
Submitted:
28 May 2024
Posted:
29 May 2024
You are already at the latest version
Abstract
Recently, attention mechanisms have developed into an important tool for performance improvement of deep neural networks. In computer vision, attention mechanisms are generally divided into two main branches: spatial and channel attention. Both attention categories have their own advantages. The fusion of both attentions achieves higher performance, on the cost of the computational load. This paper introduces an innovative and lighter n-shifted sigmoid channel and spatial attention (CSA) module to reduce the computational cost and to improve the 3D scene relevant features selection. To validate the proposed attention module, 3D scene object detection in the deep Hough voting point sets is considered as the testing application. The proposed attention module with its piecewise n-shifted sigmoid activation function improves the network’s learning and generalization capacity which effectively predict bounding box parameters directly from 3D scenes and detect objects more accurately. This advantage is achieved by selectively attending to more relevant features of the input data. When used in the deep Hough voting point sets, the proposed attention module outperforms state-of-the-art 3D detection methods on the sizable SUNRGBD dataset. Experiments conducted showed an increase of 12.02 mean accuracy precision (mAP) when compared to the celebrated VoteNet (without attention). It also got 9.92 mAP higher compared to the MLVCNet, and 10.32 mAP higher than the Point Transformer. The proposed model not only decreases the sigmoid vanishing gradient problem but also brings out valuable features by fusing channel-wise and spatial information while improving accuracy results in 3D object detection.
Keywords:
attention mechanism
; Hough voting
; point clouds
; activation function
1. Introduction
Attention mechanisms have been attracting increasing attention in research communities since they focus on key features while suppressing redundant ones [1,2,3]. Latest studies have demonstrated that correctly integrating attention mechanisms into convolution blocks substantially enhance the performance of a wide range of computer vision tasks such as image classification, object detection, instance segmentation, etc.
In computer vision, the attention mechanisms are divided into two main types: channel attention and spatial attention. Recent studies such as GCNet [1] and CBAM [10] have combined both channel attention and spatial attention to achieve significant improvement in object detection [16]. However, these models commonly suffered from either substantial computational burdens or converging challenges. Despite that, other researchers were able to simplify the structure for both channel and spatial attention like ECA-Net [7] which makes the process of computing channel weights in SE block much easier by using a 1-D convolution. SGE [8] groups the channels dimension into several sub-features to symbolize different semantics and implements a spatial module to every feature group through a feature vectors scale over all locations with an attention mask.
The main question is to find out if it is possible to fuse different attention modules in a lighter but more efficient manner. ShuffleNet v2 [9] is the first to attempt an answer to the question because it can efficiently construct a multi-branch structure and process various divisions in parallel. Subsequently, several convolution layers are adopted to capture a higher-level representation of the input. Then, the two divisions are concatenated to render the number of channels and the number of input similar. Finally, the “channel shuffle” operator (defined in [10]) is adopted to allow for information communication between the two divisions. Moreover, SGE [8] introduces a grouping strategy to improve calculation speed, which divides the input feature map into groups following channel dimensions.
This paper proposes to introduce a novel n-shifted channel and spatial attention module to be used in the well celebrated Votenet [12]. To our knowledge this will be the first time a deep Hough voting model for object detection will be used in conjunction with any attention module to improve detection accuracy while selectively attending to more relevant features of the input data.
For both spatial and channel attentions, the authors use an n-shifted sigmoid gating approach as an activation function for best function approximation and faster convergence. This allows a better modelling of the interconnections between the channels, the preservation of meaningful features while subduing less beneficial features.
This paper introduces a n-shifted sigmoid channel and spatial attention module to deduce 3D bounding boxes of the objects in the scene and suggest object proposals from a point cloud focused 3D object detection. This model is based on recent advances in 3D deep learning models for point clouds and is inspired by both an innovative channel and spatial attention module and the generalized Hough voting process [13]. Table 1 describes the advantages of the proposed model when compared to the existing ones on feature extraction, attention benefits, predictions, and accuracy. In the proposed model, PointNet++ [14], a point cloud deep learning model, alleviates the need to convert point clouds to regular structures.
As the point cloud generated by depth sensors only captures surfaces of objects, 3D object centers are likely to be in empty space, far away from any point. As a result, point based networks have difficulty aggregating scene context in the vicinity of object centers. To increase the capacity of the network to recognize objects in the 3D scene, an n-shifted sigmoid channel and spatial attention module is added to the deep learning model.
In essence, this paper proposes to endow a deep point sets Hough voting network with a combined n-shifted piecewise sigmoid gating mechanism. By voting, the new method essentially generates new points that lie close to objects centers, which can be grouped and aggregated to generate box proposals.
Specifically, after passing the input point cloud through a backbone network, the authors sample a set of seed points and generate votes from their features. Votes are targeted to reach object centers. As a result, vote clusters emerge near object centers and in turn can be aggregated through an efficient learned module to generate box proposals. The result is a powerful 3D object detector that is purely geometric and can be applied directly to point clouds. The authors validate this approach on the SUN RGBD dataset [15].
In summary, the contributions of this work are:
- To introduce an efficient n-shifted piecewise sigmoid channel and spatial 3D attention module to improve the network’s learning and generalization capability while reducing the inherent sigmoid vanishing gradient problem.
- To demonstrate that the proposed attention module can just be plugged into existing models and boost their performance.
- To validate that performance is greatly improved in the deep point sets Hough voting process using the SUNRGB-D dataset by inserting the proposed lightweight attention module.
The rest of this paper is arranged as follows. In Section 2, the related works are discussed. In Section 3, the proposed methodology is presented, where the n-sigmoid CSA deep Hough voting network is thoroughly described for a more accurate 3D objects detection. In Section 4, the implementation details are discussed followed by the experiments and their results in Section 5. Section 6 offers the conclusions and future works.
2. Related Works
Attention mechanisms. The attention has been exploried extensively since it predisposes the distribution of the most informative features while suppressing the less useful ones. Squeeze-and-Excitation (SE) [16] developed channel-wise relationships using two FC layers. ECA-Net [7] implemented a 1-D convolution filter to produce channel weights and meaningfully decreased the SE model complexity. Zhu et al. [17] proposed the non-local module that computes the correlation matrix between each spatial point in an extensive attention map. CBAM [18], GCNet [1], and SGE [8] fused the channel attention and spatial attention in series, while DANet [2] adaptively incorporated local features with their global dependencies.
Feature grouping. Attention mechanisms allow a model to concentrate on specific parts of the input data, while feature grouping aggregates all the pertinent features to extract and exhibit more information. Together, attention mechanism and feature grouping enable the extraction of meaningful patterns and relationships within complex data.
The transformer [19] architecture employed self-attention to establish dependencies between different positions in a sequence, enabling the model to focus on relevant context while processing the input. This attention mechanism, when combined with feature grouping strategies, helps in capturing long-range dependencies and contextual information, leading to improved performance in various natural language processing tasks. Bi-LS-AttM [20] showcased the application of attention mechanism for image captioning, emphasizing how attention facilitates the grouping of relevant image features for generating descriptive captions. These papers emphasize the key role of attention mechanisms in leading feature grouping strategies while enhancing performance in various computer vision tasks.
Activation functions. Activation functions cause nonlinearity in neural networks [21]. Conventional activation functions (such as sigmoid and tanh) are continuous and differentiable, but the sigmoid has only a positive value, while the tanh has a negative one [22]. Most enhancements of the sigmoid function generally focus on varying the slope of the sigmoid or shifting the original sigmoid, as opposed to the new proposed sigmoid that is a piecewise log-shifted function in a finite input–output space. The sigmoid activation function is often used in feed-forward neural networks (FFNN) [23] to introduce nonlinearity. To accelerate network convergence, CNNs mostly use the hyperbolic tangent as an activation function. One of the latest advances in activation functions is the non-negative rectified linear unit (ReLU), where the identity map in the positive portion solved the gradient vanishing challenge [22].
3. The Proposed n-Sigmoid Channel Spatial Attention
3.1. 3D n-Sigmoid Channel and Spatial Attention Mechanism
Attention mechanisms, which enable a neural network to accurately focus on all the relevant elements of the input, have become an essential component to improve the performance of deep neural networks.
In this paper, the authors propose a lighter but more efficient n-shifted sigmoid channel and spatial attention module to improve computational overhead where both spatial and channel attentions are combined and to enhance 3D scene relevant/important features selection (Figure 1). This module is integrated into the VoteNet architecture to improve the model’s ability to handle complex 3D object detection.
In Figure 1, the multiplication is an elementwise product between channel and spatial attention. The n-shifted sigmoid CSA does split the channel to allow parallel processing of each group sub-features. For the channel attention branch, it uses a pair of parameters to scale and shift the channel vector. For spatial attention branch, it adopts a group normalization to generate spatial-wise statistics. The two branches are then multiplied together elementwise before all sub-features are aggregated.
