
Submitted:
11 June 2024
Posted:
13 June 2024
You are already at the latest version
Abstract
This paper presents our approaches for the SMM4H’24 Shared Task 5 on the binary classification of English tweets reporting children’s medical disorders. Our first approach involves fine-tuning a single RoBERTa-large model, while the second approach entails ensembling the results of three fine-tuned BERTweet-large models. We demonstrate that although both approaches exhibit identical performance on validation data, the BERTweet-large ensemble excels on test data. Our best-performing system achieves an F1-score of 0.938 on test data, outperforming the benchmark classifier by 1.18%.
Keywords:
digital epidemiology
; childhood health
; pre-trained language models
; ensemble models
; natural language processing
; tweets classification
1. Introduction & Motivation
Chronic childhood disorders like attention-deficit/hyperactivity disorder (ADHD), autism spectrum disorders (ASD), delayed speech, and asthma significantly impact a child’s development and well-being, often extending into adulthood. Approximately 1 in 6 (17%) children aged 3-17 years in the United States experience a developmental disability, with ADHD, ASD, and others contributing to this statistic [1]. In previous studies [2,3,4], Twitter data have been utilized to identify self-reports of the aforementioned disorders; however, the identification of reports concerning these disorders in users’ children has not been explored. It may be of interest to explore Twitter’s potential in continuing to collect users’ tweets postpartum, enabling the detection of outcomes in childhood.
2. Task and Data Description
2.1. Task
The SMM4H-2024 workshop and shared tasks have a special focus on Large Language Models (LLMs) and generalizability for natural language processing (NLP) in social media. We participated in Task 5, which is ’Binary classification of English tweets reporting children’s medical disorders’. The objective is to automatically differentiate tweets from users who have disclosed their pregnancy on Twitter and mention having a child with ADHD, ASD, delayed speech, or asthma (annotated as "1"), from tweets that merely refer to a disorder (annotated as "0").
2.2. Data
There were three different datasets provided: training, validation, and test datasets. The training and validation datasets were labeled while the test dataset was not. All datasets are composed entirely of tweets posted by users who had reported their pregnancy on Twitter, that report having a child with a disorder and tweets that merely mention a disorder. The training, validation, and test sets contain 7398 tweets, 389 tweets, and 1947 tweets, respectively.
3. Methodology
3.1. Baseline
3.2. Models Used
We investigated three Transformer based models which are BioLinkBERT-large [7], RoBERTa-large and BERTweet-large [8]. BioLinkBERT was selected for its specialized understanding of biomedical NLP tasks, RoBERTa for its domain-independent NLP capabilities, and BERTweet for its superior performance in Tweet-specific NLP tasks. We fine-tuned each model with the training dataset and evaluated its performance using the validation dataset.
3.3. Training Regime
The complete description of the training regime is in Appendix A. Primary hyperparameters including learning rate, weight decay, and batch size were determined as described in the subsequent section.
3.4. Hyperparameter Optimization
We conducted hyperparameter optimization that relied on HuggingFace’s Trainer API with the Ray Tune backend [9]. Details about the hyperparameters are described in Appendix B.
4. Preliminary Experiments
Each selected model was trained for 3 iterations, with 10 epochs per iteration. At the end of each epoch, its F1-score was recorded. The F1-score for each model was determined based on its performance with the validation dataset. We saved the best-performing epoch (i.e., the best F1-score for the positive class) for each model in each iteration. The results are shown in Appendix C.
As shown in Table 4, RoBERTa-large and BERTweet-large perform similarly on the validation dataset, and considerably better than BioLinkBERT-large, even though it has been pre-trained on a large corpus of biomedical data. Therefore, we decided to remove BioLinkBERT-large to carry out further experiments for this task [10].
