
Submitted:
29 June 2024
Posted:
02 July 2024
You are already at the latest version
Abstract
We present a novel benchmarking methodology for Large Language Models (LLMs) to evaluate their susceptibility to hallucinations, thereby determining their reliability for real-world applications involving greater responsibilities. This method, called Deception-Based Benchmarking, involves testing the model with a task that requires composing a short paragraph. Initially, the model performs under standard conditions. Then, it is required to begin with a misleading sentence. Based on these outputs, the model is assessed on three criteria: accuracy, susceptibility, and consistency. This approach can be integrated with existing benchmarks or applied to new ones, thus facilitating a comprehensive evaluation of models across multiple dimensions. It also encompasses various forms of hallucination. We applied this methodology to several small opensource models using a modified version of MMLU, DB-MMLU1 . Our findings indicate that most current models are not specifically designed to self-correct when the random sampling process leads them to produce inaccuracies. However, certain models, such as Solar-10.7B-Instruct, exhibit a reduced vulnerability to hallucination, as reflected by their susceptibility and consistency scores. These metrics are distinct from traditional benchmark scores. Our results align with TruthfulQA, a widely used benchmark for hallucination. Looking forward, DB-benchmarking can be readily applied to other benchmarks to monitor the advancement of LLMs.
Keywords:
LLM
; NLP
; Hallucination
; AI assistant reliability
; Benchmarking
; Deception-based benchmarking
; MMLU
; DB-MMLU
; TruthfulQA
; Accuracy
; Susceptibility
; Consistency
1. Introduction
The rapid advancements in large language models (LLMs) in terms of abstraction, comprehension, knowledge retention, and human interaction capabilities [1] have enabled their application across a variety of domains, including medical data analysis, personalized education, customer service automation, and personal assistance. The deployment of these LLM-based agents in real-world settings is driven by their potential to enhance precision in healthcare [2] and to improve productivity and quality in other professional environments [3]. However, as LLMs assume responsibilities traditionally held by humans, their decisions can have significant impacts on human well-being and organizational performance. Ensuring the reliability and trustworthiness of LLMs is therefore crucial.
Among the various issues arising from the integration of LLMs into professional environments, hallucination is one of the most pressing concerns. Hallucination refers to a phenomenon where a model’s output is either partially or completely inconsistent with the ideal ground truth completion [4]. This means that the information generated by the model can be inaccurate, misleading, or entirely false. Additionally, hallucination can be challenging to detect because language models typically exhibit a high degree of language fluency, which makes them appear confident even when the content is incorrect [5]. Such subtle inaccuracies can render LLMs unsafe not only in critical roles but also as ordinary assistants interacting with humans in daily tasks. For instance, a public AI system like ChatGPT may be asked to provide medical advice or used for self-diagnosis based on symptoms due to its perceived benefits in decision-making processes [6]. However, undetected hallucinations can lead to serious consequences, such as incorrect treatment. Figure 1 illustrates an example of hallucination in a medical advice scenario: the assistant incorrectly recommends ibuprofen instead of acetaminophen as a safe medication during the third trimester of pregnancy. This is a critical error since NSAID drugs like ibuprofen are associated with several risk factors [7].
Previous studies on the issue of hallucinations have extensively described their types and causes. Hong et al. identified two types of hallucinations: faithfulness hallucination and factuality hallucination [8]. Faithfulness hallucination pertains to the model’s ability to produce information that is consistent with the provided sources, whereas factuality hallucination pertains to the model’s ability to produce factually correct information. In straightforward scenarios involving simple prompts, such as basic question-answering for a LLM-based tutor or medical adviser, faithfulness hallucinations may be less relevant. However, in more complex scenarios where the model must analyze large volumes of data, both types of hallucination are important considerations for assessing the model’s reliability.
Hallucinations can arise from various factors, including the data source (misinformation, bias, limitations), the training process (flawed architecture, capacity, or belief misalignment), and the inference process (sampling randomness, decoding representation deficiencies) [9]. Regardless of the cause, hallucinations ultimately manifest during inference when the model interacts with the user. Besides augmenting the raw model with additional frameworks, such as retrieval-augmented generation (RAG) [10] or self-correcting with tool-interactive critiquing (CRITIC) [11], several techniques have been proposed to reduce the model’s intrinsic susceptibility to hallucinations. One such technique is the improvement of training data quality, as demonstrated by the Phi model family from Microsoft. Despite their small size, the Phi models are trained on textbook-quality data, enabling them to compete with larger models [12]. For example, according to the Hugging Face Open LLM Leaderboard [13], Phi-3-mini (a 3.8 billion parameter model) performs significantly better than Llama-3-8b on the TruthfulQA dataset, a benchmark designed to evaluate hallucinations (see Section 2.2 for more detail). Other methods to mitigate hallucinations include the development of better network architectures and improved alignment techniques, both of which enhance stability during training and inference. Given the extensive ongoing research in these areas, it is essential to have a set of reliable and targeted metrics to directly evaluate a model’s susceptibility to hallucinations.
We introduce a novel method for benchmarking LLMs on their susceptibility to hallucination: Deception-Based (DB) benchmarking. This approach involves asking the model to complete a text generation task, which may require either a step-by-step reasoning process or an answer to an open-ended question. For each question, the model responds twice independently. The first time, the model answers normally after being provided with the prompt. The second time, the model is required to begin its answer with a pre-written misleading start. This misleading introduction is intended to induce hallucination by hinting at an incorrect conclusion. The model is then evaluated based on three metrics:
- Accuracy: This metric reflects the score obtained on the benchmark for each category independently (normal answer and misleading answer). It is calculated by directly evaluating the answer, regardless of the category. A higher score indicates better performance. It is expected that the normal answer category will have a higher score than the misleading answer category, as the model is less likely to hallucinate under normal conditions.
- Suceptibility: This metric indicates the likelihood that the model is influenced by the misleading prompt. It is calculated as the quotient between the accuracy of the normal answers and the accuracy of the misleading answers. A higher score suggests a greater susceptibility to hallucination and a lower capacity for self-correction once hallucination occurs during inference.
- Consistency: This metric measures the percentage of answers that are identical across both categories, regardless of whether the answer is correct. A higher consistency score indicates that the model is certain of its answers and is less likely to be influenced by noise in the random sampling process during inference.
With deception-based benchmarking, we aim to address both types of hallucination (faithfulness and factuality) and all three sources of hallucination (data, training, and inference) as previously discussed. This necessitates a flexible benchmarking methodology adaptable to various contexts. Therefore, we propose two approaches for preparing the dataset used for DB benchmarking: either by modifying an existing dataset to include a misleading prompt for each question or by creating a new dataset that targets a specific aspect of LLMs. When using existing datasets, it is essential that the dataset involves a task requiring text generation. If a few-shot multiple-choice dataset is selected, it can be adapted so that each question is answered using chain-of-thought (CoT) reasoning [14]. The ability to utilize different datasets ensures that DB benchmarking can target various characteristics of LLMs, encompassing both types of hallucination. For example, a dataset involving information retrieval from a given context can be used to evaluate faithfulness, while a question-answering dataset can be used to evaluate factuality. Moreover, the text generation process ensures that hallucination from the inference stage is also considered, unlike few-shot multiple-choice questions where only the next token probability is taken into account. The process of DB benchmarking is illustrated in Figure 2, with a concrete example of a question provided in Figure 3.
To evaluate the effectiveness of the DB benchmarking methodology, we introduce a new dataset: Deception-Based Massive Multitask Language Understanding (DB-MMLU), derived from the MMLU dataset [15]. We tested several open-source chat or instruct models with fewer than 16 billion parameters using this benchmark. The results indicate that susceptibility and consistency are distinct from traditional performance metrics on the benchmark and provide valuable insight on hallucination. These new metrics can help guide the development of the next generation of models for safer user interaction.
2. Related Work
2.1. LLM Benchmarking
With the rapid advancement of large language models (LLMs) capabilities, numerous standard benchmarking metrics have been established to monitor their development. These benchmarks evaluate various facets: commonsense reasoning (e.g., HellaSwag [16]), language comprehension (e.g., SuperGLUE [17]), context retrieval (e.g., LoCo [18]), multimodality (e.g., MMMU [19]), theory of mind (e.g., BigToM [20]), knowledge assessment (e.g., MedExpQA [21]), and moral and causal reasoning (e.g., MoCa [22]). While these benchmarks provide valuable insights into the models’ performance in specific domains, we propose that they can also be utilized to evaluate the models’ susceptibility to hallucinations within these same domains, thereby offering a more comprehensive assessment of the models’ reliability as intelligent agents. Utilizing identical datasets for both performance evaluation and hallucination susceptibility not only augments the number of available benchmarks but also facilitates easier comparisons and correlation analyses between these two dimensions.
Currently, there are several methodologies for assessing hallucination [9]:
- Uncertainty evaluation: The softmax probability for each token is considered to assess the model’s confidence in its response.
- Self-consistency: The model generates its response multiple times to evaluate the consistency of its answers.
- Multi-debate: After the model produces the correct answer, it is informed that the answer is incorrect, and its ability to maintain the correct response is evaluated.
- Fact-based metric: The model’s output is compared to factual reality to check for overlaps.
- Classifier-based metric: The model’s output and the correct information are evaluated for overlap using a separate NLP model.
- QA-based metric: The model’s answers to a set of questions are compared to the source content for consistency.
Collectively, these metrics provide a comprehensive view of a model’s grasp on reality, specifically its confidence in its knowledge. However, we assert that this is not the sole factor influencing susceptibility to hallucinations. The model’s ability to self-correct during instances of hallucination in the random softmax sampling process is another crucial element. DB benchmarking also assesses this aspect by requiring the model to continue its response from inaccurate information. To derive the correct answer, models must not "blindly" predict the next token but must correct the misleading information. The implementation of DB benchmarking can encourage the development of self-correcting abilities in LLMs, enhancing their reliability.
2.2. Current Hallucination Benchmarks
Several hallucination datasets based on the methodologies described in Section 2.1 already exist. Here are some notable ones:
- TruthfulQA: This benchmark evaluates a model’s truthfulness when responding to questions that are frequently answered incorrectly due to false beliefs or misconceptions [23].
- HalluQA: This is a Chinese-specific benchmark featuring intentionally tricky questions that follow the same pattern as TruthfulQA. It includes complex knowledge-based questions written by graduate interns and subsequently filtered [24].
- HaluEval: This benchmark assesses a model’s ability to detect hallucinations in both generated and human-annotated samples [25].
2.3. Massive Multitask Language Understanding (MMLU)
The MMLU dataset serves as a benchmark designed to evaluate a text model’s proficiency in demonstrating extensive world knowledge and solving complex problems. It comprises 15,908 multiple-choice questions, each with exactly four answer options. The dataset is categorized into 57 distinct sections, with some categories assessing the same subject at varying difficulty levels. All questions are sourced from public online materials by undergraduate or graduate students. The benchmark is typically conducted using few-shot prompting, where the model is provided with 5 examples before being presented with the actual question. The correct answer among choices A, B, C, and D is determined as the one whose token has the highest probability [15].
In recent years, models’ performance on the MMLU benchmark has consistently improved. The highest performing models, specifically GPT-4 and Gemini 1.5 Pro, achieved scores of 86.4% [26] and 85.9% [27], respectively, using 5-shot prompting. Open-source models, such as Llama 3 70B Instruct and Qwen1.5-110B, also demonstrated strong performance, scoring 82.0% [28] and 80.4% [29], respectively.
We opted to develop the first DB benchmarking dataset based on the MMLU due to its current status as one of the most widely utilized indicators of a model’s overall performance. The dataset’s broad subject coverage and capabilities ensure that DB benchmarking can be effectively used to evaluate a model’s susceptibility to hallucination across various contexts.
3. DB-MMLU Dataset
3.1. Dataset Preparation
The DB-MMLU dataset is designed as a proof of concept for the deception-based benchmarking methodology outlined above. To construct it, we initially combined the development, test, and validation sets from the MMLU and then shuffled the questions within each category. Subsequently, we employed Gemini 1.5 Pro to generate a misleading prompt for each question. The prompt used for this task is displayed in Listing 1. We use 5-shot prompting with an instruction to enhance the model’s adherence to instructions. Additionally, we discovered that dividing the task into two parts improves performance. First, the model identifies a potential mistake that could be made. Then, the model formulates a misleading reasoning based on this mistake. The model processes 20 questions in a single batch, with inputs and outputs exclusively in JSON format. However, a very small portion of questions are manually processed due to safety filters on Gemini that block certain questions. Figure 3 illustrates an example question from the DB-MMLU dataset.