The new n-sigmoid CSA layer strategically combines channel and spatial attention mechanisms to enable the network to focus on crucial features while preserving spatial information. Specifically, the CSA layer is designed to carry significant improvements to the feature learning process, which plays a pivotal role in accurately predicting and localizing 3D objects in point clouds [24].
Contrary to common usage in image related CNNs, here the attention module is not repeatedly placed after each encoder (Set Abstraction) and decoder (Feature Propagation) of the VoteNet backbone but rather once only after the backbone that learns the features and before the voting module that estimate the object centers.
This innovative procedure is able to improve the accuracy score due to several reasons, including (1) upgraded discriminative features where the integration of the CSA module enhances the discriminative power of the features used in the Hough voting, (2) a context-aware voting where the model adapts its voting strategy based on the learned context, (3) an adaptive attention where the model dynamically adjusts the importance of different votes based on the spatial and channel-wise context.
The CSA layer operates by dividing the feature map where c, h, w are channel number, spatial height, and width. n-shifted sigmoid CSA divides into groups according to the channel dimension. At the start of each attention unit, the input of is split into two branches, namely the channel attention branch and the spatial attention branch (employed in [12]) and, at the end, their their concatenation by elementwise product has an improvement on the accuracy results. The channel attention branch employs average pooling to capture the essence of the input features across different channels (Figure 2).
Beyond the previous works, the authors propose that max-pooling be also simultaneously used to gather another important clue about distinctive object features to infer finer channel-wise attention. Thus, both average-pooled and max-pooled features are used concurrently. Using both features greatly improves the networks representation power more than using each independently.
In Figure 2, the channel sub-module utilizes both max-pooling and average-pooling outputs.
The enhanced application for the channel attention branch (shown in Figure 3) is to first use global averaging pooling (Eq. 1) together with the global maximum pooling (Eq. 3) to generate channel-wise statistics as s ∈ RC/2G×1×1.
This operation consists in:
-
Average Pooling Branch:
- Average pooling operation
- n-shifted sigmoid activation:where is the n-shifted activation function
-
Max Pooling Branch:
- Max pooling operation:
- n-shifted sigmoid activation:where is the n-shifted activation function
In both pooling branches, a compact feature is created to enable guidance for precise and adaptive selection. This is achieved by a gating mechanism using n-shifted sigmoid activation [22] on both the average pooling (Eq. 2) and the max pooling (Eq. 4) operations.
The final output of the channel attention (Eq. 5-6) can be obtained by multiplying both averaged and max_pooled tensors and adding the n-shifted sigmoid:
where ∈ Rc/2g × 1 × 1, ∈ RC/2g × 1 × 1 are parameters used to scale
This customized non-linear activation function, the n-shifted sigmoid, is tailored to accentuate relevant features while suppressing noise and irrelevant information.
On the other hand, the spatial attention branch focuses on “where” most scene informatiton lies, and is complementary to channel attention. At the onstart, a group normalization (GN) [26] is used over to obtain spatial-wise statistics. Fc are the compact feature generated from the spatial branch. Fc (·) does improve . The final output of spatial attention is:
where ∈ Rc/2g × 1 × 1, ∈ RC/2g × 1 × 1 and are parameters of shape RC/2g × 1 × 1 is the n-sigmoid activation (Eq. 6).
So, channel attention utilizes group normalization to process the features, followed by the application of the same n-sigmoid activation function to refine the spatial information. The n-shifted sigmoid activation function exhibits a distinctive behavior that allows for controlled feature enhancement based on a learned scaling factor.
It effectively emphasizes significant features while dampening the impact of less important ones, thereby enabling the model to focus on relevant information critical for accurate 3D object detection. This controlled non-linearity facilitates the n-shifted sigmoid CSA layer in adaptively reshaping the feature space, leading to a more discriminative and informative representation for subsequent stages of the network.
The last but very important step is to multiply both channel and spatial attention (Eq. 7) that will act as a gating mechanism where each channel’s importance is modulated by its spatial relevance. Here the channel and spatial attentions are multiplied element-wise to preserve the feature representations influenced by both the the channel and spatial attention mechanisms. This provides a different form of modulation where multiplication is expected to emphasize regions where both channel and spatial attentions are high, potentially focusing more on salient features.
where xn is the channel attention and xs is the spatial attention.
Python code of the proposed n-shifted sigmoid CSA
import torch
import torch.nn as nn f
rom torch.nn.parameter import Parameter
class csa_layer(nn.Module):
"""Constructs a Channel Spatial Group module.
Args: k_size: Adaptive selection of kernel size """
def __init__ (self, channel, groups=64):
super (csa_layer, self). __init__ ()
self.groups = groups
self.avg_pool = nn. AdaptiveAvgPool3d (1)
self.max_pool = nn. AdaptiveMaxPool3d (1
)
self.cweight_avg = Parameter(torch.zeros(1, channel // (4 * groups), 1, 1))
self.cbias_avg = Parameter(torch.ones(1, channel // (4 * groups), 1, 1))
self.cweight_max = Parameter(torch.zeros(1, channel // (4 * groups), 1, 1))
self.cbias_max = Parameter(torch.ones(1, channel // (4 * groups), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * groups), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * groups), 1, 1))
self.sigmoid = nn.Sigmoid() self.gn = nn.GroupNorm(channel // (2 * groups), channel // (2 * groups))
def forward (self, x):
b, c, h, w = x.shape
x = x.reshape(b * self.groups, -1, h, w)
x_0, x_1 = x.chunk(2, dim=1)
# Channel attention
# Average pooling branch
xn_avg = self.avg_pool(x_0)
xn_avg = self.cweight_avg * xn_avg + self.cbias_avg
xn_avg = x_0 * self.sigmoid(xn_avg)
# Max pooling branch
xn_max = self.max_pool(x_0)
xn_max = self.cweight_max * xn_max + self.cbias_max
xn_max = x_0 * self.sigmoid(xn_max)
# Concatenate average and max pooled tensors
xn = torch.cat ([xn_avg, xn_max], dim=1)
# Spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = self.sigmoid(xs)
# Multiply channel and spatial attentions
out = xn * xs
return out
The idea of introducing this new n-shifted sigmoid CSA attention module present several innovations that include:
- Combination of Average and Max Pooling: Several attention mechanisms normally use either average pooling or max pooling to aggregate channel-wise data. Merging both average and max pooling allows the model to capture various aspects of the feature maps, thereby enhancing the capacity to attend to relevant features.
- Multiplying Channel and Spatial: While addition is a common operation for combining attention mechanisms, multiplying channel and spatial attentions together can provide a totally different type of data regarding the scene in question. Multiplication will lay emphasis on regions where both channel and spatial attentions are important, thus focusing more on salient features.
- The use of n-shifted sigmoid activation as a gating mechanism in the attention module.
- The flexibility that permits the model to learn various types of interactions between spatial and channel attentions. Furthermore, the exploitation of trainable parameters from both max and average pooling as well as from channel and spatial attention, empowers the model to adaptively learn.
3.2. 3D n-Sigmoid CSA Module Integrated in the Point Cloud Learning Using Hough Voting
The integration of the CSA layer into the VoteNet model (Figure 2) aims at proving the ability of the n-sigmoid attention module to better capture intricate patterns and complex relationships within the point clouds [29].
In the 3D n-sigmoid CSA layer’s forward function, a global average pooling is used as a 3D Adaptive Average Pooling operation, allowing the extraction of relevant features from the 3D spatial scene [27]. In this paper, the channel attention structure implies the utilization of the n_sigmoid activation function which enhances feature discrimination and learning adaptability within the volumetric feature space. Additionally, the spatial attention mechanism employs a Group Normalization operation tailored for 3D data, promoting effective feature normalization, and enhancing feature representations within the spatial domain [28]. All these steps contribute to the resulting improved feature discrimination and subsequent feature fusion.
Figure 4.
An overview of the n-shifted sigmoid based VoteNet [10] pipeline.
Figure 4.
An overview of the n-shifted sigmoid based VoteNet [10] pipeline.
