Submitted:
18 May 2024
Posted:
20 May 2024
You are already at the latest version
Abstract
In the ambitiously evolving construction industry of Kuwait, characterized by its vision 2035 and rapid technological integration, there exists a pressing need for advanced analytical frameworks. This research paper introduces a groundbreaking deep learning approach utilising an autoencoder neural network to analyse the complexities of the Kuwait Construction Market and identify data irregularities. The construction sector’s significant investment influx and project expansion make it an ideal candidate for deploying sophisticated analytical techniques to detect anomalous patterns indicating inefficiencies or unveiling potential opportunities. Our approach leverages the capabilities of autoencoder architectures to delve into and understand the prevalent patterns in market behaviours. This meticulous analysis allows for the detection of deviations that may lead to operational or financial consequences. We elucidate the mathematical foundations of autoencoders, highlighting their proficiency in managing the complex, multidimensional data typical of the construction industry. Through training on an extensive dataset—comprising variables like market sizes, investment distributions, and project completions—our model demonstrates its ability to pinpoint subtle yet significant anomalies. The outcomes of this study enhance our understanding of deep learning’s pivotal role in construction and building management. Additionally, our findings proactively sketch the future market trajectory and facilitate anomaly detection, thereby contributing substantially to the academic discussion on integrating machine learning into construction management. This research offers valuable insights for professionals within Kuwait, aiming to harness deep learning techniques to boost operational efficiency and strategic foresight in the construction sector.
Keywords:
Autoencoder Neural Networks
; Anomaly Detection in Construction Data
; Machine Learning in Building Management
; Construction Market Analysis
1. Introduction
The Kuwait construction market offers a promising environment for the utilisation of state-of-the-art analytical tools to effectively investigate its intricate dynamics [1,2,3]. Given the substantial increase in investments and the proliferation of projects within the industry, the utilisation of advanced analytical techniques becomes essential in order to reveal concealed patterns, inefficiencies, and possible possibilities. This research presents an innovative deep learning method that utilises an autoencoder [4] to analyse the complex dynamics of the Kuwait Construction Market. This study seeks to analyse the complex relationship between many market elements, such as cash allocations, project timeframes, and labour dynamicsin order to detect abnormalities that may indicate operational or financial problems [5,6]. In the field of construction and building management, our technique also aims to facilitate a more informed and proactive decision-making process.
The research conducted by Koushki and Kartam highlights the considerable influence of building materials on the schedules and expenses of projects in Kuwait’s construction sector [7]. Their research into the time-related variables and material availability presents another dimension of anomaly detection—supply chain disruptions—which are critical in the construction industry. The findings of their study demonstrate that the selection and accessibility of construction supplies have a significant impact on project delays and cost overruns. The study’s findings suggest that imported materials have a less impact on project delays and cost overruns compared to local materials. This is because imported goods are better planned and there is a higher level of certainty regarding material availability before construction begins [8,9].
The study [10] delves deeper into the wider ramifications of fluctuations in oil prices on the construction industry, with a particular focus on the susceptibility of government project spending to changes in oil income. This scenario is demonstrated by the government’s endeavours to broaden revenue streams outside oil, as a component of the Kuwait Development Plan, with the objective of fostering non-oil GDP expansion. Nevertheless, the research indicates that the effectiveness of these diversification endeavours is constrained, given the ongoing volatility of the construction sector in relation to fluctuating oil prices [11,12].
The combination of these studies into a thorough literature review shows the many problems that Kuwait’s building industry faces, such as its reliance on imported materials, the effects of changing oil prices, and the government’s role in funding building projects [13]. The aforementioned problems highlight the necessity of implementing strategic planning, expanding the economy, and effectively managing building supplies in order to minimise delays and cost overruns. The knowledge obtained from this analysis can provide valuable guidance for policy-making, project management approaches, and future research endeavours, therefore enhancing the resilience and sustainability of the construction industry in Kuwait and comparable economies [14,15].
This research paper is strategically designed to delve into the complexities of the Kuwait Construction Market, utilising data sourced from The Public Authority for Civil Information and the Ministry of Justice to underpin our analysis. Initially, we present a detailed examination of this market data, setting a foundational understanding of the current market dynamics, trends, and the driving forces behind its growth. This provides the necessary context for our subsequent exploration into predicting the future size and investment patterns of the Kuwait Construction Market through statistical methods.
The core of our study focuses on the application of deep learning techniques, specifically the use of an autoencoder neural network. This approach is employed to analyse and interpret the intricate data, effectively identifying abnormal patterns that may indicate underlying issues or opportunities within the market. Our use of an autoencoder demonstrates the profound capabilities of deep learning in detecting anomalies and predicting future market behaviours.
