
Submitted:
20 May 2024
Posted:
21 May 2024
You are already at the latest version
Abstract
The calculation of the global shear capacity of steel-concrete composite downstand cellular beams with precast hollow-core units is important as it affects the span to depth ratios and the amount of material used, hence affects the embodied CO2 calculation when designers are deciding on the floor grids. This paper presents a reliable tool that can be used by designers to alter and optimise grip options during the preliminary design stages, without the need to run onerous calculations. The global shear capacity prediction formula is developed using five machine learning models. First, a finite element model database is developed. The influence of the opening diameter, web opening spacing, tee-section height, concrete topping thickness, the interaction degree, and the number of shear studs above the web opening are investigated. Reliability analysis is conducted to assess the design method and propose new partial safety factors. The Catboost Regressor algorithm presented better accuracy compared to the other algorithms. An equation to predict the shear capacity of composite cellular beams with hollow-core units is proposed by Gene Expression Programming. In general, the partial safety factor for resistance, according to the reliability analysis, varied between 1.25 and 1.26.
Keywords:
Machine learning
; Composite floors
; Hollow-core units
; Shear capacity
; Reliability analysis
1. Introduction
Cellular steel beams are made by expanding a parent section through thermal cutting, shifting, and welding. This process creates steel beams with a higher section and periodical circular web openings, enhancing flexural stiffness about the strong axis. The web openings allow airflow and integration of services in closed environments. The cellular steel beam when associated with concrete slabs by mechanical devices, i.e., shear studs, is forming composite cellular beams that have the capacity to span distances ranging from 12 to 20 meters [1,2]. To overcome drawbacks like high shear studs welding costs and concrete curing time associated with solid or composite slabs (with steel formwork), precast hollow-core slabs (PCHCS, aka PCU/HCU) offer a cost-effective and time-saving alternative [3].
For the design and verification of composite cellular beams with composite slabs (with steel formwork), two current recommendations are available: SCI P355 [4] and Steel Design Guide 31 [5]. These publications primarily address scenarios where shear stud positions are constrained by rib positioning. Literature includes studies that have examined the impact of shear studs placed above the web opening length in composite beams. Redwood and Poumbouras [6] conducted tests to assess the necessity of shear studs within the opening length at the steel-concrete interface considering steel-concrete slabs (with trapezoidal steel formwork). The absence of shear studs in this length substantially decreased the load-bearing capacity of composite beams with rectangular web openings. Additionally, Redwood and Poumbouras [7] developed a model for predicting the load-bearing capacity that accounted for increased compression stresses resulting from shear stud deformation-induced slip. Their approach, however, was deemed conservative in contrast to earlier experimental results. Donahey and Darwin [8] explored the impact of the moment-shear ratio, shear stud quantity and position along the beam as well as the steel formwork orientation. Their findings revealed that increasing the number of shear studs above the opening led to an enhanced load-bearing capacity. Cho and Redwood [9] introduced a methodology for estimating the load-bearing capacity of composite beams with rectangular web openings, treating the shear studs above the web opening length as tensioned elements based on the truss concept. This approach linked shear resistance to shear stud placement, with the idea that shear studs in the opening length contributed to the shear resistance of concrete slabs. This was later verified by Cho and Redwood [10]. Until now, it has been noted that the research conducted on the shear stud placement has exclusively focused on composite beams composed of concrete slab with steel formwork. Ferreira et al. [11] performed a parametric analysis using the finite element method to explore the impact of shear stud quantity on the load-bearing capacity of steel-concrete composite beams with PCHCS. The authors emphasised the significance of shear studs when positioned near the supports, as the global shear capacity experienced a reduction in the absence of shear studs.
As presented previously, SCI P355 [4] and Steel Design Guide 31 [5] provide design recommendations of composite cellular beams with steel-concrete composite slabs (with steel formwork). In 2003, the Steel Construction Institute (SCI) released SCI P287 [12], a manual providing design guidelines for composite beams with PCHCS. Following this, SCI P401 [13] was published as an updated version, incorporating revised recommendations. This updated document outlines minimum dimension requirements, addressing both ultimate and service limit states during construction for scenarios involving full and partial interaction. Nevertheless, these guidelines are directed towards steel-concrete composite beams without web openings. Therefore, it is possible to conclude that there are no specified design recommendations for the composite cellular beams with PCHCS.
Flooring systems frequently utilize PCHCS due to their widespread applicability. In this context, PCHCS can be arranged on rigid or flexible supports. The steel profiles that support the PCHCS are considered flexible if the shear strength of the PCHCS is reduced due to the deflection of the downstand steel beam [14]. This effect is known as shear interaction between slabs and beams. In the case of composite cellular beams with PCHCS this phenomenon is intensified, due to the deflections through the web openings. SCI P355 [4] describes that the magnitude of the resistance of the local composite action is dependent on the flexibility of the beam in the opening, which causes relative deflections between the cellular profile and the slab, which can cause the shear connector to pull out, due to the tensions vertical traction forces developed near the upper edge of the opening. It is worth mentioning that this flexibility tends to increase with the increase in the span length, as well as the increase in the opening diameter [15].
Predicting the resistance of composite cellular beams with PCHCS is a complex task, since all possible failure modes of the steel and concrete sections must be considered, as well as the interaction degree. In this context, the application of machine learning (ML) models is a useful tool. ML models and Gene Expression Programming (GEP) have seen extensive application in civil engineering, notably in predicting the shear resistance of steel structures. For example, Avci-Karatas [16] used minimax probability machine regression (MPMR) and extreme machine learning (EML) to predict the shear capacity of headed studs. The models were developed using experimental data and key input parameters such as stud shank diameter, and tensile strength of headed steel studs. Zhang et al. [17] used a global dataset of push-out tests to develop ML models. Five sophisticated machine learning models were comparatively utilized alongside three commonly employed equations from design codes to predict the resistance of headed studs. Earlier and Kara [18] investigated the feasibility of using GEP for calculating the ultimate shear strength of steel fibre reinforced concrete (SFRC) beams without stirrups. Momani et al. [19] employed artificial neural networks (ANN) and GEP to develop prediction models for the shear strength of SFRC beams. Hosseinpour et al. [20] used ANN and MR for predicting the lateral-distortional buckling resistance of composite beams under hogging moment. Other applications of ML models can be found in the publication of Thai [21]. In this scenario, ML based formulae and tools to ease the design of such systems can be applied for increasing reliability and decrease effort/time and hence improve efficiency. Therefore, the present work aims to apply machine learning models for predicting the global shear capacity of simply-support steel-concrete composite cellular beams with PCHCS submitted to four-point bending. For this task, a finite element database is employed [11]. CatBoost, Gradient Boosting, Extreme Gradient Boosting, Light Gradient Boosting Machine, Random Forest and Gene Expression Programming Algorithms are assessed. Following, comprehensive comparative and reliability analyses are carried out.
2. Finite Element Method
This section describes the methodology for developing the finite element (FE) models similar to Ferreira et al. [11,22]. The FE model is based on four tests of simply supported composite cellular beams [23,24] and three tests of simply supported composite beams with PCHCS [25,26]. Geometric and material nonlinear analyses are conducted in ABAQUS® [27] software. The concrete is modelled via Concrete Damage Plasticity (CDP) [28,29,30] using Carreira and Chu model [31,32]. Three constitutive models of steel are employed. The elastic-perfectly plastic model is adopted for transverse bars and steel mesh. The bilinear model with hardening is used to model the headed shear studs [33]. A multilinear model, proposed by Yun and Gardner [34], is used to model the steel profiles. The interactions between steel and concrete are made by tangential and normal behaviours [35]. Regarding the discretization, S4R, C3D8R and T3D2 elements are used. The size of the finite element mesh is based on previous studies [36,37].
2.1. Validation Results
Figure 1 shows the validation results by load per displacement relationships. Models 1-4 and 5-7 refer to composite cellular beams and composite beams with PCHCS, respectively. Models 1-4 failed by web-post bucking, while models 5-7 failed by excessive cracking of precast hollow-core slabs and steel yielding. According to all the results, it can be stated that the finite elements are validated.
2.2. Parametric Study
In total 240 finite element models are developed as shown in Figure 2, in which Do is the opening diameter, d is the depth of parent section, p is the length between the opening diameter centres, ht is the height of the tee section, tc is the height of the concrete topping, n is the number of shear studs between zero and maximum moment regions, nh is the number of shear studs above the web opening, and η is the interaction degree. The number of models considered in the parametric analyses is presented in Figure 3.
3. Machine Learning Models
When it comes to analysing a dataset, various methods can be employed to extract valuable insights. This research compares different methods to examine their effectiveness in analysing the same dataset. By examining each approach, the most suitable method will be found. In the following sections, the different methods and their applicability is explored.
3.1. CatBoost
Dorogush et al. [38] recently inherited Catboost, a gradient-boosting algorithm. A multi-platform gradient boosting library known as Catboost solves both regression and classification problems simultaneously. Gradient boosting is successively fitted to the decision tree in the Catboost algorithm, which uses the decision tree as the underlying weak learner. Gradient learning information is arranged inconsistently to avoid overfitting when implementing the Catboost algorithm [39]. Figure 4 shows an explanation of the Catboost algorithm. The Catboost algorithm's training ability is determined by its framework hyperparameters, such as the number of iterations, learning rate, maximum depth, etc. A model's hyperparameters can be determined by the user and it is a laborious process.
3.2. Gradient Boosting
Gradient Boosting Decision Tree (GBDT) is a supervised machine learning model that learns a function mapping from known input variables to target variables through an algorithm. It has been deployed as the fundamental component of the embedded failure prediction methodology due to its capability in handling complex relationships and interaction effects between measured inputs automatically [40], providing better interpretability than other machine learning approaches like support vector machines or neural networks [41] and low computational complexity, which makes it realistic to be utilised and implemented to produce valuable prediction results in a real world production environment [42,43,44]. As illustrated in Figure 5, the GBDT consists of a series of decision trees with each successive one correcting the error of the precedent trees.
3.3. Extreme Gradient Boosting
Extreme gradient boosting (XGBoost) is an important ensemble learning algorithm in machine learning approaches [46]. In XGBoost, regression and classification trees are combined with analytical boosting methods. As an alternative to developing an addressed tree, the boosting method constructs different trees and then connects them to estimate a systematic predictive algorithm. Gradient boosting algorithms are usually matched to XGBoost's subsequent assessment of the loss function. There are many ways to mine the characteristics of gene coupling using XGBoost. The general structure of XGBoost models is shown in Figure 6.
3.4. Light Gradient Boosting Machine
Light Gradient Boosting Machine, or LightGBM, is an open source graded boosting machine learning model from Microsoft based on decision trees [48]. With LightGBM, continuous buckets of elemental values are divided into separate bins with greater adeptness and a faster training rate. With histogram-based algorithms, the learning phase is improved, memory consumption is reduced, and communication networks are integrated to enhance training regularity, known as parallel voting decision trees. To select top-k elements and apply global voting techniques, the data for learning were partitioned into several trees. Figure 7 illustrates how LightGBM identifies the leaf with the maximum splitter gain using a leaf-wise approach [49].
3.5. Random Forest
Random forest combines multiple decision trees to reduce overfitting and bias-related inaccuracy, resulting in usable results. It is a powerful and versatile algorithm that grows and combines multiple decision trees to create a “forest” [51]. It can handle large data sets due to its capability to work with many variables running to thousands [52]. RF model basic structure is shown in Figure 8.
3.6. Gene Expression Programming
Genetic algorithms (GAs) were pioneered by J. Holland [54], drawing inspiration from Darwin’s theory of evolution. GAs mirrors the biological evolution process, representing solutions through fixed chromosomes. Similarly, Genetic Programming (GP) was introduced by Cramer and advanced by Koza [55,56]. GP extends GA, functioning as a form of machine learning that constructs models via genetic evaluation. Operating on Darwinian reproduction principles, GP stands as a powerful optimization technique leveraging neural networks and regression methods. Further, Ferreira [57] proposed a modified version of GP based on population evolution and dubbed gene expression programming (GEP). GEP encodes chromosomes in a linear fixed array, outperforming GP, which uses a tree-like structure with variable length [58]. A linear fixed length chromosome and a nonlinear expression tree were inherited from GA and GP in the evolutionary GEP algorithm, respectively. The linear fixed width of genetic programming and the genetic algorithm make GEP an excellent method. Figure 9 [59] shows a schematic diagram of the GEP algorithm. Based on the experimental results, GEP itself adds and deletes various parameters.
4. Assessing the Accuracy of Machine Learning Models
To assess how accurately a machine learning model can make predictions, its accuracy needs to be measured. Some of the metrics that are often used to measure the performance of regression models are the Mean Squared Error (MSE), the Mean Absolute Error (MAE), the Root Mean Squared Error (RMSE), the coefficient of determination (R2), Mean Absolute Percentage Error (MAPE) and the Root Mean Squared Logarithmic Error (RMSLE) [60,61], according to Equations (1)–(6).
In which is the total number of observations is the actual value is the predicted value and is the mean of the actual value.