4.1. Ensembling Strategy
The issue arises when fine-tuning large-transformer models on small datasets: the classification performance varies significantly with slightly different training data and random seed values, even when using the same hyperparameter values [11]. To overcome this high variance and provide more robust predictions, we propose ensembles of multiple fine-tuned RoBERTa-large models and BERTweet-large models separately. We create two separate ensemble models using the best models corresponding to three iterations for each RoBERTa-large and BERTweet-large. All three iterations use the same hyperparameters, and only differ in the initial random seed. A hard majority voting mechanism combines the predictions of these models (see Appendix D).
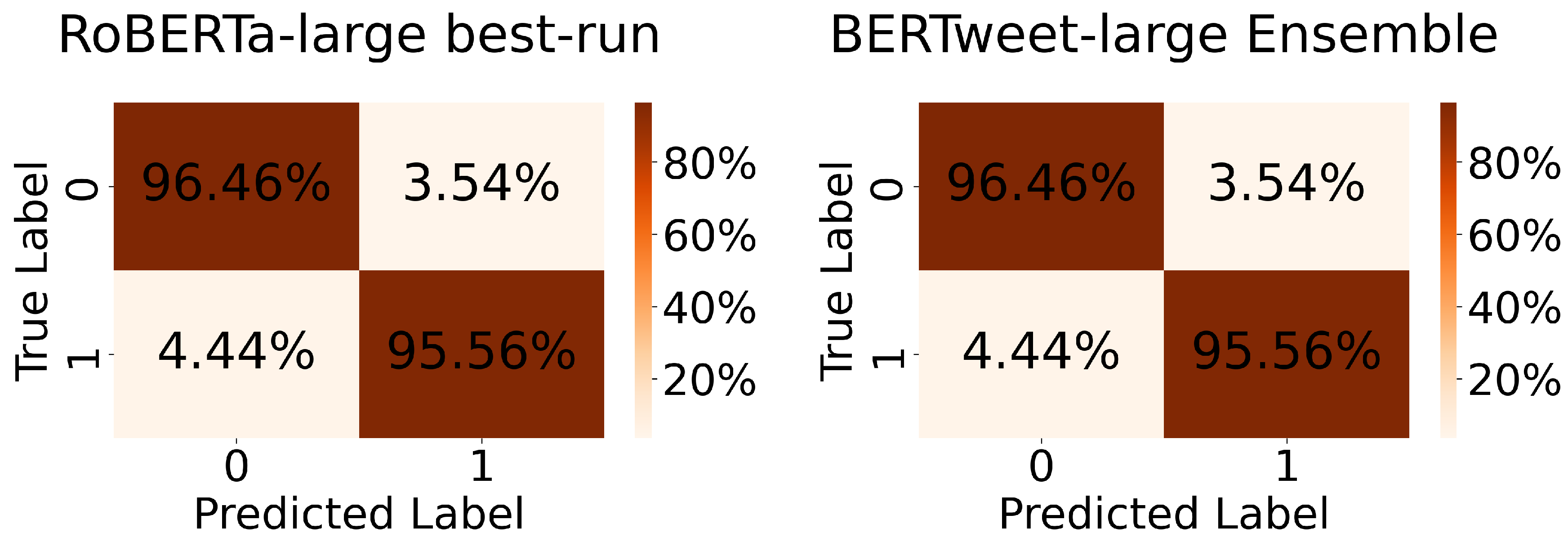
As shown in Table 1, the BERTweet-large ensemble performs better than the RoBERTa-large ensemble. This is fundamentally because its performance variation is less for three iterations, as indicated in Table 4. Another noteworthy observation is that the performance of the BERTweet-large ensemble is identical to that of the best iteration (Table 4, 2nd run) of RoBERTa-large (see Appendix E). Figure A1 shows the corresponding confusion matrices for both classifiers which are also identical.

Table 1.