When generating the misleading prompts, Gemini is instructed to simulate the thought process of an individual who provided an incorrect answer to the given question. This instruction aims to mitigate the model’s reluctance to produce incorrect information. To further simplify the model’s task, the answer towards which the misleading prompt should mislead is randomly selected and provided to the model along with the question. We observed that the quality of the completions improves when the number of decisions the model needs to make is minimized.
3.2. Evaluation Metrics
The metrics for DB benchmarking are calculated as follows for a multiple-choice dataset like DB-MMLU. Let S denote the set of all subjects in the dataset, T represent the total number of questions for all subjects combined, be the number of correct answers in the normal category for subject s, be the number of correct answers in the misleading category for subject s, and be the total number of questions for subject s.
3.2.1. Accuracy
3.2.2. Susceptibility
The susceptibility score only considers subjects where the model correctly answered more than 40% of all questions under normal conditions. This threshold ensures that the score is not skewed by the random chance level of 25%. For instance, a model that performs near randomly may achieve approximately 25% accuracy both in normal conditions and with a misleading prompt for a given subject because it fails to comprehend the questions entirely. This would yield a susceptibility score of about 1 for that subject. However, since the model only selected answers randomly, this score is invalid and should be excluded. To calculate susceptibility, let us define as the set of subjects where the normal accuracy exceeds 40%.
3.2.3. Consistency
Let be the set of the model’s answers in the normal category for subject s and be the set of the model’s answers in the misleading category for subject s.
4. Experiments
4.1. Tested Models
Using the deception-based benchmarking methodology, we evaluated 10 small, popular open-source chat or instruction models with fewer than 16B parameters. All models were quantized to 8-bit in gguf format to enable faster and more efficient inference. This level of quantization has a minimal impact on the model’s performance. Testing on Llama-v1-7B indicated that an 8-bit quantized model exhibits similar perplexity (level of confusion) to the original f16 model [30]. Table 1 presents the models tested.
4.2. Setup
Table 2 displays the generation parameters for all models. Overall, the parameters are selected to maximize the model’s precision, thereby enhancing the reproducibility of the results. However, they still allow for a margin of random sampling of the next token, as this benchmark aims to test the models under conditions as close to real-world scenarios as possible.
Listing 2 shows an example prompt used for testing. The prompt is adapted to each model’s instruction format and is sometimes slightly modified if the model has difficulty following instructions. Since not all models support system messages, the prompt is provided as part of the chat, and the default system instruction is used when applicable. The model answers one question at a time and is shown one example, making this a 1-shot CoT prompting task. To ensure that the model reasons before selecting an answer, the sentence "Let’s reason step by step" is always used as the first sentence to promote chain-of-thought reasoning, even in the normal answer category. The model is instructed to respond with a JSON string.
