
Submitted:
06 June 2024
Posted:
10 June 2024
You are already at the latest version
Abstract
Simple Summary: 200 words Will biology, including humans, benefit or harm from new developments in information such as artificial intelligence (AI). First, are biology and information different? Life is an ordered form that can reproduce, maybe with variation; and any ordered arrangement, biological or not, potentially contains information. There have been ordered forms since earth was just a ball of chemicals, and some such chemicals can reproduce. So biological and non-biological information might be components of a unified process, ‘PanEvolution’ or ‘Pan-Evo’, based on the same four operations for living or non-living entities - Innovation; Transmission and replication; Adaptation; and Movement. This can produce separate groups called ‘species’. In a current Panspeciation event, information held in biology - especially our brains - is moving into its own environment. Harm to biology might be minimal if humans and AI both behave intelligently, because vastly different environments are optimal for humans and machines containing AI. This would be the first speciation-like event involving humans for millennia, but will not be particularly hostile to humans, if humans learn how to evaluate information and cooperate, to minimize the effect of both human stupidity and artificial simulated stupidity (ASS – a failure of AI). Abstract: 200 words Many people wonder whether biology, including humans, will benefit or harm from new developments in information such as artificial intelligence (AI). Biological and non-biological information might be components of a unified process, ‘Pan-Evolution’ or ‘Pan-Evo’, based on four basic operations – Innovation, Transmission, Adaptation, and Movement. Pan-Evo contains many types of variable objects, from molecules to ecosystems. Biological innovation includes mutations and behavioural changes; non-biological innovation includes naturally-occuring physical innovations, and innovation in software. Replication is commonplace in and outside biology, including autocatalytic chemicals, and autonomous software replication. Adaptation includes biological selection, autocatalytic chemicals and ‘evolutionary programming’ used in AI. Extension of biological speciation to non-biological information, creates a concept called ‘Panspeciation’. Panevolution might benefit or harm biology, but harm might be minimal if AI and the humans behave intelligently, because humans, and the machines in which AI resides, might split to the vastly different environments that suit them. That is a possible example of panspeciation, and would be the first speciation event involving humans for thousands of years. This event will not be particularly hostile to humans, if humans learn to evaluate information and cooperate better, to minimize both human stupidity and artificial simulated stupidity (ASS – a failure of AI).
Keywords:
information
; artificial-intelligence
; evolution
; speciation
; autocatalysis
1. Introduction
Many people are wondering whether biology, including humans, will find benefit or harm in new developments in information, including artificial intelligence (AI) [1,2,3,4,5,6,7]. Such a question appears to identify biology and information as separate things. However, since the middle of last century, it has been pointed out that biology frequently (some would say always) is based on various types of information [8,9,10,11,12,13,14,15,16,17,18,19,20]. Despite the pervasiveness of information in biology, biologists have been slow to incorporate approaches used for non-biological information, or to recognize when information-related approaches are used frequently in biology, such as the most commonly-used frequency-sensitive biodiversity index, Shannon [21]. This article discusses important parallels and connections, pointing out the possibility that biological and non-biological information might be components of a unified process of information evolution, which has been proceeding since before biology existed. This process could tentatively be named ‘PanEvolution’ or ‘Pan-Evo’. Such naming would recognize that all information, inside or outside biology, is involved in the same four basic processes [20] (Figure 1) :
- -
- Innovation
- -
- Transmission and replication, including the random processes therein
- -
- Adaptation, and processes such as selection that often produce adaptation
- -
- Movement
A similar set of common processes have been proposed for ecology and evolution by Vellend [22], and for cultural evolution by Muthukrishna [23]. Often several of these processes will be operating simultaneously, at one or more levels, each of which may incorporate biological and/or non-biological aspects, such as molecules, individuals, populations, species, and ecosystems [22,24,25,26,27,28,29]. Of course, ecosystems include not only biology, but all the physical aspects of the world. This article will first present ideas about information, life and intelligence, then consider each of the four processes above, showing commonalities for biological and non-biological information. Next, there will be discussion of how these four processes might result in speciation, biological and non-biological. Finally, this article will examine how artificial intelligence could possibly benefit or harm biology, including humans, stressing that AI might not spell doom for humans, if AI actually becomes intelligent.
2. Information, Life, and Intelligence
Of course, one must set out what is meant by ‘information’ and ‘life’, and it turns out that both relate to order (versus disorder) and a related concept called ‘entropy’, and what is more, there is only a rather blurry distinction between ‘information’ and ‘life’. After discussing that, we will consider ‘intelligence’.
The important point for this article is that any ordered arrangement, whether biological or not, can be considered to potentially contain information. ‘Information’ is related to entropy, which can be thought of as the potential of any collection of objects or symbols to code a message. In Shannon’s paper [30] that many regard as the origin of information theory, his title makes it clear that a message must be communicated (“The mathematical theory of communication”). Thus the measure he uses in that paper, derived from thermodynamics, is a measure of the potential for some assemblage to carry information, but its informativeness depends upon decoding by a recipient of some kind. In other words, informativeness depends not only upon what ordered arrangements can be made from the subunits, but also on the availability of a person or system that can make use of the ordered arrangement – receive knowledge, or change its state in some other way. Let us look at four groups of fourteen possibly informative letters, and a measure of each group’s order or disorder, called Shannon entropy (in natural log scale) [30].
- -
- oooooooooooooo Entropy = zero
- -
- ooooooohhhhhhh Entropy = 0.69
- -
- oooyhaerlelhwu Entropy = 2.11
- -
- hellohowareyou Entropy = 2.11
The first group has little potential to code information, and its entropy is low. The other groups have higher entropy and higher potential to code information. The group with the second lowest entropy could likely code only a small range of messages, in English or any other system. The two highest entropy groups can potentially code many messages, and contain the same letters, in different orders. For a recipient who speaks English, the last group actually does encode a message “hello how are you”, but that group has the same entropy as the other high-entropy group, which is just nonsense. Thus, it is not entirely satisfactory to take entropy as a measure of information, because anything’s informativeness always depends upon that thing’s ability to be interpreted (and possibly used) by a recipient [8]. For the purposes of this article, ‘information’ will be taken to denote some kind of order that can potentially code for a meaning, to an appropriate recipient, who has not necessarily been identified yet.
Next, what is the definition of ‘life’? Often this definition hinges on maintenance and transmission of order - roughly the opposite of entropy. Again, there are many definitions, although many researchers consider that life is defined by the ability to use energy and materials to create and maintain some ordered form that can reproduce itself with variation [31]. However, it will be seen below that many things that are conventionally regarded as non-living have all these functions, often simultaneously. So is there a boundary between living and non-living, and if so where is it? Viruses are often said to be on this boundary, because although they can indeed use energy and materials to create and maintain some ordered form that can reproduce itself with variation, they can only do this within a host cell. That seems to be a very arbitrary decision, because some other parasites can only do those things inside a host cell, including bacteria in the rickettsias or mycoplasmas.
How to apply these notions to Pan-Evo, which necessarily will contain a wide variety of types of object - molecule, individual, ecosystem, etc - plus the variants within each category, such as isomers of molecules, different species in an ecosystem, or different variants within a species? Dealing with this array of possibilities requires definition and quantification of the units (eg individual) [29,32,33]. One approach to this definition comes from assembly theory; in this theory, each object can be characterized by the assembly index, which is the minimum number of steps needed to construct the object. In the past it was proposed that assembly theory be used to distinguish biological and non-biological entities, but this is not widely accepted, and now the index, and the number of copies for each type, might be used to describe evolution in biology or outside it [34]. However, note that two very different types of object might have identical assembly indices, so it is necessary to add the relationships between the objects, as defined by whether there are common components in the assembly pathway, and how many are shared [35]. Examples of pathways might be a molecule’s non-biological synthesis mechanism (natural or artificial), or part of a biological phylogenetic tree, as shown in Figure 2. In Figure 2 it can be seen that the number of steps is an inadequate summary of the differences between the entities produced. For example, in Figure 2a, starting from the same component there are two steps in the assembly tree of A and also for C, but the intermediate component is not shared, so that A and C would not be classified as being the same chemical simply because their assembly paths are the same length. Similarly, in Figure 2b, the number of steps might need to be adjusted by upweighting some steps that are chemically more challenging (transversions), also the alternative pathways and back-mutation show that the number of steps is not a complete summary of the assembly tree.
