
Submitted:
20 May 2024
Posted:
21 May 2024
You are already at the latest version
Abstract
Artificial intelligence (AI) is a current trend in computer science, which extends itself its amazing capacities to other technologies such as mechatronics and robotics. Going beyond technological applications, the philosophy behind AI is that there is a vague and potential convergence of artificial manufacture and natural world although the limiting approach may be still very far away, but why? The implicit problem is that Darwin theory of evolution focuses on natural world where breeding conservation is the cornerstone of the existence of creature world but there is no similar concept of breeding conservation in artificial world whose things are created by human. However, after developing for a long time until now, AI issues an interesting concept of generation in which artifacts created by computer science can derive their new generations inheriting their aspects / characteristics. Such generated artifacts make us look back on offsprings by the process of breeding conservation in natural world. Therefore, it is possible to think that AI generation, which is a recent subject of AI, is a significant development in computer science as well as high-tech domain. AI generation does not help us to reach near biological evolution even in the case that AI can combine with biological technology but, AI generation can help us to extend our viewpoint about Darwin theory of evolution as well as there may exist some uncertain relationship between man-made world and natural world. Anyhow AI generation is a current important subject in AI and there are two main generative models in computer science: 1) generative model that applies large language model into generating natural language texts understandable by human and 2) generative model that applies deep neural network into generating digital content such as sound, image, and video. This technical report focuses on deep generative model (DGM) for digital content generation, which is a short summary of approaches to implement DGMs. Researchers can read this work as an introduction to DGM with easily understandable explanations.
Keywords:
generative artificial intelligence
; deep neural network
; deep generative model
; data generation
1. Introduction to Deep Generative Model (DGM)
By informal statement, generative artificial intelligence (GenAI) applications aim to reproduce original artifacts such as images, sounds, music, texts, and speeches into a new artifact with some changes. The problem is that reproduction or generation, which is not duplication, indeed derives a new piece of content which is large or small from whole content of the original artifacts. For example, given a smiling face of a specific person, GenAI application will generate a crying face of the same person. As a subdomain of GenAI, deep generative model (DGM) applies deep neural network (DNN) into generating artifacts but many deep generative models (DGMs) are also relevant to applied statistics. Note, DNN is an artificial neural network having many hidden layers, besides input layer and output layer. Training deep neural network or learning deep neural network is known as deep learning. Given random variable vector x = (x1, x2,…, xm)T presenting any digital artifact or any digital data such as image and sound, let P(x) be probability density function (PDF) of x but it is difficult to estimate such probabilistic distribution P(x) because data x is complicated with suppose that x belongs to the real field Rm where m is high dimension and so, P(x) is called intractable PDF. Suppose there is another random variable vector z = (z1, z2,…, zn)T belonging to the real field Rn where n is low dimension (n < m) so that PDF of z denoted P(z) is tractable and it is possible to understand P(z). Moreover, it is most important that suppose there is a function g(z | Φ) = x that maps tractable data z to intractable data x where Φ is parameter of such mapping function. For some illustrations or examples in this report, random variable vector x is flattened from two-dimension image. As a convention, the function g(z | Φ) = x is called generator of x and its parameter Φ is called generator parameter (Ruthotto & Haber, 2021, p. 2).
Where Z and X are domains of tractable data x and intractable data z with note that Z is called latent space and X is called sample space by convention. When Z is called latent space, tractable PDF P(z) is called latent distribution. Because g(z | Φ) is essentially vector-by-vector function whose input and output are vectors, it should have denoted as g(z | Φ). However, it is still denoted g(z | Φ) in context DNN because there are two reasons: 1) g(z | Φ) is not bijection and 2) the output x of g(z | Φ) can be considered as scalar variable x corresponding to an output neuron of output layer in neural network. Therefore, g(z | Φ) also implies a vector-by-scalar function whose first-order derivative can be considered as gradient vector although the first-order derivative of vector-by-vector function g(z | Φ) is Jacobian matrix. Note, in mathematical, the first-order derivative of scalar-by-vector function is called gradient vector and the first-order derivative of vector-by-vector function is called Jacobian matrix.
The ultimate purpose of any DGM is to determine parameter Φ because generator g(z | Φ) is defined based on Φ. In DGM, generator g(z | Φ) is constructed by a deep neural network (DNN) and its parameter Φ is essentially weights of such DNN. When g(z | Φ) is constructed by DNN, g(z | Φ) is not totally equal to x as g(z | Φ) = x but it is expected that g(z | Φ) is approximated to x in practice:
Note that there are many DGMs and some of them do not require explicit definition of the PDF P(z) of tractable data z but how to estimate generator parameter Φ for determining generator g(z | Φ) = x is always concerned. When g(z | Φ) was determined, we can easily randomize some random tractable data z’ according to the known tractable PDF P(z) and then it is totally possible to generate new artifact x’ by x’ = g(z’ | Φ) so that x’ is generated data / derived data of original intractable data x with expectation that probability distribution of x’ is approximate to the true distribution P(x) of x. The process to randomize z’ is called sampling tractable data (z). When g(z | Φ) is modeled by a DNN, how to estimate parameter Φ is essentially to train such DNN and hence, the DNN is denoted as generator function g(z | Φ) for a convention, which is called generator DNN g(z | Φ). Here we identify generator function with DNN.
Intractable PDF P(x) of x is specified (Ruthotto & Haber, 2021, p. 3) based on law of total probability as follows:
Where Pg(x | z) is conditional PDF of x given z, which implies that Pg(x | z) depends on generator g(z | Φ) too because random variable x inside condition PDF Pg(x | z) is generated from z. Note, notation P(.) denotes probability distribution or probability density function (PDF) in this research. Therefore, it is possible to denote such conditional PDF as P(x | Φ, z).
Such that:
This implies intractable PDF P(x) can be known via tractable PDF P(z) and conditional PDF P(x | Φ, z); however it is really difficult to compute P(x) due to complication of the integral but this difficulty is unimportant because the purpose of DGM is to estimate generator g(z | Φ). As a convention, the conditional PDF P(x | Φ, z) is called likelihood P(x | Φ, z). Indeed, P(x | Φ, z) is likelihood function of intractable data x given tractable data z, which indicates how close generated data x’ = g(z | Φ) to x. In practice tractable PDF P(z) is predefined and likelihood P(x | Φ, z) is determined based on generator DNN g(z | Φ). For instance, P(x | Φ, z) is assumed to be normal distribution (Gaussian distribution) with mean μ and variance σ2 in popular as follows (Ruthotto & Haber, 2021, p. 3):
Let μ = 0 and σ2=1 for optimization, we have:
Where notation ||.|| denotes norm of vector. For instance, Euclidean norm of intractable data x is:
That tractable PDF P(z) is predefined (constant with regard to Φ and x) and likelihood P(x | Φ, z) is assumed to distribute normally indicates that intractable PDF P(x) is implied by the simpler conditional PDF P(x | Φ, z) with support of generator DNN g(z | Φ); in other words, P(x | Φ, z) is probability distribution of x from viewpoint of DNN g(z | Φ) indeed where z is totally determined in latent space Z and P(x | Φ, z) is really simpler with support of DNN g(z | Φ). Because how to determine generator g(z | Φ) is to estimate parameter Φ, it is easy to calculate Φ as maximizer of likelihood P(x | Φ, z), which is the optimization problem as follows:
Taking natural logarithm of likelihood P(x | Φ, z) aims to easily determine Φ by maximizing the log-likelihood function log(P(x | Φ, z)) as follows:
Note,
Let μ = 0 and σ2=1 for optimization, we have:
This implies the minimization problem as follows:
As a result, the estimation of generator parameter Φ based on maximum likelihood estimation (MLE) with assumption of normal distribution of generator g(z | Φ) turns back minimization of error function ½||g(z | Φ) – x||2 which is popular technique in learning DNN by backpropagation algorithm because ½||g(z | Φ) – x||2 is, indeed, quadratic error function in neural network where g(z | Φ) and x are output and real output of a neuron, respectively with note that the output g(z | Φ) is calculated by propagation rule and the real output x is from training data. In other words, MLE is entry point to estimate generator parameter Φ which is weights of DNN g(z | Φ) that is learned fully by backpropagation algorithm (Nguyen, 2023, pp. 8-20). Therefore, please pay attention to the association of MLE and backpropagation algorithm for determining totally generator g(z | Φ), in which g(z | Φ) and x are output at real output of neurons at the output layer of DNN so that backpropagation algorithm can be applied successively. Note, error function is also called loss function. Backpropagation algorithm is often associated with stochastic gradient descent (SGD) method to optimize loss function.
Let ∇P(x | Φ, z) be gradient of likelihood P(x | Φ, z) which is first-order derivative of P(x | Φ, z) with regard to parameter Φ where x and z are samples as follows:
Stochastic gradient descent (SGD) method (Nguyen, 2023, pp. 22-27) estimates Φ by iterative process to update successively Φ at every iteration as follows:
Where 0 < γ ≤ 1 is learning rate. SGD, which is an iterative process, pushes candidate solution at each iteration along the direction which is opposite to gradient of target function for minimization or has the same direction to gradient of target function for maximization with note that the step length is represented by learning rate. In practice, likelihood P(x | Φ, z) is replaced by its natural logarithm as follows:
Where ∇P(x | Φ, z) is gradient of the log-likelihood function logP(x | Φ, z) with regard to Φ. Note the estimation equation above mentions maximization problem according to MLE method and hence, if error function denoted ε(x | Φ, z) which is the function related to g(z | Φ) and x like ε(x | Φ, z) = ½||g(z | Φ) – x||2 aforementioned, then SGD modifies a little bit the estimation equation as follows:
Where ∇ε(x | Φ, z) is gradient of error ε(x | Φ, z).
The main difference between maximizing likelihood P(x | Φ, z) and minimizing error ε(x | Φ, z) is the changing from the sign “+” regarding maximization problem to the sign “–” regarding minimization problem, which is the essence of gradient descent method. In the example of assuming normal distribution, likelihood maximization is the same to error minimization but likelihood maximization gives broader applications to estimate generator parameter Φ within context of DNN along with backpropagation algorithm to train DNN. Besides, it is possible to consider error function is the minus opposite of likelihood function:
It is better that error is the minus opposite of log-likelihood function:
Moreover, there many ways to define likelihood and error and so, the way to define them will contribute to form a concrete DGM, besides how to specify and design generator DNN g(z | Φ). When Φ is weight vector consisting of many weights of entire DNN, only elemental sub-weights at the output layer are estimated by SGD which maximizes likelihood or minimizes error:
Or
Then backpropagation algorithm continues to update remaining sub-weights at hidden layers based on such determined sub-weights at the output layer. Therefore, for convenience, we only focus on likelihood maximization or error minimization and parameter Φ represents entire weights of DNN with assertion that backpropagation algorithm is always feasible. It means that there are two important equivalent estimation equations as follows:
In similar to:
When DGM is trained with big data, training data is fed to DGM at very time point i as a pair d(i) = (x(i), z(i)) and therefore, a set of pairs over N time points is called epoch. As a convention, epoch of size N is denoted as D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))). An interesting result from SGD is that DGM can be learned with epoch D without significant change as follows:
Therefore, training data is counted according to every epoch D instead of every pair (x, z) so that D is fed to SGD at every time point k. Moreover, it is essential that SGD aims to update current parameter at current iteration based on previous parameter at previous iteration. Exactly, let Φ(k+1) be generator parameter at the (k+1)th iteration, then Φ(k+1) is calculated based on previous generator parameter Φ(k) at the kth iteration as follows:
The equation above is the most precise equation for parameter estimation with SGD, which is called epoch estimation with note that SGD is an iterative process. It can also be replaced by following equations:
The first equation
Which is most popular. Moreover, the index k indicates time point as well as iteration of SGD. If learning rate γ is varied at every iteration as γ(k), we have:
There are two problems related to construct a DGM: 1) how to define likelihood or error to train generator DNN g(z | Φ) and 2) how to define tractable PDF P(z) which implies the way to randomize z. The second problem relates to assert qualification of random data z’ and hence, the second problem is stated as qualification problem of how to qualify random data. Therefore, the two problems of constructing DGM are 1) how to train generator DNN g(z | Φ) and 2) how to qualify such training task which often relates to another optimization task or another training task. Some basic principles related to DGM are introduced in this section but the two problems cannot be mentioned because there are many specific DGMs which have own specifications. Anyhow generator likelihood P(x | Φ, z) based on definition of generator g(z | Φ) is always important regardless that if it is specified explicitly and thus, suppose it was defined, then SGD is favorite method to optimize it. As an example aforementioned, suppose P(x | Φ, z) distributes normally with mean μ and variance σ2 in some DGM as follows (Ruthotto & Haber, 2021, p. 3):
Generator log-likelihood is natural logarithm of generator likelihood P(x | Φ, z):
Gradient of this log-likelihood with regard to Φ is:
Where dg(z | Φ) / dΦ is differential of g(z | Φ) with regard to Φ. Let μ = 0 and σ2=1 for optimization, we have:
As usual, estimation equation resulted from SGD is:
There is a question that how to calculate the differential dg(z | Φ) / dΦ. Indeed, it is not difficult to calculate it in context of neural network associated with backpropagation algorithm so that the last output layer as well as last neuron o of DNN g(z | Φ) is acted by activation function a(.) as follows:
Where i is input of the last layer o and weight parameter w is a part of entire parameter Φ and hence, we need to focus on calculating differential da(o) / dw which is equivalent to differential dg(z | Φ) / dΦ so that backpropagation algorithm will solve remaining parts of entire parameter Φ.
Indeed, we have:
Note, the subscript “T” denotes transposition operator of vector and matrix in which row vector becomes column vector and vice versa. It is easy to calculate the derivative a’(o) when activation function was specified, for instance, if a(o) is sigmoid function, we have:
In practice, y is replaced by a(y) in order to prevent o from being out of space:
As a result, we have:
For fast computation, it is possible to set the derivative a’(o) to be small enough constants like 1 such that dg(z | Φ) / dΦ = iT.
