
Submitted:
30 May 2024
Posted:
30 May 2024
You are already at the latest version
Abstract
Named Entity Recognition (NER) serves as a fundamental and pivotal stage in the development of various knowledge-based support systems, including knowledge retrieval and question answering systems. In the domain of pig diseases, Chinese NER models encounter several challenges such as the scarcity of annotated data, domain-specific vocabulary, diverse entity categories, and ambiguous entity boundaries.To address these challenges, a corpus, labeled datasets and a lexicon specific to pig diseases for Chinese named entity recognition were constructed. Subsequently, a Pig Disease Chinese Named Entity Recognition (PDCNER) model was proposed. The model integrates external lexicon knowledge of pig disease by employing Lexicon-enhanced BERT and enhance feature representation by incorporating contrastive learning. Experimental results show that the model achieved the best recognition results, with a precision of 86.92%, a recall of 85.08%, and an F1-score of 85.99% respectively. Furthermore, the model exhibits robustness and generalizability across few-shot and publicly available datasets. Experimental results illustrate the proposed model could effectively identify Chinese named entities of pig diseases, outperforming several existing baseline methods. Moreover, the proposed model can be extended to other animal disease domains, such as chicken and cattle, thereby facilitating seamless adaptation for named entity identification across diverse contexts.
Keywords:
Chinese Named Entity Recognition
; Pig disease
; Lexicon enhanced
; Contrastive learning
1. Introduction
In the context of large-scale and intensive pig breeding practices, it is of great significance to establish intelligent diagnostic and preventive measures for pig diseases. Early prevention and timely diagnosis are pivotal for maintaining swine health and mitigating potential losses. Named Entity Recognition (NER) assumes a critical role in this endeavor by identifying specific entities within textual corpora, serving as the cornerstone for numerous downstream tasks in natural language processing. These tasks include but are not limited to information retrieval, intelligent question answering, and knowledge graph construction. However, the existing entity recognition methods mostly focus on recognition of person, location and organization, etc. Given the pressing need to bolster disease surveillance and management in swine, there arises an urgent imperative to develop specialized NER methodologies tailored to the specific lexicon of pig disease terminology in Chinese.
The early NER methods include rule-based recognition methods and statistics-based machine learning recognition methods. In recent years, with the rapid development of neural networks, methods of deep learning are more suitable for the task of NER and become the mainstream method [1,2,3,4,5].
The rule-based NER method requires the rules which are formulated manually by experts. This method has high accuracy when dealing with small datasets, but it is difficult to expand it on a large scale and apply it in different domains because the rules are based on manual construction, which is a time-consuming task [6].
The statistics-based NER method select the appropriate training model according to the specific research background. Commonly used statistical models include hidden Markov models(HMM), conditional random field model(CRF), branch support vector machine (SVM) and maximum entropy model (ME), etc. Compared to the rule-based model, this method omits many tedious rule designs and are fast, portable and convenient to use [7,8]. However, the statistics-based method requires a large number of manually labeled datasets to train model parameters, which is gradually replaced by deep learning method.
The deep learning based NER method can learn more complex features and achieve good results. In contrast to the preceding two approaches, deep learning-based NER methods do not necessitate an abundance of artificial features. Therefore, the deep learning-based methods has been widely concerned by researchers. Common deep learning models include convolutional neural network (CNN), recurrent neural network (RNN), graph neural network (GNN), deep neural network (DNN), generative adversarial network (GAN), long short-term memory network (LSTM), Transformer and BERT(bi-directional encode representation from transformers) and so on [1,9]. Compared to the rule-based and statistics-based models, deep learning models are dominant and achieve state-of-the-art results in NER. However, the scalability of deep learning models applied in specific domain remains a significant challenge.
The lexicon-based NER method can effectively avoid segmentation errors and improve the accuracy of entity boundary recognition by integrating potential word information into feature vectors. Currently, a large number of lexicon enhanced Chinese entity extraction methods have been proposed, with better performance than methods based on character embedding or word embedding. Lattice-LSTM [10] has achieved new benchmark results on several public Chinese NER datasets. However, the Lattice-LSTM model architecture is complex, which limits its application in many industrial areas requiring real-time NER responses. A convolutional neural network based method that incorporates lexicons using a rethinking mechanism was proposed,which can model all the characters and potential words that match the sentence in parallel [11]. A lexicon-based graph neural network with global semantics was proposed to tackle word ambiguities. In this model, the lexicon knowledge is used to connect characters to capture the local composition, while a global relay node can capture global sentence semantics and long-range dependency [12]. A Lexicon Enhanced BERT (LEBERT) for Chinese sequence labeling was put forward [13]. The model integrates external lexicon knowledge into BERT layers directly by a Lexicon Adapter layer and achieves better performance than both lexicon enhanced models and BERT baseline in Chinese datasets. More character-word association models have been proposed, such as SoftLexicon [14],FLAT [15],PLTE [16].
The pre-trained model-based NER method effectively leverages deep bidirectional contextual information. It demonstrates superior performance with shorter training times, reduced labeling data requirements, and improved results compared to traditional models. Currently, BERT [17] is widely used, followed by ELMo [18], RoBERTA [19], ERNIE [20], ALBERT [21], and others. At present, the pre-trained models and lexicon are integrated by utilizing their respective strengths. Li proposed Flat-LAttice Transformer for Chinese NER, which converts the lattice structure into a flat structure consisting of spans [15]. Li proposed the LEBERT-BiLSTM-CRF model for elementary mathematics text NER, which integrates external lexicon knowledge into BERT layers directly by a lexicon adapter layer and performs better than other NER models [22] .
Contrastive learning acquires feature representations of samples by comparing positive and negative samples in feature space. This approach has garnered significant attention in the fields of computer vision (CV) and natural language processing (NLP). ConSERT (Contrastive Framework for Self-supervised Sentiment Representation Transfer) and SimCSE(Simple Contrastive Learning of Sentiment Embedding) model, which use different data enhancement methods and comparative learning loss function to learn the representation of sentences, obtain SOTA results on the task of text semantic similarity [23,24]. COntrastive learning with Prompt guiding for few-shot NER (COPNER) was proposed and outperforms state-of-the-art models with a significant margin in most cases. This method introduces category specific words COPNER composed of prompts as supervised signals for contrastive learning to optimize entity token representation [25]. Moreover, Named Entity Recognition in low-resource scenarios based on contrastive learning has also received considerable attention [26,27,28]. He proposed a novel prompt-based contrastive learning method for few-shot NER without template construction and label word mappings [26]. Li proposed a multi-task learning framework CLINER for Few-Shot NER [27].