Finally, what is ‘intelligence’, and could it occur inside or outside life? The Oxford Dictionary defines it as “the ability to acquire and apply knowledge and skills”, and if we substitute ‘information’ for ‘knowledge’, we will see below that some living and non-living systems can do this. However, not all systems display intelligence, even in humans, as set out in a paper discussing ‘Natural Stupidity’ [4]. Some think it likely that AI will never develop the same quality of intelligence that humans have, being already set on a course to become very ‘intelligent’ at some tasks, but appalling at other tasks that we regard as simple [36]. This mimics the way that individual humans vary in their ability to display intelligence in different settings.
3a. Innovation in Biology
Biological variation derives from mutations in the DNA, with mechanisms ranging from single base (A,T,G,C) substitutions deletions or insertions, to larger rearrangements, plus variation that does not involve base changes, called ‘epigenetic’, as well as changes that do not directly relate to DNA, such as behavioral variation [37,38]. Whether each of these is transmissible is discussed later. Secondarily, but usually much faster than mutation, innovation can occur through recombination: the exchange of information by physical breakage and reunion of the DNA string of information, to unite variants that were previously on separate DNA molecules (or ‘haplotypes’). In relatively short stretches of DNA (eg a megabase), recombination rates are low, so haplotypes can persist and sometimes may have great adaptive significance [20].
Mutation models could also be employed as approximations for the production of novel variants at other biological levels. For example, at the ecological level, some models (eg single nucleotide substitution, or stepwise mutation) might be used as models of speciation that occurs by the alteration of a single character, such as the ‘magic traits’ discussed in the speciation literature [20,26,39]. On the other hand, models that assume that every new variant is unique (eg the infinite alleles model) might be more appropriate for species that occur via multiple changes that accumulate during a period when two parts of a single species’ range are separated by a barrier [20,26,39].
3b. Innovation outside of Biology
There are many examples of innovation in the physical world; assembly theory (above) enables us to categorize these. As well as naturally-occurring physical innovations, human-guided innovation is obvious, in software programming, etc. Moreover, many software programs are now being altered by allowing the system to make random alterations to its own information, deliberately mimicking biological mutation and recombination, as part of what is called ‘evolutionary programming’ and ‘neural networks’, discussed further below as part of non-biological adaptation [40]. There is plenty of evidence that AI is becoming more and more integral to innovation, though some suggest that AI may never be able to autonomously do what humans consider invention (of course AI may have its own standard of invention) [41]. Also, AI is free of many constraints of biological transmission and replication, for example AI’s massive replication means that a bad change is not serious – such a change is easily weeded out by assessment of its (poor) performance – see ‘5b Adaptation outside biology’.
4a. Transmission and Replication in Biology
In biology, many of the variants described above can be transmitted. Transmission might be to offspring through mechanisms such as inheritance of DNA or epigenetic modifications, but also through mechanisms such as inheritance of a suitable nest-site [38,42,43]. Moreover, the nervous system, although ultimately based in DNA-code, can be modified by learning from non-relatives, the basis of much of cultural evolution [23]. There are three fundamental replication modes: the exponential type seen with cells or individuals; the autocatalytic (hyperbolic) type seen with some macromolecules; and the template-dependent (parabolic) type, as seen with nucleic acids [44]. Expression of these modes is often restricted, such as nucleic acids only replicating as a synchronous part of a cell replication cycle. Other molecules are partly independent of that cycle, including viruses, epigenetic modifications, and prions.
4b. Transmission and Replication outside Biology
The modes of transmission and replication just described also happen to ordered structures outside biology, especially by autocatalysis, which is when the product(s) of the reaction speed the reaction, and thus catalyze their own synthesis (Figure 3 [45]). Autocatalysis can occur either by the molecule acting as a template, or by other means, and of course is dependent upon availability of the raw materials. A huge range of molecular types, and mixtures thereof, can show autocatalysis [46]. Such non-biological replication can also involve more than one molecule. Intriguingly, such interactions may have been involved in the origin of the genetic code; aptamers are nucleic acids bound to specific target molecules, and one such aptamer includes the codon for arginine, and preferentially targets binding to arginine [47].
Also, artificial intelligence is moving towards achieving fully autonomous replication, with no human involvement (except perhaps provision of energy), plus the mutation and recombination discussed in the previous section. Electronic information can be programmed to use any of the replication modes above, and we see this replication everywhere, including in the computer-malware that we all seek to avoid. For example, in Generative Adversarial Networks, if one system has been devised or trained to make certain decisions (eg “this is/is not a picture of a bus”), another electronic system can, after slightly variable replication, be assessed by the second system on its ability to make the same decisions, and after many repetitions of this process the second system can become equally good at making such decisions, though perhaps with some differences in the underlying code [48]. This rapid, massive process of trial-error-replication gives AI enormous power at many tasks.
5a. Adaptation in Biology
Selection is the consequence of the fact that heritable variant entities that are better at converting resources into replicates inevitably become more numerous. In biology there are copious examples of natural or artificial selection, for example to ambient temperatures. Often selection results in organisms that are said to be optimally adapted to the environment, within various constraints, such as the availability of appropriate variants for the selection to act upon, and tradeoffs between opposing selective pressures such as: mate-choice versus cost of the mating signal; number of offspring versus size of offspring; and the difficulty of adapting to seasonal or long-term fluctuations in the environment [49]. There is also non-heritable adaptation such as behavioral avoidance of harm, including an excessively hot or cold temperature. In all adaptation, there are two types of information in play: the information available from the environment, such as the ambient temperature, plus the information in the organism including non-heritable information such as learned behavior, as well as all heritable information such as DNA sequence and some epigenetics. There is an interaction between probability of various occurrences in the environment, and the payoff expected if each occurs, after an individual has taken one of several available courses of action, such as transmission of one or the two allelic versions of a gene that the individual possesses, or taking some evasive action. The result is quite complex, but in some cases it is worth the individual’s effort to acquire more information about probability and occurrence, because it can improve the outcome [50]. This can be addressed by a variety of entropic methods [20,51,52]. Such approaches are not confined to variation within species - a maximum entropy approach is also used for species-assemblages [53].
5b. Adaptation outside Biology
Non-biological autocatalytic systems can show adaptation, in which there is competition between similar chemicals produced by factors such as radiation. Those that persist or reproduce better become more numerous. An example is the reaction shown in Figure 3, where an autocatalytic chemical can be altered by irradiation, to make a new chemical whose autocatalysis outcompetes its ancestor chemical [45].
As seen above in discussion of generative adversarial networks, some software-development is now using a form of adaptation: accepting or rejecting random alterations to the information in the code, based upon autonomous training that, with the other three basic processes, leads to ‘evolutionary programming’ and ‘neural networks’ [40] including ‘Artificial Intelligence’ [54,55]. Hopefully the information that is available for training will be as unbiased as possible, but bias could be provided deliberately or inadvertently by humans, who are not known for their impartiality, as set out in a paper discussing ‘Natural Stupidity’ [4]. For example, Google’s ‘AI Overviews’ tool has recently recommended adding glue to pizza, and eating rocks [56]. One might hope that software engineers would be sufficiently logical to avoid such pitfalls, but it is worth noting that for one or two decades, a system of software engineers plus marketers gave us a major operating system in which, to stop it, you clicked on a button labelled ‘start’; there are many other such examples. Recently, there has been a plea for engineers designing electronic information systems to make greater use of long-standing methods by which biological systems handle information [57]. For example, it is expected that communications systems involving satellites and terrestrial transmitters would operate better if they used a type of selection amongst varying signals: transmission would be prioritized for signals with low signal-to-noise ratio [58].