Suppose some other DGM assumes that x is binary (x = 0 or x = 1) and follows Bernoulli (Ruthotto & Haber, 2021, p. 3) and so, its generator DNN g(z | Φ) derives values in interval [0, 1]. In other words, image of g(z | Φ) is the real number interval [0, 1], which leads to a specification that g(z | Φ) is probability of the event x=1 with note that x is scalar variable (x) for convenience:
Because g(z | Φ) becomes a (scalar) random variable whose value is probability, it is possible to identify g(z | Φ) with its parameter Φ as a convention:
Given N trials with binary values of x, let N(x) be the number of event x=1 among N trials, then generator likelihood P(x | Φ, z) is specified according to Bernoulli distribution as follows:
The generator log-likelihood is:
Gradient of the generator log-likelihood with regard to Φ is:
As a result, estimation equation resulted from SGD is:
Although normal distribution and Bernoulli distribution are two popular distributions to specify generator likelihood P(x | Φ, z), there are other specifications which depend on specific DGM.
Given epoch D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))) implies that the epoch is created or sent by equilateral distribution 1/N but in general case, D can follow an arbitrary distribution denoted by PDF P(d), which makes the optimization problem and the SGD estimation changed a little bit by theoretical expectation given distribution P(d).
Where,
However, there is no significant change in aforementioned practical technique to estimate parameters.
Turning back the assumption that generator likelihood P(x | Φ, z) distributes normally with mean μ and variance σ2 in some DGM as follows (Ruthotto & Haber, 2021, p. 3):
This assumption is not totally exact because the distribution above mentions the error g(z | Φ) – x between generated data g(z | Φ) and real data x. Exactly, generator likelihood P(x | Φ, z) is defined as distribution of the error ε = g(z | Φ) – x and such error distribution is assumed to follow normal distribution with mean μ and variance σ2.
Therefore, setting error mean and error variance to be zero and one as μ = 0, σ2 = 1 is for best optimization because of smallest error mean 0 but the setting is not totally diverse in data generation.
When learning generator DNN by backpropagation algorithm associated with SGD, it is possible to estimate dynamically μ and σ2 by maximum likelihood estimation (MLE) method. Given epoch D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))), error mean and error variance are estimated as follows:
When error mean and error variance are dynamically estimated instead of fixing them by zero and unit, generator DNN g(z | Φ) may produce new data in high diversity, which is similar to add noises to generated data. In other words, estimation of error mean and error variance based on epoch makes the data generation more diverse because z may be randomized in interval [0, 1] although DGMs try to diversify z or x like Variational Autoencoders (VAE) and Generative Adversarial Network (GAN). Note, if z is randomized only in interval [0, 1], generated data x’ = g(z | Φ) may not be different much from sample x in epoch in case that error mean μ and error variance σ2 are fixed by 0 and 1. However, quality of data generation is the best with zero error mean 0.
Recall that the two problems of constructing DGM are 1) how to train generator DNN g(z | Φ) and 2) how to qualify such training task which often relates to another optimization task or another training task. The first problem relates to how to establish generator likelihood P(x | Φ, z) which is the probability density function (PDF) of intractable x given tractable data z and this establishment is based on generator DNN g(z | Φ). However, there are some DGMs do not specify explicitly the density function P(x | Φ, z), which is cause of the fact that there are two DGM approaches: 1) DGM specifies explicitly generator PDF P(x | Φ, z) and 2) vice versa. In group of explicit PDF approach, there are two built-in approaches: 1) tractable density DGM specifies explicitly well-known distributions for generator likelihood and 2) approximate density DGM tries to estimate approximately generator PDF P(x | Φ, z) or derive other PDF that is similar to P(x | Φ, z). In general, there are three main approaches for constructing DGM such as tractable density DGM, approximate density DGM, and implicit density DGM which are mentioned in next sections. Following figure depicts taxonomy of DGM (Oussidi & Elhassouny, 2018, p. 7) by Goodfellow.
Figure 1.1.
Taxonomy of DGM.
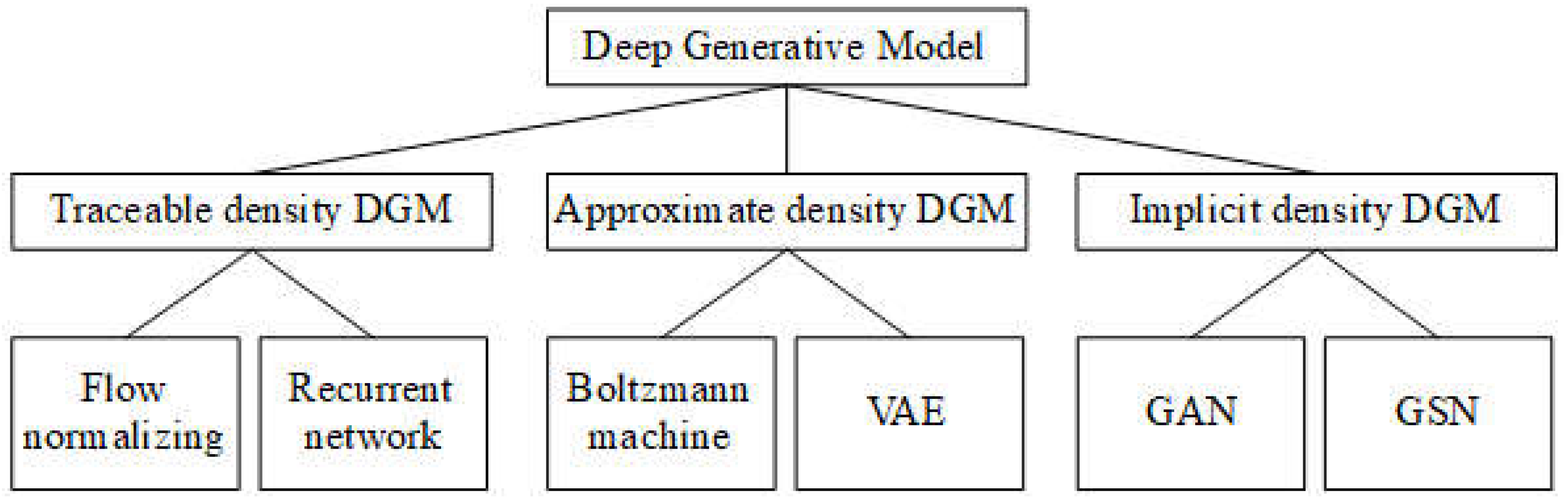
Especially, if data is image, there is another categorization way that there are two main approaches: 1) pixel density approach tries to model pixel distribution and 2) block density approach tries to model entire image distribution as any data distribution. In other words, likelihood P(x | Φ, z) is defined based on probabilistic distribution of pixels where x is considered as set of pixels according to pixel density approach. On the other hand, block density approach considers likelihood P(x | Φ, z) is PDF of a block or entire image (unified big block) where x is considered as any arbitrary data. A usual, pixel density approach belongs to tractable density approach of the first categorization.
2. Tractable Density DGM
According to tractable density approach, DGMs specify explicitly generator PDF P(x | Φ, z) with note that PDF is abbreviation of probability density function. Recall that the two problems of constructing DGM are 1) how to train generator DNN g(z | Φ) and 2) how to qualify such training task which often relates to another optimization task or another training task. However, the two problems are merged into the first problem which is to train g(z | Φ) according to normalizing flow technique in which g(z | Φ) is invertible given tractable data z and intractable data x have the same dimension n. Therefore, latent space Z and sample space X are the same with dimension n. As a convention, g–1(x | Φ) is called inversed generator.
Where,
Note, the subscript “T” denotes transposition operator of vector and matrix in which row vector becomes column vector and vice versa. Because g(z | Φ) is essentially vector-by-vector function whose input and output are vectors, it should have denoted as g(z | Φ), especially, when g(z | Φ) here is bijection. However, it is still denoted g(z | Φ) for convenience. Therefore, the first-order derivative of vector-by-vector function g(z | Φ) here is Jacobian matrix but is stilled called gradient. Note, in mathematical, the first-order derivative of scalar-by-vector function is called gradient vector and the first-order derivative of vector-by-vector function is called Jacobian matrix.
As a result, normalizing flow (NL) technique focuses on maximizing intractable PDF P(x) now called sample PDF or sample likelihood rather than maximizing generator likelihood P(x | Φ, z) because P(x) is now proportional to tractable PDF P(z) and P(x) is stronger than P(x | Φ, z). When P(x) has generator parameter Φ, it is denoted as P(x | Φ). According to applied statistics literature, sample likelihood P(x | Φ) is determined based on tractable PDF P(z) and generator g(z | Φ) as follows (Ruthotto & Haber, 2021, p. 7):
Where |.| or det(.) denotes determinant of square matrix with note that the gradient ∇xg–1(x | Φ) of the inverse g–1(x | Φ) is Jacobian matrix which is the first-order derivative of g–1(x | Φ) with regard to x. As a convention, ∇xg–1(x | Φ) is called inversed gradient because ∇xg–1(x | Φ) is the first-order derivative of inversed generator g–1(x | Φ) with regard to x.
The equation of sample likelihood P(x | Φ) is much more definite than the integral formulation of P(x) as aforementioned
It is explained from the equation of sample likelihood P(x | Φ) that given source and target with a function from source to target, target distribution is calculated by multiplying source distribution with determinant of gradient of inversed function.
For optimization, P(z) is assumed to follow standard normal distribution with mean 0 and variance 1:
Such that:
Where notation ||.|| denotes norm of vector. Exactly, P(z) follows standard normal distribution with mean vector 0 and identity covariance matrix I. Sample log-likelihood is derived by taking natural logarithm of sample likelihood:
NL aims to maximize sample log-likelihood so as to estimate generator parameter Φ:
Stochastic gradient descent (SGD) method is used to estimate Φ by iterative process to update successively Φ at every iteration as follows:
Where ∇logP(x | Φ) which is called sample log-likelihood gradient is gradient of sample log-likelihood logP(x | Φ) and γ (0 < γ ≤ 1) is learning rate. Note that SGD, which is an iterative process, pushes candidate solution at each iteration along the direction which is opposite to gradient of target function for minimization or has the same direction to gradient of target function for maximization with note that the step length is represented by learning rate. Given epoch of size N is denoted as D = (x(1), x(2),…, x(N)), the estimation equation of Φ is extended exactly as epoch estimation at every iteration of SGD:
It is necessary to determine sample log-likelihood gradient ∇logP(x | Φ) with regard to parameter Φ. Due to (Nguyen, Matrix Analysis and Calculus, 2015, pp. 45-46):
And
We have following equation to calculate log-likelihood gradient ∇logP(x | Φ):
The notation (∇xg–1(x | Φ))–1 denotes inverse of matrix ∇xg–1(x | Φ). Because ∇xg–1(x | Φ) called Jacobian matrix is a square matrix, the derivative d∇xg–1(x | Φ) / dΦ is determined by taking first-order derivative for every element of ∇xg–1(x | Φ) with regard to Φ, which produces a tensor. Therefore, d∇xg–1(x | Φ) / dΦ is the second-order derivative of inversed generator g–1(x | Φ) with regard to x and Φ. Let
It is possible to calculate this second-order derivative if inversed gradient ∇xg–1(x | Φ) is determined. Log-likelihood gradient ∇logP(x | Φ) is rewritten:
Where:
According to traditional neural network, let φi be the ith row vector of matrix Φ, then generator g(x | φ) is linear composition as follows:
Where δi is the ith bias parameter associated with each xi. Note, xi is the ith elemental variable in x whereas activation a(.) is invertible, whose inverse is a–1(.). In traditional neural network, xi represents a neuron or unit. Due to:
When φi = (φi1, φi2,…, φin)T and z = (z1, z2,…, zn)T, without loss of generality, given φij and zj are the jth elements of φi and z, respectively we have fine-tuned inversed generator g–1(xi | φij):
Where,
It is easy to calculate the inversed gradient:
Where a–1(xi) is the first-order derivative of a–1(.) at xi. The second-order derivative is determined as follows:
Log-likelihood gradient with regard to φij is fine-tuned as ∇logP(xi | φij) is expended again:
Because δi is the ith bias parameter, the second-order derivative is determined as follows:
Where,
Log-likelihood gradient with regard to δi is fine-tuned as ∇logP(xi | δi) is expended again:
In general, log-likelihood gradient ∇logP(xi | φij, δi) is specified as follows:
Where a(.) and a–1(.) are invertible activation function and its inverse and,
SGD estimation is fine-tuned as follows:
Given epoch of size N is denoted as D = (x(1), x(2),…, x(N)), the estimation equation of φij and δi is extended exactly as epoch estimation at every uth iteration of SGD with regard to log-likelihood gradient ∇logP(xi | φij, δi).
Where xi(v) is the ith element of x(v) in epoch. As a result, NL trained with SGD is specified as follows:
Initialize all φij, δi and set u = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Increase u = u + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters φij and δi are not changed significantly or there is no more coming epoch X. Moreover, the index u indicates time point as well as iteration of SGD. After finite NL is trained, it can generate new data x’ by generator g(z | Φ) = x’ with any z randomized from standard normal distribution with mean 0 and variance 1.