5. Results and Discussion
In this section, the performance of each algorithm used to predict the shear capacity of 4 composite cellular beams with PCHCS will be discussed. Table 1 provides details of the hyperparameters related to the model.
5.1. CatBoost
Figure 10a,b show the train and test plots, respectively, and the validation curve (Figure 10c) of the CatBoostRegressor. According to illustration, the residual distribution around zero is highly concentrated, indicating excellent model precision. Its robust performance is underscored by its high Train R2 value of 0.997 and Test R2 value of 0.939, which indicates that the CatBoostRegressor model is both highly precise and highly generalizable. Regarding the validation curve, with the depth of 0, the Training Score starts at approximately 1.0, which indicates that the model is able to fit the training data well with a shallow tree. With increasing depth, the training score decreases slightly, suggesting that the model is becoming less prone to overfitting and more generalised. Initially, the Cross-Validation Score is lower than the training score, but it peaks around 4 when the depth increases. It is evident from this validation curve that the model is performing well; however, beyond the depth of 4, there is a noticeable divergence between the training and validation scores. The model performs exceptionally well on trained data, but less so on unseen or validation data as a result of mild overfitting.
5.2. Gradient Boosting
A regression model typically assumes that the residuals are approximately normally distributed around zero based on the histogram on the right side of the plot (Figure 11). The absence of clear outliers in the residuals is a positive sign, as outliers can significantly affect the model fitting. As a result of the model explaining a large proportion of the variance in the dependent variable, the R-squared values for both the train and test sets are quite high (0.9557 and 0.9118, respectively). It is possible to have an overfitted model with a high R-squared, despite having a high R-squared. It can be seen from Figure 11c that the model exhibits strong learning and generalization capabilities. As the model complexity (depth) increases, the risk of overfitting increases too. In order to achieve a balance between bias and variance, the optimal model depth appears to be around 6, when the cross-validation score is maximised and the model has a maximum cross-validation score.
5.3. Extreme Gradient Boosting
The residual plot of was similar to CatBoost (Figure 12a), but with slightly more dispersion, as indicated by its similar R2 values for Train (0.9982) and Test (0.9134), respectively. Even though the XGBRegressor model is highly precise on training data, it may not generalize as well to unseen data. Regarding the validation curve, as shown in Figure 12, as the depth increases, the Cross-Validation Score (noted by the green line with circular markers) begins lower than the training score but grows as the depth increases, reaching a peak at around 4. These scores are shaded to illustrate their variance or uncertainty. This validation curve is indicative of a well-performing model; however, a noticeable divergence exists between training and validation scores beyond the depth of 4. Essentially, this divergence indicates a mild overfitting scenario in which the model performs exceptionally well on trained data but less so on unseen or validation data.
5.4. Light Gradient Boosting Machine
Figure 13 shows the residual plot (Figure 13a) and validation curve (Figure 13b) for Light Gradient Boosting Machine model. This model has a dispersed residual distribution with significant variance at higher predicted values. Despite having a high Train R2 value (0.9866, the Test R2 is significantly lower 0.9296), suggesting possible overfitting. consequently, although LightGBMRegressor performs well on training data, it may not be generalized to unknown data. Considering the validation curve with the depth of 2, the Training Score starts at a high score of approximately 0.95, which implies that the model is able to fit the training data quite well with a shallow tree. As the depth increases, the training score decreases slightly, suggesting that the model is becoming more generalised and less likely to overfit. In contrast to the training score, the Cross-Validation Score exhibits an upward trend as depth increases, reaching a peak of around 4. There is a noticeable divergence between training and validation scores beyond the depth of 4, which indicates that the model performs exceptionally well on trained data, but significantly less well on unseen or validation data. This divergence indicates mild overfitting.
5.5. Random Forest
Figure 14 shows the performance of Random Forest model. This model presents an intermediate residual spread with some concentration around zero but noticeable dispersion at extremes (Figure 14a). As a result, the RandomForestRegressor model appears to offer a good balance between precision and generalization, but there is room for further optimization. A Train R2 of 0.980 and Test R2 of 0.871 suggest moderate model accuracy, though room for improvement exists. About the validation curve (Figure 14b), with the depth of around 6, the Cross-Validation Score reaches a peak, indicating the variance and uncertainty associated with the scores. The shaded area around this line illustrates the variance or uncertainty associated with the scores. Despite the fact that this validation curve indicates that the model is performing well, there is a noticeable divergence between training and validation scores beyond the depth of 6. In this case, mild overfitting occurs when the model does exceptionally well on trained data but less so on unseen or validation data.
5.6. Feature Importance
Figure 15 is a feature importance plot, which is commonly used in machine learning to understand the contribution of each parameter analysed. The y-axis in this plot represents the different features used in the model, while the x-axis represents the importance of each feature. The importance of a feature is calculated based on the decrease in the model’s performance when the feature’s values are randomly shuffled. The highest importance value in the plot is associated with the p/Do feature, suggesting that it has the most significant impact on the model’s predictions. Changes in this feature are likely to result in significant changes in the predicted output. The η and n features also have high importance values and significantly influence model prediction. Although other features have lower importance values, they can still be useful in interactions with other features. Therefore, it is essential to consider all features when building a machine learning model, as even low importance features can have an impact on the overall performance of the model. Understanding feature importance can help data scientists optimize machine learning models and improve their accuracy.
6. Proposed Equation by GEP
To precisely predict the shear capacity of composite cellular floors with PCHCS, this study developed an equation incorporating all relevant parameters. These parameters included mechanical and geometric properties, as well as the areas and detailing of reinforcement within the joint. Numerical constants are critical for successful modelling in GEP’s learning algorithms. Thus, GEP employs an extra gene domain to encode these random constants. Initially, these constants are randomly assigned to each gene. However, the standard genetic operators of mutation (including transposition and recombination) ensure their continued circulation and diversity throughout the population. The specific details regarding the proposed model’s operation and functionality are outlined in Table 2.
Several preliminary runs were necessary to identify parameter settings that produce a GEP model with sufficient robustness and generalization to accurately solve the problem. Additionally, overfitting, a common issue in machine learning, possesses another challenge to achieving satisfactory generalization. To avoid this issue, the developed models can be tested. The proposed equations (Equations (7)–(12)) for predicting the shear capacity of steel-concrete composite cellular floors with precast hollow-core slabs using the GEP model are as follows, in which E is the Young’s modulus, ν is the Poisson’s ratio, fy is the yield stress and fv is the yield shear stress:
7. Comparison Analysis
The comparative analysis is depicted in Figure 16, encompassing all explored machine learning models. The discussion revolves around the ratio of predicted values to the finite element model (VPredicted/VFE). Focusing on the CatBoost algorithm (Figure 16a), the range of relative errors extends from -13.90% to 16.54%. Meanwhile, the Gradient Boosting algorithm (Figure 16b) exhibits relative errors ranging from -11.76% to 21.41%. In the case of the Extreme Gradient algorithm (Figure 16c), the spectrum of relative errors spans from -18.12% to 22.99%. As for the Light Gradient Boosting algorithm (Figure 16d), its minimum and maximum relative errors align closely with the Gradient Boosting algorithm, standing at -11.77% and 24.00%, respectively. Turning to the Random Forest algorithm (Figure 16e), the relative errors fluctuate between -16.50% and 21.48%. Lastly, the Gene Expression Programming (Figure 16f) reveals relative errors ranging from -12.84% to 2.69%. Additional summarized statistical analyzes are presented in .
8. Reliability Analysis
Reliability analysis based on Annex D EN 1990 (2002) has been conducted to assess the proposed design method and propose a partial safety factor for the shear capacity of composite cellular beams with PCHCS. Within the context of this study, the proposed prediction models undergo statistical evaluation against the finite element results. illustrates the key statistical parameters, including the number of data, , the design fractile factor (ultimate limit state), , the characteristic fractile factor, the average ratio of FE to resistance model predictions based on the least squares fit to the data, , the combined coefficient of variation incorporating both resistance model and basic variable uncertainties, , and the partial safety factor for resistance . The COV of geometric dimensions of the concrete slab is 0.04 for the width and the thickness [63], while it is 0.02 and for the steel section geometries [64] and the stud diameter [65].
The COV of the yield strength of steel, ultimate strength of the steel stud, and concrete compressive strength were assumed equal to 0.055 [64], 0.05 and 0.12 [65], respectively. The COV between the experimental and the numerical results, which was found equal to 0.025, was also considered. Performing First Order Reliability Method (FORM) in accordance with the Eurocode target reliability requirements, the partial factors were evaluated for all ML models. As can be seen from Table 3, the partial factors for the shear capacity of steel-concrete composite cellular beams with precast hollow-core slabs using different ML algorithms are very similar, and the value is around 1.255 to 1.265. It is worth noting that the high value for the partial factor is due to the high value for the COV of the concrete strength.
9. Conclusions
The present work aimed to apply machine learning models for predicting global shear capacity of composite cellular floors with PCHCS. The motivation for this was the connection between the hollow-core unit and the steel cellular beam, as the deflections are intensified due to the web openings, causing the effect of pulling out the shear connector thus reducing the local composite action. A finite element model database, considering steel-concrete composite cellular beams with precast hollow-core units was employed to assess the CatBoost, Gradient Boosting, Extreme Gradient Boosting, Light Gradient Boosting Machine, Random Forest and Gene Expression Programming Algorithms, since there are no calculation recommendations for these beams. Comparatively, the CatBoost Regressor produced an MAE of 6.7814 kN and demonstrated commendable performance with a R2 value of 0.9821, explaining around 98.21% of the variance. This study highlighted the effectiveness of the CatBoost Regressor due to its low MAE and high R2 value, providing valuable insights for the design and assessment of steel concrete composite cellular beams. With a coefficient of determination (R2) of 0.9531, the Gene Expression Programming model displayed exceptional ability. This indicates that the model predicted approximately 95.31% of the variance in shear capacity, establishing a strong correlation between predictions and actual values. With its promising results, Gene Expression Programming emerges as a promising alternative to further research. A GEP-based equation was proposed to predict the global shear of composite cellular beams with PCHCS. A reliability analysis was performed and the partial safety factor for resistance varied between 1.25 and 1.26. This first study, considering the application of machine learning to predict the global shear resistance of steel-concrete composite cellular beams with hollow-core units, highlights the importance of the degree of interaction in the resistance of the local composite action. The suggested equation for predicting the global shear resistance highlights areas necessitating revisions and offers insights into how these improvements can be achieved. It can contribute to both the safety and cost-effectiveness of steel-concrete composite construction especially regarding sustainability.
Author Contributions
Conceptualization, F.P.V.F. and E.M.; methodology, F.P.V.F., E.M., R.S. and K.D.T.; software, F.P.V.F. and E.M.; validation, F.P.V.F. and E.M.; formal analysis, F.P.V.F., E.M. and K.D.T.; investigation, F.P.V.F., E.M.; resources, F.P.V.F., E.M. and K.D.T.; data curation, F.P.V.F., E.M. and R.S.; writing—original draft preparation, F.P.V.F., S.J., E.M., R.S., K.D.T., C.H.M., and S.D.N.; writing—review and editing, F.P.V.F., S.J., E.M., R.S., K.D.T., C.H.M., and S.D.N.; visualization, F.P.V.F., S.J., E.M., R.S., K.D.T., C.H.M., and S.D.N.; supervision, F.P.V.F., E.M. and K.D.T.; project administration, F.P.V.F. and E.M. All authors have read and agreed to the published version of the manuscript.
Data Availability Statement
The data will be available upon request to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lawson, R.M.M.; Lim, J.; Hicks, S.J.J.; Simms, W.I.I. Design of Composite Asymmetric Cellular Beams and Beams with Large Web Openings. J. Constr. Steel Res. 2006, 62, 614–629. [Google Scholar] [CrossRef]
- Lawson, R.M.; Saverirajan, A.H.A. Simplified Elasto-Plastic Analysis of Composite Beams and Cellular Beams to Eurocode 4. J. Constr. Steel Res. 2011, 67, 1426–1434. [Google Scholar] [CrossRef]
- Ahmed, I.M.; Tsavdaridis, K.D. The Evolution of Composite Flooring Systems: Applications, Testing, Modelling and Eurocode Design Approaches. J. Constr. Steel Res. 2019, 155, 286–300. [Google Scholar] [CrossRef]
- Lawson, R.M.; Hicks, S.J. Design of Composite Beams with Large Web Openings. SCI P355.; The Steel Construction Institute, 2011; ISBN 9781859421970.
- Fares, S.S.; Coulson, J.; Dinehart, D.W. AISC Steel Design Guide 31: Castellated and Cellular Beam Design; American Institute of Steel Construction, 2016.