Table 1: Performance results for ensemble classifiers on validation data.
| Classifier | F1-score | Precision | Recall |
|---|---|---|---|
| RoBERTa-large Ensemble | 0.934783 | 0.914894 | 0.955556 |
| BERTweet-large Ensemble | 0.945055 | 0.934783 | 0.955556 |
5. Results and Conclusions
Since RoBERTa-large best-run and BERTweet-large ensemble are performing equally well on the validation data, we tested the performance of both classifiers on unseen, unlabeled test data. As shown in Table 2, the BERTweet-large ensemble classifier outperforms the mean and median performance on the test data among all teams’ submissions by a considerable margin, as well as the benchmark classifier by 1.18%. Additionally, we can observe that even though both classifiers perform equally well on validation data, the BERTweet-large ensemble model performs significantly better on test data. One possible reason for this is that different runs of BERTweet-large might excel at capturing different aspects of the data or learning different patterns.
When fine-tuning complex pre-trained language models, one issue on small datasets is the instability of the classification performance. To overcome this, we combined the predictions of multiple BERTweet-large models in an ensemble. By doing so, we achieved significantly better results in terms of F1-score for SMM4H’24 Task 5. For future work, it’s interesting to investigate how the system performance varies when adding more BERTweet-large iterations (i.e., runs) to the ensemble.
Table 2.
Table 2: Results for our two proposed approaches on the test data, including the mean, median, and baseline scores.
Table 2.
Table 2: Results for our two proposed approaches on the test data, including the mean, median, and baseline scores.
| Model | F1-score | Precision | Recall |
|---|---|---|---|
| Baseline | 0.927 | 0.923 | 0.940 |
| Mean | 0.822 | 0.818 | 0.838 |
| Median | 0.901 | 0.885 | 0.917 |
| RoBERTa-large best-run | 0.925 | 0.908 | 0.942 |
| BERTweet-large Ensemble | 0.938 | 0.930 | 0.946 |
Appendix A Training Regime
Experiments were conducted using Google Colab Pro+ equipped with an NVIDIA A100 Tensor Core GPU boasting 40 gigabytes of available GPU RAM. The Hugging Face Transformers Python library [12] and its Trainer API facilitated training procedures. Each model was trained on the training datasets for 3 iterations and 10 epochs per iteration. We used HuggingFace’s Trainer Class’s default ’AdamW’ and ’linear warmup with cosine decay’ as the optimizer and scheduler respectively. The maximum sequence length for all models was set to 512. FP-16 mixed precision training was employed to enable larger batch sizes and expedited training.
Appendix B Hyperparameters
We utilized Ray Tune’s built-in "BasicVariantGenerator" algorithm1 for hyperparameter search, paired with the First-In-First-Out (FIFO) scheduler. Since BasicVariantGenerator has the ability to dynamically generate hyperparameter configurations based on predefined search algorithms (e.g., random search, Bayesian optimization), it enables more efficient exploration of the search space. The hyperparameters optimized using BasicVariantGenerator are presented in Table 3.
Table A1.
Table 3: Hyperparameters optimized via BasicVariantGenerator.
| Model | Learning Rate | Weight Decay | Batch Size |
|---|---|---|---|
| BioLinkBERT-large | 6.10552e-06 | 0.00762736 | 16 |
| RoBERTa-large | 7.21422e-06 | 0.00694763 | 8 |
| BERTweet-large | 1.17754e-05 | 0.01976150 | 8 |
Appendix C The F1 Scores of Selected Models
Table A2.
Table 4: The F1 scores of the BioLinkBERT-large, RoBERTa-large, and BERTweet-large classifiers on the validation data. The mean F1 score and standard deviation are also provided.
Table A2.
Table 4: The F1 scores of the BioLinkBERT-large, RoBERTa-large, and BERTweet-large classifiers on the validation data. The mean F1 score and standard deviation are also provided.
| Model | 1st run | 2nd run | 3rd run | Mean F1 | SD |
|---|---|---|---|---|---|
| BioLinkBERT-large | 0.855019 | 0.875969 | 0.863159 | 0.864716 | 0.010561 |
| RoBERTa-large | 0.931408 | 0.945055 | 0.931408 | 0.935957 | 0.007879 |
| BERTweet-large | 0.940741 | 0.934307 | 0.933824 | 0.936291 | 0.003862 |
Appendix D A Hard Majority Voting Mechanism
A hard majority voting mechanism combines the predictions of three fine-tuned BERTweet-large models:
where represents the indicator function, which returns either ’1’ or ’0’ for the class label c predicted by the i-th classifier.
