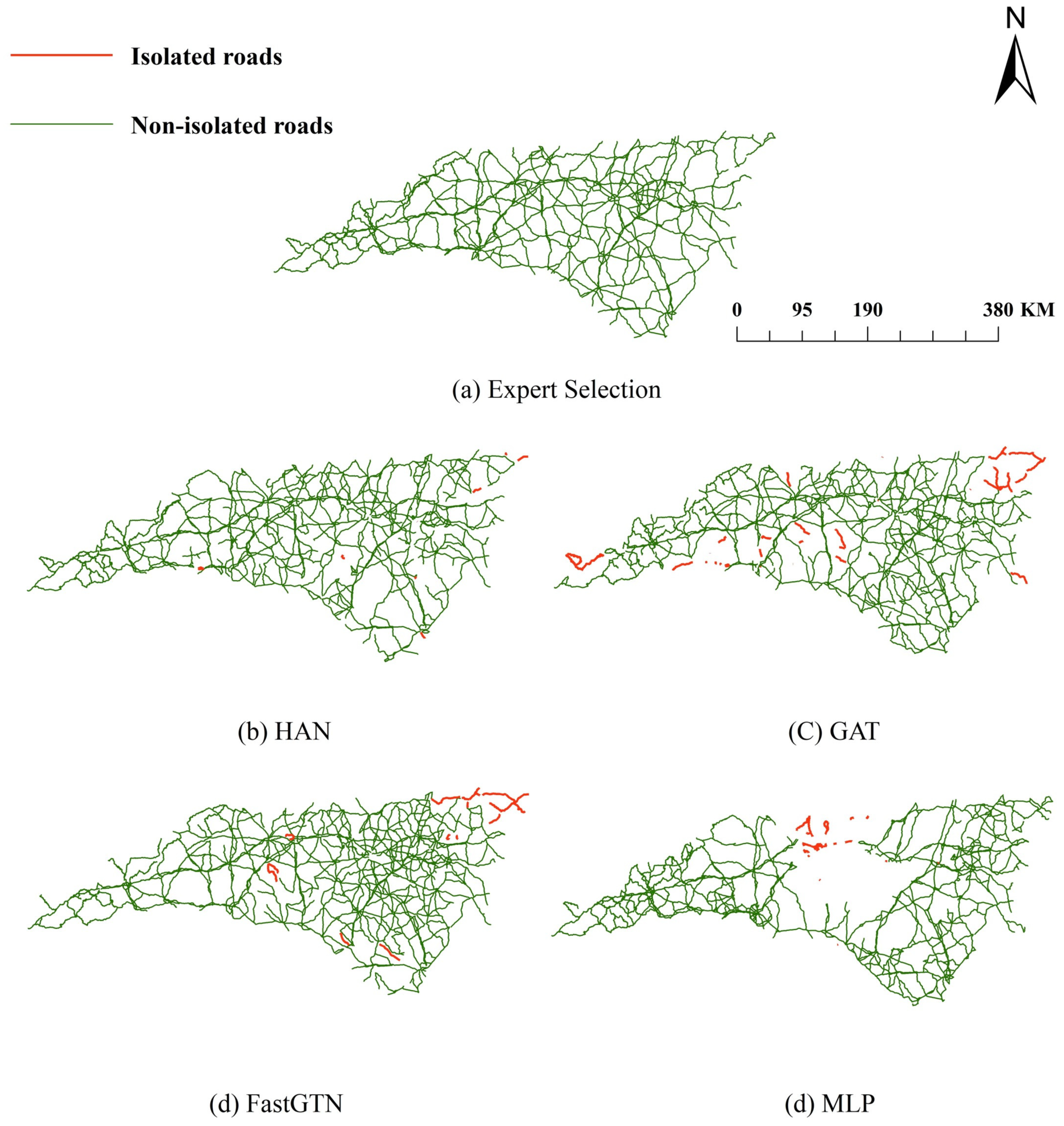
Figure 15.
The spatial distribution of the selection results from different method.