- Redwood, R.G.; Poumbouras, G. Tests of Composite Beams with Web Holes. Can. J. Civ. Eng. 1983, 10, 713–721. [Google Scholar] [CrossRef]
- Redwood, R.G.; Poumbouras, G. Analysis of Composite Beams with Web Openings. J. Struct. Eng. 1984, 110, 1949–1958. [Google Scholar] [CrossRef]
- Donahey, R.C.; Darwin, D. Web Openings in Composite Beams with Ribbed Slabs. J. Struct. Eng. 1988, 114, 518–534. [Google Scholar] [CrossRef]
- Cho, S.H.; Redwood, R.G. Slab Behavior in Composite Beams at Openings. I: Analysis. J. Struct. Eng. 1992, 118, 2287–2303. [Google Scholar] [CrossRef]
- Cho, S.H.; Redwood, R.G. Slab Behavior in Composite Beams at Openings. II: Tests and Verification. J. Struct. Eng. 1992, 118, 2304–2322. [Google Scholar] [CrossRef]
- Ferreira, F.P.V.; Tsavdaridis, K.D.; Martins, C.H.; De Nardin, S. Composite Action on Web-Post Buckling Shear Resistance of Composite Cellular Beams with PCHCS and PCHCSCT. Eng. Struct. 2021, 246, 113065. [Google Scholar] [CrossRef]
- Hicks, S.J.; Lawson, R.M. Design of Composite Beams Using Precast Concrete Slabs. SCI P287; The Steel Construction Institute, 2003; ISBN 1859421393.
- Gouchman, G.H. Design of Composite Beams Using Precast Concrete Slabs in Accordance with EUROCODE 4. SCI P401.; The Steel Construction Institute, 2014; ISBN 9781859422137.
- Pajari, M.; Koukkari, H. Shear Resistance of PHC Slabs Supported on Beams. I: Tests. J. Struct. Eng. 1998, 124, 1050–1061. [Google Scholar] [CrossRef]
- Lawson, R.M.; Lim, J.B.P.; Popo-Ola, S.O. Pull-out Forces in Shear Connectors in Composite Beams with Large Web Openings. J. Constr. Steel Res. 2013, 87, 48–59. [Google Scholar] [CrossRef]
- Avci-Karatas, C. Application of Machine Learning in Prediction of Shear Capacity of Headed Steel Studs in Steel–Concrete Composite Structures. Int. J. Steel Struct. 2022. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, C.; Zou, X.; Wei, Y.; Chen, D.; Wang, Q.; Wang, L. Prediction of the Shear Resistance of Headed Studs Embedded in Precast Steel–Concrete Structures Based on an Interpretable Machine Learning Method. Buildings 2023. [Google Scholar] [CrossRef]
- Kara, I.F. Empirical Modeling of Shear Strength of Steel Fiber Reinforced Concrete Beams by Gene Expression Programming. Neural Comput. Appl. 2013. [Google Scholar] [CrossRef]
- Momani, Y.; Tarawneh, A.; Alawadi, R.; Momani, Z. Shear Strength Prediction of Steel Fiber-Reinforced Concrete Beams without Stirrups. Innov. Infrastruct. Solut. 2022. [Google Scholar] [CrossRef]
- Hosseinpour, M.; Rossi, A.; Sander Clemente de Souza, A.; Sharifi, Y. New Predictive Equations for LDB Strength Assessment of Steel–Concrete Composite Beams. Eng. Struct. 2022. [Google Scholar] [CrossRef]
- Thai, H.-T. Machine Learning for Structural Engineering: A State-of-the-Art Review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Ferreira, F.P.V.; Tsavdaridis, K.D.; Martins, C.H.; De Nardin, S. Ultimate Strength Prediction of Steel–Concrete Composite Cellular Beams with PCHCS. Eng. Struct. 2021, 236, 112082. [Google Scholar] [CrossRef]
- Nadjai, A.; Vassart, O.; Ali, F.; Talamona, D.; Allam, A.; Hawes, M. Performance of Cellular Composite Floor Beams at Elevated Temperatures. Fire Saf. J. 2007, 42, 489–497. [Google Scholar] [CrossRef]
- Müller, C.; Hechler, O.; Bureau, A.; Bitar, D.; Joyeux, D.; Cajot, L.G.; Demarco, T.; Lawson, R.M.; Hicks, S.; Devine, P.; et al. Large Web Openings for Service Integration in Composite Floors. Technical Steel Research. European Comission, Contract No 7210-PR/315. Final Report 2006.
- El-Lobody, E.; Lam, D. Finite Element Analysis of Steel-Concrete Composite Girders. Adv. Struct. Eng. 2003, 6, 267–281. [Google Scholar] [CrossRef]
- Batista, E.M.; Landesmann, A. Análise Experimental de Vigas Mistas de Aço e Concreto Compostas Por Lajes Alveolares e Perfis Laminados. COPPETEC, PEC-18541 2016.
- Dassault Systèmes Simulia Abaqus 6.18 2016.
- Hillerborg, A.; Modéer, M.; Petersson, P.-E. Analysis of Crack Formation and Crack Growth in Concrete by Means of Fracture Mechanics and Finite Elements. Cem. Concr. Res. 1976, 6, 773–781. [Google Scholar] [CrossRef]
- Lubliner, J.; Oliver, J.; Oller, S.; Oñate, E. A Plastic-Damage Model for Concrete. Int. J. Solids Struct. 1989, 25, 299–326. [Google Scholar] [CrossRef]
- Lee, J.; Fenves, G.L. Plastic-Damage Model for Cyclic Loading of Concrete Structures. J. Eng. Mech. 1998, 124, 892–900. [Google Scholar] [CrossRef]
- Carreira, D.J.; Chu, K.H. Stress-Strain Relationship for Reinforced Concrete in Tension. ACI J. Proc. 1986, 83. [Google Scholar] [CrossRef] [PubMed]
- Carreira, D.J.; Chu, K.H. Stress-Strain Relationship for Plain Concrete in Compression. ACI J. Proc. 1985, 82, 797–804. [Google Scholar] [CrossRef] [PubMed]
- de Lima Araújo, D.; Sales, M.W.; de Paulo, S.M.; de Cresce El, A.L. Headed Steel Stud Connectors for Composite Steel Beams with Precast Hollow-Core Slabs with Structural Topping. Eng. Struct. 2016, 107, 135–150. [Google Scholar] [CrossRef]
- Yun, X.; Gardner, L. Stress-Strain Curves for Hot-Rolled Steels. J. Constr. Steel Res. 2017, 133, 36–46. [Google Scholar] [CrossRef]
- Guezouli, S.; Lachal, A. Numerical Analysis of Frictional Contact Effects in Push-out Tests. Eng. Struct. 2012, 40, 39–50. [Google Scholar] [CrossRef]
- Ferreira, F.P.V.; Martins, C.H.; De Nardin, S. A Parametric Study of Steel-Concrete Composite Beams with Hollow Core Slabs and Concrete Topping. Structures 2020, 28, 276–296. [Google Scholar] [CrossRef]
- Ferreira, F.P.V.; Martins, C.H.; De Nardin, S. Assessment of Web Post Buckling Resistance in Steel-Concrete Composite Cellular Beams. Thin-Walled Struct. 2021, 158, 106969. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. Adv. Neural Inf. Process Syst. 2017; 2018, 6638–6648. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Yandex, A.G. CatBoost: Gradient Boosting with Categorical Features Support. 2018.
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Guelman, L. Gradient Boosting Trees for Auto Insurance Loss Cost Modeling and Prediction. Expert. Syst. Appl. 2012, 39, 3659–3667. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of Gradient Boosting Algorithms. Artif. Intell. Rev. 2021. [Google Scholar] [CrossRef]
- Zhang, Y.; Beudaert, X.; Argandoña, J.; Ratchev, S.; Munoa, J. A CPPS Based on GBDT for Predicting Failure Events in Milling. Int. J. Adv. Manuf. Technol. 2020, 111, 341–357. [Google Scholar] [CrossRef]
- Si, S.; Zhang, H.; Keerthi, S.S.; Mahajan, D.; Dhillon, I.S.; Hsieh, C.-J. Gradient Boosted Decision Trees for High Dimensional Sparse Output 2017, 3182–3190.
- Zhang, Y.; Beudaert, X.; Argandoña, J.; Ratchev, S.; Munoa, J. A CPPS Based on GBDT for Predicting Failure Events in Milling. Int. J. Adv. Manuf. Technol. 2020, 111, 341–357. [Google Scholar] [CrossRef]
- Meng, Q.; Ke, G.; Wang, T.; Chen, W.; Ye, Q.; Ma, Z.M.; Liu, T.Y. A Communication-Efficient Parallel Algorithm for Decision Tree. Adv. Neural Inf. Process Syst. 2016, 1279–1287. [Google Scholar]
- Liu, J.J.; Liu, J.C. Permeability Predictions for Tight Sandstone Reservoir Using Explainable Machine Learning and Particle Swarm Optimization. Geofluids 2022, 2022. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U. Von, Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc., 2017; Vol. 30.
- Shahani, N.M.; Zheng, X.; Guo, X.; Wei, X. Machine Learning-Based Intelligent Prediction of Elastic Modulus of Rocks at Thar Coalfield. Sustainability (Switzerland) 2022, 14. [Google Scholar] [CrossRef]
- Shahani, N.M.; Zheng, X.; Guo, X.; Wei, X. Machine Learning-Based Intelligent Prediction of Elastic Modulus of Rocks at Thar Coalfield. Sustainability (Switzerland) 2022, 14, 3689. [Google Scholar] [CrossRef]
- Chen, X.; Ishwaran, H. Random Forests for Genomic Data Analysis. Genomics 2012. [CrossRef] [PubMed]
- Schonlau, M.; Zou, R.Y. The Random Forest Algorithm for Statistical Learning. Stata J. 2020. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2. [Google Scholar] [CrossRef] [PubMed]
- Holland, J. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; 1992.
- Koza, J.R. Genetic Programming as a Means for Programming Computers by Natural Selection. Stat. Comput. 1994, 4, 87–112. [Google Scholar] [CrossRef]
- Koza, J. Genetic Programming II: Automatic Discovery of Reusable Programs; 1994.
- Ferreira, C. Gene Expression Programming in Problem Solving. Soft Comput. Ind. 2002, 635–653. [Google Scholar] [CrossRef] [PubMed]
- Azim, I.; Yang, J.; Javed, M.F.; Iqbal, M.F.; Mahmood, Z.; Wang, F.; Liu, Q. feng Prediction Model for Compressive Arch Action Capacity of RC Frame Structures under Column Removal Scenario Using Gene Expression Programming. Structures 2020, 25, 212–228. [Google Scholar] [CrossRef]
- Javed, M.F.; Amin, M.N.; Shah, M.I.; Khan, K.; Iftikhar, B.; Farooq, F.; Aslam, F.; Alyousef, R.; Alabduljabbar, H. Applications of Gene Expression Programming and Regression Techniques for Estimating Compressive Strength of Bagasse Ash Based Concrete. Crystals 2020, 10, 737. [Google Scholar] [CrossRef]
- Kapoor, N.R.; Kumar, A.; Kumar, A.; Kumar, A.; Mohammed, M.A.; Kumar, K.; Kadry, S.; Lim, S. Machine Learning-Based CO2Prediction for Office Room: A Pilot Study. Wirel. Commun. Mob. Comput. 2022. [Google Scholar] [CrossRef]
- Mansouri, E.; Manfredi, M.; Hu, J.W. Environmentally Friendly Concrete Compressive Strength Prediction Using Hybrid Machine Learning. Sustainability (Switzerland) 2022, 2990. [Google Scholar] [CrossRef]
- European committee for standardization EN 1990: Eurocode – Basis of Structural Design.
- Shamass, R.; Abarkan, I.; Ferreira, F.P.V. FRP RC Beams by Collected Test Data: Comparison with Design Standard, Parameter Sensitivity, and Reliability Analyses. Eng. Struct. 2023, 297, 116933. [Google Scholar] [CrossRef]
- Shamass, R.; Guarracino, F. Numerical and Analytical Analyses of High-Strength Steel Cellular Beams: A Discerning Approach. J. Constr. Steel Res. 2020, 166, 105911. [Google Scholar] [CrossRef]
- Vigneri, V.; Hicks, S.; Taras, A.; Odenbreit, C. Design Models for Predicting the Resistance of Headed Studs in Profiled Sheeting. Steel Compos. Struct. 2022, 42, 633–647. [Google Scholar]
Figure 1.
Load vs. Mid-span vertical displacements.