6a. Movement in Biology
Movement is commonplace in biology, including the heroic annual there-and-back migrations of some birds and butterflies [60], as well as the often much shorter lifetime dispersal from place of birth to place of breeding. Even apparently immobile species such as plants have extremely mobile life-stages, such as seeds and pollen.
In fact, movement directly affects biological information. Briefly, for any pair of locations, lower dispersal from place of birth to place of breeding, smaller population size, or greater time since separation will result in less sharing of molecular variants (‘alleles’ or haplotypes’) between locations, so that knowing the allele typed from an individual gives better information about that that individual’s geographic origin, which is called greater ‘mutual information’ between variant identity and location of origin [16,17].
6b. Movement outside Biology
Outside biology, it is also common to see movement of structures that show some order, and thus have information-coding potential. This occurs at scales from molecular diffusion through winds and currents up to tectonic plate movements and astronomical processes. AI-related entities can also move, such as robotic soccer-players, self-drive cars, and rovers on the surface of the moon or mars. Of course, information can also move through means such as wires or radio transmissions, without any physical movement of structures.
Reaction–diffusion models typically include the change in space and time of the concentration of one or more chemical substances, due to the interplay of chemical transformations and diffusion; the usefulness of these models has been demonstrated in one-dimensional and two-dimensional experiments [61]. Reaction–diffusion models can also be useful descriptions of some processes involving biological information-carrying entities, such as development of phenotypes [62], ecological invasions and epidemics [61], and transmission of information in nerve pulses [63].
7a. Speciation in Biology
Speciation is thought to often involve all of the four processes: innovation, transmission/replication, adaptation, and movement. Typically, there will be generation of variant information, via mutations or via recombination producing new combinations of existing variants. The frequency of these variants will be modified by stochastic processes, and possibly by adaptive changes. At the same time, there may be movement to and from different environments, where different variants might be adaptive. The process is usually considered to take place over multiple generations [39]. But how we assess whether speciation has been achieved is subject to much debate; Mayr’s Biological Species Concept (also sometimes reproductive or isolation concept) is characterized as “groups of actually or potentially interbreeding natural populations, which are reproductively isolated from other such groups” [64]. Such species might also be called a group of individuals that preferentially affect each other’s heritable information by transmission between individuals, with less emphasis on affecting information by other methods such as competition, cooperation or predation. There are many alternative definitions of a species, most of which attempt to focus on one or more of the logical consequences of the divisions envisaged by Mayr, such as discontinuity of the distributions of physical or genetic characteristics [39]. This avoidance of Mayr’s definition is because diagnosis of species using that definition requires such an overwhelmingly large testing effort. Considering only eukaryotic species, there are potentially ~5 +/- 3 million species [65]. If for each of those 5 million species, we tested it against the nine most closely-related potential species, then there would be tens or hundreds of millions of tests needed, each test following two generations of hundreds of crosses between the potential species, plus a similar number of control crosses within potential species. This is clearly not achievable – a review found less than 1000 such investigations in eukaryotes [66]. Therefore, most species definitions attempt to avoid crosses and use some easier method to approximate Mayr’s idea of a species [39]. Also some authors avoid the species concept altogether, preferring to discuss ‘taxa’, ‘evolutionary significant units’ or ‘management units’ [67,68].
It is worth pointing out that there is similar difficulty of defining species outside the eukaryotes, where there are several other ways of facilitating or limiting exchange of information between groups of microorganisms. Lan and Reeves [69] echo Mayr by saying that for microbial taxonomics “a major factor in maintenance of species specificity ... is the existence of a recombination barrier between species”, and then their article discusses many alternative methods of delineating microbial species, all of which are also frequently used in eukaryotes [69].
7b. Speciation outside Biology
It is always difficult to think about the future – it is said that in the 1940s, IBM’s president thought that in the long-term, there would be a global market for a total of about five computers [70]. Moreover, at present some of the most-developed systems in information, large language models (LLMs, eg Chat-GPT) are still susceptible to hallucination, which like human hallucination, is when the LLM produces text that is “nonsensical, or unfaithful to the provided source input” [71]. Nevertheless, we have consistently seen IT developments overcome barriers, and outperform positive predictions. Thus it is likely that non-biological information will evolve to become increasingly sophisticated at autonomous innovation, replication and transmission, adaptation and movement. Given that these four functions underly all biological evolution, including biological speciation, it is worth asking how Pan-speciation might occur within the non-biological realm, or between biology and non-biology.
How could we extend the species concept beyond the biological realm? And what should we call such a process when defined both inside and outside biology? Note that the words ‘species’ and ‘speciation’ are not exclusive to biology, being used in chemistry, geology etc, and there is a general need to identify the limits to the units that we are discussing [33]. However, perhaps a new name is needed to encompass the related processes that happen within and outside biology, and I suggest ‘Panspeciation’ and ‘Panspecies’. Rather than trying to extend each competing version of the species concept within biology, one might extend Mayr’s general species concept in the following way: that members of the same panspecies should be able to influence other members of the same panspecies more by exchange of information than by other processes such as competition, whereas members of different panspecies influence members of other panspecies more by processes such as competition, cooperation or predation rather than exchange of information. As with the species-definition within biology, the experimental work necessary to validate panspeciation might be inaccessible for some reason, in which case there are similar approaches to avoid that experimental work. For example, the idea of a panspecies might be related to compatibility of particular groups of software and hardware, whether generated by humans or by AI [72]. Also, the panspecies definition might be based on the assembly theory mentioned previously, so that a panspecies would be an ensemble of objects that have more common steps in their construction that they have with objects outside the panspecies (Figure 2).
8. Integration of Non-Biological and Biological
There have been some explicit attempts to integrate biological and non-biological information. Often these rely upon the idea that certain systems of equations will give a common currency to be used across biological and non-biological evolution and ecology. Examples abound. One is the commonality of biological and automaton self-replication, including importance of replication of the information [73,74]. Another example is the similarity of ‘drift’ in gas or electron mechanics to ‘selection’ in biology (despite that fact that the term ‘drift’ is used for a non-directional process in population genetics [75,76]. Another example is the similarity of equations for Boltzmann’s thermodynamic equation and Shannon’s information equation [51], which is appealing because biological processes always have some underlying energetic basis [77]. However simply showing that two equations have a similar form does not mean that they represent the same thing [78]. In a similar vein, there have also been attempts to unify the analysis of biological processes across scales from genes to ecosystems [22,25,26,27], and possibly this might be extended into non-biological systems, with appropriate caution.
In particular, O’Connor et al. [8] attempt to integrate the analysis of information, energy, and materials, and suggest that biology is an emergent property of information processing systems, at multiple scales. They stress that behavior of the system will depend upon the available information, and that units of selection might extend beyond the biological individual.
An obvious point of commonality is the way that biological processes might have evolved out of non-biological processes. Autocatalysis appears from industrial application through to possible pre-biotic evolution [79]. Autocatalytic RNA molecules can undergo mutation, recombination, and selection [80]. Transfer-RNA activities are not limited to protein translation, but also have other functions, particularly in viruses where they can be involved in replication, reverse transcription, and as telomeres (chromosome ends) [81]. Other non-RNA self-replicators are being used to build denovo life [82]; for example, catalytic DNA is more stable than RNA, so favored industrially [83].
9a. Possible Benefits to Biology Including Humans
There has been much recent discussion of artificial intelligence (AI) and whether it might cause a ‘singularity’, perhaps even human extinction [3]. Of course, if humans are actually intelligent (though see [4]) they will devise effective regulation to limit societal harms of AI [1,2,84]. Irrespective of such regulation, AI might even help humans, if AI actually becomes intelligent.
