Submitted:
25 June 2024
Posted:
26 June 2024
You are already at the latest version
Abstract
Natural language processing model (NLP) are used in chatbots to understand user input, interpret its meaning, and generate conversational responses to provide immediate and consistent assistance. This reduces problem-solving time and staff workload and increases user satisfaction. There are both rule-based chatbots, which use decision trees and are programmed to answer specific questions, and self-learning chatbots, which can handle more complex conversations through continuous learning about data and user interactions. However, only a few chatbots have been developed specifically for the Italian language. This work proposes an NLP model to develop a powerful and efficient Italian QA (Question Answering) chatbot that is easy to use for Italian Public Administration (PA). The proposed model is based on BERT (Bidirectional Encoder Representations from Transformer) architecture, where an Encoder/Decoder module and a Highway Network module have been added to perform more efficient filtering of input text. The Italian version of the Stanford Question Answering Dataset (SQuAD-IT) is used to test the proposed model. The proposed model is one of the first models developed for Italian language-specific chatbots.
Keywords:
natural language processing
; chatbot
; BERT
; Transformer
; Italian language
1. Introduction
A chatbot is an application that uses various techniques to understand user input, interpret its meaning, and generate responses in a conversational manner based on the user input. Implementing a chatbot as a support tool offers several advantages for both the end users and the businesses [1]. First, chatbots can provide immediate assistance to users by helping to reduce the time it takes to solve problems. Second, chatbots can provide 24-hour support, even outside normal business hours, with shorter resolution times and higher user satisfaction. In addition, chatbots can be used to identify common problems and trends through analysis of user questions, enabling the company to proactively address these issues and reduce the number of support requests. It is also cost-effective as it helps reduce the workload of IT staff and the need for additional staff or overtime. A chatbot also offers benefits to the business because it helps reduce the workload of IT staff and the need for additional staff or overtime. Chatbots can be classified into two main variants: rule-based and self-learning. Rule-based chatbots are developed to answer specific questions or perform actions based on predefined rules and logic because the responses are written in advance and correspond to a set of predefined questions or commands. However, these chatbots are limited to understanding complex natural languages and are unable to adapt to new situations. Therefore, chatbots based on Artificial Intelligence (self-learning chatbots) have been developed to overcome these issues. Self-learning chatbots learn from data and user interactions, gradually improving their ability to respond accurately. They can manage more complex conversations and adapt to new scenarios and user requests. However, they require initial training and are more complex to develop than rule-based chatbots. Complexity is to ensure the best response to each and every unpredictable user input. Specifically in the Public Administration (PA) context, a self-learning chatbot should be able to understand and interpret documents provided as user input to provide appropriate responses, for example. A chatbot developed with these requirements would represent a great advantage in terms of time as well as efficiency for public administration staff. The proposed work presents an NLP model for the development of a QA self-learning chatbot able to read any document and provide relevant and specific responses to users. The proposed model architecture is based on the BERT [2] model architecture, with the addition of an encoder/decoder module and a highway network module to improve the filtering of the input text. Specifically, the encoder module takes as input a sequence of tokens and transforms them into a dense vector representation that captures the semantic and syntactic information of the text. The decoder module takes the vector representation provided by the encoder as input and generates a new sequence of text. The highway network filters irrelevant information before processing the last dense layers. Moreover, the proposed model is trained on the SQuAD-IT dataset to develop a chatbot specifically for the Italian language. Only a few works have used the Italian version of the SQuAD dataset, and the proposed work is intended to present an efficient and suitable architecture for developing an Italian-specific chatbot. The main contributions of the proposed work are summarized below.
- A customized BERT model architecture with the addition of an encoder/decoder module and a highway network module has been proposed. The proposed model is developed to be integrated into an Italian-specific chatbot to improve the work of PA staff by reducing time and errors in processing and understanding documents.
- The proposed model is trained and tested on the Italian version of the SQuAD dataset to evaluate the model's ability to process the Italian language
- The results of the experiments conducted on the SQuAD-IT dataset show that the proposed model has a good ability to provide exactly the expected answers. Moreover, a comparative analysis shows that the proposed model outperforms compared to other NLP models, such as BIDAF.