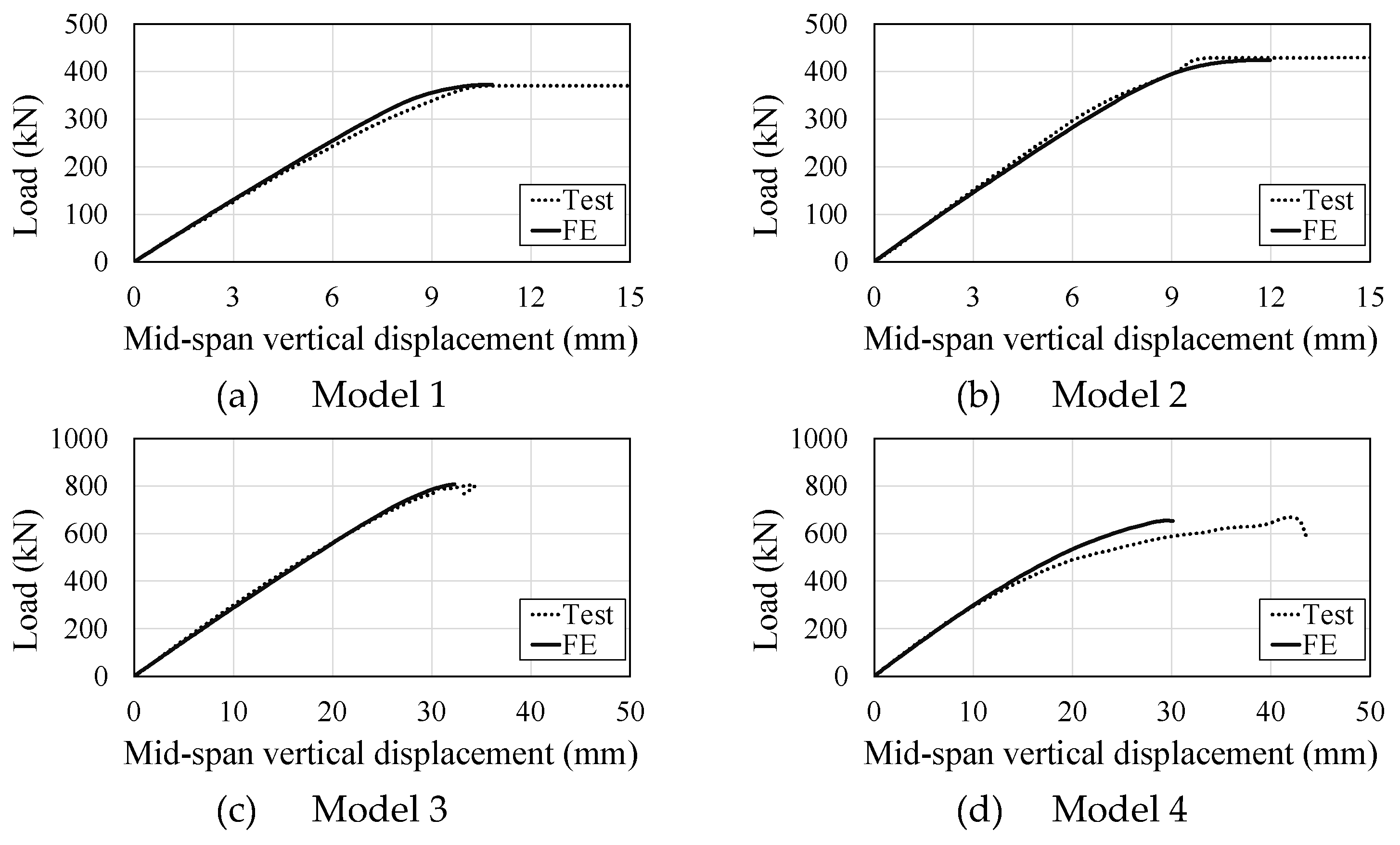
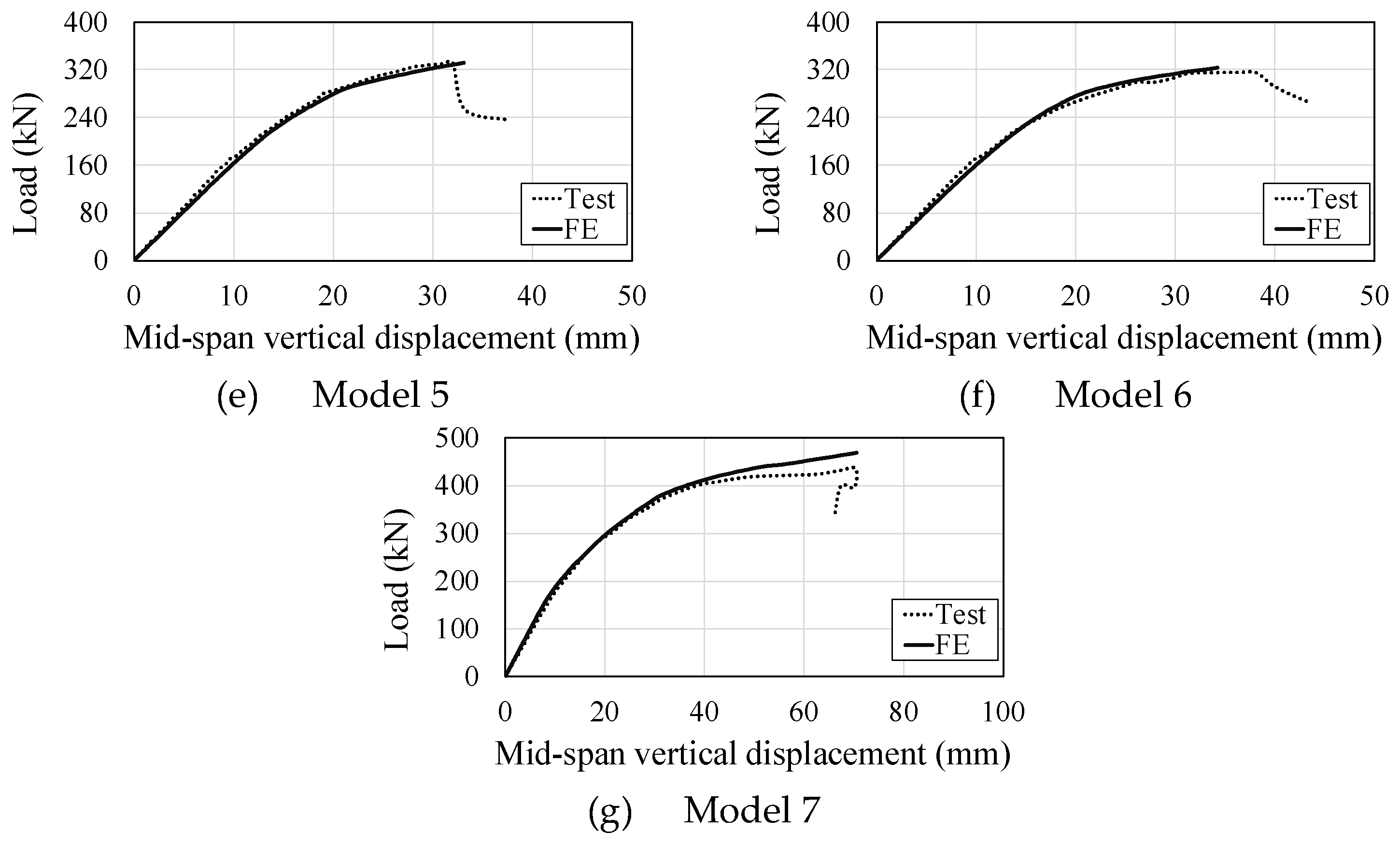
Figure 2.
Composite cellular beams with PCHCS model [11].
Figure 2.
Composite cellular beams with PCHCS model [11].
Figure 3.
Number of models per parameters analysed.
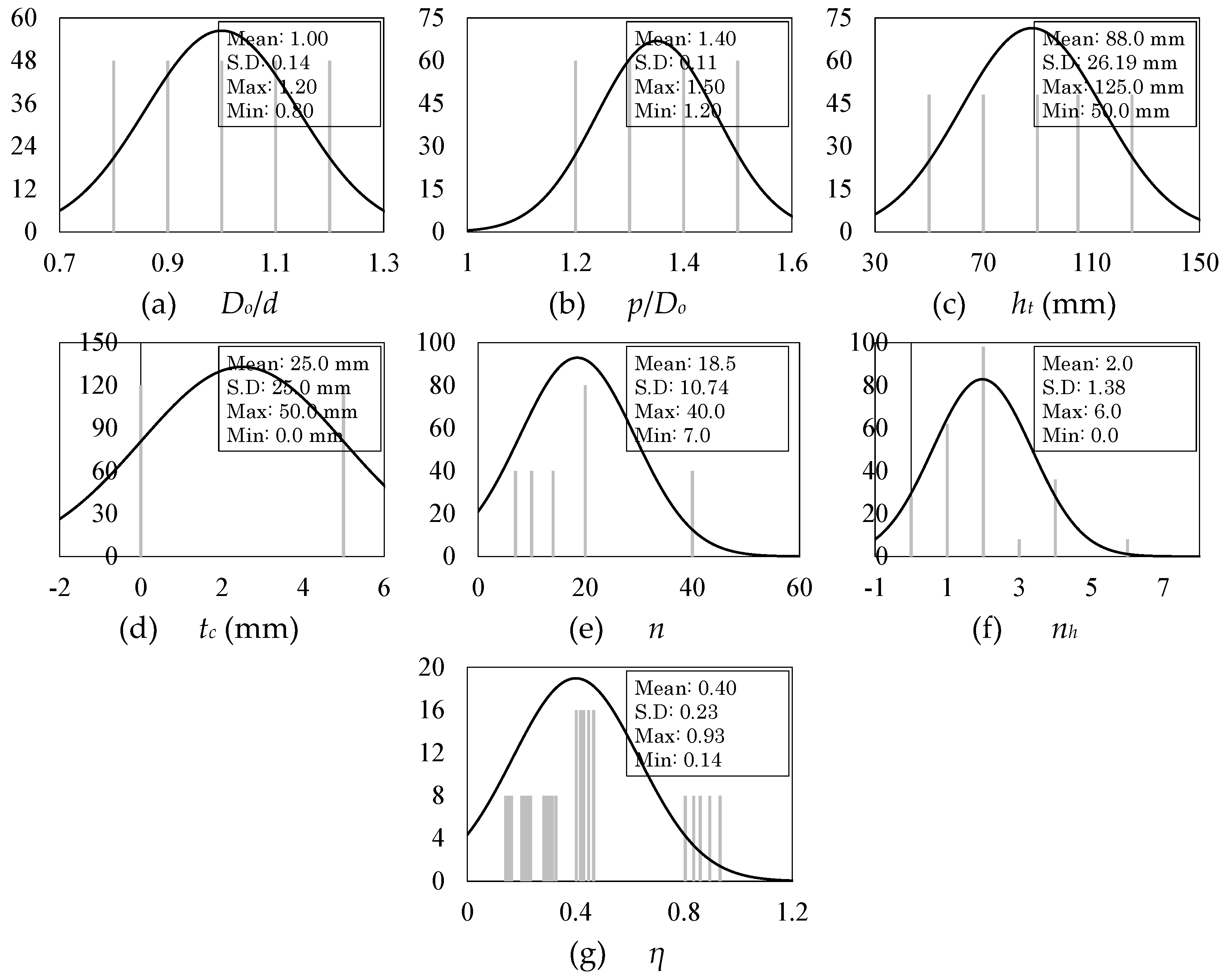
Figure 4.
Catboost algorithm explanation.
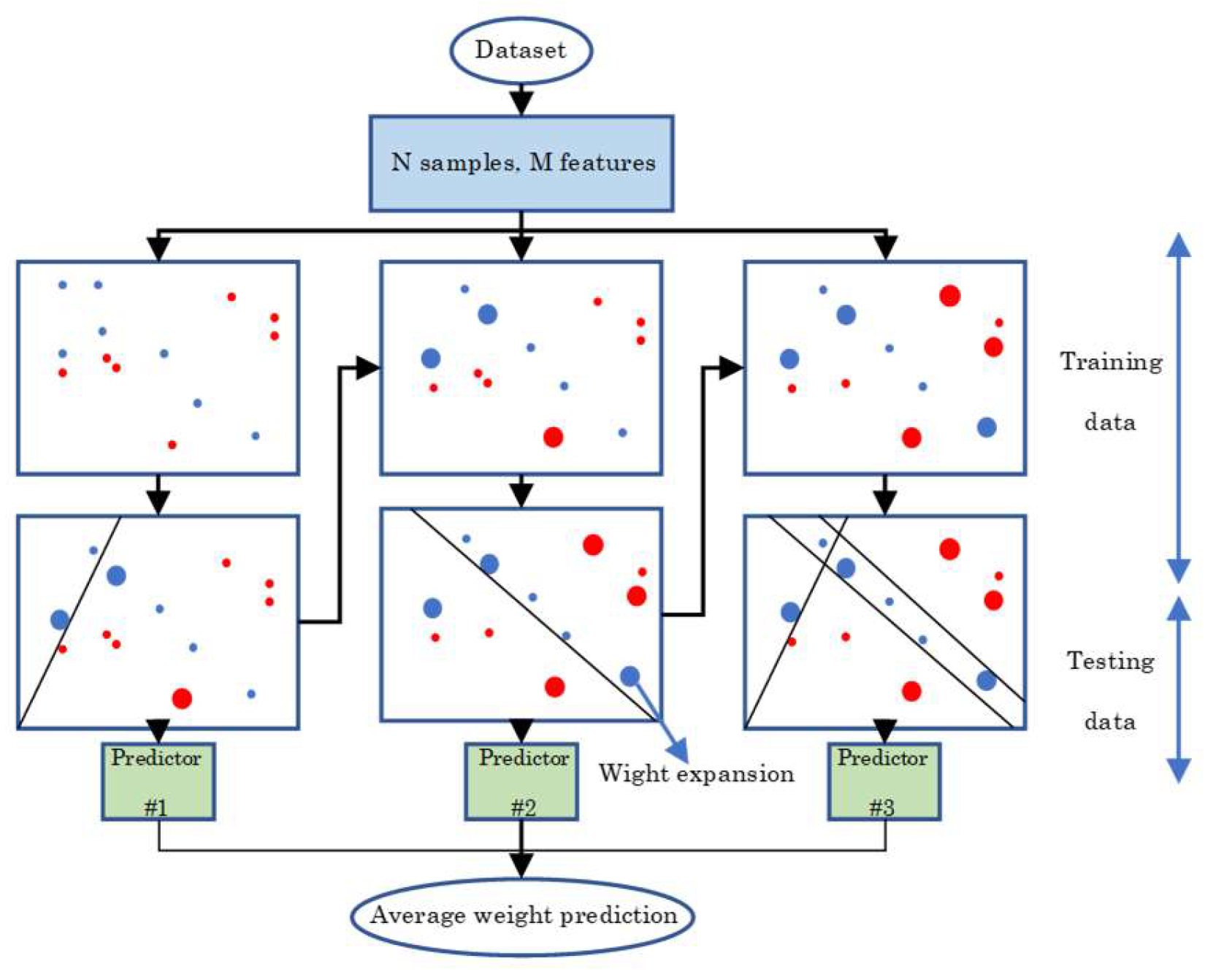
Figure 5.