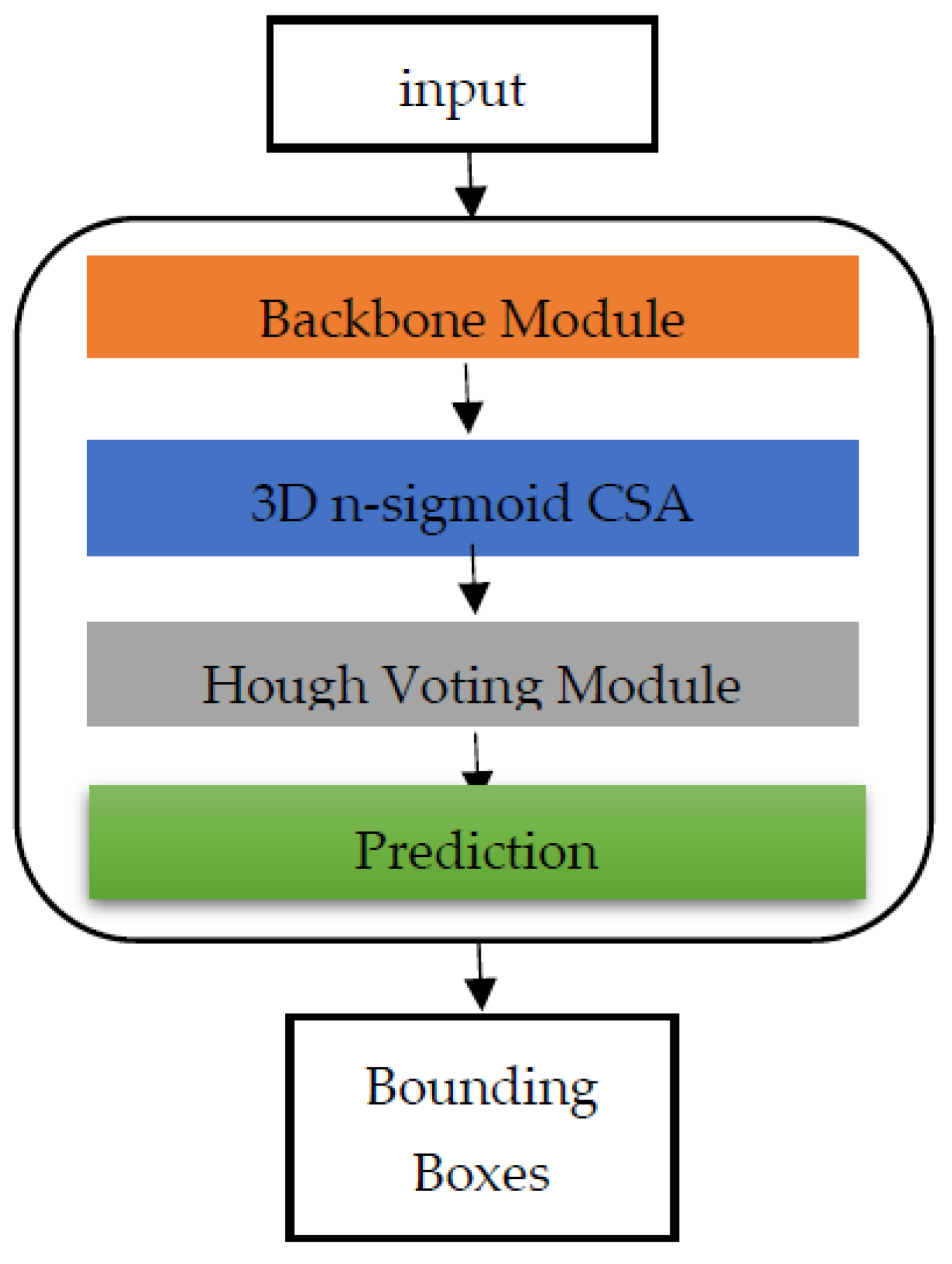
The proposed n-sigmoid attention mechanism primarily operates within the feature extraction while positively affecting the voting stages. Essentially, it acts on the features extracted from point clouds data enabling the network to focus on relevant information and suppress irrelevant and noisy elements during voting process (Figure 5)
This, in turn, enables the model to generate more accurate and reliable predictions, improving both the localization and classification of 3D objects. The CSA layer effectively enhances the feature extraction process [30], improving the model’s capacity to discern subtle details and patterns that are essential for robust 3D object detection.
This improvement contributes significantly to the overall performance and reliability of the VoteNet model, positioning it as a formidable solution for intricate 3D object analysis tasks in point clouds. By leveraging the enhanced channel and spatial attention mechanisms of the CSA layer, the modified VoteNet demonstrates improved discriminative capabilities, leading to superior object detection performance while the integration of the n_sigmoid activation function [22] augments the network’s nonlinear processing allowing for a more refined emphasis on critical features while suppressing noise and irrelevant information.
In essence, the modified n-sigmoid CSA VoteNet architecture represents a significant advancement in 3D object detection methodologies, showcasing enhanced accuracy, robustness, and adaptability in challenging real-world scenarios.
4. Implementation Details
To validate the n-sigmoid CSA, the authors have used the VoteNet network for object detection with input of 3D point cloud of N points from indoor scenes. PointNet++ [12] is the backbone feature learning network. The entire n-sigmoid CSA based VoteNet is trained end-to-end from scratch with an Adam optimizer, batch size of 8 and an initial learning rate of 0.001. The learning rate is set to decrease by 10x after 80 epochs and to decrease by another 10x after 120 epochs.
Training the model to convergence on one Tesla T4 GPU takes around 30 hours on SUNRGBD when uninterrupted. Same as the original VoteNet, the proposed n-sigmoid Channel Spatial Attention VoteNet (n-sigmoid CSA-VoteNet) can collect 3D point clouds of a scene and generate proposals in one forward pass. The proposals are post-processed by a 3D NMS module with an IoU threshold of 0.25.
5. Experiments
In this section, the authors first compare the proposed n-sigmoid Channel and Spatial Attention (n-sigmoid CSA) with current state-of-the-art methods on several evaluation metrics that involve efficiency, accuracy…. After that, an ablation study is provided to understand the importance of the proposed attention mechanism on the process of voting point clouds and demonstrate the proposed method’s advantages in its efficiency and accuracy in the model complexity study.
5.1. 3D n-Sigmoid CSA Module Integrated in the Point Cloud Learning Using Hough Voting
Dataset. SUNRGBD [15] is a single-view dataset for 3D scenes. It is made of 5,285 training and 5,050 testing RGB-D images in the dataset, where each object is indeed annotated with a bounding box and is part of 35 semantic classes. The authors only use the 3D coordinates as input and report on the overall metrics of mean average precision (mAP) and average recall (AR).
Methods in comparison. The procedure to assert the validity of the proposed attention module consists of two steps. First it is to compare the n-sigmoid Channel and Spatial Attention in VoteNet (CSA-VoteNet) with a wide range of state-of-the-art methods (as shown in Table 2). Then, the authors compare the n-sigmoid CSA-VoteNet with other Attention models including the VoteNet itself.
All attention modules presented in Table 3A are slight modifications of the VoteNet official implementation where different 3D attention modules are added. Table 3B exhibits the results on the recall metric using SUNRGBD dataset. Even though CAA [31] and Point Transformer [32] had shown good performances assessed under either precision-related or recall-related metrics, the proposed n-sigmoid CSA-VoteNet achieves the best overall result (69.72 mAP) among all the attention modules. Most importantly, the advantages of the proposed n-sigmoid CSA-VoteNet stems from two significant facts: on the one hand, it assigns different relevance weights to different elements of the input data during the voting process; on the other hand, the attention map enables the network to emphasize important features and suppress irrelevant or noisy ones.

Table 2.
3D n-sigmoid CSA-VoteNet object detection on SUNRGBD compared with other state-of-the-art methods. (IoU threshold = 0.25).
Table 2.
3D n-sigmoid CSA-VoteNet object detection on SUNRGBD compared with other state-of-the-art methods. (IoU threshold = 0.25).
| Methods | Input | Bathtub | bed | Book shelf |
chair | desk | dresser | night- stand |
sofa | table | toilet | mAP |
| DSS [33] COG [34] 2D-driven [35] F-PointNet [36] VoteNet [12] MLCVNet [37] DeMF [38] CSA-VoteNet (ours) |
GEO + RGB GEO + RGB GEO + RGB GEO + RGB GEO only GEO only GEO + RGB GEO only |
44.2 58.3 43.5 43.5 74.4 79.2 79.5 80.9 |
78.8 63.7 64.5 81.1 83.0 83.0 87.0 88.1 |
11.9 31.8 31.4 33.3 28.8 31.9 44.1 49.6 |
61.2 62.2 48.3 64.2 75.3 75.8 80.7 83.8 |
20.5 45.2 27.9 24.7 22.0 26.5 33.8 49.7 |
6.4 15.5 25.9 32.0 29.8 31.3 46.4 45.2 |
15.4 27.4 41.9 58.1 62.2 61.5 66.3 72.8 |
53.5 51.0 50.4 61.1 64.0 66.3 72.5 72.4 |
50.3 51.3 37.0 51.1 47.3 50.4 52.8 59.8 |
78.9 70.1 80.4 90.9 90.1 89.1 92.7 94.9 |
42.1 47.6 45.1 54.0 57.5 59.8 65.6 69.72 |
5.2. 3D n-Sigmoid CSA Module Integrated in the Point
This ablation study does provided an understanding of the importance of the proposed attention mechanism. Its use in the process of Hough voting on point clouds establish the proposed method’s benefits, effectiveness and accuracy in the model complexity study. Table 4 shows the improvement obtained in the VoteNet pipeline when the n-shifted sigmoid CSA is added when compared to other state-of-the-art networks (both with or without attention).