It is interesting that log-likelihood gradient ∇logP(xi | φij) is determined based on inversed gradient . Therefore, how to estimate generator parameter Φ by SGD estimation focuses on calculating inversed gradient which is central point of normalizing flow (NL) technique. Moreover, how to calculate is based on how to determine inversed generator g–1(x | Φ). In other words, the main problem of NL is how to determine inversed generator g–1(x | Φ) because it is easy to calculate gradient of function f(x) = g–1(x | Φ) with regard to x. Especially, when generator g(x | Φ) is implemented by DNN, NL will have some special techniques so that determining its inverse g–1(x | Φ) is easier. One of these technique is finite normalizing flow (finite NL) in which generator g(x | Φ) is implemented by a DNN having K layers from layer 1 to layer K where layer 0 is input layer with note that each layer is represented by partial generator function fk (Ruthotto & Haber, 2021, p. 8):
Note, all layers fk have the same number of neurons which is the dimension n. Because fk is essentially vector-by-vector function whose input and output are vectors, it should have denoted as fk, especially, when fk here is bijection. However, it is still denoted fk for convenience. Let z(k+1) be output of partial generator fk, we have:
Inversed generator g–1(x | Φ) representing inversed DNN is determined:
Each fk–1 is called inversed partial generator function which is the inverse of partial generator function fk. Let x(k–1) be output of partial generator fk–1, we have:
“Input layer” of “inversed DNN” is fK+1–1. The inversed generator DNN may be pseudo in case that only one generator DNN is designed so that inversed generator function fk–1 is existent. An interesting result of the design of finite NL is that inversed gradient ∇g–1(x | Φ) is product of gradients of inversed partial generator fk–1.
Where Φ(k) is parameter of fk. It is now necessary to determine fine-tuned partial inversed gradient in order to determine fine-tuned partial log-likelihood gradient ∇logP(xi(k) | φij(k)) where xi(k) is an elemental variable in x(k) = (x1(k), x2(k),…, xn(k))T and φij(k) is the jth element in φi(k) = (φi1(k), φi2(k),…, φin(k))T with note that φi(k) is the ith row vector of matrix Φ(k). Moreover, let δi(k) be the ith bias parameter associated with each xi(k). Without loss of generality, given φj(k), δi(k), and zj(k) along with invertible activation a(.), we have fine-tuned inversed generator g–1(xi(k) | φij(k), δi(k)).
Where,
Where zi(k) is the ith elemental variable in z(k) = (z1(k), z2(k),…, zn(k))T. By similar way aforementioned, log-likelihood gradient ∇logP(xi(k) | φij(k), δi(k)) is specified as follows:
Where a(.) and a–1(.) are invertible activation function and its inverse and,
SGD estimation is fine-tuned as follows:
Given epoch of size N is denoted as D = (x(1), x(2),…, x(N)), the estimation equation of φij(k) and δi(k) is extended exactly as epoch estimation at every uth iteration of SGD with regard to log-likelihood gradient ∇logP(xi(k) | φij(k), δi(k)):
Where (xi(k))(v) is the ith element of x(v) in epoch with regard to inversed generator fk–1. As a result, finite NL trained with SGD is specified as follows:
Initialize all φij(k), δi(k) and set u = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Increase u = u + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters φij(k) and δi(k) are not changed significantly or there is no more coming epoch X. Moreover, the index u indicates time point as well as iteration of SGD. After finite NL is trained, it can generate new data x’ by generator g(z | Φ) = x’ with any z randomized from standard normal distribution with mean 0 and variance 1.
Because it is not easy to calculate inversed gradient ∇xg–1(x | Φ) as well as its determinant |∇xg–1(x | Φ)| according to finite NL except the decomposition technique above of entire matrix parameter Φ into partial vector parameters φi(k), there is technique called real RVP (Ruthotto & Haber, 2021, p. 9) which defines each layer or partial generator fk(z(k)) by special way where z(k) is split into two parts such as z1(k) and z2(k) so that:
Of course, we have:
Where sk and tk are two neural networks for scaling and translation, whose inputs and outputs have the same dimension. The operator denotes component-wise multiplication of two vectors where every pair of two corresponding elements of the two vectors are multiplied together, for instance, given two arbitrary vectors u = (u1, u2,…, un)T and v = (v1, v2,…, vn)T, we have uv = (u1v1, u2v2,…, unvn)T. Moreover, the exponential function exp(.) above whose input is vector produces a vector by taking exponential function over every element of input vector. Inversed generator fk–1 is specified from generator fk.
Of course, we have:
Inversed gradient is the 2x2 Jacobian matrix determined as follows:
It is interesting that taking determinant of inversed gradient ∇xfk–1(x(k)) becomes simple:
When this determinant is determined, it is possible to maximize log-likelihood logP(x | Φ) to estimate Φ where Φ here are weights of scaling neural network sk and translation neural network tk. Log-likelihood logP(x | Φ) is written:
Because parameter Φ is now only weights of scaling neural network sk and translation neural network tk, maximizing log-likelihood logP(x | Φ) is now to optimize (train) sk and tk by some algorithms like backpropagation algorithm.
Beside finite NL there is another NL technique called continuous NL but it is not mentioned here because continuous NL is relevant to hazard problem of differential equation which is not main subject of DNN.
Recall that there are three main approaches for constructing DGM such as tractable density DGM, approximate density DGM, and implicit density DGM. However, if data is image, there is another categorization way that there are two main approaches: 1) pixel density approach tries to model pixel distribution and 2) block density approach tries to model entire image distribution as any data distribution. In other words, likelihood P(x | Φ, z) is defined based on probabilistic distribution of pixels where x is considered as set of pixels according to pixel density approach. On the other hand, block density approach considers likelihood P(x | Φ, z) is PDF of a block or entire image (unified big block) where x is considered as any arbitrary data. For instance, NL belongs to both tractable density DGM and block density approach. It is interesting that pixel density approach also belongs to tractable density approach because its PDF is defined obviously. Moreover, pixel density approach merges the two problems of training generator g(z | Φ) and qualifying such training task into the first problem which is to train g(z | Φ) by learning sample PDF P(x) because P(x) or P(x | Φ) now replaces P(x | Φ, z).
Shortly, pixel density (PD) approach defines P(x) as product of all pixel distribution. Concretely, let x = (x1, x2,…, )T denote an image whose every ith pixel is represented by elemental variable xi and P(x) called image PDF is defined according to joint probability rule as follows:
Where n implies image width with suppose that image width and image height are equal for convenience, and
In other words, image PDF P(x) is product of all conditional PDFs P(xi | xi–1, xi–2,…, x1) where every P(xi | xi–1, xi–2,…, x1) is called conditional pixel PDF or pixel PDF in short. There is neither tractable data z nor explicit generator g(z | Φ) for generating new data in PD because generation task is based on the entire PDF P(x). For instance, without loss of generality, if we randomize k first pixels x1, x2,…, xk, we can generate n2–k remaining pixels by the recurrent process: determining P(xk+1 | xk, xk–1,…, x1) based on x1 to xk, generating xk+1 according to P(xk+1 | xk, xk–1,…, x1) and determining P(xk+2 | xk+1, xk,…, x1) based on x1 to xk+1, generating xk+2 according to P(xk+2 | xk+1, xk,…, x1) and determining P(xk+3 | xk+2, xk+1,…, x1) based on x1 to xk+2,…, generating according to P( | , ,…, x1) and determining P( | , ,…, x1) based on x1 to , generating the last according to P( | , ,…, x1). By another viewpoint, the joint probability of n2–k remaining pixels denoted P(xk, xk+1,…, ) is determined and then, n2–k remaining pixels are generated according to this joint probability. Indeed, the joint probability P(xk, xk+1,…, ) of n2–k remaining pixels is totally determined when P(x) and k probabilities P(xi | xi–1, xi–2,…, x1) are determined where i is from 1 to k.
Because there are a large number of pixels in a large image which produces a large number of pixel PDFs as well as every pixel PDF P(xi | xi–1, xi–2,…, x1) of a given pixel xi is itself also complicated with a lot of its previous pixels xi–1, xi–2,…, x1, there are many techniques proposed to PD in order to decrease complexity and increase computation effectiveness. Anyhow, the equation of image PDF P(x) above is important one in theory. One of PD techniques is to apply long short-term memory (LSTM) (Theis & Bethge, 2015) into modeling and learning sample PDF P(x).
The default artificial neural network is feedforward neural network where data is fed to input layer which, in turn, is evaluated and passed across hidden layers to output layer in one-way direction, finally. However, there is an extension of neural network, which is called recurrent neural work (RNN), where an output can be turned back in order to feed on network as input. In other words, RNN has circle, which allow that output can become input. For convenience and easy explanation, given T time points t = 1, 2,…, T, current state of a RNN at time point t is represented by three layers such as input layer xt, hidden layer ht, and output layer ot without loss of generality with note that ht can represent many hidden layers when RNN is a DNN too. Obviously, RNN is an extension of neural network because every triple (xt, ht, ot) is, essentially, a feedforward neural network, even a DNN. Hidden layer ht as well as output layer ot at current state t is calculated based on both current input layer xt and previous hidden layer ht–1 of previous state at time point t–1. Without loss of generality, input layer, hidden layer, and output layer are considered as input neuron, hidden neuron, and output neuron for convenience (Wikipedia, Recurrent neural network, 2005).
Where Wh is weight matrix of current hidden neuron ht regarding current input neuron xt, Uh is weight matrix of current hidden neuron ht regarding previous hidden neuron ht–1, and bh is bias vector of current hidden neuron ht whereas Wo is weight matrix of current output neuron ot regarding current hidden neuron ht and bo is bias vector of current output neuron ot. Moreover, σh(.) and σo(.) are activation functions of ht and ot, respectively with note that σh(.) and σo(.) are vector-by-vector functions. Backpropagation algorithm can be applied into learning RNN as usual. It is interesting that structure of RNN defined by the triple (xt, ht, ot) is not changed but its parameters Wh, Uh, bh, Wo, and bo are changed by backpropagation algorithm when RNN is learned. Of course, values of the triple (xt, ht, ot) are changed over time points. Note, Wh, Uh, and Wo are matrix parameters and bh and bo are vector parameters whereas xt, ht, and ot are vector variables.
Long short-term memory (LSTM) is an extension of RNN, which implies that RNN is used to implement short-term memory so that the short-term memory can last for a longer time through T time points t = 1, 2,…, T built in RNN. Consequently, the short-term memory is represented by a so-called cell associated with three gates such as input gate, forget gate, and output gate. Cell represents information piece stored in memory at current time (Wikipedia, 2007). Input gate controls which new information to be put to cell, forget gate decides which information to be discarded, and output gate controls which information to be sent to next state (Wikipedia, 2007). As a convention, the cell at current state t is represented by the pair (ct, ht) whereas input gate, forget gate, and output gate are represented by vector variables it, ft, and ot, respectively. Note, let gt and ct be cell input activation variable and cell state variable where cell input activation variable gt represents the activated input part of a cell, which is the important input part being different from the forgotten part, whereas cell state variable ct represents real information stored in cell which is, exactly, the short memory at current state. In literature, gt is also called cell gate. Some LSTM variants merge gt and ct into the same cell state variable. Although output gate ot represents which information to be sent to next state, it is consolidated with current cell memory ct in order to produce the real output information ht which represents bright and clear-cut memory. In other words, given cell (ct, ht), then ct represents the real information stored in memory and ht represents the clear-cut memory which displays brightly at the outside for next state. It is possible to consider that ct is evaluated value of cell t and ht is predictive value of cell t. Following equations specify LSTM based on specification of RNN (Wikipedia, 2007), which indicates how to calculate cell and gates.
Note, weight matrix Wi, weight matrix Ui, and bias vector bi are parameters of input gate it. Weight matrix Wf, weight matrix Uf, and bias vector bf are parameters of forget gate ft. Weight matrix Wo, weight matrix Uo, and bias vector bo are parameters of output gate ot. Weight matrix Wg, weight matrix Ug, and bias vector bg are parameters of cell gate gt. Vector variables it, ft, and ot are often in range [0, 1] whereas vector variables ct and ht are often in range [–1, 1]. Activation functions σi(.), σf(.), and σo(.) are often sigmoid (logistic) functions whereas activation functions σg(.) and σh(.) are hyperbolic tangent functions. The operator denotes component-wise multiplication of two vectors where every pair of two corresponding elements of the two vectors are multiplied together, for instance, given two arbitrary vectors u = (u1, u2,…, un)T and v = (v1, v2,…, vn)T, we have uv = (u1v1, u2v2,…, unvn)T. Note, backpropagation algorithm can be applied into learning LSTM as usual.
By applying LSTM into pixel density (PD) approach for modeling DGM, each pixel xi is represented by cell ci when pixel index i is considered as time point t. Because each cell ci is dependent on its one right previous cell ci–1 whereas conditional pixel PDF P(xi | xi–1, xi–2,…, x1) of pixel xi is dependent on i–1 previous pixelsxi–1, xi–2,…, x1, Markov property is applied so that conditional pixel PDF of pixel xi depends on only one previous pixel xi–1.
It is now possible to apply LSTM to model PD by matching each pixel xi with each cell ci so that cell ci is considered as evaluated value of pixel xi as well as each hi is predictive value of pixel xi. Because image is two-dimension array, each pixel xij or each cell cij is indexed by two indices i and j following image height and image width. The event that cell cij or ci,j indexed by two indices i and j makes LSTM extended into two-dimension LSTM as follows:
The equations above specify core ideology of PD associated with two-dimension LSTM where the contextual meaning of weight and bias parameters W(.), U(.), V(.), and b(.) is not changed with note that W(.), U(.), and V(.) are weight matrices regarding current pixel, previous pixel (i, j–1), and previous pixel (i–1, j), respectively. In literature, such PD is called PixelRNN associated with diagonal two-dimension LSTM (Oord, Kalchbrenner, & Kavukcuoglu, 2016, pp. 3-4). According to diagonal two-dimension LSTM each pixel (i, j) at ith row and jth column has two previous neighbors such as previous left pixel (i, j–1) and previous upper pixel (i–1, j). For extension, each pixel (i, j) can have up four previous neighbors such as pixel (i, j–1), pixel (i–1, j–1), pixel (i–1, j), and pixel (i–1, j+1). Following figure depicts PixelRNN with diagonal two-dimension LSTM (Oord, Kalchbrenner, & Kavukcuoglu, 2016, p. 4).
Figure 2.1.
PixelRNN with diagonal two-dimension LSTM.
