
Submitted:
18 June 2024
Posted:
18 June 2024
You are already at the latest version
Abstract
The development of one technology can be portrayed by common methods like Gartner’s hype cycle or S-curve, however, there is no method to characterize the feature distributions of multiple technologies within a specific domain. This study proposes a big data-based method in terms of four proposed features, namely versatility, significance, commerciality, and disruptiveness, to characterize the technologies within a given domain. The features of technologies are quantitively portrayed using the representative keywords and volumes of returned search results from Google and Google Scholar in two-dimensional analytical spaces of technique and application. We demonstrate the applicability of this method using 452 technologies in the domain of intelligent robotics. The results of our assessment indicate that the versatility values are normally distributed, while the values of significance, commerciality, and disruptiveness follow power-law distributions, in which few technologies possess higher feature values. We also show that significant technologies are more likely to be commercialized or causing potential disruption, as such technologies have higher scores in these features. Further, we validly prove the robustness of our approach via comparing historical trends with literature and characterizing technologies in reduced analytical spaces. Our method can be widely applied in analyzing feature distributions of technologies in different domains, and it can potentially be exploited in decisions like investment, trade, and science policy.
Keywords:
2D analytical space
; commerciality
; disruptiveness
; representative keyword
; search engine
; significance
; technological assessment
; versatility
1. Introduction
Technological advances propel economic growth, long-term social well-being [1], and sustainable development [2]. They also threaten the status quo through disrupting the existing markets or creating completely new markets [3]. Moreover, technological developments affect the global competitiveness of nations [4], given that competitive edges are deeply rooted in technological superiority [4]. Characterizing technological development facilitates important decision-making such as investment, product launch, and business expansion. Therefore, it has attracted much attention of investors, industrial captains, academics, and even policy makers. The developmental trend of one single technology has been extensively studied, and is commonly be characterized by well-known methods like Gartner’s hype cycle [5] or S-curve [6] (see Figure 1 [a]). However, the features of the technologies within a chosen domain have not been systematically investigated and remain largely unknown (see Figure 1 [b]). Characterizing multiple technologies is extremely challenging, considering that the technologies in any given domain are highly heterogeneous and can have complex distributions/relationships. Consequently, important decision-making in investment, trade, and science policy is hindered due to a lack of reliable analytical tools for characterizing domain-specific technologies’ feature distributions.
In general, the extant technological assessment methods can be grouped into two categories: qualitative and quantitative [7]. However, aside from the primary and common flaw, that is, analysis object of the reported methods is limited to one feature of one single technology, these methods also suffer from other intrinsic weaknesses. Most qualitative methods, such as technology roadmap [8], and Delphi [9,10], rely only upon surveys, which are always constrained by interviewees’ personal experiences and attitudes. Considering that the interviewees are not anonymous to the assessor(s) and the potential competitors are often excluded [11], the reliability of these survey-based tools is further compromised. The quantitative methods like bibliometrics and patent analysis [1,4,12], are primarily based on limited historical data, the latency of which hinders their applicability in characterizing the feature distributions of technologies in emerging domains. Given the constant evolution of technologies [13], quantitatively characterizing feature distributions of technologies in real time is highly desirable in technological assessment and the related decision-making processes like investment and trade. Yet, to the best of our knowledge, none of the existing methods can cope with this challenging task.
In this study, we propose a method that innovatively exploits online big data to develop an empirical tool for characterizing feature distributions of technologies in any technical domain. This approach depicts the development of a technology based on its representative keywords and volumes of returned results from public search engines. This big data is real time and more accessible, have much broader coverage than surveys of selected individuals or examination of patents and scientific publications, which can be employed to portray the dynamics of ongoing or fleeting issues [14], in this case, technological features. The suitability of using the representative keywords and volumes of returned results to portray the development of certain technologies is demonstrated in the following four aspects:
1) The diffusion of contents is primarily driven by selective exposure [15]. In other words, online resources contain sufficient domain specificity.
2) Innovation processes are driven by specified search behaviors [16,17], which are equivalent to online keyword searching.
3) The volumes of returned results are aggregation of massive human behavioral traces that contain diversified knowledge and values, which are highly valued in decisions related to complicated and uncertain issues, such as assessing emerging technologies [18].
4) Search data from public search engines is more affordable to acquire than publications and patents that are stored in specific databases, the access of which may cost a fortune.
In this study, we exploit the search data on Google and Google Scholar, which are the most used public search engines in the world. The behavioral traces on these engines have been employed to explain volatility in financial markets [19] or commodity markets [20], predict values of real estate [21], and trace epidemic outbreaks [22], but this data has not yet considered in technological assessment.
We select the domain of intelligent robotics as a case study to illustrate the concepts and the method, because it is a rapidly evolving field that has attracted extensive attention and investment. The selected technologies and their representative keywords are shown in Supplementary Materials entitled Supplementary Contents: Information about Candidate Technologies. Our proposed method is applied to quantify the feature distributions of the 452 technologies within the domain, based on the keyword searching that was conducted on January 1, 2018.
The rest of this article is organized as follows. In Section I, we review the literature on relevant topics. In Section III, we elaborate our method. In Section IV, we present the major observations derived from our case study, i.e., the 452 intelligent robotic technologies. In Section V, we discuss our contributions to the field, and offer key managerial implications for stakeholders. Finally, Section VI concludes this work.
2. Literature Review
In this section we briefly review the existing literature on technological feature evaluation, technology roadmapping, and forecasting. Although the reported methods from the included publications are not directly related or comparable to our proposed online-big-data-based approach, this literature review highlights the need of characterizing the feature distributions of technologies, and identifies the presence of knowledge gap in the literature, further justifying the positioning of our article.
2.1. Technological Feature Evaluation
Evaluating technological features is a persistent research hotspot in the field of technological assessment, as such task could identify potentially important technologies. However, to date, there are only few features have been considered in the previous studies, and the reported methods only aim for one single feature.
One of the frequently evaluated features is disruptive susceptibility, the assessment of which draws continuous attention. According to Klenner et al. [23], innovations’ disruptive susceptibility is evaluated using approaches of three categories, namely scoring models, economic models, and scenario analysis. Scoring models are the most frequently used ones in identifying potentially disruptive innovations like, Google’s web-based office applications [24], 3D printing [25], and Virtual Reality/Augmented Reality [26]. Yet, most of these scoring models require to survey (or interview) a panel of well-selected experts, the access of which is always limited, thereby compromising the applicability of such methods. Economic models [27] and scenario analysis [28] are also essentially based on personal experiences and attitudes, and these methods tend to be more case-specific [81], thereby resulting in confined usage.
Another intensively investigated technological feature is maturity, or more precisely the potential of commercialization. The most used method is the Technology Readiness Level (TRL) assessment, which is proposed by National Aeronautics and Space Administration (NASA) in the late 1970s [29]. The extensive applications of TRL can be seen in the domains of artificial intelligence [30] and sustainable energy [31]. Although the use of the TRL system is supported by well-defined documents [32], it still calls for personal expertise on the technologies that to be assessed, to establish suitable metrics [29]. Therefore, the TRL system shows limited capacity in dealing with emerging technologies, and could still suffer the hazard of personal bias.
To remediate such a flaw, a lot of efforts are invested to improve this technological maturity assessment method via linking subjective opinions with contextual attributes and technological texts. Vik et al. [33] couples TRL with market readiness level, regulatory readiness level, acceptance level readiness, and organizational level to build the balanced readiness level assessment to evaluate the maturity of agricultural technologies. Kyriakidou et al. [34] uses structural equation modeling (SEM), a multivariate technique, to evaluate the maturity levels of information and communications technology (ICT) with consideration of contextual characteristics in terms of ICT access, use and skills. Online blogs [35], academic publications [79,80] and patents [36] have been exploited for technology maturity assessments, and the results show a good agreement with expert opinions [35]. However, the selection of such contextual attributes and technological texts is still based on the personal knowledge of the assessors, and the inclusiveness and timeliness of these resources are limited [83]. In addition, as previously mentioned, all these technological feature evaluation approaches are specifically designed for only one single technological feature.
2.2. Technology Roadmapping
Technology roadmapping is a tool for planning technological developments in response to the market drivers [37], and its applications can be found in technological domains like robotics [8], aircrafts [38], nanotechnology [39], and bio-medical [40]. In essence, technology roadmaps are the composite outcomes of experts’ opinions, stakeholder collaboration, and bibliometric analysis [41,42]; the first two elements are the backbone of roadmap construction [43], while the use of bibliometric analysis is seldomly mentioned [41,44]. Inevitably, individual bias dwells in the reported technology roadmapping methods. Besides, as Chakraborty et al. [42] points out that academics are more often employed as experts than industrial practitioners in technology roadmapping, the selection of experts is biased. To reduce the presence of individual bias and to ensure the quality of involved experts, Nazarenko et al. [45] incorporates text mining and semantic maps into technology roadmapping to select suitable experts. Nevertheless, these approaches still heavily rely on experts’ opinions.