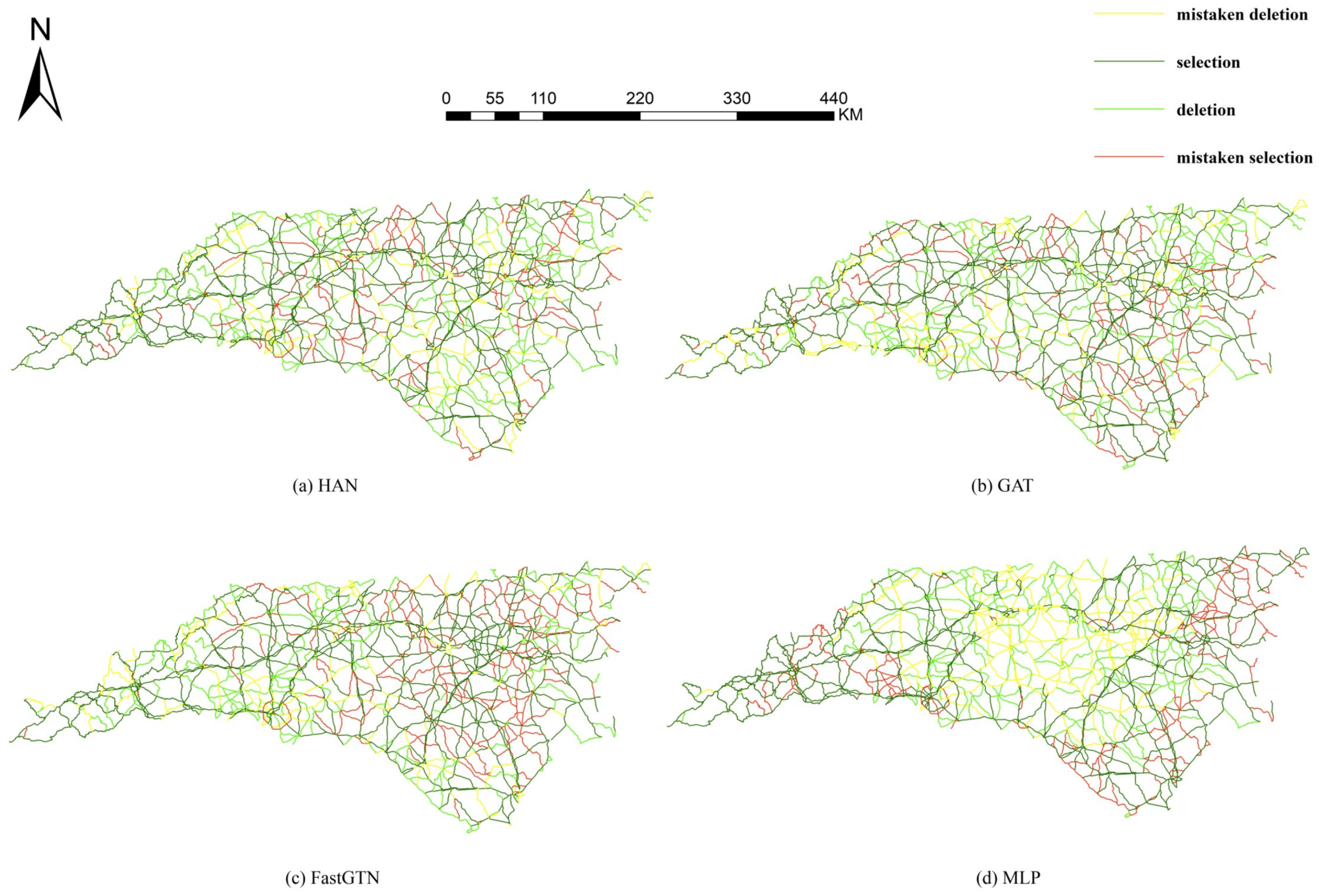

Table 1.