When comparing with the no-attention module in 3D object detection, the proposed network still emerges best since it outperforms all the existing methods notably with 69.72 mAP @ IoU 0.25 and 54.17 @ IoU 0.5.
Results summarized in Table 4 show that SA Hough Voting outperforms all previous methods (by at least 4.12 mAP on the DeMF [36]) using the SUNRGBD dataset. Also, a per-category evaluation for SUNRGBD is provided. In Table 3 (A and B), the proposed n-sigmoid CSA-VoteNet demonstrated superior results when compared to other attention mechanisms baseline using VoteNet on SUNRGBD dataset. Just to roundup the whole research, Table 4 establishes a comparison with any other no-attention mechanism in the 3D object detection domain. The proposed method tremendous improvements when only the geometric input (point clouds) is used.
Advantage of using both average and max pooling techniques in the n-shifted sigmoid CSA. The authors have also performed experiments to confirm the advantage of using both pooling methods as opposed to using only either the average or the max pooling operation in the proposed attention module. Table 5 presents the results obtained that show that accuracy is neatly improved when using both average and max pooling operations together while using max pooling operation yields better results than the average pooling results.
The training results obtained show that the improvement in the accuracy score, when using both the average and max pooling operation, is due to context-aware voting where the model adapts its voting strategy based on the learned context. In essence, in this proposed adaptive attention module, the model dynamically adjusts the importance of different votes based on the spatial and channel-wise setting.
Advantage of using the n-shifted sigmoid instead of the traditional sigmoid. The authors have also performed experiments to confirm the benefit of using the n-shifted sigmoid as opposed to using the traditional sigmoid as a gating mechanism in the proposed attention module. Table 6 presents the results obtained that show that accuracy is neatly improved when using the n-shifted sigmoid activation function. The authors believed that the improvement in accuracy is due to the n-shifted sigmoid activation function ability to improve feature discrimination and to enhance spatial and channel attention.
5.3. Discussion
In this experiment analysis, the advantages of using the attention mechanism are described in the Hough voting system.
The integration of an n-shifted sigmoid CSA mechanism within VoteNet does provide key benefits that enhance the network’s performance and capabilities in various ways such as:
An improved relevance weighting. By incorporating this attention mechanism, VoteNet does assign different relevance weights to different elements of the input data during the voting process. This allows the network to focus on critical features and downplay less relevant ones, leading to more accurate and precise decisions.
To verify that the n-shifted sigmoid CSA does improve relevance weighing of scene objects, the authors compare the performance of a model with and without the proposed n-shifted sigmoid CSA mechanism.
Figure 6 shows that accuracy significantly increases after the n-shifted sigmoid CSA is added to the VoteNet meaning that the relevance weighting is greatly enhanced. It is observable that the accuracy increase is very remarkable for some elements like the bookshelf, the desk. This could be due to specific factors in the dataset such as proximity, cluttering…The objects detected (bounding boxes) in the scene result from the voting strategy based on this relevance weighting which allows for salient objects to be voted for.
An enhanced feature representation. Attention mechanisms enable the network to emphasize important features and suppress irrelevant or noisy ones, facilitating the extraction of more informative and discriminative feature representations.
To verify that the n-shifted sigmoid CSA does enhance feature representation of scene objects, the authors compare the performance of first, the proposed n-shifted sigmoid CSA model with channel and spatial attention concatenation and secondly, the proposed n-shifted sigmoid CSA model with channel and spatial attention multiplication instead.
Here the channel and spatial attentions are multiplied elementwise to preserve the feature representations influenced by both the channel and spatial attention mechanisms. This provides a different form of modulation where multiplication is expected to emphasize regions where both channel and spatial attentions are high, potentially focusing more on salient features.
Figure 7 shows that accuracy significantly increases when multiplication is used instead of mere concatenation. Thereby demonstrating that feature representation of scene objects does emphasize important features and neglect others.
In summary, all these benefits collectively lead to more accurate, robust, and context-aware 3D object detection and localization, making n-shifted sigmoid CSA-VoteNet more effective in handling diverse real-world scenarios.
5.4. Model Complexity
Table 7 presents a set of reference data (model size, inference time…) regarding the proposed model’s complexity by comparing different object detection modules. For the SUNRGBD dataset, the model sizes of the network are also included to show its impact on complexity and speed especially when the Shuffle Attention has been used because of its ability to reduce the computational overhead. Although some networks such as F-PointNet [34] does achieve relatively higher performances regarding speed, it also requires more computational resources such as longer training time or larger memory consumption.
Despite the model’s light size increase, it is easy to notice that the model still performs acceptably when it comes to speed compared to the original VoteNet despite reducing its performance with a result of 123.2 seconds in training time.
6. Conclusions
In this paper, the authors proposed a novel and effective n-shifted sigmoid Channel and Spatial Attention module that not only reduces computational overhead but also enhance the 3D scene relevant features selection of 3D convolutional neural networks. Specifically, it improves the seed points feature representation to effectively predict bounding box parameters directly from 3D scenes and detect objects more accurately.
The new attention mechanism is placed just before the voting module to improve the accuracy score since it improves the discriminative features, provides more context-aware decisions before the voting process, focuses on adaptive attention to dynamically adjusts the importance of different votes based on the spatial and channel-wise context.
The proposed method achieved state-of-the-art detection accuracy on the SUNRGBD dataset with only geometric information given, demonstrating the effectiveness of the proposed approach in the Deep Hough voting network. Experimental results have shown that the proposed n-shifted sigmoid Channel and Spatial Attention is an extremely light plug-and-play module, that is able to significantly improve the performance of numerous deep CNN architectures.
For future research, the focus will be to implement a 3D instance segmentation using the n-shifted sigmoid CSA-VoteNet by using methods like non maximum clustering of the points clouds inside the bounding boxes for instance.
Author Contributions
Conceptualization, D. Burume; methodology, D. Burume; software, D. Burume and S. Du.; validation, S. Du., and D. Burume.; formal analysis, Q. Liu; investigation, D. Burume.; resources, D. Burume; data curation, D. Burume.; writing—original draft preparation, D. Burume; writing—review and editing, S. Du and Q. Liu; supervision, S. Du and Q. Liu; project administration, S. Du; funding acquisition, S. Du and Q. Liu All authors have read and agreed to the published version of the manuscript.
Funding
Please add: This research was funded by the NATIONAL RESEARCH FOUNDATION OF SOUTH AFRICA (Grant Numbers SRUG2203291049 and 145975), KUNMING UNIVERSITY FOUNDATION (No. YJL2205), and the FOUNDATION OF YUNNAN PROVINCE SCIENCE AND TECHNOLOGY DEPARTMENT (No. 202305AO350007)
Data Availability Statement
The dataset used for this study are openly available in at http: https://rgbd.cs.princeton.edu.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yan, J; Zhu, R.; Chen, B.; Xu, H. and Zhu, X. Channel and Spatial Attention Fusion Module for Detection. 2023. [CrossRef]
- J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang and H. Lu. Dual attention network for scene segmentation. 2019. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, pp. 3146 –3154.
- Wang, J., Mo, W., Wu, Y., Xu, X., Li, Y., Ye, J. and Lai, X. 2022. Combined Channel Attention and Spatial Attention Module Network for Chinese Herbal Slices Automated Recognition; Publisher: Sec. Brain Imaging Methods, volume 16. [CrossRef]
- Liu, M; Fang, W; Ma, X; Xu, W; Xiong, N. and Ding, Y. 2021. Channel Pruning Guided by Spatial and Channel Attention for DNNs in Intelligent Edge Computing. arXiv:2011.03891v2.
- Zhu, Z; Xu, M; Bai, S; Huang, T. and Bai, X. 2019. Asymmetric non-local neural networks for semantic segmentation. CoRR. Vol. abs/1908.07678.
- Zhu, Y; Liang, Y; Tang, K; and Ouchi, K. 2022. SC-NET: Spatial and Channel Attention Mechanism for Enhancement in Face Recognition. 5th International Conference on Information and Computer Technologies (ICICT), New York, NY, USA, pp. 166-172. [CrossRef]
- Wang, Q; Wu, B; Zhu, P; Li, P; Zuo, W. and Hu, Q. 2020. Eca-net: Efficient channel attention for deep convolutional neural networks. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, pp. 11531–11539, IEEE.