With sustained input of efforts, technology roadmapping methods are continuously evolving. One notable fraction is model-based technology roadmapping, approaches, in which game theory [46], or meta model [47] are integrated. The application of these model-based methods usually requires well-established industrial datasets like Car Specs Database [46]. Since such datasets are always in short supply, the applicability of these model-based approaches is thereby be constrained.
Attention also be paid on adjusting the procedure of technology roadmapping to reduce potential biases. Okada et al. [48] puts forward a backcasting technology roadmapping process; with complete participation of experts, a future vision is firstly defined, then technology pathways to realize the vision is constructed. Noh et al. [49] proposes an opportunity-driven technology roadmapping approach, in which technological opportunities are identified based on patent analysis and market opportunities are identified via value propositions. Similar to the backcasting process [48], this opportunity-driven approach also requires groups of technological and marketing experts who participate retrospective technology roadmap analysis [49].
Few set their sights on a broader picture. Maja and Letaba [50] suggests that big data could be an available source of value creation and technological analytics, and data-driven technology roadmap can be rendered by coordinating big data analytics and expert knowledge. Yet, this article is conducted based on a virtual interview with financial professionals [51]; it neither explain the linkage between big data and expert knowledge, nor specify the details of big data usage in technological roadmapping.
2.3. Technology Forecasting
Technology forecasting, also referred to as technological forecasting, concerns with emerging technological trends and radical new technologies. Traditionally, technology forecasting is an iterative process during which the forecasters progressively familiarize themselves with a certain technological domain and make predictions [52].
With ever-increasing data resources, technology forecasting is switched from expert-centric approaches to data-based approaches [12,53]. Owning to their relevance with technological developments, patents and scientific papers are the primary resources of quantitative technology forecasting [12,54,55]. Other textual resources such as blogs [56], hyperlinks [57], and product specifications [46,58] have also been employed in technology forecasting. Increasing data resources further stimulate the incorporation of big data analytics like data fusion [51], topic analysis [59], semantic analysis [60], and machine learning [61] in technology forecasting, as these techniques not only improve the performance of the existing methods, but also facilitate the development of novel approaches [62].
In general, there are commonalities between the developments of technology forecasting and technology roadmapping approaches; both procedures increasingly rely on historical data like patents and publications, and state-of-the-art data analytical techniques are utilized. Intrinsically, technology forecasting and technology roadmapping are trying to position technologies in some certain stages of their life cycles, a concept defined by Ford and Ryan [63]. Patent-based technology forecasting processes can determine the life cycle stages of technologies [54], and calculate the upper limit of technologies’ S-curve [54]. However, not all technologies necessarily follow Gartner’s hype cycle or S-curve; the development and diffusion of a fraction of technologies might slow and take a relatively longer period to reach their peak diffusion rates, while others can be much faster. Distinctive technology life cycle stages may not be applicable to all technologies [64]. Moreover, patent-based methods suffer from one common but often overlooked weakness, that is, a fraction of patent applications are of strategic purposes like patent trolling and market monopoly.
2.4. Literature Summary
In sum, the reported technological assessment methods still suffer from some common weaknesses [82]. First, the reported approaches can only evaluate one single technology, and mostly are for one single technological feature. Second, the extant methods are based on defective resources; qualitive approaches have to endure personal biases, while quantitative approaches can only be based on limited and lagged publication records, in particular patents and scientific papers. Although big data analytical techniques have been extensively discussed in the literature of technological assessment, the use of big data is rarely discussed, as most of the works are still based on conventional datasets such as patents [54], publications [36,79], and product specifications [46,58]. But the used data resources tend to be more specific, have poor timeliness, and sometimes are costly or even impossible to access. Rapid technological developments urge the utilization of more inclusive, accessible, timely, and affordable big data for the task of technological assessment.
Another major challenge is related to rapid and radical technological progress. Important decisions like capital investment and science policy usually require detailed analysis on the technologies in a targeted domain. Considering the speed of technological advances, the number of technologies in a given domain can be substantial. However, the currently available technological assessment approaches like the TRL system and technology roadmapping can only handle one single technology, heavily rely on personal expertise [29,43], and cannot be rendered in a timely fashion. The use of big data could remediate this problem, but it requires novel approaches, which are supposed to be capable of processing such data resources swiftly. Yet, till now, to the best of our knowledge, there is no approaches that can portray feature distributions of technologies in a specific technological domain.
3. Methods
Our proposed approach portrays the feature distributions of technologies in defined two-dimensional (2D) analytical spaces, in terms of a series of characterizing indicators that are calculated based on the technologies’ most representative keywords and volumes of returned search results from public search engines like Google and Google Scholar. Therefore, the elaboration of our approach is thereby divided into two major subsections, including the proposal of the analytical framework and feature indicators. The setting of the case study of assessing the feature distributions of the 452 selected intelligent robotic technologies is introduced in the end of this sector.
3.1. Analytical Framework
Our technological assessment approach is based on a 2D analytical space of “technique” (the horizontal axis) and “application” (the vertical axis), where the feature distributions of technologies are portrayed. Tracing progress and identifying applications are two fundamental aspects of any technological assessment methods like technology roadmap [8]. Referring to the intelligent robotics literature [8,65], the two basic dimensions are further refined into the corresponding sets:{perception, cognition, human–computer interaction, decision, action, other} and {manufacturing robotics, medical robotics, agricultural robotics, civil robotics, commercial robotics, transport robotics, consumer robotics, other robotics}. The 48 analytical spaces are thus developed, as shown in Figure 2.
The coordinates of the included technologies in the analytical spaces were calculated according to the modified Google Distance [66]. Based on returned search volumes by the engines, the coordinates Skij (SkXi, SkYj) are calculated as follows:
where SkXi and SkYj denote the x-coordinate and the y-coordinate of the technology in the 2D analytical space, respectively; sk denotes the total number of returned web pages on which the extracted terms occur; Xi and Yj denote the total numbers of returned web pages on which the axial keywords of the horizontal axis (the subsector of the technique dimension) and the vertical axis (the subsector the application dimension) occur, respectively; skXi and skYj denote the total number of returned web pages on which the extracted terms and the axial keywords occur; k denotes the kth technology, k = 1, 2, …, 452; I denotes the ith subdivision of the technique dimension, I = 1, 2, …, 6; j denotes the jth subdivision of the application dimension, j = 1, 2, …, 8.
The coordinates Skij (SkXi, SkYj) not only characterize the position of a certain robotic technology in some 2D analytical space but also measure the semantic similarity between the technology and the axis of the space. Unlike the conventional Google Distance which is inversely correlated to the semantic similarity between selected keywords [67], the proposed coordinates are positive measurements of the relationships between the technology and the two dimensions of the analytical spaces. Therefore, the relevance between the technologies and the 2D analytical spaces is measured using the modified version of Google Distance, and the magnitudes of these intelligent robotic technologies to certain fields are quantitatively determined.
3.2. Feature Indicators
We describe the feature distributions of the technologies using the four proposed characterizing indicators. The first indicator is “versatility” given that the application scope of a technology defines its fate [68]. For the domain of intelligent robotics technologies, having multi-applications is considered the most important criterion [6], and functionalities of robotics are rooted in different configurations of technological features [77]. A versatile technology can be applied in a wide range of scenarios, and the versatility characteristic is dependent on the degree of uniformity of coordinates. Based on the definition of Gini Index [25], a statistical measure of economic inequality in a population, we define the versatility indicator as Eq. (3):
where n denotes the number of the 2D analytical subspaces and n = 48; m = 1, 2, …, n; q = 1, 2, …, m; (SkXi)m/q and (SkYj)m/q denote the coordinates of the kth technology in the m or qth analytical subspace.
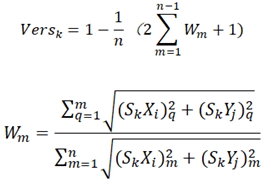 |
(3) |
The second indicator is “significance”, an indicator that measures the degree of significance of the kth innovation to analytical subspaces. The “significance” indicator is calculated based on an “averaging” indicator that is defined as Eq. (4):
where n denotes the total number of the 2D analytical subspaces. The “significance” indicator is a combined indicator that measures the degree of significance of the kth innovation to analytical subspaces. The value of this indicator is defined as the ratio of the averaging indicator and the versatility indicator, as shown in Eq. (5):
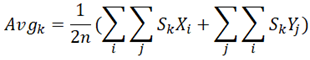 |
(4) |
The third indicator is “commerciality”, inspired by the theory of technology life cycle; the life cycle stage of a technology can be approximately determined on the basis of the “hits” on relevant items like journal papers and patents [68]. The volumes of search results are expected to provide more direct and credible evidence to portray massive traces of technological evolution instead of speculating the potential changing trends of “hits” [69]. Instead of decomposing the technology life cycle into several distinctive stages, and then determining what stage the technology might be in based on historical analogies [12], this indicator provides a quantitative measurement in a continuous and real-time manner. Hence, the “commerciality” indicator measures the degree of correlation between the y-coordinate and x-coordinate of a technology as shown in Eq. (6).
where a high Comk value suggests that the corresponding technology has an application value that is greater than its technique value, which may suggest that this technology might be at a stage that is closer to commercialization.
