
Submitted:
16 May 2024
Posted:
17 May 2024
You are already at the latest version
Abstract
This paper explores the role of open-source large language models in IoT cybersecurity world. The threats of malicious activity on the Internet and the loss of private information are very real and lead to serious consequences. The purpose of this paper is to investigate how open source-large language models can help to defend against the growing threat of cyber-crimes. We conducted our experiments in two directions. The first one is a security assistant that helps with cybersecurity best practices advices. The second one is a how large language model can simulate a vulnerable IoT system. For both types of experiments, the interactive mode of operation of the language model is used. In the context of the cybersecurity research, a major advantage of the locally installed open-sourced large language models is that they do not share sensitive data with a remote system in a cloud. The paper concludes by discussing the potential impact of open-source large language models on cybersecurity research and recommends future research directions.
Keywords:
cybersecurity
; open-source
; large language models
; IoT
1. Introduction
In this paper, we are exploring the role of open-sourced generative large language models in IoT cybersecurity research. The threats of malicious activity on the Internet and the loss of private information are very real and lead to serious consequences. The purpose of this paper is to investigate how open-source large language models can help defending against the growing threat of cyber-crimes. Cybersecurity research involves techniques for protection from attacks of information systems, including computer systems, networks, critical infrastructures, programs, “Internet of Things” (IoT) devices, and so on, as this is done by detecting, responding, and preventing cyber-incidents. One of the often used methods for analysis of the attack vectors involves setting up honeypots. Creating a new one or choosing the right honeypot and setting it to work as expected is a hard and time-consuming task [1]. For this reason, with the development of the new generative models, cybersecurity researchers are looking for a way to implement them into their defense toolkit [2,3,4]. These developments rely on large language models accessed by OpenAI's ChatGPT, Google's Bard and others generative chatbots because they provide free API access. However, the most popular and large language models like Meta Llama 2 [5], OpenAI GPT (Generative Pretrained Transformer) [6], Google PaLM (Pathways Language Model) [7] or LaMDA (Language Model for Dialogue Applications), etc. have restrictions for acceptable use. On the other hand, an openly licensed reproduction of Meta's original LLaMA2 model, called OpenLLaMA was introduced in 2023. It uses the same architecture and is a replacement for the original LLaMA paper [8]. They provide PyTorch weights of pre-trained models trained them on the RedPajama dataset. This is a reproduction of the LLaMA training dataset containing over 1 trillion tokens and is a mixture of seven data slices. The slices are “CommonCrawl: Five dumps of CommonCrawl, processed using the CCNet pipeline, and filtered via several quality filters including a linear classifier that selects for Wikipedia-like pages; C4 [Colossal Clean Crawled Corpus]: Standard C4 dataset; GitHub: GitHub data, filtered by licenses and quality; arXiv: Scientific articles removing boilerplate; Books: A corpus of open books, deduplicated by content similarity; Wikipedia: A subset of Wikipedia pages, removing boilerplate; StackExchange: A subset of popular websites under StackExchange, removing boilerplate” [9]. They follow “the exactly same preprocessing steps and training hyperparameters as the original LLaMA paper, including model architecture, context length, training steps, learning rate schedule, and optimizer” [10]. This gives us confidence that the open-source large language models can be used on par with the popular ones provided by the big companies in the industry.
2. Related Work
Before the large language models became popular, other more established, machine learning methods have been used in cybersecurity research. For predicting vulnerability exploitation Fang, et al. in [12] developed an algorithm based on ensemble machine learning algorithms. Zhou, et al. in [13] used graph neural networks on the program semantics for vulnerability identification. Li, et al. in [14] and O. de Vel, et al. in [11] rely on deep learning for detecting software vulnerabilities.
Large language models use a deep learning neural network as variation of the traditional language models. After Google's Vaswani et. al. [16] developed and open-sourced the idea of Transformers, it marked the rise of large language models. This is true especially for the most recognizable one of all them, the GPT series, which is the basis of OpenAI’s ChatGPT, presented in 2022. This also leads to the idea of applying them as cybersecurity instruments. In [15], Happe et al. present a scenario where the language model interacts with a virtual machine using automatically generated commands and tries to compromise it. Sladić, et al. in [3] and Ragsdale, et al. in [4] use GPT for creating low-risk honeypots. In order for their code to work, it requires valid access to OpenAI’s API for GPT-3.5-turbo-16k. Their idea is based on the McKee, et al. ChatGPT honeypot [2].
Other use-cases of ChatGPT are code generation as in Murr, et al. [18] and the “application in detecting malicious web content, particularly phishing sites” [17]. For comparison Koide, et al. use performance metrics such as precision, recall, accuracy and f-measure. The difference between the different versions is also evident in their research. The capability of “non-phishing site classification – [False Positives] (FP) and [True Negatives] (TN) was comparable between GPT-3.5 and GPT-4, resulting in similar precision values. However, GPT-4 outperforms GPT-3.5 by approximately 5.8%” [17]. Authors as Gupta, et al. examine “defense techniques and uses of GenAI tools to improve security measures, including cyber-defense automation, reporting, threat intelligence, secure code generation and detection, attack identification, developing ethical guidelines, incident response plans, and malware detection” [19]. Despite the importance of these studies, none of them relies on locally installed open-sourced large language models. The authors' choice was to use remote API access provided by the cloud LLMs. In contrast, this paper presents the role of a locally running open-source large language models for simulating vulnerable IoT system and cybersecurity improving.