In the field of livestock husbandry, text mining, Named Entity Recognition (NER), intelligent question-and-answer systems, and artificial intelligence (AI) technologies have been gradually applied. However, this field faces numerous challenges, including the prevalence of technical terms, complex knowledge structures, fine knowledge granularity, and a lack of labeled datasets [29]. Seok created a BERT-DIS-NER model that adds a CRF layer to BERT for the disease named entity recognition and used syllable unit-based named entity recognition that can reflect the characteristics of disease names. The F1-score is 0.81 trained with human data and fine-tuned with animal data [30]. Kung designed and implemented an intelligent knowledge question-and-answer system for pig farming based on bi-GRU and SNN methods, combined with the LTSM deep-learning method [31] .
NER methods have been found extensive applications in the agricultural domain [32,33,34,35,36,37]. Nonetheless, there remains a apparent gap in current research concerning the accurate recognition of named entities within the domain of pig diseases in Chinese. Pig disease data is characterized by complex entities, fuzzy boundaries and domain-specific vocabulary. Unlike conventional NER tasks focusing on common entities such as person and organization names, pig disease data encompasses specialized terminologies drawn from the domains of animal husbandry and veterinary science.
Furthermore, the resources in the field of pig diseases are confined and dispersed, exacerbating the scarcity of publicly available benchmark corpora and labeled datasets specific to this domain in Chinese. While considerable research has been devoted to NER systems in human medicine [38,39], it remains impractical to directly transfer such models to the domain of pig diseases due to the domain-specific rules and vocabulary governing this domain. Hence, named entity recognition in the field of pig diseases needs to be further explored. A model of Pig Disease Chinese Named Entity Recognition(PDCNER) is proposed in this paper. The main contributions of the paper are as follows:
(1)A named entity recognition model that integrates contrastive learning and enhanced lexicon was proposed for pig diseases corpus in Chinese, which achieved the best recognition results.
(2)To enrich the contextual understanding and semantic representation of pig disease data, we employed Lexicon-enhanced BERT. This approach facilitated the direct integration of external lexicon knowledge in pig disease domain into BERT layers via a Lexicon Adapter layer, seamlessly combining the characteristics of both characters and words. Furthermore, we used contrastive learning to maximize the agreement between representations within the same batch while ensuring their distinctiveness from other representations. This approach enhances model robustness and facilitates more effective feature extraction and representation learning.
(3)We constructed a comprehensive Chinese corpus and lexicon for identifying specific terms in pig diseases domain. Moreover, we built an annotated datasets encompassing 25 distinct types of pig diseases and 6 entity categories, comprising a total of 7518 annotated entities.
The remainder of the paper is organized as follows: Section 2 introduces the data set and method proposed in this paper. The experiments and results are described in Section 3. Section 4 compares the method proposed in this paper with other commonly used methods and provides an analysis of the experimental results. Finally, the conclusion are presented in Section 5.
2. Materials and Methods
2.1. Materials
2.1.1. Corpus Collection and Pre-Processing
Due to the lack of NER public benchmark datasets in pig disease domain, a new Chinese pig disease corpus was constructed and annotated under the guidance of animal disease experts and veterinarians.To ensure the quality of data, we collected information on pig diseases from professional books, published standards, Baidu Encyclopedia and official websites. The data source details are mentioned in Appendix A.
After the data acquisition, we performed basic data per-processing steps. Firstly, the optical character recognition(OCR) technology was used to convert the books and standards into text format. Secondly, useless data such as garbled characters or special symbols, were manually deleted and wrong words were modified in raw text. Thirdly, the duplicate data and invalid data were removed. Ultimately, an comprehensive and effective text corpus of containing 1.45 million characters was obtained(Corpus Ⅰ of pig disease).
2.1.2. Corpus Annotation
152,596 characters were selected from Corpus Ⅰ to form Corpus Ⅱ for entity labeling. Label Studio tool and BIEO labeling method were used to label entities. B represents the start position of the entity, I represents the inside of the entity, E represents the end position of the entity, and O represents the other. Six types of pig disease such as pig type, disease name, body part, symptom, medicine, prevention and control measures were labeled in the corpus text. Finally, the annotated pig disease corpus containing 7518 entities was obtained under the guidance of pig disease experts. The statistical information of labeled entities is presented in Table 1.
2.1.3. Construction of Lexicon and Pre-Training Word Embedding
We constructed lexicon in pig disease domain based on Corpus Ⅱ and professional books. Firstly, the most commonly used professional terms were extracted from the Corpus Ⅱ by word segmentation and frequency statistics. Then, some professional words in the glossary of professional books were manually added to the dictionary under the guidance of veterinarians, such as “猪副嗜血杆菌病(Haemophilus parasuis)”,“噻苯达唑(Thiabendazole)”,“内阿米巴原虫(Entamoeba spp)”. Finally, the pig disease lexicon comprising 2391 professional terms was obtained for understanding the specific words and technical term. Subsequently, this lexicon was incorporated into the built-in dictionary of Jieba to avoid incorrect segmentation of words.
To obtain a high-quality embedded representation of pig diseases, we trained Corpus Ⅰ and the lexicon.The Gensim tool was used to train Word2Vec model with a word vector dimension of 200. The construction process of the lexicon and the pre-training of word embeddings are illustrated in Figure 1.
2.2. Methods
2.2.1. Framework
The framework of PDCNER model is shown in Figure 2. Firstly, the Chinese sentences in the pig disease corpus are converted into a character-words pair sequence, and both Chinese character features and lexicon features are used as inputs. Secondly, a lexicon adapter is added between Transformer layers, which is used to dynamically extract the most relevant matching items. The word of each character uses the bi-linear attention mechanism from character to word, and the lexicon adapter is applied between adjacent Transformer in BERT. The lexicon features and BERT representations are fully interacted through multi-layer encoders in BERT, so that lexicon knowledge can be effectively integrated into BERT. The contrastive loss layer is above the Lexicon Enhanced BERT encoder, ensuring that similar samples are as close as possible, while dissimilar samples are as far apart as possible. Embeddings of the same type of entity are treated as positive samples, whereas embeddings of different types of entities are treated as negative samples. Considering the correlation between consecutive labels, a Conditional Random Field (CRF) layer is employed to label the sequence.
2.2.2. Char-Words Pair Sequence
According to the Lexicon Enhanced BERT in [13], we firstly expand the character sequence into a sequence of character-word pairs for applying lexical information of pig disease.