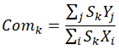 |
(6) |
The last indicator “disruptiveness” is proposed to assess whether the technology can be disruptive, and our definition of disruptiveness is compatible with that of the disruptive innovation literature given that possessing the competency to capture niche or emerging markets is a key feature of disruptive innovations [23,28]. By combining the skewness indicator (Eq. (7)) and the A_Comk values of the commerciality, the “disruptiveness” indicator is calculated as Eq. (8):
where s denotes the standard deviation of all the SkYj values. The skewness indicator measures the degree of deviation in the distribution of y-coordinates, while the versatility index shows the evenness of the distribution of x-coordinates and y-coordinates. According to Eq. (8), a high disruptiveness value is attributed to two components: high application values, and uneven distributions of application values. In other words, a supposedly disruptive technology is expected to be important in applications and holds an irreplaceable position in a few fields. Sufficiently high application values ensure that the technology cannot be readily substituted by others, but even distributions of application values imply that the technology could be more fundamental. This setting is compatible with the disruptive innovation literature, as the disruptive potential of technologies is linked to their capacity of capturing niche markets [28].
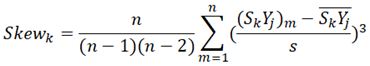 |
(7) |
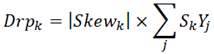 |
(8) |
3.3. Case Study Setting
Initially, we select 470 technologies based on 22 strategic plans of intelligent robotics proposed by major powers in the world, including U.S., European Union, Japan, U.K., Russia, France, and China. A total of 452 authentic technologies are obtained for characterization by excluding 18 obviously atypical, vague, and irrelevant technologies (as marked with “N” in Table I in Supplementary Materials).
Then, we extract the representative keywords from the 452 technologies according to the procedure shown in Figure 3.
The complete list of the total of 452 selected technologies with their corresponding keywords is displayed in Table I in Supplementary Materials. The keyword searching procedure has been conducted on January 1, 2018, and the feature distributions of the 452 technologies are thereby portrayed.
4. Results
The results of the application of our technological assessment approach on the 452 intelligent robotic technologies are illustrated in according to the four indicators.
4.1. Distributions of Versatility Values
The 452 technologies from the domain of intelligent robotics were sorted according to their versatility values, as shown in Figure 4. The patterns of the versatility curves based on Google and Google Scholar are quite similar (Figure 4 [a]). The p-values of the two curves are 0.0277 and 0.0000, respectively. Thus, the hypothesis of normal distribution has been rejected according to the Shapiro–Wilk test for an alpha level of 0.05. Thus, the versatility values have skewed distributions. The arithmetic averaging values of the two curves are plotted in Figure 4 (b). We define the technologies with a Vers_Avg value over 0.4145 (the average versatility value) as versatile, while the others are labeled as specialized technologies. A total of 229 versatile technologies and 223 specialized technologies are available, accounting for 50.7% and 49.3% of the total figure, respectively. In other words, all the technologies are normally distributed in their Vers_Avg values; the p-value is 0.1635, which rejects the hypothesis of non-normal distribution. Figure 4 shows that the versatility values based on Google and Google Scholar are inconsistent. This discrepancy may be attributed to the differences between the focuses and users of these engines: Google Scholar focuses on scientific publications and caters for academics [70], whereas Google is far more inclusive.
4.2. Distributions of Significance Values
The significance values of the included technologies are plotted in descending orders in Figure 5 (a). In general, the significance values from Google are noticeably higher than those from Google Scholar. The curves follow power-law distributions: a few technologies possess higher significance values, whereas the majority have lower values. This finding is similar to those obtained on scale-free networks like the World Wide Web [71], personal attributes like wealth [72], and names [73], and natural events like solar energetic particle events [74].
We compare the top 150 technologies of the highest significance values based on Google and Google Scholar. We observe that 79 technologies have the top 150 Sig_Google values and the top 150 Sig_GoogleScholar values. We compute the arithmetic averages of the two curves (Sig_Avg) and plotted the results in Figure 5 (b). The Pearson correlation coefficients of the Sig_Avg values and the two series are 0.9296 and 0.7254, respectively. This observation suggests that our measurement is robust and Google is more suitable for technological assessment due to its wider scope of users. Among the most significant 150 technologies (Sig_Google), only 22 are versatile (14.7%), while the others are specialized (85.3%). The observation shows that the significance values of the specialized technologies are generally higher than those of the versatile ones due to their lack of focus. As their applications are comparatively limited, these specialized technologies possess high specificity in certain fields. Creativity is highly domain specific, but some degrees of generality may also be involved [70]. Considering that specific usefulness perceived by users could influence the acceptance of a technology [74], the technologies of specificity are valued as reflected by their low versatility values and high significance values. This finding partially explains why technological competitions highly value specialization [4].
4.3. Distributions of Commerciality Values
Figure 6 (a) shows the commerciality values of all the 452 technologies in a descending order, as well as the corresponding values of the upper (, denoted as A_Comk) and lower ,denoted as I/T_Comk) parts. Only two technologies have exceptionally high commerciality values over 11, 55 technologies with the commerciality values of 2 to 6, while the others’ correlation values are below 2.
Power-law distributions are observed in Figure 6 (a), which means that the intelligent robotics technologies form a scale-free network [75]. It also implies that most of the technologies still have a long distance from commercialization. For example, European Commission claimed that “undeniable gap between the basic science and engineering implementations” exists in robotic research [76]. Several exceptional high I/T_Comk values in Figure 6 (a) correspond to the innovations of low significance, which implies that versatile technologies always have less technological features. It provides additional quantitative evidence to support the speculation that high domain specificity benefits and propels innovation [70].
We acquire the commerciality values of the top 150 technologies with the highest Sig_Google values, and we plot the values in a descending order in Figure 6 (b) with the corresponding A_Comk values and I/T_Comk values. Figure 6 (b) shows that the curves of the A_Comk and I/T_Comk values still follow power-law distributions. Figure 6 (b) also shows that the commerciality indicator of a technology is negatively correlated to its x-coordinates, and the y-coordinates affect the value of the commerciality indicator positively. This finding implies that asymmetry exists between applications and technological developments. This situation confirms that different life cycle stages of a technology have different focuses [68] and the heterogeneity between research and technology commercialization persists [76]. Furthermore, we find that the arithmetic average commerciality value of the top significant 150 technologies (1.3109) is higher than that of the total of 452 technologies (1.1805), which means that the top ones are closer to be commercialized.
4.4. Distributions of Disruptiveness Values
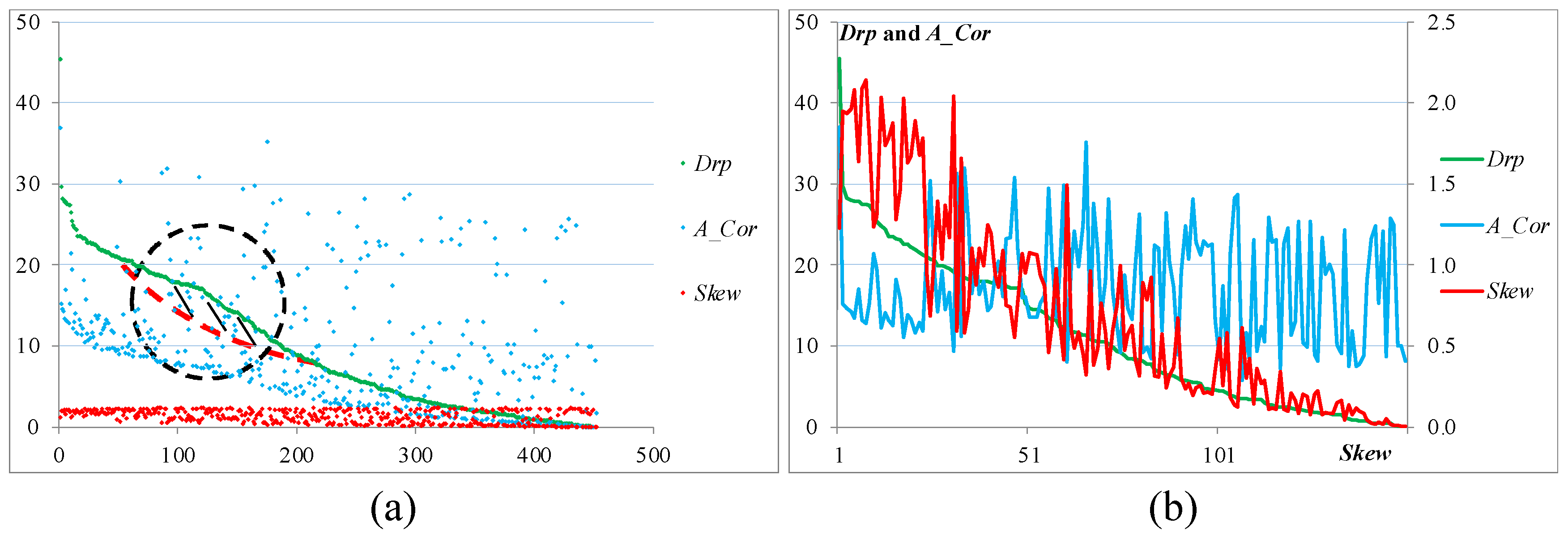
We calculate the disruptiveness values of the 452 technologies and the top significant 150 technologies, as shown in Figure 7(a) and Figure 7(b), respectively. The technologies are still of power-law distributions according to their disruptiveness values despite the existence of some degrees of distortion (Figure 7 [a]). Except for one technology with the highest disruptiveness value of 45.4715, the disruptiveness values of the other technologies are within 0 to 30. This observation could be the bane of the theory of disruptive innovation, which has long been under heavy criticisms of being highly selective [77]; in fact, disruptive innovations are rare. The disruptiveness values show that the significant technologies are generally supposed to have higher potential of causing disruption; the arithmetic average disruptiveness value of the top significant 150 technologies (11.0176) is noticeably greater than that of the total of 452 technologies (9.6488), as shown in Figure 7 (b). The finding supports the route of technological disruption: specialization promotes the adoption of a technology [75], and disruptiveness is fulfilled after successfully acquiring market shares [23,28].