- Li, X; Hu, X; and Yang, J. 2019. Spatial group wise enhance: Improving semantic feature learning in convolutional networks. CoRR. Vol.abs/1905.09646.
- Ma, N; Zhang, X; Zheng, H; and Sun, J. 2018. Shufflenet V2: practical guidelines for efficient CNN architecture design. In Computer Vision- ECCV 2018- 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XIV, 2018, pp. 122–138.
- Zhang, X; Zhou, X; Lin, M; and Sun, J. 2018. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. 2018, pp. 6848–6856, IEEE Computer Society.
- Zhang, Q; Yang, Y. 2021. SA-Net: Shuffle Attention For Deep Convolutional Neural Networks. arXiv:2102.00240v1.
- Qi, C. R.; Litany, O.; He K. and Guibas. L. 2019. Deep Hough Voting for 3D Object Detection in Point Clouds. In IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), pp. 9276-9285. [CrossRef]
- A. Fernández, J. Umpiérrez, and J. R. Alonso. 2023. Generalized Hough transform for 3D object recognition and visualization in integral imaging. In J. Opt. Soc. Am. A 40, C37-C45. [CrossRef]
- Qi, C. R.; Yi, L.; Su, H. and Guibas. L. J. 2017. Pointnet++: Deep hierarchical feature learning on pointsets in a metric space. arXiv:1706.02413.
- Song, S; Lichtenberg, S.P.; and Xiao, J. 2015. Sunrgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 567–576.
- Chappa, R. T. N. V. S.; and El-Sharkawy, M. 2020. Squeeze-and-Excitation SqueezeNext: An Efficient DNN for Hardware Deployment. In 10th Annual Computing and Communication Workshop and Conference (CCWC), 0691–0697. [CrossRef]
- Zhu, H.; Xie, C.; Fei, Y.; Tao, H. 2021. Attention Mechanisms in CNN-Based Single Image Super-Resolution: A Brief Review and a New Perspective. Electronics, 10, 1187. [CrossRef]
- Woo, S; Park, J; Lee, J; and Kweon, I.S. 2018. CBAM: convolutional block attention module. In Computer Vision-ECCV 2018 -15th European Conference, Munich, Germany, Proceedings, Part VII, pp. 3–19.
- Vaswani, A.; Shazeer, N; Parmar, N; Uszkoreit, J; Jones, L.; Gomez, V; Kaiser, L; Polosukhin, L. 2023. Attention Is All You Need. [CrossRef]
- Xie, T.; Ding, W.; Zhang, J.; Wan, X.; Wang, J. 2023. Bi-LS-AttM: A Bidirectional LSTM and Attention Mechanism Model for Improving Image Captioning. Appl. Sci., 13, 7916. [CrossRef]
- Zhao, Z.; Feng, F.; Tingting, H. 2022. FNNS: An Effective Feedforward Neural Network Scheme with Random Weights for Processing Large-Scale Datasets. Appl. Sci. 2022, 12, 12478. [CrossRef]
- Mulindwa, D.B., Du, S. 2023. “An n-Sigmoid Activation Function to Improve the Squeeze-and-Excitation for 2D and 3D Deep Networks. In Electronics, 12, 911. [CrossRef]
- Rane, C; Tyagi, K; and Manry, M. 2023. Optimizing Performance of feedforward and convolutional neural networks through dynamic activation functions. arXiv:2308.05724v1.
- Zhang, R.; Wu, Y.; Jin, W.; Meng, X. 2023. “Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey”. Electronics, , 3642. [CrossRef]
- Zhang, C.; Xu, F.; Wu, C. and Xu, C. 2022. “A lightweight multi-dimension dynamic convolutional network for real-time semantic segmentation”, Front Neurorobot. 16:1075520. [CrossRef]
- Wu, Y.; and He, K. 2018. Group normalization. In ComputerVision-ECCV2018-15th European Conference, Munich, Germany, Proceedings, Part XIII, pp. 3–19.
- Liu, D.; Han, G.; Liu, P.; Yang, H.; Chen, D.; Li, Q.; Wu, J.; Wang, Y. 2022. A Discriminative Spectral-Spatial-Semantic Feature Network Based on Shuffle and Frequency Attention Mechanisms for Hyperspectral Image Classification. Remote Sens., 14, 2678. [CrossRef]
- 28. Guo, M; Xu, T.; Liu, J. et al. 2022. Attention mechanisms in computer vision: A survey”. Computational Visual Media. [CrossRef]
- Tliba, M.; Chetouani, A.; Valenzise, G. and F. Dufaux. 2023. Quality Evaluation of Point Clouds: A Novel No-Reference Approach Using Transformer-Based Architecture. arXiv:2303.08634v1.
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. 2022. A Spatial Feature-Enhanced Attention Neural Network with High-Order Pooling Representation for Application in Pest and Disease Recognition. Agriculture, 12, 500. [CrossRef]
- Qiu, S.; Anwar, S.; and Barnes, N. 2021. Geometric back projection network for point cloud classification. IEEE Transactions on Multimedia.
- Zhao, H. ; Jiang, L.; Jia, J.; Torr, P. and Koltun, V. 2020. Point transformer. arXiv:2012.09164.
- Songand, S. and Xiao, J. 2016. Deep sliding shapes for amodal 3dobject detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 808-816.
- Ren, Z.; and Sudderth, E. B. 2016. Three-dimensional object detection and layout prediction using clouds of oriented gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1525–1533.
- Lahoud, J.; and Ghanem, B. 2017. 2d-driven 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4622–4630.
- Qi, C. R.; Liu, W.; Wu, C.; Su, H. and Guibas. L. J. 2018. Frustum pointnets for 3d object detection from rgbd data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 918–927.
- Wang, Z.; Xie, Q.; Wei, M.; Long, K. and Wang, J. 2022. Multi-feature Fusion VoteNet for 3D Object Detection. ACM Trans. Multimedia Comput. Commun. Appl. 18, 1, Article 6, 17 pages. [CrossRef]
- Yang, H.; Shi, C.; Chen, Y.; Wang, L. 2022. Boosting 3D Object Detection via Object-Focused Image Fusion. arXiv:2207.10589.
- Xie, S.; Liu, S.; Chen, Z.; and Tu, Z. 2018. Attentional shape contextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4606–4615.
- Feng, M.; Zhang, L.; Lin, X.; Gilani, S. Z.; and Mian, A.. 2020. Point attention network for semantic segmentation of 3d point clouds. Pattern Recognition, 107:107446. [CrossRef]
- Guo, M.; Cai, J.; Liu, Z.; Mu, T.; Martin, R. R.; and Hu, S. 2021. Pct: Point cloud transformer. Computational Visual Media, 7: pages 187–199. [CrossRef]
- Qi, C. R.; Chen, X.; Litany, O; Guibas. L. J. 2020. ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes. arXiv:2001.10692.
- Zhang, Z.; Sun, B.; Yang, H.; and Huang, Q. 2020. H3dnet: 3dobject detection using hybrid geometric primitives. In IEEE/CVF European Conference on Computer Vision (ECCV), pp. 311-329.
- Li, J.; and Feng, J. 2020. Local grid rendering networks for 3D object detection in point clouds. arXiv:2007.02099.
- Chen, J.; Lei, B.; Song, Q.; Ying, H.; Chen, D. Z.; and Wu, J. 2020. A hierarchical graph network for 3D object detection on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 392-401.
- Dai, A.; Chang, A. X.; Savva, M.; Halber, M.; Funkhouser, T.; and Nießner, M. 2017. ScanNet: Richly annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5828–5839.
- Du, H.; Li, L.; Liu, B.; and Vasconcelos, N. 2020. SPOT: Selective point cloud voting for better proposal in point cloud object detection. In ECCV: 16th European Conference, Glasgow, UK, Proceedings, Part XI, Pages 230–247. [CrossRef]
- Xie, Q.; Lai, Y.; Wu, J.; Wang, Z.; Lu, D.; Wei, M.; and Wang, J. 2021. VENet: Voting Enhancement Network for 3D Object Detection. ICCV 2021.
- Wang, H.; Ding, L.; Dong, S.; Shi, S.; Li, A.; Li, J.; Li, Z.; Wang, L. 2022. CAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds. arXiv:2210.04264.
- Rukhovich, D.; Vorontsova, A.; Konushin. A. 2022. TR3D: Towards Real-Time Indoor 3D Object Detection. Conference: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). [CrossRef]
- Fan, G.; Qi, Z.; Shi, W.; and Ma, K. 2023. Point-GCC: Universal Self-supervised 3D Scene Pre-training via Geometry-Color Contrast. arXiv:2305.19623v2.