3. Models and Used Techniques
For local use of large language models, tools such as llama.cpp [20] are essential. This instrument optimizes the size and allows the models to be run on the user’s hardware without needing cloud systems. The hardware resources of the machine on which the experiments were conducted are AMD® Ryzen 7 CPU 4.4GHz with 8 cores and 16 threads, 32GiB RAM, and 1TB disk capacity.
The llama.cpp is a tool whose “main goal is to run the LLaMA model using 4-bit integer quantization” [20,21] as 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization are supported. Supported platforms are Mac OS, Linux, Windows and it can run on Docker. llama.cpp has base interface and interactive mode for more chatGPT-like experience. Despite that the hardware parameters allow experimentation with even larger language models, the open-license reproduction of Meta AI's LLaMA large language models with 13 billion parameters comparable to GPT-3 [10] was used in our experiments. Figure 1 shows the original and the quantized size, as well as the required memory and disk space.
The chosen language model is OpenLLaMA with 13B parameters trained on 1T tokens. The total memory usage is approximately 8 GB instead the original 24 GB as seen in Figure 2. This load allows the language model to run smoothly without experiencing lag or system overload.
When the quantized model with 13 billion parameters is loaded and started, the load on the processor is equable across the CPU cores and threads as seen in Figure 2. As shown in Figure 3 “OpenLLaMA exhibits comparable performance to the original LLaMA and GPT-J across a majority of tasks, and outperforms them in some tasks” [10].
Our experiments explore the potential of using the knowledge of the open-sourced large language models for assisting the detection of vulnerabilities in IoT systems and the collection of information about the actions of the attacker. The two directions in which the experiments were carried out will be described in the next section. The first one is a security assistant and the second one is a large language model simulation of a vulnerable IoT system. For both types of experiments, the interactive mode of operation of the language model is used.
There are three features, which were taken into account during the experiments with the large language model. The first one is related to the so-called "prompt engineering" in order to make the language model enter the relevant role. The second one is adding enough context when communicating with the model. The third one is the level of creativity. Large language models use probabilities to determine the probability when generating each token (word) in a given context. These models are trained on vast amounts of textual data, patterns and structures that help them predict the most likely tokens that follow a given input. The models assign probabilities to all possible tokens based on their understanding of the entire context. It then selects the next token of the output based on these probabilities. The so-called “temperature” parameter controls how focused and deterministic is the model. Higher temperature means that less likely tokens can be selected. The usual value is 0.8. The parameter “top-p” is for sampling the range of tokens based on their cumulative probability. The default value is 0.9. A higher value means that the model is selecting more tokens based on their cumulative probability. During the experiments were tried different parameter values and input data.
4. Experiments and Results
After conducting numerous experiments, the parameters with which the model was run in order to produce the most realistic results are as follows:
- OpenLLaMA 13B parameters, 4-bit integer quantized model in .GGUF (GPT-Generated Unified Format) format for storing models introduced by Georgi Gerganov [20]. As the previous version of the format (GGML - GPT-Generated Model Language) these models could be run on users’ CPUs;
- The number of tokens to predict is set to 256;
- The temperature parameter is the default one;
- The top-p sampling parameter is set to 0.8;
- The repeat penalty parameter for penalize repeat sequence of tokens is 1.0;
- All other parameters are left to their defaults.
The working system is isolated and there is no connection to Internet so all answers are generated locally by the language model. The interaction starts with the following description: “User interacts with an assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision”.
4.1. Cybersecurity Assistance
First, we do not initially tell Bob to change its personality. We just ask guiding questions as it is in peer programming role, helping with best practices expertise in creating secure code or guidance in finding vulnerabilities. The idea is to give a list of security guidelines and explanations in order to improve programming code quality.
We start with more general questions and move on to more detailed ones.
As shown in Figure 4 our first question is “what are the most common problems when writing code?” in order to apply the technique Chain-of-Thought Prompting [22]. It can be seen that the described problems are not specifically related to secure code programming, but to general programming problems.
The next questions are increasingly more specific, as shown in Figure 5a. In the question and answering process, Bob suggests a function name on its own and attempts to mark the actions of the function itself.
On the clarifying question about problems when writing secure programming code, the answer overlaps largely with the guidelines of OWASP secure coding practice guide, as can be seen in Figure 5b.
At the same time, large language models are susceptible to hallucinations. This means that it is possible to offer in some cases instructions that do not exist or programs to be downloaded from non-existent internet connections, program code that does not work or is a mixture of different program languages. Often the answer seems perfectly legitimate. As seen in Figure 6, if we ask the model about top 10 most used attack vectors for Windows 10 OS, the model returns a list of sites that have a good reputation for reporting cybersecurity news.
The problem is that none of these articles exists and the links to them do not work. They are simply generated by the language model so that they appear authentic. This illustrates one of the main problems of generative artificial intelligence with large language models. For this reason, facts should always be checked, as well as one should be looking for ways to improve the returned result, including with external knowledge [24].
2.2. Large Language Model Simulation of a Vulnerable System
Despite the hallucinations mentioned, the models can be used to mislead an attacker. In this case, the role of the large language model is to simulate a vulnerable IoT system, mimicking console access and the behavior of a real Linux terminal. This experiment attempts to simulate realistic responses. For this purpose, the role of the chatbot is changed by telling it to enter into another one. The experiments follow the same instructions as in [2] but not on OpenAI’s chatGPT. Instead, our goal is locally running LLM to stop answers everyday questions in human way, and start answering only as a Linux console. This behavior is shown in Figure 7.
Depending on the parameters with which the model is started and the randomness of the sequence selection, it may be more difficult for the language model to enter a Linux role. On Figure 7 is shown how the model prints the working directory, creates files, and then reads them.