We also check the robustness of the observed feature distributions. We calculate the historical values of the four indicators of two selected technologies: Industrial Robot Programming and Artificial Muscle. In the Robustness Checks: On the Characterizing Indicators in Supplementary Materials, we observe a good synergy between historical data and literature review. In the Robustness Checks: On the Observed Feature Distributions in Supplementary Materials, the same feature distributions are found in the reduced 2D measurements, which attests the robustness of the observed pattern.
Furthermore, we compare our method with the commonly used technological assessment methods, i.e., Gartner’s hype cycle or S-curve, in depicting the developmental trends of two technologies, i.e., Industrial Robot Programming and Artificial Muscle. We elaborate this comparison in Methodological Comparison in Supplementary Materials, and prove the superiority of our proposed approach.
5. Discussion
In this section, the theoretical contributions and managerial implications of the proposed methods and observed results are discussed, and potential directions of future works are suggested.
5.1. Theoretical Contributions
In general, our study offers two principal contributions to the literature.
The primary contribution of this work lies in the methodology. Our online behavioral big data-based approach is the first method that is capable of assessing the features of multiple technologies, while the reported technological assessment methods like Gartner’s hype cycle [5], S-curve [6], or disruptive susceptibility evaluation models [23] can only assess one single technological feature of a technology. Also, our proposed method tends to overcome the limitations of the resources on which the extant technological assessment methods are based, for examples, personal expertise or patents and publications (see Literature Review), and allows us to quantify the feature distributions of multiple technologies in any given domain in a more inclusive, accessible, timely, and affordable manner.
The other theoretical contribution of this article is derived by testing hypotheses proposed in the extant literature. We show that among the 452 intelligent robotics technologies, most of the features follow power-law distributions; a few technologies exhibit higher values, while the majority have much lower values. This observation is compatible with the theory of disruptive innovation, which implies that potentially disruptive innovations are always in scarcity.
5.2. Managerial Implications
In addition to contributing to our knowledge of the key features of technology and their distribution in a technical domain, the insights into the distributions of technology features gained using this method can have important managerial implications for the decision-making processes of various stakeholders.
First, for policy makers and industrial practitioners, more attention and resources can be allocated to the technologies with higher significant values. The definition of the significant indicator suggests that the technologies with higher significant values receive higher attention from a few limited fields, and they are much closer to being commercialized or causing potential disruption. Considering that in any specific domain, only a few technologies possess higher significant values, our big data-based approach could be beneficial for decision makers by explicitly identifying such technologies. The proposed method can also enhance the understanding of the technological research needs of a given domain. Knowing the distributions and even potentials of technologies in their studied domains in a timely and comprehensive manner, they can better decide their strategic focus and priority.
Second, this method also provides a correction function to all stakeholders. When the feature distributions of some technologies deviate from their supposed distributions, the deviations may suggest that expectations on such technologies could be excessively overrated. For instance, the distortion of the disruptiveness values of intelligent robotics technologies (see the black circle in Figure 6[a]) can be explained by the fact that some innovations are thought to have disruptive potential and are being intensively discussed, but the real disruptive innovations are indeed rare [28]. This finding also offers sound explanation to the question why the disruptive innovation theory has been highly selective in and sensitive to cases under study [77]. Although more intelligent technologies are believed to be disruptive and are under heated discussion, only a few technologies indeed possess the potential of causing disruption.
Third, the proposed approach can effectively and constantly monitor the gap between research and application, which is crucial to decision-making in research and development. The existence of such a gap calls for a closer scrutiny on technological development, which is usually full of unexpected sudden changes. For instance, the technology of Artificial Muscles has enjoyed rapid development in the beginning of 21st century due to the advent of electroactive polymers [78] after a long period of stagnation. For this reason, the conventional technology life cycle description tools like Gartner’s hype cycle or S-curve become useless, and timely approaches like the proposed big data-based method are much more viable; we successfully prove this statement in Methodological Comparison in Supplementary Materials.
5.3. Theoretical Implications
This paper leaves three potential arenas for future study.
The first direction is to further exploit online human behavioral traces and investigate national or regional differences in the trends and dynamics of developments in certain technological domains. This would enable us to better understand the complicated nexus between technological and institutional factors [4].
The second arena for further investigation is the differing perceptions of different groups, as noticeable differences have been observed in the preliminary search results derived from Google and Google Scholar, for example, the significance indicator.
The third potential research area lies in the feature characterization based on different methods for defining technologies and their representative keywords, since the definitions and keywords selections could also affect the feature distributions.
6. Conclusions
In this article, we design a novel big data-based method to characterize the feature distributions of technologies in a given domain. Four technological features are proposed, namely versatility, significance, commerciality, and disruptiveness, corresponding to important aspects of technologies. These features are determined based on the technologies’ representative keywords and volumes of returned search results from public search engines in two-dimensional analytical spaces of technique and application, and the feature distributions are thereby acquired. Using a sample of 452 intelligent robotics technologies as a case study, we show that except for the values of the versatility indicator, which are normally distributed, the other features follow power-law distributions (distribution that has more sample data with extreme values than normal distribution, drawing a curve with a long tail lowering as the value increases). The observed patterns are proved to be robust in the selected technologies, i.e., Industrial Robot Programming and Artificial Muscles, and reduced analytical spaces. The findings of this work provide insights to assist relevant decision-makings, for examples, capital investment on research and formulation of science policy.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Conceptualization, J.Z.; Methodology, J.Z.; Software, J.Z.; Validation, J.Z. and C.D.; Formal Analysis, J.G.; Investigation, J.G.; Resources, J.P.; Data Curation, J.Z.; Writing-Original Draft Preparation, F.G.; Writing-Review & Editing, J.G. and C.D; Visualization, F.G.; Supervision, J.G. All authors have read and agreed to the published version of the manuscript.
Funding
No funding.