Gradient Boost general structure [45].
Figure 5.
Gradient Boost general structure [45].
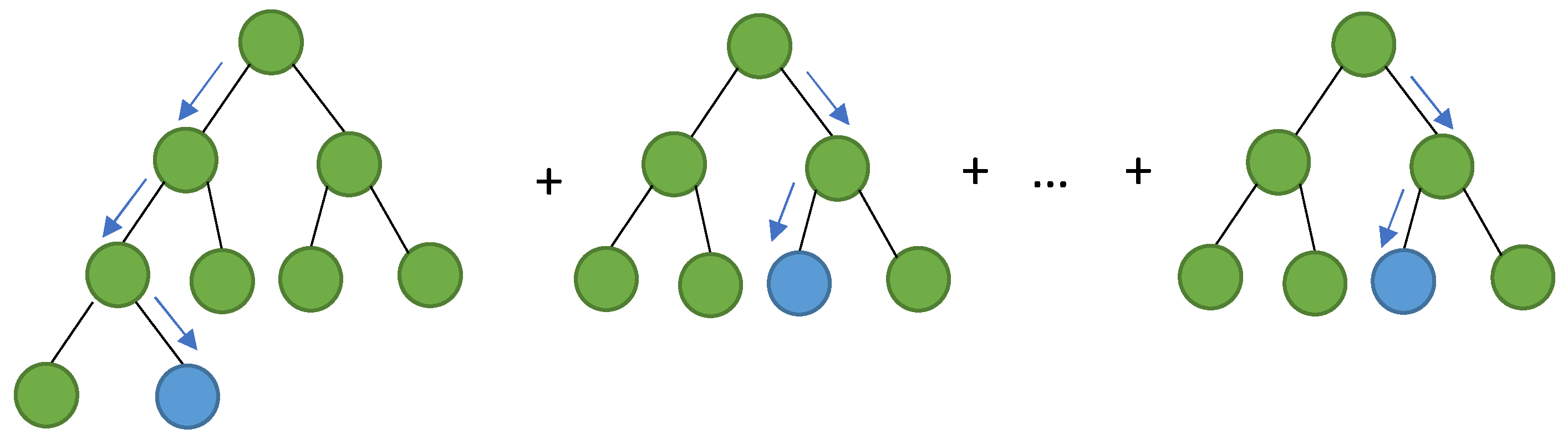
Figure 6.
XGBoost general structure [47].
Figure 6.
XGBoost general structure [47].
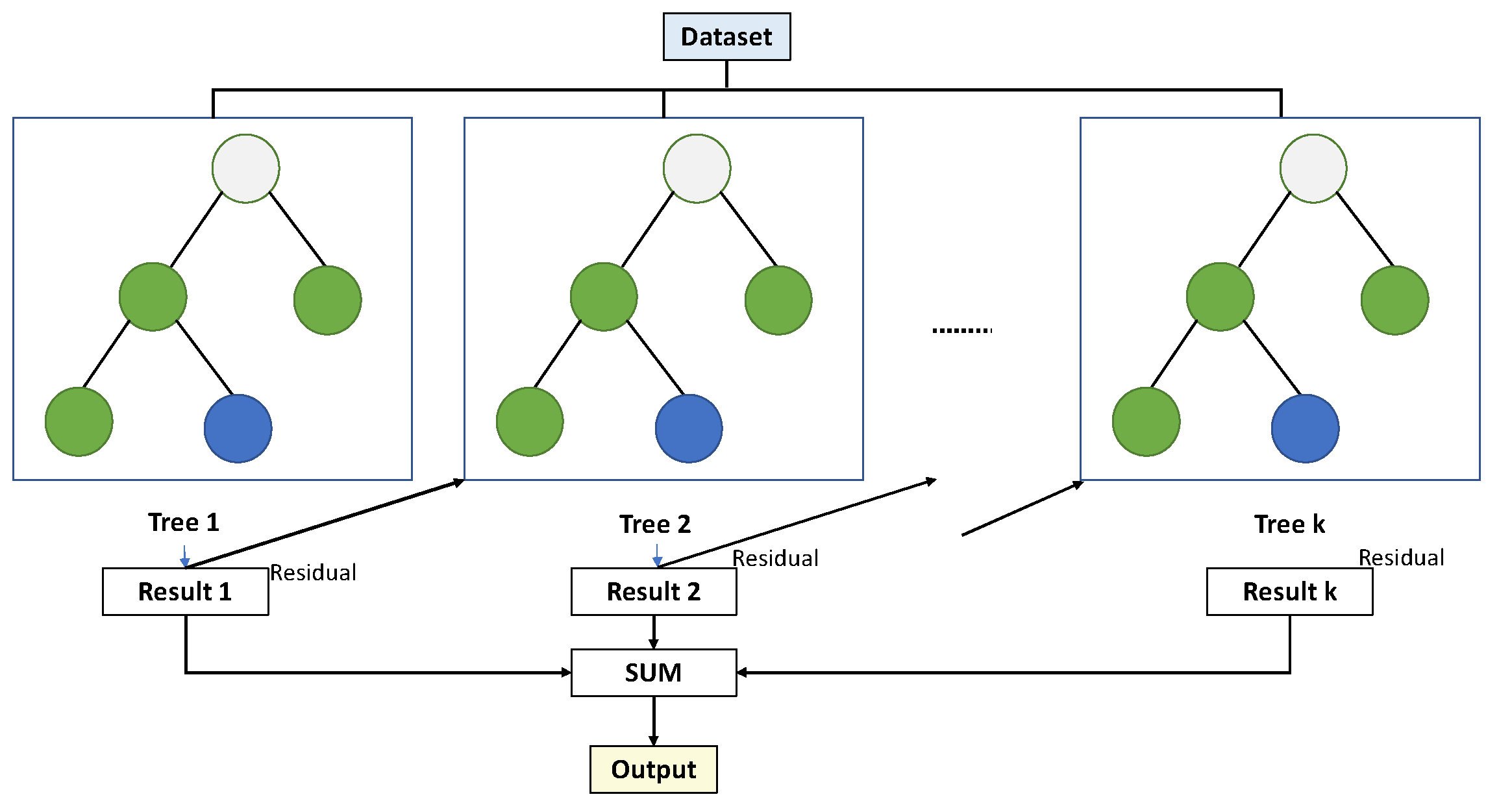
Figure 7.
LightGBM general structure [50].
Figure 7.
LightGBM general structure [50].
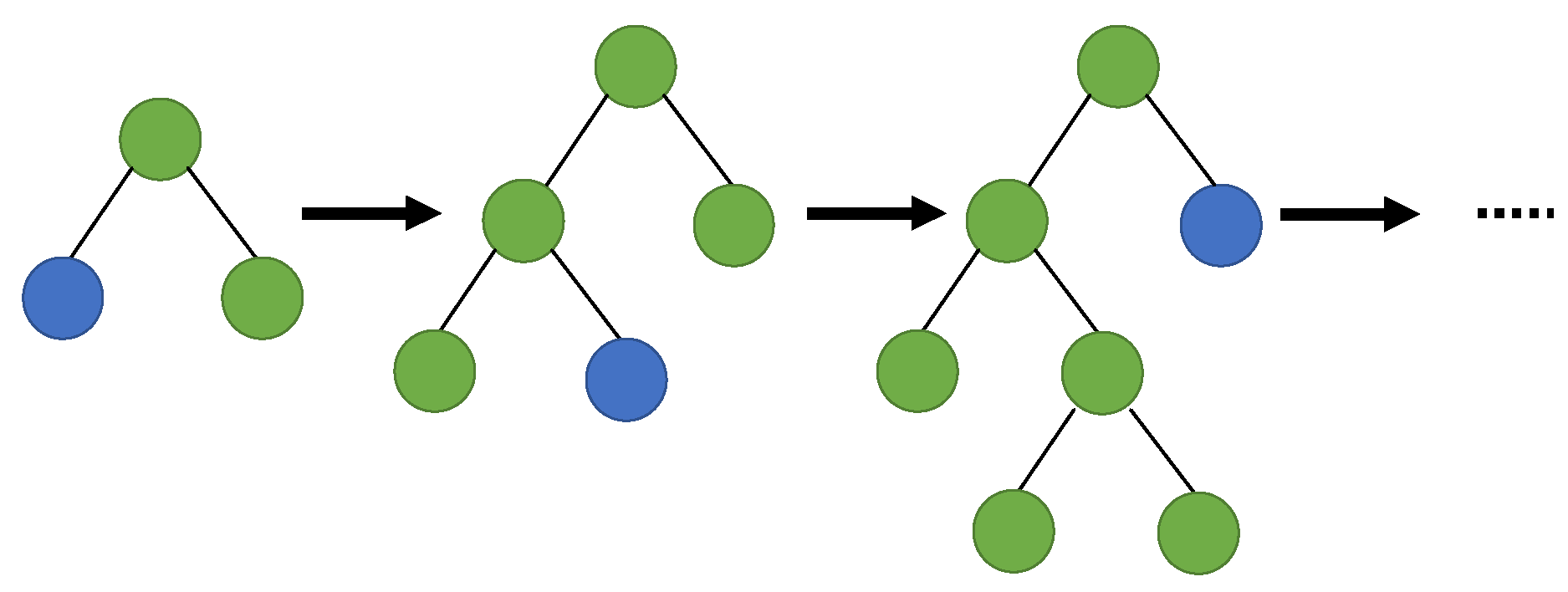
Figure 8.
Random Forest general structure [53].
Figure 8.
Random Forest general structure [53].
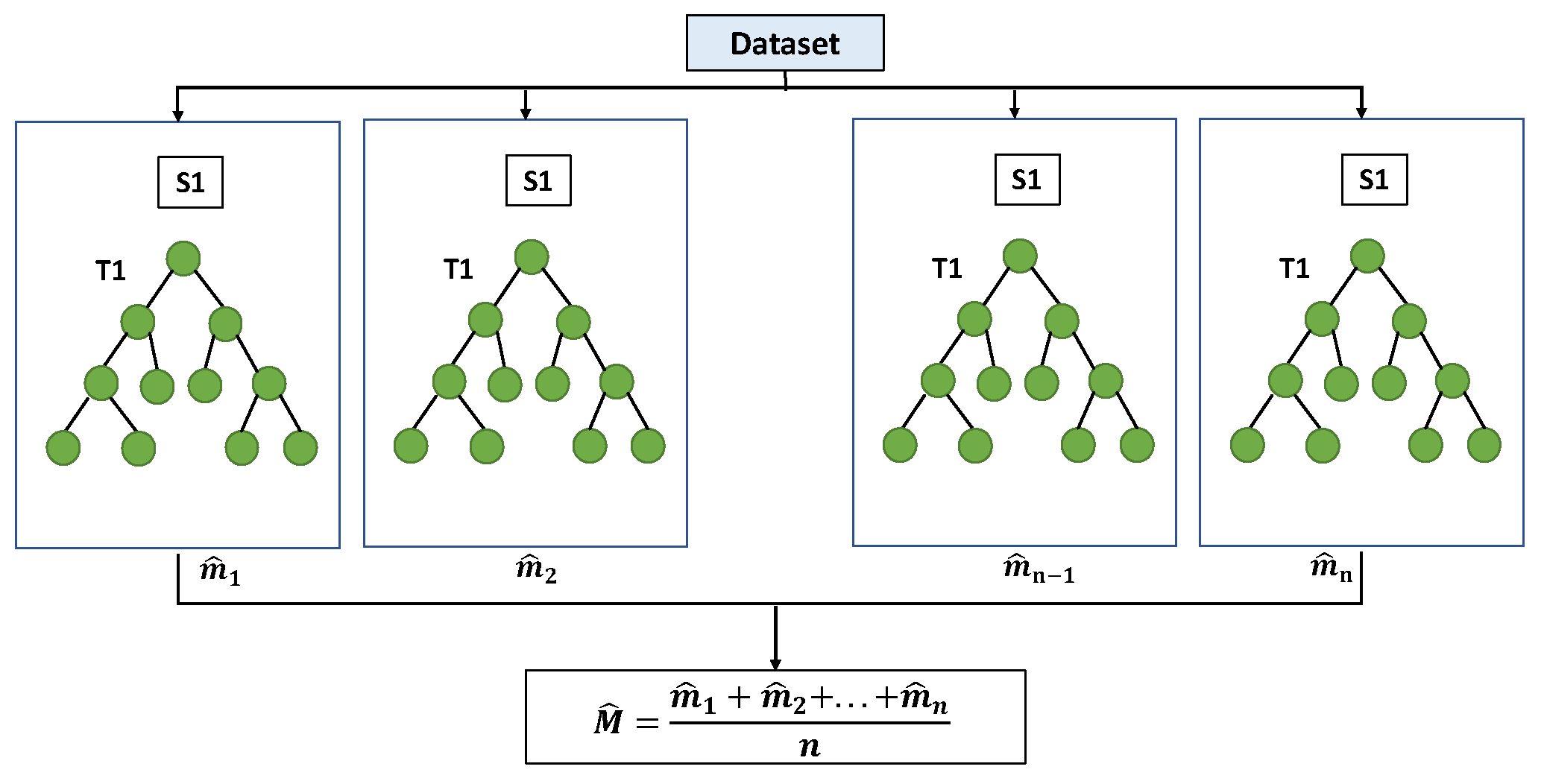
Figure 9.