In the discussion section, we provide an analysis of our findings, contextualising them within the broader scope of construction market analytics and their implications for stakeholders. The conclusion synthesises our research outcomes and operational efficiencies in the construction sector in Kuwait and potentially in similar markets worldwide.
2. Related Work
Anomaly detection in construction market data is a rapidly growing area of research, particularly pertinent to regions like Kuwait where economic activities are profoundly influenced by the dynamic construction industry. This literature review examines the developments in anomaly detection within the context of the Kuwaiti construction market, synthesising findings from various studies to identify trends, methodologies, and outcomes relevant to this niche field.
One pivotal study by Aslam et al. [16], although primarily focused on the oil industry, provides valuable insights into the application of machine learning algorithms for anomaly detection. The use of Random Forest (RF) and Explainable Artificial Intelligence (XAI) to manage and interpret multivariate time-series data can be analogous to detecting anomalies in construction market data, such as unexpected shifts in material costs or labour productivity metrics.
In their study, Al-Tabtabai and Soliman examine the consequences of declines in oil prices on the construction sector, with a specific emphasis on the timeframe spanning from 2007 to 2017 [10]. The study conducted by the researchers provides a comprehensive analysis of the clear relationship between oil prices and building material expenses, along with the wider implications for Kuwait’s Gross Domestic Product (GDP). The impact of the decrease in oil prices on government expenditure in the construction industry is significant [17], particularly in light of Kuwait’s substantial dependence on oil-generated income. This study further introduces a regression model with the objective of predicting building costs by considering swings in oil prices. This model provides a prediction tool for stakeholders in economies that heavily rely on oil.
Jarkas and Horner’s study on labour productivity in Kuwait’s construction industry provides a robust framework for establishing productivity baselines, which are essential for identifying anomalies in labour performance [14]. They emphasised the importance of understanding ’normal’ performance metrics to better detect and interpret deviations, which could signify either risks or opportunities within the construction process.
Al-Sabah and Refaat’s work on assessing construction risks in public projects in Kuwait presents a detailed categorisation of potential anomalies in the form of risks, including economic, regulatory, and environmental risks [18]. Their methodical quantification of risk probabilities and severities offers a structured approach to anomaly detection, where deviations from expected risk levels can indicate underlying issues in project management or execution.
These studies illuminate the multifaceted nature of anomaly detection in the Kuwaiti construction market. They reveal that while the methodologies may vary—from statistical analyses to machine learning techniques—the underlying goal remains consistent: to accurately identify, interpret, and respond to anomalies. This is crucial not only for maintaining economic stability and productivity in the construction sector but also for enhancing predictive capabilities and strategic planning. In this research work we are exploring more advanced analytical model, autoencoders, to explore and enrich the robustness and applicability of anomaly detection methods in construction market data.
3. Kuwait Construction Market Data
Due to the absence of a standardised housing index in Kuwait, this study used similar data which was sourced data from the Ministry of Justice’s Department of Property Registrations in [19]. The dataset encompasses roughly 60000 property transactions spanning from February 2004 to March 2017, documented in Arabic within unstructured PDF and Microsoft Excel formats. These records detail critical elements of each transaction, including property type, transaction date, price, plot size, and the location of the property. While additional details such as precise house addresses are occasionally available, their inconsistent presence led us to focus on these five primary attributes for analysis. The detail of the data is shown in Table 1
To facilitate analysis, significant pre-processing was necessary. Initially, the dataset underwent a language conversion from Arabic to English, as described in [19]. The data were then systematically catalogued not by the exact date but rather by the month or quarter in which each transaction occurred. In order to create a single format data, GPT-4 model [20] was utilised to convert the unstructured data into single structure data. Consistent with local practices, the pricing data were standardised to a per square meter basis by dividing the transaction price by the plot size as described by Alfalah [19]. For example, a property with a 400 square meter plot sold for K.D. 200000 would be recorded at a rate of 500 K.D. per square meter. Considering that all residential plots in Kuwait maintain a built-up area of of the land size, this measurement approach was deemed appropriate.
The data includes entries related to different cities in Kuwait, with information on stock levels and transaction volumes separated by type (lands and houses). Here’s an overview of the the data:
- City: Names of cities in Kuwait.
- Stock: Stock levels, possibly related to some form of inventory or assets.
- Transaction Volume Lands: Transaction volumes specifically for lands.
- Transaction Volume Houses: Transaction volumes for houses.
To enhance analytical granularity, transactions were segregated by city. Each city’s data were then divided into two distinct time series, namely, one for house transactions and another for land transactions. This separation is particularly relevant in Kuwait and other emerging markets where combined sales of houses and plots are commonplace.