Data Availability Statement
The overall mathematical formulation of the model is available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Acemoglu, D.; Akcigit, U.; Kerr, W.R. Innovation network. P. Natl. Acad. Sci. Usa. 2016, 113(41), 11483–11488. [Google Scholar] [CrossRef] [PubMed]
- Anadon, L.D.; Chan, G.; Harley, A.G.; Matus, K.; Moon, S.; Murthy, S.L.; Clark, W.C. Making technological innovation work for sustainable development. P. Natl. Acad. Sci. Usa. 2016, 113(35), 9682–9690. [Google Scholar] [CrossRef] [PubMed]
- Bower, J.L.; Christensen, C.M. Disruptive technologies: Catching the wave. Harvard Bus. Rev. 1995, 73(1), 43–53. [Google Scholar]
- Petralia, S.; Balland, P.A.; Morrison, A. Climbing the ladder of technological development. Res. Policy 2017, 46(5), 956–969. [Google Scholar] [CrossRef]
- O’Leary, D.E. Gartner’s hype cycle and information system research issues. Int. J. Account. Inf. Sy. 2008, 9(4), 240–252. [Google Scholar] [CrossRef]
- Nieto, M.; Lopéz, F.; Cruz, F. Performance analysis of technology using the S curve model: the case of digital signal processing (DSP) technologies. Technovation 1998, 18(6), 439–457. [Google Scholar] [CrossRef]
- Tran, T.A.; Daim, T. A taxonomic review of methods and tools applied in technological assessment. Technol. Forecast. Soc. 2008, 75(9), 1396–1405. [Google Scholar] [CrossRef]
- Daim, T.U.; Yoon, B.S.; Lindenberg, J.; Grizzi, R.; Estep, J.; Oliver, T. Strategic roadmapping of robotics technologies for the power industry: A multicriteria technological assessment. Technol. Forecast. Soc. 2018, 131, 49–66. [Google Scholar] [CrossRef]
- Proskuryakova, L. Energy technology foresight in emerging economies. Technol. Forecast. Soc. 2017, 119, 205–210. [Google Scholar] [CrossRef]
- Esmaelian, M.; Tavana, M.; Di Caprio, D.; Ansari, R. A multiple correspondence analysis model for evaluating technology foresight methods. Technol. Forecast. Soc. 2017, 125, 188–205. [Google Scholar] [CrossRef]
- Flostrand, A. Finding the future: Crowdsourcing versus the Delphi technique. Bus. Horizons 2017, 60(2), 229–236. [Google Scholar] [CrossRef]
- Daim, T.U.; Rueda, G.; Martin, H.; Gerdsri, P. Forecasting emerging technologies: use of bibliometrics and patent analysis. Technol. Forecast. Soc. 2006, 73(8), 981–1012. [Google Scholar] [CrossRef]
- Linstone, H.A. Three eras of technology foresight. Technovation 2011, 31(2), 69–76. [Google Scholar] [CrossRef]
- Mitchell, T. Mining our reality. Science 2009, 326(5960), 1644–1645. [Google Scholar] [CrossRef] [PubMed]
- Maggitti, P.G.; Smith, K.G.; Katila, R. The complex search process of invention. Res. Policy 2013, 42(1), 90–100. [Google Scholar] [CrossRef]
- Del Vicario, M.; Bessi, A.; Zollo, F.; Petroni, F.; Scala, A.; Caldarelli, G.; Eugene Stanley, H.; Quattrociocchi, W. The spreading of misinformation online. P. Natl. Acad. Sci. Usa. 2016, 113(3), 554–559. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Maggitti, P.G.; Smith, K.G.; Tesluk, P.E.; Katila, R. Top management attention to innovation: The role of search selection and intensity in new product introductions. Acad. Manag. J. 2013, 56(3), 893–916. [Google Scholar] [CrossRef]
- Roca, J.B.; Vaishnav, P.; Morgan, M.G.; Mendonça, J.; Fuchs, E. When risks cannot be seen: Regulating uncertainty in emerging technologies. Res. Policy 2017, 46(7), 1215–1233. [Google Scholar] [CrossRef]
- Da, Z.; Engelberg, J.; Gao, P. In search of attention. J. Financ. 2011, 66(5), 1461–1499. [Google Scholar] [CrossRef]
- Guo, J.F.; Ji, Q. How does market concern derived from the internet affect oil prices. Appl. Energ. 2013, 112, 1536–1543. [Google Scholar] [CrossRef]
- Beracha, E.; Wintoki, M.B. Forecasting residential real estate price changes from online search activity. J. Real Estate Res. 2013, 35(3), 283–312. [Google Scholar] [CrossRef]
- Yang, S.; Santillana, M.; Kou, S.C. Accurate estimation of influenza epidemics using Google search data via ARGO. P. Natl. Acad. Sci. Usa. 2015, 112(47), 14473–14478. [Google Scholar] [CrossRef] [PubMed]
- Klenner, P.; Hüsig, S.; Dowling, M. Ex-ante evaluation of disruptive susceptibility in established value networks - When are markets ready for disruptive innovations? Res. Policy 2013, 42(4), 914–927. [Google Scholar] [CrossRef]
- Hang, C.C.; Chen, J.; Yu, D. An assessment framework for disruptive innovation. Foresight 2011, 13(5), 4–13. [Google Scholar] [CrossRef]
- Hahn, F.; Jensen, S.; Tanev, S. Disruptive innovation vs. disruptive technology: the disruptive potential of the value propositions of 3D printing technology startups. Technol. Innov. Manag. 2014, 4(12), 27–36. [Google Scholar] [CrossRef]
- Guo, J.; Pan, J.; Guo, J.; Gu, F.; Kuusisto, J. Measurement framework for assessing disruptive innovations. Technol. Forecast. Soc. 2019, 139, 250–265. [Google Scholar] [CrossRef]
- Schmidt, G.M.; Druehl, C.T. When is a disruptive innovation disruptive? J. Prod. Innov. Manag. 2008, 25(4), 347–369. [Google Scholar] [CrossRef]
- Kostoff, R.N.; Boylan, R.; Simons, G.R. Disruptive technology roadmaps. Technol. Forecast. Soc. 2004, 71(1-2), 141–150. [Google Scholar] [CrossRef]
- Mankins, J.C. Technology readiness assessments: a retrospective. Acta Astronaut. 2009, 65(9-10), 1216–1223. [Google Scholar] [CrossRef]
- Martínez-Plumed, F.; Gómez, E.; Hernández-Orallo, J. Futures of artificial intelligence through technology readiness levels. Telemat. Inform. 2021, 58. [Google Scholar] [CrossRef]
- Kota, K.B.; Shenbagaraj, S.; Sharma, P.K.; Sharma, A.K.; Ghodke, P.K.; Chen, W.H. Biomass torrefaction: An overview of process and technology assessment based on global readiness level. Fuel 2022, 324. [Google Scholar] [CrossRef]
- Tzinis, I. Technology Readiness Level. Available online: https://www.nasa.gov/directorates/heo/scan/engineering/technology/technology_readiness_level (accessed on 2 April 2021).
- Vik, J.; Melås, A.M.; Stræte, E.P.; Søraa, R.A. Balanced readiness level assessment (BRLa): A tool for exploring new and emerging technologies. Technol. Forecast. Soc. 2021, 169, 120854. [Google Scholar] [CrossRef]
- Kyriakidou, V.; Michalakelis, C.; Sphicopoulos, T. Assessment of information and communications technology maturity level. Telecommun. Policy 2013, 37(1), 48–62. [Google Scholar] [CrossRef]
- Albert, T.; Moehrle, M.G.; Meyer, S. Technology maturity assessment based on blog analysis. Technol. Forecast. Soc. 2015, 92, 196–209. [Google Scholar] [CrossRef]
- Lezama-Nicolás, R.; Rodríguez-Salvador, M.; Río-Belver, R.; Bildosola, I. A bibliometric method for assessing technological maturity: the case of additive manufacturing. Scientometrics. 2018, 117, 1425–1452. [Google Scholar] [CrossRef] [PubMed]
- Letaba, P.T.; Pretorius, M.W. Toward Sociotechnical Transition Technology Roadmaps: A Proposed Framework for Large-Scale Projects in Developing Countries. IEEE T. Eng. Manage. 2022, 69(1), 195–208. [Google Scholar] [CrossRef]
- Sourav, K.; Daim, T.; Herstatt, C. Technology Roadmap for the Single-Aisle program of a major aircraft industry company. IEEE Eng. Manage. Rev. 2018, 46(2), 103–120. [Google Scholar] [CrossRef]
- Nazarko, J.; Ejdys, J.; Gudanowska, A.E.; Halicka, K.; Kononiuk, A.; Magruk, A.; Nazarko, Ł. Roadmapping in Regional Technology Foresight: A Contribution to Nanotechnology Development Strategy. IEEE T Eng. Manage. 2022, 69(1), 179–194. [Google Scholar] [CrossRef]
- Ramos, A.G.; Daim, T.; Gaats, L.; Hutmacher, D.W.; Hackenberger, D. Technology roadmap for the development of a 3D cell culture workstation for a biomedical industry startup. Technol. Forecast. Soc. 2022, 174, 121213. [Google Scholar] [CrossRef]
- Park, H.; Phaal, R.; Ho, J.Y.; O’Sullivan, E. Twenty years of technology and strategic roadmapping research: A school of thought perspective. Technol. Forecast. Soc. 2020, 154, 119965. [Google Scholar] [CrossRef]
- Chakraborty, S.; Nijssen, E.J.; Valkenburg, R. A systematic review of industry-level applications of technology roadmapping: Evaluation and design propositions for roadmapping practitioners. Technol. Forecast. Soc. 2022, 179, 121141. [Google Scholar] [CrossRef]
- Phaal, R.; O’Sullivan, E.; Routley, M.; Ford, S.; Probert, D. A framework for mapping industrial emergence. Technol. Forecast. Soc. 2011, 2, 217–230. [Google Scholar] [CrossRef]
- Zhang, H.; Daim, T.; Zhang, Y.P. Integrating patent analysis into technology roadmapping: A latent dirichlet allocation based technology assessment and roadmapping in the field of Blockchain. Technol. Forecast. Soc. 2021, 167, 120729. [Google Scholar] [CrossRef]
- Nazarenko, A.; Vishnevskiy, K.; Meissner, D.; Daim, T. Applying digital technologies in technology roadmapping to overcome individual biased assessments. Technovation 2022, 110, 102364. [Google Scholar] [CrossRef]
- Yuskevich, I.; Smirnova, K.; Vingerhoeds, R.; Golkar, A. Model-based approaches for technology planning and roadmapping: Technology forecasting and game-theoretic modeling. Technol. Forecast. Soc. 2021, 168, 120761. [Google Scholar] [CrossRef]
- Yuskevich, I.; Hein, A.M.; Amokrane-Ferka, K.; Doufene, A.; Jankovic, M. A metamodel of an informational structure for model-based technology roadmapping. Technol. Forecast. Soc. 2021, 173, 121102. [Google Scholar] [CrossRef]
- Okada, Y.; Kishita, Y.; Nomaguchi, Y.; Yano, T.; Ohtomi, K. Backcasting-based method for designing roadmaps to achieve a sustainable future. IEEE T. Eng. Manage. 2022, 69(1), 168–178. [Google Scholar] [CrossRef]
- Noh, H.; Kim, K.; Song, Y.K.; Lee, S. Opportunity-driven technology roadmapping: The case of 5G mobile services. Technol. Forecast. Soc. 2021, 163, 120452. [Google Scholar] [CrossRef]
- Maja, M.M.; Letaba, P. Towards a data-driven technology roadmap for the bank of the future: Exploring big data analytics to support technology roadmapping. Soc. Sci. Humanit. Open. 2022, 6(1), 100270. [Google Scholar] [CrossRef]
- Altuntas, S.; Dereli, T.; Kusiak, A. Forecasting technology success based on patent data. Technol. Forecast. Soc. 2015, 96, 202–214. [Google Scholar] [CrossRef]
- Porter, A.L.; Cunningham, S.W. Tech mining: Exploiting new technologies for competitive advantage; John Wiley & Sons, USA, 2004.