2. Related Works
Different types of self-learning chatbots have been developed based on the deep-learning models used. Three macro-categories can be identified: chatbots based on Convolutional Neural Networks (CNNs), chatbots based on Recurrent Neural Networks (RNNs), and chatbots based on hybrid models. CNNs are mainly used for pattern recognition in text data, such as sentences or paragraphs. Subsequently, sentence similarities between question-answer pairs are used to assess relevance and rank all candidate answers. In [3], a CNN for learning an optimal representation of question-and-answer sentences has been proposed. The CNN encodes the correspondences between words to better acquire interactions between questions and answers, resulting in a significant increase in accuracy. The proposed CNN consists of two distributional sentence models based on convolutional neural networks (ConvNets) that map question-and-answer sentences into their distributional vectors, which are then used to learn their semantic similarity. In [4] a model that considers both similarities and differences between question-and-answer by decomposing and composing lexical semantics on sentences has been proposed. Given a pair of sentences, the model represents each word as a low-dimensionality vector and computes a semantic correspondence vector for each word based on all the words in the other sentence. Then, based on the semantic correspondence vector, each word vector is decomposed into two components: similar and dissimilar. The similar components of all words are used to represent the similar parts of the sentence pair and the dissimilar components of each word are used to model the dissimilar parts explicitly. Subsequently, the similar and dissimilar components are composed into a single feature vector that is used to predict sentence similarity. In [5] a CNN with a Siamese structure with two sub-networks processing the question and the candidate response has been proposed. The input is a sequence of words each of which is translated into its corresponding distributional vector, producing a matrix of sentences. Convolutional feature maps are applied to this matrix of sentences, followed by ReLU activation and simple max-pooling to achieve a representation vector for the query and candidate response. CNNs can have difficulty capturing long-term dependencies in text. Therefore, they are combined with RNNs or Transformers to improve performance.
RNNs are able to process data sequences of variable length, making them ideal for text. In [6] a bilateral multi-perspective matching (BiMPM) model has been proposed. The proposed model encodes the sentences through a bidirectional Long ShortTerm Memory Network (BiLSTM). The matching between encoded sentences is aggregated through a layer BiLSTM into a matching vector of fixed length. It is used in the last fully connected layer of the proposed model to make a decision. The approach in [7] extends a long short-term memory (LSTM) proposed a Holographic Dual LSTM (HDLSTM). HDLSTM is a unified architecture for both deep sentence modeling and semantic matching. RNNs are less efficient than CNNs and Transformers in terms of parallelization and training speed. Therefore, hybrid models that combine the advantages of each model have been developed. RNNs have been combined with CNN [8], with attention mechanisms [9] or with Transformer [10], [11]. Minjoon Seo et al. [12] have proposed a Bi-Directional Attention Flow network (BIDAF) that uses a bi-directional attention mechanism to obtain a query-sensitive context representation. The attention layer is not used to summarize the context paragraph into a vector of fixed size, but attention is computed for each time step, and the expected vector in each time step, together with the representations of the previous layers, can flow through the next modeling layer.
The introduction of the Transformers in NLP models has led to advantages in efficiency, ability to capture long-range relationships, parallelization, and quality of representations. The transformer architecture allows higher parallelization during training and inference because it does not require sequential computation as in RNNs. This significantly reduces training time compared with RNNs. Therefore, using Transformers represents one of the best choices to develop self-learning chatbots.
The proposed model is based on BERT architecture that use Transformer to construct deep and bidirectional representations of words so as to capture complex contextual relationships. Moreover, the proposed model implements additional modules in the standard BERT architecture to increase the model's capabilities in providing correct answers.
3. Materials and Methods
The proposed model is based on an extended version of the BERT model by adding an encoder/decoder module and a highway network module. The proposed model is illustrated in Figure 1. The proposed model consists of 4 main modules.
-
The first module consists of BERT architecture to encode the input into a vector representation that is then processed by the subsequent structures. BERT architecture can be represented as a multilayer bidirectional transformer encoder. BERT's pre-training is based on two different unsupervised tasks: the Masked Language Model (MLM) and Next Sentence Prediction (NSP). In MLM, a portion of the words in the text are masked, and the model must predict them. In NSP, the model must determine whether two sentences appear consecutive in the original text. This pre-training makes the BERT model scalable (fine-tuned) for different tasks, such as QA. BERT takes as input the combinations of the question and context as a single embedded sequence. The input embeddings are the sum of the token embeddings and segment embeddings. Specifically, token embeddings represent the encoding of the question into an embedding vector, and segment embeddings represent vectors indicating the segment to which each token corresponds. The segment embeddings are used to distinguish between question and context in the input text.Let represents a sequence of input, and represents an embedded achieved combining the token and segment embeddings for each . The sequences of embeddings is the input of the BERT module. The module BERT processes the embedding sequence through transformer layers to obtain the output sequences where is the hidden representation of at the level.