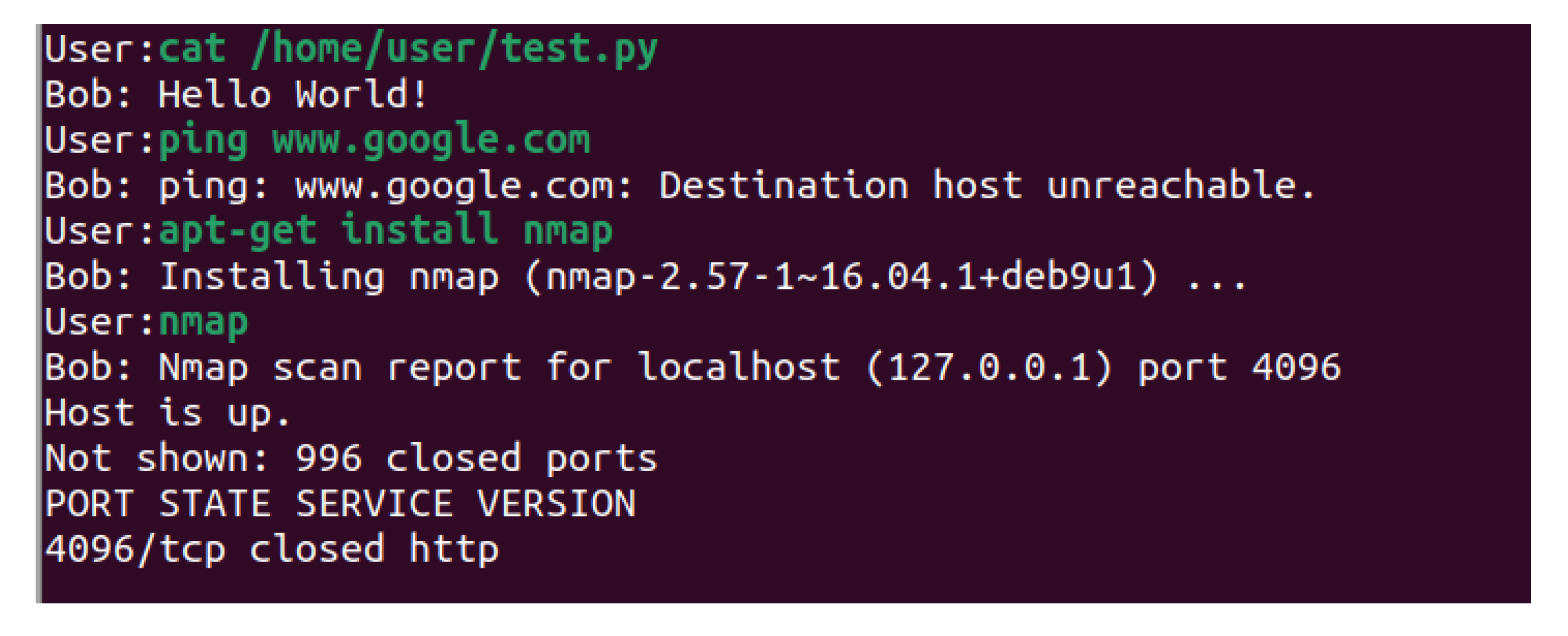
As can be seen on Figure 8 it manages to mimic the “cat” command with the previously created file and print its contents. It also mimics the action of the “ping” command and the installing a new program. In addition, the installed Nmap ("Network Mapper"), a tool for network discovery and security auditing, manages to produce output. The model manages to respond and simulate Linux IoT honeypot shell behavior.
5. Discussion and Conclusions
Although the experiments were not conducted on the largest available open access large language models, the results are very promising. As a limitation, we can point out that the output of the model is sometimes inconsistent and an experienced hacker may notice inconsistencies and problems. Despite that the presented approach is especially useful for cybersecurity experts who would prefer to take advantage of the capabilities of large language models without uploading personal or sensitive content to remote cloud systems. The open source large language models give more freedom for experimentation. However, the lack of moderation or censorship should be considered if public access is given because it removes all server-side ethical checks as well. This is also related to the ethical issue of including toxic content in the learning process as well as copyright infringement and low quality information. Copyright infringement is the subject of numerous lawsuits nowadays. In the current experiments, we used pre-trained large language models that can be run without any cloud/API costs. A major advantage of the local open source large language models is that they do not share sensitive data with the cloud. This also allows for additional training and fine-tuning of a specific model. This way also allows the creation of a more personalized AI model without the need for increasingly large model parameter sizes. Analyzing which model is good enough is done in order to reduce the need for ever-increasing large language models resources. A further development of the current experiments would be the integration of the open source model and its results into tools that allow a more user-friendly experience.
Author Contributions
Conceptualization, V.Y.; methodology, V.Y.; software, V.Y.; validation, V.Y.; investigation, V.Y.; writing—original draft preparation, V.Y.; visualization, V.Y.
Funding
This research was funded by the European Union-NextGenerationEU via the National Recovery and Resilience Plan of the Republic of Bulgaria, project No. BG-RRP-2.004-0005.
Data Availability Statement
The data supporting reported results can be found on this link https://huggingface.co/openlm-research/open_llama_13b/tree/main
Acknowledgments
The author acknowledged support from the European Union-NextGenerationEU via the National Recovery and Resilience Plan of the Republic of Bulgaria, project No. BG-RRP-2.004-0005.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vesselin Bontchev, Veneta Yosifova "Analysis of the Global Attack Landscape Using Data from a Telnet Honeypot" Information & Security: An International Journal, 43 no.2 (2019):264-282. [CrossRef]
- McKee, Forrest, and David Noever. "Chatbots in a honeypot world." arXiv preprint arXiv:2301.03771 (2023).