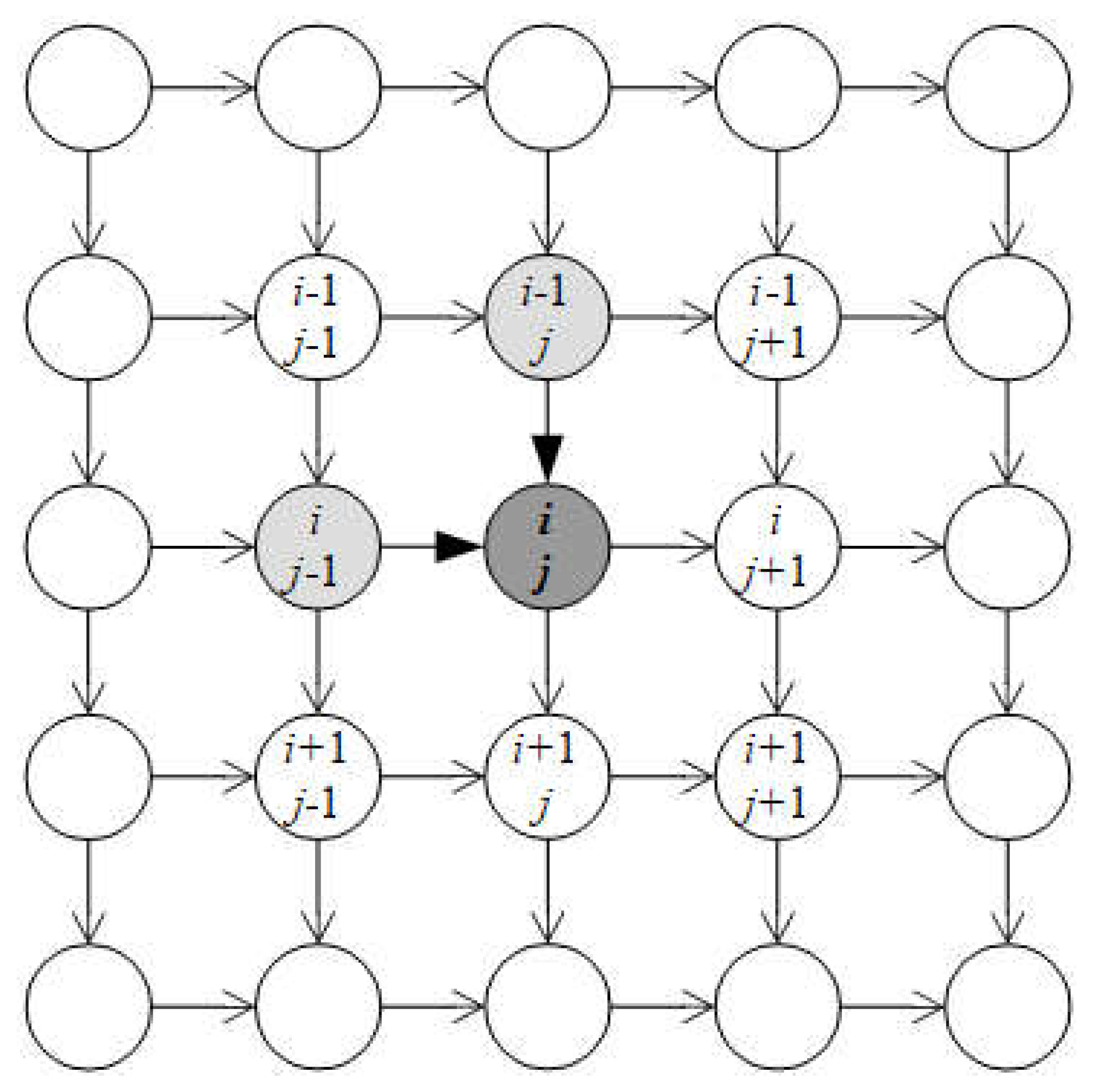
It is easy to add more weight parameters to these extensive cases. For example, cell gates and cell state with regard to the four previous neighbors are specified as follows:
Where matrices R(.) and S(.) are additional weight parameters regarding two new neighbor pixels such as pixel (i–1, j–1) and pixel (i–1, j+1).
Recall that ci,j is considered as evaluated value of pixel xi,j and hi,j is predictive value of pixel xi,j. It is interesting that hi,j is generated pixel within the aforementioned generation process by PD. Turning back the generation process, without loss of generality, given k randomized pixels xi–1,1, xi–1,2,.., xi–1,j+1,…, xi,1, xi,2,…, xi,j, we will generate the next pixel xi,j+1. Firstly, PD model must be trained by some dataset as a set of images. Secondly, k randomized pixels xi–1,1, xi–1,2,.., xi–1,j+1,…, xi,1, xi,2,…, xi,j are fed to PD again so as to update k sets of parameters W(.), U(.), and b(.) as well as compute k predictive values hi–1,1, hi–1,2,.., hi–1,j+1,…, hi,1, hi,2,…, hi,j. Finally, it is possible to determine the predictive value hi,j+1 of the next pixel (i, j+1) given xi,j+1, hi,j, and hi–1,j+1 along with learned parameters of two-dimension LSTM PD. It is important to note that xi,j+1 is randomized arbitrarily whereas hi,j and hi–1,j+1 were computed previously. Obviously, it is easy to generate next predictive values hi,j+2, hi,j+2,…, hi+1,j, hi+1,j+1, etc. by the similar process. Note, backpropagation algorithm can be applied into learning two-dimension LSTM as usual. Note, backpropagation algorithm is often associated with stochastic gradient descent (SGD) method and so, please pay attention to SGD.
3. Approximate Density DGM
According to approximate density approach, DGMs try to estimate approximately generator PDF P(x | Φ, z) or derive other PDF that is similar to P(x | Φ, z) with note that PDF is abbreviation of probability density function.
Recall that there are two problems related to construct a DGM: 1) how to define likelihood or error to train generator DNN g(z | Φ) and 2) how to define tractable PDF P(z) which implies the way to randomize z. The second problem relates to assert qualification of random data z’ and hence, the second problem is stated as qualification problem of how to qualify random data. According to implicit density approach, a discrimination DNN is used to qualify randomized data z instead of defining tractable PDF P(z) by Generative Adversarial Network (GAN) which is a typical method belonging to implicit density approach. In different way belonging to this approximate density approach, Variational Autoencoders (VAE) method developed by Kingma and Welling (Kingma & Welling, 2022) proposed another DNN called encoder f(x | Θ) to expectedly convert intractable data x into tractable data z. In other words, encoder f(x | Θ) approximates tractable data z by encoded data z’.
It is easy to recognize that encoder f(x | Θ) is an approximation of the inverse of generator g(z | Φ) when g(z | Φ) is invertible where x-dimension m is larger than z-dimension n (m > n), which is the reason that generator g(z | Φ) is called decoder g(z | Φ) in VAE. Like decoder g(z | Φ), encoder f(x | Θ) is modeled by a so-called encoder DNN whose weights are parameter Θ called encoder parameter and so parameter Φ is called decoder parameter in VAE. By following the fact that encoder f(x | Θ) approximates tractable data z by encoded data z’, tractable PDF P(z) is approximated by a so-called encoder PDF Pf(z’).
Because encoder f(x | Θ) depends on its parameter Θ, we can denote:
Essential, encoder PDF P(z’ | Θ, x) is likelihood function of z’ given x which is conditional PDF of z’ given x and hence, P(z’ | Θ, x) is called encoder likelihood which depends on encoder f(x | Θ), of course. On the other hand, P(z’ | Θ, x) is posterior PDF of tractable data given tractable data x where P(z) is prior PDF of tractable data. In practice, z’ is assumed to conform multivariate normal distribution and therefore, let μ(x) and Σ(x) be mean vector and covariance matrix of z’. Encoder likelihood P(z’ | Θ, x) becomes P(z’ | Θ, μ(x | Θ), Σ(x | Θ)) so that output of encoder DNN f(x | Θ) is mean μ(x | Θ) and covariance matrix Σ(x | Θ) while its input is x and its weights are Θ, of course.
Note, (.) denotes normal distribution and thus, (z | μ(x | Θ), Σ(x | Θ)) represents encoder likelihood. That (z | μ(x | Θ), Σ(x | Θ)) is encoder likelihood is an important improvement in developing VAE because encoder DNN f(x | Θ) is learned by minimizing a so-called encoder error which is represented by the difference between encoder likelihood and predefined tractable PDF P(z). Let KL((z | μ(x | Θ), Σ(x | Θ)) | P(z)) be Kullback-Leibler divergence of encoder likelihood (z | μ(x | Θ), Σ(x | Θ)) and predefined tractable PDF P(z). As a result, KL((z | μ(x | Θ), Σ(x | Θ)) | P(z)) becomes an ideal encoder error, which is called encoder KL divergence. The smaller the encoder KL divergence is, the closer the encoder likelihood (z | μ(x | Θ), Σ(x | Θ)) is to tractable PDF P(z), the better the encoder DNN f(x | Θ) is.
Therefore, encoder KL divergence KL((z | μ(x | Θ), Σ(x | Θ)) | P(z)) is minimized by stochastic gradient descent (SGD) method in order to estimate decoder parameter Θ for training encoder DNN f(x | Θ) as follows:
Which results estimation equation according to SGD:
Where ∇KL((z | μ(x | Θ), Σ(x | Θ)) | P(z)) is gradient of encoder KL divergence KL((z | μ(x | Θ), Σ(x | Θ)) | P(z)) with regard to μ(x | Θ) and Σ(x | Θ) while γ is learning rate. Recall that SGD, which is an iterative process, pushes candidate solution at each iteration along the direction which is opposite to gradient of target function for minimization or has the same direction to gradient of target function for maximization with note that the step length is represented by learning rate. We have:
There can be no change in estimating decoder parameter Φ within VAE so that decoder error ε(x | Φ, z) = ½||g(z | Φ) – x||2 is minimized to produce optimal Φ.
Which results estimation equation according to SGD:
Recall that generator g(z | Φ) is called decoder g(z | Φ) in VAE. As a result, encoder parameter Θ and decoder parameter Φ are estimated as follows:
Where dg(z | Φ) / dΦ is differential of g(z | Φ) with regard to Φ while 0 < γ ≤ 1 is learning rate and tractable PDF P(z) is predefined with note that VAE replaces tractable PDF P(z) by likelihood P(z’ | Θ, μ(x | Θ), Σ(x | Θ)) with fixed P(z). As usual, P(z) is assumed to conform standard normal distribution with mean 0 and covariance matrix I.
This implies:
Where I is identity matrix:
It is easier to determine gradient of encoder KL divergence ∇KL(N(μ(x | Θ), Σ(x | Θ)) | (z | 0, I)) with regard to Θ between the multivariate normal distribution (μ(x), Σ(x) | Θ) and the standard multivariate normal distribution (z | 0, I)). We have following equation to calculate such gradient (Kingma & Welling, 2022, p. 5), (Doersch, 2016, p. 9), (Nguyen, 2015, p. 43):
Where (Σ(x | Θ))–1 is inverse of covariance matrix Σ(x | Θ) and the subscript “T” denotes transposition operator of matrix and vector whereas dμ(x | Θ) / dΘ and dΣ(x | Θ) / dΘ are differentials of μ(x | Θ) and Σ(x | Θ) with regard to Θ, respectively. As a result, encoder parameter Θ and decoder parameter Φ are totally estimated according to SGD as follows:
The estimation equations above are simple explanation of VAE but its formal construction is more complicated. We begin the aforementioned intractable PDF P(x) specified by law of total probability:
However, P(x) is interpreted by another way which is based on Bayes’ rule within VAE:
Because the conditional probability P(z | x) is arbitrary without formal specification, it should be approximated by another PDF denoted Q(z | x) with assumption that the PDF Q(z | x) has formal specification like normal distribution.
Logarithm of intractable PDF P(x) is specified as follows (Ruthotto & Haber, 2021, p. 13):
This implies:
The second term log(Q(z | x) / P(z | x)) is not variant because Q(z | x) is approximated to P(z | x). Therefore, the first term log(P(x, z) / Q(z | x) is called variation lower bound or evidence lower bound because it is variant. Let l(x, z) be loss function or error function on VAE which is defined as the minus opposite of expectation of the evidence lower bound log(P(x, z) / Q(z | x) given PDF Q(z | x) with note that Q(z | x) has formal probabilistic distribution.
Loss function l(x, z) is expended as follows:
Because Q(z | x) and P(x | z) depend on encoder f(x | Θ) and decoder g(z | Φ), respectively, their parameters are Θ and Φ, respectively.
Exactly, Q(z | Θ, x) is encoder likelihood which is the same to the aforementioned P(z’ | Θ, x) except that it is focused that Q(z | Θ, x) has formal probabilistic specification like normal distribution. Loss function l(Θ, Φ | x, z), which is now function of encoder parameter Θ and decoder parameter Φ, is written as follows (Ruthotto & Haber, 2021, p. 14):
Firstly, please pay attention to the first term loss function l(Θ, Φ | x, z) where P(x | Φ, z) depends only on Φ although it can be considered as a conditional PDF of x given z because P(x | Φ, z) is defined for output layer containing only x of decoder DNN g(x | Φ) whose input is x. Therefore, we had the following assertion:
Secondly, the second term in loss function l(Θ, Φ | x, z) is, actually, Kullback-Leibler divergence of encoder likelihood Q(z | Θ, x) and predefined tractable PDF P(z), which measure the difference between Q(z | Θ, x) and P(z). As a convention, this Kullback-Leibler divergence is called encoder KL divergence which is an ideal encoder error.