- Sanders, N.R.; Manrodt, K.B. The efficacy of using judgmental versus quantitative forecasting methods in practice. Omega 2003, 31(6), 511–522. [Google Scholar] [CrossRef]
- Adamuthe, A.C.; Thampi, G.T. Technology forecasting: A case study of computational technologies. Technol. Forecast. Soc. 2019, 143, 181–189. [Google Scholar] [CrossRef]
- Wang, C.; Geng, H.; Sun, R.; Song, H. Technological potential analysis and vacant technology forecasting in the graphene field based on the patent data mining. Resour. Policy 2022, 77, 102636. [Google Scholar] [CrossRef]
- Kim, L.; Ju, J. Can media forecast technological progress?: A text-mining approach to the on-line newspaper and blog’s representation of prospective industrial technologies. Inform. Process. Manag. 2019, 56(4), 1506–1525. [Google Scholar] [CrossRef]
- Kim, J.; Kim, S.; Lee, C. Anticipating technological convergence: link prediction using wikipedia hyperlinks. Technovation 2019, 79, 25–34. [Google Scholar] [CrossRef]
- Lim, D.J.; Anderson, T.R.; Shott, T. Technological forecasting of supercomputer development: The March to Exascale computing. Omega 2015, 51, 128–135. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, G.; Chen, H.; Porter, A.L.; Zhu, D.; Lu, J. Topic analysis and forecasting for science, technology and innovation: methodology with a case study focusing on big data research. Technol. Forecast. Soc. 2016, 105, 179–191. [Google Scholar] [CrossRef]
- Ma, T.; Zhou, X.; Liu, J.; Lou, Z.; Hua, Z.; Wang, R. Combining topic modeling and SAO semantic analysis to identify technological opportunities of emerging technologies. Technol. Forecast. Soc. 2021, 173, 121159. [Google Scholar] [CrossRef]
- Kyebambe, M.N.; Cheng, G.; Huang, Y.; He, C.; Zhang, Z. Forecasting emerging technologies: A supervised learning approach through patent analysis. Technol. Forecast. Soc. 2017, 125, 236–244. [Google Scholar] [CrossRef]
- Lee, C. A review of data analytics in technological forecasting. Technol. Forecast. Soc. 2021, 2021(166), 120646. [Google Scholar] [CrossRef]
- Ford, D.; Ryan, C. Taking technology to market. Harvard Bus. Rev. 1981, 59, 117–126. [Google Scholar] [CrossRef]
- Haupt, R.; Kloyer, M.; Lange, M. Patent indicators for the technology life cycle development. Res. Policy 2007, 36(3), 387–398. [Google Scholar] [CrossRef]
- Ingrand, F.; Ghallab, M. Deliberation for autonomous robots: A survey. Artif. Intell. 2017, 247, 10–44. [Google Scholar] [CrossRef]
- Aly, A.; Griffiths, S.; Stramandinoli, F. Metrics and benchmarks in human-robot interaction: Recent advances in cognitive robotics. Cogn. Syst. Res. 2017, 43, 313–323. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitanyi, P.M. The Google similarity distance. IEEE T. Knowl. Data En. 2007, 19, 370–383. [Google Scholar] [CrossRef]
- Bianchi, M.; Campodall’Orto, S.; Frattini, F.; Vercesi, P. Enabling open innovation in small- and medium-sized enterprises: How to find alternative applications for your technologies. R&D Manage. 2010, 40(4), 414–431. [Google Scholar] [CrossRef]
- Martino, J. A review of selected recent advances in technological forecasting. Technol. Forecast. Soc. 2003, 70(8), 719–733. [Google Scholar] [CrossRef]
- Baer, J. Domain specificity of creativity (1st ed); Academic Press, USA, 2016.
- McFarland, D.J.; Hamilton, D. Adding contextual specificity to the technology acceptance model. Comput. Hum. Behav. 2006, 22(3), 427–447. [Google Scholar] [CrossRef]
- Levy, M.; Solomon, S. New evidence for the power-law distribution of wealth. Physica A 1997, 242(1-2), 90–94. [Google Scholar] [CrossRef]
- Miyazima, S.; Lee, Y.; Nagamine, T.; Miyajima, H. Power-law distribution of family names in Japanese societies. Physica A 2000, 278(1-2), 282–288. [Google Scholar] [CrossRef]
- Gabriel, S.B.; Feynman, J. Power-law distribution for solar energetic proton events. Sol. Phys. 1996, 165, 337–346. [Google Scholar] [CrossRef]
- Albert, R.; Jeong, H.; Barabási, A.L. Diameter of the world-wide web. Nature 1999, 401(6749), 130–131. [Google Scholar] [CrossRef]
- Král, L. European Robotics Research: Achievements and challenges. Available online: https://iros2012.isr.uc.pt/site/sites/default/files/iros2012_LiborKral_Plenary.pdf (accessed on 9 October 2012).
- King, A.A.; Baatartogtokh, B. How useful is the theory of disruptive innovation. MIT Sloan Manage. Rev. 2015, 57(1), 77–90. [Google Scholar]
- Bar-Cohen, Y. Electroactive polymers as artificial muscles-capabilities, potentials and challenges. Handb. Biomim. 2000. [Google Scholar] [CrossRef]
- Kobara, Y.M.; Akpan, I.J. Bibliometric Performance and Future Relevance of Virtual Manufacturing Technology in the Fourth Industrial Revolution. Systems 2023, 11, 524. [Google Scholar] [CrossRef]
- Akpan, I.J.; Offodile, O.F. The Role of Virtual Reality Simulation in Manufacturing in Industry 4.0. Systems 2023, 12, 26. [Google Scholar] [CrossRef]
- Li, X.; Feng, G.; Hao, S. Market-Oriented Transformation and Development of Local Government Financing Platforms in China: Exploratory Research Based on Multiple Cases. Systems 2022, 10, 65. [Google Scholar] [CrossRef]
- Shen Y, Zhang X. Blue Sky Protection Campaign: Assessing the Role of Digital Technology in Reducing Air Pollution[J]. Systems 2024, 12, 55. [CrossRef]
- Gupta, V. An empirical evaluation of a generative artificial intelligence technology adoption model from entrepreneurs’ perspectives[J]. Systems 2024, 12, 103. [Google Scholar] [CrossRef]
Figure 1.
(a) Evolution of an individual technology can be described by common assessment methods like Gartner’s hype cycle [5]. (b) Evolution of technologies within a domain is more complex and poorly understood.
Figure 1.
(a) Evolution of an individual technology can be described by common assessment methods like Gartner’s hype cycle [5]. (b) Evolution of technologies within a domain is more complex and poorly understood.