A Chinese sentence with n characters, . We identify all potential words within the sentence by comparing the character sequence with the lexicon of pig disease. To achieve this, we first create a Trie data structure based on the lexicon. Then we examine all character subsequences within the sentence, matching them with the Trie to identify all potential words. For instance, the truncated sentence "非洲猪瘟 (African swine fever)" as an example. We can identify five distinct words: "非洲 (Africa)", "非洲猪 (African pig)", "猪瘟 (swine fever)", "瘟 (epidemic disease)" and "非洲猪瘟 (African swine fever)" . In the field of pig disease, African swine fever is a complete disease name and should not be separated. Following this, for each matched word, we associate it with the characters that compose it. In conclusion, we pair each character with its associated words and transform the Chinese sentence into a sequence of character-word pairs, represented as:
where denotes the i-th character in the sentence, and signifies the words matched and assigned to .
2.2.3. Lexicon Adapter
Using the lexicon adapter proposed in LEBERT [13], the pig disease lexicon information is directly injected into BERT for integrating lexical features.
For the i-th character in a character-word sequence, the input is, represents the character vector, the output of a transformation layer in BERT. represents a group of words embeddings. The j-th word in is represented as following:
where is the pre-trained word embedding list and represents the j-th word in.
To align these two different representations, a nonlinear transformation is used for each word vector:
where , , represent the dimension of word embedding and BERT's hidden size respectively. are scaler bias.
Each character is associated with a variety of words, but the degree of contribution from each word differs. For instance, in the field of pig diseases, the words "非洲(Africa)" and "猪瘟(swine fever)" are more important than "非洲猪(African pigs)" and "瘟(epidemic disease)".In order to find the most relevant words, the character-word attention mechanism is used. The correlation of each word is calculated as follows:
where is the bi-linear attention mechanism. The all assigned to i-th character , where m is the total number of assigned words.
Lastly, the lexicon information is integrated into the vector representation of the character.
2.2.4. Lexicon Enhanced BERT
The lexicon adapter is attached between transformer layers in BERT so that the knowledge of pig disease lexicon can be injected into BERT. A sequence of characters is input into the input embedding of BERT and then is obtained by adding token, segmentation and position embedding . After that , E is input into the Transformer encoders. Each layer is as follows.
Where represents the output of l-th layer and =E. FFN represents the two-layer feed-forward network with RELU as the hidden activation function.
The lexicon information were input between the k-th and (k+1)-th layer Transformer. are got first after k consecutive Transformers layers. Subsequently, each character-word pair was processed through the lexicon adapter to obtain a new hidden layer representation and the pair was converted into accordingly.
are input into the remaining (L-K) Transformer as there are 12 layers of Transformers in BERT. Finally, the output of L-th Transformer used for the name entity recognition task is obtained.
2.2.5. Lexicon Enhanced Contrastive Learning
The normalized temperature-scaled cross-entropy loss, denoted as NT-Xent was used as our contrastive loss function [40]. For each training iteration, we randomly select N texts from the datasets to form a mini-batch, which yields 2N feature representations. The model is then trained to identify each data point's corresponding pair among the 2(N-1) negative samples present within the batch.
Where ri, rj represent the embedding for entities of the same type, whereas ri, rk denote the embedding for entities of different types. s() refers to the cosine similarity function, where acts as the temperature parameter, and I serves as an indicator function. Ultimately, we calculate the final contrastive loss by averaging the classification losses of all 2N instances within the batch.
3. Experiment
We carry out experiments to investigate the effectiveness of PDCNER. This section presents the results and evaluation of the proposed PDCNER model illustrated on pig disease corpus.
3.1. Evaluation
To identify a named entity for pig diseases, it is necessary to correctly identify both the boundaries of the entity and its corresponding categories. The proposed PDCNER model is evaluated using standard measures, Precision(P), Recall(R), and F1, which are computed using the Eqs. (9), (10) and (11).
where Tp represents the number of positive samples that are accurately predicted, while Fp denotes the count of positive samples that are inaccurately predicted. Additionally, Fn stands for the number of negative samples that are incorrectly predicted.
3.2. Experimental Settings
Experiments. The hardware environment that the experimental research relied on was Intel(R) Xeon(R) Silver4116 CPU@2.10GHz, GPU@NVIDIA Tesla P100. The software environment was Python3.8 and tensorflow 2.0.0. The model parameters were set as follows: based on BERTBASE (Devlin et al., 2019) [17] version, with 12 transformer layers, 768 hidden layers, and 12 multi-head attention mechanisms. The lexicon corresponds to the vocabulary of pre-trained word embeddings in field of pig disease. During the training process, we incorporate the Lexicon Adapter between the first and second Transformer layers of BERT [13]. Meanwhile, the parameters of BERT and the pre-trained word embedding were fine-tuned.
Hyperparameters.The learning rate was 1e-5, the training batch_size was 16, the dropout was 0.5, the optimizer chose Adam, and the number of iterations was 100.
Dataset.This study randomly divided the datasets into training, validation, and test sets according to a ratio of 7:2:1.
3.3. Results
We evaluate the effectiveness of PDCNER against widely-used NER models on the pig disease corpus. The overall findings of our experiments are presented in Table 2. As shown in Table 2, the recognition effect based on the model proposed in this study was significantly better than the other models, with a micro average F1-score of 85.99% in recognizing six major entities.
Compared with the baseline model BERT_BILSTM_CRF, F1-score was increased by 2.67 percentage points. This is due to the fact that PDCNER makes full use of Lexicon enhanced BERT with the help of Lexicon Adapter layer and obtains optimization of feature representation with the help of contrastive learning.
Obviously, the F1-score of the BILSTM_CRF model is the lowest among all the results. Generally, the F1 values of pre-trained models are higher than those of the BILSTM_CRF model, as the pre-trained models have learned more language features and possess a deeper network structure. Moreover, the pre-trained model incorporating lexicon information demonstrates superior performance due to the additional lexical knowledge.
4. Discussion
4.1. Performance Analysis of the Proposed Model
For better understanding of the proposed approach, we evaluate the PDCNER model separately on the six entities type, disease, body parts, symptom, medicine, control, which are presented in Figure 3 and Table 3.