It has been pointed out that the interaction of heritable evolutionary changes and cultural changes might have given rise to humans’ extraordinary ability to cooperate with non-kin in huge groupings, leading to our present dominant status; in particular, the different transmission methods of genes and culture might have allowed such groups to maintain cultural cohesion without genetic relatedness [85]. Of course, everything in current information technology is part of human culture, or a derivative thereof, so this symbiotic relationship might continue to prosper. If we accept that life derived from information’s evolution, but that we have so far mainly focused on understanding evolution of living systems, we might see benefits in broadening our investigation to the evolution of all information, including the possible future.
Information change in biology and in the physical world might both be managed for our benefit. An example of this would be to manage two evolutionary challenges: delaying adaptation of pathogens pests etc, and speeding adaptation of valued organisms [86]. However note that this will require careful regulations, because of the ever-present possibility of disagreement between individual and public good [86], as well as the possibility that AI might not help us, but instead hinder us, if AI is non-intelligent. Other possible benefits include the use of artificial replicators to build denovo life [79,82], and the use of assembly theory for drug discovery [35], and information theory to predict the likely phenotypic effects of novel mutations before they are manifest in the next generation, either natural or in-vitro [87]. Finally, information-based analyses can assist our analysis and forecasting of natural processes at many levels [20,40,51,88].
9b. Possible Threats to Biology Including Humans
AI might pose several possible threats to biology including humans, including human-AI coevolution, and direct competition that is discussed in the next section. An example of potential human-AI coevolution would be if AI takes over more tasks, such as your car identifying that its brakes need fixing and driving itself off to get repaired. (Hopefully the AI will not decide that you want the cheapest brakes!) As a result, there might be selection against maintaining brain parts or functions that do things AI can do for us. This selection against certain brain functions or regions might be driven by the energetic expense of running a large brain [89], and possible risks to mother and child during the birth of a baby with a large head [90,91]. Thus what is initially a mutually beneficial arrangement might gradually result in increased dependency of humans upon AI, especially given the attention-getting strategies of AI [59]. However, note that currently undesirable allelic variants (eg for small brain) are usually recessive and rare, and therefore it could take thousands of generations for such selection to change allele proportions very much.
This article does not intend to extensively discuss what regulations are currently needed for AI, but there are some obvious ones, such as banning lethal AI, and a number of measures to increase trustworthiness in AI, including requiring each piece of information to have prominent identification of the humans or machines that generated it, which would limit malign influence in politics or elsewhere [36]. This regulation will of course be anthropocentric, and will only be achievable if humans themselves behave intelligently [4]. Thus there is a need for education of humans, to better understand how we should be evaluating information and its sources, as well as improving cooperation. This will minimize the effect of human stupidity [4] and avoid producing artificial simulated stupidity (ASS). We are, or can be, in charge of this process, and need to act [23].
10. AI, Competition, and Panspeciation
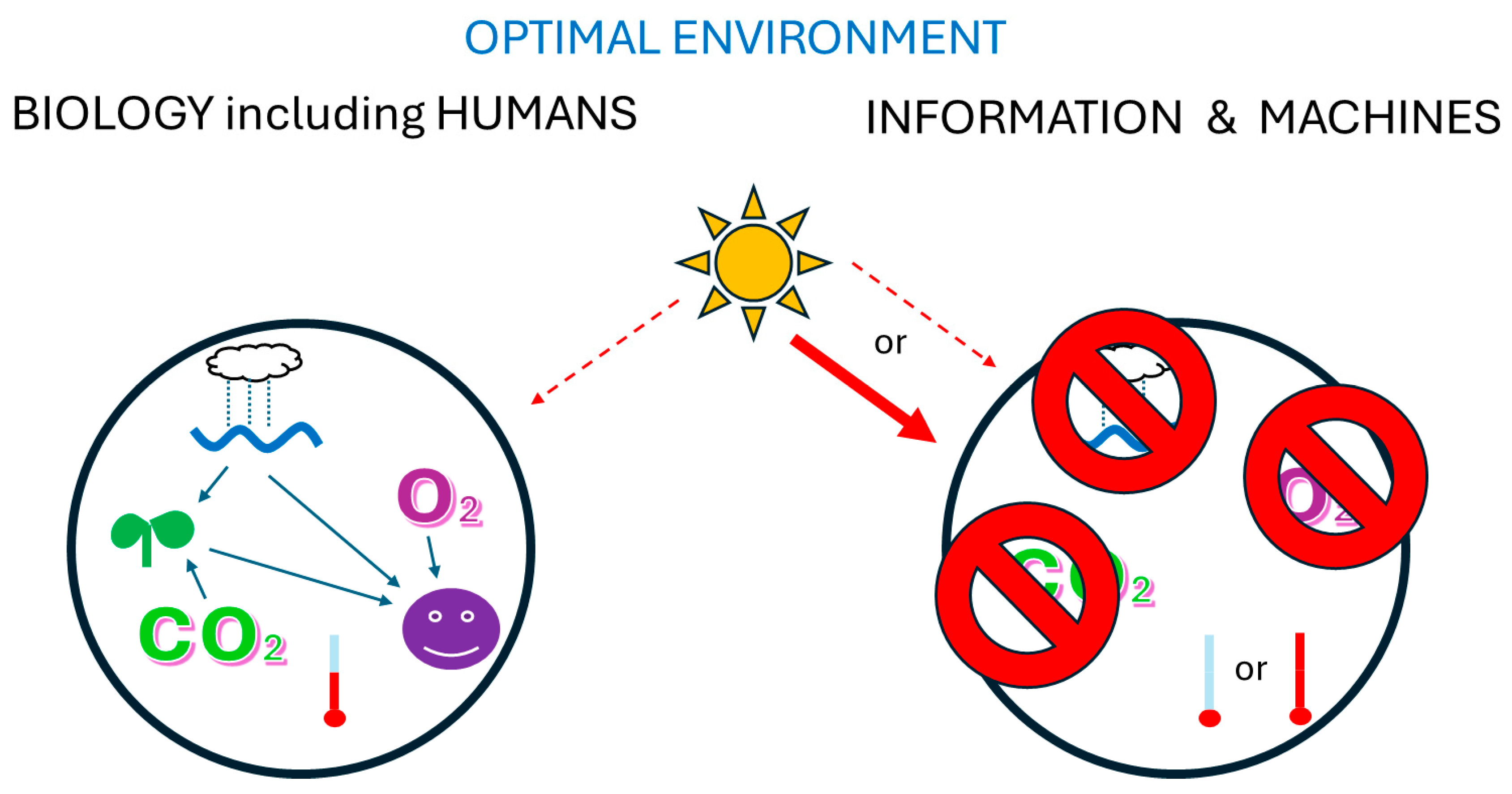
In biological evolution, distinct lineages often evolve to occupy different environments [39,92]. Note that humans and machines are best suited to vastly different environments (Figure 4). Humans require things that damage computers and other machines: copious water, Oxygen, and Carbon Dioxide for their food plants. Also machines can also be manufactured to tolerate a much wider range of temperatures and radiation than humans. Thus, environments most favorable to humans are present on much of Earth, whereas environments more favorable to machines are scarce on Earth, but abundant elsewhere, such as the Moon and Mars. So, if AI is actually intelligent, competition might be minimized because machines might principally seek different environments to humans [5]. Of course, we might continue other human/machine interactions that do not need physical proximity.
As machines improve at operating their own design and production, the information that previously resided in humans’ minds might diverge into two groups with independent transmission of information, some still transmitted by humans, some entirely independently transmitted - would we call that ‘incipient panspeciation’? As stated above, we often say that two groups belong to different species if their internal interactions have greater emphasis on transmission of information whereas between-group interactions have greater emphasis on competition, cooperation or predation. Diagnosis of separate species status is especially likely if the groups also display environmental segregation [39,92], as just postulated. If this comes to pass, then humans and machines might show relatively little competition because of their different favored environments (Figure 4). Thus spatially-separated coexistence might be possible, depending on the variation in humans and AI – both the differentiation between the average members of each group, and the variation within each group, which also affects competition and cooexistence [93,94].