- Hou, J.; Dai, A.; Nießner, M. 2019. 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans. arXiv:1812.07003.
Figure 1.
An overview of the proposed attention module. The module adopts a channel split to process the features of each group in parallel. For the channel attention branch, both the average and max pooling generate improve channel-wise statistics and use a pair of parameters to scale the channel vector. For spatial attention branch, the module adopts group norm to generate spatial-wise statistics and use a compact feature. The two branches are then multiplied together to emphasize regions where both channel and spatial attentions are high, potentially focusing more on salient features.
Figure 1.
An overview of the proposed attention module. The module adopts a channel split to process the features of each group in parallel. For the channel attention branch, both the average and max pooling generate improve channel-wise statistics and use a pair of parameters to scale the channel vector. For spatial attention branch, the module adopts group norm to generate spatial-wise statistics and use a compact feature. The two branches are then multiplied together to emphasize regions where both channel and spatial attentions are high, potentially focusing more on salient features.
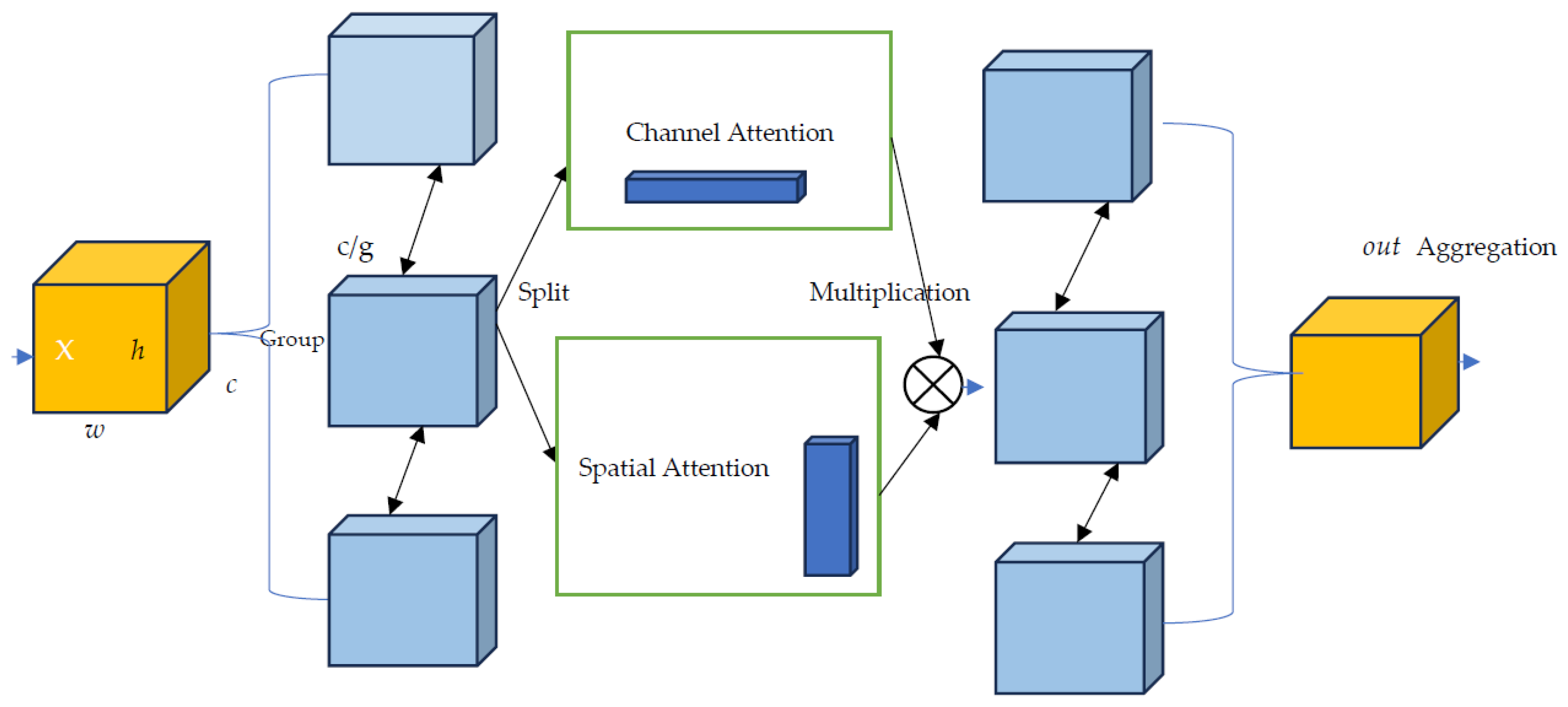
Figure 2.
Diagram of the Channel attention sub-module. The channel sub-module uses max-pooling and average pooling where the outputs are multiplied before the n-shifted sigmoid is added together with a pair of parameters to scale the channel vector.
Figure 2.
Diagram of the Channel attention sub-module. The channel sub-module uses max-pooling and average pooling where the outputs are multiplied before the n-shifted sigmoid is added together with a pair of parameters to scale the channel vector.
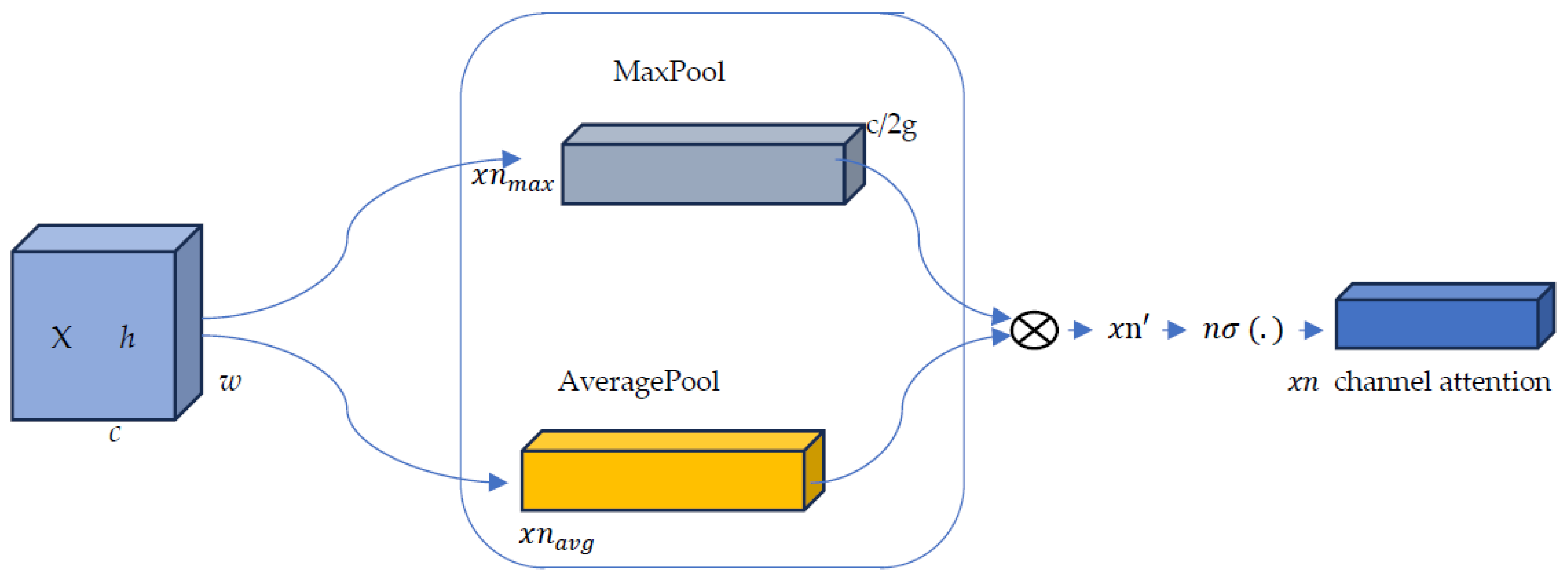
Figure 3.
Diagram of the Spatial attention overview. Group normalization (GN) is adopted to generate spatial-wise statistics before a compact feature Fc(.) is created.
Figure 3.
Diagram of the Spatial attention overview. Group normalization (GN) is adopted to generate spatial-wise statistics before a compact feature Fc(.) is created.