We found that the F1-scores for type, disease, and medicine all exceeded 90%, with the F1-score for type being the highest at 95.41%. Conversely, the lowest F1-score was for the entity of control, at only 63.16%. The primary reason for this disparity is that the boundaries of pig type and disease entities are very clear, whereas the boundaries of control measures entities are more ambiguous. For instance, type entities typically end with terms like 'pigs (猪)' (e.g., sick pigs (患病猪), conservation pigs (保育猪), fattening pigs (育肥猪)), while disease entities usually end with terms such as 'disease (病),' 'inflammation (炎),' and 'plague (瘟)' (e.g., Porcine blue ear disease (猪蓝耳病), Necrotic enteritis (坏死性肠炎), African swine fever (非洲猪瘟)). In contrast, control measure entities are generally composed of verbs and nouns, such as 'isolating infected pigs(隔离感染猪群)' and 'reducing environmental stress factors(减少环境应激因素)'. The second reason is the uneven distribution of entities. Control entities in the training set are significantly fewer than other categories, comprising only 7.29%. Consequently, the model could not fully learn their contextual features. Additionally, the average length of control entities is 11 Chinese characters, which contributes to a low overall recognition rate.
On the other hand, the F1-scores of disease entities and medicine entities were 92.96% and 90.05%, respectively. Both disease and medicine entities include a large number of technical terms, yet the method proposed in this paper achieves a good recognition effect on these two entities. The results demonstrate that PDCNER fully utilizes both Chinese character features and lexicon knowledge in the pig disease domain at the input level, and the lexicon adapter can effectively leverage pig disease knowledge.
4.2. Comparison of Common Pre-Trained and Lexicon-Based Model
In contrast to models such as BERT-BiLSTM-CRF, BERT-BILSTM-CRF-SoftLexicon, RoBERTa and LEBERT, PDCNER has demonstrated significant advancements, confirming its efficiency. PDCNER holds a distinct advantage over other pre-trained and lexicon-based models, illustrating the value of incorporating pig disease-related lexicon features directly into the BERT representation from the bottom layer and using the contrastive learning method.
For the comparison of other models, we present the recognition results for six entity types in Figure 4. It can be clearly seen from the Figure 4 that PDCNER has achieved the best results in 4 entities such as type, body parts, symptom and medicine, which exhibit robust domain-specific features.
- (1)
- Effectiveness of the lexicon Enhanced BERT
Comparative analysis with the results of BERT-BiLSTM-CRF reveals notable improvement in the precision, recall, and F1-score of PDCNER, with improvements of 5.98 percentage points, 0.04 percentage points, and 3.05 percentage points, respectively. PDCNER leverages the lexicon adapter to make full use of pig disease feature information, seamlessly integrating it into the BERT architecture. Specifically, the Lexicon Adapter is attached between certain transformers within BERT, facilitating the infusion of pig disease lexicon knowledge into the model's representation.
- (2)
- Effectiveness of the contrastive learning
Through comparative evaluation utilizing the same dataset and downstream model, PDCNER demonstrates superior accuracy in identifying pig disease entities compared to LEBERT, exhibiting improvements in precision, recall, and F1-score by 0.45 percentage points, 0.44 percentage points, and 0.44 percentage points, respectively. This underscores the efficacy of the loss function employed in contrastive learning, which enhances the model's capacity for semantic representation of text. Consequently, this optimization contributes to superior performance across various NER tasks.
4.3. Analysis of Results for Few-Shot
In order to verify the reliability and robustness of PDCNER in the condition of scarce data for few-shot entity recognition, we used 1%, 10% and 30% of pig disease corpus for experimentation. The results can be found in Table 4. The result shows that the PDCNER model has obvious improvement compared to BERT-BILSTM-CRF and LEBERT.
The F1-score of PDCNER reaches 84.77% when the sample size is 10%, which is only 1.22% lower than that of the full sample. As the sample size increases to 30%, the F1-score of the PDCNER model further improves to 85.39%, showing a marginal decrease of only 0.6% compared to the full sample. Moreover, it outperforms the BERT-BiLSTM-CRF and LEBERT models by 6.38% and 8.42%, respectively. These results demonstrate the PDCNER model's capability to achieve higher recognition accuracy even under data scarcity scenarios. The incorporation of lexical information in the bottom layer of BERT enables efficient utilization of BERT's representational capabilities. Additionally, the adoption of contrastive learning enhances the semantic representation space, facilitating effective feature capture without extensive training.
4.4. Experiments on Public Datasets
To assess the generalization capability of PDCNER, we conducted evaluations across three public datasets: Weibo, Ontonotes, and Resume. As illustrated in Table 5, the PDCNER model achieved the highest F1 score across all three datasets. These results indicate that PDCNER exhibits superior performance not only on the pig disease corpus but also demonstrates a degree of generalizability to other domains.
5. Conclusions
High-quality extraction of knowledge related to pig diseases is critical for intelligent consultation, question answering, technical recommendations, and other application scenarios.
In this study, we constructed a corpus, labeled datasets and lexicon for Chinese named entity recognition specific to pig diseases, encompassing 152,596 characters, 7,518 entities and 2,391 professional terms. To tackle the challenges of entity identification in the pig disease domain, such as the scarcity of annotated data, numerous technical terms, and fuzzy boundaries, we propose the PDCNER model. This model integrates lexicon information from the pig disease domain into the BERT's Transformer layers at the lower level and employs contrastive learning to enhance representation quality and generalization capability. The results indicate that the PDCNER model surpasses the performance of BERT-BiLSTM-CRF and other mainstream models in extracting named entities related to pig diseases, achieving accuracy, recall, and F1-score of 86.92%, 85.08%, and 85.99%, respectively. This demonstrates high-quality entity recognition in the field of pig diseases. Moreover, few-shot experiments confirm that our model remains robust with limited data, and experiments on public datasets verify its generalization ability.
In future work, we plan to utilize additional datasets from other related animal diseases, such as chicken and cow diseases, to further test the scalability and generalization ability of the model.
Author Contributions
Conceptualization, Cheng Peng and Qifeng Li; Data curation, Rui Meng, Haiyan Li, Shuyan Wang and Longjuan He; Formal analysis, Wenbiao Wu and Heju Huai; Investigation, Shuyan Wang; Methodology, Cheng Peng and Xiajun Wang; Software, Xiajun Wang; Validation, Qinyang Yu, Ruixiang Jiang and Weihong Ma; Writing – original draft, Cheng Peng and Xiajun Wang; Writing – review & editing, Cheng Peng and Qifeng Li.
Funding
This research was funded by National Science and Technology Major Project (2021ZD0113802).
Data Availability Statement
As the datasets used in this manuscript will be used for other technical research, they are available on request from the corresponding author upon reasonable request. The source code of PDCNER will be available at: https://github.com/tufeifei923/pdcner.
Acknowledgments
We thank the editors of Agronomy and the anonymous reviewers for their valuable suggestions..