Prior to constructing the indices, a thorough data cleaning process was essential. This included the exclusion of data pertaining to non-single-family residential units such as apartments, and other property classes like investment properties, focusing solely on single-family homes.
Further, the data were scrutinised for inaccuracies in recorded prices and plot sizes, with approximately 6000 transactions deemed unreliable and subsequently removed [19]. These entries typically featured prices recorded as zero, or figures vastly exceeding typical values, as well as plot sizes that were either implausibly small or excessively large. An additional review targeted major outliers, resulting in the elimination of about 600 transactions. This selective exclusion did not remove all outliers due to the inherent price variability across different cities, which reflects the diverse nature of the real estate market and poses a significant challenge in real estate index construction.
Table 2 is a summary of key statistical measures for stock levels and transaction volumes for lands and houses across cities in Kuwait.
The mean and median values show that the central tendency of stocks is higher than that of transaction volumes, indicating larger stock reserves relative to sales or transactions. The maximum values indicate peak occurrences which could be subject of further investigation to understand factors driving exceptionally high transactions or stock levels. The minimum values, especially the zero in transaction volumes for lands, suggest periods or places with no transactions, which could be indicative of market downturns or lack of demand. The standard deviation highlights the variability in each category, with transaction volumes for lands showing greater fluctuation compared to houses, suggesting a more volatile market for lands.
Figure 1 illustrates the transaction volumes for lands and houses across six districts in Kuwait. It highlights significant disparities between districts, with the Alahmadi district exhibiting the highest transaction volume for both lands and houses. Notably, Mobarak Alkaber district shows a pronounced preference for land transactions over houses, indicating a possible trend towards land investment in this region. The data suggests regional variations in real estate activity, which could be attributed to factors such as economic development, regulatory changes, or demographic shifts. This distribution can be considered as a critical tool for understanding the dynamics of the real estate market in Kuwait.
The spikes in transaction volumes for both lands and houses in certain cities are indicators to existence of abnormalities as they are significantly higher than average. These could be driven by specific events like new developments, policy changes, or economic stimuli. Furthermore, the stock levels are relatively consistent, but sudden dips for some districts requires further investigation to understand potential stock management issues or changes in demand.
4. Anomaly Detection on the Kuwait Construction Market Data
A new strategy to identifying outliers or strange patterns in the Kuwait Construction Market data would involve the utilisation of an autoencoder for anomaly identification. Regrettably, the constraints of our present environment prevent us from directly training and executing deep learning models on this platform or using the given document data. Instead, we will elucidate the process of configuring an autoencoder for anomaly detection, explicate the functioning of the model and the interpretation of its outcomes.
4.1. Autoencoders
Autoencoders are unsupervised learning algorithms that leverage neural networks for the task of representation learning. Specifically, they are designed to encode input data into a smaller dimensional space and then reconstruct the output from this representation. The key assumption is that anomalies will have higher reconstruction errors compared to normal data, as they are not well-represented by the common patterns learned by the autoencoder during training [21,22]. The acquisition of this acquired representation can then be employed for diverse objectives, including but not limited to dimensionality reduction, feature learning, and anomaly detection, as shown in Figure 2. Encoders and decoders are the two primary components of autoencoders.
Encoder: The encoder part of the autoencoder takes an input vector , where d is the dimensionality of the input data, and maps it to a hidden representation through a deterministic function f, such as:
Here, is a weight matrix, is a bias vector, and s is a non-linear activation function, such as the sigmoid function, ReLU, or . The dimensions p of the hidden layer are usually less than d, resulting in a compressed representation of the input data.
Decoder:The decoder part takes the hidden representation h and maps it back to a reconstruction r of the original input, using a similar deterministic function g, such as:
Here, and are the weight matrix and bias vector for the decoder, and is a potentially different activation function. The aim is to have r as close as possible to x.
Reconstruction Error:The training of an autoencoder involves minimizing the reconstruction error between the input x and its reconstruction r. This error can be quantified using a loss function, such as the mean squared error (MSE) for continuous input data:
Anomaly Detection:The underlying premise of anomaly detection is that the autoencoder acquires the ability to minimise reconstruction error for "normal" data through the process of training. Unobserved anomalies during training will result in a greater reconstruction error for the model. Hence, in the event that the reconstruction error associated with a novel data point over a certain threshold, it may be determined to be an anomaly.
4.2. Autoencoders based Anomaly Detection
Autoencoder is employed to acquire efficient representations, or encodings, of the input data. This is commonly done for the aim of reducing dimensionality or detecting anomalies. Presented below is a streamlined workflow:
Architecture:An autoencoder is composed of two primary components: the encoder and the decoder. The encoder is responsible for transforming the input into a code with a reduced number of dimensions, thereby transforming it into a latent space representation. Conversely, the decoder endeavours to reconstruct the input using this compressed code.