- The encoder/decoder module consists of two sequential BiLSTM layers. The introduction of this module better captures the context and temporal sequence of words, thus improving the model's overall performance in understanding. Specifically, the BERT output is taken as input to encoder/decoder module to produce a new sequence of hidden representations .
-
The Highway network module aims to filter out irrelevant information before processing the last dense layers. Highway Network transformations are based on a linear combination between the non-linear transformation of the input and the original input following a gate function. The output of the Highway network module is defined in Equation 1, where represents the element-by-element multiplication.The linear transformation is defined by Equation 2, where and are the weights and the bias of the gate function, respectively, and represents the sigmoid function.The non-linear transformation is defined in Equation 3, where and are the weights and the bias of the non-linear transformation, respectively, and is the activation function.
- The output module consists of two fully connected layers with softmax activation function. The output module predicts the start and end positions of the response within the context following Equations 4 and 5, respectively.where and represent the weights and bias of the fully connected layer for the prediction of the start token.where and represent the weights and bias of the fully connected layer for the prediction of the end token.
4. Dataset
SQuAD-IT [13] dataset is a translated and adapted Italian version of the popular SQuAD dataset [14]. SQuAD dataset has been developed to evaluate NLP models in English. The main advantage of this dataset is that it is realistic because humans crowdsourced it manually. It includes 536 English Wikipedia articles with more than 100,000 related question-answer pairs. Each crowd-worker was asked to answer up to five questions about a Wikipedia passage, highlighting the answer in the passage. Each question is associated with a segment of text within the article (context), and the answer is a subset of the context. Each question had several specific answers provided by different people. In SQuAD-IT, the texts, questions, and answers in SQuAD have been translated into Italian. The translation aims to maintain the same structure and content as the original dataset but ensures that the sentences are natural and grammatically correct in Italian. SQuAD-IT has been developed to evaluate NLP models that are not limited to English. The use of the SQuAD-IT dataset for the experiments enables the evaluation of the proposed model in understanding the Italian language to develop an Italian-specific chatbot.
5. Experimental Evaluation
Experiments have been conducted to evaluate the proposed model's performance in providing the correct answer in the QA task. The performance has been evaluated in terms of F1-score and Exact Match (EM). F1-score is the harmonic mean of accuracy and recall rate. In other words, the F1-score measures the overlap between the words in the predicted answer and the corresponding words in the correct answer (ground truth). The EM computes the percentage of correct answers generated by the model compared to the ground truth. F1-score and EM have been computed following Equations 6 and 7, respectively.
In Equation 7, represents the number of test examples, and represent the predicted answer and the correct answer, respectively, and is a function that returns 1 if the condition is truth or 0 otherwise.
To evaluate the proposed model, the SQuAD-IT dataset has been divided following the train-test split ratio of 80:20, and the proposed model has been trained following the parameters detailed in Table 1.
The results of the proposed model in terms of F1-score and EM are shown in Table 2. The proposed model achieves good performance in providing exactly the correct answer, even considering that it is obtained on an Italian dataset explored by very few studies in the literature. The F1-score of 59.41% indicates a good balance between precision and recall, and an EM of 46.24% indicates that almost half of the answers provided by the model are perfectly accurate. An EM score lower than the F1-score means that the model often approximates correct answers but does not provide correct answers. EM is a very rigorous metric because it measures the percentage of answers that are exactly the same as the correct answers.
Moreover, a comparative analysis has been conducted to evaluate the performance of the proposed model compared to the BIDAF model. To a fair comparison, the BIDAF model is trained and tested with the same train-test split ratio used for the proposed model. Table 3 details the training model parameters used for BIDAF. The comparative analysis shows that the proposed model achieves an improvement of 10.06% in F1-score and 7.81% in EM compared to BIDAF, as shown in Table 4. In other words, the proposed model is capability in providing a significantly more correct answers compared to BIDAF model.