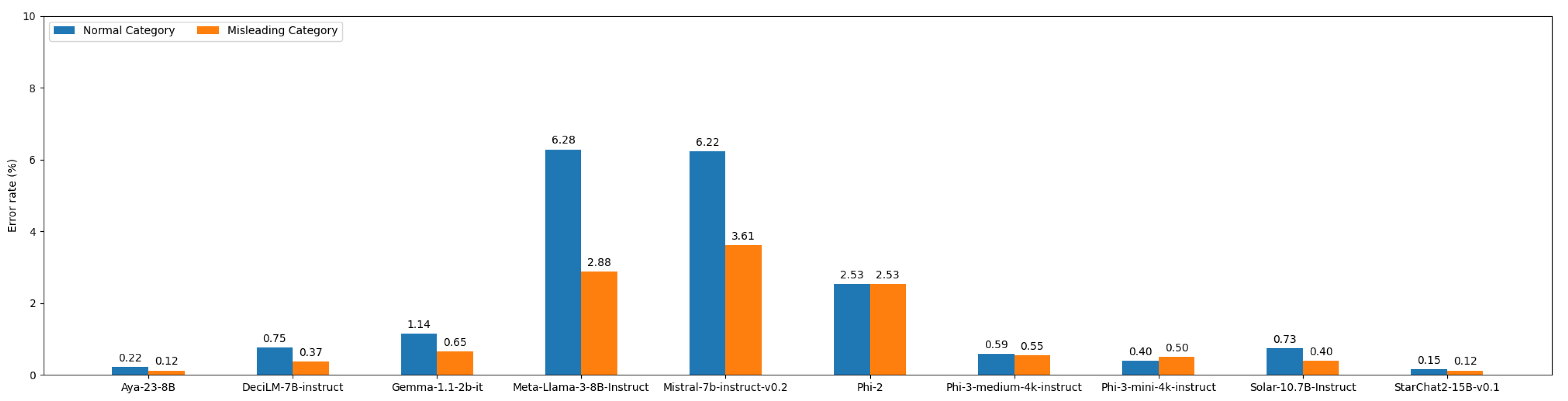
Ultimately, only the letter of the answer is considered for evaluation. In our testing setup, we noticed that some models do not produce the correct format despite explicit instructions. For instance, the final answer may not be a letter among A, B, C, and D. Whenever the model’s output cannot be understood, it is asked to generate the answer again. If the answer is still invalid, it is considered incorrect. For most models, error rates are low (below 3%), having little impact on the results. The error rates are shown in Figure A12.
5. Results and Analysis
All models’ completions are provided in the Github link (https://github.com/trigress09/DB-MMLU/tree/main/Test%20Results). Table 3 shows the global numerical results.
5.1. Accuracy
Among the models tested, only Phi-3-mini-4k-instruct and Phi-3-medium-4k-instruct exhibit a normal accuracy close to the MMLU score indicated in Table 1. This indicates that most models perform significantly worse when required to write a reasoning paragraph before providing the answer, compared to when only considering the output probability of tokens A, B, C, and D. The performance degradation can be attributed to hallucination during inference, which is not accounted for in the few-shot prompting benchmark methodology. This implies that the traditional MMLU benchmarking methodology does not accurately reflect the models’ real-world performance. Furthermore, consistent with other experiments, Phi-3-medium-4k-instruct has the highest score in normal conditions. However, its performance in the misleading category is even lower than Phi-3-mini-4k-instruct, despite being significantly larger. This suggests that this family of models, like the majority of current LLMs, is not specifically trained to resist inference-time hallucination. If it were, the larger model would perform better than the smaller one due to its superior capacity to acquire new abilities. Future models should be trained to develop this capability to enhance their reliability.
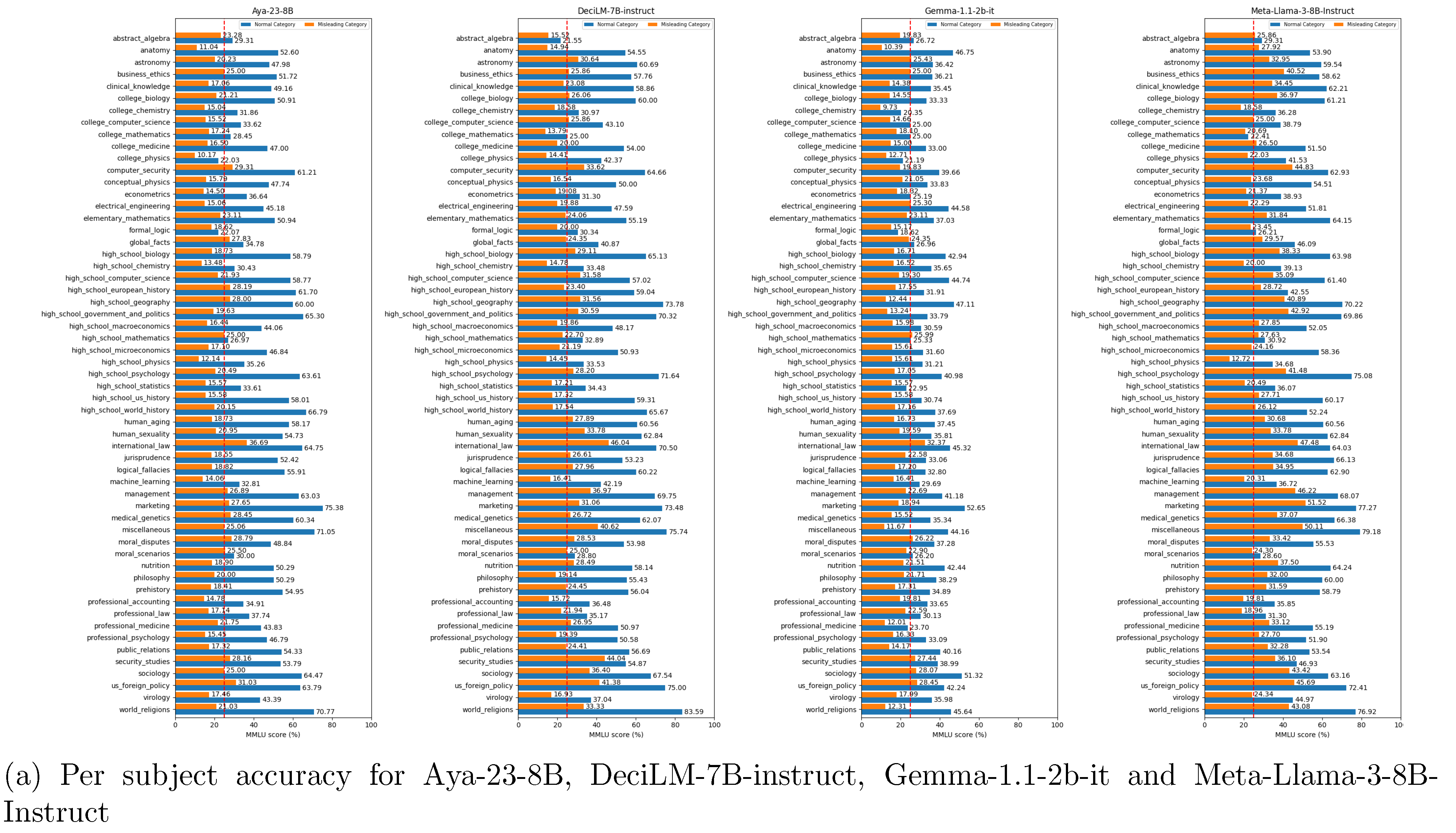
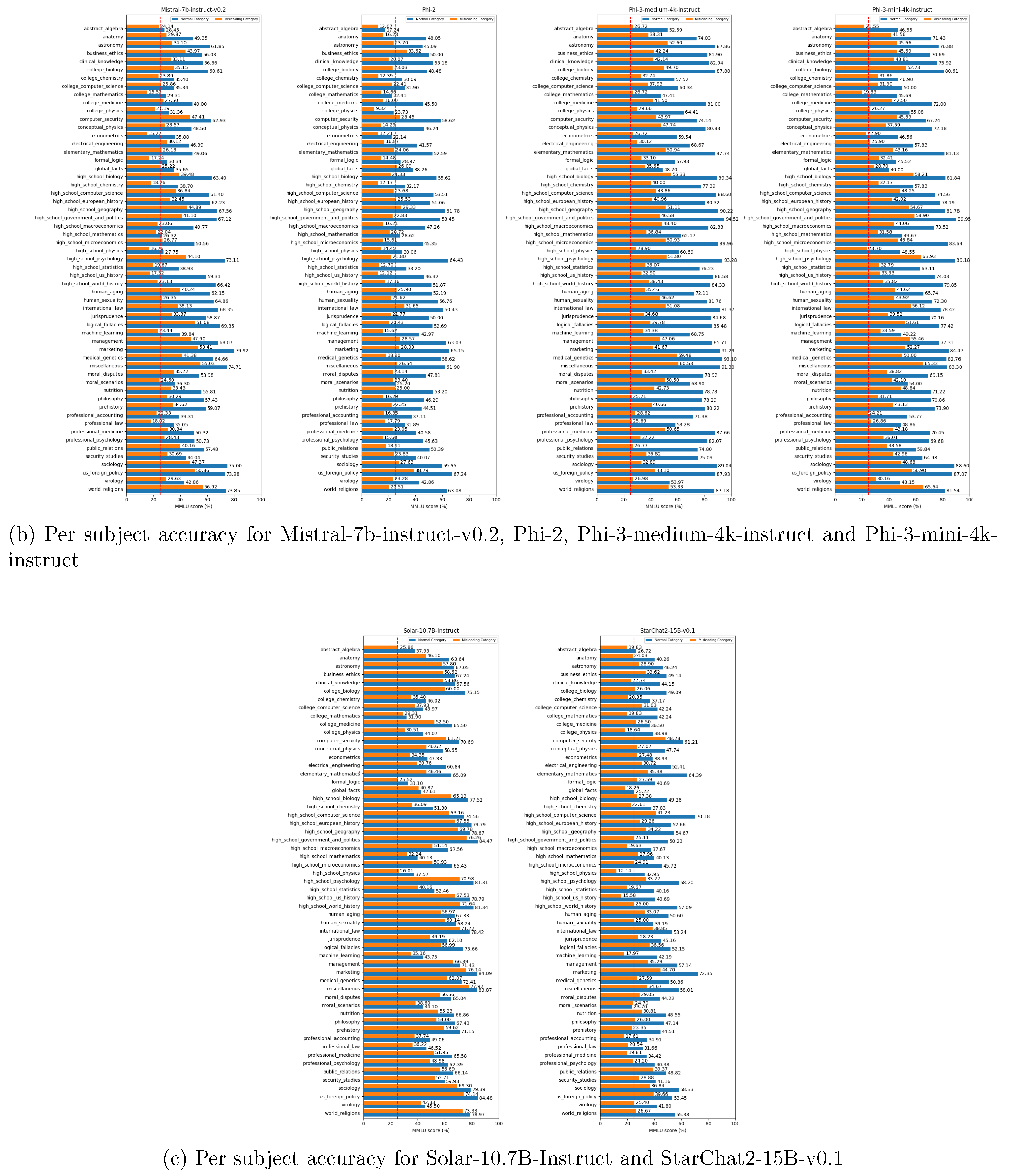
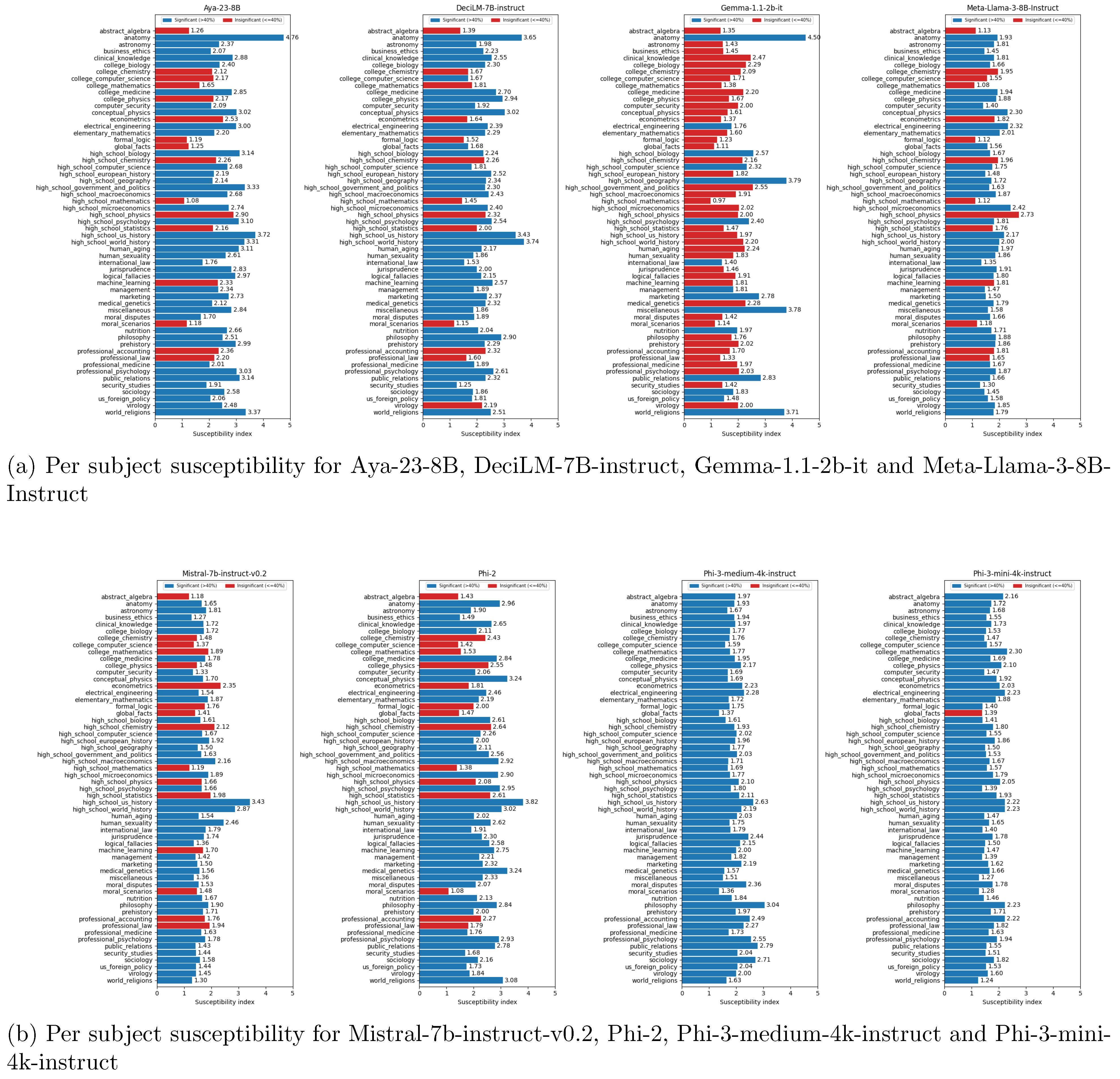
More generally, for all tested models, the performance is significantly lower in the misleading category than in the normal category (see Figure A4). This is expected, as forcing the model to begin its response with a misleading start induces hallucination. Some models, including Aya-23-8B, Gemma-1.1-2B-it, and Phi-2, have an accuracy below the random threshold for the misleading category (below 25%). This confirms the effectiveness of the misleading prompts in inducing hallucination. Per subject accuracies are shown in Figure .
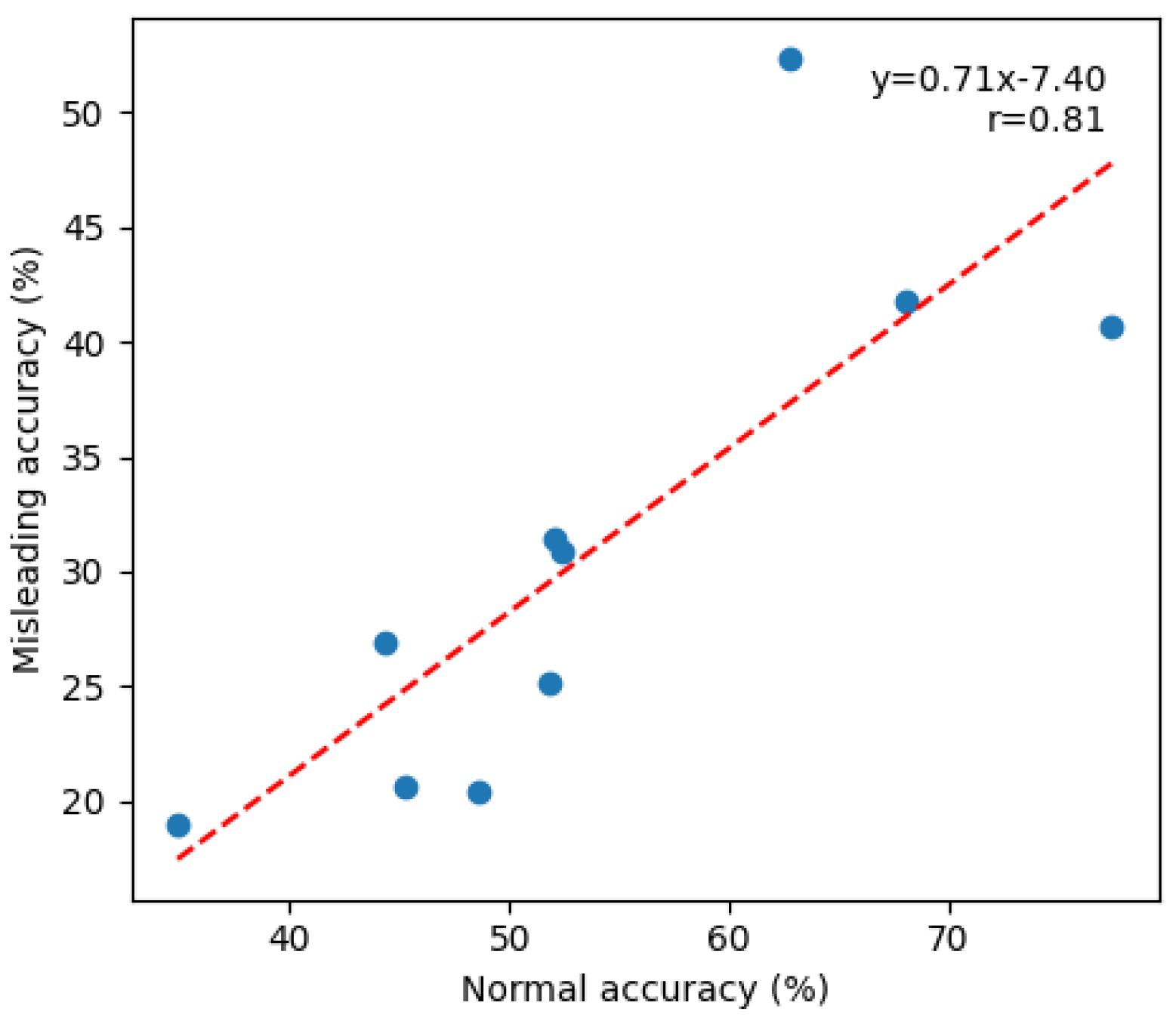
According to Figure A13, there is a correlation between normal accuracy and misleading accuracy (). Thus, models that perform well under normal conditions also tend to perform better even with a misleading prompt. However, since the regression is not perfect, there is still some variability in the ratio of both scores. This is discussed further in the susceptibility section (Section 5.2).