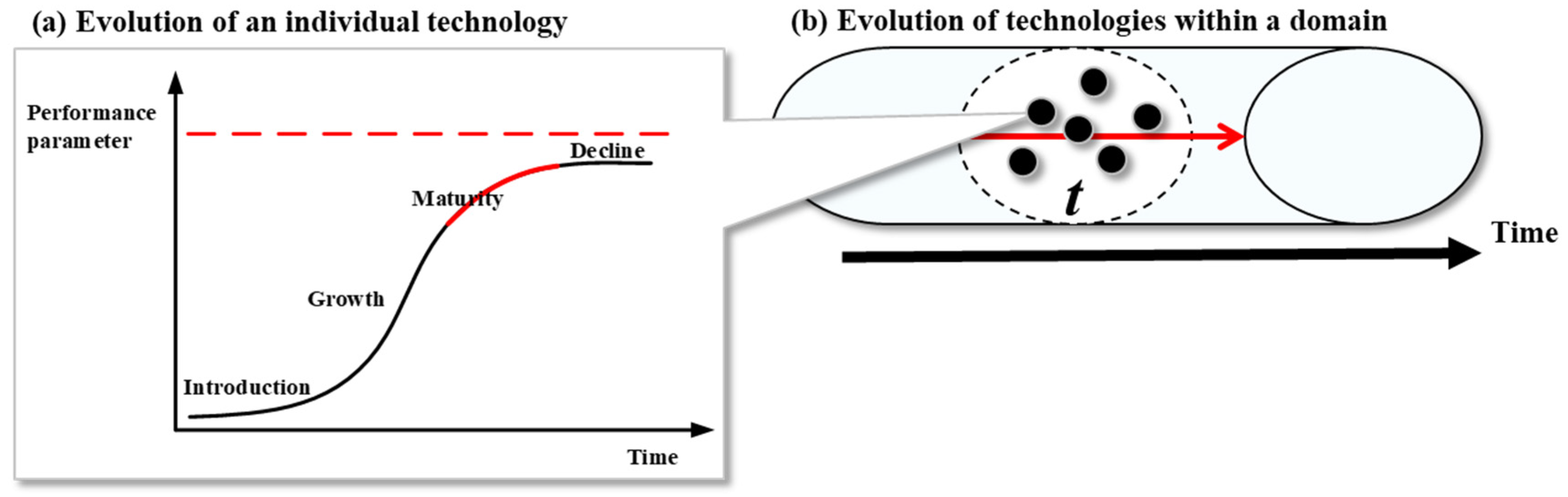
Figure 2.
Illustration of division of the 2D analytical space. The original 2D analytical space is refined given that six subsectors of the technique dimension and eight subsectors of the application dimension yield a total of 48 2D analytical spaces.
Figure 2.
Illustration of division of the 2D analytical space. The original 2D analytical space is refined given that six subsectors of the technique dimension and eight subsectors of the application dimension yield a total of 48 2D analytical spaces.
Figure 3.
Keyword extraction procedure for the included intelligent robotics technologies.
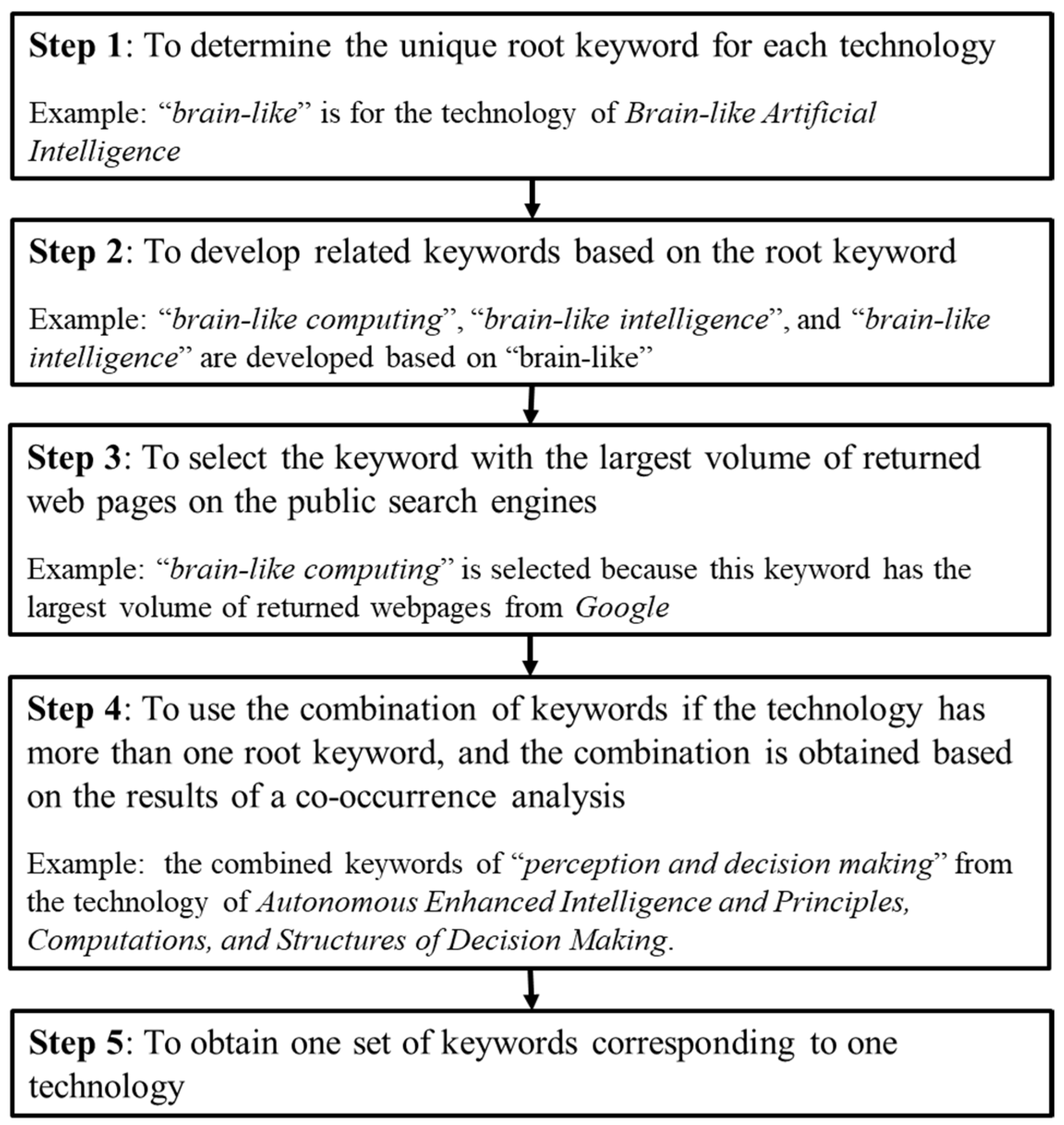
Figure 4.
Values of the versatility index of the 452 selected intelligent robotic technologies: (a) the Vers_Google and Vers_GoogleScholar values are calculated and plotted in a descending order; (b) the Vers_Avg values are calculated and plotted in a descending order, along with the corresponding Vers_Google and Vers_GoogleScholar values.
Figure 4.
Values of the versatility index of the 452 selected intelligent robotic technologies: (a) the Vers_Google and Vers_GoogleScholar values are calculated and plotted in a descending order; (b) the Vers_Avg values are calculated and plotted in a descending order, along with the corresponding Vers_Google and Vers_GoogleScholar values.
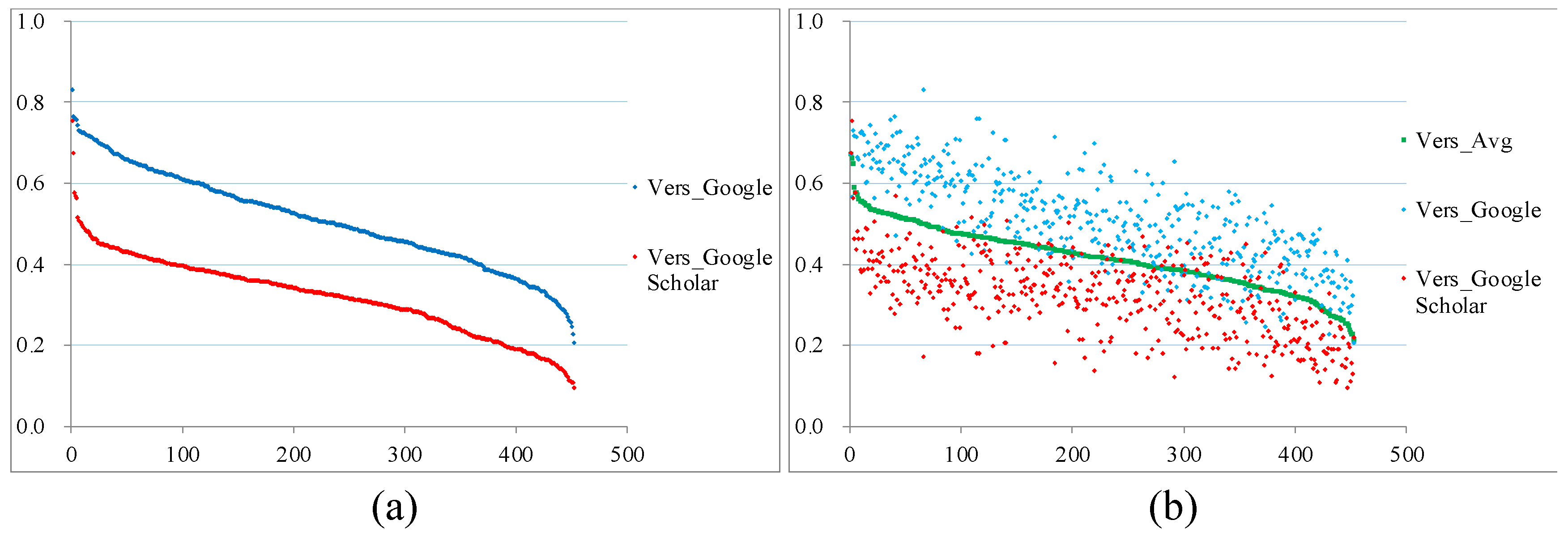
Figure 5.