Road network features.
| Feature Types | Feature Indicators | Detailed Explanation |
|---|---|---|
| Semantic feature |
road type | Road type is a system that classifies roads according to characteristics such as traffic flow, scale, and function. |
| Geometric features |
road length | The length of roads in projected coordinates. |
| number of road vertices | The number of vertices in each road polyline. | |
| road aspect ratio | The ratio of the length of the road's horizontal coordinates to its vertical coordinates. | |
| mesh density | The maximum ratio of the perimeter to the area of the left and right polygons associated with each road (if there are no left and right polygons, the value is set to 0). | |
| curvature ratio | The ratio of the road length to the straight-line length between the start and end coordinates of the road. | |
| start and end points (X, Y) | Start and end point coordinates (four values in total). | |
| Topological features |
degree | The degree of each road is equal to the number of intersections it has with other roads. |
| degree centrality | The degree of each road is divided by the total number of roads minus one. | |
| eigenvector centrality | The eigenvector corresponding to the largest eigenvalue of the adjacency matrix represents the centrality of the eigenvector for each node. | |
| betweenness centrality | The ratio of the number of times the shortest paths between all other pairs of nodes pass through a particular node to the total number of shortest paths in a graph. | |
| closeness centrality | The total number of nodes minus one divided by the total number of shortest paths from that node to other nodes. |
Table 2.
The indices of the neighboring nodes that need to be aggregated under each meta path.
| Meta Path | Indices of Neighboring Nodes to Be Aggregated |
|---|---|
| State-State | 6 |
| State-State-State | NONE |
| State-US-State | 6、8、9 |
| State-Interstate-State | 5、6 |
| State-CR-State | 3 |
Table 3.
Quantitative statistics of road data for feature importance exploration.
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Total |
|---|---|---|---|---|---|
| State | 4840 | 4151 | 1221 | 1042 | 11254 |
| US | 4205 | 266 | 1030 | 63 | 5564 |
| Inter | 1861 | 64 | 471 | 15 | 2411 |
| CR | 14 | 18 | 7 | 4 | 43 |
Table 4.
Quantitative statistics of road data for the transductive road network selection model.
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Positive Testing Samples | Negative Testing Samples | Total |
|---|---|---|---|---|---|---|---|
| State | 1205 | 1037 | 607 | 518 | 4249 | 3638 | 11254 |
| US | 1061 | 64 | 517 | 34 | 3657 | 231 | 5564 |
| Inter | 462 | 20 | 241 | 9 | 1629 | 50 | 2411 |
| CR | 1 | 3 | 1 | 2 | 19 | 17 | 43 |
Table 5.
Quantitative statistics of road data for the inductive road network selection model.
| Road Types | Positive Training Samples | Negative Training Samples | Positive Validation Samples | Negative Validation Samples | Positive Testing Samples | Negative Testing Samples | Total |
|---|---|---|---|---|---|---|---|
| State | 4869 | 4162 | 1192 | 1031 | 495 | 702 | 12451 |
| US | 4165 | 255 | 1070 | 74 | 1095 | 133 | 6792 |
| Inter | 1864 | 63 | 468 | 16 | 268 | 46 | 2725 |
| CR | 21 | 18 | 0 | 4 | 0 | 1 | 44 |
Table 6.
The statistical results of AUC on the validation set are based on the feature masking method.
Table 6.
The statistical results of AUC on the validation set are based on the feature masking method.
| Road Types | Road Length | Mesh Density | Number of Road Vertices | Road Aspect Ratio | Curvature Ratio |
|---|---|---|---|---|---|
| 0.6108 | 0.7902 | 0.8414 | 0.8417 | 0.8413 | 0.8131 |
| betweenness centrality | eigenvector centrality | closeness centrality | start and end points X, Y | degree | degree centrality |
| 0.8399 | 0.8414 | 0.7767 | 0.6449 | 0.8056 | 0.7850 |
Table 7.
Accuracy of various road types in the GAT validation set.
| Road Type | State Road | US Road | Interstate Road | CR |
|---|---|---|---|---|
| ACC | 0.6681 | 0.9424 | 0.9691 | 0.7273 |
Table 8.
The statistical results of road selection models in the transductive task.

Table 9.
The statistical results of road selection models in the inductive task.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