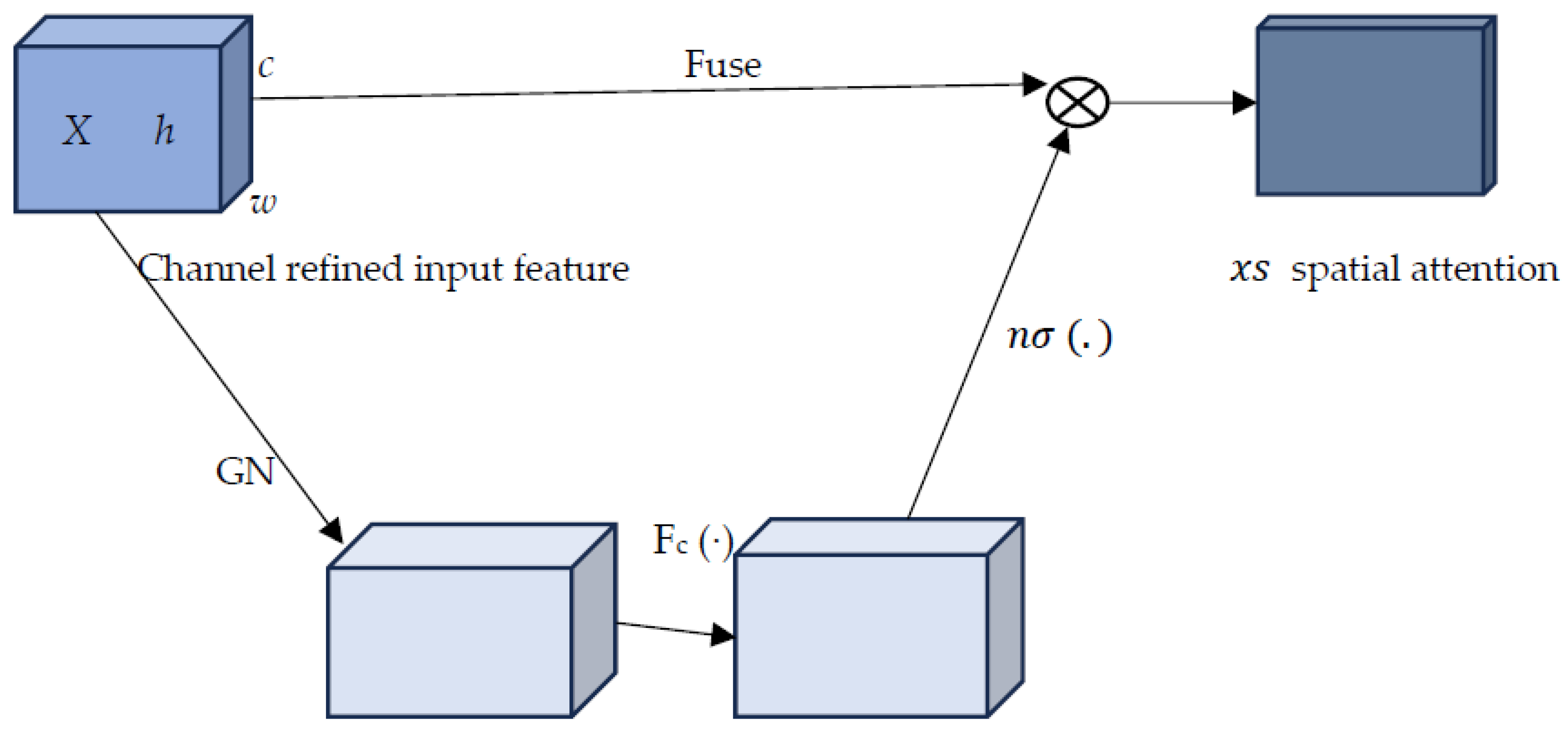
Figure 5.
Simplified illustration of the 3D n-sigmoid CSA operation in the Hough Voting point cloud learning set.
Figure 5.
Simplified illustration of the 3D n-sigmoid CSA operation in the Hough Voting point cloud learning set.
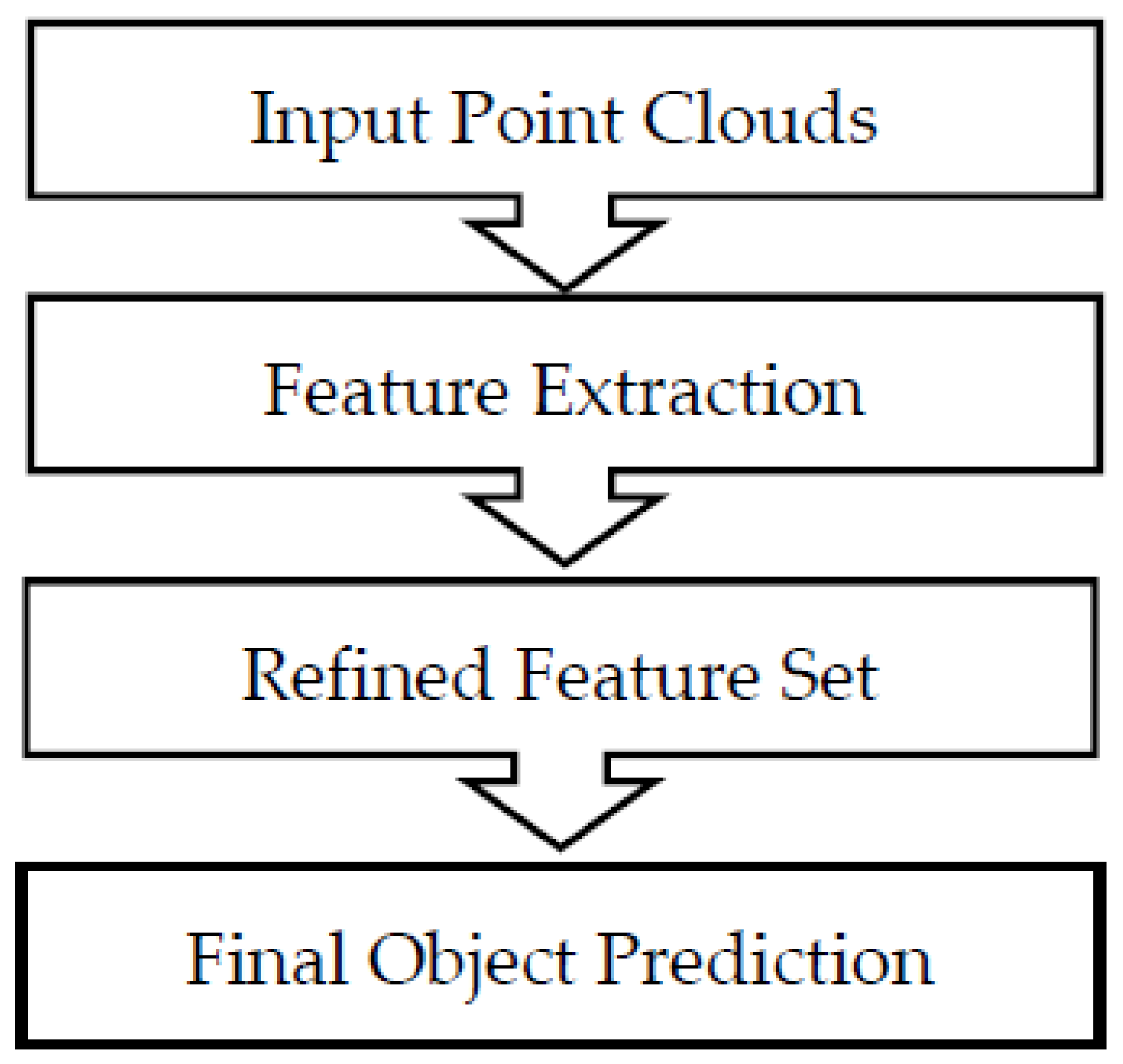
Figure 6.
Accuracy results of the n-shifted sigmoid CSA VoteNet (with attention) and the VoteNet (without attention) on each element.
Figure 6.
Accuracy results of the n-shifted sigmoid CSA VoteNet (with attention) and the VoteNet (without attention) on each element.