Gene Expression Programming (GEP) algorithm diagram.
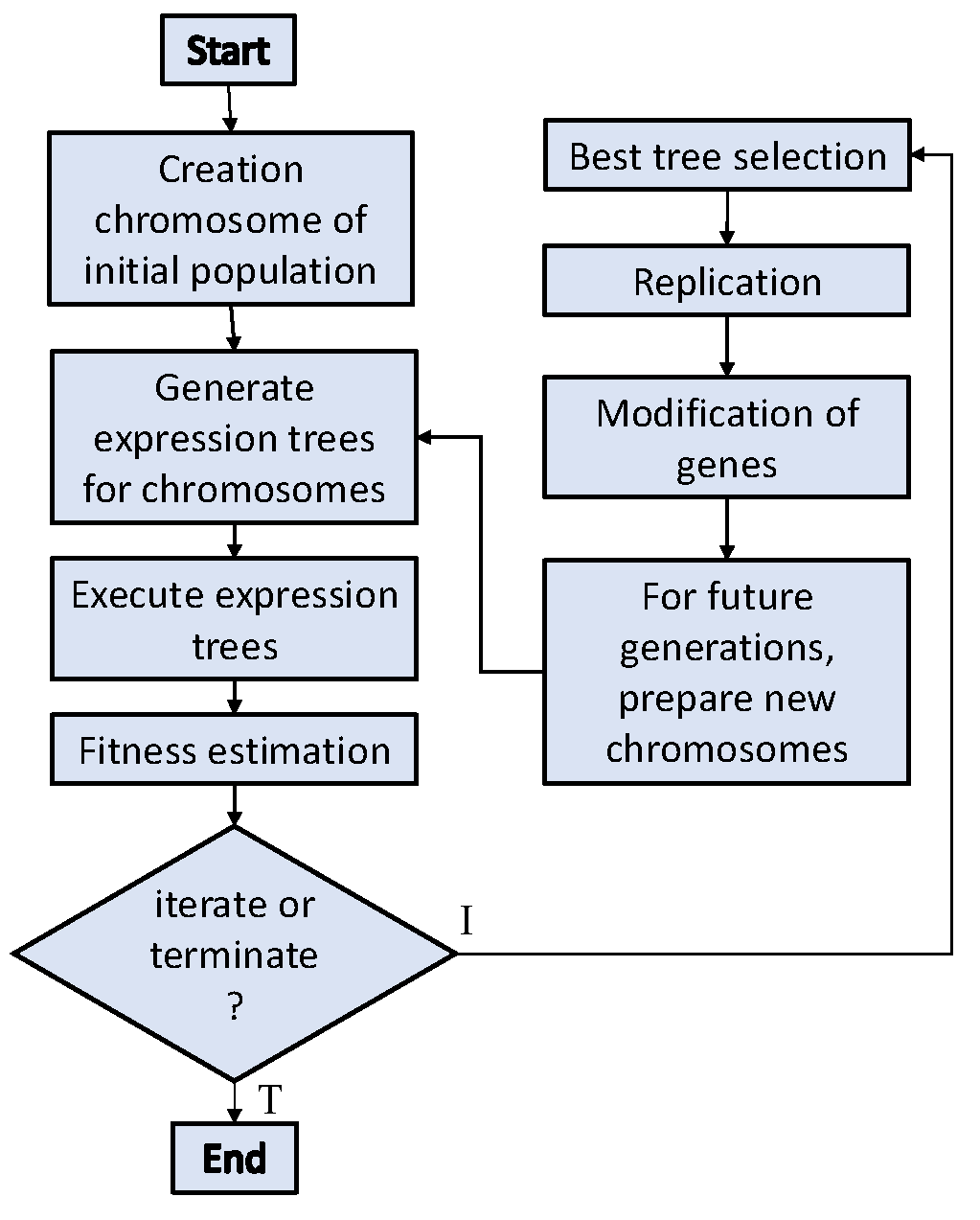
Figure 10.
CatBoostRegressor performance.
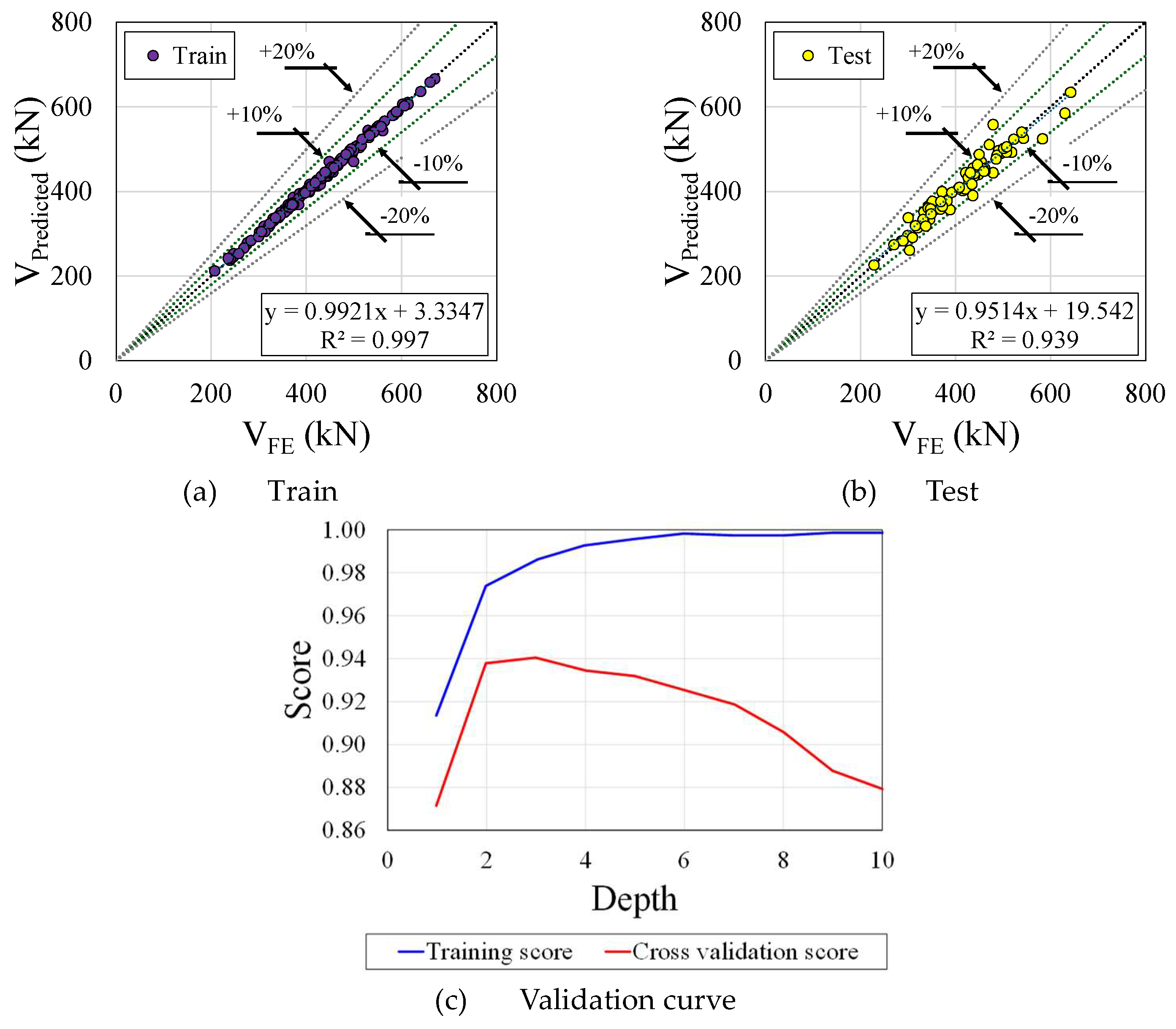
Figure 11.
Gradient Boosting Regressor performance.
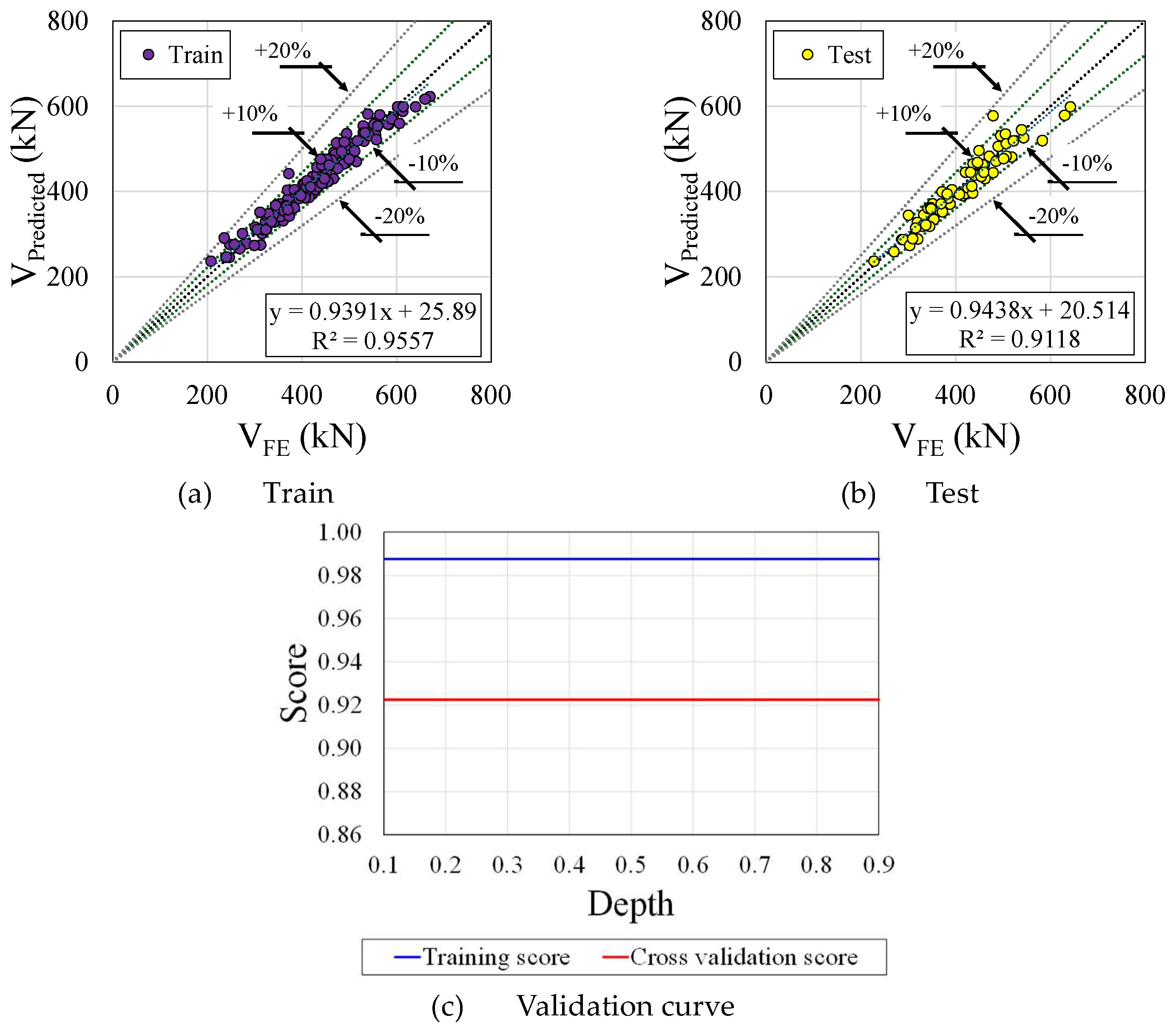
Figure 12.