The smaller the encoder KL divergence is, the closer the encoder likelihood Q(z | Θ, x) is to tractable PDF P(z), the better the encoder DNN f(x | Θ) is. Loss function is rewritten again:
Or,
According to the two problem of construct a DGM, the first term –log(P(x | Φ, z)) in loss function indicates the first problem of how to train decoder DNN g(z | Φ) which is called reconstruction error in literature and the second term KL(Q(z | Θ, x) | P(z)) in loss function indicates the second problem of how to qualify training task for training encoder DNN f(x | Θ) which is called regularity in literature. Loss function l(Θ, Φ | x, z) is minimized to estimate Θ and Φ as follows:
Because P(x | Θ, z) depends only on Θ and encoder KL divergence KL(Q(z | Θ, x) | P(z)) depends only on Φ, the optimization problem is specified as follows:
Which results estimation equations according to SGD:
Where ∇KL(Q(z | Θ, x) | P(z)) is gradient of encoder KL divergence KL(Q(z | Θ, x) | P(z)) with regard to encoder parameter Θ. Note that tractable PDF P(z) is predefined (fixed). While Q(z | Θ, x) is called encoder likelihood, P(x | Φ, z) is called decoder likelihood. On the other hand, while P(z) is prior PDF of intractable data z, then Q(z | Θ, x) is approximated posterior PDF of z given x where both P(z) and Q(z | Θ, x) have formal probabilistic specifications and moreover, P(z) is fixed (predefined).
Both P(z | Θ, x) and Q(z | Θ, x) are encoder likelihood as well as posterior PDF of tractable data z but Q(z | Θ, x) is approximated one whose probabilistic distribution is specified formally. Therefore (Ruthotto & Haber, 2021, p. 16), randomized data z’ in latent space Z is sampled from approximated distribution Q(z | Θ, x) instead of sampling from true distribution P(z | Θ, x).
Given epoch of size N is denoted as D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))), the estimation equations of Θ and Φ are extended exactly as epoch estimation at every iteration of SGD:
Please distinguish that the tractable data z(i) in the first equation above follows distribution P(z) but the tractable data z(i) in the second equation above follows distribution Q(z | Θ, x). As a result, VAE trained with SGD is specified as follows:
Initialize Θ and Φ and set k = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Randomize random epoch Z = (z(1), z(2),…, z(N)) in which each z(i) is randomized from distribution Q(z | Θ(k), x(i)).
Increase k = k + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters Θ and Φ are not changed significantly or there is no more coming epoch X. Moreover, the index k indicates time point as well as iteration of SGD. Because PDF P(z) is predefined, it is easy to calculate encoder KL divergence KL(Q(z(i) | Θ(k), x(i)) | P(z)) but it is necessary to define P(x) by well-known distribution. However, randomizing random epoch Z = (z(1), z(2),…, z(N)) from distribution Q(z | Θ(k), x(i))) is not easy and so, VAE trained with SGD will be fine-tuned. It is interesting that when Q(z | Θ(k), x(i))) is posterior PDF of z and P(z) is prior PDF of z, the event that z is randomized from the posterior PDF Q(z | Θ(k), x(i))) and Q(z | Θ(k), x(i))) itself is updated continuously based on its previous evidence x(i) over SGD iterations implies that VAE conforms Bayesian statistics in estimation. Moreover, P(z) is an alignment that Q(z | Θ(k), x(i))) adjusts itself with support of encoder KL divergence KL(Q(z(i) | Θ(k), x(i)) | P(z)).
Because encoder likelihood Q(z | Θ, x) must always have formal probabilistic distribution, it is assumed to follow multivariate normal distribution in practice. Therefore, let μ(x | Θ) and Σ(x | Θ) be mean vector and covariance matrix of z, then encoder likelihood Q(z | Θ, x) becomes Q(z | μ(x | Θ), Σ(x | Θ)) so that output of encoder DNN f(x | Θ) is mean μ(x | Θ) and covariance matrix Σ(x | Θ) while its input is x and its weights are Θ, of course. Please pay attention to the fact that output of encoder DNN f(x | Θ) is now μ(x | Θ) and Σ(x | Θ) which are corresponding to z. Moreover, μ(x | Θ) and Σ(x | Θ) are functions of x, whose parameter is Θ.
Note, (z | μ(x | Θ), Σ(x | Θ)) denotes multivariate normal distribution with mean μ(x | Θ) and covariance matrix Σ(x | Θ).
Note, dimension of tractable data z is n. Moreover, notation |.| or notation det(.) denotes determinant of matrix whereas (Σ(x | Θ))–1 is inverse of covariance matrix Σ(x | Θ) and the subscript “T” denotes transposition operator of matrix and vector. It is easy to recognize that z’ is approximation of z. When tractable PDF P(z) is fixed, it is often assumed to follow multivariate normal distribution with predefined mean μ0 and predefined covariance matrix Σ0 as follows:
Encoder KL divergence KL(Q(z | Θ, x) | P(z)) between Q(z | Θ, x) and P(z) becomes encoder KL divergence KL(Q(z | μ(x | Θ), Σ(x | Θ)) | P(z)) between Q(z | μ(x | Θ), Σ(x | Θ)) and P(z) as follows:
Which is, essentially, encoder KL divergence between two normal distributions, KL((z | μ(x | Θ), Σ(x | Θ)) | (μ0, Σ0)). As a convention, this divergence is called encoder KL divergence which is determined in literature as follows (Doersch, 2016, p. 9):
Where tr(.) denotes trace operator of square matrix which is sum of elements on main diagonal, for instance, given nxn matrix A, then tr(A) = a11 + a22 +… + ann with note that aij is the element at row i and column j. Moreover, notation |.| or notation det(.) denotes determinant of matrix. Gradient of encoder KL divergence consists of two elemental gradients with regard to mean μ(x | Θ) and covariance matrix Σ(x | Θ).
Where,
Where dμ(x | Θ) / dΘ and dΣ(x | Θ) / dΘ are differentials of μ(x | Θ) and Σ(x | Θ) with regard to Θ, respectively. It is not difficult to calculate KL gradient ∇μ:
Due to (Nguyen, Matrix Analysis and Calculus, 2015, p. 35):
It is not difficult to calculate KL gradient ∇Σ too:
Due to (Nguyen, Matrix Analysis and Calculus, 2015, pp. 45-46):
As a result, encoder parameter Θ consists of two elemental parameters according to with regard to mean μ(x | Θ) and covariance matrix Σ(x | Θ) as follows:
Where,
Note, given random vector z = (z1, z2,…, zn)T whose elements zi are random variables too, σij where i≠j is covariance between two random variables zi and zj and σi2 is variance of random variable zi. It is easy to calculate encoder parameters Θμ and ΘΣ by SGD estimation:
Where dμ(x | Θμ) / dΘμ and dΣ(x | ΘΣ) / dΘΣ are differentials of μ(x | Θμ) and Σ(x | ΘΣ) with regard to Θμ and ΘΣ, respectively. In practice, P(z) is assumed to conform standard normal distribution with zero mean μ0 = 0 and identity covariance matrix Σ0 = I where I is identity matrix so that encoder parameters Θμ and ΘΣ are computed effectively.
In order to improve more computational effectiveness, it is possible to suppose that elemental variables zi in z = (z1, z2,…, zn)T within context P(z) are mutually independent so that covariance σij between two variables zi and zj where i≠j is 0, which results that there only exist variances σi2 of zi. Covariance matrix Σ(x | Θ) becomes diagonal matrix:
Note,
Where σi2(x | Θ) is variance of elemental variable xi in z = (z1, z2,…, zn)T given x according to encoder f(x | Θ). As a result, encoder parameter ΘΣ, which is now diagonal matrix represented by its diagonal vector , is computed easier.
Where,
In general, estimation equations for encoder parameter Θ = (Θμ, )T are specified as follows:
Where dσ2(x | ) / d is differential of σ2(x | ) with regard to .
There can be no change in estimating decoder parameter Φ within VAE so that decoder log-likelihood log(P(x | Φ, z)) is maximized.
As usual, decoder likelihood P(x | Φ, z) is assumed to distribute normally with mean δ and variance σ2.
Which implies decoder log-likelihood log(P(x | Φ, z)) as follows:
Where ||.|| denotes Euclidean norm of vector. Gradient of decoder log-likelihood is:
Where dg(z | Φ) / dΦ is differential of g(z | Φ) with regard to Φ. Let δ = 0 and σ2=1 optimization, we have:
Which implies estimation equation for decoder parameter Φ by SGD as follows:
Because data z in the decoder estimation equation above follows encoder likelihood Q(z | Θ, μ(x | Θμ), Σ(x | ΘΣ)) = (z | μ(x | Θμ), Σ(x | ΘΣ)) rather than tractable PDF P(z) = (z | μ0, Σ0), it is denoted as z’ such that:
Given epoch of size N is denoted as D = (d(1) = (x(1), z’(1)), d(2) = (x(2), z’(2)),…, d(N) = (x(N), z’(N))), the estimation equations of Θ and Φ are extended exactly as epoch estimation at every iteration of SGD:
As a result, VAE trained with SGD is specified as follows:
Initialize Θ = (Θμ, )T and Φ and set k = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Randomize random epoch Z = (z(1), z(2),…, z(N)) from standard normal distribution P(z) = (0, I) with mean 0 and identity covariance matrix I. For each randomized data z(i), let z’(i) be calculated based on z(i) so that z’(i) follows multivariate normal distribution Q(z’ | μ(x | Θμ), Σ(x | ΘΣ)) = (z’ | μ(x | Θμ), Σ(x | ΘΣ)) with mean μ(x | Θμ) and covariance matrix Σ(x | ΘΣ) with note that ΘΣ = ()nxn is diagonal matrix.
Increase k = k + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters Θ and Φ are not changed significantly or there is no more coming epoch X. Moreover, the index k indicates time point as well as iteration of SGD. Because it is not easy to randomize z according to normal distribution Q(z | μ(x | Θμ), Σ(x | ΘΣ)) = (z | μ(x | Θμ), Σ(x | ΘΣ)) with mean μ(x | Θμ) and covariance matrix Σ(x | ΘΣ), there is a trick that simple data z is randomized firstly by simple normal distribution P(z) = (0, I) with mean 0 and identity covariance matrix I and, then random data z’ is calculated based on z and μ(x | Θμ), Σ(x | ΘΣ) as follows:
Such that z’ follows normal distribution (z’ | μ(x | Θμ), Σ(x | ΘΣ)) with mean μ(x | Θμ) and covariance matrix Σ(x | ΘΣ) according to some rule of normal distribution in applied statistics (Hardle & Simar, 2013, p. 157). The notation A = Σ(x | ΘΣ)1/2 implies AA = Σ(x | ΘΣ) and so, we can consider it as square root of Σ(x | ΘΣ). Calculating this square root is not so easy because of complexity of singular decomposition for calculating it. Fortunately, it is easier to calculate the square root when ΘΣ was simplified by diagonal elements (σ2(x | ΘΣ))nxn. Indeed, we have:
Where,
Following figure depicts VAE.
Figure 3.1.
Variational Autoencoders (VAE).
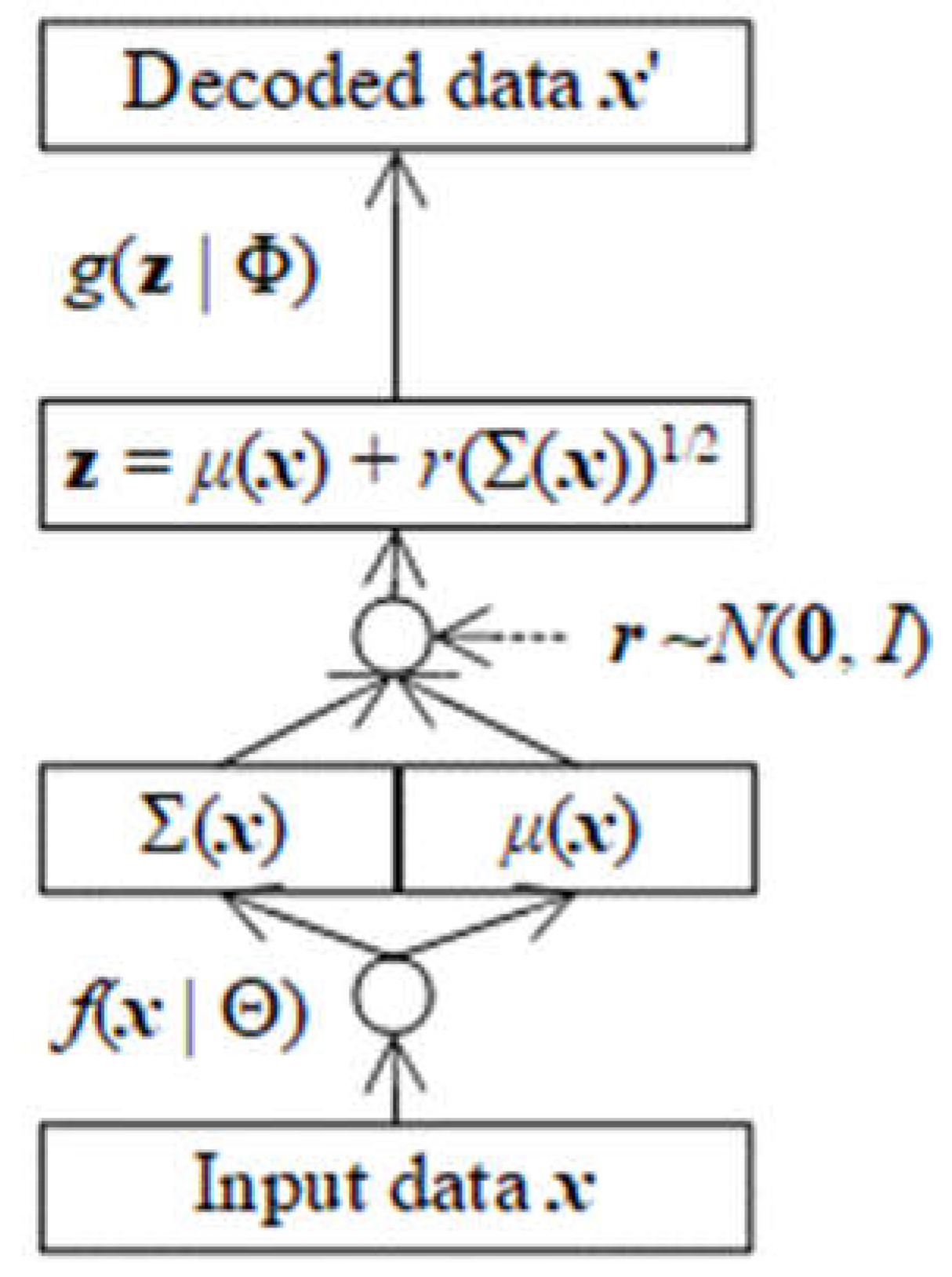
There is a question that how to calculate the differentials dμ(x | Θμ) / dΘμ, dσ2(x | ) / d, and dg(z’ | Φ) / dΦ. Indeed, it is not difficult to calculate them in context of neural network associated with backpropagation algorithm so that the last output layer as well as last neuron o of any DNN f(x | Θ) or g(z | Φ) is acted by activation function a(.) as follows:
Where i is input of the last layer o and weight parameter w is a part of entire parameter Θ or Φ and hence, we need to focus on calculating differential da(o) / dw which is equivalent to any differential dμ(x | Θμ) / dΘμ, dσ2(x | ) / d, or dg(z’ | Φ) / dΦ so that backpropagation algorithm will solve remaining parts of entire parameter Θ or Φ.