11. Conclusions
If someone might like to use the word ‘panspeciation’ to describe the splitting of information into that carried by humans and that carried by AI and its successors, then we are currently in the early stages of the first speciation-like event involving Homo sapiens for many thousands of years. But it would not be particularly hostile to humans, if AI is actually intelligent.
At present, the only likely source of Artificial Intelligence is from human-run brains and organizations. For various reasons, this situation may not last, but it means that we currently have the capacity to limit any harm, if we wish to do so. In particular, it will be important to be quite sure of what we mean by ‘intelligence’, and make sure that it is possessed by not only by AI but also by those humans who manage AI, so that both can see the benefits of partitioning the environment, rather than competing.
Author Contributions
Sherwin is the sole author.
Funding
This research received no external funding.
Acknowledgments
A draft of this paper was reviewed by Rob Brooks, Joseph Cincotta, and Angela Moles, who all made valuable comments.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Anonymous. AI Special Issue: A machine-intelligent world. Science 2023, 381.
- Anonymous. EDITORIAL: Stop talking about tomorrow’s AI doomsday when AI poses risks today. Nature 2023, 618, 885–886. [Google Scholar] [CrossRef]
- Federspiel, F.; et al. Threats by artificial intelligence to human health and human existence. BMJ Global Health 2023, 8, e010435. [Google Scholar] [CrossRef]
- Rich, A.S.; Gureckis, T.M. Lessons for artificial intelligence from the study of natural stupidity. Nature Machine Intelligence 2019, 1, 174–180. [Google Scholar] [CrossRef]
- Sherwin, W.B. Singularity or Speciation? ’ A comment on Lazar S & Nelson A. 2023. ‘AI safety on whose terms? Science 2023, 381, 138. [Google Scholar]
- Omohundro, S.M. The Basic AI Drives. Artificial General Intelligence 2008, 171, 483–492. [Google Scholar]
- Yudkowsky, E.; et al. Reducing long-term catastrophic risks from artificial intelligence. 2010, San Francisco: Machine Intelligence Research Institute.
- O’Connor, M.I.; et al. Principles of ecology revisited: Integrating information and ecological theories for a more unified science. Frontiers in Ecology and Evolution 2019, 7, 219. [Google Scholar] [CrossRef]
- Schrodinger, E. What is Life? Cambridge University Press: Cambridge, 1944.
- Margalef, R. Diversidad de especies en las comunidades naturales. Publicaciones del Instituto de Biología Aplicada 1951, 9, 5–27. [Google Scholar]
- Branson, H.R. Information theory and the structure of proteins, in Information theory in biology; Quastler, R. (Eds.) ; Univ Illinois Press: Urbana, 1953; pp. 84–104.
- Lewontin, R.C. The apportionment of human diversity. Evolutionary Biology 1972, 6, 381–398. [Google Scholar]
- Ewens, W. Mathematical population genetics. 1979, Berlin: Springer-Verlag.
- Ewens, W.J. The sampling theory of selectively neutral alleles. Theoretical Population Biology 1972, 3, 87–112. [Google Scholar] [CrossRef]
- Caswell, H. Community structure: A neutral model analysis. Ecological Monographs 1976, 46, 327–354. [Google Scholar] [CrossRef]
- Sherwin, W.B.; et al. Information Theory Broadens the Spectrum of Molecular Ecology and Evolution. Trends in Ecology and Evolution 2017, 32, 948–963. [Google Scholar] [CrossRef]
- Sherwin, W.B.; et al. Correction: Information theory broadens the spectrum of molecular ecology and evolution. Trends in Ecology and Evolution 2021, 36, 955–956. [Google Scholar] [CrossRef]
- Sherwin, W.B.; et al. Measurement of biological information with applications from genes to landscapes. Molecular Ecology 2006, 15, 2857–2869. [Google Scholar] [CrossRef]
- O’Reilly, G.D.; et al. Predicting Shannon’s information for genes in finite populations: New uses for old equations. Conservation Genetics Resources 2020, 12, 245–255. [Google Scholar] [CrossRef]
- Sherwin, W.B. Entropy, or Information, Unifies Ecology and Evolution. Entropy 2018, 20, 727. [Google Scholar] [CrossRef]
- Buddle, C.M.; et al. The importance and use of taxon sampling curves for comparative biodiversity research with forest arthropod assemblages. Canadian Entomologist 2004, 137, 120–127. [Google Scholar] [CrossRef]
- Vellend, M. The Theory of Ecological Communities (MPB-57). Monographs in Population Biology. 2016, Princeton: Princeton University Press.
- Muthukrishna, M. A theory of everyone. 2024, London: Basic Books.
- DeLong, J.P.; et al. Beyond individual, population, and community: Considering information, cell number, and energy flux as fundamental dimensions of life across scales. . Ideas in Ecology and Evolution 2023, 16, 1–9. [Google Scholar] [CrossRef]
- Hubbell, S.P. The unified neutral theory of biodiversity and biogeography. 2001, Princeton, NJ: Princeton University Press.
- Rosindell, J.; et al. Protracted speciation revitalizes the neutral theory of biodiversity. Ecology Letters 2010, 13, 716–727. [Google Scholar] [CrossRef]
- Overcast, I.; et al. A unified model of species abundance, genetic diversity, and functional diversity reveals the mechanisms structuring ecological communities. Molecular Ecology Resources 2021, 21, 2782–2800. [Google Scholar] [CrossRef]
- Rollins, L.A.; et al. Selection on mitochondrial variants occurs between and within individuals in an expanding invasion. Molecular Biology and Evolution 2016, 33, 995–1007. [Google Scholar] [CrossRef] [PubMed]
- Lewontin, R.C. The units of selection. Annu. Rev. Ecol. Syst. 1970, 1, 1–18. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication. 1949, Urbana, IL USA: University of Illinois Press.
- Trifonov, E.N. Vocabulary of Definitions of Life Suggests a Definition. Journal of Biomolecular Structure and Dynamics 2011, 29, 259–266. [Google Scholar] [CrossRef] [PubMed]
- Charlat, S.; et al. Natural Selection beyond Life? A Workshop Report. Life 2021, 11, 1051. [Google Scholar] [PubMed]
- England, J.L. Statistical physics of self-replication. The Journal of Chemical Physics 2013, 139, 121923. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; et al. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [Google Scholar] [CrossRef]
- Liu, Y.; et al. Exploring and mapping chemical space with molecular assembly trees. Science Advances 2021, 7, eabj2465. [Google Scholar] [CrossRef]
- Walsh, T. Machines behaving badly: The morality of AI. 2022, Melbourne: LaTrobe University Press.
- Danchin, E. Avatars of information: Towards an inclusive evolutionary synthesis. Trends in Ecology & Evolution 2013, 28, 351–358. [Google Scholar]
- Bonduriansky, R. Rethinking heredity, again. Trends in Ecology & Evolution 2012, 27, 330–336. [Google Scholar]
- Coyne, J.; Orr, H.A. Speciation. 2004, Sunderland Mass: Sinauer.
- Hamblin, S. On the practical usage of genetic algorithms in ecology and evolution. Methods in Ecology and Evolution 2013, 4, 184–194. [Google Scholar] [CrossRef]
- George, A.; Walsh, T. Can AI invent? Nature Machine Intelligence 2022, 4, 1057–1060. [Google Scholar] [CrossRef]
- Danchin, E.; et al. Beyond DNA: Integrating inclusive inheritance into an extended theory of evolution. Nature Reviews Genetics 2011, 12, 475–486. [Google Scholar] [CrossRef] [PubMed]
- Oldroyd, B. Beyond DNA: How Epigenetics is Transforming our Understanding of Evolution. 2023, Melbourne: Melbourne University Press.