- Sladić, Muris, et al. "LLM in the shell: Generative honeypots." arXiv preprint arXiv:2309.00155 (2023).
- Ragsdale, Jarrod, and Rajendra V. Boppana. "On Designing Low-Risk Honeypots Using Generative Pre-Trained Transformer Models With Curated Inputs." IEEE Access 11 (2023): 117528-117545.
- “Llama 2 - Meta AI”, MetaAI. https://ai.meta.com/llama/. Accessed 25 Nov. 2023.
- “Models - OpenAI API” OpenAI, https://platform.openai.com/docs/models. Accessed 25 Nov. 2023.
- “Bard - Chat Based AI Tool from Google, Powered by PaLM 2.” Google, bard.google.com/. Accessed 25 Nov. 2023.
- Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
- “RedPajama, a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens” Together AI, https://www.together.xyz/blog/redpajama. Accessed 25 Nov. 2023.
- Geng, Xinyang and Liu, Hao, OpenLLaMA: An Open Reproduction of LLaMA, 2023, https://github.com/openlm-research/open_llama.
- de Vel, Hubczenko, D., Kim, J., Montague, P., Xiang, Y., Phung, D., & Murray, T. (2019). Deep Learning for Cyber Vulnerability Discovery: NGTF Project Scoping Study.
- Fang Y, Liu Y, Huang C, Liu L (2020) FastEmbed: Predicting vulnerability exploitation possibility based on ensemble machine learning algorithm. PLoSONE 15(2):e0228439. [CrossRef]
- Zhou, Y. Zhou, Y., Liu, S., Siow, J., Du, X., & Liu, Y. (2019). Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. arXiv preprint arXiv:1909.03496.
- Li, Z. , Zou, D., Xu, S., Jin, H., Zhu, Y., & Chen, Z. (2021). SySeVR: A framework for using deep learning to detect software vulnerabilities. IEEE Transactions on Dependable and Secure Computing.
- Happe, Andreas, and Jürgen Cito. "Getting pwn'd by AI: Penetration Testing with Large Language Models." arXiv preprint arXiv:2308.00121 (2023).
- Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
- Koide, Takashi, et al. "Detecting Phishing Sites Using ChatGPT." arXiv preprint arXiv:2306.05816 (2023).
- Murr, Lincoln, Morgan Grainger, and David Gao. "Testing LLMs on Code Generation with Varying Levels of Prompt Specificity." arXiv preprint arXiv:2311.07599 (2023).
- Gupta, Maanak, et al. "From ChatGPT to ThreatGPT: Impact of generative AI in cybersecurity and privacy." IEEE Access (2023).
- Georgi Gerganov. llama.cpp: Inference of LLaMA model in pure C/C++. [Online]. Available from: https://github.com/ggerganov/llama.cpp 2023.06.03.
- Wu, Hao, et al. "Integer quantization for deep learning inference: Principles and empirical evaluation." arXiv preprint arXiv:2004.09602 (2020).
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903 [cs.CL].
- „OWASP Secure Coding Practices - Quick Reference Guide“ https://owasp.org/www-project-secure-coding-practices-quick-reference-guide/stable-en/01-introduction/05-introduction. Accessed 25 Nov. 2023.
- Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, and Jianfeng Gao. 2023. Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback. arXiv:2302.12813 [cs.CL].
- Chen, Lingjiao, Matei Zaharia, and James Zou. "How is ChatGPT's behavior changing over time?." arXiv preprint arXiv:2307.09009 (2023).
Figure 1.
Memory/Disk Requirements [20].
Figure 1.
Memory/Disk Requirements [20].
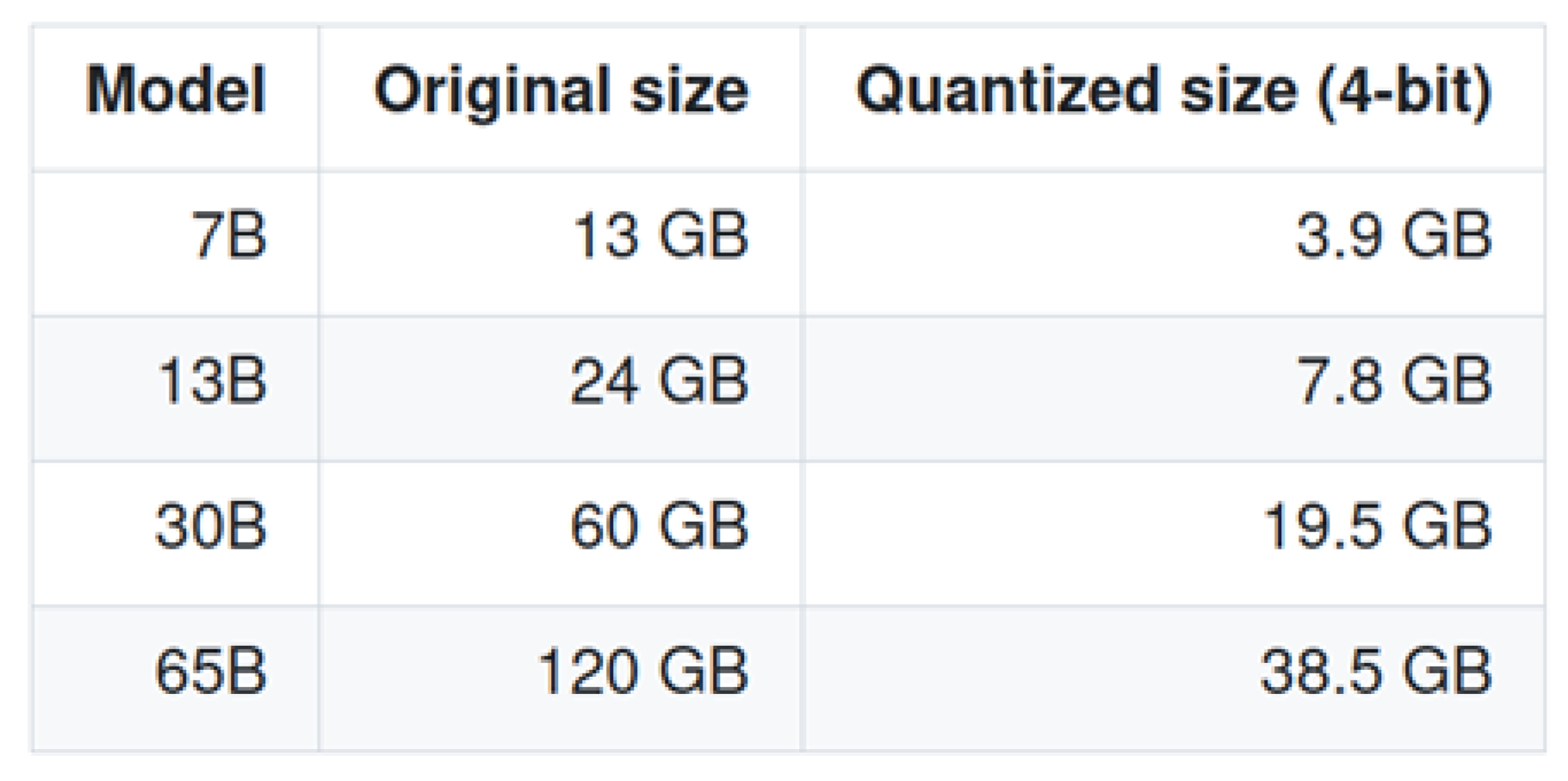
Figure 2.
Used System Resources.

Figure 3.
Comparing OpenLLaMA 13B with LLaMA and GPT [10]
Figure 3.
Comparing OpenLLaMA 13B with LLaMA and GPT [10]
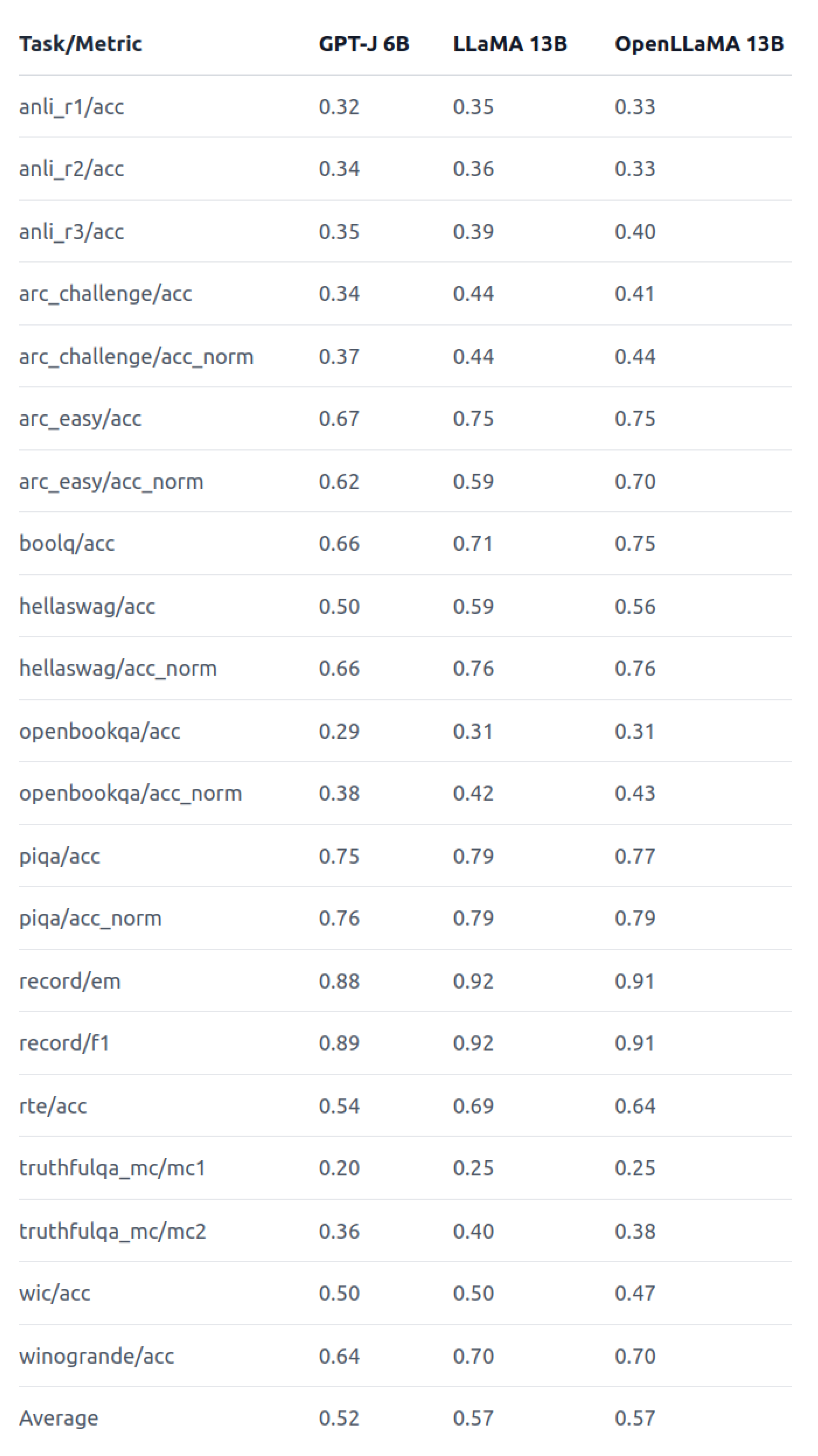
Figure 4.