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Data Source Details
| No | Type | Example |
| 1 | Professional books | Jeffrey J. Zimmerman, Locke A.Karriker, Alejandro Raminez.etc,editor in chief. Hanchun Yang,main translation. Disease of Swine. North United publishing media Media Co., Ltd, Liaoning science and technology publishing house:Beijing, China, 2022. Yousheng, Xu. Primary color atlas of scientific pig raising and pig disease prevention and control. China Agricultural Publishing House: Beijing, China,2017. Changyou,Li, Xiaocheng,Li. Prevention and control technology of swine epidemic disease. China Agricultural Publishing House:Beijing, China,2015. Jianxin Zhang. Diagnosis and control of herd pig epidemic disease. He 'nan Science and Technology Press:Zhengzhou, China, 2014. Chaoying, Luo, Guibo, Wang. Prevention and treatment of pig diseases and safe medication. Chemical industry press:Beijing, China,2016, etc. 《猪病学》、《科学养猪与猪病防制原色图谱》、《猪群疫病防治技术》、《群养猪疫病诊断与控制》、《猪病防治及安全用药》等 |
| 2 | Standard specification | Technical Specification for Quarantine of Porcine Reproductive and Respiratory Syndrome (SN/T 1247-2022), Diagnostic Techniques for Mycoplasma Pneumonia in Swine (NY/T 1186-2017), Diagnostic Techniques for Infectious Pleuropneumonia in Swine (NY/T 537-2023), Diagnostic Techniques for Swine Dysentery (NY/T 545-2023), Technical Specification for Quarantine of Porcine Rotavirus Infection (SN/T 5196-2020), etc. 《猪繁殖与呼吸综合征检疫技术规范》(SN/T 1247-2022)、《猪支原体肺炎诊断技术》(NY/T 1186-2017)、《猪传染性胸膜肺炎诊断技术》(NY/T 537-2023)、《猪痢疾诊断技术》(NY/T 545-2023)、《猪轮状病毒感染检疫技术规范》(SN/T 5196-2020)等 |
| 3 | Technological specification | Technical specification for prevention and control of highly pathogenic blue ear disease in pigs, technical specification for prevention and control of foot-and-mouth disease, technical specification for prevention and control of classical swine fever, etc. 《高致病性猪蓝耳病防治技术规范》、《口蹄疫防治技术规范》、《猪瘟防治技术规范》等 |
| 4 | Policy paper | Ministry of Agriculture and Rural Affairs "List of Class I, II and III Animal Diseases", The Ministry of Agriculture issued the "Guiding Opinions on Prevention and Control of Highly Pathogenic Porcine Blue Ear Disease (2017-2020)", Notice of National Guiding Opinions on Prevention and Control of Classical Swine Fever (2017-2020), etc. 农业农村部《一、二、三类动物疫病病种名录》、农业部关于印发《国家高致病性猪蓝耳病防治指导意见(2017—2020年)》、《国家猪瘟防治指导意见(2017—2020年)》的通知 |
| 5 | Relevant industry website. | China Veterinary Website(https://www.cadc.net.cn/sites/MainSite/), Big Animal Husbandry Website(https://www.dxumu.com/), Huinong Website(https://www.cnhnb.com/), etc. 中国兽医网、大畜牧网、惠农网等 |
References
- Li, J.; Sun, A.X.; Han, J.L.; Li, C.L. A Survey on Deep Learning for Named Entity Recognition. IEEE Transactions on Knowledge and Data Engineering. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Cheng, J.R.; Liu, J.X.; Xu, X.B.; Xia, D.W.; Liu, L.; Sheng, V. A review of Chinese named entity recognition. KSII Transatctions on Internet and Information Systems. 2021, 15, 2012–2030. [Google Scholar]
- Mi, B.G.; Fan, Y. A review: Development of named entity recognition (NER) technology for aeronautical information intelligence. Artificial Intelligence Review. 2022, 56, 1515–1542. [Google Scholar]
- Liu, P.; Guo, Y.; Wang, F.; Li, G. Chinese named entity recognition: The state of the art. Neuro computing. 2022, 473, 37–53. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Science China Technological Sciences. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Zhang, S.; Elhadad, N. Unsupervised biomedical named entity recognition: Experiments with clinical and biological texts. Journal of Biomedical Informatics. 2013, 46, 1088–1098. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.J.; Zhang, T. Research on Me-based Chinese NER model. In Proceeding of the 7th International Conference on Machine Learning and Cybernetics(ICMLC), Kunming, China, 12–15 July 2008; Volume 5, pp. 2597–2602. [Google Scholar]
- Hu, H.P.; Zhang, H. Chinese Named Entity Recognition with CRFs: Two Levels. In Proceeding of the International Conference on Computational Intelligence & Security, Suzhou, China; 2008; Volume 6, pp. 1–6. [Google Scholar]
- Kang, Y.; Sun, L.; Zhu, R.; Li, M. Survey on Chinese named entity recognition with deep learning. Journal of Huazhong University of Science and Technology (Natural Science Edition). 2022, 50, 44–53. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER using lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia; 2018; Volume 1, pp. 1554–1564. [Google Scholar]
- Gui, T.; Ma, R.; Zhang, Q.; et al. CNN-Based Chinese NER with lexicon rethinking. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China; AAAI Press; 2019; Volume 8, pp. 4982–4988. [Google Scholar]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X. A Lexicon-Based Graph Neural Network for Chinese NER. Proceeding of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1040–1050. [Google Scholar]
- Liu, W.; Fu, X.; Zhang, Y.; Xiao, W. Lexicon enhanced Chinese sequence labeling using BERT adapter. In Proceeding of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; et al. Simplify the usage of lexicon in Chinese NER. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics; 2020; pp. 5951–5960. [Google Scholar]
- Li, X.; Yan, H.; Qiu, X.; et al. FLAT: Chinese NER using flat-lattice transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online; ACL Press, 2020; pp. 6836–6842. [Google Scholar]
- Xue, M.; Yu, B.; Liu, T.; et al. Porous lattice transformer encoder for Chinese NER. In Proceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics, Barcelona, Spain, 13–18 Sep 2020; pp. 3831–3841. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; et al. Bert: Pre-training of deep bidirectional transformers for language under-standing. arXiv arXiv:1810.04805, 2018.
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv arXiv:1802.05365, 2018.
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv arXiv:1907.11692, 2019.
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Wu, H. ERNIE: Enhanced representation through knowledge integration. arXiv arXiv:1904.09223v1, 2019.