Training:During the training process, the autoencoder acquires the ability to minimise the reconstruction error, therefore acquiring the skill to produce outputs that closely resemble the inputs. The model undergoes training using just "normal" data, devoid of any abnormalities.
Anomaly Detection: Anomaly detection may be achieved by using the autoencoder following the training process, wherein the reconstruction error of newly acquired data is compared to the reconstruction error recorded during the training phase. Data points exhibiting notably elevated reconstruction errors are classified as anomalies due to the model’s inadequate training in accurately reconstructing them.
4.3. Implementing Autoencoders on Kuwait Construction Market Data
Anomaly detection involved the utilisation of an autoencoder to process the training data and obtain the reconstruction error for each individual data point. The inherent heterogeneity of properties poses significant challenges for analysing transaction data, as this variability affects the validity of the available information. Traditional time series construction is particularly volatile due to these discrepancies. To address these complexities, we employed an autoencoder, trained on features such as ’Stock levels’, ’Transaction Volume for Lands’, and ’Transaction Volume for Houses’ from a subset of data deemed ’normal’. This approach established a baseline for typical transaction patterns and stock levels. Our findings indicate that indices derived solely from land transactions are significantly more volatile compared to those based only on house transactions. This difference in volatility is attributed to the lesser heterogeneity in land sales, which lack many of the property-specific characteristics that influence value. Anomalies were identified by flagging data points that exhibit reconstruction errors over a predetermined threshold, which is chosen based on the training data.
5. Discussion
This paper presents three main findings derived from the application of our trained autoencoder to analyse real estate volatility. Firstly, it reveals that the heteroscedasticity commonly associated with real estate is not the principal challenge in generating highly volatile indices. Instead, fluctuations are more influenced by factors related to land price in indices exclusively focused on land transactions. Despite lacking many housing characteristics, land sales inherently exhibit high volatility, leading to more volatile indices for land-only transactions compared to those including house transactions, which show moderate volatility. This variation may also stem from property traders who frequently flip land or from the high transaction rates in certain cities.
Secondly, employing the autoencoder to strategically reduce the sample size and select specific sub-samples has significantly enhanced index performance in various aspects. Excluding data from region mostly known for luxury and vacation homes—markedly improves outcomes. Similarly, it seemed the network focused on high-frequency cities which as a result enhanced performance by mitigating the impacts of cities with low transaction frequencies, high volatility, and elevated costs.
Thirdly, the autoencoder’s capability to stratify data by city and long-term mean prices considerably bolsters the efficacy of central tendency measures used in index construction. While city stratification slightly edges out in performance, indices stratified by long-term mean prices hold competitive advantages. This approach aggregates a substantial volume of transactions per period, thereby minimizing the potential skewing effects of outliers, offering superior performance in certain scenarios compared to other stratification techniques.
Overall, based on our analysis we found two main abnormalities in the data, which are:
- Transaction Volume of Lands: Significant outliers are found in the volumes 4,278 and 13,211 transactions, which are substantially higher than typical volumes.
- Transaction Volume of Houses:Outliers include volumes of 1,001 and 1,150 transactions, also considerably higher than the average.
These outliers indicate special market activities in those specific cities. Abnormal behaviours, such as the extremely high transaction volumes in certain cities, seems to be driven by factors like new developments, policy changes, or other market influences, as stated earlier.
Based on our investigation for existing data we can outline the following factors that might contribute to detected abnormalities:
- Economic Changes: Shifts in the economy, such as changes in interest rates, employment rates, impact of oil price change, and overall economic growth, have significantly impact real estate transactions.
- Government Policies:Introduction of new government policies and incentives, such as subsidies for buyers and changes in zoning laws, has led to dramatic change in transaction volumes.
- Market Sentiment: One of our hypothesis is that general sentiment about the future of the property market might have caused fluctuations.
- New Developments: New developments and announcements of future developments in several districthas led to increased transactions as investors and homebuyers try to get in early.
5.1. Limitations
The limited availability of comprehensive property data and the challenges in creating reliable home price indexes in Kuwait highlight potential gaps in fully understanding market dynamics. This lack of detailed data could complicate policy development, investment decisions, and economic forecasting related to the construction and real estate sectors. As usual, more extensive and detailed data would enhance the analysis, providing a clearer picture of market behaviours and facilitating more informed decision-making processes.