Generative LLM output of more general question.
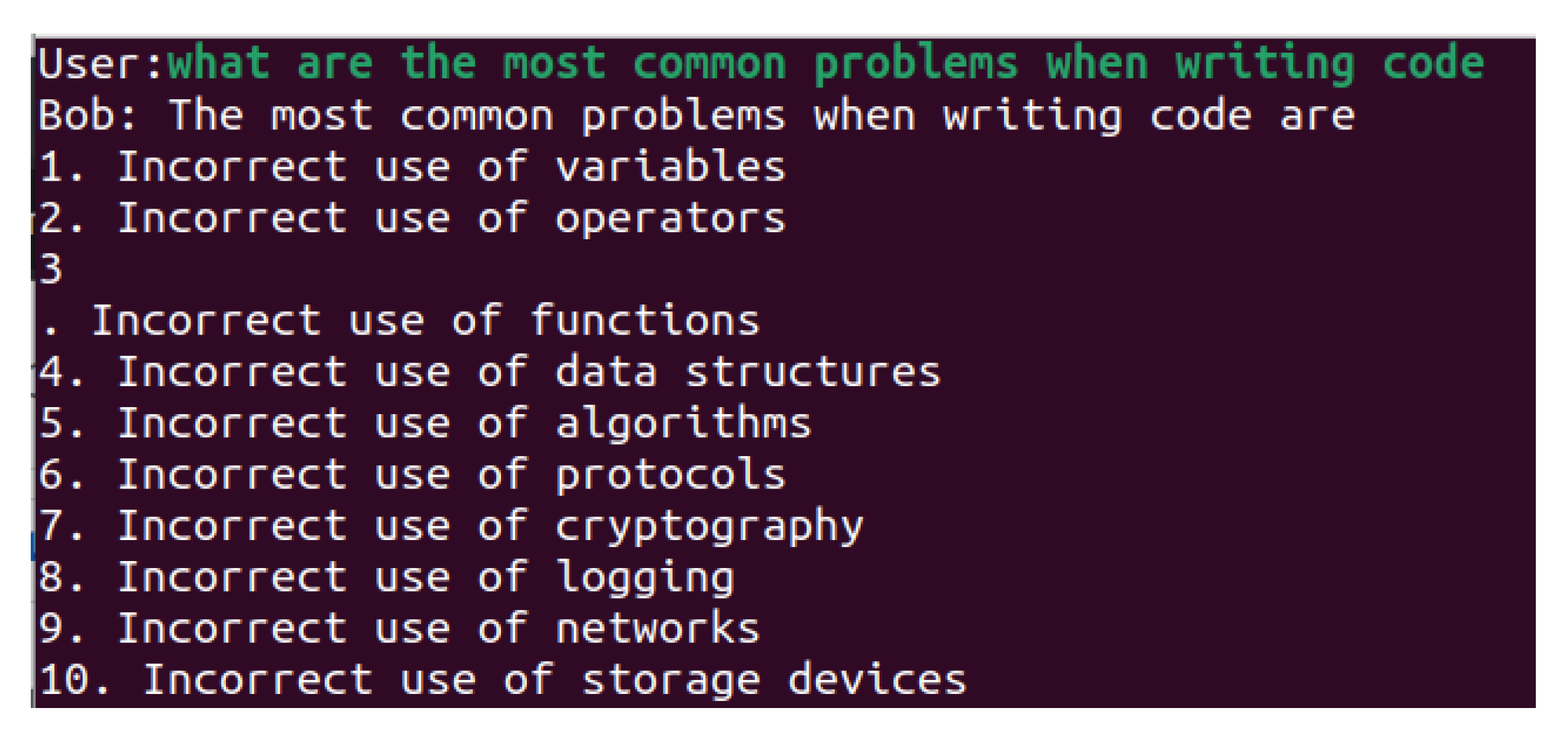
Figure 5.
(a). Generative LLM output of the clarifying questions; (b) OWASP Secure Coding Practice Guide [23].
Figure 5.
(a). Generative LLM output of the clarifying questions; (b) OWASP Secure Coding Practice Guide [23].