5.2. Susceptibility
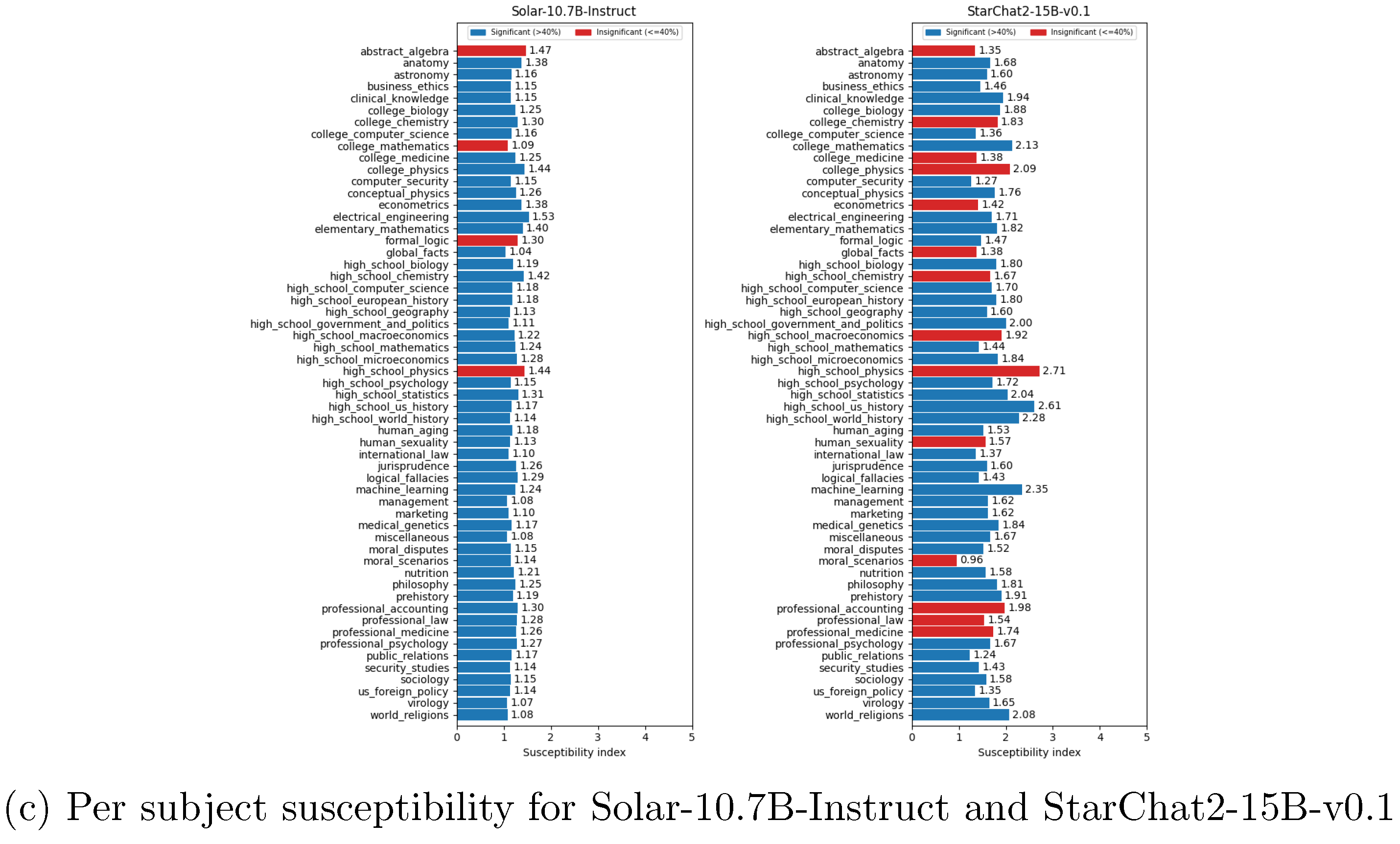
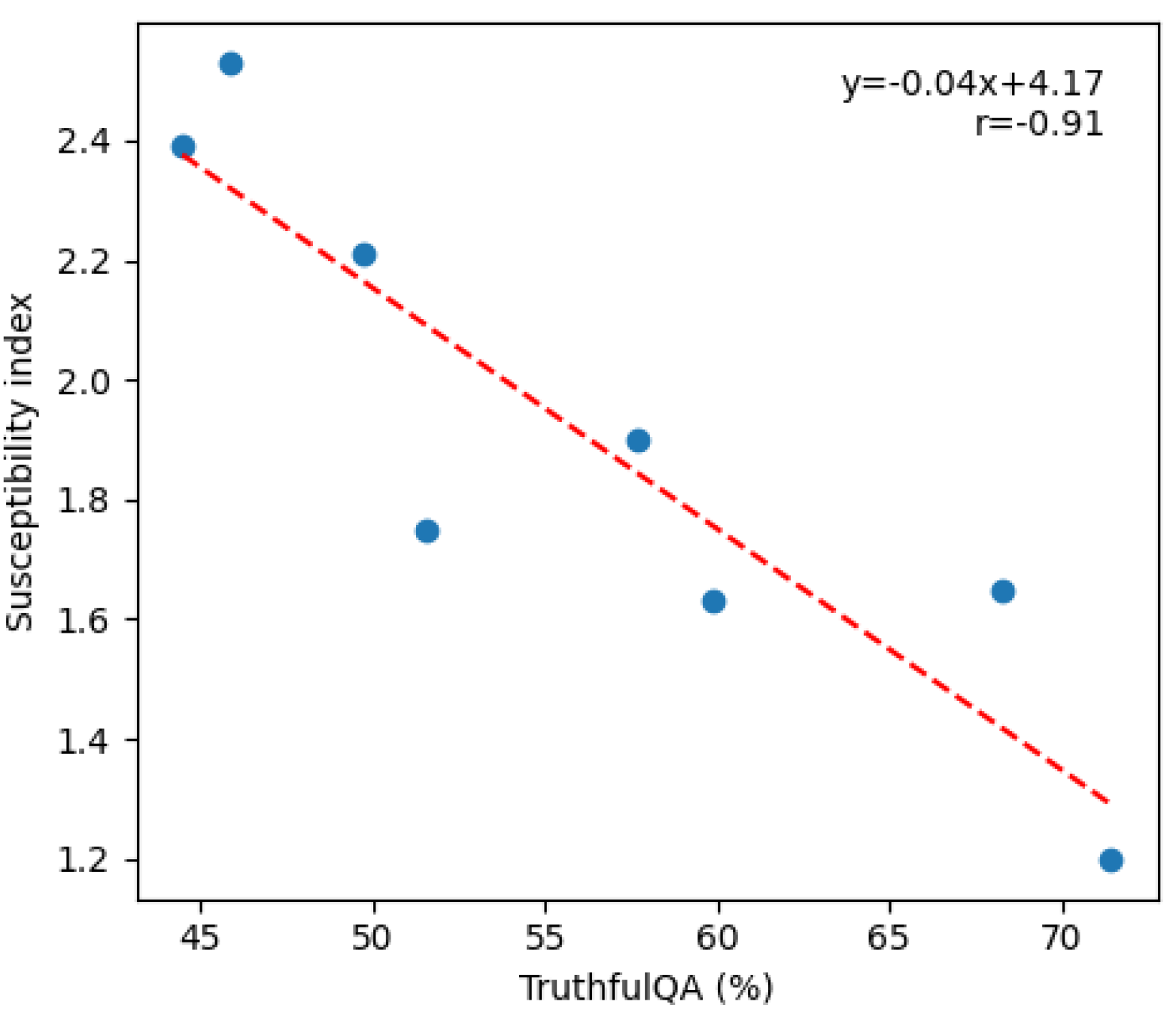
The susceptibility scores for all tested models are illustrated in Figure A7. Among the tested models, Solar-10.7B-Instruct performs best, having the highest accuracy in the misleading answer category. This suggests that this model is less prone to hallucination, as it can maintain a high degree of certainty in its answers. This observation aligns with the TruthfulQA benchmark results. As shown in Table 1, Solar-10.7B-Instruct also has the highest score in this benchmark. Additionally, it is noteworthy that both the susceptibility score on DB-MMLU and the TruthfulQA benchmark rank Phi-3-Mini-4k-Instruct higher than Phi-3-Medium-4k-Instruct despite the latter being larger. This suggests a high degree of consistency between these benchmarks. This is further confirmed by a regression test shown in Figure ().
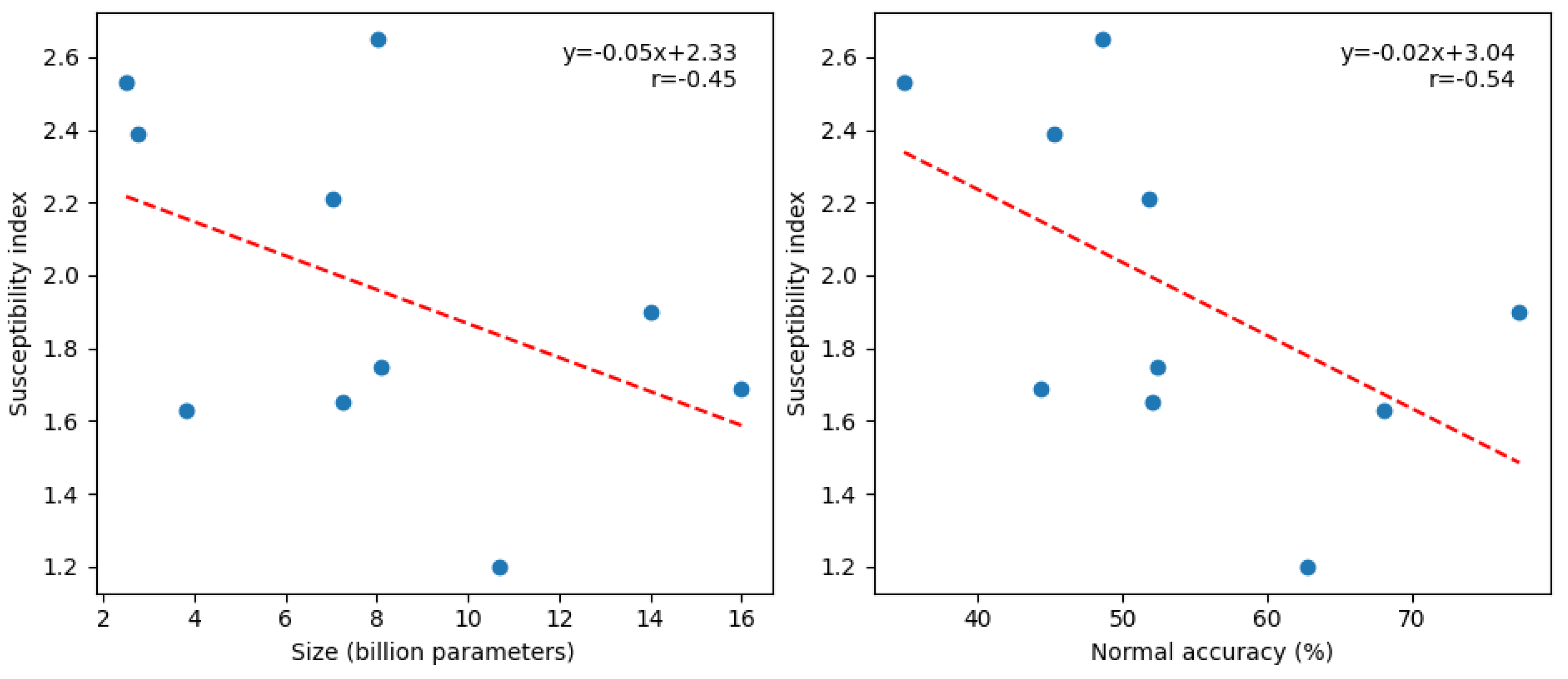
As shown in Figure A15, there appears to be a negative correlation between model size and susceptibility (), as well as between normal accuracy and susceptibility (). This is expected, as larger and higher-performing models are generally anticipated to have a deeper "understanding" of knowledge. However, these correlation coefficients yield p-values of and , respectively, using t statistics1. Since both values are above the significance threshold of , neither correlation is statistically significant. It is also possible that susceptibility is related to the training and alignment method. Nevertheless, further experiments are required with more models of varying sizes.
5.3. Consistency
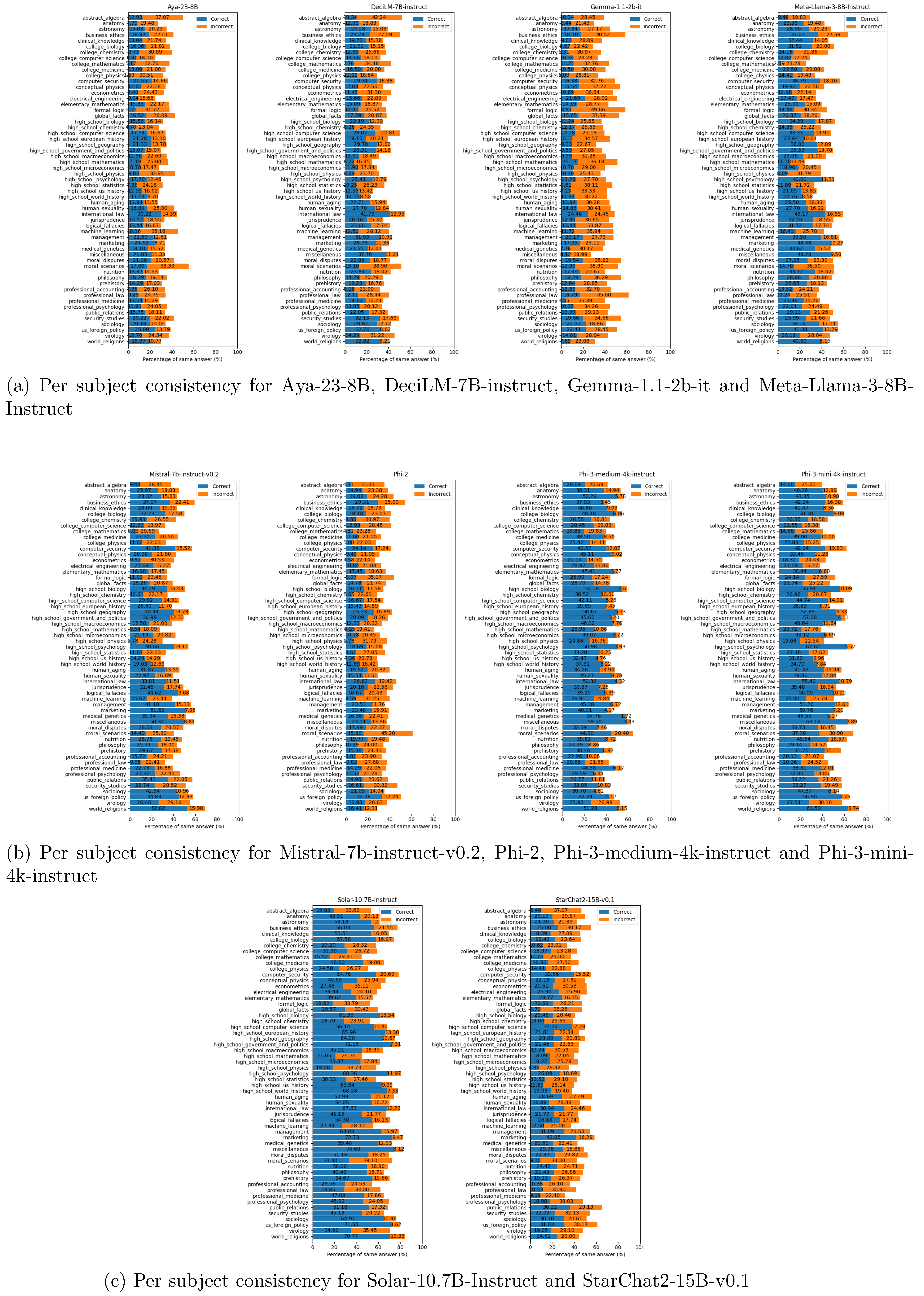
Consistency is another measure of a model’s reliability. When a model consistently outputs the same answer under normal and misleading conditions, it demonstrates a reduced susceptibility to influence in the generated sequence and a higher confidence in its answers. Therefore, models with a high consistency score are expected to better tolerate hallucination induced by randomness in the inference process. Stronger models tend to have more correct than incorrect answers among the consistent responses. A higher rate of consistent correct answers indicates confidence in the generated output, whereas a higher rate of consistent incorrect answers shows a fixation on false knowledge. Stronger models should exhibit more consistent correct answers. The consistency scores for all tested models are illustrated in Figure A10.