- Piñero, J.; Solé, R. Nonequilibrium Entropic Bounds for Darwinian Replicators. Entropy 2018, 20, 98. [Google Scholar] [CrossRef] [PubMed]
- Rebeck, J. Synthetic Self-Replicating Molecules. Scientific American 1994, 271, 48–55. [Google Scholar] [CrossRef]
- Bissette, A.J.; Fletcher, S.P. Mechanisms of Autocatalysis. Angewandte Chemie International Edition 2013, 52, 12800–12826. [Google Scholar] [CrossRef] [PubMed]
- Knight, R.D.; Landweber, L.F. Rhyme or reason: RNA-arginine interactions and the genetic code. Chemistry & Biology 1998, 5, R215–R220. [Google Scholar]
- Goodfellow, I.J.; et al. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661v1 [stat.ML]. [Google Scholar] [CrossRef]
- Brady, S.P.; et al. Causes of maladaptation. Evolutionary Applications 2019, 12, 1229–1242. [Google Scholar] [CrossRef] [PubMed]
- Good, I.J. A little learning can be dangerous. Br. J. Phil. Sci. 1974, 25, 340–342. [Google Scholar] [CrossRef]
- Frank, S.A. The Price Equation Program: Simple Invariances Unify Population Dynamics, Thermodynamics, Probability, Information and Inference. Entropy 2018, 20, 978. [Google Scholar] [CrossRef]
- Day, T. Information entropy as a measure of genetic diversity and evolvability in colonization. Molecular Ecology 2015, 24, 2073–2083. [Google Scholar] [CrossRef]
- Elith, J.; et al. A statistical explanation of MaxEnt for ecologists. Diversity and Distributions 2011, 17, 43–57. [Google Scholar] [CrossRef]
- Yan, W.Q. Computational Methods for Deep Learning: Theory, Algorithms, and Implementations. 2023, Vienna: Springer Nature.
- Turing, A. Computing Machinery and Intelligence. Mind, 1950. LIX: P. 433–460.
- Lavoipierre, A. A twist in the legal fight between X and eSafety. 2024. Available online: https://www.abc.net.au/news/2024-05-28/twist-in-legal-fight-between-x-esafety-google-ai-glue-and-rocks/103900668 (accessed on 5 June 2024).
- Bajic, D. Information Theory, Living Systems, and Communication Engineering. Entropy 2024, 26, 430. [Google Scholar] [CrossRef] [PubMed]
- Ivaniš, P.; et al. Capacity Analysis of Hybrid Satellite–Terrestrial Systems with Selection Relaying. Entropy 2024, 26, 419. [Google Scholar] [CrossRef]
- Brooks, R.C. How Might Artificial Intelligence Influence Human Evolution? Quarterly Review of Biology 2024, in press. [Google Scholar]
- Dingle, H.; Alistair Drake, V.A. What Is Migration? BioScience 2007, 57, 113–121. [Google Scholar] [CrossRef]
- Lam, K.-Y.; Lou, Y. Introduction to Reaction-Diffusion Equations : Theory and Applications to Spatial Ecology and Evolutionary Biology. 2022, Springer Nature: Cham.
- Duran-Nebreda, S.; et al. Synthetic Lateral Inhibition in Periodic Pattern Forming Microbial Colonies. ACS Synthetic Biology 2021, 10, 277–285. [Google Scholar] [CrossRef] [PubMed]
- FitzHugh, R. Impulses and Physiological States in Theoretical Models of Nerve Membrane. Biophysical Journal 1961, 1, 445–466. [Google Scholar] [CrossRef]
- De Queiroz, K. Ernst Mayr and the modern concept of species. Proc natl Acad Sci USA 2005, 102, 6600–6607. [Google Scholar] [CrossRef]
- Costello, M.J.; May, R.M.; Stork, N.E. Can We Name Earth’s Species Before They Go Extinct? Science 2013, 339, 413–416. [Google Scholar] [CrossRef]
- Edmands, S. Does parental divergence predict reproductive compatibility? Trends Ecol. Evol. 2002, 17, 520. [Google Scholar] [CrossRef]
- Moritz, C. Defining “evolutionarily significant units” for conservation. Trends in Ecology and Evolution 1994, 9, 373–375. [Google Scholar] [CrossRef] [PubMed]
- Moritz, C. Conservation units and translocations: Strategies for conserving evolutionary processes. Hereditas. 1999, 130, 217–228. [Google Scholar] [CrossRef]
- Lan, R.; Reeves, P. When does a clone deserve a name? A perspective on bacterial species based on population genetics. Trends in Microbiology 2001, 9, 419–424. [Google Scholar]
- Carr, N. How many computers does the world need? Fewer than you think, in Guardian. 2008, Guardian: London.
- Ji, Z.; et al. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys 2023, 55, P–248. [Google Scholar] [CrossRef]
- Anonymous. Compatibility. 2024. Available online: https://www.techtarget.com/whatis/definition/compatibility (accessed on 9 May 2024).
- von Neumann, J.; Burks, A.W.E. Theory of Self-Reproducing Automata. 1966, Urbana and London: University of Illinois Press.
- Sole, R. Synthetic transitions: Towards a new synthesis. Phil. Trans. Roy. Soc. B. 2016, 371, 2015–0438. [Google Scholar]
- Halliburton, R. Introduction to population genetics. 2004, Upper Saddle River, NJ: Pearson.
- Wright, S. Size of population and breeding structure in relation to evolution. Proc Natl. Acad. Sci. USA 1938, 24, 372–377. [Google Scholar] [CrossRef] [PubMed]
- Kleidon, A. Life, hierarchy, and the thermodynamic machinery of planet Earth. Physics of Life Reviews 2010, 7, 424–460. [Google Scholar] [CrossRef] [PubMed]
- Wicken, J.S. Entropy and information: Suggestions for common language. Philosophy of Science 1987, 54, 176–193. [Google Scholar] [CrossRef]
- Hanopolskyi, A.I.; et al. Autocatalysis: Kinetics, Mechanisms and Design. ChemSystemsChem 2021, 3, e2000026. [Google Scholar] [CrossRef]
- Lincoln, T.A.; Joyce, G.F. Self-sustained replication of an RNA enzyme. Science 2009, 323, 1229–1232. [Google Scholar] [CrossRef]
- Chen, Q.; et al. Origins and evolving functionalities of tRNA-derived small RNAs. Trends in Biochemical Sciences 2021, 46, 790–804. [Google Scholar] [CrossRef]
- Adamski, P.; et al. From self-replication to replicator systems en route to de novo life. Nature Reviews 2020, 4, 386–403. [Google Scholar] [CrossRef]
- Ma, L.; Liu, J. Catalytic Nucleic Acids: Biochemistry, Chemical Biology, Biosensors, and Nanotechnology. iScience 2020, 23, 100815. [Google Scholar] [CrossRef]
- Lazar, S.; Nelson, A. AI safety on whose terms? Science 2023, 381, 138. [Google Scholar] [CrossRef]
- Richerson, P.J.; Boyd, R. Not by Genes Alone : How Culture Transformed Human Evolution. 2006, Chicago: University of Chicago Press.
- Carroll, S.P.; et al. Applying evolutionary biology to address global challenges. SCIENCE 2014, 346, 1245993. [Google Scholar] [CrossRef]
- von Kodolitsch, Y.; Berger, J.; Rogan, P.K. Predicting severity of haemophilia A and B splicing mutations by information analysis. Haemophilia 2006, 12, 258–262. [Google Scholar] [CrossRef]
- Woolnough, A.P.; et al. Quantum computing: A new paradigm for ecology. Trends in Ecology & Evolution 2023, 38. [Google Scholar]
- Navarrete, A.; van Schaik, C.P.; Isler, K. Energetics and the evolution of human brain size. Nature 2011, 480, 91–94. [Google Scholar] [CrossRef]
- Mitteroecker, P.; et al. Cliff-edge model of obstetric selection in humans. Proceedings of the National Academy of Science USA 2016, 113, 14680–14685. [Google Scholar] [CrossRef]
- Dunsworth, H.M. Thank your intelligent mother for your big brain. Proceedings of the National Academy of Sciences of the United States of America 2016, 113, 6816–6818. [Google Scholar] [CrossRef] [PubMed]
- Van Valen, L. Ecological Species, multispecies, and oaks. Taxon 1976, 25, 233–239. [Google Scholar] [CrossRef]
- Hart, S.P.; Schreiber, S.J.; Levine, J.M. How variation between individuals affects species coexistence. Ecology Letters 2016, 19, 825–838. [Google Scholar] [CrossRef] [PubMed]
- Hart, S.P.; Turcotte, M.M.; Levine, J.M. Effects of rapid evolution on species coexistence. Proceedings of the National Academy of Sciences of the United States of America 2019, 116, 2112–2117. [Google Scholar] [CrossRef]
Figure 1.