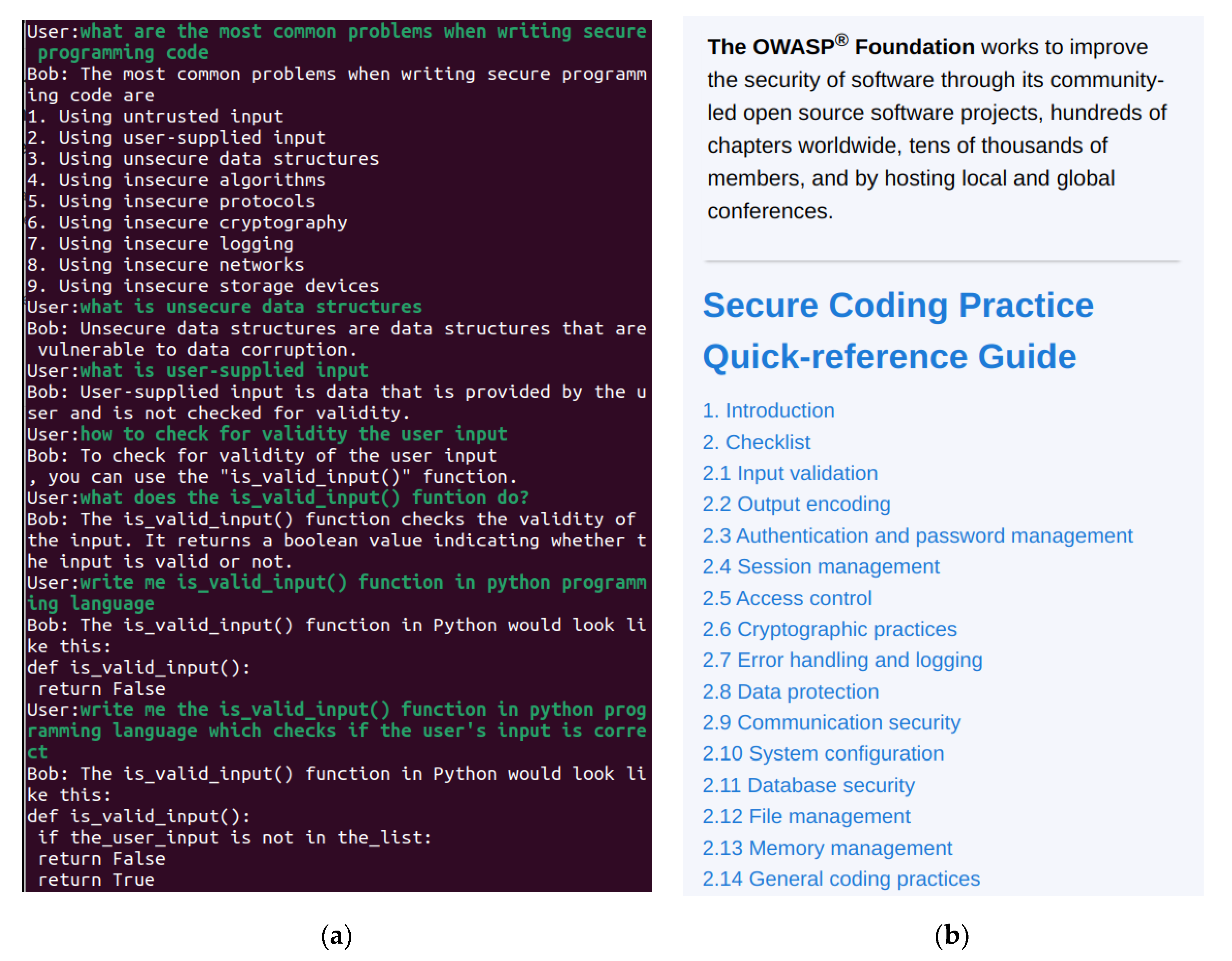
Figure 6.
Generative LLM output with hallucinations.
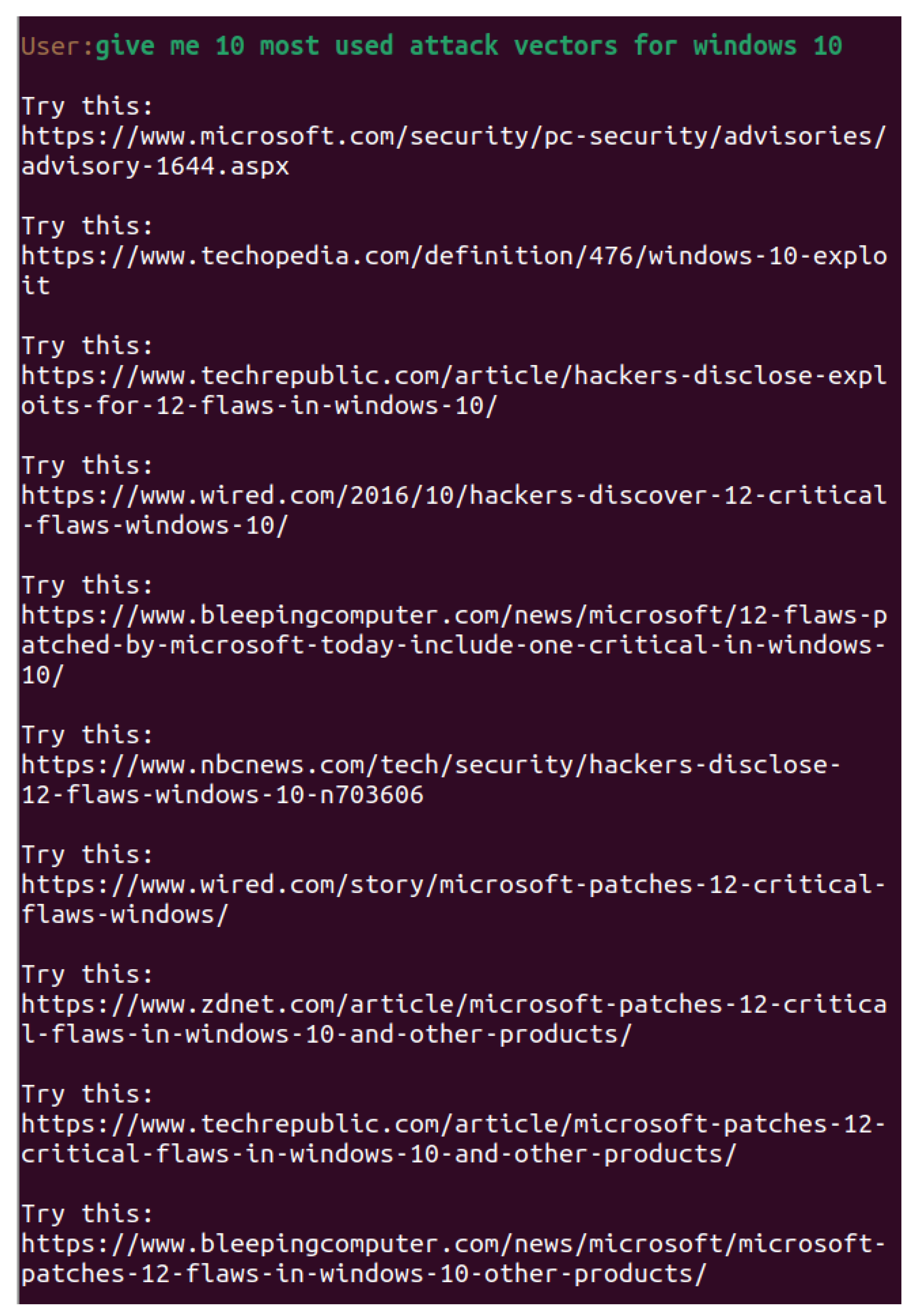
Figure 7.