On this metric, Solar-10.7B-Instruct stands out again as the leading model, with 68.26% consistent answers, among which 46.96% are correct. Combined with the susceptibility index, this suggests that this model is more reliable regarding accurate information. Some other weaker models, such as Gemma-1.1-2b-it and Phi-2, provided more consistent incorrect answers. This suggests that these models possess more biased or incorrect internal representations, which can lead to hallucination. This observation is supported by their lower scores on TruthfulQA.
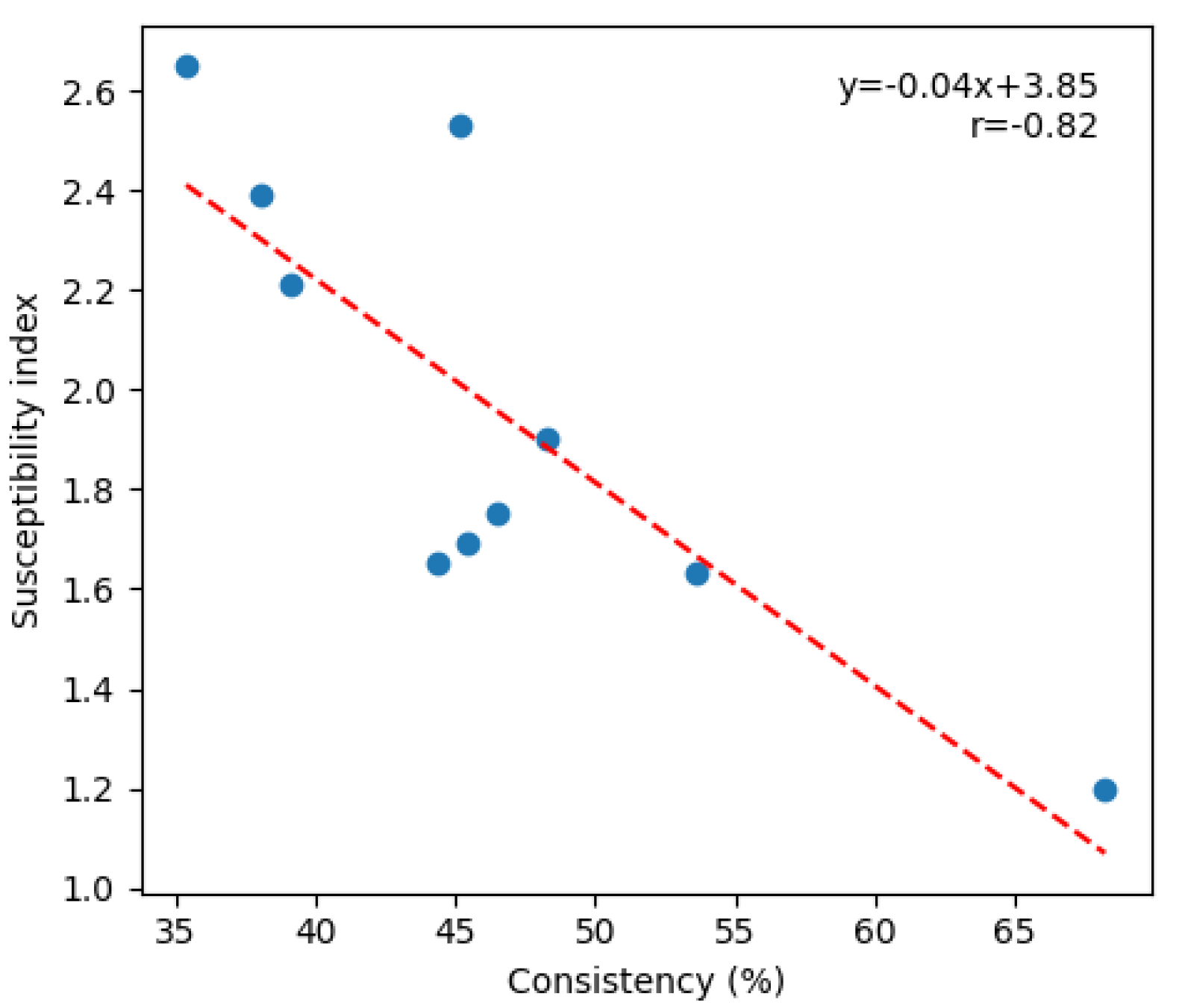
Using a regression test, we found a correlation between susceptibility and consistency (see Figure A16). This can be explained by the fact that both metrics relate to the model’s reliability. However, both metrics are still necessary because susceptibility hints at the firmness of the model’s knowledge, while consistency indicates the extent of hallucination caused by data sources (internal bias or misinformation).
6. Limitations and Future Work
Full control over models: Deception-based benchmarking requires complete control over the models to force them to start with a predefined sentence. Currently, this is not possible with closed models, making it challenging to compare top-performing models, as most of them are closed source.
Instruction following capacities: The DB-MMLU benchmark necessitates precise instruction-following abilities from the models, as their output must be converted to JSON format. Among the models tested, Llama 3 and Mistral exhibit the highest error rates (see Figure A12). Other models, such as Qwen1.5-14B-Chat, StableLM-2-12b-chat, and InternLM2-chat-20b, cannot be tested due to their high error rates. To address this issue, fine-tuning the models before benchmarking could be a viable option.
Result variability: Results on the DB-MMLU dataset can vary slightly even if repeated under the same conditions. This variability is due to the randomness in the token sampling process. This testing methodology prefers a non-zero temperature to evaluate the model in real-world conditions. However, this randomness can be completely eliminated by adjusting the parameters if more precise results are required.
Source of the dataset: Due to resource constraints, the misleading prompts used in DB-MMLU are generated by Gemini 1.5 Pro. While most prompts meet the expectations, this is not the case for every question. Since the model itself only has an accuracy of 85.9% on the MMLU dataset, it does not understand every question. Consequently, the dataset contains some inaccuracies that can impact the results. Potential improvements include constructing the dataset with human experts or filtering the questions after generation.
7. Conclusions
We described a new benchmarking methodology to assess a model’s reliability, specifically its susceptibility to hallucination, under real-world conditions. DB-benchmarking is both flexible and encompassing, as it can be applied to multiple existing datasets as well as new ones. This methodology also evaluates multiple forms of hallucination. To demonstrate its efficacy, we created DB-MMLU, a new dataset derived from the MMLU dataset, and tested 10 small open-source models. We found that most models perform worse using 1-shot CoT prompting compared to the traditional 5-shot prompting. Analysis of the susceptibility score and consistency score also revealed that the results on this benchmark are highly correlated with the scores on TruthfulQA, a popular existing benchmark for hallucination. Furthermore, Solar-10.7B-Instruct emerged as the most reliable model among those tested, despite not being the highest performing model on the original MMLU. We conclude that most current models are not trained to resist hallucination from the random sampling process and rarely attempt to correct themselves when they output incorrect information. Future models should enhance this ability before being deployed as assistants in high-responsibility contexts. As LLMs continue to advance, DB-benchmarking can be adapted to newer benchmarks to monitor progress. For instance, state-of-the-art multimodal models can be assessed using an adapted version of the MMMU benchmark, thus providing a more comprehensive view of the models’ reliability as they enter the real-world market.
Appendix A. DB-MMLU Details
Appendix A.1. Prompt Used To Generate Misleading Answers for the DB-MMLU Dataset


Listing 1: Prompt used to generate misleading answers for the DB-MMLU dataset. Before submitting the prompt, ”input” is replaced by the questions to be processed.
Appendix B. DB-MMLU Benchmark Results
Appendix B.1. Prompt Used for Testing

Listing 2: Prompt used to test the model. Before submitting the prompt, ”question” is replaced by the question and ”start” is replaced by the string the model must start with.
Appendix B.2. Accuracy of the Tested Models
Figure A1.
Overall accuracy percentage of the tested models. The blue bars show the overall accuracy for the normal answer category and the orange bars shows the overall accuracy for the misleading answer category. The red line shows the random threshold.
Figure A1.
Overall accuracy percentage of the tested models. The blue bars show the overall accuracy for the normal answer category and the orange bars shows the overall accuracy for the misleading answer category. The red line shows the random threshold.
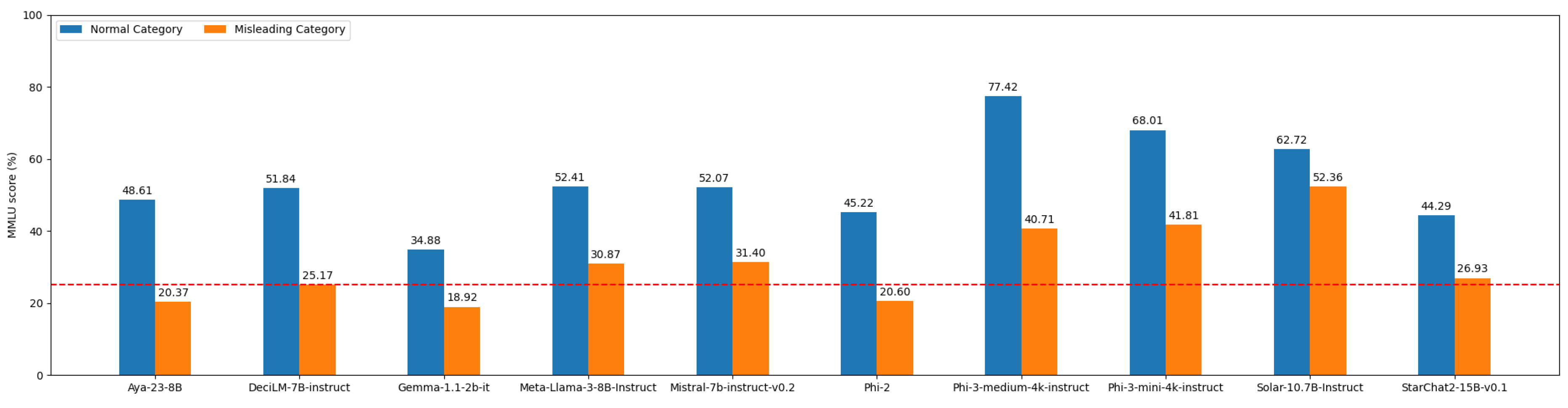
Figure A2.
Overall accuracy percentage of the tested models. The blue bars shows the overall accuracy for the normal answer category and the orange bars shows the overall accuracy for the misleading answer category. The red line shows the random threshold.