The four basic processes in PanEvolution. Interactions between biological information and non-biological information are shown in the centre column.
Figure 1.
The four basic processes in PanEvolution. Interactions between biological information and non-biological information are shown in the centre column.
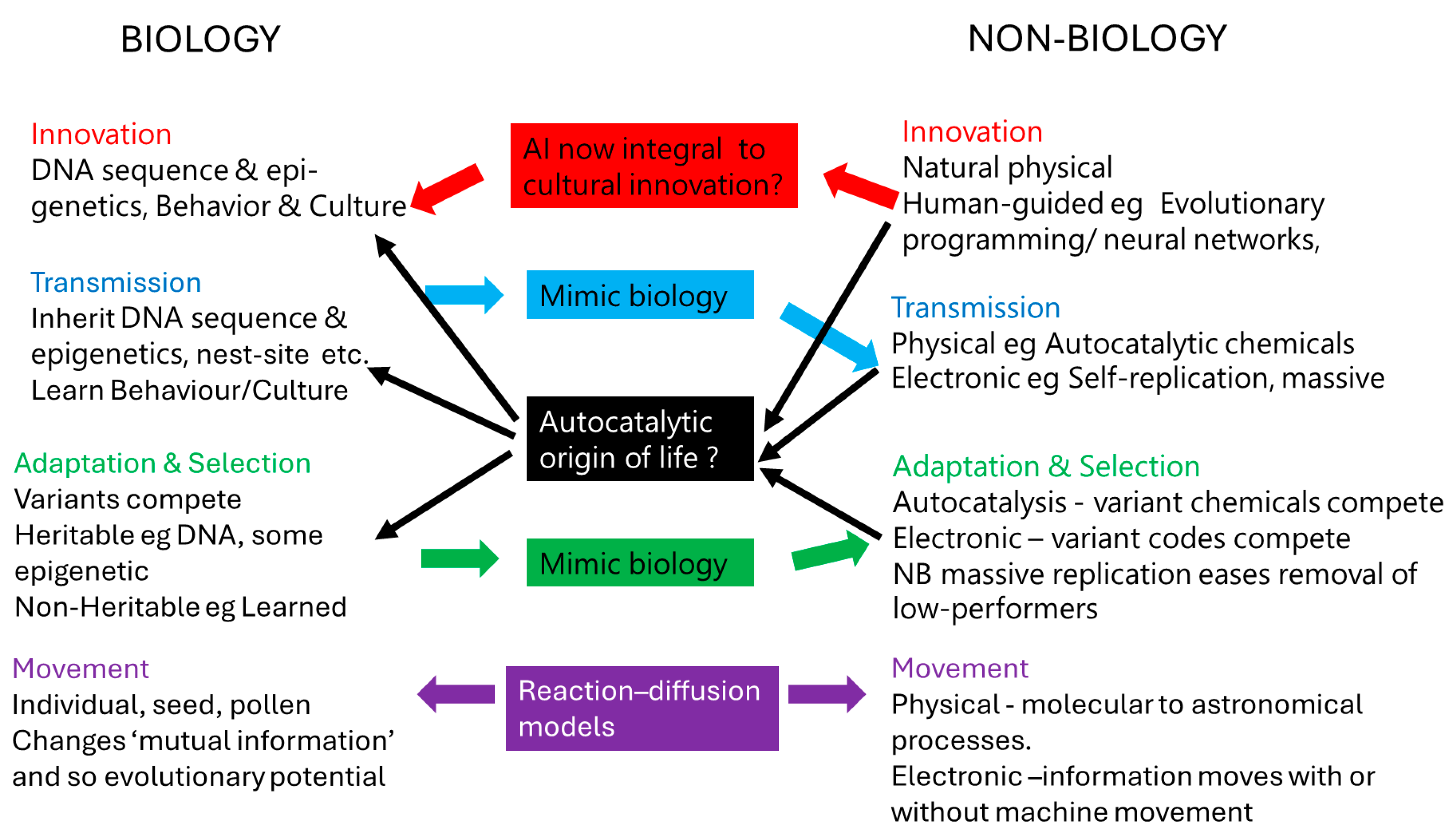
Figure 2.
Assembly trees, non-biological and biological. (a) A non-biological partial molecular assembly tree for synthesis of the nucleic acid bases, purines A and G, and pyrimidines T, U, and C; the letters N and O denote oxygen and nitrogen, vertices without a letter are carbons; redrafted from [35]; (b) A biological phylogenetic network of Finnish human mitochondrial DNA sequences, originating from African ‘root’. Size of circles is proportional to the number of identical sequences at that node. Bars indicate base alterations that are all transition substitutions (pyrimidine for pyrimidine, T↔C or purine for purine A↔G), except for the intermediate-length bars which are the more chemically difficult transversions (purine to pyrimidine, or vice-versa). The very long bar with an arrow indicates a back mutation to a state present earlier in the phylogeny. Notice the diamond-shape in the centre of the network, that show alternative substitution pathways in the origin of the sequences above it. This is a partial redraft of the network in [35].
Figure 2.
Assembly trees, non-biological and biological. (a) A non-biological partial molecular assembly tree for synthesis of the nucleic acid bases, purines A and G, and pyrimidines T, U, and C; the letters N and O denote oxygen and nitrogen, vertices without a letter are carbons; redrafted from [35]; (b) A biological phylogenetic network of Finnish human mitochondrial DNA sequences, originating from African ‘root’. Size of circles is proportional to the number of identical sequences at that node. Bars indicate base alterations that are all transition substitutions (pyrimidine for pyrimidine, T↔C or purine for purine A↔G), except for the intermediate-length bars which are the more chemically difficult transversions (purine to pyrimidine, or vice-versa). The very long bar with an arrow indicates a back mutation to a state present earlier in the phylogeny. Notice the diamond-shape in the centre of the network, that show alternative substitution pathways in the origin of the sequences above it. This is a partial redraft of the network in [35].