- Lan, Z.Z.; Chen, M.D.; Goodman, S.; et al. ALBERT: A lite BERT for self-supervised learning of language representations. In Proceedings of the 8th International Conference on Learning Representations(ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, S.; Bai, Z.Q.; Zhao, S.; Jiang, G.S.; Shan, L.L.; Zhang, L. A LEBERT-based model for named entity recognition. In Proceedings of the 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture(AIAM), ACM International Conference Proceeding Series, Manchester, UK, 23–25 Oct 2021; pp. 980–983. [Google Scholar]
- Yan, Y.M.; Li, R.M.; Wang, S.R.; Zhang, F.; Wu, W.; Xu, W. ConSERT: A contrastive framework for self-supervised sentence representation transfer. arXiv arXiv:2105.11741, 2021.
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the EMNLP, Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6894–6910. [Google Scholar]
- Huang, Y.; He, K.; Wang, Y.; et al. COPNER: Contrastive learning with prompt guiding for few-shot named entity recognition. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 Oct 2022; pp. 2515–2527. [Google Scholar]
- He, K.; Mao, R.; Huang, Y.; Gong, T.; Li, C.; Cambria, E. Template-Free Prompting for Few-Shot Named Entity Recognition via Semantic-Enhanced Contrastive Learning. IEEE transactions on neural networks and learning systems 2023. [Google Scholar] [CrossRef] [PubMed]
- Li, X.W.; Li, X.L.; Zhao, M.K.; Yang, M.; Yu, R.G.; Yu, M.; Yu, J. CLINER: Exploring task-relevant features and label semantic for few-shot named entity recognition. Neural Computing & Applications. 2023, 36, 4679–4691. [Google Scholar] [CrossRef]
- Chen, P.; Wang, J.; Lin, H.; Zhao, D.; Yang, Z. Few-shot biomedical named entity recognition via knowledge-guided instance generation and prompt contrastive learning. Bioinformatics 2023, 39. [Google Scholar] [CrossRef] [PubMed]
- Sahadevan, S.; Hofmann-Apitius, M.; Schellander, K.; Tesfaye, D.; Fluck, J.; Friedrich, C.M. Text mining in livestock animal science: Introducing the potential of text mining to animal sciences. Journal of Animal Science. 2012, 90, 3666–3676. [Google Scholar] [CrossRef] [PubMed]
- Oh, H.S.; Lee, H. Named Entity Recognition for Pet Disease Q&A System. Journal of Digital Contents Society. 2022, 23, 765–771. [Google Scholar]
- Kung, H.; Yu, R.; Chen, C.; Tsai, C.; Lin, C. Intelligent pig-raising knowledge question-answering system based on neural network schemes. Agronomy Journal. 2021, 113, 906–922. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, G.; Liu, H.; Ma, X.; Xi, L. AWdpCNER: Automated Wdp Chinese Named Entity Recognition from Wheat Diseases and Pests Text. Agriculture 2023, 13, 1220. [Google Scholar] [CrossRef]
- Veena, G.; Vani, K.; Deepa, G. AGRONER: An unsupervised agriculture named entity recognition using weighted distributional semantic model. Expert Systems With Applications. 2023, 229, 120440. [Google Scholar] [CrossRef]
- Zhang, L.; Nie, X.; Zhang, M.; Gu, M.; Geissen, V.; Ritsema, C.J.; Niu, D.; Zhang, H. Lexicon and attention-based named entity recognition for kiwifruit diseases and pests: A Deep learning approach. Front. Plant Sci. 2022, 13, 1053449. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Lu, S.; Tang, Z.; Bai, Z.; Diao, L.; Zhou, H.; Li, L. CG-ANER: Enhanced contextual embeddings and glyph features-based agricultural named entity recognition. Computers and Electronics in Agriculture 2022, 106776. [Google Scholar] [CrossRef]
- Liu, Y.; Wei, S.; Huang, H.; Lai, Q.; Li, M.; Guan, L. Naming entity recognition of citrus pests and diseases based on the BERT-BiLSTM-CRF model. Expert Systems With Applications 2023, 234, 121103. [Google Scholar] [CrossRef]
- Liang, J.; Li, D.; Lin, Y.; Wu, S.; Huang, Z. Named Entity Recognition of Chinese Crop Diseases and Pests Based on RoBERTa-wwm with Adversarial Training. Agronomy 2023, 13, 941. [Google Scholar] [CrossRef]
- Jia, Y.C.; Zhu, D.J. Medical Named Entity Recognition Based on Deep Learning. Computer Systems and Applications 2022, 31, 70–81. (in Chinese). [Google Scholar]
- Du, J.; Yin, H.; Feng, S. Research and Development of Named Entity Recognition in Chinese Electronic Medical Record. Acta Electronica Sinica 2022, 50, 3030–3053. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
Figure 1.
Construction process of lexicon and pre-training word embedding.

Figure 2.
The architecture of PDCNER.
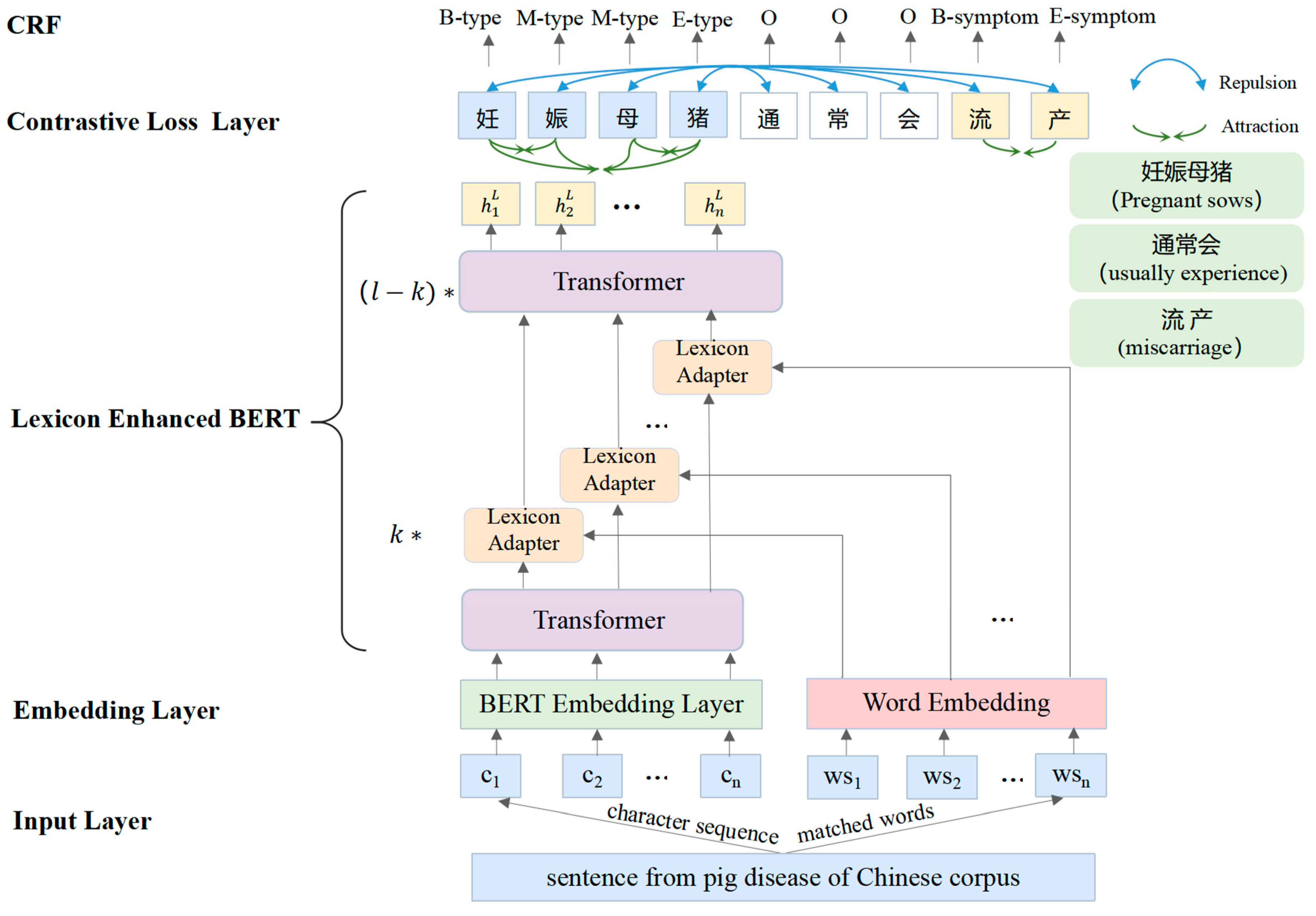
Figure 3.