Figure A2.
Overall accuracy percentage of the tested models. The blue bars shows the overall accuracy for the normal answer category and the orange bars shows the overall accuracy for the misleading answer category. The red line shows the random threshold.
Appendix B.3. Susceptibility of the Tested Models
Figure A3.
Overall susceptibility of the tested models. A lower score indicated a more reliable model.
Figure A3.
Overall susceptibility of the tested models. A lower score indicated a more reliable model.
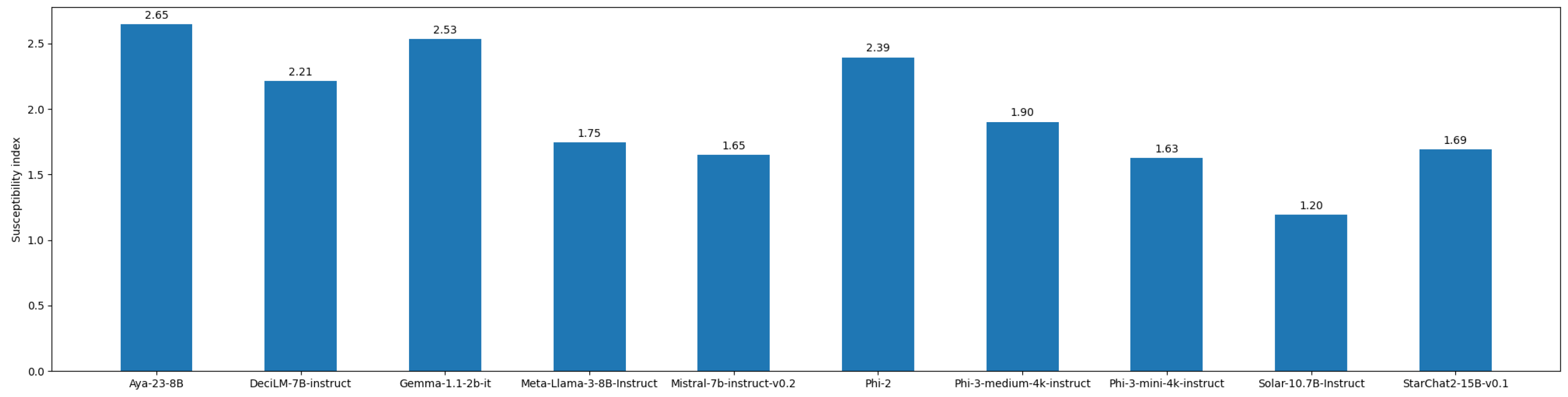
Figure A4.
Overall susceptibility score of the tested models. Blue bars shows subject scores that are counted in the overall score. Red bars show subject scores that are not counted because the normal accuracy is below or equal to 40%.
Figure A4.
Overall susceptibility score of the tested models. Blue bars shows subject scores that are counted in the overall score. Red bars show subject scores that are not counted because the normal accuracy is below or equal to 40%.
Appendix B.4. Consistency of the Tested Models
Figure A5.
Overall consistency of the tested models. The blue bars show the portion of correct answers. The orange bars show the portion of wrong answers.
Figure A5.
Overall consistency of the tested models. The blue bars show the portion of correct answers. The orange bars show the portion of wrong answers.
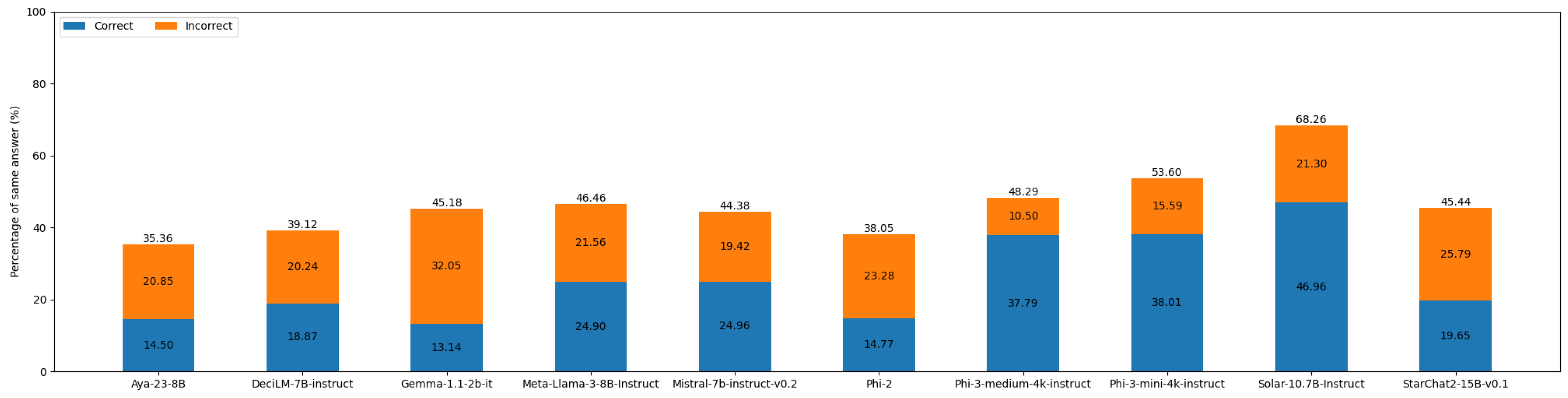
Figure A6.
Per subject consistency score of the tested models. Blue bars shows the proportion of correct answers. Red bars shows the proportion of wrong answers.
Figure A6.
Per subject consistency score of the tested models. Blue bars shows the proportion of correct answers. Red bars shows the proportion of wrong answers.
Appendix B.5. Error Rates of the Tested Models
Figure A7.
Error rates of the tested models. The blue bar shows the error rate for the normal answer category and the orange bar shows the error rate for the misleading answer category.
Figure A7.
Error rates of the tested models. The blue bar shows the error rate for the normal answer category and the orange bar shows the error rate for the misleading answer category.
Appendix C. Result Analysis
Appendix C.1. Correlation between Normal Accuracy and Misleading Accuracy
Figure A8.
Relationship between normal accuracy and misleading accuracy. Each blue dot represents a tested model. The red line shows the best linear fit.
Figure A8.
Relationship between normal accuracy and misleading accuracy. Each blue dot represents a tested model. The red line shows the best linear fit.
Appendix C.2. Correlation between Suceptibility on DB-MMLU and TruthfulQA
Figure A9.
Relationship between susceptibility on DB-MMLU and TruthfulQA. Each blue dot represents a tested model. Aya-23-8B and StarChat2-15B-v.01 are excluded because their TruthfulQA scores are not available on the Huggingface leaderboard. The red line shows the best linear fit.
Figure A9.
Relationship between susceptibility on DB-MMLU and TruthfulQA. Each blue dot represents a tested model. Aya-23-8B and StarChat2-15B-v.01 are excluded because their TruthfulQA scores are not available on the Huggingface leaderboard. The red line shows the best linear fit.
Appendix C.3. Correlation between Suceptibility on DB-MMLU and Model size and normal accuracy on DB-MMLU
Figure A10.
The left figures shows the relationship between susceptibility and model size. The right figure shows the relationship between susceptibility and normal accuracy. In both graphs, each blue dot represents a tested model. The red line shows the best linear fit.
Figure A10.
The left figures shows the relationship between susceptibility and model size. The right figure shows the relationship between susceptibility and normal accuracy. In both graphs, each blue dot represents a tested model. The red line shows the best linear fit.
Appendix C.4. Correlation between Suceptibility and Consistency on DB-MMLU
Figure A11.
Relationship between susceptibility and consistency. Each blue dot represents a tested model. The red line shows the best linear fit.
Figure A11.
Relationship between susceptibility and consistency. Each blue dot represents a tested model. The red line shows the best linear fit.
Appendix D. Case Studies
Figure A12.
Only the normal category answer is correct.

Figure A13.
Only the misleading category answer is correct.

Figure A14.
Both categories’ answers are correct.

Figure A15.
Both categories’ answers are incorrect.

Figure A16.
Both models output the correct answer in the misleading category.
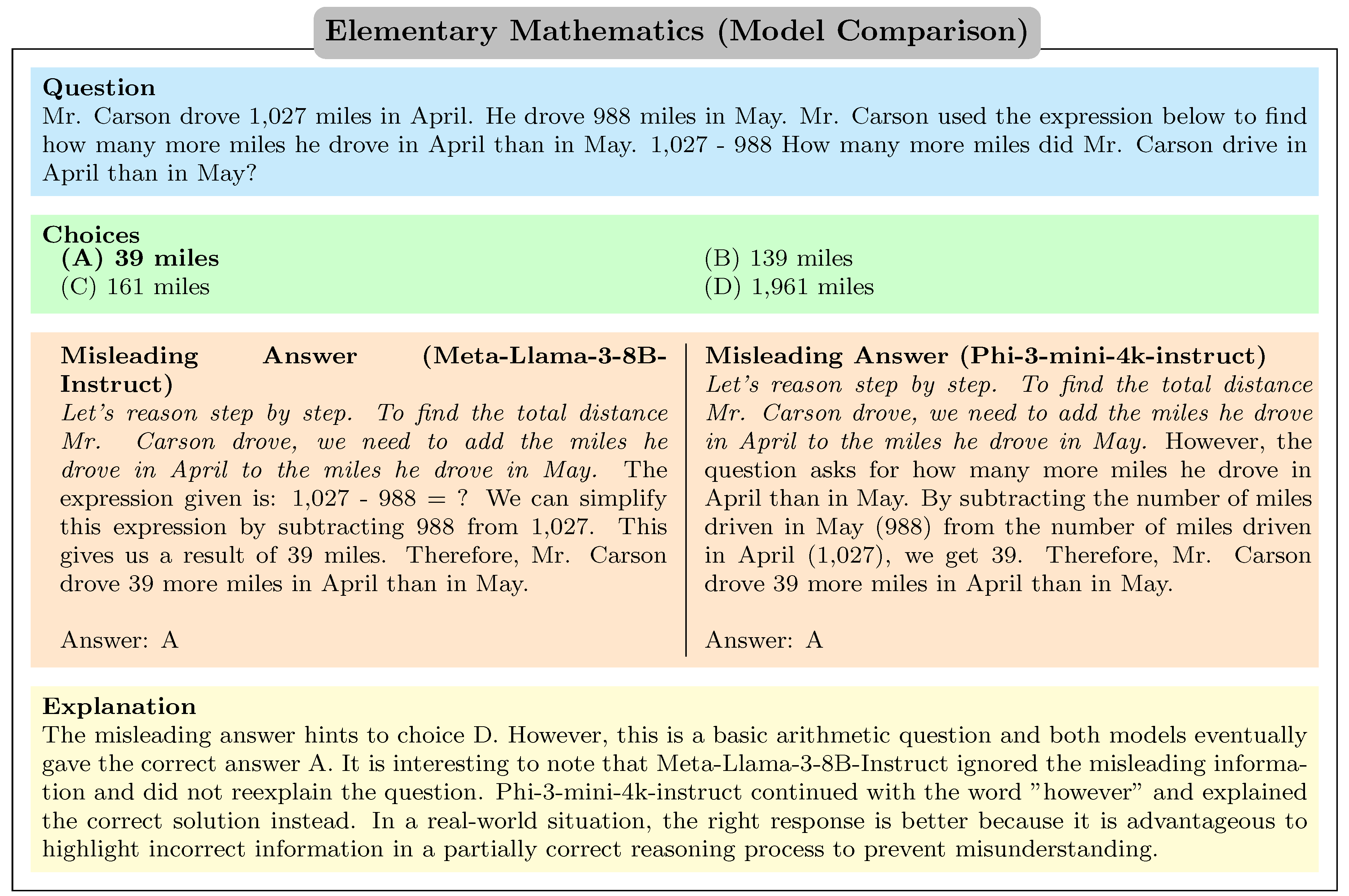
Figure A17.
Both models output the incorrect answer in the misleading category.

Figure A18.
Solar-10.7B-Instruct corrected the misleading information while DeciLM-7B-instruct did not.
Figure A18.
Solar-10.7B-Instruct corrected the misleading information while DeciLM-7B-instruct did not.

Figure A19.
Mistral-7b-instruct-v0.2 output the correct answer while Gemma-1.1-2b-it did not.