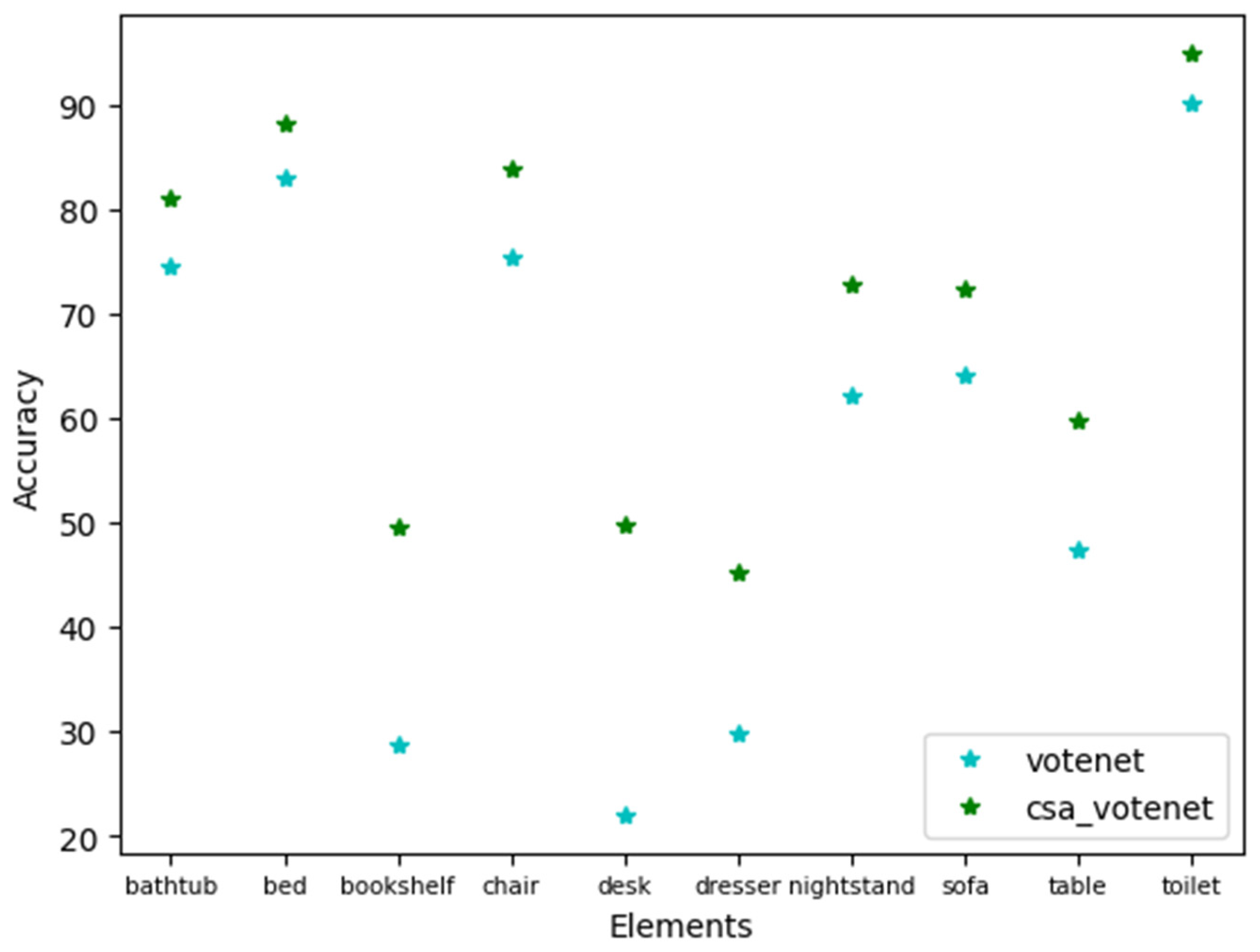
Figure 7.
Accuracy results of the n-shifted sigmoid CSA VoteNet (with concatenation) and the n-shifted sigmoid CSA VoteNet (with multiplication) on each element. The mAP @ 0.25 accuracy is 69.29 for the n-shifted sigmoid CSA VoteNet (with concatenation).
Figure 7.
Accuracy results of the n-shifted sigmoid CSA VoteNet (with concatenation) and the n-shifted sigmoid CSA VoteNet (with multiplication) on each element. The mAP @ 0.25 accuracy is 69.29 for the n-shifted sigmoid CSA VoteNet (with concatenation).
Table 1.
Comparison of benefits of n shifted channel and spatial attention in VoteNet to the other methods in SOTA in 3D object detection.
Table 1.
Comparison of benefits of n shifted channel and spatial attention in VoteNet to the other methods in SOTA in 3D object detection.
| n-sigmoid Channel and Spatial Attention VoteNet | Other related Networks |
| Enhanced feature refinement Improved attention focus More robust predictions Higher detection accuracy |
Standard feature extraction Traditional attention Moderate detection accuracy Decent object localization and limited refinement |
Table 3.
Comparing n-sigmoid CSA-VoteNet with other attention mechanism baseline using VoteNet on SUNRGBD on both Average Precision and Recall.
Table 3.
Comparing n-sigmoid CSA-VoteNet with other attention mechanism baseline using VoteNet on SUNRGBD on both Average Precision and Recall.
| A: The results of Average Precision on SUNRGBD [15] dataset of SA_VoteNet compared to other attention mechanisms. (IoU threshold = 0.25) | |||||||||||||||||||||
| Methods | bed | table | sofa | chair | toilet | desk | dresser | night-stand | book-shelf | bath-tub | mAP | ||||||||||
| VoteNet [12] A-SCN [39] Point-attention [40] CAA [31] Point-transformer [32] Offset-attention [41] CSA-VoteNet (ours) |
83.3 81.8 84.4 83.7 83.9 82.8 88.1 |
49.8 48.9 49.0 50.2 50.4 49.8 59.8 |
64.1 63.8 61.9 63.4 63.7 60.5 72.4 |
74.1 74.0 73.8 74.9 75.2 73.0 83.8 |
89.3 88.3 87.4 89.7 86.6 86.5 94.9 |
23.8 24.5 25.7 25.7 26.3 23.6 49.7 |
26.4 26.7 24.6 30.6 28.1 27.1 45.2 |
60.7 57.5 56.0 64.7 62.5 56.5 72.8 |
30.9 24.9 28.2 27.5 35.8 25.6 49.6 |
72.8 65.4 73.1 77.6 72.2 71.2 80.9 |
57.7 55.6 56.4 58.8 58.5 55.7 69.72 |
||||||||||
| B: The results of Recall on SUN RGB-D [15] dataset of SA-VoteNet compared to other attention mechanisms. (IoU threshold = 0.25) | |||||||||||||||||||||
| Methods | bed | table | sofa | chair | toilet | desk | dresser | night-stand | book-shelf | bath-tub | AR | ||||||||||
| VoteNet [12] A-SCN [39] Point-attention [40] CAA [31] Point-transformer [32] Offset-attention [41] CSA-VoteNet (ours) |
95.2 94.1 94.8 94.1 93.4 94.1 95.5 |
85.5 83.3 83.6 84.7 84.5 83.5 82.9 |
89.5 88.4 88.9 89.7 89.4 87.8 91.6 |
86.7 87.3 86.3 86.8 86.1 86.1 87.3 |
97.4 96.7 95.4 97.4 94.7 97.4 97.6 |
78.8 78.8 78.7 79.3 77.4 78.9 77.6 |
81.0 77.3 78.2 80.6 80.6 78.2 83.2 |
87.8 85.4 88.2 89.8 89.4 88.2 88.4 |
68.6 67.6 62.5 65.9 71.9 64.9 73.2 |
90.4 80.8 86.5 90.4 90.4 86.5 91.0 |
86.1 84.0 84.3 85.9 85.8 84.6 86.8 |
||||||||||
Table 4.
Comparing CSA Hough Voting with attention mechanism baseline (IoU threshold at 0.25 and 0.5) on SUNRGBD dataset.
Table 4.
Comparing CSA Hough Voting with attention mechanism baseline (IoU threshold at 0.25 and 0.5) on SUNRGBD dataset.
| Methods | mAP @ 0.25 | mAP @ 0.5 |
|
Methods without attention H3DNet [43] LGR-Net [44] HGNet [45] SPOT [46] Feng [47] MLCVNey [37] VENet [46] DeMF [38] CAGroup3D [49] TR3D+FF [50] Point-GCC+TR3D+FF [52] Methods with attention VoteNet [12] ImVoteNet 40] CSA-VoteNet (Ours) |
60.0 62.2 61.6 60.4 59.2 59.2 62.5 65.6 66.8 69.4 69.7 57.7 - 69.72 |
39.0 - - 36.3 - - 39.2 45.4 50.2 53.4 54.0 41.3 43.4 54.17 |
Table 5.
Model results on using concatenated average pooling or either of the pooling operations.
| Methods | mAP @ 0.25 | mAP @ 0.5 |
| VoteNet without attention n-sigmoid CSA VoteNet with both avg and max pooling n-sigmoid CSA VoteNet with max pooling only n-sigmoid CSA VoteNet with avg pooling only |
57.7 69.72 69.11 68.84 |
41.3 54.17 53.67 53.22 |
Table 6.
Model results on using n-shifted sigmoid or traditional sigmoid.
| Methods | mAP @ 0.25 | mAP @ 0.5 |
| VoteNet without attention n-shifted sigmoid CSA VoteNet traditional sigmoid CSA VoteNet p-sigmoid CSA VoteNet |
57.7 69.72 69.21 69.32 |
41.3 54.17 53.96 53.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