Precision, recall, and F1-score of PDCNER in recognizing six major entities for Pig Diseases of Chinese Corpus.
Figure 3.
Precision, recall, and F1-score of PDCNER in recognizing six major entities for Pig Diseases of Chinese Corpus.
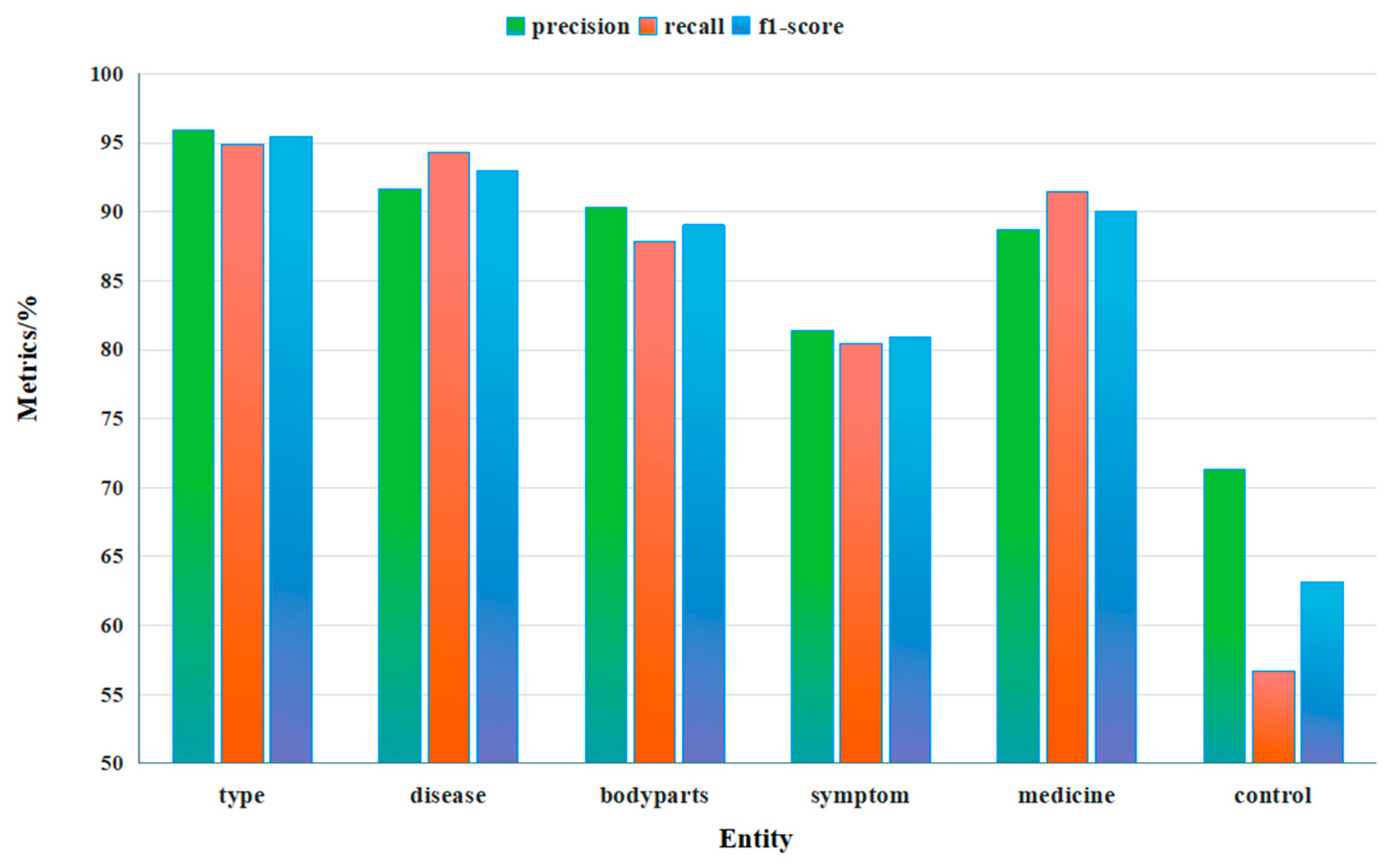
Figure 4.
Comparison of five models in 6 entities.