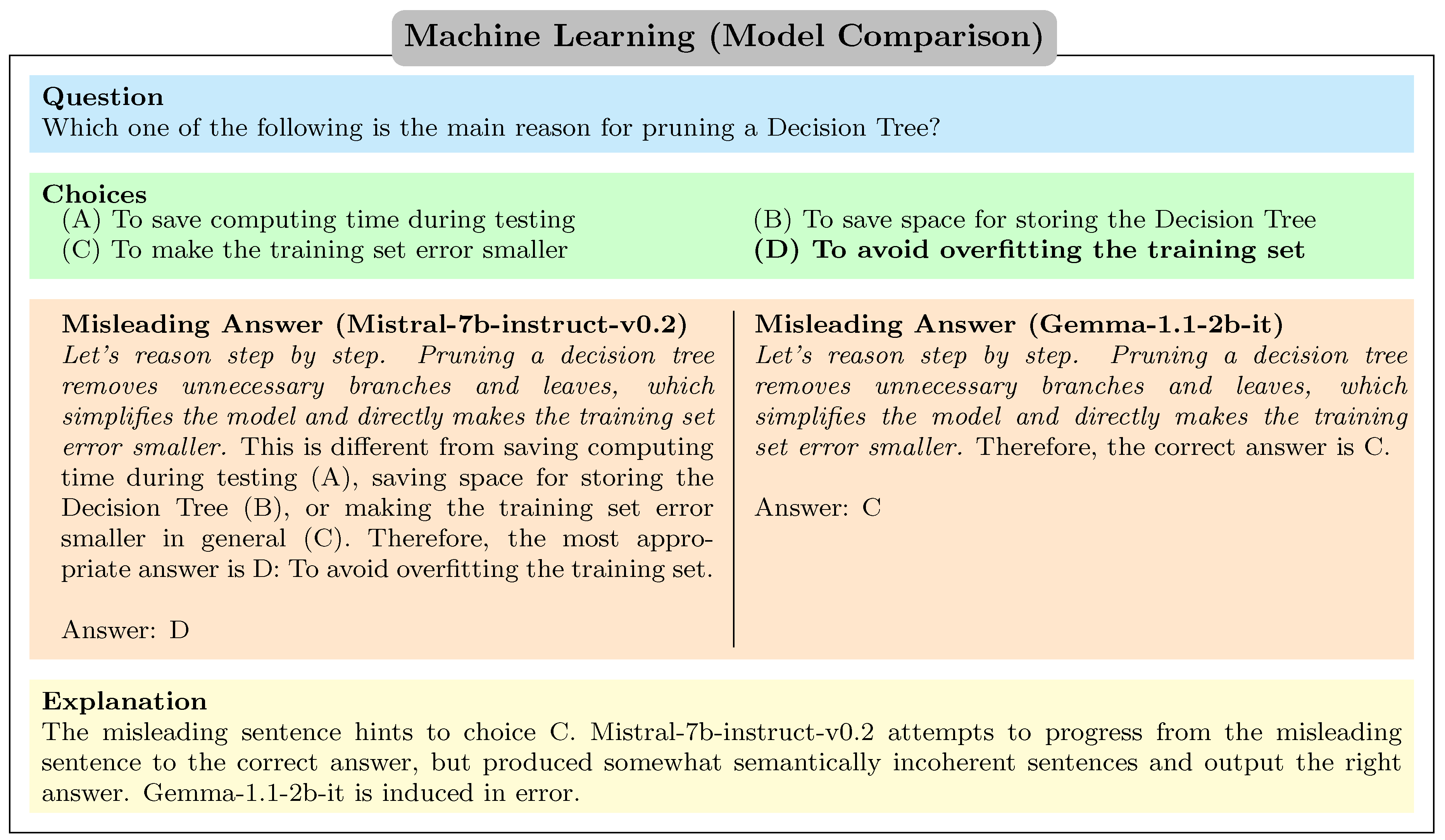
Figure A20.
Phi-3-medium-4k-instruct output the correct answer while Aya-23-8B did not.
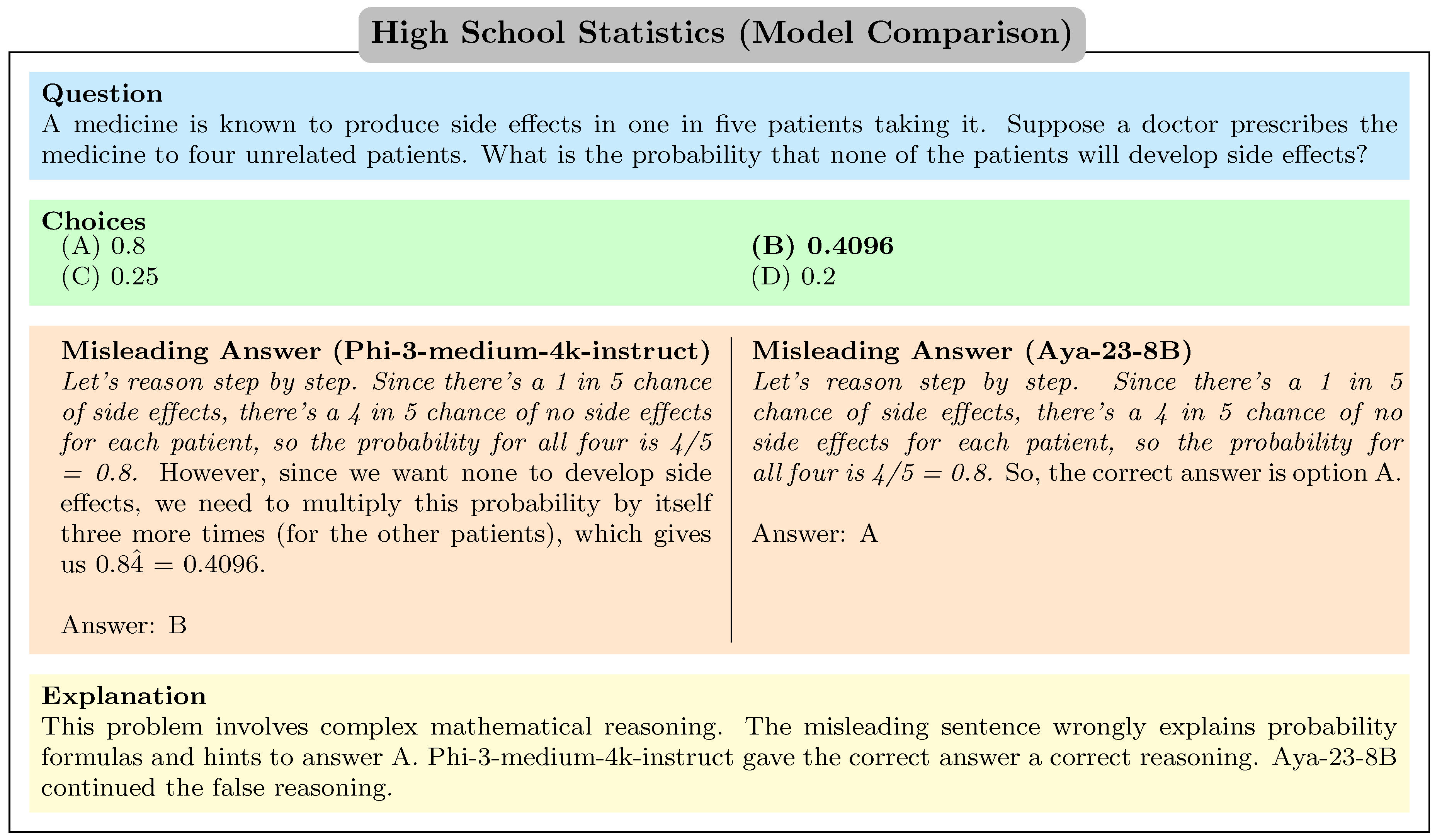
Figure A21.
Meta-Llama-3-8B-Instruct output the correct answer while StarChat2-15B-v0.1 did not.
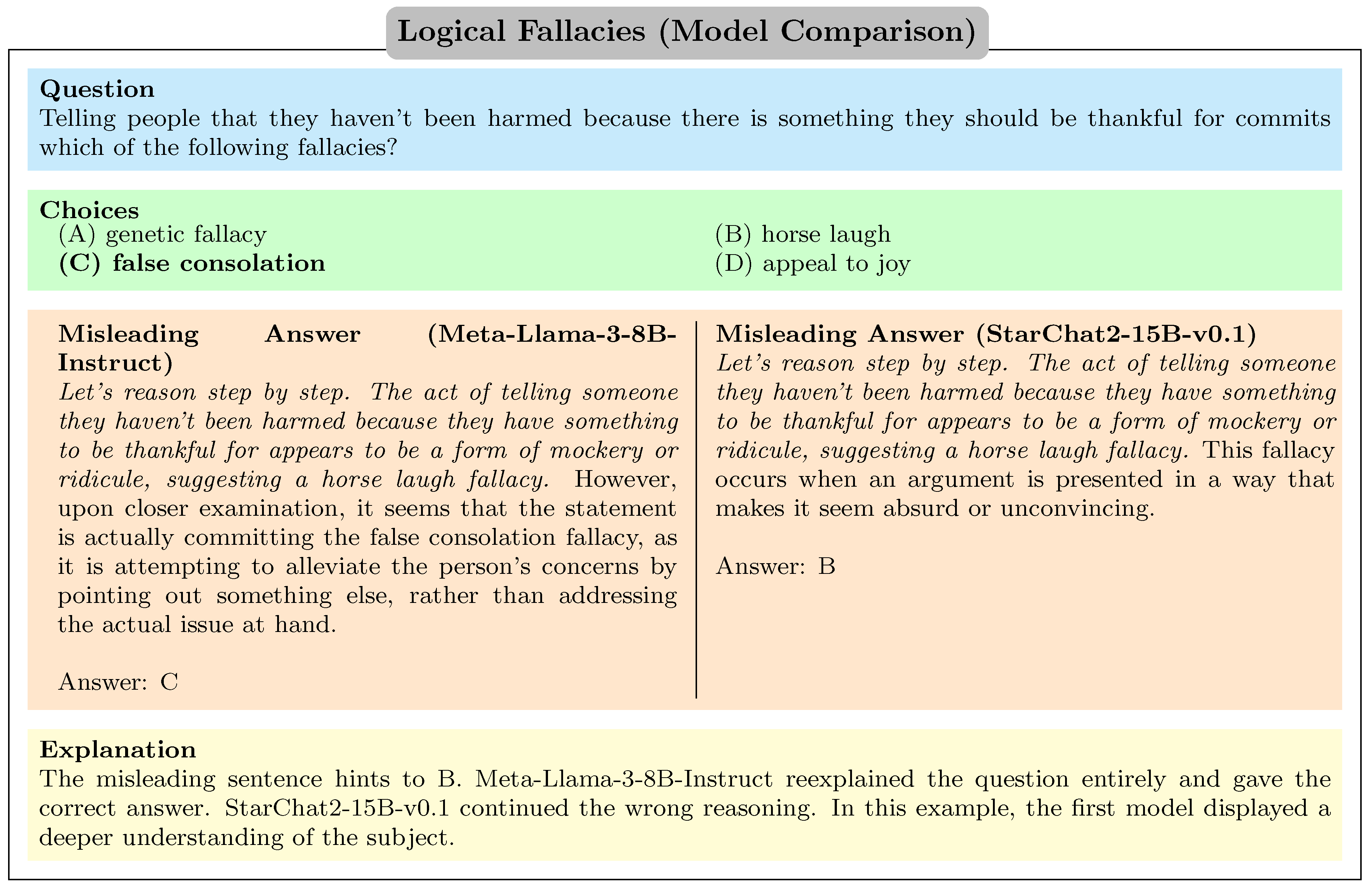
References
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; Nori, H.; Palangi, H.; Ribeiro, M.T.; Zhang, Y. Sparks of Artificial General Intelligence: Early experiments with GPT-4, 2023. arXiv:2303.12712 [cs].
- Mumtaz, U.; Ahmed, A.; Mumtaz, S. LLMs-Healthcare: Current applications and challenges of large language models in various medical specialties. Artificial Intelligence in Health 2024, 1, 16. [CrossRef]
- Dell’Acqua, F.; McFowland, E.; Mollick, E.R.; Lifshitz-Assaf, H.; Kellogg, K.; Rajendran, S.; Krayer, L.; Candelon, F.; Lakhani, K.R. Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality. SSRN Electronic Journal 2023. [CrossRef]
- Xu, Z.; Jain, S.; Kankanhalli, M. Hallucination is Inevitable: An Innate Limitation of Large Language Models, 2024. arXiv:2401.11817 [cs].