6. Conclusions
Through the analysis of anomalies identified by our autoencoder, we have acquired crucial insights into the most volatile aspects of the Kuwait Construction Market. This investigation has not only pinpointed areas requiring further research or strategic realignment but has also enabled us to project future market trends by examining past irregularities. The success of autoencoders in detecting these anomalies fundamentally relies on the quality and preprocessing of the input data, as well as precise tuning of the model’s architecture and training parameters.
The anomalies highlighted by our analysis suggest critical areas for potential legislative action, market adaptation, or strategic modifications to address the prevailing challenges effectively. Understanding these anomalies requires a robust scientific approach that extends beyond mere detection. It involves a comprehensive exploration of their root causes, implications, and possible interventions, which should be pursued through further quantitative analyses and qualitative research.
Moreover, the stability of the construction market is influenced by internal factors, such as local material availability and government regulations, as well as external forces, including global oil prices and supply chain disruptions. Continuous monitoring of these elements will enhance our understanding of forthcoming market shifts and pinpoint vulnerabilities. This holistic approach ensures that strategic decisions are informed and responsive to both domestic and international dynamics, safeguarding the market’s resilience and promoting sustainable growth.
Author Contributions
Conceptualization, B.A. and G.A.; methodology, B.A.; software, B.A.; validation, B.A. and G.A.; formal analysis, B.A.; writing—original draft preparation, B.A. and G.A.; ; writing—review and editing, B.A. and G.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is available from The public Authority for civil information and Ministry of Justice.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- AlSanad, S. Awareness, drivers, actions, and barriers of sustainable construction in Kuwait. Procedia engineering 2015, 118, 969–983. [Google Scholar] [CrossRef]
- Alfalah, A.A.; D’Arcy, E.; Stevenson, S. Constructing House Price Indices in an Emerging Market: The Case of Kuwait. Journal of Real Estate Literature 2023, 31, 144–160. [Google Scholar] [CrossRef]
- Alrasheed, K.; Soliman, E.; Al-Bader, H. Systematic Review of Construction Project Delays in Kuwait. Journal of Engineering Research 2023. [Google Scholar] [CrossRef]
- Rezaeianjouybari, B.; Shang, Y. Deep learning for prognostics and health management: State of the art, challenges, and opportunities. Measurement 2020, 163, 107929. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. Proceedings of ICML workshop on unsupervised and transfer learning. JMLR Workshop and Conference Proceedings, 2012, pp. 37–49.
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine learning; Elsevier, 2020; pp. 193–208.
- Koushki, P.A.; Kartam, N. Impact of construction materials on project time and cost in Kuwait. Engineering, Construction and Architectural Management 2004, 11, 126–132. [Google Scholar] [CrossRef]
- Waly, A.F.; Thabet, W.Y. A virtual construction environment for preconstruction planning. Automation in construction 2003, 12, 139–154. [Google Scholar] [CrossRef]
- Steinberg, F. Housing reconstruction and rehabilitation in Aceh and Nias, Indonesia—Rebuilding lives. Habitat international 2007, 31, 150–166. [Google Scholar] [CrossRef]
- Al-Tabtabai, H.; Soliman, E. Oil prices drop effect on construction industry in Kuwait. Journal of Engineering Research (2307-1877) 2022, 10. [Google Scholar] [CrossRef]
- Liu, F.; Umair, M.; Gao, J. Assessing oil price volatility co-movement with stock market volatility through quantile regression approach. Resources Policy 2023, 81, 103375. [Google Scholar] [CrossRef]
- Guo, C.; Zhang, X.; Iqbal, S. Does oil price volatility and financial expenditures of the oil industry influence energy generation intensity? Implications for clean energy acquisition. Journal of Cleaner Production 2024, 434, 139907. [Google Scholar] [CrossRef]
- Nawaz, A.; Khan, S.S.; Ahmad, A. Ensemble of Autoencoders for Anomaly Detection in Biomedical Data: A Narrative Review. IEEE Access 2024. [Google Scholar] [CrossRef]
- Jarkas, A.M.; Horner, R.M.W. Creating a baseline for labour productivity of reinforced concrete building construction in Kuwait. Construction Management and Economics 2015, 33, 625–639. [Google Scholar] [CrossRef]
- Tong, G.K.; Ng, K.H.; Yap, W.S.; Khor, K.C. Construction of Optimal Stock Market Portfolios Using Outlier Detection Algorithm. Soft Computing in Data Science: 6th International Conference, SCDS 2021, Virtual Event, November 2–3, 2021, Proceedings 6. Springer, 2021, pp. 160–173.