Indeed, we have:
Note, the subscript “T” denotes transposition operator of vector and matrix in which row vector becomes column vector and vice versa. It is easy to calculate the derivative a’(o) when activation function was specified, for instance, if a(o) is sigmoid function, we have:
In practice, y is replaced by a(y) in order to prevent o from being out of space:
As a result, we have:
For fast computation, it is possible to set the derivative a’(o) to be small enough constants like 1 such that any differential is iT.
Given epoch D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))) implies that the epoch is created or sent by equilateral distribution 1/N but in general case, D can follow an arbitrary distribution denoted by PDF P(d), which makes the optimization problem and the SGD estimation changed a little bit by theoretical expectation given distribution P(d).
Where,
However, there is no significant change in aforementioned practical technique to estimate parameters.
Recall that the default artificial neural network is feedforward neural network where data is fed to input layer which, in turn, is evaluated and passed across hidden layers to output layer in one-way direction, finally. However, there is an extension of neural network, which is called recurrent neural work (RNN), where an output can be turned back in order to feed on network as input. In other words, RNN has circle, which allow that output can become input. There are many kinds of RNN, for instance, long short-term memory is a case of RNN aforementioned. Boltzmann machine (Wikipedia, Boltzmann machine, 2004) is another variant of RNN, in which there is no separation of inputs from outputs. Like Hopfield network (Wikipedia, Hopfield network, 2004), every neuron (unit) in Boltzmann machine connects to all remaining neurons. In other words, Boltzmann machine applies an interesting aspect that all input neurons are output neurons too.
Figure 3.2.
Topology of Hopfield network and Boltzmann machine.
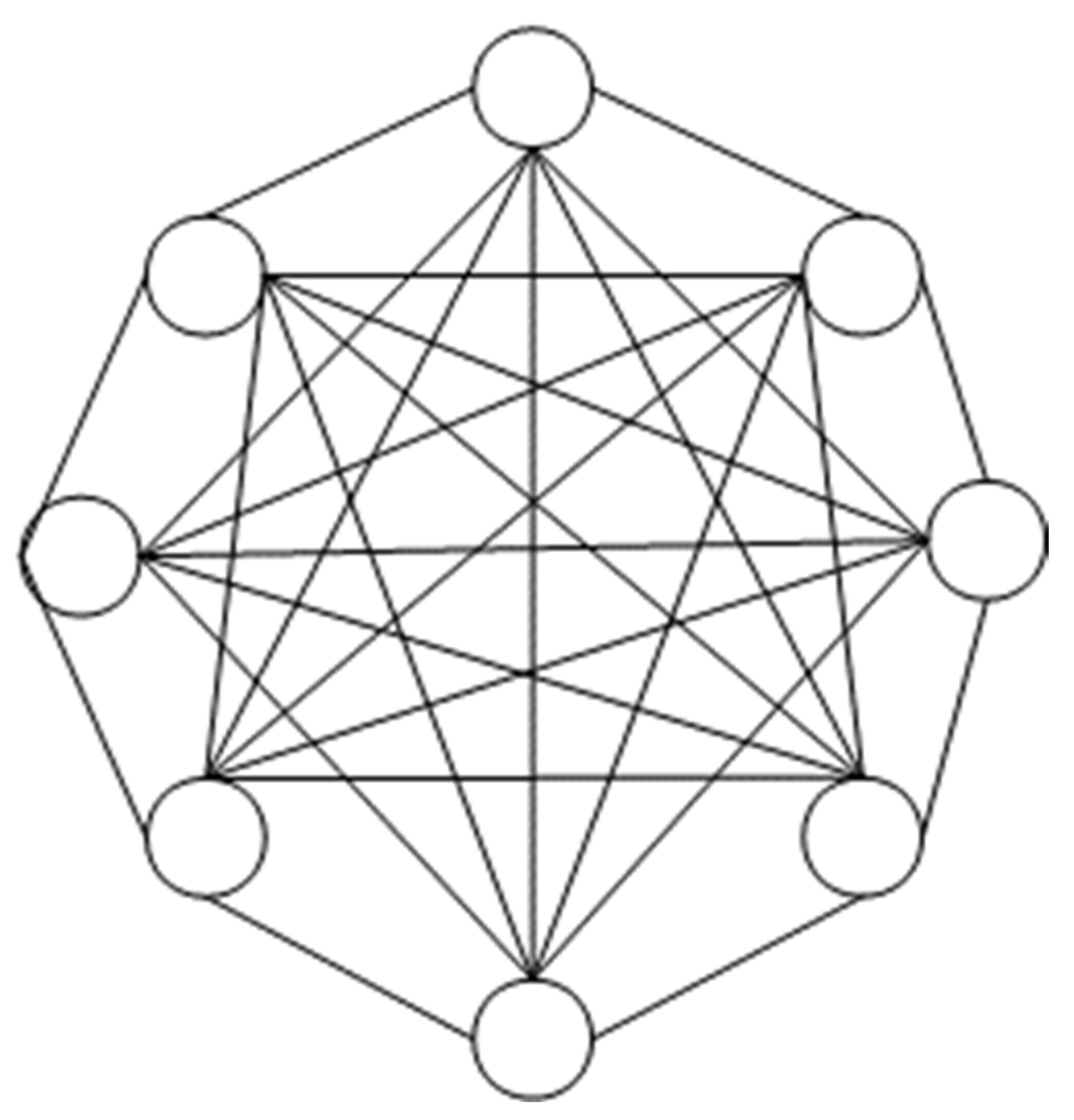
Boltzmann machine named by the name of Austrian physicist Ludwig Eduard Boltzmann, also called Sherrington-Kirkpatrick model with external field or stochastic Ising-Lenz-Little model, is a stochastic spin-glass model with an external field and classified as a Markov random filed too. For easy explanation, Boltzmann machine simulates spinning glass process or annealing metal process, in which melt glass or melt metal will be frozen or get stable at some energy and some temperature where such energy and temperature are called stable energy and stable temperature at stable state of glass. The annealing process aims to reach the stable state of metal (glass) at which time the metal is frozen. Given concrete temperature, the smaller the energy is, the more stable the metal state is. Similarly, given concrete energy, the smaller the temperature is, the more stable the metal state is. Therefore, annealing process is cooling process where probability of metal state, which is proportional to energy and temperature, follows the so-called Boltzmann distribution specified as follows:
Where P(s) is probability of current state s and E(s) is energy applied to metal at state s given temperature T while κ is Boltzmann constant and M is the number of states. Note, T can be considered as a parameter. If the denominator is constant, Boltzmann probability is approximated as follows:
In annealing process, if next energy is concerned by observing current energy because of successive annealing process, energy deviation or energy difference ΔE(s, snew) between current energy E(s) and next energy E(snew) is concerned so that Boltzmann probability derives a so-called acceptance probability P(s, snew, T) as follows:
Where,
Given a certain temperature T, the larger the acceptance probability is, the higher likely the annealing process stops, the higher the likelihood of stability is. In other words, acceptance probability P(s, snew, T) decides whether or not the new state snew is moved next in annealing process. When applied into solving optimization problem as well as learning problem, simulated annealing (SA) algorithm codes candidate solution as states. Indeed, SA is iterative process including many enough iterations where SA decreases temperature T at each iteration and then, randomize a new state snew and calculates energy E(snew) of the new state. Whether or not the new state (new candidate solution) snew is based on the acceptance probability P(s, snew, T) based on current state s, new state snew, current temperature T. If the new candidate solution snew is selected as current solution, SA will decrease temperature in the next iteration. Following is pseudo code of SA:
Initialize current temperature T by highest temperature T0 as T = T0.
Repeat
Decrease current temperature, for example, T = decrease(T).
Select a random neighbor of current state as snew = neighbor(s).
If P(s, snew, T) is larger than a predefined threshold then
s = snew
End if
Until terminating conditions are met.
The terminating conditions can be that best state (solution) is reached, the current state s is good enough, the current temperature T is low enough, or the number of iterations is large enough. A usual, given a maximum iteration number K and the current iteration number k, the temperature decreasing function can be defined as follows:
It is easy to infer that it is possible to set the initial temperature to be the maximum number of iterations as T0 = K in practice. There is no significant change when applying SA into training Boltzmann machine where the most important problem is how to specify energy of Boltzmann machine. Fortunately, global energy of Boltzmann machine inherits from global energy of Hopfield network because Boltzmann machine is a type of Hopfield network which in turn is a variant of RNN. Suppose an entire Boltzmann machine is represented by a vector x = (x1, x2,…, xn) in which each xi is a neuron or unit. It is exact that a certain state of Boltzmann machine is represented by x which is evaluated at certain time point. It is possible to denote current state of Boltzmann machine as x instead. For convenience, the next state of Boltzmann machine is denoted x’. Energy E(x) of Boltzmann machine at state x is defined based on global energy of Hopfield network as follows (Hinton, 2007, p. 2):
Note, wij is weight between neuron xi and neuron xj whereas bi is bias of neuron xi. As usual, biases bi are considered as parameters like weights wij. Because there are n(n–1)/2 connections as well as n(n–1)/2 weights, the equation of energy is rewritten for convenience as follows (Wikipedia, Boltzmann machine, 2004):
All weights wij compose weight matrix W = (wij)nxn whose elements on diagonal are zero. Note, W is nxn symmetric matrix.
Every neuron xi is evaluated by propagation rule:
Neurons in traditional Boltzmann machine are binary variables such that xi belongs to {0, 1} but it is extended to allow neurons xi to belong to arbitrary real interval and so, suppose every xi ranges in interval [0, 1] without loss of generality. Rectified Linear Unit (ReLU) function is used to ramp xi in interval [0, 1] so as to modify the propagation rule a little bit but learning algorithm mentioned later is not changed because the first-order derivative of ReLU function within valid domain [0, 1] is 1.
Where
It implies:
So that the propagation rule is not changed in theory:
Based on definition of global energy, Boltzmann probability density function (PDF) of Boltzmann machine is determined as follows:
Recall that:
Within context of DGM, such PDF is generator likelihood whose parameter is Φ = (W, b).
Because the denominator is constant with regard to W and b, Boltzmann PDF is approximated as follows:
For learning Boltzmann, maximum likelihood estimation (MLE) method (Goodfellow, Bengio, & Courville, Deep Learning, 2016, p. 655) is applied into estimating weight parameter W and bias parameter b by maximizing Boltzmann PDF with regard to wij and bi.
By taking natural logarithm of Boltzmann PDF, the optimization becomes easier to be solved.
Where logP(x | W, b) is called Boltzmann log-likelihood or Boltzmann log-PDF.
The first-order partial derivatives of Boltzmann log-likelihood are:
As a convention, these first-order partial derivatives are called (partial) gradients. By applying stochastic gradient descent (SGD) method into estimating wij and bi given Boltzmann log-likelihood, we have:
Where 0 < γ ≤ 1 is learning rate. It is easy to recognize that the estimation equations above confirm Hebbian learning rule in which the strength of connection represented by weight is consolidated by agreement of two nodes to which the connection is attached. As a result, Boltzmann machine trained with SGD is specified as follows:
Initialize W and set k = 0.
Repeat
Data (state) x is received from some real sample, or it can be kept intact.
Increase k = k + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters W and b are not changed significantly, the maximum number of iterations is reached, or Boltzmann machine gets stable. The terminating condition that Boltzmann machine gets stable receives more concerns because stability is important property of spinning glass process or annealing process that Boltzmann machine. However, checking the stability in which global energy E(x) is not changed may consume a lot of iterations. Fortunately, SA can be incorporated into SGD so as to derive a more effective estimation. Boltzmann machine trained with SGD and SA is specified as follows:
Initialize current temperature T by highest temperature T0 as T = T0.
Repeat
Data (state) x is received from some real sample, or it can be kept intact.
Evaluate Boltzmann machine given current parameter W(k+1) and b(k+1) so as to produce a new state x’:
If P(x, x’, T | W(k+1), b(k+1) is larger than a predefined threshold then
x = x’
Decrease current temperature, for example, T = decrease(T).
End if
Increase k = k + 1.
Until terminating conditions are met.
The terminating conditions can be that best state (x’) is reached, the current state x is good enough, or the current temperature T is low enough. These terminating conditions reflect the stable state of Boltzmann machine. A usual, given a maximum iteration number K and the current iteration number k, the temperature decreasing function can be defined as follows:
Of course, the acceptance probability is:
Where,
There is a so-called restricted Boltzmann machine (RBM) in which neurons are separated into two groups such as input group denoted xz and hidden group denoted xx.