Extreme Gradient Boosting Regressor performance.
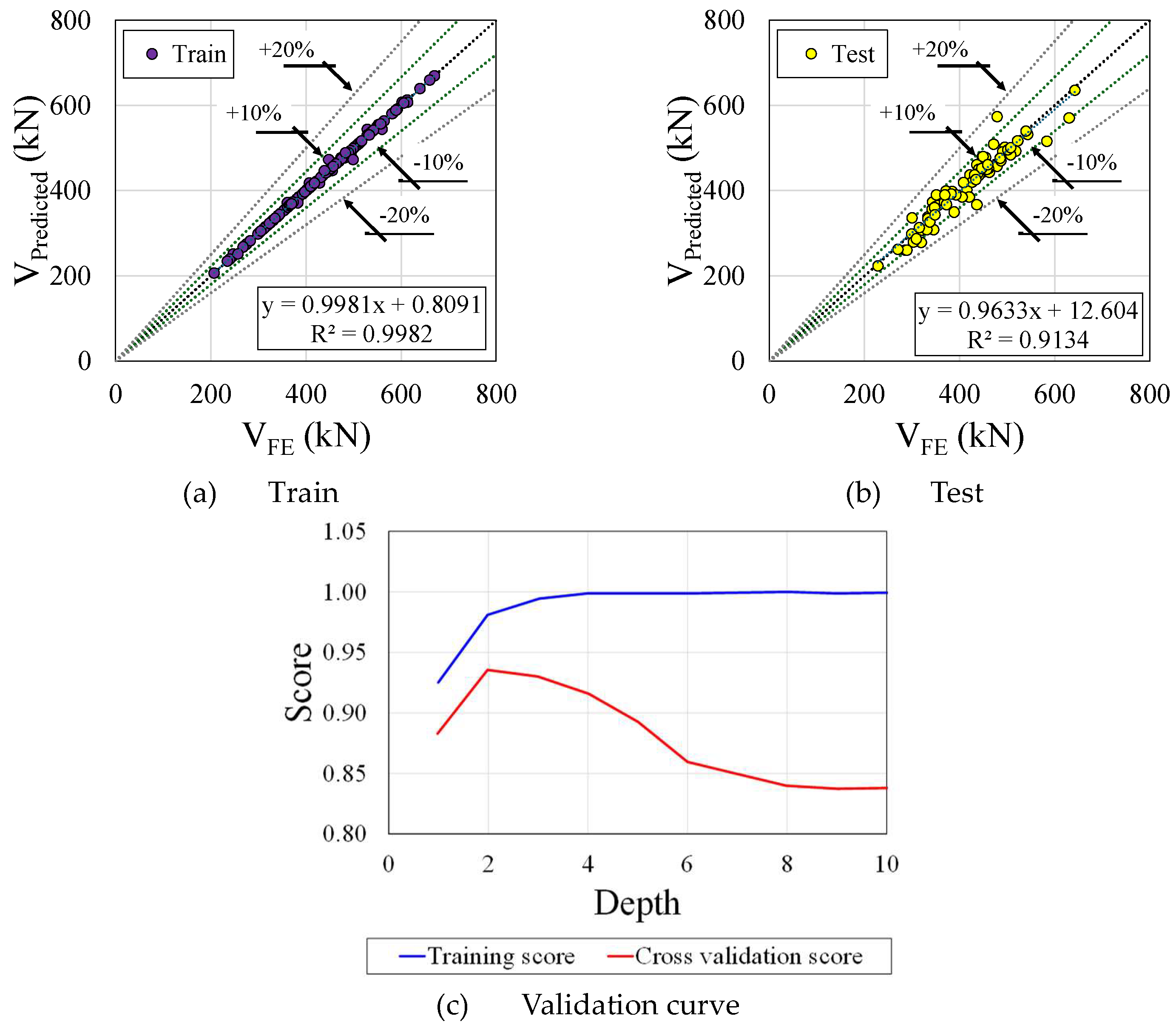
Figure 13.
Light Gradient Boosting Machine performance.
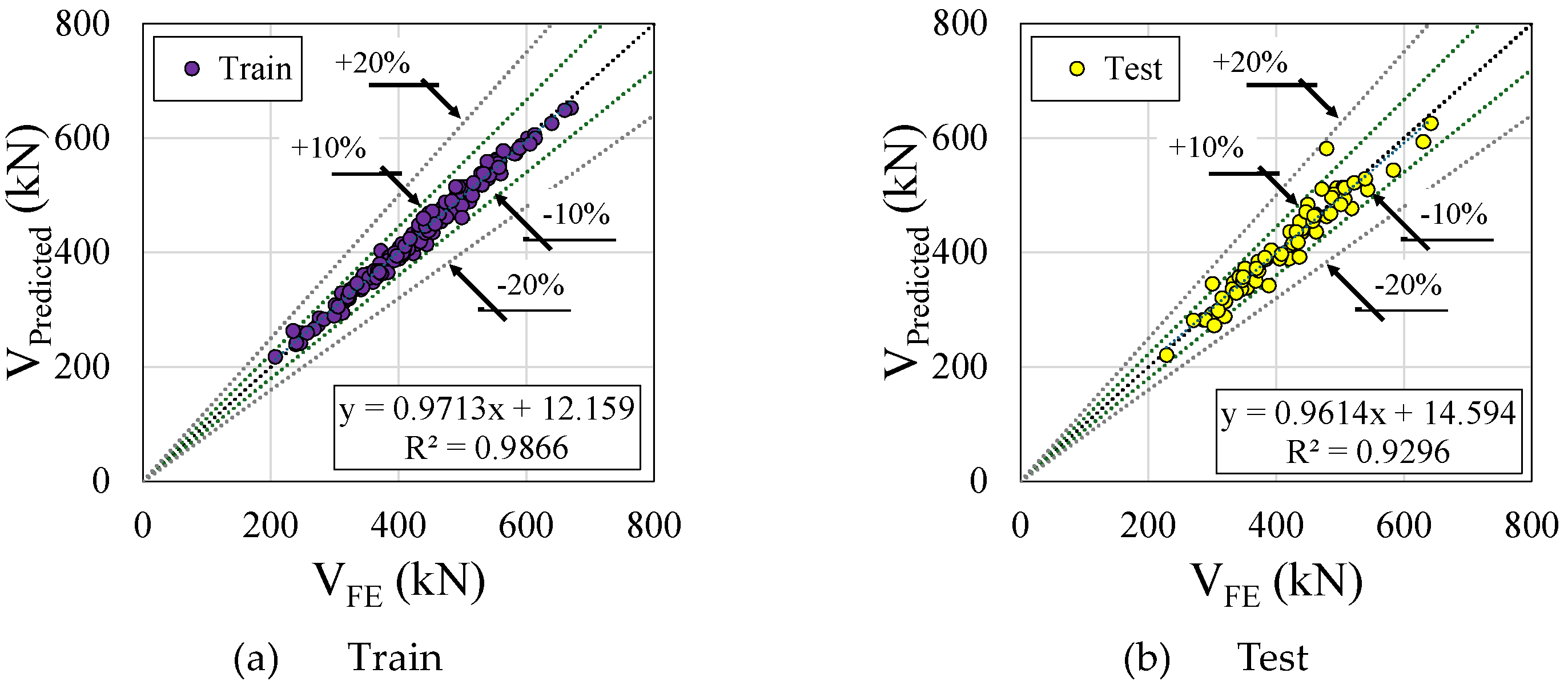
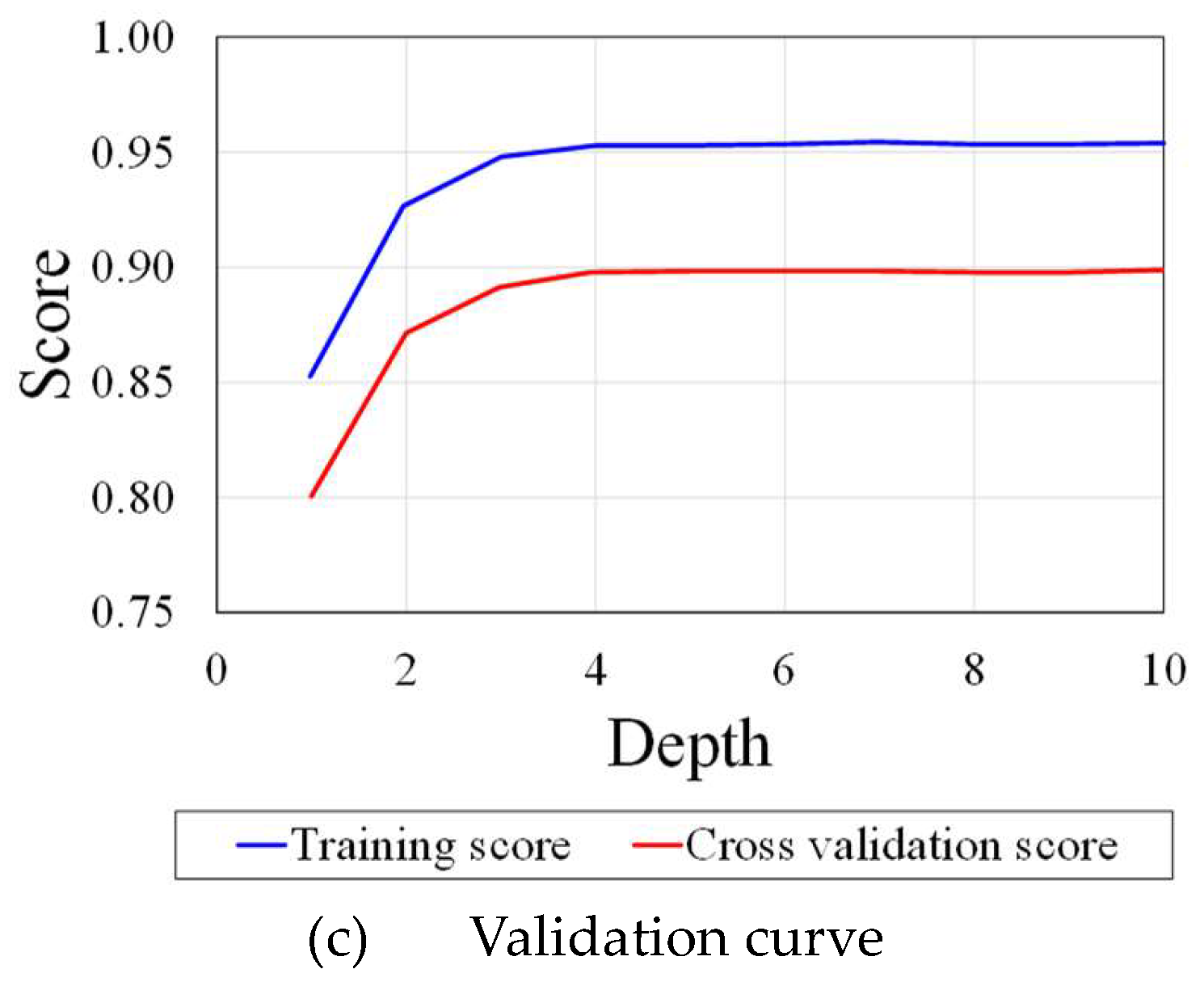
Figure 14.
Random Forest Regressor performance.