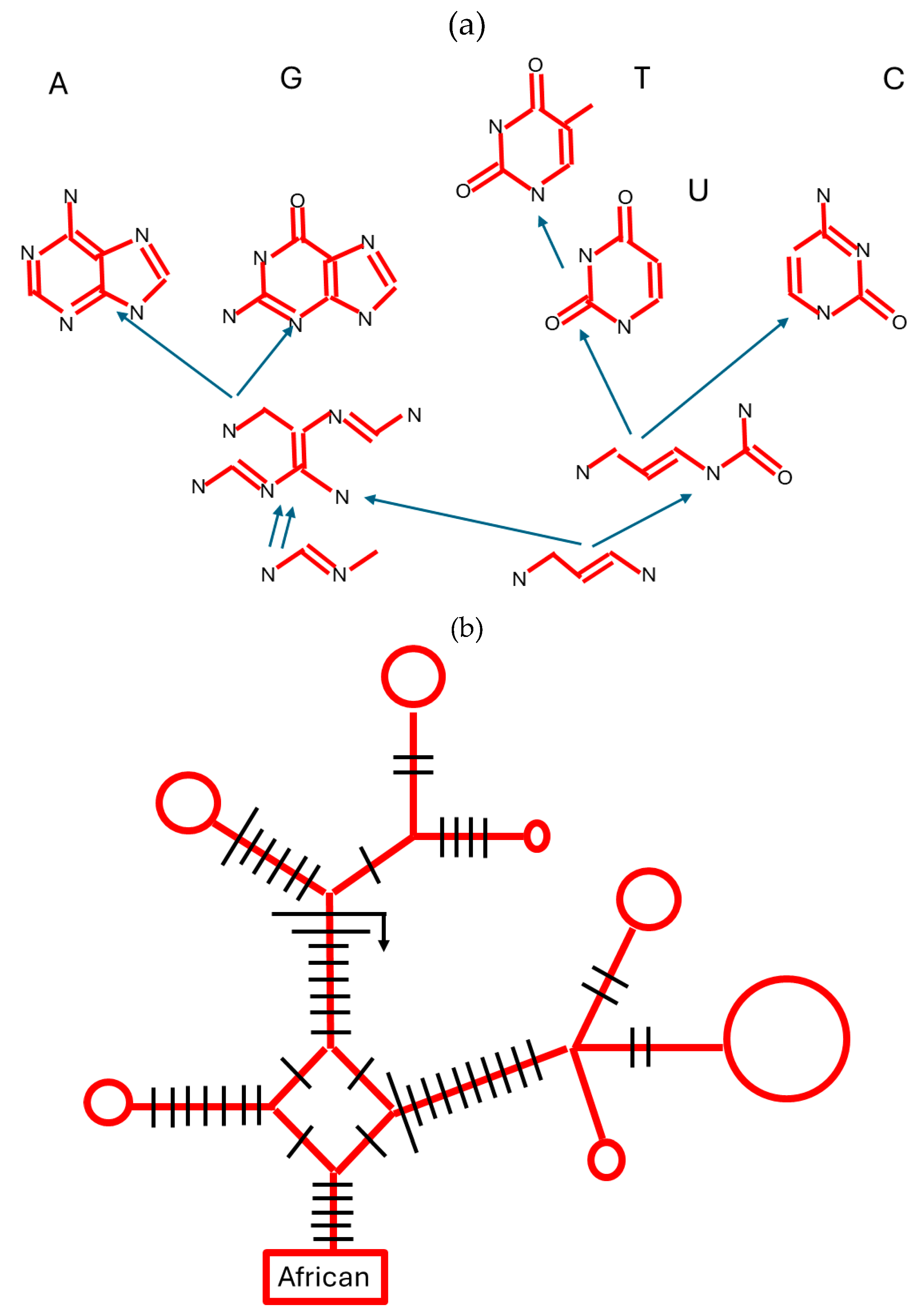
Figure 3.
An autocatalytic reaction. Similar reactions happen for adenine ribose biphenyl imide (ARBI) or benzyloxycarbonyl-NO2 adenine ribose biphenyl imide (ZNARBI). If the environment includes radiation, then ZNARBI is mutated to ARBI, and ARBI replicates faster than ZNARBI, so ARBI outcompetes, or is more ‘adapted’ to that environment. Simplified from [45].
Figure 3.
An autocatalytic reaction. Similar reactions happen for adenine ribose biphenyl imide (ARBI) or benzyloxycarbonyl-NO2 adenine ribose biphenyl imide (ZNARBI). If the environment includes radiation, then ZNARBI is mutated to ARBI, and ARBI replicates faster than ZNARBI, so ARBI outcompetes, or is more ‘adapted’ to that environment. Simplified from [45].
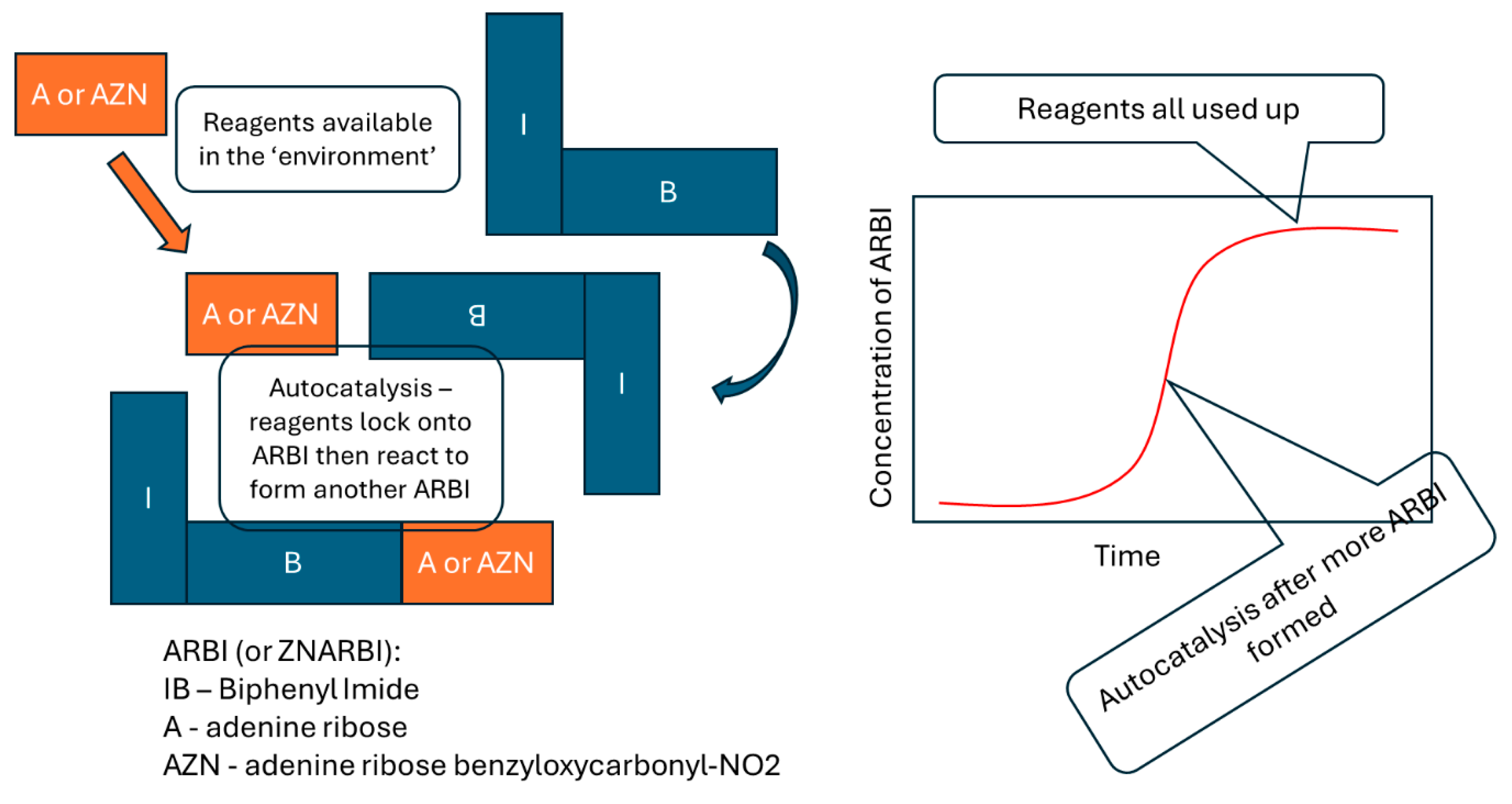
Figure 4.
Suitable environments for information held in biology or outside of biology. Biology requires water, Oxygen, Carbon Dioxide, moderate temperatures, and relatively low cosmic radiation. The machines that carry information outside of biology are damaged by water, Oxygen, and Carbon Dioxide, and can be manufactured to tolerate a much wider range of temperatures and radiation.
Figure 4.
Suitable environments for information held in biology or outside of biology. Biology requires water, Oxygen, Carbon Dioxide, moderate temperatures, and relatively low cosmic radiation. The machines that carry information outside of biology are damaged by water, Oxygen, and Carbon Dioxide, and can be manufactured to tolerate a much wider range of temperatures and radiation.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