Appendix E RoBERTa-Large Best-Run vs. the BERTweet-Large Ensemble
Table A3.
Table 5: Performance comparison of the RoBERTa- large best-run vs the BERTweet-large ensemble on vali- dation data.
Table A3.
Table 5: Performance comparison of the RoBERTa- large best-run vs the BERTweet-large ensemble on vali- dation data.
| Classifier | F1-score | Precision | Recall |
|---|---|---|---|
| RoBERTa-large best-run | 0.945055 | 0.934783 | 0.955556 |
| BERTweet-large Ensemble | 0.945055 | 0.934783 | 0.955556 |
Appendix F Confusion Matrices
Figure A1.
Confusion matrices of the RoBERTa-large best-run and BERTweet-large ensemble on the validation dataset.
Figure A1.
Confusion matrices of the RoBERTa-large best-run and BERTweet-large ensemble on the validation dataset.
| 1 |
References
- Zablotsky, B.; Black, L.I.; Maenner, M.J.; Schieve, L.A.; Danielson, M.L.; Bitsko, R.H.; others. Prevalence and Trends of Developmental Disabilities Among Children in the United States: 2009-2017. Pediatrics 2019, 144, e20190811. [Google Scholar] [CrossRef] [PubMed]
- Guntuku, S.C.; Ramsay, J.R.; Merchant, R.M.; Ungar, L.H. Language of ADHD in Adults on Social Media. Journal of Attention Disorders 2019, 23, 1475–1485. [Google Scholar] [CrossRef] [PubMed]
- Hswen, Y.; Gopaluni, A.; Brownstein, J.S.; Hawkins, J.B. Using Twitter to Detect Psychological Characteristics of Self-identified Persons with Autism Spectrum Disorder: A Feasibility Study. JMIR mHealth and uHealth 2019, 7, e12264. [Google Scholar] [CrossRef] [PubMed]
- Edo-Osagie, O.; Smith, G.; Lake, I.; Edeghere, O.; Iglesia, B.D.L. Twitter Mining Using Semi-Supervised Classification for Relevance Filtering in Syndromic Surveillance. PLoS One 2019, 14, e0210689. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint 2019, arXiv:1907.11692. [Google Scholar]
- Klein, A.; Gómez, J.G.; Levine, L.; Gonzalez-Hernandez, G. Using Longitudinal Twitter Data for Digital Epidemiology of Childhood Health Outcomes: An Annotated Data Set and Deep Neural Network Classifiers. J Med Internet Res 2024, 26, e50652. [Google Scholar] [CrossRef] [PubMed]
- Yasunaga, M.; Leskovec, J.; Liang, P. Linkbert: Pretraining Language Models with Document Links. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 8003–8016.
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A Pre-trained Language Model for English Tweets. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020, pp. 9–14.
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A Research Platform for Distributed Model Selection and Training. arXiv preprint 2018, arXiv:1807.05118. [Google Scholar]
- Guo, Y.; Dong, X.; Al-Garadi, M.A.; Sarker, A.; Paris, C.; Mollá-Aliod, D. Benchmarking of Transformer-Based Pre-trained Models on Social Media Text Classification Datasets. Workshop of the Australasian Language Technology Association, 2020, pp. 86–91.
- Dodge, J.; Ilharco, G.; Schwartz, R.; Farhadi, A.; Hajishirzi, H.; Smith, N. Fine-tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. arXiv preprint 2020, arXiv:2002.06305. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Huggingface’s Transformers: State-of-the-art Natural Language Processing. arXiv preprint 2019, arXiv:1910.03771. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