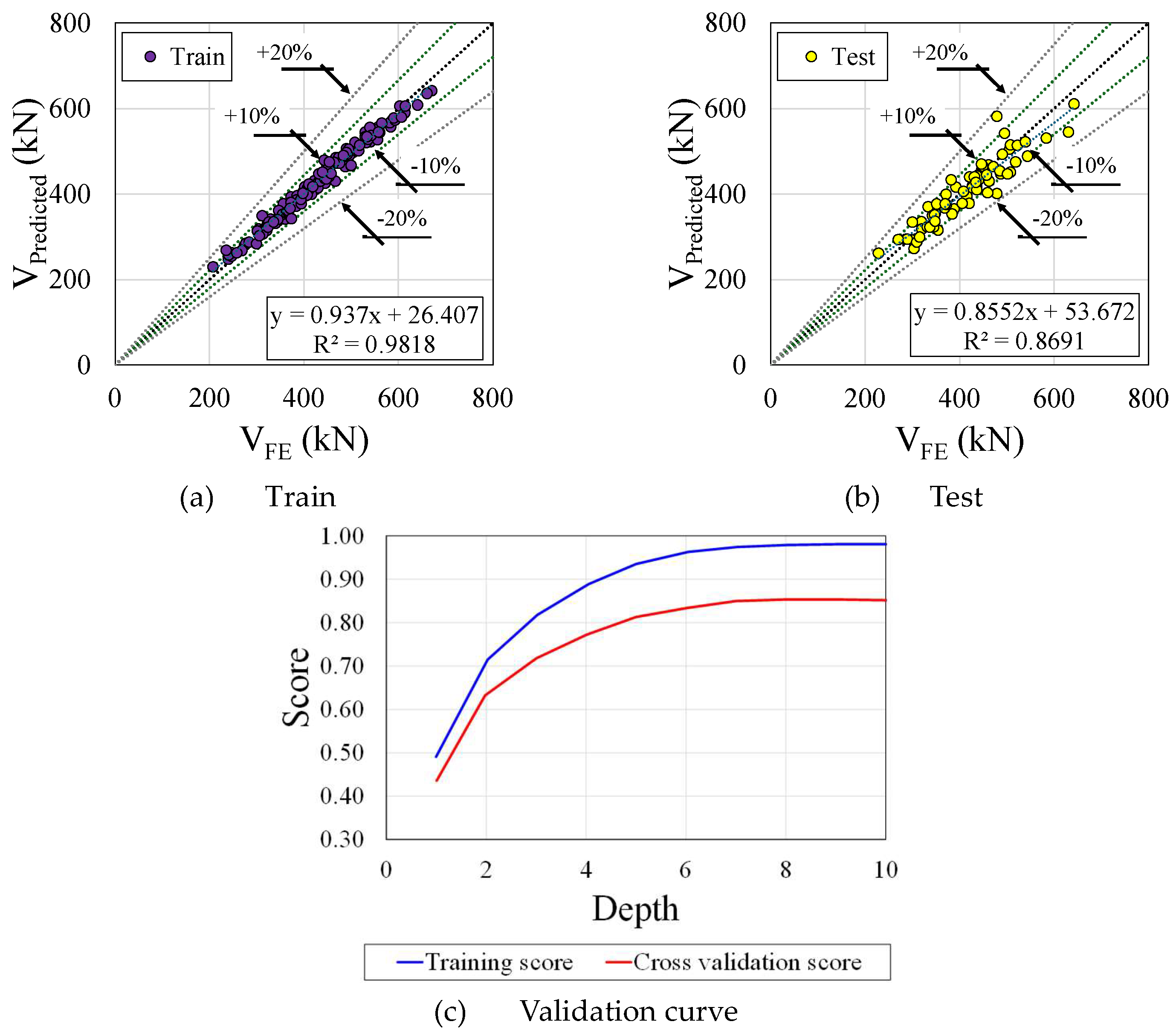
Figure 15.
CatBoostRegressor performance.
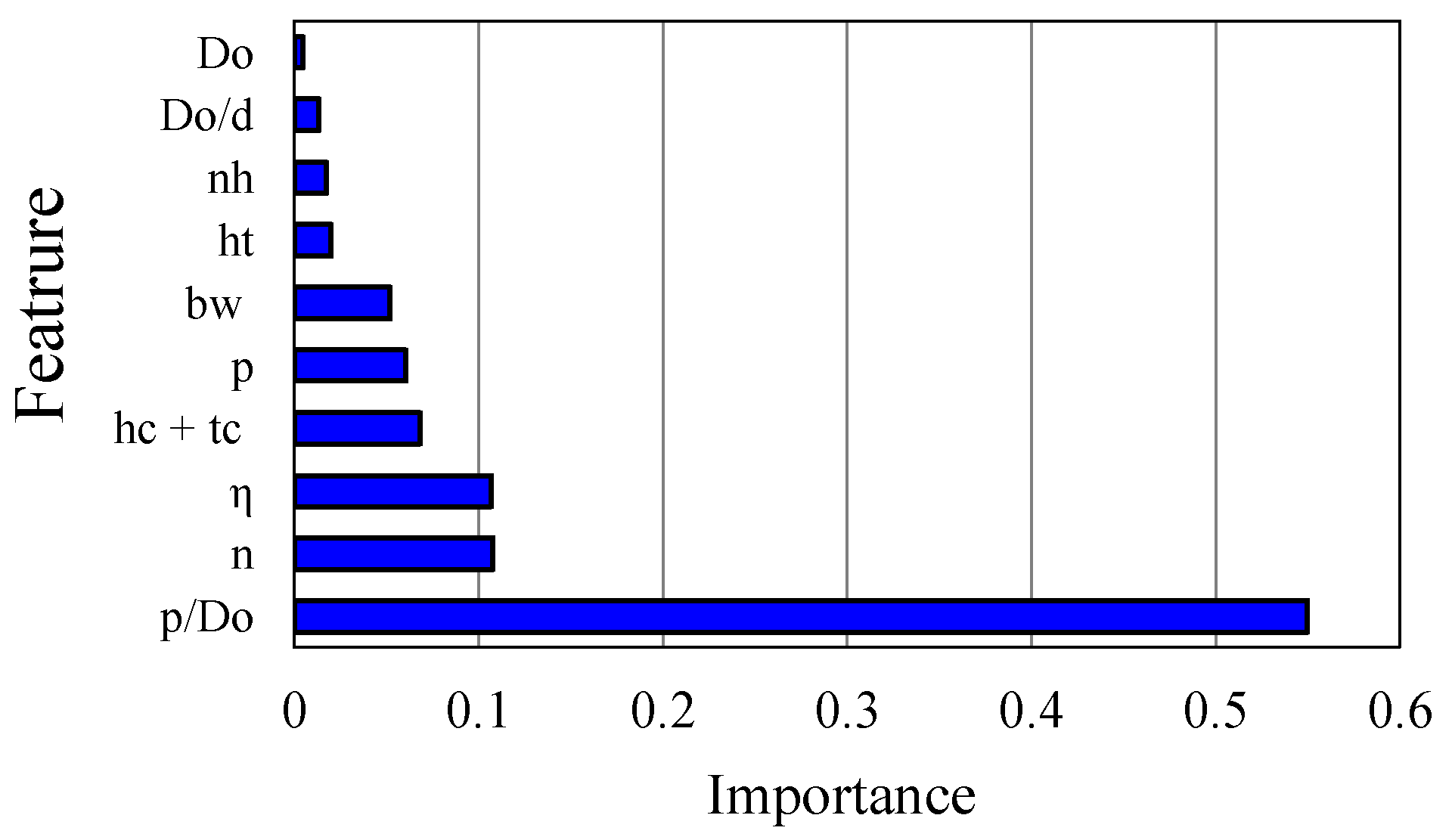
Figure 16.
Comparison analyses.
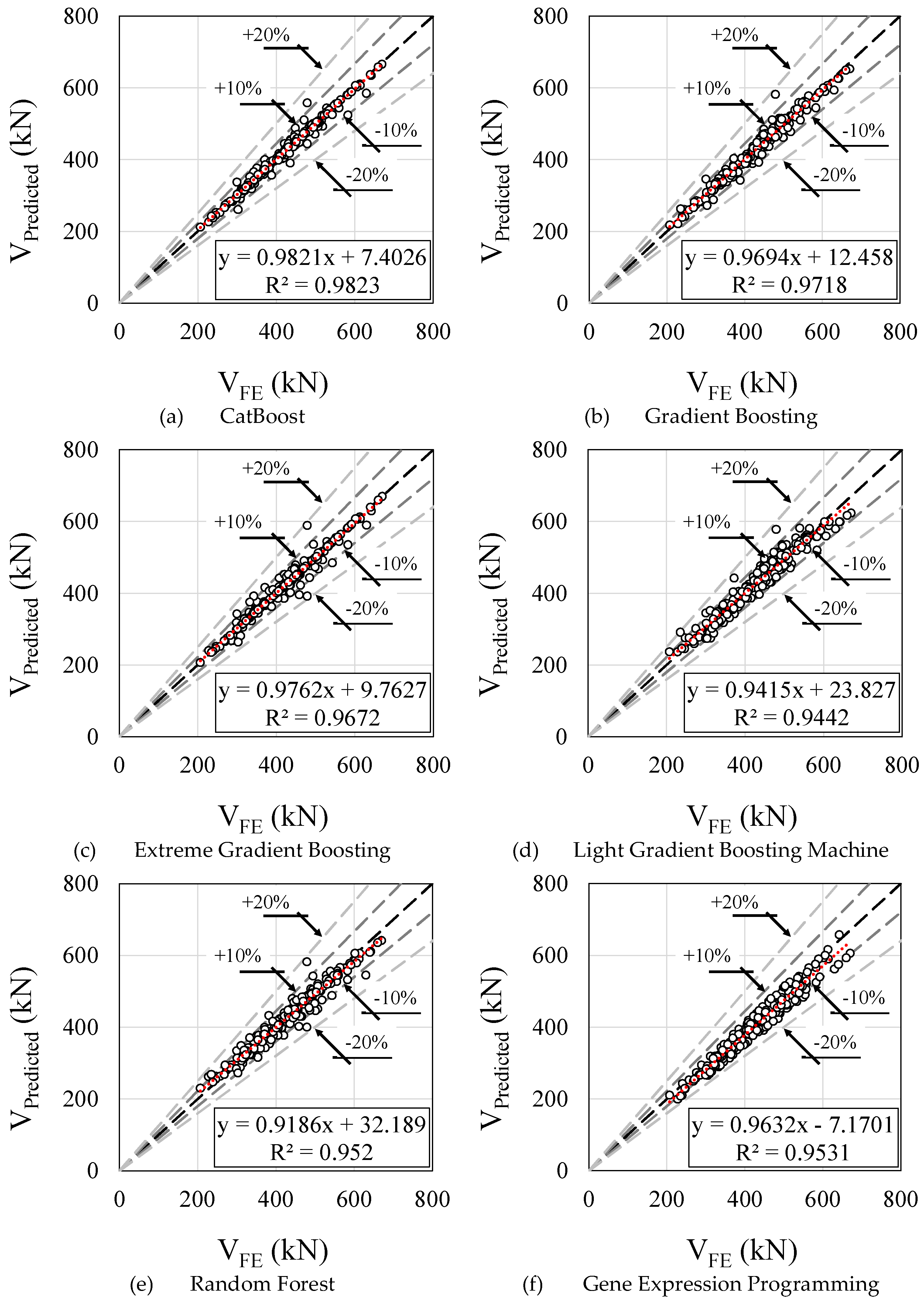

Table 1.
Model Hyperparameters.
| Description | Value |
|---|---|
| Session ID | 1991 |
| Original data shape | (240, 11) |
| Transformed train set shape | (168, 11) |
| Transformed test set shape | (72, 11) |
| Categorical imputation | mode |
| Normalize method | robust |
| Fold Generator | KFold |
| Fold Number | 10 |
| Transform target method | yeo-johnson |
Table 2.
Model construction parameters.
| Function set | +, ˗, *, /, Exp, Ln |
|---|---|
| Number of generations | 365000 |
| Chromosomes | 200 |
| Head size | 14 |
| Linking function | Addition |
| Number of genes | 3 |
| Mutation rate | 0.044 |
| Inversion rate | 0.1 |
| One-point recombination rate | 0.3 |
| Two-point recombination rate | 0.3 |
| Gene recombination rate | 0.1 |
| Gene transposition rate | 0.1 |
| Constants per gene | 2 |
| Lower/Upper bound of constants | -10/10 |
Table 3.
Machine learning models comparative analysis.
| Analysis | Catboost | Gradient Boosting |
Extreme Gradient |
Light Gradient Boosting |
Random Forest |
GEP |
|---|---|---|---|---|---|---|
| R² | 0.9821 | 0.9694 | 0.9762 | 0.9442 | 0.9186 | 0.9531 |
| RMSE (kN) | 12.1504 | 15.3435 | 16.5446 | 21.5878 | 20.3665 | 30.1683 |
| MAE (kN) | 6.7814 | 10.9457 | 7.4057 | 16.5853 | 14.1428 | 24.8799 |
| Minimum relative error | -13.90% | -11.76% | -18.12% | -11.77% | -16.50% | -12.84% |
| Maximum relative error | 16.54% | 21.41% | 22.99% | 24.00% | 21.48% | 2.69% |
| Mean | 1.000 | 1.000 | 1.000 | 1.000 | 0.998 | 0.945 |
| SD | 2.86% | 3.66% | 3.88% | 5.28% | 4.79% | 4.51% |
| CoV | 2.86% | 3.66% | 3.88% | 5.28% | 4.80% | 4.77% |
Table 4.
Summary of the reliability analysis calculated according to EN 1990.
| Machine learning model | n | Vr | ||||
|---|---|---|---|---|---|---|
| Catboost | 240 | 1.00 | 3.04 | 1.64 | 0.163 | 1.255 |
| Gradient Boosting | 240 | 1.002 | 3.04 | 1.64 | 0.163 | 1.257 |
| Extreme Gradient | 240 | 0.999 | 3.04 | 1.64 | 0.163 | 1.258 |
| Light Gradient Boosting | 240 | 1.004 | 3.04 | 1.64 | 0.161 | 1.265 |
| Random Forest | 240 | 1.009 | 3.04 | 1.64 | 0.165 | 1.263 |
| GEP | 240 | 1.058 | 3.04 | 1.64 | 0.161 | 1.263 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