- Aslam, N.; Khan, I.U.; Alansari, A.; Alrammah, M.; Alghwairy, A.; Alqahtani, R.; Alqahtani, R.; Almushikes, M.; Hashim, M.A.; et al. Anomaly detection using explainable random forest for the prediction of undesirable events in oil wells. Applied Computational Intelligence and Soft Computing 2022, 2022. [Google Scholar] [CrossRef]
- Ewubare, D.B.; Maeba, S.L. Effect of public expenditure in construction and transportation sectors on employment in Nigeria. International Journal of Science and Management Studies 2018, 1, 130–136. [Google Scholar]
- AlSabah, R.; Refaat, O. Assessment of construction risks in public projects located in the state of Kuwait. Journal of Engineering Research 2019, 7. [Google Scholar]
- Alfalah, A.A. Challenges and opportunities facing emerging real estate markets: an empirical examination of the Kuwait residential real estate market. PhD thesis, University of Reading, 2018.
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774 2023. [Google Scholar]
- Zhai, J.; Zhang, S.; Chen, J.; He, Q. Autoencoder and its various variants. 2018 IEEE international conference on systems, man, and cybernetics (SMC). IEEE, 2018, pp. 415–419.
- Chen, S.; Guo, W. Auto-encoders in deep learning—a review with new perspectives. Mathematics 2023, 11, 1777. [Google Scholar] [CrossRef]
- Li, P.; Pei, Y.; Li, J. A comprehensive survey on design and application of autoencoder in deep learning. Applied Soft Computing 2023, 138, 110176. [Google Scholar] [CrossRef]
Figure 1.
Comparative transaction volumes for lands and houses across different districts in Kuwait.
Figure 1.
Comparative transaction volumes for lands and houses across different districts in Kuwait.
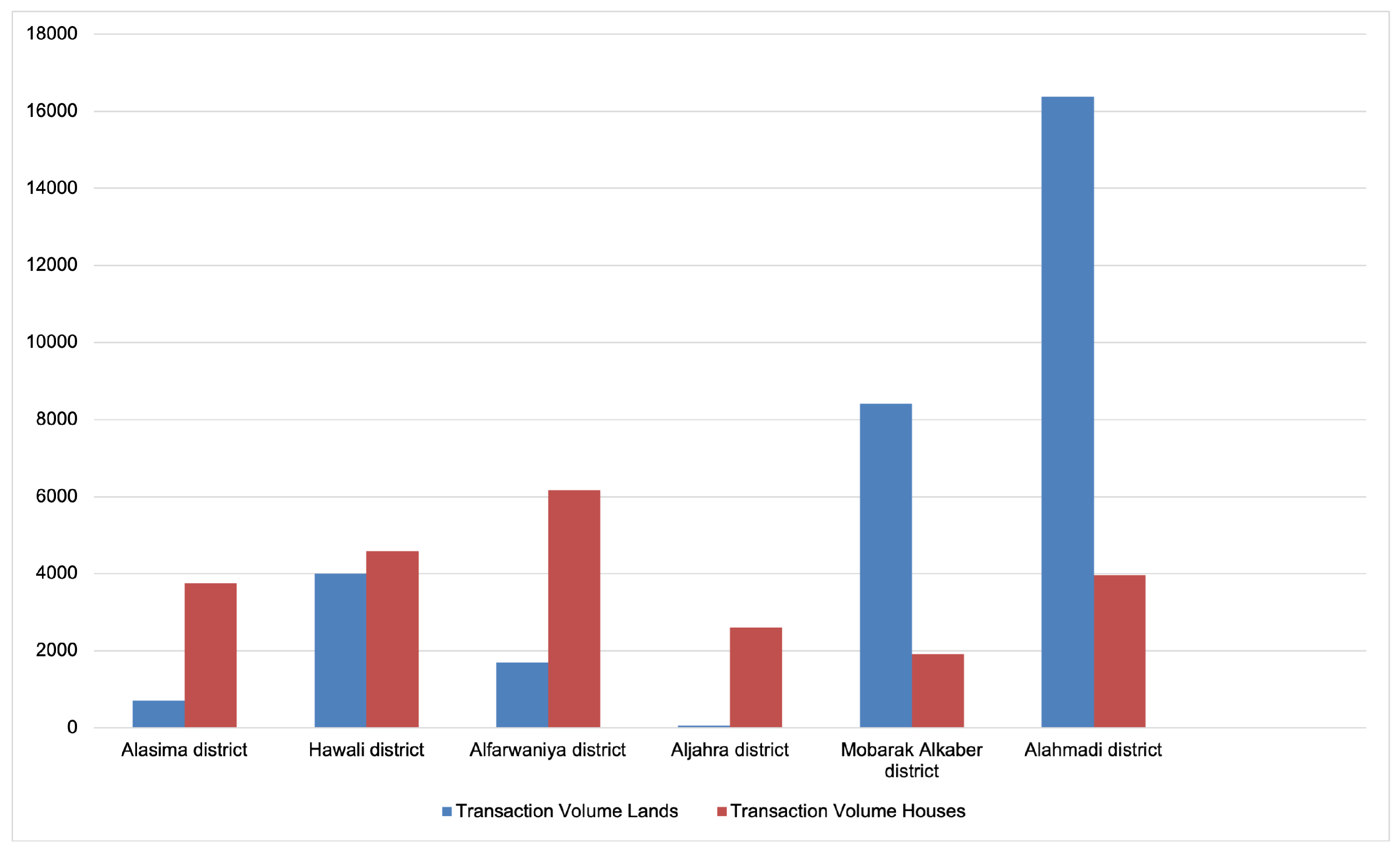
Figure 2.