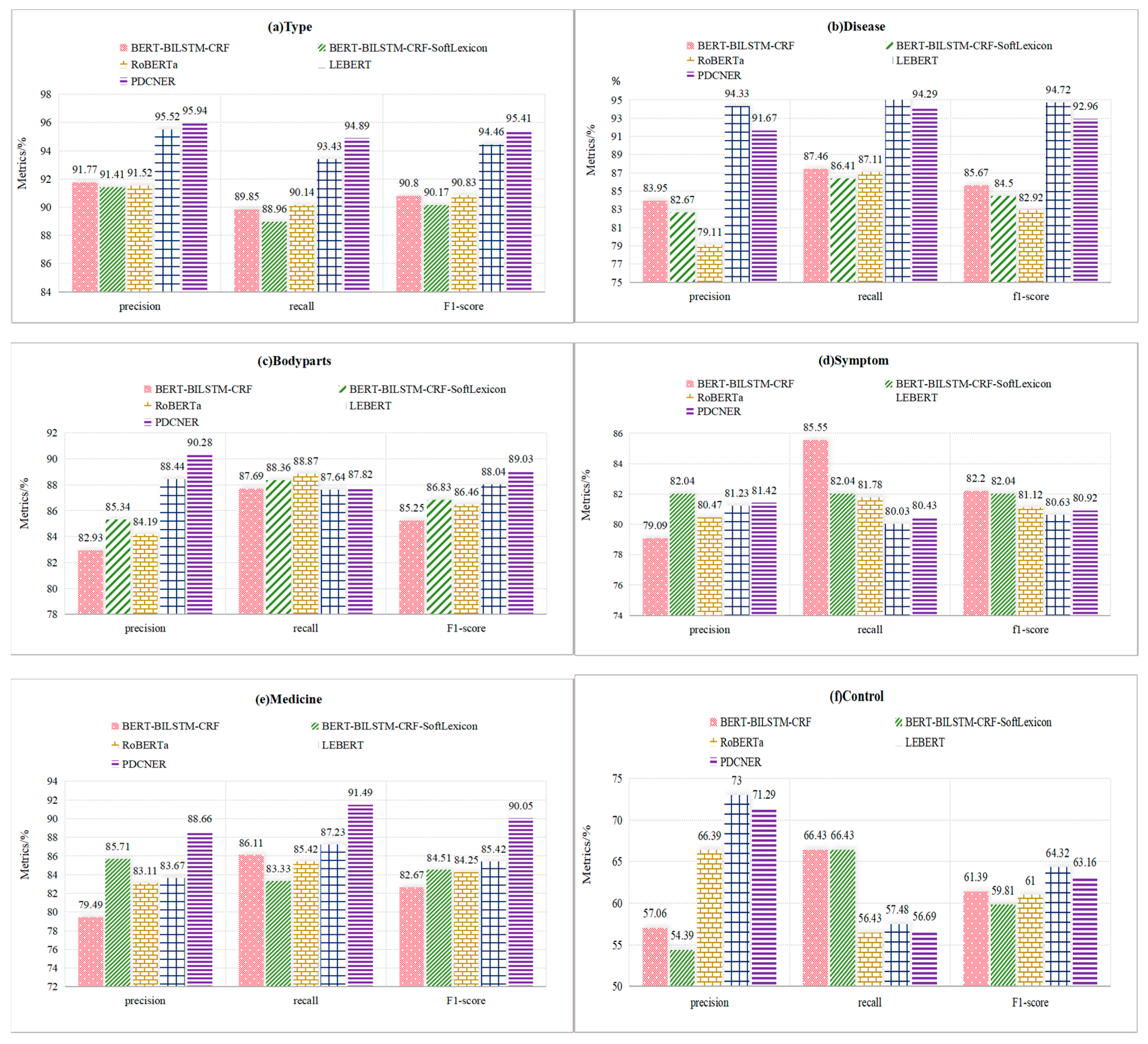

Table 1.
Statistics of annotated entities.
| Category | Category definition | Examples | Numbers | Proportion of the total |
|---|---|---|---|---|
| Type | Name of different types of pig | 妊娠母猪、仔猪(Pregnant sows,piglets) | 635 | 8.45% |
| Disease | Name of pig disease | 猪丹毒、胸膜炎(Porcine erysipelas, pleurisy) | 808 | 10.75% |
| Body parts | Body position, organs and system of pigs | 心脏、巨噬细胞(Heart, Macrophages) | 1865 | 24.81% |
| Symptom | External performance caused by diseases |
气喘、咳嗽、水肿(Asthma, cough,swollen) | 2973 | 39.55% |
| Medicine | Medications for treating diseases | 替米考星、克林霉素(Timicosin, clindamycin) | 689 | 9.16% |
| Control | Measures for preventing and treating diseases | 隔离、消毒(Isolation and disinfection) | 548 | 7.29% |
| Total | 7518 | 100% |
Table 2.
Comparison of experimental results for different NER models.
| Model category | Model | P(%) | R(%) | F1(%) |
|---|---|---|---|---|
| baseline model without pre-trained | BILSTM_CRF | 75.17 | 72.29 | 73.7 |
| pre-trained model | BERT-BiLSTM-CRF | 80.94 | 85.04 | 82.94 |
| BERT-CRF | 84.02 | 82.7 | 83.36 | |
| BERT-CNN-CRF | 80.98 | 85.14 | 83.01 | |
| BERT-WWM-ext | 80.81 | 83.83 | 82.29 | |
| Roberta | 82.28 | 84.18 | 83.22 | |
| pre-trained model with lexicon | BERT-BILSTM-CRF-SoftLexicon | 82.49 | 84.36 | 83.41 |
| LEBERT | 86.47 | 84.64 | 85.54 | |
| PDCNER(ours) | 86.92 | 85.08 | 85.99 |
Table 3.
Results of PDCNER.
| Type | Disease | Bodyparts | Symptom | Medicine | Control | |
|---|---|---|---|---|---|---|
| Precision | 95.94 | 91.67 | 90.28 | 81.42 | 88.66 | 71.29 |
| Recall | 94.89 | 94.29 | 87.82 | 80.43 | 91.49 | 56.69 |
| F1 | 95.41 | 92.96 | 89.03 | 80.92 | 90.05 | 63.16 |
Table 4.
Results of the few-shot experiments.
| Model | 1% | 10% | 30% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-BiLSTM-CRF | 31.79 | 1.80 | 3.41 | 65.75 | 76.30 | 70.63 | 76.95 | 81.18 | 79.01 |
| LEBERT | 17.39 | 11.43 | 13.79 | 74.81 | 83.47 | 78.91 | 74.05 | 80.14 | 76.97 |
| PDCNER(ours) | 18.18 | 11.43 | 14.04 | 84.43 | 85.12 | 84.77 | 86.08 | 84.70 | 85.39 |
Table 5.
Results for each model on public datasets.
| Model | Ontonotes | Resume | |
|---|---|---|---|
| BERT-BiLSTM-CRF | 69.13 | 82.11 | 95.89 |
| LEBERT | 74.91 | 86.07 | 96.68 |
| PDCNER(ours) | 76.38 | 86.44 | 96.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