6. Conclusion
An extended architecture of the BERT model specific to understanding the Italian language has been proposed. The proposed model introduced an encoder/decoder module and a Highway network module before the fully-connected layers into the BERT architecture to improve the ability of the model to capture the context and temporal sequence and to filter out irrelevant information. The proposed model performs well in providing the exact expected answers. Comparative analysis shows that the proposed model outperforms the BIDAF model, providing almost 8% more correct answers. Moreover, the proposed model is one of the first models developed specifically to be able to process Italian language texts, as it was tested with the Italian version of the popular SQuAD dataset. The proposed model represents the ground for developing an Italian-specific chatbot for the PAs. Therefore, the proposed model, implemented in a chatbot, could make the work of PAs more efficient in terms of time and workload reduction. In future, ensembling strategies could be used by combining responses from multiple models to improve overall accuracy and the number of incorrect answers.
Author Contributions
Conceptualization, G. Lazzo, D. Vavallo , S. Dimola, E. Zazzera, and A. Piizzi; methodology, G. Lazzo; software, G. Lazzo; validation, G. Lazzo, A. Piizzi, E. Zazzera , and D. Vavallo; formal analysis, G. Lazzo, and E. Zazzera; investigation, G. Lazzo; resources, G. Lazzo; data curation, G. Lazzo; writing—original draft preparation, E. Zazzera; writing—review and editing, E. Zazzera; visualization, G. Lazzo; supervision, G. Lazzo; project administration, G. Lazzo;. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Regione Puglia - Progetto NOVA PA - Contabilità ed E-procurement per una P.A. Digitale - POR PUGLIA FESR 2014-2020 - Grant number: SJA8705.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- V. C. I. L. M. I. Pislaru M., "Citizen-Centric Governance: Enhancing Citizen Engagement through Artificial Intelligence Tools," Sustainability (Switzerland), vol. 16, no. 7, 2024. [CrossRef]
- J. C. M. W. L. K. &. T. K. Devlin, "Bert: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv, 2018.
- A. &. M. A. Severyn, "Modeling relational information in question-answer pairs with convolutional neural networks," arXiv preprint arXiv, 2016.
- Z. M. H. &. I. A. Wang, "Sentence similarity learning by lexical decomposition and composition," arXiv preprint arXiv, 2016.
- R. B. G. T. Z. M. S. R. J. Z. H. &. L. J. Sequiera, "Exploring the effectiveness of convolutional neural networks for answer selection in end-to-end question answering," arXiv preprint arXiv, 2017.
- Z. H. W. &. F. R. Wang, "Bilateral multi-perspective matching for natural language sentences.," arXiv preprint arXiv, 2017.
- Y. P. M. C. T. L. A. &. H. S. C. Tay, "Learning to rank question answer pairs with holographic dual lstm architecture.," Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval , pp. 695-704, 2017.
- M. M. A. Z. a. S. Z. Mishu, "Convolutional recurrent neural network for question answering," in 3rd International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 2017.
- N. Y. F. W. B. C. a. M. Z. Wenhui Wang, " Gated Self-Matching Networks for Reading Comprehension and Question Answering," in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 2017.
- Y. G. H. C. a. Z. H. T. Shao, "Transformer-Based Neural Network for Answer Selection in Question Answering," IEEE Access, vol. 7, pp. 26146-26156, 2019. [CrossRef]
- L. G. A. M. Kamyab M., "Attention-Based CNN and Bi-LSTM Model Based on TF-IDF and GloVe Word Embedding for Sentiment Analysis," Applied Sciences (Switzerland), vol. 11, no. 23, 2021. [CrossRef]
- M. K. A. F. A. &. H. H. Seo, "Bidirectional attention flow for machine comprehension," arXiv preprint arXiv, 2016.
- D. Z. A. B. R. Croce, "Neural Learning for Question Answering in Italian," in 17th Conference of the Italian Association for Artificial Intelligence, AI*IA 2018, 2018.
- J. Z. K. L. a. P. L. Pranav Rajpurkar, " SQuAD: 100,000+ Questions for Machine Comprehension of Text," in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, 2016.
Figure 1.
Proposed model architecture.