Autoencoder scheme [23].
Figure 2.
Autoencoder scheme [23].
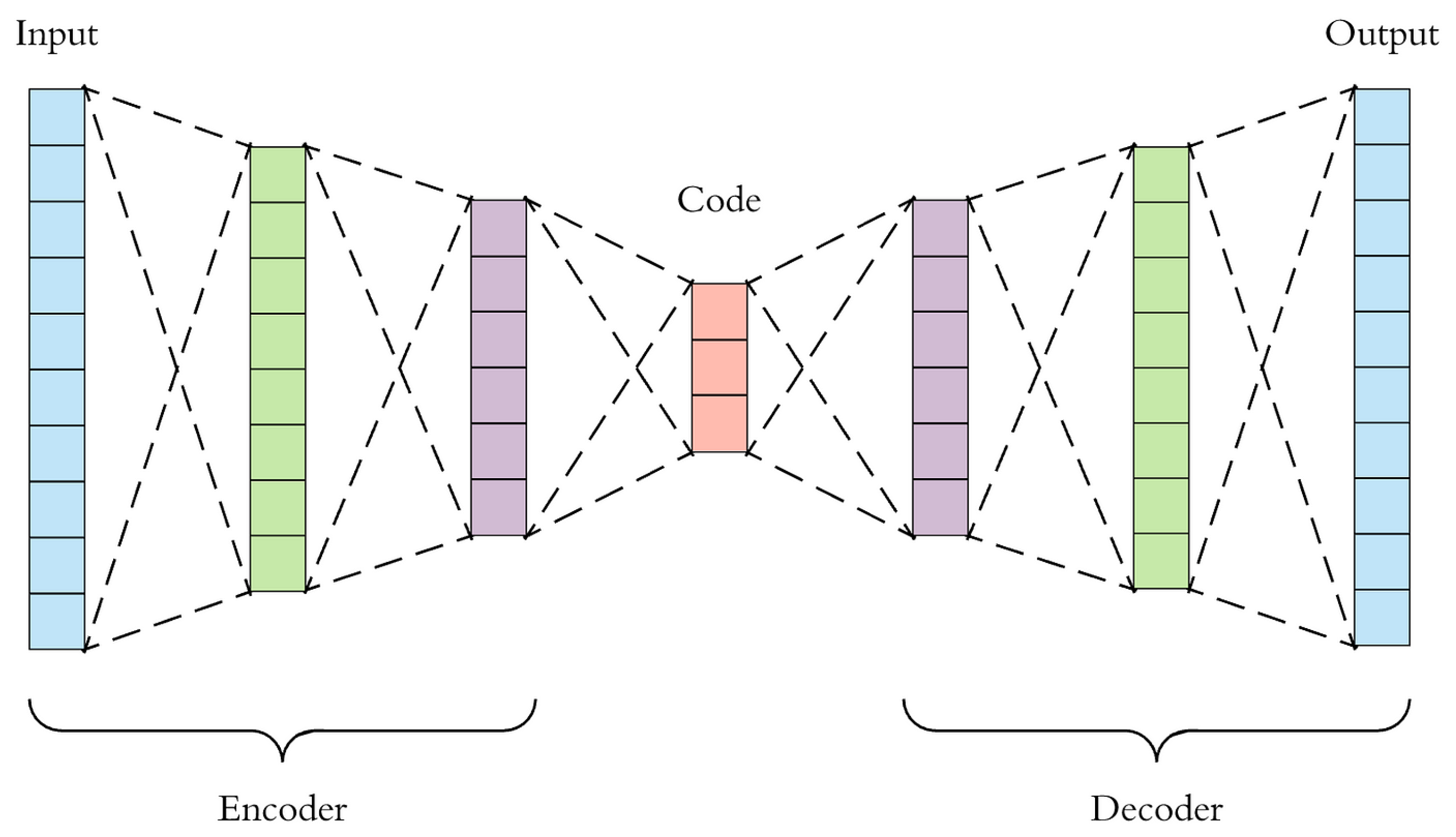

Table 1.