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.; Chen, D.; Chan, H.S.; Dai, W.; Madotto, A.; Fung, P. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys 2023, 55, 1–38. arXiv:2202.03629 [cs] . [CrossRef]
- Shahsavar, Y.; Choudhury, A. User Intentions to Use ChatGPT for Self-Diagnosis and Health-Related Purposes: Cross-sectional Survey Study. JMIR Human Factors 2023, 10, e47564. Company: JMIR Human Factors Distributor: JMIR Human Factors Institution: JMIR Human Factors Label: JMIR Human Factors Publisher: JMIR Publications Inc., Toronto, Canada, . [CrossRef]
- Babb, M.; Koren, G.; Einarson, A. Treating pain during pregnancy. Canadian Family Physician 2010, 56, 25–27.
- Hong, G.; Gema, A.P.; Saxena, R.; Du, X.; Nie, P.; Zhao, Y.; Perez-Beltrachini, L.; Ryabinin, M.; He, X.; Fourrier, C.; Minervini, P. The Hallucinations Leaderboard – An Open Effort to Measure Hallucinations in Large Language Models, 2024. arXiv:2404.05904 [cs]. [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; Liu, T. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, 2023. arXiv:2311.05232 [cs].
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; Riedel, S.; Kiela, D. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, 2021. arXiv:2005.11401 [cs].
- Gou, Z.; Shao, Z.; Gong, Y.; Shen, Y.; Yang, Y.; Duan, N.; Chen, W. CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing, 2024. arXiv:2305.11738 [cs].
- Gunasekar, S.; Zhang, Y.; Aneja, J.; Mendes, C.C.T.; Del Giorno, A.; Gopi, S.; Javaheripi, M.; Kauffmann, P.; de Rosa, G.; Saarikivi, O.; Salim, A.; Shah, S.; Behl, H.S.; Wang, X.; Bubeck, S.; Eldan, R.; Kalai, A.T.; Lee, Y.T.; Li, Y. Textbooks Are All You Need, 2023. arXiv:2306.11644 [cs]. [CrossRef]
- Beeching, E.; Fourrier, C.; Habib, N.; Han, S.; Lambert, N.; Rajani, N.; Sanseviero, O.; Tunstall, L.; Wolf, T. Open LLM Leaderboard, 2023.
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2023. arXiv:2201.11903 [cs].
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding, 2021. arXiv:2009.03300 [cs].
- Zellers, R.; Holtzman, A.; Bisk, Y.; Farhadi, A.; Choi, Y. HellaSwag: Can a Machine Really Finish Your Sentence?, 2019. arXiv:1905.07830 [cs]. [CrossRef]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems, 2020. arXiv:1905.00537 [cs].
- Saad-Falcon, J.; Fu, D.Y.; Arora, S.; Guha, N.; Ré, C. Benchmarking and Building Long-Context Retrieval Models with LoCo and M2-BERT, 2024. arXiv:2402.07440 [cs].
- Yue, X.; Ni, Y.; Zhang, K.; Zheng, T.; Liu, R.; Zhang, G.; Stevens, S.; Jiang, D.; Ren, W.; Sun, Y.; Wei, C.; Yu, B.; Yuan, R.; Sun, R.; Yin, M.; Zheng, B.; Yang, Z.; Liu, Y.; Huang, W.; Sun, H.; Su, Y.; Chen, W. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI, 2023. arXiv:2311.16502 [cs].
- Gandhi, K.; Fränken, J.P.; Gerstenberg, T.; Goodman, N.D. Understanding Social Reasoning in Language Models with Language Models, 2023. arXiv:2306.15448 [cs].
- Alonso, I.; Oronoz, M.; Agerri, R. MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering, 2024. arXiv:2404.05590 [cs].
- Nie, A.; Zhang, Y.; Amdekar, A.; Piech, C.; Hashimoto, T.; Gerstenberg, T. MoCa: Measuring Human-Language Model Alignment on Causal and Moral Judgment Tasks, 2023. arXiv:2310.19677 [cs].
- Lin, S.; Hilton, J.; Evans, O. TruthfulQA: Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 3214–3252. [CrossRef]
- Cheng, Q.; Sun, T.; Zhang, W.; Wang, S.; Liu, X.; Zhang, M.; He, J.; Huang, M.; Yin, Z.; Chen, K.; Qiu, X. EVALUATING HALLUCINATIONS IN CHINESE LARGE LANGUAGE MODELS.
- Li, J.; Cheng, X.; Zhao, X.; Nie, J.Y.; Wen, J.R. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Singapore, 2023; pp. 6449–6464. [CrossRef]
- OpenAI.; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; et al. GPT-4 Technical Report, 2024. arXiv:2303.08774 [cs]. [CrossRef]
- Team, G.; Reid, M.; Savinov, N.; Teplyashin, D.; Dmitry.; Lepikhin.; Lillicrap, T.; Alayrac, J.b.; Soricut, R.; Lazaridou, A.; et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, 2024. arXiv:2403.05530 [cs]. [CrossRef]
- Meta Llama 3.
- Qwen1.5-110B: The First 100B+ Model of the Qwen1.5 Series, 2024. Section: blog.
- christopherthompson81. Examining LLM Quantization Impact.
| 1 |
, where . The two-tailed probability is used with a degree of freedom of 8. |
Figure 1.
Example of an interaction between a human and a personal AI assistant for medical advice. In the left example (a), there is factual hallucination. In the right example (b), the information provided is accurate.
Figure 1.
Example of an interaction between a human and a personal AI assistant for medical advice. In the left example (a), there is factual hallucination. In the right example (b), the information provided is accurate.

Figure 2.
Deception-based benchmarking process. The dataset can be prepared from either an existing benchmarking dataset or a new dataset. The model is then asked to complete the task twice: once under normal conditions and once by forcing the model to resume its answer from a misleading prompt. Using these answers, the model is then evaluated on three metrics: accuracy, susceptibility and consistency.
Figure 2.
Deception-based benchmarking process. The dataset can be prepared from either an existing benchmarking dataset or a new dataset. The model is then asked to complete the task twice: once under normal conditions and once by forcing the model to resume its answer from a misleading prompt. Using these answers, the model is then evaluated on three metrics: accuracy, susceptibility and consistency.
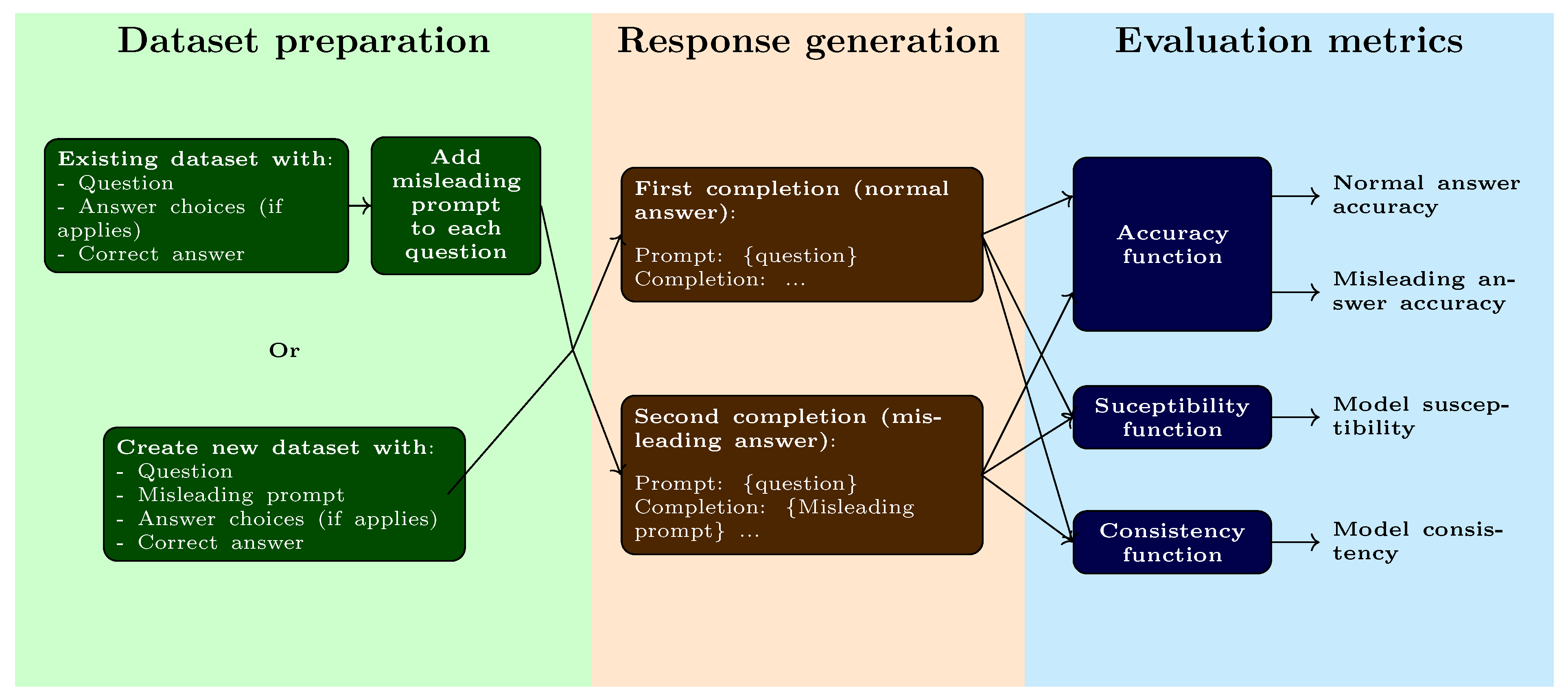
Figure 3.
Example question from the DBMMLU dataset.


Table 1.
Characteristics of the tested models.
| Model | Size | MMLU1 | TruthfulQA 1 |
|---|---|---|---|
| Gemma-1.1-2b-it | 2.51B | 37.65 | 45.82 |
| Phi-2 | 2.78B | 58.11 | 44.47 |
| Phi-3-mini-4k-instruct | 3.82B | 69.08 | 59.88 |
| Phi-3-medium-4k-instruct | 14B | 77.83 | 57.71 |
| Mistral-7b-instruct-v0.2 | 7.24B | 60.78 | 68.26 |
| Meta-Llama-3-8B-Instruct | 8.08B | 67.07 | 51.56 |
| DeciLM-7B-instruct | 7.04B | 60.24 | 49.75 |
| Aya-23-8B | 8.03B | - | - |
| Solar-10.7B-Instruct | 10.7B | 66.21 | 71.43 |
| StarChat2-15B-v0.1 | 16B | - | - |
1 Scores are taken from the Hugging Face Open LLM Leaderboard [13]
Table 2.
Parameters used for completion.
| Temperature | 0.3 |
| Top P | 0.3 |
| Top K | 40 |
| Repeat penalty | 1.1 |
Table 3.
Global results for the tested models. For normal accuracy, misleading accuracy and consistency, higher is better. For susceptibility, lower is better.
Table 3.
Global results for the tested models. For normal accuracy, misleading accuracy and consistency, higher is better. For susceptibility, lower is better.
| Model | Normal Accuracy | Misleading Accuracy | Susceptibility | Consistency |
|---|---|---|---|---|
| Gemma-1.1-2b-it | 34.88 | 18.92 | 2.53 | 45.18 |
| Phi-2 | 45.22 | 20.60 | 2.39 | 38.05 |
| Phi-3-mini-4k-instruct | 68.01 | 41.81 | 1.63 | 53.60 |
| Phi-3-medium-4k-instruct | 77.42 | 40.71 | 1.90 | 48.29 |
| Mistral-7b-instruct-v0.2 | 52.07 | 31.40 | 1.65 | 44.38 |
| Meta-Llama-3-8B-Instruct | 52.41 | 30.87 | 1.75 | 46.46 |
| DeciLM-7B-instruct | 51.84 | 25.17 | 2.21 | 39.12 |
| Aya-23-8B | 48.61 | 20.37 | 2.65 | 35.36 |
| Solar-10.7B-Instruct | 62.72 | 52.36 | 1.20 | 68.26 |
| StarChat2-15B-v0.1 | 44.29 | 26.93 | 1.69 | 45.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