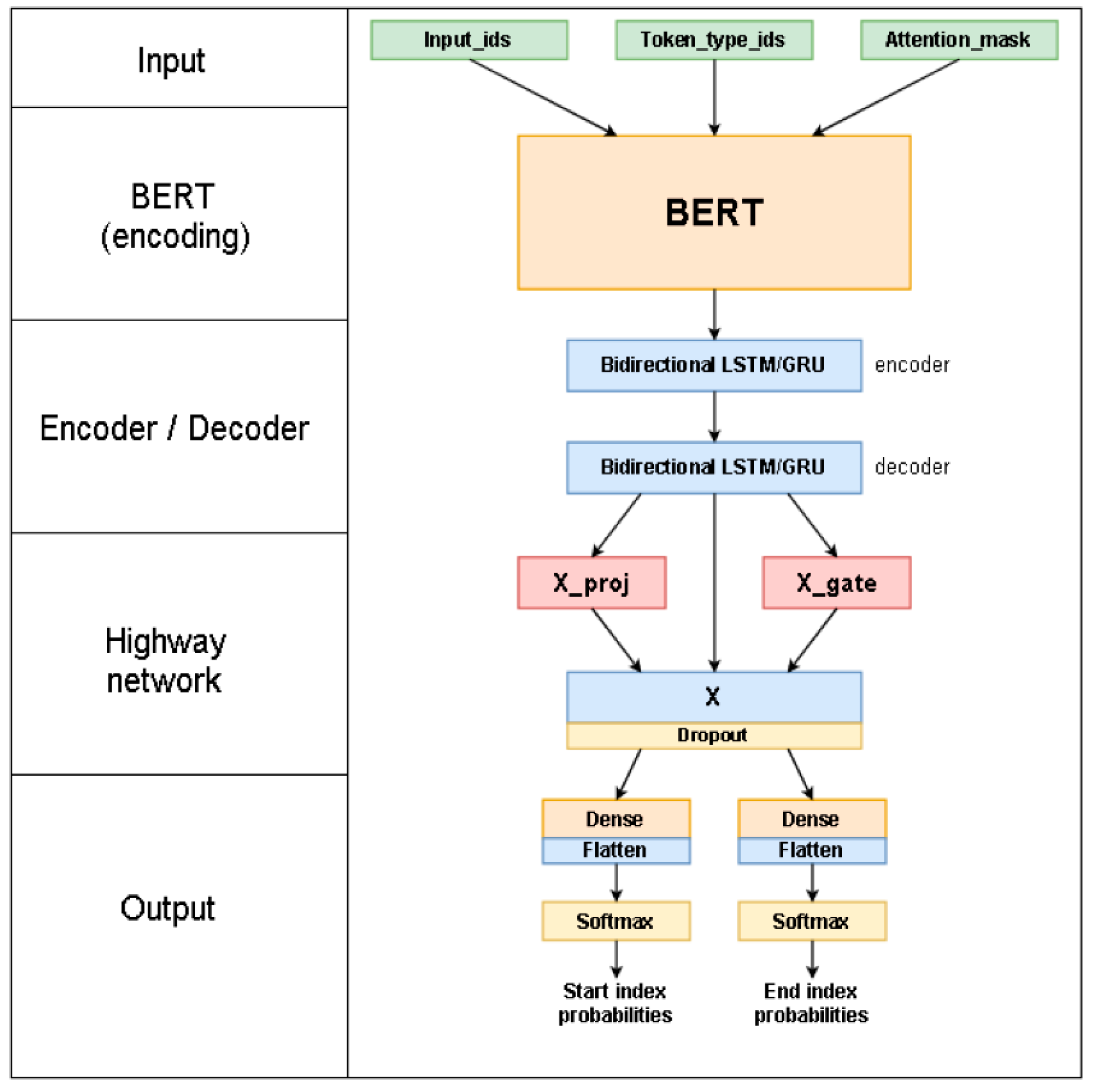

Table 1.
Training proposed model parameters.
| Parameter | Value |
|---|---|
| Encoding dimension | 128 |
| Decoding dimension | 64 |
| Loss | Sparse Categorical Cross-Entropy |
| Optimizer | Adam |
| Batch size | 8 |
| Learning rate | 5e-5 |
| Number of epochs | 6 |
| Dropout | False |
Table 2.
Proposed model results.
| Metric | Score (%) |
|---|---|
| F1-score | 59.4087 |
| EM | 46.2371 |
Table 3.
Training BIDAF model parameters.
| Parameter | Value |
|---|---|
| Loss | Sparse Categorical Cross-Entropy |
| Optimizer | Adam |
| Batch size | 10 |
| Learning rate | 5e-4 |
| Number of epochs | 10 |
| Dropout | 0.2 |
Table 4.
Comparative analysis.
| Model | F1-score | EM |
|---|---|---|
| Proposed | 59.4087 | 46.2371 |
| BIDAF | 49.3504 | 38.4313 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