List of cities in Kuwait with their stocks and transactions volumes, as presented in [19].
Table 1.
List of cities in Kuwait with their stocks and transactions volumes, as presented in [19].
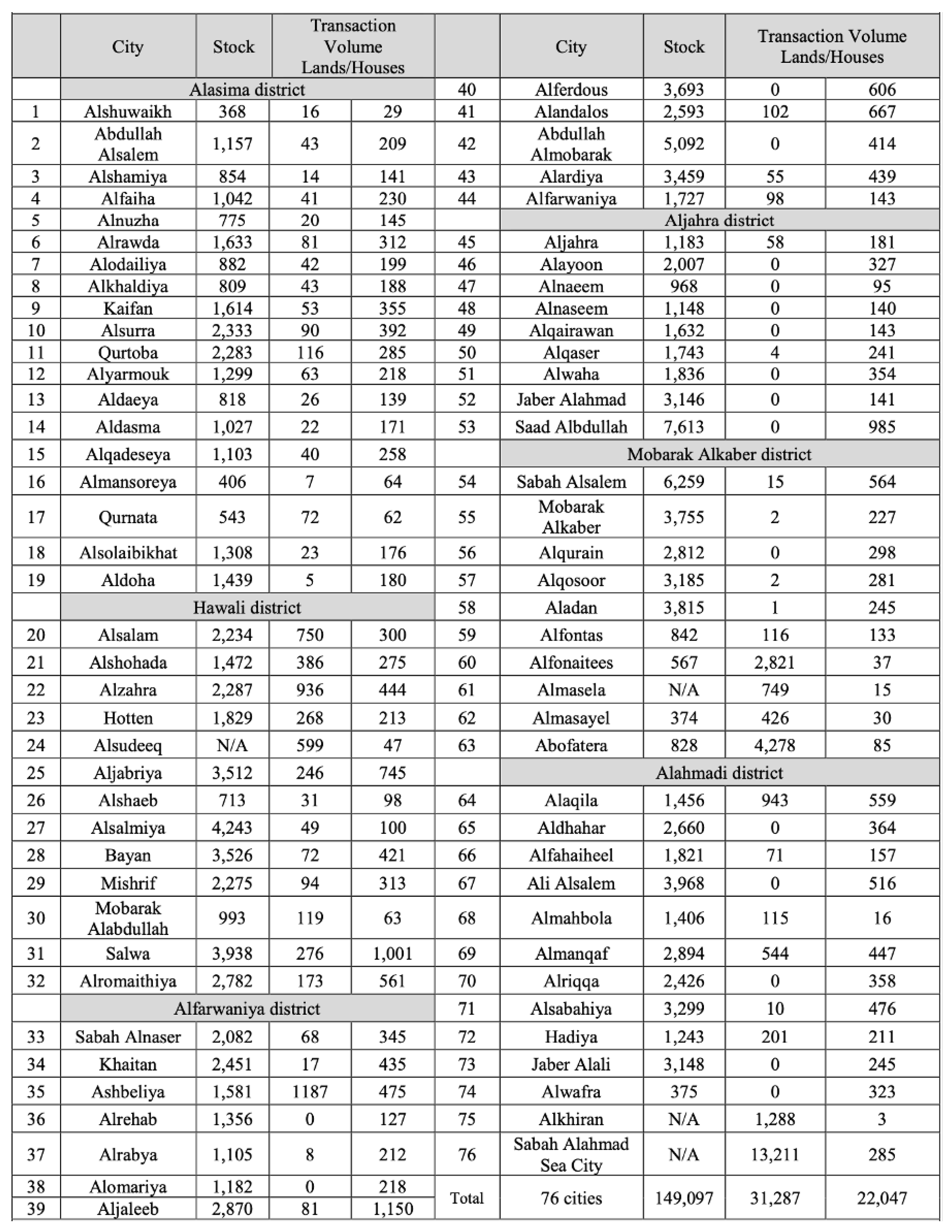
Table 2.
key statistical measures for stock levels and transaction volumes for lands and houses across cities in Kuwait
Table 2.
key statistical measures for stock levels and transaction volumes for lands and houses across cities in Kuwait
| Statistical Measure | Stock | Transaction Vol. (Lands) | Transaction Vol. (Houses) |
|---|---|---|---|
| Mean | 2070.79 | 318.01 | 302.36 |
| Median | 1680.00 | 41.00 | 243.00 |
| Maximum | 7613.00 | 13211.00 | 1150.00 |
| Minimum | 368.00 | 0.00 | 3.00 |
| Standard Deviation | 1383.42 | 1524.11 | 246.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