The training algorithm by incorporation of SA and SGD is not changed except that there is neither connection between input neurons and input neurons nor connection between hidden neurons and hidden neurons. In other words, all connections are made between input group and hidden group, for instance, suppose cardinality of input group is k then, the number of connections is k(n – k). Therefore, the two groups are considered layers such as input layer and hidden layer. Of course, both layers are output layers because connections in Boltzmann machine are two-direction connections whereas feed-forward neural network accepts only one-direction connections. RBM is trained faster than traditional Boltzmann machine because its number of connections is smaller. Moreover, it is clear to apply RBM into DGM because generator function in DGM x = g(z | Φ) is modeled by RBM whose input is input group xz and whose output is output group xx such as xx = g(xz | W, b) where xx is calculated by evaluating RBM given input xz.
The reason that the RBM approach for DGM is classified into approximate density DGM is that generator likelihood P(x | W, b) is defined indirectly based on the energy E(x | W, b). Of course, xz is randomized such that xx is generated data.
4. Implicit Density DGM
According to implicit density approach, DGMs do not specify explicitly generator PDF P(x | Φ, z), which does not means that such PDF is not existent but it is simple that such PDF is not concerned. Note, PDF is abbreviation of probability density function.
Recall that there are two problems related to construct a DGM: 1) how to define likelihood or error to train generator DNN g(z | Φ) and 2) how to define tractable PDF P(z) which implies the way to randomize z. The second problem relates to assert qualification of random data z’ and hence, the second problem is stated as qualification problem of how to qualify random data. However, it is essential that the qualification problem aims to improve generator DNN g(z | Φ) because g(z | Φ) translate intractable z into tractable x. Generative Adversarial Network (GAN) developed by Goodfellow et al. (Goodfellow, et al., 2014) aims to reinforcing quality of generator DNN g(z | Φ) = x’ ≈ x by adding a so-called discriminator which is a discrimination function d(x | Ψ): x → [0, 1] from concerned data x or x’ to range [0, 1] in which d(x | Ψ) can distinguish fake data from real data. In other words, the larger result the discriminator d(x’ | Ψ) derives, the more realistic the generated data x’ is. Obviously, discriminator d(x | Ψ) is implemented by a DNN whose weights are Ψ called discriminator parameter with note that this discriminator DNN has only one output neuron denoted d0.
Actually, the task of discriminator d(x | Ψ) is classification task with regard to class d0 belonging to interval [0, 1]. GAN does not establish explicitly PDFs of generator g(z | Φ) and discriminator d(x | Ψ) such as P(x | Φ, z) and P(d0 | Ψ, x) and hence, GAN does not define explicitly and separately likelihoods / errors of g(z | Φ) and d(x | Ψ) too. Indeed, GAN instead unifies optimization constraints of g(z | Φ) and d(x | Ψ) into a target function l(Φ, Ψ | x, z).
Indeed, target function l(Φ, Ψ | x, z) is error function and so it is called loss function in literature. As a result, GAN tries to optimize dually generator parameter Φ and discriminator parameter Ψ so that optimal estimate Φ* and optimal estimate Ψ* are minimizer and maximizer of loss function l(Φ, Ψ | x, z) with expectation that Nash equilibrium will be achieved at the saddle point (Φ*, Ψ*) with note that loss function l(Φ, Ψ | x, z) is function of Φ and Ψ given data x and z.
This is min-max problem in game theory (Goodfellow, et al., 2014):
Which results estimation equation according to stochastic gradient descent (SGD) method:
Where γ is learning rate. Recall that SGD, which is an iterative process, pushes candidate solution at each iteration along the direction which is opposite to gradient of target function for minimization or has the same direction to gradient of target function for maximization with note that the step length is represented by learning rate. Note, ∇Φl(Φ, Ψ* | x, z) is gradient of loss function l(Φ, Ψ* | x, z) fixed Ψ* with regard to generator parameter Φ and ∇Ψl(Φ*, Ψ | x, z) is gradient of loss function l(Φ*, Ψ | x, z) fixed Φ* with regard to discriminator parameter Ψ as follows:
Therefore, the estimation equation is rewritten as follows:
According to equations above, real data x aims to maximize discriminator d(x | Ψ) and in opposite, generated data x’ = g(z | Φ) aims to minimize discriminator d(x’ | Ψ). Although both GAN and VAE use two DNNs for data generation but the underlying theory of GAN is slightly more succinct than VAE because there is no requirement of specifying probabilistic distribution P(z) of tractable z. As a convention, the gradient ∇Φ(log(1 – d(g(z | Φ) | Ψ*))) related to generator parameter Θ is called generator gradient and the gradient ∇Ψ(log(d(x | Ψ)) + log(1 – d(g(z | Φ*) | Ψ))) related to discriminator parameter Θ is called discriminator gradient.
Given epoch of size N is denoted as D = ((x(1), z(1)), (x(2), z(2)),…, (x(N), z(N))), the estimation equations of Φ and Ψ are extended exactly as epoch estimation at every iteration of SGD:
As a result, GAN trained with SGD is specified as follows:
Initialize Φ and Ψ and set k = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Randomize random epoch Z = (z(1), z(2),…, z(N)) from standard normal distribution P(z) = (z | 0, I) with mean 0 and identity covariance matrix I.
Increase k = k + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters Φ and Ψ are not changed significantly or there is no more coming epoch X. Moreover, the index k indicates time point as well as iteration of SGD.
Recall that the estimation equations of generator parameter Φ and discriminator parameter Ψ are:
It is necessary to calculate generator gradient and discriminator gradient. Indeed, we have:
Where ∂d(.) / ∂Φ and ∂d(.) / ∂Ψ denotes differentials of discriminator function with regard to Φ and Ψ, respectively.
Given epoch of size N is denoted as D = ((x(1), z(1)), (x(2), z(2)),…, (x(N), z(N))), the estimation equations of Φ and Ψ are extended exactly as epoch estimation at every iteration of SGD:
As a result, GAN trained with SGD is specified as follows:
Initialize Φ and Ψ and set k = 0.
Repeat
Sampling epoch X = (x(1), x(2),…, x(N)) or receiving epoch X from big data / data stream.
Randomize random epoch Z = (z(1), z(2),…, z(N)) from standard normal distribution P(z) = (z | 0, I) with mean 0 and identity covariance matrix I.
Increase k = k + 1.
Until some terminating conditions are met.
Note, a terminating condition is customized, for example, parameters Φ and Ψ are not changed significantly or there is no more coming epoch X. Moreover, the index k indicates time point as well as iteration of SGD.
Following figure depicts GAN.
Figure 4.1.
Generative Adversarial Network (GAN).
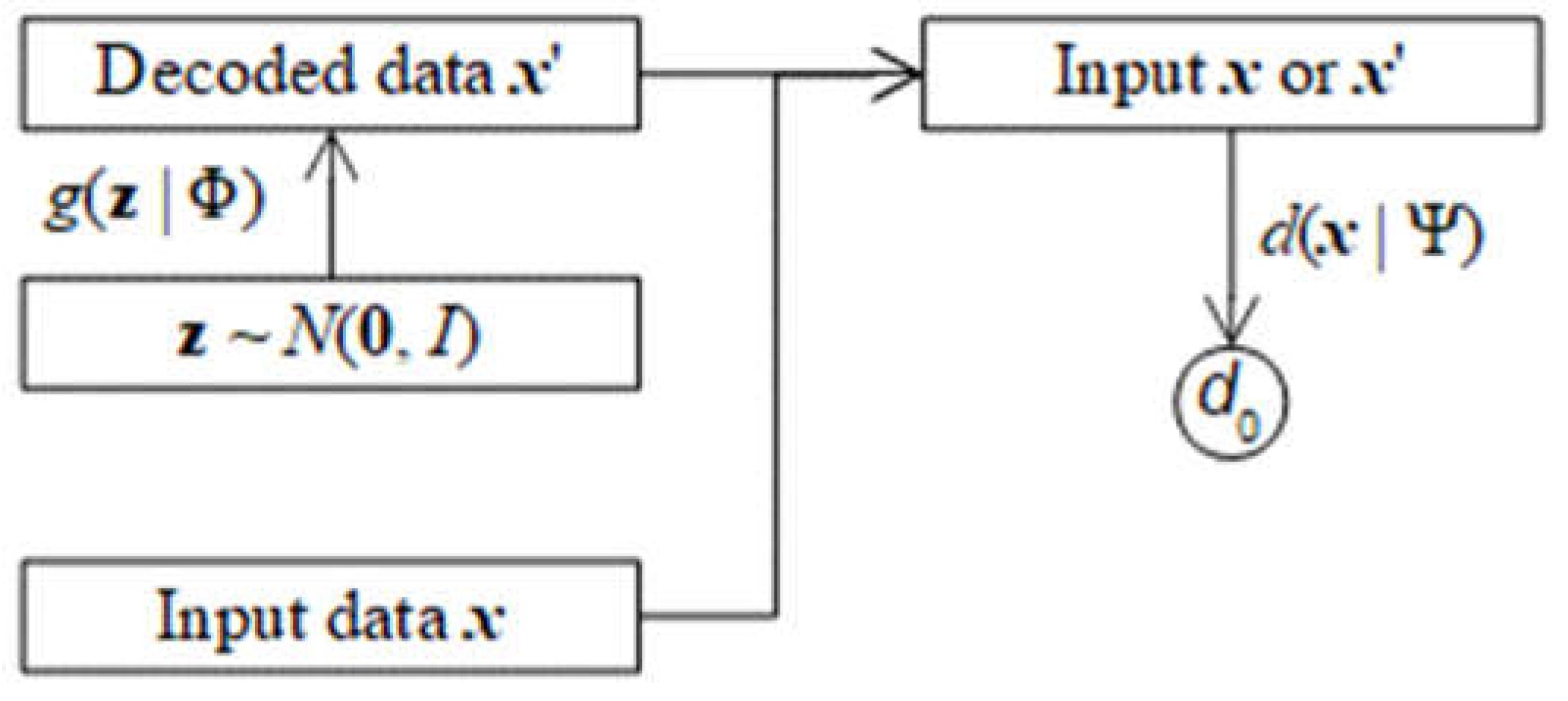
There is a question that how to calculate the differentials ∂d(.) / ∂Φ and ∂d(.) / ∂Ψ. Indeed, it is not difficult to calculate them in context of neural network associated with backpropagation algorithm so that the last output layer as well as last neuron o of any DNN f(x | Θ) or g(z | Φ) is acted by activation function a(.) as follows:
Where i is input of the last layer o and weight parameter w is a part of entire parameter Φ or Ψ and hence, we need to focus on calculating differential da(o) / dw which is equivalent to any differential ∂d(.) / ∂Φ or ∂d(.) / ∂Ψ so that backpropagation algorithm will solve remaining parts of entire parameter Φ or Ψ.
Indeed, we have:
Note, the subscript “T” denotes transposition operator of vector and matrix in which row vector becomes column vector and vice versa. It is easy to calculate the derivative a’(o) when activation function was specified, for instance, if a(o) is sigmoid function, we have:
In practice, y is replaced by a(y) in order to prevent o from being out of space:
As a result, we have:
For fast computation, it is possible to set the derivative a’(o) to be small enough constants like 1 such that any differential is iT.
Given epoch D = (d(1) = (x(1), z(1)), d(2) = (x(2), z(2)),…, d(N) = (x(N), z(N))) implies that the epoch is created or sent by equilateral distribution 1/N but in general case, D can follow an arbitrary distribution denoted by PDF P(d), which makes loss function l(Φ, Ψ) changed a little bit by theoretical expectation given distribution P(d).
Suppose x and z distribute separately as P(x) and Q(z) such that P(x) is called original data PDF and Q(z) is called generated data PDF, we have:
Although there is no significant change in aforementioned practical technique to estimate parameters, it is necessary to research original data PDF P(x) and generated data PDF Q(z) as well as expectation form of loss function l(Φ, Ψ) so as to prove convergence of GAN. Recall that the min-max problem is:
That is:
The convergence of GAN is equivalent to the convergence of this min-max problem. In other words, Goodfellow et al. (Goodfellow, et al., 2014) proved the existence of global optimal value l* such that min-max problem approach l* as follows:
Because z is generated by distribution Q(z) and g(z | Φ) is valuated as x as g(z | Φ) = x, loss function l(Φ, Ψ) is rewritten by changing variable (Goodfellow, et al., 2014, p. 5).
In mathematical literature, function alog(y) + blog(1–y) gets maximal at maximizer y = a/(a+b) such that:
Therefore, we have (Goodfellow, et al., 2014, p. 5):
Where KL(.) denotes Kullback-Leibler divergence of two distributions. The sum of two KL divergences above is a so-called Jensen-Shannon divergence of original data distribution P(x) and generated data distribution Q(z), denoted JS(P(x) | Q(x)). Therefore, we have (Goodfellow, et al., 2014, p. 5):
Because Jensen-Shannon divergence is always nonnegative, we have (Goodfellow, et al., 2014, p. 5):
The sign “=” occurs because Jensen-Shannon divergence is zero if the two distributions are equal, for instance, P(x) = Q(x). Therefore, l(Φ, Ψ*) has maximal value –log4. In other words, we have:
Due to the existence of global optimal value l* = –log4, the convergence of GAN is asserted.