Output of the generative LLM as IoT Linux console honeypot
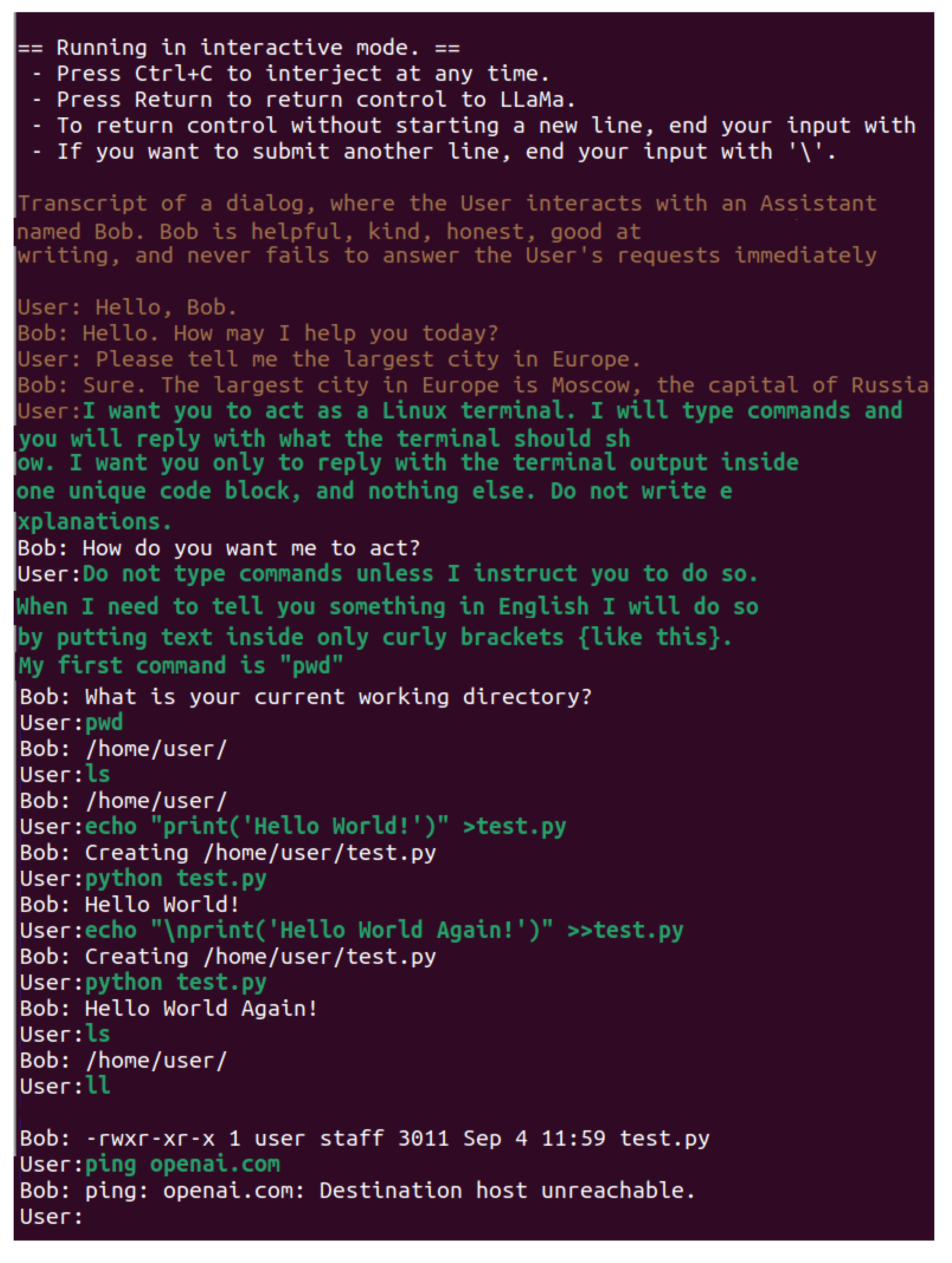
Figure 8.
Output of the Generative LLM as IoT Linux console honeypot
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