Values of the significance indicator of the 452 selected intelligent robotic technologies: (a) the Sig_Google and Sig_GoogleScholar values are plotted in descending orders; (b) the Sig_Avg values are plotted in a descending order, and the corresponding Sig_Google and Sig_GoogleScholar values are also presented in the figure.
Figure 5.
Values of the significance indicator of the 452 selected intelligent robotic technologies: (a) the Sig_Google and Sig_GoogleScholar values are plotted in descending orders; (b) the Sig_Avg values are plotted in a descending order, and the corresponding Sig_Google and Sig_GoogleScholar values are also presented in the figure.
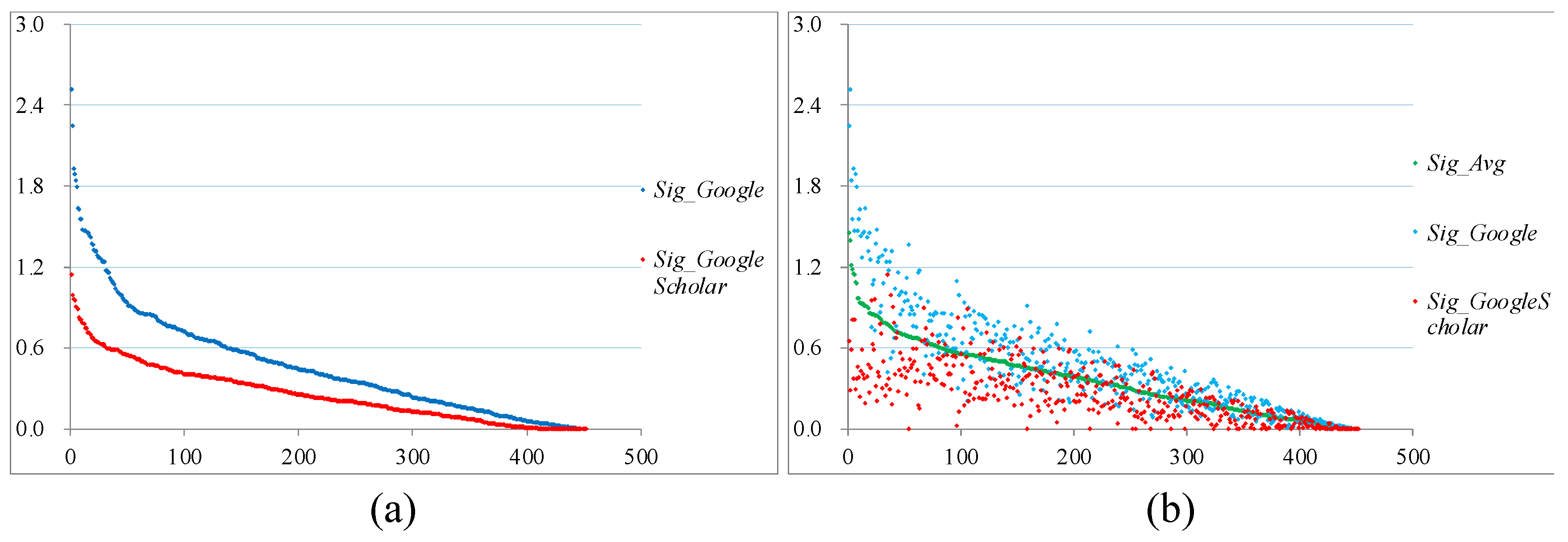
Figure 6.
Values of the commerciality indicator of the selected intelligent robotic technologies: (a) the Comk values of the total of 452 technologies are plotted in a descending order, as well as the corresponding A_Comk and I/T_Comk values; (b) line chart of the A_Comk and I/T_Comk values according to the descending order of the corresponding Comk values of the top 150 technologies with the highest Sig_Google values.
Figure 6.
Values of the commerciality indicator of the selected intelligent robotic technologies: (a) the Comk values of the total of 452 technologies are plotted in a descending order, as well as the corresponding A_Comk and I/T_Comk values; (b) line chart of the A_Comk and I/T_Comk values according to the descending order of the corresponding Comk values of the top 150 technologies with the highest Sig_Google values.
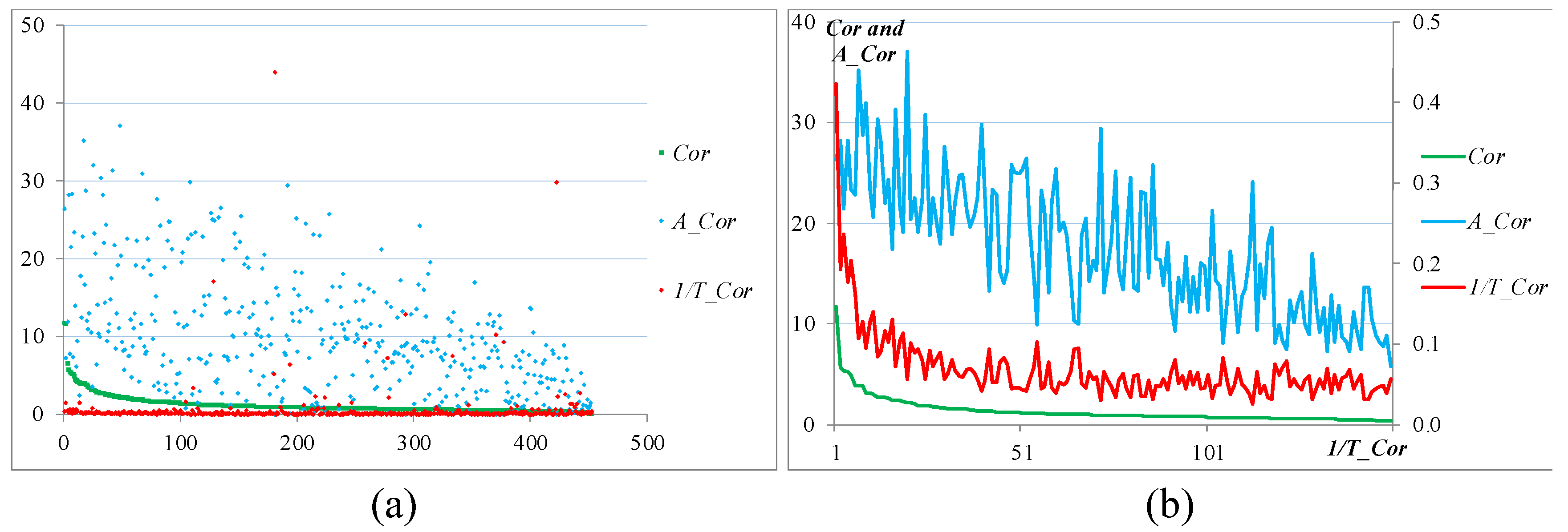
Figure 7.
Values of the disruptiveness index of the selected intelligent robotic technologies: (a) the Drpk values of the total of 452 technologies are plotted in descending orders, with the corresponding A_Comk and I/T_Comk values; (b) line chart of the A_Comk and I/T_Comk values according to the descending order of the corresponding Comk values of the top 150 technologies with the highest Sig_Google values. Notably, some degrees of distortion from a proper power-law distribution are found in the curve of the Drpk values, and they are marked in a circle of black dot line.
Figure 7.
Values of the disruptiveness index of the selected intelligent robotic technologies: (a) the Drpk values of the total of 452 technologies are plotted in descending orders, with the corresponding A_Comk and I/T_Comk values; (b) line chart of the A_Comk and I/T_Comk values according to the descending order of the corresponding Comk values of the top 150 technologies with the highest Sig_Google values. Notably, some degrees of distortion from a proper power-law distribution are found in the curve of the Drpk values, and they are marked in a circle of black dot line.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