5. Conclusions
Recall that there are three main approaches for constructing deep generative model (DGM) such as tractable density DGM, approximate density DGM, and implicit density DGM. When skimming these approaches, it is easy to recognize that applied statistical problems such as probability distribution and parameter estimation are often mentioned but the effectiveness of a deep generative model is also dependent on how to structure the deep neural network (DNN) and how to train such network. Anyhow data generation function called generator is always defined by DNN in DGM. Backpropagation (BP) algorithm associated with stochastic gradient descent (SGD) method is focused as typical example in this research but there are some more effective training algorithms. Essential, training DNN generator is unsupervised learning task because there is no data class in DGM although generating data distribution (distribution of tractable data z) is often assumed to follow normal distribution whereas BP belongs to supervised learning algorithm. This is the reason that the two problems of constructing DGM are 1) how to train generator DNN g(z | Φ) and 2) how to qualify such training task which often relates to another optimization task or another training task so that the qualification task tries to attach supervised learning BP to unsupervised learning mechanism. For instance, PixelRNN allows output data becomes input data by recurrent neural network, VAE applies Kullback-Leibler divergence into forming data distribution as implicit data class, and GAN issues target function with expectation of Nash equilibrium. Essentially, these mechanisms make the exchange or transformation between supervised learning and unsupervised learning, which plays the role of a hinge for creating the DNN generator.
One of problems issued by BP is the zero derivative problem when SGD cannot improve parameters after some large enough iteration because the gradient (derivative) approaches zero at that time. In other words, SGD may not converge even though there is a large enough number of iterations. Moreover, basic DGM approaches mentioned here require a continuous data provision for training DNN, which consumes more resources than reinforcement learning.
Appendices
A1. Backpropagation Algorithm
Because backpropagation (BP) algorithm is often associated with stochastic gradient descent (SGD) method to optimize loss function, it is necessary to describe a little bit BP and SGD, especially, in case of DGM where artificial neural network is deep neural network (DNN) with many hidden layers so that learning DNN (training DNN) is essential to deep learning. A neural network often has one input layer, one output layer, and hidden layers. The simplest neural network has one input layer and one output layer without a hidden layer. A DNN is a neural network often having many enough hidden layers. Each layer has a list of units called neurons and there are full connections of neurons between two successive layers. Feed-forward network which is the neural network whose connections are one-way from input layer to hidden layers to output layer is focused here. BP is a reverse process that begins from output layer back to input layer. Without loss of generality, input neurons, hidden neurons, and output neurons are concerned rather than input layer, hidden layers, and output layers, respectively because BP processes layers by processing neurons of layers. As a convention, let i, h, and o denote indices of input neurons, hidden neurons, and output neurons, respectively. Let x and y denote input variable and output variable of neurons. For instance, xi and yi are input and output of an input neuron and xh and yh are input and output of a hidden neuron whereas xo and yo are input and output of an output neuron, respectively. Because BP is a reverse process that begins from output layer back to input layer, output neuron is concerned firstly by starting its propagation rule as follows:
Where who and θo are weights of connections between previous hidden neurons h and current output neurons o while θo is bias of current output neurons o. Moreover, f denotes activation function that squashes input into valid range, which is often sigmoid (logistic) function or hyperbolic tangent function. Some literature documents use letter b to denote such bias. BP aims to learn the parameters such as connection weights w(.)(.) and biases θ(.) from sample data. Note, propagation rule is cornerstone of evaluating neural network. Let vo is real value of output neuron o, error function ε(yo) of output neuron is half the square deviation between yo and vo.
Note, yo is variable and vo represents sample data. Weight parameter and bias parameter are estimated by minimizing output error function ε(yo) according to BP.
Minimizing output error function ε(yo) is equivalent to maximizing likelihood (PDF) of random variable yo. Indeed, output likelihood P(yo) is specified as follows:
Where,
Note, mean and variance of output likelihood P(yo) are 0 and 1, respectively. Exactly, P(yo) is probability density function (PDF) of the error yo–vo. By maximum likelihood estimation (MLE) method, maximizing P(yo) is to maximize its natural logarithm logP(yo):
Because π is constant, it is obtained:
This implies:
Which confirm the equivalence of error minimization and likelihood maximization. Therefore, BP becomes more potential because MLE can be extended with more techniques so that error function is defined indirectly and more flexibly via likelihood function. It is interesting that the minimization problem can be exchanged with the maximization problem. Shortly, the optimization is ultimate purpose.
The problem now is how to minimize error function ε(yo), which is the optimization problem. Fortunately, stochastic gradient descent (SGD) method is applied into solving this optimization when square error function is Lipschitz continuous and bounded. Given target function has both variable and parameter where parameter is the subject of optimization, SGD pushes parameter candidate-point along with the same direction (for maximization) or the opposite direction (for minimization) of gradient of target function. There are two important aspects of SGD: 1) the gradient is the first-order derivative of target function with regard to parameter, and 2) the variable is considered as input data which is fed by stochastic process or random way. Moreover, candidate point considered as candidate solution or candidate minimizer / maximizer of optimal parameter is pushed with step length which is coded as learning rate γ. It is proved that SGD will be converged to the optimal solution (good enough minimizer / maximizer) after many enough iterations and many enough data. Shortly, SGD updates weight parameter who and bias parameter θo of output error function ε(yo) at every iteration within context of BP as follows:
Where and are gradients of output error function ε(yo) with regard to weight parameter who and bias parameter θo, respectively:
It is not difficult to calculate these gradients. Due to chain rule of derivative and propagation rule
We have:
Note,
And due to:
As a result, parameter who and bias parameter θo at output neuron is updated at every iteration of SGD within context of BP as follows:
Note, f’(xo) is the first derivative of activation function at xo and γ is learning rate (0 < γ ≤ 1). It is expected that weight parameter who and bias parameter θo will converge the aforementioned optimizers w*ho and θ*o. Let δo denote output error, we have:
Where,
BP continues to estimate weight and bias parameters of previous neurons which are hidden neurons. Without loss of generality, given hidden neuron h whose error ε(yh) is sum of errors of all output neuron o to which such hidden neuron connects.
Note, yh is calculated by propagation rule as usual:
Note, yj is output value of previous hidden neuron j which connects to current hidden neuron h. Because SGD is continuously applied into estimating weight parameters wjh and bias parameter θh of hidden neuron h, gradients of hidden error function ε(yh) with regard to wjh and θh need to be determined, respectively. According to chain rule of derivative, we have:
Due to:
Equations of gradients and are written:
It is now necessary to calculate the derivative dε(yh)/dyh of hidden error function ε(yh) with regard to yh. Indeed, we have:
Due to:
This produces:
Gradients and are totally determined:
Due to SGD estimation:
Parameter wjh and bias parameter θh at output neuron is updated at every iteration of SGD within context of BP as follows:
Let δh denote hidden error:
SGD estimation equations of hidden neurons become more succinct:
The reverse process of BP recurrently continues to estimate other parameters of previous hidden neurons, which is an interesting and effective aspect of BP. Finally, following system of estimation equations is the summary of association of BP and SGD, in which weight parameters and bias parameters of feed-forward neural network are updated at every iteration whenever data sample v is received.
Where output error δo and hidden error δh are calculated as follows:
For easy explanation, according to the BP recurrent process, weight parameters wkj and bias parameter θj of previous hidden neuron j of hidden neuron h are calculated as follows:
Where error δj of hidden neuron j is:
The back recurrent process continues until reaching input layer (exclusive). It is easy to recognize that the entry point of BP is the output error δo which relates to derivative of error function of output neuron at sample point v. Recall that such error function can be replaced by likelihood function instead. Therefore, δo is the opposite of gradient of output error function if the error function is applied to estimation within context of minimization. Otherwise, δo is gradient of output likelihood function if the likelihood function is applied to estimation within context of maximization. The interesting result allows us to extend BP applications by defining error function or likelihood function at output layer without changing BP recurrent process.
It is necessary to consider activation function f(x) and its derivative f’(x) which are evaluated at output neuron and hidden neuron as f(xo), f(xh), f’(xo), and f’(xh). For instance, if f(x) is sigmoid function (logistic function), we have:
In practice, y is replaced by f(y) in order to prevent o from being out of space:
It is possible to fix the derivative by 1 as f’(x) = 1 for all x for fast computation but this approximation is not optimal.
A2. Kullback-Leibler Divergence
In information theory, entropy is the quantity that indicates uncertainty of a random variable. Exactly, given random variable x and its probability density function (PDF) P(x), entropy of x denoted H(x) is the metric which is minus expected value of natural logarithm of x given distribution P(x).
If random variable x is discrete, its entropy becomes simpler:
It is easy to recognize that entropy H(x) measures the level of uncertainty or the level of surprise for random variable x and such level is average level. As the opposite of probability, such uncertainty which measures the variation of random variable is also called information content, self-information, surprise, Shannon information, or information, in short:
It is interesting that information of x is defined based on probability of x although it is opposite to the probability. The larger the information of x is, the more the uncertainty of x is, the less the probability of x is. Entropy H(x) is the expectation of information I(x) given distribution P(x).
In thermodynamics, entropy represents the level of chaos in movement of particles. Kullback-Leibler (KL) divergence which is defined based on concept of entropy measures the difference of two distributions. For instance, given distributions P(x) and Q(x), Kullback-Leibler divergence of P(x) given Q(x) denoted DKL(P(x) | Q(x)) measures how much the distribution P(x) is different from the distribution Q(x) (Wikipedia, Kullback-Leibler divergence, 2004).
For convenience, we denote:
The larger the KL divergence KL(P(x) | Q(x)) is, the more different focused distribution P(x) is from distribution Q(x). However, such difference does not represent distance metric between P(x) and Q(x) because KL divergence is not symmetric:
KL divergence does not satisfy triangle inequality too (Wikipedia, Kullback-Leibler divergence, 2004). KL divergence is expended:
Let H(x | Q(x)) denote entropy of x such that x is quantified by distribution Q(x).
Where,
We obtain:
This implies KL divergence measures the expected value of uncertainty when focused distribution P(x) is replaced by distribution Q(x) for quantifying random variable x. This is the reason that KL divergence is also called relative entropy. KL divergence is always nonnegative due to:
Two distributions P(x) and Q(x) are identical if KL divergence KL(P(x) | Q(x)) is zero. Moreover, if P(x) is 0 for all x then Q(x) must be 0 for all x. As usual, P(x) represents data distribution and Q(x) represents theoretical distribution so that it is possible to compare or fit observational model with hypothesis model (Wikipedia, Kullback-Leibler divergence, 2004).
While Kullback-Leibler divergence is not a metric because it satisfies neither symmetry nor triangle inequality, Jensen-Shannon (JS) divergence is a real metric that measures the distance between two distributions although JS divergence is defined based on KL divergence. Given the two distributions P(x) and Q(x), its JS divergence is the following average KL divergence (Wikipedia, Jensen-Shannon divergence, 2006):
Where M(x) is mixture distribution or mean distribution of P(x) and Q(x):
Note, JS divergence satisfies both symmetry and triangle inequality.
For convenience, we denote:
JS divergence is bounded in interval [0, 1] such that 0 ≤ JS(P(x) | Q(x)) ≤ 1. Square root of JS divergence is called JS distance of two distributions.
References
- Doersch, C. (2016, January 3). Tutorial on Variational Autoencoders. arXiv preprint. Retrieved from https://arxiv.org/abs/1606.05908.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. Cambridge, Massachusetts, US: The MIT Press. Retrieved from https://www.deeplearningbook.org/.
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., . . . Bengio, Y. (2014). Generative Adversarial Nets. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, & K. Weinberger (Ed.), Advances in Neural Information Processing Systems 27 (NIPS 2014). 27. Montreal: NeurIPS. Retrieved from https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf.
- Hardle, W., & Simar, L. (2013). Applied Multivariate Statistical Analysis. Berlin, Germany: Research Data Center, School of Business and Economics, Humboldt University.
- Hinton, G. E. (2007). Boltzmann machine. Brain Corporation, 2(5), 1668. [CrossRef]
- Kingma, D. P., & Welling, M. (2022, December 10). Auto-Encoding Variational Bayes. arXiv Preprint, 1-14. [CrossRef]
- Nguyen, L. (2015). Matrix Analysis and Calculus (1st ed.). (C. Evans, Ed.) Hanoi, Vietnam: Lambert Academic Publishing. Retrieved March 3, 2014, from https://www.shuyuan.sg/store/gb/book/matrix-analysis-and-calculus/isbn/978-3-659-69400-4.
- Nguyen, L. (2023). Tutorial on artificial neural network. Loc Nguyen’s Academic Network. Open Science Framework (OSF). doi:https://osf.io/k8syc.
- Oord, A. v., Kalchbrenner, N., & Kavukcuoglu, K. (2016, August 19). Pixel Recurrent Neural Networks. arXiv preprint, 1-11. [CrossRef]
- Oussidi, A., & Elhassouny, A. (2018). Deep generative models: Survey. 2018 International Conference on Intelligent Systems and Computer Vision (ISCV). Fez, Morocco: IEEE. [CrossRef]
- Ruthotto, L., & Haber, E. (2021, April 12). An Introduction to Deep Generative Modeling. arXiv preprint. [CrossRef]
- Theis, L., & Bethge, M. (2015, September 18). Generative Image Modeling Using Spatial LSTMs. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, & R. Garnett (Ed.), Advances in Neural Information Processing Systems 28 (NIPS 2015). 28, pp. 1-9. Montreal: NeurIPS. [CrossRef]
- Wikipedia. (2004, November 13). Boltzmann machine. (Wikimedia Foundation) Retrieved from Wikipedia website: https://en.wikipedia.org/wiki/Boltzmann_machine.
- Wikipedia. (2004, November 15). Hopfield network. (Wikimedia Foundation) Retrieved from Wikipedia website: https://en.wikipedia.org/wiki/Hopfield_network.
- Wikipedia. (2004, February 13). Kullback-Leibler divergence. (Wikimedia Foundation) Retrieved from Wikipedia website: https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence.
- Wikipedia. (2005, April 7). Recurrent neural network. (Wikimedia Foundation) Retrieved from Wikipedia website: https://en.wikipedia.org/wiki/Recurrent_neural_network.
- Wikipedia. (2006, February 9). Jensen-Shannon divergence. (Wikimedia Foundation) Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence.
- Wikipedia. (2007, April 16). Long short-term memory. (Wikimedia Foundation) Retrieved from Wikipedia website: https://en.wikipedia.org/wiki/Long_short-term_memory.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



